
Self-Weighted LSE and Residual-Based QMLE of ARMA-GARCH Models †


1
Department of Mathematics, Hong Kong University of Science and Technology, Clear Water Bay, Hong Kong, China
2
Department of Statistics & Actuarial Science, The University of Hong Kong, Pok Fu Lam Road, Hong Kong, China
*
Author to whom correspondence should be addressed.
†
This article is devoted to memorize Professor Michael McAleer for his friendship and long-term support of us.
J. Risk Financial Manag. 2022, 15(2), 90; https://doi.org/10.3390/jrfm15020090
Submission received: 6 January 2022
/
Revised: 12 February 2022
/
Accepted: 16 February 2022
/
Published: 19 February 2022
(This article belongs to the Special Issue A Commemorative Issue in Honor of Professor Michael McAleer, 1952–2021)
Abstract
:This paper studies the self-weighted least squares estimator (SWLSE) of the ARMA model with GARCH noises. It is shown that the SWLSE is consistent and asymptotically normal when the GARCH noise does not have a finite fourth moment. Using the residuals from the estimated ARMA model, it is shown that the residual-based quasi-maximum likelihood estimator (QMLE) for the GARCH model is consistent and asymptotically normal, but if the innovations are asymmetric, it is not as efficient as that when the GARCH process is observed. Using the SWLSE and residual-based QMLE as the initial estimators, the local QMLE for ARMA-GARCH model is asymptotically normal via an one-step iteration. The importance of the proposed estimators is illustrated by simulated data and five real examples in financial markets.
1. Introduction
Time series models have been extensively applied in various areas and many methodologies were proposed in the literature; for example, Zhang (2003) proposed a hybrid methodology that combines both ARIMA and ANN models to improve forecasting accuracy. Since Engle (1982), the ARCH-type models have been widely used in economics and finance. In particular, the GARCH model proposed by Bollerslev (1986) has been a benchmark in the risk management. Zhang and Zhang (2020) showed that the GARCH-based option-pricing models are able to price the SPX one-month variance swap rate, that is, the CBOE Volatility Index (VIX) accurately. Setiawan et al. (2021) used the GARCH() model to analyze stock market turmoil during COVID-19 outbreak in an emerging and developed Economy.
However, recent research showed that the usual statistical inference procedure does not work if the fourth moment of the GARCH process does not exist. To make it clear, let us consider the AR(1)-GARCH() model
where , , , and is a sequence of independent and identically distributed (i.i.d.) innovations with zero mean and unit variance. For model (1), the least squares estimator (LSE) of is
where n is the sample size. Weiss (1986) and Pantula (1989) showed that is -consistent and asymptotically normal if . However, when the tail index of is in . In this case, Davis and Mikosch (1998) and Basrak et al. (2002) showed that has a heavy-tailed feature and its sample autocorrelation function is neither -consistent nor asymptotically normal. Lange (2011) showed that is -consistent and converges to a stable random variable when . Furthermore, for the AR model with being G-GARCH() noise in He and Teräsvirta (1999), Zhang and Ling (2015) showed that
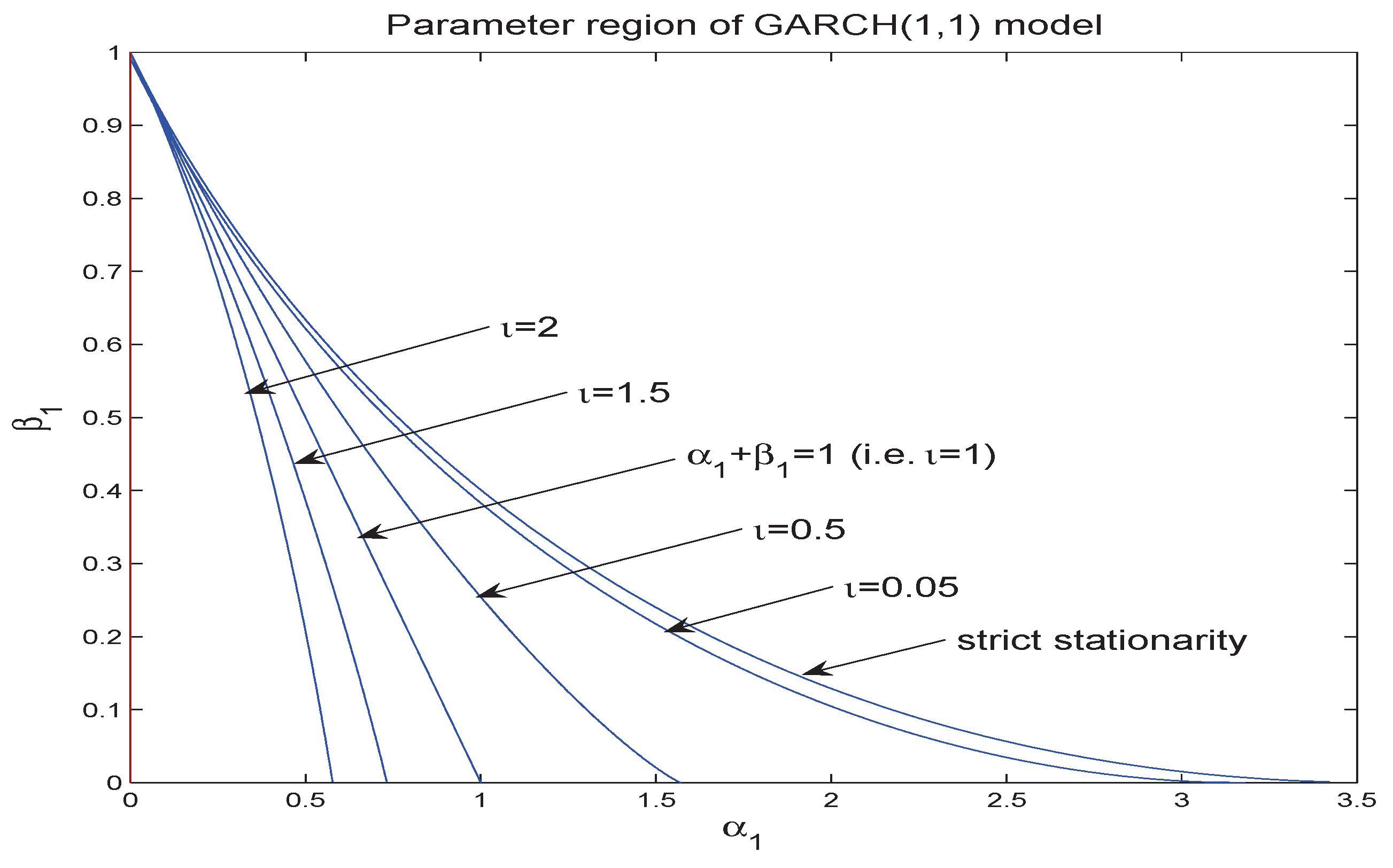
when , where denotes the convergence in distribution. From (3)–(6), we find that the LSE not only has a slower rate of convergence but also is not asymptotically normal when . Thus, based on the LSE, the classical theory and methodology (e.g., t-test, Wald test, and Ljung-Box test, among others) do not work in this case. Using a simulation method, we give the regime of parameter vector with in Figure 1 when . It can be seen that the regime of is very small for (i.e., ). In practice, the estimated value of does not lie in this regime, usually. Thus, it is very important to study the statistical inference when . Zhu and Ling (2015) studied the self-weighted least absolute deviation estimator (SLADE) of the ARMA-GARCH model and showed that it is consistent and asymptotically normal when .
