1. Introduction
Fault diagnosis of wind turbines plays an important role in improving the reliability of wind turbines. However, the operating conditions of wind turbines change randomly, and multiple faults often occur simultaneously. In reality, wind turbines are not allowed to run with faults; when a fault occurs, the wind turbine will shut down. As a result, very few fault samples are available. Most deep learning will fall into overfitting when dealing with small sample problems, resulting in a low diagnostic accuracy. Few-shot learning (FSL) can train deep models with very limited data and solve the overfitting problem. The current few-shot learning includes generative modeling, meta-learning, and metric learning [
1].
Generative adversarial networks (GAN) have been widely used to enhance the diversity of data [
2,
3,
4]. Subsequently, there has been a proliferation of adversarial models presented by GAN, such as AnoGANs [
5], GANormaly [
6], etc.; auto-encoder (AE) is another way of generating samples. AE has now developed numerous variants, e.g., variational AE (VAE) [
7], adversarial AE (AAE) [
8], etc. However, generative modeling cannot solve the problem of very scarce data because of pattern collapse.
Meta-learning attempts to improve the network’s ability to learn higher-level tasks by learning the feature representation of the task and generalizing on new tasks [
9]. Wu et al. constructed seven few-shot transfer learning methods based on meta-learning [
10]. Wang et al. proposed a meta-learning model based on a feature space metric for the fault diagnosis of bearings [
11]. Feng et al. proposed a semi-supervised meta-learning network for low-probability fault diagnosis [
12]. Su et al. proposed a novel method called data reconstruction hierarchical recurrent meta-learning for bearing fault diagnosis [
13]. Wang et al. proposed a metric-based meta-learning method named Reinforce Relation Network for bearing fault diagnosis [
14].
Metric learning refers to learning a similarity metric under which a pair of similar samples can obtain a higher similarity score while non-similar pairs obtain a lower similarity score. Based on metric learning, Siamese neural networks [
15,
16], neural networks with external memories [
17,
18], relation networks [
19], and graph neural networks [
20] have been applied to few-shot learning.
The results of metric learning depend on the sampling strategy. The recent study of [
21] suggests that the core of improving FSL also lies in improving the embedding learned. Self-supervised approaches based on contrast learning (CL) have recently become dominant. CL aims at grouping similar samples closer to and diverse samples far from each other [
22], which is a kind of metric learning. CL learns the feature representation of samples by comparing data with positive samples and negative samples, respectively, in feature space. The model only needs to learn differentiation in feature space and does not pay too much attention to pixel details. This not only simplifies optimization, but also facilitates the establishment of a sampling strategy conducive to differentiation.
CL-based FSL has been widely used in few-shot image recognition [
22,
23,
24,
25,
26]. At present, CL is seldom used in the field of fault diagnosis. Chen et al. proposed a new deep learning algorithm based on CL for the automated diagnosis of COVID-19 [
27]. Ding et al. proposed a specific architecture for a self-supervised pre-training via contrast learning (SSPCL) deployment on bearing vibration signals [
28].
At present, there are some limitations in the few-shot fault diagnosis: (1) The current few-shot fault diagnosis is mainly aimed at the testbed data under certain working conditions and realizing the data transfer learning from one fixed working condition to another working condition; (2) Currently, there are few analysis results when the sample size is very small (e.g., five samples); (3) At present, CL is seldom used in the few-shot fault diagnosis. Therefore, the innovations of this paper are as follows: (1) The actual operating conditions of wind turbines vary randomly, and the specific operating conditions at each moment are difficult to obtain. This paper proposes a stable few-shot fault diagnosis model of wind turbines that can adapt to various working conditions. (2) This paper analyzes the few-shot diagnosis results when the amount of data are very small. (3) This paper establishes a few-shot diagnosis model by combining contrastive learning with meta-learning.
Humans learn new concepts with little supervision; e.g., a child can generalize the concept of a giraffe from a picture in a book. In deep learning, the model can recognize the category from a single sample, which is called one-shot learning. How to learn transferable feature representations from a limited number of samples is a key challenge in few-shot learning. The data itself provide far more information than sparse labels. Contrast learning directly uses the data as supervised information to learn feature representations of sample data, and use them for downstream tasks. So, contrast learning is better able to learn generic knowledge to improve the characterization of the model and adapt it to the migration of different working conditions. Momentum contrast learning (MOCO) uses dictionary queuing and momentum updates to avoid losing consistency in features due to drastic changes in the encoder, while also keeping the encoder in a constant state of being updated. The stable updates of MOCO allow for better learning of the general knowledge of the data and, thus, better transfer of features to other tasks. Meta-learning equips models with certain prior knowledge or learning skills by learning multiple tasks; thus, they can better generalize and learn new tasks.
In this paper, we proposed a novel one-shot fault detection model named meta-analogical momentum contrast learning (MA-MOCO) for wind turbine drivetrain. By improving the momentum contrast learning (MOCO) and using the training idea of meta-learning, the one-shot fault diagnosis of wind turbines is analyzed. All the training data are used to train a basic classifier, which is used to construct the MA-MOCO model. Using the idea of meta-learning, some meta-learning tasks are constructed by randomly selecting samples from the training dataset to form support sets and query sets. The MA-MOCO is further updated by comparing the query set with the positive and negative samples in the support set, and a simple and effectively differentiated feature space is established.
The rest of this paper is organized as follows:
Section 2 introduces the basic concepts of meta-learning and MOCO. In
Section 3, a one-shot fault diagnosis model named MA-MOCO for wind turbines is proposed. In
Section 4, the field wind turbine datasets are input to the proposed model for training and testing; the results are analyzed.
Section 5 presents the conclusion.
