

Compositional Classification of Financial Statement Profiles: The Weighted Case



Abstract
:1. Introduction
2. Materials and Methods
2.1. What Is Compositional Data Analysis?
- Scale invariance means that compositional data only carry relative information. So, proportional X matrices are equivalent, and any change in the scale of the dataset has no effect and produces compatible results.
- Sub compositional coherence means that the relationships among a subset of parts of a composition are the same as in the full composition.
- Permutation invariance means that the results do not depend on the order of the parts in a compositional dataset. The parts can be re-ordered across the whole dataset without affecting the results.
2.2. Logratio Transformations and Compositional Distances
- Most of the ratios used in finance “are distributed between zero and infinity, and thus make fully symmetric distributions impossible to achieve” (Linares-Mustarós et al. 2018, p. 1). More particularly, they usually have positive skewness and outliers, thus deviating from the normal distribution (Linares-Mustarós et al. 2022; So 1987).
- The results of financial ratio analysis depend on the arbitrary decision regarding which accounting figure is in the numerator and which is in the denominator of the financial ratio, so that standard financial ratios are not permutation invariant (Creixans-Tenas et al. 2019; Frecka and Hopwood 1983; Linares-Mustarós et al. 2022).
- Financial statement analysis is subject to redundancy problems when several ratios conveying similar information are included in the dataset (Chen and Shimerda 1981). For example, the inverse of the liability-to-asset ratio is the equity-to-debt ratio plus one. In cluster analysis, such redundancy increases distances among companies along the added redundant information, which is tantamount to inadvertently giving this redundant information greater weight in the results (Linares-Mustarós et al. 2018).
