
Regularized Denoising Masked Visual Pretraining for Robust Embodied PointGoal Navigation

Abstract
:1. Introduction
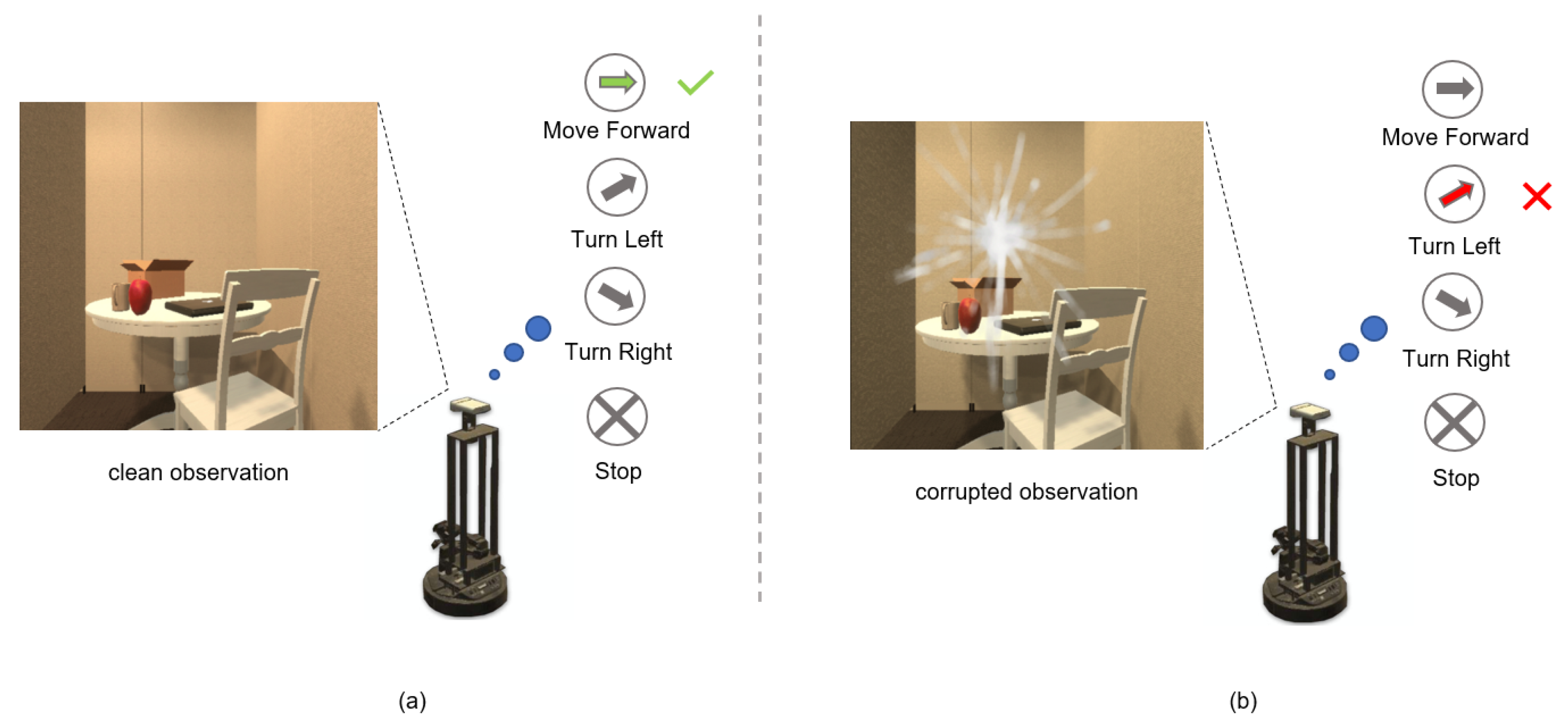
- We propose a robust PointGoal navigation framework RDMAE-Nav as the first attempt to apply denoising masked visual pretraining for embodied PointGoal navigation, which is a robust navigation agent for various visual corruptions.
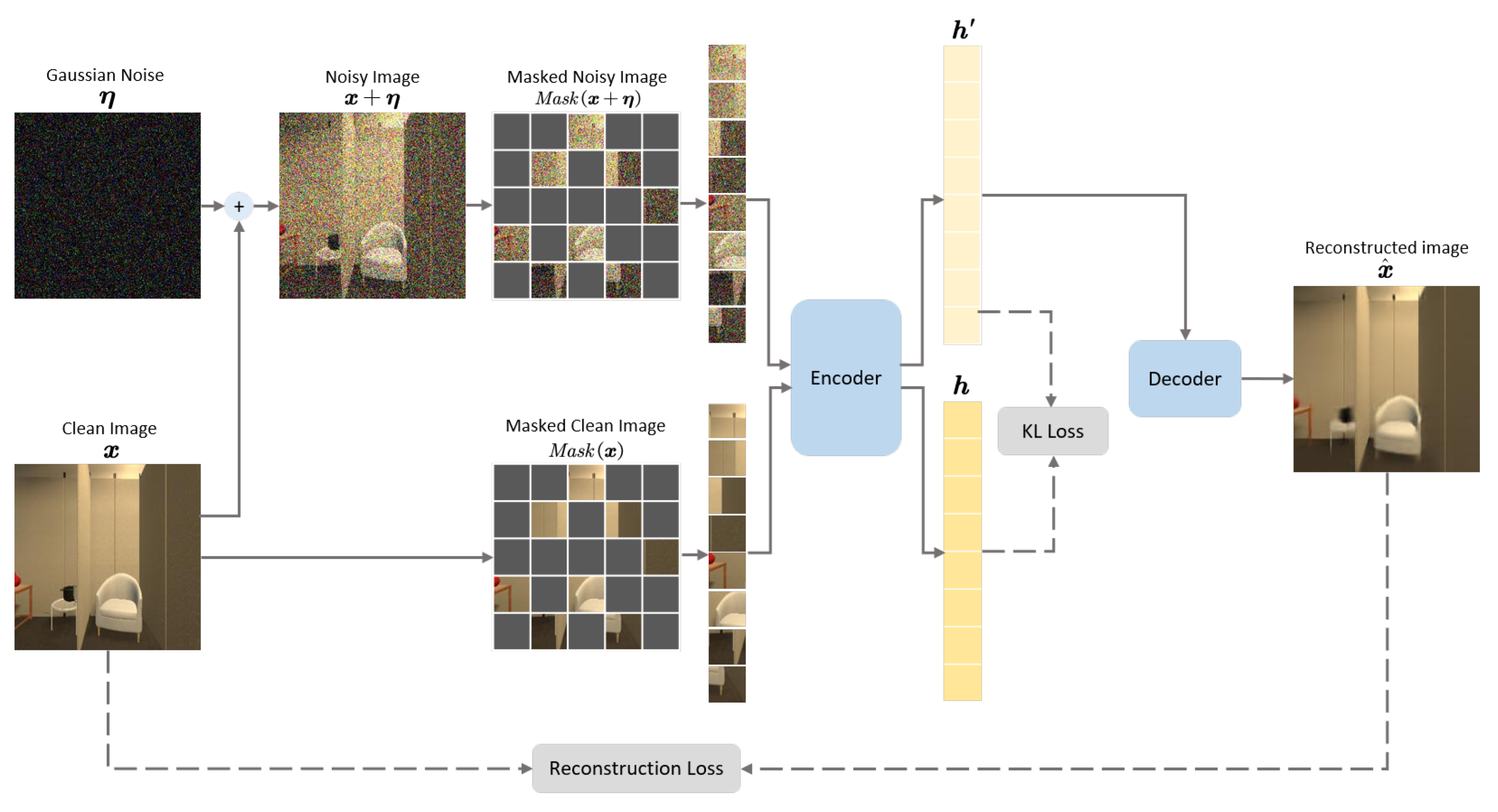
- We design a novel pretraining method, dubbed RDMAE, which introduces a regularization term for a denoising masked modeling task. RDMAE mitigates the gap of representation distributions between clean images and noisy ones by minimizing the bidirectional