
FedBranched: Leveraging Federated Learning for Anomaly-Aware Load Forecasting in Energy Networks
 , , , , and
, , , , and
Abstract
:1. Introduction
1.1. Related Work
1.2. Motivation and Contributions
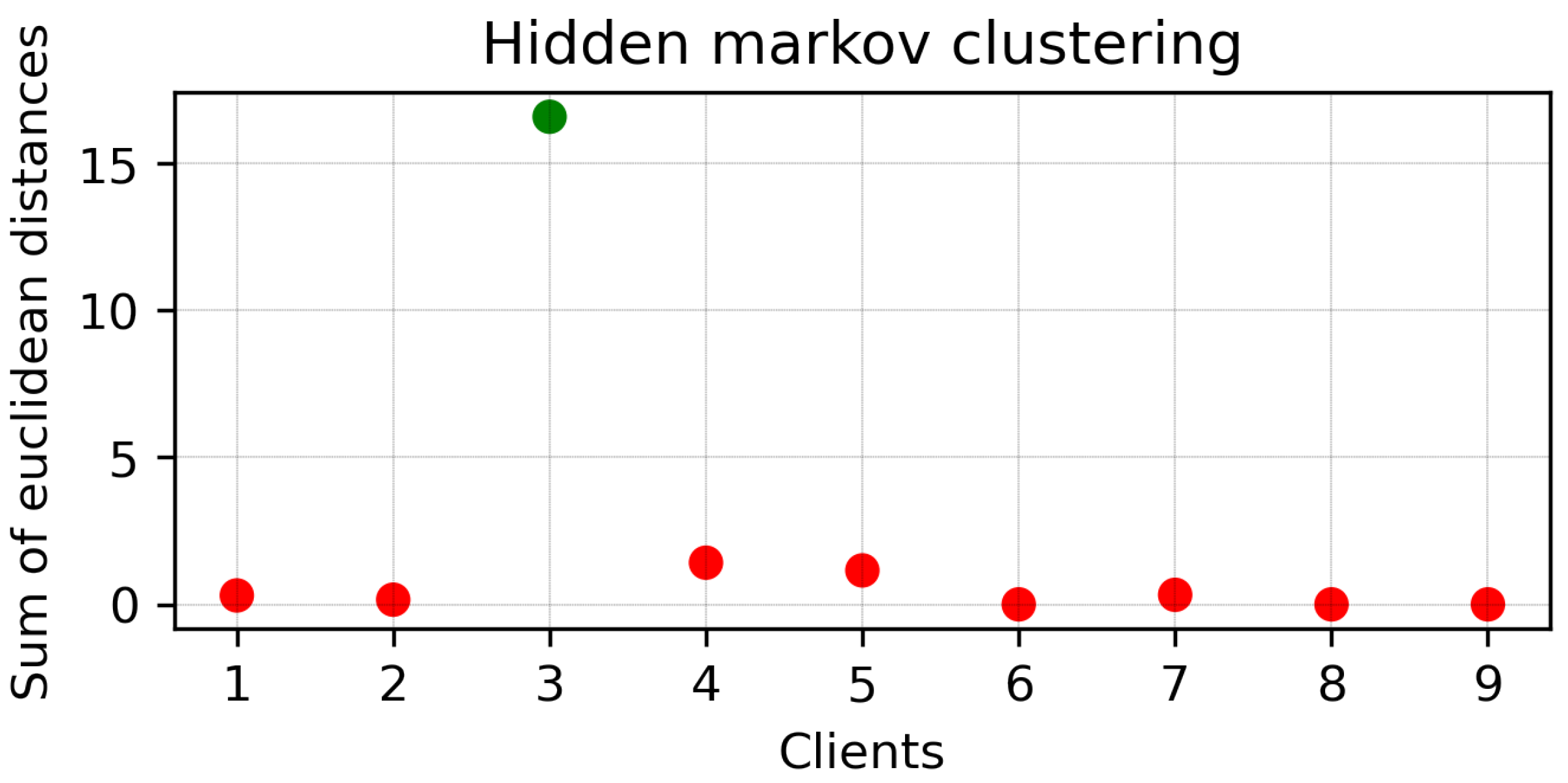
- We propose a zero-knowledge-based client clustering approach using HMM, which uses the Euclidean distances of loss functions. In each communication round, the clients share the model parameter and value of the loss function, in our case MAPE, to measure the similarity among different clients.
- The proposed FedBranched framework deals with diverse client data in the FL environment to make multiple global models based on the level of data diversity. Furthermore, there is no predefined limit for the number of clusters, which makes this approach more flexible for highly diverse data.
- The use of FedBranched guarantees convergence of the loss function.
- We propose an ANN and selected features for short-term energy forecasting.
- We perform an analysis of energy consumption before and after applying FedBranched.
