
Chained Deep Learning Using Generalized Cross-Entropy for Multiple Annotators Classification
 , , , and
, , , and
Abstract
:1. Introduction
2. Literature Review
3. Methods
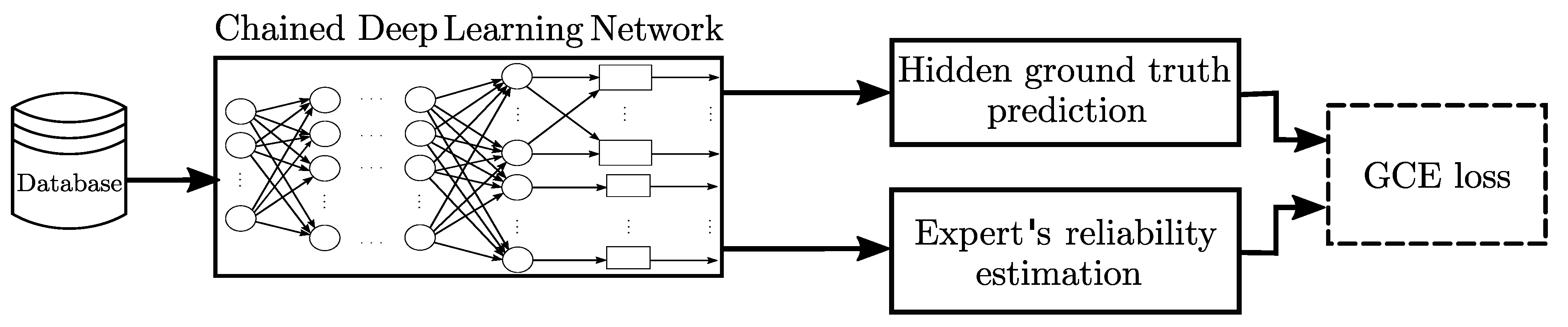
3.1. Generalized Cross-Entropy
3.2. Chained Deep Learning Fundamentals
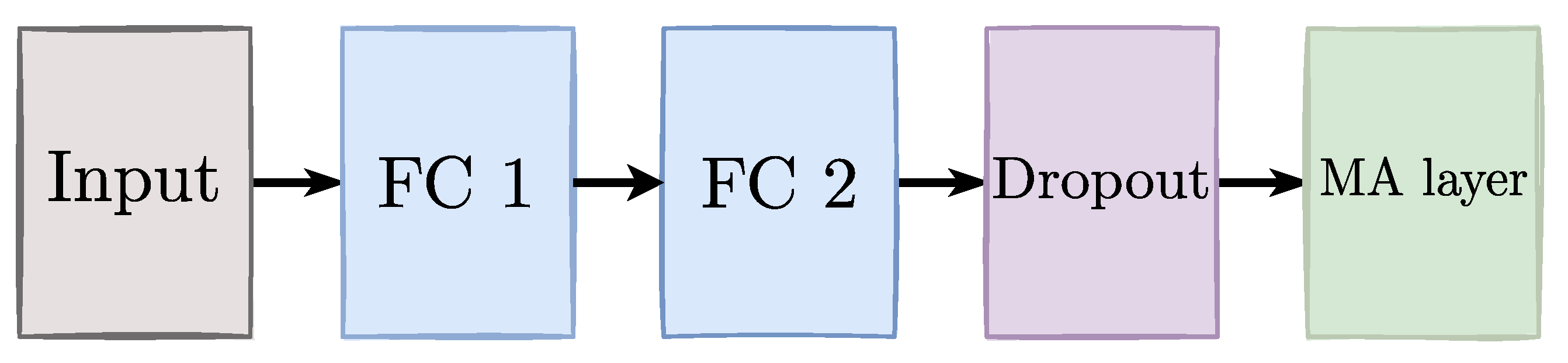
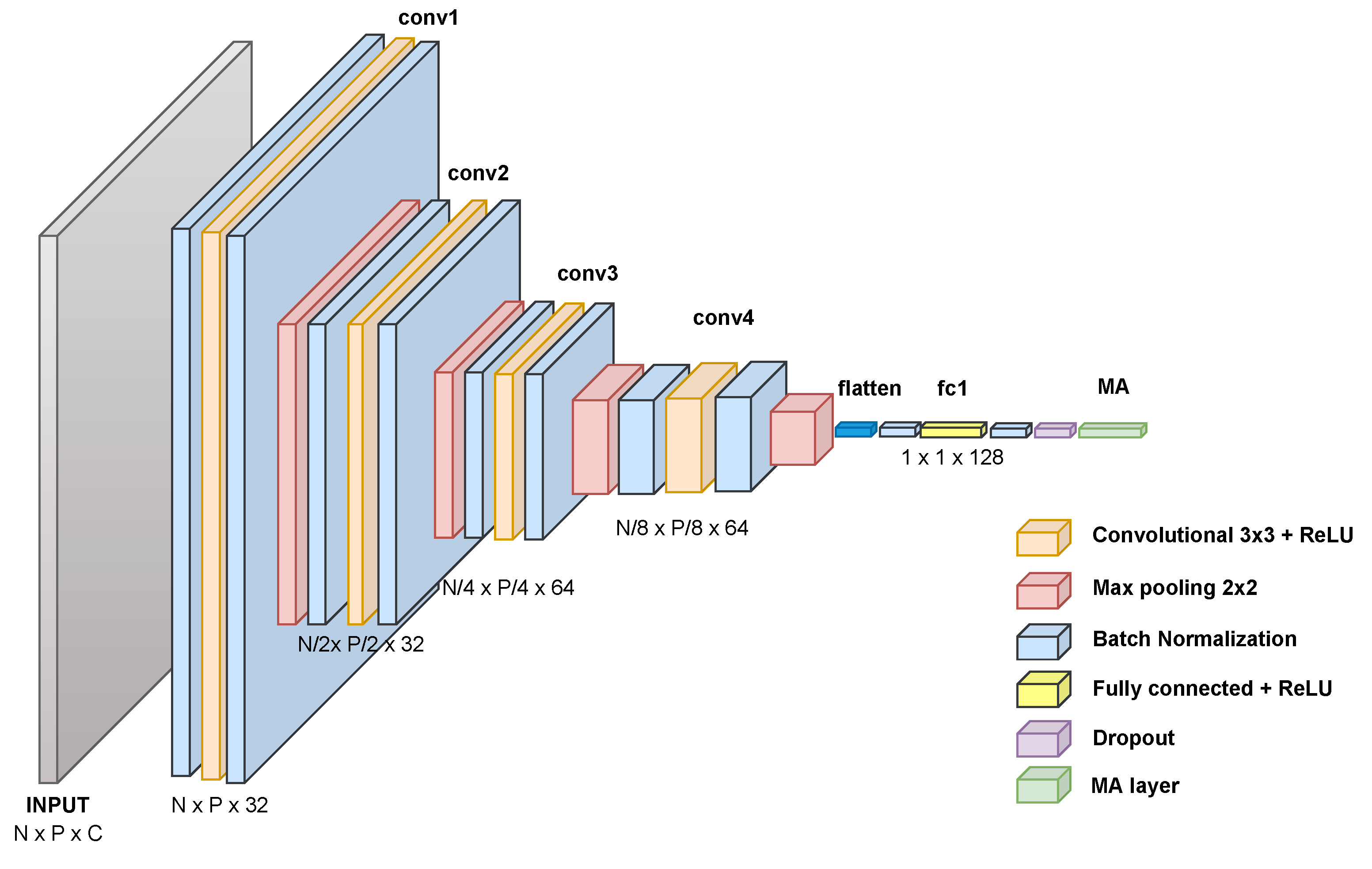
3.3. Generalized Cross-Entropy-Based Chained Deep Learning for Multiple Annotators
4. Experimental Set-Up
4.1. Tested Datasets
4.2. Provided and Simulated Annotations
- Define Q deterministic functions and their combination parameters .
