
Deep Learning Based Vehicle Detection on Real and Synthetic Aerial Images: Training Data Composition and Statistical Influence Analysis


Abstract
:1. Introduction
1.1. Current State of Research
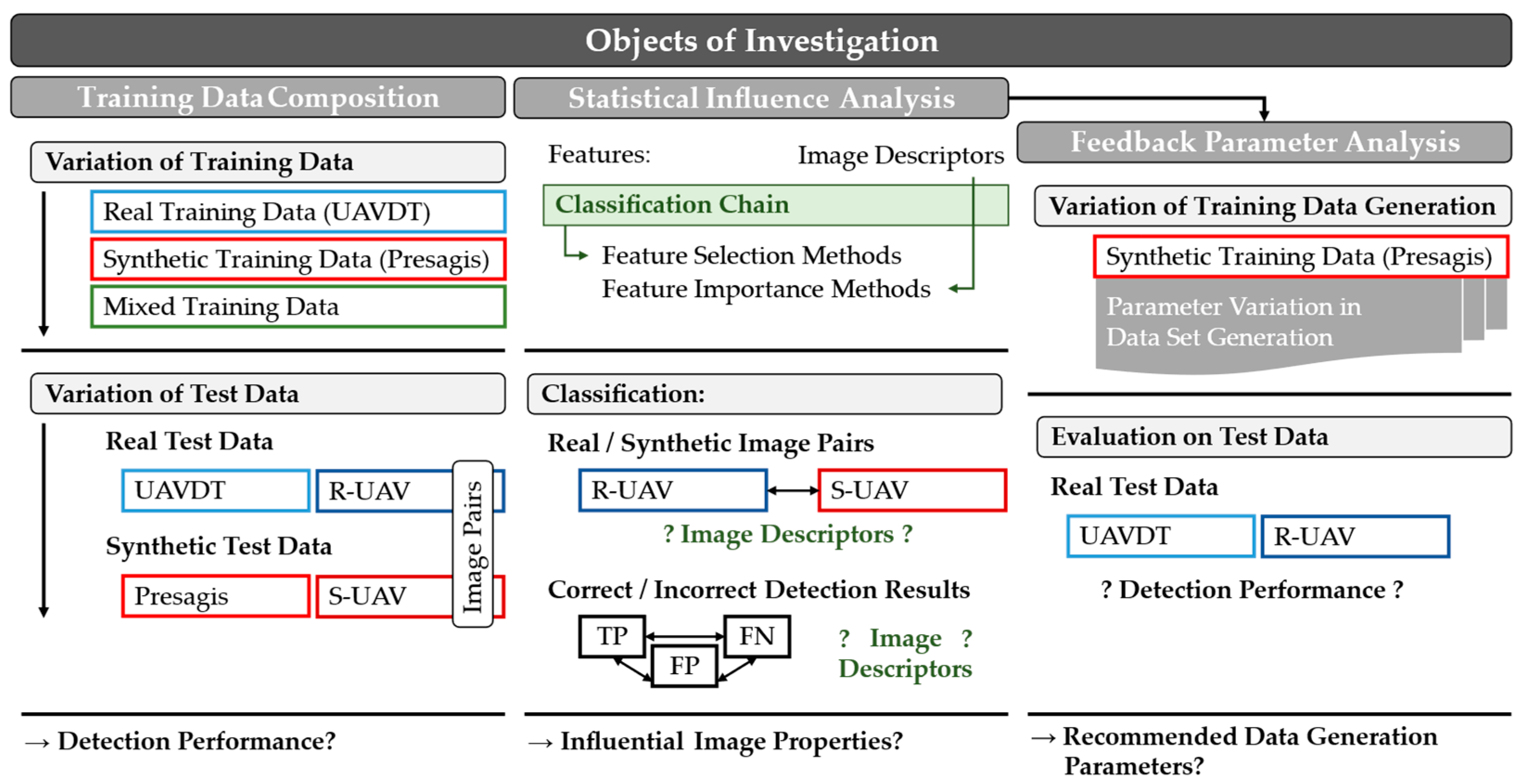
1.2. Objects of Investigation
What performance differences do different training configurations (real, synthetic, mixed) show on the associated test data compared to independent content-equivalent image pairs? What conclusions can be derived with respect to the Reality Gap?
Which image properties play a role in the distinction between real and synthetic image pairs and between correct and incorrect detections? Which influencing factors can be derived to minimize the image and performance differences when using synthetic data?
What design parameters in synthetic data set generation positively and negatively affect model performance?
