
An Extended Review Concerning the Relevance of Deep Learning and Privacy Techniques for Data-Driven Soft Sensors

Abstract
:1. Introduction
- A comprehensive analysis of the personal data collected using mobile background sensors and the related machine-learning- and deep-learning-based automated methods that focus on sociological and demographic aspects.
- A presentation of the generally considered applications and real-world use case scenarios related to the use of mobile devices.
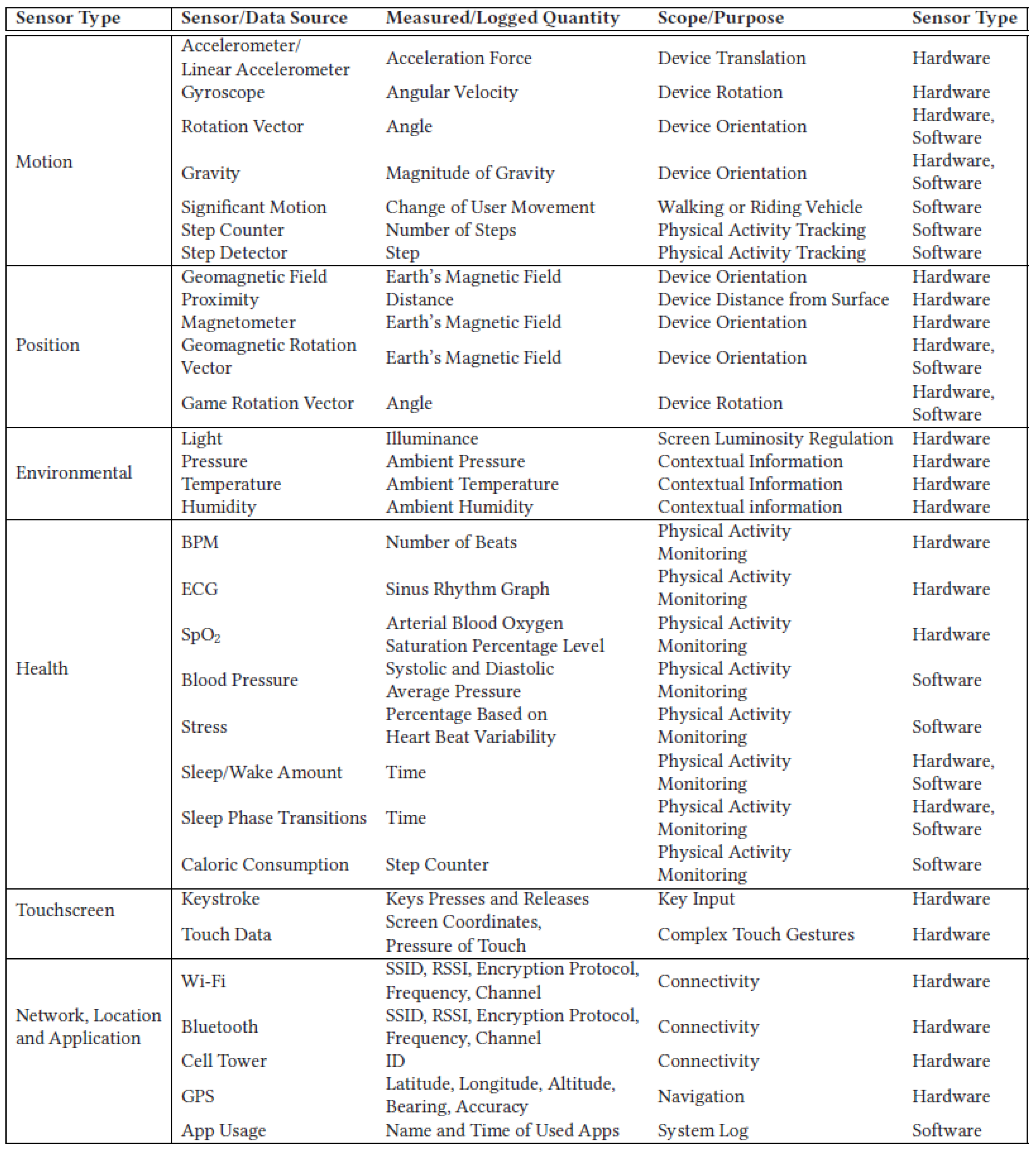
- An overview of the relevant sensors and the related raw data usually available in mobile computing environments and mobile devices. This particularly analyzes the background sensors, as they are usually perceived as harmless by the average end user.
- A presentation of the metrics introduced in the relevant scientific and technical literature.
2. Research Methodology
2.1. Research Questions
- What are the sensors and the raw data commonly available on modern mobile devices, paying special attention to background sensors, which are often considered harmless by the end users?
- What are the typical related real-world use case scenarios?
- What are the relevant practical purposes of the data that are collected using mobile sensors?
- What are the specific features and logical structure of the data, which pertain to the various analyzed real-world use-case scenarios?
- What are the most frequently used data privacy and anonymization techniques?
- What are the metrics that quantify the level of data anonymization processes?
2.2. Research Process
2.3. Exclusion and Inclusion Criteria
- Step 1. Abstract-based filtering: irrelevant scientific contributions are ignored based on the information that is extracted from the abstract and also considering the keywords. Thus, papers that meet at least 50% of the relevance threshold are considered further.
- Step 2. Full text-based filtering: papers that address only a small part of the scientific scope, which is defined by the abstract and the keywords, are ignored.
- Step 3. Quality analysis-based filtering: the remaining papers are further filtered out if any of the following conditions are not satisfied: <The paper proposes a comprehensive solution regarding the usage of data-driven soft sensors.> AND <The paper thoroughly describes the technical implementation of the proposed solution.> AND <The paper reviews related similar scientific contributions.> AND <The paper discusses and analyzes the obtained results.>
3. Data Acquisition through Mobile Devices and Sensors
3.1. Remarks Concerning Full Privacy-Preserving Data Computation
- The collection of personal data is conducted using mobile client devices.
- The data is transferred to central data processing components.
- The data are properly and securely stored, and privacy-preserving data is processed.
- The system should be specified considering a flexible and decoupled system architecture which would allow for an efficient extension and re-structuring of the system in the future.
- The legal and formal requirements that are formalized by American and European regulations are also considered.
- The efficient integration of the system in the target software frameworks considers the specifics of the respective use cases, as well as all the technical and legal requirements.
