1. Introduction
Given the explosive growth of smart phones and other new applications that result in huge amounts of data transmission apart from the conventional telephone voice service, the massive Internet of Things (IoT) is currently facing significant challenges, such as achieving intelligent implementations [
1] and ensuring secure and trustworthy operations [
2]. To address these challenges, technologies, such as semi-federated learning [
1] and blockchain [
2], can be employed. Cellular-based mobile networks will continue to play a crucial role in the development of fifth-generation (5G) and beyond 5G (B5G) wireless communications for IoT, enabling innovative solutions to these challenges.
In such networks, frequency bands are usually reused to mitigate inter-cell interference. Herein, a frequency band shared by all cells is usually considered to have a harmful impact on communication. However, owing to the excessive increase of data traffic, such sharing becomes a possible solution to the problem of scarce radio resources to be used in ultra-dense cellular networks. For this, coordinated multi-point (CoMP) [
3] is a promising concept to manage the resulting interference. Specifically, if each BS in the cellular network can perform downlink beamforming [
4] for transmitting to its UE appropriately, the intra-cell and inter-cell interference would be mitigated. Given the significant advantage, CoMP is included in the specifications of long term evolution-advanced (LTE-A) [
5].
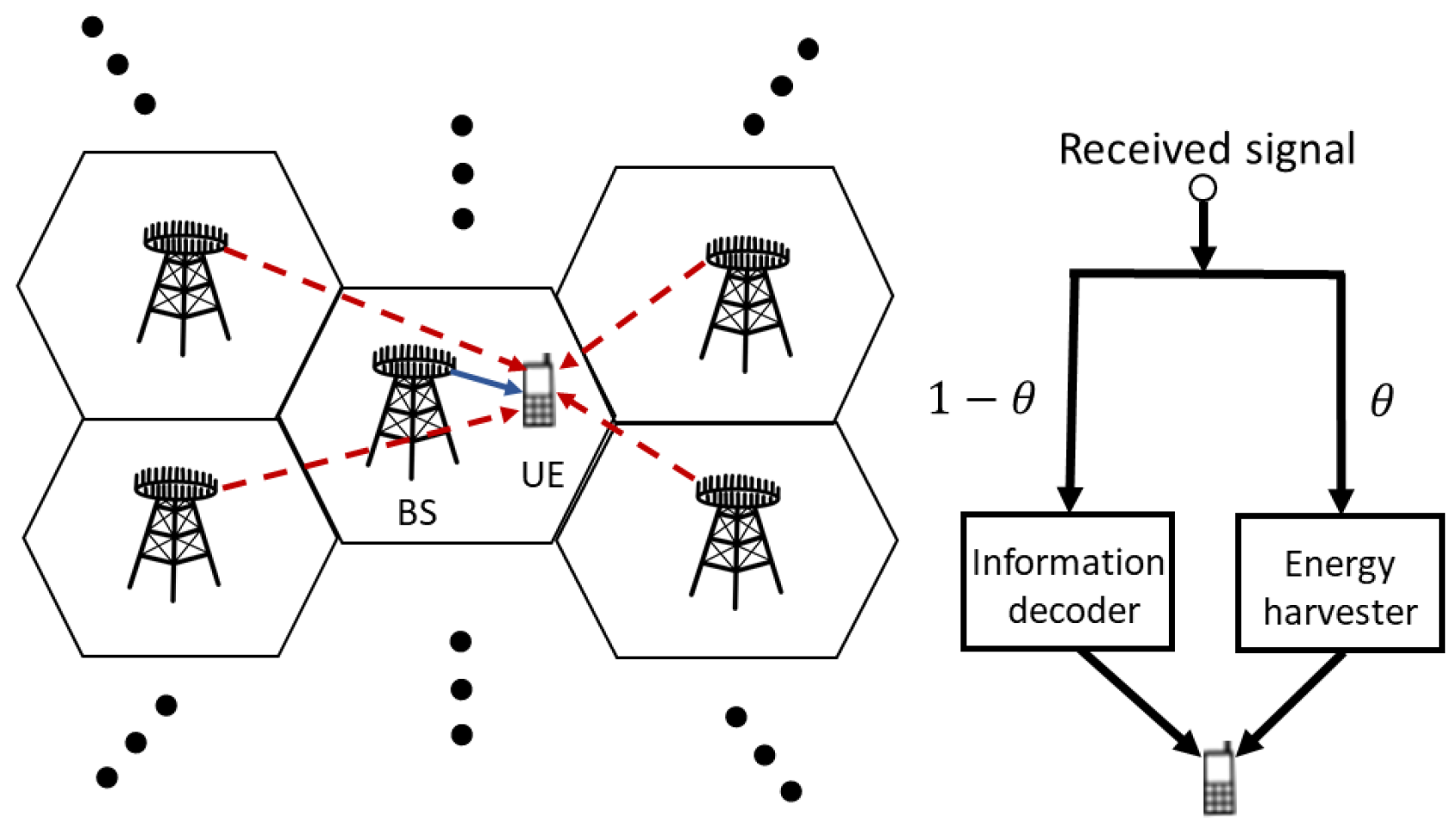
Apart from the interference issue, user equipment (UE) in 5G or B5G is still energy-constrained due to its battery with limited capacity, which is especially true for low-power IoT devices acting as femto UEs within these networks. Despite the slow progress of the battery capacity in recent decades, energy harvesting techniques have emerged to address the crucial issue. As expected, various renewable energy resources could be adopted to refill batteries, such as wind and solar, but their usability is restricted to weather, position, and many other conditions.
In view of these problems, the radio frequency (RF)-based wireless energy transfer (WET) technique would be an alternative that can charge low-power devices over the air, simplify the maintenance procedure, and significantly contribute to the realization of scalable wireless networks [
6]. As an extension, WET combined with the wireless network for transmitting information by default results in simultaneous wireless information and power transfer (SWIPT), which enables a UE to harvest energy from the electromagnetic waves in RF from its surroundings while it simultaneously performs information decoding (ID) for the data transmitted from its source [
7,
8].
1.1. Related Work
Based on SWIPT, many related works have been performed. Among them, a pioneering work [
9] with a multi-antenna BS transmitting to its UE in downlink was proposed that provides the rate-energy trade-offs for the broadcast SWIPT system involved. In addition, it is shown that each UE can perform ID and EH at the same time with a power splitting (PS) scheme or at different time slots with a time switching (TS) scheme. As an extension of TS, the authors in [
10] proposed two new time-splitting schemes, namely time-division mode switching (TDMS) and time-division multiple access (TDMA) for a multi-input single-output (MISO) interference channel (IC). With the possibility of simplifying the receiver design, TS, however, does not actually perform ID and EH simultaneously and would only provide limited exploitation of radio resources [
11,
12], which motivates the use of PS in this work.
As an example adopting PS, the work [
13] resolves a throughput maximization problem subject to energy and temperature constraints at transmitting and receiving nodes, respectively, for a hybrid SWIPT relay system. Extending its viewpoint beyond throughput, the work [
14] addresses a fundamental problem to characterize the trade-offs for maximizing energy efficiency (EE) vs. spectrum efficiency (SE) under a point-to-point additive white Gaussian noise (AWGN) channel.
In addition, with respect to orthogonal frequency division multiple access (OFDMA) systems, the related work [
15] considered a resource-allocation problem to maximize EE in SWIPT with a PS scheme, and developed fractional programming models and sub-optimal iterative resource allocation algorithms to tackle the nonconvex problems encountered. In [
16], with the assumption of using zero-forcing (ZF) beamforming patterns (BPs), the authors aimed to maximize EE under a PS-based MISO downlink system. In [
17], a multi-user MISO SWIPT system was considered, and an iterative algorithm was proposed, which is guaranteed to achieve a Karush–Kuhn–Tucker solution for maximizing the EE of this system. Similarly, by focusing on wireless sensor networks, the authors in [
18] tackled nonconvex EE optimization problems and proposed sub-optimal iterative algorithms through nonlinear fractional programming and Lagrangian dual decomposition.
Apart from the above, different EH-enabled frameworks can be also found in the literature. For example, the authors in [
19] proposed a MOO formulation for a multi-pair two-way relay network to maximize the achievable rates of all
K UE pairs involved. In that work, by using zero-forcing to null the multi-user interference, the achievable rate of a UE pair can only depend on their own PRs, and the MOO problem can be converted to
K independent single objective optimization problems. Thus, the trade-off on data rate can be made between UE pairs. However, in our MOO formulation, the inter-cell interference would be involved, and the trade-off between SE and EH in the system is mainly considered rather than the trade-off for the rate between UE pairs in [
19].
