
Defect Detection for Metal Shaft Surfaces Based on an Improved YOLOv5 Algorithm and Transfer Learning
Abstract
:1. Introduction
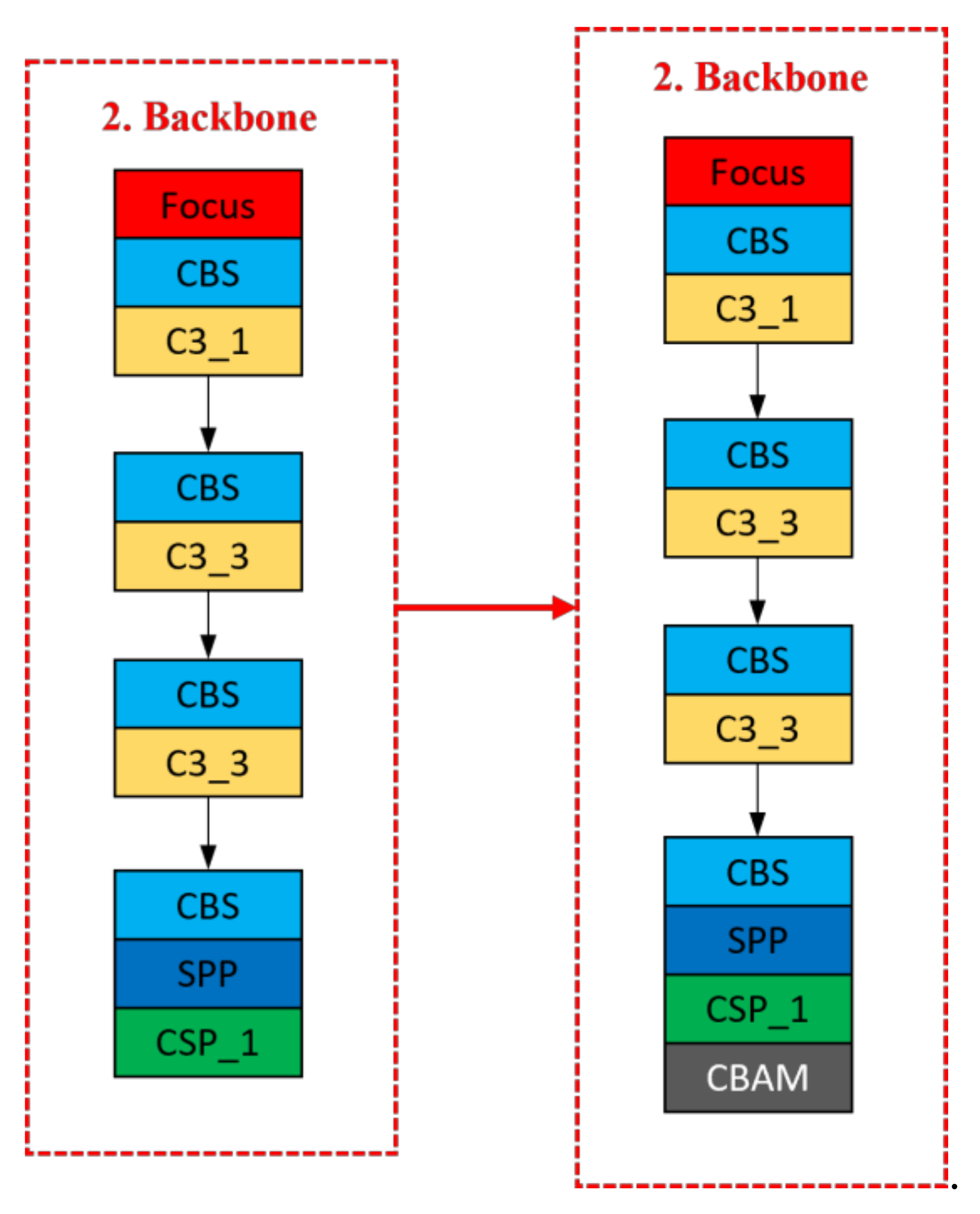
- We add a CBAM attention mechanism to improve the model’s expression effect and detection effect.
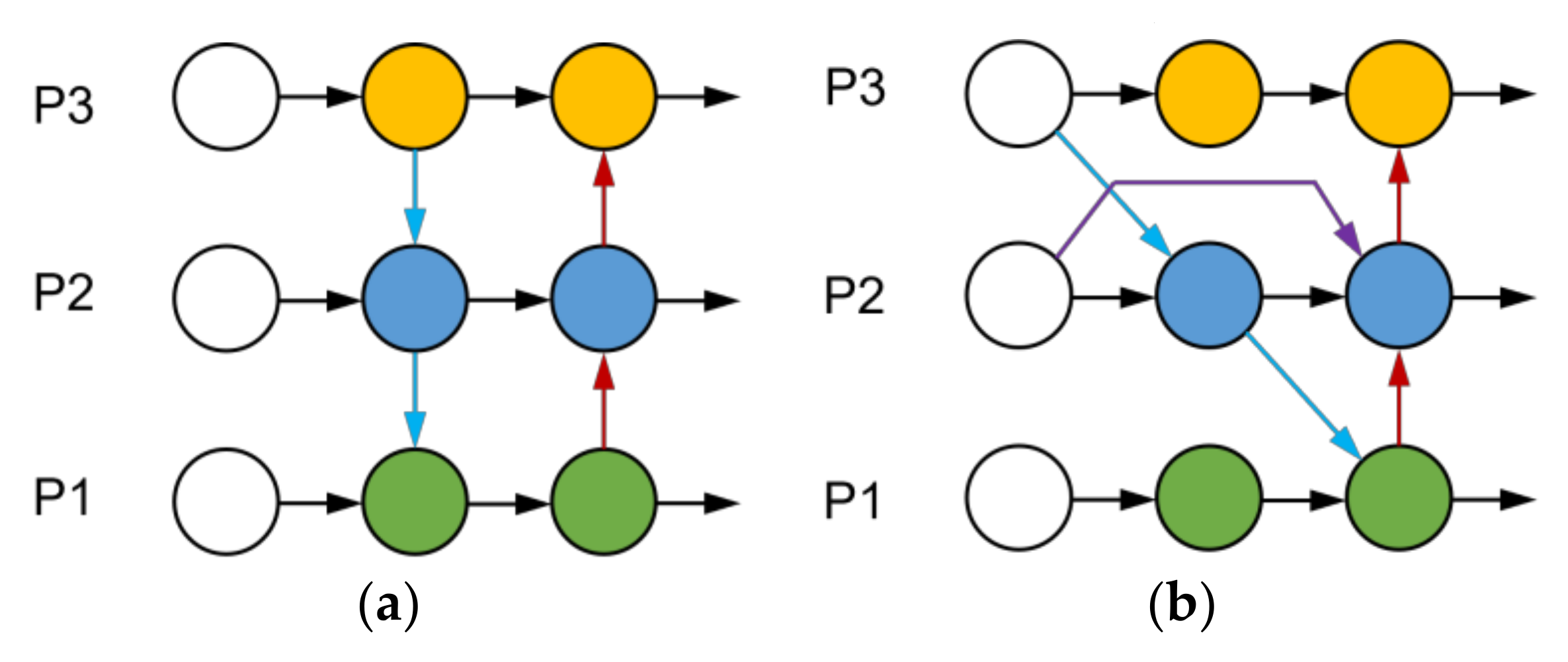
- The original PANet feature fusion framework in the YOLOv5 neck network is replaced with the BiFPN module.
