
Sentiment Analysis Techniques Applied to Raw-Text Data from a Csq-8 Questionnaire about Mindfulness in Times of COVID-19 to Improve Strategy Generation

 , ,
, ,  ,
,  and
and 
Abstract
:1. Introduction
2. Materials and Methods
2.1. Survey
- Q1:
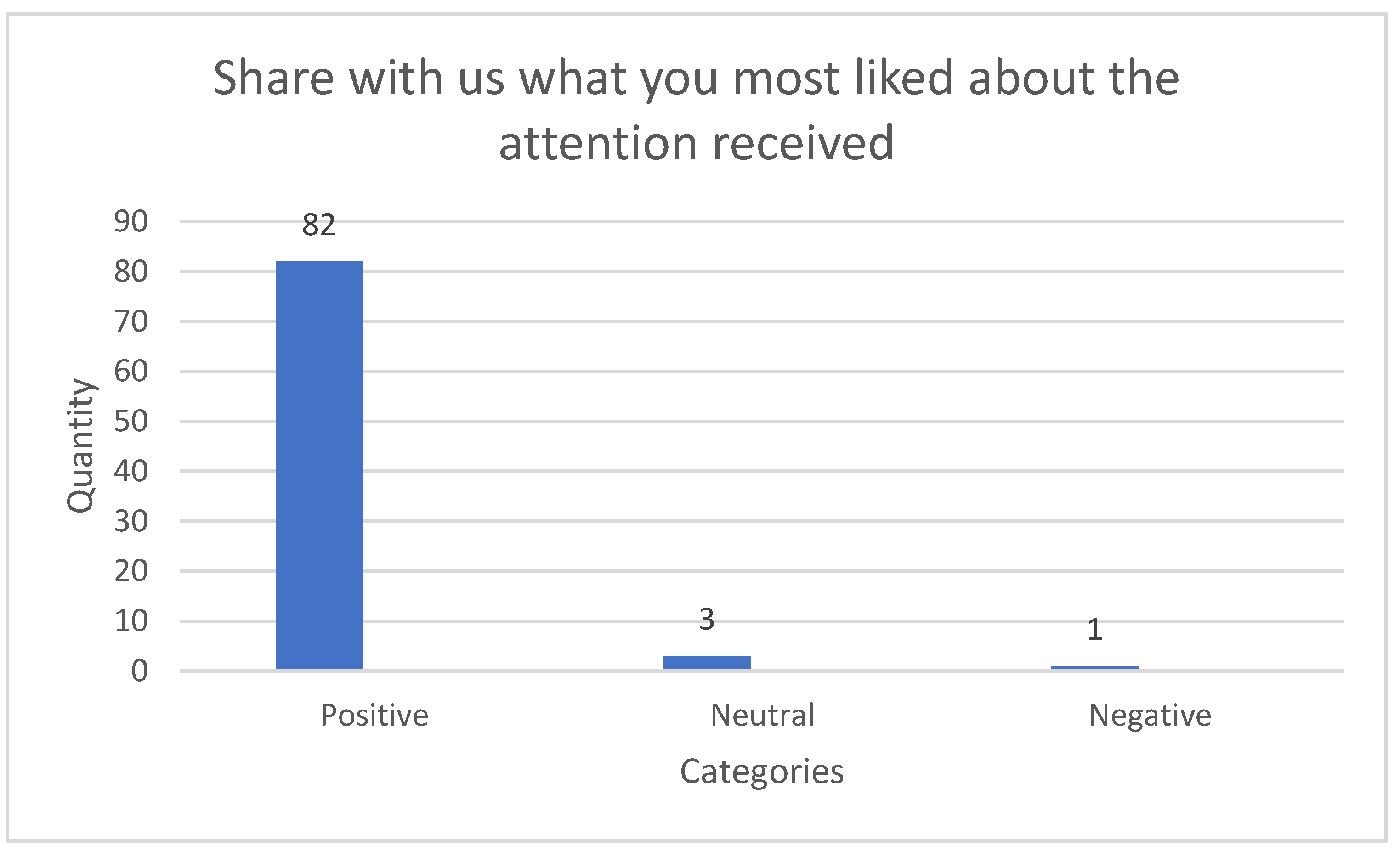
- Share with us what you most liked about the attention received.
- Q2:
- Share your suggestions and recommendations for improvement with us.