This paper studies the self-weighted LSE (SWLSE) of the ARMA model with GARCH noises. It is shown that the SWLSE is consistent and asymptotically normal when the GARCH noise does not have a finite fourth moment (i.e., ). Using the residuals from the estimated ARMA model, it is shown that the residual-based quasi-maximum likelihood estimator (QMLE) for the GARCH model is consistent and asymptotically normal, but if the innovations are asymmetric, it is not as efficient as that when the GARCH process is observed. Using the SWLSE and residual-based QMLE as the initial estimators, the local QMLE for ARMA-GARCH model is asymptotically normal via an one-step iteration.
This paper is arranged as follows. Section 2 presents the model and assumptions. Section 3 presents our main results. Section 4 presents simulation results and Section 5 gives real examples. All the proofs are deferred into the Appendix A.
2. Model and Assumptions
Assume that are generated by the ARMA-GARCH model
where and , , , and is defined as in (2). Denote , , and . Let , , and be the true values of , , and , respectively. The parameter subspaces and are compact, where and . Denote , , , , , and . We introduce the following conditions:
Assumption 1.
is an interior point in Θ and for each , and when , and and have no common root with or .
Assumption 2.
and have no common root, , and for each .
Assumption 1 is the stationarity and invertibility condition of ARMA models, under which it follows that
where and with . Assumption 2 ensures that is strictly stationary and ergodic with , see Ling and Li (1997) and Ling and McAleer (2002). It is also the identifiability condition for model (2) and, by Lemma 2.1 in Ling (1999), the condition is equivalent to
is the identity matrix, and is the spectral radius of matrix B. Under this condition, we have
where and with .
Given the observations and initial value , we can write the parametric model as
It is easy to see that , , and . In practice, we do not observe those in and hence they have to be replaced by some constants. This does not affect our asymptotic results, see Ling and McAleer (2003a). For simplicity, we do not study this case in details.
3. Main Results
The self-weighted estimation approach was proposed by Ling (2005) and it has been used to solve the problem on statistical inference of the heavy-tailed ARMA-GARCH model in Ling (2007) and Zhu and Ling (2011). Using a similar idea, we define the SWLSE as
where . We can state the following result:
Theorem 1.
Suppose that Assumptions 1 and 2 hold. Then, as ,
where denotes the convergence in probability, , , and .
The preceding result holds for any kind of ARCH-type errors only if , see the proof in the Appendix A. To easily understand it, we refer to model (1) and (2) again. In this case, the information function is . The score function is and , which is the condition we need for the GARCH errors. This result holds when , but it is not as efficient as the LSE in this case. When and , the process has a heavy tailed feature and the SWLSE has a faster rate of convergence than that of LSE. The weight function can be replaced by others, see Ling (2007).
Next, we use the residual from ARMA parts as the artificial observation of . The log-quasi-likelihood function based on can be written as
where . We define the residual-based QMLE of as
Denote and by . We now give the asymptotic properties of as follows.
Theorem 2.
Suppose that Assumptions 1 and 2 hold. Then, as ,
where , , , , , and .
