
Multi-Sensor Medical-Image Fusion Technique Based on Embedding Bilateral Filter in Least Squares and Salient Detection

Abstract
:1. Introduction
- A medical image fusion method based on the BLF-LS and salient detection is proposed. To the best of our knowledge, this is the first time the BLF-LS has been applied in medical-image fusion. The source images are decomposed into the detail and base layers.
- A detail-layer fusion rule based on DSC and RGF is proposed, which fully considers the low contrast between the target and background.
- A fusion rule based on modified Laplace energy and local energy (MLEN) was designed to maintain detailed information and energy in the base layer.
- The proposed fusion method can be effectively extended to the IR- and VIS-image fusion problem and yield competing fusion performance.
2. Related Work
2.1. Embedding Bilateral Filter in Least Squares
2.2. Salient Detection via Deformed Smoothness Constraint
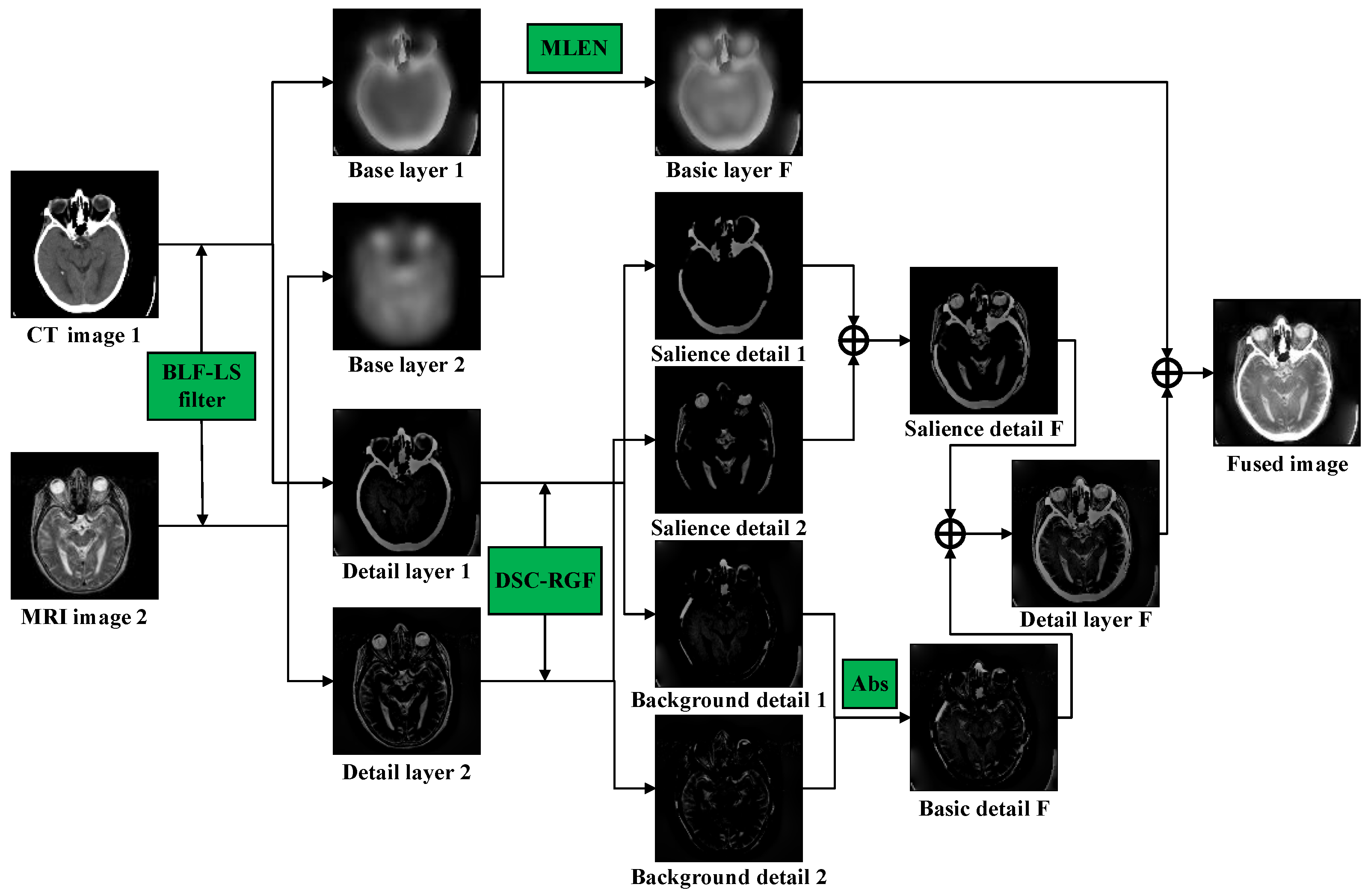
3. Proposed Method
3.1. Decomposition of Base Layer and Detail Layer
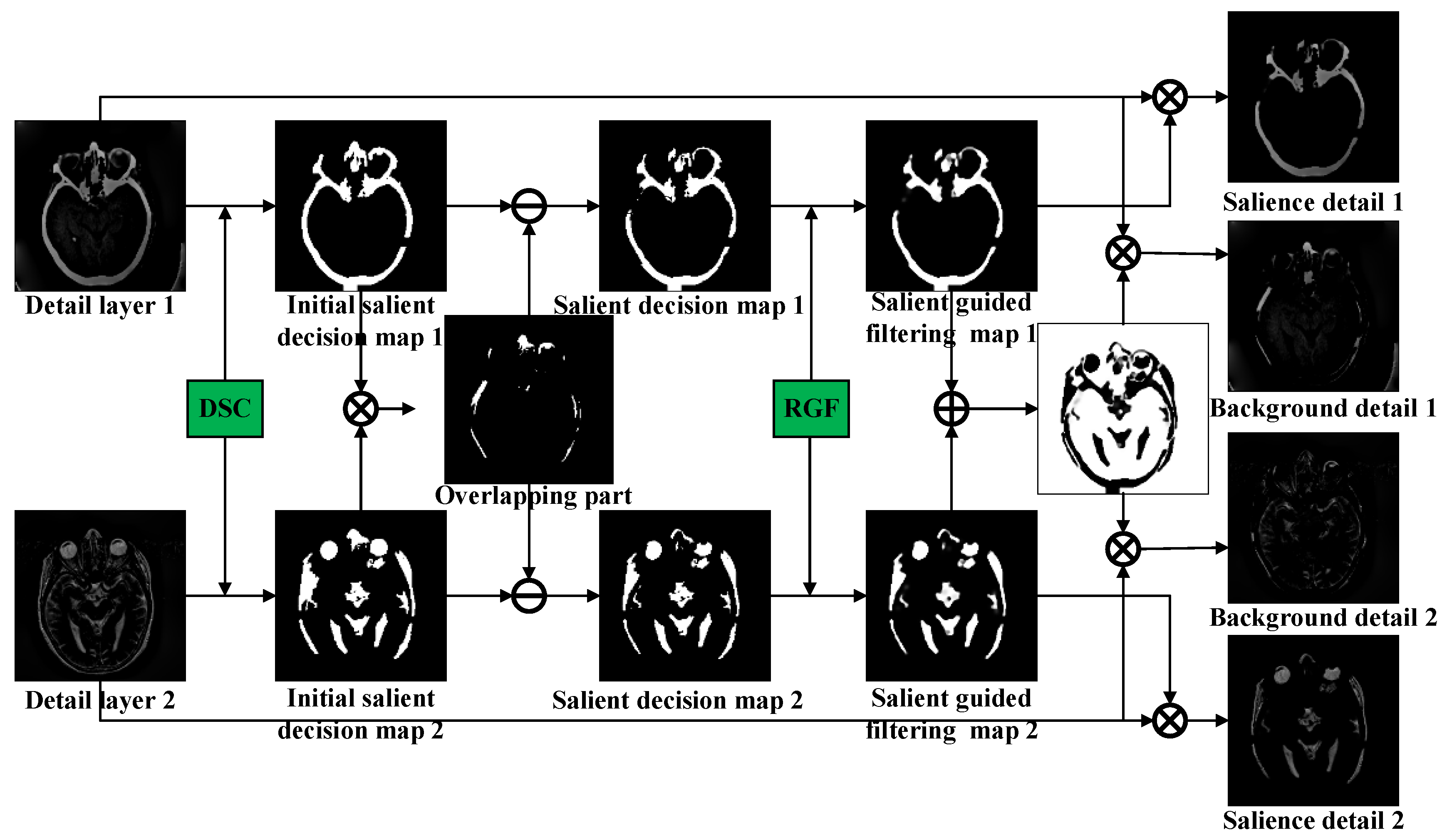
3.2. Decomposition of Detail Layer Based on DSC-RGF Algorithm
3.3. Fusion of Base Layer Based on MLEN
3.4. Fusion Result
| Algorithm 1 Steps in proposed fusion method |
| Inputs: Medical CT Image ; Medical MRI Image Output: Fused image F Step 1: The BLF-LS is employed to decompose and to obtain the corresponding base layers and and detail layers and (Equations (6) and (7)). Step 2: The DSC-RGF algorithm is utilized to decompose the detail layers to obtain the corresponding significant-detail layers and and background-detail layers and (Equations (8)–(12)). Step 3: The fusion base layer is obtained using the MLEN rule (Equations (13)–(16)). Then, the fusion Abs rule is employed to fuse and and thereby obtain the fusion base layer (Equation (17)). and are added to obtain the significant-detail layer of the fused image (Equation (18)). Step 4: The fused image is obtained by summing , , and (Equation (19)). |
4. Experimental Results and Comparisons
4.1. Experimental Setup
4.1.1. Test Data
4.1.2. Quantitative Evaluation Metrics
4.1.3. Methods Compared with Proposed Methods
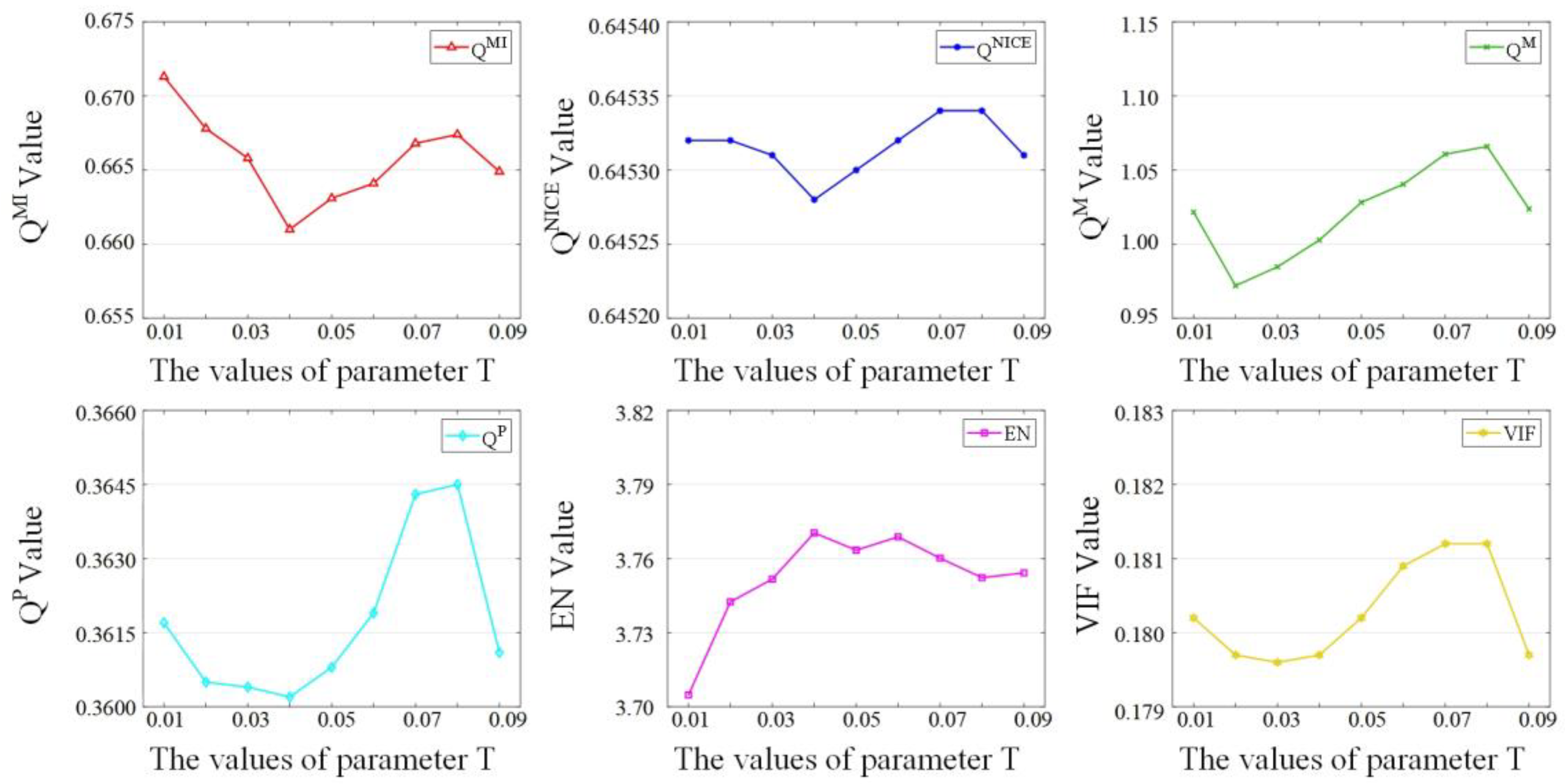
4.2. Parameter Analysis
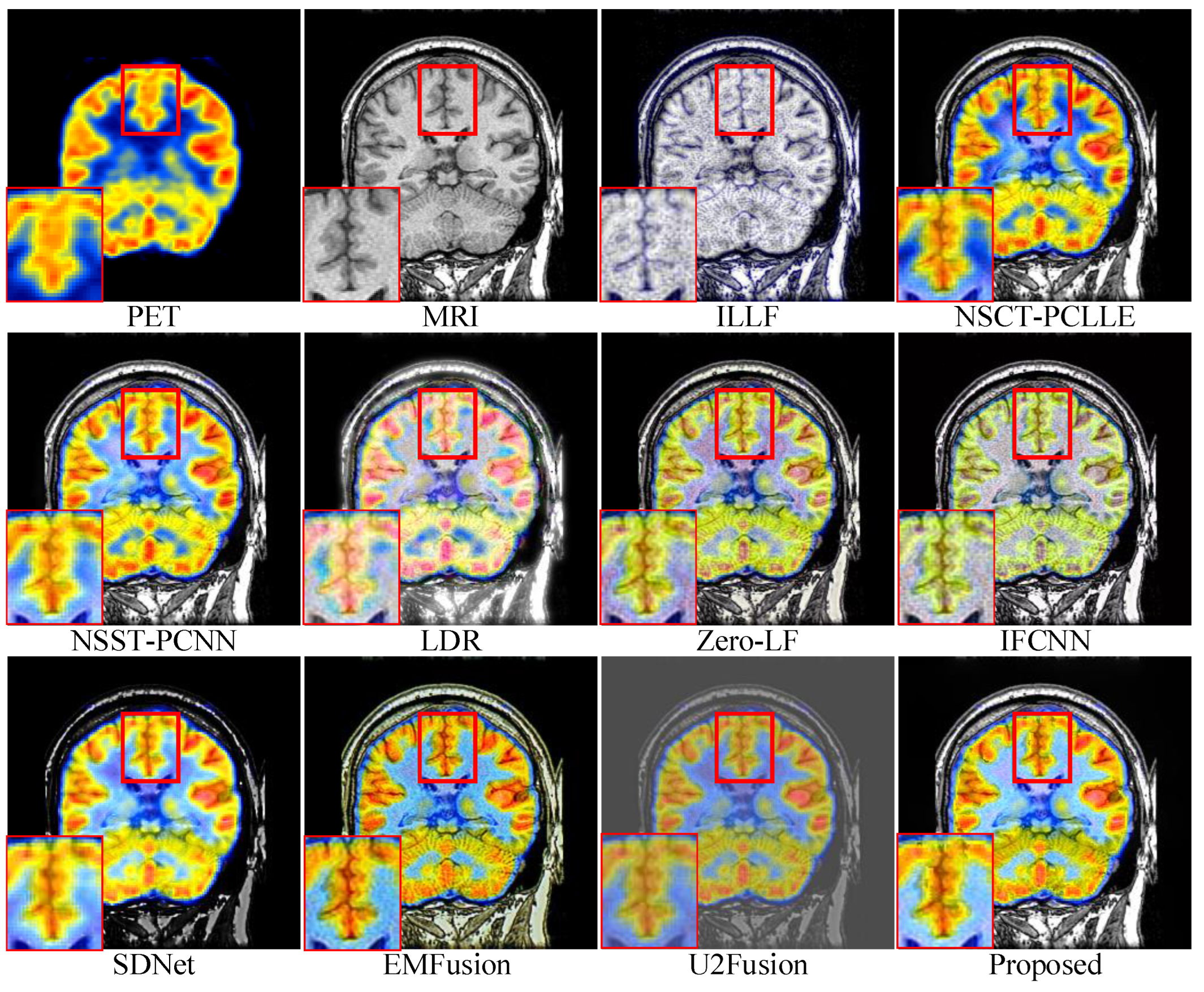
