
Efficient Memory-Enhanced Transformer for Long-Document Summarization in Low-Resource Regimes
 , , ,
, , ,  , and
, and
Abstract
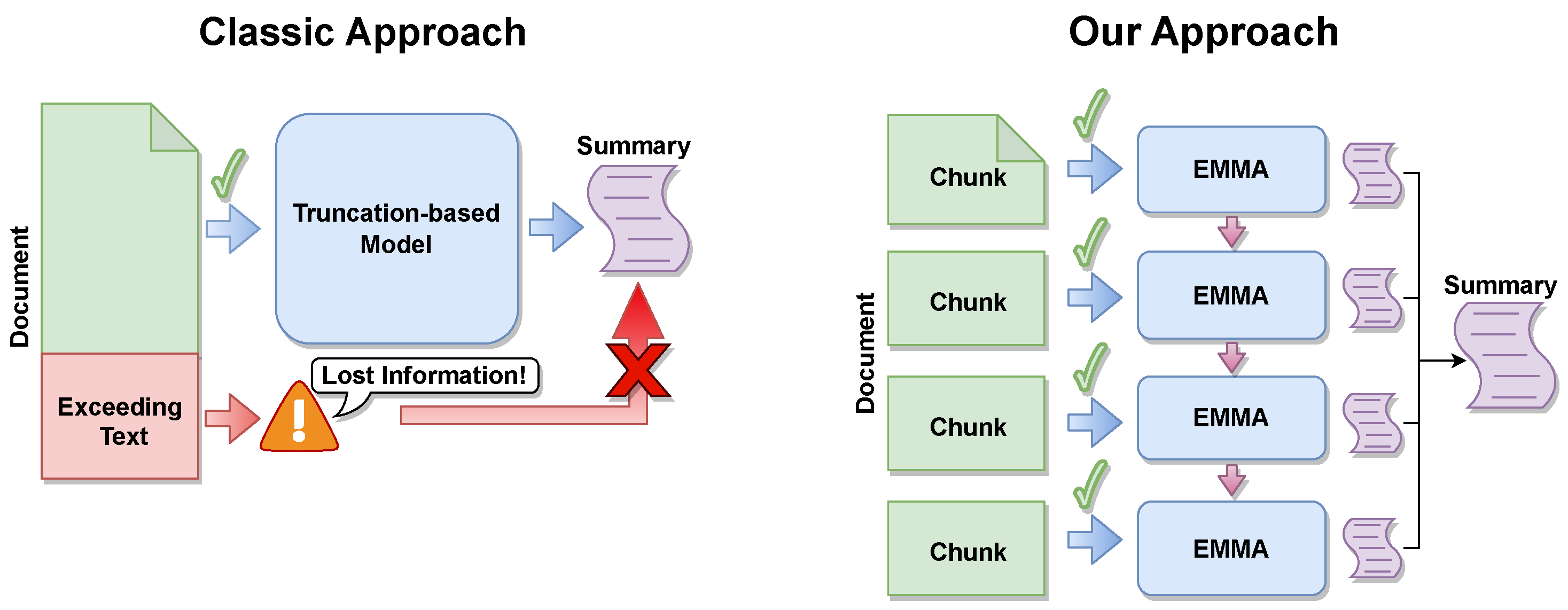
:1. Introduction
- We introduce Emma, a novel memory-enhanced encoder–decoder transformer for LDS.
- We perform extensive analyses showing SOTA’s performance at low GPU cost, on full-resource summarization (i.e., training on all training samples), and few-shot learning.
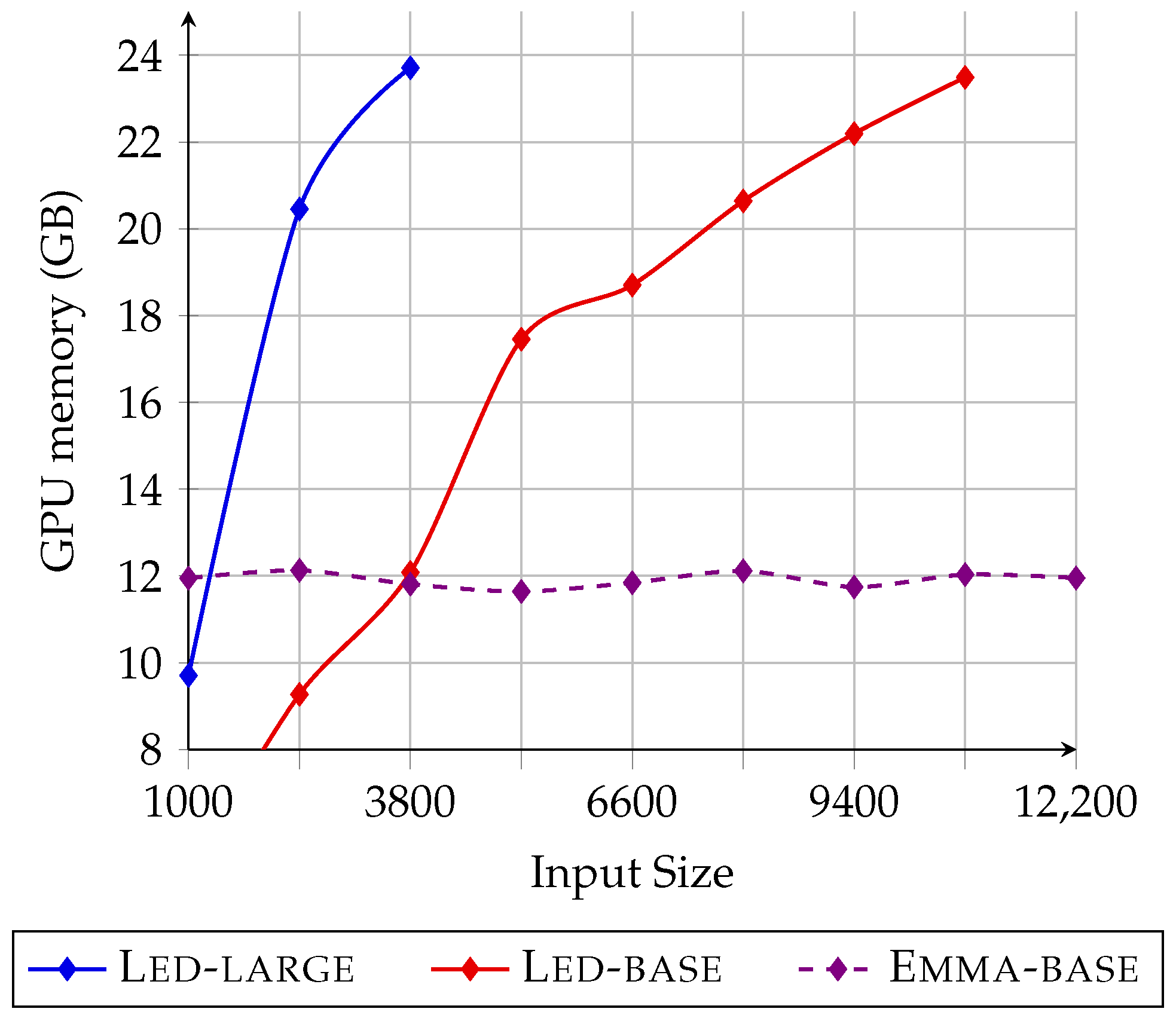
- The GPU impact of Emma remained fixed regardless of input length.
2. Related Work
2.1. Transformers
2.2. Memory-Based Transformers
2.3. Long Document Summarization
3. Background
4. Method
4.1. Text Segmentation
| Algorithm 1 Text Segmentation | |
| Input: Parameters: Output: | ▹ Input sentences ▹ Number of tokens per chunk ▹ Set of chunks |
