
RCML: A Novel Algorithm for Regressing Price Movement during Commodity Futures Stress Testing Based on Machine Learning
Abstract
:1. Introduction
2. Materials
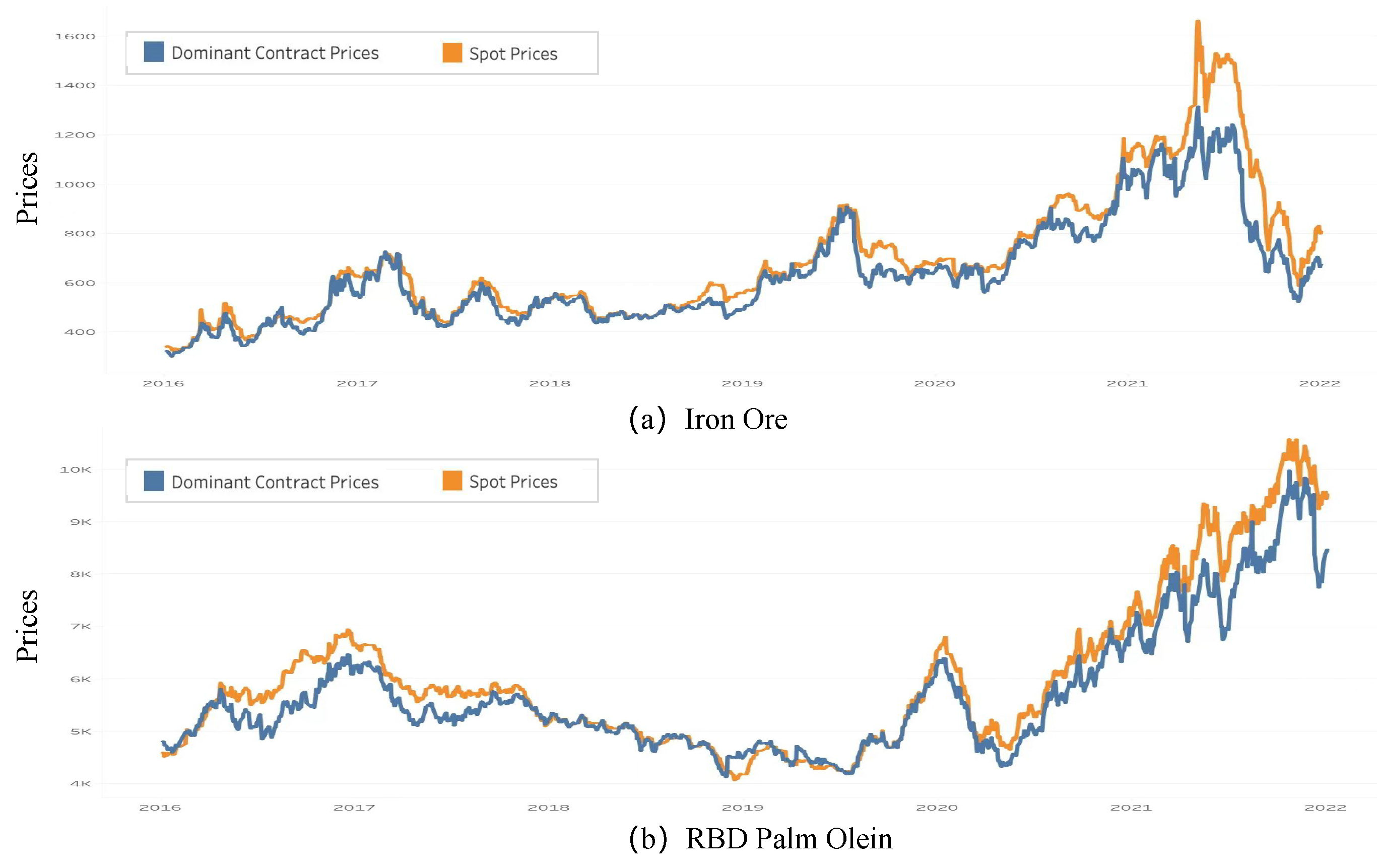
2.1. Historical Extreme Events
2.2. Multi-View Information
3. Method
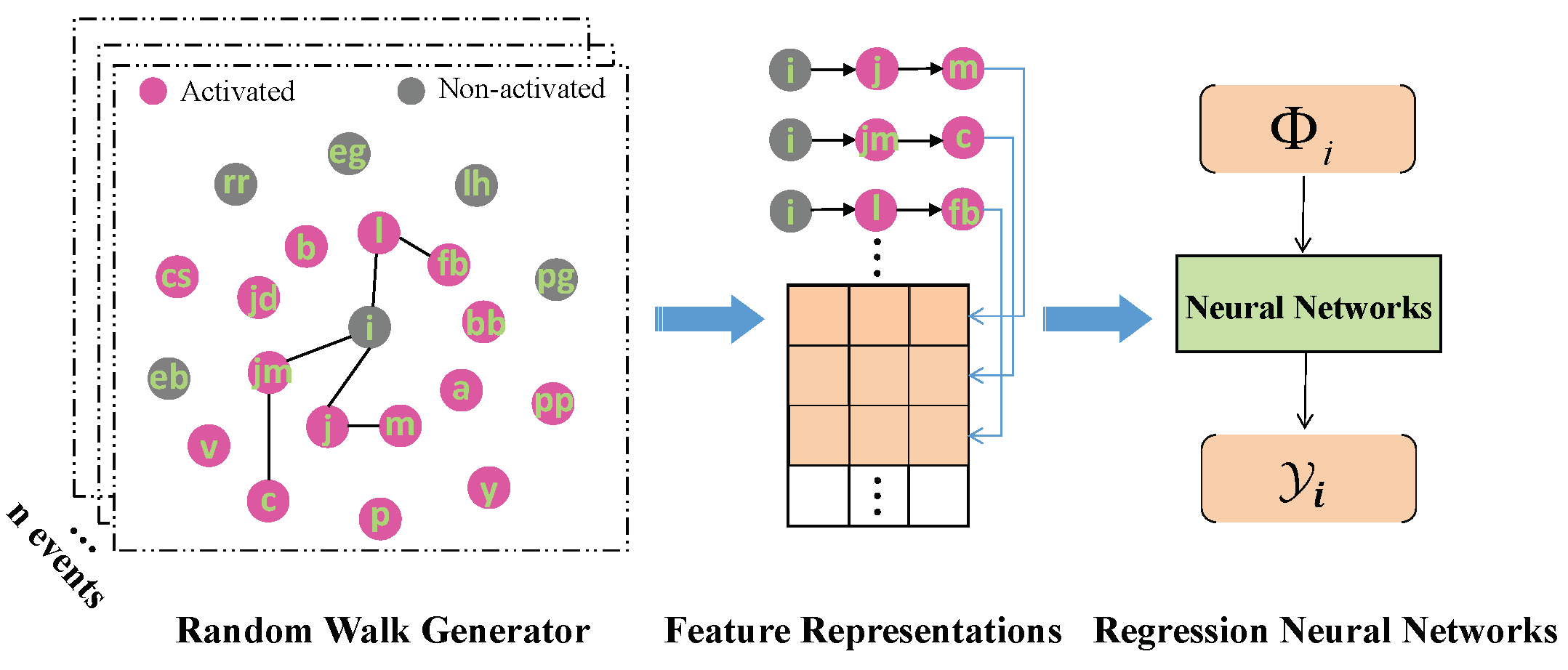
3.1. Approach Overview
3.2. Random Walk Generator
| Algorithm 1: Training process of RCML model |
 |