4.3. Subjective Quality Assessment
4.4. Objective Quality Assessment
4.5. Discussion on Time Efficiency
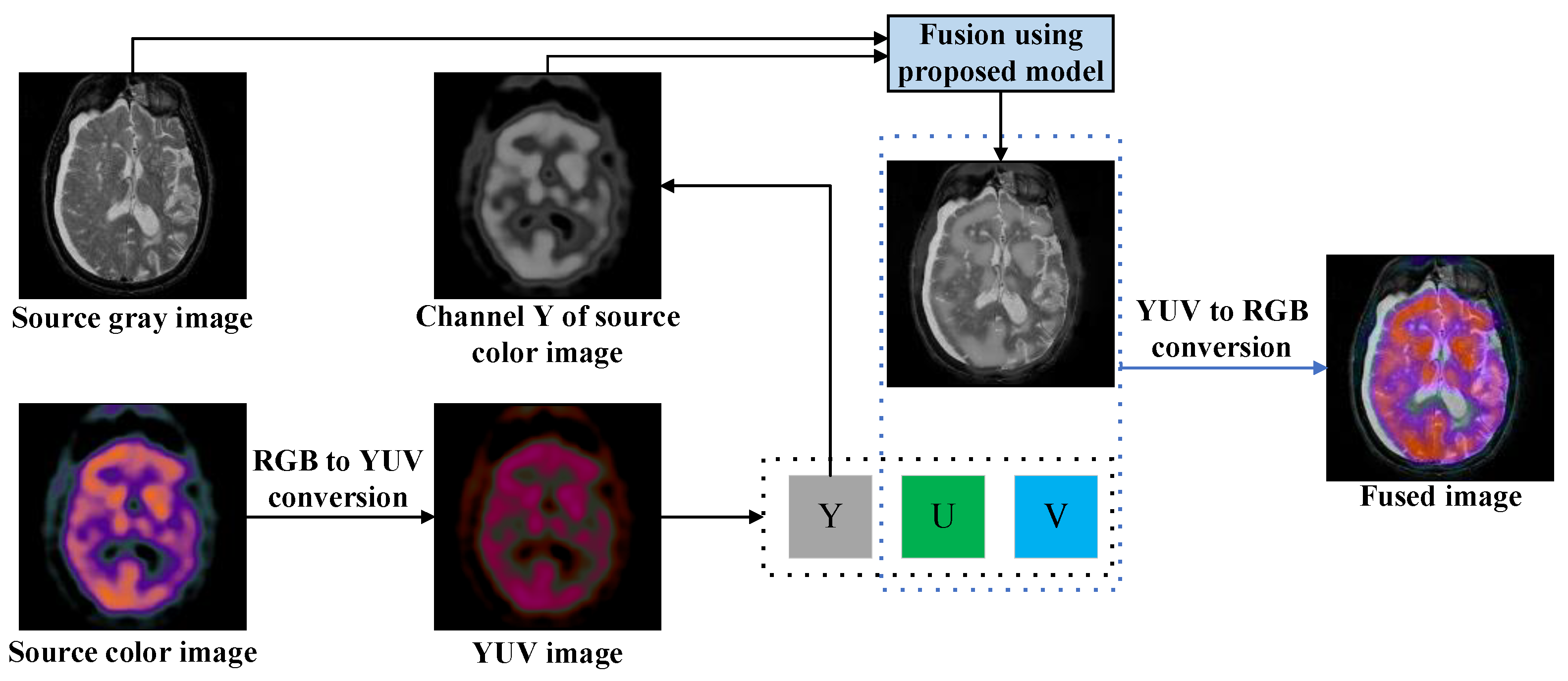
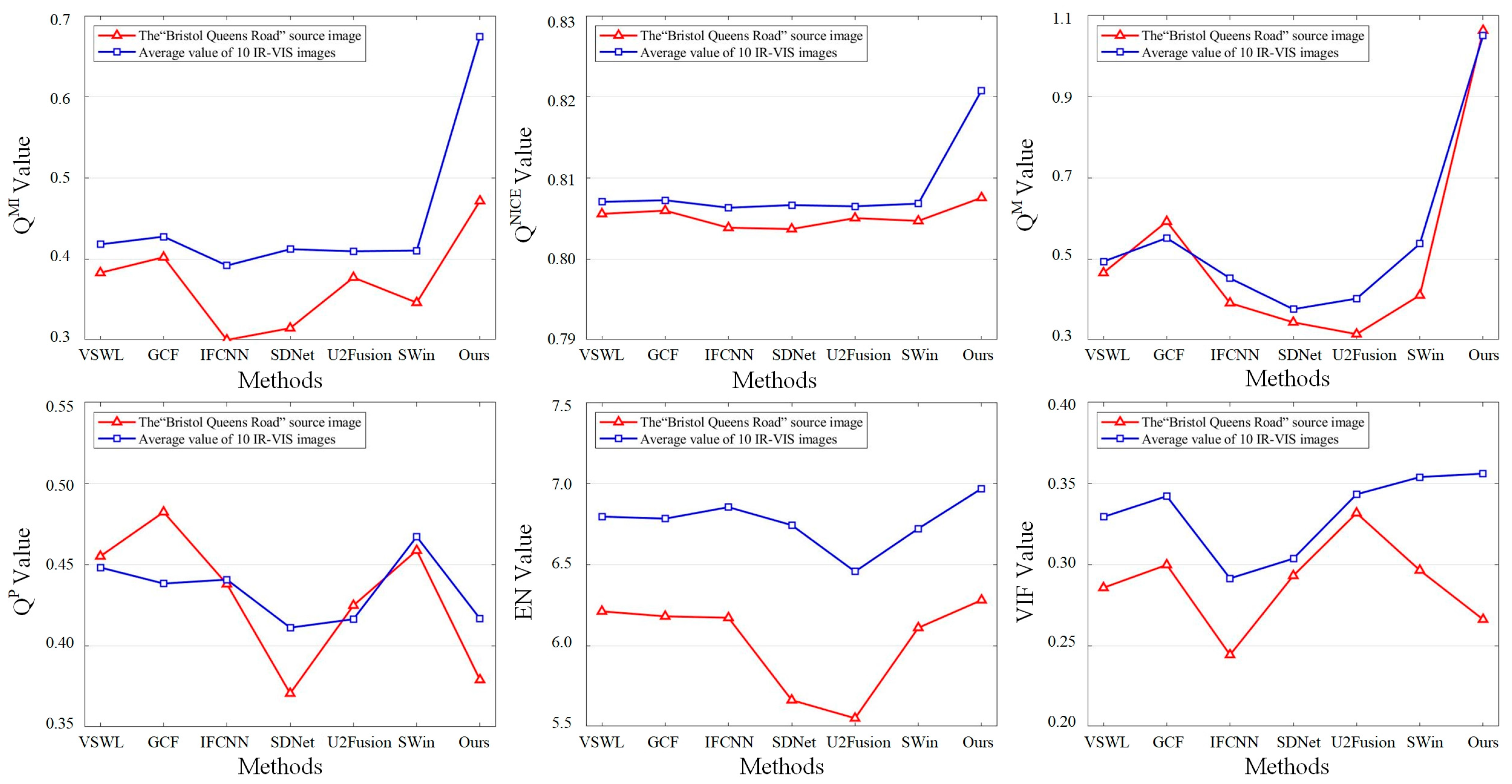
4.6. Extension to Infrared (IR) and Visible (VIS) Image Fusion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Goyal, B.; Dogra, A.; Khoond, R.; Gupta, A.; Anand, R. Infrared and Visible Image Fusion for Concealed Weapon Detection using Transform and Spatial Domain Filters. In Proceedings of the 2021 9th International Conference on Reliability, Infocom Technologies and Optimization (Trends and Future Directions) (ICRITO), Noida, India, 3–4 September 2021; pp. 1–4. [Google Scholar]
- Hermessi, H.; Mourali, O.; Zagrouba, E. Multimodal medical image fusion review: Theoretical background and recent advances. Signal Process. 2021, 183, 108036. [Google Scholar] [CrossRef]
- Li, S.T.; Kang, X.D.; Fang, L.Y.; Hu, J.W.; Yin, H.T. Pixel-level image fusion: A survey of the state of the art. Inf. Fusion 2017, 33, 100–112. [Google Scholar] [CrossRef]
- Zhang, Q.; Liu, Y.; Blum, R.S.; Han, J.G.; Tao, D.C. Sparse representation based multi-sensor image fusion for multi-focus and multi-modality images: A review. Inf. Fusion 2018, 40, 57–75. [Google Scholar] [CrossRef]
- Zhang, H.; Xu, H.; Tian, X.; Jiang, J.J.; Ma, J.Y. Image fusion meets deep learning: A survey and perspective. Inf. Fusion 2021, 76, 323–336. [Google Scholar] [CrossRef]
- Li, X.S.; Zhou, F.Q.; Tan, H.S.; Chen, Y.Z.; Zuo, W.X. Multi-focus image fusion based on nonsubsampled contourlet transform and residual removal. Signal Process. 2021, 184, 108062. [Google Scholar] [CrossRef]
- Zhu, Z.Q.; Zheng, M.G.; Qi, G.Q.; Wang, D.; Xiang, Y. A Phase Congruency and Local Laplacian Energy Based Multi-Modality Medical Image Fusion Method in NSCT Domain. IEEE Access 2019, 7, 20811–20824. [Google Scholar] [CrossRef]
- Li, X.; Guo, X.; Han, P.; Wang, X.; Li, H.; Luo, T. Laplacian Redecomposition for Multimodal Medical Image Fusion. IEEE Trans. Instrum. Meas. 2020, 69, 6880–6890. [Google Scholar] [CrossRef]
- Khan, H.; Sharif, M.; Bibi, N.; Usman, M.; Haider, S.A.; Zainab, S.; Shah, J.H.; Bashir, Y.; Muhammad, N. Localization of radiance transformation for image dehazing in wavelet domain. Neurocomputing 2020, 381, 141–151. [Google Scholar] [CrossRef]