2.2. Study Participants and Procedure
2.3. Labeling
Histograms of Labeled Text According to Sentiment Categories
2.4. NLP Techniques
2.4.1. Sentiment Analysis
Word Embedding
- Swivel Embedding
Classifiers
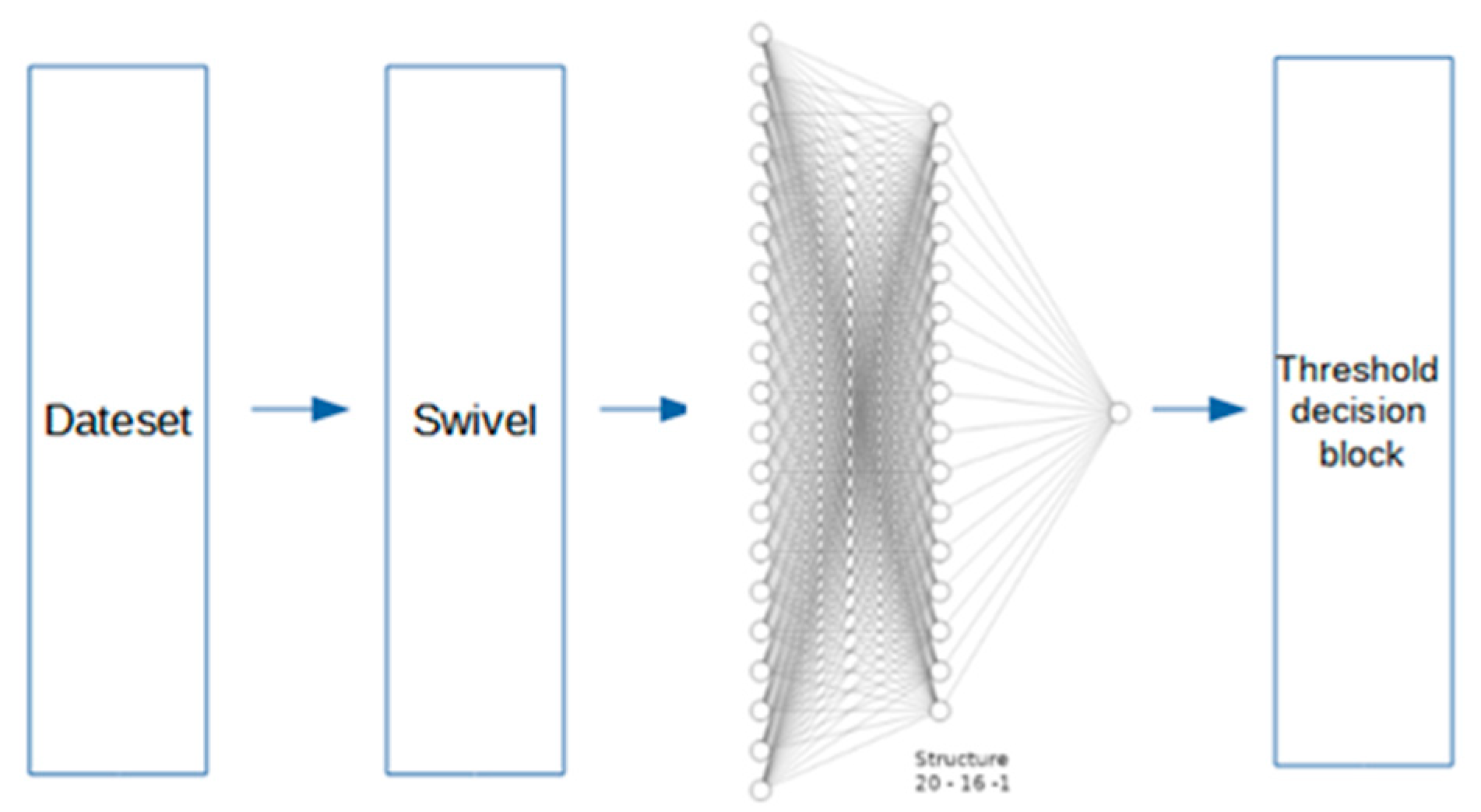
- MLP Multilayer Perceptron Structure 1
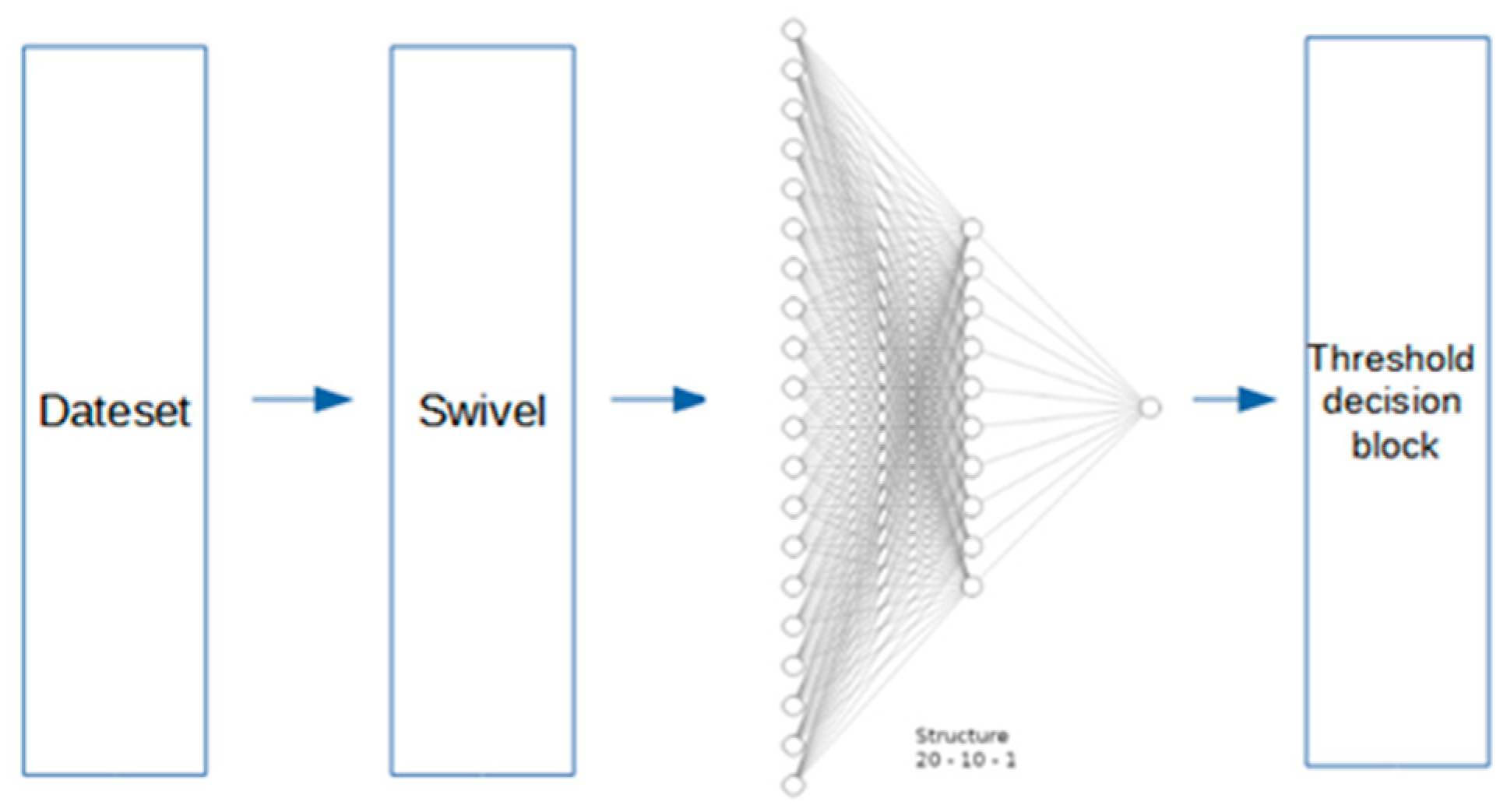
- MLP Multilayer Perceptron Structure 2
- Hyperparameters Adjustment
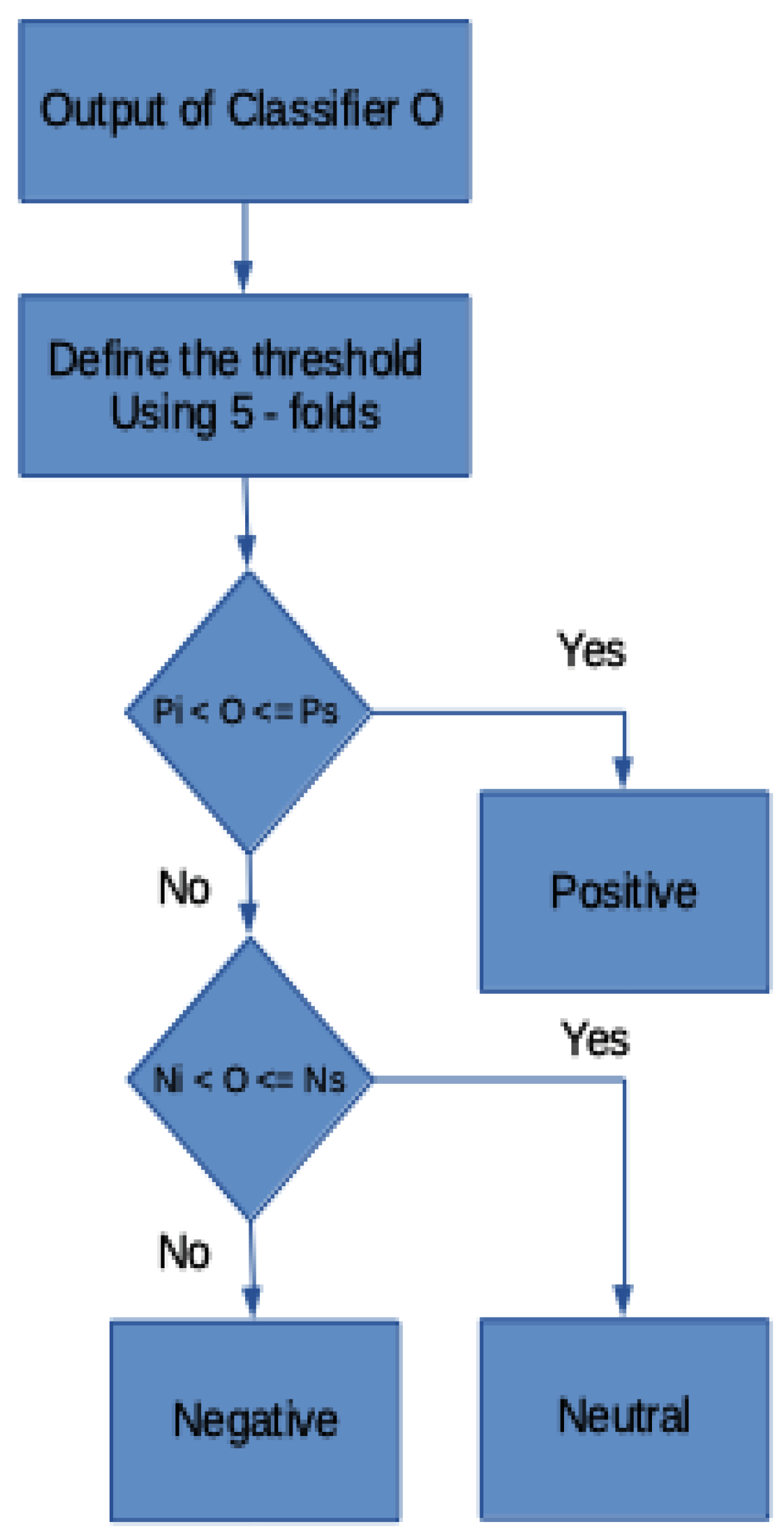
- Decision Model Based on Interval Comparison
2.4.2. Word Clouds
3. Results
3.1. NLP Techniques
3.1.1. Sentiment Analysis
Decision Thresholds for Each Case
Confusion Matrices for the Classifier Model Based on MLP1
- I found the online connection to be very bad and the time was not very suitable for me
- Training mental health professionals so as to be able to amplify the effect
- Timetables sometimes did not fit in with my availability
- GREATER PRIVACY
- More timetable options
Confusion Matrices for the Classifier Model Based on MLP2
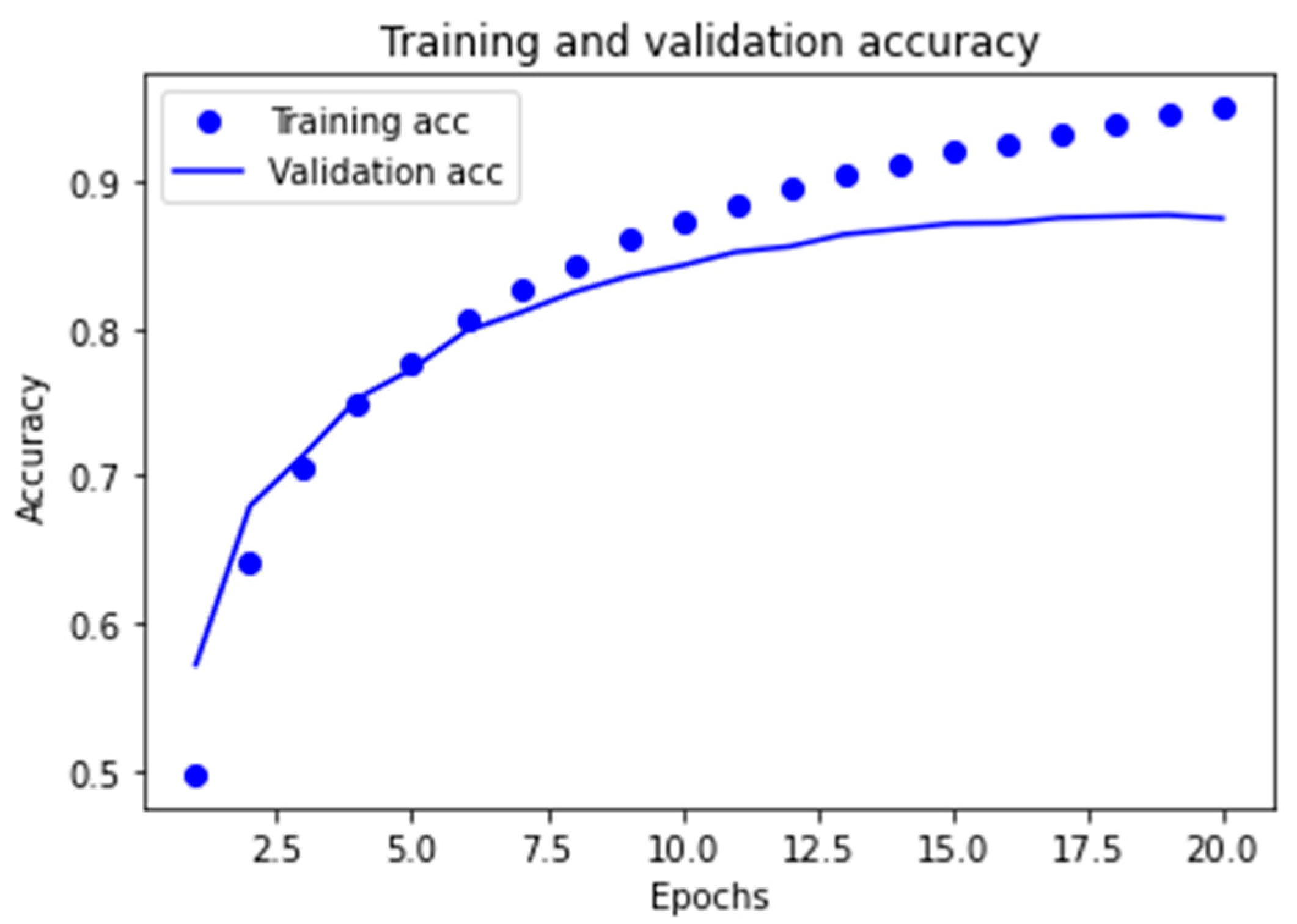
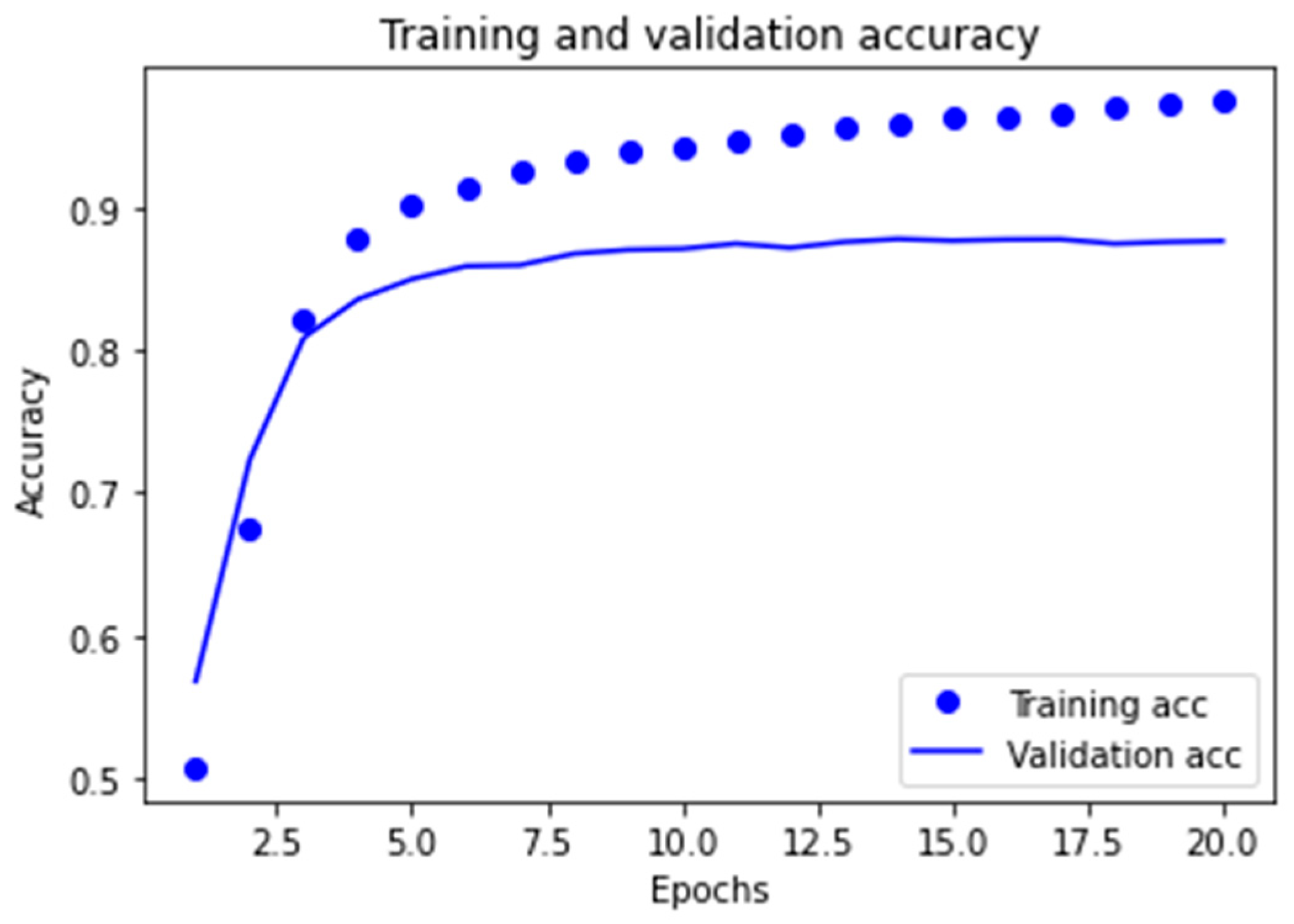
Learning Curves for the Two Best Models Obtained
3.1.2. Word Clouds
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| ID | Question | Answers |
|---|---|---|
| Item 0 | Valid email | |
| Name and surname(s) | Text | |
| Age | Expressed as a number | |
| Sex | Female Male | |
| Post | Nurse TCAE (auxiliary nurse) TCAE (psychiatric auxiliary nurse at HURH (Rio Hortega University Hospital, Valladolid)) Social worker for SACYL (Castile and Leon Health Care Service) Pediatrician Dermatologist Doctor Laboratory technician Physiotherapist Psychologist Psychiatrist Other Midwife Hospital-other Hospital–accident and emergency | |
| 1 | Awareness of the program and type of contact: | By email By direct contact By telephone Via the traditional system (Interconsulta) Social networks |
