

Fault Voiceprint Signal Diagnosis Method of Power Transformer Based on Mixup Data Enhancement

Abstract
:1. Introduction
2. Voiceprint Signal Preprocessing and Classifier
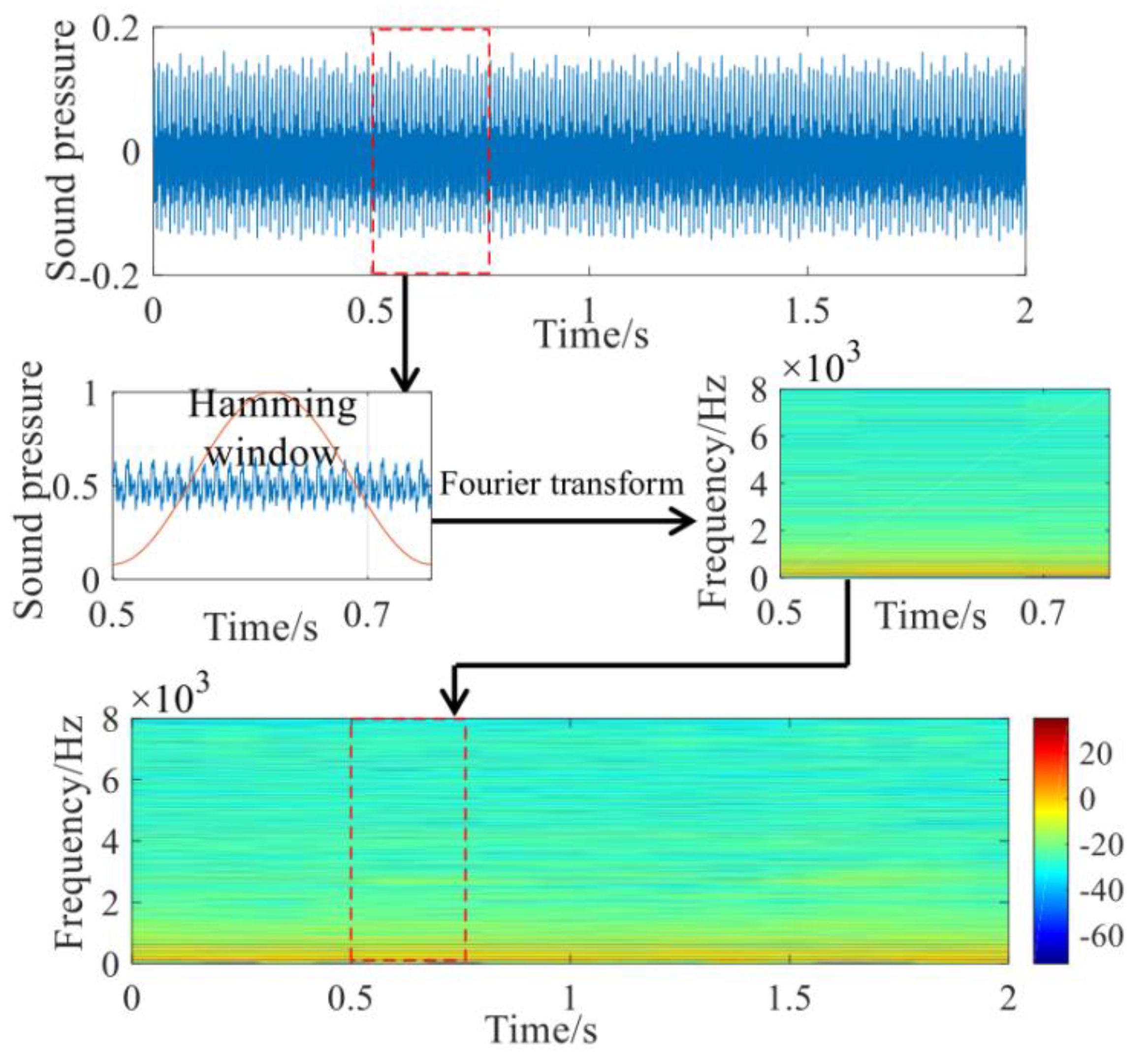
2.1. Voiceprint Time Spectrum
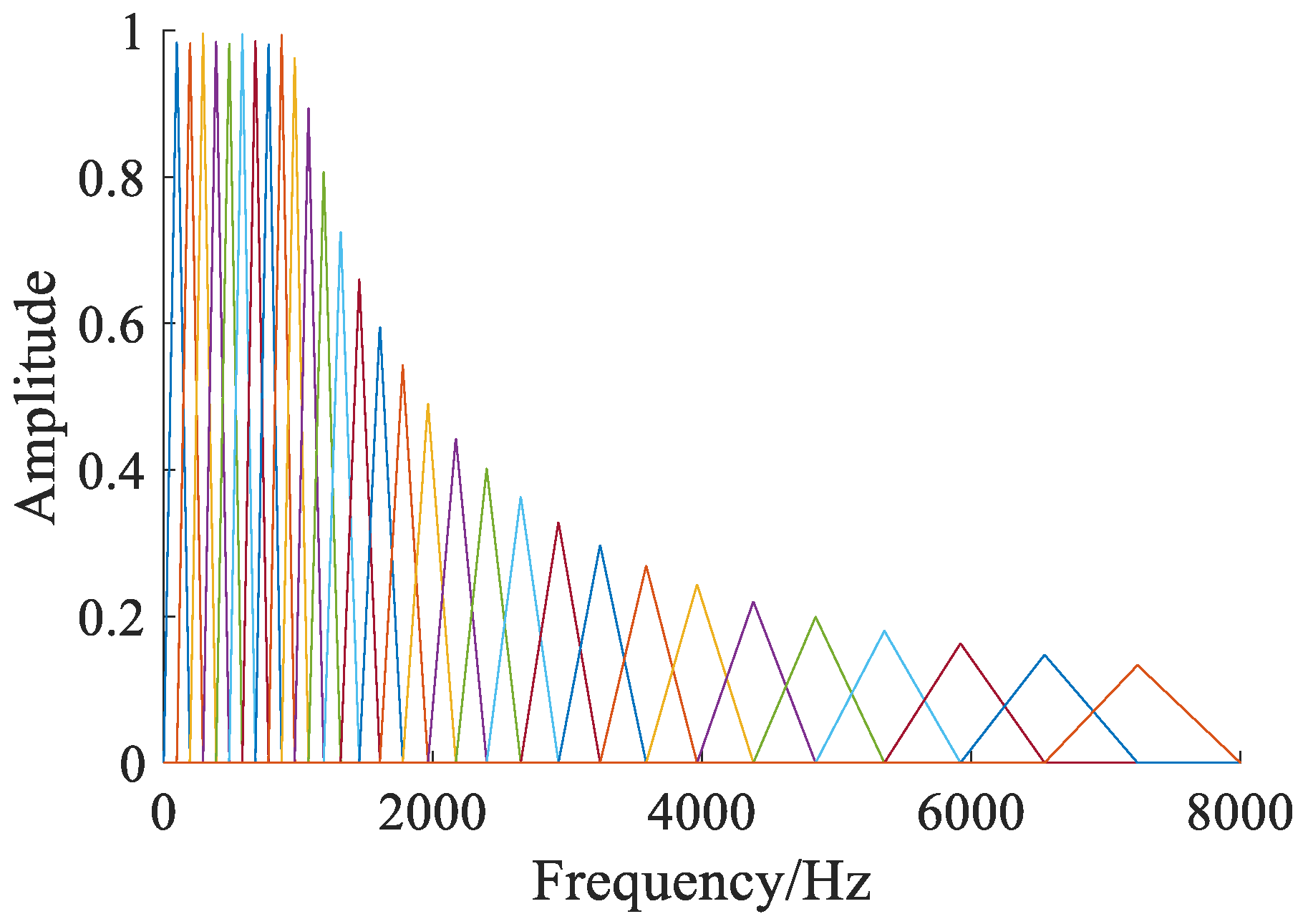
2.2. Mel Time Spectrum
2.3. Mixup Data Enhancement
2.4. CNN
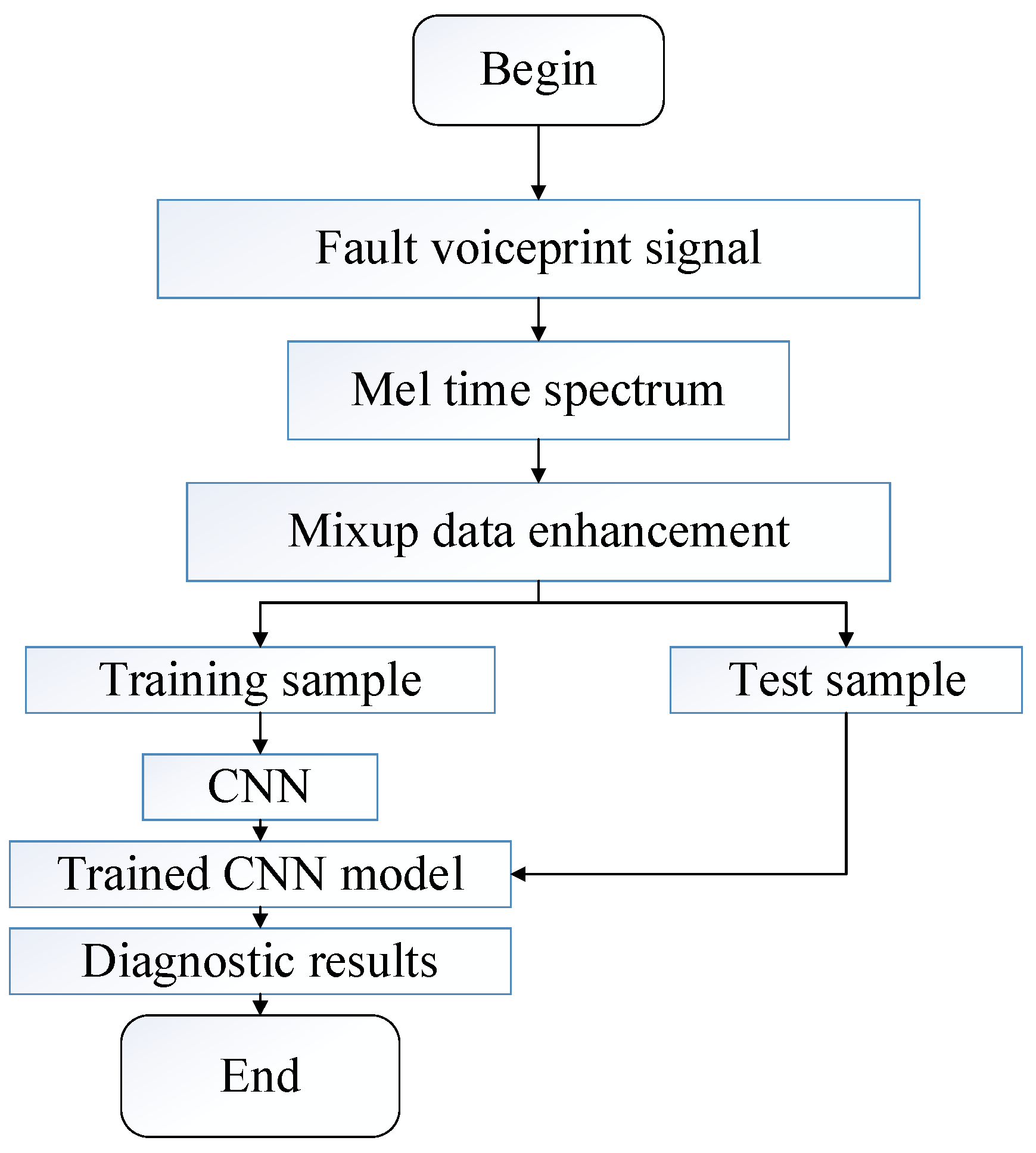
3. Voiceprint Signal Diagnosis Process
4. Experiments and Results
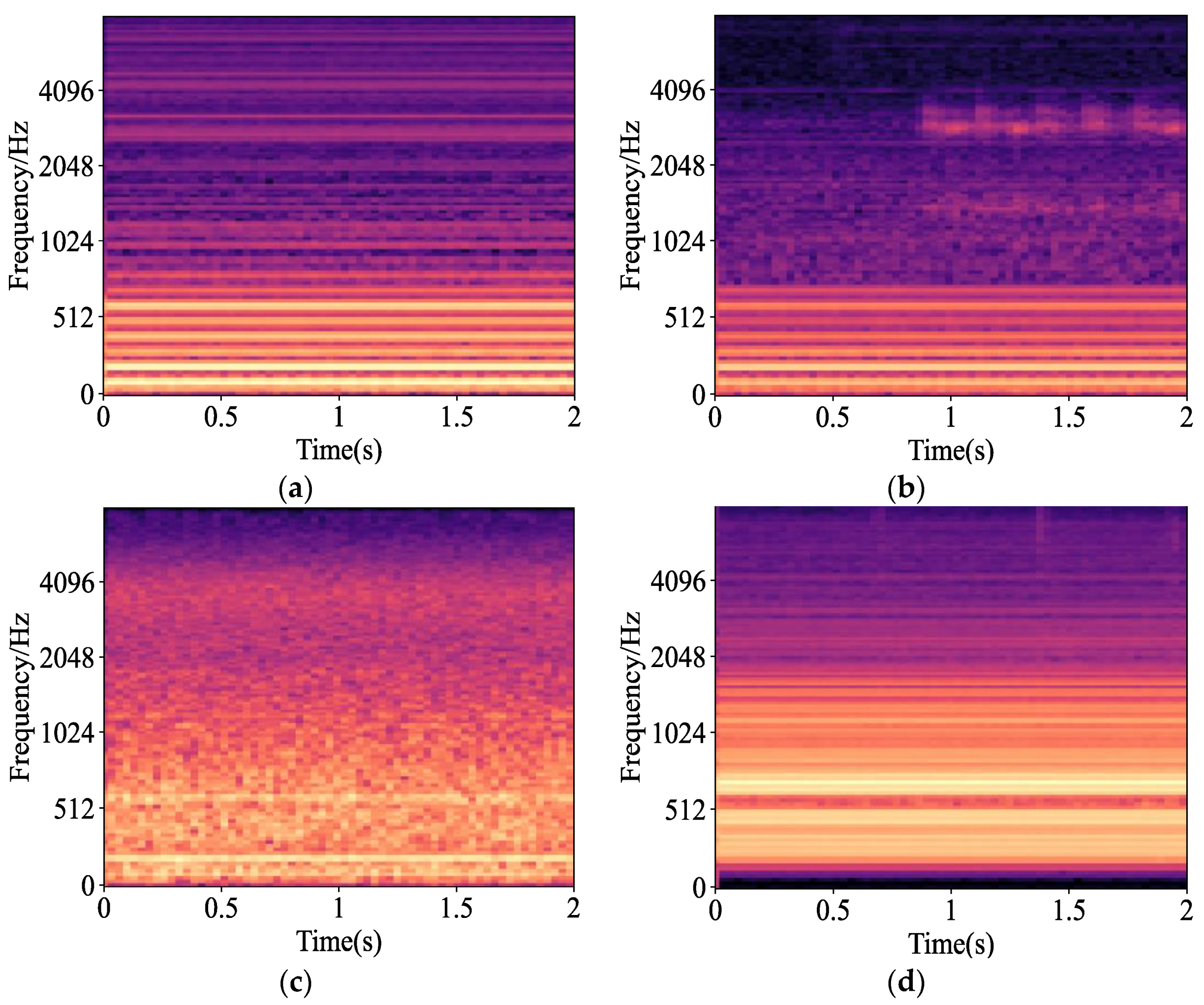
4.1. Source of Experimental Data
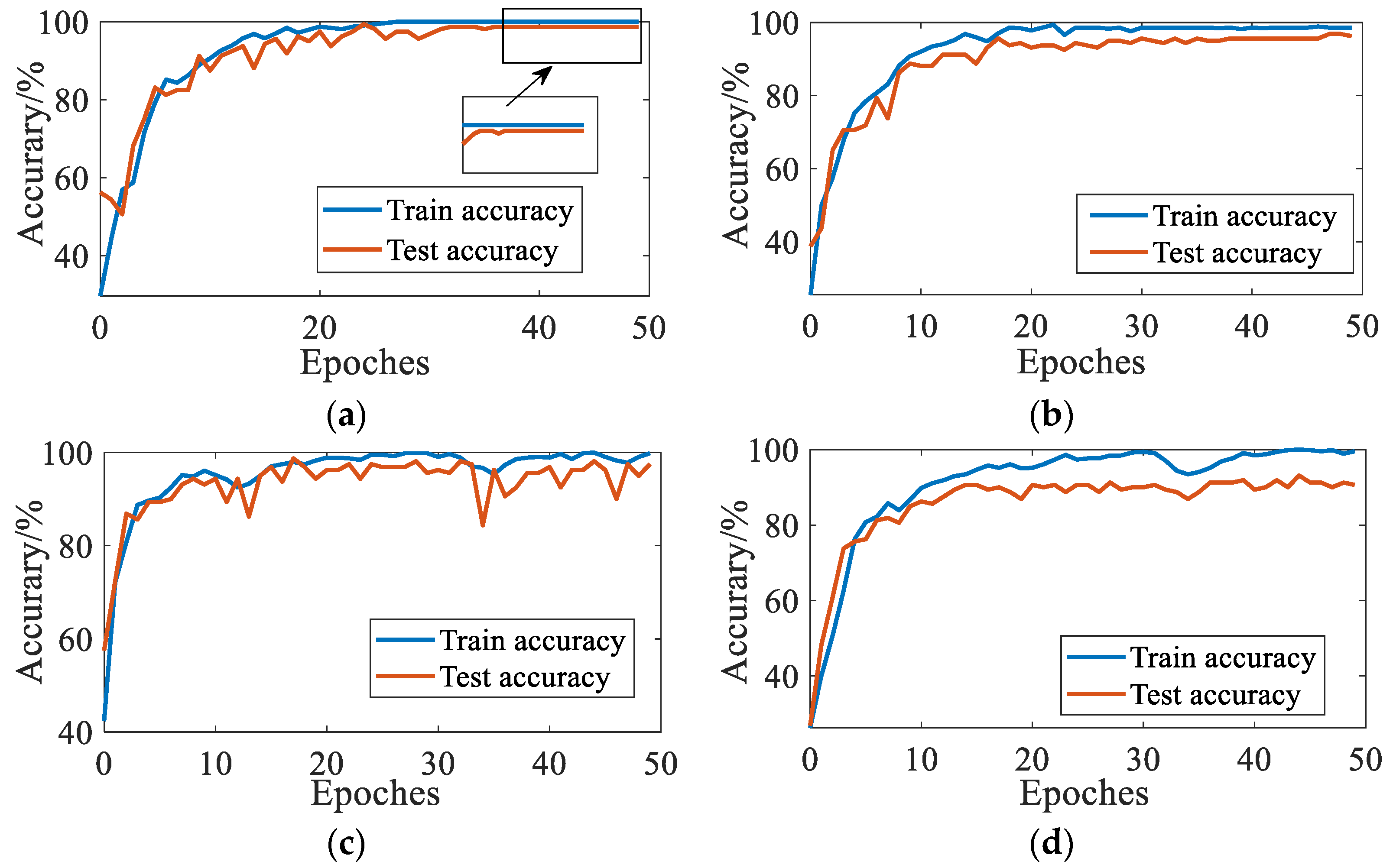
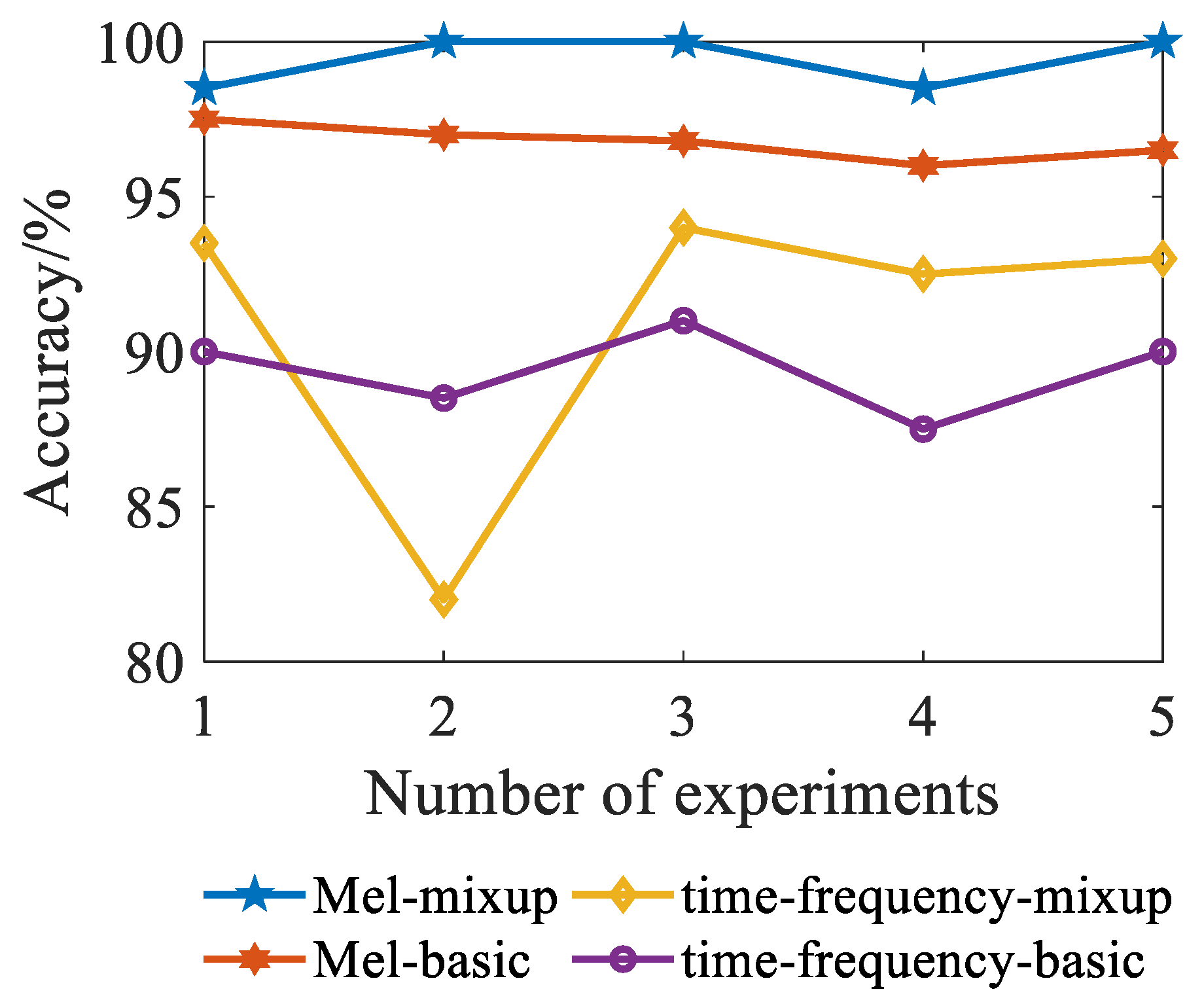
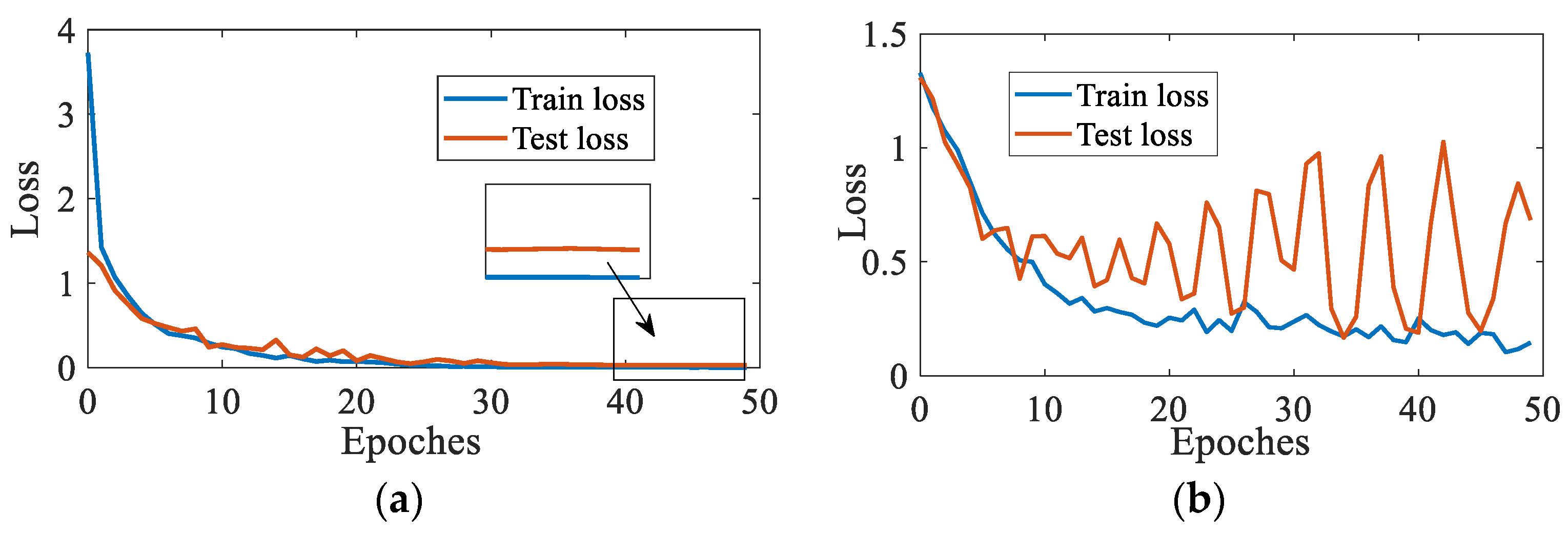
4.2. Experimental Result
5. Conclusions
- The operating environment of a power transformer is complex and prone to various faults. Since some faults are prone to low probability and few samples exist, it is necessary to enhance and expand the fault set with insufficient samples to make the diagnosis model have good generalization performance. Simple basic data enhancement methods such as flipping and color matching have certain defects when processing spectral images. The dataset enhanced by mixup can increase the robustness of the learning model.
- Compared with the voiceprint time-frequency map, in the Mel time-frequency map, it is easier to distinguish the frequency change of the frequency voiceprint signal. It can greatly reduce the data size of the sample and facilitate the feature extraction of the subsequent depth learning algorithm.