- We use the transfer learning method to reduce the dependence of the training process on large samples.
- All of these new features were tested and validated on the defect dataset of the metal shaft surface, and the conclusions confirmed the algorithm’s feasibility.
2. Related Work
2.1. Defect Detection Method Based on Traditional Machine Vision
2.2. Defect Detection Method Based on Deep Learning
3. Proposed Method
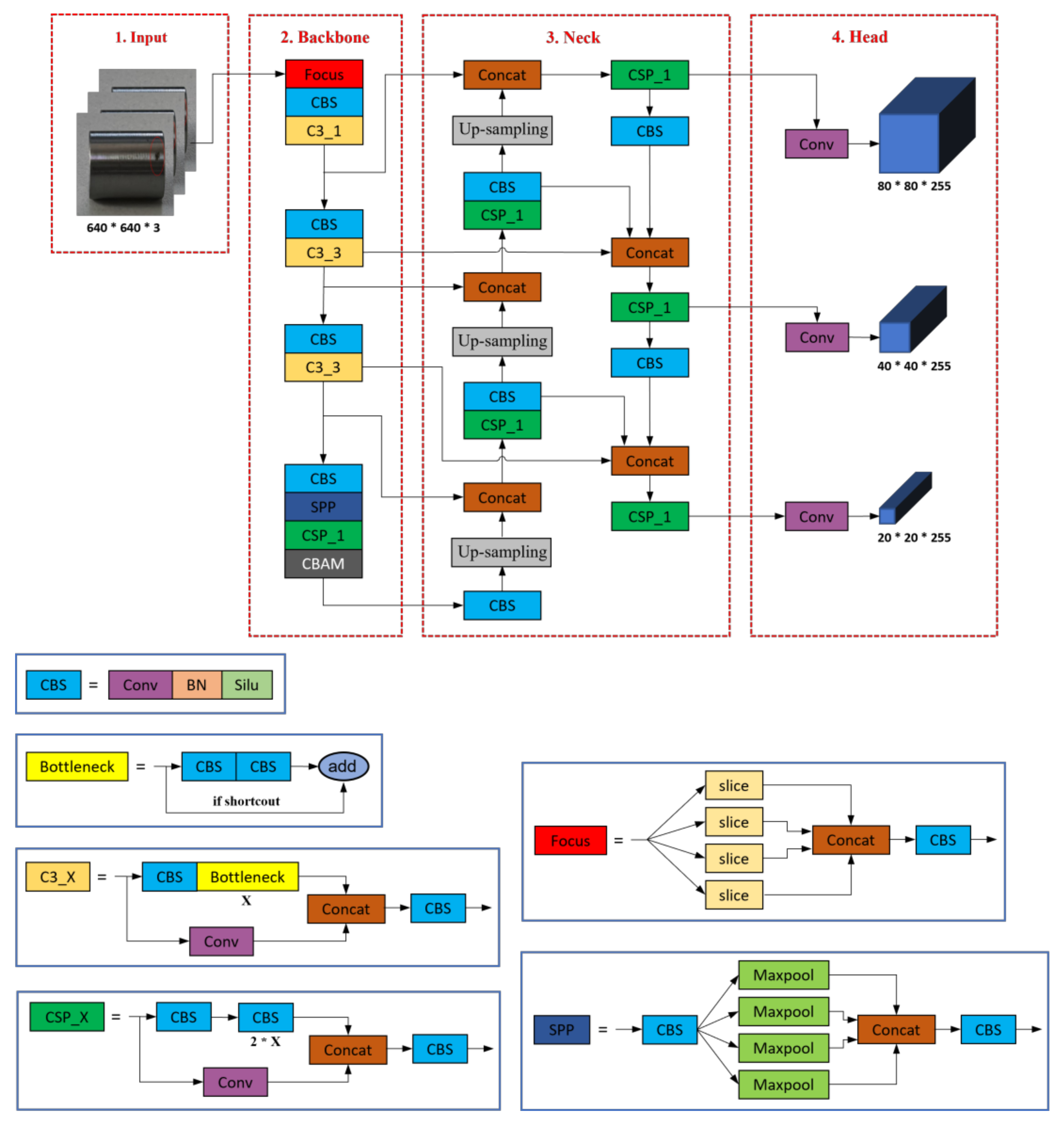
3.1. Network Architecture
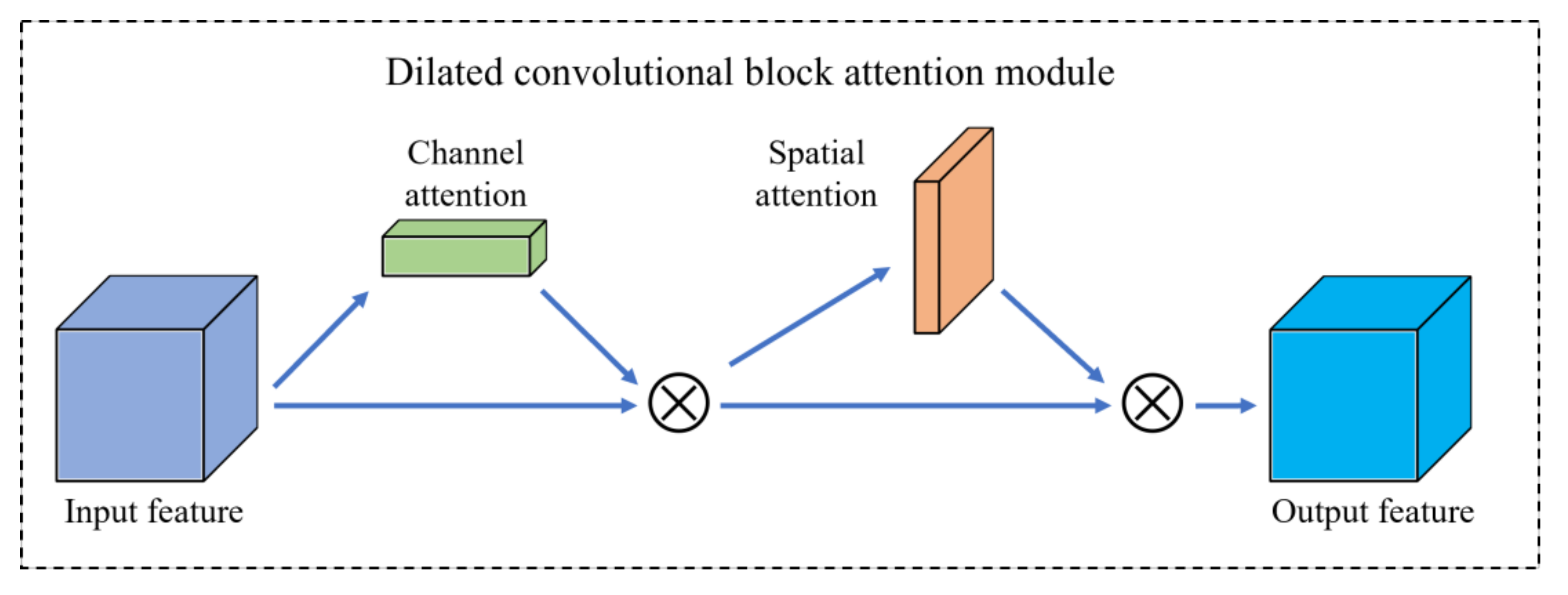
3.2. Extended CBAM Mixed Attention Module
3.2.1. Channel Attention Module
3.2.2. Spatial Attention Module
3.3. BiFPN Characteristic Pyramid
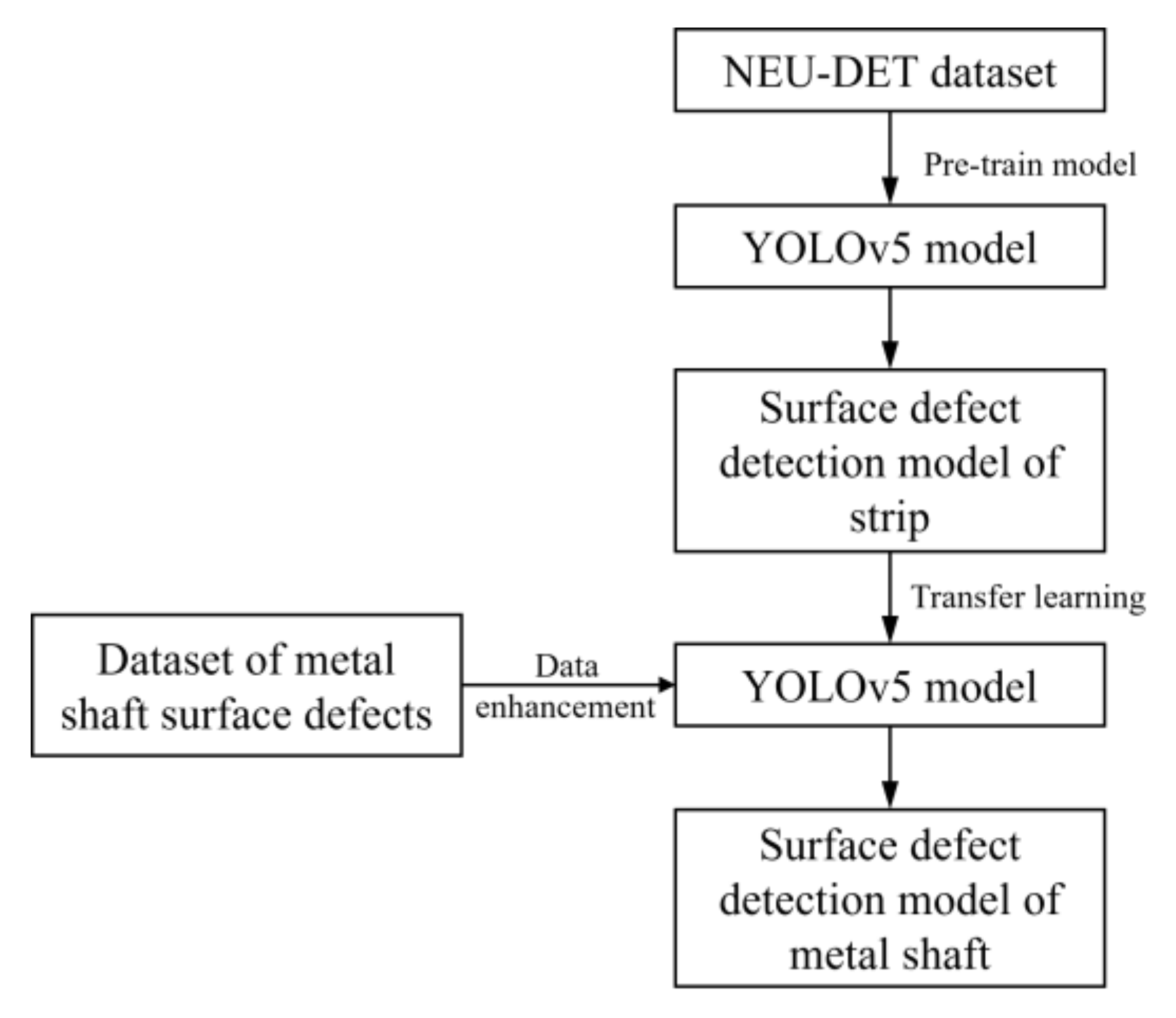
3.4. Transfer Learning
4. Experiments Results and Analysis
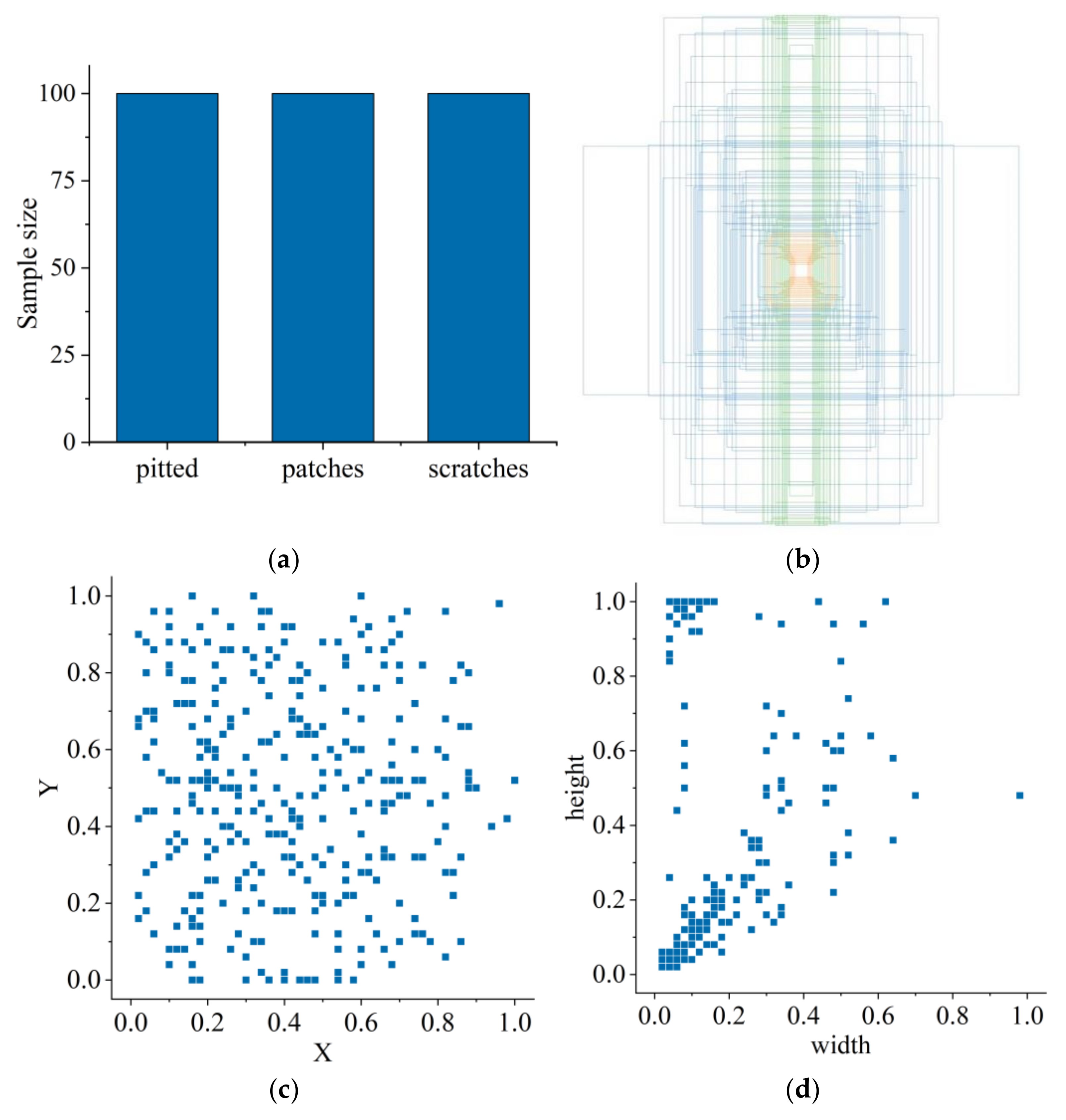
4.1. Data Preparation
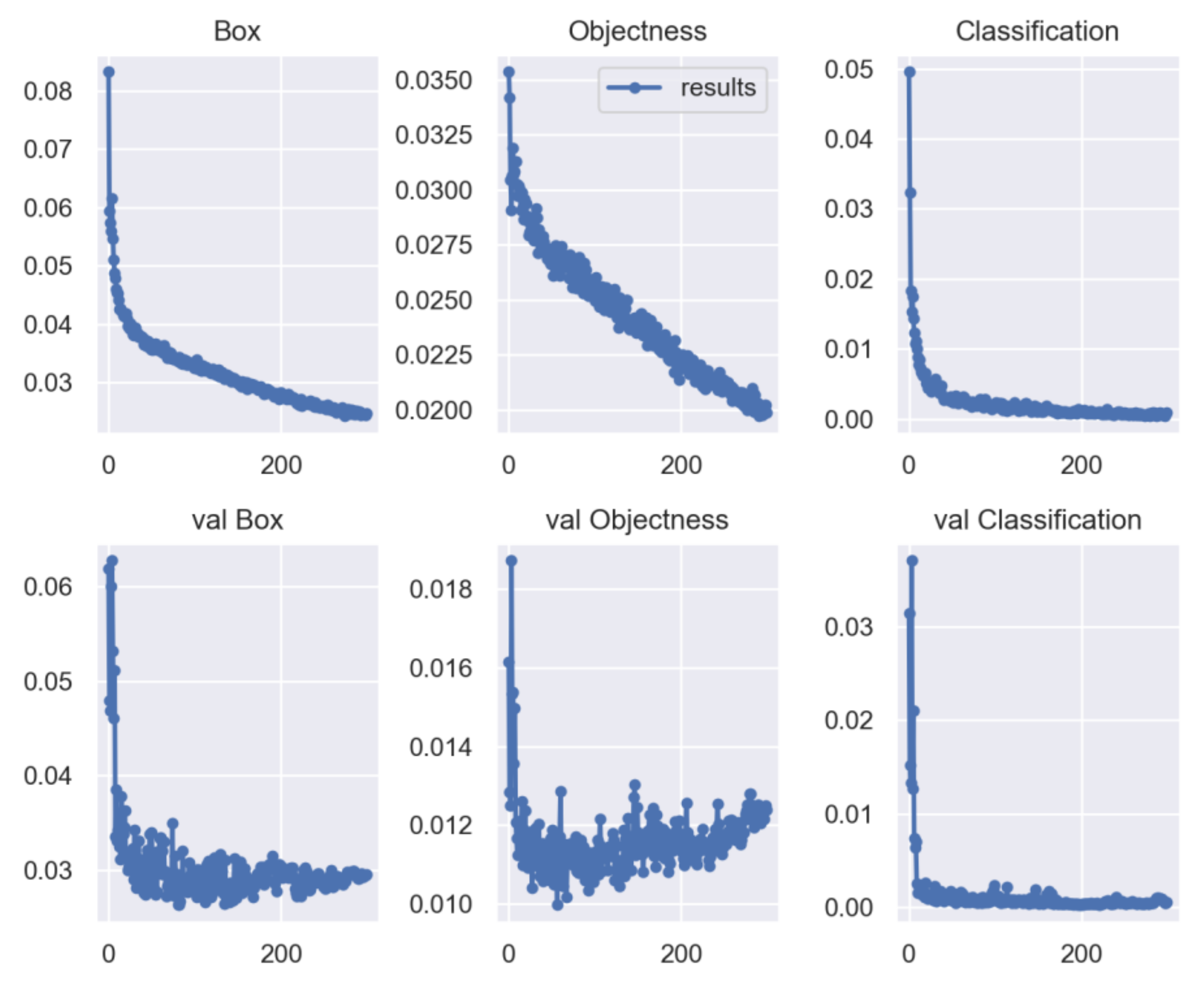
4.2. Experiment and Parameter Determination
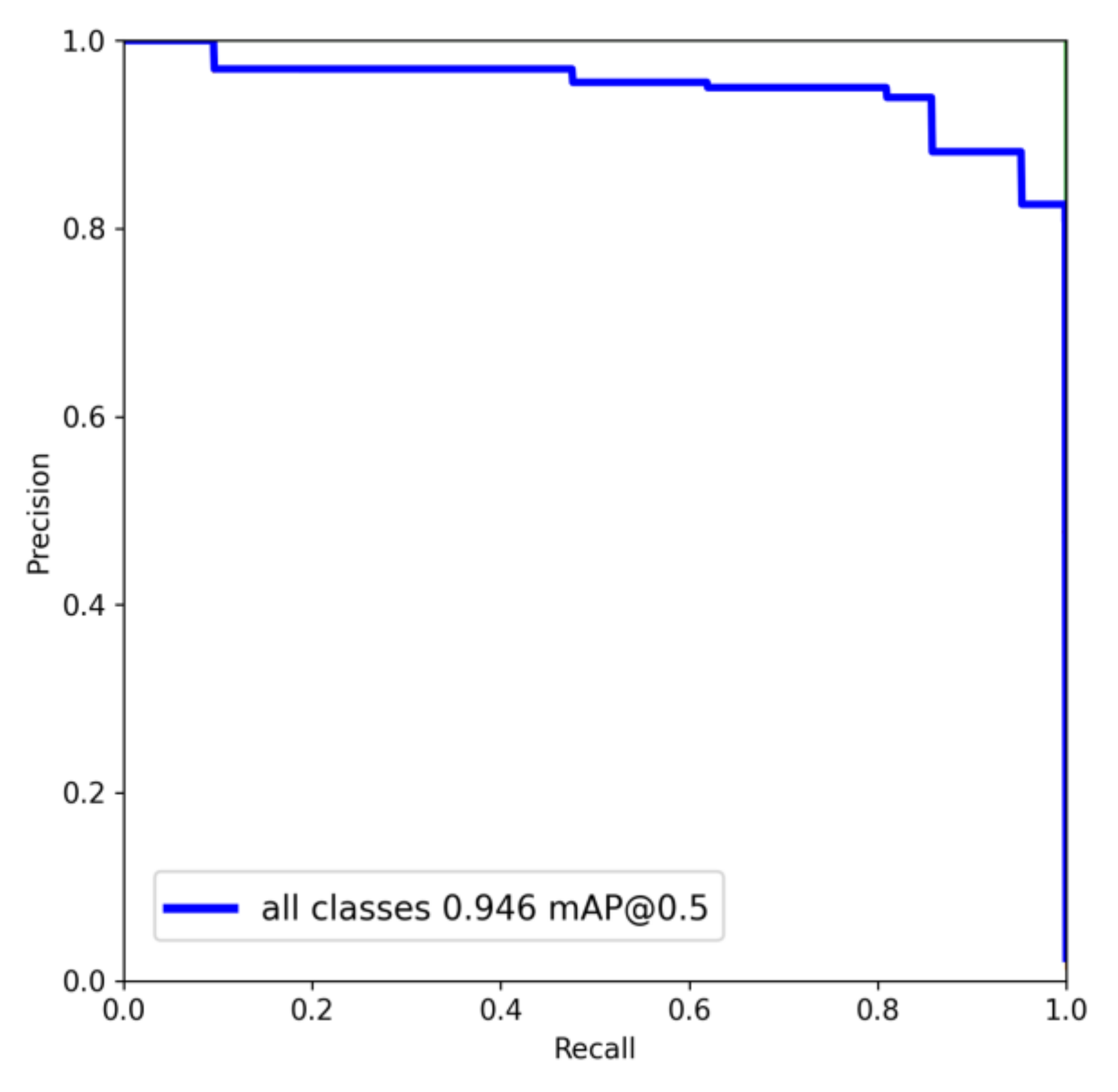
4.3. Network Evaluation
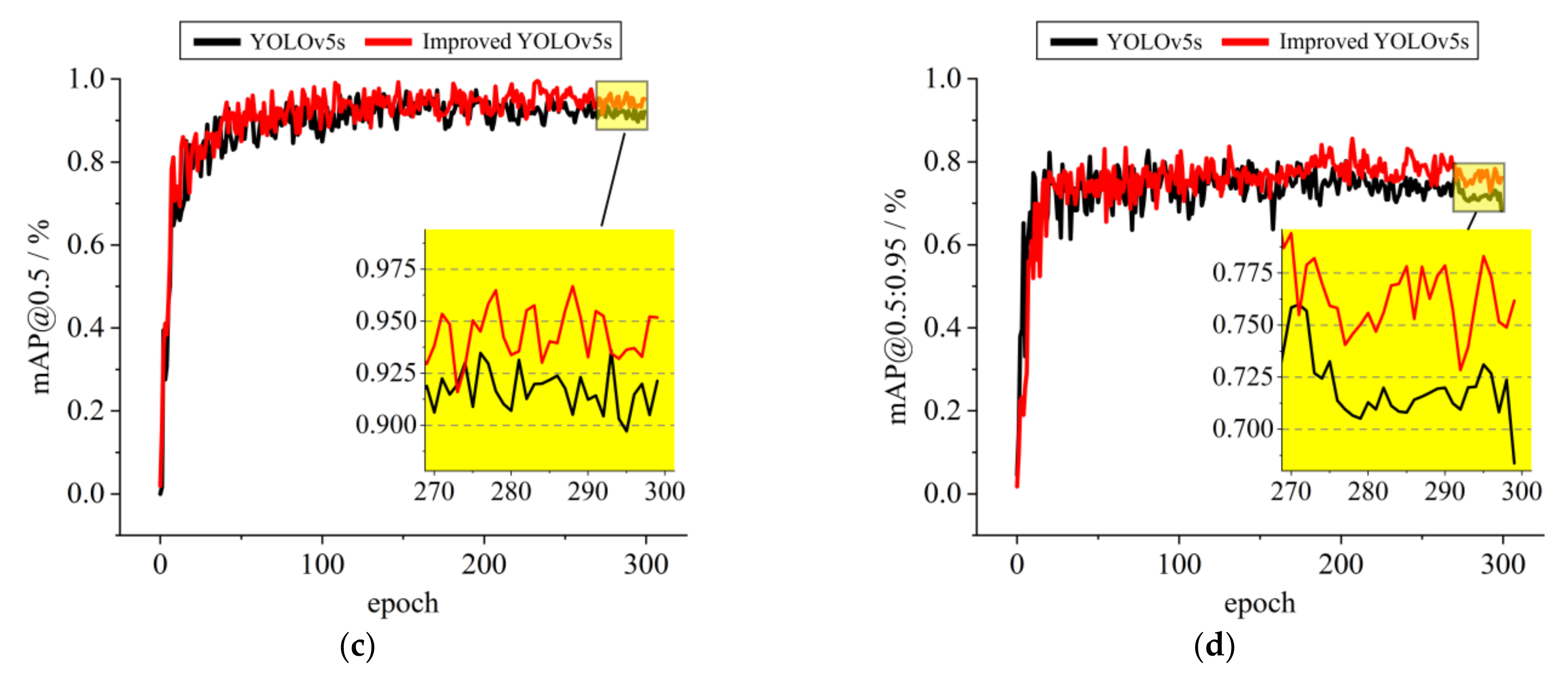
4.4. Performance Analysis of the Improved YOLOv5
4.5. Ablation Experiments
4.6. Comparison with Other Networks
4.7. Test Result
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Xie, Z. Study on the Torque Transmission Characteristics of Heavy-Duty Shaft-Hub Composite Connection. Master’s Thesis, Zhejiang University, Hangzhou, China, 2014. [Google Scholar]
- Yang, C.; Liu, P.; Yin, G.; Jiang, H.; Li, X. Defect Detection in Magnetic Tile Images Based on Stationary Wavelet Transform. NDT E Int. 2016, 83, 78–87. [Google Scholar] [CrossRef]