1.3. Paper Organisation
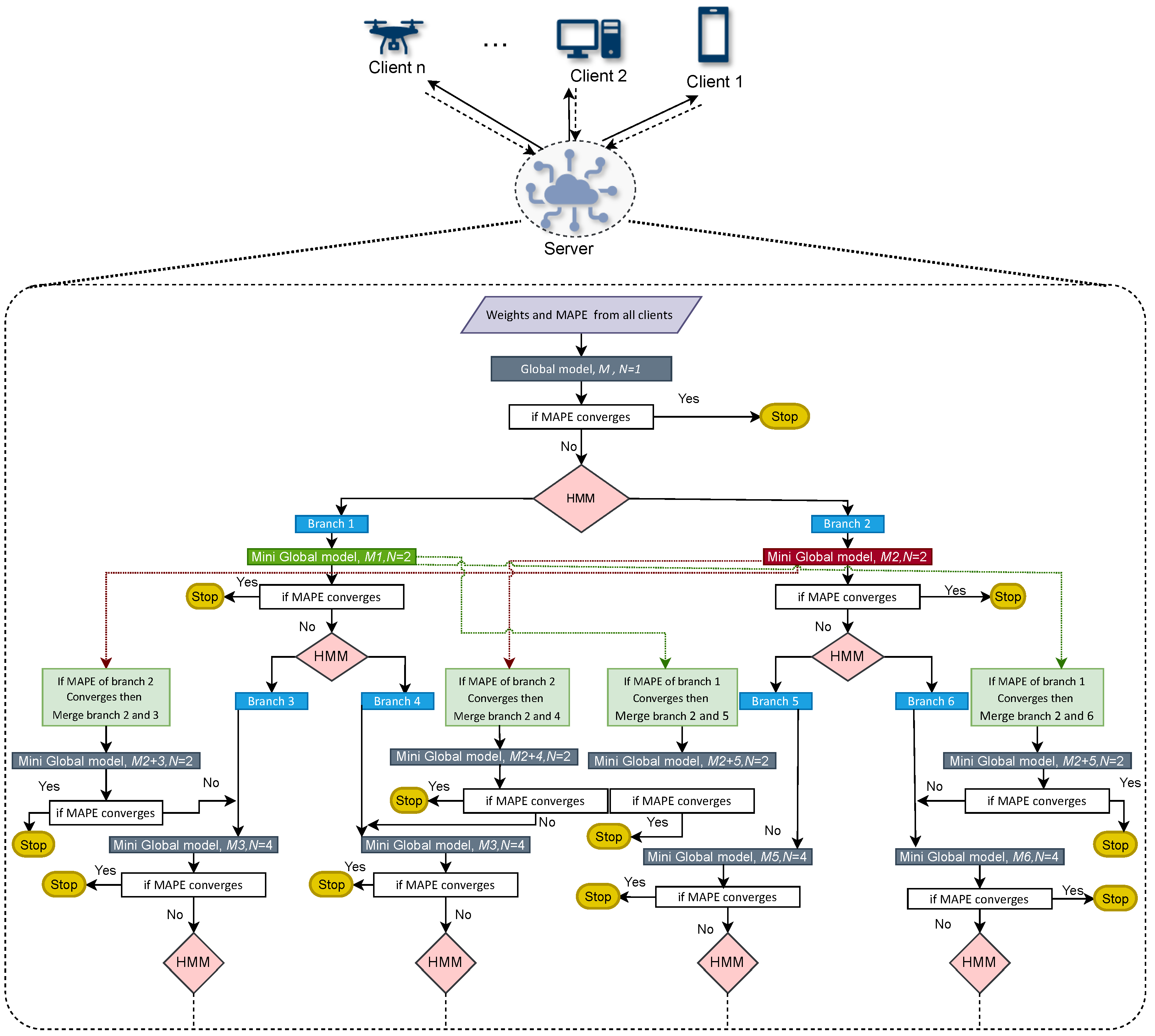
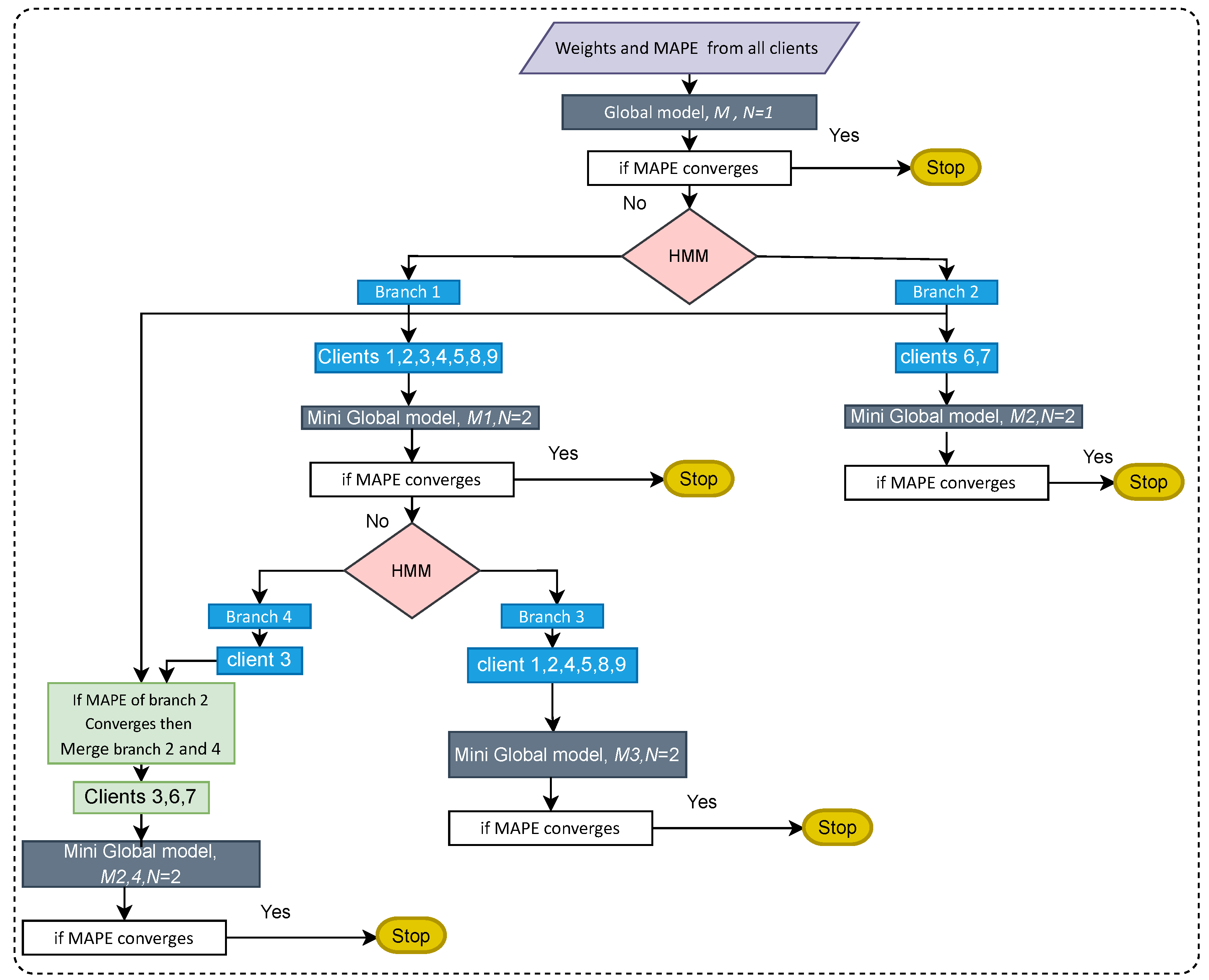
2. FedBranched
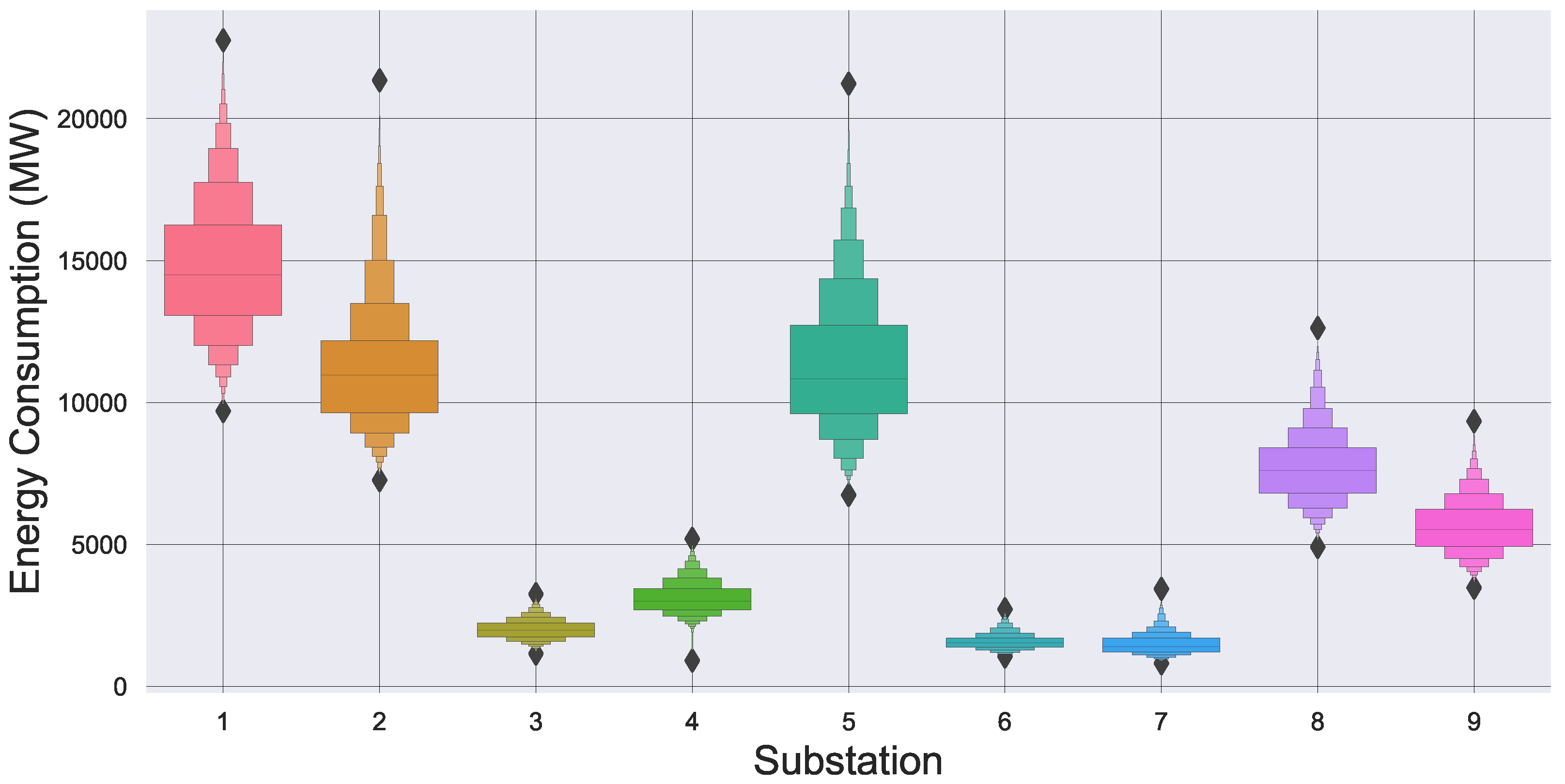
3. Simulation Setup
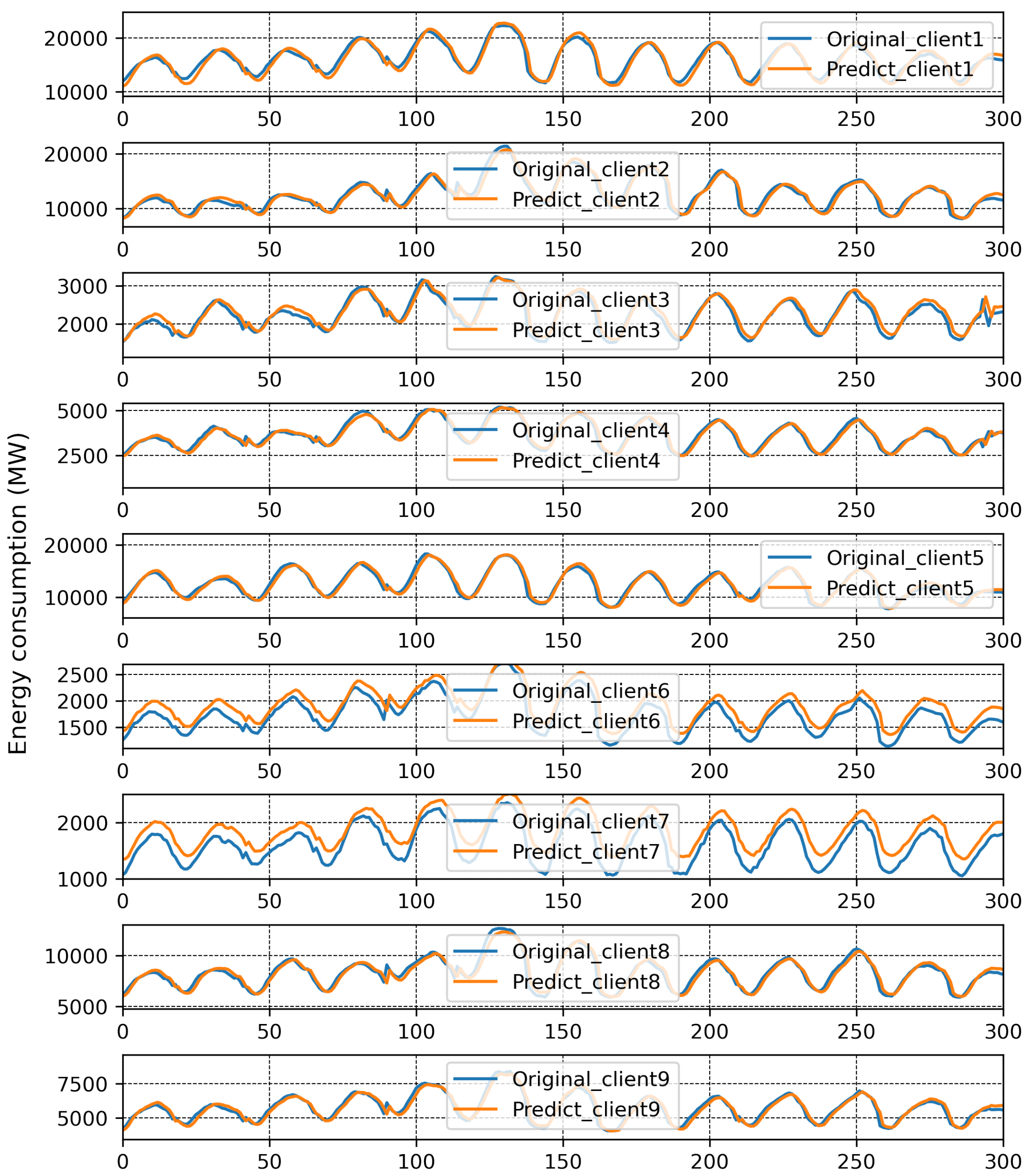
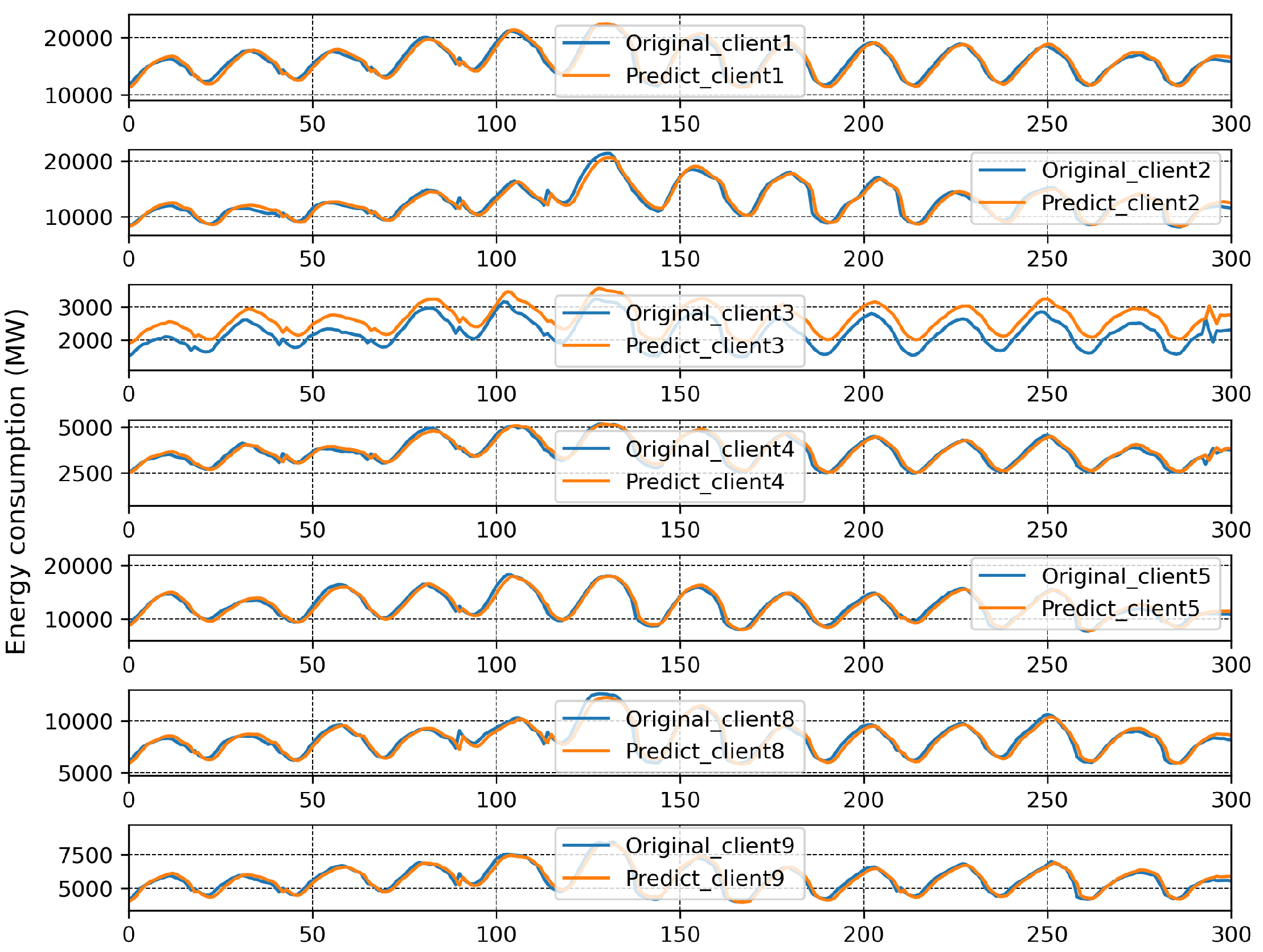
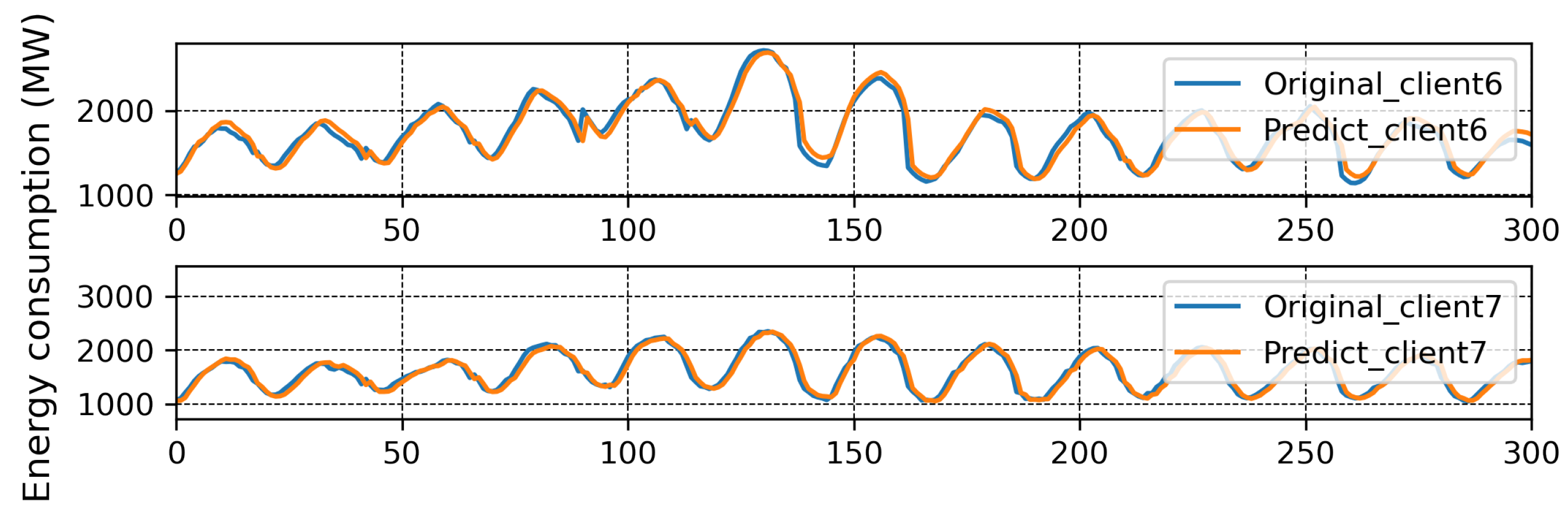
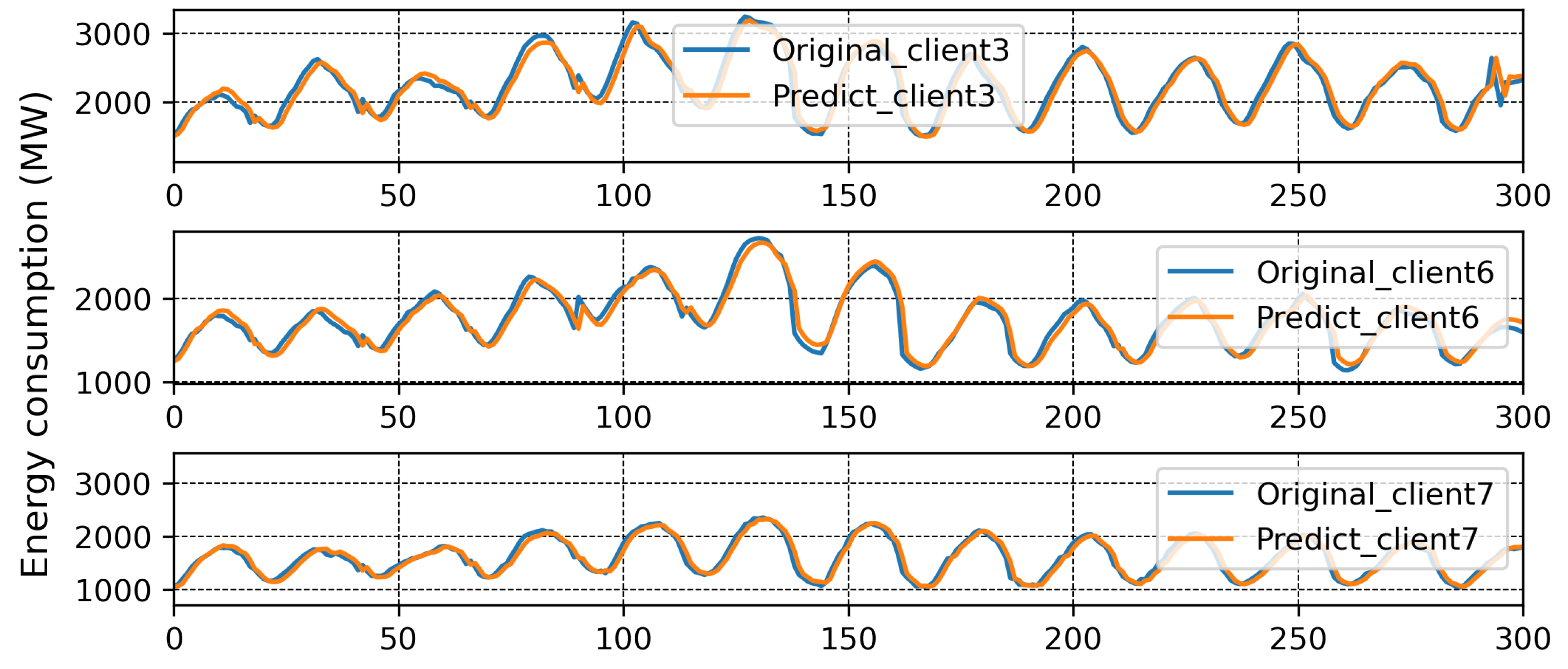
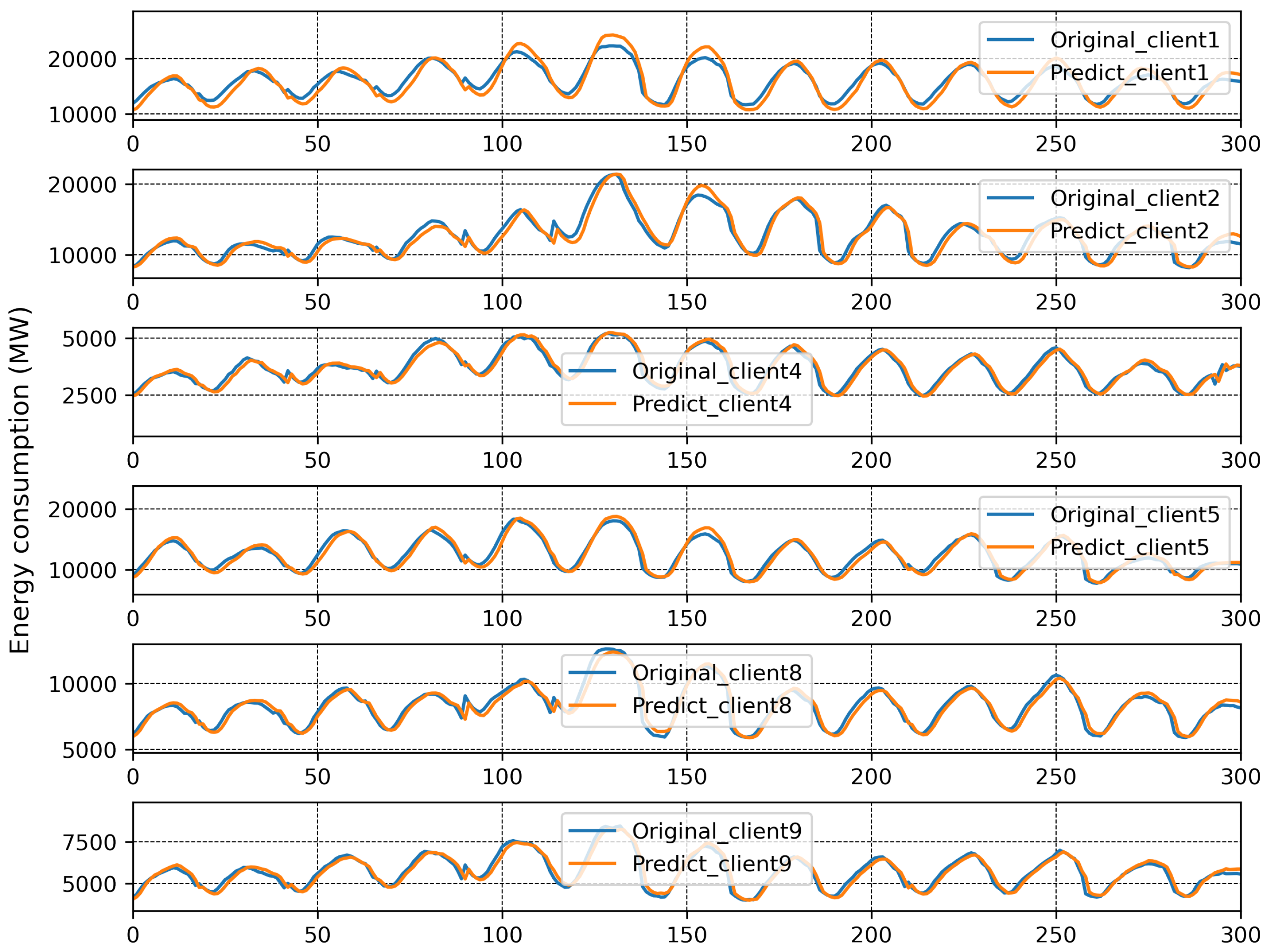
4. Experiment and Results
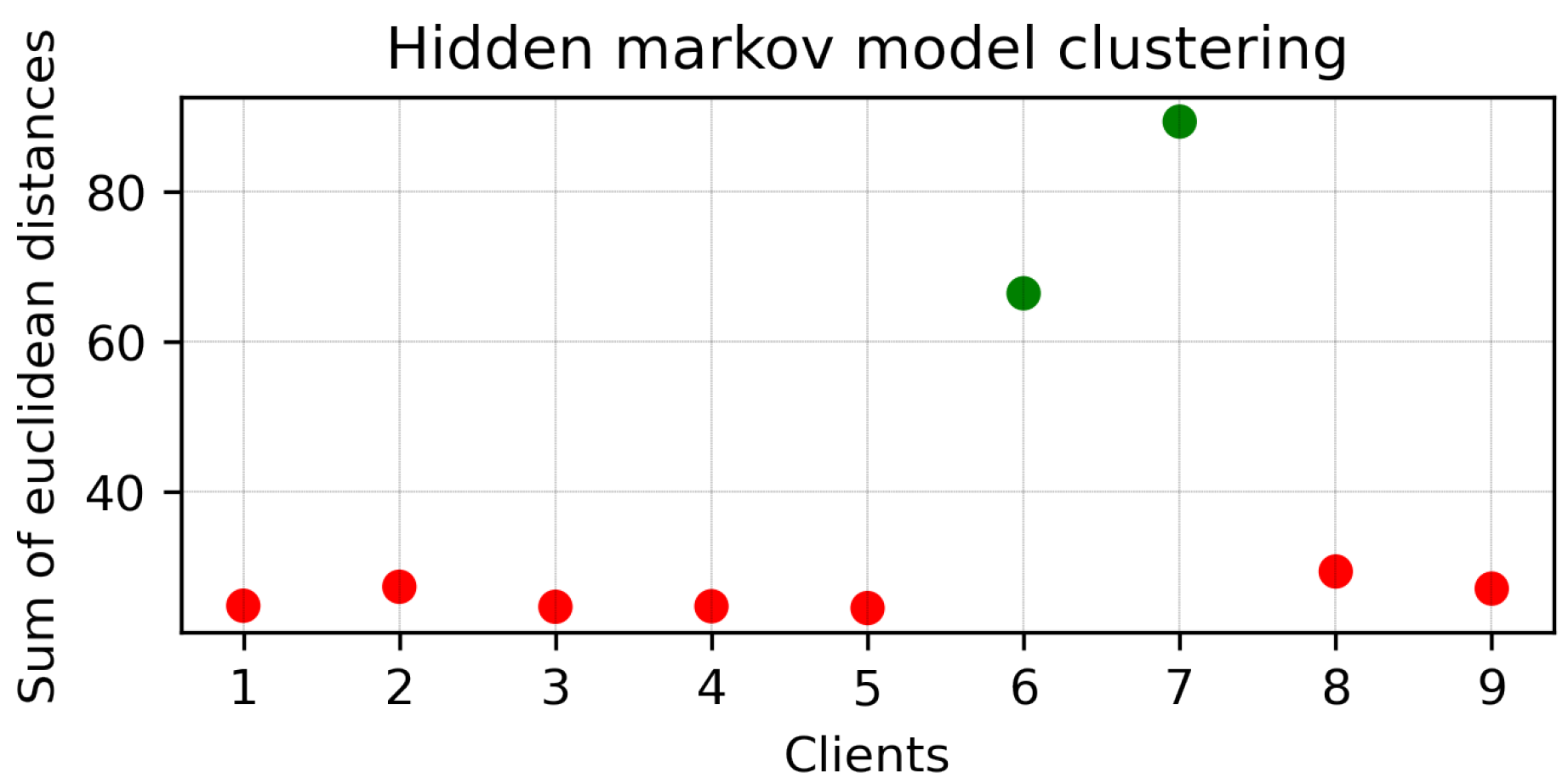
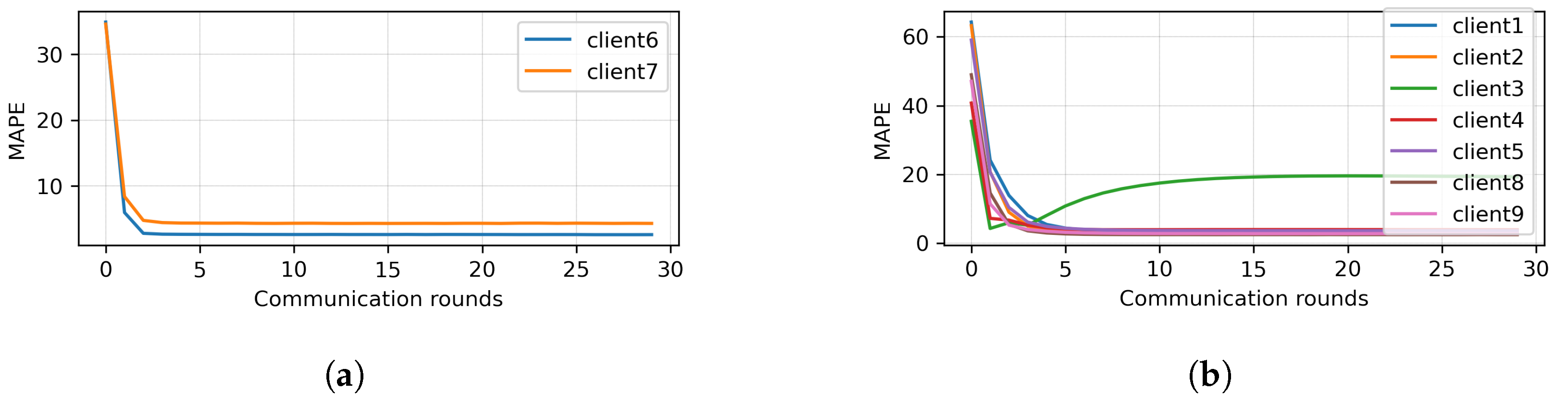
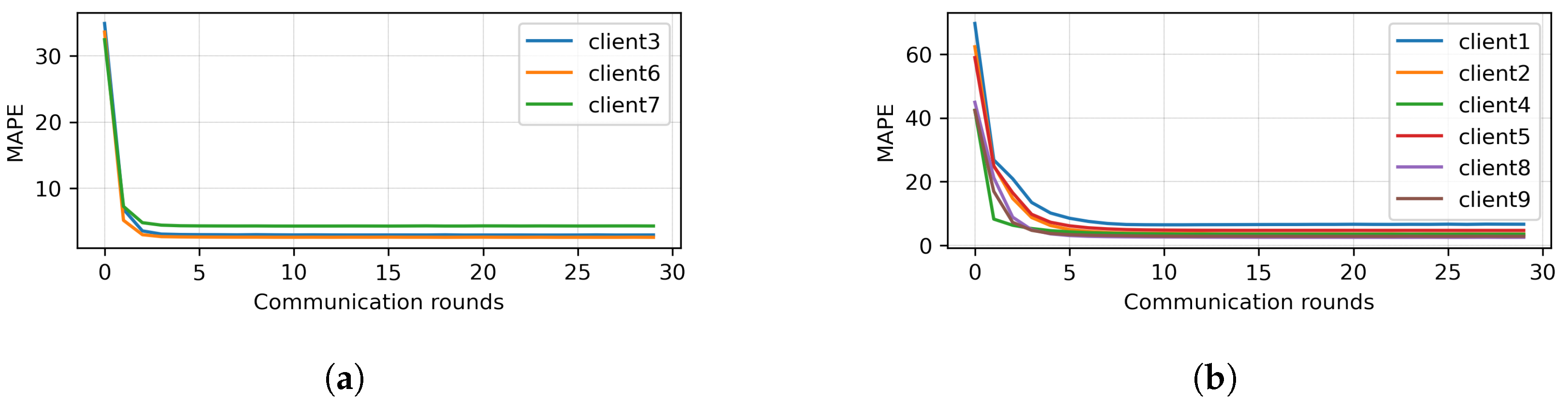
4.1. Clustering Round 1
4.2. Clustering Round 2
4.3. Discussion
5. Design Insights and Analysis
- Key features: FedBranched is capable of clustering clients without looking at the user’s data. Clustering is performed on the sum of Euclidean distances of a loss function using HMM. Here, a multi-stage clustering mechanism is adopted to minimize the required clusters and global models. At any stage, there can be only two clusters. The purpose of restricting the number of clusters is to have control and restrict the number of clusters to a minimum.
- Limitations: Because it is a clustering-based approach, it might not work well when the number of clients is less than five.
- Drawbacks: FedBranched uses a multistage clustering approach depending upon the diversity of data. At each stage, new branches are created and their respective global models are decided after running FL for pre-decided communication rounds. This will increase the computation power and time required