- Mel time-frequency diagram of a power transformer enhanced by mixup data has a good effect when using the CNN algorithm for classification diagnosis. It improved the generalization ability of the model and the diagnostic accuracy is up to 99%. Compared with other similar deep learning algorithms, it has good diagnostic performance for power-transformer fault voiceprint signals.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Sun, X. Numerical analysis of an exponentially ill-conditioned boundary value problem with applications to metastable problems. IMA J. Numer. Anal. 2001, 21, 817–842. [Google Scholar] [CrossRef]
- Li, Z.; Jiao, Z.; He, A.; Xu, N. A denoising-classification neural network for power transformer protection. Prot. Control. Mod. Power Syst. 2022, 7, 52. [Google Scholar] [CrossRef]
- Do, T.D.; Tuyet-Doan, V.N.; Cho, Y.S.; Sun, J.H.; Kim, Y.H. Convolutional-Neural-Network-Based Partial Discharge Diagnosis for Power Transformer Using UHF Sensor. IEEE Access 2020, 8, 207377–207388. [Google Scholar] [CrossRef]
- Zhang, L.; Sheng, G.; Hou, H.; Jiang, X. A Fault Diagnosis Method of Power Transformer Based on Cost Sensitive One-Dimensional Convolution Neural Network. In Proceedings of the 2020 5th Asia Conference on Power and Electrical Engineering (ACPEE), Chengdu, China, 9–12 April 2020; pp. 1824–1828. [Google Scholar]