- Islam, M.J.; Ahmadi, M.; Sid-Ahmed, M.A. Image Processing Techniques for Quality Inspection of Gelatin Capsules in Pharmaceutical Applications Automation. In Proceedings of the Robotics and Vision 2008 10th International Conference on Control, Hanoi, Vietnam, 17–20 December 2008; pp. 862–867. [Google Scholar] [CrossRef]
- Nikam, P.A.; Sawant, S.D. Circuit Board Defect Detection Using Image Processing and Microcontroller. In Proceedings of the 2017 International Conference on Intelligent Computing and Control Systems (ICICCS), Madurai, India, 15–17 June 2017; pp. 1096–1098. [Google Scholar] [CrossRef]
- Park, J.-K.; Kwon, B.-K.; Park, J.-H.; Kang, D.-J. Machine Learning-Based Imaging System for Surface Defect Inspection. Int. J. Precis. Eng. Manuf. Green Technol. 2016, 3, 303–310. [Google Scholar] [CrossRef]
- Masci, J.; Meier, U.; Ciresan, D.; Schmidhuber, J.; Fricout, G. Steel Defect Classification with Max-Pooling Convolutional Neural Networks. In Proceedings of the 2012 International Joint Conference on Neural Networks (IJCNN), Brisbane, QLD, Australia, 10–15 June 2012; IEEE: Brisbane, Australia; pp. 1–6. [Google Scholar] [CrossRef] [Green Version]
- Liu, Z.; Liu, X.; Li, C.; Li, B.; Wang, B. Fabric Defect Detection Based on Faster R-CNN. In Proceedings of the Ninth International Conference on Graphic and Image Processing (ICGIP 2017), Qingdao, China, 10 April 2018; Volume 10615, pp. 55–63. [Google Scholar] [CrossRef]
- Silvén, O.; Niskanen, M.; Kauppinen, H. Wood Inspection with Non-Supervised Clustering. Mach. Vis. Appl. 2003, 13, 275–285. [Google Scholar] [CrossRef] [Green Version]
- Li, Y.; Huang, H.; Xie, Q.; Yao, L.; Chen, Q. Research on a Surface Defect Detection Algorithm Based on MobileNet-SSD. Appl. Sci. 2018, 8, 1678. [Google Scholar] [CrossRef] [Green Version]
