1. Introduction
With the rapid development of mobile internet technology and the advancement of technology, smartphones are becoming increasingly indispensable in people’s daily lives. Many sensors equipped on smartphones are mainly used to process and record information. This data information can be used to effectively monitor people’s daily behavior and identify people’s transportation modes [
1,
2,
3,
4].
Transportation mode recognition is a judgment of the current transportation mode of the user, which is a considerable branch of people’s activity recognition. Daily transportation modes include: stationary, walking, running, bicycle, bus, car, train and subway. Users often use different means of transportation during travel and have different travel needs. These requirements require intelligent mobile terminals to determine in advance the transportation modes within the user’s location. Transportation mode recognition is a fundamental problem that plays a crucial role in several fields. Transportation mode detection can help individuals avoid congested routes and have a comfortable transportation experience. It is also beneficial for transportation planning and management departments to carry out urban road planning and vehicle scheduling and solve the problem of transportation congestion. Furthermore, it can also quickly arrange the most suitable driving plan for ambulances.
To date, researchers have proposed machine learning algorithms to solve transportation mode recognition problems, such as decision tree (DT) [
5], random forest (RF) [
6,
7,
8], support vector machine (SVM) [
9], etc. Nick et al. [
10] used a plain Bayesian classifier and a support vector machine to preprocess the sensor data and extract features manually for transportation mode recognition. Hemminki et al. [
11] preprocessed the collected dataset and gravity estimation, manually performed feature extraction and finally placed the extracted features in a classifier to identify the transportation mode. Ashqar et al. [
6] use a two-layer framework that employs machine learning techniques, including a k-nearest neighbor, classification and regression tree, support vector machine and random forest. The framework combines the newly extracted features with traditional time-domain features to form a feature pool, improving classification accuracy. These traditional machine learning algorithms have certain drawbacks, i.e., they require specialized domain knowledge to extract features manually, which can affect the accuracy of classification on the one hand, and on the other hand, they can cause a large workload due to the difficult feature design.
Deep learning algorithms can effectively solve the above problems, i.e., they can autonomously learn the intrinsic laws and potential features of data, improve efficiency and enhance recognition accuracy. As a result, researchers started to shift from traditional machine learning algorithms to deep learning algorithms [
12,
13,
14], such as convolutional neural network (CNN) [
15,
16,
17], recurrent neural network (RNN) [
18,
19], long short-term memory network (LSTM) [
20,
21], etc. Liu et al. [
22] proposed an end-to-end bi-directional LSTM-based classification framework to classify users’ trajectories into different modes of transportation. Qin et al. [
23] first used convolutional neural networks to learn features and then used LSTM to further extract features from the CNN output. Features are further extracted using LSTM, which ultimately leads to an improved accuracy of transportation mode recognition. Sharma et al. [
24] used deep learning networks, recurrent neural networks and convolutional neural networks to learn time-related mode information, which performed well on the validation dataset. Gong et al. [
25] proposed a convolutional neural network-based approach to identify subways, trains and buses with high accuracy and showed good robustness.
However, these deep learning algorithms still have some shortcomings: recurrent neural network computation does not support parallelism and has high training overhead. The convolutional neural network can only extract short-time local features due to perceptual wilderness. In addition, the existing methods do not assign reasonable weights to the extracted potential features, and the algorithms only show good recognition effects on a single small-scale dataset with insufficient generalization ability.
This paper proposes a novel transportation mode recognition algorithm consisting a multi-head attention (MHA) mechanism, temporal convolutional network (TCN) and convolutional neural network (CNN), with the following main contributions:
We leverage the temporal convolutional networks to the transportation feature learning on individual sensor data. The temporal convolutional network uses inflated convolution to increase the perceptual field of view and learn the long-time dependent features of the sensor data. Simultaneously, it is trained with parallel computation and short-time overhead.
We adopt the multi-headed attention mechanisms to extract multiple spatial features. Compared with single-headed attention, the multi-headed attention model assigns more moderate weights to the features and highlights the vital feature information. It has high identification accuracy for similar modes of transportation, such as trains and subways.
Our proposed algorithm was validated on SHL [
26] and HTC [
27] datasets and compared with machine learning algorithms (DT, RF, SVM) and deep learning algorithms (LSTM, CNN, CNN + LSTM, MSRLSTM). The experimental results show that the TCMH model significantly improves the accuracy, precision, recall and F1-score classification metrics compared with the above algorithms.
The rest of this paper is organized as follows:
Section 2 introduces the overall architecture of the TCMH model and explains the basic principle of the algorithm.
Section 3 describes two datasets and evaluation metrics and shows the experimental results of the TCMH model. Finally,
Section 4 summarizes the work of this paper.