- Wang, Y.; Wei, W.; Xue, P.; Yan, B. Analysis on comprehensive fault rate of oil-immersed power transformer based on FTA. In Proceedings of the 2021 International Conference on Electronic Information Engineering and Computer Science (EIECS), Changchun, China, 23–26 September 2021; pp. 972–975. [Google Scholar]
- Wang, Y.; Li, X.; Ma, J.; Li, S. Fault diagnosis of power transformer based on fault-tree analysis (FTA). In Proceedings of the International Symposium on Resource Exploration and Environmental Science, Ordos, China, 14–16 April 2017. [Google Scholar]
- Li, X.; Liao, X.; Lu, D.; Qiu, Z. A Robust Classification Method for Power Transformer Status Recognition Based on Sound Signals. In Proceedings of the 2021 5th International Conference on Power and Energy Engineering (ICPEE), Xiamen, China, 2–4 December 2021; pp. 153–157. [Google Scholar]
- Dang, X.; Wang, F.; Ma, W. Fault Diagnosis of Power Transformer by Acoustic Signals with Deep Learning. In Proceedings of the 2020 IEEE International Conference on High Voltage Engineering and Application (ICHVE), Beijing, China, 6–10 September 2020; pp. 1–4. [Google Scholar]
- Han, S.; Wang, B.; Zhu, G.; Wang, G.; Yue, H.; Gao, F.; Yao, H. Pattern recognition of partial discharge ultrahigh frequency signal based on similar matrix BSS and deep learning CNN. In Proceedings of the 16th IET International Conference on AC and DC Power Transmission (ACDC 2020), Online, 23 June 2020; pp. 1204–1209. [Google Scholar]
