MiCrowd: Vision-Based Deep Crowd Counting on MCU

 ,
,
Abstract
:1. Introduction
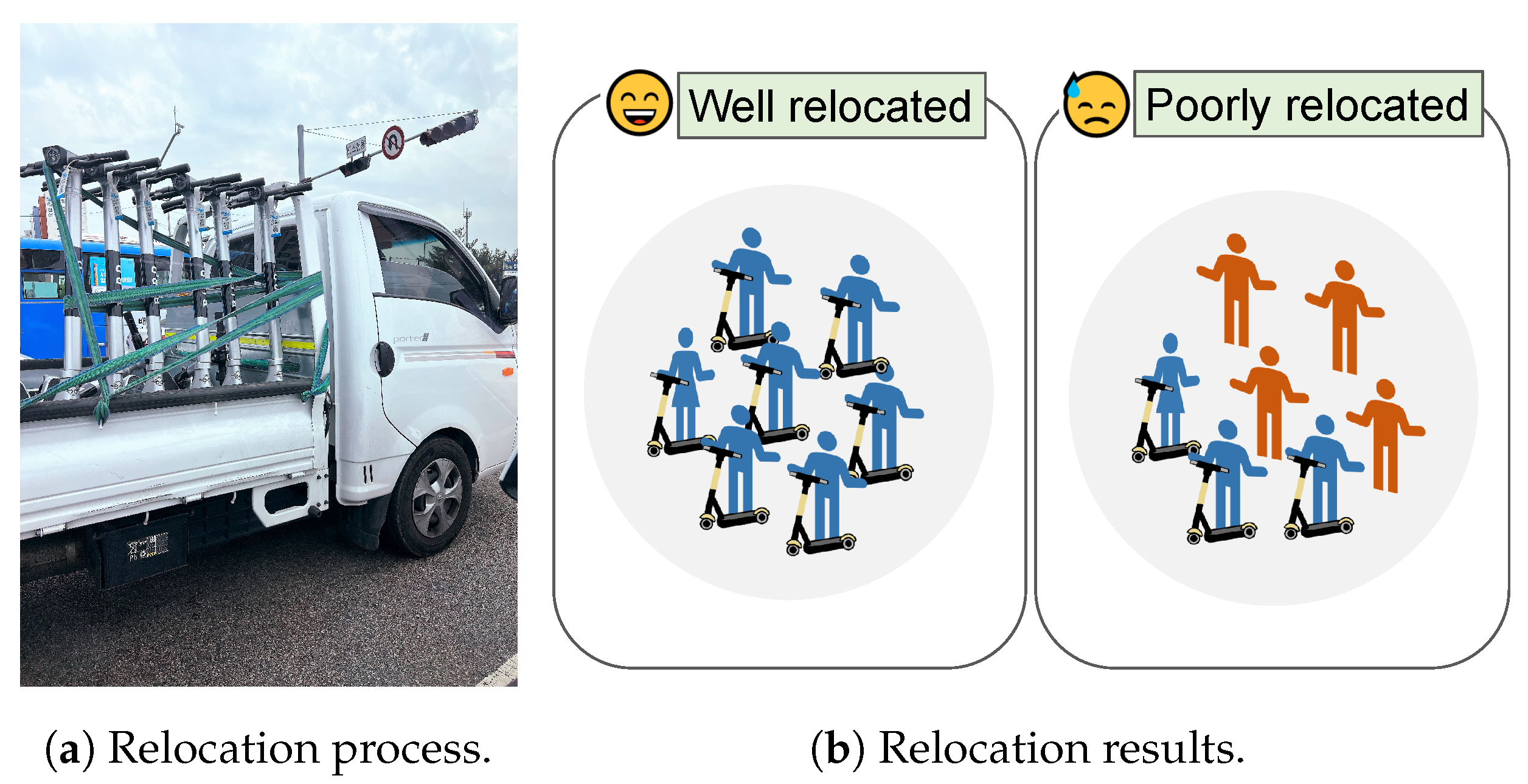
- Application scenario. The E-scooter-sharing market is rapidly growing since E-scooters are cheap to rent and easy to park and drive in crowded cities [6,7]. The volume of the global E-scooter-sharing market is expected to reach USD 40–50 billion by 2025 [7]. Now that E-scooters are pervasive in many cities, if each parked E-scooter periodically measures the number of people around it and reports the information to the E-scooter vendor, the vendor can obtain floating populations in these cities. In addition, floating populations measured by E-scooters are uniquely valuable, i.e., they can focus on pedestrians, regardless of which MNO they use.
- Challenges. Crowd counting, despite its value and practicality, is a relatively difficult task and it needs to count people in a noisy outdoor environment. Typically, the model becomes heavier and more complex. In this manner, most of the recent works adopted deep neural networks (DNNs) owing to their capability of understanding complex scenes and remarkable performances. As mentioned above, MCUs have extremely strict memory and storage constraints, which are not ideal for running DNNs on them. Various types of alternative sensors can be combined with MCUs, such as wireless transceivers (e.g., Bluetooth and Wi-Fi) and passive infrared (PIR) sensors. However, they are not viable options for crowd counting in outdoor environments because the signals are frequently interrupted by various noises or security settings. Sending images to the server cannot be an alternative since the communication costs are too high and it can cause privacy issues.