As another example, a wirelessly powered IoT system was also investigated in [
20], wherein sensors harvested energies from the distributed access points (APs) and then transmitted data to the APs with the harvested energies. Although this is different from the SWIPT scenario considered here, how to extend the current work based on the results in [
20] giving a higher WET efficiency could be an interesting future work. To see more related works on SWIPT, WET, or both, one may refer to survey papers, such as [
21,
22].
Despite the various mathematical approaches adopted in the related works that we mentioned, the computational complexity of mobile wireless network has made it impossible to decide all the system parameters required in time. To meet the time constraint, deep learning is a promising data-driven approach that adopts a deep neural network (DNN) to resolve complex nonlinear problems without explicitly formulating complicated mathematical models [
23]. Recently, DNN-based learning algorithms have also been developed to resolve different problems in SWIPT-enabled networks as another way to find the solutions in time apart from the analytical-based methods under consideration, which may be not sufficiently time-efficient in usual cases.
As a method based on learning with DNN, the work in [
24] proposed a long short-term memory (LSTM) recurrent neural network (RNN)-based mode-switching algorithm to maximize the achievable rate under the energy-causality constraint for its dual mode SWIPT system. In [
25], the authors determine the subchannel allocation, power splitting ratio (PR), and transmit power for the SWIPT-based device-to-device (D2D) networks through the deep-reinforcement-learning (DRL)-based algorithm developed therein. For similar D2D SWIPT-based networks, an EE optimization problem was formulated in [
26], and the authors adopted exhaustive search (ES) and gradient search (GS), respectively, to obtain the global optimum and local optimum for the formulated nonconvex optimization problem.
In [
27], by clustering the antennas into two multiple-input multiple-output (MIMO) subsystems, the authors developed a sub-optimal method and a hybrid DRL method to resolve the combinatorial problem for the full-duplex MIMO system involved, which jointly optimized the antenna clusters and pre-coding matrices for ID and EH so that the weighted sum of their performance metrics can be maximized. In [
28], with the multi-user MISO SWIPT-enabled heterogeneous wireless networks as the target, the authors maximized the achievable sum information rate of the femtocells by jointly optimizing BP and PR under the achievable data rate requirements through a multi-agent DDQN algorithm.
1.2. The Motivations and Characteristics of This Work
Taking both ID and EH into account, the previous works on SWIPT usually focused on throughput maximization [
10,
13], EE optimization [
15,
16,
18], or both [
14]. As a complement to the above, our work concerns the trade-off between SE and EH in the SWIPT-enabled networks with MISO channels, which is similar to the objective given in [
29] for D2D networks without BP decision.
However, the objective considered here is to decide both BP and PR, and our work further reveals that, in addition to the interference management concerned by CoMP, the decisions on BP and PR in SWIPT lead to an overall system utility reflecting both SE and EH with weights to achieve the optimal trade-off subject to the transmit power constraint and the feasible PR constraint. As we know, such a trade-off for the coordinated beamforming in the MISO downlink SWIPT-enabled networks with FP and DRL under the logarithmic nonliner EH model [
30,
31] is not explicitly explored in the previous works. Specifically, the contributions of this work can be summarized as follows.
We derive a multi-objective optimization (MOO) formulation to obtain the optimal BP and PR for the MISO downlink SWIPT-enabled wireless networks under the logarithmic nonliner EH model. Then, with a weighted sum approach, we transform this formulation to obtain an objective function for the resulting multiple-ratio FP problem.
To solve the non-convex FP problem, instead of using the Dinkelbach’s transformation that is usually considered, we develop an evolutionary algorithm (EA)-aided quadratic transform technique that can obtain the desired PR with EA first, and then feed it to an effective iterative algorithm for near-optimal solutions.
To further reduce the computational complexity while avoiding the collection of global channel state information (CSI), we propose a distributed multi-agent learning-based approach that requires only partial observations of CSI. Specifically, we develop a multi-agent double DQN (DDQN) algorithm for each BS to decide its BP and PR based only on local observations with lower overheads of communication and computation.
Instead of centralized operations, such as centralized training centralized executing (CTCE) and centralized training distributed executing (CTDE), we adopt a distributed training distributed executing (DTDE) scheme, which makes the offline training and online decision making performed by each single agent or BS distributive and independent and limits the amount of information to be exchanged between neighboring BSs.
We verify the trade-off between SE and EH with simulations and show that our proposal can outperform the state-of-the-art centralized learning-based algorithm, Advantage Actor Critic (A2C), and baseline approaches, such as greedy and random algorithms. More specifically, it can be seen that, in addition to the introduced FP algorithm to provide superior solutions, the proposed DDQN algorithm can also show its performance gain in terms of utility up to 1.23-, 1.87-, and 3.45-times larger than the A2C, greedy, and random algorithms, respectively, in comparison.
The rest of this paper is structured as follows. In
Section 2, we introduce the network, channel model, and problem formulation for this work. Next, we present the EA-aided quadratic transform technique and the FP-based iterative algorithm in
Section 3. Then, the limited channel information exchange mechanism is summarized in
Section 4, and the distributed multi-agent learning-based DDQN approach is introduced in
Section 5. After that, the proposed algorithms are numerically examined in
Section 6 to show the trade-offs between SE and EH and their performance differences when compared with other DRL-based algorithms and baseline approaches. Finally, our conclusions are drawn in
Section 7.
3. Fractional Programming-Based Approach
In this work, instead of using the classic Dinkelbach’s transformation [
36] that is typically adopted for single-ratio FP problems, we adopt the quadratic transform technique developed in [
37] for multi-ratio FP problems. Specifically, for the first objective in (
10) aiming at SE, which involves SINR with fractional terms in the logarithm function, we adopt a Lagrangian dual reformulation with a set of dual or auxiliary variables
. According to Proposition 2 of [
37], the SE objective can be reformulated as
where
, and this ignores the time index
t as noted previously. Then, by taking partial differentiation with respect to
and leading the result to zero, i.e.,
, we can obtain the optimal dual variable for SE as
On the other hand, the EH objective in (
10) can be also denoted by
with
. Then, as the SE counterpart, we can conduct a set of dual variables
, and apply the transform similar to that in Proposition 2 of [
37] to reformulate the EH objective as
Similarly, by
, the optimal dual variable for EH with respect to
i can be given by
However, for the consistency with
, we adopt
to have the same denominator in the last term of
as follows:
Finally, (
11) and (
15) can be combined, leading to the new overall utility as
where
is the independent part that does not directly relate to the transmit signal
in the numerator of (
20), including
where
, and
. However, with the signal from BS
i to its receiver, i.e.,
, as the major part to be optimized, this formulation would lead to a BP focusing on the data rate to its receiver while ignoring the interference powers from the others to be harvested. To resolve this problem, the numerator part of
is modified to account for the powers transmitted from BS
i to the others as
rather than the powers received from the others that cannot be controlled by BS
i itself in the original form. Consequently, the overall utility function is modified as
where
is not directly related to the transmit signals,
, of BS
i. Then, by using the quadratic transform in the multidimensional and complex case in Theorem 2 of [
37] on the UE part and the SE part of (
20) without
, respectively, we have the system objective as
where
is the dual variable in this case. Essentially, the objective is developed to facilitate solving this problem iteratively. That is, when
and the other variables are fixed, the optimal
can be found by solving the first-order optimality, i.e.,
, and the result is
Similarly, the optimal
can be obtained by
In the above,
is the dual variable introduced for the power constraint, and its optimal value can be denoted by
which can be efficiently determined by means of a bisection search algorithm.