- Alauthman, M.; Al-qerem, A.; Sowan, B.; Alsarhan, A.; Eshtay, M.; Aldweesh, A.; Aslam, N. Enhancing Small Medical Dataset Classification Performance Using GAN. Informatics 2023, 10, 28. [Google Scholar] [CrossRef]
- Shah, M.; Vakharia, V.; Chaudhari, R.; Vora, J.; Pimenov, D.; Giasin, K. Tool wear prediction in face milling of stainless steel using singular generative adversarial network and LSTM deep learning models. Int. J. Adv. Manuf. Technol. 2022, 121, 723–736. [Google Scholar] [CrossRef]
- Li, Y.; Zhang, M.; Chen, C. A Deep-Learning intelligent system incorporating data augmentation for Short-Term voltage stability assessment of power systems. Appl. Energy 2022, 308, 118347. [Google Scholar] [CrossRef]
- Sofia, M.d.A.L.; Rogério, A.F.; Ruy, A.C.A. Incipient fault diagnosis in power transformers by data-driven models with over-sampled dataset. Electr. Power Syst. Res. 2021, 201, 107519. [Google Scholar]
- Li, P.; Chen, M.; Hu, F.; Xu, Y. A spectrogram-based voiceprint recognition using deep neural network. In Proceedings of the 27th Chinese Control and Decision Conference (2015 CCDC), Qingdao, China, 23–25 May 2015; pp. 2923–2927. [Google Scholar]
- Li, M.; Zhan, H.; Qiu, A. Voiceprint Recognition of Transformer Fault Based on Blind Source Separation and Convolutional Neural Network. In Proceedings of the 2021 IEEE Electrical Insulation Conference (EIC), Denver, CO, USA, 7–28 June 2021; pp. 618–621. [Google Scholar]