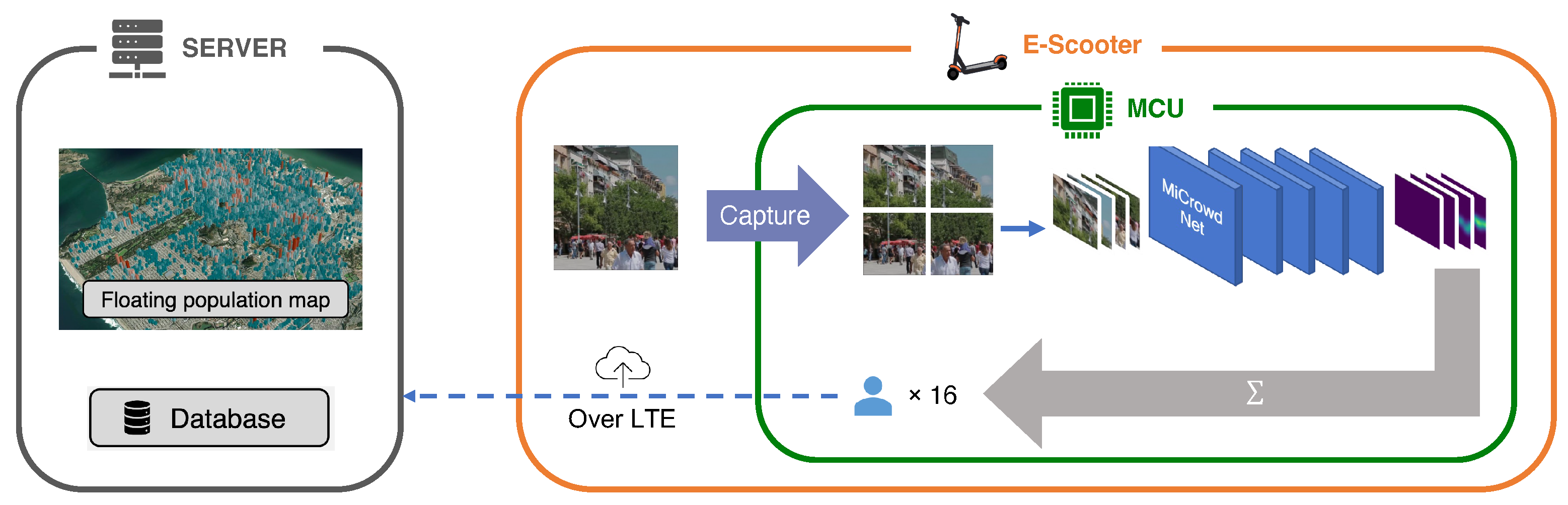
- Approach. To address the resource constraints, we devised a lightweight crowd-counting DNN, MiCrowdNet, and applied patch-based training and inference to keep image resolution with low memory usage. In addition, we deliberately selected Person Re-identification in the Wild (PRW) dataset [8] since existing datasets for crowd counting contain congested crowds or are taken from high places [9,10,11,12], which was not the case in our mobility-based scenario. Moreover, we completely relabeled the dataset because PRW was originally not for crowd-counting tasks. As a result, MiCrowdNet achieves 1.12 in the mean absolute error (MAE) (comparable to state-of-the-art DNNs) with a 4× smaller model size compared to the existing lightest model [12]. It runs on Espressif ESP32-S3, a high-end microcontroller unit (MCU) of 240 MHz clock, 512 kB SRAM, and 4 MB flash.
- Contributions. We summarize key contributions as follows:
- Our MiCrowd system provides a novel and practical application scenario: on-device floating population measurements with low communication/hardware costs and privacy preservation.
- To the best of our knowledge, MiCrowdNet is the first attempt to run a vision-based crowd-counting DNN on resource-constrained MCUs.
- We built a testbed to evaluate on the MCU. Our results show that MiCrowdNet is exceedingly smaller but competitive with previous models in the PRW dataset [8].
- We envision that MiCrowd can serve as a valuable floating population data source for other business and/or research uses.
2. Background and Related Work
3. MiCrowd
3.1. Design Principles
- Vision-based Crowd Counting. In MiCrowd, an E-scooter takes a picture, which is fed into MiCrowdNet, a vision-based DNN. In fact, several sensors can be considered for crowd counting. For example, since smartphones have Bluetooth Low Energy (BLE) radios, counting the number of beacons received nearby may represent the number of pedestrians. However, smartphones broadcast BLE beacons only when requested by the user for security reasons, which makes smartphones unviable for crowd counting. A passive infrared (PIR) sensor array might be another option since it has been used for counting occupants [17,18]. However, PIR-based techniques work only in delicately designed indoor environments since the raw PIR signal is notoriously noisy [19]. For these reasons, we chose images as our data sources, which contain dense data and do not suffer from the aforementioned issues in alternative sensors.