- Juneja, S.; Anand, R. Contrast Enhancement of an Image by DWT-SVD and DCT-SVD; Springer: Singapore, 2018; pp. 595–603. [Google Scholar]
- Li, X.S.; Zhou, F.Q.; Tan, H.S. Joint image fusion and denoising via three-layer decomposition and sparse representation. Knowl.-Based Syst. 2021, 224, 107087. [Google Scholar] [CrossRef]
- Li, S.T.; Yin, H.T.; Fang, L.Y. Group-Sparse Representation With Dictionary Learning for Medical Image Denoising and Fusion. IEEE Trans. Biomed. Eng. 2012, 59, 3450–3459. [Google Scholar] [CrossRef]
- Zhang, Q.; Levine, M.D. Robust Multi-Focus Image Fusion Using Multi-Task Sparse Representation and Spatial Context. IEEE Trans. Image Process. 2016, 25, 2045–2058. [Google Scholar] [CrossRef] [PubMed]
- Wang, J.; Peng, J.Y.; Feng, X.Y.; He, G.Q.; Fan, J.P. Fusion method for infrared and visible images by using non-negative sparse representation. Infrared Phys. Technol. 2014, 67, 477–489. [Google Scholar] [CrossRef]
- Gu, S.; Meng, D.; Zuo, W.; Zhang, L. Joint Convolutional Analysis and Synthesis Sparse Representation for Single Image Layer Separation. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 1717–1725. [Google Scholar]
- Jie, Y.; Zhou, F.; Tan, H.; Wang, G.; Cheng, X.; Li, X. Tri-modal medical image fusion based on adaptive energy choosing scheme and sparse representation. Measurement 2022, 204, 112038. [Google Scholar] [CrossRef]
- Muhammad, N.; Bibi, N.; Jahangir, A.; Mahmood, Z. Image denoising with norm weighted fusion estimators. Pattern Anal. Appl. 2018, 21, 1013–1022. [Google Scholar] [CrossRef]
- Zhang, Y.; Liu, Y.; Sun, P.; Yan, H.; Zhao, X.L.; Zhang, L. IFCNN: A general image fusion framework based on convolutional neural network. Inf. Fusion 2020, 54, 99–118. [Google Scholar] [CrossRef]
- Ma, J.Y.; Yu, W.; Liang, P.W.; Li, C.; Jiang, J.J. FusionGAN: A generative adversarial network for infrared and visible image fusion. Inf. Fusion 2019, 48, 11–26. [Google Scholar] [CrossRef]
- Luo, X.; Gao, Y.; Wang, A.; Zhang, Z.; Wu, X.J. IFSepR: A general framework for image fusion based on separate representation learning. IEEE Trans. Multimed. 2021, 25, 608–623. [Google Scholar] [CrossRef]