| 2 | Current work situation (regarding COVID-19): | Active Sick leave Self-isolation Unemployed Other: telecommuting, maternal leave, freelance, vacation |
| 3 | Reason for the request | Anxiety Insomnia Depression Psycho-emotional support Other |
| 4 | Reason for main concern about Covid-19 | Work-related stress Stress owing to family members (not ill with Covid-19) Stress owing to family members (ill with Covid-19) Stress owing to Covid-19 infection Other (concern with social consequences (unemployment, financial situation) regarding the pandemic, emotional control, uncertainty, closeness to vulnerable people, family members who have died from Covid-19), hostility among work colleagues, etc. |
| ID | Question | Answers | |
|---|---|---|---|
| Item 0 | Professional health care category | ||
| Age | Expressed as a number | ||
| Sex | Female Male | ||
| Place of work | |||
| Item 1 | 1. How would you rate the quality of the online emotional mindfulness support service received? | Excellent | |
| Good | |||
| Average | |||
| Poor | |||
| Item 2 | 2. Did you receive the type of support you required? | Definitely not On few occasions In general, yes Definitely yes | |
| Item 3 | 3. To what extent has this program helped you solve your problems? | Almost entirely Mostly Only to some extent Not at all | |
| Item 4 | 4. If a friend needed similar help, would you recommend this program to them? | Definitely not I don’t think so I think so Definitely yes | |
| Item 5 | 5. How satisfied are you with the amount of help you have received? | Not satisfied at all Indifferent or moderately satisfied Moderately satisfied Very satisfied | |
| Item 6 | 6. Have the services you received helped you deal better with your problems? | Yes, they helped me a lot Yes, they helped me to a certain extent No, they didn’t really help me No, they seemed to make things worse | |