- Yu, N.; Chen, H.; Xu, Q.; Hasan, M.M.; Sie, O. Wafer Map Defect Patterns Classification Based on a Lightweight Network and Data Augmentation. CAAI Trans. Intell. Technol 2022. (early view). [Google Scholar] [CrossRef]
- Jian, C.; Gao, J.; Ao, Y. Automatic Surface Defect Detection for Mobile Phone Screen Glass Based on Machine Vision. Appl. Soft Comput. 2017, 52, 348–358. [Google Scholar] [CrossRef]
- Mak, K.L.; Peng, P.; Yiu, K.F.C. Fabric Defect Detection Using Morphological Filters. Image Vis. Comput. 2009, 27, 1585–1592. [Google Scholar] [CrossRef]
- Yuan, X.; Wu, L.; Peng, Q. An Improved Otsu Method Using the Weighted Object Variance for Defect Detection. Appl. Surf. Sci. 2015, 349, 472–484. [Google Scholar] [CrossRef] [Green Version]
- Kalaiselvi, T.; Nagaraja, P. A Rapid Automatic Brain Tumor Detection Method for MRI Images Using Modified Minimum Error Thresholding Technique. Int. J. Imaging Syst. Technol. 2015, 1, 77–85. [Google Scholar] [CrossRef]
- Wang, L.; Zhao, Y.; Zhou, Y.; Hao, J. Calculation of Flexible Printed Circuit Boards (FPC) Global and Local Defect Detection Based on Computer Vision. Circuit World 2016, 42, 49–54. [Google Scholar] [CrossRef]
- Hu, G.-H. Automated Defect Detection in Textured Surfaces Using Optimal Elliptical Gabor Filters. Optik 2015, 126, 1331–1340. [Google Scholar] [CrossRef]
- Borwankar, R.; Ludwig, R. An Optical Surface Inspection and Automatic Classification Technique Using the Rotated Wavelet Transform. IEEE Trans. Instrum. Meas. 2018, 67, 690–697. [Google Scholar] [CrossRef]
- Bai, X.; Fang, Y.; Lin, W.; Wang, L.; Ju, B.-F. Saliency-Based Defect Detection in Industrial Images by Using Phase Spectrum. IEEE Trans. Ind. Inform. 2014, 10, 2135–2145. [Google Scholar] [CrossRef]