- Compute , where is the n-th component of , being the 1-D representation of the input features in by using t-SNE approach [29].
- Calculate , where is the sigmoid function.
- Finally, find the r-th label as , where is a flipped version of the actual label .
4.3. Performance Measures, Method Comparison, and Training
5. Results and Discussion
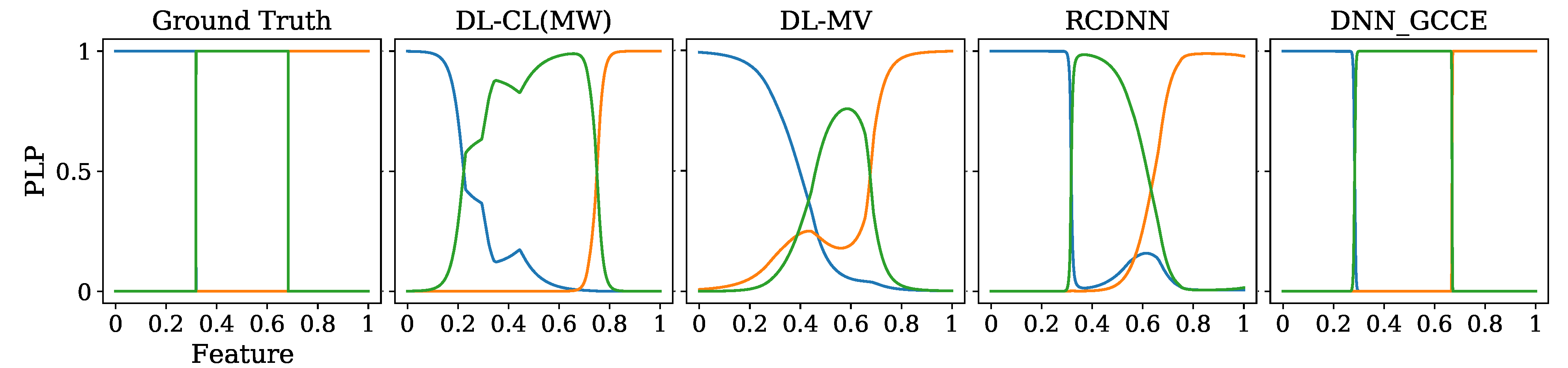
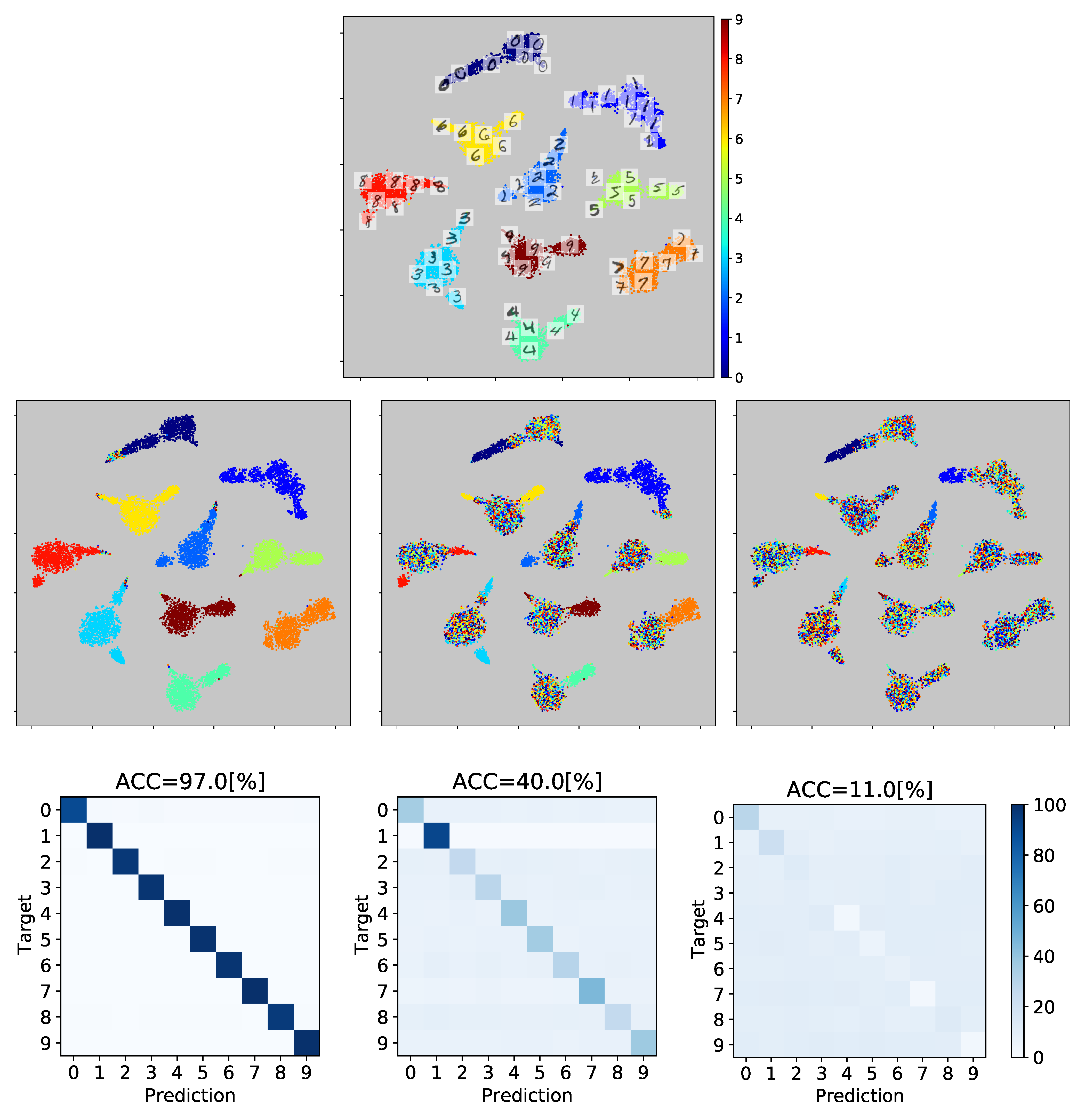
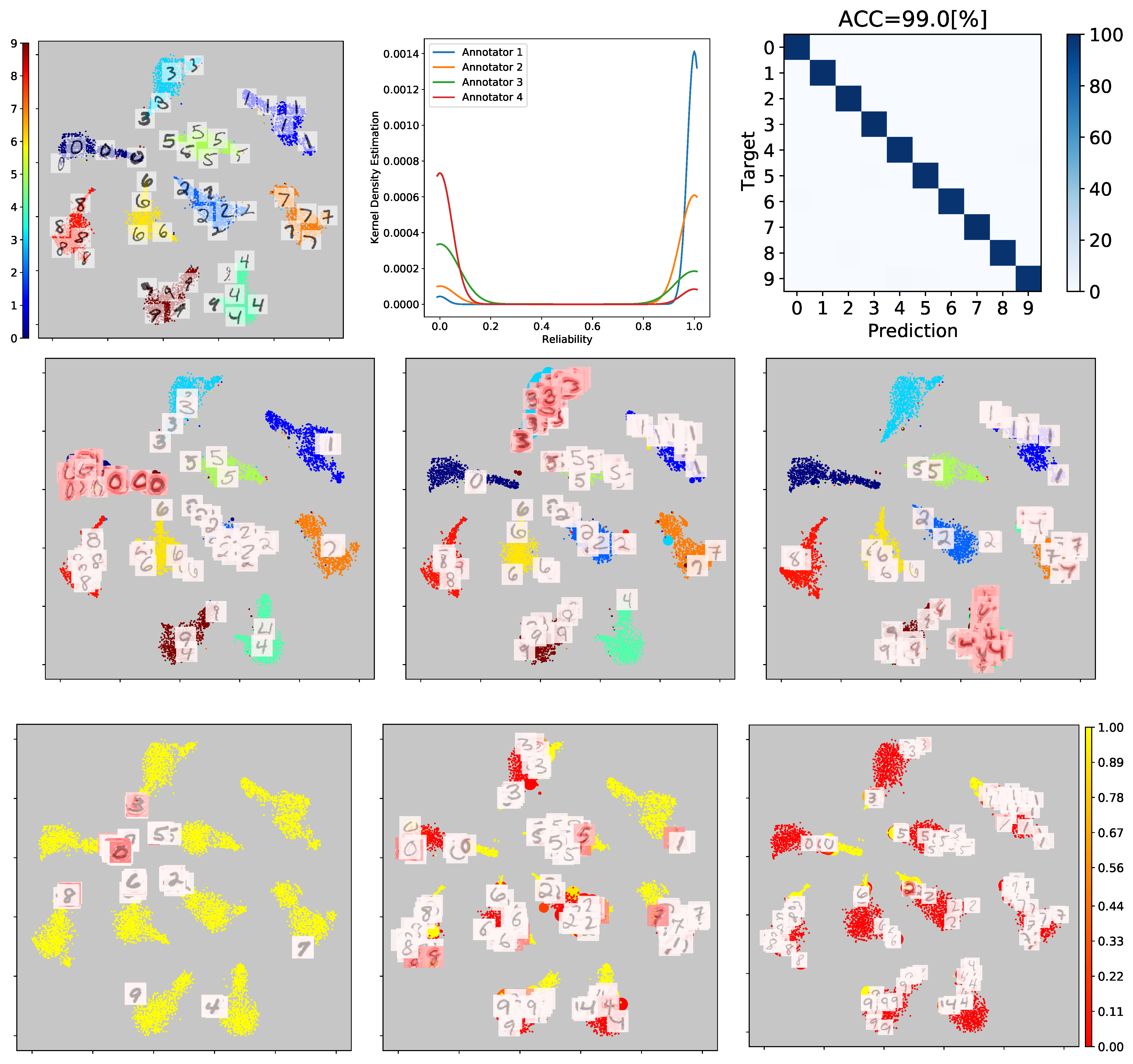
5.1. Reliability Estimation and Visual Inspection Results
5.2. Method Comparison Results for Multiple-Annotator Classification
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Zhang, J.; Sheng, V.S.; Wu, J. Crowdsourced label aggregation using bilayer collaborative clustering. IEEE Trans. Neural Netw. Learn. Syst. 2019, 30, 3172–3185. [Google Scholar] [CrossRef] [PubMed]
- Parvat, A.; Chavan, J.; Kadam, S.; Dev, S.; Pathak, V. A survey of deep-learning frameworks. In Proceedings of the 2017 International Conference on Inventive Systems and Control (ICISC), Coimbatore, India, 19–20 January 2017; pp. 1–7. [Google Scholar]
- Liu, Y.; Zhang, W.; Yu, Y. Truth inference with a deep clustering-based aggregation model. IEEE Access 2020, 8, 16662–16675. [Google Scholar]
- Gil-Gonzalez, J.; Orozco-Gutierrez, A.; Alvarez-Meza, A. Learning from multiple inconsistent and dependent annotators to support classification tasks. Neurocomputing 2021, 423, 236–247. [Google Scholar] [CrossRef]
- Sung, H.E.; Chen, C.K.; Xiao, H.; Lin, S.D. A Classification Model for Diverse and Noisy Labelers. In Proceedings of the Pacific-Asia Conference on Knowledge Discovery and Data Mining; Springer: Berlin/Heidelberg, Germany, 2017; pp. 58–69. [Google Scholar]
- Yan, Y.; Rosales, R.; Fung, G.; Subramanian, R.; Dy, J. Learning from multiple annotators with varying expertise. Mach. Learn. 2014, 95, 291–327. [Google Scholar] [CrossRef] [Green Version]
- Xu, G.; Ding, W.; Tang, J.; Yang, S.; Huang, G.Y.; Liu, Z. Learning effective embeddings from crowdsourced labels: An educational case study. In Proceedings of the 2019 IEEE 35th International Conference on Data Engineering (ICDE), Macao, China, 8–11 April 2019; pp. 1922–1927. [Google Scholar]
- Tanno, R.; Saeedi, A.; Sankaranarayanan, S.; Alexander, D.C.; Silberman, N. Learning from noisy labels by regularized estimation of annotator confusion. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 11244–11253. [Google Scholar]
- Davani, A.M.; Díaz, M.; Prabhakaran, V. Dealing with disagreements: Looking beyond the majority vote in subjective annotations. Trans. Assoc. Comput. Linguist. 2022, 10, 92–110. [Google Scholar] [CrossRef]
- Kara, Y.E.; Genc, G.; Aran, O.; Akarun, L. Modeling annotator behaviors for crowd labeling. Neurocomputing 2015, 160, 141–156. [Google Scholar] [CrossRef]
- Cao, P.; Xu, Y.; Kong, Y.; Wang, Y. Max-mig: An information theoretic approach for joint learning from crowds. arXiv 2019, arXiv:1905.13436. [Google Scholar]