Kullback–Leibler (KL) divergence and consequently enables the visual encoder to obtain more robust and efficient visual priors.
- Our method can achieve competitive performance over all competitors through experiments on the ROBUSTNAV benchmark [13], demonstrating the effectiveness and efficiency of the proposed RDMAE-Nav by employing Regularized Denoising masked visual pretraining for various visual corruptions.
2. Related Work
2.1. Embodied PointGoal Navigation
2.2. Pretrained Visual Encoders in Embodied Visual Navigation
2.3. Masked Autoencoders in Reinforcement Learning and Robotics
3. Method
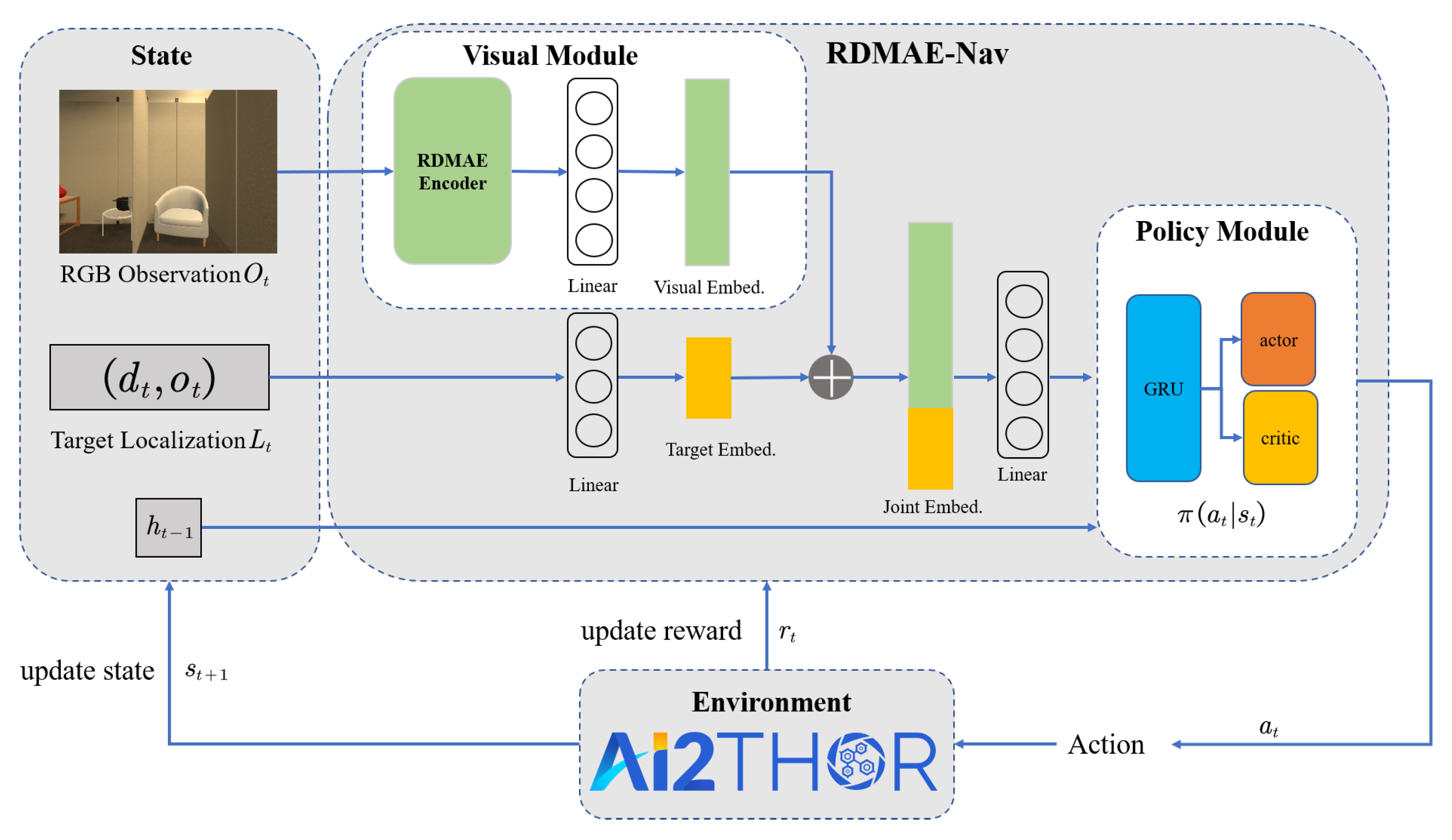
3.1. Task Definition
3.2. Overall Architecture of RDMAE-Nav