2. Momentum Contrast Learning and Meta-Learning
2.1. Momentum Contrast Learning
Self-supervised learning mainly uses auxiliary pretext to mine its own supervised information from large-scale unsupervised data; it uses this structured supervised information to train the network so that it can learn valuable representations for downstream tasks. CL is a kind of self-supervised learning, which constructs representations by learning to code the similarities or dissimilarities of two things and then measuring the distance between the positive and negative samples. The distance between the core idea sample and the positive sample is much larger than the distance between the sample and the negative sample:
where
x+ and
x− are positive (similar) and negative (dissimilar) samples to
x, respectively.
f(•) is the encoder model for CL.
score is a function to quantify similarity, e.g., cosine similarity.
CL aims at grouping similar samples closer to and diverse samples far from each other [
29]. To achieve this target, a similarity metric is used to measure how close the two embeddings are, e.g., noise contrastive estimation (NCE) [
30], as follows:
where
x+ and
x− are positive (similar) and negative (dissimilar) samples to
x, respectively.
Currently, common CL models include MOCO [
31], a simple framework for contrastive learning (SimCLR) [
32], contrastive predictive coding (CPC) [
33], and contrastive multiview coding (CMC) [
21]. He et al. presented momentum contrast (MOCO) for unsupervised visual representation learning, and built a dynamic dictionary with a queue and a moving-averaged encoder [
31]. Chen implemented SimCLR in the MOCO framework to establish stronger baselines that outperform SimCLR [
34].
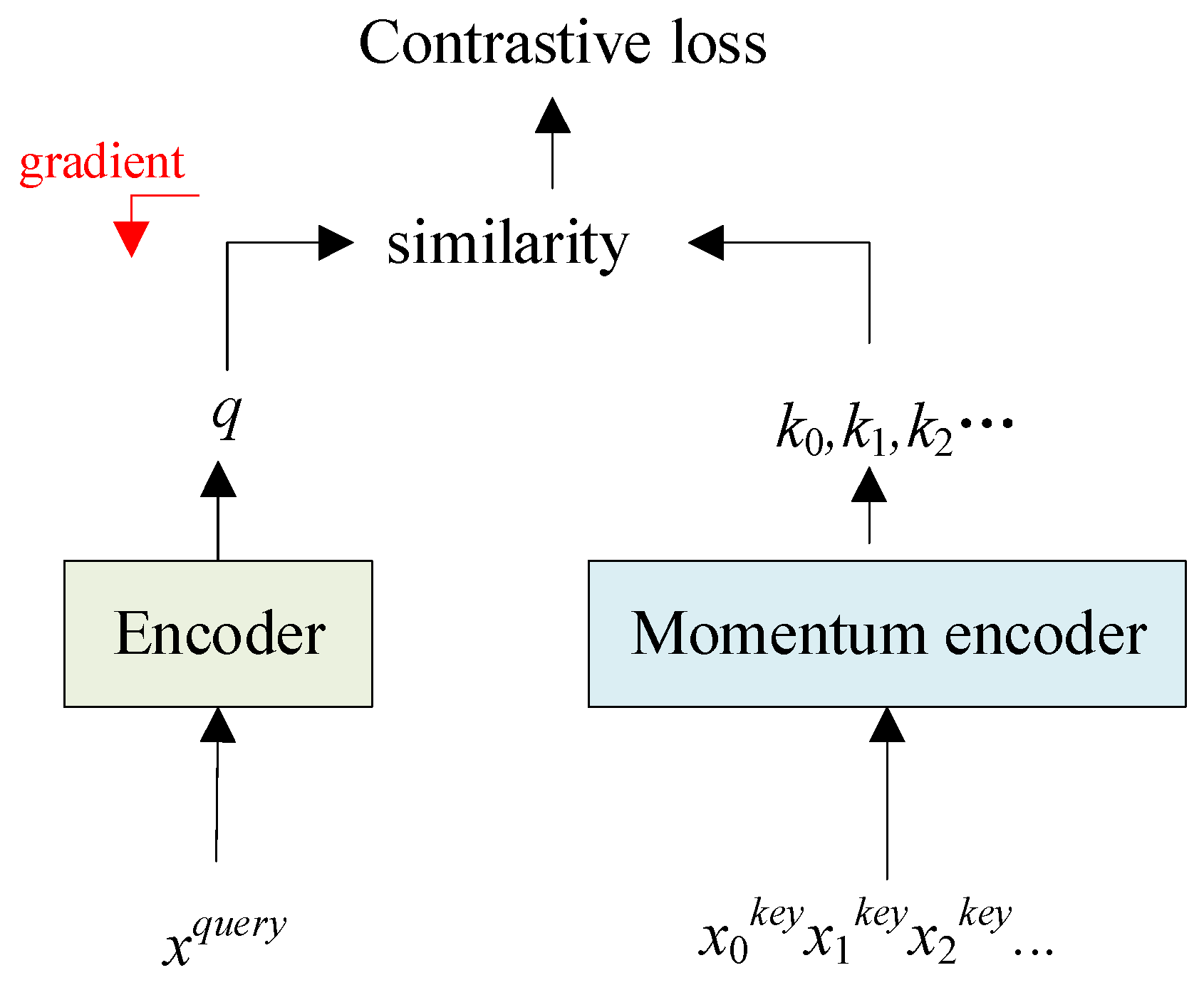
The structure diagram of MOCO is shown in
Figure 1. MOCO trains a visual representation encoder by matching an encoded query q to a dictionary of encoded keys using a contrastive loss. The dictionary is built as a queue. The keys are encoded by a slowly progressing encoder, driven by a momentum update with the query encoder.
The query data are input to the encoder and the key data are input to the momentum encoder. Consider an encoded query
q and a set of encoded samples {
k0,
k1,
k2,…} that are the keys of a dictionary. Assume that there is a single key (denoted as
k+) in the dictionary that
q matches. With similarity measured by a dot product, a form of a contrastive loss function, called InfoNCE [
33], is as follows:
where
τ is a temperature hyper-parameter. The sum is over one positive and
K negative sample.
