
A Model for Cognitive Personalization of Microtask Design
 , , and
, , and 
Abstract
:1. Introduction
- RQ1: How can the administration of cognitive ability tests, specifically in the evaluation of executive functions, be used to allocate crowd workers to microtasks with or without personalization?
- RQ1.1: Is a deep learning model able to allocate crowd workers to microtasks with different characteristics of UI and complexities of the content presented?
- RQ2: Can task fingerprinting, based on the identification of behavioral traces, be used to allocate crowd workers to microtasks with or without personalization?
2. Background
3. Methodology
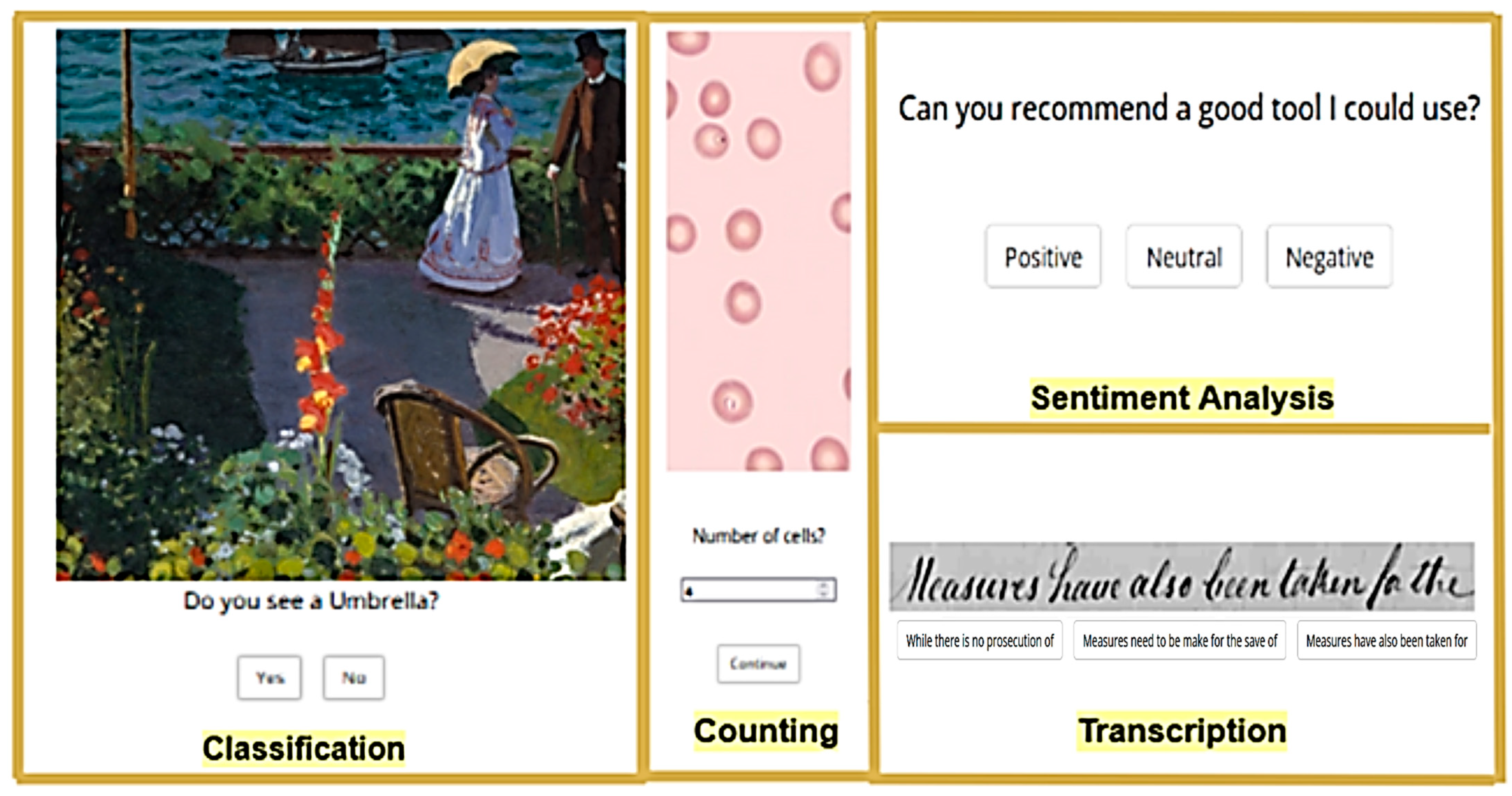
- Personalization of microtasks (with or without personalization). This condition focuses on the personalization of the interface. For this purpose, two interfaces were designed: one without any personalization and implying a normal difficulty, and the other one with personalization, where the content or the input elements were adapted to make it easier to solve each microtask. The elements required to make user interface (UI) adaptations were based on the ontology for cognitive personalization in a crowd work context proposed by Paulino and colleagues [38]. The cognitive knowledge that is represented in the ontology is based on mental functions, as defined by the international classification of functioning, disability and health (ICF), a framework for the classification of health and disability [1]. Furthermore, the ontology includes the concepts of microtasks, cognitive abilities, and types of adaptation, in order to personalize the interface to the crowd worker. To this end, an existing ontology called ACCESIBILITIC [54] was incorporated, which represents knowledge about accessibility and activity-centered design and includes a taxonomy with the classification of cognition-related concepts from the ICF scheme, which supported the personalization of the microtasks used in this case study. The group of microtasks with personalization (presented in Figure 1) was expected to have better microtask accuracy results when compared to the group without personalization (described in [32]).