| Item 7 | 7. Generally speaking, how satisfied are you with the services you have received? | Very satisfied Moderately satisfied Somewhat satisfied Very unsatisfied | |
| Item 8 | 8. If you needed help again, would you return to our program? | Definitely not Possibly not Yes, I think so Yes, for sure | |
| Item 9 | 9. About the course:
| I completely agree I agreeI don’t agree I disagree I totally disagree | |
| Item 10 | 10. Comparing face-to-face with online intervention, if you had to choose and in light of the experience gained, what would be your preferences (Five [5] would mean indifferent to either type of intervention): | 1 | Online |
| 10 | Face to-face | ||
| Item 11 | Optional: Q1-Share with us what you most liked about the attention received. Q2-Share your suggestions and recommendations for improvement with us. | Open responses | |
References
- Xiang, Y.T.; Li, W.; Zhang, Q.; Jin, Y.; Rao, W.W.; Zeng, L.N.; Lok, G.K.I.; Chow, I.H.I.; Cheung, T.; Hall, B.J. Timely research papers about COVID-19 in China. Lancet 2020, 395, 684–685. [Google Scholar] [CrossRef] [Green Version]
- Xiang, Y.T.; Yang, Y.; Li, W.; Zhang, L.; Zhang, Q.; Cheung, T.; Ng, C.H. Timely mental health care for the 2019 novel coronavirus outbreak is urgently needed. Lancet Psych. 2020, 7, 228–229. [Google Scholar] [CrossRef] [Green Version]
- Xiao, C. A novel approach of consultation on 2019 novel coronavirus (COVID-19)-related psychological and mental problems: Structured letter therapy. Psychiatry Investig. 2020, 17, 175–176. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kang, L.; Li, Y.; Hu, S.; Chen, M.; Yang, C.; Yang, B.X.; Wang, Y.; Hu, J.; Lai, J.; Ma, X.; et al. The mental health of medical workers in Wuhan, China dealing with the 2019 novel coronavirus. Lancet Psychiatry 2020, 7, e14. [Google Scholar] [CrossRef] [Green Version]
