1. Introduction
Acquired Immunodeficiency Syndrome (AIDS), caused by the Human Immunodeficiency Virus (HIV), is one of the most devastating infectious diseases in human history since its discovery in 1981: approximately 78 million people have been infected and some 35 million individuals have died from HIV/AIDS-associated diseases since the beginning of the epidemic worldwide [
1]. These facts, combined with the governmental action of each nation, have determined the worrying variety of scenarios that have characterized the problem that this disease represents and the need to study its nature and spread [
2,
3].
The term “AIDS” refers to a set of symptoms that occur in the final stage of an infection caused by the Human Immunodeficiency Virus. In the same perspective, HIV is a virus that attacks immune cells called CD4 cells, which are a type of T-cell [
4]. When HIV attacks and infiltrates these cells, it reduces the body’s ability to fight other diseases. It is transmitted by contact with certain body fluids of an individual infected with HIV (blood, semen, vaginal fluid, anal mucus and breast milk), most commonly during unprotected sex or by sharing contaminated needles [
4]. On the other hand, Sims [
4] states that AIDS occurs when the virus has destroyed the immune system, leaving the patient highly susceptible to other life-threatening infections. Without treatment, an HIV infection is likely to develop into AIDS as the immune system gradually weakens. Nonetheless, advances in antiretroviral therapy (ART) mean that a decreasing number of individuals are progressing to this stage: antiretroviral drugs can help patients reduce their viral load, improving their quality of life and prolonging their life expectancy [
4].
However, despite advances in the field of health sciences over the past twenty years, namely, the reduction in the number of new HIV infections worldwide from 3.4 million in 1996 to 1.5 million in 2021 and 650,000 people dying of HIV-related causes in 2021 [
5,
6], HIV and AIDS continue to be a health threat for numerous countries around the world, with implications for the design and implementation of public policies and for the day-to-day development of various population groups at risk. Through the adverse economic and social consequences of HIV/AIDS on individuals and households, the epidemic also creates challenges for social policy in the form of a diminished state [
7]. Furthermore, the current service coverage is still inadequate, and the pace of its expansion is too slow to meet global targets (by 2021, there were 38.4 million people globally living with HIV, and about 5.9 million people did not know that they were living with HIV) [
8]. Success in the global HIV response is not evenly or equitably distributed (human rights violations, along with widespread gender-based violence, stigmatization and discrimination, continue to obstruct access to health services, particularly for children, adolescents, young women and vulnerable populations such as LGBT communities, among others) in some countries and regions [
9].
Nowadays, the response against HIV/AIDS is considered a crucial and priority matter within public health policies globally due to the devastating effects of the disease for its high potential for spread and lethality in the absence of treatment and countermeasures [
10]. In that sense, spreading knowledge and awareness about HIV/AIDS results in one of the key strategies used in the prevention and control of the epidemic worldwide. Inadequate knowledge and risky practices are the main obstacles in preventing the spread of the virus [
11]. In many countries, sexually transmitted infections (STIs) and unplanned pregnancies are frequently observed among adolescents. Young people started having sex with one or multiple sexual partners indiscriminately, and this facilitated the spread of STIs and HIV. Therefore, adolescents in general are at an increased risk of contracting HIV through sexual transmission. Thus, the need to understand the knowledge and attitude of young people towards HIV/AIDS and public efforts for a personalized approach to disease control and prevention through key education and awareness programs becomes even more important [
12]. Successful disease-control efforts depend on understanding both the distribution and frequency of health behaviors and measuring the general public’s knowledge of HIV/AIDS and the associations of their knowledge and attitudes with different socio-demographic factors [
12].
Faced with this, the epidemiological analysis of infections and diseases (which translates into prospective studies, trends in the evolution and patterns of infection dynamics and influences that various indicators have on these) allows for better decision-making at a governmental level in public/social health and the actions that derive from the evaluations of the results are established as the main axes of the efforts against the epidemic and its ravages [
9]. In the case of HIV/AIDS studies, mathematical modeling and computational simulations of epidemiological infection-control efforts have become imperative tools for the evaluation of different policies at the state level, of the evolution of health at the population level and of interventions in governmental sectors related to health that have generated promising results in recent decades [
13].
Under these circumstances, artificial intelligence has the potential to improve clinical care, including HIV care, by optimizing HIV/AIDS diagnosis, treatment selection and risk stratification for prevention strategies [
14]. Artificial intelligence (i.e., ML) has been introduced into the healthcare field as a means of improving the exactness and accuracy while reducing the number of time-consuming tasks that require human intervention [
15]. Because of its ease of use, this innovation could provide a useful tool, allowing for quicker intervention [
15]. Given the advances in the scientific understanding of HIV diagnosis and treatment, novel strategies are urgently needed to prevent new HIV infections [
14]. These models in the medical industry have an immense capacity to develop diagnostic and prognosis indicator applications that can aid in the proper initial treatment of life-threatening diseases, such as HIV/AIDS [
16,
17]. In this sense, artificial intelligence for HIV prevention has been applied by using machine learning to identify people who might benefit from HIV testing, pre-exposure prophylaxis or other risk-reduction strategies [
14], including studies from the USA [
18,
19,
20,
21,
22], Denmark [
23], and eastern Africa [
24]. In addition, natural language processing is a potential strategy for optimizing future tools including electronic health records to identify patients who might benefit from pre-exposure prophylaxis or other medications, although the benefits of predictive performance will need to be evaluated against the additional computational resources required [
14]. Moreover, random forest machine learning algorithms were applied to predict virologic outcomes among HIV infected adults in countries such as Switzerland using electronically monitored combined antiretroviral treatment adherence [
25].
In that regard, the major contributions that the current research has provided to the existing literature may prove useful and relevant to policy makers and health promoters working in the Peruvian government. First, it has described the characteristics of adolescents and young adults (our target population) in Peru according to their knowledge about HIV/AIDS. Second, this study has pinpointed the structural determinants of health (demographic, economic and social factors) in the Peruvian territory that have an empirical influence on the knowledge about HIV/AIDS among the target population. Finally, this research has established the machine learning model that provided the best goodness-of-fit and accuracy for the classification of the HIV/AIDS knowledge in the youth population in Peru by comparing parametric and non-parametric estimation techniques. Thus, our study could aid the design and management of public health policies in Peru since, through the evaluation and monitoring of infection at the population level, it is possible to analyze the trends that the disease has adopted and the factors that influence it in order to choose strategies and measures to control and, subsequently, eradicate it in the long term [
26].
