
A Lightweight Double-Stage Scheme to Identify Malicious DNS over HTTPS Traffic Using a Hybrid Learning Approach



Abstract
:1. Introduction
- We use a hybrid learning approach to design and implement a lightweight, double-stage anomaly-based IDS to identify malicious DoH traffic.
- We reduce the dimensionality of the feature set using PCA and balance the dataset using RUS to attain a high-performance model using only 18% of the feature set and 17% of the sample set distributed in balanced classes.
- We report on the performance of three supervised learning methods (Adaboost trees, random fine trees, and support vector machines) for DoH IDSs using the CIRA-CIC-DoHBrw-2020 dataset.
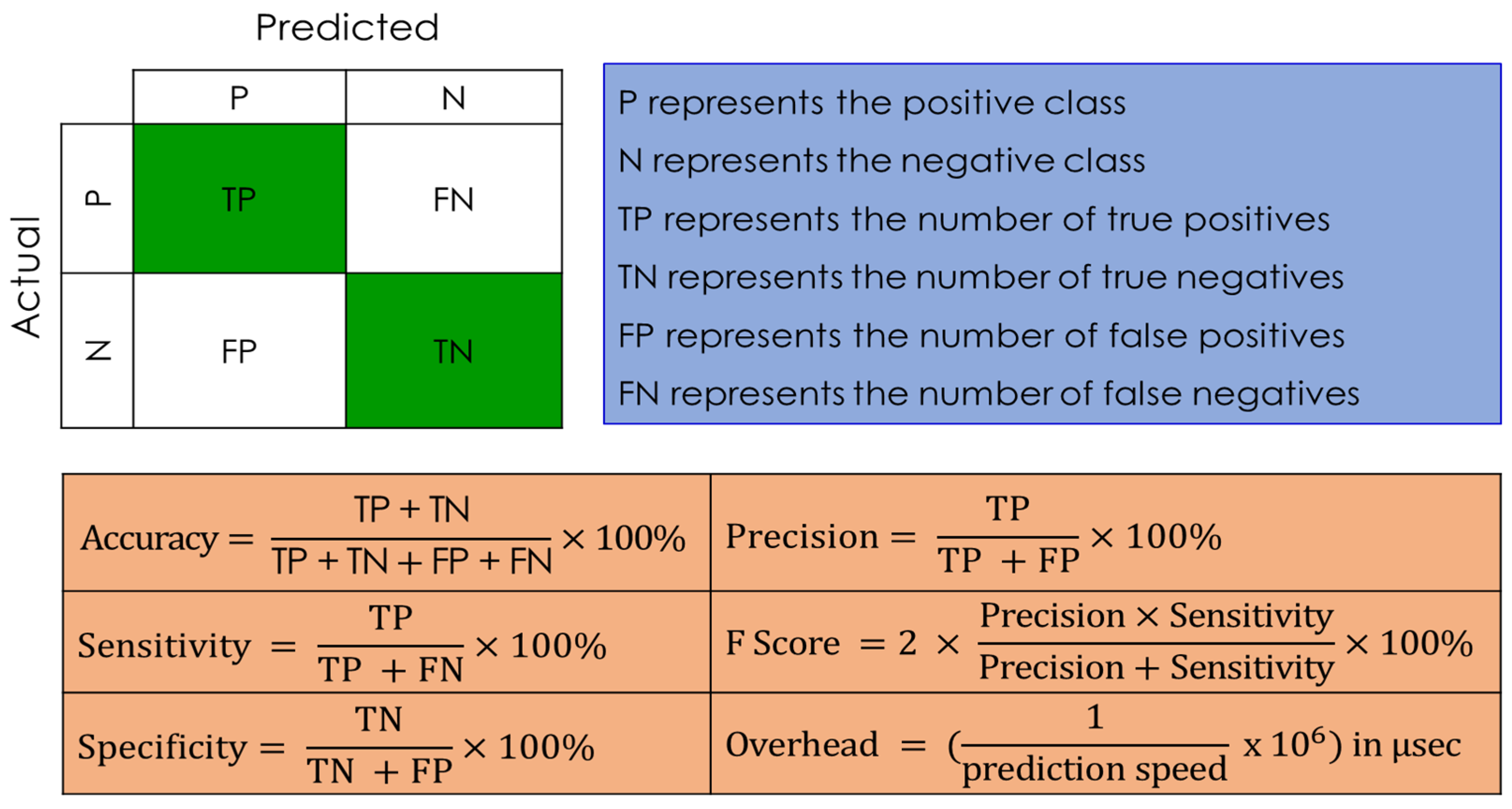
- We thoroughly evaluate the developed DoH IDS models using typical evaluation metrics, including accuracy, sensitivity, specificity, F-score, prediction time, classification error, confusion matrix, sensitivity matrix, and precision matrix.
- We contrast our best findings with state-of-the-art DoH IDS models and demonstrate that our hybrid learning-based DoH IDS is better than any former.