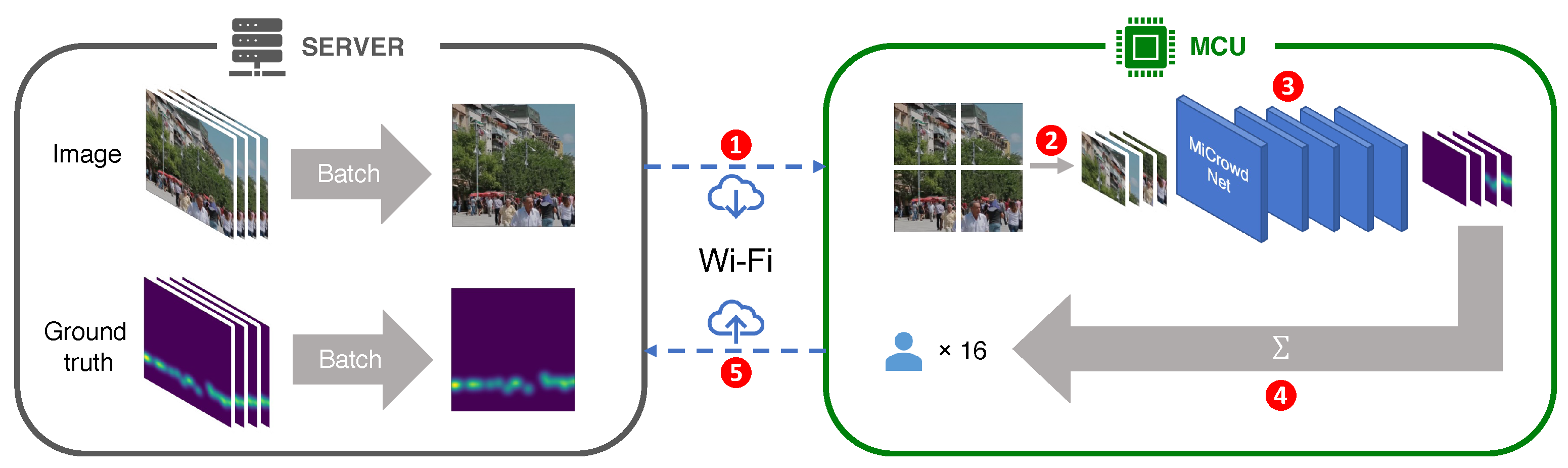
- On-MCU Inference. Our target scenario expects E-scooters to periodically capture photos on the street while being parked. However, sending photos that capture pedestrians without their consent not only raises privacy concerns but also results in significant communication overhead. Thus, our primary goal in devising a DNN is to make it lightweight enough to support on-MCU inference to mitigate those issues. As our target-embedded platform, we selected Espressif ESP32-S3, one of the widely-used high-end MCUs that runs at 240 MHz with 512 kB SRAM and 4 MB flash, considering previous work on E-scooters that utilized ESP32 variants [20,21].
3.2. Dataset Considering Mobility View
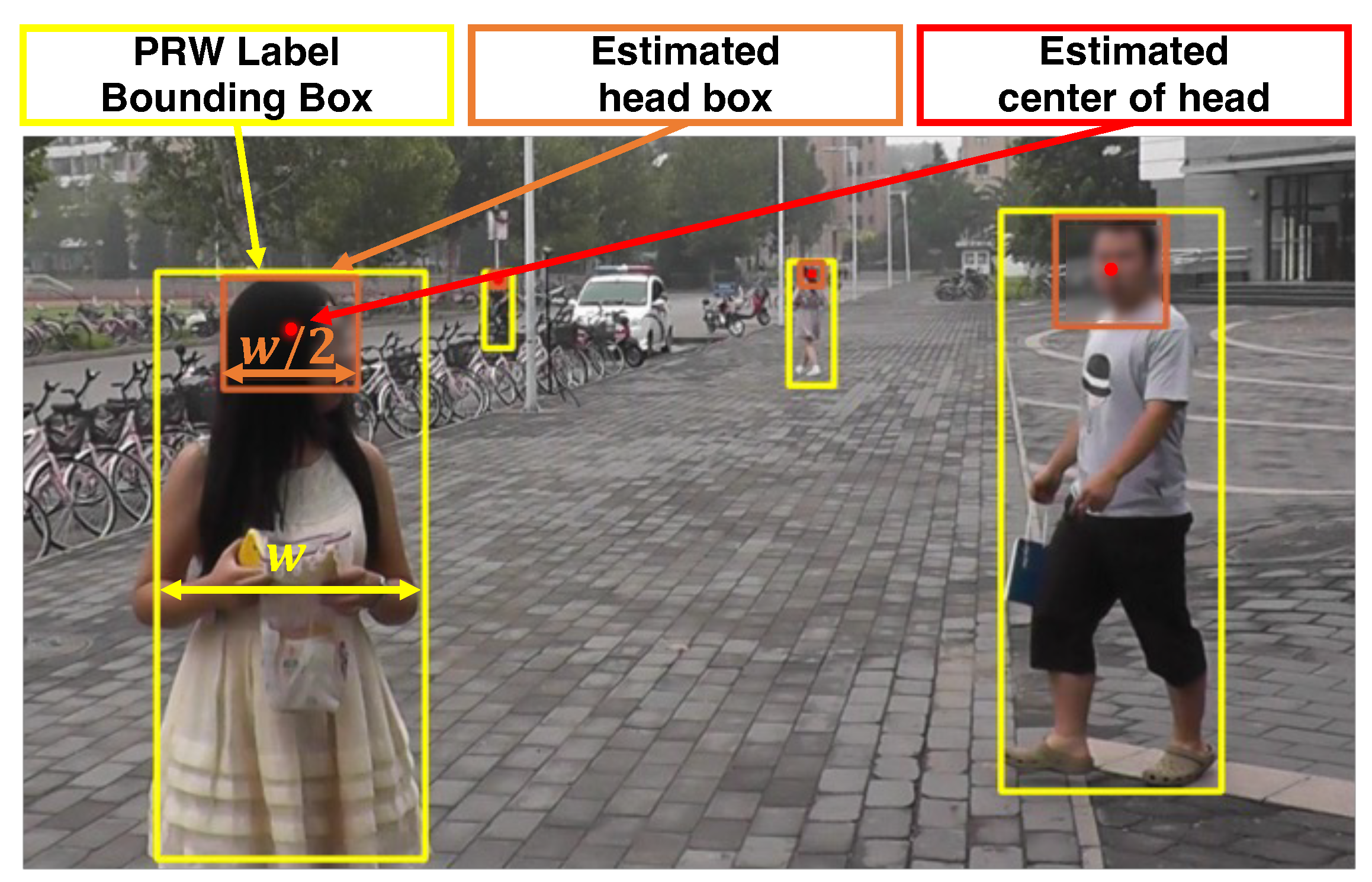
- Relabeling Process. For a crowd-counting task, it is necessary to create a ground-truth density map for each image, which requires detecting each person’s head position and applying a Gaussian kernel at its center point. However, the PRW dataset, originally built for pedestrian detection and person re-identification, contains bounding boxes of people (i.e., the entire body) but not those of their heads.