- Zhu, Z.Q.; He, X.Y.; Qi, G.Q.; Li, Y.Y.; Cong, B.S.; Liu, Y. Brain tumor segmentation based on the fusion of deep semantics and edge information in multimodal MRI. Inf. Fusion 2023, 91, 376–387. [Google Scholar] [CrossRef]
- Liu, Y.; Chen, X.; Wang, Z.F.; Wang, Z.J.; Ward, R.K.; Wang, X.S. Deep learning for pixel-level image fusion: Recent advances and future prospects. Inf. Fusion 2018, 42, 158–173. [Google Scholar] [CrossRef]
- Mo, Y.; Kang, X.D.; Duan, P.H.; Sun, B.; Li, S.T. Attribute filter based infrared and visible image fusion. Inf. Fusion 2021, 75, 41–54. [Google Scholar] [CrossRef]
- Wang, G.F.; Li, W.S.; Du, J.; Xiao, B.; Gao, X.B. Medical Image Fusion and Denoising Algorithm Based on a Decomposition Model of Hybrid Variation-Sparse Representation. IEEE J. Biomed. Health Inform. 2022, 26, 5584–5595. [Google Scholar] [CrossRef] [PubMed]
- Xu, G.X.; Deng, X.X.; Zhou, X.K.; Pedersen, M.; Cimmino, L.; Wang, H. FCFusion: Fractal Componentwise Modeling With Group Sparsity for Medical Image Fusion. IEEE Trans. Ind. Inform. 2022, 18, 9141–9150. [Google Scholar] [CrossRef]
- Li, X.S.; Zhou, F.Q.; Tan, H.S.; Zhang, W.N.; Zhao, C.Y. Multimodal medical image fusion based on joint bilateral filter and local gradient energy. Inf. Sci. 2021, 569, 302–325. [Google Scholar] [CrossRef]
- Liu, W.; Zhang, P.P.; Chen, X.G.; Shen, C.H.; Huang, X.L.; Yang, J. Embedding Bilateral Filter in Least Squares for Efficient Edge-Preserving Image Smoothing. IEEE Trans. Circuits Syst. Video Technol. 2020, 30, 23–35. [Google Scholar] [CrossRef] [Green Version]
- Wu, X.; Ma, X.; Zhang, J.; Wang, A.; Jin, Z. Salient Object Detection Via Deformed Smoothness Constraint. In Proceedings of the 2018 25th IEEE International Conference on Image Processing (ICIP), Athens, Greece, 7–10 October 2018; pp. 2815–2819. [Google Scholar]
- Huang, W.; Jing, Z. Evaluation of focus measures in multi-focus image fusion. Pattern Recognit. Lett. 2007, 28, 493–500. [Google Scholar] [CrossRef]
- Qu, G.H.; Zhang, D.L.; Yan, P.F. Information measure for performance of image fusion. Electron. Lett. 2002, 38, 313–315. [Google Scholar] [CrossRef] [Green Version]
- Wang, P.W.; Liu, B. A Novel Image Fusion Metric Based on Multi-Scale Analysis. In Proceedings of the 9th International Conference on Signal Processing, Beijing, China, 26–29 October 2008; pp. 965–968. [Google Scholar]