Apart from the above, it can also be seen that the formulations for
, and
explored so far all involve
. In fact,
is highly coupled among these formulas, and could not be easily resolved through them. For the resulting non-convexity, we resort to evolutionary algorithms (EAs) to find its value to approach the overall optimal solution. Specifically, we develop a simulated annealing (SA) algorithm for this aim as was implemented in [
38]. Given this, the FP algorithm to maximize the objective (
21) is summarized in Algorithm 1.
| Algorithm 1 EA-aided FP algorithm. |
- 1:
Provide , , , , and ; - 2:
Initialize , , , and set ; - 3:
repeat - 4:
Obtain with SA; - 5:
Update , with ( 22) while fixing , , , and ; - 6:
for each BS or direct link i do - 7:
Set , , and ; - 8:
while and do - 9:
Obtain and with and , respectively, through ( 23) while fixing , , , and ; - 10:
Let and ; - 11:
Let ; - 12:
Obtain with through ( 23) while fixing , , , and ; - 13:
Let ; - 14:
if then - 15:
Let ; - 16:
else - 17:
Let ; - 18:
end if - 19:
; - 20:
end while - 21:
Update as ; - 22:
end for - 23:
Update with ( 12) and ( 14), respectively, while fixing and ; - 24:
; - 25:
until convergence or
|
Note that, although SA is well defined in the literature, our work still requires the FP iterative update procedure with certain modifications to be the fitness function for SA. Specifically, by regarding as the variable to be updated by the SA algorithm with the same FP iterative update process on the others (i.e., , , , and ), the resulting iterative-based fitness function, for example, the SA-Fitness function, can output the desired with a very limited number of iterations. More explicitly, let be the iteration number of the outer loop and be that of the inner loop in the SA-Fitness function.
Through our experiments,
and
can be found to quickly estimate
, and we can then input the obtained
into the EA-aided FP algorithm. Given this, our simulations in
Section 6.2 confirm the effectiveness of the FP algorithm to provide the system performance metrics outperforming those from the learning-based algorithms and the baseline approaches in comparison.
In summary, the FP-based approach is developed to be an iterative algorithm, which involves (1) obtaining
through SA, (2) updating
with (
22), (3) updating
with (
23), (4) updating
with (
12), (5) updating
with (
14), and (6) finding
with the bisection search under the limit of
iterations, while fixing the other variables in each step within the total number of
iterations. In the iterative updates, the inverse operation is required to find, e.g.,
, with the time complexity
, and the number of
bisection-search iterations is also required to find
. Further, to obtain
, SA implemented in [
38] would expand
steps to perform the cost evaluation, where
is the number of individuals to evaluate in a chain for every generation of SA, and
is the number of generations to evolve. Given this, its total time complexity would be
).
4. Limited Channel Information Exchange
In the networks with MISO downlink channels, a practical approach that is frequently adopted is using BSs to collect the channel information. That is, a BS will obtain the channel measurement through the feedback from UE. To this end, there would exist a backhaul network to carry the global instantaneous CSI collected and transmit it to the central controller for global optimization. However, the signal overhead can be huge, which makes a centralized optimization approach infeasible in a highly dynamic environment.
To alleviate the problem in a practical way, our distributed learning-based approach will utilize only the basic operations of BS to exchange information with other BSs through predefined interfaces, such as
in LTE, resulting in a considerably lower signal overhead than that of the backhaul network for centralized optimization. Given this, we consider that each direct link
k has two limited sets, namely interferers and interfered neighbors, similar to those in [
39,
40]. Specifically, we limit the number of neighbor
U of link
k with the dynamic thresholds
and
in the following two limited sets:
where the two thresholds lead to
and
, respectively.
Now, with a control channel to return the feedback, BS k at current time t can obtain the channel gain and the interference-plus-noise through , measured by UE k at the previous time as well as the current channel vector . Similarly, BS k can send its own measurements to its interferers and interfered neighbors and receive the measurements from the two sets of neighbors as conducted in the previous works. The information for these measurements locally exchanged among the neighbors would then be utilized in the following multi-agent DDQN algorithm, which details the measurements to be adopted therein.
5. Learning-Based Approach
In addition to the indicated signal overhead, an optimization-based approach could also have a computational complexity for solving the MOO problem that is non-deterministic polynomial time (NP) in general. Although the FP-based algorithm could be computationally-efficient with the iterative update procedure proposed, to further reduce the signal overhead as well as the computational complexity, we develop a deep-reinforcement-learning-based algorithm to track the fast time-varying channels involved and provide its solutions in a time that could hardly be achieved by using the traditional optimization methods. Specifically, a multi-agent DDQN algorithm is introduced next to make each single agent or BS share only limited information exchanged among its neighbors, effectively reducing the overhead and complexity as mentioned.
5.1. Overview of DDQN
In principle, a reinforcement-learning (RL) algorithm has one or more agents to interact with the environment and to take actions based on certain strategies so that the accumulated reward can be maximized in the long term. The interaction between agent(s) and the environment is usually modeled as a Markov decision process (MDP). The well-known Q-learning algorithm is a MDP-based approach, represented here by a four-tuple structure <
>, where
is the set of states,
is the set of discrete actions,
is the reward, and
P is the transition probability. Specifically, given
r as the instant reward and
as the discount factor, the cumulative discounted reward can be obtained by
Given this, the Q-function associated with a policy
is the expected reward defined by
where
is an action taken in state
in time
t, and the optimal policy
is a mapping from states to actions that maximizes the long-term cumulative discount reward. Then, through the concept of a one-step Markov process, it considers
as the expected instant reward resulting from taking action
a in state
s and the transition probability
. Given this, the Q-function can be iteratively obtained by using the Bellman Equation [
41]
Accordingly, to find the optimal policy
, the Q-learning algorithm is conducted to find the optimal action
a in state
s.Through the Bellman equation shown in above, the optimal Q-function associated with the optimal policy
can be represented by
Clearly, to obtain the optimal results, all state–action pairs should be stored in a place, namely the Q-table, in this algorithm, whose dimensions are
, and this could be huge for a general application. Thus, the primitive Q-learning algorithm may be useful only when the state–action space is relatively small, which seriously limits its applicability. Fortunately, by replacing the Q-table with a neural network to find the optimum, the deep-learning algorithm that results, namely DQN, can significantly reduce the overhead, where the Q-function is denoted by
with
to denote the weight of DNN. Now, with the learning rate
, the Q-value can be updated by
The weights of DNN, however, can diverge due to a high correlation between the actions and states that exist, and the algorithm is not guaranteed to converge on the optimal value function. To resolve this problem, apart from the introduced DNN,
, another DNN,
, is added to keep a copy of DNN and use it for the Q-value update in the Bellman equation. The two different DNNs have different Q-functions,
and
. The loss between them can then be defined by
where
, and minimizing this loss would lead to the optimal solution. Now, even given the loss function, the DQN algorithm may still significantly diverge by overestimating the value of
. The overestimating problem with respect to the deep deterministic policy gradient (DDPG) algorithm was also indicated in [
42,
43]. Additionally, DDPG has the potential to become unstable, and its performance may rely on finding the appropriate hyperparameters for a given problem [
42]. Therefore, it is currently not being considered in this work.
Instead, a variant approach, namely double DQN (DDQN) as proposed in [
44], is considered to select the actions and evaluate the Q-values separately. In particular, unlike DQN directly using the maximum Q-value for the target network, DDQN selects the action from the train network that yields the maximum Q-value, i.e.,
and then identifies the Q-value in the target network by means of the selected action, i.e.,
. Finally, the Q-value for
in DDQN can be obtained by
Apart from the potential to resolve the overestimating problem, DDQN was also shown to obtain the best results through certain datasets for training [
45] and the lowest cost for the dynamic context delivery when compared with the others [
46]. In addition, as shown in [
44], the lower bound on the absolute error of DDQN estimate is zero. Given these good properties, we develop, in the sequel, a distributed multi-agent DDQN algorithm to resolve the MOO problem (
9) with the objective (
10).