- Chen, Z.; Wang, H.; Sun, H.; Chen, P.; Han, T.; Liu, X.; Yang, J. Structured Probabilistic End-to-End Learning from Crowds. In Proceedings of the IJCAI, Yokohama, Japan, 7–21 January 2021; pp. 1512–1518. [Google Scholar]
- Ruiz, P.; Morales-Álvarez, P.; Molina, R.; Katsaggelos, A.K. Learning from crowds with variational Gaussian processes. Pattern Recognit. 2019, 88, 298–311. [Google Scholar] [CrossRef]
- G. Rodrigo, E.; Aledo, J.A.; Gámez, J.A. Machine learning from crowds: A systematic review of its applications. Wiley Interdiscip. Rev. Data Min. Knowl. Discov. 2019, 9, e1288. [Google Scholar] [CrossRef]
- Zhang, P.; Obradovic, Z. Learning from inconsistent and unreliable annotators by a gaussian mixture model and bayesian information criterion. In Proceedings of the Joint European Conference on Machine Learning and Knowledge Discovery in Databases, Athens, Greece, 5–9 September 2011; pp. 553–568. [Google Scholar]
- Zhang, J. Knowledge learning with crowdsourcing: A brief review and systematic perspective. IEEE/CAA J. Autom. Sin. 2022, 9, 749–762. [Google Scholar] [CrossRef]
- Zhu, T.; Pimentel, M.A.; Clifford, G.D.; Clifton, D.A. Unsupervised Bayesian inference to fuse biosignal sensory estimates for personalizing care. IEEE J. Biomed. Health Inform. 2018, 23, 47–58. [Google Scholar] [CrossRef] [PubMed]
- Song, H.; Kim, M.; Park, D.; Shin, Y.; Lee, J.G. Learning from noisy labels with deep neural networks: A survey. IEEE Trans. Neural Netw. Learn. Syst. 2022. [Google Scholar] [CrossRef] [PubMed]
- Cheng, L.; Zhou, X.; Zhao, L.; Li, D.; Shang, H.; Zheng, Y.; Pan, P.; Xu, Y. Weakly supervised learning with side information for noisy labeled images. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020, Proceedings, Part XXX 16; Springer: Berlin/Heidelberg, Germany, 2020; pp. 306–321. [Google Scholar]
- Lee, K.; Yun, S.; Lee, K.; Lee, H.; Li, B.; Shin, J. Robust inference via generative classifiers for handling noisy labels. In Proceedings of the International Conference on Machine Learning, PMLR, Long Beach, CA, USA, 9–15 June 2019; pp. 3763–3772. [Google Scholar]
- Chen, P.; Liao, B.B.; Chen, G.; Zhang, S. Understanding and utilizing deep neural networks trained with noisy labels. In Proceedings of the International Conference on Machine Learning, PMLR, Long Beach, CA, USA, 9–15 June 2019; pp. 1062–1070. [Google Scholar]
- Yu, X.; Han, B.; Yao, J.; Niu, G.; Tsang, I.; Sugiyama, M. How does disagreement help generalization against label corruption? In Proceedings of the International Conference on Machine Learning, PMLR, Long Beach, CA, USA, 9–15 June 2019; pp. 7164–7173. [Google Scholar]
- Lyu, X.; Wang, J.; Zeng, T.; Li, X.; Chen, J.; Wang, X.; Xu, Z. TSS-Net: Two-stage with sample selection and semi-supervised net for deep learning with noisy labels. In Proceedings of the Third International Conference on Intelligent Computing and Human-Computer Interaction (ICHCI 2022), SPIE, Guangzhou, China, 12–14 August 2022; Volume 12509, pp. 575–584. [Google Scholar]