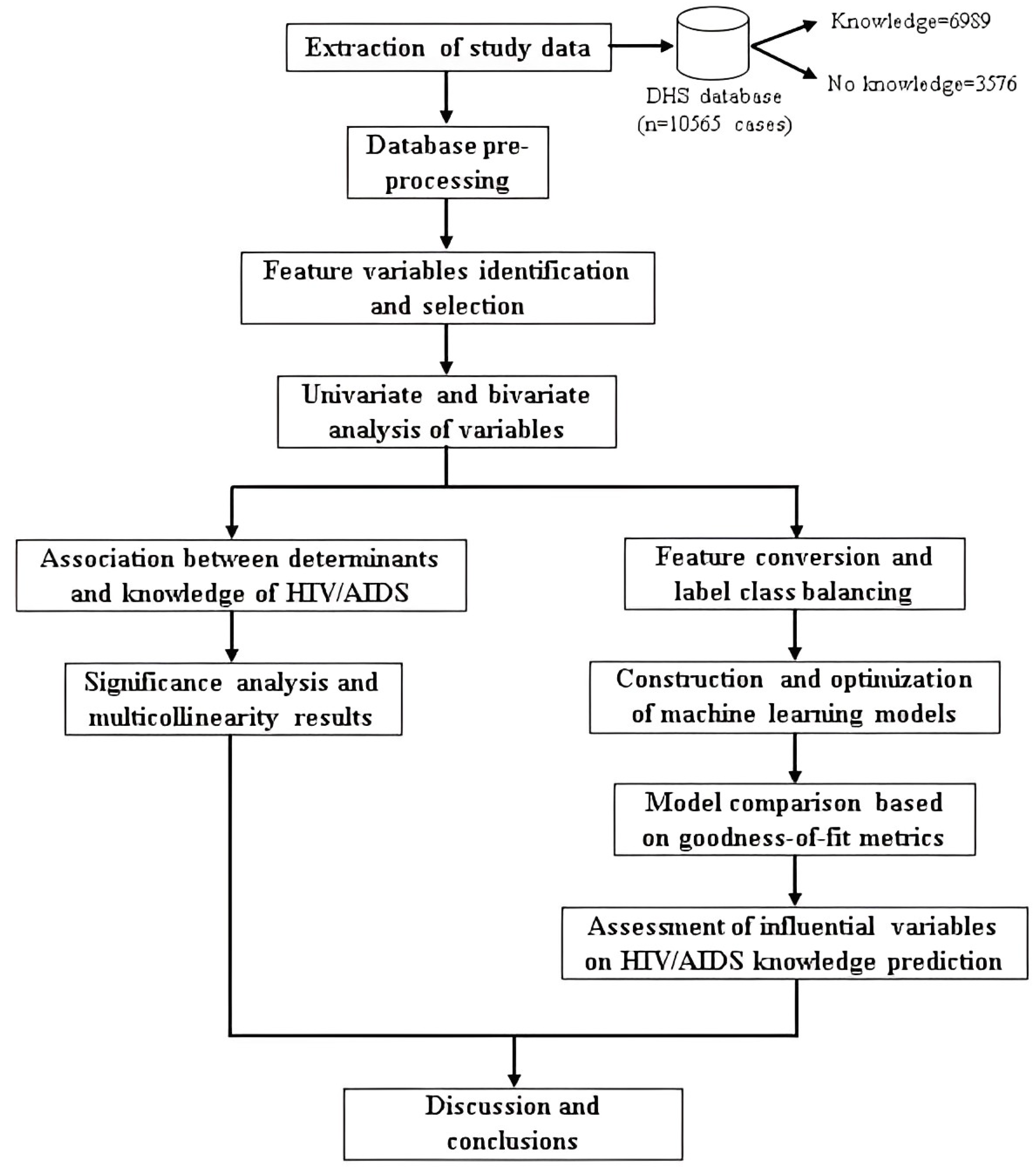
4. Results
4.1. Statistical Analysis of Factors Associated with Knowledge about HIV/AIDS
According to
Section 3.3.3,
Table 3 shows the results of the level of knowledge about HIV/AIDS of the interviewed population aged 15–29 years according to the characteristics of the sample collected in the DHS database.
From a sample of 10,565 individuals, there is a significant contrast in the distribution of the level of knowledge about the virus and the disease among the target population, estimating that only 3576 (33.80%) respondents had an adequate level of knowledge and the rest of the people (6989 (66.20%)) had incorrect notions or perceptions about the epidemic. Considering socio-demographic, economic and health factors, differences can be seen in terms of knowledge about the epidemic, both as a result of percentage sample estimates (which ignore the complex design of data collection) and weighted estimates (which include weights and the structure of the sampling frame).
On the other hand, taking into account the results of the independence tests of Pearson’s statistic, it was established that the variables Marital status ( = 3.087, p-value = 0.499) and Nationality ( = 4.047, p-value = 0.275) did not show a significant association or statistical relationship with the response variable since both p-values shown above exceed the confidence levels considered for the study, so they were dismissed or discarded from the subsequent logistic regression model. The remaining independent variables showed a significant association with the dependent variable, considering the obtained p-values.
4.2. Association between Structural Determinants and Knowledge about HIV/AIDS in Peru
The results of the quasi-binomial logistic regression employed to measure the relationship between the knowledge about HIV/AIDS and the independent variables, described above, are analyzed with a significance level (
p-value) of 10%, 5% and 1% and reported in
Table 4.
Gender is a significant predictor of the knowledge among adolescents and young adults in the country (p < 0.01). Being of the male gender is negatively correlated with the probability of having an adequate and correct understanding of HIV/AIDS ( = −0.334).
The regression coefficients associated with the economic-level categories show a positive association with the probability of possessing knowledge and these variables are significant (p < 0.01).
There is a propensity in those individuals living in the Sierra region of Peru not to possess a correct level of knowledge about the interaction with HIV/AIDS and its forms of transmission (they are negatively correlated with the response variable considering that = −0.178).
Those within the age range of 25 to 29 years have a significant positive correlation (p < 0.01) with the dependent variable ( = 0.285).
The results in terms of the highest educational level attained significantly demonstrate that individuals who completed high school ( = 1.911, p < 0.05) and higher education ( = 2.198, p < 0.01) are more likely to have an adequate knowledge than those individuals without any accredited education (or illiterate).
Adolescents and young adults who self-identify as Afro-Peruvian ( = −0.328, p < 0.05) or other ethnicity ( = −0.387, p < 0.05) are less likely to have an appropriate knowledge than those who self-identify as indigenous or of native origin in the country.
Having heard some type of information regarding HIV/AIDS has a significant positive impact on determining the knowledge of these that an adolescent or young adult may have ( = −0.635, p < 0.01).
Adolescents’ and young adults’ performance of an HIV/AIDS screening test is positively linked to the individual’s adequate knowledge about the epidemic ( = 0.174, p < 0.05).
Finally, having Spanish as a primary language shows a positive and significant correlation ( = 0.233, p = 0.052) with the dependent variable. However, speaking a foreign language as a primary language is negatively associated ( = −1.915, p = 0.082).