Define the encoder as
fq and the momentum encoder as
fk. Denote the parameter of
fk as
θk and those of
fq as
θq. Update the parameter
θq by back-propagation, and update the parameter
θq by:
where
m ϵ [0, 1) is a momentum coefficient. In experiments, a relatively large momentum works much better than a smaller value, suggesting that a slowly evolving key encoder is core to making use of a queue.
2.2. Meta-Learning-Based Few-Shot Learning
Meta-learning is a general paradigm for few-shot learning, which involves two core processes: learning the transfer of knowledge across tasks; and rapidly adapting to new tasks. In the meta-learning training process, k data are selected from the training set as the support set S, and q data as the query set Q. If the training sample contains c categories and each category in the support set contains k-labeled data, the few-shot problem is called the c-way k-shot problem. When k = 1, this is one-shot learning.
The support set S and query set Q are extracted from the source domain data. The support set is used as a labeled sample to generate prototype features for the model, and the query set is used as a training sample to update the model; the support set and query set are to form a meta-task, and multiple meta-tasks form a training set. For a c-way k-shot problem, during the training phase, c categories are randomly selected in the training set, and k samples are selected from each category (a total of k × c data) to construct a meta-task as the support set of the model (m = k × c); then, a batch of samples from the remaining data in these c categories are selected as the query set (n = q × c) to update the model.
During the training process, different meta-tasks are sampled for each training; thus, overall, the training contains different combinations of categories, and this mechanism enables the model to learn common parts of different meta-tasks. The models that are learned through this learning mechanism will perform better in relation to classifying when faced with new unseen meta-tasks.
3. Meta-Analogical Momentum Contrast Learning
In this paper, we proposed a novel few-shot fault detection model named meta-analogical momentum contrast learning (MA-MOCO) for wind turbine drivetrain. By improving the momentum contrast learning (MOCO) and using the training idea of meta-learning, the one-shot fault diagnosis of wind turbines is analyzed. The model structure is shown in
Figure 2.
All the training data are used to train a basic classifier, which is used to construct the MA-MOCO model. Using the idea of meta-learning, some meta-learning tasks are constructed by randomly selecting samples from the training dataset to form support sets and query sets. The MA-MOCO is further updated by comparing the query set with the positive and negative samples in the support set, and a simple and effectively differentiated feature space is established.
The classifier model contains three convolution layers, three BatchNorm1d, three MaxPool1d, and one fully-connected layer. The number of neurons in each layer is marked in
Figure 2. The activation functions of all the layers are rectified linear units (Relu), except for the last layer where the activation function is Softmax. All the data go through the fast Fourier transform and are then fed into the model. When a bearing or gear fails, the period
T of the shock pulse is determined by the area where the defect is generated; the inverse
fi of its period reflects the fault characteristics as the fault characteristic frequency. When a bearing or gear fails, the period
T of the shock pulse is determined by the area where the defect is generated; the inverse
fi of its period reflects the fault characteristics as the fault characteristic frequency. When a machine is faulty, the spectral peaks of the fault characteristic frequency will appear in its vibration spectrum; thus, the fault characteristic frequency can be used as a feature for fault diagnosis. Spectrum analysis is the most useful fault diagnosis method. The fast Fourier transform converts complex time-domain signals into easy-to-analyze frequency-domain signals, which can more clearly represent the fault characteristic frequencies. After converting the data into spectral data by the fast Fourier transform, they can reflect the fault features more clearly and facilitate the neural network model to better learn and classify the features.
The one-shot fault diagnosis model is divided into the following steps:
In the first step, the baseline model is trained. All the training sets are input to the classifier model; the model is set as
f. The base model parameters are updated with the learning rate
lr1 as 0.01. Backpropagation updates are carried out according to Equation (5).
where
y is the label corresponding to data
x.
In the second step, the MA-MOCO model is trained. Assuming a c-way k-shot learning task, k pieces of data of each class are randomly selected from the training data as the support set S, and other q pieces of data are selected as the query set Q; the support set and query set form a meta-learning task. N meta-learning tasks are constructed. The initial parameters of the model are selected from the trained baseline model, and each task is used to update the MA-MOCO parameters. The updated learning rate of each task is lr2 as 0.002.
The loss of the MA-MOCO model is represented in Equations (6) and (7). Equation (6) is the loss of the MOCO, and Equation (7) is the loss of classification.
where
q is the query set data,
k is the support set data, and
τ is a temperature hyper-parameter.
Backpropagation updates are carried out according to Equation (8).
where
γ is set to 0.2 because by comparison, loss
Loss1 plays a more important role in updating the MA-MOCO model; the classification loss
Loss22 only plays a fine-tuning role. In Equation (8),
Loss1 is the contrast loss, and
Loss22 is the cross-entropy loss of the classification. The two losses jointly promote the model to achieve better optimization results and are not directly related. Because of the small sample size of the known fault data and the severe sample imbalance problem, the classification loss
Loss22 does not optimize the classification results well. Contrast loss
Loss1 is a loss function with the negative sample self-discovery property, which is essential for learning high-quality self-supervised representations and effectively learning knowledge common to the data. Therefore, this paper mainly relies on the contrast loss
Loss1 to update the model, and the classification loss
Loss22 as a supplement to further improve the model accuracy; thus, the coefficient
γ is taken as 0.2.
In the last step, the testing sets are fed into the trained model for classification and solved for accuracy. The feature embedding is visualized by t-distributed stochastic neighbor embedding (t-SNE) to test the effectiveness of the proposed model.