2. Algorithm
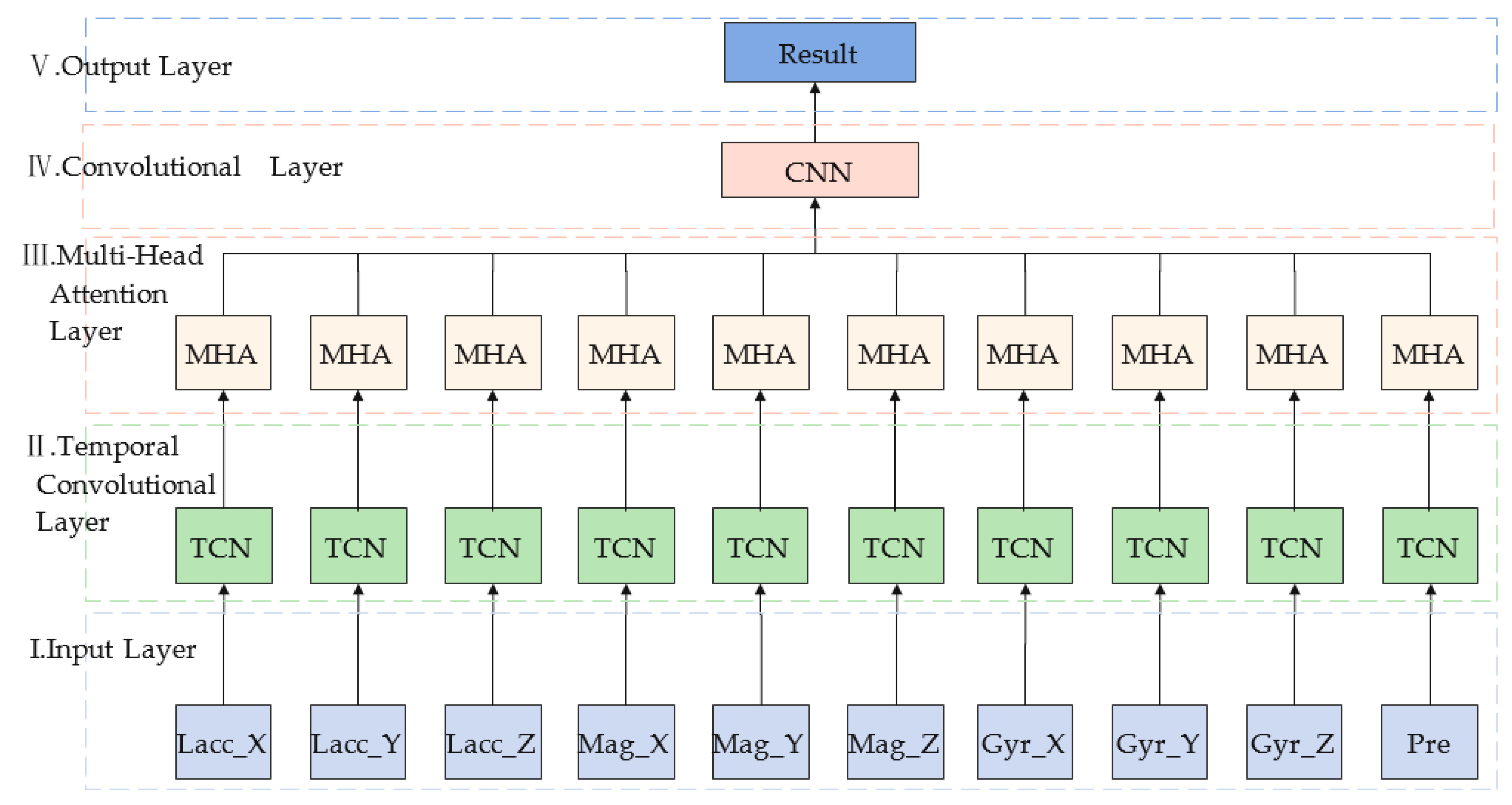
This paper proposes a TCMH model for transportation mode recognition. The model mainly consists an input layer, a temporal convolutional network layer, a multi-headed attention layer, a convolutional neural network layer and an output layer, and the overall architecture is shown in
Figure 1 as follows:
Input layer: Multiple sensor data are input to the input layer after normalization and its output is used as the input of the temporal convolutional neural network.
Temporal convolutional layer (TCN): A network structure is superior to recurrent neural networks and convolutional neural networks, consisting causal convolution, expansion convolution and residual connectivity.
Multi-head attention layer (MHA): The output of the TCN is used as the input of this module. The features acquired by each head are fused so that the final developed features can represent global dependencies.
Convolutional layer (CNN): this network consists a convolutional layer with a convolutional kernel size of 64, a maximum pooling layer and a global average pooling layer.
Output layer: it consists a fully connected layer with neurons of eight and a Softmax activation function. The maximum subscript of neurons is used as the final output of transportation mode classification, i.e., eight transportation mode classification results.
2.1. Input Layer
The sensor data collected by smartphones changes with time and is a typical time series data. Ten sets of data, linear acceleration sensors X, Y and Z axes, gyroscope sensors X, Y and Z axes, geomagnetic sensors X, Y and Z axes and barometric sensors are selected and processed through the input layer to obtain 10 tensors of size. Where B is the number of samples selected for each training, which is set to 32. 500, and is generated using a non-overlapping sliding window segment with a sampling frequency of 100 Hz at 5 s. One refers to the specific features used for transportation mode recognition, such as linear acceleration X-axis data features.
2.2. Temporal Convolutional Layer
A recurrent neural network (RNN) is the preferred neural network in processing time series data, which can reflect the relationship between the current moment and the previous moment information and has certain short-term memory capabilities. As variants of recurrent neural networks (long short-term memory networks (LSTM) and gated recurrent neural networks (GRU)), they can solve the problems of gradient explosion and small memory capacity of recurrent neural networks. However, it also has the disadvantage of processing data serially and having high computational overhead.
Temporal convolutional neural networks can effectively solve the above problems. Firstly, the TCN can easily obtain stable gradients, which can avoid the gradient explosion problem to a certain extent. Secondly, it can extract time-dependent features and increase memory capacity by increasing the perceptual field size. Furthermore, it can perform large-scale parallel computation, accelerate the computation speed and improve the computation efficiency.