3.3. Regularized Denoising Masked AutoEncoders (RDMAE) for Visual Pretraining
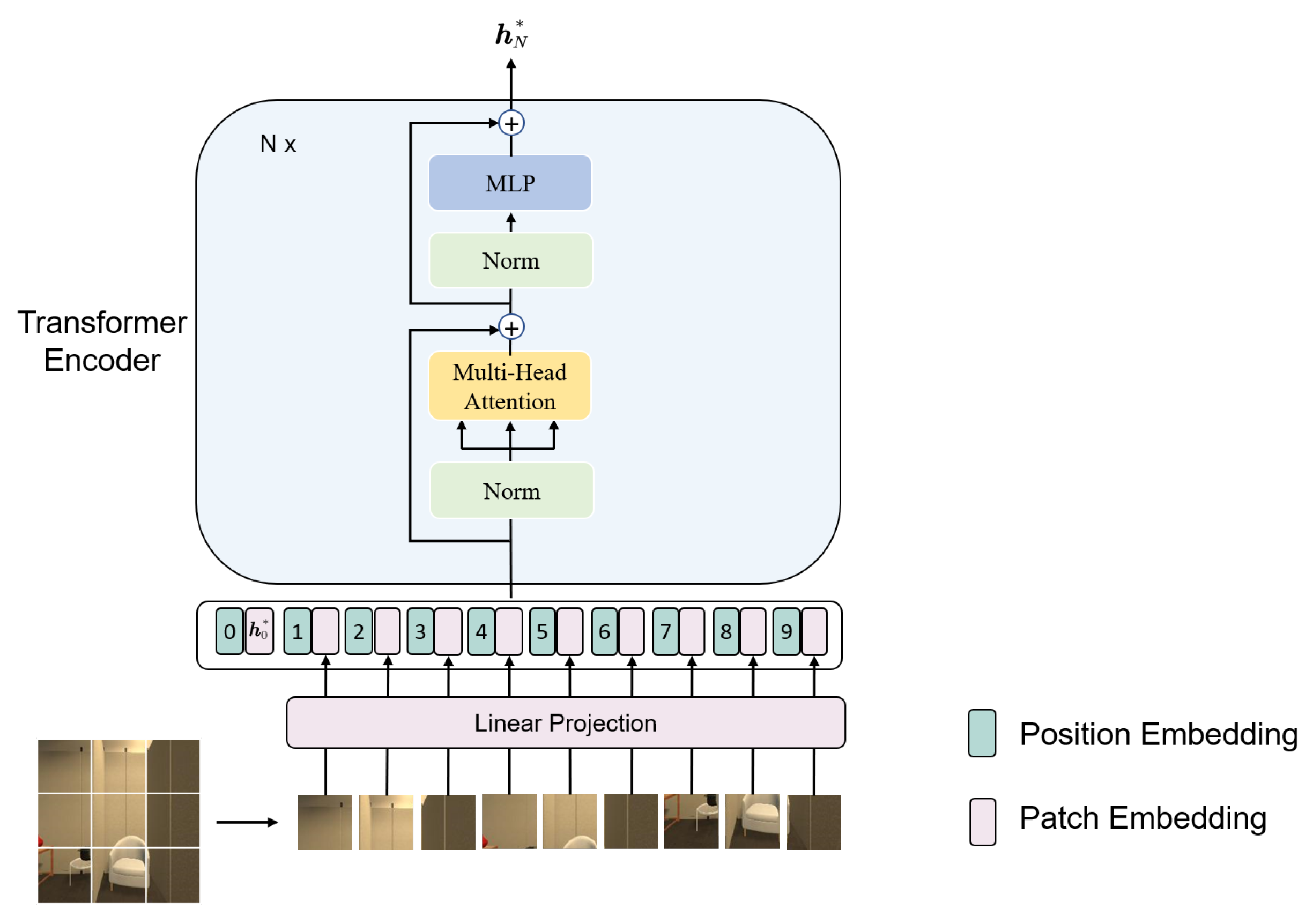
3.4. Vision-Transformer-Based Visual Encoder
4. Experiments
4.1. Simulation Platform
4.2. Data Preraration
4.3. Visual Corruptions Description
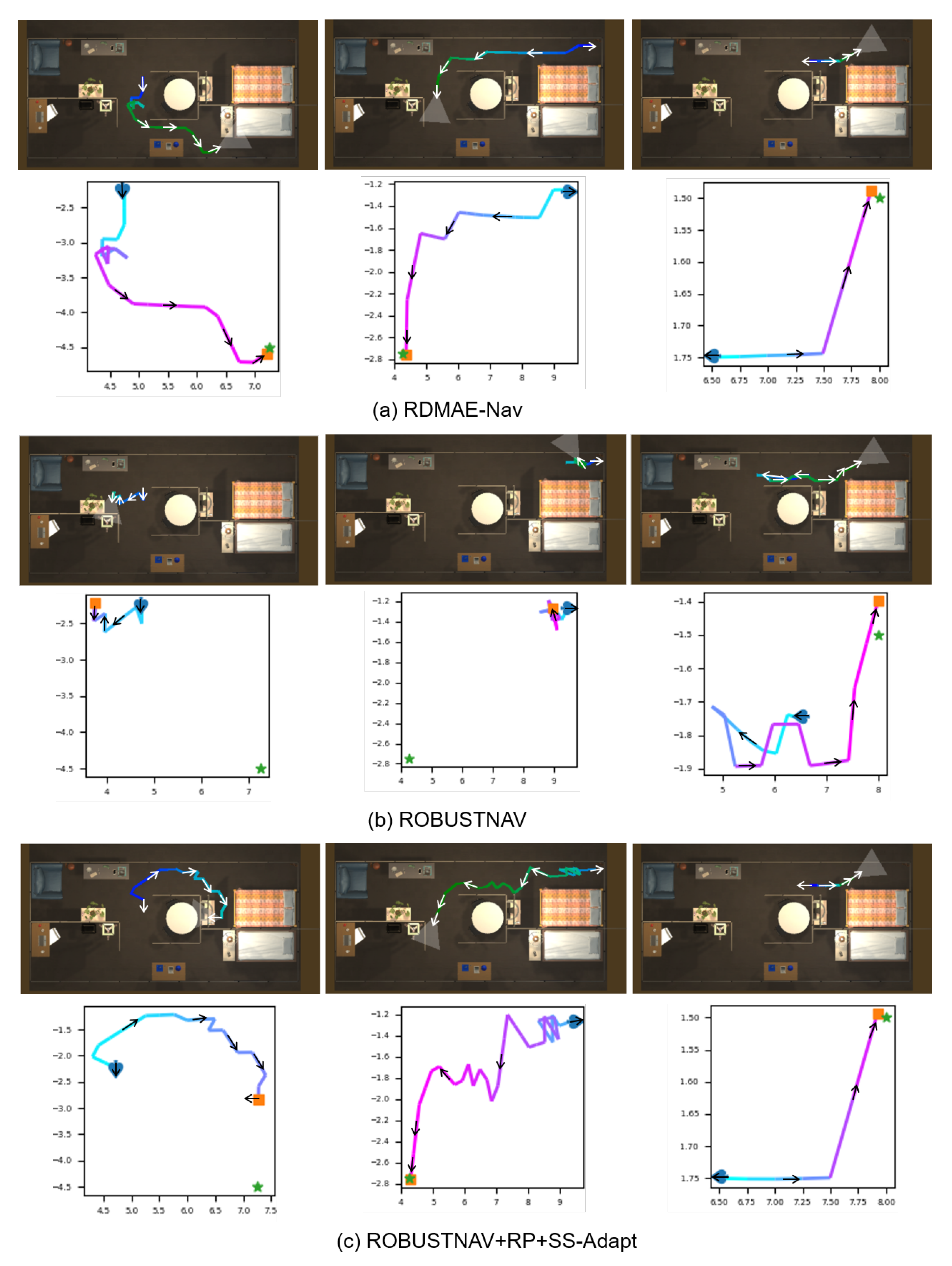
5. Experimental Results and Discussion
5.1. Evaluation Metrics
5.2. RDMAE Pretraining Configuration
5.3. RDMAE-Nav Training Configuration
5.4. Performance on Visual Corruptions
- (1)
- ROBUSTNAV is the standard approach to evaluate the benchmarks by using ResNet18 to extract visual features.
- (2)
- ROBUSTNAV+AP is based on ROBUSTNAV by introducing an additional action prediction self-supervised task to resist visual corruptions.
- (3)
- ROBUSTNAV+AP+SS-Adapt is based on ROBUSTNAV+AP by introducing self-supervised adaptation on specific corruptions (Spatter, Camera Crack, Lower-FOV, and Defocus Blur).
- (4)
- ROBUSTNAV+RP is based on ROBUSTNAV by introducing an additional rotation prediction task to resist visual corruptions.
- (5)
- ROBUSTNAV+RP+SS-Adapt is based on ROBUSTNAV+RP by introducing the self-supervised adaptation on specific corruptions (Spatter, Camera Crack, Lower-FOV, and Defocus Blur).
- (6)
- ROBUSTNAV+Data Aug introduces various data augmentation methods during training. For more information about the above approaches, please refer to [13].