3.2. Analytical Remarks Concerning Similar Contributions
4. General Mobile Collection of Sensitive Data
5. Real-World Sensors Use Case Scenarios
5.1. User Authentication Systems
5.2. Fitness and Healthcare Systems and Services
5.3. Services Based on Location Data
5.4. Remarks Concerning Other Relevant Use Cases
6. Proper Management of Sensitive Private Data
6.1. Demographic Data
6.1.1. Sensors That Detect Movement
6.1.2. Touchscreen Data
6.1.3. Sensor Data Related to Mobile Applications, Location, and Network
6.2. Remarks Concerning the Study of Human Behaviour
6.2.1. Motion Sensors
6.2.2. Sensor Data Related to Mobile Applications, Location, and Network
6.3. Remarks Regarding Body Features and Health Parameters
6.3.1. Motion Sensors
6.3.2. Remarks Concerning the Touchscreen
6.3.3. Sensors Data Related to Mobile Applications, Location, and Network
6.4. The Detection of Psychological Mood and Emotions
6.4.1. Motion Sensors
6.4.2. Touchscreen Data
6.4.3. Sensors Data Related to Mobile Applications, Location, and Network
6.5. User Tracking through Location Data
6.5.1. Motion Sensors
6.5.2. Sensor Data Related to Mobile Applications, Location, and Network
6.6. Logging Keystroke Data and Text Inference Using Motion Sensors
7. Metrics Related to the Privacy of Personal Sensitive Data
7.1. General Considerations
7.1.1. Metrics That Relate to Data Anonymity
7.1.2. Differential Metrics
7.1.3. Metrics That Consider Entropy
7.1.4. Metrics Based on the Probability of Success
7.1.5. Metrics Based on the Concept of Error
7.1.6. Metrics Based on the Concept of Accuracy
7.1.7. Metrics Based on the Concept of Time
8. Analytical Discussion Concerning Relevant Research Aspects and Gaps
Further Remarks
9. Conclusions and Open Questions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Rajkumar, N.; Kannan, E. Attribute-based collusion resistance in group-based cloud data sharing using LKH model. J. Circuits Syst. Comput. 2020, 29, 2030001. [Google Scholar] [CrossRef]
- Tolosana, R.; Ruiz-Garcia, J.C.; Vera-Rodriguez, R.; Herreros-Rodriguez, J.; Romero-Tapiador, S.; Morales, A.; Fierrez, J. Child-computer interaction: Recent works, new dataset, and age detection. arXiv 2021, arXiv:2102.01405. [Google Scholar]
- Abuhamad, M.; Abusnaina, A.; Nyang, D.; Mohaisen, D. Sensor-based continuous authentication of smartphones’ users using behavioral biometrics: A contemporary survey. arXiv 2020, arXiv:2001.08578. [Google Scholar] [CrossRef]
- Hussain, A.; Ali, T.; Althobiani, F.; Draz, U.; Irfan, M.; Yasin, S.; Shafiq, S.; Safdar, Z.; Glowacz, A.; Nowakowski, G.; et al. Security framework for IOT based real-time health applications. Electronics 2021, 10, 719. [Google Scholar] [CrossRef]
- Ellavarason, E.; Guest, R.; Deravi, F.; Sanchez-Riello, R.; Corsetti, B. Touch-dynamics based behavioural biometrics on mobile devices—A review from a usability and performance perspective. ACM Comput. Surv. (CSUR) 2020, 53, 120. [Google Scholar] [CrossRef]
- Gentry, C. A Fully Homomorphic Encryption Scheme; Stanford University: Stanford, CA, USA, 2009. [Google Scholar]
- Li, Q.; Cao, G.; La Porta, T. Efficient and privacy-aware data aggregation in mobile sensing. IEEE Trans. Dependable Secur. Comput. 2014, 11, 115–129. [Google Scholar] [CrossRef]
- Zhang, R.; Shi, J.; Zhang, Y.; Zhang, C. Verifiable privacy-preserving aggregation in people-centric urban sensing systems. IEEE J. Sel. Areas Commun. 2013, 31, 268–278. [Google Scholar] [CrossRef]
- Zhou, J.; Cao, Z.; Dong, X.; Lin, X. PPDM: Privacy-preserving protocol for dynamic medical text mining and image feature extraction from secure data aggregation in cloud-assisted e-healthcare systems. IEEE J. Sel. Top. Signal Process. 2015, 9, 1332–1344. [Google Scholar] [CrossRef]
- Shi, E.; Chan, T.-h.H.; Rieffel, E.G.; Chow, R.; Song, D. Privacy-preserving aggregation of time-series data. In Proceedings of the NDSS Symposium, San Diego, CA, USA, 6–9 February 2011; Volume 2, p. 4. [Google Scholar]
- Li, F.; Luo, B.; Liu, P. Secure information aggregation for smart grids using homomorphic encryption. In Proceedings of the 2010 First IEEE International Conference on Smart Grid Communications, Gaithersburg, MD, USA, 4–6 October 2010; pp. 327–332. [Google Scholar]
- Gennaro, R.; Gentry, C.; Parno, B. Non-interactive verifiable computing: Outsourcing computation to untrusted workers. In Proceedings of the Annual Cryptology Conference, Santa Barbara, CA, USA, 15–19 August 2010; Springer: Berlin/Heidelberg, Germany, 2010; pp. 465–482. [Google Scholar]
- Benabbas, S.; Gennaro, R.; Vahlis, Y. Verifiable delegation of computation over large datasets. In Proceedings of the Annual Cryptology Conference, Santa Barbara, CA, USA, 14–18 August 2011; Springer: Berlin/Heidelberg, Germany, 2011; pp. 111–131. [Google Scholar]
- Fiore, D.; Gennaro, R. Publicly verifiable delegation of large polynomials and matrix computations, with applications. In Proceedings of the 2012 ACM Conference on Computer and Communications Security, Raleigh, NC, USA, 6–8 October 2012; pp. 501–512. [Google Scholar]
- Papamanthou, C.; Tamassia, R.; Triandopoulos, N. Optimal verification of operations on dynamic sets. In Proceedings of the Annual Cryptology Conference, Santa Barbara, CA, USA, 14–18 August 2011; Springer: Berlin/Heidelberg, Germany, 2011; pp. 91–110. [Google Scholar]
- Guo, L.; Fang, Y.; Li, M.; Li, P. Verifiable privacy-preserving monitoring for cloud-assisted mHealth systems. In Proceedings of the 2015 IEEE Conference on Computer Communications, Hong Kong, 26 April–1 May 2015; pp. 1026–1034. [Google Scholar]
- Zhuo, G.; Jia, Q.; Guo, L.; Li, M.; Fang, Y. Privacy-preserving verifiable proximity test for location-based services. In Proceedings of the 2015 IEEE Global Communications Conference, San Diego, CA, USA, 6–10 December 2015; pp. 1–6. [Google Scholar]
- Fiore, D.; Gennaro, R.; Pastro, V. Efficiently verifiable computation on encrypted data. In Proceedings of the 2014 ACM SIGSAC Conference on Computer and Communications Security, Scottsdale, AZ, USA, 3–7 November 2014; pp. 844–855. [Google Scholar]
- Jaeger, D.; Schiffman, J. Outlook: Cloudy with a Chance of Security Challenges and Improvements. J. IEEE Secur. Priv. 2010, 8, 77–80. [Google Scholar] [CrossRef]
- Kuzu, M.; Saiful Islam, M.; Kantarcioglu, M. Efficient similarity search over encrypted data. In Proceedings of the 2012 IEEE International Conference on Data Engineering, Washington, DC, USA, 1–5 April 2012; pp. 1156–1167. [Google Scholar]
- Cao, N.; Wang, C.; Li, M.; Ren, K.; Lou, W.; Kantarcioglu, M. Privacy-preserving multi-keyword ranked search over encrypted cloud data. IEEE Trans. Parallel Distrib. Syst. 2014, 25, 222–233. [Google Scholar] [CrossRef] [Green Version]
- Orencik, C.; Savas, E. An efficient privacy-preserving multi-keyword search over encrypted cloud data with ranking. J. Parallel Distrib. Databases 2014, 32, 119–160. [Google Scholar] [CrossRef]
- Yu, J.; Lu, P.; Zhu, Y.; Xue, G.; Li, M. Toward Secure Multikeyword Top-k Retrieval over Encrypted Cloud Data. IEEE Trans. Dependable Secur. Comput. 2013, 10, 239–250. [Google Scholar] [CrossRef]
- Boldyreva, A.; Chenette, N.; Lee, Y.; O’Neill, A. Order-preserving symmetric encryption. In Proceedings of the 28th Conference on Theory and Applications of Cryptography Techniques, Trondheim, Norway, 30 May–3 June 2009; pp. 224–241. [Google Scholar]
- Breiter, G.; Behrendt, M. Life cycle and characteristics of services in the world of cloud computing. IBM J. Res. Dev. 2009, 53, 3:1–3:8. [Google Scholar] [CrossRef]
- Brakerski, Z.; Vaikuntanathan, V. Efficient fully homomorphic encryption from (standard) LWE. SIAM J. Comput. 2011, 43, 831–871. [Google Scholar] [CrossRef]
- van Dijk, M.; Gentry, C.; Halevi, S.; Vaikuntanathan, V. Fully homomorphic encryption over the integers. In Proceedings of the 2010 EUROCRYPT Conference, French Riviera, France, 30 May–3 June 2010; pp. 24–43. [Google Scholar]
- Coron, J.; Mandal, A.; Naccache, D.; Tibouchi, M. Fully homomorphic encryption over the integers with shorter public keys. In Proceedings of the Annual Cryptology Conference, Santa Barbara, CA, USA, 14–18 August 2011; Springer: Berlin/Heidelberg, Germany, 2011; pp. 487–504. [Google Scholar]
- Steffen, S.; Bichsel, B.; Baumgartner, R.; Vechev, M. ZeeStar: Private Smart Contracts by Homomorphic Encryption and Zero-knowledge Proofs. In Proceedings of the IEEE Symposium on Security and Privacy (SP), San Francisco, CA, USA, 23–25 May 2022. [Google Scholar]
- Gentry, C.; Halevi, S.; Smart, N.P. Fully homomorphic encryption with polylog overhead. In Proceedings of the Annual Cryptology Conference, Santa Barbara, CA, USA, 14–18 August 2011; Springer: Berlin/Heidelberg, Germany, 2011; pp. 465–482. [Google Scholar]
- Brakerski, Z.; Gentry, C.; Vaikuntanathan, V. Fully homomorphic encryption without bootstrapping. In Proceedings of the 3rd Innovations in Theoretical Computer Science Conference, Cambridge, MA, USA, 8–12 January 2012; pp. 309–325. [Google Scholar]
- Gentry, C.; Sahai, A.; Waters, B. Homomorphic encryption from learning with errors: Conceptually-simpler, asymptotically-faster, attribute-based. In Proceedings of the Annual Cryptology Conference, Santa Barbara, CA, USA, 18–22 August 2013; Springer: Berlin/Heidelberg, Germany, 2013; pp. 75–92. [Google Scholar]
- General Data Protection Regulation. 2022. Available online: https://gdprinfo.eu/ro (accessed on 29 November 2022).