- Cognitive profile (above or below the median overall score of cognitive abilities tests). The median value can be calculated based on the executive functions assessed using the administration of the cognitive ability tests. This value was used as a threshold for allocating the crowd workers to microtasks with or without personalization.
4. Results
4.1. Cognitive Tests
4.2. Prototypical Microtasks
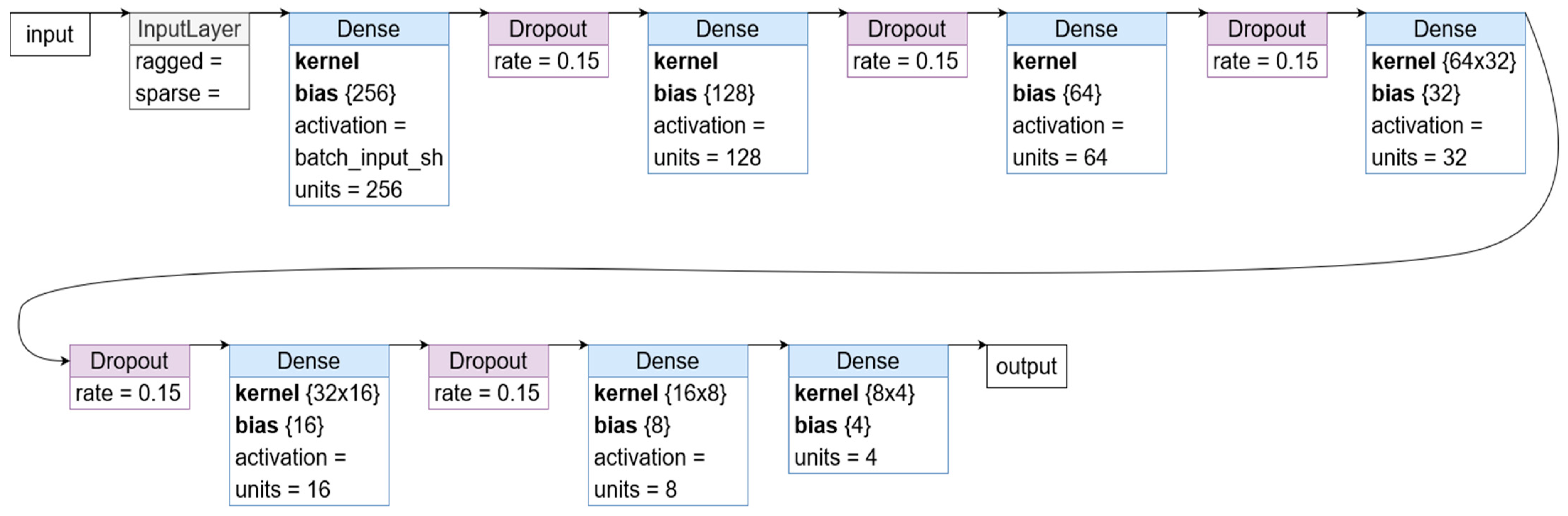
4.3. Prediction Based on Microtask Fingerprinting with a Deep Learning Model
5. Discussion
5.1. RQ1: How Can the Administration of Cognitive Ability Tests, Specifically in the Evaluation of Executive Functions, Be Used to Allocate Crowd Workers to Microtasks with or without Personalization?
5.2. RQ1.1: Is a Deep Learning Model Able to Allocate Crowd Workers to Microtasks with Different Characteristics of UI and Complexities of the Content Presented?
5.3. RQ2: Can Task Fingerprinting, Based on the Identification of Behavioral Traces, Be Used to Allocate Crowd Workers to Microtasks with or without Personalization?