- Shen, Y.; Sanghavi, S. Learning with bad training data via iterative trimmed loss minimization. In Proceedings of the International Conference on Machine Learning, PMLR, Long Beach, CA, USA, 9–15 June 2019; pp. 5739–5748. [Google Scholar]
- Ghosh, A.; Manwani, N.; Sastry, P. Making risk minimization tolerant to label noise. Neurocomputing 2015, 160, 93–107. [Google Scholar] [CrossRef] [Green Version]
- Ghosh, A.; Kumar, H.; Sastry, P.S. Robust loss functions under label noise for deep neural networks. In Proceedings of the AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017; Volume 31. [Google Scholar]
- Albarqouni, S.; Baur, C.; Achilles, F.; Belagiannis, V.; Demirci, S.; Navab, N. Aggnet: Deep learning from crowds for mitosis detection in breast cancer histology images. IEEE Trans. Med. Imaging 2016, 35, 1313–1321. [Google Scholar] [CrossRef] [PubMed]
- Rodrigues, F.; Pereira, F. Deep learning from crowds. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; Volume 32. [Google Scholar]
- Van der Maaten, L.; Hinton, G. Visualizing data using t-SNE. J. Mach. Learn. Res. 2008, 9, 2579–2605. [Google Scholar]
- Chattopadhay, A.; Sarkar, A.; Howlader, P.; Balasubramanian, V.N. Grad-cam++: Generalized gradient-based visual explanations for deep convolutional networks. In Proceedings of the 2018 IEEE Winter Conference on Applications of Computer Vision (WACV), Lake Tahoe, NV, USA, 12–15 March 2018; pp. 839–847. [Google Scholar]
- Rizos, G.; Schuller, B.W. Average jane, where art thou?–recent avenues in efficient machine learning under subjectivity uncertainty. In Proceedings of the International Conference on Information Processing and Management of Uncertainty in Knowledge-Based Systems, Lisbon, Portugal, 15–19 June 2020; pp. 42–55. [Google Scholar]
- Zhang, J.; Wu, X.; Sheng, V.S. Imbalanced multiple noisy labeling. IEEE Trans. Knowl. Data Eng. 2014, 27, 489–503. [Google Scholar] [CrossRef]
- Dawid, A.P.; Skene, A.M. Maximum likelihood estimation of observer error-rates using the EM algorithm. J. R. Stat. Soc. Ser. C (Appl. Stat.) 1979, 28, 20–28. [Google Scholar] [CrossRef]
- Raykar, V.C.; Yu, S.; Zhao, L.H.; Valadez, G.H.; Florin, C.; Bogoni, L.; Moy, L. Learning from crowds. J. Mach. Learn. Res. 2010, 11, 1297–1322. [Google Scholar]
- Groot, P.; Birlutiu, A.; Heskes, T. Learning from multiple annotators with Gaussian processes. In Proceedings of the International Conference on Artificial Neural Networks, Espoo, Finland, 14–17 June 2011; pp. 159–164. [Google Scholar]
- Xiao, H.; Xiao, H.; Eckert, C. Learning from multiple observers with unknown expertise. In Proceedings of the Pacific-Asia Conference on Knowledge Discovery and Data Mining, Gold Coast, Australia, 14–17 April 2013; pp. 595–606. [Google Scholar]