The complete algorithm flow is shown in Algorithm 1.
| Algorithm 1: One-Shot Fault Diagnosis Based on MA-MOCO. |
| Input: Input training data , testing data , classified model fϕ, encoder fq and momentum encoder fk, updated learning rate lr1 of baseline and lr2 of MA-MOCO, the model parameters θ, the momentum coefficient m, and the temperature hyper-parameter τ. |
| ########################(1) Pre-training baseline models #################### |
| 1: For each training epoch, do: |
| 2: For each batch, do: |
| 3: ci = f(xi) |
| 4: Backward propagation (with the learning rate as lr1) by Equation (5). |
| 5: end |
| ########################(2) train MA-MOCO models ############################ |
| 6: Randomly draw data from Tr to form N tasks, each task containing k support sets and q query sets, to form |
| 7: For each training, do: |
| 8: For each batch, do: |
| 9: qi = fq (Qi), ki = fk (Si), ci = Softmax(qi) |
10: Update parameters of the encoder by:
|
| 11: Backward propagation of the encoder: |
| 12: Backward propagation of the momentum decoder: |
| 13: end |
| ###################### (3) testing results and t-SNE ######################### |
| 14: For the test set, calculate cTi = f (Tei), calculate the accuracy, and draw the t-SNE diagram. |
| Output: testing results. |
The update function used within this model is Adam, with 100 training epochs for the pre-trained base model and 200 training epochs for the MA-MOCO update. The batch size is 32. Based on most CL experiences, the momentum coefficient m is set to 0.999; the temperature hyper-parameter τ is set to 0.5.
4. Case Analysis
In this section, one-shot learning cases are analyzed to verify the advantages of the proposed model, including the one-shot case of the wind turbine generator bearing and gearbox. To further validate the proposed model of MA-MOCO, we will compare it with some transfer learning algorithms, such as the Siamese net [
16] and the model-agnostic meta-learning (MAML) net [
34]. To make a fair comparison, we used the same datasets, the same data preprocessing methods (fast Fourier transform), the same classified model, the same epochs, and the same learning rates.
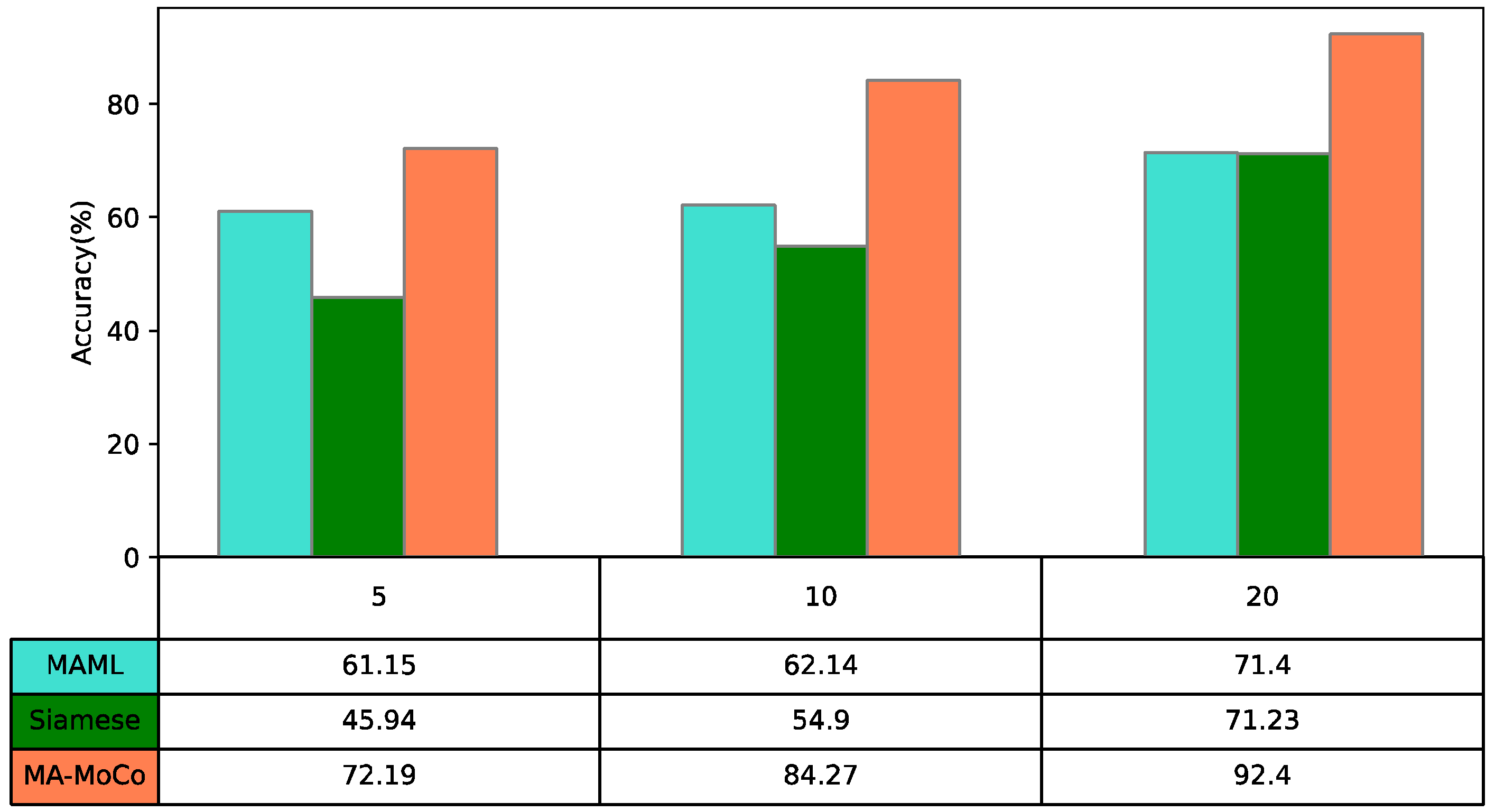
In general, the data of proper health operation are easy to obtain; however, failure data are difficult to obtain. This paper analyzes the classification results of the proposed model when there are only 5, 10, and 20 samples of fault data for training. Two case studies with one-shot settings are conducted. In order to assess the accuracy of all the proposed algorithms, data from 240 wind turbines operating under different conditions with different faults that are not involved in the training are fed into the model in this paper. The accuracy of the model is evaluated by comparing the predicted categories with the corresponding labels of the data and solving for the classification accuracy.