- Aljeraisy, A.; Barati, M.; Rana, O.; Perera, C. Privacy laws and privacy by design schemes for the Internet of Things: A developer’s perspective. ACM Comput. Surv. 2021, 54, 102. [Google Scholar] [CrossRef]
- Barth, S.; de Jong, M.D.T.; Junger, M.; Hartel, P.H.; Roppelt, J.C. Putting the privacy paradox to the test: Online privacy and security behaviors among users with technical knowledge, privacy awareness, and financial resources. Telemat. Inform. 2019, 41, 55–69. [Google Scholar] [CrossRef]
- European Commission. PriMa: Privacy Matters, H2020-MSCA-ITN-2019-860315. 2022. Available online: https://www.prima-itn.eu/ (accessed on 5 December 2022).
- European Commission. TReSPAsS-ETN: TRaining in Secure and PrivAcy-Preserving Biometrics, H2020-MSCAITN-2019-860813. 2022. Available online: https://www.trespass-etn.eu/ (accessed on 4 November 2022).
- Halevi, S.; Shoup, V. Algorithms in HElib. In Proceedings of the Annual Cryptology Conference, Santa Barbara, CA, USA, 17–21 August 2014; Springer: Berlin/Heidelberg, Germany, 2014; pp. 554–571. [Google Scholar]
- ISO/TC 215 Health Informatics. Health Informatics-Pseudonymization; Technical Report; International Organization for Standardization: Geneva, Switzerland, 2017. [Google Scholar]
- Immanuel, S.A.; Sadrieh, A.; Baumert, M.; Couderc, J.P.; Zareba, W.; Hill, A.P.; Vandenberg, J. T-wave morphology can distinguish healthy controls from LQTS patients. Physiol. Meas. 2016, 37, 1456–1473. [Google Scholar] [CrossRef]
- Agrawal, R.; Srikant, R. Privacy-preserving data mining. In Proceedings of the ACM SIGMOD International Conference on Management of Data, Dallas, TX, USA, 15–18 May 2000. [Google Scholar]
- Atallah, M.; Bertino, E.; Elmagarmid, A.; Ibrahim, M.; Verykios, V. Disclosure limitation of sensitive rules. In Proceedings of the Workshop on Knowledge and Data Engineering Exchange, Chicago, IL, USA, 7 November 1999; pp. 45–52. [Google Scholar]
- Barker, K.; Askari, M.; Banerjee, M.; Ghazinour, K.; Mackas, B.; Majedi, M.; Pun, S.; Williams, A. A data privacy taxonomy. In Proceedings of the British National Conference on Databases, Birmingham, UK, 7–9 July 2009; pp. 42–54. [Google Scholar]
- Bassi, G.; Mancinelli, E.; Dell’Arciprete, G.; Rizzi, S.; Gabrielli, S.; Salcuni, S. Efficacy of eHealth interventions for adults with diabetes: A systematic review and meta-analysis. Int. J. Environ. Res. Public Health 2021, 18, 8982. [Google Scholar] [CrossRef]
- Kogge, P.M.; Stone, H.S. A Parallel Algorithm for the Efficient Solution of a General Class of Recurrence Equations. IEEE Trans. Comput. 1973, 100, 786–793. [Google Scholar] [CrossRef]
- Dalenius, T. Finding a needle in a haystack or identifying anonymous census records. J. Off. Stat. 1986, 2, 329. [Google Scholar]
- Garfinkel, S.L. De-Identification of Personal Information; National Institute of Standards and Technology: Gaithersburg, MA, USA, 2015. [Google Scholar]
- Moher, D.; Liberati, A.; Tetzlaff, J.; Altman, D.G. Preferred reporting items for systematic reviews and meta-analyses: The PRISMA statement. Ann. Intern. Med. 2009, 151, 264–269. [Google Scholar] [CrossRef] [Green Version]
- Rokade, A.; Singh, M.; Arora, S.K.; Nizeyimana, E. IOT-Based Medical Informatics Farming System with Predictive Data Analytics Using Supervised Machine Learning Algorithms. Comput. Math. Methods Med. 2022, 2022, 8434966. [Google Scholar] [CrossRef]
- Kadu, A.; Singh, M.; Ogudo, K. A Novel Scheme for Classification of Epilepsy Using Machine Learning and a Fuzzy Inference System Based on Wearable-Sensor Health Parameters. Sustainability 2022, 14, 15079. [Google Scholar] [CrossRef]
- Codina-Filba, J.; Escalera, S.; Escudero, J.; Antens, C.; Buch-Cardona, P.; Farrus, M. Mobile eHealth platform for home monitoring of bipolar disorder. In Proceedings of the International Conference on Multimedia Modeling, Prague, Czech Republic, 22–24 January 2021; pp. 330–341. [Google Scholar]
- Bazett, H.C. An analysis of the time-relations of the electrocardiograms. Ann. Noninvasive Electrocardiol. 1997, 2, 177–194. [Google Scholar] [CrossRef]
- Bokolo, A.J. Application of telemedicine and eHealth technology for clinical services in response to COVID-19 pandemic. Health Technol. 2021, 11, 359–366. [Google Scholar] [CrossRef]
- Seo, H.J.; Kim, S.Y.; Sheen, S.S.; Cha, Y. e-Health Interventions for Community-Dwelling Type 2 Diabetes: A Scoping Review. Telemed. E-Health 2021, 27, 276–285. [Google Scholar] [CrossRef]
- El Benny, M.; Kabakian-Khasholian, T.; El-Jardali, F.; Bardus, M. Application of the eHealth literacy model in digital health interventions: Scoping review. J. Med. Internet Res. 2021, 23, e23473. [Google Scholar] [CrossRef]
- Thakur, N.; Han, C.Y. An Ambient Intelligence-Based Human Behavior Monitoring Framework for Ubiquitous Environments. Information 2021, 12, 81. [Google Scholar] [CrossRef]
- Suma, V. Wearable IoT based distributed framework for ubiquitous computing. J. Ubiquitous Comput. Commun. Technol. 2021, 3, 23–32. [Google Scholar]
- IBM Cloud Infrastructure. 2022. Available online: https://www.ibm.com/cloud (accessed on 20 May 2022).
- Mondragón Martínez, O.H.; Solarte Astaíza, Z.M. Architecture for the Creation of Ubiquitous Services Devoted to Health. Universidad Católica de Pereira. 2022. Available online: http://hdl.handle.net/10785/9861 (accessed on 10 May 2022).
- IBM Cloudant Storage Service. 2022. Available online: https://www.ibm.com/cloud/cloudant (accessed on 22 May 2022).
- Apache OpenWhisk Service. 2022. Available online: ttps://developer.ibm.com/components/apache-openwhisk (accessed on 30 May 2022).