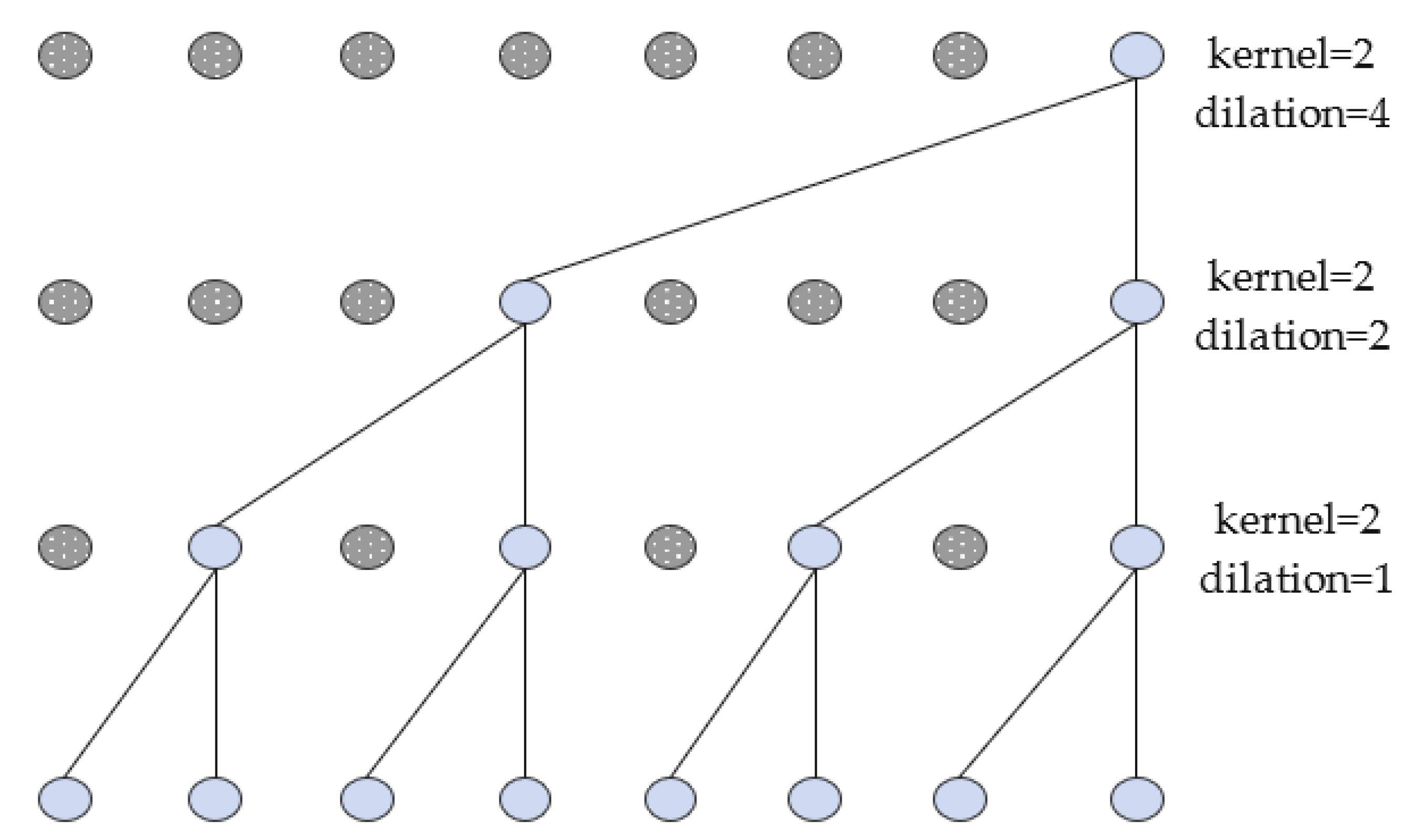
Temporal convolutional neural networks include the following concepts: causal convolution, expansion convolution and residual connection. Causal convolution only utilizes the sensor time series data before that moment and does not focus on the data information after that moment. Thus, it can solve the information leakage problem of relying on future data at that moment. Since causal convolution can only focus on the sensor time data of the preceding shorter moments, if we want to obtain information features on long-time scales, we need to add expansion convolution. Expansion convolution obtains more feature information by injecting voids into the convolution. The dilation convolution has a hyperparameter dilation, which refers to the number of intervals performed during sampling. The hyperparameter
indicates that the sample is required for each data point.
suggests that the sample is performed every two data points, and so on. The causal expansion convolutional structure is shown in
Figure 2. Adding residual connections in TCN can avoid the loss of transportation mode features due to the deepening of network layers, thus ensuring that the transportation mode recognition accuracy does not drop significantly.
The number of filters used in this paper is 32. Therefore, a data tensor with the input of can obtain a feature tensor of size after the temporal convolutional neural network and maximum pooling. At the same time, the internal features of the eight transportation modes with long-time dependencies are fully explored to improve the training efficiency when the sensor input data are used.
2.3. Multi-Head Attention Layer
In recent years, the attention mechanism has been widely used [
28,
29,
30] and has become one of the research hotspots in deep learning. It uses weight size to measure different feature information when processing data information, providing a larger weight to important features and a smaller weight to relatively unimportant features. It improves the efficiency of feature learning and can dig out more valuable implicit information from the massive data. However, the ordinary attention mechanism only extracts the sensor data feature dependencies from one dimension, which can only learn the feature information with limitations. In view of this, the multi-headed attention mechanism is introduced to solve this problem.
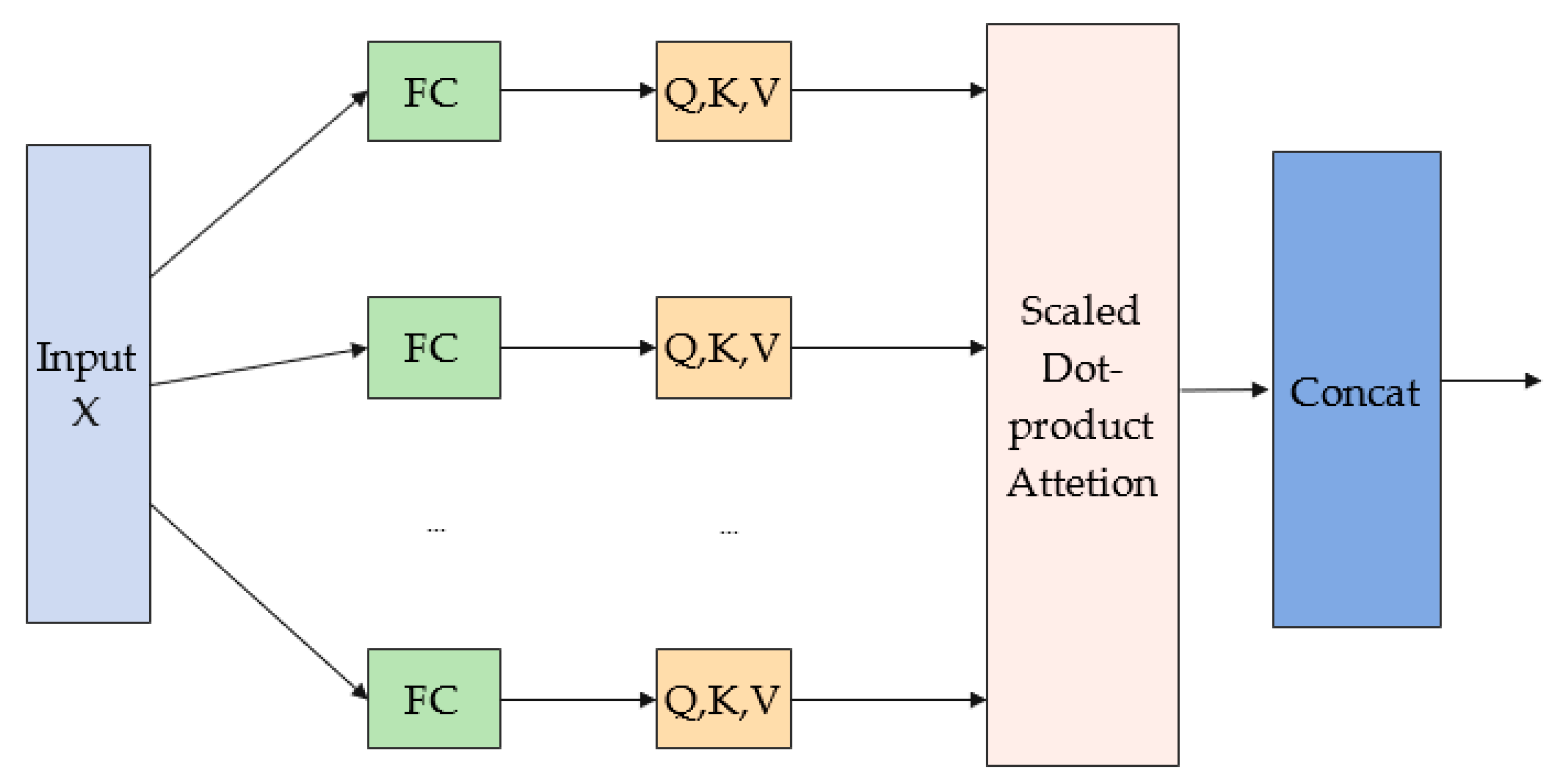
The multi-headed attention mechanism first maps the input into b different subspaces through a fully connected layer (FC). Each subspace contains a query matrix
, key matrix
and value matrix
, where
. Then, the attention calculation is performed in parallel in the b subspaces using the scaled dot-product attention function, and the attention calculation formula is shown in Equation (1).