2.3. Dataset and Software
2.4. Selected Parts from the Balance Sheet and Profit and Losses Account and Financial Ratios
- xi1 = non-current assets;
- xi2 = current assets;
- xi3 = non-current liabilities;
- xi4 = current liabilities;
- xi5 = net sales;
- xi6 = costs.
- The turnover ratio measures the efficiency of a company assets in generating revenues:
- The margin ratio measures the part of sales that is turned into profit:
- The asset-structure ratio measures the share of non-current assets in total assets:
- The liquidity ratio compares current assets and current liabilities:
- The debt-maturity ratio measures the share of non-current liabilities within total liability:
- The indebtedness ratio measures the share of assets paid for by debt:
- The leverage ratio relates assets to net worth:
- The Return On Assets (ROA) divides the company’s net income by its total assets:
- The Return On Equity (ROE) divides the company’s net income by net worth:
2.5. Zero Replacement
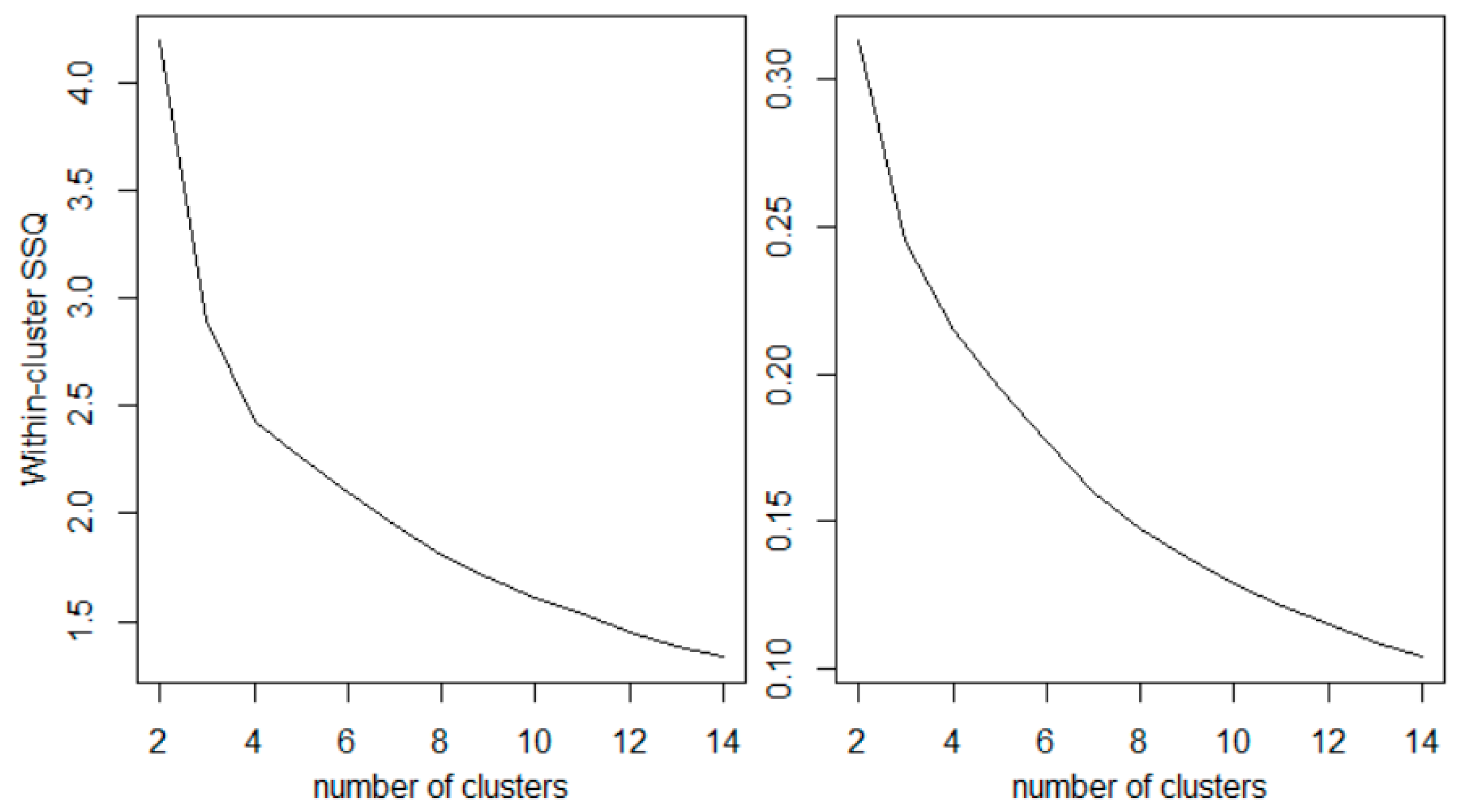
2.6. Cluster Analysis
3. Results
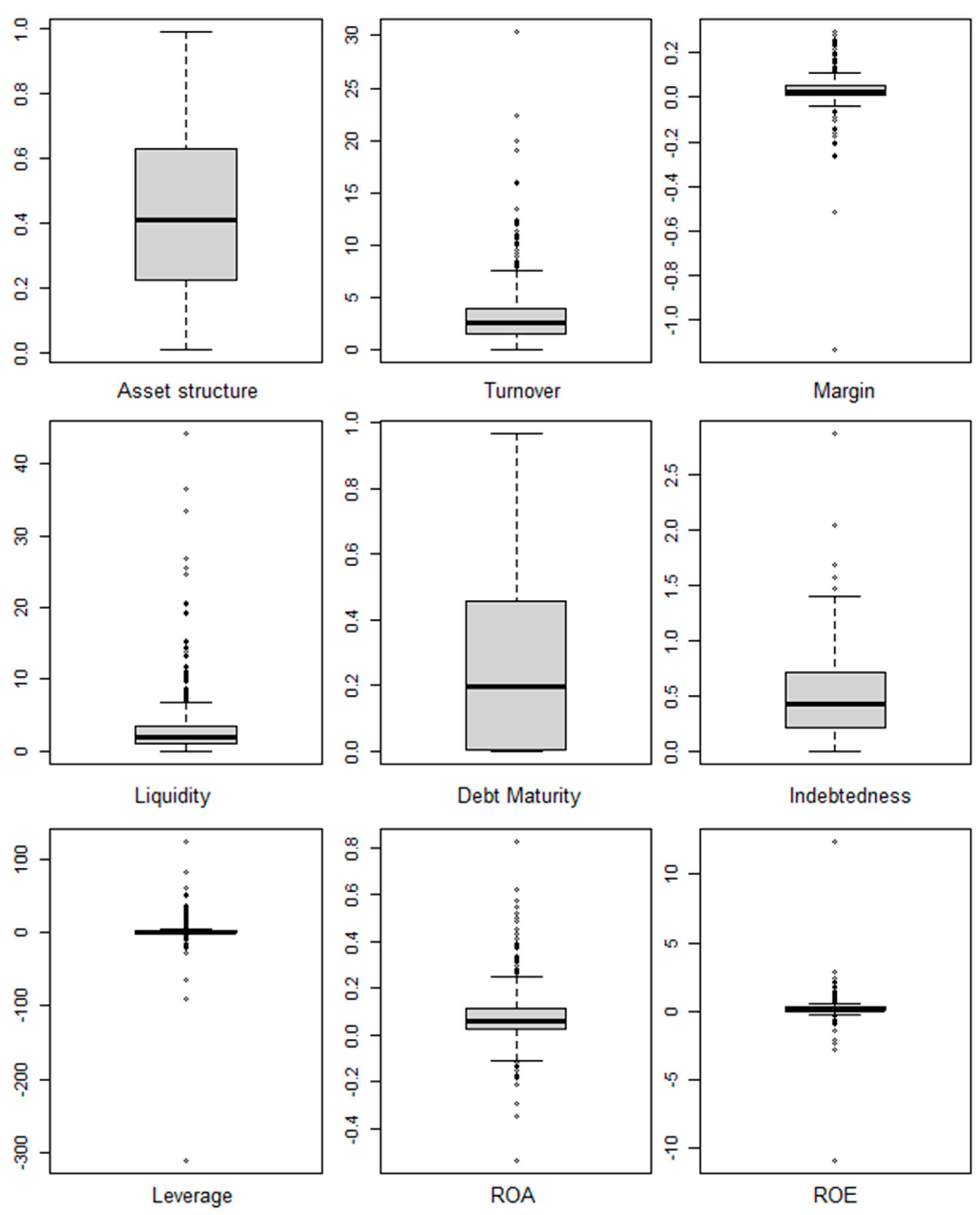
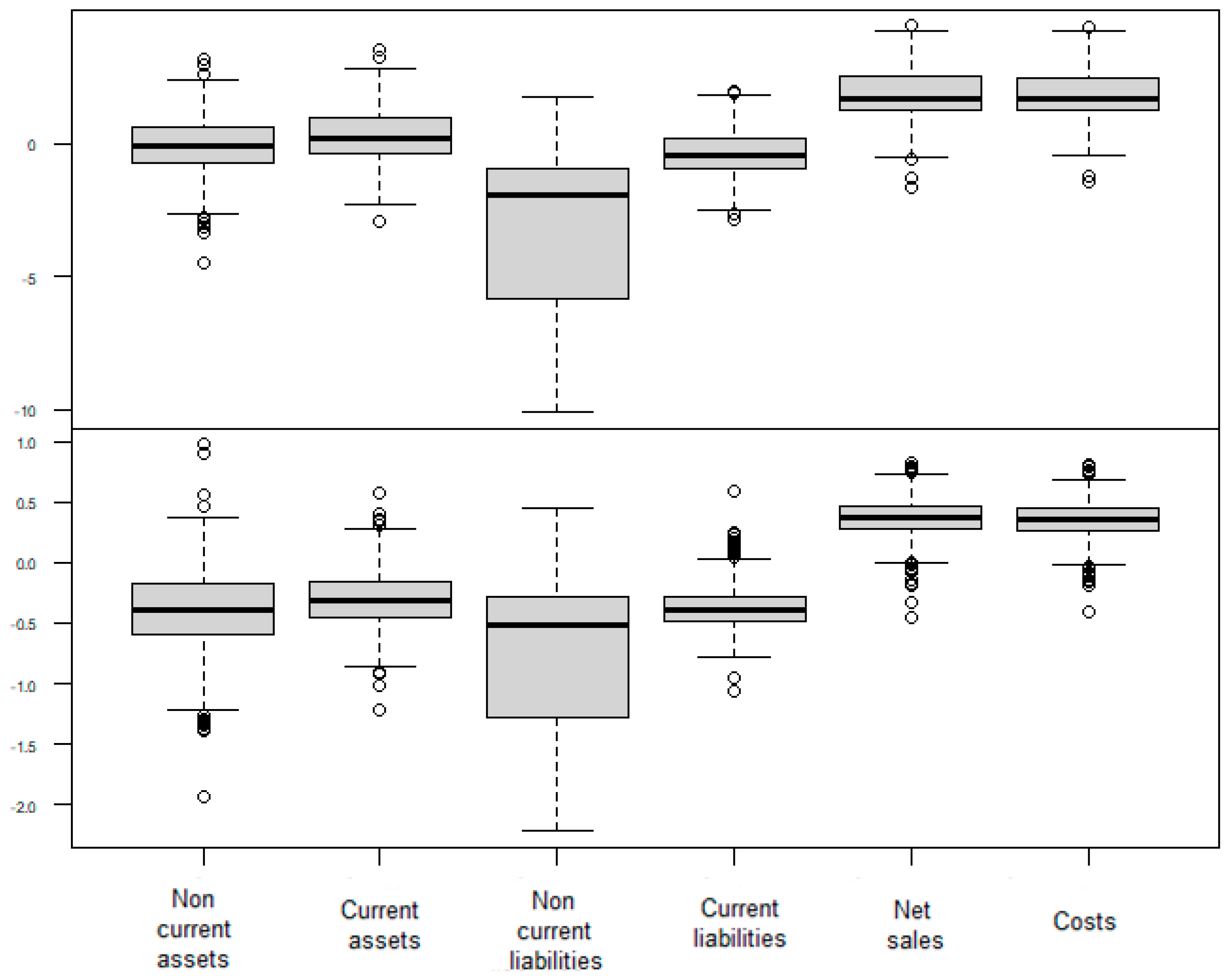
3.1. Exploratory Analysis
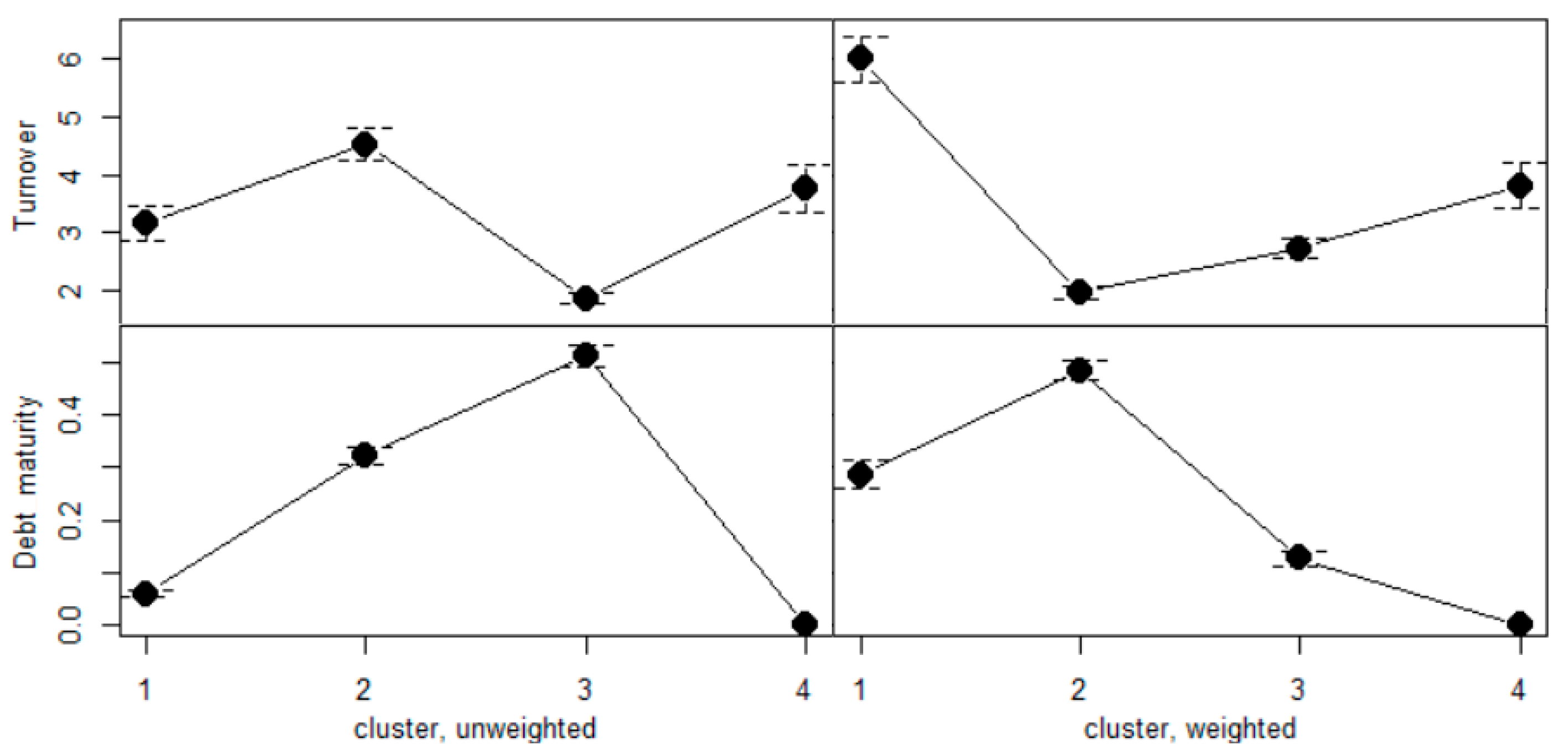
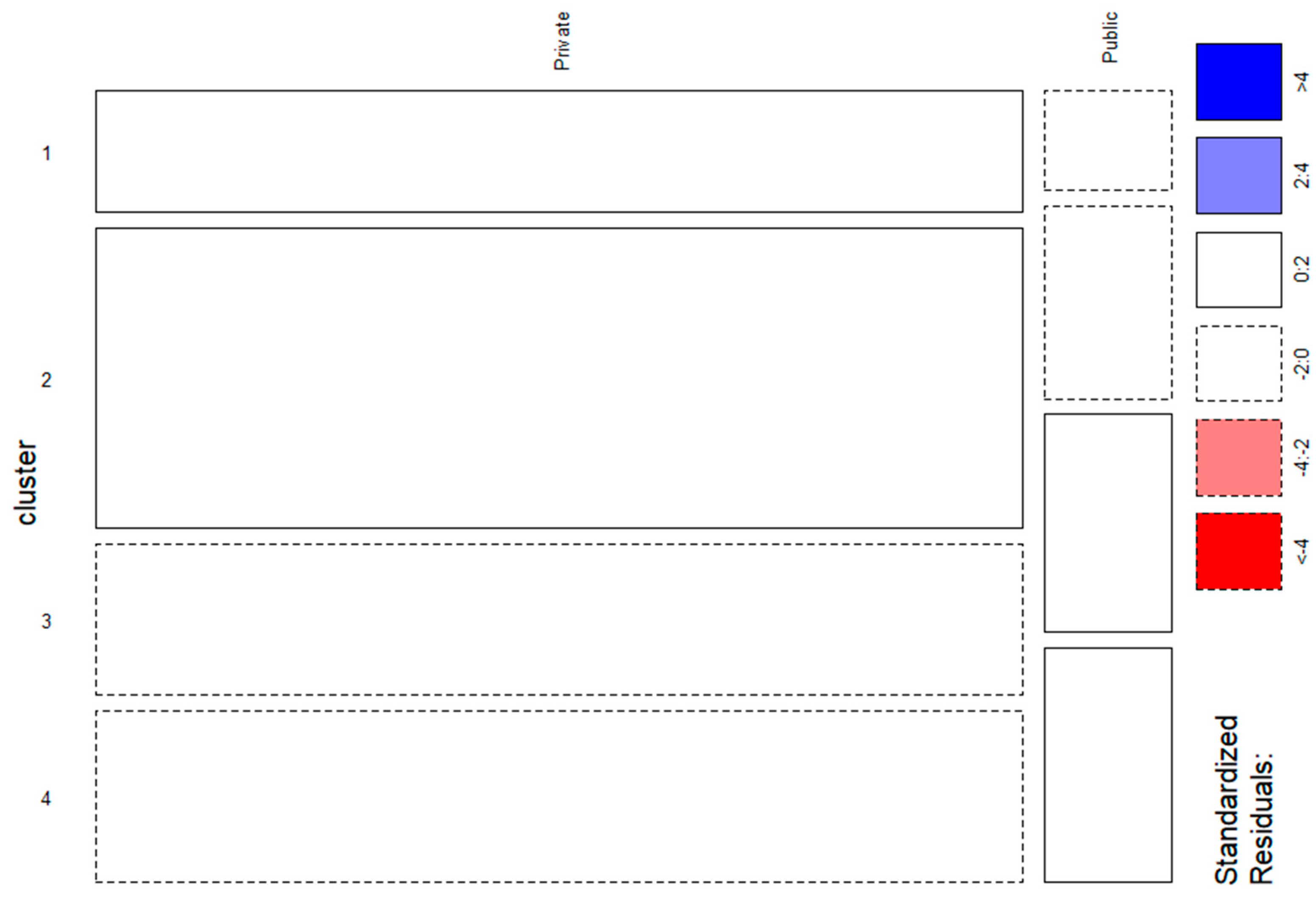
3.2. Comparison of Weighted and Unweighted Analysis
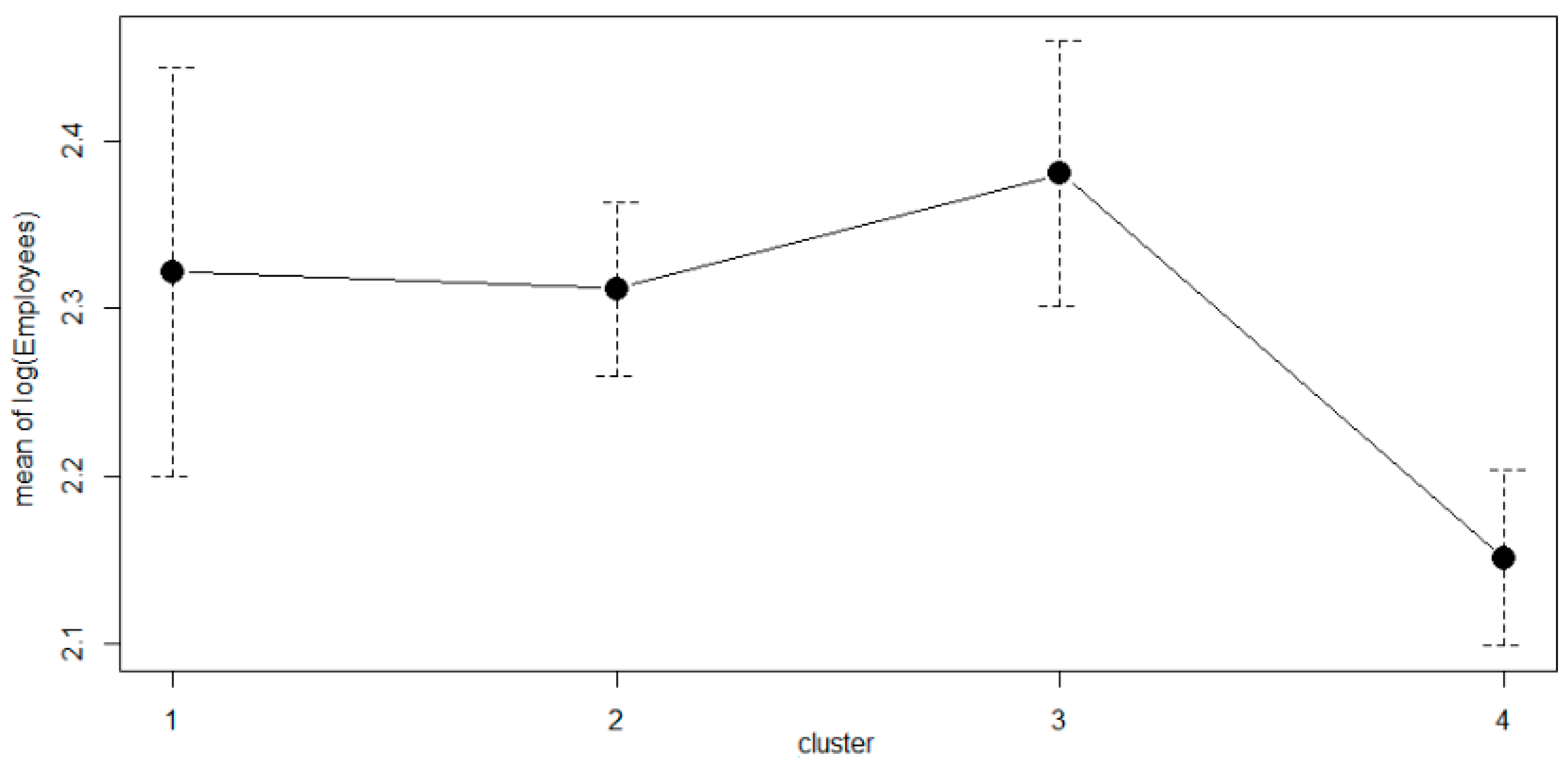
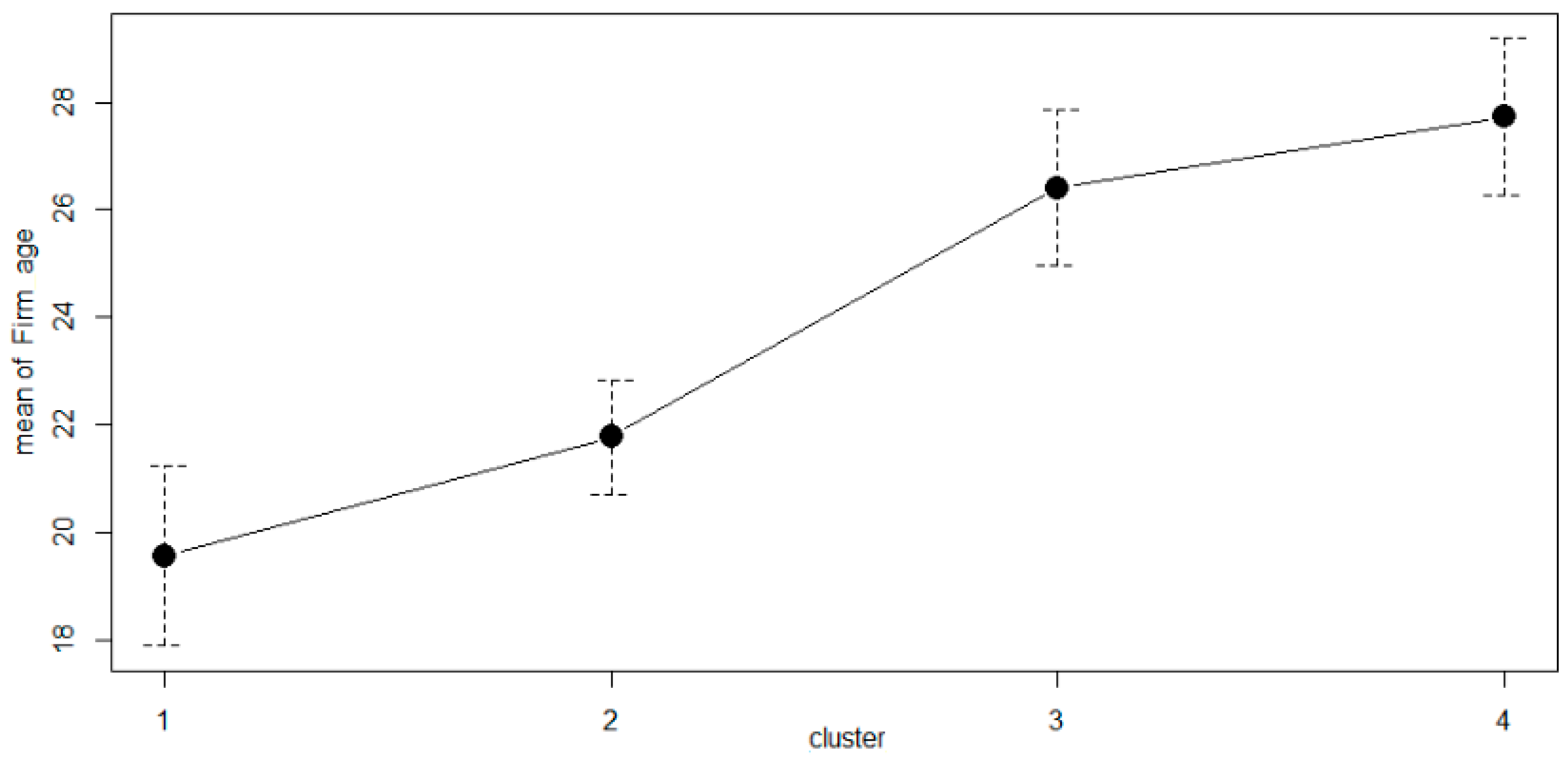
3.3. Interpretation of the Weighted Analysis
4. Discussion
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Aitchison, John. 1982. The statistical analysis of compositional data (with discussion). Journal of the Royal Statistical Society: Series B (Statistical Methodology) 44: 139–77. [Google Scholar] [CrossRef]