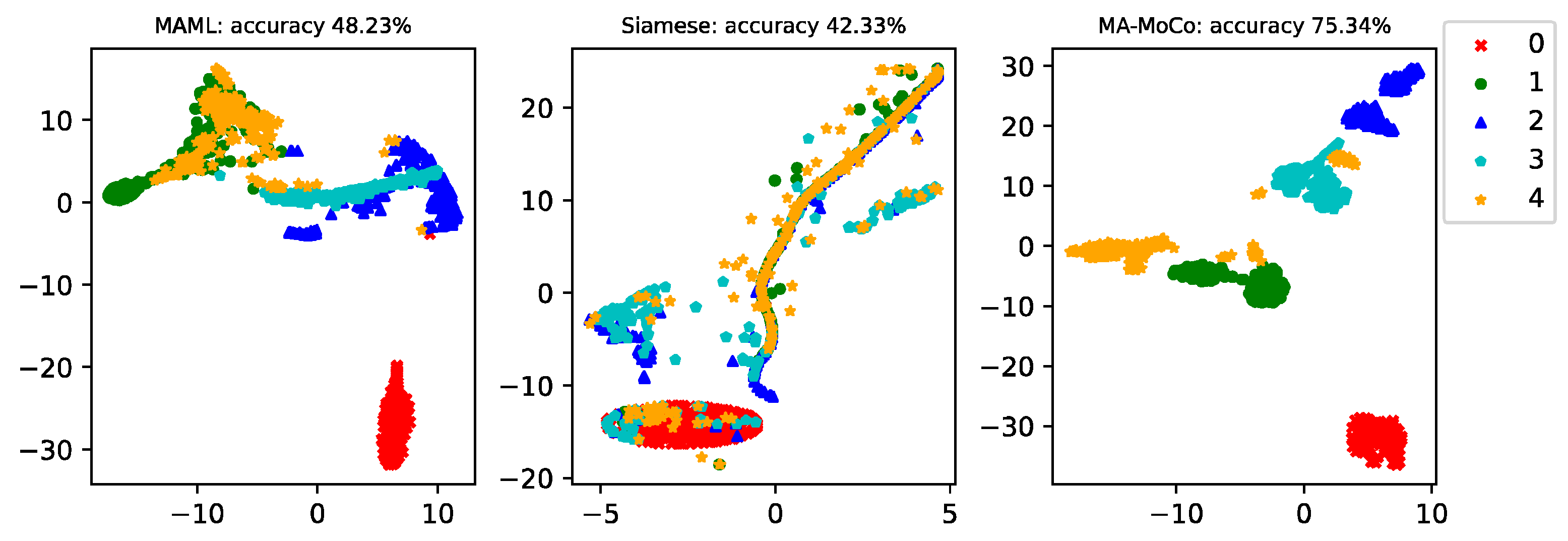
In this paper, the feature embeddings are visualized by t-SNE to test the validity of the proposed model. MAML and MA-MOCO have a classification layer; therefore, both use the output of the Softmax activation function to plot t-SNE. Siamese does not have a classification layer and relies on distance to determine the categories. Hence, Siamese plots t-SNE using the distance metric between the test data and each category of data.
4.1. Case One: One-Shot Fault Diagnosis of the Generator Bearings for Wind Turbines
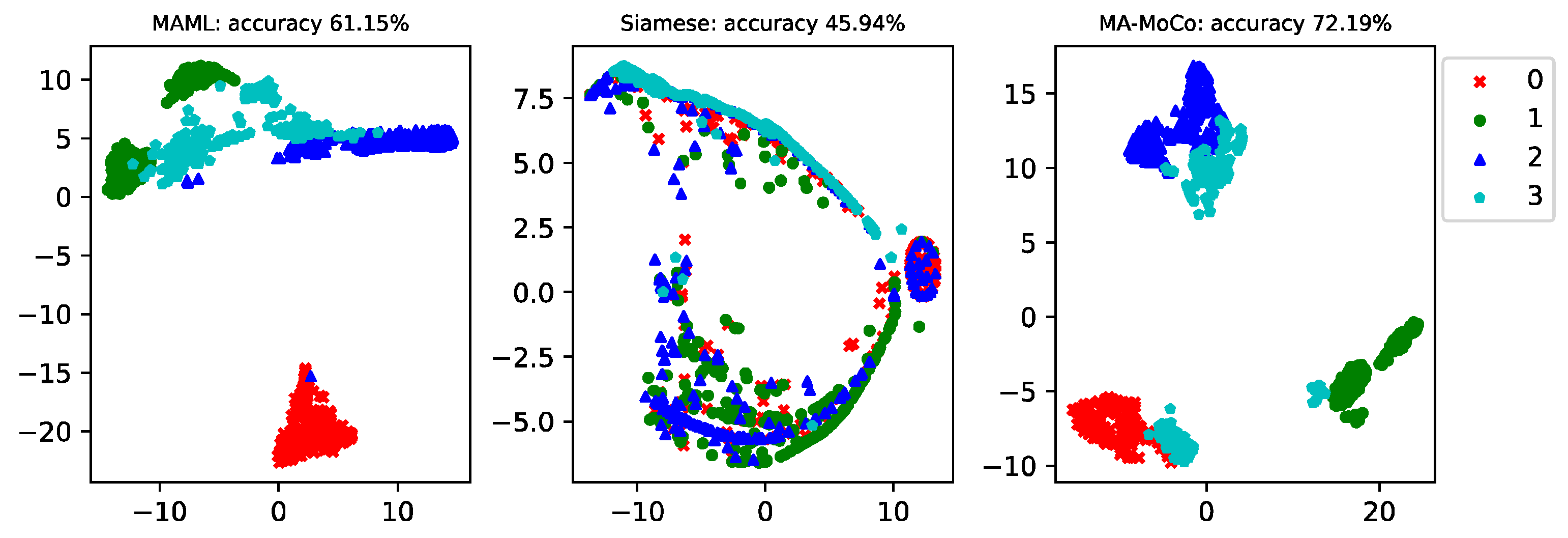