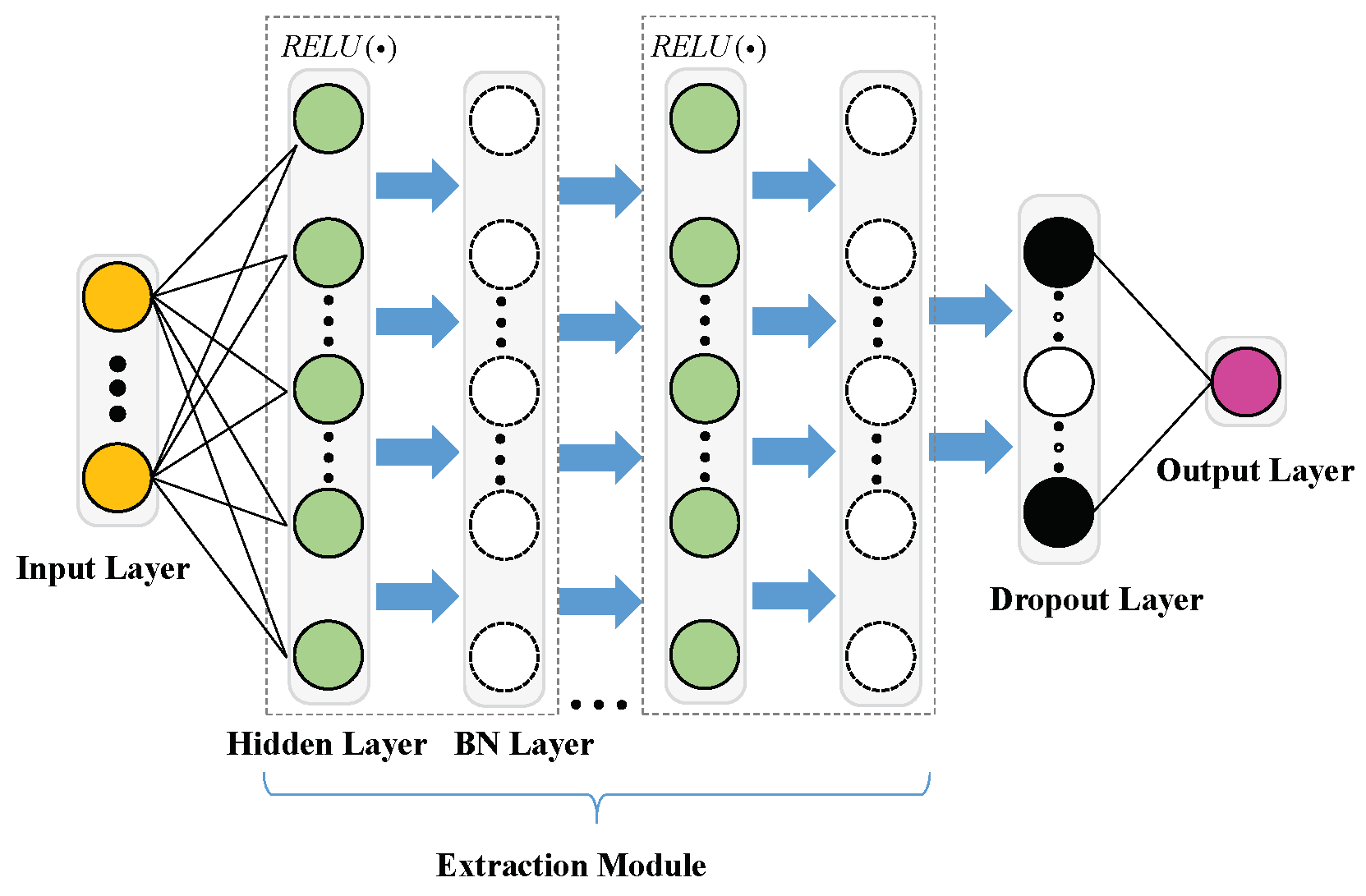
3.3. Neural Networks Regressor
4. Experiments
4.1. Dataset
4.2. Model Setup
4.3. Back Testing
4.4. Hypothesis Testing
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
| 1 | Data taken from the open source: www.100ppi.com (accessed on 18 October 2022). |
| 2 | Data taken from the wind public application programming interface (API): www.wind.com.cn (accessed on 1 September 2022). |
| 3 | See Duch and Jankowski (1999) for a survey of different activation functions. |
References
- Agarap, Abien Fred. 2018. Deep learning using rectified linear units (relu). arXiv arXiv:1803.08375. [Google Scholar]
- Aldous, David, and James Fill. 2002. Reversible Markov Chains and Random Walks on Graphs. Unfinished Monograph, Recompiled 2014. Available online: http://www.stat.berkeley.edu/~aldous/RWG/book.html (accessed on 16 September 2022).