- Aitchison, John, Carles Barceló-Vidal, Josep Antoni Martín-Fernández, and Vera Pawlowsky-Glahn. 2000. Logratio analysis and compositional distances. Mathematical Geology 32: 271–75. [Google Scholar] [CrossRef]
- Arimany-Serrat, Núria, Àngels Farreras-Noguer, and Germà Coenders. 2022. New developments in financial statement analysis. Liquidity in the winery sector. Accounting 8: 355–66. [Google Scholar] [CrossRef]
- Barceló-Vidal, Carles, and Josep Antoni Martín-Fernández. 2016. The mathematics of compositional analysis. Austrian Journal of Statistics 45: 57–71. [Google Scholar] [CrossRef] [Green Version]
- Carreras-Simó, Miquel, and Germà Coenders. 2020. Principal component analysis of financial statements. A compositional approach. Revista de Métodos Cuantitativos para la Economía y la Empresa 29: 18–37. [Google Scholar] [CrossRef]
- Carreras-Simó, Miquel, and Germà Coenders. 2021. The relationship between asset and capital structure: A compositional approach with panel vector autoregressive models. Quantitative Finance and Economics 5: 571–90. [Google Scholar] [CrossRef]
- Chen, Kung H., and Thomas A. Shimerda. 1981. An empirical analysis of useful financial ratios. Financial Management 10: 51–60. [Google Scholar] [CrossRef]
- Chnar Abdullah, Rashid. 2021. The efficiency of financial ratios analysis to evaluate company’s profitability. Journal of Global Economics and Business 2: 119–32. [Google Scholar]
- Coenders, Germà, and Berta Ferrer-Rosell. 2020. Compositional data analysis in tourism. Review and future directions. Tourism Analysis 25: 153–68. [Google Scholar] [CrossRef]
- Cowen, Scott S., and Jeffrey A. Hoffer. 1982. Usefulness of financial ratios in a single industry. Journal of Business Research 10: 103–18. [Google Scholar] [CrossRef]
- Creixans-Tenas, Judit, Germà Coenders, and Núria Arimany-Serrat. 2019. Corporate social responsibility and financial profile of Spanish private hospitals. Heliyon 5: e02623. [Google Scholar] [CrossRef] [PubMed]