1.3. Content Overview
2. Materials and Methods
2.1. Real Training Dataset
2.2. Synthetic Training Dataset
2.2.1. Simulation Environment and Modeling
2.2.2. Training Data Generation and Parameter Distribution
2.2.3. Parameter Variation in Dataset Generation
2.3. Real and Synthetic Image Pairs
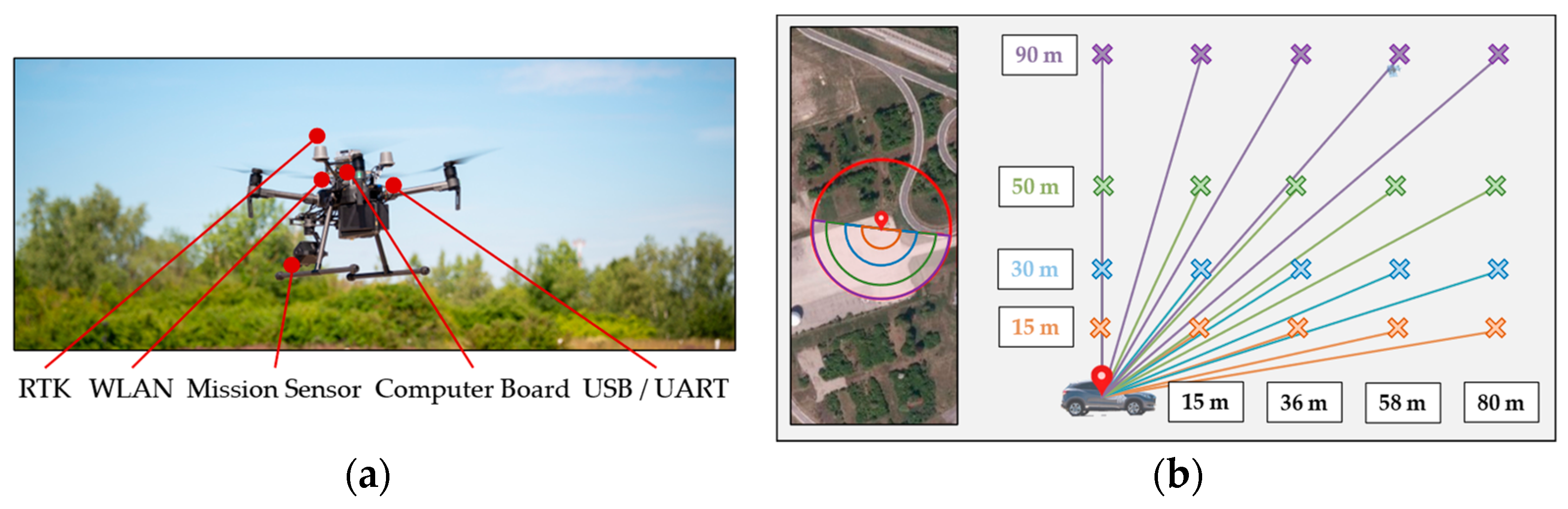
2.3.1. Real Data Acquisition
2.3.2. Synthetic Duplication
2.4. Test Algorithm Selection
Implementation and Training of YOLOv3
2.5. Statistical Evaluation Method
2.5.1. Image Descriptors
2.5.2. Classification Chain
3. Results
3.1. Examination and Evaluation of Training Datasets
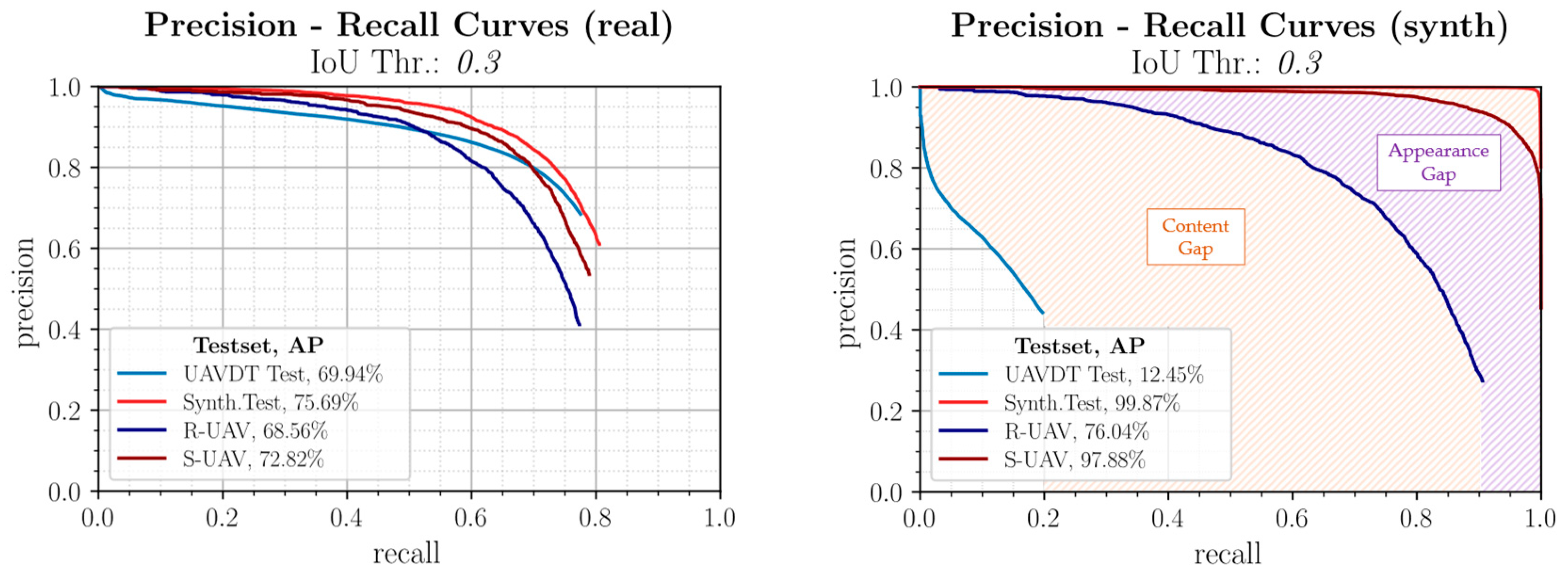
3.1.1. Real Trained Model
3.1.2. Synthetic Trained Model
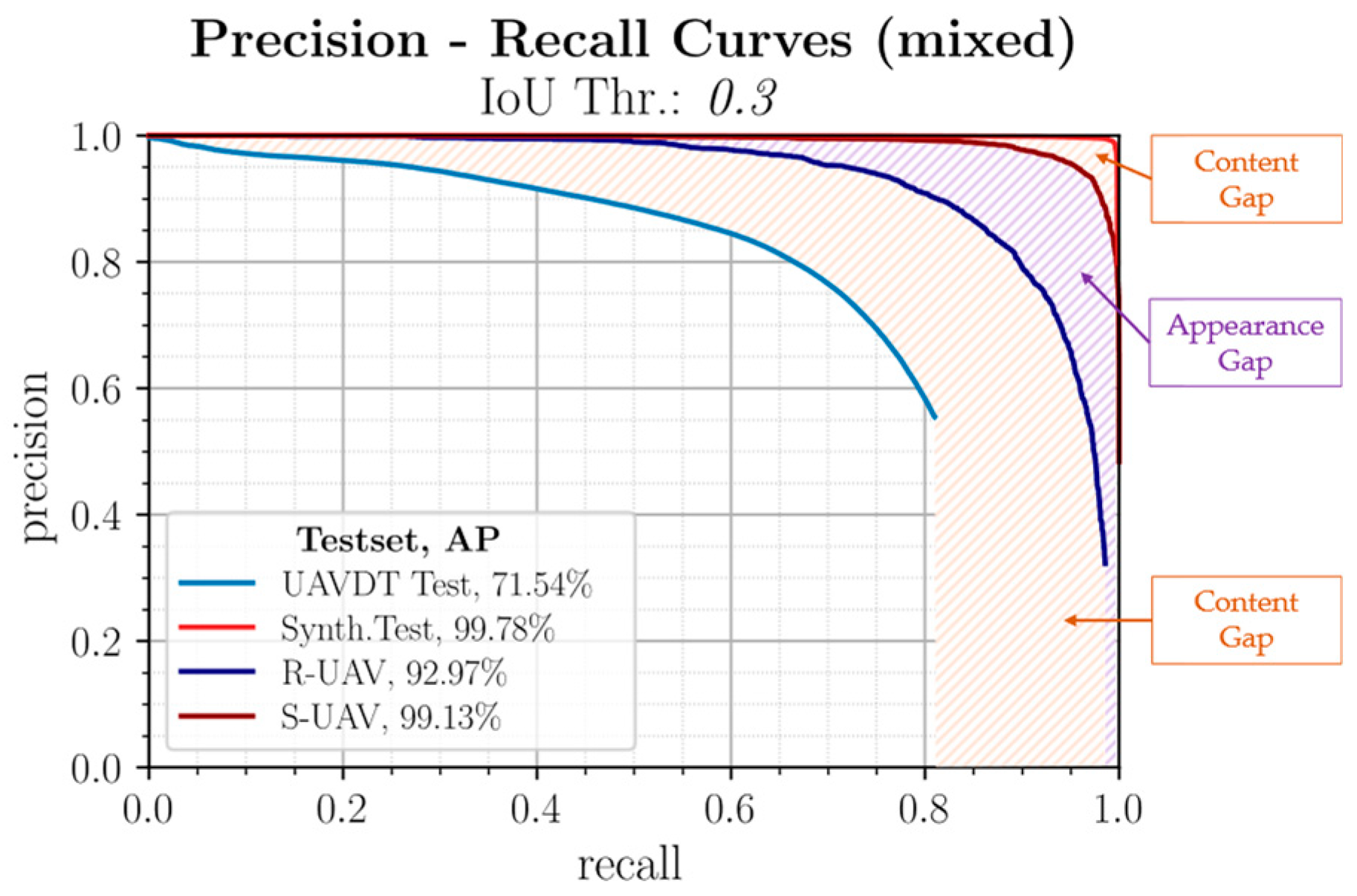
3.1.3. Mixed Trained Model
3.1.4. Evaluation with Different IoU Thresholds
3.2. Statistical Influencing Factor Analysis
3.2.1. Classification of Content-Equivalent Real and Synthetic Image Pairs
3.2.2. Classification of Correct and Incorrect Detection Results
3.3. Influence of Training Data Generation Parameters
3.3.1. Analysis on the UAVDT Test Data
3.3.2. Analysis on the R-UAV Test Data
3.4. Summary and Derivation of Design Guidelines
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Geng, L.; Zhang, Y.F.; Wang, J.J.; Fuh, J.Y.H.; Teo, S.H. Mission Planning of Autonomous UAVs for Urban Surveillance with Evolutionary Algorithms. In Proceedings of the 2013 10th IEEE International Conference on Control and Automation (ICCA), Hangzhou, China, 12–14 June 2013; pp. 828–833. [Google Scholar]
- Kanistras, K.; Martins, G.; Rutherford, M.J.; Valavanis, K.P. A Survey of Unmanned Aerial Vehicles (UAVs) for Traffic Monitoring. In Proceedings of the 2013 International Conference on Unmanned Aircraft Systems (ICUAS), Atlanta, GA, USA, 28–31 May 2013; pp. 221–234. [Google Scholar]
- Metni, N.; Hamel, T. A UAV for Bridge Inspection: Visual Servoing Control Law with Orientation Limits. Autom. Constr. 2007, 17, 3–10. [Google Scholar] [CrossRef]
- Máthé, K.; Buşoniu, L. Vision and Control for UAVs: A Survey of General Methods and of Inexpensive Platforms for Infrastructure Inspection. Sensors 2015, 15, 14887–14916. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Nagai, M.; Chen, T.; Shibasaki, R.; Kumagai, H.; Ahmed, A. UAV-Borne 3-D Mapping System by Multisensor Integration. IEEE Trans. Geosci. Remote Sens. 2009, 47, 701–708. [Google Scholar] [CrossRef]
- Remondino, F.; Barazzetti, L.; Nex, F.; Scaioni, M.; Sarazzi, D. UAV Photogrammetry for Mapping and 3D Modeling—Current Status and Future Perspectives. ISPRS—Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2012, XXXVIII-1/C22, 25–31. [Google Scholar] [CrossRef] [Green Version]
- Waharte, S.; Trigoni, N. Supporting Search and Rescue Operations with UAVs. In Proceedings of the 2010 International Conference on Emerging Security Technologies, Canterbury, UK, 6–7 September 2010; pp. 142–147. [Google Scholar]
- Erdelj, M.; Natalizio, E.; Chowdhury, K.R.; Akyildiz, I.F. Help from the Sky: Leveraging UAVs for Disaster Management. IEEE Pervasive Comput. 2017, 16, 24–32. [Google Scholar] [CrossRef]
- Benjdira, B.; Khursheed, T.; Koubaa, A.; Ammar, A.; Ouni, K. Car Detection Using Unmanned Aerial Vehicles: Comparison between Faster R-CNN and YOLOv3. In Proceedings of the 2019 1st International Conference on Unmanned Vehicle Systems-Oman (UVS), Muscat, Oman, 5–7 February 2019; pp. 1–6. [Google Scholar]
- Schmitt, M.; Stuetz, P. Multi-UAV Based Helicopter Landing Zone Reconnaissance: Information Level Fusion and Decision Support. In Engineering Psychology and Cognitive Ergonomics: Cognition and Design, Proceedings of the 14th International Conference, EPCE 2017, Held as Part of HCI International 2017, 9–14 July 2017; Springer International Publishing: Vancouver, BC, Canada, 2017; pp. 266–283. [Google Scholar]