- Abulizi, J.; Chen, Z.; Liu, P.; Sun, H.; Ji, C.; Li, Z. Research on Voiceprint Recognition of Power Transformer Anomalies Using Gated Recurrent Unit. In Proceedings of the 2021 Power System and Green Energy Conference (PSGEC), Shanghai, China, 20–22 August 2021; pp. 743–747. [Google Scholar]
- Feng, Z.; Zhao, Z.; Chen, H.; Dou, B.; Hu, L. Power Plant Production Equipment Sound Recognition Method Combined with Attention Mechanism. In Proceedings of the 2022 IEEE 4th International Conference on Power, Intelligent Computing and Systems (ICPICS), Shenyang, China, 29–31 July 2022; pp. 185–188. [Google Scholar]
- Badreldine, O.M.; Elbeheiry, N.A.; Haroon, A.N.M.; ElShehaby, S.; Marzook, E.M. Automatic Diagnosis of Asphyxia Infant Cry Signals Using Wavelet Based Mel Frequency Cepstrum Features. In Proceedings of the 2018 14th International Computer Engineering Conference (ICENCO), Cairo, Egypt, 29–30 December 2018; pp. 96–100. [Google Scholar]
- Zhang, Y.; Zhao, L.; Tian, Q.; Fan, J. Optical Fiber Intrusion Signal Recognition Based on Improved Mel Frequency Cepstrum Coefficient. In Proceedings of the 2018 11th International Congress on Image and Signal Processing, BioMedical Engineering and Informatics (CISP-BMEI), Beijing, China, 13–15 October 2018; pp. 1–9. [Google Scholar]
- Gu, X.; Song, H.; Wang, T.; Lu, F.; Li, R. Chemical process fault diagnosis based on mixup-convolution neural network. In Proceedings of the 2019 14th IEEE International Conference on Electronic Measurement & Instruments (ICEMI), Changsha, China, 1–3 November 2019; pp. 1268–1274. [Google Scholar]