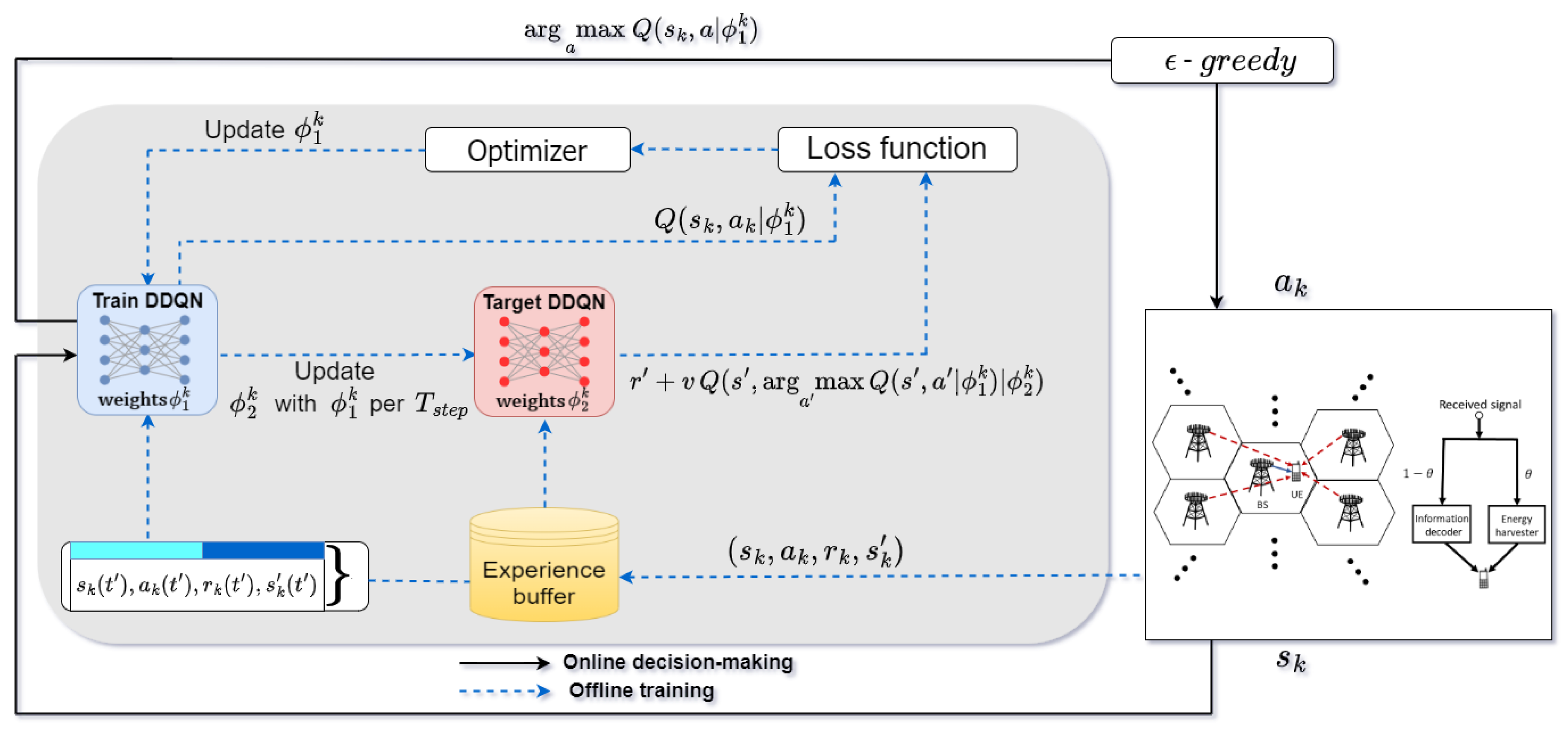
5.2. Distributed Multi-Agent DDQN Algorithm
In
Section 3, the FP-based algorithm is introduced to represent a baseline to be obtained by an optimization-based algorithm. Given its merits on the centralized process, a distributed approach with lower time complexity is still considered better if each BS can independently determine its BP and PR with only limited information shared among their neighbors.
To this end, the proposed DDQN algorithm is conducted to follow the concept of DTDE as shown in
Figure 2, wherein each agent
k takes its action
based on its current state
obtained from the information exchanged among its neighbors, representing the concept of
distributed executing (DE). In addition, each agent
k trains its own DNNs,
and
, by using the experiences
stored in its replay buffer
, representing
distributed training (DT) in this algorithm. Specifically, the main MDP components for the proposed DDQN algorithm are summarized as follows:
- (1)
Action: In this algorithm, each action of agent
k or
is composed of BP
and PR
. As the action space of value-based DRL algorithm must be finite, the feasible actions should be taken from a set of discrete values of
and
, respectively. Here, as each BP is a complex vector, it should be discretized with real values. To this end, it is first decomposed into two parts as
wherein the first part,
, is the transmit power of BS
k, and the second part,
, represents the beam direction of BS
k. On the one hand, the transmit power can be discretized linearly to constitute a set of values, such as
of
equal-spacing values.
On the other hand,
could be discretized by using a codebook
composed of
code vectors
, each specifying a beam direction in
. Providing a sufficient number of code
to be adopted and a number of
S available phase values for each antenna element, we can consider a codebook matrix
similar to that in [
47]. Specifically, for the
-th antenna element in the
q-th code, its value can be given by
Apart from BP, we can similarly discretize each PR
into
levels with a set
, representing its values to be selected. Finally, by taking all the discrete-value sets into account, we have the action space for each agent as
from which an agent
k can choose its action
at time
t.
- (2)
Reward: Apart from the above to select PR within
from
to comply with the feasible PR constraint, for the MOO problem, which is also required to meet the transmit power constraint, we conduct a dual form of this optimization by conceptually lifting the power constraint as the penalty term added in the objective to represent a reward to be obtained by the distributed multi-agent DDQN algorithm. Specifically, the reward function is denoted by
where
is the penalty weight, and
is the total transmit power consumption in the network. Given this, the reward of agent
k at time
t can be denoted by
.
- (3)
State: Conventionally, a state in MDP for RL-based algorithms is designed to represent the environmental information perceived by an agent. Given the same aim to represent as much available information as possible in the environment, the different problems involved, however, could realize their state spaces differently in the different related works, such as [
39,
40,
48]. Here, to construct a state for this algorithm, an agent or BS
k at time
t will provide its local information about the direct link
k at the previous time slot
to its interferers
, including (1) the interference power received from
j,
; (2) the interference-plus-noise power,
; (3) the achievable data rate,
; and (4) the channel gain,
. At the same time, it will also send the information to its interfered neighbors
, including the index
for the beam direction
adopted and the achievable data rate
.
In parallel, each interferer will send the index for the beam direction and the achievable data rate to agent k. Similarly, each interfered neighbor will send its measurements to agent k, including (1) the interference power, ; (2) the interference-plus-noise power, ; (3) the achievable data rate, ; and (4) the channel gain, .
Given this, each agent k includes the following as the local information of its state, denoted by , as
the normalized identity of BS, ;
the normalized channel gain, ;
the normalized interference-plus-noise power,
;
the normalized reward, ,
where
, and
denote the normalization factors corresponding to the above four items, respectively. These factors (as well as the others to be introduced) for state normalization actually play a key role on preprocessing the training sample sets to lead to a much easier and faster training process as noted in [
49,
50]. Apart from that, the state of agent
k also includes a set of information from its interferers, denoted by
. Specifically, for each interferer
, it involves
the normalized identity of the interferer BS, ;
the normalized beam direction index adopted by the interferer BS, ;
the normalized interference power, ;
the normalized utility, ,
where , and denote the corresponding normalization factors. In addition, a set of information from the interfered neighbors, denoted by , is also included in the state to completely describe the interference-limited environment for the MISO transmission. Specifically, the information for each interfered neighbor is represented by
the normalized channel gain, ;
the normalized utility, ;
the normalized SINR with respect to k,
;
the normalized totally-received power,
,
where , and are the normalization factors for the above four items, respectively. Note that, if agent k is not active in tim , the numerator as well as the whole SINR shown in the above are zero and will be excluded from the total received power as well.
Concatenating all three parts, we now have the state = for each agent k. Here, is the state size for each agent k to include the information from its U neighbors. Given this, the system state at time t can be denoted by . Then, following the principle of MDP, each agent k at time t will observe its own state and choose its action with the transition probability determined by its DNN to move to the next state .