- Ruf, C.; Stütz, P. Model-Driven Sensor Operation Assistance for a Transport Helicopter Crew in Manned-Unmanned Teaming Missions: Selecting the Automation Level by Machine Decision-Making. In Advances in Human Factors in Robots and Unmanned Systems: Proceedings of the AHFE 2016 International Conference on Human Factors in Robots and Unmanned Systems; Savage-Knepshield, P., Chen, J., Eds.; Springer International Publishing: Cham, Switzerland, 2017; pp. 253–265. [Google Scholar]
- Ruf, C.; Stütz, P. Model-Driven Payload Sensor Operation Assistance for a Transport Helicopter Crew in Manned–Unmanned Teaming Missions: Assistance Realization, Modelling Experimental Evaluation of Mental Workload. In Engineering Psychology and Cognitive Ergonomics: Performance, Emotion and Situation Awareness, Proceedings of the International Conference on Engineering Psychology and Cognitive Ergonomics, Vancouver, BC, Canada, 9–14 July 2017; Springer International Publishing: Vancouver, BC, Canada, 2017; pp. 51–63. [Google Scholar]
- Girshick, R. Fast R-CNN. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. In Advances in Neural Information Processing Systems 28 (NIPS 2015), Proceedings of 29th Annual Conference on Neural Information Processing Systems 2015, Montreal, QC, Canada, 7–12 December 2015; Curran Associates, Inc.: Red Hook, NY, USA, 2015; pp. 91–99. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, Faster, Stronger. arXiv 2016, arXiv:1612.08242, 1–9. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. arXiv 2018, arXiv:1804.02767, 1–6. [Google Scholar]
- Johnson-Roberson, M.; Barto, C.; Mehta, R.; Sridhar, S.N.; Vasudevan, R. Driving in the Matrix: Can Virtual Worlds Replace Human-Generated Annotations for Real World Tasks? In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), Singapore, 29 May–3 June 2017; pp. 746–753. [Google Scholar]
- Richter, S.R.; Vineet, V.; Roth, S.; Koltun, V. Playing for Data: Ground Truth from Computer Games. In Proceedings of the Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Volume 9906 LNCS, pp. 102–118. [Google Scholar]
- Carrillo, J.; Gates, B.; Monroe, G.; Newell, B.; Durst, P. Using Physics-Based M&S for Training and Testing Machine Learning Algorithms. In Proceedings of the Modelling and Simulation for Autonomous Systems: 5th International Conference, MESAS 2018, Prague, Czech Republic, 17–19 October 2018; Volume 11472 LNCS, pp. 445–455. [Google Scholar]
- Tobin, J.; Fong, R.; Ray, A.; Schneider, J.; Zaremba, W.; Abbeel, P. Domain Randomization for Transferring Deep Neural Networks from Simulation to the Real World. In Proceedings of the 2017 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Vancouver, BC, Canada, 24–29 September 2017. [Google Scholar]
- Orjales, F.; Lopez Peña, F.; Paz-Lopez, A.; Deibe, A.; Duro, R.J. On the Use of Mixed Reality for Setting up Control and Coordination Strategies for Teams of Autonomous UAV. In Proceedings of the ROBOT 2017: Third Iberian Robotics Conference, Seville, Spain, 22–24 November 2017; Volume 693, pp. 529–540. [Google Scholar]
- Ferwerda, J.A. Three Varieties of Realism in Computer Graphics. In Proceedings of the Human Vision and Electronic Imaging VIII (SPIE 5007), Santa Clara, CA, USA, 17 June 2003. [Google Scholar]
- Pepik, B.; Stark, M.; Gehler, P.; Schiele, B. Teaching 3D Geometry to Deformable Part Models. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 3362–3369. [Google Scholar]
- Carrillo, J.; Davis, J.; Osorio, J.; Goodin, C.; Durst, J. High-Fidelity Physics-Based Modeling and Simulation for Training and Testing Convolutional Neural Networks for UGV Systems. In Proceedings of the Modelling & Simulation for Autonomous Systems (MESAS 2019), Palermo, Italy, 29–31 October 2019. [Google Scholar]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the Inception Architecture for Computer Vision. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 2818–2826. [Google Scholar]