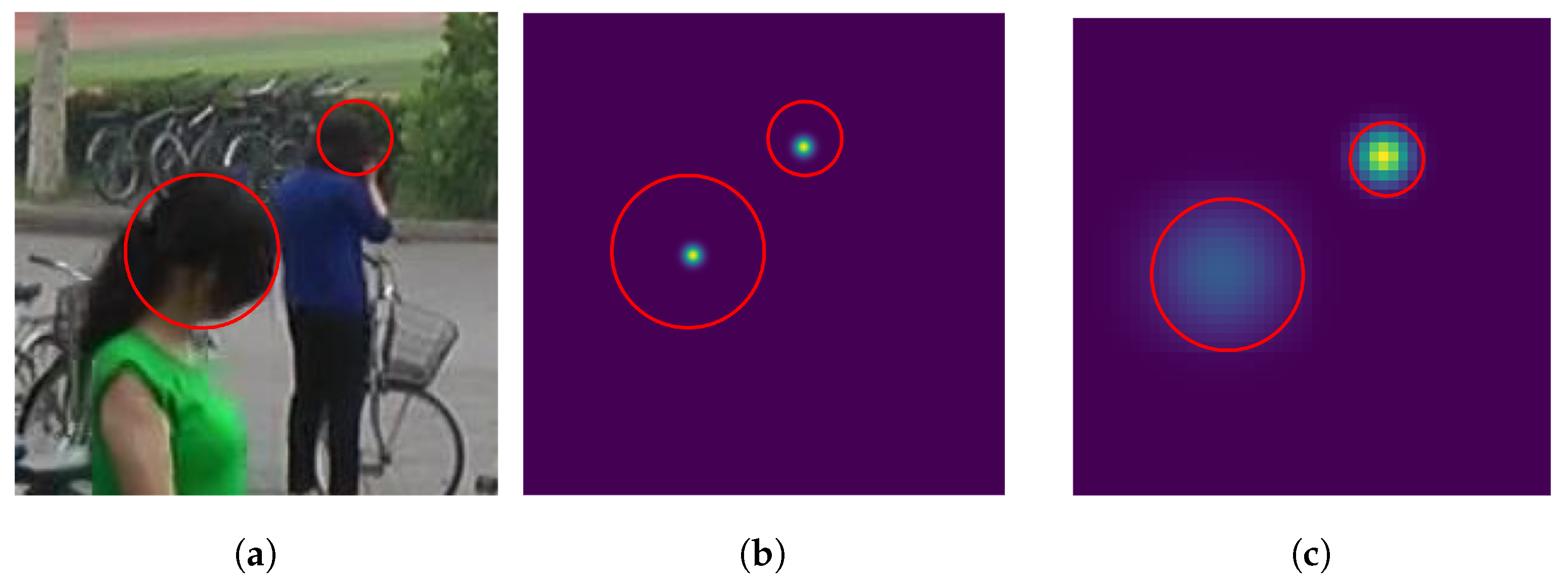
- Adaptive Gaussian Kernel Sizes. One of the crucial challenges in crowd-counting tasks is the variation in head sizes [23]; using a fixed Gaussian kernel for different head sizes would be detrimental to the performance. This is because DNN would capture the size variations of the heads through training, while a fixed Gaussian kernel does not have any information about the size of each head. To address the issue, each head’s kernel width should be proportional to the head size.