- (4)
Selection policy and experience replay: Apart from MDP, the DDQN algorithm also adopts the same mechanisms usually found in DQN, such as
-greedy selection policy and experience replay. First, by using the
-greedy selection policy, each agent can explore the environment with the probability
and can exploit with the probability
, where
is a hyperparameter for the trade-off between exploration and exploitation and decays with a rate of
to its minimum value
, similar to that in [
51]. Further, by means of experience replay, each agent
k can store its transactions
in a buffer memory
, and then randomly sample
to construct a mini-batch for training its DNNs through, e.g., a stochastic gradient descent (SGD) algorithm to update the weights
and
for
and
, respectively. As a summary, the proposed multi-agent DDQN algorithm is is shown in Algorithm 2 for reference.
| Algorithm 2 Multi-agent DDQN algorithm. |
- 1:
(Input) Simulated SWIPT MISO network and hyperparameters for the DDQN algorithm; - 2:
(Output) Learned DDQN to decide , for MOO in ( 9) with objective in ( 10); - 3:
Initialize a pair of and with and for each agent/BS - 4:
Initialize state , action and replay buffer for each agent k; - 5:
for each time slot t do - 6:
for each agent/BS k do - 7:
Observe current state in time slot t; - 8:
generate a random number ; - 9:
if then - 10:
Randomly select from the action space ; - 11:
else - 12:
Select ; - 13:
end if - 14:
Observe next state , and obtain reward ; - 15:
Store the new transition in ; - 16:
Randomly sample a mini-batch with for experience; - 17:
Compute the Q-value for DDQN with ( 32) - 18:
Perform SGD to minimize the loss in ( 31), finding the optimal weights and of agent k; - 19:
Update weight (for ); - 20:
Update weight (for ) with every time slots; - 21:
end for - 22:
end for
|
Now, to evaluate its time complexity, we can assume that the neural network involved has
J fully connected layers at most, in which
denotes the number of neural units at the
j layer, and
is the input state size, leading to the complexity
for its operations as noted in [
49]. In addition, the DDQN algorithm is assumed to have
time slots to learn, and, in each time slot, there are
L distributed agents/BSs to train their own neural networks. Given this, the total complexity would be
.
Apart from the time complexity, each agent or BS requires at most four U messages from its neighbors with the limited channel information exchange. Otherwise, if a centralized approach in convention is adopted, the signal overhead would include the collection of -dimension complex vectors. In general, the number of neighbors for an agent or BS (i.e., U) is much less than the number of cells or BSs (i.e., L); thus, our approach can pay a lower signal overhead than can the centralized counterpart.
6. Numerical Experiments
In this section, we conduct simulation experiments to evaluate the proposed EA-aided FP algorithm (denoted by “FP”) and distributed multi-agent DDQN algorithm (denoted by “dis-DDQN”). To validate the proposed algorithms, we include a greedy-based algorithm and a random-based algorithm (denoted by “greedy” and “random”, respectively) as the comparison baselines. In addition, to verify the effectiveness of the DDQN algorithm based on DTDE, we introduce a CTDE variant (denoted by “glo-DDQN”), which uses the global state
=
introduced in
Section 5.2, to be the state for training each BS
k instead of using only its local state
. Furthermore, to show the effectiveness of distributed computing, we also compare the Advantage Actor Critic (denoted by “A2C”) algorithm, which represents the state-of-the-art centralized RL algorithm to resolve this problem.
6.1. Simulation Setup
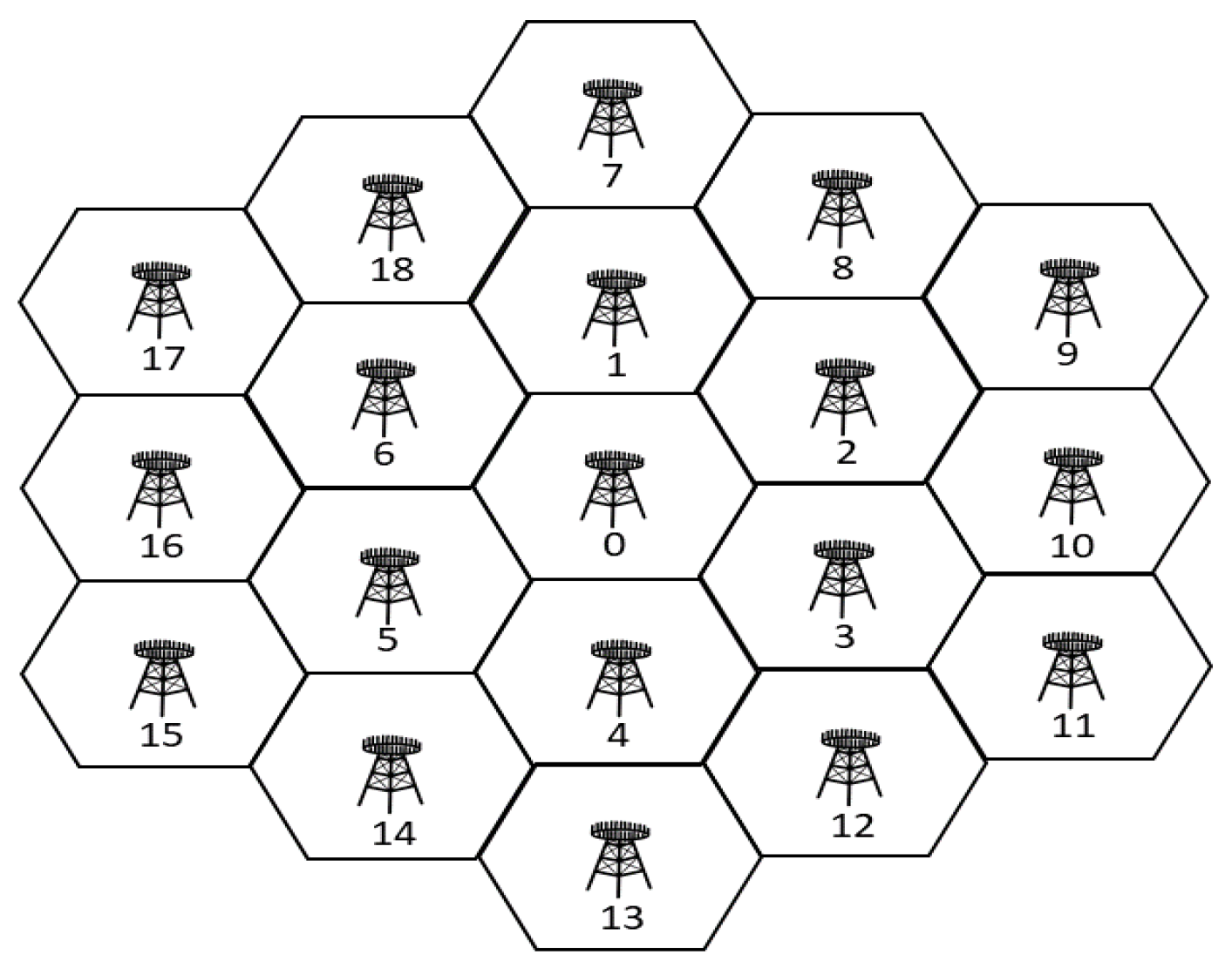
With the network and channel models introduced in
Section 2, we set a simulation environment with 19 hexagonal cells with BS 0 located at the center, BSs 1–6 located in the first tier, and BSs 7–18 located in the second tier as shown in
Figure 3, similar to the environment in [
40]. However, unlike the previous, the cell radius was limited to 20 m for SWIPT to resemble that in a small cell, wherein the harvested energy would be significant enough in addition to the data transmitted.
Each UE is randomly located in each cell, and the path loss between BS k and UE j is similarly given by dB, where the distance between them, , is denoted in kilometers. Apart from the path loss, the signal was also generated with the log-normal shadowing effect, which had a standard deviation of 8 dB and AWGN noise power of −114 dBm. In addition, the number of multi-path was set to 4, and the difference between the maximum angle and the minimum angle, i.e., the angular spread, was . Further, as UEs are located with random positions initially, the azimuth angle of UE to its BS serves as the direction of departure (DoD) of the wireless channel.
Apart from that, each channel had a time slot duration of 20 ms and a correlation coefficient of 0.64 for the successive time slots. As a summary, the important radio parameters with respect to the environment are tabulated in
Table 1, and the import parameters and hyperparameters for DDQN are summarized in
Table 2. Finally, along with
for fairly weighting SE and EH in the first set of experiments and
=
for the penalty of power consumption, the DDQN algorithms were conducted by a DNN with two hidden layers composed of 128 and 64 neurons, respectively.
In the parametric analysis, we first conducted different experiments to find the most suitable parameters for the multi-agent DDQN algorithm to be compared in the following, including the number of transmit power levels (), the number of beam directions (), and the number of power splitting ratios (). After that, we compared the proposed algorithms with the other schemes, and the results obtained confirm our proposal to outperform these benchmark schemes in terms of the utility , data rate , and harvested energy .
6.2. Parametric Analysis
6.2.1. The Number of Power Levels
As shown in (
33), there are two parts to constitute a BP. With respect to the first part of BP, transmit power, we set the transmit power to have 4, 8, and 16 levels of value for the Q learning to see its impact on the system performance. The results are summarized in
Figure 4, showing that the different numbers of power levels
provided similar utilities, data rates, and harvested energies. It implies that the algorithm may not, in this case, find the optimum represented through the values shown in these power sets even if
and the overall state space increase. Thus,
is considered sufficient in the sequel as it pays the lowest overhead for the algorithm to converge.