- Susan, S.; Sharma, M. Automatic Texture Defect Detection Using Gaussian Mixture Entropy Modeling. Neurocomputing 2017, 239, 232–237. [Google Scholar] [CrossRef]
- Cen, Y.-G.; Zhao, R.-Z.; Cen, L.-H.; Cui, L.-H.; Miao, Z.-J.; Wei, Z. Defect Inspection for TFT-LCD Images Based on the Low-Rank Matrix Reconstruction. Neurocomputing 2015, 149, 1206–1215. [Google Scholar] [CrossRef]
- Liu, B.; Yang, Y.; Wang, S.; Bai, Y.; Yang, Y.; Zhang, J. An Automatic System for Bearing Surface Tiny Defect Detection Based on Multi-Angle Illuminations. Optik 2020, 208, 164517. [Google Scholar] [CrossRef]
- Shafarenko, L.; Petrou, M.; Kittler, J. Automatic Watershed Segmentation of Randomly Textured Color Images. IEEE Trans. Image Process. 1997, 6, 1530–1544. [Google Scholar] [CrossRef]
- Medina, R.; Llamas, J.; Gómez-García-Bermejo, J.; Zalama, E.; Segarra, M.J. Crack Detection in Concrete Tunnels Using a Gabor Filter Invariant to Rotation. Sensors 2017, 17, 1670. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. arXiv 2016, arXiv:1506.01497. [Google Scholar] [CrossRef] [Green Version]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. arXiv 2016, arXiv:1506.02640. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.-Y.; Berg, A.C. SSD: Single Shot MultiBox Detector. In Proceedings of the Computer Vision–ECCV, Amsterdam, The Netherlands, 11–14 October 2016; Springer: Cham, Switzerland; pp. 21–37. [Google Scholar] [CrossRef] [Green Version]
- He, Y.; Song, K.; Meng, Q.; Yan, Y. An End-to-End Steel Surface Defect Detection Approach via Fusing Multiple Hierarchical Features. IEEE Trans. Instrum. Meas. 2020, 69, 1493–1504. [Google Scholar] [CrossRef]