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- World Health Organization. International Classification of Functioning, Disability and Health (ICF); World Health Organization: Geneva, Switzerland, 2001. [Google Scholar]
- Cieza, A.; Fayed, N.; Bickenbach, J.; Prodinger, B. Refinements of the ICF Linking Rules to strengthen their potential for establishing comparability of health information. Disabil. Rehabil. 2019, 41, 574–583. [Google Scholar] [CrossRef] [PubMed]
- Larkins, B. The Application of the ICF in Cognitive-Communication Disorders following Traumatic Brain Injury. Semin. Speech Lang. 2007, 28, 334–342. [Google Scholar] [CrossRef] [PubMed]
- Gauthier, S.; Reisberg, B.; Zaudig, M.; Petersen, R.C.; Ritchie, K.; Broich, K.; Belleville, S.; Brodaty, H.; Bennett, D.; Chertkow, H.; et al. Mild cognitive impairment. Lancet 2006, 367, 1262–1270. [Google Scholar] [CrossRef]
- Wimo, A.; Guerchet, M.; Ali, G.-C.; Wu, Y.-T.; Prina, A.M.; Winblad, B.; Jönsson, L.; Liu, Z.; Prince, M. The worldwide costs of dementia 2015 and comparisons with 2010. Alzheimer’s Dement. 2017, 13, 1–7. [Google Scholar]
- Holthe, T.; Halvorsrud, L.; Karterud, D.; Hoel, K.-A.; Lund, A. Usability and acceptability of technology for community-dwelling older adults with mild cognitive impairment and dementia: A systematic literature review. Clin. Interv. Aging 2018, 13, 863. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Braley, R.; Fritz, R.; Van Son, C.R.; Schmitter-Edgecombe, M. Prompting Technology and Persons With Dementia: The Significance of Context and Communication. Gerontology 2018, 59, 101–111. [Google Scholar] [CrossRef] [PubMed]
- Oliver, M.; Molina, J.P.; Fernandez-Caballero, A.; Gonzalez, P. Collaborative computer-assisted cognitive rehabilitation system. ADCAIJ Adv. Distrib. Comput. Artif. Intell. J. 2017, 6, 57–74. [Google Scholar] [CrossRef] [Green Version]
- Ge, S.; Zhu, Z.; Wu, B.; McConnell, E.S. Technology-based cognitive training and rehabilitation interventions for individuals with mild cognitive impairment: A systematic review. BMC Geriatr. 2018, 18, 213. [Google Scholar] [CrossRef] [Green Version]
- Shraga, R.; Scharf, C.; Ackerman, R.; Gal, A. Incognitomatch: Cognitive-aware matching via crowdsourcing. In Proceedings of the 2020 ACM SIGMOD International Conference on Management of Data, Portland, OR, USA, 14–19 June 2020. [Google Scholar]
- Schmidt, L.I.; Wahl, H.-W. Predictors of Performance in Everyday Technology Tasks in Older Adults With and Without Mild Cognitive Impairment. Gerontology 2018, 59, 90–100. [Google Scholar] [CrossRef]
- Schmidt, F.L.; Hunter, J. General mental ability in the world of work: Occupational attainment and job performance. J. Personal. Soc. Psychol. 2004, 86, 162. [Google Scholar] [CrossRef] [Green Version]
- Peng, P.; Kievit, R.A. The development of academic achievement and cognitive abilities: A bidirectional perspective. Child Dev. Perspect. 2020, 14, 15–20. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Miller, E.; Wallis, J. Executive function and higher-order cognition: Definition and neural substrates. Encycl. Neurosci. 2009, 4, 99–104. [Google Scholar]
- Schmitt, N. Personality and cognitive ability as predictors of effective performance at work. Annu. Rev. Organ. Psychol. Organ. Behav. 2014, 1, 45–65. [Google Scholar] [CrossRef] [Green Version]
