
Automatic Speech Recognition Performance Improvement for Mandarin Based on Optimizing Gain Control Strategy



Abstract
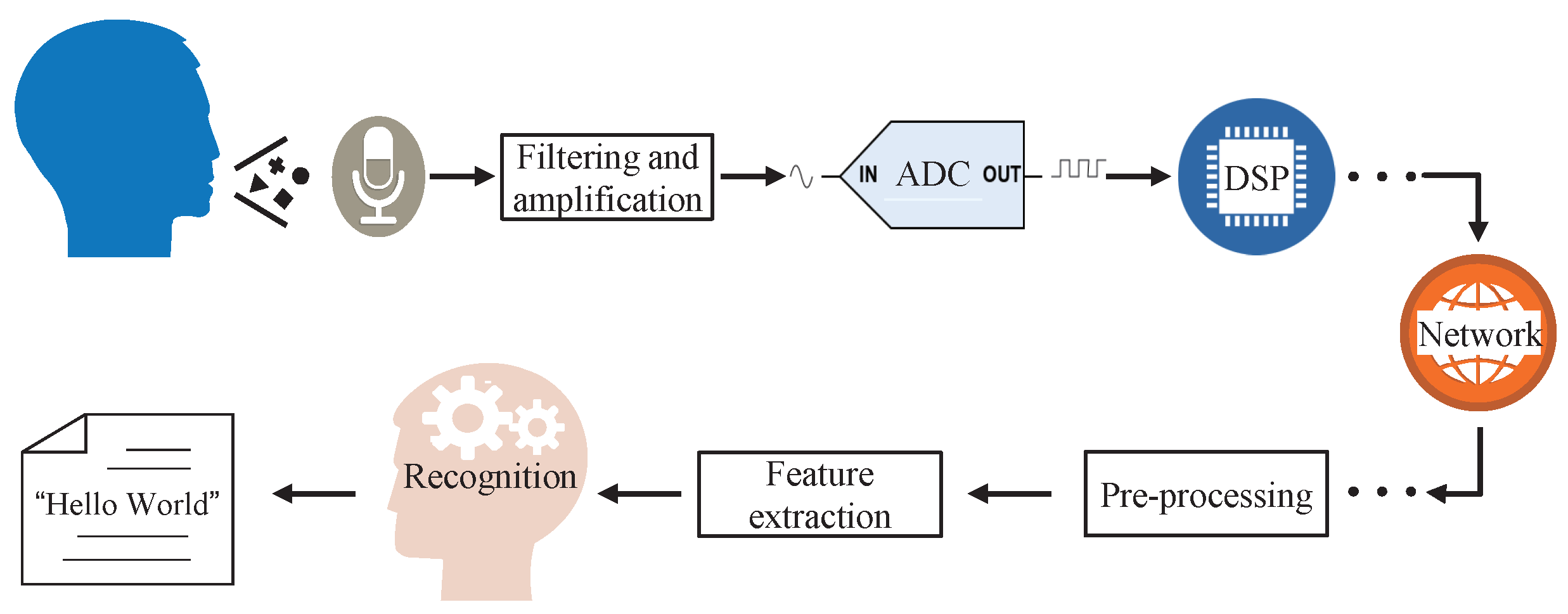
:1. Introduction