- Benesty, Jacob, Jingdong Chen, Yiteng Huang, and Israel Cohen. 2009. Pearson correlation coefficient. In Noise Reduction in Speech Processing. Berlin/Heidelberg: Springer, pp. 1–4. [Google Scholar]
- Blaschke, Winfrid, Matthew T. Jones, Giovanni Majnoni, and Maria Soledad Martinez Peria. 2001. Stress Testing of Financial Systems: An Overview of Issues, Methodologies, and FSAP Experiences. IMF Working Papers 2001/088. Washington, DC: International Monetary Fund. [Google Scholar]
- Duch, Włodzisław, and Norbert Jankowski. 1999. Survey of neural transfer functions. Neural Computing Surveys 2: 163–212. [Google Scholar]
- EUR. 2017. Draft Guidelines on Institution’s Stress Testing, (Consultation Paper). Technical Report, European Banking Authority. Available online: https://www.eba.europa.eu (accessed on 12 June 2022).
- Fabozzi, Frank J., Hasan Fallahgoul, Vincentius Franstianto, and Gregoire Loeper. 2019. Towards Explaining Deep Learning: Asymptotic Properties of Relu FFN Sieve Estimators. Available online: https://ssrn.com/abstract=3499324 (accessed on 12 June 2022).
- Fuhrman, Roger D. 1997. Stress testing portfolios to measure the risk faced by futures clearinghouses. Paper presented at NCR-134 Conference on Applied Commodity Forecasting and Risk Management, Chicago, IL, USA, April 20; pp. 401–11. [Google Scholar]
- Gogas, Periklis, Theophilos Papadimitriou, and Anna Agrapetidou. 2018. Forecasting bank failures and stress testing: A machine learning approach. International Journal of Forecasting 34: 440–55. [Google Scholar] [CrossRef]
- Hassani, Hossein, and Emmanuel Sirimal Silva. 2015. A kolmogorov-smirnov based test for comparing the predictive accuracy of two sets of forecasts. Econometrics 3: 590–609. [Google Scholar] [CrossRef]
- Huang, Xin, Hao Zhou, and Haibin Zhu. 2009. A framework for assessing the systemic risk of major financial institutions. Journal of Banking & Finance 33: 2036–49. [Google Scholar]
- Ivanov, Alexei, and Giuseppe Riccardi. 2023. Meng wang, rethinking data-free quantization as a zero-sum game. Paper presented at AAAI Conference on Artificial Intelligence, Washington, DC, USA, February 7–14. [Google Scholar]
- Karlik, Bekir, and A. Vehbi Olgac. 2011. Performance analysis of various activation functions in generalized mlp architectures of neural networks. International Journal of Artificial Intelligence and Expert Systems 1: 111–22. [Google Scholar]