5.5. Ablations
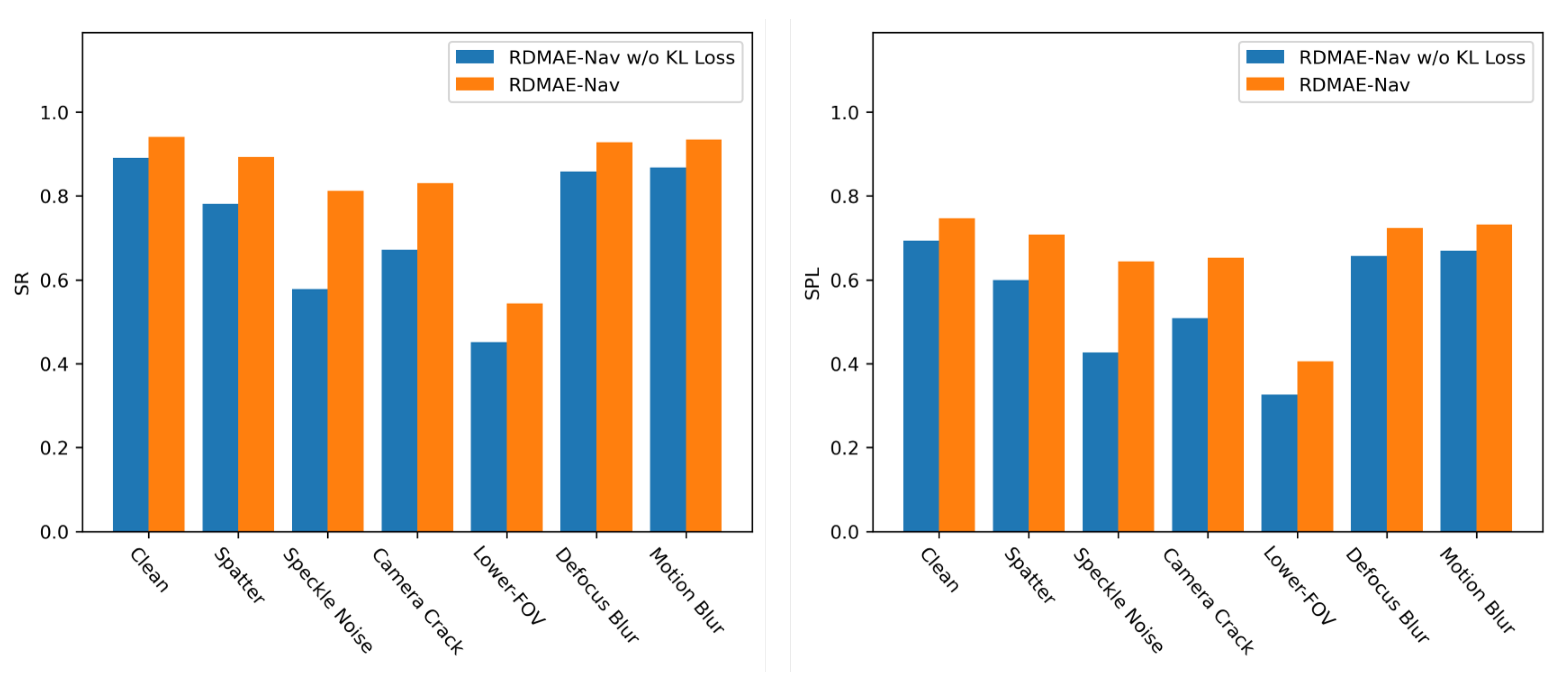
5.5.1. Contributions of KL Loss
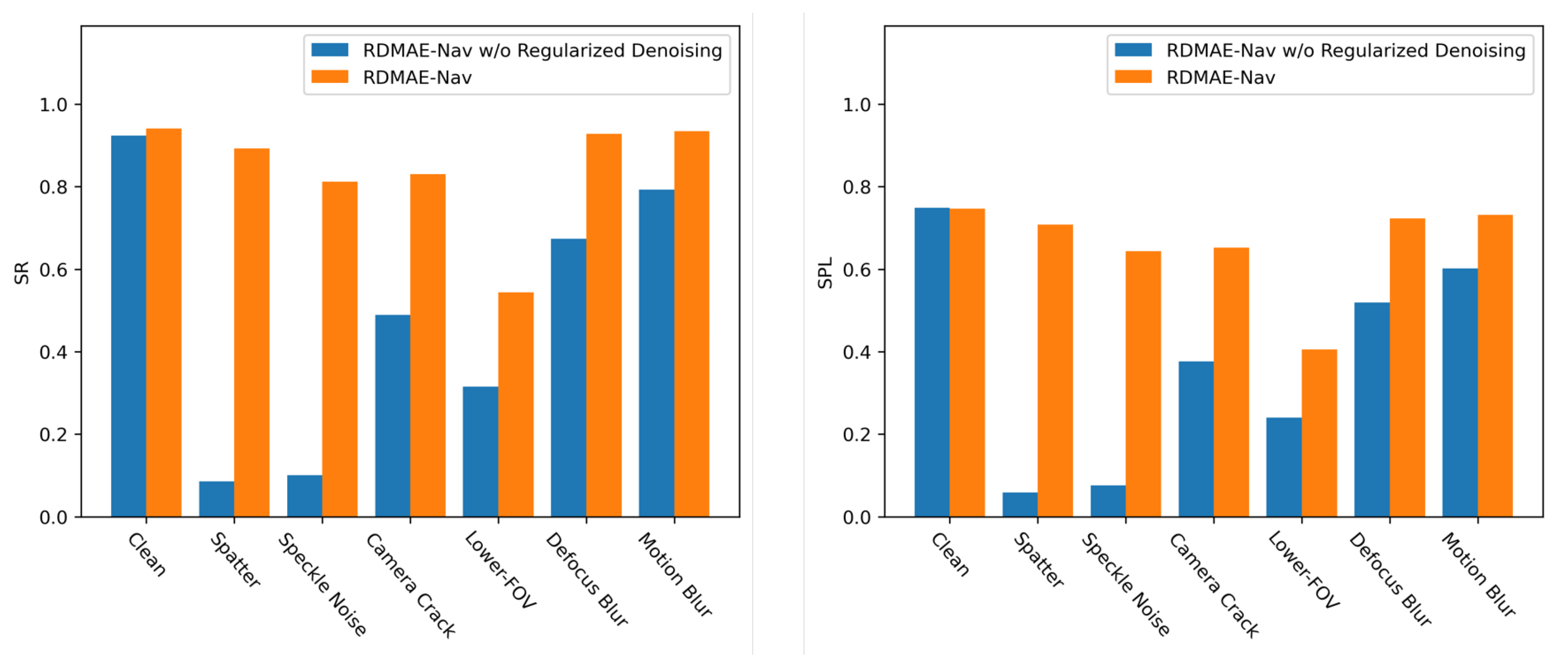
5.5.2. Contributions of Regularized Denoising
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Duan, J.; Yu, S.; Tan, H.L.; Zhu, H.; Tan, C. A survey of embodied ai: From simulators to research tasks. IEEE Trans. Emerg. Top. Comput. Intell. 2022, 6, 230–244. [Google Scholar] [CrossRef]
- Kolve, E.; Mottaghi, R.; Han, W.; VanderBilt, E.; Weihs, L.; Herrasti, A.; Gordon, D.; Zhu, Y.; Gupta, A.; Farhadi, A. Ai2-thor: An interactive 3d environment for visual ai. arXiv 2017, arXiv:1712.05474. [Google Scholar]
- Li, C.; Xia, F.; Martín-Martín, R.; Lingelbach, M.; Srivastava, S.; Shen, B.; Vainio, K.E.; Gokmen, C.; Dharan, G.; Jain, T.; et al. iGibson 2.0: Object-Centric Simulation for Robot Learning of Everyday Household Tasks. In Proceedings of the Conference on Robot Learning, London, UK, 8–11 November 2022; pp. 455–465. [Google Scholar]
- Szot, A.; Clegg, A.; Undersander, E.; Wijmans, E.; Zhao, Y.; Turner, J.; Maestre, N.; Mukadam, M.; Chaplot, D.S.; Maksymets, O.; et al. Habitat 2.0: Training home assistants to rearrange their habitat. Adv. Neural Inf. Process. Syst. 2021, 34, 251–266. [Google Scholar]
- Anderson, P.; Chang, A.; Chaplot, D.S.; Dosovitskiy, A.; Gupta, S.; Koltun, V.; Kosecka, J.; Malik, J.; Mottaghi, R.; Savva, M.; et al. On evaluation of embodied navigation agents. arXiv 2018, arXiv:1807.06757. [Google Scholar]
- Tai, L.; Paolo, G.; Liu, M. Virtual-to-real deep reinforcement learning: Continuous control of mobile robots for mapless navigation. In Proceedings of the 2017 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Vancouver, BC, Canada, 24–28 September 2017; pp. 31–36. [Google Scholar]
- Bansal, S.; Tolani, V.; Gupta, S.; Malik, J.; Tomlin, C. Combining optimal control and learning for visual navigation in novel environments. In Proceedings of the Conference on Robot Learning, Virtual, 16–18 November 2020; pp. 420–429. [Google Scholar]
- Wijmans, E.; Kadian, A.; Morcos, A.; Lee, S.; Essa, I.; Parikh, D.; Savva, M.; Batra, D. Dd-ppo: Learning near-perfect pointgoal navigators from 2.5 billion frames. arXiv 2019, arXiv:1911.00357. [Google Scholar]
- Wijmans, E.; Essa, I.; Batra, D. How to Train PointGoal Navigation Agents on a (Sample and Compute) Budget. In Proceedings of the 21st International Conference on Autonomous Agents and Multiagent Systems, Virtual, 9–13 May 2022; pp. 1762–1764. [Google Scholar]
- Zhao, X.; Agrawal, H.; Batra, D.; Schwing, A.G. The surprising effectiveness of visual odometry techniques for embodied pointgoal navigation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 16127–16136. [Google Scholar]
- Karkus, P.; Cai, S.; Hsu, D. Differentiable slam-net: Learning particle slam for visual navigation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Montreal, BC, Canada, 11–17 October 2021; pp. 2815–2825. [Google Scholar]
- Tang, T.; Du, H.; Yu, X.; Yang, Y. Monocular Camera-based Point-goal Navigation by Learning Depth Channel and Cross-modality Pyramid Fusion. Proc. AAAI Conf. Artif. Intell. 2022, 36, 5422–5430. [Google Scholar] [CrossRef]
- Chattopadhyay, P.; Hoffman, J.; Mottaghi, R.; Kembhavi, A. Robustnav: Towards benchmarking robustness in embodied navigation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 15691–15700. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16 × 16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Wu, Q.; Ye, H.; Gu, Y.; Zhang, H.; Wang, L.; He, D. Denoising Masked AutoEncoders are Certifiable Robust Vision Learners. arXiv 2022, arXiv:2210.06983. [Google Scholar]