In contrast, area of residence, access to mass media and gender of the head of household are not correlated with the knowledge about HIV/AIDS (p > 0.10).
Considering the variances of the estimated regression coefficients, it can be established that there is no multicollinearity problem in the model, since the GVIF values are less than 5 [
60].
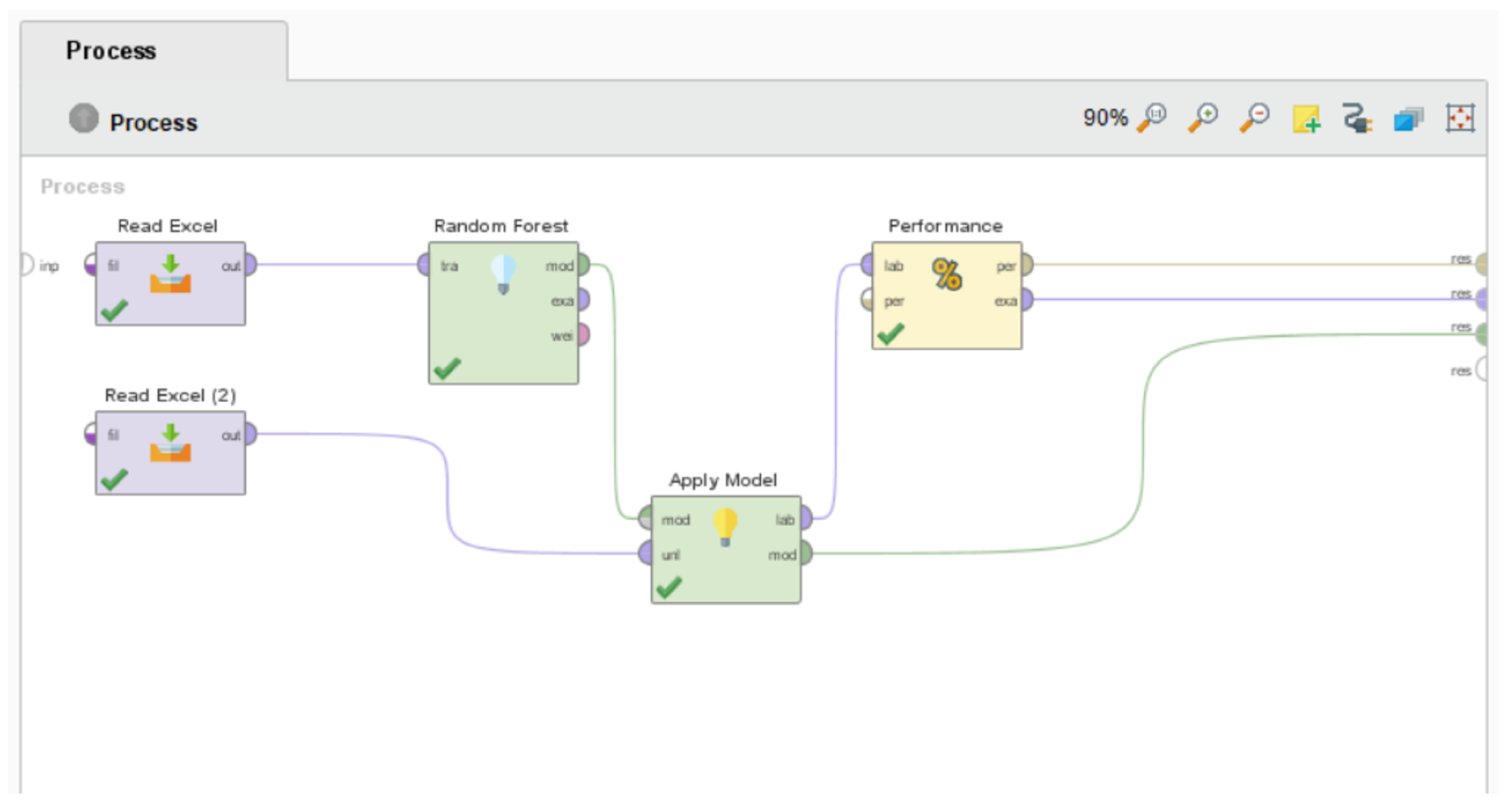
4.3. Construction and Optimization of Computational Models
Considering the representation of categorical variables chosen on
Section 3.3.5 to minimize the impact on the structure of the proposed models,
Figure 3 presents the data-transformation process carried out in the study using the software RapidMiner.
On the other hand, based on the selection of available hyper-parameters to be optimized and the cross-validation procedure presented above, the available test alternatives for each model and the selected value that optimizes each of them are given in
Table 5.
These models (with the specifications presented above) were generalized to the test set to determine comparatively which one best allows classification of the knowledge about HIV/AIDS of adolescents and young adults in the national territory.
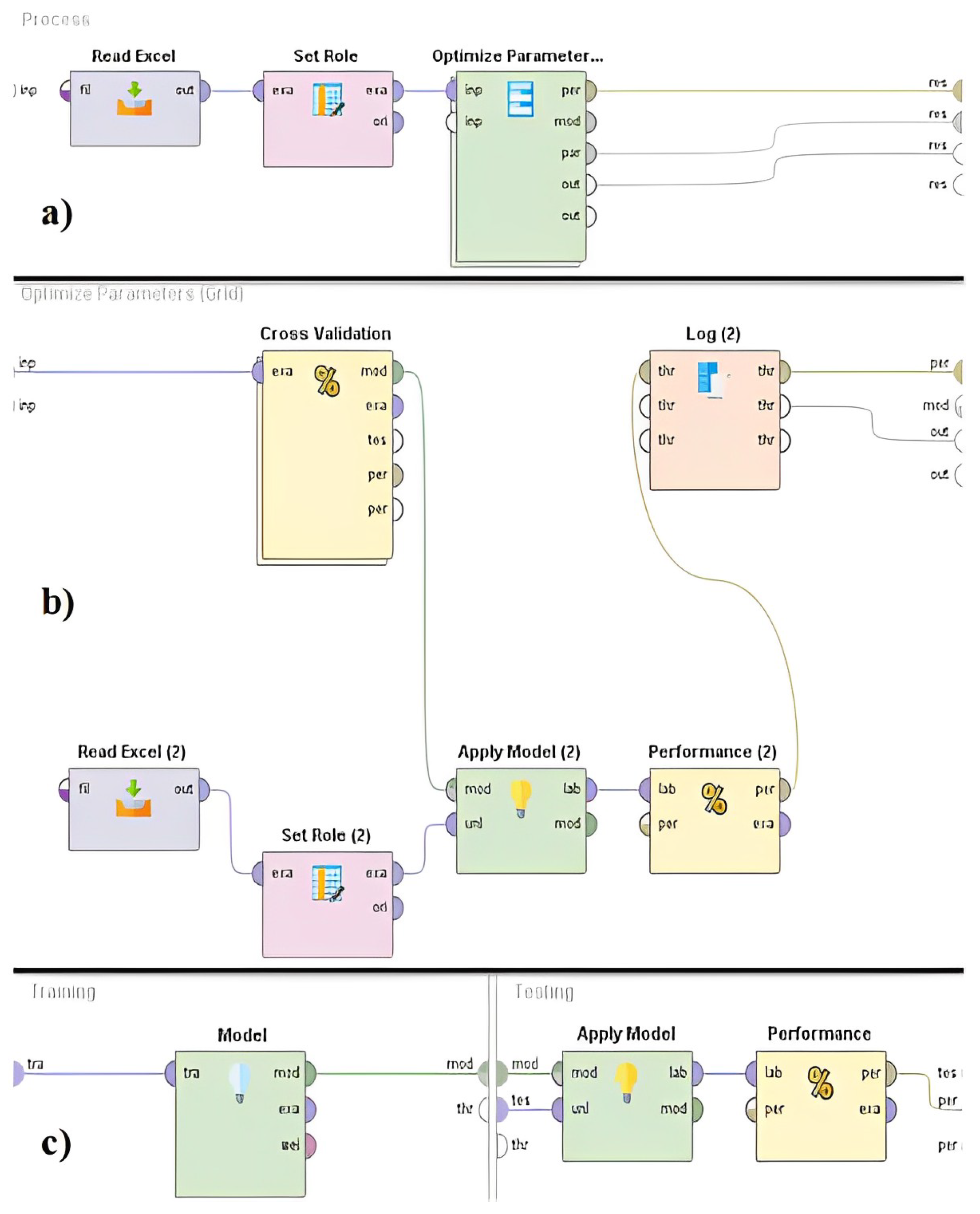
In that perspective, subsequent to the constraint of the hyper-parameters to be used in each algorithm in
Table 2, a process of model fitting using grid search and cross validation was carried out. The architecture of the workflow performed in RapidMiner is shown in
Figure 4.