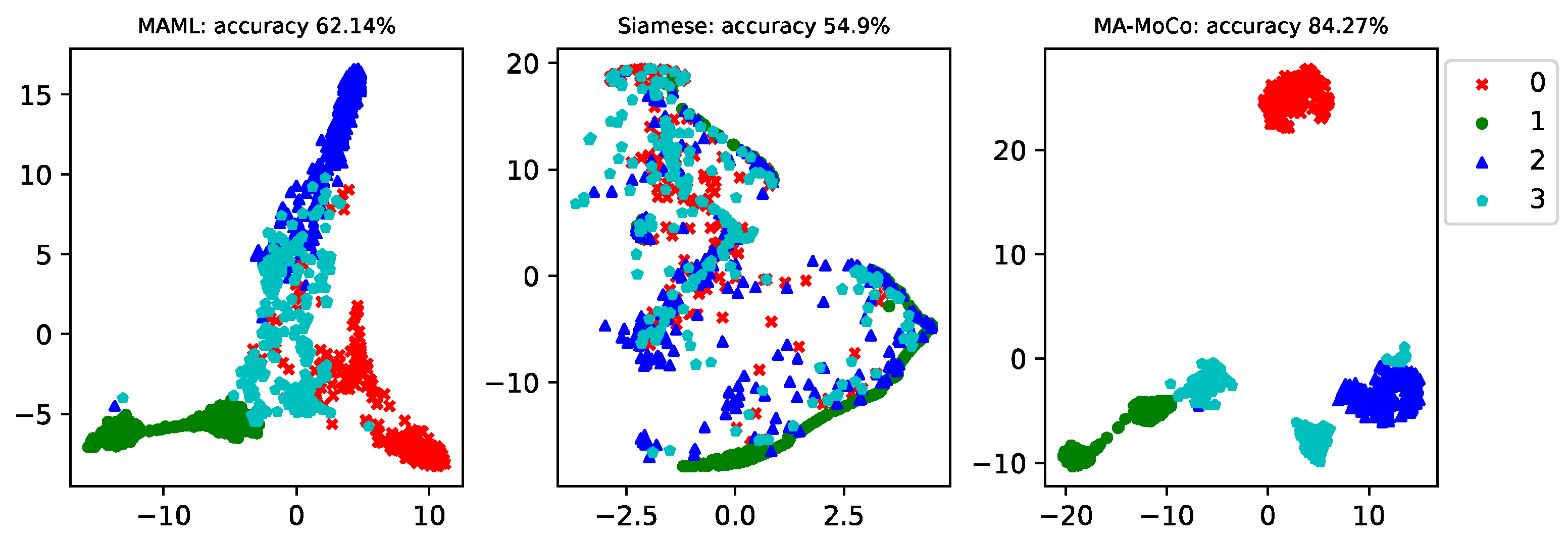
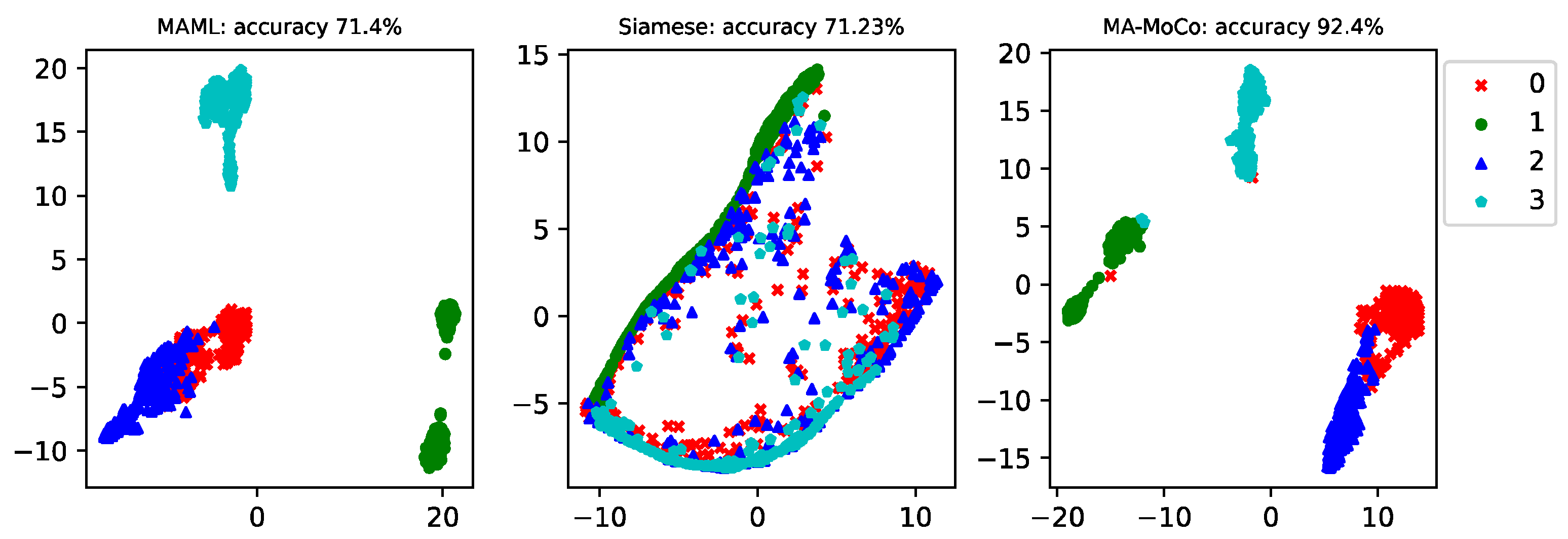
In this case, a one-shot fault diagnosis of the generator bearings for wind turbines is conducted. The available samples are shown in
Table 1. The generator bearing data for the wind turbine includes proper health operation data and three types of faults; each category contains 260 data. The latter two faults are compound faults. In the actual operating conditions, wind turbines have mostly compound faults; this paper studies the one-shot problem of compound faults, which has better engineering significance.