to achieve an optimal number of global models that can satisfy the user’s requirements. In this paper, Vanilla FL was carried out for 30 communication rounds, whereas FedBranched was run for 150 (30*5) communication rounds, as shown in Figure 14.
- Energy consumption: Energy consumption, , in the training process of a global model depends on many factors, such as energy consumed per kb when local and global data are shared between clients and server, time of data transfer, type of IoT device used, the communication channel used, computation time on each device, etc. Here, is described based on the work of [29]:where R represents number of communication rounds, represents energy per second, t is for time, represents energy consumed per kb, and D represents amount of data transfer. In our experiments, each global or local model is of 38 kb and is taken as kWh/GB from [30], while is assumed as kWh/sec; then, baseline , when t is min, is equal to 27 W. However, using FedBranched, reached 136 W.
6. Conclusions and Future Work
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| FL | Federated learning |
| ML | Machine learning |
| n | Total number of clients |
| N | Total number of global models |
| M | Global model |
| ANN | Artificial neural network |
| STLF | Short-term load forecasting |
References
- Lim, W.Y.B.; Luong, N.C.; Hoang, D.T.; Jiao, Y.; Liang, Y.C.; Yang, Q.; Niyato, D.; Miao, C. Federated learning in mobile edge networks: A comprehensive survey. IEEE Commun. Surv. Tutor. 2020, 22, 2031–2063. [Google Scholar]