- Cho, K.; Van Merriënboer, B.; Gulcehre, C.; Bahdanau, D.; Bougares, F.; Schwenk, H.; Bengio, Y. Learning phrase representations using RNN encoder-decoder for statistical machine translation. arXiv 2014, arXiv:1406.1078. [Google Scholar]
- Savva, M.; Kadian, A.; Maksymets, O.; Zhao, Y.; Wijmans, E.; Jain, B.; Straub, J.; Liu, J.; Koltun, V.; Malik, J.; et al. Habitat: A platform for embodied ai research. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Rrepublic of Korea, 27 October–2 November 2019; pp. 9339–9347. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Schulman, J.; Moritz, P.; Levine, S.; Jordan, M.; Abbeel, P. High-dimensional continuous control using generalized advantage estimation. arXiv 2015, arXiv:1506.02438. [Google Scholar]
- Truong, J.; Chernova, S.; Batra, D. Bi-directional domain adaptation for sim2real transfer of embodied navigation agents. IEEE Robot. Autom. Lett. 2021, 6, 2634–2641. [Google Scholar] [CrossRef]
- Sadek, A.; Bono, G.; Chidlovskii, B.; Wolf, C. An in-depth experimental study of sensor usage and visual reasoning of robots navigating in real environments. In Proceedings of the 2022 International Conference on Robotics and Automation (ICRA), Philadelphia, PA, USA, 23–27 May 2022; pp. 9425–9431. [Google Scholar]
- Partsey, R.; Wijmans, E.; Yokoyama, N.; Dobosevych, O.; Batra, D.; Maksymets, O. Is Mapping Necessary for Realistic PointGoal Navigation? In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 17232–17241. [Google Scholar]
- Lee, E.S.; Kim, J.; Kim, Y.M. Self-Supervised Domain Adaptation for Visual Navigation with Global Map Consistency. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, New Orleans, LA, USA, 18–24 June 2022; pp. 1707–1716. [Google Scholar]
- Sax, A.; Emi, B.; Zamir, A.R.; Guibas, L.; Savarese, S.; Malik, J. Mid-level visual representations improve generalization and sample efficiency for learning visuomotor policies. arXiv 2018, arXiv:1812.11971. [Google Scholar]
- Ramakrishnan, S.K.; Nagarajan, T.; Al-Halah, Z.; Grauman, K. Environment predictive coding for embodied agents. arXiv 2021, arXiv:2102.02337. [Google Scholar]
- Du, H.; Yu, X.; Zheng, L. VTNet: Visual transformer network for object goal navigation. arXiv 2021, arXiv:2105.09447. [Google Scholar]
- Khandelwal, A.; Weihs, L.; Mottaghi, R.; Kembhavi, A. Simple but effective: Clip embeddings for embodied ai. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 14829–14838. [Google Scholar]
- Radford, A.; Kim, J.W.; Hallacy, C.; Ramesh, A.; Goh, G.; Agarwal, S.; Sastry, G.; Askell, A.; Mishkin, P.; Clark, J.; et al. Learning transferable visual models from natural language supervision. In Proceedings of the International Conference on Machine Learning, Baltimore, MD, USA, 6–14 December 2021; pp. 8748–8763. [Google Scholar]
- Saavedra-Ruiz, M.; Morin, S.; Paull, L. Monocular Robot Navigation with Self-Supervised Pretrained Vision Transformers. arXiv 2022, arXiv:2203.03682. [Google Scholar]
- Caron, M.; Touvron, H.; Misra, I.; Jégou, H.; Mairal, J.; Bojanowski, P.; Joulin, A. Emerging properties in self-supervised vision transformers. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 9650–9660. [Google Scholar]