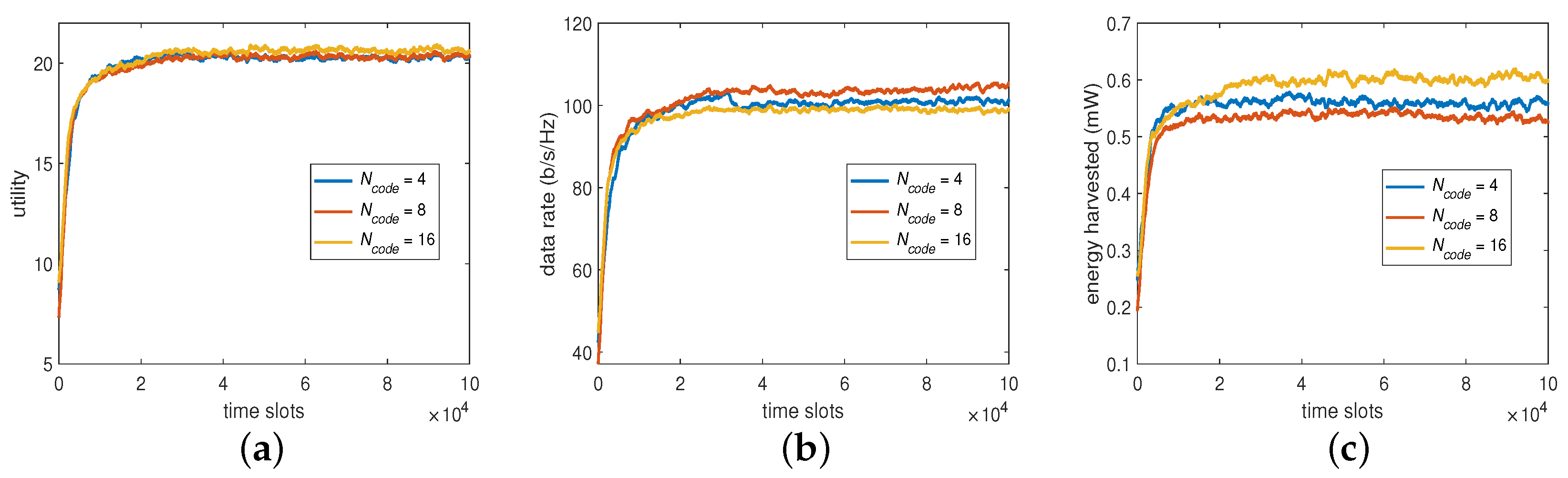
6.2.2. The Number of Beam Directions
For the second part of BP, the beam direction, we set the codebook to have 4, 8, and 16 vectors or directions, respectively, to see its impact on the system performance. The results are now summarized in
Figure 5, showing that
could produce a higher data rate to compensate for a lower harvested energy and that
could obtain a higher harvested energy to compensate for a lower data rate when compared with that of
. However, the trend is still the same in that increasing
would provide similar utility as that on
. This suggests that, despite the slight trade-off between the data rate and harvested energy,
would be sufficient for the algorithm to converge for the desired overall utility without further increasing its learning overhead.
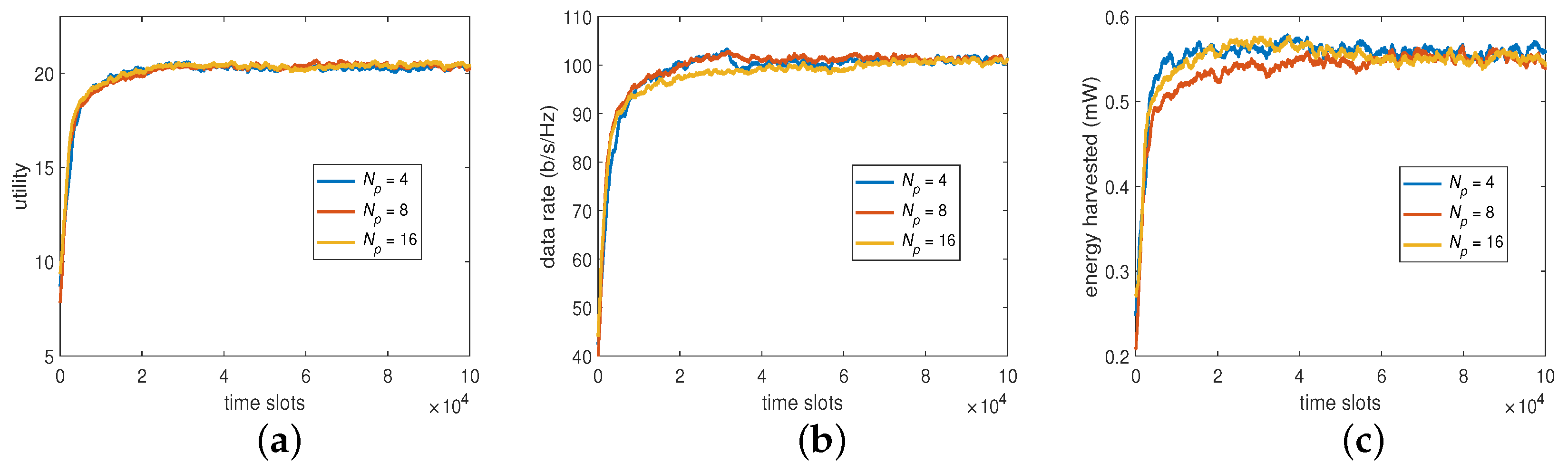
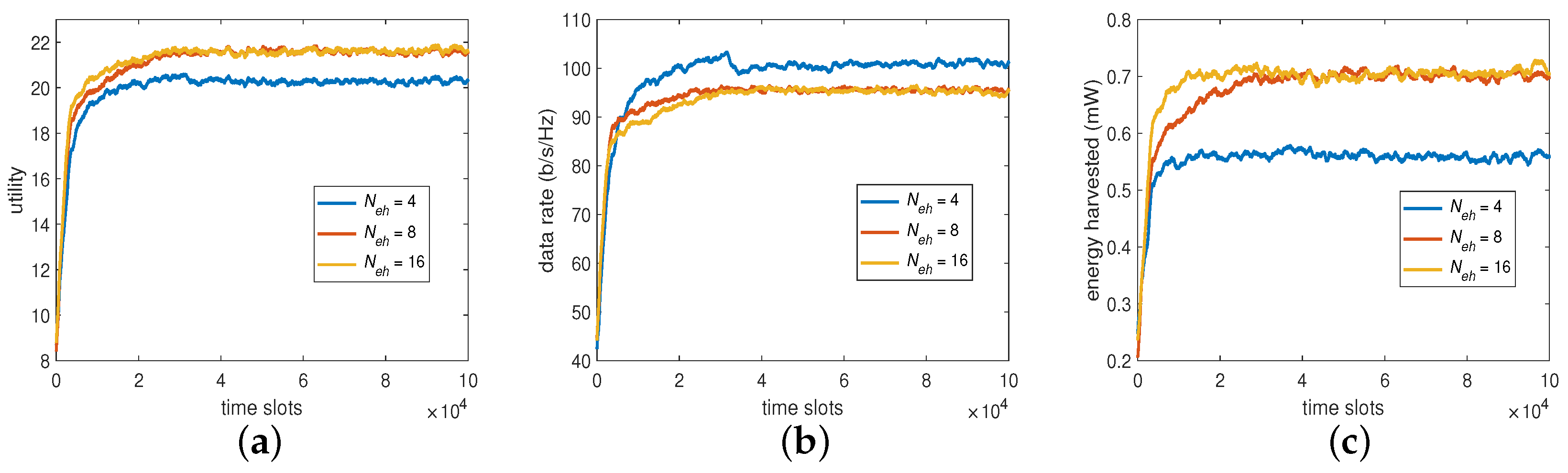
6.2.3. The Number of Power Splitting Ratios (PR)
Apart from BP, PR is another objective in our MOO problem. For the distributed DDQN algorithm, the number of PR level has the same importance as the former. To see its impact on the system performance, we provided a set of 4, 8, and 16 real values equally distributed between 0 and 1, for the experiments. As shown in
Figure 6,
(i.e.,
= 8 and 16) provided higher harvested energies and lower data rates, which eventually led to higher utilities compared with that of
. However, to conduct the baseline for comparison without loss of generality, we adopted
as well as
, which exhibited the performance differences significantly enough for the DDQN algorithm in comparison and had a reasonable overall computational overhead.