- Li, P.; Li, J.; Huang, Z.; Li, T.; Gao, C.Z.; Yiu, S.M.; Chen, K. Multi-key privacy-preserving deep learning in cloud computing. Future Gener. Comput. Syst. 2017, 74, 76–85. [Google Scholar] [CrossRef]
- Custers, B.; Sears, A.M.; Dechesne, F.; Georgieva, I.; Tani, T.; van der Hof, S. EU Personal Data Protection in Policy and Practice; Springer: Cham, Switzerland, 2019. [Google Scholar]
- Yang, K.; Jiang, T.; Shi, Y.; Ding, Z. yang2020federated. IEEE Trans. Wirel. Commun. 2020, 19, 2022–2035. [Google Scholar] [CrossRef]
- McMahan, H.B.; Moore, E.; Ramage, D.; y Arcas, B.A. Federated learning of deep networks using model averaging. arXiv 2016, arXiv:1602.05629. [Google Scholar]
- Konečnỳ, J.; McMahan, H.B.; Yu, F.X.; Richtárik, P.; Suresh, A.T.; Bacon, D. Federated learning: Strategies for improving communication efficiency. arXiv 2016, arXiv:1610.05492. [Google Scholar]
- Moradzadeh, A.; Mohammadpourfard, M.; Konstantinou, C.; Genc, I.; Kim, T.; Mohammadi-Ivatloo, B. Electric load forecasting under False Data Injection Attacks using deep learning. Energy Rep. 2022, 8, 9933–9945. [Google Scholar] [CrossRef]
- Khan, A.R.; Mahmood, A.; Safdar, A.; Khan, Z.A.; Khan, N.A. Load forecasting, dynamic pricing and DSM in smart grid: A review. Renew. Sustain. Energy Rev. 2016, 54, 1311–1322. [Google Scholar] [CrossRef]
- Petrangeli, E.; Tonellotto, N.; Vallati, C. Performance Evaluation of Federated Learning for Residential Energy Forecasting. IoT 2022, 3, 381–397. [Google Scholar] [CrossRef]
