
Survey of Explainable AI Techniques in Healthcare


Abstract
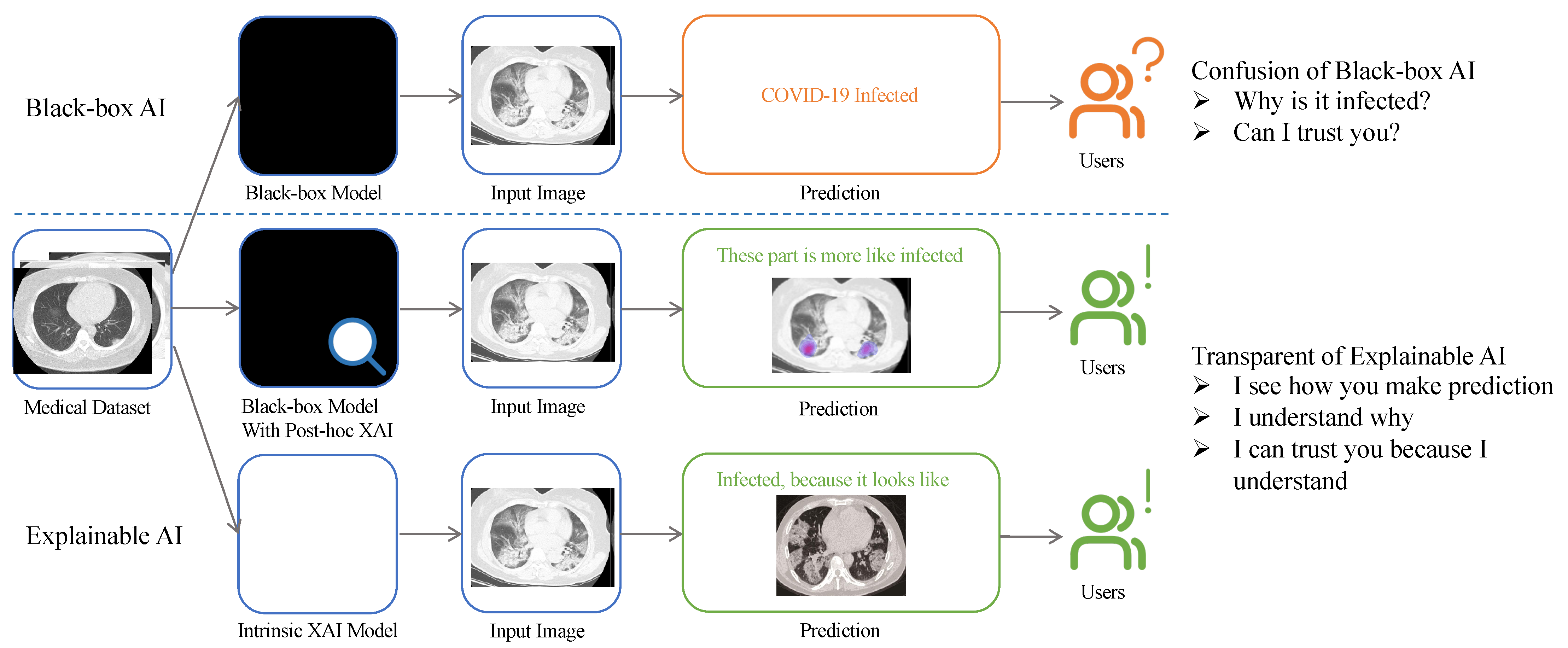
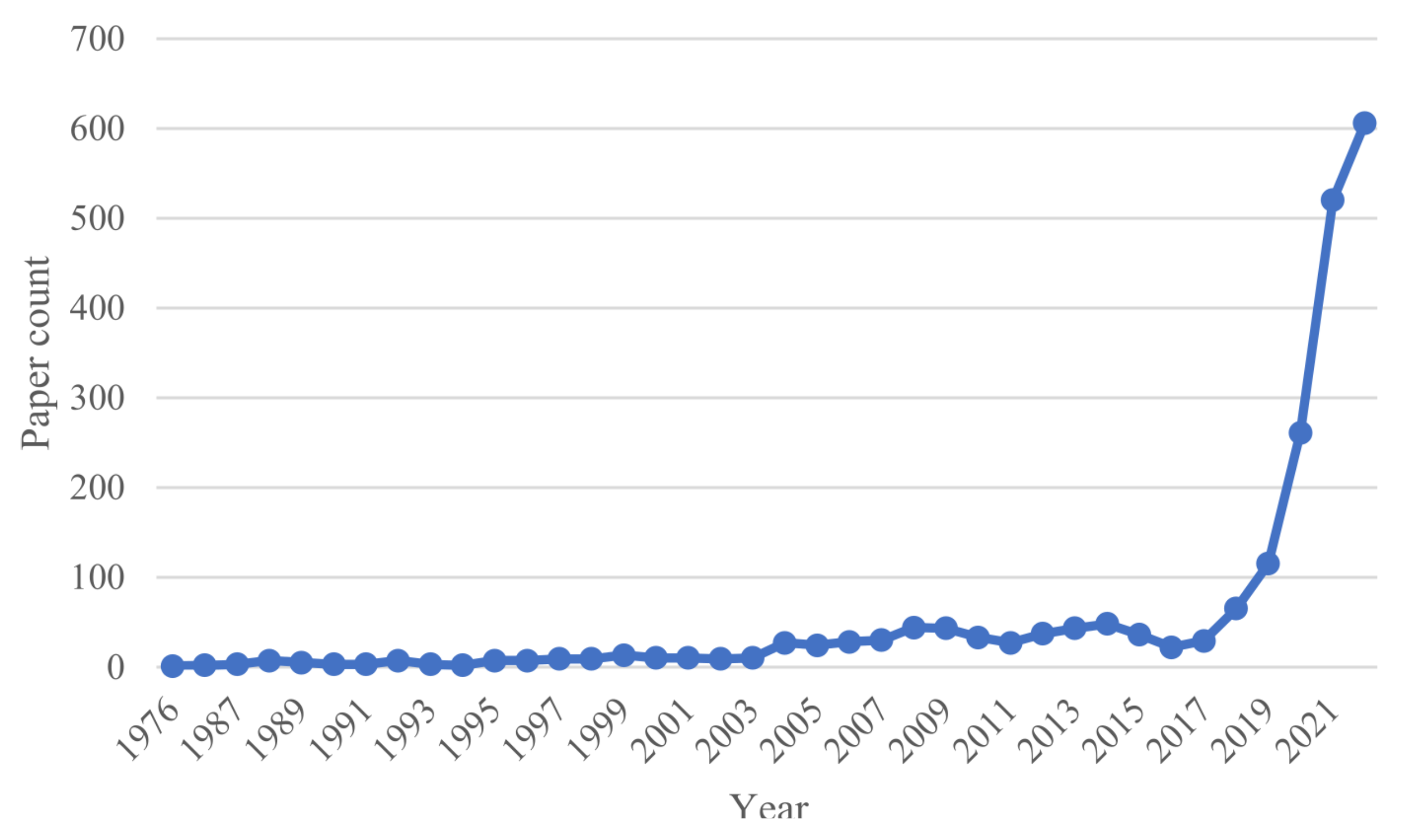
:1. Introduction
2. XAI Techniques Related to Medical Imaging
2.1. Confidentiality and Privacy
2.2. Ethics and Responsibilities
2.3. Bias and Fairness
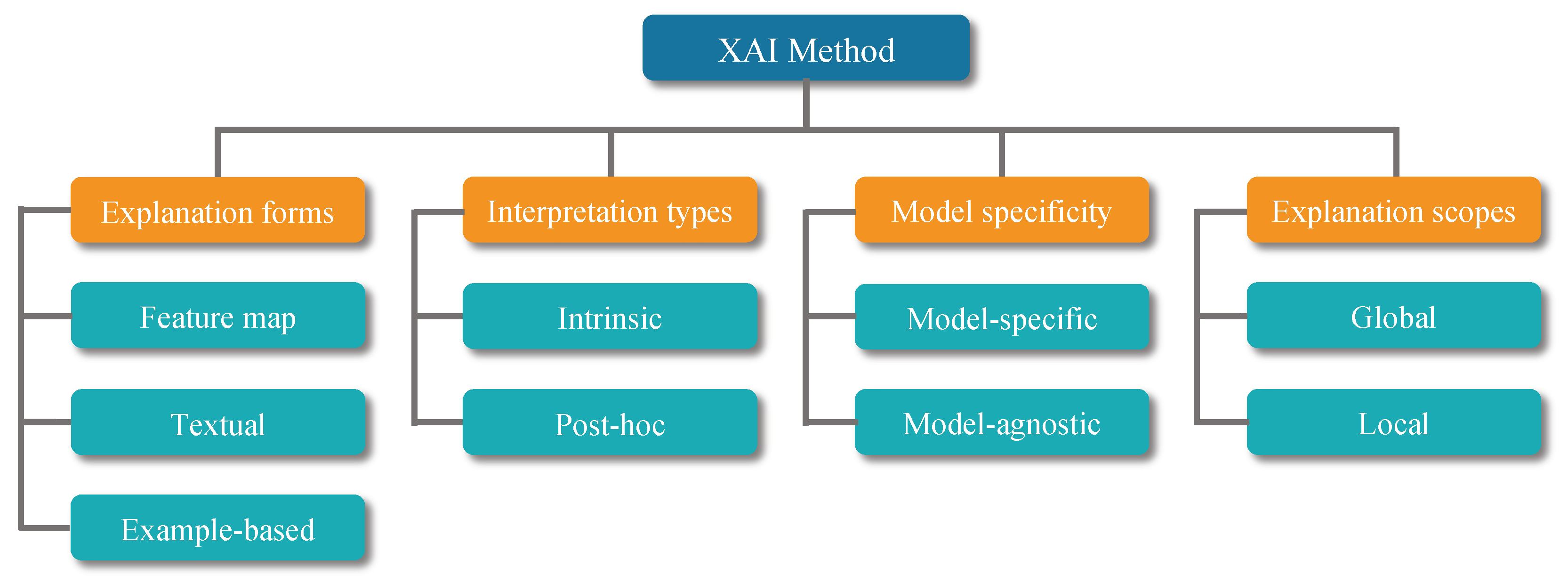
3. Explainable Artificial Intelligence Techniques
3.1. Interpretation Types
3.1.1. Intrinsic Explanation
3.1.2. Post Hoc Explanation
3.2. Model Specificity
3.2.1. Model-Specific Explanation
3.2.2. Model-Agnostic Explanation
3.3. Explanation Scopes
3.3.1. Local Explanation
3.3.2. Global Explanation
3.4. Explanation Forms
3.4.1. Feature Map
3.4.2. Textual Explanation
3.4.3. Example-Based Explanation
4. Introduction of the Explainable AI Method: A Brief Overview
4.1. Saliency
4.2. Class Activation Mapping
| Algorithm 1 Class activation mapping. | |
| Require: Image ; Network N | |
| Ensure: Replace FC layer with average pooling layer in Network N | |
| procedure CAM(I, N) | |
| N(I) | ▹ Input image into network |
| ▹ Get weights from average polling layer | |
| ▹ Feature map of the last convolution layer | |
| layer | |
| ▹ Weighted linear summation | |
| ▹ Normalize and up-sample to Network input size | |
| ▹ Final image heat map | |
| end procedure | |
4.3. Occlusion Sensitivity
4.4. Testing with Concept Activation Vectors
4.5. Triplet Networks
4.6. Prototypes
4.7. Trainable Attention
4.8. Shapley Additive Explanations
4.9. Local Interpretable Model-Agnostic Explanations
| Algorithm 2 Sparse linear explanation using LIME. | |
| Require: Classifier f; Features number K; Instance x to be explained; Similarity kernel | |
| = SAMPLE_AROUND | |
| for in do | |
| end for | |
| = K-Lasso() | |
| return | ▹ Explanation for an individual predict |
4.10. Image Captioning
4.11. Recent XAI Methods
5. Making an Explainable Model through Radiomics
6. Discussion, Challenges, and Prospects
6.1. Human-Centered XAI
6.2. AI System Deployment
6.3. Quality of Explanation
6.4. Future Directions of Interpretable Models
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Nazar, M.; Alam, M.M.; Yafi, E.; Mazliham, M. A systematic review of human-computer interaction and explainable artificial intelligence in healthcare with artificial intelligence techniques. IEEE Access 2021, 9, 153316–153348. [Google Scholar] [CrossRef]
- von Eschenbach, W.J. Transparency and the black box problem: Why we do not trust AI. Philos. Technol. 2021, 34, 1607–1622. [Google Scholar] [CrossRef]
- Devlin, J.; Chang, M.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Gunning, D.; Aha, D. DARPA’s explainable artificial intelligence (XAI) program. AI Mag. 2019, 40, 44–58. [Google Scholar]
- Angelov, P.; Soares, E. Towards explainable deep neural networks (xDNN). Neural Netw. 2020, 130, 185–194. [Google Scholar] [CrossRef]
- Arrieta, A.B.; Díaz-Rodríguez, N.; Del Ser, J.; Bennetot, A.; Tabik, S.; Barbado, A.; García, S.; Gil-López, S.; Molina, D.; Benjamins, R.; et al. Explainable Artificial Intelligence (XAI): Concepts, taxonomies, opportunities and challenges toward responsible AI. Inf. Fusion 2020, 58, 82–115. [Google Scholar] [CrossRef] [Green Version]
- Tjoa, E.; Guan, C. A survey on explainable artificial intelligence (xai): Toward medical xai. IEEE Trans. Neural Netw. Learn. Syst. 2020, 32, 4793–4813. [Google Scholar] [CrossRef]
- Rudin, C. Stop explaining black box machine learning models for high stakes decisions and use interpretable models instead. Nat. Mach. Intell. 2019, 1, 206–215. [Google Scholar] [CrossRef] [Green Version]
- Gunning, D.; Stefik, M.; Choi, J.; Miller, T.; Stumpf, S.; Yang, G.Z. XAI—Explainable artificial intelligence. Sci. Robot. 2019, 4, eaay7120. [Google Scholar] [CrossRef] [Green Version]
- Yang, X.; He, X.; Zhao, J.; Zhang, Y.; Zhang, S.; Xie, P. COVID-CT-dataset: A CT scan dataset about COVID-19. arXiv 2020, arXiv:2003.13865. [Google Scholar]
- Falk, T.; Mai, D.; Bensch, R.; Çiçek, Ö.; Abdulkadir, A.; Marrakchi, Y.; Böhm, A.; Deubner, J.; Jäckel, Z.; Seiwald, K.; et al. U-Net: Deep learning for cell counting, detection, and morphometry. Nat. Methods 2019, 16, 67–70. [Google Scholar] [CrossRef] [PubMed]
- Smuha, N.A. The EU approach to ethics guidelines for trustworthy artificial intelligence. Comput. Law Rev. Int. 2019, 20, 97–106. [Google Scholar] [CrossRef]