- Gautam, R.; Sharma, M. 2019-nCoV pandemic: A disruptive and stressful atmosphere for Indian academic fraternity. Brain Behav. Immun. 2020, 88, 948–949. [Google Scholar] [CrossRef] [PubMed]
- Wu, P.; Fang, Y.; Guan, Z.; Fan, B.; Kong, J.; Yao, Z.; Liu, X.; Fuller, C.J.; Susser, E.; Lu, J.; et al. The psychological impact of the SARS epidemic on hospital employees in China: Exposure, risk perception, and altruistic acceptance of risk. Can. J. Psychiatry 2009, 54, 302–311. [Google Scholar] [CrossRef]
- Shigemura, J.; Ursano, R.J.; Morganstein, J.C.; Kurosawa, M.; Benedek, D.M. Public responses to the novel 2019 coronavirus (2019-nCoV) in Japan: Mental health consequences and target populations. Psychiatry Clin. Neurosci. 2020, 74, 281–282. [Google Scholar] [CrossRef]
- Lee, S.M.; Kang, W.S.; Cho, A.R.; Kim, T.; Park, J.K. Psychological impact of the 2015 MERS outbreak on hospital workers and quarantined hemodialysis patients. Compr. Psychiatry 2018, 87, 123–127. [Google Scholar] [CrossRef] [PubMed]
- Huang, J.Z.; Han, M.F.; Luo, T.D.; Ren, A.K.; Zhou, X.P. Mental health survey of medical staff in a tertiary infectious disease hospital for COVID-19. Zhonghua Lao Dong Wei Sheng Zhi Ye Bing Za Zhi 2020, 38, 192–195. [Google Scholar] [CrossRef] [PubMed]
- Cohen, S.; Doyle, W.J.; Skoner, D.P. Psychological stress, cytokine production, and severity of upper respiratory illness. Psychosom. Med. 1999, 61, 175–180. [Google Scholar] [CrossRef]
- Dutheil, F.; Aubert, C.; Pereira, B.; Dambrun, M.; Moustafa, F.; Mermillod, M.; Baker, J.S.; Trousselard, M.; Lesage, F.X.; Navel, V. Suicide among physicians and health-care workers: A systematic review and meta-analysis. PLoS ONE 2019, 14, e0226361. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Reger, M.A.; Stanley, I.H.; Joiner, T.E. Suicide Mortality and Coronavirus Disease 2019—A Perfect Storm? JAMA Psychiatry 2020. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Shonin, E.; Van Gordon, W.; Griffiths, M.D. Mindfulness-based interventions: Towards mindful clinical integration. Front. Psychol. 2013, 4. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zhu, Y.; Chen, L.; Ji, H.; Xi, M.; Fang, Y.; Li, Y. The Risk and Prevention of Novel Coronavirus Pneumonia Infections Among Inpatients in Psychiatric Hospitals. Neurosci. Bull. 2020, 36, 299–302. [Google Scholar] [CrossRef] [Green Version]
- Koh, D.; Meng, K.L.; Sin, E.C.; Soo, M.K.; Qian, F.; Ng, V.; Ban, H.T.; Kok, S.W.; Wuen, M.C.; Hui, K.T.; et al. Risk perception and impact of severe acute respiratory syndrome (SARS) on work and personal lives of healthcare workers in Singapore: What can we learn? Med. Care 2005, 43, 676–682. [Google Scholar] [CrossRef] [PubMed]
- Zandifar, A.; Badrfam, R. Iranian mental health during the COVID-19 epidemic. Asian J. Psychiatr. 2020, 51. [Google Scholar] [CrossRef]
- Baer, R.A. Mindfulness Training as a Clinical Intervention: A Conceptual and Empirical Review. Clin. Psychol. Sci. Pract. 2003, 10, 125–143. [Google Scholar] [CrossRef]
- Arlt Mutch, V.K.; Evans, S.; Wyka, K. The role of acceptance in mood improvement during Mindfulness-Based Stress Reduction. J. Clin. Psychol. 2020. [Google Scholar] [CrossRef]
- Hofmann, S.G.; Gómez, A.F. Mindfulness-Based Interventions for Anxiety and Depression. Psychiatr. Clin. N. Am. 2017, 40, 739–749. [Google Scholar] [CrossRef]
- Crane, C.; Barnhofer, T.; Duggan, D.S.; Hepburn, S.; Fennell, M.V.; Williams, J.M.G. Mindfulness-based cognitive therapy and self-discrepancy in recovered depressed patients with a history of depression and suicidality. Cogn. Ther. Res. 2008, 32, 775–787. [Google Scholar] [CrossRef]
- World Health Organization. WHO Statement on Cases of COVID-19 Surpassing 100,000. Available online: https://www.who.int/news/item/07-03-2020-who-statement-on-cases-of-covid-19-surpassing-100-000 (accessed on 22 November 2020).