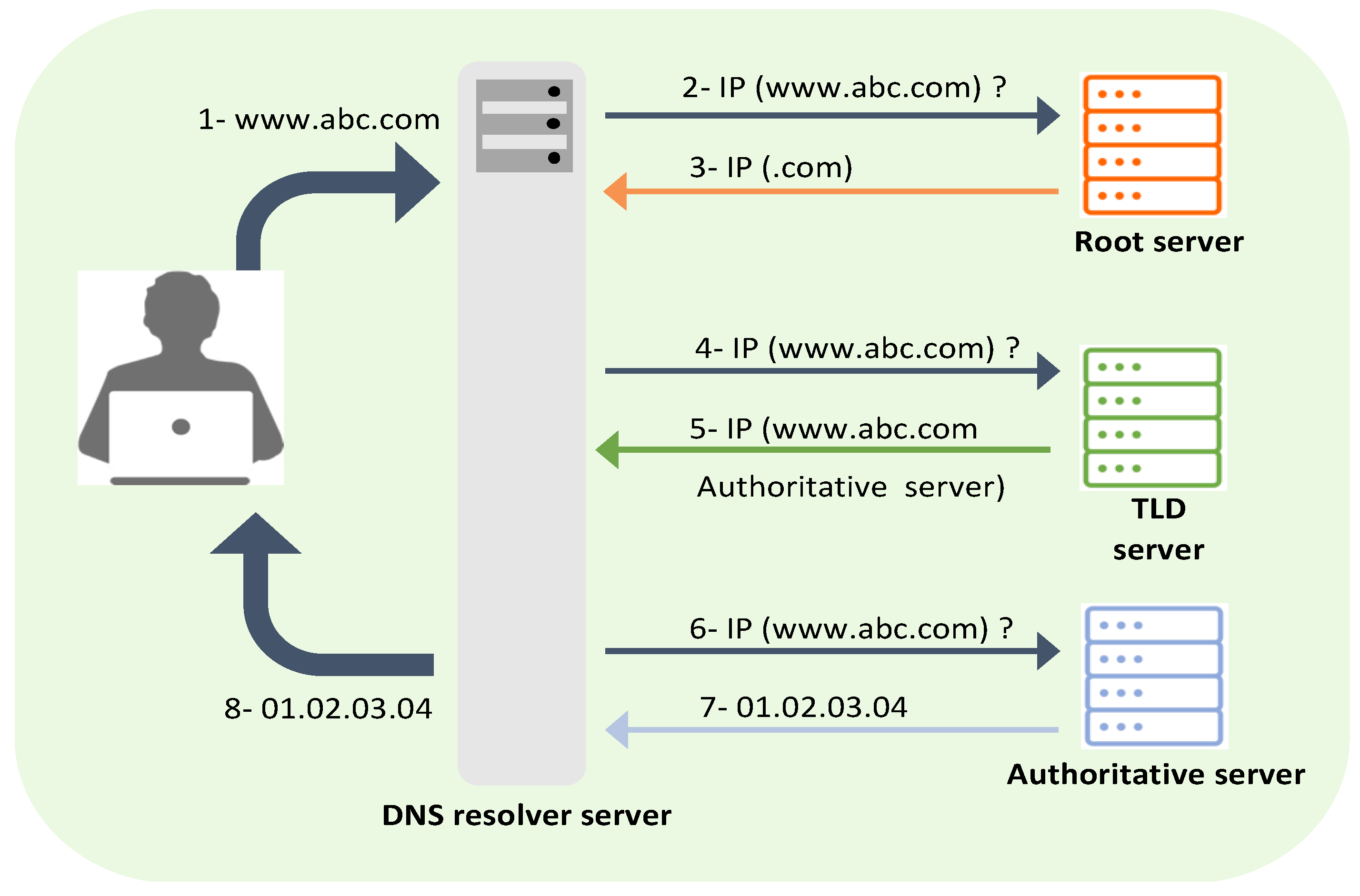
2. Background
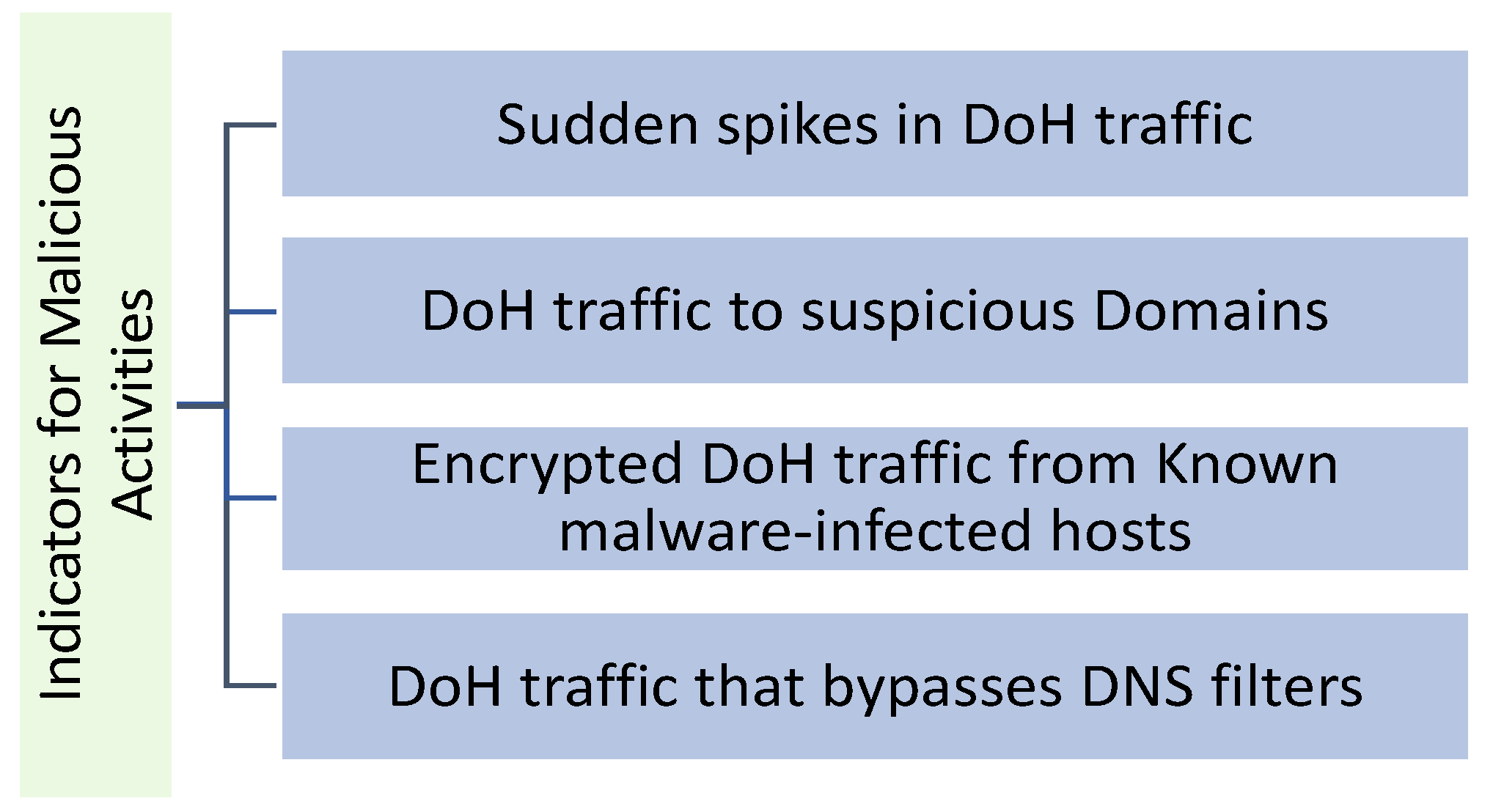
- Sudden spikes in DoH traffic: a sudden increase in network traffic could indicate malicious actors are using DoH to bypass DNS filters [14].
- DoH traffic to suspicious domains: if a lot of DoH traffic goes to domains known to be associated with malware, phishing, or other types of malicious activity, it could be a sign that malicious actors are using DoH to access those domains [15].
- Encrypted DoH traffic from known malware-infected hosts: if hosts on the network are known to be infected with malware, and encrypted DoH traffic is coming from those hosts, it could be a sign that the malware is using DoH to communicate with its command and control servers [16].
- DoH traffic bypassing DNS filters: if the implemented DNS filters block access to known malicious sites and DoH traffic sidesteps these filters, it could be a sign that someone is using DoH to bypass the implemented DNS filters [17].