- Stanek, K.C.; Ones, D.S. Taxonomies and compendia of cognitive ability and personality constructs and measures relevant to industrial, work and organizational psychology. In Handbook of Industrial, Work & Organizational Psychology: Personnel Psychology and Employee Performance; Ones, D.S., Anderson, N., Viswesvaran, C., Sinangil, H.K., Eds.; Sage Publications: Thousand Oaks, CA, USA, 2018; pp. 366–407. [Google Scholar]
- Herreen, D.; Zajac, I.T. The reliability and validity of a self-report measure of cognitive abilities in older adults: More personality than cognitive function. J. Intell. 2018, 6, 1. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Murtza, M.H.; Gill, S.A.; Aslam, H.D.; Noor, A. Intelligence quotient, job satisfaction, and job performance: The moderating role of personality type. J. Public Aff. 2020, 21, e2318. [Google Scholar] [CrossRef]
- Nguyen, N.N.; Nham, P.T.; Takahashi, Y. Relationship between Ability-Based Emotional Intelligence, Cognitive Intelligence, and Job Performance. Sustainability 2019, 11, 2299. [Google Scholar] [CrossRef] [Green Version]
- Zhang, S.; Grenhart, W.C.M.; McLaughlin, A.C.; Allaire, J.C. Predicting computer proficiency in older adults. Comput. Hum. Behav. 2017, 67, 106–112. [Google Scholar] [CrossRef]
- Hosseini, M.; Shahri, A.; Phalp, K.; Taylor, J.; Ali, R. Crowdsourcing: A taxonomy and systematic mapping study. Comput. Sci. Rev. 2015, 17, 43–69. [Google Scholar] [CrossRef] [Green Version]
- Bhatti, S.S.; Gao, X.; Chen, G. General framework, opportunities and challenges for crowdsourcing techniques: A Comprehensive survey. J. Syst. Softw. 2020, 167, 110611. [Google Scholar] [CrossRef]
- Füller, J.; Bartl, M.; Ernst, H.; Mühlbacher, H. Community based innovation: How to integrate members of virtual communities into new product development. Electron. Commer. Res. 2006, 6, 57–73. [Google Scholar] [CrossRef]
- Zyskowski, K.; Morris, M.R.; Bigham, J.P.; Gray, M.L.; Kane, S.K. Accessible crowdwork? Understanding the value in and challenge of microtask employment for people with disabilities. In Proceedings of the 18th ACM Conference on Computer Supported Cooperative Work & Social Computing, Vancouver, BC, Canada, 14–18 March 2015. [Google Scholar]
- Cheng, J.; Teevan, J.; Iqbal, S.T.; Bernstein, M.S. Break it down: A comparison of macro-and microtasks. In Proceedings of the 33rd Annual ACM Conference on Human Factors in Computing Systems, Seoul, Republic of Korea, 18–23 April 2015. [Google Scholar]
- Rzeszotarski, J.M.; Kittur, A. Instrumenting the crowd: Using implicit behavioral measures to predict task performance. In Proceedings of the 24th Annual ACM Symposium on User Interface Software and Technology, Santa Barbara, CA, USA, 16–19 October 2011. [Google Scholar]
- Han, S.; Dai, P.; Paritosh, P.; Huynh, D. Crowdsourcing Human Annotation on Web Page Structure: Infrastructure Design and Behavior-Based Quality Control. ACM Trans. Intell. Syst. Technol. 2016, 7, 56. [Google Scholar] [CrossRef] [Green Version]
- Zheng, Y.; Wang, J.; Li, G.; Cheng, R.; Feng, J. QASCA: A quality-aware task assignment system for crowdsourcing applications. In Proceedings of the 2015 ACM SIGMOD International Conference on Management of Data, Melbourne, Australia, 31 May–4 June 2015. [Google Scholar]
- Gadiraju, U.; Demartini, G.; Kawase, R.; Dietze, S. Crowd Anatomy Beyond the Good and Bad: Behavioral Traces for Crowd Worker Modeling and Pre-selection. Comput. Support. Coop. Work (CSCW) 2019, 28, 815–841. [Google Scholar] [CrossRef]