- Gholizadeh, N.; Musilek, P. Federated learning with hyperparameter-based clustering for electrical load forecasting. IoT 2022, 17, 100470. [Google Scholar] [CrossRef]
- Wei, K.; Li, J.; Ding, M.; Ma, C.; Yang, H.H.; Farokhi, F.; Jin, S.; Quek, T.Q.; Poor, H.V. Federated learning with differential privacy: Algorithms and performance analysis. IEEE Trans. Inf. Forensics Secur. 2020, 15, 3454–3469. [Google Scholar] [CrossRef]
- Manzoor, H.U.; Khan, M.S.; Khan, A.R.; Ayaz, F.; Flynn, D.; Imran, M.A.; Zoha, A. FedClamp: An Algorithm for Identification of Anomalous Client in Federated Learning. In Proceedings of the 2022 29th IEEE International Conference on Electronics, Circuits and Systems (ICECS), Glasgow, UK, 24–26 October 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 1–4. [Google Scholar]
- Zhao, Y.; Li, M.; Lai, L.; Suda, N.; Civin, D.; Chandra, V. Federated learning with non-iid data. arXiv 2018, arXiv:1806.00582. [Google Scholar] [CrossRef]
- Savi, M.; Olivadese, F. Short-term energy consumption forecasting at the edge: A federated learning approach. IEEE Access 2021, 9, 95949–95969. [Google Scholar] [CrossRef]
- Manzoor, H.U.; Khan, A.R.; Al-Quraan, M.; Mohjazi, L.; Taha, A.; Abbas, H.; Hussain, S.; Imran, M.A.; Zoha, A. Energy Management in an Agile Workspace using AI-driven Forecasting and Anomaly Detection. In Proceedings of the 2022 4th Global Power, Energy and Communication Conference (GPECOM), Nevsehir, Turkey, 14–17 June 2022; IEEE: Piscatawy, NJ, USA, 2022; pp. 644–649. [Google Scholar]