- Dolnicar, Sara, Bettina Grün, and Friedrich Leisch. 2018. Market Segmentation Analysis: Understanding It, Doing It, and Making It Useful. Singapore: Springer Nature, pp. 1–324. [Google Scholar]
- Egozcue, Juan José, and Vera Pawlowsky-Glahn. 2016. Changing the reference measure in the simplex and its weighting effects. Austrian Journal of Statistics 45: 25–44. [Google Scholar] [CrossRef] [Green Version]
- Egozcue, Juan José, and Vera Pawlowsky-Glahn. 2019. Compositional data: The sample space and its structure. Test 28: 599–638. [Google Scholar] [CrossRef]
- Ferrer-Rosell, Berta, and Germà Coenders. 2018. Destinations and crisis. Profiling tourists’ budget share from 2006 to 2012. Journal of Destination Marketing & Management 7: 26–35. [Google Scholar] [CrossRef] [Green Version]
- Frecka, Thomas J., and William S. Hopwood. 1983. The effects of outliers on the cross-sectional distributional properties of financial ratios. Accounting Review 58: 115–28. [Google Scholar]
- Goldstein, Harvey, and Michael J. R. Healy. 1995. The graphical presentation of a collection of means. Journal of the Royal Statistical Society: Series A (Statistics in Society) 158: 175–77. [Google Scholar] [CrossRef]
- Greenacre, Michael. 2018. Compositional Data Analysis in Practice. New York: Chapman and Hall/CRC press, pp. 1–121. [Google Scholar]
- Greenacre, Michael. 2020. Amalgamations are valid in compositional data analysis, can be used in agglomerative clustering, and their logratios have an inverse transformation. Applied Computing and Geosciences 5: 100017. [Google Scholar] [CrossRef]
- Greenacre, Michael, and Paul Lewi. 2009. Distributional equivalence and subcompositional coherence in the analysis of compositional data, contingency tables and ratio-scale measurements. Journal of Classification 26: 29–54. [Google Scholar] [CrossRef]