| |
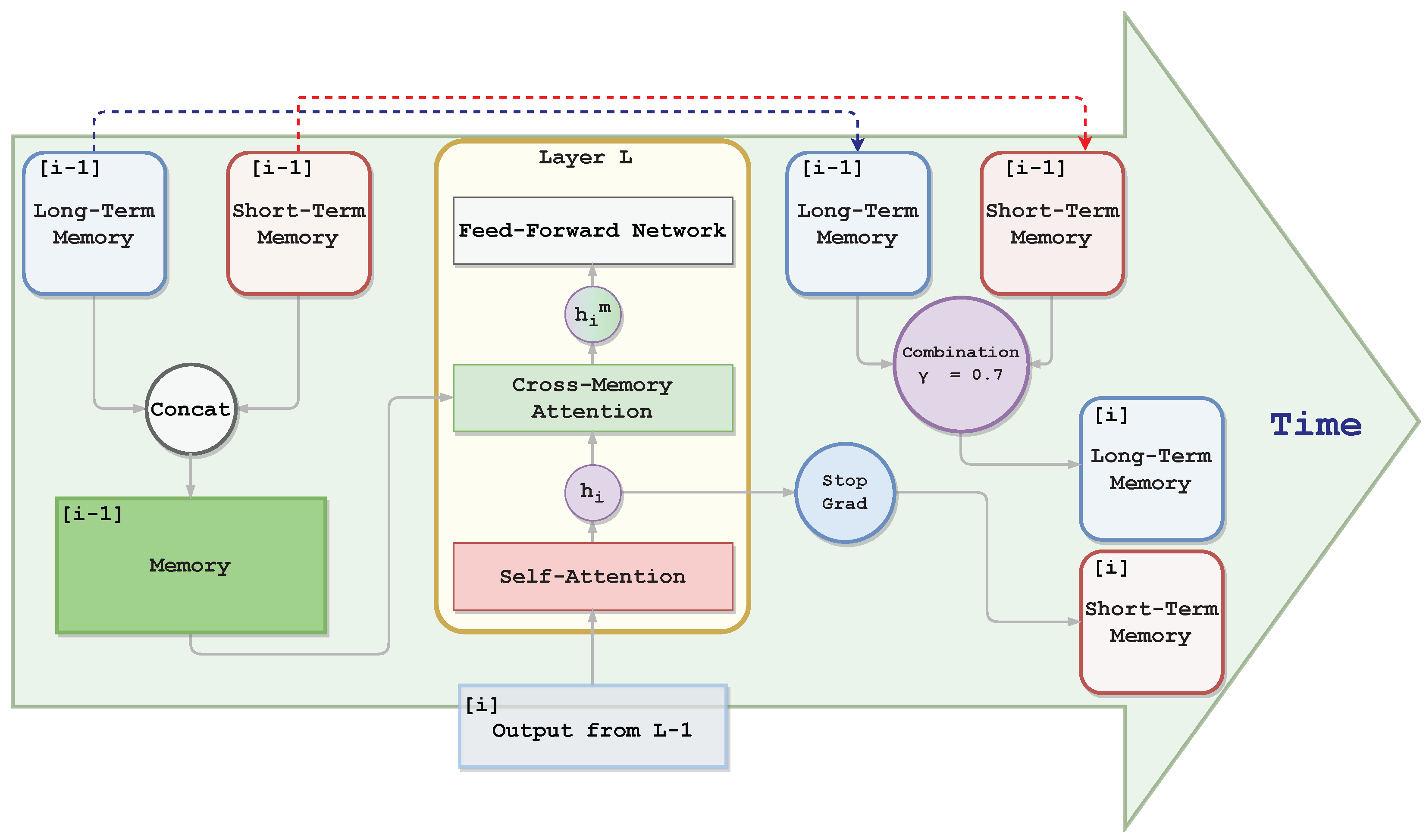
4.2. Model Architecture
4.2.1. Cross-Memory Attention
4.2.2. Memory Writing
4.2.3. Long-Term Memory
4.3. Training and Inference
4.4. Space Complexity
5. Experiments
5.1. Evaluation Datasets and Training Settings
5.2. Baselines
- Full training. To understand the contribution of our new memory, we examined Bart [33], the skeleton model that we had extended. Then, we contemplated SOTA models on Bart that do not perform any further pre-training, like ours. We chose Led [4] and Hepos [3], which leverage various efficient attention mechanisms and are capable of reading the entire long input. In particular, in Hepos, we considered locality-sensitive hashing (lsh) and sinkhorn. We lastly evaluated our model against Summ [41], a segmentation-based solution.