- Geiger, A.; Lenz, P.; Stiller, C.; Urtasun, R. Vision Meets Robotics: The KITTI Dataset. Int. J. Robot. Res. 2013, 32, 1231–1237. [Google Scholar] [CrossRef] [Green Version]
- Gaidon, A.; Wang, Q.; Cabon, Y.; Vig, E. Virtual Worlds as Proxy for Multi-Object Tracking Analysis. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 4340–4349. [Google Scholar]
- Nentwig, M.; Miegler, M.; Stamminger, M. Concerning the Applicability of Computer Graphics for the Evaluation of Image Processing Algorithms. In Proceedings of the 2012 IEEE International Conference on Vehicular Electronics and Safety, Istanbul, Turkey, 24–27 July 2012; pp. 205–210. [Google Scholar]
- Nentwig, M.; Stamminger, M. Hardware-in-the-Loop Testing of Computer Vision Based Driver Assistance Systems. In Proceedings of the 2011 IEEE Intelligent Vehicles Symposium, Baden-Baden, Germany, 5–9 June 2011; pp. 339–344. [Google Scholar]
- Yang, S.; Deng, W.; Liu, Z.; Wang, Y. Analysis of Illumination Condition Effect on Vehicle Detection in Photo-Realistic Virtual World. SAE Tech. Pap. 2017, 1, 1998. [Google Scholar]
- Peng, X.; Sun, B.; Ali, K.; Saenko, K. Learning Deep Object Detectors from 3D Models. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015. [Google Scholar]
- Li, Q.; Mou, L.; Xu, Q.; Zhang, Y.; Zhu, X.X. R^3-Net: A Deep Network for Multi-Oriented Vehicle Detection in Aerial Images and Videos. IEEE Geosci. Remote Sens. Soc. 2019, 57, 5028–5042. [Google Scholar] [CrossRef] [Green Version]
- Radovic, M.; Adarkwa, O.; Wang, Q. Object Recognition in Aerial Images Using Convolutional Neural Networks. J. Imaging 2017, 3, 21. [Google Scholar] [CrossRef] [Green Version]
- Xu, Y.; Yu, G.; Wang, Y.; Wu, X.; Ma, Y. Car Detection from Low-Altitude UAV Imagery with the Faster R-CNN. J. Adv. Transp. 2017, 2017, 2823617. [Google Scholar] [CrossRef] [Green Version]
- Tayara, H.; Soo, K.G.; Chong, K.T. Vehicle Detection and Counting in High-Resolution Aerial Images Using Convolutional Regression Neural Network. IEEE Access 2017, 6, 2220–2230. [Google Scholar] [CrossRef]
- Tang, T.; Deng, Z.; Zhou, S.; Lei, L.; Zou, H. Fast Vehicle Detection in UAV Images. In Proceedings of the 2017 International Workshop on Remote Sensing with Intelligent Processing (RSIP), Shanghai, China, 18–21 May 2017; pp. 1–5. [Google Scholar]
- Li, W.; Li, H.; Wu, Q.; Chen, X.; Ngan, K.N. Simultaneously Detecting and Counting Dense Vehicles From Drone Images. IEEE Trans. Ind. Electron. 2019, 66, 9651–9662. [Google Scholar] [CrossRef]
- Lu, J.; Ma, C.; Li, L.; Xing, X.; Zhang, Y.; Wang, Z.; Xu, J. A Vehicle Detection Method for Aerial Image Based on YOLO. J. Comput. Commun. 2018, 6, 98–107. [Google Scholar] [CrossRef] [Green Version]
- Lechgar, H.; Bekkar, H.; Rhinane, H. Detection of Cities Vehicle Fleet Using YOLO V2 and Aerial Images. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci.-ISPRS Arch. 2019, 42, 121–126. [Google Scholar] [CrossRef] [Green Version]
- Du, D.; Qi, Y.; Yu, H.; Yang, Y.; Duan, K.; Li, G.; Zhang, W.; Huang, Q.; Tian, Q. The Unmanned Aerial Vehicle Benchmark: Object Detection and Tracking. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 375–391. [Google Scholar]
- Krump, M.; Ruß, M.; Stütz, P. Deep Learning Algorithms for Vehicle Detection on UAV Platforms: First Investigations on the Effects of Synthetic Training. In Proceedings of the Modelling and Simulation for Autonomous Systems: 6th International Conference, MESAS 2019, Palermo, Italy, 29–31 October 2019; pp. 50–70. [Google Scholar]
- Presagis—Modelling and Simulation Software. Available online: https://www.presagis.com/en/; https://www.presagis.com/en/page/academic-programs/ (accessed on 4 April 2023).
- OGC (OpenGeoSpatial): Common Database Standard. Available online: https://www.opengeospatial.org/standards/cdb (accessed on 4 April 2023).