- Bai, T.; Zhao, J.; Zhu, J.; Han, S.; Chen, J.; Li, B.; Kot, A. Ai-gan: Attack-inspired generation of adversarial examples. In Proceedings of the 2021 IEEE International Conference on Image Processing (ICIP), Anchorage, AK, USA, 19–22 September 2021; pp. 2543–2547. [Google Scholar]
- Papernot, N.; McDaniel, P.; Jha, S.; Fredrikson, M.; Celik, Z.B.; Swami, A. The limitations of deep learning in adversarial settings. In Proceedings of the 2016 IEEE European symposium on security and privacy (EuroS&P), Saarbrücken, Germany, 21–24 March 2016; pp. 372–387. [Google Scholar]
- Kiener, M. Artificial intelligence in medicine and the disclosure of risks. AI Soc. 2021, 36, 705–713. [Google Scholar] [CrossRef] [PubMed]
- Vigano, L.; Magazzeni, D. Explainable security. In Proceedings of the 2020 IEEE European Symposium on Security and Privacy Workshops (EuroS&PW), Genoa, Italy, 7–11 September 2020; pp. 293–300. [Google Scholar]
- Kuppa, A.; Le-Khac, N.A. Black Box Attacks on Explainable Artificial Intelligence(XAI) methods in Cyber Security. In Proceedings of the 2020 International Joint Conference on Neural Networks (IJCNN), Glasgow, UK, 19–24 July 2020; pp. 1–8. [Google Scholar] [CrossRef]
- Trocin, C.; Mikalef, P.; Papamitsiou, Z.; Conboy, K. Responsible AI for digital health: A synthesis and a research agenda. Inf. Syst. Front. 2021, 1–19. [Google Scholar] [CrossRef]
- Arun, N.; Gaw, N.; Singh, P.; Chang, K.; Aggarwal, M.; Chen, B.; Hoebel, K.; Gupta, S.; Patel, J.; Gidwani, M.; et al. Assessing the trustworthiness of saliency maps for localizing abnormalities in medical imaging. Radiol. Artif. Intell. 2021, 3, e200267. [Google Scholar] [CrossRef]
- Smith, H. Clinical AI: Opacity, accountability, responsibility and liability. AI Soc. 2021, 36, 535–545. [Google Scholar] [CrossRef]
- Tigard, D.W. Responsible AI and moral responsibility: A common appreciation. AI Ethics 2021, 1, 113–117. [Google Scholar] [CrossRef]
- Hazirbas, C.; Bitton, J.; Dolhansky, B.; Pan, J.; Gordo, A.; Ferrer, C.C. Casual conversations: A dataset for measuring fairness in ai. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 2289–2293. [Google Scholar]
- Castelvecchi, D. Can we open the black box of AI? Nat. News 2016, 538, 20. [Google Scholar] [CrossRef] [Green Version]
- Mehrabi, N.; Morstatter, F.; Saxena, N.; Lerman, K.; Galstyan, A. A survey on bias and fairness in machine learning. ACM Comput. Surv. (CSUR) 2021, 54, 1–35. [Google Scholar] [CrossRef]
- Lipton, Z.C. The mythos of model interpretability: In machine learning, the concept of interpretability is both important and slippery. Queue 2018, 16, 31–57. [Google Scholar] [CrossRef]
- Du, M.; Liu, N.; Hu, X. Techniques for Interpretable Machine Learning. Commun. ACM 2019, 63, 68–77. [Google Scholar] [CrossRef] [Green Version]
- Yang, G.; Ye, Q.; Xia, J. Unbox the black-box for the medical explainable AI via multi-modal and multi-centre data fusion: A mini-review, two showcases and beyond. Inf. Fusion 2022, 77, 29–52. [Google Scholar] [CrossRef] [PubMed]
- Simonyan, K.; Vedaldi, A.; Zisserman, A. Deep inside convolutional networks: Visualising image classification models and saliency maps. arXiv 2013, arXiv:1312.6034. [Google Scholar]
- Springenberg, J.T.; Dosovitskiy, A.; Brox, T.; Riedmiller, M. Striving for simplicity: The all convolutional net. arXiv 2014, arXiv:1412.6806. [Google Scholar]
- Zeiler, M.D.; Fergus, R. Visualizing and understanding convolutional networks. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; pp. 818–833. [Google Scholar]
- Bach, S.; Binder, A.; Montavon, G.; Klauschen, F.; Müller, K.R.; Samek, W. On pixel-wise explanations for non-linear classifier decisions by layer-wise relevance propagation. PLoS ONE 2015, 10, e0130140. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zhou, B.; Khosla, A.; Lapedriza, A.; Oliva, A.; Torralba, A. Learning deep features for discriminative localization. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2921–2929. [Google Scholar]
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-cam: Visual explanations from deep networks via gradient-based localization. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 618–626. [Google Scholar]
- Ribeiro, M.T.; Singh, S.; Guestrin, C. “Why should i trust you?” Explaining the predictions of any classifier. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 1135–1144. [Google Scholar]