4.4. Comparison of Classifiers for the Prediction of Knowledge about HIV/AIDS
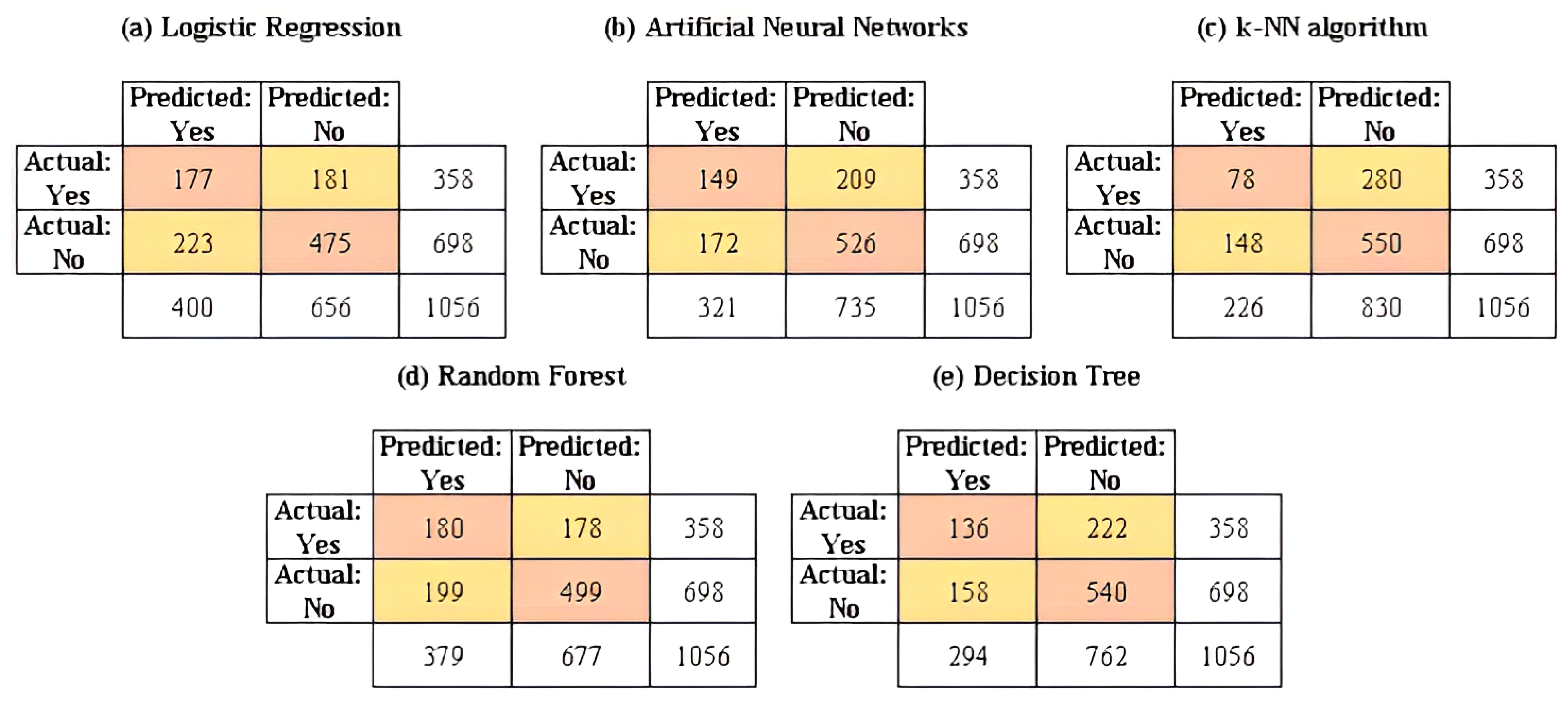
Once the training process is completed, the validation of the predictive performance of the machine learning models is performed by generalizing them to the test data. The results of the confusion matrices for the machine learning models considered in this study are reported in
Figure 5. In addition, the results of the computational models built in the training stage and applied to the test set are reported in
Table 6.
Regarding the goodness-of-fit indicators considered in this study, it can be established that the random forest method presents the best scores in each indicator (except for the AUC value, FPR and specificity). This algorithm shows the greatest predictive performance in contrast to the other parametric and non-parametric models included in this study.