- Geodatenbasis: Bayerische Vermessungsverwaltung (Landesamt Für Digitalisierung, Breitband Und Vermessung). Available online: https://geodatenonline.bayern.de (accessed on 4 April 2023).
- SpeedTree—3D Vegetation Modelling and Middleware. Available online: https://store.speedtree.com/ (accessed on 4 April 2023).
- Turbosquid Fahrzeugmodelle. Available online: https://www.turbosquid.com (accessed on 4 April 2023).
- PPG Industries, Inc.: 2018 Global Color Trend Popularity. Available online: https://news.ppg.com/automotive-color-trends (accessed on 1 August 2019).
- Kar, A.; Prakash, A.; Liu, M.Y.; Cameracci, E.; Yuan, J.; Rusiniak, M.; Acuna, D.; Torralba, A.; Fidler, S. Meta-Sim: Learning to Generate Synthetic Datasets. Proc. IEEE Int. Conf. Comput. Vis. 2019, 4550–4559. [Google Scholar]
- Cheng, P.; Zhou, G.; Zheng, Z. Detecting and Counting Vehicles from Small Low-Cost UAV Images. In American Society for Photogrammy and Remote Sensing Annual Conference 2009 (ASPRS 2009), Baltimore, USA, 9–13 March 2009; Curran Associates: Red Hook, NY, USA, 2009; Volume 1, p. 138. [Google Scholar]
- Azevedo, C.L.; Cardoso, J.L.; Ben-Akiva, M.; Costeira, J.P.; Marques, M. Automatic Vehicle Trajectory Extraction by Aerial Remote Sensing. Procedia Soc. Behav. Sci. 2014, 111, 849–858. [Google Scholar] [CrossRef] [Green Version]
- Zheng, Z.; Wang, X.; Zhou, G.; Jiang, L. Vehicle Detection Based on Morphology from Highway Aerial Images. Int. Geosci. Remote Sens. Symp. 2012, 5997–6000. [Google Scholar]
- Choi, J.; Yang, Y. Vehicle Detection from Aerial Images Using Local Shape Information. Adv. Image Video Technol. 2009, 5414, 227–236. [Google Scholar]
- Hinz, S.; Stilla, U. Car Detection in Aerial Thermal Images by Local and Global Evidence Accumulation. Pattern Recognit. Lett. 2006, 27, 308–315. [Google Scholar] [CrossRef]
- Niu, X. A Semi-Automatic Framework for Highway Extraction and Vehicle Detection Based on a Geometric Deformable Model. ISPRS J. Photogramm. Remote Sens. 2006, 61, 170–186. [Google Scholar] [CrossRef]
- Xu, Y.; Yu, G.; Wang, Y.; Wu, X.; Ma, Y. A Hybrid Vehicle Detection Method Based on Viola-Jones and HOG + SVM from UAV Images. Sensors 2016, 16, 1325. [Google Scholar] [CrossRef] [Green Version]
- Moranduzzo, T.; Melgani, F. Automatic Car Counting Method for Unmanned Aerial Vehicle Images. IEEE Trans. Geosci. Remote Sens. 2014, 52, 1635–1647. [Google Scholar] [CrossRef]
- Moranduzzo, T.; Melgani, F. Detecting Cars in UAV Images with a Catalog-Based Approach. IEEE Trans. Geosci. Remote Sens. 2014, 52, 6356–6367. [Google Scholar] [CrossRef]
- Krump, M.; Stütz, P. UAV Based Vehicle Detection with Synthetic Training: Identification of Performance Factors Using Image Descriptors and Machine Learning. In Modelling and Simulation for Autonomous Systems. MESAS 2020. Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2021; pp. 62–85. [Google Scholar]
- Krump, M.; Stütz, P. UAV Based Vehicle Detection on Real and Synthetic Image Pairs: Performance Differences and Influence Analysis of Context and Simulation Parameters. In Modelling and Simulation for Autonomous Systems; MESAS 2021. Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2022; pp. 3–25. [Google Scholar]
- Russakovsky, O.; Li, L.-J.; Fei-Fei, L. Best of Both Worlds: Human-Machine Collaboration for Object Annotation. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 2121–2131. [Google Scholar]
- Manjunath, B.S.; Salembier, P.; Sikora, T. Introduction to MPEG-7: Multimedia Content Description Interface; Wiley: Hoboken, NJ, USA, 2002. [Google Scholar]
- Sikora, T. The MPEG-7 Visual Standard for Content Description—An Overview. IEEE Trans. Circuits Syst. Video Technol. 2001, 11, 696–702. [Google Scholar] [CrossRef]
- ISO/IEC JTC1/SC29/WG11N6828 MPEG-7; International Organisation for Standardisation ISO/IEC JTC1/SC29/WG11N6828 MPEG-7 Overview (Version 10). International Organisation for Standardisation: Geneva, Switzerland, 2004.