- Pei, W.; Yang, Z.; Chen, M.; Yue, C. Quality Control in Crowdsourcing based on Fine-Grained Behavioral Features. Proc. ACM Hum.-Comput. Interact. 2021, 5, 1–28. [Google Scholar] [CrossRef]
- Goncalves, J.; Feldman, M.; Hu, S.; Kostakos, V.; Bernstein, A. Task routing and assignment in crowdsourcing based on cognitive abilities. In Proceedings of the 26th International Conference on World Wide Web Companion, Perth, Australia, 3–7 April 2017. [Google Scholar]
- Hettiachchi, D.; van Berkel, N.; Hosio, S.; Kostakos, V.; Goncalves, J. Effect of Cognitive Abilities on Crowdsourcing Task Performance. In Human-Computer Interaction–INTERACT 2019; Lecture Notes in Computer Science (Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics); Springer: Berlin/Heidelberg, Germany, 2019; pp. 442–464. [Google Scholar]
- Hettiachchi, D.; van Berkel, N.; Kostakos, V.; Goncalves, J. CrowdCog: A Cognitive Skill based System for Heterogeneous Task Assignment and Recommendation in Crowdsourcing. Proc. ACM Hum.-Comput. Interact. 2020, 4, 1–22. [Google Scholar] [CrossRef]
- Paulino, D.; Pinheiro, P.; Rocha, J.; Martins, P.; Rocha, T.; Barroso, J.; Paredes, H. Assessment of wizards for eliciting users’ accessibility preferences. In Proceedings of the 9th International Conference on Software Development and Technologies for Enhancing Accessibility and Fighting Info-Exclusion, Online, 2–4 December 2020. [Google Scholar]
- Eickhoff, C. Cognitive biases in crowdsourcing. In Proceedings of the Eleventh ACM International Conference on Web Search and Data Mining, Marina Del Rey, CA, USA, 5–9 February 2018. [Google Scholar]
- Stewart, A.E.B.; Vrzakova, H.; Sun, C.; Yonehiro, J.; Stone, C.A.; Duran, N.D.; Shute, V.; D’Mello, S.K. I Say, You Say, We Say: Using Spoken Language to Model Socio-Cognitive Processes during Computer-Supported Collaborative Problem Solving. Proc. ACM Hum.-Comput. Interact. 2019, 3, 194. [Google Scholar] [CrossRef] [Green Version]
- Alagarai Sampath, H.; Rajeshuni, R.; Indurkhya, B. Cognitively inspired task design to improve user performance on crowdsourcing platforms. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems, Toronto, ON, Canada, 26 April–1 May 2014. [Google Scholar]
- Paulino, D.; Correia, A.; Reis, A.; Guimarães, D.; Rudenko, R.; Nunes, C.; Silva, T.; Barroso, J.; Paredes, H. Cognitive Personalization in Microtask Design. In Universal Access in Human-Computer Interaction: Novel Design Approaches and Technologies; Springer International Publishing: Cham, Switzerland, 2022. [Google Scholar]
- Paulino, D.; Correia, A.; Guimarães, D.; Barroso, J.; Paredes, H. Uncovering the Potential of Cognitive Personalization for UI Adaptation in Crowd Work. In Proceedings of the 2022 IEEE 25th International Conference on Computer Supported Cooperative Work in Design (CSCWD), Hangzhou, China, 4–6 May 2022. [Google Scholar]
- Rzeszotarski, J.; Kittur, A. CrowdScape: Interactively visualizing user behavior and output. In Proceedings of the 25th annual ACM Symposium on User Interface Software and Technology, Cambridge, MA, USA, 7–10 October 2012; Association for Computing Machinery: New York, NY, USA, 2012; pp. 55–62. [Google Scholar]
- Yuasa, S.; Nakai, T.; Maruichi, T.; Landsmann, M.; Kise, K.; Matsubara, M.; Morishima, A. Towards quality assessment of crowdworker output based on behavioral data. In Proceedings of the 2019 IEEE International Conference on Big Data (Big Data), Los Angeles, CA, USA, 9–12 December 2019. [Google Scholar]