- Kingma, Diederik P., and Jimmy Ba. 2014. Adam: A method for stochastic optimization. arXiv arXiv:1412.6980. [Google Scholar]
- Kristjanpoller, Werner, and Marcel C. Minutolo. 2015. Gold price volatility: A forecasting approach using the artificial neural network–garch model. Expert Systems with Applications 42: 7245–51. [Google Scholar] [CrossRef]
- Kulkar, Siddhivinayak, and Imad Haidar. 2009. Forecasting model for crude oil price using artificial neural networks and commodity future prices. International Journal of Computer Science and Information Security 2: 81–88. [Google Scholar]
- Labach, Alex, Hojjat Salehinejad, and Shahrokh Valaee. 2019. Survey of dropout methods for deep neural networks. arXiv arXiv:1904.13310. [Google Scholar]
- Lau, Mian Mian, and King Hann Lim. 2017. Investigation of activation functions in deep belief network. Paper presented at 2017 2nd International Conference on Control and Robotics Engineering (ICCRE), Bangkok, Thailand, April 1–3; pp. 201–6. [Google Scholar]
- Liu, Caifeng, Lin Feng, Guochao Liu, Huibing Wang, and Shenglan Liu. 2021. Bottom-up broadcast neural network for music genre classification. Multimedia Tools and Applications 80: 7313–31. [Google Scholar] [CrossRef]
- Marreiros, André C., Jean Daunizeau, Stefan J. Kiebel, and Karl J. Friston. 2008. Population dynamics: Variance and the sigmoid activation function. Neuroimage 42: 147–57. [Google Scholar] [CrossRef] [PubMed]
- Montgomery, Douglas C., Elizabeth A. Peck, and G. Geoffrey Vining. 2021. Introduction to Linear Regression Analysis. Hoboken: John Wiley & Sons. [Google Scholar]
- Mudry, Pierre-Antoine, and Florentina Paraschiv. 2016. Stress-testing for portfolios of commodity futures with extreme value theory and copula functions. In Computational Management Science. Berlin/Heidelberg: Springer, pp. 17–22. [Google Scholar]
- Nas. 2014. Nasdaq Clearing Ab Ccar Model Instructions. Technical Report, Nasdaq Clearing’s Risk Management Department. Available online: https://www.nasdaq.com/docs/CCaR-Model-Instructions-171110.pdf (accessed on 3 June 2022).
- Petropoulos, Anastasios, Vassilis Siakoulis, Konstantinos P. Panousis, Theodoros Christophides, and Sotirios Chatzis. 2020. A deep learning approach for dynamic balance sheet stress testing. arXiv arXiv:2009.11075. [Google Scholar]
- PSS. 2009. Principles for Sound Stress Testing Practices and Supervision. Technical Report, Basel Committee on Banking Supervision. Available online: https://www.bis.org/publ/bcbs155.htm (accessed on 1 July 2022).