- Taïk, A.; Cherkaoui, S. Electrical load forecasting using edge computing and federated learning. In Proceedings of the ICC 2020-2020 IEEE International Conference on Communications (ICC), Dublin, Ireland, 7–11 June 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 1–6. [Google Scholar]
- Huang, L.; Shea, A.L.; Qian, H.; Masurkar, A.; Deng, H.; Liu, D. Patient clustering improves efficiency of federated machine learning to predict mortality and hospital stay time using distributed electronic medical records. J. Biomed. Inform. 2019, 99, 103291. [Google Scholar] [CrossRef] [PubMed]
- Briggs, C.; Fan, Z.; Andras, P. Federated learning with hierarchical clustering of local updates to improve training on non-IID data. In Proceedings of the 2020 International Joint Conference on Neural Networks (IJCNN), Glasgow, UK, 19–24 July 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 1–9. [Google Scholar]
- Luo, Y.; Liu, X.; Xiu, J. Energy-efficient clustering to address data heterogeneity in federated learning. In Proceedings of the ICC 2021-IEEE International Conference on Communications, Montreal, QC, Canada, 14–23 June 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 1–6. [Google Scholar]
- Li, C.; Li, G.; Varshney, P.K. Federated Learning With Soft Clustering. IEEE IoT J. 2021, 9, 7773–7782. [Google Scholar] [CrossRef]