- Goyal, T.; McDonnell, T.; Kutlu, M.; Elsayed, T.; Lease, M. Your behavior signals your reliability: Modeling crowd behavioral traces to ensure quality relevance annotations. In Proceedings of the Sixth AAAI Conference on Human Computation and Crowdsourcing, Zurich, Switzerland, 5–8 July 2018. [Google Scholar]
- Kazai, G.; Zitouni, I. Quality Management in Crowdsourcing using Gold Judges Behavior. In Proceedings of the Ninth ACM International Conference on Web Search and Data Mining, San Francisco, CA, USA, 22–25 February 2016; Association for Computing Machinery: New York, NY, USA, 2016; pp. 267–276. [Google Scholar]
- Paulino, D.; Barroso, J.; Paredes, H. Introducing People with Autism to Inclusive Digital Work using Microtask Fingerprinting. ERCIM News, 5 July 2022. [Google Scholar]
- Difallah, D.E.; Demartini, G.; Cudré-Mauroux, P. Pick-a-crowd: Tell me what you like, and I’ll tell you what to do. In Proceedings of the 22nd International Conference on World Wide Web, Rio de Janeiro, Brazil, 13–17 May 2013; Association for Computing Machinery: New York, NY, USA, 2013; pp. 367–374. [Google Scholar]
- Gadiraju, U.; Kawase, R.; Dietze, S. A taxonomy of microtasks on the web. In Proceedings of the 25th ACM Conference on Hypertext and Social Media, Santiage de Chile, Chile, 1–4 September 2014. [Google Scholar]
- Eriksen, B.A.; Eriksen, C.W. Effects of noise letters upon the identification of a target letter in a nonsearch task. Percept. Psychophys. 1974, 16, 143–149. [Google Scholar] [CrossRef] [Green Version]
- Owen, A.M.; McMillan, K.M.; Laird, A.R.; Bullmore, E. N-back working memory paradigm: A meta-analysis of normative functional neuroimaging studies. Hum. Brain Mapp. 2005, 25, 46–59. [Google Scholar] [CrossRef] [Green Version]
- Petrides, M.; Alivisatos, B.; Evans, A.C.; Meyer, E. Dissociation of human mid-dorsolateral from posterior dorsolateral frontal cortex in memory processing. Proc. Natl. Acad. Sci. USA 1993, 90, 873–877. [Google Scholar] [CrossRef] [Green Version]
- MacLeod, C.M. Half a century of research on the Stroop effect: An integrative review. Psychol. Bull. 1991, 109, 163. [Google Scholar] [CrossRef]
- Monsell, S. Task switching. Trends Cogn. Sci. 2003, 7, 134–140. [Google Scholar] [CrossRef]
- Washington, G. Papers, Series 5: Financial Papers, 1750–1796; Library of Congress: Washington, DC, USA, 1796. [Google Scholar]
- Damerau, F.J. A technique for computer detection and correction of spelling errors. Commun. ACM 1964, 7, 171–176. [Google Scholar] [CrossRef]
- Mariño, B.D.R.; RodríGuez-FóRtiz, M.J.; Torres, M.V.H.; Haddad, H.M. Accessibility and activity-centered design for ICT users: ACCESIBILITIC ontology. IEEE Access 2018, 6, 60655–60665. [Google Scholar] [CrossRef]
- de Leeuw, J.R. jsPsych: A JavaScript library for creating behavioral experiments in a Web browser. Behav. Res. Methods 2015, 47, 1–12. [Google Scholar] [CrossRef] [PubMed]
- Chandler, J.; Shapiro, D. Conducting clinical research using crowdsourced convenience samples. Annu. Rev. Clin. Psychol. 2016, 12, 53–81. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Adjerid, I.; Kelley, K. Big data in psychology: A framework for research advancement. Am. Psychol. 2018, 73, 899. [Google Scholar] [CrossRef] [PubMed]