- Hron, Karel, Peter Filzmoser, Patrice de Caritat, Eva Fišerová, and Alžběta Gardlo. 2017. Weighted pivot coordinates for compositional data and their application to geochemical mapping. Mathematical Geosciences 49: 797–814. [Google Scholar] [CrossRef]
- Hron, Karel, Alessandra Menafoglio, Javier Palarea-Albaladejo, Peter Filzmoser, Renáta Talská, and Juan José Egozcue. 2022. Weighting of parts in compositional data analysis: Advances and applications. Mathematical Geosciences 54: 71–93. [Google Scholar] [CrossRef]
- Kacani, Jolta, Lindita Mukli, and Eglantina Hysa. 2022. A framework for short-vs. long-term risk indicators for outsourcing potential for enterprises participating in global value chains: Evidence from Western Balkan countries. Journal of Risk and Financial Management 15: 401. [Google Scholar] [CrossRef]
- Kalinová, Eva. 2021. Artificial intelligence for cluster analysis: Case study of transport companies in Czech republic. Journal of Risk and Financial Management 14: 411. [Google Scholar] [CrossRef]
- Linares-Mustarós, Salvador, Germà Coenders, and Marina Vives-Mestres. 2018. Financial performance and distress profiles. From classification according to financial ratios to compositional classification. Advances in Accounting 40: 1–10. [Google Scholar] [CrossRef]
- Linares-Mustarós, Salvador, Maria Àngels Farreras-Noguer, Núria Arimany-Serrat, and Germà Coenders. 2022. New financial ratios based on the compositional data methodology. arXiv arXiv:2210.11138. [Google Scholar] [CrossRef]
- Lukáč, Jozef, Katarína Teplická, Katarína Čulková, and Daniela Hrehová. 2021. Evaluation of the financial performance of the municipalities in Slovakia in the context of multidimensional statistics. Journal of Risk and Financial Management 14: 570. [Google Scholar] [CrossRef]