- Akyildiz, I.F.; Wang, P.; Lin, S.C. SoftAir: A software defined networking architecture for 5G wireless systems. Comput. Netw. 2015, 85, 1–18. [Google Scholar] [CrossRef]
- Xia, X.; Xu, K.; Wang, Y.; Xu, Y. A 5G-Enabling Technology: Benefits, Feasibility, and Limitations of In-Band Full-Duplex mMIMO. IEEE Veh. Technol. Mag. 2018, 13, 81–90. [Google Scholar] [CrossRef]
- Boulogeorgos, A.-A.A.; Alexiou, A.; Merkle, T.; Schubert, C.; Elschner, R.; Katsiotis, A.; Stavrianos, P.; Kritharidis, D.; Chartsias, P.-K.; Kokkoniemi, J.; et al. Terahertz Technologies to Deliver Optical Network Quality of Experience in Wireless Systems Beyond 5G. IEEE Commun. Mag. 2018, 56, 144–151. [Google Scholar] [CrossRef] [Green Version]
- Kal, B.; Hamdaoui, B.; Guizani, M. Extracting and Exploiting Inherent Sparsity for Efficient IoT Support in 5G: Challenges and Potential Solutions. IEEE Wirel. Commun. 2017, 24, 68–73. [Google Scholar]
- Simsek, M.; Aijaz, A.; Dohler, M.; Sachs, J.; Fettweis, G. 5G-Enabled Tactile Internet. IEEE J. Sel. Areas Commun. 2016, 34, 460–473. [Google Scholar] [CrossRef]
- Xu, L.; Collier, R.; O’Hare, G.M.P. A Survey of Clustering Techniques in WSNs and Consideration of the Challenges of Applying Such to 5G IoT Scenarios. IEEE Internet Things J. 2017, 4, 1229–1249. [Google Scholar] [CrossRef]
- Sekander, S.; Tabassum, H.; Hossain, E. Multi-Tier Drone Architecture for 5G/B5G Cellular Networks: Challenges, Trends, and Prospects. IEEE Commun. Mag. 2018, 56, 96–103. [Google Scholar] [CrossRef] [Green Version]
- Dhyani, K.; Bhachawat, S.; Prabhu, J.; Kumar, M.S. A Novel Survey on Ubiquitous Computing. In Data Intelligence and Cognitive Informatics; Springer: Singapore, 2022; pp. 109–123. [Google Scholar]
- Hassan, M.; Singh, M.; Hamid, K.; Saeed, R.; Abdelhaq, M.; Alsaqour, R. Design of Power Location Coefficient System for 6G Downlink Cooperative NOMA Network. Energies 2022, 15, 6996. [Google Scholar] [CrossRef]
- Bolla, S.; Singh, M. Energy Harvesting Technique for Massive MIMO Wireless Communication Networks. J. Phys. Conf. Ser. 2022, 2327, 012059. [Google Scholar] [CrossRef]
- Marwah, G.P.K.; Jain, A.; Malik, P.K.; Singh, M.; Tanwar, S.; Safirescu, C.O.; Mihaltan, T.C.; Sharma, R.; Alkhayyat, A. An Improved Machine Learning Model with Hybrid Technique in VANET for Robust Communication. Mathematics 2022, 10, 4030. [Google Scholar] [CrossRef]
- Bocu, R.; Costache, C. A homomorphic encryption-based system for securely managing personal health metrics data. IBM J. Res. Dev. 2018, 62, 1:1–1:10. [Google Scholar] [CrossRef]
- Bocu, R.; Vasilescu, A.; Duca Iliescu, D.M. Personal Health Metrics Data Management Using Symmetric 5G Data Channels. Symmetry 2022, 14, 1387. [Google Scholar] [CrossRef]
- Acien, A.; Morales, A.; Fierrez, J.; Vera-Rodriguez, R.; Delgado-Mohatar, O. Becaptcha: Bot detection in smartphone interaction using touchscreen biometrics and mobile sensors. arXiv 2020, arXiv:2005.13655. [Google Scholar]
- Hsieh, Y.P.; Lee, K.C.; Lee, T.F.; Su, G.J. Extended Chaotic-Map-Based User Authentication and Key Agreement for HIPAA Privacy/Security Regulations. Appl. Sci. 2022, 12, 5701. [Google Scholar] [CrossRef]
- Cohen, I.G.; Mello, M.M. HIPAA and protecting health information in the 21st century. JAMA 2018, 320, 231–232. [Google Scholar] [CrossRef] [Green Version]
- Sivan, R.; Zukarnain, Z.A. Security and Privacy in Cloud-Based E-Health System. Symmetry 2021, 13, 742. [Google Scholar] [CrossRef]
- Madan, S. Privacy-Preserved Access Control in E-Health Cloud-Based System. In Disruptive Technologies for Society 5.0; CRC Press: Boca Raton, FL, USA, 2021; pp. 145–162. [Google Scholar]
- Daoud, W.B.; Meddeb-Makhlouf, A.; Zarai, F. A trust-based access control scheme for e-Health Cloud. In Proceedings of the 2018 IEEE/ACS 15th International Conference on Computer Systems and Applications (AICCSA), Aqaba, Jordan, 28 October–1 November 2018; pp. 1–7. [Google Scholar]
- Idoga, P.E.; Toycan, M.; Nadiri, H.; Çelebi, E. Factors affecting the successful adoption of e-health cloud based health system from healthcare consumers’ perspective. IEEE Access 2018, 6, 71216–71228. [Google Scholar] [CrossRef]
- Rokade, A.; Singh, M.; Malik, P.K.; Singh, R.; Alsuwian, T. Intelligent Data Analytics Framework for Precision Farming Using IoT and Regressor Machine Learning Algorithms. Appl. Sci. 2022, 12, 9992. [Google Scholar] [CrossRef]
- Yadav, V.K.; Yadav, R.K.; Verma, S.; Venkatesan, S. CP2EH: A comprehensive privacy-preserving e-health scheme over cloud. J. Supercomput. 2022, 78, 2386–2416. [Google Scholar] [CrossRef]
- Pussewalage, H.S.G.; Oleshchuk, V. A Delegatable Attribute Based Encryption Scheme for a Collaborative E-health Cloud. IEEE Trans. Serv. Comput. 2022. [Google Scholar] [CrossRef]
- Esenogho, E.; Djouani, K.; Kurien, A. Integrating Artificial Intelligence Internet of Things and 5G for Next-Generation Smartgrid: A Survey of Trends Challenges and Prospect. IEEE Access 2022, 10, 4794–4831. [Google Scholar] [CrossRef]
- Delgado-Mohatar, O.; Tolosana, R.; Fierrez, J.; Morales, A. Blockchain in the Internet of Things: Architectures and implementation. In Proceedings of the IEEE 44th Annual Computers, Software, and Applications Conference, Madrid, Spain, 13–17 July 2020; pp. 1072–1077. [Google Scholar]
- John Dian, F.; Vahidnia, R.; Rahmati, A. Wearables and the Internet of Things (IoT), applications, opportunities, and challenges: A survey. IEEE Access 2020, 8, 69200–69211. [Google Scholar] [CrossRef]
- Chen, Z.; Lin, M.; Chen, F.; Lane, N.D.; Cardone, G.; Wang, R.; Li, T.; Chen, Y.; Choudhury, T.; Campbell, A.T. Unobtrusive sleep monitoring using smartphones. In Proceedings of the International Conference on Pervasive Computing Technologies for Healthcare and Workshops, Venice, Italy, 5–8 May 2013; pp. 145–152. [Google Scholar]
- Tayfur, I.; Afacan, M.A. Reliability of smartphone measurements of vital parameters: A prospective study using a reference method. Am. J. Emerg. Med. 2019, 37, 1527–1530. [Google Scholar] [CrossRef]
- Morales, A.; Fierrez, J.; Tolosana, R.; Ortega-Garcia, J.; Galbally, J.; Gomez-Barrero, M.; Anjos, A.; Marcel, S. Keystroke biometrics ongoing competition. IEEE Access 2016, 4, 7736–7746. [Google Scholar] [CrossRef]
- Tolosana, R.; Vera-Rodriguez, R.; Fierrez, J.; Ortega-Garcia, J. BioTouchPass2: Touchscreen password biometrics using time-aligned recurrent neural networks. IEEE Trans. Inf. Forensics Secur. 2020, 15, 2616–2628. [Google Scholar] [CrossRef] [Green Version]
- Acien, A.; Morales, A.; Monaco, J.V.; Vera-Rodriguez, R.; Fierrez, J. TypeNet: Deep learning keystroke biometrics. arXiv 2021, arXiv:2101.05570. [Google Scholar] [CrossRef]
- Tramèr, F.; Boneh, D. BioTouchPass2: Differentially private learning needs better features (or much more data). arXiv 2020, arXiv:2011.11660. [Google Scholar]
- David, K.; Berndt, H. 6G vision and requirements: Is there any need for beyond 5G? IEEE Veh. Technol. Mag. 2018, 13, 72–80. [Google Scholar] [CrossRef]
- Statista. Number of Apps Available in Leading App Stores as of 2nd Quarter 2022. 2022. Available online: https://www.statista.com/statistics/276623/number-of-apps-available-in-leading-app-stores/ (accessed on 4 November 2022).