Note that, as indicated in [
52], when a multi-agent setting is modified by the actions of all agents, the environment becomes non-stationary from a single agent perspective, in which the effectiveness of most reinforcement-learning algorithms would not hold [
53]. Thus, the performance of a multi-agent DRL algorithm does not guarantee an increase as the number of action increases through a trial-and-error mechanism in such environments [
40] but could be explored by selecting suitable numbers of actions to constitute the action space as when performed for the proposed DDQN algorithm with the above experiments.
6.3. Performance Comparison
In this subsection, we exhibit the performance differences between the proposed algorithms and the other schemes. Specifically, based on the parametric analysis that we introduced, we set for the multi-agent DDQN algorithm as well as a CTDE counterpart for a benchmark to be introduced in the following and for the FP algorithm. Then, we conducted a performance comparison between these algorithms and the other four benchmark schemes shown as follows:
Global state information-based scheme: In principle, this scheme is the same as the distributed multi-agent DDQN algorithm. However, instead of adopting its own state only, each agent k adopts the full state information, i.e., for its own DDQN operations, based on the concept of centralized training distributed executing (CTDE). Clearly, collecting such information would require a centralized processor or a full information exchange mechanism to exist in the network and, thus, is denoted as “glo-DDQN” as noted at the beginning of this section.
Single-agent DRL scheme: As a branch of machine learning, DRL is conventionally developed with a single agent operated centrally in a processor. Here, the state-of-the-art RL algorithm, Advantage Actor Critic, is adopted as a centralized DRL-based benchmark scheme for resolving the MOO problem and is simply denoted as “A2C”.
Random-based scheme: As a baseline algorithm, the scheme leads each agent to randomly choose an action in each time slot and is denoted here as “random”.
Greedy-based scheme: As another baseline algorithm, each agent in this scheme adopts the beam direction with the maximum channel gain and the maximum transmit power while randomly selecting its PR from the set of elements for the DDQN. For easy reference, this scheme is denoted as “greedy” in the sequel.
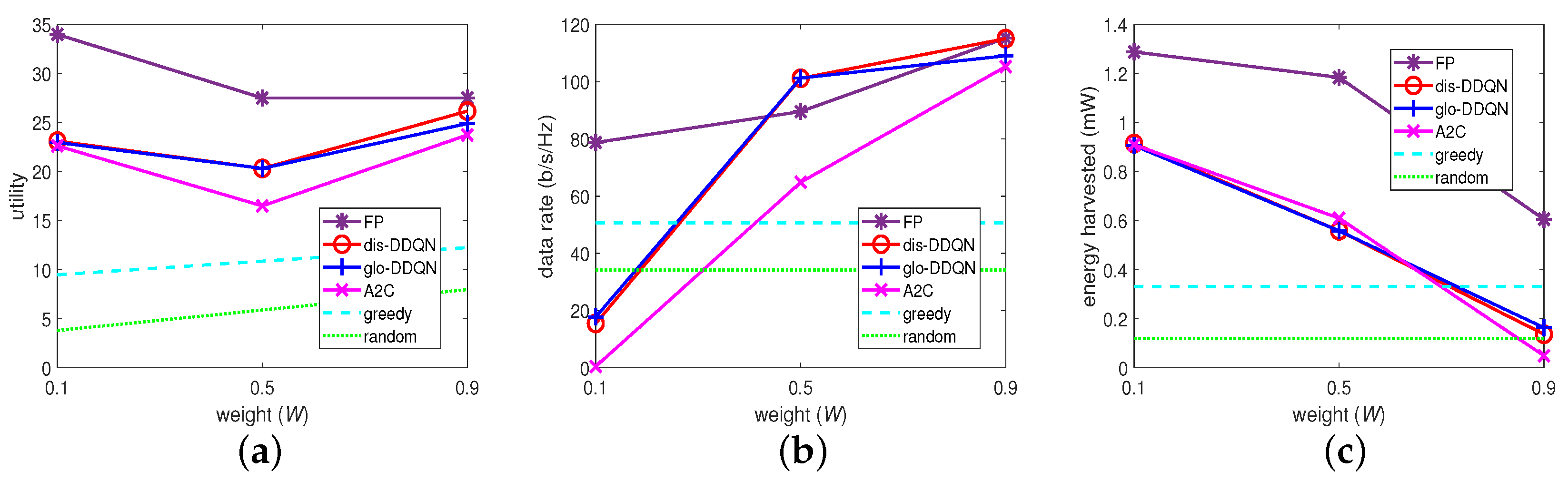
For these algorithms, we set
, 0.5, and 0.9 in (
10) to represent a “low”, “middle”, and “high” weight on the data rate (or a “high”, “middle”, and “low” weight on the harvested energy), and we examined the performance differences on these weights applied to these algorithms. Their results are summarized in
Figure 7. Specifically, in
Figure 7b,c, the random algorithm, which randomly chooses BP from the codebook despite
W is shown to retain the same performance on these metrics, as expected. Similarly, given a non-zero
W, each agent with the greedy algorithm chooses the best BP for its data rate despite the harvestable powers from the others, which are out of its control on BP, and this is also shown to remain the same on the two metrics when varying the weight.
Apart from these, the other algorithms exhibited similar trends, where increasing
W increased the data rate and decreased the harvested energy, thus confirming the design aim of
W. However, as the amount of the increased rate can be different from that of the decreased energy, their weighted sum or the resulting utility cannot be guaranteed to increase when
W increases as shown in
Figure 7a.
Given the similar trend, the FP-based algorithm (FP), which represents an optimization-based approach, is shown to provide the most effective solutions for the MOO problem, confirming our design aim. As shown in
Figure 7a as well, the distributed multi-agent DDQN algorithm (dis-DDQN) has its overall utility under that of FP but outperforms the other schemes in comparison through the following viewpoints.
First, with respect to its variant (glo-DDQN), it can be observed that both algorithms (dis-DDQN and glo-DDQN) converge to similar results, and glo-DDQN can barely obtain a higher utility. The latter is possible because equipped with the global state information, each agent may need even more time to learn the strategy approaching the optimal system performance. It implies further that, with a higher overhead for learning, the large system state caused by glo-DDQN may not lead to a better result, a faster converging speed, or both, in time.
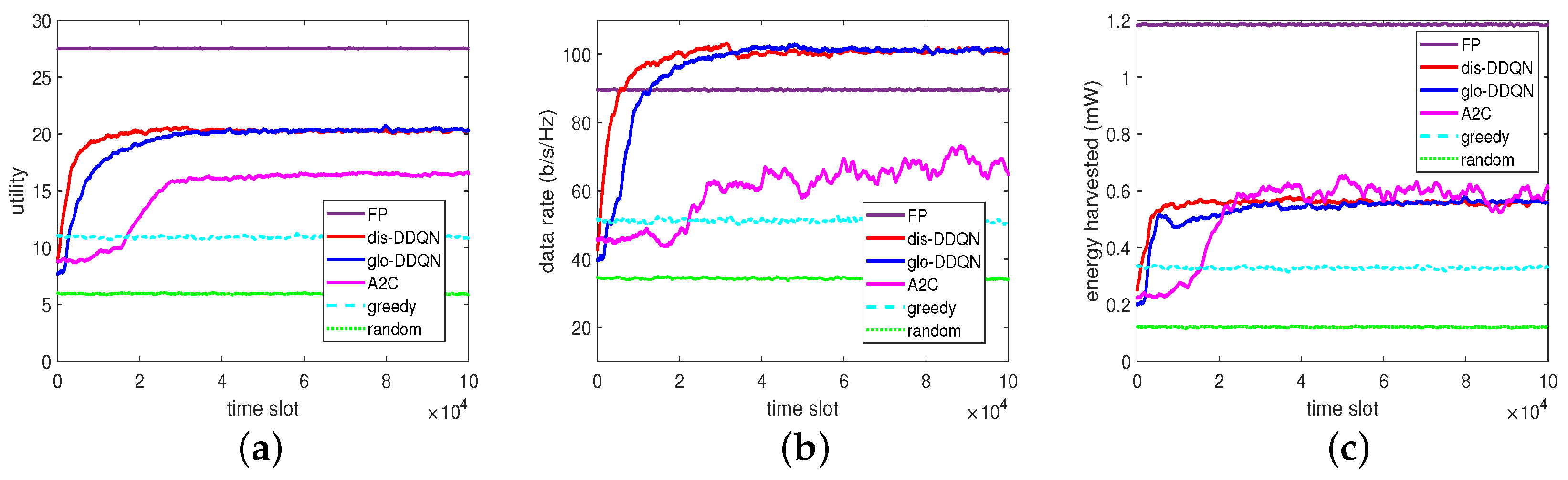
From
Figure 8, which exemplifies the converging progresses of these algorithms with
, it can be observed with more evidence that glo-DDQN actually converges more slowly than dis-DDQN in the time domain for all the metrics involved. Apart from the above, it can be also seen that the DDQN-based algorithms can obtain higher rates but provide relatively lower energies, which eventually leads to the overall utilities being lower than those obtained by the FP algorithm.