- Few-shot learning. We compared it with well-known low-resource abstractive summarizers. Pegasus [34] is a transformer-based model with a summarization-specific pre-training objective that allows for fast adaption through a few labeled samples. Mtl-Abs [37] combines transfer learning and meta-learning from multiple corpora by using adapter modules as bridges. To judge the contribution of document segmentation versus memory, we contrasted Emma with Se3 [26], a semantic self-segmentation approach for LDS under low-resource regimes with proven strength in data scarcity conditions. Similarly to our model, Se3 avoids truncation by creating highly correlated source–target chunk-level pairs with lengths modulated to fit into the GPU memory. Despite empowering the chunk definition process with deep metric learning following information retrieval techniques [42,43,44,45], Se3 represents a general pre-processing technique for any transformer where chunks are individually summarized and then concatenated (no memory extension or architectural changes). To ensure fairness, we refer to Se3+Bart.
5.3. Experimental Settings
5.4. Performance Evaluation
5.4.1. Full-Training Results
5.4.2. Few-Shot Learning
5.4.3. Ablation Studies
- w/Backprop: We attempted not to stop the backpropagation within the current chunk but allowed it to go back in time to previous steps. Results show a performance drop, probably due to the increased learning complexity. This approach is unexplored in memory-enhanced transformers and deserves greater research attention.
- w/Long-term memory: we removed the long-term memory module. Results worsened, ascertaining the contribution of this component to the final summary quality.
- Memory layers: We performed a series of experiments to determine which layers turned the memory on. The last two were the best ones, aligned with Rae and Razavi [46], where the authors claimed that TransformerXL operated better with memory only on layers in the second half of the encoder.
5.5. Analysis of the GPU Impact
5.5.1. GPU Memory Usage
5.5.2. Chunk Size Analysis
5.6. Human Evaluation
6. Conclusions
7. Limitations and Future Directions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| LDS | Long document summarization |
| LSH | Locality-sensitive hashing |
Appendix A. References to Models and Datasets

{kind=link}
{kind=link}
{kind=link}
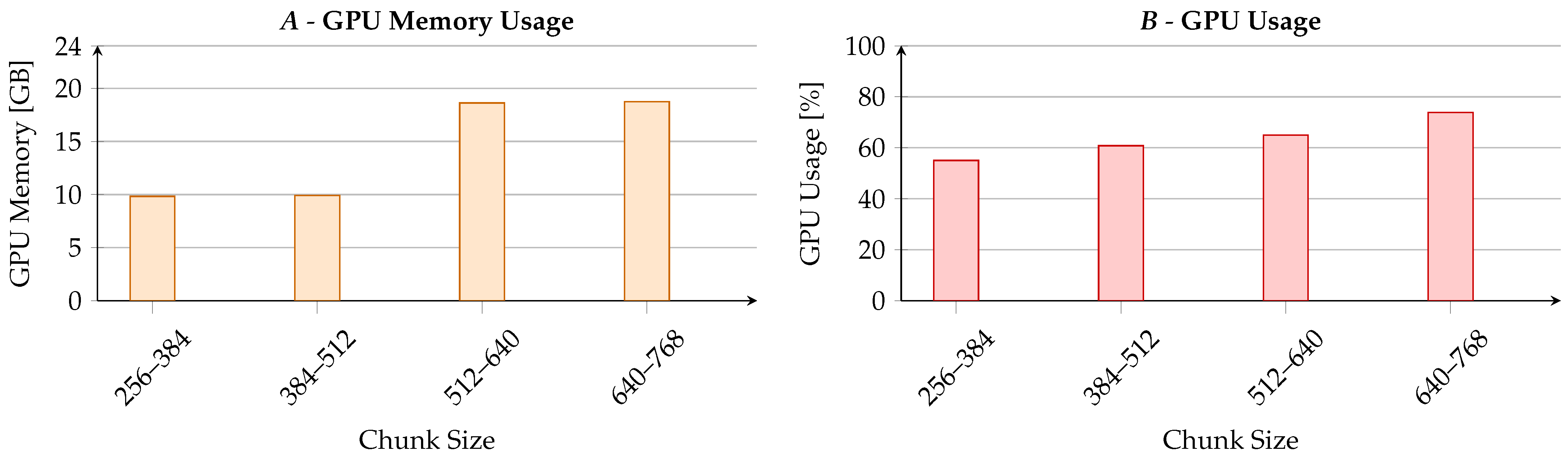{kind=link}
{kind=link}
{kind=link}
Appendix B. Human Evaluation Insights

References
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is All you Need. In Proceedings of the Advances in Neural Information Processing Systems 30: Annual Conference on Neural Information Processing Systems 2017, Long Beach, CA, USA, 4–9 December 2017; Guyon, I., von Luxburg, U., Bengio, S., Wallach, H.M., Fergus, R., Vishwanathan, S.V.N., Garnett, R., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2017; pp. 5998–6008. [Google Scholar]
- Choromanski, K.M.; Likhosherstov, V.; Dohan, D.; Song, X.; Gane, A.; Sarlós, T.; Hawkins, P.; Davis, J.Q.; Mohiuddin, A.; Kaiser, L.; et al. Rethinking Attention with Performers. In Proceedings of the 9th International Conference on Learning Representations, ICLR 2021, Virtual Event, Austria, 3–7 May 2021. [Google Scholar]
- Huang, L.; Cao, S.; Parulian, N.; Ji, H.; Wang, L. Efficient Attentions for Long Document Summarization. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Online, 6–11 June 2021; Association for Computational Linguistics: Cedarville, OH, USA, 2021; pp. 1419–1436. [Google Scholar] [CrossRef]
- Beltagy, I.; Peters, M.E.; Cohan, A. Longformer: The Long-Document Transformer. arXiv 2020, arXiv:2004.05150. [Google Scholar]
- Dai, Z.; Yang, Z.; Yang, Y.; Carbonell, J.G.; Le, Q.V.; Salakhutdinov, R. Transformer-XL: Attentive Language Models beyond a Fixed-Length Context. In Proceedings of the 57th Conference of the Association for Computational Linguistics, ACL 2019, Florence, Italy, 28 July–2 August 2019; Korhonen, A., Traum, D.R., Màrquez, L., Eds.; Volume 1: Long Papers. Association for Computational Linguistics: Cedarville, OH, USA, 2019; pp. 2978–2988. [Google Scholar] [CrossRef] [Green Version]