- Agrawal, M.; Peterson, J.C.; Griffiths, T.L. Scaling up psychology via scientific regret minimization. Proc. Natl. Acad. Sci. USA 2020, 117, 8825–8835. [Google Scholar] [CrossRef] [PubMed]
- Hara, K.; Tanaka, Y. Understanding Crowdsourcing Requesters’ Wage Setting Behaviors. In Proceedings of the CHI Conference on Human Factors in Computing Systems, New Orleans, LA, USA, 29 April–5 May 2022. Extended Abstracts. [Google Scholar]
- Ahmed, M.; Islam, A.N. Deep learning: Hope or hype. Ann. Data Sci. 2020, 7, 427–432. [Google Scholar] [CrossRef]
- Wei, J.; Chu, X.; Sun, X.Y.; Xu, K.; Deng, H.X.; Chen, J.; Wei, Z.; Lei, M. Machine learning in materials science. InfoMat 2019, 1, 338–358. [Google Scholar] [CrossRef] [Green Version]
- Liang, H.; Wang, M.-M.; Wang, J.-J.; Xue, Y. How intrinsic motivation and extrinsic incentives affect task effort in crowdsourcing contests: A mediated moderation model. Comput. Hum. Behav. 2018, 81, 168–176. [Google Scholar] [CrossRef]
- Krzywdzinski, M.; Gerber, C. Between automation and gamification: Forms of labour control on crowdwork platforms. Work Glob. Econ. 2021, 1, 161–184. [Google Scholar] [CrossRef]
- Paulino, D.; Correia, A.; Barroso, J.; Liberato, M.; Paredes, H. Using Expert Crowdsourcing to Annotate Extreme Weather Events. In World Conference on Information Systems and Technologies; Springer: Berlin/Heidelberg, Germany, 2021. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Cognitive Test | Executive Function | Main Finding | Description of the Cognitive Test | Indicated Microtasks | ||
|---|---|---|---|---|---|---|
| Cognitive Flexibility | Inhibition Control | Working Memory | ||||
| Flanker [47] | X | Assesses the ability to override the prepotent answer for incongruent elements. | Composed in trials of images showing five arrows. The congruent version has all arrows in the same direction. The incongruent version has the middle arrow pointing in the opposite direction. | Classification, Counting, Sentiment Analysis | ||
| N-Back [48] | X | Check if the individual can keep up with a sequence of stimuli | Presents a sequence of letters (each one represents a trial) and asks which one matches the three previous trials. | Classification, Counting | ||
| Pointing [49] | X | This test evaluates the ability to memorize a series of recent actions. | Composed of three to twelve squares, the individual must find each square, which may contain a visual reward, without repeating the previously clicked square. | Classification, Counting | ||
| Stroop [50] | X | Identical to the Flanker test, but in this version, it has words and different (or same) colors. | The words are presented with the name of a color. This test is composed of three diverse types of trial: congruent, incongruent, or unrelated. | Classification, Counting, Sentiment Analysis | ||
| Task-Switching [51] | X | Obligates the participant in some trials to change the question, by answering only if in some squares there is a vowel or a number even. | The letters and numbers are presented in four aligned squares. | Transcription | ||
| Research Condition | Flanker | N-Back | Pointing | Stroop | Task-Switching | |||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| A. | D. | C. | K. | A. | D. | C. | K. | A. | D. | C. | K. | A. | D. | C. | K. | A. | D. | C. | K. | |