where
denotes the attention value of the
jth space and
represents the dimension of the key.
Finally, the obtained attention values are stitched together and the output can be obtained after the matrix
.
where
is the matrix of learnable parameters.
The schematic diagram of the multi-headed attention structure is shown in
Figure 3. According to the above principle, the output result x of TCN is passed through the multi-head attention module to make the final extracted data feature information more comprehensive, which is helpful in improving the accuracy of transportation mode recognition. The input and output of this layer are all feature tensors of size
.
2.4. Convolutional Layer
The convolutional neural network is a feed−forward neural network proposed by researchers inspired by the concept of perceptual wilderness. The convolutional neural network is good at mining local features in a small range and extracting characteristic values of targets and has strong applicability. It is used for target recognition and classification in complex and diverse environments [
31,
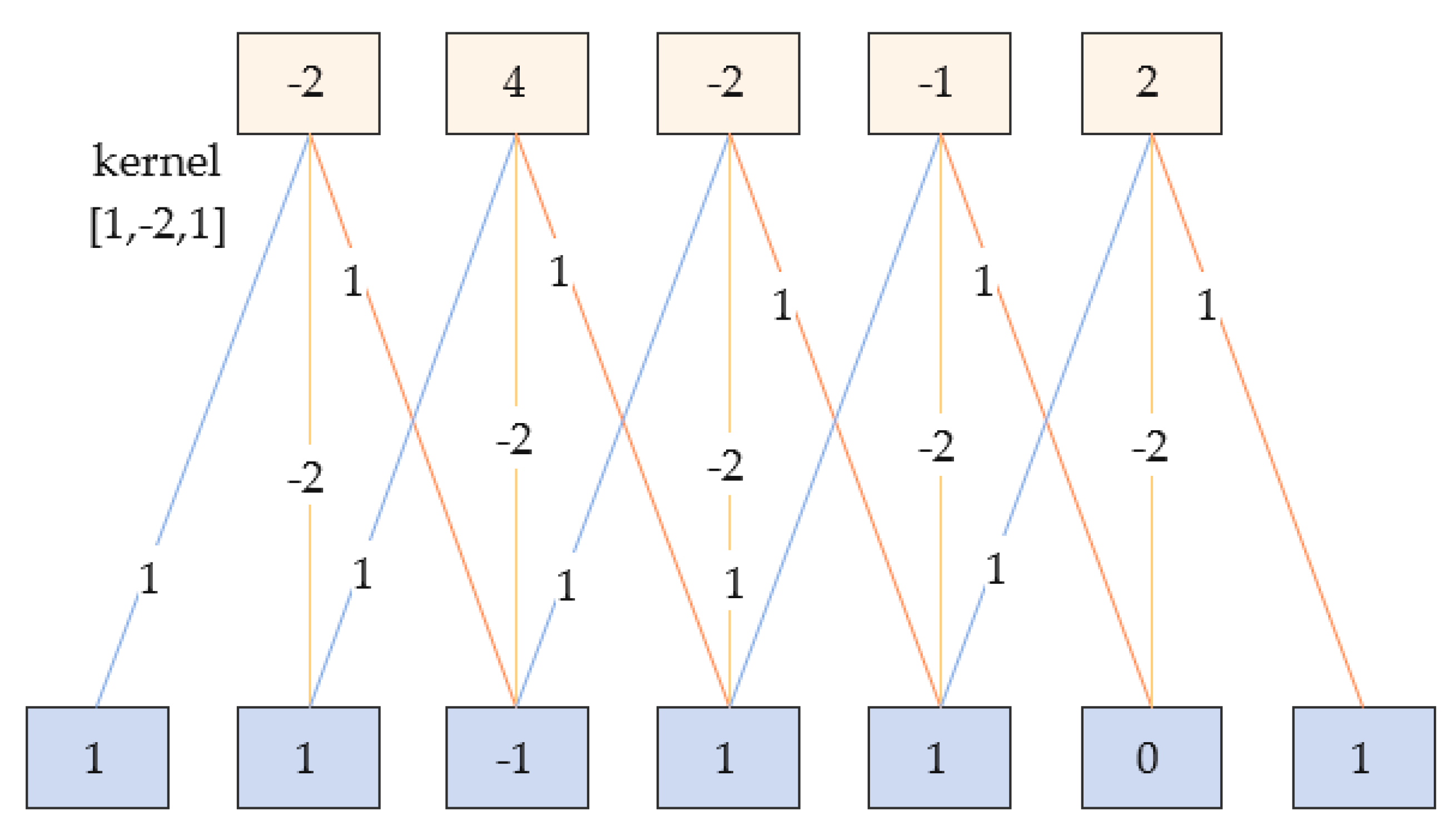
32]. It has three properties: local connection, weight sharing and pooling. Local connection means that the neurons in the nth layer are connected to only some neurons in the (n − 1)th layer, and only local features are extracted. Weight sharing means that the neurons in the previous layer are scanned with a convolution kernel (the values in the convolution kernel are called weights), i.e., the same set of weights is used to convolve the neurons in the previous layer. The 1D convolution example in
Figure 4 exemplifies the two properties of local connection and weight sharing. The role of pooling is to perform feature selection and reduce the number of transportation mode features. Maximum pooling is chosen, which reduces the number of neurons used in the transportation mode recognition network while maintaining the constancy of the local features of the fused data.