3. Literature Review
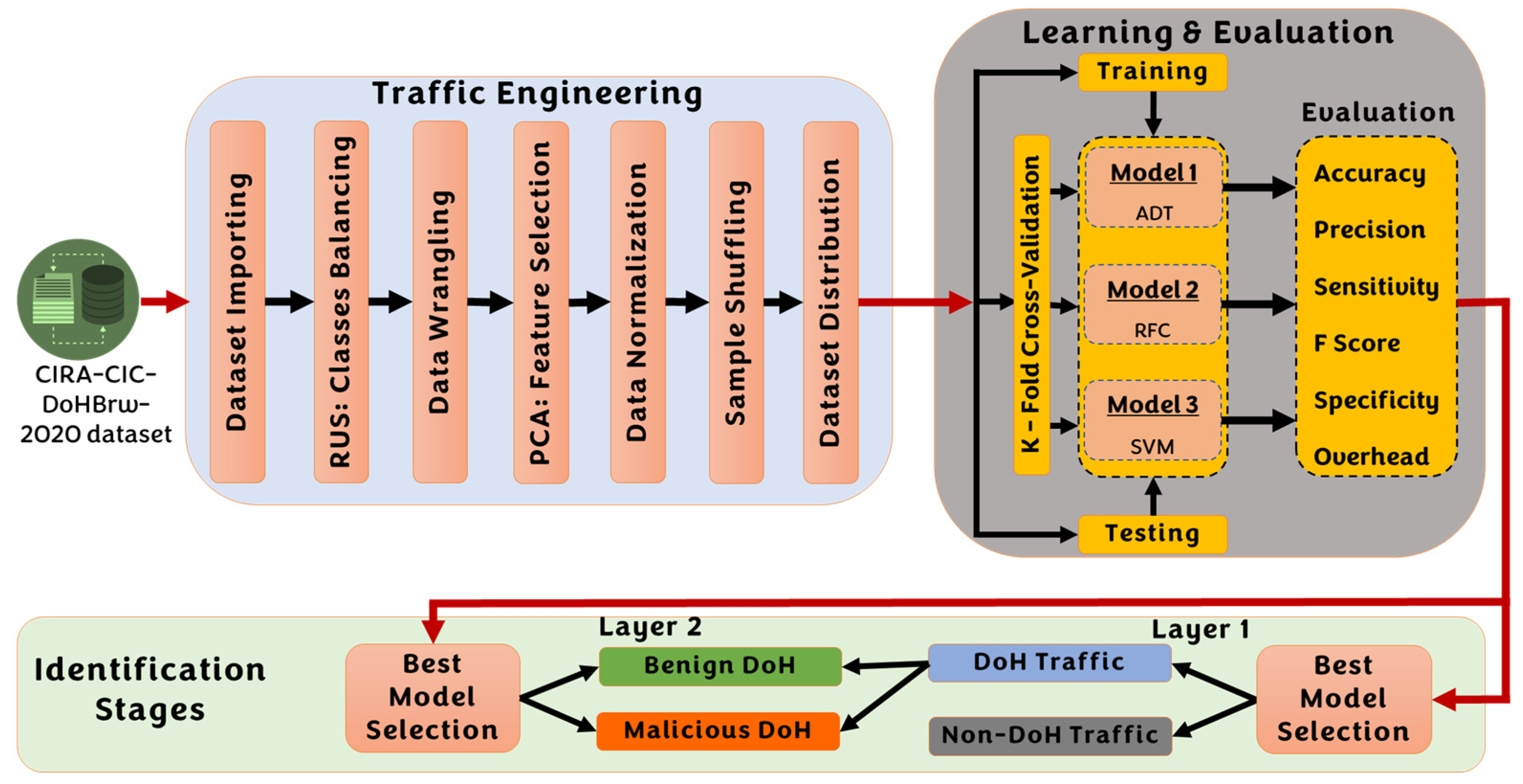
4. DoH Identification Architecture
4.1. Traffic Engineering Subsystem
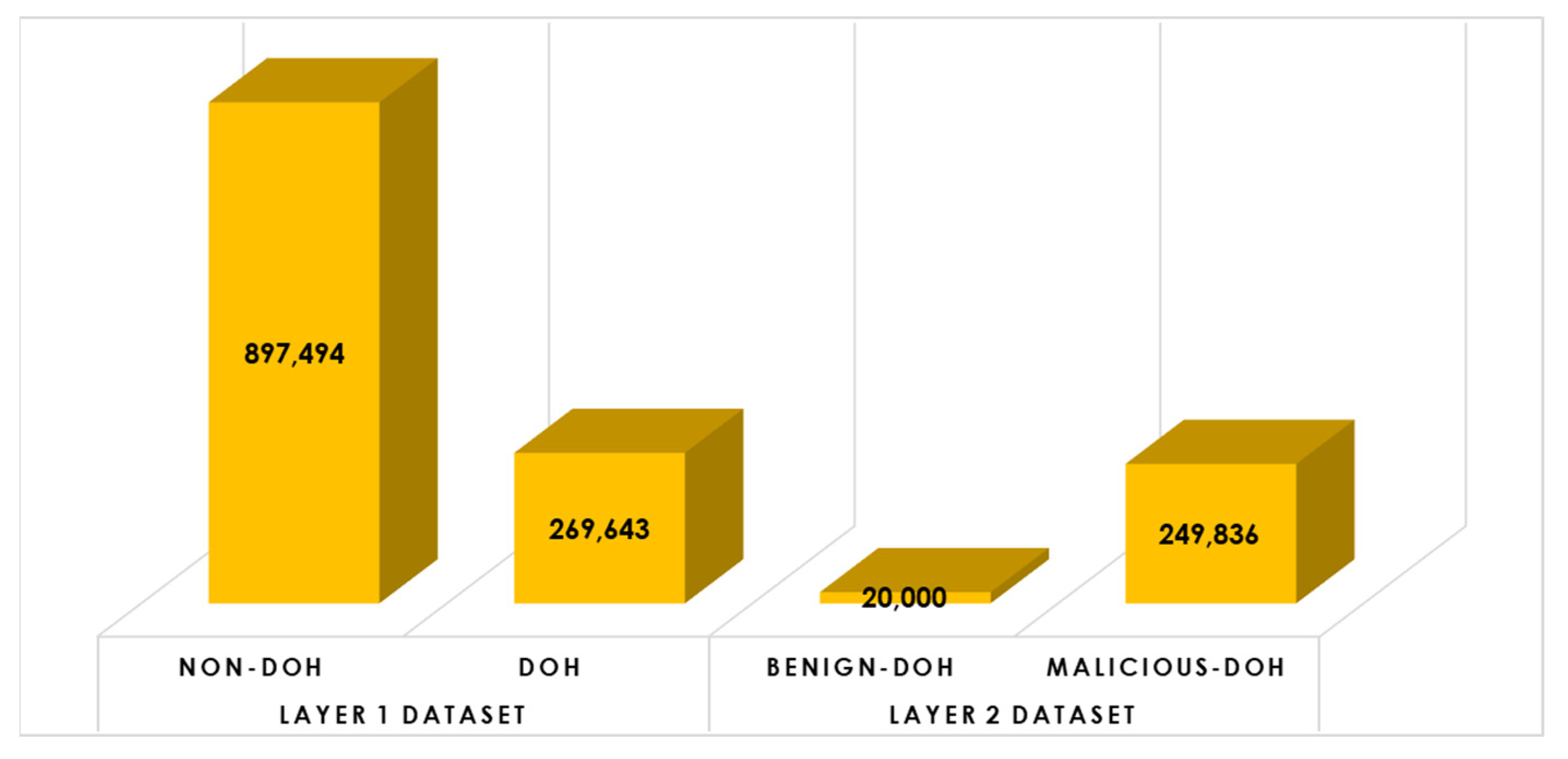
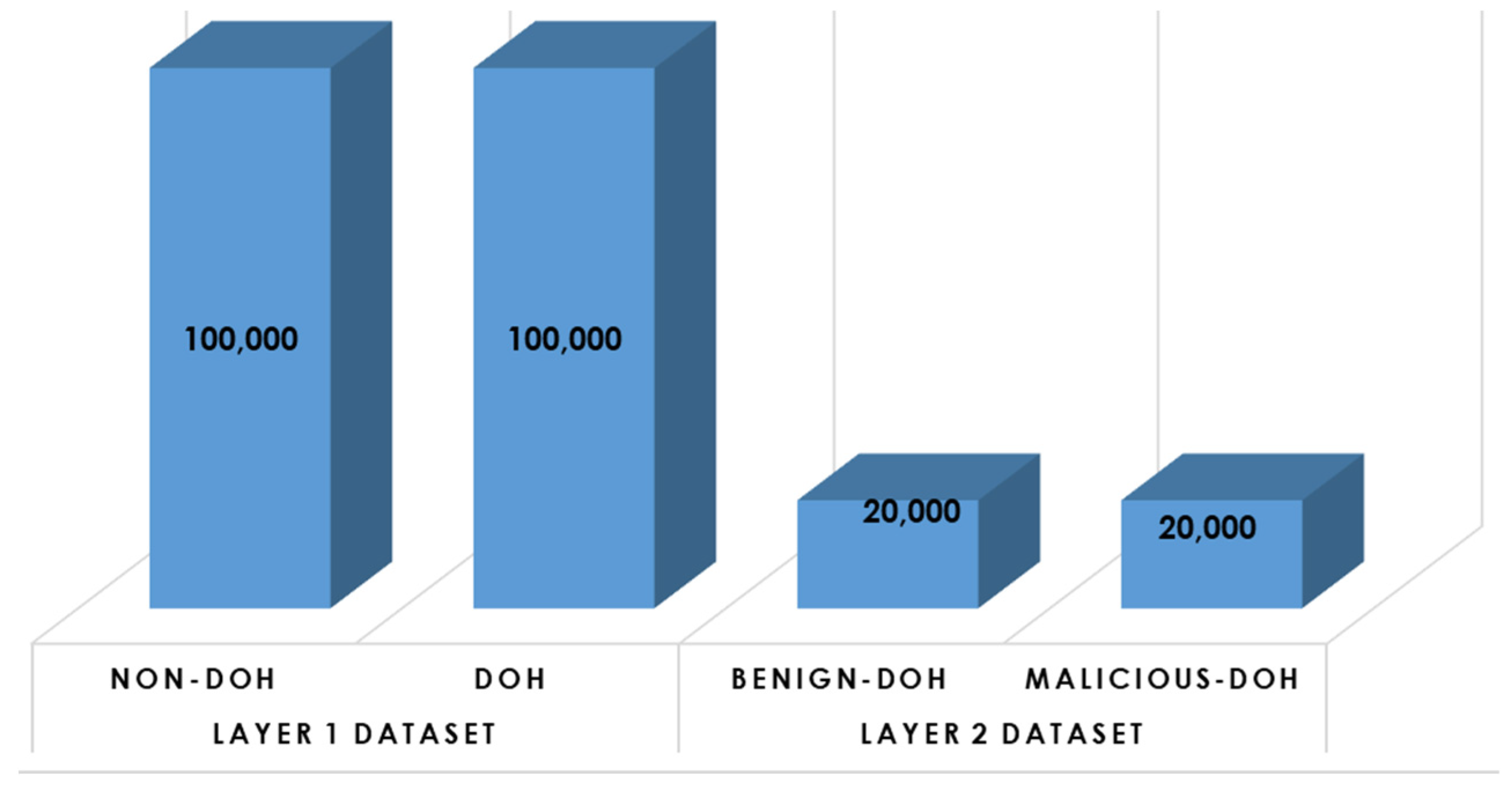
- Class Balancing: Since the CIRA-CIC-DoHBrw-2020 dataset is class-imbalanced, we have employed the random under-sampling (RUS) approach [40] in an attempt to balance all classes in the dataset and to minimize the number of samples in each class. As a result, the dataset for layer one after RUS is composed of 10,000 samples for DoH traffic and 10,000 samples for non-DoH traffic, and the dataset for layer two after RUS is composed of 20,000 samples for benign-DoH traffic and 20,000 samples for malicious-DoH traffic. Figure 5 illustrates the histogram distribution for the balanced-reduced dataset.
- Data Wrangling: this is the process of assuring that data is error-free and ready for use by other learning modules. At data wrangling [41], several activities are applied, including data cleaning from any noisy or mistakenly entered records, eliminating duplications in the samples, filling missing data with (zero, min, max, or mean values), and data exploration to validate the distribution and frequency (using a histogram) for each target label.
- Feature Selection: This procedure reduces the number of input attributes to be supplied and handled by a supervised detection/classification model [42]. This improves the model performance by boosting the prediction speed and minimizing the prediction overhead. In this research, we have employed principal component analysis (PCA) at the preprocessing stages to reduce the dimensionality (reduce the number of input feature sets). PCA decreases the number of dimensions (features) while increasing the interpretation of data and preserving the maximum amount of information [43]. As a result, to satisfy the