- Eidenberger, H. Statistical Analysis of Content-Based MPEG-7 Descriptors for Image Retrieval. Multimed. Syst. 2004, 10, 84–97. [Google Scholar] [CrossRef]
- Messing, D.S.; van Beek, P.; Errico, J.H. The MPEG-7 Color Structure Descriptor: Image Description Using Color and Local Spatial Information. In Proceedings of the Proceedings 2001 International Conference on Image Processing (Cat. No.01CH37205), Thessaloniki, Greece, 7–10 October 2001. [Google Scholar]
- Ro, Y.M.; Kim, M.; Kang, H.K.; Manjunath, B.S.; Kim, J. MPEG-7 Homogeneous Texture Descriptor. ETRI J. 2001, 23, 41–51. [Google Scholar] [CrossRef] [Green Version]
- Cao, G.; Huang, L.; Tian, H.; Huang, X.; Wang, Y.; Zhi, R. Contrast Enhancement of Brightness-Distorted Images by Improved Adaptive Gamma Correction. Comput. Electr. Eng. 2018, 66, 569–582. [Google Scholar] [CrossRef] [Green Version]
- Ke, Y.; Tang, X.; Jing, F. The Design of High-Level Features for Photo Quality Assessment. In Proceedings of the 2006 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’06), New York, NY, USA, 17–22 June 2006; Volume 1, pp. 419–426. [Google Scholar]
- Wang, J.; Allebach, J. Automatic Assessment of Online Fashion Shopping Photo Aesthetic Quality. In Proceedings of the 2015 IEEE International Conference on Image Processing (ICIP), Quebec City, QC, Canada, 27–30 September 2015; pp. 2915–2919. [Google Scholar]
- Hasler, D.; Sabine, S. Measuring Colourfulness in Natural Images. In Proceedings of the Human Vision and Electronic Imaging VIII, Santa Clara, CA, USA, 21–24 January 2003; pp. 87–95. [Google Scholar]
- Li, F.; Wu, J.; Wang, Y.; Zhao, Y.; Zhang, X. A Color Cast Detection Algorithm of Robust Performance. In Proceedings of the 2012 IEEE Fifth International Conference on Advanced Computational Intelligence (ICACI), Nanjing, China, 18–20 October 2012; pp. 662–664. [Google Scholar]
- Robertson, A.R. Computation of Correlated Color Temperature and Distribution Temperature. J. Opt. Soc. Am. 1968, 58, 1528. [Google Scholar] [CrossRef]
- Hernández-Andrés, J.; Lee, R.L.; Romero, J. Calculating Correlated Color Temperatures across the Entire Gamut of Daylight and Skylight Chromaticities. Appl. Opt. 1999, 38, 5703. [Google Scholar] [CrossRef] [Green Version]
- Talebi, H.; Milanfar, P. NIMA: Neural Image Assessment. IEEE Trans. Image Process. 2017, 27, 3998–4011. [Google Scholar] [CrossRef] [Green Version]
- Mittal, A.; Moorthy, A.K.; Bovik, A.C. No-Reference Image Quality Assessment in the Spatial Domain. IEEE Trans. Image Process. 2012, 21, 4695–4708. [Google Scholar] [CrossRef]
- Mai, L.; Le, H.; Niu, Y.; Liu, F. Rule of Thirds Detection from Photograph. In Proceedings of the 2011 IEEE International Symposium on Multimedia, Dana Point, CA, USA, 5–7 December 2011; pp. 91–96. [Google Scholar]
- Kumar, J.; Chen, F.; Doermann, D. Sharpness Estimation for Document and Scene Images. In Proceedings of the 21st International Conference on Pattern Recognition (ICPR2012), Tsukuba, Japan, 1–15 November 2012; pp. 3292–3295. [Google Scholar]
- Narvekar, N.D.; Karam, L.J. A No-Reference Image Blur Metric Based on the Cumulative Probability of Blur Detection (CPBD). IEEE Trans. Image Process. 2011, 20, 2678–2683. [Google Scholar] [CrossRef] [PubMed]
- Su, B.; Lu, S.; Tan, C.L. Blurred Image Region Detection and Classification. In MM ’11: Proceedings of the 19th ACM international conference on Multimedia; ACM Press: New York, New York, USA, 2011; p. 1397. [Google Scholar]
- Hanghang, T.; Mingjing, L.; Hongjiang, Z.; Changshui, Z. Blur Detection for Digital Images Using Wavelet Transform. In Proceedings of the 2004 IEEE International Conference on Multimedia and Expo (ICME) (IEEE Cat. No.04TH8763), Taipei, Taiwan, 27–30 June 2004. [Google Scholar]
- Rakhshanfar, M.; Amer, M.A. Estimation of Gaussian, Poissonian-Gaussian, and Processed Visual Noise and Its Level Function. IEEE Trans. Image Process. 2016, 25, 4172–4185. [Google Scholar] [CrossRef] [PubMed]
- Chen, G.; Zhu, F.; Heng, P.A. An Efficient Statistical Method for Image Noise Level Estimation. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 477–485. [Google Scholar]
- Hu, M.K. Visual Pattern Recognition by Moment Invariants. IEEE Trans. Inf. Theory 1962, 8, 179–187. [Google Scholar]
- DeepLabv3 ResNet101. Available online: https://pytorch.org/hub/pytorch_vision_deeplabv3_resnet101/ (accessed on 30 July 2020).