- Rae, J.W.; Potapenko, A.; Jayakumar, S.M.; Hillier, C.; Lillicrap, T.P. Compressive Transformers for Long-Range Sequence Modelling. In Proceedings of the 8th International Conference on Learning Representations, ICLR 2020, Addis Ababa, Ethiopia, 26–30 April 2020. [Google Scholar]
- Floridi, L.; Chiriatti, M. GPT-3: Its Nature, Scope, Limits, and Consequences. Minds Mach. 2020, 30, 681–694. [Google Scholar] [CrossRef]
- Devlin, J.; Chang, M.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, NAACL-HLT 2019, Minneapolis, MN, USA, 2–7 June 2019; Burstein, J., Doran, C., Solorio, T., Eds.; Volume 1 (Long and Short Papers). Association for Computational Linguistics: Cedarville, OH, USA, 2019; pp. 4171–4186. [Google Scholar] [CrossRef]
- Liu, Y.; Ott, M.; Goyal, N.; Du, J.; Joshi, M.; Chen, D.; Levy, O.; Lewis, M.; Zettlemoyer, L.; Stoyanov, V. RoBERTa: A Robustly Optimized BERT Pretraining Approach. arXiv 2019, arXiv:1907.11692. [Google Scholar]
- Raffel, C.; Shazeer, N.; Roberts, A.; Lee, K.; Narang, S.; Matena, M.; Zhou, Y.; Li, W.; Liu, P.J. Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer. J. Mach. Learn. Res. 2020, 21, 140:1–140:67. [Google Scholar]
- Zaheer, M.; Guruganesh, G.; Dubey, K.A.; Ainslie, J.; Alberti, C.; Ontañón, S.; Pham, P.; Ravula, A.; Wang, Q.; Yang, L.; et al. Big Bird: Transformers for Longer Sequences. In Proceedings of the Advances in Neural Information Processing Systems 33: Annual Conference on Neural Information Processing Systems 2020, NeurIPS 2020, Virtual, 6–12 December 2020. [Google Scholar]
- Xiong, Y.; Zeng, Z.; Chakraborty, R.; Tan, M.; Fung, G.; Li, Y.; Singh, V. Nyströmformer: A Nystöm-based Algorithm for Approximating Self-Attention. In Proceedings of the AAAI Conference on Artificial Intelligence, Online, 3 February 2021; National Institutes of Health (NIH) Public Access 2021. Volume 16, p. 14138. [Google Scholar]
- Goyal, T.; Li, J.J.; Durrett, G. News Summarization and Evaluation in the Era of GPT-3. arXiv 2022, arXiv:2209.12356. [Google Scholar] [CrossRef]
- Graves, A.; Wayne, G.; Danihelka, I. Neural Turing Machines. arXiv 2014, arXiv:1410.5401. [Google Scholar]
- Gülçehre, Ç.; Chandar, S.; Cho, K.; Bengio, Y. Dynamic Neural Turing Machine with Continuous and Discrete Addressing Schemes. Neural Comput. 2018, 30, 857–884. [Google Scholar] [CrossRef]
- Graves, A.; Wayne, G.; Reynolds, M.; Harley, T.; Danihelka, I.; Grabska-Barwinska, A.; Colmenarejo, S.G.; Grefenstette, E.; Ramalho, T.; Agapiou, J.P.; et al. Hybrid computing using a neural network with dynamic external memory. Nature 2016, 538, 471–476. [Google Scholar] [CrossRef] [PubMed]
- Moro, G.; Pagliarani, A.; Pasolini, R.; Sartori, C. Cross-domain & In-domain Sentiment Analysis with Memory-based Deep Neural Networks. In Proceedings of the IC3K 2018, Seville, Spain, 18–20 September 2018; SciTePress: Setúbal, Portugal, 2018; Volume 1, pp. 127–138. [Google Scholar] [CrossRef]
- Ding, S.; Shang, J.; Wang, S.; Sun, Y.; Tian, H.; Wu, H.; Wang, H. ERNIE-Doc: A Retrospective Long-Document Modeling Transformer. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing, ACL/IJCNLP 2021, Virtual Event, 1–6 August 2021; Zong, C., Xia, F., Li, W., Navigli, R., Eds.; Volume 1: Long Papers. Association for Computational Linguistics: Cedarville, OH, USA, 2021; Volume 1, pp. 2914–2927. [Google Scholar] [CrossRef]
- Martins, P.H.; Marinho, Z.; Martins, A.F.T. ∞-former: Infinite Memory Transformer. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), ACL 2022, Dublin, Ireland, 22–27 May 2022; Muresan, S., Nakov, P., Villavicencio, A., Eds.; Association for Computational Linguistics: Cedarville, OH, USA, 2022; pp. 5468–5485. [Google Scholar]
- Martins, A.F.T.; Farinhas, A.; Treviso, M.V.; Niculae, V.; Aguiar, P.M.Q.; Figueiredo, M.A.T. Sparse and Continuous Attention Mechanisms. In Proceedings of the Advances in Neural Information Processing Systems 33: Annual Conference on Neural Information Processing Systems 2020, NeurIPS 2020, Virtual, 6–12 December 2020. [Google Scholar]