- Wang, Q.; Shen, Y.; Zhang, J.Q. A nonlinear correlation measure for multivariable data set. Phys. D-Nonlinear Phenom. 2005, 200, 287–295. [Google Scholar] [CrossRef]
- Zhao, J.Y.; Laganiere, R.; Liu, Z. Performance assessment of combinative pixel-level image fusion based on an absolute feature measurement. Int. J. Innov. Comput. Inf. Control 2007, 3, 1433–1447. [Google Scholar]
- Ma, J.Y.; Ma, Y.; Li, C. Infrared and visible image fusion methods and applications: A survey. Inf. Fusion 2019, 45, 153–178. [Google Scholar] [CrossRef]
- Sheikh, H.R.; Bovik, A.C. Image information and visual quality. IEEE Trans. Image Process. 2006, 15, 430–444. [Google Scholar] [CrossRef]
- Liu, Z.; Blasch, E.; Xue, Z.Y.; Zhao, J.Y.; Laganiere, R.; Wu, W. Objective Assessment of Multiresolution Image Fusion Algorithms for Context Enhancement in Night Vision: A Comparative Study. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 34, 94–109. [Google Scholar] [CrossRef] [PubMed]
- Du, J.; Li, W.S.; Xiao, B. Anatomical-Functional Image Fusion by Information of Interest in Local Laplacian Filtering Domain. IEEE Trans. Image Process. 2017, 26, 5855–5866. [Google Scholar] [CrossRef] [PubMed]
- Yin, M.; Liu, X.N.; Liu, Y.; Chen, X. Medical Image Fusion With Parameter-Adaptive Pulse Coupled Neural Network in Nonsubsampled Shearlet Transform Domain. IEEE Trans. Instrum. Meas. 2019, 68, 49–64. [Google Scholar] [CrossRef]
- Lahoud, F.; Süsstrunk, S. Zero-Learning Fast Medical Image Fusion. In Proceedings of the 2019 22th International Conference on Information Fusion (FUSION), Ottawa, ON, Canada, 2–5 July 2019; pp. 1–8. [Google Scholar]
- Zhang, H.; Ma, J.Y. SDNet: A Versatile Squeeze-and-Decomposition Network for Real-Time Image Fusion. Int. J. Comput. Vis. 2021, 129, 2761–2785. [Google Scholar] [CrossRef]
- Xu, H.; Ma, J.Y. EMFusion: An unsupervised enhanced medical image fusion network. Inf. Fusion 2021, 76, 177–186. [Google Scholar] [CrossRef]
- Xu, H.; Ma, J.Y.; Jiang, J.J.; Guo, X.J.; Ling, H.B. U2Fusion: A Unified Unsupervised Image Fusion Network. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 44, 502–518. [Google Scholar] [CrossRef]
- Ma, J.L.; Zhou, Z.Q.; Wang, B.; Zong, H. Infrared and visible image fusion based on visual saliency map and weighted least square optimization. Infrared Phys. Technol. 2017, 82, 8–17. [Google Scholar] [CrossRef]