When is symmetric and , we have , , and hence . When the conditional mean is zero (i.e., ), model (7) and (8) reduces to the GARCH model. In this case, the log-quasi-likelihood function based on can be written as
Then, the global QMLE of is defined as . Berkes et al (2003) and Hall and Yao (2003) showed that is consistent and as ,
From Theorem 2, we see that the efficiency of the estimated is affected by the estimated parameters in ARMA parts unless has a symmetric density and is known to be zero without estimation. This gives a reminder to practitioners that we need to be careful when ones use the residuals to estimate the GARCH model.
Given and the initial value , we can write down the log-quasi-likelihood function of model (7) and (8) as follows:
Then, the global QMLE of is defined as the maximizer of in . Ling and McAleer (2003a) proved the consistency of this QMLE. But the asymptotic normality of this QMLE requires , see also Francq and Zakoïan (2004).
Based on , we obtain the local QMLE through an one-step iteration
As in Ling (2007), we can show that as ,
where , , , and . When , the local QMLE is efficient. So, Theorems 1 and 2 provide an approach to obtain an efficient estimator for the full ARMA-GARCH models under the finite second moment condition of . When is not normal, the efficient and adaptive estimators can be obtained by using the results in this section and following the similar lines as in Drost et al. (1997), Drost and Klaassen (1997), Ling (2003), and Ling and McAleer (2003b).
4. Simulation Study
In this section, we assess the finite sample performance of and , where is the SWLSE, is the residual-based QMLE, and is the local QMLE. We generate 1000 replications of sample size and 2000 from the following model
where , , and is chosen to be the standard normal N() distribution, re-scaled Laplace distribution, or re-scaled student’s distribution with . Table 1 reports the sample bias (Bias), the sample standard deviations (SD), and the average estimated asymptotic standard deviation (AD) of and . From this table, we find that (i) each considered estimator has a small bias, and its value of SD is close to that of AD, demonstrating the validity of its asymptotic normality; (ii) could be slightly more efficient than , whereas is as efficient as ; (iii) all estimators for are more efficient than the corresponding ones for or . All these findings are consistent with our theory in Section 3. We should mention that the QMLE of is not reliable when the sample size n is less than 800 according to our simulation experiments and hence the results are not reported here.