- Sharma, S.; Sharma, M.; Singh, G. A chaotic and stressed environment for 2019-nCoV suspected, infected and other people in India: Fear of mass destruction and causality. Asian J. Psychiatr. 2020, 51, 102049. [Google Scholar] [CrossRef] [PubMed]
- Sacyl. +Salud Mental. 2020. Available online: https://www.massaludmental.es/ (accessed on 10 June 2021).
- Sacyl. Ciudadanos|Main Page. Available online: https://www.saludcastillayleon.es/en (accessed on 22 November 2020).
- Sun, P.; Lu, X.; Xu, C.; Sun, W.; Pan, B. Understanding of COVID-19 based on current evidence. J. Med. Virol. 2020, 92, 548–551. [Google Scholar] [CrossRef]
- Franco-Martín, M.A.; Muñoz-Sánchez, J.L.; Sainz-de-Abajo, B.; Castillo-Sánchez, G.; Hamrioui, S.; de la Torre-Díez, I. A Systematic Literature Review of Technologies for Suicidal Behavior Prevention. J. Med. Syst. 2018. [Google Scholar] [CrossRef]
- Alamoodi, A.H.; Zaidan, B.B.; Zaidan, A.A.; Albahri, O.S.; Mohammed, K.I.; Malik, R.Q.; Almahdi, E.M.; Chyad, M.A.; Tareq, Z.; Albahri, A.S.; et al. Sentiment analysis and its applications in fighting COVID-19 and infectious diseases: A systematic review. Expert Syst. Appl. 2021, 167, 114155. [Google Scholar] [CrossRef]
- Asgari-Chenaghlu, M.; Nikzad-Khasmakhi, N.; Minaee, S. Covid-Transformer: Detecting Covid-19 Trending Topics on Twitter Using Universal Sentence Encoder. arXiv 2020, arXiv:2009.03947v3. [Google Scholar]
- Stewart, R.; Velupillai, S. Applied natural language processing in mental health big data. Neuropsychopharmacology 2021, 46, 252–253. [Google Scholar] [CrossRef] [PubMed]
- Valle-Cruz, D. Does Twitter affect Stock Market Decisions? Financial Sentiment Analysis in Pandemic Seasons: A Comparative Study of H1N1 and COVID-19. Cogn. Comput. 2021. [Google Scholar] [CrossRef]
- Garcia, K.; Berton, L. Topic detection and sentiment analysis in Twitter content related to COVID-19 from Brazil and the USA. Appl. Soft Comput. 2021, 101, 107057. [Google Scholar] [CrossRef] [PubMed]
- Jang, H.; Rempel, E.; Roth, D.; Carenini, G.; Janjua, N.Z. Tracking COVID-19 Discourse on Twitter in North America: Infodemiology Study Using Topic Modeling and Aspect-Based Sentiment Analysis. J. Med. Internet Res. 2021, 23, e25431. [Google Scholar] [CrossRef] [PubMed]
- Yun-tao, Z.; Ling, G.; Yong-cheng, W. An improved TF-IDF approach for text classification. J. Zhejiang Univ. A 2005, 6, 49–55. [Google Scholar] [CrossRef]
- Gardner, M.; Artzi, Y.; Basmova, V.; Berant, J.; Bogin, B.; Chen, S.; Dasigi, P.; Dua, D.; Elazar, Y.; Gottumukkala, A.; et al. Evaluating Models’ Local Decision Boundaries via Contrast Sets. 2020, pp. 1307–1323. Available online: http://arxiv.org/abs/2004.02709 (accessed on 11 March 2021).
- Tixier, A.J.-P. Notes on Deep Learning for NLP. arXiv 2018, arXiv:1808.09772. [Google Scholar]
- Shaukat, Z.; Zulfiqar, A.A.; Xiao, C.; Azeem, M.; Mahmood, T. Sentiment analysis on IMDB using lexicon and neural networks. SN Appl. Sci. 2020, 2, 1–10. [Google Scholar] [CrossRef] [Green Version]
- Manuel, S.; Soldara, M.; Paulo, J.; Rodríguez, M.; Vladimir, J.; Espino, M. MINERÍA DE DATOS EN UN SERVIDOR LOCAL PARA CLASIFICAR PALABRAS POR EL MÉTODO DE LOS COSENOS (DATAMINING IN A LOCAL SERVER TO CLASSIFY WORDS BASED ON COSINE METHOD). Inicio 2020, 42, 137. [Google Scholar]
- Pennington, J.; Socher, R.; Manning, C.D. GloVe: Global vectors for word representation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014. [Google Scholar]
- Church, K.W. Emerging Trends: Word2Vec. Nat. Lang. Eng. 2017, 23, 155–162. [Google Scholar] [CrossRef] [Green Version]
- Shazeer, N.; Doherty, R.; Evans, C.; Waterson, C. Swivel: Improving Embeddings by Noticing What’s Missing. 2016. Available online: http://arxiv.org/abs/1602.02215 (accessed on 11 March 2021).