- Sattler, F.; Müller, K.R.; Samek, W. Clustered federated learning: Model-agnostic distributed multitask optimization under privacy constraints. IEEE Trans. Neural Netw. Learn. Syst. 2020, 32, 3710–3722. [Google Scholar] [CrossRef] [PubMed]
- Ma, X.; Zhang, J.; Guo, S.; Xu, W. Layer-wised model aggregation for personalized federated learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 10092–10101. [Google Scholar]
- Ghassempour, S.; Girosi, F.; Maeder, A. Clustering multivariate time series using hidden Markov models. Int. J. Environ. Res. Public Health 2014, 11, 2741–2763. [Google Scholar] [CrossRef]
- Candelieri, A. Clustering and support vector regression for water demand forecasting and anomaly detection. Water 2017, 9, 224. [Google Scholar] [CrossRef]
- Mulla, R. Hourly Energy Consumption. Available online: https://www.kaggle.com/datasets/robikscube/hourly-energy-consumption (accessed on 8 August 2022).
- Zhou, Y.; Ye, Q.; Lv, J. Communication-efficient federated learning with compensated overlap-fedavg. IEEE Trans. Parallel Distrib. Syst. 2021, 33, 192–205. [Google Scholar] [CrossRef]
- Dwork, C. Differential privacy: A survey of results. In Proceedings of the International Conference on Theory and Applications of Models of Computation, Xi’an, China, 25–29 April 2008; Springer: Cham, Switzerland, 2008; pp. 1–19. [Google Scholar]
- Fontaine, C.; Galand, F. A survey of homomorphic encryption for nonspecialists. EURASIP J. Inf. Secur. 2007, 2007, 1–10. [Google Scholar] [CrossRef]
- Mian, A.N.; Shah, S.W.H.; Manzoor, S.; Said, A.; Heimerl, K.; Crowcroft, J. A value-added IoT service for cellular networks using federated learning. Comput. Netw. 2022, 213, 109094. [Google Scholar] [CrossRef]