- Evangelidis, A.; Dimitriou, N.; Leontaris, L.; Ioannidis, D.; Tinker, G.; Tzovaras, D. A Deep Regression Framework Toward Laboratory Accuracy in the Shop Floor of Microelectronics. IEEE Trans. Ind. Inform. 2023, 19, 2652–2661. [Google Scholar] [CrossRef]
- Cha, Y.-J.; Choi, W.; Suh, G.; Mahmoudkhani, S.; Büyüköztürk, O. Autonomous Structural Visual Inspection Using Region-Based Deep Learning for Detecting Multiple Damage Types. Comput. Aided Civ. Infrastruct. Eng. 2018, 33, 731–747. [Google Scholar] [CrossRef]
- Lv, X.; Duan, F.; Jiang, J.; Fu, X.; Gan, L. Deep Metallic Surface Defect Detection: The New Benchmark and Detection Network. Sensors 2020, 20, 1562. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Chen, J.; Liu, Z.; Wang, H.; Núñez, A.; Han, Z. Automatic Defect Detection of Fasteners on the Catenary Support Device Using Deep Convolutional Neural Network. IEEE Trans. Instrum. Meas. 2018, 67, 257–269. [Google Scholar] [CrossRef] [Green Version]
- Li, Z.; Tian, X.; Liu, X.; Liu, Y.; Shi, X. A Two-Stage Industrial Defect Detection Framework Based on Improved-YOLOv5 and Optimized-Inception-ResnetV2 Models. Appl. Sci. 2022, 12, 834. [Google Scholar] [CrossRef]
- Xiong, C.; Hu, S.; Fang, Z. Application of Improved YOLOV5 in Plate Defect Detection. Int. J. Adv. Manuf. Technol. 2022, 1–13. [Google Scholar] [CrossRef]
- Zheng, L.; Wang, X.; Wang, Q.; Wang, S.; Liu, X. A Fabric Defect Detection Method Based on Improved YOLOv5. In Proceedings of the 2021 7th International Conference on Computer and Communications (ICCC), Chengdu, China, 10–15 December 2021; pp. 620–624. [Google Scholar] [CrossRef]