lightweight performance of our proposed model, we have used the least number of features that maximize the system performance. The final set includes only six out of thirty-four features (FlowBytesSent, FlowReceivedRate, PacketLengthStandardDeviation, PacketLengthMean, PacketLengthMedian, PacketLengthMode).
- Data Normalization: While processing the dataset, we may find some features with values scattered over wide scales. This can negatively affect the classifier’s performance/stability during the training process. Data normalization is employed to overcome this issue by converting features to an analogous scale. The most common way to perform the normalization is the use of the min-max normalization technique [44], which we employ in our research. The normalized value of () is given as follows:
- Samples Shuffling: This process involves mixing the data sample (rows) while retaining logical associations between features (columns). This means randomly changing the locations for several samples but keeping the feature values in the same order. Shuffling is essential to eliminate any sort order in the dataset, ensuring the classifier is not overfitting to particular class duo sort order [45].
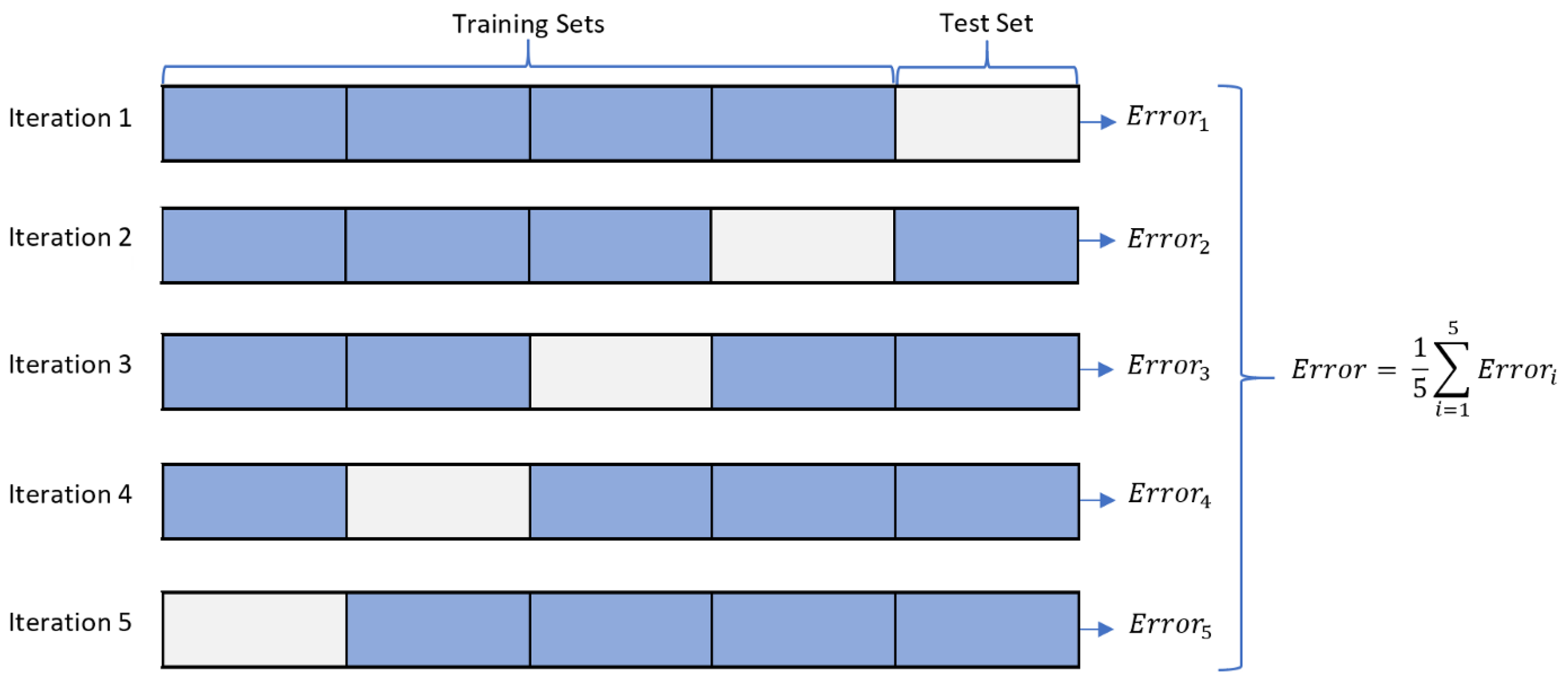
- Dataset Distribution: This process involves dividing the dataset into training and testing (validation) datasets. In this research, we have used 75% of the dataset for training, while 25% is left for testing the model using five-fold cross-validation to evaluate the model’s performance for all folds of data in the dataset. Five-fold cross-validation is commonly used to eliminate classifier biasing toward one of the target classes during the validation process [46]. Figure 6 illustrates the process of five-fold cross-validation. The performance metrics are calculated as the average of the five experiments’ results (five folds) [47].