In this paper, 10 sensors are first stitched together, and then a convolutional network with a convolutional kernel of 64 is used for local feature extraction. The maximum pooling is used to select beneficial features for improving the accuracy of transport mode recognition. Where , which in turn yields a feature tensor of size . The global average pooling is calculated by averaging the 64 transportation mode data feature maps obtained through the convolutional neural network, which can reduce the dimensionality of the output and prevent overfitting. After averaging pooling, the feature tensor of the maximum pooling output becomes a tensor of .
2.5. Output Layer
Since there are eight transportation mode labels in the dataset, the number of neurons in the last fully connected layer is set to eight; then, the Softmax activation function (the function can compress the data range of each neuron in the range of 0 to 1, and the sum of all data is 1) is used to output the probabilities corresponding to the eight transportation modes. Finally, the position corresponding to the maximum probability is used as the final result of transportation mode classification.
3. Experiments and Analysis
3.1. Datasets
Here, experiments are conducted on two public datasets to evaluate the performance of the TCMH model:
SHL dataset. The dataset was recorded in 2017 by three volunteers who placed a Huawei Mate 9 phone on a part of their body, and it took the volunteers more than 7 months. The SHL dataset contains 272 h of sensor data. The SHL dataset can be used to analyze transportation conditions and estimate satellite coverage, which this paper uses for transportation mode recognition. Eight transportation modes are classified as still, walk, run, bike, car, bus, train and subway. Ten sets of data are selected from the dataset as raw data: three-axis linear acceleration, three-axis gyroscope, three-axis magnetometer and barometric pressure sensor.
HTC dataset. The HTC dataset was collected by more than 100 volunteers using HTC phones in 2012. It contains nine sensor types: acceleration sensors on the X, Y and Z axes, geomagnetic sensors on the X, Y and Z axes and gyroscopic sensors on the X, Y and Z axes. The dataset contains 8311 h of sensor data. Unlike the SHL dataset, the HTC dataset classifies transportation modes into 10 categories. Two transportation categories, motorcycle and high-speed rail, were dropped to maintain consistency between the two datasets.
3.2. Data Preprocessing
Since different sensor timing data have different dimensions, the final recognition effect will be affected if not processed. To eliminate the influence of the magnitude, improve the convergence speed of the model and to increase the recognition accuracy, we use the Z-score normalization method to operate on the data. The data processed by this method conform to the standard normal distribution. The formula of Z-score normalization is as follows:
where
is the mean of the original data used for mode recognition and
is the standard deviation of the original data used for mode recognition in the dataset.
To better evaluate the model effect, the two datasets, SHL and HTC, are divided into training, validation and test sets, respectively, and the allocation ratio is 3:1:1.
3.3. Metrics
To verify the effectiveness of the TCMH model, we use the accuracy rate as the main index to evaluate the model. We use precision, recall and F1-score to assess the recognition effect of eight transportation modes.
Accuracy is used to describe the proportion of correctly predicted samples to all samples, i.e., the proportion of correctly classified transportation mode samples to all samples used for transportation mode classification, as shown in Equation (4):
where
k is the number of classified transportation modes,
N is the total number of all experimental samples and
is the number of samples correctly classified by transportation mode
j.
Precision is relative to the classification prediction results of transportation mode and describes the proportion of samples with correct positive predictions to all samples with positive predictions, as shown in Equation (5):
where
is the number of samples that misclassify other transportation modes as mode
j.
Recall is the proportion of samples correctly predicted as positive to all actual positive samples relative to the transportation mode classification samples, as shown in Equation (6):
where
is the number of samples that misclassify transportation mode
j as other modes.
The F1-score is determined by both precision and recall, as shown in Equation (7):
3.4. Experimental Configuration
We adopt the Keras deep learning framework to train the TCMH model. The Adam optimizer (learning rate is set to 0.001) is selected. For the multi-classification problem, the cross-entropy loss function is selected. The number of training epochs is set to 100, and the batch size is set to 32. The experimental configuration is shown in
Table 1.
3.5. Experimental Comparison of Different Algorithms
The RF, DT, SVM, CNN, LSTM, CNN + LSTM and MSRLSTM [
13] are used as the baseline algorithms to evaluate the performance of our proposed TCMH model. Among these baselines, CNN is a part of the proposed model in this paper, and CNN + LSTM is composed of the above algorithms, CNN and LSTM. Three machine learning algorithms, RF, DT and SVM, are implemented using Sklearn. The detailed parameters of the baseline algorithms are shown in
Table 2.