- Borgeaud, S.; Mensch, A.; Hoffmann, J.; Cai, T.; Rutherford, E.; Millican, K.; van den Driessche, G.; Lespiau, J.; Damoc, B.; Clark, A.; et al. Improving Language Models by Retrieving from Trillions of Tokens. In Proceedings of the International Conference on Machine Learning, ICML 2022, Baltimore, MA, USA, 17–23 July 2022; Chaudhuri, K., Jegelka, S., Song, L., Szepesvári, C., Niu, G., Sabato, S., Eds.; Proceedings of Machine Learning Research 2022. Volume 162, pp. 2206–2240. [Google Scholar]
- Frisoni, G.; Mizutani, M.; Moro, G.; Valgimigli, L. BioReader: A Retrieval-Enhanced Text-to-Text Transformer for Biomedical Literature. In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, Abu Dhabi, United Arab Emirates, 7–11 December 2022; Association for Computational Linguistics: Cedarville, OH, USA, 2022; pp. 770–5793. [Google Scholar]
- Rohde, T.; Wu, X.; Liu, Y. Hierarchical Learning for Generation with Long Source Sequences. arXiv 2021, arXiv:2104.07545. [Google Scholar]
- Zhang, Y.; Ni, A.; Mao, Z.; Wu, C.H.; Zhu, C.; Deb, B.; Awadallah, A.H.; Radev, D.R.; Zhang, R. Summ^N: A Multi-Stage Summarization Framework for Long Input Dialogues and Documents. arXiv 2021, arXiv:2110.10150. [Google Scholar]
- Wu, J.; Ouyang, L.; Ziegler, D.M.; Stiennon, N.; Lowe, R.; Leike, J.; Christiano, P.F. Recursively Summarizing Books with Human Feedback. arXiv 2021, arXiv:2109.10862. [Google Scholar]
- Moro, G.; Ragazzi, L. Semantic Self-Segmentation for Abstractive Summarization of Long Documents in Low-Resource Regimes. In Proceedings of the Thirty-Sixth AAAI Conference on Artificial Intelligence, AAAI 2022, Virtual Event, 22 February–1 March 2022; Association for the Advancement of Artificial Intelligence Press: Palo Alto, CA, USA, 2022; pp. 11085–11093. [Google Scholar]
- Ivgi, M.; Shaham, U.; Berant, J. Efficient Long-Text Understanding with Short-Text Models. arXiv 2022, arXiv:2208.00748. [Google Scholar] [CrossRef]
- Liu, Y.; Ni, A.; Nan, L.; Deb, B.; Zhu, C.; Awadallah, A.H.; Radev, D.R. Leveraging Locality in Abstractive Text Summarization. arXiv 2022, arXiv:2205.12476. [Google Scholar] [CrossRef]
- Bajaj, A.; Dangati, P.; Krishna, K.; Ashok Kumar, P.; Uppaal, R.; Windsor, B.; Brenner, E.; Dotterrer, D.; Das, R.; McCallum, A. Long Document Summarization in a Low Resource Setting using Pretrained Language Models. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing: Student Research Workshop; Association for Computational Linguistics: Cedarville, OH, USA, 2021; pp. 71–80. [Google Scholar] [CrossRef]
- Mao, Z.; Wu, C.H.; Ni, A.; Zhang, Y.; Zhang, R.; Yu, T.; Deb, B.; Zhu, C.; Awadallah, A.H.; Radev, D.R. DYLE: Dynamic Latent Extraction for Abstractive Long-Input Summarization. arXiv 2021, arXiv:2110.08168. [Google Scholar]
- Moro, G.; Ragazzi, L.; Valgimigli, L.; Freddi, D. Discriminative Marginalized Probabilistic Neural Method for Multi-Document Summarization of Medical Literature. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), ACL 2022, Dublin, Ireland, 22–27 May 2022; Muresan, S., Nakov, P., Villavicencio, A., Eds.; Association for Computational Linguistics: Cedarville, OH, USA, 2022; pp. 180–189. [Google Scholar]
- Tay, Y.; Dehghani, M.; Bahri, D.; Metzler, D. Efficient Transformers: A Survey. ACM Comput. Surv. 2023, 55, 109:1–109:28. [Google Scholar] [CrossRef]
- Lewis, M.; Liu, Y.; Goyal, N.; Ghazvininejad, M.; Mohamed, A.; Levy, O.; Stoyanov, V.; Zettlemoyer, L. BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, ACL 2020, Online, 5–10 July 2020; Jurafsky, D., Chai, J., Schluter, N., Tetreault, J.R., Eds.; Association for Computational Linguistics: Cedarville, OH, USA, 2020; pp. 7871–7880. [Google Scholar] [CrossRef]
- Zhang, J.; Zhao, Y.; Saleh, M.; Liu, P.J. PEGASUS: Pre-training with Extracted Gap-sentences for Abstractive Summarization. In Proceedings of the 37th International Conference on Machine Learning, ICML 2020, Virtual Event, 13–18 July 2020; Proceedings of Machine Learning Research 2020. Volume 119, pp. 11328–11339. [Google Scholar]
- Cohan, A.; Dernoncourt, F.; Kim, D.S.; Bui, T.; Kim, S.; Chang, W.; Goharian, N. A Discourse-Aware Attention Model for Abstractive Summarization of Long Documents. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 2 (Short Papers); Association for Computational Linguistics: New Orleans, LA, USA, 2018; pp. 615–621. [Google Scholar] [CrossRef] [Green Version]