4.2. Learning and Evaluation Subsystem
4.3. Traffic Identification Subsystem
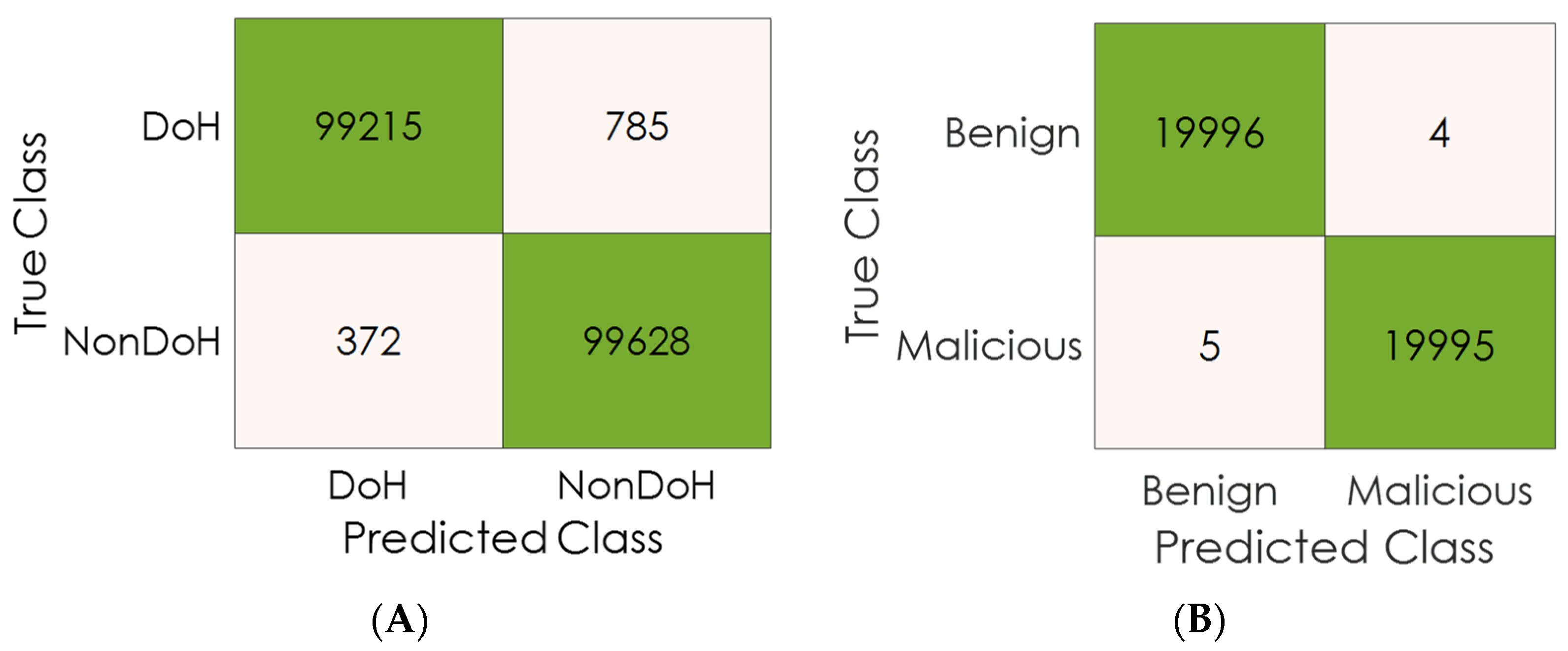
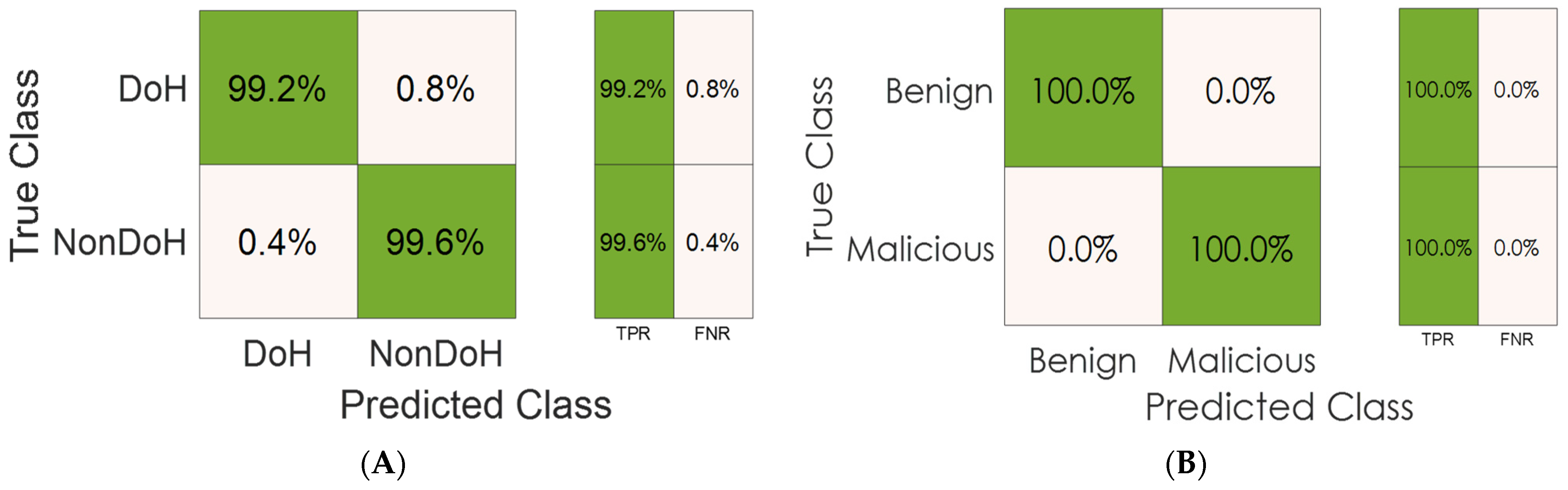
5. Results and Discussion
6. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| ADT | Adaboost trees |
| BiLSTM | Bidirectional LSTM |
| DNS | Domain Name System |
| DoH | DNS over HTTPS |
| DoT | DNS over TLS |
| DT | Decision trees |
| DTC | Decision trees classifier |
| EL-ADT | Ensemble learning of Adaboost trees |
| EL-DT | Ensemble learning of Decision trees |
| FDR | False discovery rate |
| FN | False negative |
| FNR | False negative rate |
| FP | False positive |
| Fuz-CL | Fuzzy clustering |
| GBC | Gradient boosting classifier |
| GRU | Gated recurrent units |
| HTTPS | Hypertext transfer protocol secure |
| IDC | International data corporation |
| IDS | Intrusion detection system |
| IP | Internet protocol |
| IPFIX | Internet protocol flow information export |
| ISPs | Internet service provider |
| KNC | K-nearest classifier |
| KNN | K-nearest neighbors |
| LGBM | Light gradient boosting machine |
| LSTM | Long short-term memory networks |
| MAE | Mean absolute error |
| MCE | Minimum classification error |
| MSE | Mean squared error |
| NB | Naive Bayes |
| NETFLOW | Network traffic flow |
| O-KNN | Optimizable K-nearest neighbors |
| OCSVM | One class support vector machine |
| PCA | Principal component analysis |
| PPV | Positive predictive value |
| RFC | Random Forest classifier |
| RNN | Recurrent neural networks |
| RUS | Random under-sampling |
| SOC | Security operation center |
| SSSVM | Semi-supervised support vector machine |
| TLD | Top-level domain |
| TLS | Transport Layer Security |
| TN | True negative |
| TP | True Positive |
| TPR | True positive rate |
| UDP | User Datagram Protocol |
| UNB | University of New Brunswick |
| XGBC | eXtreme Gradient Boosting |
References
- Jose, G.-L.; Mary, K.S.; Carol, A.W. Internet Protocol Handbook. In The Domain Name System (DNS) Handbook; DTIC: Fort Belvoir, VA, USA, 1989; Volume 4. [Google Scholar]
- Paul, M. Domain Names—Implementation and Specification; Internet Engineering Task Force; ISI: Marina del Rey, CA, USA, 1987. [Google Scholar]
- Usman Aijaz, N.; Misbahuddin, M.; Raziuddin, S. Survey on DNS-Specific Security Issues and Solution Approaches. In Data Science and Security; Jat, D.S., Shukla, S., Unal, A., Mishra, D.K., Eds.; Lecture Notes in Networks and Systems; Springer: Singapore, 2021; Volume 132, pp. 79–89. ISBN 9789811553080. [Google Scholar]
- Romain, F. DNS Security for Business Continuity and Resilience; IDC: Needham, MA, USA, 2022. [Google Scholar]
- Hu, Z.; Zhu, L.; Heidemann, J.; Mankin, A.; Wessels, D.; Hoffman, P.E. Specification for DNS over Transport Layer Security (TLS); Internet Engineering Task Force: Fremont, CA, USA, 2016. [Google Scholar]
- Hoffman, P.E.; McManus, P. DNS Queries over HTTPS (DoH); Internet Engineering Task Force: Fremont, CA, USA, 2018. [Google Scholar]
- Albulayhi, K.; Smadi, A.A.; Sheldon, F.T.; Abercrombie, R.K. IoT Intrusion Detection Taxonomy, Reference Architecture, and Analyses. Sensors 2021, 21, 6432. [Google Scholar] [CrossRef] [PubMed]
- Chang, D.; Chen, J.Q.; Li, Z.; Li, X. Hide and Seek: Revisiting DNS-based User Tracking. In Proceedings of the 2022 IEEE 7th European Symposium on Security and Privacy (EuroS&P), Genoa, Italy, 6–10 June 2022; pp. 188–205. [Google Scholar]
- Park, J.; Khormali, A.; Mohaisen, M.; Mohaisen, A. Where are you taking me? Behavioral analysis of open DNS resolvers. In Proceedings of the 2019 49th Annual IEEE/IFIP International Conference on Dependable Systems and Networks (DSN), Portland, OR, USA, 24–27 June 2019; pp. 493–504. [Google Scholar]
- Cheng, Y.; Liu, Y.; Li, C.; Zhang, Z.; Li, N.; Du, Y. In-Depth Evaluation of the Impact of National-Level DNS Filtering on DNS Resolvers over Space and Time. Electronics 2022, 11, 1276. [Google Scholar] [CrossRef]
- Pavur, J.; Moser, D.; Lenders, V.; Martinovic, I. Secrets in the sky: On privacy and infrastructure security in dvb-s satellite broadband. In Proceedings of the 12th Conference on Security and Privacy in Wireless and Mobile Networks, Miami, FL, USA, 15–17 May 2019; pp. 277–284. [Google Scholar]
- Böttger, T.; Cuadrado, F.; Antichi, G.; Fernandes, E.L.; Tyson, G.; Castro, I.; Uhlig, S. An Empirical Study of the Cost of DNS-over-HTTPS. In Proceedings of the Internet Measurement Conference, Amsterdam, The Netherlands, 21–23 October 2019; pp. 15–21. [Google Scholar]