3.3. MiCrowdNet
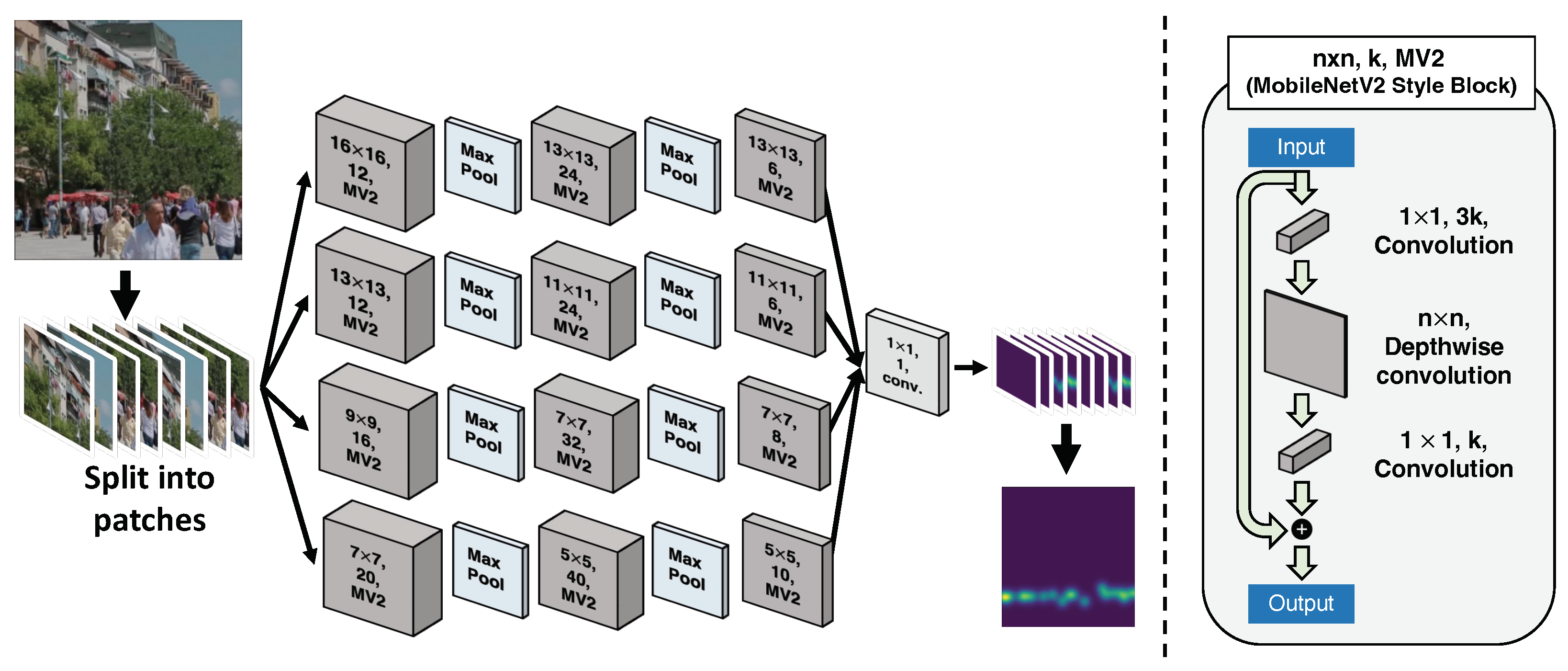
- Optimizing for Mobility View. In contrast to common crowd-counting scenarios that utilize images taken from a high place, we aim to count people in images taken from human-eye levels; conventional crowd-counting DNNs might not work in this particular scenario. Specifically, the variations of head sizes are larger as pedestrians can be close to or far from parked E-scooters. To capture the multi-scale features simultaneously, MiCrowdNet has four branches of different kernel sizes. Compared to the popular MCNN [12], which considers images taken from high places, MiCrowdNet has one more branch and bigger kernel sizes since the heads in our target dataset (i.e., mobility view) are bigger. The biggest kernel in MCNN [12] is a 9 × 9 kernel, whereas that in MiCrowdNet is 16 × 16.
- Minimizing the Model Size. For on-MCU inference, it is essential to reduce the size of the model since the previous crowd-counting vision models are often too large to fit in the MCU’s memory (Table 1). To this end, we leverage only three layers for each branch, which is one layer fewer than MCNN, to capture multi-scale features with a smaller number of parameters and peak memory usage. Our intuition is that the previous crowd-counting models, including the original MCNN, are designed to detect a group of people who appear small in high-resolution images, while our scenario involves counting people who appear relatively larger and, thus, are present in smaller numbers. Therefore, we speculate that our task requires less computation compared to the other crowd-counting models, and removing a layer from MCNN may not significantly affect the model’s performance, but potentially result in faster and more efficient crowd-counting.
- Minimizing the Input Size (Patch-based Operation). To enable on-MCU inference, it is necessary to reduce not only the model size but also the input image resolution. Thus, we propose dividing the image into smaller patches and feeding them to MiCrowdNet one by one; both training and inference are based on a patch rather than an entire image. In our case, the resolution of an original image is 640 × 480, and it is split into non-overlapping 80 patches where each patch is 64 × 64 in resolution. Although complex patch-based techniques can improve accuracy [27], we adopted a simple slicing technique that could run on the MCU.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Number of Params. | Model Size | MAE |
|---|---|---|---|
| P2PNet [28] | 6.86 M | 82.4 MB | 1.00 |
| CSRNet [13] | 16.26 M | 65.1 MB | 1.14 |
| MCNN [12] | 0.13 M | 543 kB | 1.57 |
| MiCrowdNet (float) | 0.07 M | 309 kB | 1.08 |
| MiCrowdNet (quantized) | 0.07 M | 137 kB | 1.12 |
3.4. Testbed for On-MCU Inference
4. Evaluation
- Comparison with Baselines. To compare MiCrowdNet with existing crowd-counting models, we selected baselines for our experiment: CSRNet [13], P2PNet [28], and MCNN [12], all trained on PRW for 64 × 64 patch-based inference. Table 1 shows the results in terms of the number of parameters, model size, and MAE.