As a comparison, we compute the classical LSE for in model (19) and (20), where is computed in a similar way as with . Table 2 reports the corresponding results of . Compared with in Table 1, we find that is less efficient than for all examined cases. This finding suggests that it seems better to fit the ARMA model by the SWLSE rather than the LSE method when the data exhibit the conditionally heteroscedastic effect.
5. Real Examples
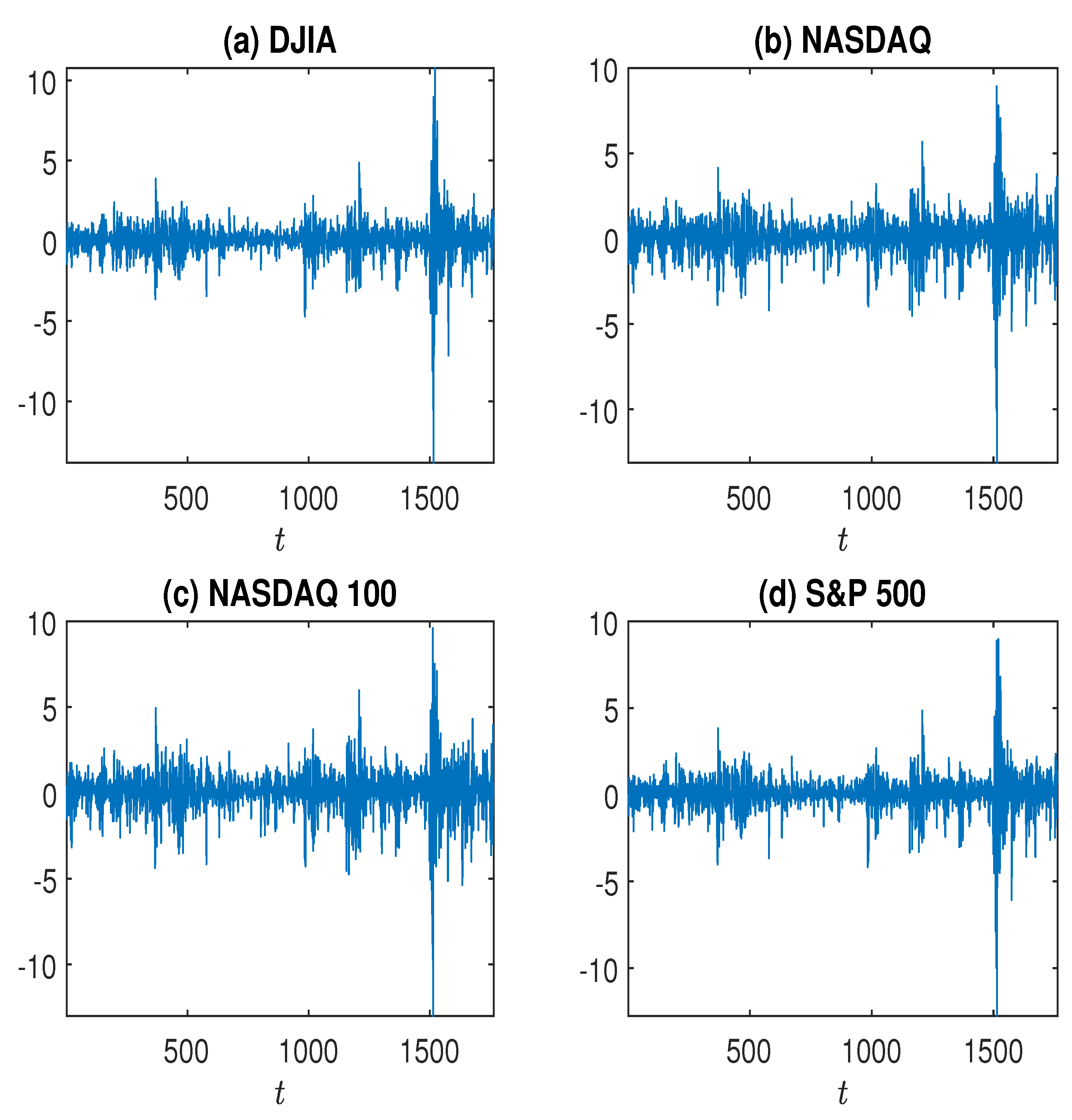
This section first studies the log returns () of DJIA, NASDAQ, NASDAQ 100, and S&P 500 from 11 March 2015 to 10 March 2021, with a total of 1764 observations (see Figure 2). Denote each log return series by . Before fitting an AR(1)-GARCH() to , we first estimate , the tail index of , and get the following results:
where is the proposed estimator of in Hill (2010), and the value in parentheses is the AD of . From the above results, we can conclude that each has a finite second moment, but does not have a finite fourth moment. Hence, it is reasonable to fit four return series by using the procedure in Section 3, that is, we first obtain the SWLSE and the residual-based QMLE , and then obtain the local QMLE . The resulting fitted models are as follows:
where all estimated parameters are the local QMLE , and the values in parentheses are the ADs of . From these fitted models, we can find that all estimated parameters are significantly different from zero at the level of 5%. In particular, the significant parameters in the fitted AR models imply that the U.S. stock market is not efficient during the examined period.
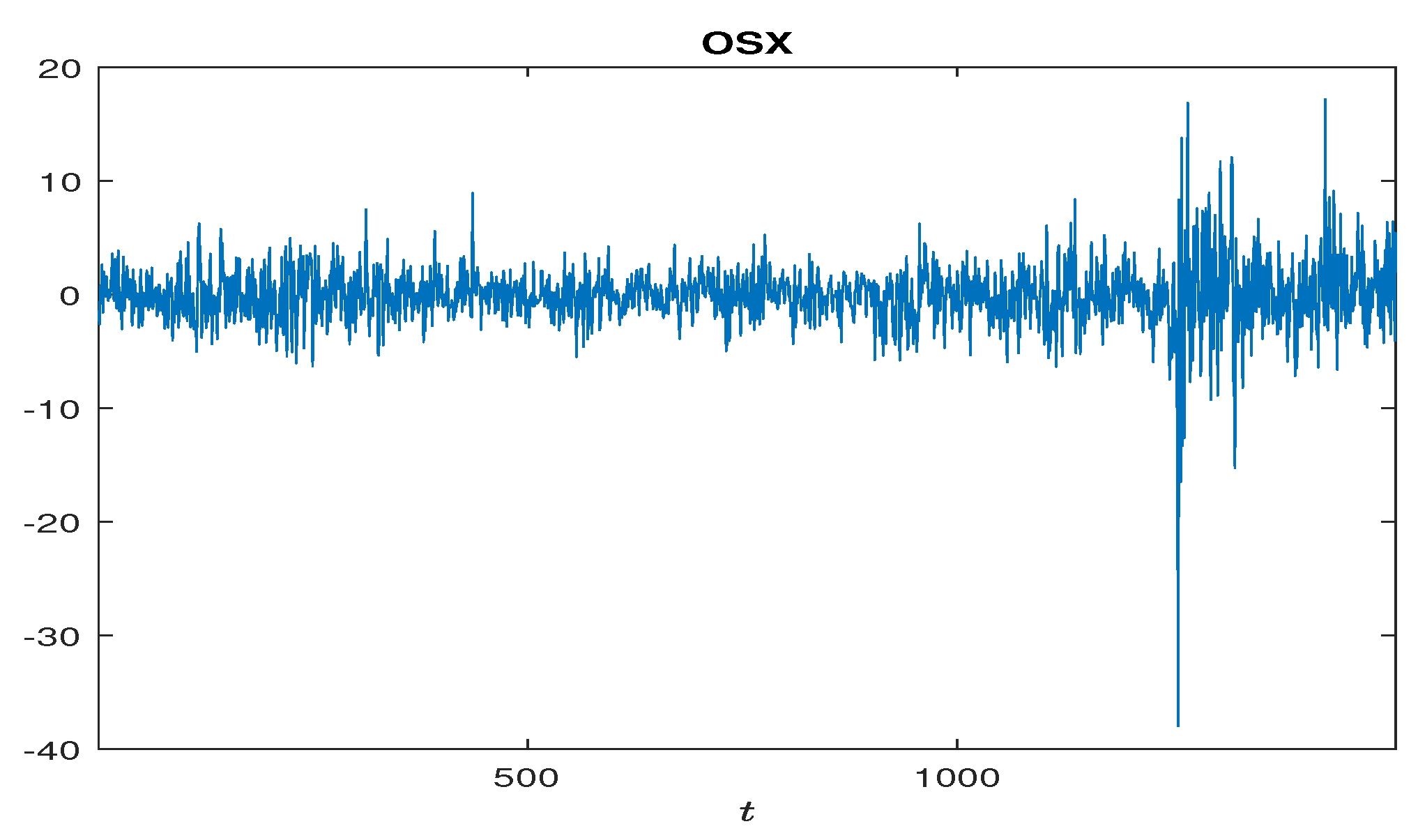
Next, this section considers the log returns () of PHLX Oil Service Index OSX from 11 March 2015 to 10 March 2021, with a total of 1510 observations (see Figure 3). As before, we denote this log return series by , and obtain its estimate with . This implies that has a finite second moment, but does not have a finite fourth moment. Hence, we apply the local QMLE method to get the following fitted model for :
Unlike the fitted results for the four U.S. stock indexes above, the fitted AR coefficient for the OSX index is not significantly different from zero at the level of 5%, indicating that the oil market is efficient during the examined period.