- Kornilova, A.; Eidelman, V. BillSum: A Corpus for Automatic Summarization of US Legislation. In Proceedings of the 2nd Workshop on New Frontiers in Summarization; Association for Computational Linguistics: Hong Kong, China, 2019; pp. 48–56. [Google Scholar] [CrossRef] [Green Version]
- Chen, Y.; Shuai, H. Meta-Transfer Learning for Low-Resource Abstractive Summarization. In Proceedings of the Thirty-Fifth AAAI Conference on Artificial Intelligence, AAAI 2021, Thirty-Third Conference on Innovative Applications of Artificial Intelligence, IAAI 2021, The Eleventh Symposium on Educational Advances in Artificial Intelligence, EAAI 2021, Virtual Event, 2–9 February 2021; Association for the Advancement of Artificial Intelligence Press: Palo Alto, CA, USA, 2021; pp. 12692–12700. [Google Scholar]
- Lin, C.Y. ROUGE: A Package for Automatic Evaluation of Summaries. In Proceedings of the Text Summarization Branches Out; Association for Computational Linguistics: Barcelona, Spain, 2004; pp. 74–81. [Google Scholar]
- Moro, G.; Ragazzi, L.; Valgimigli, L. Carburacy: Summarization Models Tuning and Comparison in Eco-Sustainable Regimes with a Novel Carbon-Aware Accuracy. In Proceedings of the Thirty-Seventh AAAI Conference on Artificial Intelligence, AAAI 2023, Washington, DC, USA, 7–14 February 2023; Association for the Advancement of Artificial Intelligence Press: Palo Alto, CA, USA, 2023; pp. 1–9. [Google Scholar]
- Frisoni, G.; Carbonaro, A.; Moro, G.; Zammarchi, A.; Avagnano, M. NLG-Metricverse: An End-to-End Library for Evaluating Natural Language Generation. In Proceedings of the 29th International Conference on Computational Linguistics; International Committee on Computational Linguistics: Gyeongju, Republic of Korea, 2022; pp. 3465–3479. [Google Scholar]
- Zhang, Y.; Ni, A.; Mao, Z.; Wu, C.H.; Zhu, C.; Deb, B.; Awadallah, A.; Radev, D.; Zhang, R. SummN: A Multi-Stage Summarization Framework for Long Input Dialogues and Documents. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Dublin, Ireland, 22–27 May 2022; Association for Computational Linguistics: Dublin, Ireland, 2022; pp. 1592–1604. [Google Scholar] [CrossRef]
- Moro, G.; Valgimigli, L. Efficient Self-Supervised Metric Information Retrieval: A Bibliography Based Method Applied to COVID Literature. Sensors 2021, 21, 6430. [Google Scholar] [CrossRef]
- Moro, G.; Valgimigli, L.; Rossi, A.; Casadei, C.; Montefiori, A. Self-supervised Information Retrieval Trained from Self-generated Sets of Queries and Relevant Documents. In Proceedings of the Similarity Search and Applications—15th International Conference, SISAP 2022, Bologna, Italy, 5–7 October 2022; Skopal, T., Falchi, F., Lokoc, J., Sapino, M.L., Bartolini, I., Patella, M., Eds.; Lecture Notes in Computer Science. Springer: Cham, Switzerland, 2022; Volume 13590, pp. 283–290. [Google Scholar] [CrossRef]
- Moro, G.; Salvatori, S. Deep Vision-Language Model for Efficient Multi-modal Similarity Search in Fashion Retrieval. In Proceedings of the SISAP 2022, Bologna, Italy, 5–7 October 2022; Lecture Notes in Computer Science. Springer: Cham, Switzerland, 2022; Volume 13590, pp. 40–53. [Google Scholar] [CrossRef]
- Meng, Z.; Liu, F.; Shareghi, E.; Su, Y.; Collins, C.; Collier, N. Rewire-then-Probe: A Contrastive Recipe for Probing Biomedical Knowledge of Pre-trained Language Models. In Proceedings of the ACL (1), Association for Computational Linguistics, Dublin, Ireland, 22–27 May 2022; pp. 4798–4810. [Google Scholar]
- Rae, J.W.; Razavi, A. Do Transformers Need Deep Long-Range Memory? In Proceedings of the ACL, Association for Computational Linguistics, Online, 5–10 July 2020; pp. 7524–7529. [Google Scholar]
- Louviere, J.J.; Woodworth, G.G. Best-worst scaling: A model for the largest difference judgments. In Technical Report; Working paper; University of Alberta: Edmonton, AB, Canada, 1991. [Google Scholar]
- Louviere, J.J.; Flynn, T.N.; Marley, A.A.J. Best-Worst Scaling: Theory, Methods and Applications; Cambridge University Press: Cambridge, UK, 2015. [Google Scholar]