- PFM. 2017. Principles for Financial Market Infrastructures. Technical Report, International Organization of Securities Commission & Committee on Payments and Market Infrastructures. Available online: https://www.bis.org/cpmi/info_pfmi.htm (accessed on 1 July 2022).
- RMG. 1999. Risk Management: A Practical Guide. Technical Report, RiskMetrics Group. Available online: https://www.msci.com/documents/10199/3c2dcea9-97be-4fb4-befe-a03b75c885aa (accessed on 1 July 2022).
- Santurkar, Shibani, Dimitris Tsipras, Andrew Ilyas, and Aleksander Madry. 2018. How does batch normalization help optimization? arXiv arXiv:1805.11604. [Google Scholar]
- Wang, Huibing, Guangqi Jiang, Jinjia Peng, Ruoxi Deng, and Xianping Fu. 2022. Towards adaptive consensus graph: Multi-view clustering via graph collaboration. IEEE Transactions on Multimedia 1–13. [Google Scholar] [CrossRef]
- Wang, Huibing, Jinjia Peng, Dongyan Chen, Guangqi Jiang, Tongtong Zhao, and Xianping Fu. 2020. Attribute-guided feature learning network for vehicle reidentification. IEEE MultiMedia 27: 112–21. [Google Scholar] [CrossRef]
- Wang, Lu, Feng Ma, Tianjiao Niu, and Chao Liang. 2021. The importance of extreme shock: Examining the effect of investor sentiment on the crude oil futures market. Energy Economics 99: 105319. [Google Scholar] [CrossRef]
- Wang, Yang. 2021. Survey on deep multi-modal data analytics: Collaboration, rivalry, and fusion. ACM Transactions on Multimedia Computing, Communications, and Applications (TOMM) 17: 1–25. [Google Scholar] [CrossRef]
- Wang, Yang, Jinjia Peng, Huibing Wang, and Meng Wang. 2022. Progressive learning with multi-scale attention network for cross-domain vehicle re-identification. Science China Information Sciences 65: 1–15. [Google Scholar] [CrossRef]
- Worrachartdatchai, Usanee, and Pitikhate Sooraksa. 2007. Credit scoring using least squares support vector machine based on data of thai financial institutions. Paper presented at The 9th International Conference on Advanced Communication Technology, Phoenix Park, Republic of Korea, February 12–14; Volume 3, pp. 2067–70. [Google Scholar]
- Xia, Feng, Jiaying Liu, Hansong Nie, Yonghao Fu, Liangtian Wan, and Xiangjie Kong. 2019. Random walks: A review of algorithms and applications. IEEE Transactions on Emerging Topics in Computational Intelligence 4: 95–107. [Google Scholar] [CrossRef]