6. Concluding Remarks
This paper studied the SWLSE of the ARMA model with GARCH noises and the residual-based QMLE for the GARCH model. The consistency and asymptotic normality of SWLSE were established under a little moment condition. The importance of the proposed estimators was illustrated by simulated data and four major stock indexes and one major oil index in U.S. The ARMA-GARCH model is very important in the risk management, see He et al. (2019). In practice, ones need to build the ARMA-GARCH model from the historical data. The major contribution of our paper is to present a way to build an efficient and reliable model for this purpose. Several potential future research topics are listed as follows: first, we may extend our procedure for the hybrid methodology that combines both ARIMA and ANN models with GARCH errors as in Zhang (2003); second, we could use our procedure to analyze the energy data and build an ARMA-GARCH model for the green energy, renewable energy, and bio-energy data as discussing in An and Mikhaylov (2020); third, we may explore a linear programming or a genetic algorithm to find the QMLE of ARMA-GARCH model as presented in An et al. (2021).
Author Contributions
Conceptualization and methodology, S.L.; Data analysis, K.Z. All authors have read and agreed to the published version of the manuscript.
Funding
Ling’s research was funded by Hong Kong Research Grants Commission Grants (nos. 16500117, 16303118, 16301620, and 16300621), Australian Research Council, and the NSFC. Zhu’s research was funded by Hong Kong Research Grants Commission Grants (nos. 17304421, 17306818, and 17305619) and the NSFC (nos. 11690014 and 11731015).
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Publicly available data sets were analyzed in this study and can be found at https://www.wsj.com/, accessed on 5 January 2022.
Acknowledgments
The authors thank the referees for careful reading and useful comments that helped to improve the paper.
Conflicts of Interest
The authors declare no conflict of interest.
Appendix A. Proofs
The following lemma gives two basic properties for model (7) and (8).
Lemma A1.
Suppose is generated by model (8) satisfying Assumption 2. Then (i) is strictly stationary and ergodic with , and has the following causal representation:
and (ii) there exists some such that if for some , where with the first component and the th component 1, and with the th component 1, and
Proof.
The result in (i) is from Theorem 2.1 of Ling and Li (1997). For (ii), we first show that there exists an integer such that, for some ,
where for a vector or matrix B. Let with , C be defined as with all the elements of its first row replaced by 0, and
Since , the spectral radius is continuous in terms of x in . By Lemma 3.2 in Ling (1999) and Assumption 2, we know that , and there exists a constant such that
By Corollary A.2 in Johansen (1995, p. 220) and (A2),
as , where c is a constant. Let with the jth element being 1. Since all the elements of are nonnegative, it follows that
By Minkowskii’s inequality and (A3) and (A4), we have that
as . Thus, there is large enough such that (A1) holds. Using (A1) and the representation in (i), we can show that (ii) holds. This completes the proof. □
Lemma A2.
Proof of Theorem 1.
(i) Let . First, the space is compact and is an interior point in . Second, is continuous in and is a measurable function of , for all . Third, by Lemma A2(i),
where C is a constant. Moreover, by the ergodic theorem, for each . Furthermore, by Theorem 3.1 in Ling and McAleer (2003a), uniformly in . Fourth,
where . Thus,
where the equality holds if and only if , that is, , which holds if and only if under Assumption 1, that is, reaches its unique minimum at . Thus, we have established all the conditions for consistency in Theorem 4.1.1 in Amemiya (1985) and hence (i) holds.
(ii) First, is a consistent estimator of . Second,
exists and is continuous in . Third, let
By Lemma A2, we can show that . By the ergodic theorem and Theorem 3.1 in Ling and McAleer (2003a), we can show that converges to uniformly in in probability. Since is continuous in terms of , we can show that converges to in probability for any sequence , such that in probability. Fourth,
By Lemma A2, it follows that
Similar to the proof of Lemma 4.2 in Ling and McAleer (2003a), we can show that A and B are positive definite. By the central limit theorem, we have that . Thus, we have established all the conditions in Theorem 4.1.3 in Amemiya (1985), and hence . This completes the proof. □
The following Lemma A3(i)–(ii) is Lemma A.2 in Ling (2007) and Lemma A3(iii) is Lemma A.3(i) in Ling (2007).
Lemma A3.
If Assumptions 1 and 2 hold, then it follows that
where with constants and C for any .
To prove Theorem 2, we need to introduce another three lemmas. For their proofs, we need the condition that for some . Here and in the sequel, and .
Lemma A4.
If Assumptions 1 and 2 hold with for some , then it follows that
Proof.