- Morales-Alvarez, P.; Ruiz, P.; Coughlin, S.; Molina, R.; Katsaggelos, A.K. Scalable variational Gaussian processes for crowdsourcing: Glitch detection in LIGO. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 44, 1534–1551. [Google Scholar] [CrossRef]
- Gil-Gonzalez, J.; Alvarez-Meza, A.; Orozco-Gutierrez, A. Learning from multiple annotators using kernel alignment. Pattern Recognit. Lett. 2018, 116, 150–156. [Google Scholar] [CrossRef]
- Morales-Álvarez, P.; Ruiz, P.; Santos-Rodríguez, R.; Molina, R.; Katsaggelos, A.K. Scalable and efficient learning from crowds with Gaussian processes. Inf. Fusion 2019, 52, 110–127. [Google Scholar] [CrossRef]
- Rodrigues, F.; Pereira, F.; Ribeiro, B. Sequence labeling with multiple annotators. Mach. Learn. 2014, 95, 165–181. [Google Scholar] [CrossRef] [Green Version]
- Wang, X.; Bi, J. Bi-convex optimization to learn classifiers from multiple biomedical annotations. IEEE/ACM Trans. Comput. Biol. Bioinform. 2016, 14, 564–575. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Z.; Sabuncu, M. Generalized cross entropy loss for training deep neural networks with noisy labels. Adv. Neural Inf. Process. Syst. 2018, 31, 1–11. [Google Scholar]
- Gil-González, J.; Valencia-Duque, A.; Álvarez-Meza, A.; Orozco-Gutiérrez, Á.; García-Moreno, A. Regularized chained deep neural network classifier for multiple annotators. Appl. Sci. 2021, 11, 5409. [Google Scholar] [CrossRef]
- Zhao, X.; Li, X.; Bi, D.; Wang, H.; Xie, Y.; Alhudhaif, A.; Alenezi, F. L1-norm constraint kernel adaptive filtering framework for precise and robust indoor localization under the internet of things. Inf. Sci. 2022, 587, 206–225. [Google Scholar] [CrossRef]
- Box, G.E.; Cox, D.R. An analysis of transformations. J. R. Stat. Soc. Ser. B (Methodol.) 1964, 26, 211–243. [Google Scholar] [CrossRef]
- Saul, A.; Hensman, J.; Vehtari, A.; Lawrence, N. Chained Gaussian processes. In Proceedings of the Artificial Intelligence and Statistics, Cadiz, Spain, 9–11 May 2016; pp. 1431–1440. [Google Scholar]
- Géron, A. Hands-On Machine Learning with Scikit-Learn, Keras, and TensorFlow: Concepts, Tools, and Techniques to Build Intelligent Systems; O’Reilly Media: Sebastopol, CA, USA, 2019. [Google Scholar]
- Xiao, H.; Rasul, K.; Vollgraf, R. Fashion-mnist: A novel image dataset for benchmarking machine learning algorithms. arXiv 2017, arXiv:1708.07747. [Google Scholar]
- Hernández-Muriel, J.A.; Bermeo-Ulloa, J.B.; Holguin-Londoño, M.; Álvarez-Meza, A.M.; Orozco-Gutiérrez, Á.A. Bearing health monitoring using relief-F-based feature relevance analysis and HMM. Appl. Sci. 2020, 10, 5170. [Google Scholar] [CrossRef]
- LeCun, Y.; Boser, B.; Denker, J.; Henderson, D.; Howard, R.; Hubbard, W.; Jackel, L. Handwritten digit recognition with a back-propagation network. Adv. Neural Inf. Process. Syst. 1989, 2, 396–404. [Google Scholar]
- Dogs vs. Cats—Kaggle.com. Available online: https://www.kaggle.com/c/dogs-vs-cats (accessed on 6 January 2023).