- Chen, L.-C.; Papandreou, G.; Schroff, F.; Adam, H. Rethinking Atrous Convolution for Semantic Image Segmentation. arXiv 2017, arXiv:1706.05587. [Google Scholar]
- Zhu, L.; Deng, Z.; Hu, X.; Fu, C.W.; Xu, X.; Qin, J.; Heng, P.A. Bidirectional Feature Pyramid Network with Recurrent Attention Residual Modules for Shadow Detection. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 122–137. [Google Scholar]
- CNN Weather Classification Models. Available online: https://github.com/666-zhf/weather-predicition; https://github.com/imaaditya-stack/Weather-image-classification; https://github.com/NgoJunHaoJason/weather-classification; https://github.com/berkgulay/WeatherPredictionFromImage (accessed on 30 July 2020).
- Haralick, R.M.; Shanmugam, K.; Dinstein, I. Textural Features for Image Classification. IEEE Trans. Syst. Man. Cybern. 1973, SMC-3, 610–621. [Google Scholar] [CrossRef] [Green Version]
- Ros, G.; Sellart, L.; Materzynska, J.; Vazquez, D.; Lopez, A.M. The SYNTHIA Dataset: A Large Collection of Synthetic Images for Semantic Segmentation of Urban Scenes. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 3234–3243. [Google Scholar]
- Prakash, A.; Boochoon, S.; Brophy, M.; Acuna, D.; Cameracci, E.; State, G.; Shapira, O.; Birchfield, S. Structured Domain Randomization: Bridging the Reality Gap by Context-Aware Synthetic Data. In Proceedings of the International Conference on Robotics and Automation (ICRA), Montreal, Canada, 20–24 May 2019. [Google Scholar]
- Tremblay, J.; Prakash, A.; Acuna, D.; Brophy, M.; Jampani, V.; Anil, C.; To, T.; Cameracci, E.; Boochoon, S.; Birchfield, S. Training Deep Networks with Synthetic Data: Bridging the Reality Gap by Domain Randomization. In Proceedings of the CVPR 2018 Workshop on Autonomous Driving, Salt Lake City, UT, USA, 19–21 June 2018. [Google Scholar]
- Hummel, G. On Synthetic Datasets for Development of Computer Vision Algorithms in Airborne Reconnaissance Applications. Ph.D. Thesis, Universität der Bundeswehr München, Neubiberg, Germany, 2017. [Google Scholar]
- Rozantsev, A.; Lepetit, V.; Fua, P. On Rendering Synthetic Images for Training an Object Detector. Comput. Vis. Image Underst. 2015, 137, 24–37. [Google Scholar] [CrossRef] [Green Version]
- Sun, B.; Saenko, K. From Virtual to Reality: Fast Adaptation of Virtual Object Detectors to Real Domains. In Proceedings of the British Machine Vision Conference 2014, Nottingham, UK, 1–5 September 2014; pp. 82.1–82.12. [Google Scholar]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| No. | 11 | 9 | 9 | 8 | 7 | 6 | 5 | 4 | 4 | 4 | 4 | 3 | 3 | 3 | 3 | 3 | 3 |