- Tan, W.; Zhou, H.X.; Song, J.L.Q.; Li, H.; Yu, Y.; Du, J. Infrared and visible image perceptive fusion through multi-level Gaussian curvature filtering image decomposition. Appl. Opt. 2019, 58, 3064–3073. [Google Scholar] [CrossRef]
- Ma, J.Y.; Tang, L.F.; Fan, F.; Huang, J.; Mei, X.G.; Ma, Y. SwinFusion: Cross-domain Long-range Learning for General Image Fusion via Swin Transformer. IEEE-CAA J. Autom. Sin. 2022, 9, 1200–1217. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Metric | Mathematical Expression | Definition | Best Value Outcomes | |
|---|---|---|---|---|
| 1 | [30] | Measure of retention value of edge information | Higher | |
| 2 | [32] | Measure of nonlinear correlation information entropy | Higher | |
| 3 | [31] | Measure of retention value of edge information | Higher | |
| 4 | [33] | Measure of phase congruency | Higher | |
| 5 | [34] | Evaluation metrics based on information theory | Higher | |
| 6 | [35] | A fusion measure inspired by human perception | Higher |
| Methods | |||||||
|---|---|---|---|---|---|---|---|
| Objective evaluation of different fused images in Figure 5 | ILLF | 0.5554 | 0.8054 | 0.1583 | 0.2049 | 5.7517 | 0.1330 |
| NSST-PCNN | 0.6502 | 0.8050 | 0.6791 | 0.3444(3) | 4.7473 | 0.2048 | |
| NSCT-PCLLE | 0.6232 | 0.8047 | 0.6962(3) | 0.2792 | 4.6168 | 0.2194(3) | |
| LRD | 0.7302 | 0.8056(3) | 0.2218 | 0.3292 | 4.5160 | 0.1702 | |
| Zero-LF | 0.7918(3) | 0.8056 | 1.5481 | 0.1172 | 4.0112 | 0.0874 | |
| IFCNN | 0.6690 | 0.8047 | 0.1469 | 0.2907 | 4.2017 | 0.1669 | |
| SDNet | 0.6513 | 0.8051 | 0.1084 | 0.2840 | 4.8154(2) | 0.1712 | |
| EMFusion | 0.8345(2) | 0.8063(2) | 0.1309 | 0.5829 | 4.2328 | 0.3247 | |
| U2Fusion | 0.6059 | 0.8045 | 0.0849 | 0.2925 | 4.4836 | 0.1862 | |
| Proposed | 0.8443 | 0.8070 | 1.1038(2) | 0.4424(2) | 4.7689(3) | 0.2293(2) | |
| Average evaluation mean of 100 groups of images | ILLF | 0.7265 | 0.8048 | 0.1635 | 0.2890 | 4.1261 | 0.2087 |
| NSST-PCNN | 0.7532 | 0.8049 | 0.6157 | 0.2896 | 3.9475 | 0.2488 | |
| NSCT-PCLLE | 0.7319 | 0.8048 | 0.7197(3) | 0.2726 | 3.9428 | 0.2736(3) | |
| LRD | 0.7861 | 0.8052 | 0.3345 | 0.2548 | 3.8813 | 0.1994 | |
| Zero-LF | 0.8749(3) | 0.8057(3) | 1.6937 | 0.1465 | 3.6424 | 0.0993 | |