- Woo, S.; Park, J.; Lee, J.-Y.; Kweon, I.S. CBAM: Convolutional Block Attention Module. In Proceedings of the Computer Vision–ECCV 2018; Munich, Germany, 8–14 September 2018, Ferrari, V., Hebert, M., Sminchisescu, C., Weiss, Y., Eds.; Lecture Notes in Computer Science; Springer International Publishing: Cham, Switzerland, 2018; Volume 11211, pp. 3–5. [Google Scholar]
- Tan, M.; Pang, R.; Le, Q.V. EfficientDet: Scalable and Efficient Object Detection. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 10778–10787. [Google Scholar]
- Yang, Y.; Song, X. Research on Face Intelligent Perception Technology Integrating Deep Learning under Different Illumination Intensities. J. Comput. Cogn. Eng. 2022, 1, 32–36. [Google Scholar] [CrossRef]
- Gilani, S.Z.; Mian, A.; Eastwood, P. Deep, Dense and Accurate 3D Face Correspondence for Generating Population Specific Deformable Models. Pattern Recognit. 2017, 69, 238–250. [Google Scholar] [CrossRef] [Green Version]
- Zhang, Z.; Wang, L.; Zheng, W.; Yin, L.; Hu, R.; Yang, B. Endoscope Image Mosaic Based on Pyramid ORB. Biomed. Signal Process. Control. 2022, 71, 103261. [Google Scholar] [CrossRef]
- Wang, C.-Y.; Bochkovskiy, A.; Liao, H.-Y.M. YOLOv7: Trainable Bag-of-Freebies Sets New State-of-the-Art for Real-Time Object Detectors. arXiv 2022, arXiv:2207.02696. [Google Scholar]
- Ge, Z.; Liu, S.; Wang, F.; Li, Z.; Sun, J. YOLOX: Exceeding YOLO Series in 2021. arXiv 2021, arXiv:2107.08430. [Google Scholar]

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Defects | Precision (%) | Recall (%) | mAP@0.5 (%) | mAP@0.5:0.95 (%) |
|---|---|---|---|---|
| scratches | 90.9 | 98.4 | 95.9 | 80.2 |