- O’Gorman, L. Comparing passwords, tokens, and biometrics for user authentication. Proc. IEEE 2003, 91, 2021–2040. [Google Scholar] [CrossRef]
- Jain, A.K.; Nandakumar, K.; Ross, A. 50 years of biometric research: Accomplishments, challenges, and opportunities. Pattern Recognit. Lett. 2016, 79, 80–105. [Google Scholar] [CrossRef]
- Patel, V.M.; Chellappa, R.; Chandra, D.; Barbello, B. Continuous user authentication on mobile devices: Recent progress and remaining challenges. IEEE Signal Process. Mag. 2016, 13, 49–61. [Google Scholar] [CrossRef]
- Boakes, M.; Guest, R.; Deravi, F.; Corsetti, B. Exploring mobile biometric performance through identification of core factors and relationships. IEEE Trans. Biom. Behav. Identity Sci. 2019, 1, 278–291. [Google Scholar] [CrossRef] [Green Version]
- Acien, A.; Morales, A.; Vera-Rodriguez, R.; Fierrez, J.; Tolosana, R. Multilock: Mobile active authentication based on multiple biometric and behavioral patterns. In Proceedings of the International Workshop on Multimodal Understanding and Learning for Embodied Applications, Nice, France, 15 October 2019. [Google Scholar]
- Wan, C.; Wang, L.; Phoha, V.V. A survey on gait recognition. ACM Comput. Surv. 2018, 51, 89. [Google Scholar] [CrossRef] [Green Version]
- Santopietro, M.; Vera-Rodriguez, R.; Guest, R.; Morales, A.; Acien, A. Assessing the quality of swipe interactions for mobile biometric systems. In Proceedings of the IEEE International Joint Conference on Biometrics (IJCB’20), Houston, TX, USA, 28 September–1 October 2020; pp. 1–8. [Google Scholar]
- Li, G.; Bours, P. Studying Wifi and accelerometer data based authentication method on mobile phones. In Proceedings of the International Conference on Biometric Engineering and Applications, Amsterdam, The Netherlands, 16–18 May 2018; pp. 18–23. [Google Scholar]
- Nussbaum, R.; Kelly, C.; Quinby, E.; Mac, A.; Parmanto, B.; Dicianno, B.E. Systematic review of mobile health applications in rehabilitation. Arch. Phys. Med. Rehabil. 2019, 100, 115–127. [Google Scholar] [CrossRef]
- Gravenhorst, F.; Muaremi, A.; Bardram, J.; Grünerbl, A.; Mayora, O.; Wurzer, G.; Frost, M.; Osmani, V.; Arnrich, B.; Lukowicz, P.; et al. Mobile phones as medical devices in mental disorder treatment: An overview. Pers. Ubiquitous Comput. 2015, 19, 335–353. [Google Scholar] [CrossRef] [Green Version]
- Faundez-Zanuy, M.; Fierrez, J.; Ferrer, M.A.; Diaz, M.; Tolosana, R.; Plamondon, R. Handwriting biometrics: Applications and future trends in e-security and e-health. Cogn. Comput. 2020, 12, 940–953. [Google Scholar] [CrossRef]
- Majumder, S.; Deen, M.J. Smartphone sensors for health monitoring and diagnosis. Sensors 2019, 19, 2164. [Google Scholar] [CrossRef]
- Anjum, A.; Ilyas, M.U. Activity recognition using smartphone sensors. In Proceedings of the IEEE Consumer Communications and Networking Conference, Las Vegas, NV, USA, 11–14 January 2013; pp. 914–919. [Google Scholar]
- Antar, A.D.; Ahmed, M.; Ahad, M. Challenges in sensor-based human activity recognition and a comparative analysis of benchmark datasets: A review. In Proceedings of the International Conference on Informatics, Electronics and Vision and International Conference on Imaging, Vision and Pattern Recognition (icIVPR’19), Washington, DC, USA, 26 April 2019; pp. 134–139. [Google Scholar]
- Khan, S.; Parkinson, S.; Grant, L.; Liu, N.; Mcguire, S. Biometric systems utilising health data from wearable devices: Applications and future challenges in computer security. ACM Comput. Surv. 2020, 53, 85. [Google Scholar] [CrossRef]
- Haris, M.; Haddadi, H.; Hui, P. Privacy leakage in mobile computing: Tools, methods, and characteristics. arXiv 2014, arXiv:1410.4978. [Google Scholar]
- Saha, D.; Mukherjee, A. Pervasive computing: A paradigm for the 21st century. Computer 2003, 36, 25–31. [Google Scholar] [CrossRef] [Green Version]
- Luca, D.G.; Alberto, M. From proximity to accurate indoor localization for context awareness in mobile museum guides. Int. J. Uncertainty Fuzziness Knowl. Based Syst. 2016, 20, 1002–1009. [Google Scholar]
- De Capitani Di Vimercati, S.; Foresti, S.; Livraga, G.; Amarati, P. Data privacy: Definitions and techniques. Int. J. Uncertainty Fuzziness Knowl. Based Syst. 2012, 20, 793–817. [Google Scholar] [CrossRef] [Green Version]
- Kim, S.J.; Kang, S.; Choi, Y.; Choi, M.; Hong, M. Augmented-reality survey: From concept to application. KSII Trans. Internet Inf. Syst. 2017, 11, 982–1004. [Google Scholar]
- Burke, J.; Estrin, D.; Hansen, M.; Parker, A.; Ramanathan, N.; Reddy, S.; Srivastava, M.B. Participatory Sensing; UCLA: Center for Embedded Network Sensing: Los Angeles, CA, USA, 2006. [Google Scholar]
- Melo, G.; Oliveira, L.; Schneider, D.; de Souza, J. Towards an observatory for mobile participatory sensing applications. In Proceedings of the International Conference on Computer Supported Cooperative Work in Design, Wellington, New Zealand, 26–28 April 2017; pp. 305–312. [Google Scholar]
- Labati, R.D.; Piuri, V.; Scotti, F. Biometric privacy protection: Guidelines and technologies. In Proceedings of the International Conference on E-Business and Telecommunications, Seville, Spain, 18–21 July 2011; pp. 3–19. [Google Scholar]
- Davarci, E.; Soysal, B.; Erguler, I.; Aydin, S.O.; Dincer, O.; Anarim, E. Age group detection using smartphone motion sensors. In Proceedings of the European Signal Processing Conference, Kos, Greece, 28 August 28–2 September 2017. [Google Scholar]
- Nguyen, T.; Roy, A.; Memon, N. Kid on the phone! Toward automatic detection of children on mobile devices. Comput. Secur. 2019, 84, 334–348. [Google Scholar] [CrossRef] [Green Version]
- Jain, A.; Kanhangad, V. Investigating gender recognition in smartphones using accelerometer and gyroscope sensor readings. In Proceedings of the International Conference on Computational Techniques in Information and Communication Technologies, New Delhi, India, 11–13 March 2016. [Google Scholar]
- Meena, T.; Sarawadekar, K. Gender recognition using in-built inertial sensors of smartphone. In Proceedings of the IEEE Region 10 Conference, Hyderabad, India, 16–19 November 2020; pp. 462–467. [Google Scholar]
- Singh, S.; Shila, D.M.; Kaiser, G. Side channel attack on smartphone sensors to infer gender of the user: Poster abstract. In Proceedings of the Conference on Embedded Networked Sensor Systems, New York, NY, USA, 10 November 2019; pp. 436–437. [Google Scholar]
- Ngo, T.T.; Ahad, M.A.R.; Antar, A.D.; Ahmed, M.; Muramatsu, D.; Makihara, Y.; Yagi, Y.; Inoue, S.; Hossain, T.; Hattori, Y. OU-ISIR wearable sensor-based gait challenge: Age and gender. In Proceedings of the International Conference on Biometrics, Crete, Greece, 4–7 June 2019. [Google Scholar]
- Sabir, A.; Maghdid, H.; Asaad, S.; Ahmed, M.; Asaad, A. Gait-based gender classification using smartphone accelerometer sensor. In Proceedings of the International Conference on Frontiers of Signal Processing, Marseille, France, 18–20 September 2019; pp. 12–20. [Google Scholar]
- Acien, A.; Morales, A.; Fierrez, J.; Vera-Rodriguez, R.; Hernandez-Ortega, J. Active detection of age groups based on touch interaction. IET Biom. 2019, 8, 101–108. [Google Scholar] [CrossRef] [Green Version]
- Miguel-Hurtado, O.; Stevenage, S.; Bevan, C.; Guest, R. Predicting sex as a soft-biometrics from device interaction swipe gestures. Pattern Recognit. Lett. 2016, 79, 44–51. [Google Scholar] [CrossRef]
- Jain, A.; Kanhangad, V. Gender recognition in smartphones using touchscreen gestures. Pattern Recognit. Lett. 2019, 125, 604–611. [Google Scholar] [CrossRef]
- Almaatouq, A.; Prieto Castrillo, F.; Pentland, A. Mobile communication signatures of unemployment. In Proceedings of the International Conference on Social Informatics, Bellevue, WA, USA, 14–17 November 2016; pp. 407–418. [Google Scholar]
- Yuan, Y.; Raubal, M.; Liu, Y. Correlating mobile phone usage and travel behavior—A case study of Harbin, China. Comput. Environ. Urban Syst. 2012, 36, 118–130. [Google Scholar] [CrossRef]
- Scherrer, L.; Tomko, M.; Ranacher, P.; Weibel, R. Travelers or locals? Identifying meaningful sub-populations from human movement data in the absence of ground truth. EPJ Data Sci. 2018, 7, 19. [Google Scholar] [CrossRef] [Green Version]
- Riederer, C.; Zimmeck, S.; Phanord, C.; Chaintreau, A.; Bellovin, S. I don’t have a photograph, but you can have my footprints. Revealing the demographics of location data. In Proceedings of the ACM on Conference on Online Social Networks, Palo Alto, CA, USA, 2–3 November 2015; pp. 185–195. [Google Scholar]
- Wu, L.; Yang, L.; Huang, Z.; Wang, Y.; Chai, Y.; Peng, X.; Liu, Y. Inferring demographics from human trajectories and geographical context. Comput. Environ. Urban Syst. 2019, 77, 101368. [Google Scholar] [CrossRef]
- The eXtreme Gradient Boosting Library. 2022. Available online: https://xgboost.ai/about (accessed on 4 November 2022).