- Domeniconi, G.; Moro, G.; Pagliarani, A.; Pasolini, R. Markov Chain based Method for In-Domain and Cross-Domain Sentiment Classification. In Proceedings of the KDIR, Lisbon, Portugal, 12–14 November 2015; SciTePress: Setúbal, Portugal, 2015; pp. 127–137. [Google Scholar]
- Domeniconi, G.; Moro, G.; Pagliarani, A.; Pasolini, R. On Deep Learning in Cross-Domain Sentiment Classification. In Proceedings of the 9th International Joint Conference on Knowledge Discovery, Knowledge Engineering and Knowledge Management—(Volume 1), Funchal, Portugal, 1–3 November 2017; Fred, A.L.N., Filipe, J., Eds.; SciTePress: Setúbal, Portugal, 2017; pp. 50–60. [Google Scholar] [CrossRef]
- Frisoni, G.; Moro, G.; Carbonaro, A. Learning Interpretable and Statistically Significant Knowledge from Unlabeled Corpora of Social Text Messages: A Novel Methodology of Descriptive Text Mining. In Proceedings of the 9th International Conference on Data Science, Technology and Applications (DATA 2020), Online, 7–9 July 2020; SciTePress: Setúbal, Portugal, 2020; pp. 121–134. [Google Scholar]
- Frisoni, G.; Moro, G. Phenomena Explanation from Text: Unsupervised Learning of Interpretable and Statistically Significant Knowledge. In Proceedings of the 9th International Conference on Data Science, Technology and Applications (DATA 2020), Online, 7–9 July 2020; Revised Selected Papers. Volume 1446, pp. 293–318. [Google Scholar] [CrossRef]
- Frisoni, G.; Moro, G.; Carbonaro, A. A Survey on Event Extraction for Natural Language Understanding: Riding the Biomedical Literature Wave. IEEE Access 2021, 9, 160721–160757. [Google Scholar] [CrossRef]
- Frisoni, G.; Moro, G.; Balzani, L. Text-to-Text Extraction and Verbalization of Biomedical Event Graphs. In Proceedings of the 29th International Conference on Computational Linguistics; International Committee on Computational Linguistics: Gyeongju, Republic of Korea, 2022; pp. 2692–2710. [Google Scholar]
- Frisoni, G.; Italiani, P.; Salvatori, S.; Moro, G. Cogito Ergo Summ: Abstractive Summarization of Biomedical Papers via Semantic Parsing Graphs and Consistency Rewards. In Proceedings of the AAAI, Washington, DC, USA, 7–14 February 2023; pp. 1–9. [Google Scholar]
- Frisoni, G.; Italiani, P.; Boschi, F.; Moro, G. Enhancing Biomedical Scientific Reviews Summarization with Graph—Based Factual Evidence Extracted from Papers. In Proceedings of the 11th International Conference on Data Science, Technology and Applications, DATA 2022, Lisbon, Portugal, 11–13 July 2022; pp. 168–179. [Google Scholar] [CrossRef]
- Ferrari, I.; Frisoni, G.; Italiani, P.; Moro, G.; Sartori, C. Comprehensive Analysis of Knowledge Graph Embedding Techniques Benchmarked on Link Prediction. Electronics 2022, 11, 3866. [Google Scholar] [CrossRef]
- Cao, J.; Fang, J.; Meng, Z.; Liang, S. Knowledge Graph Embedding: A Survey from the Perspective of Representation Spaces. arXiv 2022, arXiv:2211.03536. [Google Scholar]
- Frisoni, G.; Moro, G.; Carlassare, G.; Carbonaro, A. Unsupervised Event Graph Representation and Similarity Learning on Biomedical Literature. Sensors 2022, 22, 3. [Google Scholar] [CrossRef]
- Chen, G.; Fang, J.; Meng, Z.; Zhang, Q.; Liang, S. Multi-Relational Graph Representation Learning with Bayesian Gaussian Process Network. In Proceedings of the AAAI, Virtual Event, 22 February–1 March 2022; pp. 5530–5538. [Google Scholar]
- Singh, R.; Meduri, V.V.; Elmagarmid, A.K.; Madden, S.; Papotti, P.; Quiané-Ruiz, J.; Solar-Lezama, A.; Tang, N. Generating Concise Entity Matching Rules. In Proceedings of the SIGMOD Conference, Chicago, IL, USA, 14–19 May 2017; pp. 1635–1638. [Google Scholar]
- Domeniconi, G.; Masseroli, M.; Moro, G.; Pinoli, P. Cross-organism learning method to discover new gene functionalities. Comput. Methods Programs Biomed. 2016, 126, 20–34. [Google Scholar] [CrossRef] [PubMed]
- Moro, G.; Masseroli, M. Gene function finding through cross-organism ensemble learning. BioData Min. 2021, 14, 14. [Google Scholar] [CrossRef] [PubMed]
- Monti, G.; Moro, G. Multidimensional Range Query and Load Balancing in Wireless Ad Hoc and Sensor Networks. In Proceedings of the IEEE Computer Society Peer-to-Peer Computing, Aachen, Germany, 8–11 September 2008; pp. 205–214. [Google Scholar]