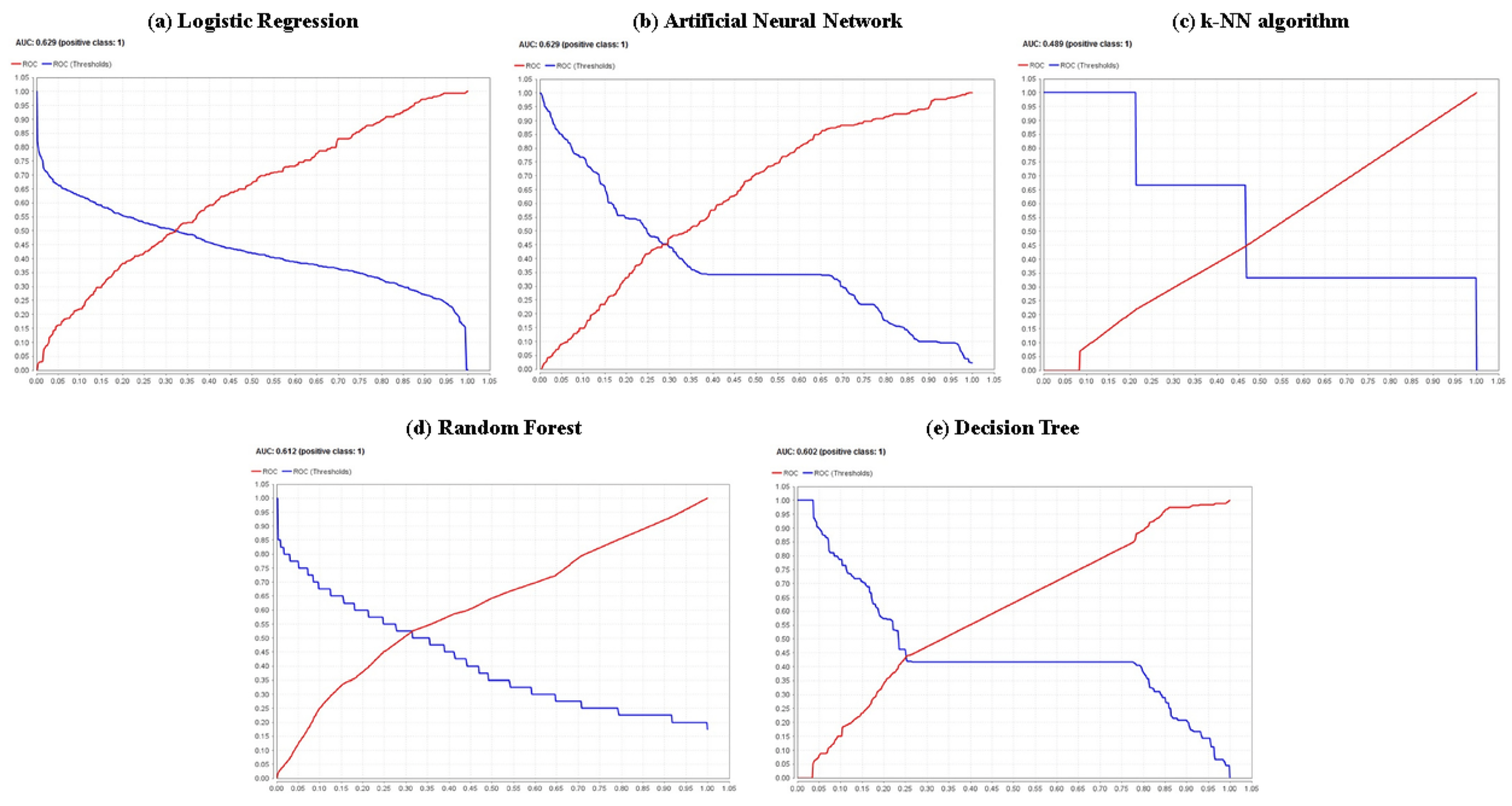
The highest identification of the number of true positives (TP) was using the random forest method (180 cases); the highest identification of the number of false negatives (FN) also occurred in the random forest method (178 cases). Regarding the false negative rate (FNR), the lower value (49.72%) was achieved by the random forest model; considering the accuracy, the highest value (64.30%) was reached by the random forest model. Regarding the sensitivity, it can be pointed out that the random forest model has the highest percentage or proportion of correct positive predictions among the total positive predictions among all the models used (50.28%); Analyzing the specificity, it is noted that the k-NN algorithm is the model with the best performance in terms of this goodness-of-fit metric, with a value that amounts to 78.80%. From another point of view, examining metrics such as Cohen’s kappa and the F1 score, it can be shown that the random forest model is the one that presents the best performance in both indicators, with values of 0.215 and 48.85%, respectively. In the same sense, a visualization of the receiver operating characteristics (ROC) curve is shown in
Figure 6; considering the AUC, the curves of the binomial regression and artificial neural network models show the highest AUC value (62.90% for both cases), indicating they are the best models for classifying the knowledge and lack of knowledge of HIV/AIDS at the target population, among the models. However, it is necessary to remark that the random forest model offers the second-best value for said indicator with 61.20%, with a minimal difference of 1.70% and, in the same line, for high levels of specificity, this same model obtains moderate levels of sensitivity. Only in the cases of metrics such as the number of true negatives (TN), the number of false positives (FP) and the false positive rate (FPR), the k-nearest neighbors algorithm offered the best fit with 550, 148 and 21.20% values for these indicators, respectively.