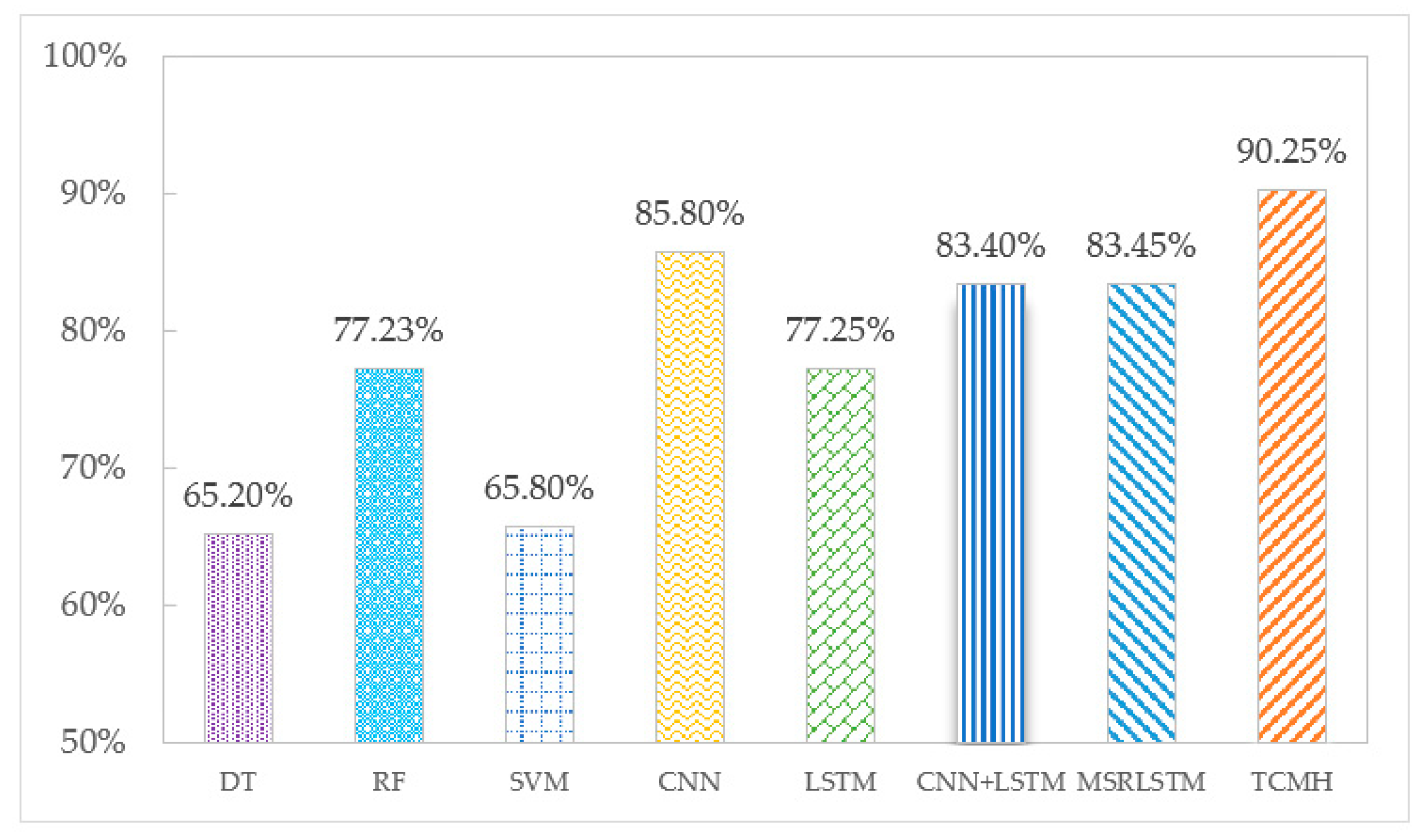
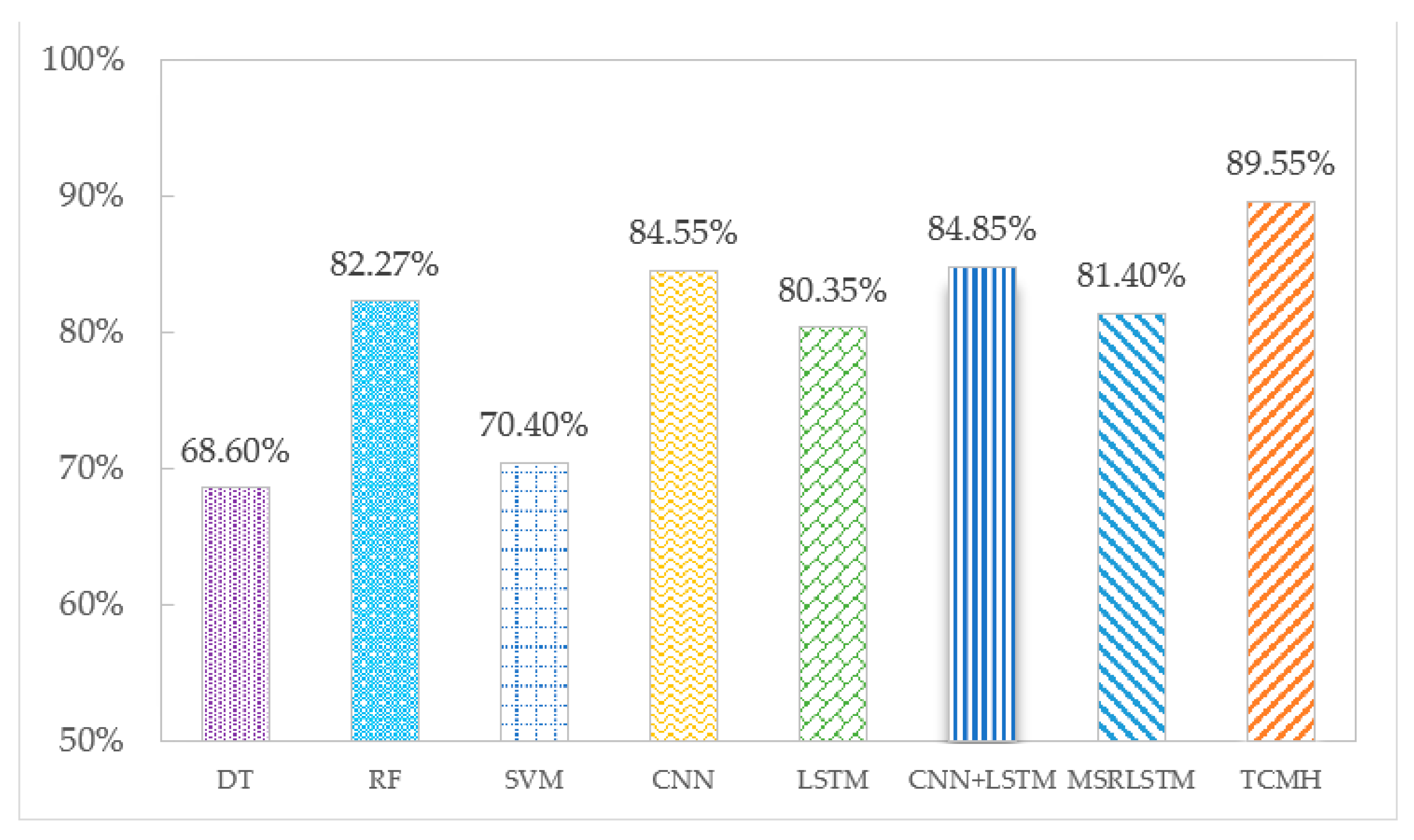
The accuracy of each algorithm on the SHL and HTC datasets is shown in
Figure 5 and
Figure 6. According to the experimental results, the following conclusions can be drawn:
Deep learning algorithms show a higher recognition effectiveness than machine learning algorithms. This is due to the ability of deep learning algorithms to learn deep potential features from the sensor temporal data, which are more helpful for transportation mode classification.