| W/pers. and < median cognit. | 0.425 ± 0.260 | 1.262 ± 0.548 | 0.606 ± 2.633 | 12.545 ± 10.935 | 0.328 ± 0.180 | 0.968 ± 0.566 | 0.121 ± 0.415 | 9.000 ± 18.655 | 0.216 ± 0.170 | 0.779 ± 0.354 | 135.909 + 52.162 | 9.303 ± 23.115 | 0.855 ± 0.203 | 1.385 ± 0.298 | 0.121 + 0.415 | 7.909 ± 9.586 | 0.409 ± 0.139 | 1.178 ± 0.584 | 0.121 ± 0.415 | 16.455 ± 24.160 |
| W/pers. and ≥ median cognit. | 0.856 ± 0.183 | 0.945 ± 0.467 | 0.000 ± 0.000 | 10.333 ± 17.155 | 0.483 ± 0.180 | 1.172 ± 0.479 | 0.000 ± 0.000 | 7.056 ± 13.630 | 0.567 ± 0.315 | 0.792 ± 0.401 | 92.528 ± 43.663 | 3.417 ± 8.768 | 0.960 ± 0.098 | 1.129 ± 0.291 | 0.028 ± 0.167 | 6.472 ± 7.077 | 0.551 ± 0.176 | 1.584 ± 0.681 | 0.000 ± 0.00 | 12.472 ± 14.306 |
| W/o pers. and < median cognit. | 0.454 ± 0.285 | 1.109 ± 0.453 | 0.313 ± 1.768 | 23.938 ± 45.173 | 0.396 ± 0.201 | 0.686 ± 0.522 | 1.500 ± 6.730 | 13.375 ± 29.160 | 0.258 ± 0.224 | 0.920 ± 1.125 | 126.219 ± 71.174 | 27.031 ± 64.597 | 0.656 ± 0.296 | 1.239 ± 0.551 | 0.063 ± 0.246 | 7.938 ± 8.277 | 0.411 ± 0.128 | 1.024 ± 0.788 | 0.031 ± 0.177 | 14.875 ± 13.102 |
| W/o pers. and ≥ median cognit. | 0.863 ± 0.165 | 0.978 ± 0.389 | 0.000 + 0.000 | 7.455 ± 10.019 | 0.461 ± 0.184 | 1.082 ± 0.466 | 0.182 ± 1.044 | 3.879 ± 5.042 | 0.596 + 0.261 | 0.745 ± 0.370 | 85.970 ± 34.023 | 9.000 ± 27.393 | 0.955 ± 0.068 | 1.178 ± 0.237 | 0.000 ± 0.000 | 6.182 ± 6.182 | 0.515 ± 0.187 | 1.560 ± 0.687 | 0.030 ± 0.174 | 8.727 ± 11.181 |
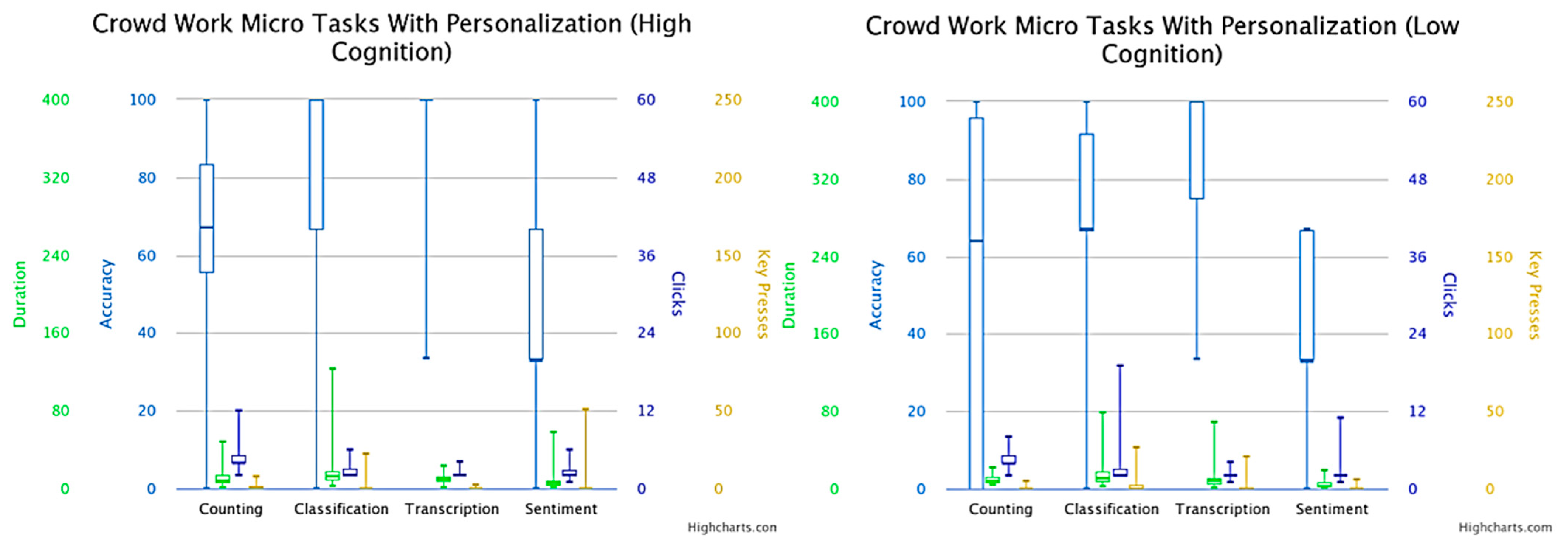
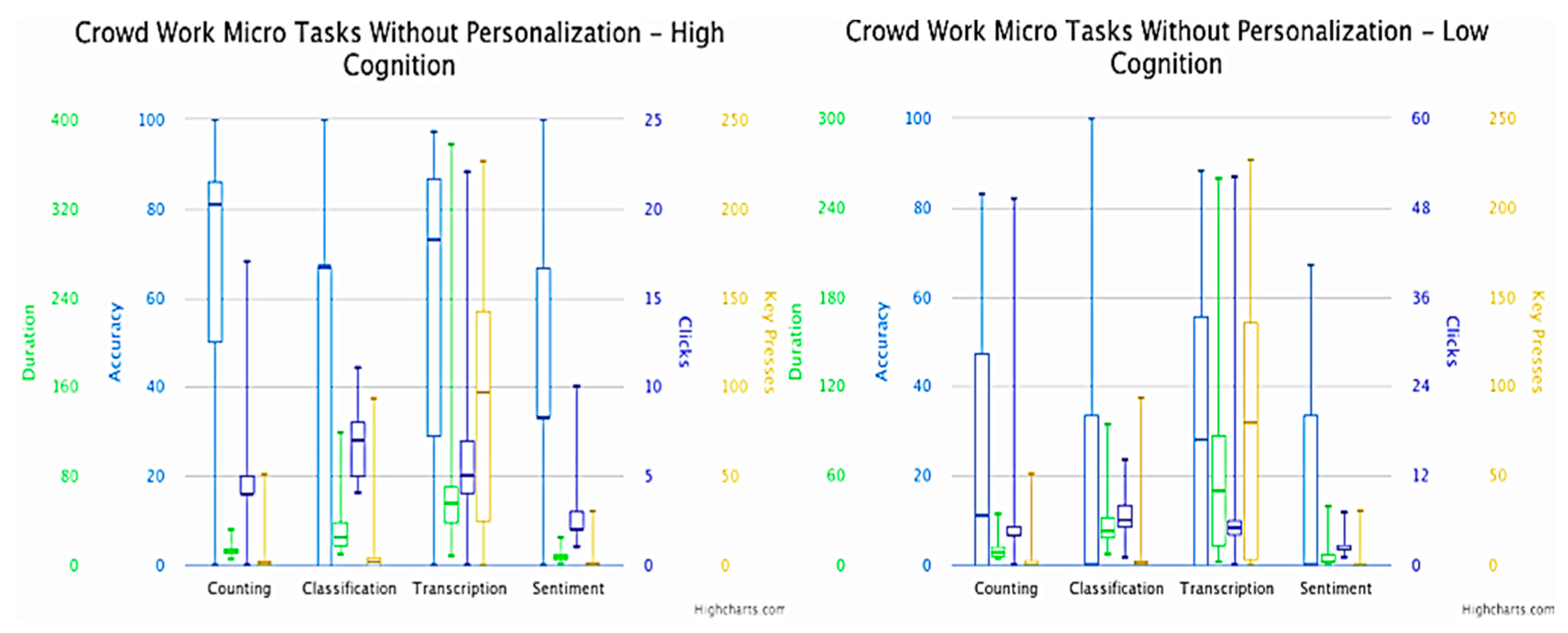
| Micro Task and Behavior/Version | Counting | Classification | Transcription | Sentiment | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Hu. | He. | Co. | Sp. | Hu. | He. | Co. | Sp. | Hu. | He. | Co. | Sp. | Hu. | He. | Co. | Sp. | |
| W/pers. (clicks) | 0.014 ± 0.120 | 0.797 ± 2.090 | 1.681 ± 2.110 | 0.000 ± 0.000 | 0.028 ± 0.168 | 0.956 ± 3.465 | 0.637 ± 1.042 | 0.000 ± 0.000 | 0.869 ± 0.339 | 0.057 ± 0.235 | 0.188 ± 0.393 | 0.000 ± 0.000 | 0.898 ± 0.304 | 0.115 ± 0.403 | 0.405 ± 0.845 | 0.000 ± 0.000 |
| W/pers. (key- presses) | 0.014 ± 0.120 | 0.376 ± 0.940 | 1.086 ± 2.605 | 0.231 ± 1.456 | 0.000 ± 0.000 | 0.101 ± 0.546 | 0.260 ± 1.024 | 0.086 ± 0.331 | 0.000 ± 0.000 | 0.463 ± 3.616 | 0.101 ± 0.425 | 0.275 ± 2.168 | 0.000 ± 0.000 | 0.000 ± 0.000 | 0.913 ± 3.716 | 0.362 ± 2.196 |
| W/o pers. (clicks) | 0.000 ± 0.000 | 0.985 ± 3.21 | 0.892 ± 0.886 | 0.000 ± 0.000 | 0.000 ± 0.000 | 3.246 ± 5.111 | 1.107 ± 1.985 | 0.000 ± 0.000 | 0.830 ± 0.377 | 1.400 ± 3.831 | 1.215 ± 1.231 | 0.000 ± 0.000 | 0.784 ± 0.414 | 0.153 ± 0.592 | 0.384 ± 0.896 | 0.000 ± 0.000 |
| W/o pers. (key presses) | 0.030 ± 0.174 | 0.800 ± 2.237 | 1.800 ± 3.700 | 0.323 ± 1.160 | 0.000 ± 0.000 | 1.769 ± 6.022 | 0.738 ± 4.176 | 0.353 ± 1.931 | 0.076 ± 0.268 | 51.938 ± 45.670 | 6.830 ± 8.1076 | 3.953 ± 5.421 | 0.000 ± 0.000 | 0.138 ± 0.788 | 0.892 ± 2.298 | 0.215 ± 1.038 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Paulino, D.; Guimarães, D.; Correia, A.; Ribeiro, J.; Barroso, J.; Paredes, H. A Model for Cognitive Personalization of Microtask Design. Sensors 2023, 23, 3571. https://doi.org/10.3390/s23073571
Paulino D, Guimarães D, Correia A, Ribeiro J, Barroso J, Paredes H. A Model for Cognitive Personalization of Microtask Design. Sensors. 2023; 23(7):3571. https://doi.org/10.3390/s23073571
Chicago/Turabian StylePaulino, Dennis, Diogo Guimarães, António Correia, José Ribeiro, João Barroso, and Hugo Paredes. 2023. "A Model for Cognitive Personalization of Microtask Design" Sensors 23, no. 7: 3571. https://doi.org/10.3390/s23073571