- Singh, S.K.; Roy, P.K. Detecting malicious dns over https traffic using machine learning. In Proceedings of the 2020 International Conference on Innovation and Intelligence for Informatics, Computing and Technologies (3ICT), Sakheer, Bahrain, 20–21 December 2020; pp. 1–6. [Google Scholar]
- Badhwar, R.; Badhwar, R. Defensive Measures in the Wake of the SolarWinds Fallout. In The CISO’s Transformation: Security Leadership in a High Threat Landscape; Springer: Berlin/Heidelberg, Germany, 2021; pp. 59–64. [Google Scholar]
- Mitsuhashi, R.; Satoh, A.; Jin, Y.; Iida, K.; Shinagawa, T.; Takai, Y. Identifying malicious dns tunnel tools from doh traffic using hierarchical machine learning classification. In Proceedings of the Information Security: 24th International Conference, ISC 2021, Virtual Event, 10–12 November 2021; pp. 238–256. [Google Scholar]
- Lyu, M.; Gharakheili, H.H.; Sivaraman, V. A Survey on DNS Encryption: Current Development, Malware Misuse, and Inference Techniques. ACM Comput. Surv. 2022, 55, 1–28. [Google Scholar] [CrossRef]
- S. Alrayes, F.; Maray, M.; Gaddah, A.; Yafoz, A.; Alsini, R.; Alghushairy, O.; Mohsen, H.; Motwakel, A. Modeling of Botnet Detection Using Barnacles Mating Optimizer with Machine Learning Model for Internet of Things Environment. Electronics 2022, 11, 3411. [Google Scholar] [CrossRef]
- Rawat, R.; Shedbalkar, K.; Moharir, M.; Deepamala, N.; Kumar, P.R.; Tanmayananda, M. Analysis and detection of malicious activity on doh traffic. In Proceedings of the 2021 2nd Global Conference for Advancement in Technology (GCAT), Bangalore, India, 1–3 October 2021; pp. 1–5. [Google Scholar]
- Parra, G.D.L.T.; Rad, P.; Choo, K.-K.R. Implementation of deep packet inspection in smart grids and industrial Internet of Things: Challenges and opportunities. J. Netw. Comput. Appl. 2019, 135, 32–46. [Google Scholar] [CrossRef]
- Naz, N.; Khan, M.A.; Alsuhibany, S.A.; Diyan, M.; Tan, Z.; Khan, M.A.; Ahmad, J. Ensemble learning-based IDS for sensors telemetry data in IoT networks. Math. Biosci. Eng. 2022, 19, 10550–10580. [Google Scholar] [CrossRef]
- Fisher, W.W.; Piazza, C.C.; Roane, H.S. Handbook of Applied Behavior Analysis; Guilford Publications: New York, NY, USA, 2021. [Google Scholar]
- Behnke, M.; Briner, N.; Cullen, D.; Schwerdtfeger, K.; Warren, J.; Basnet, R.; Doleck, T. Feature Engineering and Machine Learning Model Comparison for Malicious Activity Detection in the DNS-Over-HTTPS Protocol. IEEE Access 2021, 9, 129902–129916. [Google Scholar] [CrossRef]
- Miloslavskaya, N.; Tolstoy, A. Internet of Things: Information security challenges and solutions. Clust. Comput. 2019, 22, 103–119. [Google Scholar] [CrossRef]
- Yan, Z.; Lee, J.-H. The road to DNS privacy. Future Gener. Comput. Syst. 2020, 112, 604–611. [Google Scholar] [CrossRef]
- Vekshin, D.; Hynek, K.; Cejka, T. Doh insight: Detecting dns over https by machine learning. In Proceedings of the 15th International Conference on Availability, Reliability and Security, Virtual Event, 25–28 August 2020; pp. 1–8. [Google Scholar]
- Deccio, C.; Davis, J. DNS privacy in practice and preparation. In Proceedings of the 15th International Conference on Emerging Networking Experiments and Technologies, Orlando, FL, USA, 9–12 December 2019; pp. 138–143. [Google Scholar]
- Csikor, L.; Singh, H.; Kang, M.S.; Divakaran, D.M. Privacy of DNS-over-HTTPS: Requiem for a Dream? In Proceedings of the 2021 IEEE European Symposium on Security and Privacy (EuroS&P), Virtual Event, 6–10 September 2021; pp. 252–271. [Google Scholar]
- Jerabek, K.; Rysavy, O.; Burgetova, I. Measurement and characterization of DNS over HTTPS traffic. arXiv 2022, arXiv:2204.03975. [Google Scholar]
- Qayyum, A.; Usama, M.; Qadir, J.; Al-Fuqaha, A. Securing Connected & Autonomous Vehicles: Challenges Posed by Adversarial Machine Learning and the Way Forward. IEEE Commun. Surv. Tutor. 2020, 22, 998–1026. [Google Scholar] [CrossRef] [Green Version]
- Casanova, L.F.G.; Lin, P.-C. Generalized Classification of DNS over HTTPS Traffic with Deep Learning. In Proceedings of the 2021 Asia-Pacific Signal and Information Processing Association Annual Summit and Conference (APSIPA ASC), Tokyo, Japan, 14–17 December 2021; pp. 1903–1907. [Google Scholar]
- Banadaki, Y.M.; Robert, S. Detecting malicious dns over https traffic in domain name system using machine learning classifiers. J. Comput. Sci. Appl. 2020, 8, 46–55. [Google Scholar] [CrossRef]
- Zebin, T.; Rezvy, S.; Luo, Y. An Explainable AI-Based Intrusion Detection System for DNS Over HTTPS (DoH) Attacks. IEEE Trans. Inf. Forensics Secur. 2022, 17, 2339–2349. [Google Scholar] [CrossRef]