4.5. Identification of Variables That Influence the Prediction of HIV/AIDS Knowledge
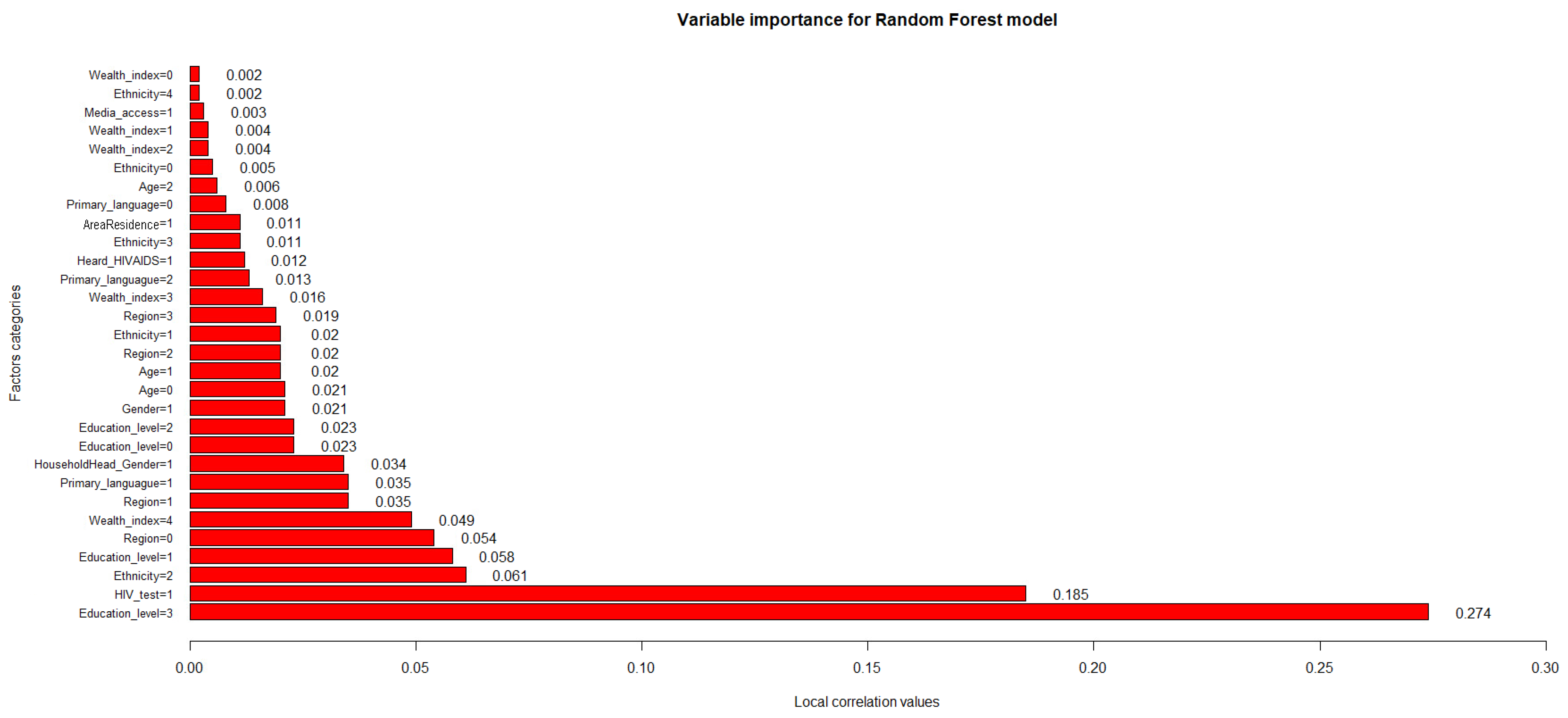
Regarding the variables’ influence on the performance of the best predictive model obtained,
Figure 7 shows the importance values of the factor categories used in this study.
The random forest, being the best model evaluated, allowed us to establish the characteristics or factors that have the greatest influence over the predictive capacity (the performance of the classification predictions) and the performance in estimating the knowledge about HIV/AIDS in adolescents and young adults in Peru: urban area of residence (AreaResidence = 1, correlation value = 0.011); Afro-Peruvian ethnic self-perception (Ethnicity = 3, correlation value = 0.011), Caucasian ethnic self-perception (Ethnicity = 1, correlation value = 0.02) and mixed ethnic self-perception (Ethnicity = 2, correlation value = 0.061); having previously heard information about HIV/AIDS (Heard_HIVAIDS = 1, correlation value = 0.0.012), having Spanish (Primary_language = 1, correlation value = 0.035) and a foreign language as a primary tongue (Primary_language = 2, correlation value = 0.013); belonging to the second highest (Wealth_index = 3, correlation value = 0.016) and highest wealth indexes (Wealth_index = 4, correlation value = 0.049); living in the capital (Region = 0, correlation value = 0.054) or in inland regions of the country (Region = 1, Region = 2 and Region = 3 with correlation values of 0.035, 0.02 and 0.019, respectively); age ranges of 15–20 (Age = 0, correlation value = 0.021) and 21–24 (Age = 1, correlation value = 0.02); being of the male gender (Gender = 1, correlation value = 0.021); all established educational levels (Education_level = 0, Education_level = 1, Education_level = 2 and Education_level = 3 with correlation values of 0.023, 0.058, 0.023 and 0.274, respectively); head of household of the male gender (HouseholdHead_Gender = 1, correlation value = 0.034); and the performance of prior HIV/AIDS screening tests (HIV_test = 1, correlation value = 0.185).
Thus, it can be specified that the obtained values of local correlations between 0.01 and 30.00% are the most feasible and beneficial to use within the random forest since they allow estimation of the response variable by positively influencing the model’s predictive performance, emphasizing that having a higher education level is the most relevant factor (highest correlation value = 0.274) among the considered variables.
5. Discussion
This study aimed to describe the characteristics of adolescents and young adults in Peru according to their knowledge about HIV/AIDS, identify structural determinants of health that possess an influence on this knowledge and build a computational model to estimate the knowledge of HIV/AIDS in the target population through a comparison of parametric and non-parametric techniques.
As an overall result, the association between certain socio-demographic, economic and health factors and the level of knowledge about the forms of prevention and rejection of misconceptions about HIV/AIDS transmission in Peru was established. On the other hand, the predictive capacity of the level of knowledge about the epidemic was estimated as between 59.47% and 64.30% for the models considered, with the random forest model (64.30%) being the one that showed the best performance. In addition, the study showed that this algorithm allows identification of the following main variables that have an influence on the prediction of HIV/AIDS knowledge: gender of the respondent, area of residence of the interviewee, wealth index of the respondent, region of residence, interviewee’s age, highest educational level attained by the respondent, ethnic self-perception of the interviewee, having heard about HIV/AIDS in the past, the performance of an HIV/AIDS screening test by the respondent, mass media access by the interviewee, the gender of the household head and the primary language of the interviewee.
First, this research showed that the level of knowledge associated with HIV/AIDS among Peruvian adolescents and young adults aged 15–29 years can be considered low, given that only 3576 individuals out of the entire study sample reported an appropriate knowledge of the epidemic, which translates into 33.80% of the cohort having a correct understanding of the risks posed by the virus and the forms of prevention and sexual care that can be used to avoid infection and respond proactively to HIV and people living with the disease. Such categorization of low level of knowledge coincides with other research conducted elsewhere, which obtained similar findings in terms of the percentage of the sample that effectively reported a correct understanding of the dimensions of the epidemic: Shokoohi et al. [
61] (37.30%), Dadi et al. [
62] (30.31%) and De Wet et al. [
63] (10.00%). Furthermore, in a study published in Peru, Becerra et al. [
64] reported a correct understanding of 33.3%.
Second, the current study identified the socio-demographic, economic and health variables that significantly predict (under a significance level of
p < 0.10) the probability of a young adult having an adequate knowledge about HIV/AIDS in Peru, which are shown in
Table 4.
It was established that males are less likely to have an adequate perception of HIV/AIDS. Research conducted in 45 countries around the world, through survey analysis, shows that there is a steady increase in knowledge of HIV prevention and concepts among young women, surpassing that recorded, over time, by men [
65]. In the same vein, a study in Brazil that explores the factors associated with the knowledge, attitudes and practices of young Brazilians about HIV, STIs and viral hepatitis points out that young Brazilian men aged 18–29 years are more likely to adopt risky sexual behaviors than young women as they have a lower level of health knowledge [
66].