| IFCNN | 0.7512 | 0.8047 | 0.1797 | 0.2904 | 3.7007 | 0.1915 | |
| SDNet | 0.7578 | 0.8052 | 0.1282 | 0.2713 | 4.1732(2) | 0.1928 | |
| EMFusion | 0.8933(2) | 0.8057(2) | 0.1510 | 0.4295 | 3.6298 | 0.3504 | |
| U2Fusion | 0.6976 | 0.8045 | 0.1138 | 0.3130 | 3.9285 | 0.2249 | |
| Proposed | 0.8935 | 0.8064 | 1.1555 (2) | 0.3820 (2) | 4.0829(3) | 0.2903(2) |
| Methods | |||||||
|---|---|---|---|---|---|---|---|
| Objective evaluation of performance for images in Figure 6 | ILLF | 0.3732 | 0.8035 | 0.0547 | 0.0167 | 4.6800 | 0.0095 |
| NSST-PCNN | 0.6509(2) | 0.8078(2) | 1.4767(2) | 0.4576 | 5.8536 | 0.2977 | |
| NSCT-PCLLE | 0.6040 | 0.8069 | 1.3982(3) | 0.4276 | 5.9460(3) | 0.2982(3) | |
| LRD | 0.5225 | 0.8060 | 0.2486 | 0.3397 | 6.4027 | 0.1808 | |
| Zero-LF | 0.6229(3) | 0.8074(3) | 0.3195 | 0.4543 | 5.6813 | 0.2352 | |
| IFCNN | 0.6073 | 0.8072 | 0.2155 | 0.4949(2) | 5.8007 | 0.2461 | |
| SDNet | 0.6062 | 0.8057 | 0.1035 | 0.2804 | 5.0403 | 0.1451 | |
| EMFusion | 0.5906 | 0.8072 | 0.2717 | 0.5669 | 5.8329 | 0.2688 | |
| U2Fusion | 0.5653 | 0.8055 | 0.0879 | 0.3689 | 5.0805 | 0.3071(2) | |
| Proposed | 0.8319 | 0.8129 | 1.9020 | 0.4902(3) | 6.2604(2) | 0.3170 | |
| Average evaluation mean of 100 groups of images | ILLF | 0.3448 | 0.8035 | 0.1230 | 0.0956 | 5.1814 | 0.0503 |
| NSST-PCNN | 0.7019(2) | 0.8088(3) | 1.6547(2) | 0.5141 | 5.7223 | 0.3330 | |
| NSCT-PCLLE | 0.6635(3) | 0.8081 | 1.6272(3) | 0.4939 | 5.7743 | 0.3369 | |
| LRD | 0.5533 | 0.8064 | 0.3332 | 0.3583 | 6.2651 | 0.1920 | |
| Zero-LF | 0.6558 | 0.8077 | 0.6523 | 0.4809 | 5.6436 | 0.2434 | |
| IFCNN | 0.6187 | 0.8072 | 0.3018 | 0.5403(2) | 5.6759 | 0.2572 | |
| SDNet | 0.6235 | 0.8057 | 0.1288 | 0.2815 | 4.9340 | 0.1528 | |
| EMFusion | 0.6160 | 0.8242 | 0.3305 | 0.6479 | 5.8601(3) | 0.2819 | |
| U2Fusion | 0.5753 | 0.8055 | 0.1161 | 0.4202 | 4.9477 | 0.3341(3) | |
| Proposed | 0.8836 | 0.8134(2) | 2.0628 | 0.5148(3) | 5.9378(2) | 0.3342(2) |
| Methods | |||||||
|---|---|---|---|---|---|---|---|
| Objective evaluation of different fused images in Figure 7 | ILLF | 0.5339 | 0.8063 | 0.2813 | 0.2664 | 5.8953 | 0.1818 |
| NSST-PCNN | 0.6030 | 0.8073 | 1.0805(3) | 0.3283 | 6.0048(2) | 0.3171 | |
| NSCT-PCLLE | 0.5940 | 0.8072 | 1.0262 | 0.3452(3) | 5.9899(3) | 0.3561(2) | |