- Huang, Q.; Yamada, M.; Tian, Y.; Singh, D.; Chang, Y. Graphlime: Local interpretable model explanations for graph neural networks. IEEE Trans. Knowl. Data Eng. 2022. [Google Scholar] [CrossRef]
- Lundberg, S.M.; Lee, S.I. A unified approach to interpreting model predictions. Adv. Neural Inf. Process. Syst. 2017, 30, 4768–4777. [Google Scholar]
- Jetley, S.; Lord, N.A.; Lee, N.; Torr, P.H.S. Learn To Pay Attention. arXiv 2018, arXiv:1804.02391. [Google Scholar]
- Chen, C.; Li, O.; Tao, D.; Barnett, A.; Rudin, C.; Su, J.K. This Looks Like That: Deep Learning for Interpretable Image Recognition. In Proceedings of the Advances in Neural Information Processing Systems; Wallach, H., Larochelle, H., Beygelzimer, A., d’Alché-Buc, F., Fox, E., Garnett, R., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2019; Volume 32. [Google Scholar]
- Hoffer, E.; Ailon, N. Deep metric learning using triplet network. In Proceedings of the International Workshop on Similarity-Based Pattern Recognition, Copenhagen, Denmark, 12–14 October 2015; pp. 84–92. [Google Scholar]
- Kim, B.; Wattenberg, M.; Gilmer, J.; Cai, C.; Wexler, J.; Viegas, F.; sayres, R. Interpretability Beyond Feature Attribution: Quantitative Testing with Concept Activation Vectors (TCAV). In Proceedings of the 35th International Conference on Machine Learning, Stockholm, Sweden, 10–15 July 2018; Dy, J., Krause, A., Eds.; 2018; Volume 80, pp. 2668–2677. [Google Scholar]
- Vinyals, O.; Toshev, A.; Bengio, S.; Erhan, D. Show and Tell: A Neural Image Caption Generator. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Pierson, E.; Cutler, D.M.; Leskovec, J.; Mullainathan, S.; Obermeyer, Z. An algorithmic approach to reducing unexplained pain disparities in underserved populations. Nat. Med. 2021, 27, 136–140. [Google Scholar] [CrossRef]
- Born, J.; Wiedemann, N.; Cossio, M.; Buhre, C.; Brändle, G.; Leidermann, K.; Goulet, J.; Aujayeb, A.; Moor, M.; Rieck, B.; et al. Accelerating detection of lung pathologies with explainable ultrasound image analysis. Appl. Sci. 2021, 11, 672. [Google Scholar] [CrossRef]
- Shen, Y.; Wu, N.; Phang, J.; Park, J.; Liu, K.; Tyagi, S.; Heacock, L.; Kim, S.G.; Moy, L.; Cho, K.; et al. An interpretable classifier for high-resolution breast cancer screening images utilizing weakly supervised localization. Med. Image Anal. 2021, 68, 101908. [Google Scholar] [CrossRef] [PubMed]
- Jia, G.; Lam, H.K.; Xu, Y. Classification of COVID-19 chest X-ray and CT images using a type of dynamic CNN modification method. Comput. Biol. Med. 2021, 134, 104425. [Google Scholar] [CrossRef] [PubMed]
- Song, Y.; Zheng, S.; Li, L.; Zhang, X.; Zhang, X.; Huang, Z.; Chen, J.; Wang, R.; Zhao, H.; Chong, Y.; et al. Deep learning enables accurate diagnosis of novel coronavirus (COVID-19) with CT images. IEEE/ACM Trans. Comput. Biol. Bioinform. 2021, 18, 2775–2780. [Google Scholar] [CrossRef] [PubMed]
- Wang, S.H.; Govindaraj, V.V.; Górriz, J.M.; Zhang, X.; Zhang, Y.D. COVID-19 classification by FGCNet with deep feature fusion from graph convolutional network and convolutional neural network. Inf. Fusion 2021, 67, 208–229. [Google Scholar] [CrossRef] [PubMed]
- Fan, Z.; Gong, P.; Tang, S.; Lee, C.U.; Zhang, X.; Song, P.; Chen, S.; Li, H. Joint localization and classification of breast tumors on ultrasound images using a novel auxiliary attention-based framework. arXiv 2022, arXiv:2210.05762. [Google Scholar]
- Wang, Z.; Xiao, Y.; Li, Y.; Zhang, J.; Lu, F.; Hou, M.; Liu, X. Automatically discriminating and localizing COVID-19 from community-acquired pneumonia on chest X-rays. Pattern Recognit. 2021, 110, 107613. [Google Scholar] [CrossRef]
- Sutton, R.T.; zaiane, O.R.; Goebel, R.; Baumgart, D.C. Artificial intelligence enabled automated diagnosis and grading of ulcerative colitis endoscopy images. Sci. Rep. 2022, 12, 1–10. [Google Scholar] [CrossRef]
- Yamashita, R.; Long, J.; Longacre, T.; Peng, L.; Berry, G.; Martin, B.; Higgins, J.; Rubin, D.L.; Shen, J. Deep learning model for the prediction of microsatellite instability in colorectal cancer: A diagnostic study. Lancet Oncol. 2021, 22, 132–141. [Google Scholar] [CrossRef]
- Wu, Y.H.; Gao, S.H.; Mei, J.; Xu, J.; Fan, D.P.; Zhang, R.G.; Cheng, M.M. Jcs: An explainable covid-19 diagnosis system by joint classification and segmentation. IEEE Trans. Image Process. 2021, 30, 3113–3126. [Google Scholar] [CrossRef]
- Lu, S.; Zhu, Z.; Gorriz, J.M.; Wang, S.H.; Zhang, Y.D. NAGNN: Classification of COVID-19 based on neighboring aware representation from deep graph neural network. Int. J. Intell. Syst. 2022, 37, 1572–1598. [Google Scholar] [CrossRef]