- Bernard, A. Solving Interoperability and Performance Challenges over Heterogeneous IoT Networks: DNS-Based Solutions; Institut Polytechnique de Paris: Palaiseau, France, 2021. [Google Scholar]
- Mitsuhashi, R.; Jin, Y.; Iida, K.; Shinagawa, T.; Takai, Y. Malicious DNS Tunnel Tool Recognition using Persistent DoH Traffic Analysis. IEEE Trans. Netw. Serv. Manag. 2022, 2022, 3215681. [Google Scholar] [CrossRef]
- Nguyen, T.A.; Park, M. DoH Tunneling Detection System for Enterprise Network Using Deep Learning Technique. Appl. Sci. 2022, 12, 2416. [Google Scholar] [CrossRef]
- Hynek, K.; Vekshin, D.; Luxemburk, J.; Cejka, T.; Wasicek, A. Summary of DNS Over HTTPS Abuse. IEEE Access 2022, 10, 54668–54680. [Google Scholar] [CrossRef]
- Abu Al-Haija, Q.; Al-Badawi, A. Attack-Aware IoT Network Traffic Routing Leveraging Ensemble Learning. Sensors 2021, 22, 241. [Google Scholar] [CrossRef]
- MontazeriShatoori, M.; Davidson, L.; Kaur, G.; Lashkari, A.H. Detection of DoH Tunnels using Time-series Classification of Encrypted Traffic. In Proceedings of the 2020 IEEE Intl. Conf. on Dependable, Autonomic and Secure Computing, Calgary, AB, Canada, 17–22 August 2020; pp. 63–70. [Google Scholar] [CrossRef]
- Yusof, M.H.M.; Almohammedi, A.A.; Shepelev, V.; Ahmed, O. Visualizing Realistic Benchmarked IDS Dataset: CIRA-CIC-DoHBrw-2020. IEEE Access 2022, 10, 94624–94642. [Google Scholar] [CrossRef]
- Arafat, M.Y.; Hoque, S.; Farid, D.M. Cluster-based under-sampling with random forest for multi-class imbalanced classification. In Proceedings of the 2017 11th International Conference on Software, Knowledge, Information Management and Applications (SKIMA), Malabe, Sri Lanka, 6–8 December 2017; pp. 1–6. [Google Scholar] [CrossRef]
- Azeroual, O. Data Wrangling in Database Systems: Purging of Dirty Data. Data 2020, 5, 50. [Google Scholar] [CrossRef]
- Al-Qudah, M.; Ashi, Z.; Alnabhan, M.; Abu Al-Haija, Q. Effective One-Class Classifier Model for Memory Dump Malware Detection. J. Sens. Actuator Netw. 2023, 12, 5. [Google Scholar] [CrossRef]
- Kurita, T. Principal Component Analysis (PCA). In Computer Vision; Springer: Cham, Switzerland, 2020. [Google Scholar] [CrossRef]
- Abu Al-Haija, Q.; Zein-Sabatto, S. An Efficient Deep-Learning-Based Detection and Classification System for Cyber-Attacks in IoT Communication Networks. Electronics 2020, 9, 2152. [Google Scholar] [CrossRef]
- Nguyen, T.T.; Trahay, F.; Domke, J.; Drozd, A.; Vatai, E.; Liao, J.; Wahib, M.; Gerofi, B. Why Globally Re-shuffle? Revisiting Data Shuffling in Large Scale Deep Learning. In In Proceedings of the 2022 IEEE International Parallel and Dis-tributed Processing Symposium (IPDPS), Lyon, France, 30 May–3 June 2022; pp. 1085–1096. [Google Scholar] [CrossRef]
- Abu Al-Haija, Q.; Odeh, A.; Qattous, H. PDF Malware Detection Based on Optimizable Decision Trees. Electronics 2022, 11, 3142. [Google Scholar] [CrossRef]
- Khan, J.; Lee, E.; Kim, K. A higher prediction accuracy–based alpha–beta filter algorithm using the feedforward artificial neural network. CAAI Trans. Intell. Technol. 2022, 2022, 1–16. [Google Scholar] [CrossRef]
- Schapire, R.E. Explaining AdaBoost. In Empirical Inference; Schölkopf, B., Luo, Z., Vovk, V., Eds.; Springer: Berlin/Heidelberg, Germany, 2013; pp. 37–52. [Google Scholar] [CrossRef]
- Naser, M.; Abu Al-Haija, Q. Spyware Identification for Android Systems Using Fine Trees. Information 2023, 14, 102. [Google Scholar] [CrossRef]
- Abu Al-Haija, Q.; Smadi, A.A.; Allehyani, M.F. Meticulously Intelligent Identification System for Smart Grid Network Stability to Optimize Risk Management. Energies 2021, 14, 6935. [Google Scholar] [CrossRef]
- Mbona, I.; Eloff, J.H.P. Detecting Zero-Day Intrusion Attacks Using Semi-Supervised Machine Learning Approaches. IEEE Access 2022, 10, 69822–69838. [Google Scholar] [CrossRef]
- Du, X.; Liu, D.; Ding, S.; Liu, Z.; Yuan, X.; Li, T.; Deng, H. Design of an Autoencoder-based Anomaly Detection for the DoH traffic System. In Proceedings of the 2022 IEEE 25th International Conference on Computer Supported Cooperative Work in Design (CSCWD), Hangzhou, China, 4–6 May 2022; pp. 763–768. [Google Scholar] [CrossRef]
- Ahakonye, L.A.C.; Nwakanma, C.I.; Ajakwe, S.O.; Lee, J.M.; Kim, D.-S. Countering DNS Vulnerability to Attacks Using Ensemble Learning. In Proceedings of the 2022 International Conference on Artificial Intelligence in Information and Communication (ICAIIC), Jeju-si, Republic of Korea, 21–24 February 2022; pp. 007–010. [Google Scholar] [CrossRef]