The results show that the higher the level of income or wealth, the higher the probability of having an adequate level of knowledge about the epidemic increases progressively. A study conducted in Nigeria based on economic inequality as a predictor of HIV-related knowledge concurs with the findings obtained, establishing that the probabilities of low HIV-related knowledge increase significantly in each wealth category as wealth decreased [
67]. In the same perspective, a cross-sectional analysis of youth aged 15–24 years in Nigeria shows that youth from middle and wealthy households, respectively, had significantly higher HIV-related knowledge than youth from poor households [
68].
It is noted that those individuals coming from the natural region of the Sierra are less likely to possess correct knowledge about HIV/AIDS. Research conducted in Pakistan shows that the region of residence recorded a significant relationship with HIV/AIDS knowledge in young respondents, in which it is pointed out that the level of discernment was higher in the capital city than in the provinces of the country [
69].
It is recognized that those respondents with education levels of secondary school and above are more likely to be aware of the transmission and risks associated with the epidemic. Findings from a study considering adult individuals aged 15 years and older in Pakistan and Afghanistan specify that, in both countries, education is a fundamental factor in HIV knowledge, establishing that people with higher levels of education were more likely to have accurate and comprehensive knowledge about HIV/AIDS, emphasizing that understanding about various aspects related to the epidemic increases when the educational level of the person increases progressively [
70].
It is established that those individuals who were tested for the virus prior to the survey are more likely to have adequate perceptions of HIV/AIDS progress and prevention. An analysis conducted in Iran, based on the assessment of HIV-related attitudes, practices and knowledge among young men and women, indicates that, given the limitations of Iranian youth in terms of sexual health and risk practices linked to STIs and HIV/AIDS, the low prevalence rates of testing for the virus express low levels of knowledge of the epidemic and erroneous attitudes about it, which calls for specific interventions to increase the acceptability of testing [
61].
Those adolescents and young adults who have inadvertently come into contact with some information about HIV/AIDS previously are more likely to have adequate knowledge about the epidemic. A study developed in South Sudan on the knowledge, attitudes and practices related to HIV/AIDS among adolescents in the country determines that, in general, the vast majority of young students who have good knowledge about HIV/AIDS have heard about HIV/AIDS through different avenues (such as school, media or their parents); thus, promoting the increase in the level of understanding of the epidemic with increased sex education and contact with information regarding the virus is recommended [
71].
Those who speak Spanish or who have Spanish as their primary language have a higher level of understanding than individuals who speak dialects native to Peru; conversely, those who have a foreign language as their native language are less likely to have an appropriate understanding of the epidemic. A study conducted in Indian adolescents on their knowledge and attitudes about HIV/AIDS and STIs indicates that the language taught and spoken at home had an important relationship with knowledge of the epidemic, emphasizing that those who spoke English as a foreign language were less likely to have correct perceptions about HIV/AIDS than those who had a Hindi dialect as their native language [
72]. Likewise, Rachlis [
73], in relation to individuals who had dialects and/or native languages as their primary language in Canada, indicates that there are barriers related to native languages that result in a low level of knowledge about HIV/AIDS in these people because the absence of a common language between people who are part of these isolated communities and the bulk of the population with a consolidated and massified language generates an inability to communicate clearly and directly.
It is noted that those individuals who self-identify as Afro-Peruvian or who do not self-identify through one of the categories that the state offered in the questionnaire are less likely to have an adequate understanding of HIV/AIDS. Research conducted in London based on young people from ethnic minorities indicates that they are far from being a homogeneous group and that they are related to different ethnic differences in sexual health knowledge; namely, the lowest levels of sexual health knowledge about HIV/AIDS that represent a major concern for the British authorities are recorded in the black African youth population, white minorities of unidentified ethnicity and individuals from Asian areas with relevant knowledge gaps [
74].
It is determined that belonging to the age range of 25 to 29 years represents a higher probability of having an adequate perception about HIV/AIDS than belonging to the reference range. Shokoohi et al. [
61], in their study of the practices, attitudes and knowledge associated with HIV/AIDS in individuals of the youth segment in Iran, detailed that participants aged 25–29 years possessed much more knowledge about ways of transmission, prevention and perception of HIV compared to other age groups, reflecting that knowledge and positive attitudes about HIV increased with age, which could be attributed to older people’s greater interest in seeking information about sexual health or greater exposure to sexual health education.
Third, this research unveiled that, subsequent to a literature review in the health field, it is noticeable that little work has been conducted on the assessment and intervention research of an understanding of the HIV/AIDS epidemic employing machine learning methods or, in particular, an approach based on a random forest model. The accuracy linked to the prediction of classifications of the level of adequate knowledge about HIV/AIDS is between moderate limits previously reported in the field of healthcare and medical research [
75,
76,
77,
78], with values between 59.47% and 64.30% generated in the validation set. The final results of the computational experiments indicated that the random forest had the best predictive performance among all the proposed algorithms, with the highest goodness-of-fit metrics, such as accuracy (64.30%), sensitivity (50.28%), Cohen’s kappa (0.215) and F1 score (48.85%). This could be due to the remarkable properties and benefits offered by the random forest as a machine learning model. First, this technique has the advantage of obtaining better levels of predictive performance and robustness by obviating the need for a cross-validation process because they produce an unbiased estimate of the test set error internally by constructing many bootstrap samples from the original data [
79]. Second, this algorithm has the advantage of preventing over-fitting by reducing inter-tree dependence, which makes majority voting an effective strategy in forest construction [
79]. Third, random forest can automatically handle continuous, nominal, ordinal, and missing independent variables, capturing nonlinear effects and interaction terms with an ability to adaptively use a large number or dimensionality of covariates, even if most are correlated [
80]. In the same perspective, the random forest technique allows quantitatively assessing the contributions of predictor variables to the response variable for the selection of relevant co-factors within a model importance analysis covering the impact of each predictor variable individually, as well as in multivariate interactions with other predictor variables [
81]. Finally, the random forest algorithm reduces the risk of overall bias in its development since there are several trees and each tree is trained on a subset of the data [
82] and it is relatively stable in the face of etiological variability and a reasonably low amount of missed data [
15].
Fourth, by examining whether parametric and non-parametric algorithms could learn from existing national data and help predict the level of HIV/AIDS knowledge, our research presented an approach that allowed us to establish the most predictive features for the level of knowledge by considering the complex nature of various predictors of HIV/AIDS understanding to provide an intuitive understanding of the key features. The random forest, being the best model evaluated, allowed us to establish the characteristics or factors that have the greatest influence on the predictive ability (the performance of the classification predictors) and the performance in estimating the level of knowledge about HIV/AIDS in adolescents and young adults in Peru. Analyzing the most relevant characteristics (the ten categories with the highest correlation value), the following can be established: In the case of economic status or wealth distribution, Pellowski et al. [
83] suggest that a person’s economic status may affect the likelihood of having adequate knowledge about HIV/AIDS by affecting their quality of life. In terms of primary language, HIV prevention and knowledge is a major priority in communities that are still recovering from the impacts of the existence of a language barrier that inhibits the proper access to the healthcare system [
84]. In relation to the educational level, education protects against HIV infection through information and knowledge that can affect long-term behavior change [
85]. Considering the region of residence, the effects of residential segregation and regional disparities combine to negatively impact the knowledge about HIV/AIDS that individuals may have [
86]. In reference to ethnicity, a challenge that remains in the delivery of HIV/AIDS prevention and knowledge-building interventions is the ability to incorporate measures to address the unique needs of diverse members of social communities [
87]. In terms of HIV/AIDS screening, this health tool can help prevent HIV infection through counseling to discourage high-risk behavior and support protective behaviors and proper sex education [
88].