- Morad, S.D.; Mecca, R.; Poudel, R.P.; Liwicki, S.; Cipolla, R. Embodied visual navigation with automatic curriculum learning in real environments. IEEE Robot. Autom. Lett. 2021, 6, 683–690. [Google Scholar] [CrossRef]
- He, K.; Chen, X.; Xie, S.; Li, Y.; Dollár, P.; Girshick, R. Masked autoencoders are scalable vision learners. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 16000–16009. [Google Scholar]
- Zhang, C.; Zhang, C.; Song, J.; Yi, J.S.K.; Zhang, K.; Kweon, I.S. A survey on masked autoencoder for self-supervised learning in vision and beyond. arXiv 2022, arXiv:2208.00173. [Google Scholar]
- Xu, H.; Ding, S.; Zhang, X.; Xiong, H.; Tian, Q. Masked autoencoders are robust data augmentors. arXiv 2022, arXiv:2206.04846. [Google Scholar]
- Xiao, T.; Radosavovic, I.; Darrell, T.; Malik, J. Masked visual pre-training for motor control. arXiv 2022, arXiv:2203.06173. [Google Scholar]
- Tao, T.; Reda, D.; van de Panne, M. Evaluating Vision Transformer Methods for Deep Reinforcement Learning from Pixels. arXiv 2022, arXiv:2204.04905. [Google Scholar]
- Schulman, J.; Wolski, F.; Dhariwal, P.; Radford, A.; Klimov, O. Proximal policy optimization algorithms. arXiv 2017, arXiv:1707.06347. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30, 1–11. [Google Scholar]
- Deitke, M.; Han, W.; Herrasti, A.; Kembhavi, A.; Kolve, E.; Mottaghi, R.; Salvador, J.; Schwenk, D.; VanderBilt, E.; Wallingford, M.; et al. Robothor: An open simulation-to-real embodied ai platform. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 3164–3174. [Google Scholar]
- Murali, A.; Chen, T.; Alwala, K.V.; Gandhi, D.; Pinto, L.; Gupta, S.; Gupta, A. Pyrobot: An open-source robotics framework for research and benchmarking. arXiv 2019, arXiv:1906.08236. [Google Scholar]
- Loshchilov, I.; Hutter, F. Decoupled Weight Decay Regularization. In Proceedings of the International Conference on Learning Representations, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Approach | Visual Corruption | |||||||
|---|---|---|---|---|---|---|---|---|
| Clean | Spatter | Speckle Noise | Camera Crack | Lower-FOV | Defocus Blur | Motion Blur | ||
| ROBUSTNAV | SR | 98.82 | 33.58 | 67.42 | 82.07 | 42.49 | 75.89 | 95.72 |
| SPL | 83.13 | 24.72 | 48.57 | 63.83 | 31.73 | 53.55 | 73.37 | |
| ROBUSTNAV+AP | SR | 98.45 | 20.38 | 65.61 | 72.70 | 45.68 | 83.35 | 94.81 |
| SPL | 83.28 | 15.70 | 47.03 | 56.82 | 35.14 | 61.51 | 74.3 | |
| ROBUSTNAV+AP+SS-Adapt | SR | 37.31 | 14.19 | \ | 57.87 | 32.94 | 40.95 | \ |
| SPL | 31.03 | 10.29 | \ | 46.72 | 26.09 | 33.35 | \ | |
| ROBUSTNAV+RP | SR | 98.73 | 23.48 | 78.98 | 67.06 | 44.95 | 32.21 | 91.63 |
| SPL | 82.53 | 18.63 | 55.92 | 53.70 | 32.74 | 22.47 | 65.27 | |
| ROBUSTNAV+RP+SS-Adapt | SR | 94.63 | 61.06 | \ | 60.42 | 50.59 | 79.16 | \ |
| SPL | 77.25 | 47.16 | \ | 49.37 | 36.10 | 62.74 | \ | |
| ROBUSTNAV+Data Aug | SR | 98.45 | 23.93 | 77.25 | 88.44 | 71.70 | 81.26 | 96.91 |
| SPL | 81.08 | 18.41 | 57.95 | 71.57 | 54.54 | 61.32 | 75.97 | |
| RDMAE-Nav | SR | 94.09 | 89.26 | 81.26 | 83.08 | 54.41 | 92.81 | 93.45 |
| SPL | 74.64 | 70.84 | 64.36 | 65.27 | 40.58 | 72.29 | 73.22 | |
| Approach | Visual Corruption | |||||||
|---|---|---|---|---|---|---|---|---|
| Clean | Spatter | Speckle Noise | Camera Crack | Lower-FOV | Defocus Blur | Motion Blur | ||
| ROBUSTNAV | R | 9.513 | 0.458 | 3.577 | 5.043 | 2.321 | 5.425 | 8.017 |
| Dist | 0.1393 | 3.306 | 2.2 | 1.554 | 2.115 | 1.468 | 0.6826 | |