- Peterson, J.C.; Battleday, R.M.; Griffiths, T.L.; Russakovsky, O. Human uncertainty makes classification more robust. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27–28 October 2019; pp. 9617–9626. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Tzanetakis, G.; Cook, P. Musical genre classification of audio signals. IEEE Trans. Speech Audio Process. 2002, 10, 293–302. [Google Scholar] [CrossRef]
- Rodrigues, F.; Pereira, F.; Ribeiro, B. Learning from multiple annotators: Distinguishing good from random labelers. Pattern Recognit. Lett. 2013, 34, 1428–1436. [Google Scholar] [CrossRef]
- Gil-Gonzalez, J.; Giraldo, J.J.; Alvarez-Meza, A.; Orozco-Gutierrez, A.; Alvarez, M. Correlated Chained Gaussian Processes for Datasets with Multiple Annotators. IEEE Trans. Neural Netw. Learn. Syst. 2021. [Google Scholar] [CrossRef]
- MacKay, D.J.; Mac Kay, D.J. Information Theory, Inference and Learning Algorithms; Cambridge University Press: Cambridge, UK, 2003. [Google Scholar]
- Demšar, J. Statistical comparisons of classifiers over multiple data sets. J. Mach. Learn. Res. 2006, 7, 1–30. [Google Scholar]
- Li, Z.L.; Zhang, G.W.; Yu, J.; Xu, L.Y. Dynamic Graph Structure Learning for Multivariate Time Series Forecasting. Pattern Recognit. 2023, 138, 109423. [Google Scholar] [CrossRef]
- Leroux, L.; Castets, M.; Baron, C.; Escorihuela, M.J.; Bégué, A.; Seen, D.L. Maize yield estimation in West Africa from crop process-induced combinations of multi-domain remote sensing indices. Eur. J. Agron. 2019, 108, 11–26. [Google Scholar] [CrossRef]
- Montavon, G.; Binder, A.; Lapuschkin, S.; Samek, W.; Müller, K.R. Layer-wise relevance propagation: An overview. In Explainable AI: Interpreting, Explaining and Visualizing Deep Learning; Springer Nature: Cham, Switzerland, 2019; pp. 193–209. [Google Scholar]
- Holzinger, A.; Saranti, A.; Molnar, C.; Biecek, P.; Samek, W. Explainable AI methods-a brief overview. In Proceedings of the xxAI-Beyond Explainable AI: International Workshop, Held in Conjunction with ICML 2020, Vienna, Austria, 18 July 2020, Revised and Extended Papers; Springer: Berlin/Heidelberg, Germany, 2022; pp. 13–38. [Google Scholar]
- Bennetot, A.; Donadello, I.; Qadi, A.E.; Dragoni, M.; Frossard, T.; Wagner, B.; Saranti, A.; Tulli, S.; Trocan, M.; Chatila, R.; et al. A practical tutorial on explainable ai techniques. arXiv 2021, arXiv:2111.14260. [Google Scholar]
- Saranti, A.; Hudec, M.; Mináriková, E.; Takáč, Z.; Großschedl, U.; Koch, C.; Pfeifer, B.; Angerschmid, A.; Holzinger, A. Actionable Explainable AI (AxAI): A Practical Example with Aggregation Functions for Adaptive Classification and Textual Explanations for Interpretable Machine Learning. Mach. Learn. Knowl. Extr. 2022, 4, 924–953. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Name | Input Shape (P) | Number of Instances (N) | Number of Classes (K) |
|---|---|---|---|
| 1D Synthetic | 1 | 500 | 3 |
| Ocupancy | 7 | 20,560 | 2 |
| Skin | 4 | 245,057 | 2 |
| Tic-Tac-Toe | 9 | 958 | 2 |
| Balance | 4 | 625 | 3 |
| Iris | 4 | 150 | 3 |
| New Thyroid | 5 | 215 | 3 |
| Wine | 13 | 178 | 3 |
| Fashion-Mnist | 784 | 70,000 | 10 |
| Segmentation | 18 | 2310 | 7 |
| Western | 7 | 3413 | 4 |
| Cat vs. Dog | 200 × 200 × 3 | 25,000 | 2 |
| Mnist | 28 × 28 × 1 | 70,000 | 10 |
| CIFAR-10H | 32 × 32 × 3 | 19,233 | 10 |
| LabelMe | 256 × 256 × 3 | 2688 | 8 |
| Music | 124 | 1000 | 10 |
| Algorithm | Description |
|---|---|
| DL-GOLD | A DL classification model using the real labels (upper bound). |
| DL-MV | A DL classification model using the MV of the labels as the ground truth. |