| LRD | 0.6423 | 0.8081 | 0.7759 | 0.3395 | 6.1174 | 0.3051 | |
| Zero-LF | 0.6972(3) | 0.8087(3) | 1.3326(2) | 0.3233 | 5.7236 | 0.2191 | |
| IFCNN | 0.5995 | 0.8069 | 0.5536 | 0.3206 | 5.6857 | 0.2846 | |
| SDNet | 0.6525 | 0.8074 | 0.2431 | 0.2395 | 5.6691 | 0.2214 | |
| EMFusion | 0.7402(2) | 0.8102(2) | 0.6409 | 0.5500 | 5.6414 | 0.3927 | |
| U2Fusion | 0.5883 | 0.8063 | 0.2151 | 0.2791 | 5.2268 | 0.3342(3) | |
| Proposed | 0.8526 | 0.8132 | 1.4879 | 0.4283(2) | 5.9386(4) | 0.3226(4) | |
| Average evaluation mean of 100 groups of images | ILLF | 0.5761 | 0.7898 | 0.2838 | 0.3237 | 5.1492 | 0.1933 |
| NSST-PCNN | 0.6856 | 0.7914 | 1.1394(3) | 0.4271 | 5.1601(3) | 0.3365 | |
| NSCT-PCLLE | 0.6908 | 0.7915 | 1.0820 | 0.4422(3) | 5.1117 | 0.3657(3) | |
| LRD | 0.6687 | 0.7912 | 0.6880 | 0.4002 | 5.3850 | 0.2965 | |
| Zero-LF | 0.7677(2) | 0.7921(3) | 1.3337(2) | 0.3971 | 4.8929 | 0.2486 | |
| IFCNN | 0.6542 | 0.7903 | 0.5443 | 0.4083 | 4.8430 | 0.2917 | |
| SDNet | 0.7127 | 0.7904 | 0.2070 | 0.2964 | 4.5649 | 0.2427 | |
| EMFusion | 0.7638(3) | 0.7927(2) | 0.5768 | 0.6211 | 4.8813 | 0.3799 | |
| U2Fusion | 0.6307 | 0.7896 | 0.1951 | 0.3483 | 4.4321 | 0.3703(2) | |
| Proposed | 0.8736 | 0.7955 | 1.4704 | 0.4701(2) | 5.2540(2) | 0.3194(5) |
| Methods | ILLF | NSST-PCNN | NSCT-PCLLE | LRD | Zero-LF |
|---|---|---|---|---|---|
| Time | 161.51 | 10.01 | 3.26 | 126.64 | 2.45 |
| Methods | IFCNN | SDNet | EMFusion | U2Fusion | Proposed |
| Time | 0.21 | 0.16 | 0.57 | 0.36 | 4.24 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, J.; Han, D.; Wang, X.; Yi, P.; Yan, L.; Li, X. Multi-Sensor Medical-Image Fusion Technique Based on Embedding Bilateral Filter in Least Squares and Salient Detection. Sensors 2023, 23, 3490. https://doi.org/10.3390/s23073490
Li J, Han D, Wang X, Yi P, Yan L, Li X. Multi-Sensor Medical-Image Fusion Technique Based on Embedding Bilateral Filter in Least Squares and Salient Detection. Sensors. 2023; 23(7):3490. https://doi.org/10.3390/s23073490
Chicago/Turabian StyleLi, Jiangwei, Dingan Han, Xiaopan Wang, Peng Yi, Liang Yan, and Xiaosong Li. 2023. "Multi-Sensor Medical-Image Fusion Technique Based on Embedding Bilateral Filter in Least Squares and Salient Detection" Sensors 23, no. 7: 3490. https://doi.org/10.3390/s23073490