Since in Lemma A2 is strictly stationary with , we have that . By Taylor’s expansion, Lemma A2(i), and Theorem 1(ii), it follows that
where holds uniformly in t, and lies between and . By (A5), we can readily show that
since uniformly in . Note that
where and lies between and . By Lemma A1(ii), we can show that as is small enough. By Lemma A3(iii) and the ergodic theorem, it follows that
as is small enough. Thus,
where holds uniformly in . By (A6) and (A8), it follows that
Moreover, we can show that
where and lies between and . Note that there exists an such that . For any , first taking small enough such that and then taking n large enough such that , it follows that
where the last second inequality holds by Jensen’s inequality. Thus, as n is large enough,
Similarly, we can show that
Furthermore, by (A9), the conclusion holds. This completes the proof. □
Lemma A5.
If the assumptions of Lemma A3 hold, then it follows that
Proof.
Denote and similarly for . Then
Similarly, we can have the formula of . By (A5), we have
By Lemma A3(i), . Furthermore, by Lemma A1, we can take in small enough such that the leading factors in the last terms are bounded uniformly in . Thus, the last two terms are , and hence it follows that
where holds uniformly in . Moreover, by Lemma A3(i), we have
By Lemma A1 and taking and in small enough, we have
where C is a constant. By the dominated convergence theorem, we can show that
Thus, we can show that (A13) is uniformly in . Furthermore, by (A12),
Similarly, we can show that
Similar to (A8), we can show that
The in (A14)–(A16) hold uniformly in . By (A12) and (A14)–(A16), we have that
We can show that a similar equation holds for other terms in (A10). Thus, (i) holds. By Lemmas A2 and A3, it is straightforward to show that (ii) holds. This completes the proof. □
Lemma A6.
Proof of Theorem 2.
Let . First, the space is compact and is an interior point in . Second, is continuous in and is a measurable function of , for all . Third, by Lemma A2(ii), there exist constants C and such that
uniformly in . By Jensen’s inequality, . Thus, we can show that . By the ergodic theorem, for each . Furthermore, by Theorem 3.1 in Ling and McAleer (2003a), uniformly in . By Lemma A4, uniformly in . Fourth, similar to the proof of Lemma A.10 of Ling (2007), we can show that reaches its unique maximum at . Thus, we have established all the conditions for consistency in Theorem 4.1.1 in Amemiya (1985) and hence (i) holds.
For (ii), we first have a consistent estimator of . Second, exists and is continuous in . Third, by Lemma A5(ii), . By the ergodic theorem and Theorem 3.1 in Ling and McAleer (2003a), we can show that uniformly in . Since is continuous in terms of , we can show that for any sequence , such that . Furthermore, by Lemma A5(i), for any sequence , such that . Fourth, by Taylor’s expansion, it follows that
where and lies between and . By Lemma A6, we have
Furthermore, by Theorem 1, we can show that
By Lemma A4, we can see that and . Thus, is finite. Similar to the proof of Lemma 4.2 in Ling and McAleer (2003a), we can show that and are positive definite. By the central limit theorem, we have that . Thus, we have established all the conditions in Theorem 4.1.3 in Amemiya (1985), and hence . This completes the proof. □
References
- An, Jaehyung, Alexey Mikhaylov, and Sang-Uk Jung. 2021. A linear programming approach for robust network revenue management in the airline industry. Journal of Air Transport Management 91: 101979. [Google Scholar] [CrossRef]
- An, Jaehyung, and Alexey Mikhaylov. 2020. Russian energy projects in South Africa. Journal of Energy in Southern Africa 31: 58–64. [Google Scholar] [CrossRef]
- Amemiya, Takeshi. 1985. Advanced Econometrics. Cambridge: Harvard University Press. [Google Scholar]
- Basrak, Bojan, Richard A. Davis, and Thomas Mikosch. 2002. Regular variation of GARCH processes. Stochastic Processes and Their Applications 99: 95–115. [Google Scholar] [CrossRef] [Green Version]
- Berkes, István, Lajos Horváth, and Piotr Kokoszka. 2003. GARCH processes: Structure and estimation. Bernoulli 9: 201–7. [Google Scholar] [CrossRef]
- Bollerslev, Tim. 1986. Generalized autoregressive conditional heteroskedasticity. Journal of Econometrics 31: 307–27. [Google Scholar] [CrossRef] [Green Version]
- Davis, Richard A., and Thomas Mikosch. 1998. The sample autocorrelations of heavy-tailed processs with applications to ARCH. Annals of Statistics 26: 2049–80. [Google Scholar] [CrossRef]
- Drost, Feike C., and Chris A. J. Klaassen. 1997. Efficient estimation in semiparametric GARCH models. Journal of Econometrics 81: 193–221. [Google Scholar] [CrossRef] [Green Version]
- Drost, Feike C., Chris A. J. Klaassen, and Bas J. M. Werker. 1997. Adaptive estimation in time series models. Annals of Statistics 25: 786–817. [Google Scholar] [CrossRef]