Among the three machine learning algorithms, compared to DT and SVM algorithms, RF reduces the risk of overfitting by building many trees and has the highest recognition accuracy on SHL and HTC datasets, which are 77.23% and 82.27%, respectively.
Among the deep learning algorithms, the TCMH model outperforms other baseline algorithms. This is because the temporal convolutional network included in the TCMH model can capture more transportation mode information without losing information features, and the multi-headed attention mechanism can fuse the features so that the final acquired features have a global view. The accuracy of the TCMH model exceeds the other algorithms on both the SHL dataset and HTC dataset at 90.25% and 89.55%, respectively, while the accuracy of the other algorithms in transportation mode recognition is below 86%.
For each transportation mode recognition case, the precision, recall and F1-score of each baseline algorithm and the TCMH model are shown in
Table 3 and
Table 4.
Table 3 and
Table 4 show that the recognition effect of three transportation modes, bus, train and subway, is poor. Transportation modes’ recognition, such as running and cycling, relies only on short-time data information, while recognition of the same three transportation modes relies on longer-time data information. Each baseline algorithm is limited by the small memory capacity and short-time local features. Therefore, the precision, recall, and F1-score are all low in these three modes, with an average of about 60%. The TCMH model has good recognition results on all three transportation modes, with precision, recall and F1-score higher than 70%, reflecting the advantage of the TCMH model in recognizing transportation modes that depend on long-time information. Meanwhile, the experimental results show that the precision, recall and F1-score are higher for all algorithms when classifying the three transportation modes of walking, running and cycling. The intrinsic reason is that when people perform these three sports, there are large swaying and regular movements of the human body, which have more obvious characteristics. Although each baseline algorithm reflects good classification results on these three transportation modes, the proposed TCMH model in this paper has an advantage over the recognition results of each other baseline algorithm. All three metrics are above 89% on the SHL dataset and above 84% on the HTC dataset. In particular, the transportation mode of running achieves a precision of 100% on the SHL dataset.
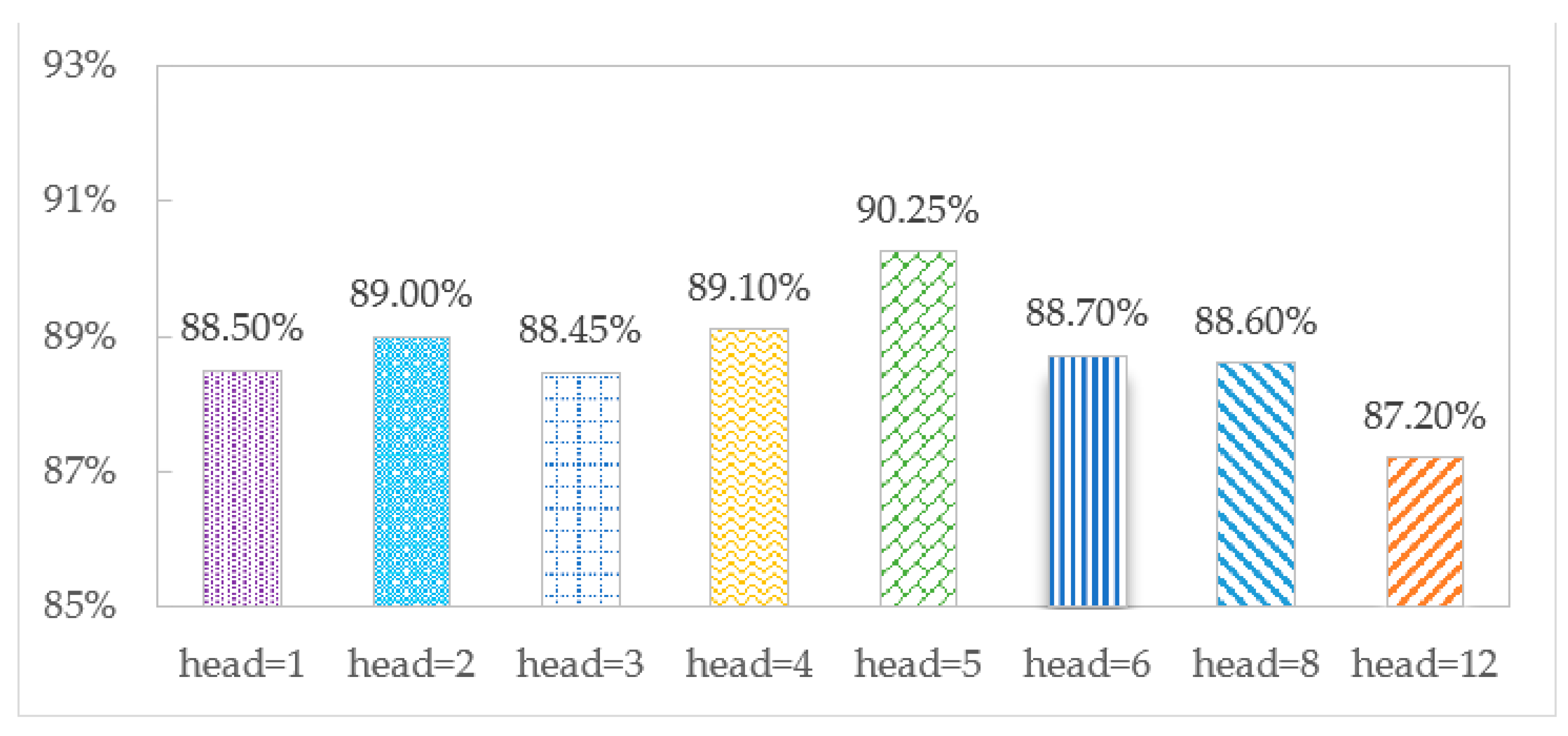
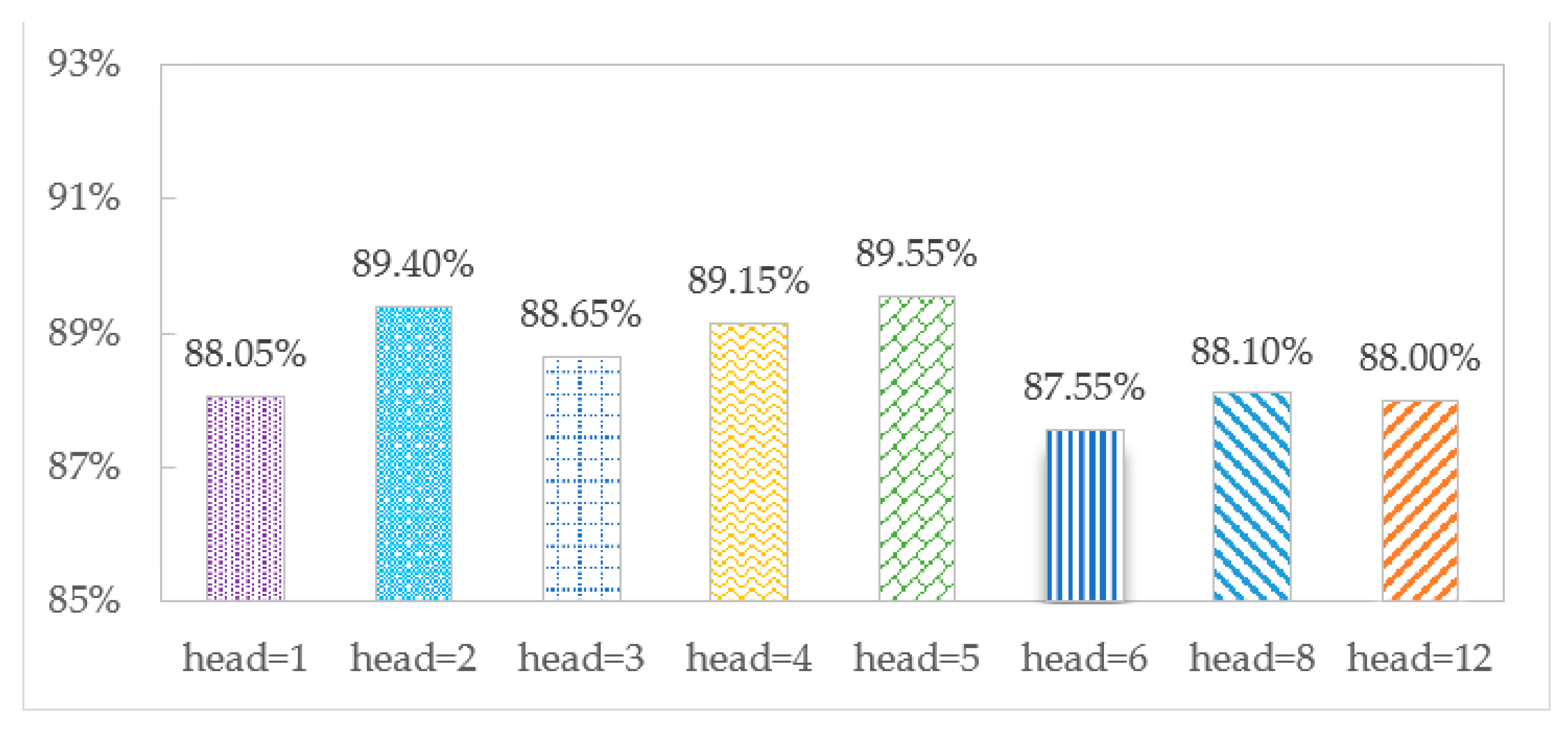
3.6. Effect of the Number of Heads of Multi-Headed Attention Modules
The accuracy of the TCMH model is affected by the number of multi-head attention heads. To explore the optimal number of heads, we set the different numbers to observe the effect of identification on the SHL and HTC datasets, as shown in
Figure 7 and
Figure 8, respectively.
Figure 7 and
Figure 8 show that when head = 5, the accuracy is the largest, 90.25% and 89.55% on the SHL and HTC datasets, respectively. When head = 1, there is only one head in the model, and the accuracies are 88.50% and 88.05%, respectively, which shows the advantage of multi-headed attention over single-headed attention in transportation mode recognition. When head = 12, the model has an overfitting phenomenon, and the accuracy decreases to 87.20% and 88.00%, respectively.