- Haghanifar, A.; Majdabadi, M.M.; Choi, Y.; Deivalakshmi, S.; Ko, S. COVID-cxnet: Detecting COVID-19 in frontal chest X-ray images using deep learning. Multimed. Tools Appl. 2022, 81, 30615–30645. [Google Scholar] [CrossRef] [PubMed]
- Punn, N.S.; Agarwal, S. Automated diagnosis of COVID-19 with limited posteroanterior chest X-ray images using fine-tuned deep neural networks. Appl. Intell. 2021, 51, 2689–2702. [Google Scholar] [CrossRef] [PubMed]
- Wang, H.; Wang, S.; Qin, Z.; Zhang, Y.; Li, R.; Xia, Y. Triple attention learning for classification of 14 thoracic diseases using chest radiography. Med. Image Anal. 2021, 67, 101846. [Google Scholar] [CrossRef] [PubMed]
- Fu, X.; Bi, L.; Kumar, A.; Fulham, M.; Kim, J. Multimodal spatial attention module for targeting multimodal PET-CT lung tumor segmentation. IEEE J. Biomed. Health Inf. 2021, 25, 3507–3516. [Google Scholar] [CrossRef] [PubMed]
- Yeung, M.; Sala, E.; Schönlieb, C.B.; Rundo, L. Focus U-Net: A novel dual attention-gated CNN for polyp segmentation during colonoscopy. Comput. Biol. Med. 2021, 137, 104815. [Google Scholar] [CrossRef] [PubMed]
- Hu, B.; Vasu, B.; Hoogs, A. X-MIR: EXplainable Medical Image Retrieval. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), Waikoloa, HI, USA, 4–8 January 2022; pp. 440–450. [Google Scholar]
- Alsinglawi, B.; Alshari, O.; Alorjani, M.; Mubin, O.; Alnajjar, F.; Novoa, M.; Darwish, O. An explainable machine learning framework for lung cancer hospital length of stay prediction. Sci. Rep. 2022, 12, 607. [Google Scholar] [CrossRef] [PubMed]
- Du, Y.; Rafferty, A.R.; McAuliffe, F.M.; Wei, L.; Mooney, C. An explainable machine learning-based clinical decision support system for prediction of gestational diabetes mellitus. Sci. Rep. 2022, 12, 1170. [Google Scholar] [CrossRef] [PubMed]
- Severn, C.; Suresh, K.; Görg, C.; Choi, Y.S.; Jain, R.; Ghosh, D. A Pipeline for the Implementation and Visualization of Explainable Machine Learning for Medical Imaging Using Radiomics Features. Sensors 2022, 22, 5205. [Google Scholar] [CrossRef]
- Le, N.Q.K.; Kha, Q.H.; Nguyen, V.H.; Chen, Y.C.; Cheng, S.J.; Chen, C.Y. Machine learning-based radiomics signatures for EGFR and KRAS mutations prediction in non-small-cell lung cancer. Int. J. Mol. Sci. 2021, 22, 9254. [Google Scholar] [CrossRef]
- Moncada-Torres, A.; van Maaren, M.C.; Hendriks, M.P.; Siesling, S.; Geleijnse, G. Explainable machine learning can outperform Cox regression predictions and provide insights in breast cancer survival. Sci. Rep. 2021, 11, 6968. [Google Scholar] [CrossRef]
- Abeyagunasekera, S.H.P.; Perera, Y.; Chamara, K.; Kaushalya, U.; Sumathipala, P.; Senaweera, O. LISA: Enhance the explainability of medical images unifying current XAI techniques. In Proceedings of the 2022 IEEE 7th International Conference for Convergence in Technology (I2CT), Mumbai, India, 7–9 April 2022; pp. 1–9. [Google Scholar] [CrossRef]
- Duell, J.; Fan, X.; Burnett, B.; Aarts, G.; Zhou, S.M. A Comparison of Explanations Given by Explainable Artificial Intelligence Methods on Analysing Electronic Health Records. In Proceedings of the 2021 IEEE EMBS International Conference on Biomedical and Health Informatics (BHI), Athens, Greece, 27–30 July 2021; pp. 1–4. [Google Scholar] [CrossRef]
- Liu, G.; Liao, Y.; Wang, F.; Zhang, B.; Zhang, L.; Liang, X.; Wan, X.; Li, S.; Li, Z.; Zhang, S.; et al. Medical-VLBERT: Medical Visual Language BERT for COVID-19 CT Report Generation with Alternate Learning. IEEE Trans. Neural Netw. Learn. Syst. 2021, 32, 3786–3797. [Google Scholar] [CrossRef] [PubMed]
- Ghassemi, M.; Oakden-Rayner, L.; Beam, A.L. The false hope of current approaches to explainable artificial intelligence in health care. Lancet Digit. Health 2021, 3, e745–e750. [Google Scholar] [CrossRef] [PubMed]
- Wu, J.; Mooney, R.J. Faithful Multimodal Explanation for Visual Question Answering. arXiv 2018, arXiv:1809.02805. [Google Scholar]
- Adadi, A.; Berrada, M. Peeking inside the black-box: A survey on explainable artificial intelligence (XAI). IEEE Access 2018, 6, 52138–52160. [Google Scholar] [CrossRef]
- Das, A.; Rad, P. Opportunities and challenges in explainable artificial intelligence (xai): A survey. arXiv 2020, arXiv:2006.11371. [Google Scholar]