| ROBUSTNAV+AP | R | 9.51 | −0.08434 | 5.217 | 6.047 | 3.053 | 7.349 | 8.937 |
| Dist | 0.1316 | 3.673 | 1.652 | 1.289 | 2.115 | 0.8785 | 0.349 | |
| ROBSUTNAV+AP+SS-Adapt | R | 1.478 | −1.193 | \ | 4.175 | 1.124 | 6.834 | \ |
| Dist | 2.591 | 3.397 | \ | 1.971 | 3.082 | 1.126 | \ | |
| ROBUSTNAV+RP | R | 9.602 | 0.1546 | 6.816 | 5.29 | 2.843 | 1.165 | 8.411 |
| Dist | 0.09848 | 4.052 | 1.164 | 1.65 | 2.31 | 2.961 | 0.4539 | |
| ROBUSTNAV+RP+SS-Adapt | R | 9.046 | 5.014 | \ | 4.506 | 3.524 | 6.741 | \ |
| Dist | 0.3248 | 1.838 | \ | 1.88 | 1.965 | 1.136 | \ | |
| ROBUSTNAV+Data Aug | R | 9.465 | 0.08564 | 6.662 | 8.11 | 6.006 | 6.722 | 9.183 |
| Dist | 0.1531 | 3.811 | 1.077 | 0.5868 | 1.245 | 1.015 | 0.1957 | |
| RDMAE-Nav | R | 8.895 | 8.238 | 7.253 | 7.459 | 3.79 | 8.687 | 8.778 |
| Dist | 0.3458 | 0.5502 | 0.9784 | 0.9005 | 1.982 | 0.3905 | 0.3561 | |
| Approach | Visual Corruption | |||||||
|---|---|---|---|---|---|---|---|---|
| Clean | Spatter | Speckle Noise | Camera Crack | Lower-FOV | Defocus Blur | Motion Blur | ||
| RDMAE-Nav w/o KL Loss | SR | 89.08 | 78.16 | 57.78 | 67.15 | 45.13 | 85.81 | 86.81 |
| SPL | 69.36 | 60 | 42.73 | 50.89 | 32.62 | 65.65 | 66.91 | |
| RDMAE-Nav | SR | 94.09 | 89.26 | 81.26 | 83.08 | 54.41 | 92.81 | 93.45 |
| SPL | 74.64 | 70.84 | 64.36 | 65.27 | 40.58 | 72.29 | 73.22 | |
| Approach | Visual Corruption | |||||||
|---|---|---|---|---|---|---|---|---|
| Clean | Spatter | Speckle Noise | Camera Crack | Lower-FOV | Defocus Blur | Motion Blur | ||
| RDMAE-Nav w/o KL Loss | R | 8.198 | 6.809 | 4.229 | 5.419 | 2.616 | 7.786 | 7.906 |
| Dist | 0.5581 | 1.022 | 2.013 | 1.531 | 2.366 | 0.7601 | 0.7233 | |
| RDMAE-Nav | R | 8.895 | 8.238 | 7.253 | 7.459 | 3.79 | 8.687 | 8.778 |
| Dist | 0.3458 | 0.5502 | 0.9784 | 0.9005 | 1.982 | 0.3905 | 0.3561 | |
| Approach | Visual Corruption | |||||||
|---|---|---|---|---|---|---|---|---|
| Clean | Spatter | Speckle Noise | Camera Crack | Lower-FOV | Defocus Blur | Motion Blur | ||
| RDMAE-Nav w/o Regularized Denoising | SR | 92.36 | 8.553 | 10.1 | 48.95 | 31.57 | 67.42 | 79.34 |
| SPL | 74.94 | 5.923 | 7.656 | 37.67 | 23.99 | 51.95 | 60.14 | |
| RDMAE-Nav | SR | 94.09 | 89.26 | 81.26 | 83.08 | 54.41 | 92.81 | 93.45 |
| SPL | 74.64 | 70.84 | 64.36 | 65.27 | 40.58 | 72.29 | 73.22 | |
| Approach | Visual Corruption | |||||||
|---|---|---|---|---|---|---|---|---|
| Clean | Spatter | Speckle Noise | Camera Crack | Lower-FOV | Defocus Blur | Motion Blur | ||
| RDMAE-Nav w/o Regularized Denoising | R | 8.678 | −1.909 | −1.715 | 3.166 | 0.9692 | 5.465 | 6.941 |
| Dist | 0.3938 | 3.671 | 3.44 | 2.428 | 2.853 | 1.583 | 1.096 | |
| RDMAE-Nav | R | 8.895 | 8.238 | 7.253 | 7.459 | 3.79 | 8.687 | 8.778 |
| Dist | 0.3458 | 0.5502 | 0.9784 | 0.9005 | 1.982 | 0.3905 | 0.3561 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Peng, J.; Xu, Y.; Luo, L.; Liu, H.; Lu, K.; Liu, J. Regularized Denoising Masked Visual Pretraining for Robust Embodied PointGoal Navigation. Sensors 2023, 23, 3553. https://doi.org/10.3390/s23073553
Peng J, Xu Y, Luo L, Liu H, Lu K, Liu J. Regularized Denoising Masked Visual Pretraining for Robust Embodied PointGoal Navigation. Sensors. 2023; 23(7):3553. https://doi.org/10.3390/s23073553
Chicago/Turabian StylePeng, Jie, Yangbin Xu, Luqing Luo, Haiyang Liu, Kaiqiang Lu, and Jian Liu. 2023. "Regularized Denoising Masked Visual Pretraining for Robust Embodied PointGoal Navigation" Sensors 23, no. 7: 3553. https://doi.org/10.3390/s23073553