We analyzed the results when the failure data of the training set are only 5, 10, and 20, respectively. The latter 240 data in different operating conditions are the testing data. The model can also be further tested under different operating conditions. The Siamese net [
16] and the MAML net [
34] are used for comparison with the proposed model. The final t-SNE is shown in
Figure 3,
Figure 4 and
Figure 5. The classification accuracy of each algorithm is shown at the top of each graph.
Figure 3,
Figure 4 and
Figure 5 show the classification results and t-SNE plots of the model for the sample sizes of 5, 10, and 20 for each class of fault data in the training set, respectively. In the t-SNE plots in
Figure 3,
Figure 4 and
Figure 5, t-SNE reduces the classification result data to two dimensions, and the horizontal and vertical coordinates represent the two dimensions of the data after t-SNE reduction, respectively.
The fault classification accuracy of the generator bearings for wind turbines using different algorithms is shown in
Figure 6. In order to analyze the influence of different sample sizes in the training set on the diagnostic accuracy of the model, this paper investigates the diagnostic accuracy of the model when the sample sizes of each type of fault in the training set are 5, 10, and 20, respectively. It can be seen that the higher the training sample size, the higher the classification accuracy of the model. The average accuracy of MA-MOCO is 18.05% higher than MAML and 25.59% higher than Siamese net.
4.2. Case Two: One-Shot Fault Diagnosis of the Wind Turbine Gearbox
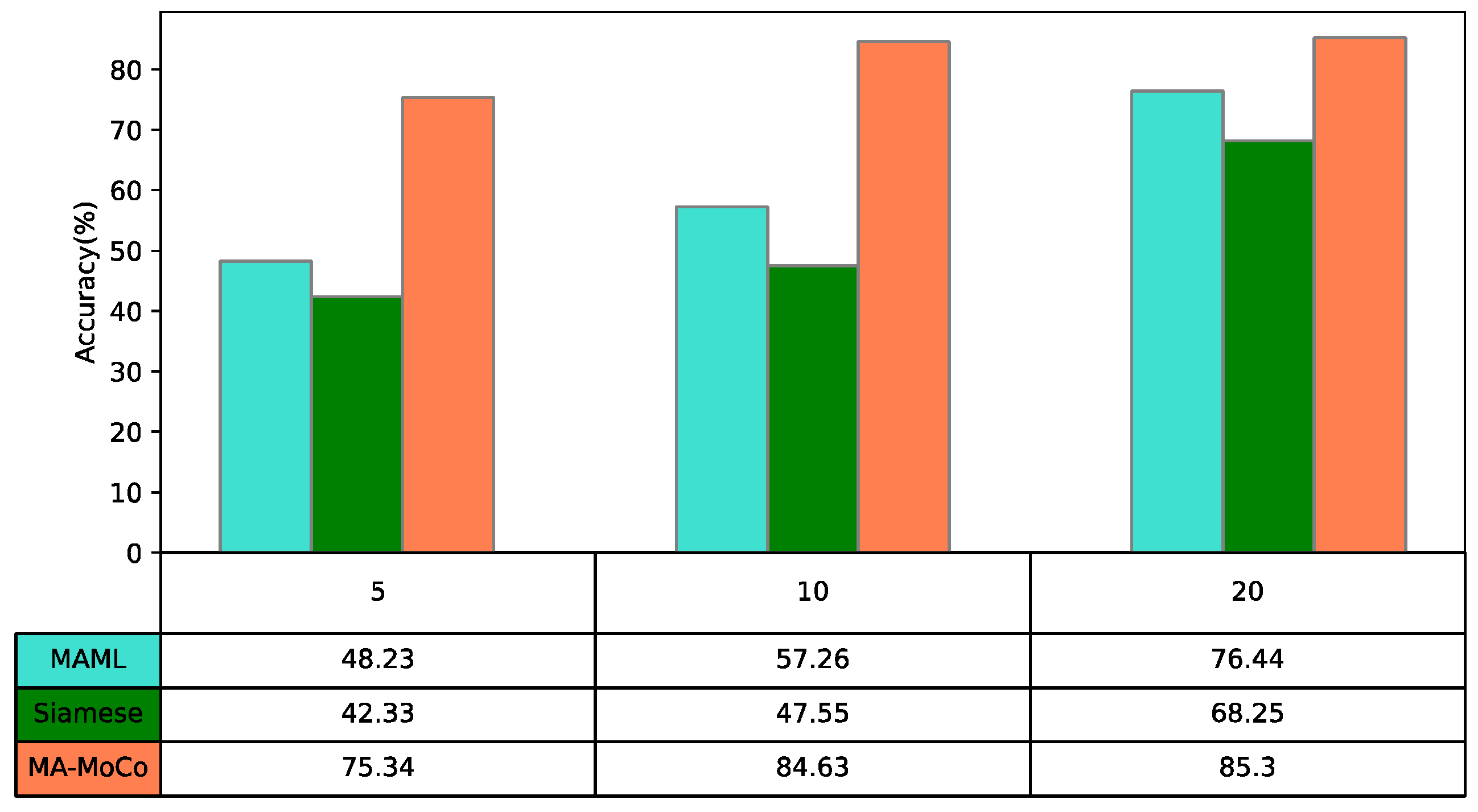
This case focuses on a one-shot fault diagnosis of the gearbox of wind turbines. The available gearbox samples are shown in
Table 2. The samples contain one category of proper health operation data and four categories of fault data; each category contains 260 data. Fault 2 is a compound fault. We analyzed the results when the failure data of the training set are only 5, 10, and 20, respectively. The latter 240 data that are in different operating conditions are the testing data. The model can also be further tested for different operating conditions. The Siamese net [
16] and the MAML net [
34] are used for comparison with the proposed model. The final t-SNE is shown in
Figure 7,
Figure 8 and
Figure 9. The classification accuracy of each algorithm is shown at the top of each graph.