- Martín-Fernández, Josep-Antoni, Carles Barceló-Vidal, and Vera Pawlowsky-Glahn. 1998. A critical approach to non-parametric classification of compositional data. In Advances in Data Science and Classification. Edited by Alfredo Rizzi, Maurizio Vichi and Hans-Hermann Bock. Berlin: Springer Science & Business Media, pp. 49–56. [Google Scholar]
- Martín-Fernández, Josep-Antoni, Carles Barceló-Vidal, and Vera Pawlowsky-Glahn. 2003. Dealing with zeros and missing values in compositional data sets using nonparametric imputation. Mathematical Geology 35: 253–78. [Google Scholar] [CrossRef]
- Martín-Fernández, Josep Antoni, Javier Palarea-Albaladejo, and Ricardo Antonio Olea. 2011. Dealing with zeros. In Compositional Data Analysis. Theory and Applications. Edited by Vera Pawlowsky Glahn and Antonella Buccianti. New York: Wiley, pp. 47–62. [Google Scholar]
- Palarea-Albaladejo, Javier, and Josep Antoni Martín-Fernández. 2008. A modified EM alr-algorithm for replacing rounded zeros in compositional data sets. Computers & Geosciences 34: 902–17. [Google Scholar] [CrossRef]
- Palarea-Albaladejo, Javier, and Josep Antoni Martín-Fernández. 2015. zCompositions—R package for multivariate imputation of left-censored data under a compositional approach. Chemometrics and Intelligent Laboratory Systems 143: 85–96. [Google Scholar] [CrossRef]
- Pawlowsky-Glahn, Vera, Juan José Egozcue, and Raimon Tolosana-Delgado. 2015. Modeling and Analysis of Compositional Data. Chichester: Wiley, pp. 1–247. [Google Scholar]
- Qin, Zixuan, Abeer Hassan, and Mahalaxmi Adhikariparajuli. 2022. Direct and indirect implications of the COVID-19 pandemic on Amazon’s financial situation. Journal of Risk and Financial Management 15: 414. [Google Scholar] [CrossRef]