- Choi, J.; Lee, C.; Lee, D.; Jung, H. SalfMix: A Novel Single Image-Based Data Augmentation Technique Using a Saliency Map. Sensors 2021, 21, 8444. [Google Scholar] [CrossRef] [PubMed]
- Wu, Y.; Inkpen, D.; El-Roby, A. Mixup Regularized Adversarial Networks for Multi-Domain Text Classification. In Proceedings of the ICASSP 2021—2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Toronto, ON, Canada, 25–30 April 2021; pp. 7733–7737. [Google Scholar]
- Zhang, X.; Jin, M.; Cheng, R.; Li, R.; Han, E.; Stolcke, A. Contrastive-mixup Learning for Improved Speaker Verification. In Proceedings of the ICASSP 2022—2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Singapore, 22–27 May 2022; pp. 7652–7656. [Google Scholar]
- Duvvuri, K.; Kanisettypalli, H.; Jayan, S. Detection of Brain Tumor Using CNN and CNN-SVM. In Proceedings of the 2022 3rd International Conference for Emerging Technology (INCET), Belgaum, India, 27–29 May 2022; pp. 1–7. [Google Scholar]
- Kannojia, S.P.; Jaiswal, G. Ensemble of Hybrid CNN-ELM Model for Image Classification. In Proceedings of the 2018 5th International Conference on Signal Processing and Integrated Networks (SPIN), Noida, India, 22–23 February 2018; pp. 538–541. [Google Scholar]
- Biot-Monterde, V.; Navarro-Navarro, A.; Zamudio-Ramirez, I.; Antonino-Daviu, J.A.; Osornio-Rios, R.A. Automatic Classification of Rotor Faults in Soft-Started Induction Motors, Based on Persistence Spectrum and Convolutional Neural Network Applied to Stray-Flux Signals. Sensors 2023, 23, 316. [Google Scholar] [CrossRef] [PubMed]