Second, with respect to A2C, which represents a state-of-the-art single-agent algorithm for the conventional environment to be evaluated centrally, it can be seen that such an algorithm may not work well in the distributed network with multiple BSs for a large state space, a large action space, or both. In other words, although A2C can handle the spaces involving both discrete and continuous variables (e.g., the beam direction is discretized while the transmit power, and the PR remains continuous in this case), its solution is not always efficient for the dynamic network environment. In contrast, by suitably discretizing the spaces involved, the distributed multi-agent DDQN (dis-DDQN) can be more easily handled by each agent to learn its strategy based on the limited discrete values in these spaces to approach the optimal solution.
Finally, in addition to the performance trends shown in the beginning, the greedy algorithm exhibits itself as a baseline scheme to provide a higher low-bound when no specific learning mechanism other than a greedy approach is adopted to resolve the MOO problem, and the random algorithm is shown to provide a lower low-bound on the performance if only randomly choosing an action is considered for solving this problem. As a summary, apart from the FP introduced, which represents an optimization-based approach to obtain outperforming solutions, the proposed DDQN algorithm (dis-DDQN) can also outperform the others in terms of the utility up to 1.23-, 1.87-, and 3.45-times larger than that of the A2C, greedy, and random algorithms, respectively, in comparison in the case of .
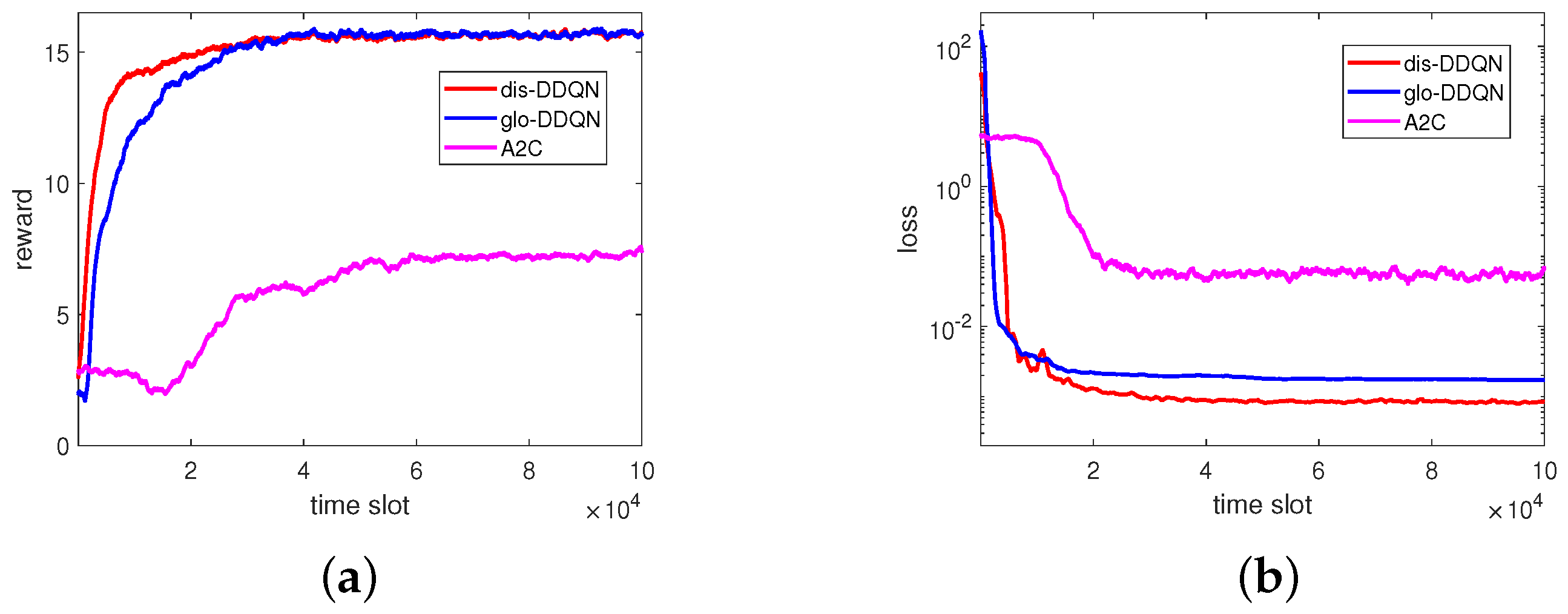
Apart from the above, we show, in
Figure 9, the reward and loss for the RL-based algorithms in comparison. As can be easily seen, the reward increases and the loss decreases as time elapses, and dis-DDQN and glo-DDQN have higher rewards and lower losses compared to A2C, as expected. In particular, the lower losses found for the two DDQN algorithms suggest that the obtained models would perform better compared to A2C. To further validate the trained models from these RL-based algorithms, we prepared a set of 5000 test data by randomly generating channel fading conditions different from those of the training set.
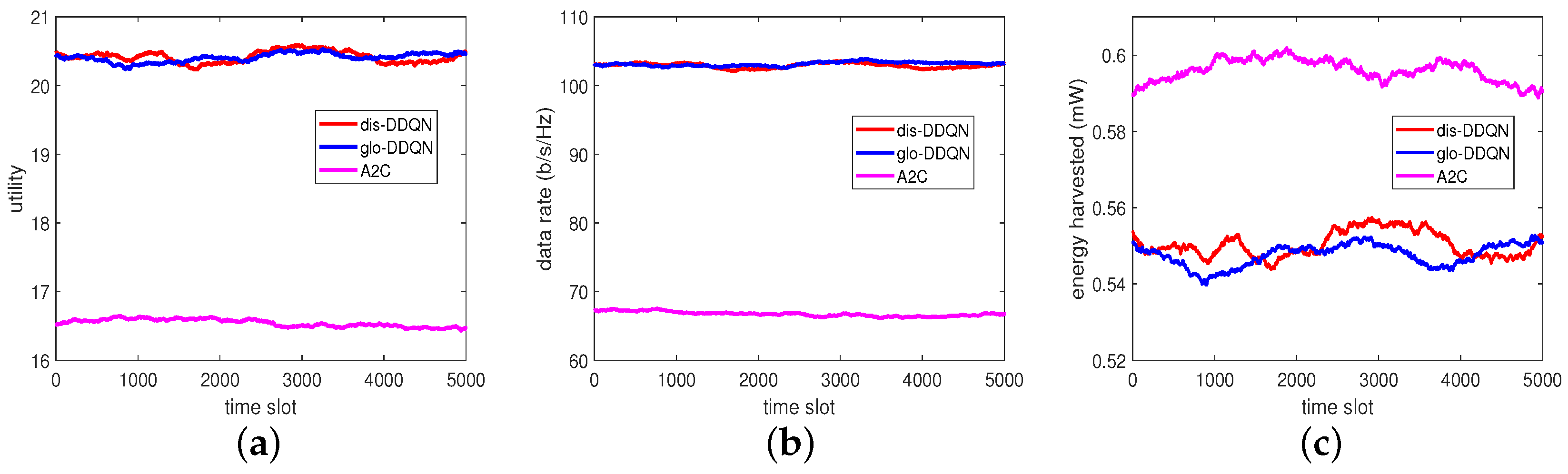
By reacting to the random data, each trained model can provide its own BPs and PRs, leading to the performance results summarized in
Figure 10. From this figure, we can see that the test can consistently give outputs similar to those at the end of training, despite the different random unseen data for testing. This observation indicates that the trained models would have good generalization performance as expected.















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}