- Engle, Robert F. 1982. Autoregressive conditional heteroskedasticity with estimates of variance of U.K. inflation. Econometrica 50: 987–1008. [Google Scholar] [CrossRef]
- Francq, Christian, and Jean-Michel Zakoïan. 2004. Maximum likelihood estimation of pure GARCH and ARMA-GARCH processes. Bernoulli 10: 605–637. [Google Scholar] [CrossRef]
- Hall, Peter, and Qiwei Yao. 2003. Inference in ARCH and GARCH models. Eonometrica 71: 285–317. [Google Scholar] [CrossRef] [Green Version]
- He, Changli, and Timo Teräsvirta. 1999. Properties of moments of a family of GARCH processes. Journal of Econometrics 92: 173–92. [Google Scholar] [CrossRef]
- He, Yi, Yanxi Hou, Liang Peng, and Jiliang Sheng. 2019. Statistical inference for a relative risk measure. Journal of Business & Economic Statistics 37: 301–11. [Google Scholar]
- Hill, Jonathan B. 2010. On tail index estimation for dependent, heterogeneous data. Econometric Theory 26: 1398–436. [Google Scholar] [CrossRef] [Green Version]
- Johansen, Søren. 1995. Likelihood-based Inference in Cointegrated Vector Autoregressive Models. Oxford: OUP Oxford. [Google Scholar]
- Lange, Theis. 2011. Tail behavior and OLS estimation in AR-GARCH models. Statistica Sinica 21: 1191–200. [Google Scholar] [CrossRef] [Green Version]
- Ling, Shiqing. 1999. On the stationarity and the existence of moments of conditional heteroskedastic ARMA models. Statistica Sinica 9: 1119–30. [Google Scholar]
- Ling, Shiqing. 2003. Adaptive estimators and tests of stationary and non-stationary short and long memory ARIMA-GARCH models. Journal of the American Statistical Association 98: 955–67. [Google Scholar] [CrossRef]
- Ling, Shiqing. 2005. Self-weighted LAD estimation for infinite variance autoregressive models. Journal of the Royal Statistical Society: Series B 67: 381–93. [Google Scholar] [CrossRef]
- Ling, Shiqing. 2007. Self-weighted and local quasi-maximum likelihood estimator for ARMA-GARCH/IGARCH models. Journal of Econometrics 140: 849–73. [Google Scholar] [CrossRef]
- Ling, Shiqing, and Michael McAleer. 2002. Necessary and sufficient moment conditions for the GARCH(r, s) and asymmetric power GARCH(r, s) models. Econometric Theory 18: 722–29. [Google Scholar] [CrossRef] [Green Version]
- Ling, Shiqing, and Wai Keung Li. 1997. Fractional autoregressive integrated moving-average time series with conditional heteroskedasticity. Journal of the American Statistical Association 92: 1184–94. [Google Scholar] [CrossRef]
- Ling, Shiqing, and Michael McAleer. 2003a. Asymptotic theory for a new vector ARMA-GARCH model. Econometric Theory 19: 280–310. [Google Scholar] [CrossRef] [Green Version]
- Ling, Shiqing, and Michael McAleer. 2003b. On adaptive estimation in nonstationary ARMA models with GARCH errors. Annals of Statistics 31: 642–74. [Google Scholar] [CrossRef]
- Pantula, Sastry G. 1989. Estimation of autoregressive models with ARCH errors. Sankhyā: The Indian Journal of Statistics, Series B 50: 119–38. [Google Scholar]
- Setiawan, Budi, Marwa Ben Abdallah, Maria Fekete-Farkas, Robert Jeyakumar Nathan, and Zoltan Zeman. 2021. GARCH (1, 1) models and analysis of stock market turmoil during COVID-19 outbreak in an emerging and developed economy. Journal of Risk and Financial Management 14: 576. [Google Scholar] [CrossRef]
- Weiss, Andrew A. 1986. Asymptotic theory for ARCH models: Estimation and testing. Econometrics Theory 2: 107–31. [Google Scholar] [CrossRef] [Green Version]
- Zhang, G. Peter. 2003. Time series forecasting using a hybrid ARIMA and neural network model. Neurocomputing 50: 159–75. [Google Scholar] [CrossRef]
- Zhang, Rongmao, and Shiqing Ling. 2015. Asymptotic inference for AR models with heavy-tailed G-GARCH noises. Econometric Theory 31: 880–90. [Google Scholar] [CrossRef]
- Zhang, Wenjun, and Jin E. Zhang. 2020. GARCH option pricing models and the variance risk premium. Journal of Risk and Financial Management 13: 51. [Google Scholar] [CrossRef] [Green Version]
- Zhu, Ke, and Shiqing Ling. 2011. Global self-weighted and local quasi-maximum exponential likelihood estimators for ARMA-GARCH/ IGARCH models. Annals of Statistics 39: 2131–63. [Google Scholar] [CrossRef]
- Zhu, Ke, and Shiqing Ling. 2015. LADE-based inference for ARMA models with unspecified and heavy-tailed heteroscedastic noises. Journal of the American Statistical Association 110: 784–94. [Google Scholar] [CrossRef] [Green Version]
Figure 1.
Parameter regime of with .

Figure 2.
Log returns () of DJIA, NASDAQ, NASDAQ 100, and S&P 500 from 11 March 2015 to 10 March 2021.
Figure 2.
Log returns () of DJIA, NASDAQ, NASDAQ 100, and S&P 500 from 11 March 2015 to 10 March 2021.

Figure 3.
Log returns () of OSX from 11 March 2015 to 10 March 2021.


{kind=link}
{kind=link}
{kind=link}
Table 1.