Figure 7,
Figure 8 and
Figure 9 show the classification results and t-SNE plots of the model for the sample sizes of 5, 10, and 20 for each class of fault data in the training set, respectively. In the t-SNE plots in
Figure 7,
Figure 8 and
Figure 9, t-SNE reduces the classification result data to two dimensions; the horizontal and vertical coordinates represent the two dimensions of the data after t-SNE reduction, respectively.
The fault classification accuracy of the gearboxes for the turbines using different algorithms is shown in
Figure 10. In order to analyze the influence of different sample sizes in the training set on the diagnostic accuracy of the model, this paper investigates the diagnostic accuracy of the model when the sample sizes of each type of fault in the training set are 5, 10, and 20, respectively. It can be seen that the higher the training sample size, the higher the classification accuracy of the model. The average accuracy of MA-MOCO is 21.12% higher than MAML and 29.05% higher than Siamese net.
4.3. Discussion of the Results
Supervised learning models trained by labels often learn only some task-specific knowledge, but not generic knowledge, making the feature representations difficult to transfer to other tasks. The data provide far more information than sparse labels, and self-supervised learning directly uses the data themselves as supervised information to learn feature representations of the sample data and use them for downstream tasks. So, self-supervised learning is better able to learn generic knowledge to improve the characterization of the model and adapt it to the migration of different working conditions. Contrast learning, as a self-supervised method, uses contrast loss, which makes representations from the same data (positive examples) closer and representations from different data (negative examples) more dispersed. Momentum contrast learning (MOCO) uses dictionary queuing and momentum updates to avoid losing consistency in features due to drastic changes in the encoder, while also keeping the encoder in a constant state of being updated. Meta-learning, also known as ‘learning to learn’, equips models with certain prior knowledge or learning skills by learning multiple tasks so that they can better generalize and learn new tasks.
How to learn transferable feature representations from a limited number of samples is a key challenge in few-shot learning. In this paper, MOCO is added to few-shot learning to improve the representational power by learning generic knowledge of different categories. At the same time, the original few-shot classification further optimizes the model to achieve a complementary role. The few-shot model is trained through the task-based training idea in meta-learning. Support sets are input to the model, and the query sets are used to update the model to improve its ability to adapt to different working conditions. By combining MOCO and meta-learning, the model achieves better results and is able to adapt to the different operating conditions of wind turbines.
5. Conclusions
Fault diagnosis of wind turbines plays an important role in improving the reliability of wind turbines. However, wind turbines are not allowed to operate with faults. If an abnormality is detected during operation, the turbine will immediately shut down; thus, it is difficult to obtain a sample of faults. When the fault samples are small, ordinary deep learning can fall into overfitting, resulting in a low diagnostic accuracy. Therefore, few-shot fault diagnosis of wind turbines is of great practical importance.
In reality, the operating conditions of wind turbines change randomly; often, multiple faults occur simultaneously. Sample data for different fault types under different operating conditions are difficult to obtain. Therefore, it is necessary to study fault diagnosis when the fault samples are very few, i.e., one-shot learning.
A novel method based on meta-analogical momentum contrast learning (MA-MOCO) is proposed in this paper to solve the problem of very few samples of wind turbine failures, especially one-shot. By improving the momentum contrast learning (MOCO) and using the training idea of meta-learning, the one-shot fault diagnosis of wind turbine drivetrain is analyzed.
This paper analyzes the diagnosis of one-shot tasks of single and compound faults in wind turbine generator bearings and wind turbine gearboxes. It is also compared with other algorithms to verify the accuracy and stability of the proposed method. The results are also presented by t-SNE. All the training data are used to train a basic classifier, which is used to construct the MA-MOCO model. Using the idea of meta-learning, some meta-learning tasks are constructed by randomly selecting samples from the training dataset to form support sets and query sets. The MA-MOCO is further updated by comparing the query set with the positive and negative samples in the support set; thus, a simple and effectively differentiated feature space is established.
The proposed model MA-MOCO combines the advantages of CL in the establishment of a differentiated feature space and meta-learning in learning new tasks. In order to assess the accuracy of all the proposed algorithms, data from 240 wind turbines operating under different operating conditions with different faults that are not involved in the training are fed into the model in this paper. The accuracy of the model is evaluated by comparing the predicted categories with the corresponding labels of the data and solving for the classification accuracy. The results show that the proposed model MA-MOCO is superior to the Siamese net and model-agnostic meta-learning (MAML) net in the classification accuracy of wind turbine datasets. The proposed model can better solve the problems of the variable operating conditions and composite diagnosis of wind turbines.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}