- Zhang, Heng-Guo, Chi-Wei Su, Yan Song, Shuqi Qiu, Ran Xiao, and Fei Su. 2017. Calculating value-at-risk for high-dimensional time series using a nonlinear random mapping model. Economic Modelling 67: 355–67. [Google Scholar] [CrossRef]
- Zhang, Y., and S. Nadarajah. 2018. A review of backtesting for value at risk. Communications in Statistics-Theory and Methods 47: 3616–39. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Commodity | RCML | Baseline | Commodity | RCML | Baseline |
|---|---|---|---|---|---|
| C | 0.64% | 0.72% | PP | 0.83% | 0.80% |
| CS | 0.80% | 0.89% | J | 0.97% | 1.21% |
| A | 0.89% | 0.94% | Y | 0.56% | 0.59% |
| B | 0.71% | 0.94% | P | 0.59% | 0.54% |
| M | 0.56% | 0.58% | FB | 0.99% | 1.11% |
| I | 0.95% | 1.06% | BB | 0.45% | 0.47% |
| JD | 1.02% | 1.21% | JM | 1.38% | 1.65% |
| L | 0.90% | 1.01% | V | 0.93% | 0.82% |
| Commodity | Inferring Results Size | Observed Sample Size | p-Value | Statistic D | Decision |
|---|---|---|---|---|---|
| EB | 139 | 157 | 0.226 | 0.1185 | Cannot Reject |
| PG | 162 | 134 | 0.222 | 0.1194 | Cannot Reject |
| EG | 134 | 162 | 0.033 | 0.163 | Rejected |
| RR | 136 | 160 | 0.036 | 0.162 | Rejected |
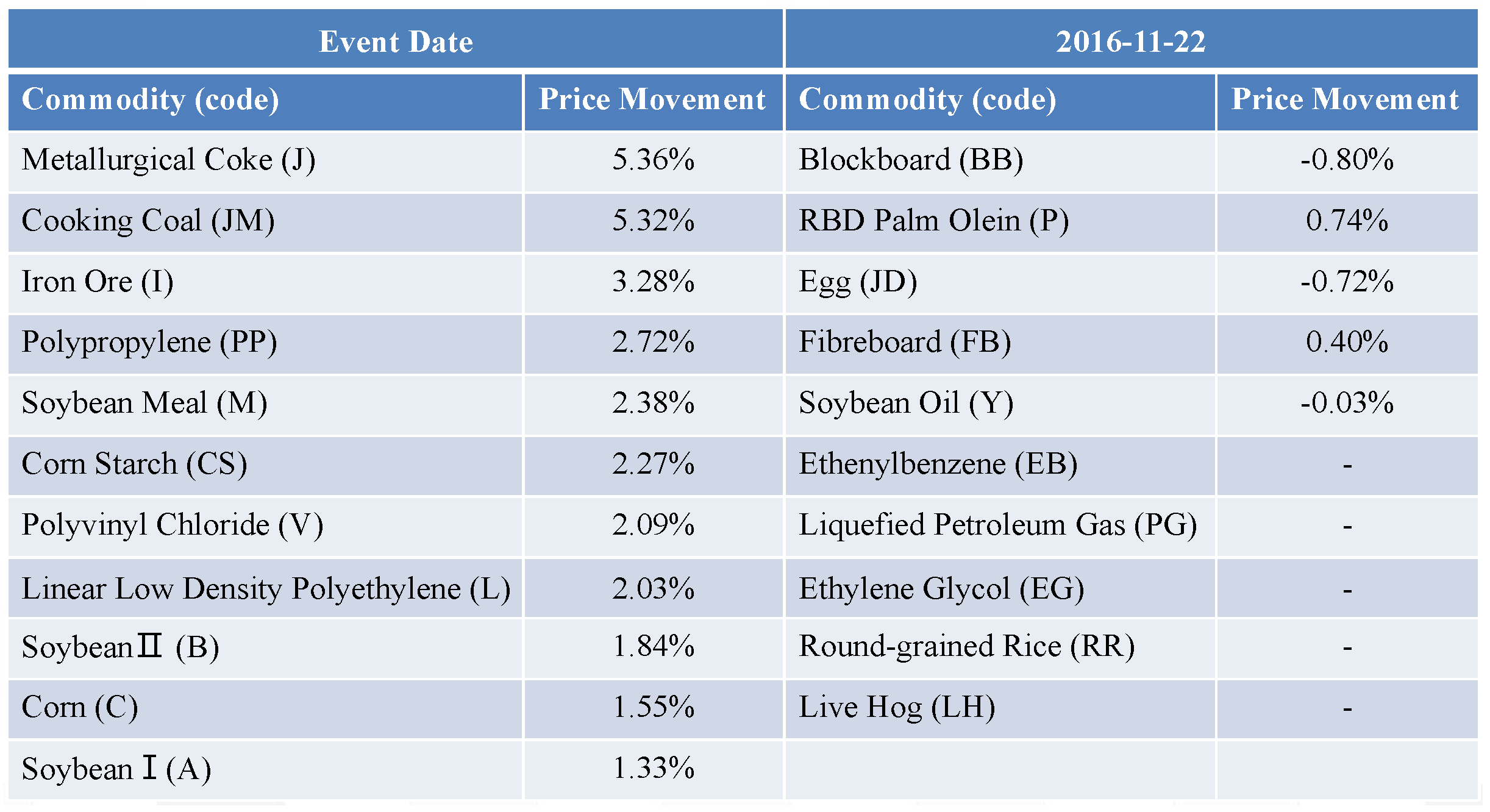
| Date | 22 November 2016 | ||||
|---|---|---|---|---|---|
| Commodity | Price Movement | Product | Price Movement | Commodity | Price Movement |
| C | 1.55% | Y | −0.03% | V | 2.09% |
| CS | 2.27% | P | 0.74% | I | 3.28% |
| A | 1.33% | FB | 0.40% | EB | 3.32% |
| B | 1.84% | BB | −0.80% | EG | −0.17% |
| M | 2.38% | JD | −0.72% | PG | −1.28% |
| PP | 2.72% | L | 2.03% | RR | −0.1% |
| J | 5.36% | JM | 5.32% | LH | - |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, C.; Pan, W.; Zhou, H. RCML: A Novel Algorithm for Regressing Price Movement during Commodity Futures Stress Testing Based on Machine Learning. J. Risk Financial Manag. 2023, 16, 285. https://doi.org/10.3390/jrfm16060285
Liu C, Pan W, Zhou H. RCML: A Novel Algorithm for Regressing Price Movement during Commodity Futures Stress Testing Based on Machine Learning. Journal of Risk and Financial Management. 2023; 16(6):285. https://doi.org/10.3390/jrfm16060285
Chicago/Turabian StyleLiu, Caifeng, Wenfeng Pan, and Hongcheng Zhou. 2023. "RCML: A Novel Algorithm for Regressing Price Movement during Commodity Futures Stress Testing Based on Machine Learning" Journal of Risk and Financial Management 16, no. 6: 285. https://doi.org/10.3390/jrfm16060285