| pitted | 89.6 | 86.2 | 86.8 | 66.1 |
| patches | 91.7 | 97.8 | 95.1 | 75.9 |
| all | 90.7 | 95.3 | 94.6 | 76.7 |
| Model | YOLOv5s | Improved YOLOv5s | ||||
|---|---|---|---|---|---|---|
| Add transfer learning | - | + | - | - | - | + |
| Add CBAM | - | - | + | - | + | + |
| Add BiFPN | - | - | - | + | + | + |
| Precision (%) | 86.3 | 89.1 | 90.3 | 87.4 | 90.6 | 90.7 |
| Recall (%) | 92.7 | 93 | 94.1 | 93.8 | 95.1 | 95.3 |
| mAP@0.5 (%) | 91.4 | 93.7 | 94.2 | 92.3 | 94.5 | 94.6 |
| mAP@0.5:0.95 (%) | 72.1 | 69.4 | 70.7 | 68.2 | 72.5 | 76.7 |
| FPS | 19.5 | 19.4 | 18.1 | 17 | 17.4 | 16.7 |
| Model | Precision (%) | Recall (%) | mAP@0.5 (%) | mAP@0.5:0.95 (%) | Memory Usage (MB) | FPS |
|---|---|---|---|---|---|---|
| Faster R-CNN | 85.4 | 93.0 | 88.2 | 72.7 | 361 | 2.2 |
| YOLOv3 | 87.8 | 84.1 | 86.9 | 70.6 | 237 | 9.4 |
| SSD300 | 89.6 | 85.9 | 89.3 | 73.6 | 100 | 13.1 |
| YOLOXs | -- | -- | 95.1 | 78.4 | 68.7 | 18.3 |
| YOLOv7 | 85.4 | 92.1 | 91.8 | 73.9 | 72.1 | 16.2 |
| Improved YOLOv5s | 90.7 | 95.3 | 94.6 | 74.3 | 14.1 | 16.7 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, B.; Gao, Q. Defect Detection for Metal Shaft Surfaces Based on an Improved YOLOv5 Algorithm and Transfer Learning. Sensors 2023, 23, 3761. https://doi.org/10.3390/s23073761
Li B, Gao Q. Defect Detection for Metal Shaft Surfaces Based on an Improved YOLOv5 Algorithm and Transfer Learning. Sensors. 2023; 23(7):3761. https://doi.org/10.3390/s23073761
Chicago/Turabian StyleLi, Bi, and Quanjie Gao. 2023. "Defect Detection for Metal Shaft Surfaces Based on an Improved YOLOv5 Algorithm and Transfer Learning" Sensors 23, no. 7: 3761. https://doi.org/10.3390/s23073761