| RCDNN [43] | A regularized chained deep neural network which predicts the ground truth and annotators’ performance from input space samples. |
| DL-CL(MW) [28] | A crowd Layer for DL, where annotators’ parameters are constant across the input space. |
| Database | Measure | DL-GOLD | DL-CL(MW) | DL-MV | RCDNN | GCECDL |
|---|---|---|---|---|---|---|
| Ocupancy | ACC [%] | 97.59 ± 0.11 | 90.89 ± 0.92 | 90.31 ± 0.80 | 96.61 ± 0.42 | 97.50 ± 0.06 (0.1) |
| BACC [%] | 95.92 ± 0.09 | 74.30 ± 3.04 | 75.50 ± 0.99 | 93.22 ± 1.27 | 95.86 ± 0.10 (0.1) | |
| NMI [%] | 83.91 ± 0.35 | 57.98 ± 2.16 | 52.32 ± 3.56 | 77.93 ± 2.51 | 83.64 ± 0.31 (0.1) | |
| AUC [%] | 97.96 ± 0.05 | 87.17 ± 1.52 | 87.75 ± 0.49 | 99.03 ± 0.14 | 97.92 ± 0.05 (0.1) | |
| Skin | ACC [%] | 99.74 ± 0.13 | 56.48 ± 0.36 | 80.55 ± 3.23 | 89.45 ± 2.06 | 96.06 ± 0.59 (0.1) |
| BACC [%] | 99.62 ± 0.15 | 45.07 ± 0.46 | 79.80 ± 1.79 | 64.27 ± 10.66 | 90.60 ± 4.31 (0.1) | |
| NMI [%] | 96.86 ± 1.15 | 18.31 ± 0.21 | 13.56 ± 1.06 | 38.99 ± 8.25 | 71.14 ± 5.22 (0.1) | |
| AUC [%] | 99.81 ± 0.08 | 91.80 ± 1.03 | 80.45 ± 6.22 | 82.13 ± 5.33 | 99.30 ± 0.10 (0.1) | |
| Tic-Tac-Toe | ACC [%] | 98.47 ± 0.17 | 80.00 ± 3.73 | 78.26 ± 1.85 | 90.49 ± 17.16 | 97.28 ± 1.17 (0.2) |
| BACC [%] | 96.00 ± 0.27 | 66.24 ± 5.98 | 56.09 ± 2.14 | 78.74 ± 38.93 | 93.10 ± 2.78 (0.2) | |
| NMI [%] | 88.57 ± 1.52 | 36.88 ± 6.07 | 23.90 ± 2.05 | 71.42 ± 24.79 | 83.52 ± 6.13 (0.2) | |
| AUC [%] | 98.05 ± 0.14 | 96.48 ± 1.00 | 85.37 ± 1.21 | 91.71 ± 21.93 | 96.55 ± 1.39 (0.2) | |
| Balance | ACC [%] | 91.91 ± 2.50 | 85.27 ± 1.93 | 73.72 ± 1.51 | 91.33 ± 1.14 | 90.21 ± 0.83 (0.1) |
| BACC [%] | 60.00 ± 5.68 | 74.9 ± 4.09 | 43.39 ± 0.8 | 46.93 ± 1.00 | 75.27 ± 7.33 (0.1) | |
| NMI [%] | 73.34 ± 3.32 | 61.98 ± 3.58 | 59.43 ± 2.04 | 66.52 ± 3.30 | 68.00 ± 2.19 (0.1) | |
| AUC [%] | 83.66 ± 4.91 | 84.97 ± 4.08 | 70.66 ± 3.35 | 64.51 ± 17.36 | 81.11 ± 8.25 (0.1) | |
| Iris | ACC [%] | 97.34 ± 0.94 | 95.11 ± 2.59 | 95.33 ± 1.59 | 96.89 ± 1.15 | 97.34 ± 0.94 (0.1) |
| BACC [%] | 96.47 ± 1.24 | 91.67 ± 4.54 | 91.56 ± 1.84 | 94.24 ± 2.03 | 96.06 ± 2.11 (0.1) | |
| NMI [%] | 91.69 ± 1.91 | 86.82 ± 5.59 | 87.61 ± 2.86 | 89.68 ± 3.74 | 91.15 ± 3.07 (0.1) | |
| AUC [%] | 100.00 ± 0.00 | 100.00 ± 0.00 | 100.00 ± 0.00 | 99.83 ± 0.00 | 100.00 ± 0.00 (0.1) | |
| New Thyroid | ACC [%] | 96.15 ± 0.77 | 95.69 ± 1.15 | 97.69 ±1.03 | 95.08 ± 0.62 | 96.00 ± 1.84 (0.01) |
| BACC [%] | 92.5 ± 1.94 | 92.61 ± 2.8 | 93.88 ±2.65 | 88.41 ± 2.22 | 90.52 ± 4.36 (0.01) | |
| NMI [%] | 82.98 ± 3.44 | 82.38 ± 3.86 | 90.44 ±3.61 | 80.40 ± 2.42 | 83.61 ± 6.85 (0.01) | |
| AUC [%] | 96.19 ± 0.96 | 95.46 ± 1.78 | 97.80 ± 0.6 | 94.72 ± 1.67 | 95.19 ± 2.23 (0.01) | |
| Wine | ACC [%] | 97.59 ± 0.85 | 95.74 ± 1.67 | 73.15 ± 3.73 | 94.26 ± 2.10 | 96.48 ± 2.38 (0.01) |
| BACC [%] | 96.59 ± 1.08 | 94.17 ± 2.52 | 64.44 ± 5.42 | 91.99 ± 2.59 | 96.68 ± 2.92 (0.01) | |
| NMI [%] | 91.50 ± 3.07 | 85.54 ± 4.03 | 44.18 ± 4.39 | 82.91 ± 5.97 | 89.87 ± 5.37 (0.01) | |
| AUC [%] | 98.88 ± 0.37 | 99.88 ± 0.37 | 87.76 ± 2.88 | 97.13 ± 1.26 | 100.0 ± 0.00 (0.01) | |
| F-Mnist | Acc [%] | 86.45 ± 0.25 | 79.54 ± 9.16 | 85.83 ± 0.35 | 86.98 ± 0.71 | 88.26 ± 0.26 (0.01) |
| BACC [%] | 84.92 ± 0.27 | 77.28 ± 10.11 | 84.23 ± 0.38 | 85.50 ± 0.77 | 86.94 ± 0.28 (0.01) | |
| NMI [%] | 77.16 ± 0.21 | 72.92 ± 3.84 | 76.46 ± 0.38 | 78.75 ± 0.48 | 79.89 ± 0.21 (0.01) | |
| AUC [%] | 88.75 ± 1.61 | 85.61 ± 13.95 | 90.42 ± 1.46 | 89.33 ± 2.93 | 89.11 ± 2.27 (0.01) | |
| Segmentation | ACC [%] | 95.17 ± 0.25 | 94.65 ± 0.95 | 91.11 ± 0.94 | 91.85 ± 0.67 | 94.88 ± 0.8 (0.01) |
| BACC [%] | 94.49 ± 0.59 | 93.81 ± 1.09 | 89.79 ± 1.09 | 90.69 ± 0.77 | 94.15 ± 0.95 (0.01) | |