- Abu Al-Haija, Q.; Krichen, M.; Abu Elhaija, W. Machine-Learning-Based Darknet Traffic Detection System for IoT Applications. Electronics 2022, 11, 556. [Google Scholar] [CrossRef]
- Yue, C.; Wang, L.; Wang, D.; Duo, R.; Nie, X. An Ensemble Intrusion Detection Method for Train Ethernet Consist Network Based on CNN and RNN. IEEE Access 2021, 9, 59527–59539. [Google Scholar] [CrossRef]
- Alenezi, R.; Ludwig, S.A. Classifying DNS Tunneling Tools For Malicious DoH Traffic. In Proceedings of the 2021 IEEE Symposium Series on Computational Intelligence (SSCI), Orlando, FL, USA, 5–7 December 2021; pp. 1–9. [Google Scholar] [CrossRef]
- Li, Y.; Dandoush, A.; Liu, J. Evaluation and Optimization of learning-based DNS over HTTPS Traffic Classification. In Proceedings of the 2021 International Symposium on Networks, Computers and Communications (ISNCC), Dubai, United Arab Emirates, 31 October–2 November 2021; pp. 1–6. [Google Scholar] [CrossRef]
- Nguyen, A.T.; Park, M. Detection of DoH Tunneling using Semi-supervised Learning method. In Proceedings of the 2022 International Conference on Information Networking (ICOIN), Jeju-si, Republic of Korea, 12–15 January 2022; pp. 450–453. [Google Scholar] [CrossRef]
- Dang, Q.-V. Studying the Fuzzy clustering algorithm for intrusion detection on the attacks to the Domain Name System. In Proceedings of the 2021 Fifth World Conference on Smart Trends in Systems Security and Sustainability (WorldS4), London, UK, 29–30 July 2021; pp. 271–274. [Google Scholar] [CrossRef]
- Alsulami, A.A.; Abu Al-Haija, Q.; Tayeb, A.; Alqahtani, A. An Intrusion Detection and Classification System for IoT Traffic with Improved Data Engineering. Appl. Sci. 2022, 12, 12336. [Google Scholar] [CrossRef]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Ref. | Method | Limitations |
|---|---|---|
| [30] | LGBM and XGBoost algorithms | Requires a huge number of labeled datasets |
| [22] | LGBM | Overfitting and time-consuming to filter data and eliminate the noise |
| [32] | Balanced and stacked Random Forest | The model is inefficient and too slow to make real-time predictions. |
| [17] | RNN, RFC, DTC, LSTM, GRU, They used GBC, KNC, and XGBoost | Require a huge amount of labeled data |
| [33] | Multi-Layer Perceptron | The model’s structure is complex, and real-time performance is poor. |
| [34] | LSTM model | Model complexity and more training data required to learn effectively |
| [13] | K-nearest neighbors (KNN), C4.5 Decision tree (DT), Random Forest (RF), and Naive Bayes (NB) | Time-consuming, requires a huge number of labeled datasets, and the real-time performance could be better. |
| [25] | K-nearest neighbors, C4.5 Decision tree, Random Forest, Naïve Bayes, and Adaboost Decision tree | Due to similarities with other requests and responses, the suggested ML algorithm cannot identify a DoH connection with a single query. |
| [35] | Transformer | Requires a high volume of labeled data, more complex than other models |
| Ref. | Model | # of Features | # of Samples | Overhead | Accuracy | F1 Score |
|---|---|---|---|---|---|---|
| Davidson et al. [38] | LSTM | 34 | 1,436,973 | 20.4 µs | 99.0% | 98% |
| Mbona et al. [51] | OCSVM | 34 | 1,436,973 | - | - | 85% |
| X. Du et al. [52] | Bi-LSTM | 34 | 1,436,973 | 1.14 ms | 99.6% | 99.6% |
| Chijioke et al. [53] | EL-ADT | 34 | 1,436,973 | - | 99.5% | - |
| Al-Haija et al. [54] | O-KNN | 34 | 141,530 | 100 µs | 97.1% | 97.3% |
| C. Yue et al. [55] | LSTM | 34 | 1,436,973 | >1 ms | 97.5% | - |
| Rafa et al. [56] | XGBC | 34 | 1,436,973 | - | 99.2% | |
| Y. Li et al. [57] | RFC | 34 | 1,436,973 | - | 98.5% | 98.5% |
| Nguyen et al. [58] | SSSVM | 34 | 1,436,973 | - | 94.0% | 93.2% |
| Dang et al. [59] | Fuz-Cl | 34 | 1,436,973 | - | 85.0% | 87.0% |
| This work | Hybrid | 6 | 240,000 | 3.5 µs | 100% | 100% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Abu Al-Haija, Q.; Alohaly, M.; Odeh, A. A Lightweight Double-Stage Scheme to Identify Malicious DNS over HTTPS Traffic Using a Hybrid Learning Approach. Sensors 2023, 23, 3489. https://doi.org/10.3390/s23073489
Abu Al-Haija Q, Alohaly M, Odeh A. A Lightweight Double-Stage Scheme to Identify Malicious DNS over HTTPS Traffic Using a Hybrid Learning Approach. Sensors. 2023; 23(7):3489. https://doi.org/10.3390/s23073489
Chicago/Turabian StyleAbu Al-Haija, Qasem, Manar Alohaly, and Ammar Odeh. 2023. "A Lightweight Double-Stage Scheme to Identify Malicious DNS over HTTPS Traffic Using a Hybrid Learning Approach" Sensors 23, no. 7: 3489. https://doi.org/10.3390/s23073489