3.7. Self-Contrasting Experiments
To verify the necessity of the temporal convolutional neural network and the multi-headed attention mechanism of the TCMH model, the removal of the temporal neural network and the multi-headed attention mechanism are experimentally compared with the TCMH model, respectively. The precision, recall and F1-score are used as the metrics to measure the model.
Table 5 and
Table 6 show that removing the temporal convolutional network part of the TCMH model leads to a decrease in the precision, recall and F1-score, which reflects the contribution of the temporal convolutional network to the TCMH model. For subway, on the SHL dataset, the difference between the TCMH model and TCMH model when removing the temporal convolutional network part is obvious, with 13.97%, 28.18% and 22.03% difference in precision, recall and F1-score, respectively. On the HTC dataset, the difference in precision, recall, and F1-score is 19.91%, 17.67% and 18.76%, respectively.
Table 6 and
Table 7 show that the TCMH model has lower recognition results than the removal of the multi-headed attention mechanism part. However, three evaluation indexes have been improved from the overall classification results of the eight transportation modes. Especially for still, on the SHL dataset, the precision, recall and F1-score improved by 4.99%, 1.56% and 3.37%, respectively. On the HTC dataset, the precision, recall and F1-score enhanced by 3.30%, 1.99% and 2.68%, respectively.
3.8. Experiment of Hyperparameter Adjustment
The primary hyperparameters in the TCMH model are adjusted: the number of filters and convolutional kernel size in TCN, the dimensional value of keys in multi-headed attention, and the number of filters and convolutional kernel size in CNN.
According to the variable control method, one hyperparameter value is adjusted each time, and the results obtained are shown in
Table 8 and
Table 9. It can be seen that the adjustment of hyperparameters has a certain influence on the recognition precision of transportation modes. In particular, the precision of recognizing trains on the SHL and HTC datasets differed by 11.39% and 8.91%, respectively.
4. Conclusions
This paper proposes a novel transportation mode recognition model, TCMH. By combining TCN and MHA, the accuracy of transportation mode recognition is increased, and the training process is speeded up. The TCMH algorithm is also energy efficient, using only the multiple lightweight sensors integrated in the smartphone to detect transport patterns. The experimental results on two datasets show that the proposed model is significantly better than baseline algorithms such as the RF-, DT-, SVM-, CNN-, LSTM-, CNN + LSTM- and MSRLSTM-based transportation mode algorithms. It also confirms the reasonable scalability of TCMH.
There are some limitations in the TCMH model. The accuracy of recognition can be further improved, and the complexity of the model can be further reduced. In future scientific work, we will continue to research deep learning models with lower computational overhead and higher recognition accuracy, and further improve transportation mode recognition performance in practical application scenarios.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}