| NMI [%] | 91.07 ± 0.77 | 90.38 ±1.18 | 84.46 ± 1.65 | 86.27 ± 0.70 | 89.92 ± 1.25 (0.01) | |
| AUC [%] | 99.95 ± 0.13 | 99.76 ± 0.20 | 98.71 ± 0.44 | 98.94 ± 0.33 | 99.79 ± 0.22 (0.01) | |
| Western | ACC [%] | 99.25 ± 0.38 | 95.94 ± 4.39 | 95.11 ± 1.15 | 97.89 ± 0.40 | 98.31 ± 0.61 (0.01) |
| BACC [%] | 99.22 ± 0.42 | 94.37 ± 5.54 | 93.47 ± 1.45 | 97.25 ± 0.57 | 98.00 ± 0.97 (0.01) | |
| NMI [%] | 98.61 ± 0.70 | 96.80 ± 1.70 | 94.33 ± 0.97 | 97.16 ± 0.30 | 97.35 ± 0.60 (0.01) | |
| AUC [%] | 100.00 ± 0.00 | 100.00 ± 0.00 | 98.97 ± 0.85 | 99.99 ± 0.01 | 100.00 ± 0.00 (0.01) | |
| Cats vs. Dogs | ACC [%] | 85.00 ± 0.44 | 68.97 ± 0.84 | 58.69 ± 1.02 | 70.84 ± 4.71 | 74.15 ± 0.58 (0.1) |
| BACC [%] | 70.19 ± 0.22 | 37.44 ± 0.35 | 16.50 ± 0.51 | 43.51 ± 2.08 | 48.24 ± 0.54 (0.1) | |
| NMI [%] | 40.66 ± 0.41 | 11.03 ± 0.25 | 2.50 ± 0.12 | 16.02 ± 1.04 | 20.79 ± 0.33 (0.1) | |
| AUC [%] | 93.17 ± 0.22 | 68.94 ± 0.80 | 58.63 ± 0.98 | 70.98 ± 4.57 | 82.99 ± 0.30 (0.1) | |
| Mnist | ACC [%] | 99.32 ± 0.06 | 87.99 ± 2.73 | 92.88 ± 0.54 | 99.09 ± 0.05 | 99.11 ± 0.08 (0.01) |
| BACC [%] | 99.22 ± 0.06 | 86.49 ± 3.11 | 91.97 ± 0.59 | 98.98 ± 0.06 | 99.02 ± 0.09 (0.01) | |
| NMI [%] | 97.95 ± 0.15 | 82.82 ± 2.29 | 83.43 ± 1.02 | 97.28 ± 0.11 | 97.39 ± 0.21 (0.01) | |
| AUC [%] | 99.81 ± 0.08 | 99.82 ± 0.02 | 97.88 ± 0.33 | 99.71 ± 0.06 | 99.68 ± 0.08 (0.01) | |
| CIFAR-10H | ACC [%] | 71.72 ± 1.12 | 60.80 ± 1.59 | 68.24 ± 1.05 | 69.53 ± 0.63 | 69.24 ± 0.67 (0.01) |
| BACC [%] | 68.46 ± 0.28 | 56.56 ± 1.72 | 64.69 ± 1.18 | 66.18 ± 0.72 | 65.88 ± 0.76 (0.01) | |
| NMI [%] | 64.2 ± 0.23 | 43.09 ± 1.21 | 49.55 ± 1.4 | 51.44 ± 0.81 | 50.95 ± 0.78 (0.01) | |
| AUC [%] | 96.08 ± 0.11 | 89.42 ± 0.7 | 94.81 ± 0.35 | 95.17 ± 0.16 | 95.01 ± 0.19 (0.01) | |
| LabelMe | ACC [%] | 90.91 ± 0.44 | 83.11 ± 0.96 | 76.94 ± 1.15 | 89.09 ± 0.41 | 88.97 ± 0.55 (0.01) |
| BACC [%] | 90.03 ± 0.42 | 81.85 ± 0.86 | 75.08 ± 1.25 | 88.01 ± 0.42 | 87.97 ± 0.57 (0.01) | |
| NMI [%] | 81.36 ± 0.79 | 73.92 ± 0.80 | 68.36 ± 0.54 | 77.82 ± 0.55 | 78.00 ± 0.70 (0.01) | |
| AUC [%] | 99.37 ± 0.06 | 96.34 ± 0.88 | 97.65 ± 0.13 | 99.14 ± 0.06 | 99.11 ± 0.08 (0.01) | |
| Music | ACC [%] | 76.4 ± 0.88 | 57.13 ± 2.80 | 62.8 ± 1.06 | 65.80 ± 2.83 | 65.63 ± 2.41 (0.01) |
| BACC [%] | 74.32 ± 0.91 | 51.47 ± 2.91 | 57.67 ± 1.27 | 61.96 ± 3.32 | 61.83 ± 2.84 (0.01) | |
| NMI [%] | 65.86 ± 1.16 | 57.25 ± 1.55 | 53.87 ± 1.49 | 57.02 ± 2.63 | 57.36 ± 1.40 (0.01) | |
| AUC [%] | 96.34 ± 0.13 | 88.62 ± 3.08 | 93.58 ± 0.21 | 94.07 ± 0.94 | 94.13 ± 0.50 (0.01) | |
| Average Ranking | ACC [%] | 3.26 ± | 3.40 ± | 2.00 ± | 1.33 ± | |
| BACC [%] | 3.00 ± | 3.40 ± | 2.33 ± | 1.26 ± | ||
| NMI [%] | 3.14 ± | 3.46 ± | 2.21 ± | 1.20 ± | ||
| AUC [%] | 2.67 ± | 3.13 ± | 2.47 ± | 1.73 ± |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Triana-Martinez, J.C.; Gil-González, J.; Fernandez-Gallego, J.A.; Álvarez-Meza, A.M.; Castellanos-Dominguez, C.G. Chained Deep Learning Using Generalized Cross-Entropy for Multiple Annotators Classification. Sensors 2023, 23, 3518. https://doi.org/10.3390/s23073518
Triana-Martinez JC, Gil-González J, Fernandez-Gallego JA, Álvarez-Meza AM, Castellanos-Dominguez CG. Chained Deep Learning Using Generalized Cross-Entropy for Multiple Annotators Classification. Sensors. 2023; 23(7):3518. https://doi.org/10.3390/s23073518
Chicago/Turabian StyleTriana-Martinez, Jenniffer Carolina, Julian Gil-González, Jose A. Fernandez-Gallego, Andrés Marino Álvarez-Meza, and Cesar German Castellanos-Dominguez. 2023. "Chained Deep Learning Using Generalized Cross-Entropy for Multiple Annotators Classification" Sensors 23, no. 7: 3518. https://doi.org/10.3390/s23073518