6. Conclusions
The results obtained in this study suggest the usefulness of the associations found between structural determinants and the suitability of machine learning models for characterizing and predicting knowledge of HIV/AIDS in the target population and are relevant for policy makers and health-promotion decision makers working at the Peruvian government to provide a starting point for reinforcing, justifying, directing and supporting the planning and execution of improvements and new measures in the efforts to counteract the HIV/AIDS epidemic in the country. It provides grounds for the identification of potential focuses of attention of current and new health policies based on those determinants that exhibit an association with the knowledge that individuals may have about HIV/AIDS, for the evaluation of computational models for the prediction of this knowledge in a prospective way, and for the detection of relevant factors that influence the predictive performance of the models, thus representing the first initiative for the evaluation of the role of the Peruvian government in relation to this public health problem and for possible ways to optimize and encourage an efficient control and reduction in this problem in the future. Future research should consider supplementary techniques and/or methods to those previously presented to analyze the epidemiological situation of HIV/AIDS in Peru and to promote new spaces for scientific research under different configurations or contexts due to the scarce national literature on the subject and the presence of difficulties and/or technical complexities in the area of study.
6.1. Implications
Our findings contribute to the wealth of literature by indicating that it is more likely that certain structural factors (including demographic, social, familial and cultural), rather than behavioral and medical factors, are associated with the level of perception of the modes of transmission and evolution of HIV/AIDS and by confirming that there is a marked difference in this knowledge at the national level. In the evaluation of the results, there are distinct factors that offer the possibility of modifications with the purpose of designing and implementing preventive programs under a structural approach.
Furthermore, by examining whether parametric and non-parametric algorithms could learn from existing national data and aid in the prediction of the knowledge about HIV/AIDS, the study shows that such an approach is feasible and that the algorithms achieved accuracy levels similar to those found in the literature review for predicting the perception and understanding of the dynamics and nature of the epidemic. This approach allowed us to establish the most predictive features for the knowledge by considering the complex nature of various predictors of HIV/AIDS understanding to provide an intuitive understanding of the key features. Similarly, this study demonstrates the potential of machine learning models to identify adolescents and young adults who have a greater exposure or predisposition to accept incorrect notions about HIV/AIDS transmission and engage in risky behaviors under those ideas based on certain regressors. In addition, this methodology facilitates the selection of a model based on resource-constrained performance and stability of performance over time. Incorporating such information into the algorithms can potentially improve the discriminative properties of the models. By experimenting with the design and execution of these machine learning algorithms, is clear that such models can identify relationships even when some of the input data are very complex, poorly defined or structured.
6.2. Limitations and Recommendations
In a general framework, the restricted availability of data on HIV/AIDS in Peru is a serious limitation in this study. The nature of the available data, to a large extent, adapted the direction of this thesis. The aggregation of the data at the national level made it impossible to perform an analysis at more detailed or specific levels. In addition, the study and modeling of the epidemic trend in the different demographic strata of Peruvian society were hampered by the lack of stratification of the data. It is recommended that, in the medium and long term, the data be expanded in favor of greater availability for the public domain after removing all patient identities and be more accessible to researchers.
In a different perspective, in computational terms, the use of the software established in the study presented difficulties for the development of the proposed models. In the case of RStudio (in particular, the survey package), it was challenging to correctly identify and use the proper complex survey designs in the study; it was difficult to includw non-response bias into the analyses; and when dealing with enormous datasets, it can be resource-intensive, and users may need access to sophisticated computational resources to operate successfully. For the software RapidMiner, preliminarily, the program has several features and functions that might be unfamiliar without adequate training; as processes become larger and more sophisticated, the workflows may become more complicated and harder to manage, making it difficult to discover and address issues; importing data from particular formats (Excel or CSV files) may pose a problem, needing data pre-processing or conversion prior to analysis; and when working with huge datasets or performing complicated analyses, it may be resource-intensive, requiring strong computational resources. Future research should consider employing solutions in programming languages that are more compatible with the programming skills of the researchers and with greater possibilities for scalability and efficient design.
On the other hand, it can be established that a limitation in the analysis is the static and associative measurement of knowledge about the epidemic and the socioeconomic, health and family factors inherent to the cross-sectional design. Future research should include longitudinal designs that can measure an individual’s current level of knowledge as well as future behavior to confirm the temporal and causal relationship. This type of data would allow for a convincing assessment of the effects of risk perception and knowledge on behavior.
Similarly, the use of data from secondary sources (such as the DHS survey) generated drawbacks that translate into the fact that the selection of variables, data quality and measurement indicators were beyond the control or determination of the researcher a priori. Similarly, the study may have had response biases during the collection of perceived risk or sensitive factors (i.e., performance of HIV/AIDS testing, self-perceived ethnicity, among others), although this concern is common to most studies of self-reported behavior. In addition, the data collected were from 2019; meanwhile, the knowledge of the target population may have changed and the results presented previously may not accurately reflect the present situation of knowledge among adolescents and young adults in Peru. Therefore, the patterns found in this study should be evaluated by health experts and researchers (who have expertise in the problem domain) to decide whether they are logical, practical and novel to drive new directions of biological and clinical research. Additionally, the use of additional covariates and perhaps sexual history data collected from different samples is recommended to draw further inferences about differences associated with community or individual characteristics. The identification of such differences could improve our understanding of the variation in HIV/AIDS knowledge observed in the population.
In another perspective, additional future studies are needed to further evaluate the usefulness and effects of the parametric and nonparametric algorithms employed and should be aimed at improving them. This may include the exploration of other machine learning techniques and configurations to improve model performance: variation in the complexity and dimensionality associated with model building, models that cater to the time-series nature of the problem, redefinition or inclusion of new predictors and exploration of underlying interactions in current models that can be exploited. In turn, noting the interpretability and comprehensibility deficiency from which certain machine learning methods employed in this section still suffer (e.g., if a machine learning method is exploiting some interaction and nonlinearity effects, the model-based examination of the importance of variables cannot fully explain and account for such predictive mechanisms), improving the interpretability mechanism in generating results is a critical and attractive, but largely understudied, direction for further research.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}