- Neal, T.; Woodard, D. A gender-specific behavioral analysis ofmobile device usage data. In Proceedings of the International Conference on Identity, Security, and Behavior Analysis, Singapore, 10–18 January 2018; pp. 1–8. [Google Scholar]
- Chen, K.; Zhang, D.; Yao, L.; Guo, B.; Yu, Z.; Liu, Y. Deep learning for sensor-based human activity recognition: Overview, challenges, and opportunities. ACM Comput. Surv. 2021, 54, 77. [Google Scholar] [CrossRef]
- Sun, L.; Zhang, D.; Li, B.; Guo, B.; Li, S. Activity recognition on an accelerometer embedded mobile phone with varying positions and orientations. Ubiquitous Intell. Comput. 2010, 6406, 548–562. [Google Scholar]
- Thomaz, E.; Essa, I.; Abowd, G.D. A practical approach for recognizing eating moments with wrist-mounted inertial sensing. In Proceedings of the ACM International Joint Conference on Pervasive and Ubiquitous Computing, Osaka, Japan, 7–11 September 2015; pp. 1029–1040. [Google Scholar]
- Santani, D.; Do, T.; Labhart, F.; Landolt, S.; Kuntsche, E.; Gatica-Perez, D. DrinkSense: Characterizing youth drinking behavior using smartphones. IEEE Trans. Mob. Comput. 2018, 17, 2279–2292. [Google Scholar] [CrossRef] [Green Version]
- Arnold, Z.; Larose, D.; Agu, E. Smartphone inference of alcohol consumption levels from gait. In Proceedings of the 2015 International Conference on Healthcare Informatics, Dallas, TX, USA, 21–23 October 2015; pp. 417–426. [Google Scholar]
- Chang, L.; Lu, J.; Wang, J.; Chen, X.; Fang, D.; Tang, Z.; Nurmi, P.; Wang, Z. SleepGuard: Capturing rich sleep information using smartwatch sensing data. In Proceedings of the 2015 ACM on Interactive, Mobile, Wearable and Ubiquitous Technologies; ACM: New York, NY, USA, 2018; Volume 2, pp. 1–34. [Google Scholar]
- Wan, N.; Lin, G. Classifying human activity patterns from smartphone collected GPS data: A fuzzy classification and aggregation approach. Trans. GIS 2016, 20, 869–886. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Chen, Z.; Zhang, L.; Jiang, C.; Cao, Z.; Cui, W. WiFi CSI based passive human activity recognition using attention based BLSTM. IEEE Trans. Mob. Comput. 2018, 18, 2714–2724. [Google Scholar] [CrossRef]
- Ma, Y.; Arshad, S.; Muniraju, S.; Torkildson, E.; Rantala, E.; Doppler, K.; Zhou, G. Location-and person-independent activity recognition with Wifi, deep neural networks, and reinforcement learning. ACM Trans. Internet Things 2021, 2, 1–25. [Google Scholar] [CrossRef]
- Yao, Y.; Song, L.; Ye, J. Motion-To-BMI: Using motion sensors to predict the body mass index of smartphone users. Sensors 2020, 20, 1134. [Google Scholar] [CrossRef] [Green Version]
- Albanese, E.; Launer, L.; Egger, M.; Prince, M.; Giannakopoulos, P.; Wolters, F.; Egan, K. Body mass index in midlife and dementia: Systematic review and meta-regression analysis of 589,649 men and women followed in longitudinal studies. Alzheimer’s Dementia Diagn. Assess. Dis. Monit. 2017, 8, 165–178. [Google Scholar] [CrossRef]
- Dobner, J.; Kaser, S. Body mass index and the risk of infection-from underweight to obesity. Clin. Microbiol. Infect. 2018, 24, 24–28. [Google Scholar] [CrossRef] [Green Version]
- Garcia-Ceja, E.; Riegler, M.; Nordgreen, T.; Jakobsen, P.; Oedegaard, K.J.; Tørresen, J. Mental health monitoring with multimodal sensing andmachine learning: A survey. Pervasive Mob. Comput. 2018, 51, 1–26. [Google Scholar] [CrossRef]
- Arroyo-Gallego, T.; Ledesma-Carbayo, M.J.; Sanchez-Ferro, A.; Butterworth, I.; Mendoza, C.S.; Matarazzo, M.; Montero, P.; Lopez-Blanco, R.; Puertas-Martin, V.; Trincado, R.; et al. Detection of motor impairment in Parkinson’s disease via mobile touchscreen typing. IEEE Trans. Biomed. Eng. 2017, 64, 1994–2002. [Google Scholar] [CrossRef]
- Castrillon, R.; Acien, A.; Orozco-Arroyave, J.R.; Morales, A.; Vargas, J.F.; Vera-Rodrıguez, R.; Fierrez, J.; Ortega-Garcia, J.; Villegas, A. Characterization of the handwriting skills as a biomarker for parkinson disease. In Proceedings of the IEEE International Conference on Automatic Face and Gesture Recognition (FG’19)–Human Health Monitoring Based on Computer Vision, Lille, France, 14–18 May 2019. [Google Scholar]
- Bevan, C.; Fraser, D. Different strokes for different folks? Revealing the physical characteristics of smartphone users from their swipe gestures. Int. J. Hum. Comput. Stud. 2016, 88, 51–61. [Google Scholar] [CrossRef] [Green Version]
- Palmius, N.; Tsanas, A.; Saunders, K.; Bilderbeck, A.C.; Geddes, J.R.; Goodwin, G.M.; De Vos, M. Detecting bipolar depression from geographic location data. IEEE Trans. Biomed. Eng. 2016, 64, 1761–1771. [Google Scholar] [CrossRef]
- Tal, A.; Shinar, Z.; Shaki, D.; Codish, S.; Goldbart, A. Validation of contact-free sleep monitoring device with comparison to polysomnography. J. Clin. Sleep Med. 2017, 13, 517–522. [Google Scholar] [CrossRef] [Green Version]
- Behar, J.; Roebuck, A.; Shahid, M.; Daly, J.; Hallack, A.; Palmius, N.; Stradling, J.; Clifford, G.D. SleepAp: An automated obstructive sleep apnoea screening application for smartphones. IEEE J. Biomed. Health Inform. 2014, 19, 325–331. [Google Scholar] [CrossRef]
- Kostopoulos, P.; Nunes, T.; Salvi, K.; Togneri, M.; Deriaz, M. StayActive: An application for detecting stress. In Proceedings of the International Conference on Communications, Computation, Networks and Technologies, Barcelona, Spain, 15–20 November 2015. [Google Scholar]
- Neal, T.; Canavan, S. Mood versus identity: Studying the iinfluence of affective states on mobile biometrics. In Proceedings of the IEEE International Conference on Automatic Face and Gesture, Buenos Aires, Argentina, 16–20 November 2020. [Google Scholar]
- Quiroz, J.C.; Geangu, E.; Yong, M.H. Emotion recognition using smart watch sensor data: Mixed-design study. JMIR Mental Health 2018, 5, e10153. [Google Scholar] [CrossRef] [Green Version]
- Cao, B.; Zheng, L.; Zhang, C.; Yu, P.; Piscitello, A.; Zulueta, J.; Ajilore, O.; Ryan, K.; Leow, A. DeepMood: Modeling mobile phone typing dynamics for mood detection. In Proceedings of the ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Halifax, NS, Canada, 13–17 August 2017. [Google Scholar]
- Hung, G.; Yang, P.; Chang, C.; Chiang, J.; Chen, Y. Predicting negative emotions based on mobile phone usage patterns: An exploratory study. JMIR Res. Protoc. 2016, 5, e160. [Google Scholar] [CrossRef] [Green Version]
- Gao, Y.; Bianchi-Berthouze, N.; Meng, H. What does touch tell us about emotions in touchscreen-based gameplay? ACM Trans. Comput. Hum. Interact. 2012, 19, 1–30. [Google Scholar] [CrossRef] [Green Version]