- Saus-Sala, Elisabet, Àngels Farreras-Noguer, Núria Arimany-Serrat, and Germà Coenders. 2021. Compositional DuPont analysis. A visual tool for strategic financial performance assessment. In Advances in Compositional Data Analysis. Festschrift in Honour of Vera Pawlowsky-Glahn. Edited by Peter Filzmoser, Karel Hron, Josep Antoni Martín-Fernández and Javier Palarea-Albaladejo. Cham: Springer Nature, pp. 189–206. [Google Scholar]
- Shingade, Sudam, Shailesh Rastogi, Venkata Mrudula Bhimavarapu, and Abhijit Chirputkar. 2022. Shareholder activism and its impact on profitability, return, and valuation of the firms in India. Journal of Risk and Financial Management 15: 148. [Google Scholar] [CrossRef]
- So, Jacquie C. 1987. Some empirical evidence on the outliers and the non-normal distribution of financial ratios. Journal of Business Finance & Accounting 14: 483–96. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Non-current assets | 0.090 |
| Current assets | 0.096 |
| Non-current liabilities | 0.028 |
| Current liabilities | 0.051 |
| Net sales | 0.373 |
| Costs | 0.362 |
| Unweighted | Weighted | |
|---|---|---|
| Non-current assets | 7.1 | 17.4 |
| Current assets | 6.8 | 7.7 |
| Non-current liabilities | 71.2 | 63.4 |
| Current liabilities | 4.2 | 4.4 |
| Net sales | 5.3 | 3.5 |
| Costs | 5.4 | 3.6 |
| Cluster 1 | Cluster 2 | Cluster 3 | Cluster 4 | Total | |
|---|---|---|---|---|---|
| Cluster 1 | 29 | 89 | 0 | 0 | 118 |
| Cluster 2 | 4 | 42 | 238 | 0 | 284 |
| Cluster 3 | 94 | 52 | 5 | 6 | 157 |
| Cluster 4 | 3 | 0 | 0 | 173 | 176 |
| Total | 130 | 183 | 243 | 179 |
| Unweighted | Weighted | |
|---|---|---|
| Non-current assets | 0.35 | 0.43 |
| Current assets | 0.64 | 0.60 |
| Non-current liabilities | 0.95 | 0.91 |
| Current liabilities | 0.43 | 0.37 |
| Net sales | 0.73 | 0.76 |
| Costs | 0.73 | 0.76 |
| Cluster 1 17.7% | Cluster 2 24.9% | Cluster 3 33.1% | Cluster 4 24.4% | |
|---|---|---|---|---|