- Mimno, D.; Thompson, L. The strange geometry of skip-gram with negative sampling. In Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, Copenhagen, Denmark, 7–11 September 2017; Association for Computational Linguistics: Stroudsburg, PA, USA, 2017; pp. 2873–2878. [Google Scholar]
- Van De Cruys, T. Two Multivariate Generalizations of Pointwise Mutual Information. In Proceedings of the Workshop on Distributional Semantics and Compositionality (DiSCo’2011), Portland, OR, USA, 24 June 2011; pp. 16–20. [Google Scholar]
- Caballero, L.; Jojoa, M.; Percybrooks, W.S. Optimized neural networks in industrial data analysis. SN Appl. Sci. 2020, 2, 300. [Google Scholar] [CrossRef] [Green Version]
- Kötz, B.; Schaepman, M.; Morsdorf, F.; Bowyer, P.; Itten, K.; Allgöwer, B. IEEE Xplore sFull-Text PDF. In Proceedings of the 2003 IEEE International Geoscience and Remote Sensing Symposium (IGARSS ’03), Toulouse, France, 21–25 July 2003; Volume 4, pp. 2869–2871. [Google Scholar] [CrossRef]
- Xu, Q.-S.; Liang, Y.-Z.; Du, Y.-P. Monte Carlo cross-validation for selecting a model and estimating the prediction error in multivariate calibration. J. Chemom. 2004, 18, 112–120. [Google Scholar] [CrossRef]
- Basiri, M.E.; Nemati, S.; Abdar, M.; Cambria, E.; Acharya, U.R. ABCDM: An Attention-based Bidirectional CNN-RNN Deep Model for sentiment analysis. Futur. Gener. Comput. Syst. 2021, 115, 279–294. [Google Scholar] [CrossRef]
- Manguri, K.H.; Ramadhan, R.N.; Amin, P.R.M. Twitter Sentiment Analysis on Worldwide COVID-19 Outbreaks. Kurd. J. Appl. Res. 2020, 54–65. [Google Scholar] [CrossRef]
- Minaee, S.; Kalchbrenner, N.; Cambria, E.; Nikzad, N.; Chenaghlu, M.; Gao, J. Deep Learning—Based Text Classification. ACM Comput. Surv. 2021, 54, 1–40. [Google Scholar] [CrossRef]












| Hyperparameters | Values |
|---|---|
| Number of Hidden Layers | 1–2 |
| Activation Function of Hidden Layers | RELU |
| Number of Neurons of the Hidden Layers | 1–20 |
| Model | Dataset | Positive | Mean Positive—Neutral Threshold | Mean Neutral—Negative Threshold | Negative | Mean Accuracy |
|---|---|---|---|---|---|---|
| MLP1 | Question 1 | 1 | 0 | −0.5 | −1 | 93.02% |
| MLP1 | Question 2 | 1 | 0 | −0.1 | −1 | 72.05% |
| MLP2 | Question 1 | 1 | 0 | −0.4 | −1 | 90.53% |
| MLP2 | Question 2 | 1 | 0 | −0.22 | −1 | 70.25% |
| Predicted | Real | ||||||
| Class | Positive | Neutral | Negative | Precision | Recall | F1 Score | |
| Positive | 78 | 2 | 0 | 0.98 | 0.95 | 0.96 | |
| Neutral | 3 | 1 | 0 | 0.25 | 0.33 | 0.29 | |
| Negative | 1 | 0 | 1 | 0.50 | 1.00 | 0.67 | |
| Predicted | Real | ||||||
| Class | Positive | Neutral | Negative | Precision | Recall | F1 Score | |
| Positive | 46 | 13 | 5 | 0.72 | 0.98 | 0.83 | |
| Neutral | 0 | 0 | 0 | NA | NA | NA | |
| Negative | 1 | 0 | 3 | 0.75 | 0.38 | 0.50 | |
| Predicted | Real | ||||||
| Class | Positive | Neutral | Negative | Precision | Recall | F1 Score | |
| Positive | 70 | 2 | 0 | 0.97 | 0.85 | 0.91 | |
| Neutral | 3 | 1 | 0 | 0.25 | 0.33 | 0.29 | |
| Negative | 9 | 0 | 1 | 0.10 | 1.00 | 0.18 | |
| Predicted | Real | ||||||
| Class | Positive | Neutral | Negative | Precision | Recall | F1 Score | |
| Positive | 39 | 5 | 5 | 0.80 | 0.83 | 0.81 | |
| Neutral | 0 | 0 | 0 | NA | NA | NA | |
| Negative | 8 | 8 | 3 | 0.16 | 0.38 | 0.22 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Acosta, M.J.; Castillo-Sánchez, G.; Garcia-Zapirain, B.; de la Torre Díez, I.; Franco-Martín, M. Sentiment Analysis Techniques Applied to Raw-Text Data from a Csq-8 Questionnaire about Mindfulness in Times of COVID-19 to Improve Strategy Generation. Int. J. Environ. Res. Public Health 2021, 18, 6408. https://doi.org/10.3390/ijerph18126408
Acosta MJ, Castillo-Sánchez G, Garcia-Zapirain B, de la Torre Díez I, Franco-Martín M. Sentiment Analysis Techniques Applied to Raw-Text Data from a Csq-8 Questionnaire about Mindfulness in Times of COVID-19 to Improve Strategy Generation. International Journal of Environmental Research and Public Health. 2021; 18(12):6408. https://doi.org/10.3390/ijerph18126408
Chicago/Turabian StyleAcosta, Mario Jojoa, Gema Castillo-Sánchez, Begonya Garcia-Zapirain, Isabel de la Torre Díez, and Manuel Franco-Martín. 2021. "Sentiment Analysis Techniques Applied to Raw-Text Data from a Csq-8 Questionnaire about Mindfulness in Times of COVID-19 to Improve Strategy Generation" International Journal of Environmental Research and Public Health 18, no. 12: 6408. https://doi.org/10.3390/ijerph18126408