- Zhang, Z.; Chen, P.; Sapkota, M.; Yang, L. Tandemnet: Distilling knowledge from medical images using diagnostic reports as optional semantic references. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Quebec City, QC, Canada, 10–14 September 2017; pp. 320–328. [Google Scholar]
- Li, O.; Liu, H.; Chen, C.; Rudin, C. Deep Learning for Case-Based Reasoning Through Prototypes: A Neural Network That Explains Its Predictions. Proc. AAAI Conf. Artif. Intell. 2018, 32, 3530–3537. [Google Scholar] [CrossRef]
- Montavon, G.; Lapuschkin, S.; Binder, A.; Samek, W.; Müller, K.R. Explaining nonlinear classification decisions with deep taylor decomposition. Pattern Recognit. 2017, 65, 211–222. [Google Scholar] [CrossRef]
- Mohamed, E.; Sirlantzis, K.; Howells, G. A review of visualisation-as-explanation techniques for convolutional neural networks and their evaluation. Displays 2022, 73, 102239. [Google Scholar] [CrossRef]
- Soares, E.; Angelov, P.; Biaso, S.; Froes, M.H.; Abe, D.K. SARS-CoV-2 CT-scan dataset: A large dataset of real patients CT scans for SARS-CoV-2 identification. MedRxiv 2020. [Google Scholar] [CrossRef]
- Jiang, C.; Chen, Y.; Chang, J.; Feng, M.; Wang, R.; Yao, J. Fusion of medical imaging and electronic health records with attention and multi-head machanisms. arXiv 2021, arXiv:2112.11710. [Google Scholar]
- Ron, T.; Hazan, T. Dual Decomposition of Convex Optimization Layers for Consistent Attention in Medical Images. In Proceedings of the 39th International Conference on Machine Learning, Baltimore, MD, USA, 17–23 July 2022; Chaudhuri, K., Jegelka, S., Song, L., Szepesvari, C., Niu, G., Sabato, S., Eds.; 2022; Volume 162, pp. 18754–18769. [Google Scholar]
- Shapley, L.S. 17. A value for n-person games. In Contributions to the Theory of Games (AM-28), Volume II; Princeton University Press: Princeton, NJ, USA, 2016; pp. 307–318. [Google Scholar]
- Shrikumar, A.; Greenside, P.; Kundaje, A. Learning Important Features Through Propagating Activation Differences. arXiv 2017, arXiv:1704.02685. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Liu, F.; Ge, S.; Wu, X. Competence-based multimodal curriculum learning for medical report generation. arXiv 2022, arXiv:2206.14579. [Google Scholar]
- Malhi, A.; Kampik, T.; Pannu, H.; Madhikermi, M.; Främling, K. Explaining machine learning-based classifications of in-vivo gastral images. In Proceedings of the 2019 Digital Image Computing: Techniques and Applications (DICTA), Perth, Australia, 2–4 December 2019; pp. 1–7. [Google Scholar]
- Ye, Q.; Xia, J.; Yang, G. Explainable AI for COVID-19 CT classifiers: An initial comparison study. In Proceedings of the 2021 IEEE 34th International Symposium on Computer-Based Medical Systems (CBMS), Aveiro, Portugal, 7–9 June 2021; pp. 521–526. [Google Scholar]
- Serrano, S.; Smith, N.A. Is attention interpretable? arXiv 2019, arXiv:1906.03731. [Google Scholar]
- Chaddad, A.; Kucharczyk, M.J.; Daniel, P.; Sabri, S.; Jean-Claude, B.J.; Niazi, T.; Abdulkarim, B. Radiomics in glioblastoma: Current status and challenges facing clinical implementation. Front. Oncol. 2019, 9, 374. [Google Scholar] [CrossRef] [Green Version]
- Chaddad, A.; Kucharczyk, M.J.; Cheddad, A.; Clarke, S.E.; Hassan, L.; Ding, S.; Rathore, S.; Zhang, M.; Katib, Y.; Bahoric, B.; et al. Magnetic resonance imaging based radiomic models of prostate cancer: A narrative review. Cancers 2021, 13, 552. [Google Scholar] [CrossRef]
- Chaddad, A.; Toews, M.; Desrosiers, C.; Niazi, T. Deep radiomic analysis based on modeling information flow in convolutional neural networks. IEEE Access 2019, 7, 97242–97252. [Google Scholar] [CrossRef]
- Singh, G.; Manjila, S.; Sakla, N.; True, A.; Wardeh, A.H.; Beig, N.; Vaysberg, A.; Matthews, J.; Prasanna, P.; Spektor, V. Radiomics and radiogenomics in gliomas: A contemporary update. Br. J. Cancer 2021, 125, 641–657. [Google Scholar] [CrossRef] [PubMed]
- Chaddad, A.; Hassan, L.; Desrosiers, C. Deep radiomic analysis for predicting coronavirus disease 2019 in computerized tomography and X-ray images. IEEE Trans. Neural Netw. Learn. Syst. 2021, 33, 3–11. [Google Scholar] [CrossRef]
- Gupta, S.; Gupta, M. Deep Learning for Brain Tumor Segmentation using Magnetic Resonance Images. In Proceedings of the 2021 IEEE Conference on Computational Intelligence in Bioinformatics and Computational Biology (CIBCB), Melbourne, Australia, 13–15 October 2021; pp. 1–6. [Google Scholar] [CrossRef]