- Shah, S.; Teja, J.; Bhattacharya, S. Towards affective touch interaction: Predicting mobile user emotion from finger strokes. J. Interact. Sci. 2015, 3, 6. [Google Scholar] [CrossRef] [Green Version]
- Zhang, X.; Li, W.; Chen, X.; Lu, S. MoodExplorer: Towards compound emotion detection via smartphone sensing. Proc. Acm Interactive Mobile Wearable Ubiquitous Technol. 2018, 1, 1–30. [Google Scholar] [CrossRef]
- Nguyen, K.A.; Akram, R.N.; Markantonakis, K.; Luo, Z.; Watkins, C. Location tracking using smartphone accelerometer and magnetometer traces. In Proceedings of the International Conference on Availability, Reliability and Security, University of Kent, Canterbury, UK, 26–29 August 2019. [Google Scholar]
- Hua, J.; Shen, Z.; Zhong, S. We can track you if you take the metro: Tracking metro riders using accelerometers on smartphones. IEEE Trans. Inf. Forensics Secur. 2017, 12, 286–297. [Google Scholar] [CrossRef]
- Han, J.; Owusu, E.; Nguyen, L.T.; Perrig, A.; Zhang, J. ACComplice: Location inference using accelerometers on smartphones. In Proceedings of the 4th International Conference on Communication Systems and Networks, Rajkot, Gujrat, India, 11–13 May 2012. [Google Scholar]
- Singh, V.; Aggarwal, G.; Ujwal, B.V.S. Ensemble based real-time indoor localization using stray Wifi signal. In Proceedings of the IEEE International Conference on Consumer Electronics (ICCE’18), Las Vegas, NV, USA, 12–15 January 2018; pp. 1–5. [Google Scholar]
- Cai, L.; Chen, H. TouchLogger: Inferring keystrokes on touch screen from smartphone motion. HotSec 2011, 11, 9. [Google Scholar]
- Owusu, E.; Han, J.; Das, S.; Perrig, A.; Zhang, J. ACCessory: Password inference using accelerometers on smartphones. In Proceedings of the Workshop on Mobile Computing Systems and Applications, San Diego, CA, USA, 28–29 February 2012. [Google Scholar]
- Aviv, A.J.; Sapp, B.; Blaze, M.; Smith, J.M. Practicality of accelerometer side channels on smartphones. In Proceedings of the Annual Computer Security Applications Conference, Orlando, FL, USA, 3–7 December 2012. [Google Scholar]
- Sadhya, D.; Chakraborty, B. Quantifying the Effects of Anonymization Techniques over Micro-databases. IEEE Trans. Emerg. Top. Comput. 2022. [Google Scholar] [CrossRef]
- Nam, H.; Kim, S.H.; Park, Y.H. Filteraugment: An acoustic environmental data augmentation method. In Proceedings of the 2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Singapore, 22–27 May 2022; pp. 4308–4312. [Google Scholar]
- Wagner, I.; Eckhoff, D. Technical privacy metrics: A systematic survey. ACM Comput. Surv. (CSUR) 2018, 51, 1–38. [Google Scholar] [CrossRef] [Green Version]
- Sweeney, L. K-anonymity: A model for protecting privacy. Int. J. Uncertainty Fuzziness Knowl. Based Syst. 2002, 10, 557–570. [Google Scholar] [CrossRef] [Green Version]
- Xiao, X.; Tao, Y. M-invariance: Towards privacy preserving re-publication of dynamic datasets. In Proceedings of the ACM SIGMOD International Conference on Management of Data, Beijing, China, 11–14 June 2007; pp. 689–700. [Google Scholar]
- Wong, R.C.; Li, J.; Fu, A.W.; Wang, K. (α, k)-Anonymity: An enhanced k-anonymity model for privacy preserving data publishing. In Proceedings of the ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Philadelphia, PA, USA, 20–23 August 2006; pp. 754–759. [Google Scholar]
- Machanavajjhala, A.; Kifer, D.; Gehrke, J.; Venkitasubramaniam, M. L-diversity: Privacy beyond K-anonymity. ACM Trans. Knowl. Discov. Data 2007, 1, 3. [Google Scholar] [CrossRef]
- Li, N.; Ti, N. T-closeness: Privacy beyond K-anonymity and L-diversity. In Proceedings of the Conference on Data Engineering, Istanbul, Turkey, 15–20 April 2007. [Google Scholar]
- Domingo-Ferrer, J.; Soria-Comas, J. From t-Closeness to differential privacy and vice versa in data anonymization. Knowl. Based Syst. 2015, 74, 151–158. [Google Scholar] [CrossRef] [Green Version]
- Chawla, S.; Dwork, C.; McSherry, F.; Smith, A.; Wee, H. Toward privacy in public databases. In Proceedings of the Theory of Cryptography Conference, Cambridge, MA, USA, 10–12 February 2005; pp. 363–385. [Google Scholar]
- Zhang, Q.; Koudas, N.; Srivastava, D.; Yu, T. Aggregate query answering on anonymized tables. In Proceedings of the International Conference on Data Engineering, Istanbul, Turkey, 15–20 April 2007; pp. 116–125. [Google Scholar]
- Aggarwal, C.C. On K-anonymity and the curse of dimensionality. In Proceedings of the International Conference on Very Large Data Bases, Trondheim, Norway, 30 August–2 September 2005; pp. 901–909. [Google Scholar]
- Dwork, C.; Roth, A. The algorithmic foundations of differential privacy. Found. Trends Theor. Comput. Sci. 2014, 9, 211–407. [Google Scholar] [CrossRef]
- Dwork, C.; Kenthapadi, K.; McSherry, F.; Mironov, I.; Naor, M. Our data, ourselves: Privacy via distributed noise generation. In Proceedings of the International Conference on the Theory and Applications of Cryptographic Techniques, St. Petersburg, Russia, 28 May–1 June 2006; pp. 486–503. [Google Scholar]
- Kearns, M.; Pai, M.; Roth, A.; Ullman, J. Mechanism design in large games: Incentives and privacy. In Proceedings of the Conference on Innovations in Theoretical Computer Science, Princeton, NJ, USA, 12–14 January 2014; pp. 403–410. [Google Scholar]
- Andrés, M.E.; Bordenabe, N.E.; Chatzikokolakis, K.; Palamidessi, C. Geo-indistinguishability: Differential privacy for location-based systems. In Proceedings of the ACM SIGSAC Conference on Computer and Communications Security, Berlin, Germany, 4–8 November 2013; pp. 901–914. [Google Scholar]
- Mironov, I.; Pandey, O.; Reingold, O.; Vadhan, S. Computational differential privacy. In Proceedings of the International Cryptology Conference, Santa Barbara, CA, USA, 16–20 August 2009; pp. 126–142. [Google Scholar]
- Wu, Y.; Xu, W.; Huang, H.; Huang, J. Bayesian Posterior-Based Winter Wheat Yield Estimation at the Field Scale through Assimilation of Sentinel-2 Data into WOFOST Model. Remote Sens. 2022, 14, 3727. [Google Scholar] [CrossRef]
- Du Pin Calmon, F.; Fawaz, N. Privacy against statistical inference. In Proceedings of the Allerton Conference on Communication, Control, and Computing, Monticello, IL, USA, 1–5 October 2012; pp. 1401–1408. [Google Scholar]
- Shannon, C.E. A mathematical theory of communication. Bell Syst. Tech. J. 1948, 27, 379–423. [Google Scholar] [CrossRef] [Green Version]
- Merugu, S.; Ghosh, J. Privacy-preserving distributed clustering using generative models. In Proceedings of the IEEE International Conference on Data Mining, Melbourne, FL, USA, 19–22 November 2003; pp. 211–218. [Google Scholar]
- Julien, F.; Raya, M.; Felegyhazi, M.; Papadimitratos, P. Mix-Zones for location privacy in vehicular networks. In Proceedings of the ACM Workshop on Wireless Networking for Intelligent Transportation Systems, Vancouver, CB, Canada, 14 August 2007. [Google Scholar]