| Turnover | 2.77 | 4.32 | 1.61 | 3.08 |
| Margin | 0.04 | 0.03 | 0.04 | 0.03 |
| Asset structure | 0.37 | 0.27 | 0.65 | 0.28 |
| Liquidity | 2.70 | 1.97 | 1.28 | 2.99 |
| Debt maturity | 0.03 | 0.30 | 0.52 | 0.00 |
| Indebtedness | 0.24 | 0.53 | 0.57 | 0.24 |
| Leverage | 1.32 | 2.13 | 2.33 | 1.32 |
| ROA | 0.11 | 0.11 | 0.06 | 0.09 |
| ROE | 0.15 | 0.24 | 0.14 | 0.12 |
| Cluster 1 16.1% | Cluster 2 38.6% | Cluster 3 21.4% | Cluster 4 23.9% | |
|---|---|---|---|---|
| Turnover | 5.69 | 1.77 | 2.45 | 3.18 |
| Margin | 0.02 | 0.04 | 0.03 | 0.03 |
| Asset structure | 0.16 | 0.60 | 0.45 | 0.28 |
| Liquidity | 2.09 | 1.34 | 2.41 | 3.12 |
| Debt maturity | 0.20 | 0.48 | 0.06 | 0.00 |
| Indebtedness | 0.50 | 0.57 | 0.24 | 0.23 |
| Leverage | 2.01 | 2.32 | 1.32 | 1.30 |
| ROA | 0.12 | 0.06 | 0.09 | 0.11 |
| ROE | 0.24 | 0.15 | 0.11 | 0.14 |
| Unweighted | Weighted | |
|---|---|---|
| Turnover | 2.704 | 3.920 |
| Margin | 0.014 | 0.014 |
| Asset structure | 0.379 | 0.441 |
| Liquidity | 1.709 | 1.782 |
| Debt maturity | 0.515 | 0.481 |
| Indebtedness | 0.329 | 0.339 |
| Leverage | 1.009 | 1.024 |
| ROA | 0.056 | 0.058 |
| ROE | 0.126 | 0.129 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jofre-Campuzano, P.; Coenders, G. Compositional Classification of Financial Statement Profiles: The Weighted Case. J. Risk Financial Manag. 2022, 15, 546. https://doi.org/10.3390/jrfm15120546
Jofre-Campuzano P, Coenders G. Compositional Classification of Financial Statement Profiles: The Weighted Case. Journal of Risk and Financial Management. 2022; 15(12):546. https://doi.org/10.3390/jrfm15120546
Chicago/Turabian StyleJofre-Campuzano, Pol, and Germà Coenders. 2022. "Compositional Classification of Financial Statement Profiles: The Weighted Case" Journal of Risk and Financial Management 15, no. 12: 546. https://doi.org/10.3390/jrfm15120546