- Chaddad, A.; Daniel, P.; Zhang, M.; Rathore, S.; Sargos, P.; Desrosiers, C.; Niazi, T. Deep radiomic signature with immune cell markers predicts the survival of glioma patients. Neurocomputing 2022, 469, 366–375. [Google Scholar] [CrossRef]
- Chaddad, A.; Zhang, M.; Desrosiers, C.; Niazi, T. Deep radiomic features from MRI scans predict survival outcome of recurrent glioblastoma. In Proceedings of the International Workshop on Radiomics and Radiogenomics in Neuro-Oncology, Shenzhen, China, 13 October 2019; pp. 36–43. [Google Scholar]
- Moridian, P.; Ghassemi, N.; Jafari, M.; Salloum-Asfar, S.; Sadeghi, D.; Khodatars, M.; Shoeibi, A.; Khosravi, A.; Ling, S.H.; Subasi, A.; et al. Automatic Autism Spectrum Disorder Detection Using Artificial Intelligence Methods with MRI Neuroimaging: A Review. arXiv 2022, arXiv:2206.11233. [Google Scholar] [CrossRef] [PubMed]
- Scapicchio, C.; Gabelloni, M.; Barucci, A.; Cioni, D.; Saba, L.; Neri, E. A deep look into radiomics. Radiol. Med. 2021, 126, 1296–1311. [Google Scholar] [CrossRef] [PubMed]
- Garin, E.; Tselikas, L.; Guiu, B.; Chalaye, J.; Edeline, J.; de Baere, T.; Assénat, E.; Tacher, V.; Robert, C.; Terroir-Cassou-Mounat, M.; et al. Personalised versus standard dosimetry approach of selective internal radiation therapy in patients with locally advanced hepatocellular carcinoma (DOSISPHERE-01): A randomised, multicentre, open-label phase 2 trial. Lancet Gastroenterol. Hepatol. 2021, 6, 17–29. [Google Scholar] [CrossRef] [PubMed]
- Akula, A.R.; Wang, K.; Liu, C.; Saba-Sadiya, S.; Lu, H.; Todorovic, S.; Chai, J.; Zhu, S.C. CX-ToM: Counterfactual explanations with theory-of-mind for enhancing human trust in image recognition models. iScience 2022, 25, 103581. [Google Scholar] [CrossRef] [PubMed]
- Ehsan, U.; Liao, Q.V.; Muller, M.; Riedl, M.O.; Weisz, J.D. Expanding explainability: Towards social transparency in ai systems. In Proceedings of the 2021 CHI Conference on Human Factors in Computing Systems, Yokohama, Japan, 8–13 May 2021; pp. 1–19. [Google Scholar]
- Kumarakulasinghe, N.B.; Blomberg, T.; Liu, J.; Leao, A.S.; Papapetrou, P. Evaluating local interpretable model-agnostic explanations on clinical machine learning classification models. In Proceedings of the 2020 IEEE 33rd International Symposium on Computer-Based Medical Systems (CBMS), Rochester, MN, USA, 28–30 July 2020; pp. 7–12. [Google Scholar]
- Evans, T.; Retzlaff, C.O.; Geißler, C.; Kargl, M.; Plass, M.; Müller, H.; Kiehl, T.R.; Zerbe, N.; Holzinger, A. The explainability paradox: Challenges for xAI in digital pathology. Future Gener. Comput. Syst. 2022, 133, 281–296. [Google Scholar] [CrossRef]
- Salahuddin, Z.; Woodruff, H.C.; Chatterjee, A.; Lambin, P. Transparency of deep neural networks for medical image analysis: A review of interpretability methods. Comput. Biol. Med. 2022, 140, 105111. [Google Scholar] [CrossRef]
- Gebru, B.; Zeleke, L.; Blankson, D.; Nabil, M.; Nateghi, S.; Homaifar, A.; Tunstel, E. A Review on Human–Machine Trust Evaluation: Human-Centric and Machine-Centric Perspectives. IEEE Trans. Hum.-Mach. Syst. 2022, 52, 952–962. [Google Scholar] [CrossRef]
- Adebayo, J.; Muelly, M.; Abelson, H.; Kim, B. Post hoc explanations may be ineffective for detecting unknown spurious correlation. In Proceedings of the International Conference on Learning Representations, Virtual Event, 3–7 May 2021. [Google Scholar]
- Alqaraawi, A.; Schuessler, M.; Weiß, P.; Costanza, E.; Berthouze, N. Evaluating saliency map explanations for convolutional neural networks: A user study. In Proceedings of the 25th International Conference on Intelligent User Interfaces, Cagliari, Italy, 17–20 March 2020; pp. 275–285. [Google Scholar]
- Stepin, I.; Alonso, J.M.; Catala, A.; Pereira-Fariña, M. A Survey of Contrastive and Counterfactual Explanation Generation Methods for Explainable Artificial Intelligence. IEEE Access 2021, 9, 11974–12001. [Google Scholar] [CrossRef]
- Sutton, R.T.; Pincock, D.; Baumgart, D.C.; Sadowski, D.C.; Fedorak, R.N.; Kroeker, K.I. An overview of clinical decision support systems: Benefits, risks, and strategies for success. NPJ Digit. Med. 2020, 3, 17. [Google Scholar] [CrossRef] [Green Version]
- Mitchell, M.; Wu, S.; Zaldivar, A.; Barnes, P.; Vasserman, L.; Hutchinson, B.; Spitzer, E.; Raji, I.D.; Gebru, T. Model cards for model reporting. In Proceedings of the Conference on Fairness, Accountability, and Transparency, Atlanta, GA, USA, 29–31 January 2019; pp. 220–229. [Google Scholar]