- Botros, J.; Mourad-Chehade, F.; Laplanche, D. CNN and SVM-Based Models for the Detection of Heart Failure Using Electrocardiogram Signals. Sensors 2022, 22, 9190. [Google Scholar] [CrossRef] [PubMed]
- Zegarra, F.C.; Vargas-Machuca, J.; Coronado, A.M. Comparison of CNN and CNN-LSTM Architectures for Tool Wear Estimation. In Proceedings of the 2021 IEEE Engineering International Research Conference (EIRCON), Lima, Peru, 26–28 October 2021; pp. 1–4. [Google Scholar]
- Luan, Y.; Lin, S. Research on Text Classification Based on CNN and LSTM. In Proceedings of the 2019 IEEE International Conference on Artificial Intelligence and Computer Applications (ICAICA), Dalian, China, 29–31 March 2019; pp. 352–355. [Google Scholar]
- Wang, Y.; Xu, H.; Song, M.; Zhang, F.; Li, Y.; Zhou, S.; Zhang, L. A convolutional Transformer-based truncated Gaussian density network with data denoising for wind speed forecasting. Appl. Energy 2023, 333, 120601. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Network Layer | Number and Size of Convolution Kernels | Step | Network Layer Output |
|---|---|---|---|
| Convolution layer 1 | 32@3 × 3 | 1 | 32@171 × 170 |
| Pool layer 1 | 3 × 3 | 3 | 32@57 × 56 |
| Convolution layer 2 | 64@3 × 3 | 1 | 64@55 × 54 |
| Pool layer 2 | 3 × 3 | 3 | 64@18 × 18 |
| Convolution layer 3 | 128@3 × 3 | 1 | 128@16 × 16 |
| Pool layer 3 | 3 × 3 | 3 | 128@5 × 5 |