- Impact of Quantization. Given that our target application scenario involves MCUs, it is critical to consider the limited resources of these devices. As most MCUs lack floating point units, floating point operations are typically emulated, which creates a significant processing burden. To address this issue, we applied quantization to the model, which reduces the precision of the model’s weights and activations.
- Impact of Patch Sizes. Table 3 shows the impact of patch sizes on the MiCrowdNet performance. Using the whole 640 × 480 image requires ∼10 MB in memory, far exceeding the memory constraint of ESP32-S3. It verifies that patch-based inference is essential to run MiCrowdNet on MCU. In addition, Table 3 shows that the larger the input size, the slower the inference for each patch and the larger the peak memory. On the other hand, input sizes that are too small could lead to severe performance degradation. Considering the trade-off, we chose a patch size of for MiCrowdNet as in Section 3.3.
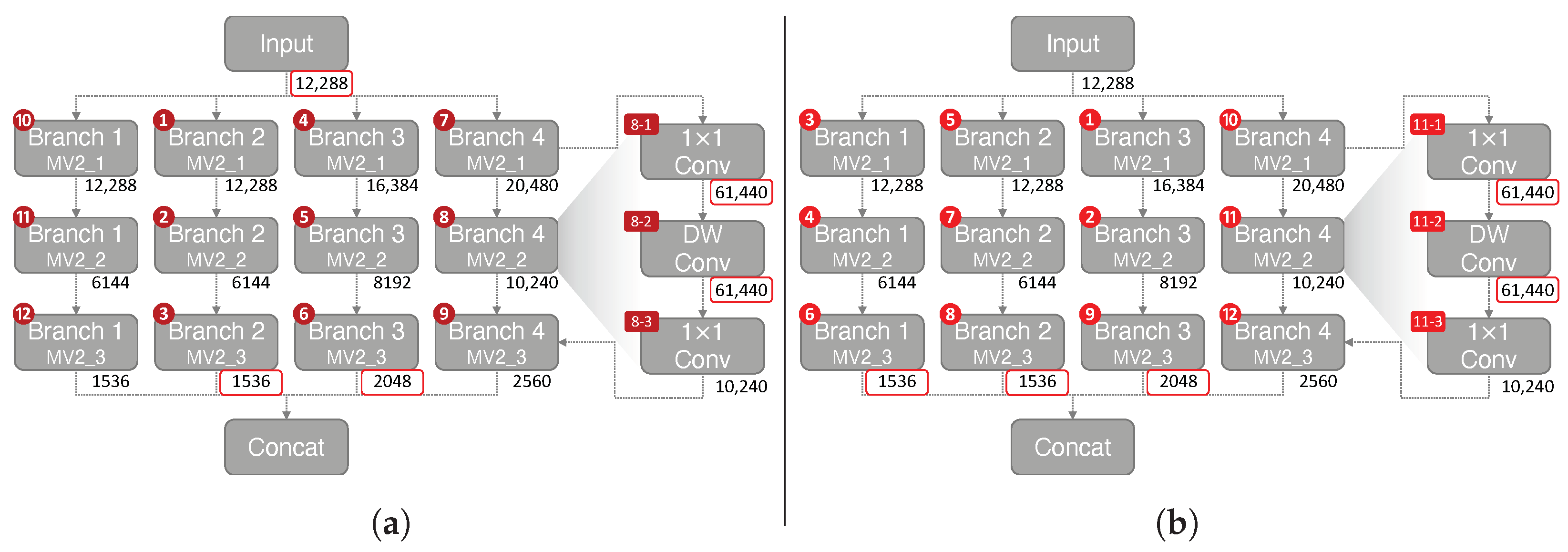
- Impact of Reordering Operations. When performing convolutional operations, the MCU needs to allocate memory space for the input and output tensor to perform calculations. Furthermore, when a tensor is reused for future operation, the tensor must be stored in memory to perform calculations. The tensor can be removed only after no future operation exists using the tensor. Figure 10a shows the order of operations when using MiCrowdNet on TensorFlow Lite. The peak memory occurs when performing the DW Conv on Branch 4 MV2_2 block (operation 8-2 in Figure 10a. This is due to the greater output channel (40) compared to other blocks. The tensors stored during peak memory for TFLite default ordering (Figure 10a) are the input tensor, Branch 2 MV2_3, Branch 3 MV2_3, 1 × 1 Conv (operation 8-1), and DW Conv (operation 8-2). The sum of these tensors equals 135.5 kB.
- Impact of Camera Viewpoints. Next, we evaluate the importance of a dataset that reflects the E-scooter view. We used ShanghaiTech [12], a popular dataset for crowd counting (high-place view), and CSRNet [13], a heavy DNN for crowd counting. For ShanghaiTech, we used 400 images for training and 316 images for testing, as in [12]. Since we focus only on accuracy in this experiment, the models were trained and tested on full-resolution images.