- Aslan, J.; Mayers, K.; Koomey, J.G.; France, C. Electricity intensity of internet data transmission: Untangling the estimates. J. Ind. Ecol. 2018, 22, 785–798. [Google Scholar] [CrossRef]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Client | Vanilla FL (%) | FedBranched (%) | Percentage Improvement (%) |
|---|---|---|---|
| 1 | 4.13 | 2.78 | 1.35 |
| 2 | 2.80 | 2.66 | 0.14 |
| 3 | 4.05 | 2.98 | 1.07 |
| 4 | 3.63 | 3.95 | −0.32 |
| 5 | 3.88 | 3.65 | 0.23 |
| 6 | 12.43 | 2.61 | 9.82 |
| 7 | 15.71 | 4.35 | 11.36 |
| 8 | 2.51 | 2.50 | −0.01 |
| 9 | 2.85 | 2.82 | 0.03 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Manzoor, H.U.; Khan, A.R.; Flynn, D.; Alam, M.M.; Akram, M.; Imran, M.A.; Zoha, A. FedBranched: Leveraging Federated Learning for Anomaly-Aware Load Forecasting in Energy Networks. Sensors 2023, 23, 3570. https://doi.org/10.3390/s23073570
Manzoor HU, Khan AR, Flynn D, Alam MM, Akram M, Imran MA, Zoha A. FedBranched: Leveraging Federated Learning for Anomaly-Aware Load Forecasting in Energy Networks. Sensors. 2023; 23(7):3570. https://doi.org/10.3390/s23073570
Chicago/Turabian StyleManzoor, Habib Ullah, Ahsan Raza Khan, David Flynn, Muhammad Mahtab Alam, Muhammad Akram, Muhammad Ali Imran, and Ahmed Zoha. 2023. "FedBranched: Leveraging Federated Learning for Anomaly-Aware Load Forecasting in Energy Networks" Sensors 23, no. 7: 3570. https://doi.org/10.3390/s23073570