| Image Descriptor | Noise | Dominant Color (CLD) | Dominant Color (DCD) | Color Distribution (CSD) | Dominant Color (DCD) | Dominant Color (DCD) | Color Distribution (SCD) | Color Cast | Dominant Color (DCD) | Dominant Color (DCD) | Dominant Color (DCD) | Dominant Color (CLD) | Color Distribution (SCD) | Color Temperature | Segmentation Scenery | Color Distribution (CSD) | Color Distribution (CSD) |
| G/L | G | L | G | L | G | G | G | G | G | G | G | L | G | G | G | L | L |
| No. | 13 | 9 | 7 | 7 | 6 | 5 | 5 | 4 | 3 | 3 |
| Image Descriptor | Dominant Color (DCD) | Image Capture Position | Dominant Color (CLD) | Aesthetic Image Quality | Dominant Color (DCD) | Dominant Color (DCD) | Dominant Color (DCD) | Foreground Segmentation | Dominant Color (DCD) | GLCM: Contrast |
| G/L | G | G | L | G | G | G | G | L | G | G |
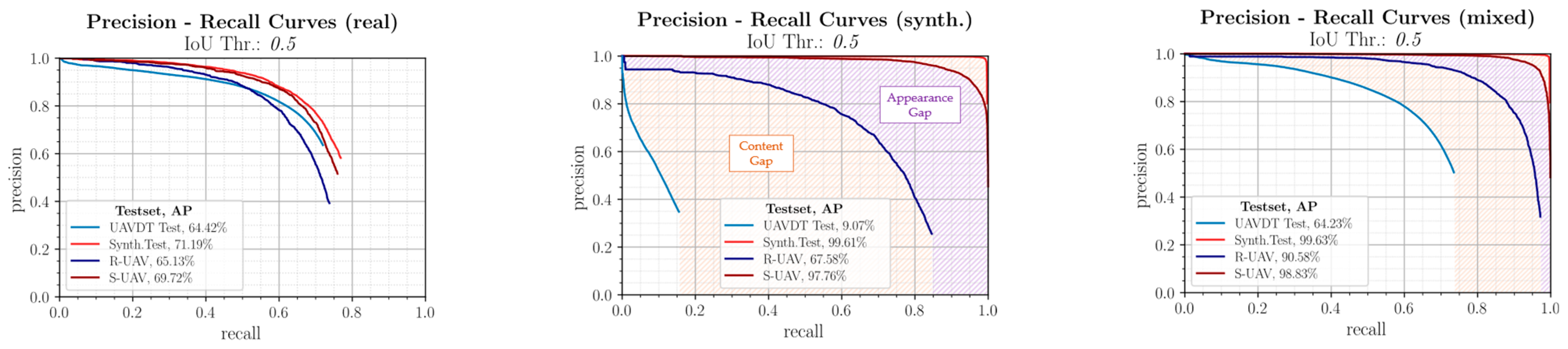
| Real Benchmark Training Data |
|
|
|
| Purely Synthetic Training Data |
|
|
|
|
| Mixed Training Data |
|
|
| The adaptability of the detector model to subsequent operational conditions can be significantly increased by selectively augmenting general real-world training data with specifically generated synthetic data from the subsequent operational area. |
| Classification of Content-Equivalent Image Pairs (Real/Synthetic) |
| F1-Score: 0.996 |
|
| - The identified image properties are visually comprehensible. |
| Classification of Detection Results (TP/FP/FN) |
| F1-Score: 0.968 |
|
| In general, global parameters predominate, so the overall impression of the image is more important than the optimization of local parameters. |
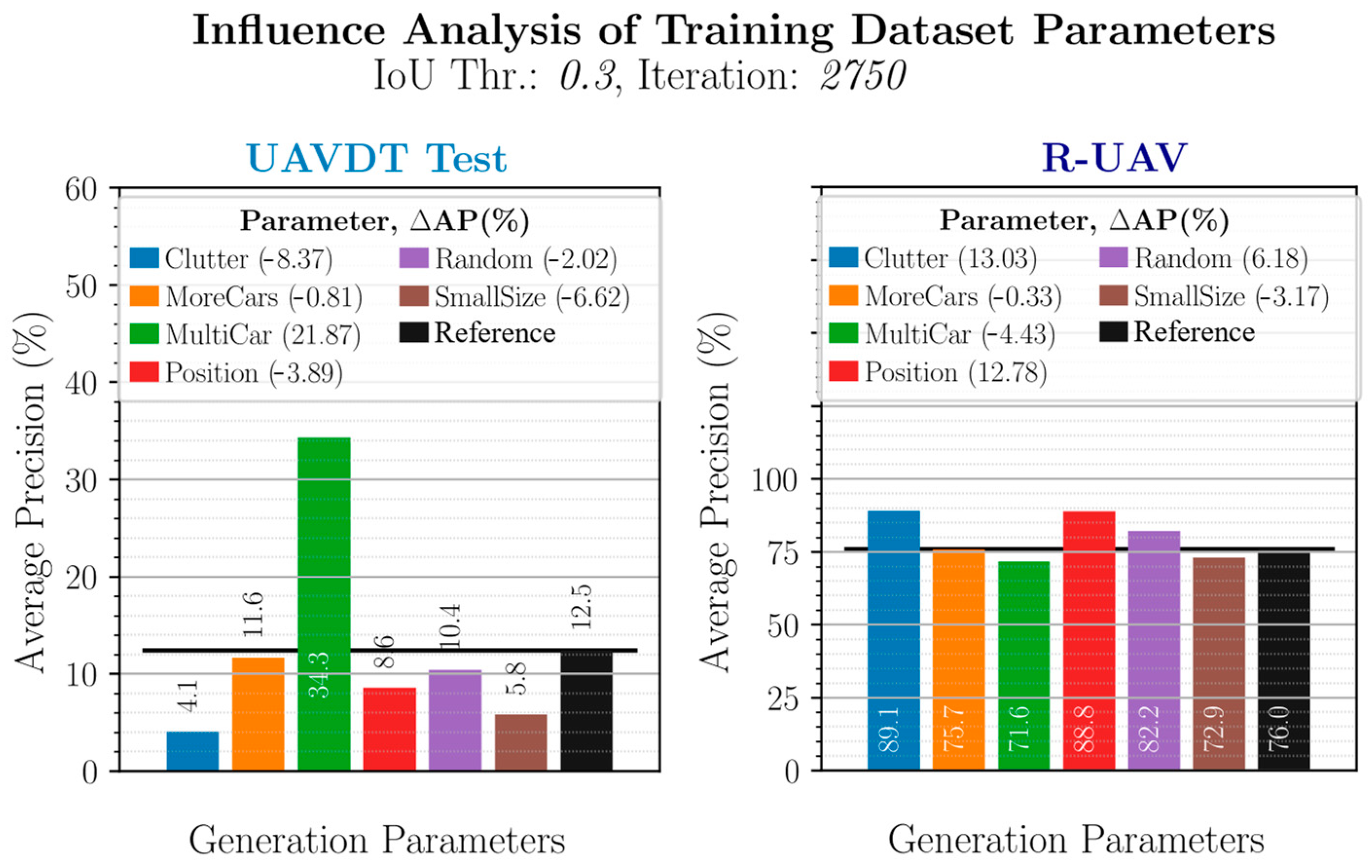
| Effects of Individual Parameter Variations |
|
| Conclusions |
|
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Krump, M.; Stütz, P. Deep Learning Based Vehicle Detection on Real and Synthetic Aerial Images: Training Data Composition and Statistical Influence Analysis. Sensors 2023, 23, 3769. https://doi.org/10.3390/s23073769
Krump M, Stütz P. Deep Learning Based Vehicle Detection on Real and Synthetic Aerial Images: Training Data Composition and Statistical Influence Analysis. Sensors. 2023; 23(7):3769. https://doi.org/10.3390/s23073769
Chicago/Turabian StyleKrump, Michael, and Peter Stütz. 2023. "Deep Learning Based Vehicle Detection on Real and Synthetic Aerial Images: Training Data Composition and Statistical Influence Analysis" Sensors 23, no. 7: 3769. https://doi.org/10.3390/s23073769