- Lodi, S.; Moro, G.; Sartori, C. Distributed data clustering in multi-dimensional peer-to-peer networks. In Proceedings of the Database Technologies 2010, Twenty-First Australasian Database Conference (ADC 2010), Brisbane, Australia, 18–22 January 2010; Volume 104, pp. 171–178. [Google Scholar]
- Moro, G.; Monti, G. W-Grid: A scalable and efficient self-organizing infrastructure for multi-dimensional data management, querying and routing in wireless data-centric sensor networks. J. Netw. Comput. Appl. 2012, 35, 1218–1234. [Google Scholar] [CrossRef]
- Cerroni, W.; Moro, G.; Pirini, T.; Ramilli, M. Peer-to-Peer Data Mining Classifiers for Decentralized Detection of Network Attacks. In Proceedings of the Australasian Database Conference, Adelaide, Australia, 29 January–1 February 2013; Volume 137, pp. 101–108. [Google Scholar]
- Kryscinski, W.; McCann, B.; Xiong, C.; Socher, R. Evaluating the Factual Consistency of Abstractive Text Summarization. In Proceedings of the EMNLP (1), Association for Computational Linguistics, Online Event, 16–20 November 2020; pp. 9332–9346. [Google Scholar]
- Saeed, M.; Traub, N.; Nicolas, M.; Demartini, G.; Papotti, P. Crowdsourced Fact-Checking at Twitter: How Does the Crowd Compare With Experts? In Proceedings of the CIKM, Atlanta, GA, USA, 17–21 October 2022; pp. 1736–1746. [Google Scholar]





| Dataset | Samples | Source | Target |
|---|---|---|---|
| #avg Words | #avg Words | ||
| GovReport | 19,466 | 9409.4 | 553.4 |
| PubMed | 133,215 | 3224.4 | 214.4 |
| BillSum | 23,455 | 1813 | 207.7 |
| GovReport | PubMed | Average | |||
|---|---|---|---|---|---|
| Model | R1/R2/RL | R1/R2/RL | |||
| Baselines | |||||
| Bart [33] | 52.83/20.50/50.14 | 40.29 | 45.36/18.74/40.26 | 34.33 | 37.31 |
| Hepos-lsh [3] | 55.00/21.13/51.67 | 41.63 | 48.12/21.06/42.72 | 36.80 | 39.99 |
| Hepos-sinkhorn [3] | 56.86/22.62/53.82 | 43.39 | 47.96/20.78/42.53 | 36.59 | 39.99 |
| Led [4] | 59.42/26.53/56.63 | 46.50 | 47.00/20.20/42.90 | 36.20 | 41.35 |
| Summ [41] | 56.77/23.25/53.90 | 43.64 | – | – | – |
| Ours | |||||
| Emma-base | 58.78/24.30/55.29 | 45.04 | 44.31/17.35/40.91 | 33.70 | 39.37 |
| Emma-large | 59.39/25.27/55.90 | 45.77 | 46.70/19.51/43.42 | 36.01 | 40.89 |
| BillSum (10) | BillSum (100) | Average | |||
|---|---|---|---|---|---|
| Model | R1/R2/RL | R1/R2/RL | |||
| Baselines | |||||
| Pegasus [34] | 40.48/18.49/27.27 | 28.52 | 44.78/26.40/34.40 | 34.99 | 31.76 |
| Mtl-Abs [37] | 41.22/18.61/26.33 | 28.47 | 45.29/22.74/29.56 | 32.24 | 30.36 |
| Se3 [26] | 46.58/22.03/28.23 | 31.93 | 49.88/26.84/33.33 | 36.34 | 34.14 |
| Ours | |||||
| Emma-base | 46.77/22.95/28.81 | 32.51 | 50.78/28.58/34.27 | 37.55 | 35.03 |
| GovReport | |||
|---|---|---|---|
| Model | R1 | R2 | RL |
| Full | 59.99 | 23.96 | 56.35 |
| w/Backprop | 41.44 | 12.66 | 39.98 |
| w/o Long-term memory | 58.83 | 22.61 | 55.03 |
| GovReport | |||
|---|---|---|---|
| Memory-Layer | R1 | R2 | RL |
| All | 58.71 | 23.18 | 55.73 |
| Last three | 59.22 | 24.10 | 55.96 |
| Last two | 59.99 | 23.96 | 56.35 |
| Last one | 58.76 | 22.91 | 55.51 |
| Chunk Size | R1 | R2 | RL |
|---|---|---|---|
| 256–384 | 58.43 | 23.44 | 54.31 |
| 384–512 | 60.92 | 25.21 | 56.93 |
| 512–640 | 61.65 | 26.50 | 58.12 |
| 640–768 | 61.46 | 26.15 | 58.21 |
| Model | GovReport | PubMed | Overall |
|---|---|---|---|
| Led | 22.67 | 42.33 | 32.50 |
| Emma | 77.33 | 57.67 | 67.50 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Moro, G.; Ragazzi, L.; Valgimigli, L.; Frisoni, G.; Sartori, C.; Marfia, G. Efficient Memory-Enhanced Transformer for Long-Document Summarization in Low-Resource Regimes. Sensors 2023, 23, 3542. https://doi.org/10.3390/s23073542
Moro G, Ragazzi L, Valgimigli L, Frisoni G, Sartori C, Marfia G. Efficient Memory-Enhanced Transformer for Long-Document Summarization in Low-Resource Regimes. Sensors. 2023; 23(7):3542. https://doi.org/10.3390/s23073542
Chicago/Turabian StyleMoro, Gianluca, Luca Ragazzi, Lorenzo Valgimigli, Giacomo Frisoni, Claudio Sartori, and Gustavo Marfia. 2023. "Efficient Memory-Enhanced Transformer for Long-Document Summarization in Low-Resource Regimes" Sensors 23, no. 7: 3542. https://doi.org/10.3390/s23073542