5. Discussion and Future Work
- Optimal Camera Placement. As our focus is to measure the floating population with a single camera attached to a scooter, proper camera placement is important to cover a population of interest. Note that the effectiveness of camera placement largely depends on the lens used. In this study, the OV2640 camera was considered, which has a coverage range between 68 to 160.
- More Realistic Dataset. We assume that the PRW dataset is similar to real-world data in terms of the number of people, angles, and sizes of the heads. Nevertheless, real-world data might have differences from the PRW dataset. For example, the PRW dataset covers limited weather and time conditions. In future work, we will collect our own real-world dataset to reflect more diverse outdoor conditions using E-scooters with low-cost IoT cameras and MCUs.
- Multi-scooter Collaboration. It has become increasingly common for E-scooters to be parked in designated areas to avoid disturbing pedestrians. If the people counts from E-scooters in the same location are similar, running MiCrowdNet on all of these E-scooters may be redundant. Investigating this hypothesis could be an interesting area for future research. If it is true, E-scooters can be clustered using GPS information and only a representative of the cluster can run MiCrowdNet to reduce communication costs and save the battery‘s lifetime. The cluster leader might also offload some patches to the cluster members to run MiCrowdNet in parallel. Otherwise, if neighboring E-scooters report different people counts, several cluster members that have different camera angles can be selected to improve accuracy.
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- MCU Market, Microcontroller Market Size, Share, Growth, Forecast 2030. Available online: https://www.precedenceresearch.com/microcontroller-mcu-market (accessed on 21 February 2023).
- Microcontroller Market Size: Industry Report, 2022–2030. Available online: https://www.grandviewresearch.com/industry-analysis/microcontroller-market (accessed on 21 February 2023).
- Choi, Y.; Seo, A.; Kim, H.S. ScriptPainter: Vision-based, On-device Test Script Generation for Mobile Systems. In Proceedings of the 2022 21st ACM/IEEE International Conference on Information Processing in Sensor Networks (IPSN), Milano, Italy, 4–6 May 2022; IEEE: New York, NY, USA, 2022; pp. 477–490. [Google Scholar]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Ricciato, F.; Widhalm, P.; Craglia, M.; Pantisano, F. Estimating Population Density Distribution from Network-Based Mobile Phone Data; Publications Office of the European Union: Luxembourg, 2015.
- Fact.MR. E-Scooter Sharing Market, 2022. Available online: https://www.factmr.com/report/e-scooter-sharing-market (accessed on 21 February 2023).
- Schellong, D.; Sadek, P.; Schaetzberger, C.; Barrack, T. The promise and pitfalls of e-scooter sharing. Europe 2019, 12, 15. [Google Scholar]
- Zheng, L.; Zhang, H.; Sun, S.; Chandraker, M.; Yang, Y.; Tian, Q. Person Re-identification in the Wild. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 3346–3355. [Google Scholar] [CrossRef] [Green Version]
- Chan, A.B.; Liang, Z.S.J.; Vasconcelos, N. Privacy preserving crowd monitoring: Counting people without people models or tracking. In Proceedings of the 2008 IEEE Conference on Computer Vision and Pattern Recognition, Anchorage, AK, USA, 23–28 June 2008; pp. 1–7. [Google Scholar] [CrossRef] [Green Version]
- Idrees, H.; Tayyab, M.; Athrey, K.; Zhang, D.; Al-Maadeed, S.; Rajpoot, N.; Shah, M. Composition Loss for Counting, Density Map Estimation and Localization in Dense Crowds. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar]
- Idrees, H.; Saleemi, I.; Seibert, C.; Shah, M. Multi-source Multi-scale Counting in Extremely Dense Crowd Images. In Proceedings of the 2013 IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 2547–2554. [Google Scholar] [CrossRef] [Green Version]
- Zhang, Y.; Zhou, D.; Chen, S.; Gao, S.; Ma, Y. Single-Image Crowd Counting via Multi-Column Convolutional Neural Network. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 589–597. [Google Scholar] [CrossRef]
- Li, Y.; Zhang, X.; Chen, D. CSRNet: Dilated Convolutional Neural Networks for Understanding the Highly Congested Scenes. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Los Alamitos, CA, USA, 18–23 June 2018; pp. 1091–1100. [Google Scholar]
- Cao, X.; Wang, Z.; Zhao, Y.; Su, F. Scale Aggregation Network for Accurate and Efficient Crowd Counting. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar]