- Arnold, M.; Bellamy, R.K.; Hind, M.; Houde, S.; Mehta, S.; Mojsilović, A.; Nair, R.; Ramamurthy, K.N.; Olteanu, A.; Piorkowski, D.; et al. FactSheets: Increasing trust in AI services through supplier’s declarations of conformity. IBM J. Res. Dev. 2019, 63, 6:1–6:13. [Google Scholar] [CrossRef]
- Gebru, T.; Morgenstern, J.; Vecchione, B.; Vaughan, J.W.; Wallach, H.; Iii, H.D.; Crawford, K. Datasheets for datasets. Commun. ACM 2021, 64, 86–92. [Google Scholar] [CrossRef]
- van der Velden, B.H.; Kuijf, H.J.; Gilhuijs, K.G.; Viergever, M.A. Explainable artificial intelligence (XAI) in deep learning-based medical image analysis. Med. Image Anal. 2022, 79, 102470. [Google Scholar] [CrossRef] [PubMed]
- Lopes, P.; Silva, E.; Braga, C.; Oliveira, T.; Rosado, L. XAI Systems Evaluation: A Review of Human and Computer-Centred Methods. Appl. Sci. 2022, 12, 9423. [Google Scholar] [CrossRef]
- Lin, Y.S.; Lee, W.C.; Celik, Z.B. What do you see? Evaluation of explainable artificial intelligence (XAI) interpretability through neural backdoors. arXiv 2020, arXiv:2009.10639. [Google Scholar]
- Nguyen, H.T.T.; Cao, H.Q.; Nguyen, K.V.T.; Pham, N.D.K. Evaluation of Explainable Artificial Intelligence: SHAP, LIME, and CAM. In Proceedings of the FPT AI Conference 2021, Ha Noi, Viet Nam, 6–7 May 2021; pp. 1–6. [Google Scholar]
- Nauta, M.; Trienes, J.; Pathak, S.; Nguyen, E.; Peters, M.; Schmitt, Y.; Schlötterer, J.; van Keulen, M.; Seifert, C. From anecdotal evidence to quantitative evaluation methods: A systematic review on evaluating explainable ai. arXiv 2022, arXiv:2201.08164. [Google Scholar]
- Zhang, Y.; Xu, F.; Zou, J.; Petrosian, O.L.; Krinkin, K.V. XAI Evaluation: Evaluating Black-Box Model Explanations for Prediction. In Proceedings of the 2021 II International Conference on Neural Networks and Neurotechnologies (NeuroNT), Saint Petersburg, Russia, 16 June 2021; pp. 13–16. [Google Scholar]
- Zhang, Q.; Wu, Y.N.; Zhu, S.C. Interpretable Convolutional Neural Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Geiger, A.; Wu, Z.; Lu, H.; Rozner, J.; Kreiss, E.; Icard, T.; Goodman, N.; Potts, C. Inducing causal structure for interpretable neural networks. In Proceedings of the International Conference on Machine Learning, Baltimore, MD, USA, 17–23 July 2022; pp. 7324–7338. [Google Scholar]
- Zhang, Z.; Liu, Q.; Wang, H.; Lu, C.; Lee, C. ProtGNN: Towards Self-Explaining Graph Neural Networks. Proc. AAAI Conf. Artif. Intell. 2022, 36, 9127–9135. [Google Scholar] [CrossRef]
- Chaddad, A.; Li, J.; Katib, Y.; Kateb, R.; Tanougast, C.; Bouridane, A.; Abdulkadir, A. Explainable, Domain-Adaptive, and Federated Artificial Intelligence in Medicine. arXiv 2022, arXiv:2211.09317. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
| Explanation Type | Paper | Technique | Intrinsic | Post Hoc | Global | Local | Model-Specify | Model-Agnostic |
|---|---|---|---|---|---|---|---|---|
| Feature | [28] | BP | * | * | * | |||
| [29] | Guided-BP | * | * | * | ||||
| [30] | Deconv Network | * | * | * | ||||
| [31] | LRP | * | * | * | ||||
| [32] | CAM | * | * | * | ||||
| [33] | Grad-CAM | * | * | * | ||||
| [34] | LIME | * | * | * | ||||
| [35] | GraphLIME | * | * | * | ||||
| [36] | SHAP | * | * | * | ||||
| [37] | Attention | * | * | * | ||||
| Example-based | [38] | ProtoPNet | * | * | * | |||
| [39] | Triplet Network | * | * | * | * | |||
| [5] | xDNN | * | * | * | ||||
| Textual | [40] | TCAV | * | * | * | * | ||
| [41] | Image Captioning | * | * | * |
| Paper | Organ | XAI | Modality | Contribution |
|---|---|---|---|---|
| [42] | bone | CAM | X-ray | The model aims to predict the degree of knee damage and pain value through X-ray image. |
| [43] | lung | CAM | Ultrasound, X-ray | It uses three kinds of lung ultrasound images as datasets, and two networks, VGG-16 and VGG-CAM, to classify three kinds of pneumonia. |
| [44] | breast | CAM | X-ray | It proposes a globally-aware multiple instance classifier (GMIC) that uses CAM to identify the most informative regions with local and global information. |
| [45] | lung | CAM | X-ray, CT | The study improves two models, one of them based on MobileNet to classify COVID-19 CXR images, the other one is ResNet for CT image classification. |
| [46] | lung | CAM | CT | It selects healthy and COVID-19 patient’s data for training DRE-Net model. |
| [47] | lung | Grad-CAM | CT | It proposes a method of deep feature fusion. It achieves better performance than the single use of CNN. |