The results of and .
| n | |||||||
| 1000 | Bias | −0.0012 | 0.0032 | 0.0189 | 0.0012 | −0.0235 | |
| SD | 0.0443 | 0.0423 | 0.0650 | 0.0278 | 0.0839 | ||
| AD | 0.0424 | 0.0402 | 0.0524 | 0.0290 | 0.0726 | ||
| 2000 | Bias | −0.0017 | 0.0015 | 0.0083 | −0.0000 | −0.0103 | |
| SD | 0.0300 | 0.0293 | 0.0342 | 0.0204 | 0.0471 | ||
| AD | 0.0300 | 0.0285 | 0.0332 | 0.0201 | 0.0469 | ||
| 1000 | Bias | −0.0010 | 0.0022 | 0.0172 | 0.0015 | −0.0210 | |
| SD | 0.0425 | 0.0406 | 0.0657 | 0.0282 | 0.0845 | ||
| AD | 0.0405 | 0.0380 | 0.0526 | 0.0291 | 0.0729 | ||
| 2000 | Bias | −0.0016 | 0.0012 | 0.0073 | −0.0000 | −0.0087 | |
| SD | 0.0283 | 0.0274 | 0.0340 | 0.0205 | 0.0470 | ||
| AD | 0.0286 | 0.0270 | 0.0332 | 0.0202 | 0.0469 | ||
| 1000 | Bias | −0.0032 | 0.0035 | 0.0241 | 0.0020 | −0.0304 | |
| SD | 0.0454 | 0.0414 | 0.0806 | 0.0381 | 0.1079 | ||
| AD | 0.0456 | 0.0433 | 0.0639 | 0.0385 | 0.0909 | ||
| 2000 | Bias | −0.0001 | 0.0014 | 0.0116 | 0.0016 | −0.0148 | |
| SD | 0.0328 | 0.0307 | 0.0426 | 0.0268 | 0.0599 | ||
| AD | 0.0323 | 0.0307 | 0.0397 | 0.0269 | 0.0577 | ||
| 1000 | Bias | −0.0027 | 0.0028 | 0.0237 | 0.0028 | −0.0296 | |
| SD | 0.0444 | 0.0402 | 0.0918 | 0.0390 | 0.1183 | ||
| AD | 0.0443 | 0.0416 | 0.0641 | 0.0387 | 0.0913 | ||
| 2000 | Bias | −0.0008 | 0.0013 | 0.0109 | 0.0019 | −0.0138 | |
| SD | 0.0316 | 0.0296 | 0.0424 | 0.0270 | 0.0598 | ||
| AD | 0.0313 | 0.0295 | 0.0397 | 0.0270 | 0.0578 | ||
| 1000 | Bias | −0.0012 | 0.0016 | 0.0300 | 0.0046 | −0.0395 | |
| SD | 0.0460 | 0.0445 | 0.0867 | 0.0432 | 0.1137 | ||
| AD | 0.0454 | 0.0431 | 0.0734 | 0.0443 | 0.1038 | ||
| 2000 | Bias | 0.0014 | 0.0005 | 0.0126 | 0.0025 | −0.0164 | |
| SD | 0.0312 | 0.0305 | 0.0463 | 0.0325 | 0.0657 | ||
| AD | 0.0323 | 0.0308 | 0.0459 | 0.0316 | 0.0666 | ||
| 1000 | Bias | −0.0022 | 0.0018 | 0.0291 | 0.0054 | −0.0381 | |
| SD | 0.0472 | 0.0448 | 0.0897 | 0.0444 | 0.1166 | ||
| AD | 0.0443 | 0.0417 | 0.0737 | 0.0445 | 0.1042 | ||
| 2000 | Bias | 0.0006 | 0.0007 | 0.0119 | 0.0030 | −0.0155 | |
| SD | 0.0317 | 0.0296 | 0.0462 | 0.0330 | 0.0656 | ||
| AD | 0.0315 | 0.0297 | 0.0459 | 0.0317 | 0.0667 | ||
Table 2.
The results of .
| n | |||||||||
| 1000 | Bias | 0.0001 | 0.0012 | −0.0034 | 0.0024 | −0.0033 | 0.0015 | ||
| SD | 0.0441 | 0.0412 | 0.0482 | 0.0473 | 0.0518 | 0.0487 | |||
| AD | 0.0437 | 0.0411 | 0.0507 | 0.0474 | 0.0525 | 0.0490 | |||
| 2000 | Bias | −0.0018 | 0.0015 | −0.0009 | 0.0011 | −0.0008 | 0.0010 | ||
| SD | 0.0307 | 0.0299 | 0.0350 | 0.0325 | 0.0382 | 0.0349 | |||
| AD | 0.0311 | 0.0293 | 0.0367 | 0.0344 | 0.0382 | 0.0358 | |||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Ling, S.; Zhu, K. Self-Weighted LSE and Residual-Based QMLE of ARMA-GARCH Models. J. Risk Financial Manag. 2022, 15, 90. https://doi.org/10.3390/jrfm15020090
AMA Style
Ling S, Zhu K. Self-Weighted LSE and Residual-Based QMLE of ARMA-GARCH Models. Journal of Risk and Financial Management. 2022; 15(2):90. https://doi.org/10.3390/jrfm15020090
Chicago/Turabian StyleLing, Shiqing, and Ke Zhu. 2022. "Self-Weighted LSE and Residual-Based QMLE of ARMA-GARCH Models" Journal of Risk and Financial Management 15, no. 2: 90. https://doi.org/10.3390/jrfm15020090