- Zhu, L.; Zhao, Z.; Lu, C.; Lin, Y.; Peng, Y.; Yao, T. Dual path multi-scale fusion networks with attention for crowd counting. arXiv 2019, arXiv:1902.01115. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2015, arXiv:1409.1556. [Google Scholar]
- Raykov, Y.P.; Ozer, E.; Dasika, G.; Boukouvalas, A.; Little, M.A. Predicting Room Occupancy with a Single Passive Infrared (PIR) Sensor through Behavior Extraction. In Proceedings of the 2016 ACM International Joint Conference on Pervasive and Ubiquitous Computing; Association for Computing Machinery, UbiComp ’16, New York, NY, USA, 12–16 September 2016; pp. 1016–1027. [Google Scholar] [CrossRef] [Green Version]
- Tsou, P.R.; Wu, C.E.; Chen, Y.R.; Ho, Y.T.; Chang, J.K.; Tsai, H.P. Counting people by using convolutional neural network and a PIR array. In Proceedings of the 2020 21st IEEE International Conference on Mobile Data Management (MDM), Versailles, France, 30 June–3 July 2020; IEEE: New York, NY, USA, 2020; pp. 342–347. [Google Scholar]
- Yang, T.; Guo, P.; Liu, W.; Liu, X.; Hao, T. A Deep-learning-based Method for PIR-based Multi-person Localization. arXiv 2020, arXiv:2004.04329. [Google Scholar]
- Rubio-Aparicio, J.; Santa, J. Embedded Crowdsensing Unit for Mobile Urban Pollution Monitoring. IEEE Commun. Mag. 2023, 61, 1–7. [Google Scholar] [CrossRef]
- Wozinski, S.; He, L.; Shin, K.G. Protecting Electric Scooters from Thefts Using Batteries. In Proceedings of the 20th Annual International Conference on Mobile Systems, Applications and Services; Association for Computing Machinery, MobiSys ’22, New York, NY, USA, 27 June–1 July 2022; pp. 595–596. [Google Scholar] [CrossRef]
- Chi, C.; Zhang, S.; Xing, J.; Lei, Z.; Li, S.Z.; Zou, X. Relational Learning for Joint Head and Human Detection. Proc. AAAI Conf. Artif. Intell. 2020, 34, 10647–10654. [Google Scholar] [CrossRef]
- Gao, G.; Gao, J.; Liu, Q.; Wang, Q.; Wang, Y. Cnn-based density estimation and crowd counting: A survey. arXiv 2020, arXiv:2003.12783. [Google Scholar]
- Oghaz, M.M.; Khadka, A.R.; Argyriou, V.; Remagnino, P. Content-aware density map for crowd counting and density estimation. arXiv 2019, arXiv:1906.07258. [Google Scholar]
- Sandler, M.; Howard, A.G.; Zhu, M.; Zhmoginov, A.; Chen, L. Inverted Residuals and Linear Bottlenecks: Mobile Networks for Classification, Detection and Segmentation. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 4510–4520. [Google Scholar]
- Available online: https://www.tensorflow.org/lite (accessed on 21 February 2023).
- Babu Sam, D.; Surya, S.; Venkatesh Babu, R. Switching convolutional neural network for crowd counting. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 5744–5752. [Google Scholar]
- Song, Q.; Wang, C.; Jiang, Z.; Wang, Y.; Tai, Y.; Wang, C.; Li, J.; Huang, F.; Wu, Y. Rethinking Counting and Localization in Crowds:A Purely Point-Based Framework. arXiv 2021, arXiv:2107.12746. [Google Scholar] [CrossRef]
- Krishnamoorthi, R. Quantizing deep convolutional networks for efficient inference: A whitepaper. arXiv 2018, arXiv:1806.08342. [Google Scholar]
- Liberis, E.; Lane, N.D. Neural networks on microcontrollers: Saving memory at inference via operator reordering. arXiv 2019, arXiv:1910.05110. [Google Scholar] [CrossRef]










| CPU Xeon Gold 5120 | GPU Nvidia V100 | MCU ESP32-S3 | |
|---|---|---|---|
| MiCrowdNet (float) | 0.26 s | 0.035 s | 12.6 s |
| MiCrowdNet (quantized) | 0.13 s | - | 5.7 s |
| Patch Size (Pixels) | Number of Patchs | Peak Mem. (kB) | Inference Time (s/patch) | MAE |
|---|---|---|---|---|
| 32 × 32 | 300 | 31.25 | 1.3 | 1.28 |
| 64 × 64 | 80 | 125 | 5.7 | 1.12 |
| 128 × 128 | 20 | 500 | (OOM) | 1.04 |
| 640 × 480 (Whole image) | 1 | 9375 | (OOM) | 1.03 |
| Model | Train Dataset | Test on PRW | Test on Shanghai B |
|---|---|---|---|
| CSRNet | Shanghai B | 99.86 | 10.67 |
| CSRNet | PRW | 0.96 | 101.49 |
| CSRNet | Shanghai B + PRW | 0.95 | 65.05 |
| MiCrowdNet | Shanghai B | 113.24 | 18.92 |
| MiCrowdNet | PRW | 1.03 | 103.33 |
| MiCrowdNet | Shanghai B + PRW | 1.02 | 84.98 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Son, S.; Seo, A.; Eo, G.; Gill, K.; Gong, T.; Kim, H.-S. MiCrowd: Vision-Based Deep Crowd Counting on MCU. Sensors 2023, 23, 3586. https://doi.org/10.3390/s23073586
Son S, Seo A, Eo G, Gill K, Gong T, Kim H-S. MiCrowd: Vision-Based Deep Crowd Counting on MCU. Sensors. 2023; 23(7):3586. https://doi.org/10.3390/s23073586
Chicago/Turabian StyleSon, Sungwook, Ahreum Seo, Gyeongseon Eo, Kwangyeon Gill, Taesik Gong, and Hyung-Sin Kim. 2023. "MiCrowd: Vision-Based Deep Crowd Counting on MCU" Sensors 23, no. 7: 3586. https://doi.org/10.3390/s23073586