| [48] | chest | Grad-CAM | ultrasound | The paper proposes a semi-supervised model based on attention mechanism and disentangled. It then uses Grad-CAM to improve model’s explainable. |
| [49] | lung | Grad-CAM | X-ray | It provides a computer-aided detection, which is composed of the Discrimination-DL and the Localization-DL, and uses Grad-CAM to locate abnormal areas in the image. |
| [50] | colon | Grad-CAM | colonoscopy | The study proposes DenseNet121 to predict if the patient has ulcerative colitis (UC). |
| [51] | colon | Grad-CAM | whole-slide images | It investigates the potential of a deep learning-based system for automated MSI prediction. |
| [52] | lung | Grad-CAM | CT | It shows a classifier based on the Res2Net network. The study uses Activation Mapping to increase the interpretability of the overall Joint Classification and Segmentation system. |
| [53] | chest | Grad-CAM | CT | It proposes a neighboring aware graph neural network (NAGNN) for COVID-19 detection based on chest CT images. |
| [54] | lung | Grad-CAM, LIME | X-ray | This work provides a COVID-19 X-ray dataset, and proposes a COVID-CXNet based on CheXNet using transfer learning. |
| [55] | lung | Grad-CAM, LIME | X-ray, CT | It compares five DL models and uses the visualization method to explain NASNetLarge. |
| [56] | breast | Attention | X-ray | It provides the triple-attention learning Net model to diagnose 14 chest diseases. |
| [57] | bone | Attention | CT | The study introduces a multimodal spatial attention module (MSAM). It uses an attention mechanism to focus on the area of interest. |
| [58] | colon | Attention | colonoscopy | The proposed Focus U-Net achieves an average DSC and IoU of 87.8% and 80.9%, respectively. |
| [59] | lung, skin | Saliency | CT, X-ray | The work presents quantitative assessment metrics for saliency XAI. Three different saliency algorithms were evaluated. |
| [60] | lung | SHAP | EHR | The study introduces a predictive length of stay framework to deal with imbalanced EHR datasets. |
| [61] | - | SHAP | EHR | The study presents an explainable clinical decision support system (CDSS) to help clinicians identify women at risk for Gestational Diabetes Mellitus (GDM). |
| [62] | - | SHAP | radiomics | The study proposes a pipeline for interactive medical image analysis via radiomics. |
| [63] | lung | SHAP | CT | This paper provides a model to predict mutation in patients with non-small cell lung cancer. |
| [64] | chest | SHAP | EHR | In this paper, it compares the performance of different ML methods (RSFs, SSVMs, and XGB and CPH regression) and uses SHAP value to interpret the models. |
| [65] | chest | LIME, SHAP | X-ray | The study proposes a unified pipeline to improve explainability for CNN using multiple XAI methods. |
| [66] | lung | SHAP, LIME, Scoped Rules | EHR | The study provides a comparison among three feature-based XAI techniques on EHR dataset. The results show that the use of these techniques can not replace human experts. |
| [67] | chest | Image caption | CT | It proposes Medical-VLBERT for COVID-19 CT report generation. |
| Paper | Technique | Simple to Use | Stability | Efficient | Trustworthy | Code | Feature |
|---|---|---|---|---|---|---|---|
| [33] | Gradient-weighted class activation mapping (Grad-CAM) | + | − | + | − | c1 |
|
| [34] | Local Interpretable Model-agnostic Explanations (LIME) | + | − | − | + | c2 |
|
| [35] | GraphLIME | − | − | − | + | * c3 |
|
| [36] | SHapley Additive exPlanations (SHAP) | + | − | − | na. | c4 |
|
| [37] | Trainable attention | − | na. | − | +/− | * c5 |
|
| [5] | xDNN | − | na. | − | + | c6 |
|
| [40] | Testing with Concept Activation Vectors (TCAV) | + | na. | na. | + | c7 |
|
| [38] | ProtoPNet | +/− | na. | − | − | c8 |
|
| [41] | Image Caption | +/− | na. | − | +/− | na. |
|
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chaddad, A.; Peng, J.; Xu, J.; Bouridane, A. Survey of Explainable AI Techniques in Healthcare. Sensors 2023, 23, 634. https://doi.org/10.3390/s23020634
Chaddad A, Peng J, Xu J, Bouridane A. Survey of Explainable AI Techniques in Healthcare. Sensors. 2023; 23(2):634. https://doi.org/10.3390/s23020634
Chicago/Turabian StyleChaddad, Ahmad, Jihao Peng, Jian Xu, and Ahmed Bouridane. 2023. "Survey of Explainable AI Techniques in Healthcare" Sensors 23, no. 2: 634. https://doi.org/10.3390/s23020634