- Agrawal, D.; Aggarwal, C. On the design and quantification of privacy preserving data mining algorithms. In Proceedings of the ACM SIGMOD-SIGACT-SIGART Symposium on Principles of Database Systems, Santa Barbara, CA, USA, 1 May 2001; pp. 247–255. [Google Scholar]
- Lin, Z.; Hewett, M.; Altman, R.B. Using binning to maintain confidentiality of medical data. In Proceedings of the AMIA Symposium, San Antonio, TX, USA, 9–13 November 2002; Volume 454. [Google Scholar]
- Evfimievski, A.; Srikant, R.; Agrawal, R.; Gehrke, J. Privacy preserving mining of association rules. Inf. Syst. 2004, 29, 343–364. [Google Scholar] [CrossRef]
- Rastogi, V.; Suciu, D.; Hong, S. The boundary between privacy and utility in data publishing. In Proceedings of the International Conference on Very Large Data Bases, Vienna, Austria, 23–27 September 2007; pp. 531–542. [Google Scholar]
- Nergiz, M.E.; Atzori, M.; Clifton, C. Hiding the presence of individuals from shared databases. In Proceedings of the ACM SIGMOD International Conference on Management of Data, Beijing, China, 11–14 June 2007; pp. 665–676. [Google Scholar]
- Oliveira, S.R.M.; Zaiane, O.R. Privacy preserving frequent itemset mining. In Proceedings of the IEEE International Conference on Privacy, Security and Data Mining, Maebashi City, Japan, 9 December 2002. [Google Scholar]
- Shokri, R.; Theodorakopoulos, G.; Le Boudec, J.; Hubaux, J. Quantifying location privacy. In Proceedings of the IEEE Symposium on Security and Privacy, Oakland, CA, USA, 22–25 May 2011; pp. 247–262. [Google Scholar]
- Kantarcioglu, M.; Jin, J.; Clifton, C. When do data mining results violate privacy? In Proceedings of the CM SIGKDD International Conference on Knowledge Discovery and Data Mining, Seattle, Washington, DC, USA, 22–25 August 2004; pp. 599–604. [Google Scholar]
- Zhai, J.; Qi, J.; Zhang, S. Imbalanced data classification based on diverse sample generation and classifier fusion. Int. J. Mach. Learn. Cybern. 2022, 13, 735–750. [Google Scholar] [CrossRef]
- Cheng, R.; Zhang, Y.; Bertino, E.; Prabhakar, S. Preserving user location privacy in mobile data management infrastructures. In Proceedings of the International Workshop on Privacy Enhancing Technologies, Cambridge, UK, 28–30 June 2006; pp. 393–412. [Google Scholar]
- Ardagna, C.A.; Cremonini, M.; Damiani, E.; Di Vimercati, S.; Samarati, P. Location privacy protection through obfuscation-based techniques. In Proceedings of the IFIP Annual Conference on Data and Applications Security and Privacy, Redondo Beach, CA, USA, 8–11 July 2007; pp. 47–60. [Google Scholar]
- Sampigethaya, K.; Huang, L.; Li, M.; Poovendran, R.; Matsuura, K.; Sezaki, K. CARAVAN: Providing Location Privacy for VANET; Technical Report; Department of Electrical Engineering, Washington University: Seattle, WA, USA, 2005. [Google Scholar]
- Hoh, B.; Gruteser, M.; Xiong, H.; Alrabady, A. Preserving privacy in GPS traces via uncertainty-aware path cloaking. In Proceedings of the ACM Conference on Computer and Communications Security, Alexandria, VI, USA, 28 October 2007; pp. 161–171. [Google Scholar]
- Polar H10 Heart Rate Sensor. 2022. Available online: https://www.polar.com/us-en/products (accessed on 27 May 2022).
- Azeez, N.A.; Van der Vyver, C. Security and privacy issues in e-health cloud-based system: A comprehensive content analysis. Egypt. Inform. J. 2019, 20, 97–108. [Google Scholar] [CrossRef]


{kind=link}
| Scientific Literature Source | Source Type | Public URL |
|---|---|---|
| Science Direct-Elsevier | Digital library | Science Direct (http://www.sciencedirect.com/, accessed on 23 December 2022) |
| Scopus | Search engine | Scopus (http://www.scopus.com/, accessed on 23 December 2022) |
| IEEE Xplore | Digital library | IEEE Xplore (http://ieeexplore.ieee.org/Xplore/home.jsp, accessed on 23 December 2022) |
| ACM Digital library | Digital library | ACM Digital library (http://dl.acm.org/dl.cfm, accessed on 23 December 2022) |
| Web of science | Search engine | Web of science (https://www.webofknowledge.com/, accessed on 23 December 2022) |
| Wiley online library | Digital library | Wiley online library (https://onlinelibrary.wiley.com/, accessed on 23 December 2022) |
| Google Scholar | Search engine | Google Scholar (https://scholar.google.ro/, accessed on 23 December 2022) |
| Sensors | Digital library | MDPI Sensors Journal https://www.mdpi.com/journal/sensors, accessed on 23 December 2022) |
| Springer | Digital library | Springer digital library (https://www.springer.com/, accessed on 23 December 2022) |
| ResearchGate | Scientific social networking | ResearchGate (https://www.researchgate.net/, accessed on 23 December 2022) |
| Edinburgh library database | Digital library | Edinburgh library database (https://my.napier.ac.uk/Library/, accessed on 23 December 2022) |
| Inclusion Criteria |
|---|
| Papers should be indexed by at least one of the presented scientific paper sources. |
| Contributions are reported in the period 2010–2022, while relevant older historic papers are also considered. |
| Papers should fulfill at least one of the search terms, as designated by the title, abstract, and keywords of this survey paper. |
| Contributions should be published in indexed journals, conference proceedings, or mainstream technical journals. |
| Surveyed papers should clearly address and answer defined research questions. |
| A search that considers title, abstract, and full text is sufficient. |
| Exclusion Criteria |
|---|
| Papers that are not written in English. |
| Duplicated papers, which are found using more than one of the specified scientific literature sources. |
| Papers with full texts that are impossible to access. |
| Papers that are only marginally relevant to the usage of data-driven soft sensors, related deep learning models, and data anonymization techniques. |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bocu, R.; Bocu, D.; Iavich, M. An Extended Review Concerning the Relevance of Deep Learning and Privacy Techniques for Data-Driven Soft Sensors. Sensors 2023, 23, 294. https://doi.org/10.3390/s23010294
Bocu R, Bocu D, Iavich M. An Extended Review Concerning the Relevance of Deep Learning and Privacy Techniques for Data-Driven Soft Sensors. Sensors. 2023; 23(1):294. https://doi.org/10.3390/s23010294
Chicago/Turabian StyleBocu, Razvan, Dorin Bocu, and Maksim Iavich. 2023. "An Extended Review Concerning the Relevance of Deep Learning and Privacy Techniques for Data-Driven Soft Sensors" Sensors 23, no. 1: 294. https://doi.org/10.3390/s23010294