| Full connection layer 1 | 128 | 128 | |
| Full connection layer 2 | 4 | 4 |
| Fault Number | Fault Type | Training Set | Test Set |
|---|---|---|---|
| 0 | normal | 450 | 150 |
| 1 | Short-circuit impulse | 450 | 150 |
| 2 | partial discharge | 450 | 150 |
| 3 | DC bias | 450 | 150 |
| λ | Accuracy/% | Precision/% | Recall/% | F1/% |
|---|---|---|---|---|
| 0 | 96.5 | 96.8 | 96.5 | 96.6 |
| 0.1 | 97.7 | 97.8 | 97.7 | 97.7 |
| 0.2 | 98.1 | 99.0 | 98.1 | 98.5 |
| 0.3 | 98.1 | 98.3 | 98.1 | 98.2 |
| 0.4 | 98.3 | 99.1 | 98.3 | 98.7 |
| 0.5 | 99.7 | 99.8 | 99.7 | 99.7 |
| 0.6 | 99.1 | 99.2 | 99.1 | 99.1 |
| 0.7 | 98.1 | 99.0 | 98.1 | 98.5 |
| 0.8 | 97.5 | 97.8 | 97.5 | 97.7 |
| 0.9 | 97.1 | 97.2 | 97.1 | 97.1 |
| 1.0 | 96.5 | 97.0 | 96.5 | 96.7 |
| random | 98.1 | 98.3 | 98.1 | 98.2 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wan, S.; Dong, F.; Zhang, X.; Wu, W.; Li, J. Fault Voiceprint Signal Diagnosis Method of Power Transformer Based on Mixup Data Enhancement. Sensors 2023, 23, 3341. https://doi.org/10.3390/s23063341
Wan S, Dong F, Zhang X, Wu W, Li J. Fault Voiceprint Signal Diagnosis Method of Power Transformer Based on Mixup Data Enhancement. Sensors. 2023; 23(6):3341. https://doi.org/10.3390/s23063341
Chicago/Turabian StyleWan, Shuting, Fan Dong, Xiong Zhang, Wenbo Wu, and Jialu Li. 2023. "Fault Voiceprint Signal Diagnosis Method of Power Transformer Based on Mixup Data Enhancement" Sensors 23, no. 6: 3341. https://doi.org/10.3390/s23063341