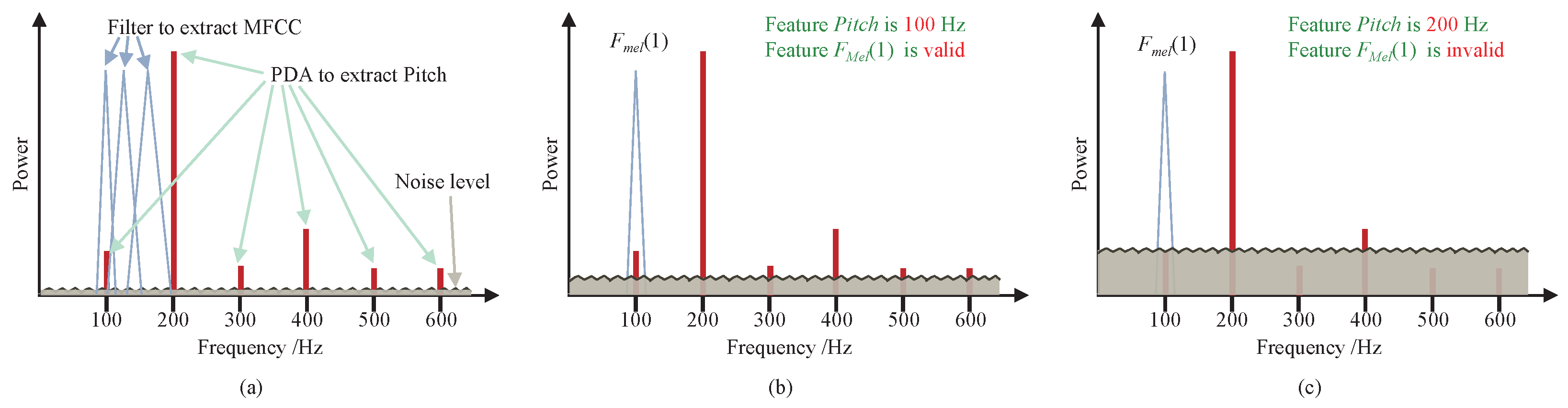
2. Related Work
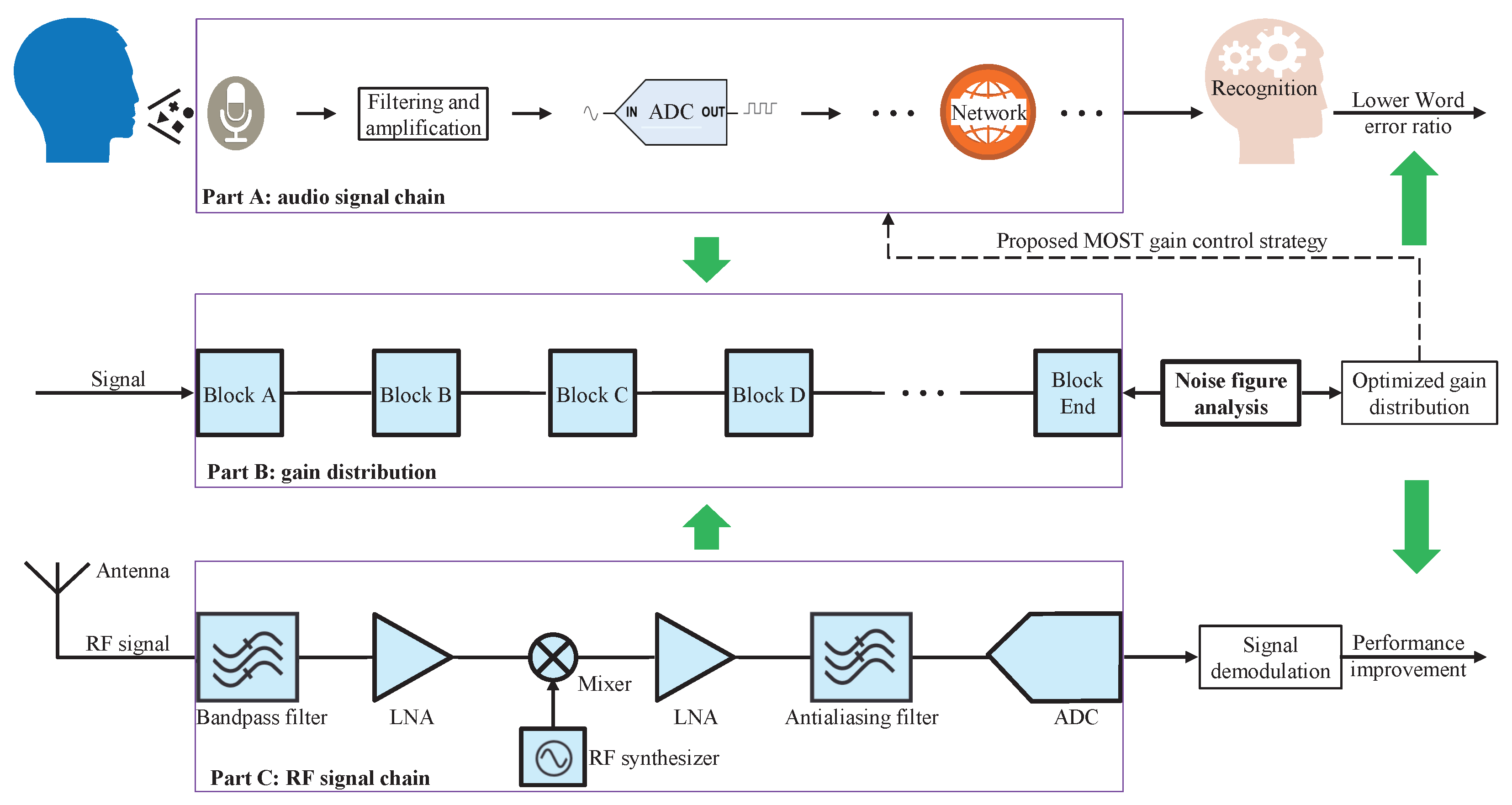
3. Proposed Gain Control Strategy and Modeling Analysis
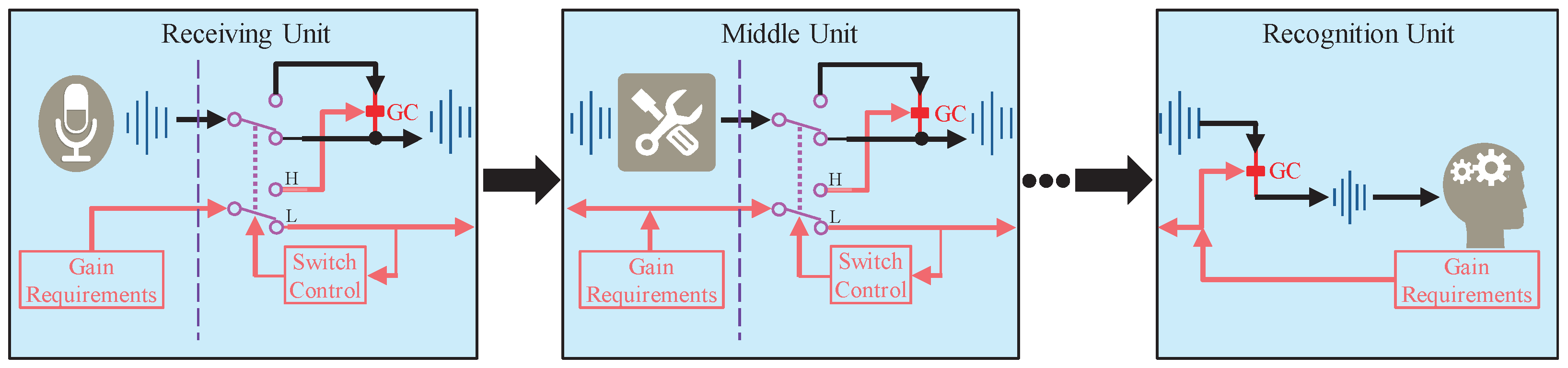
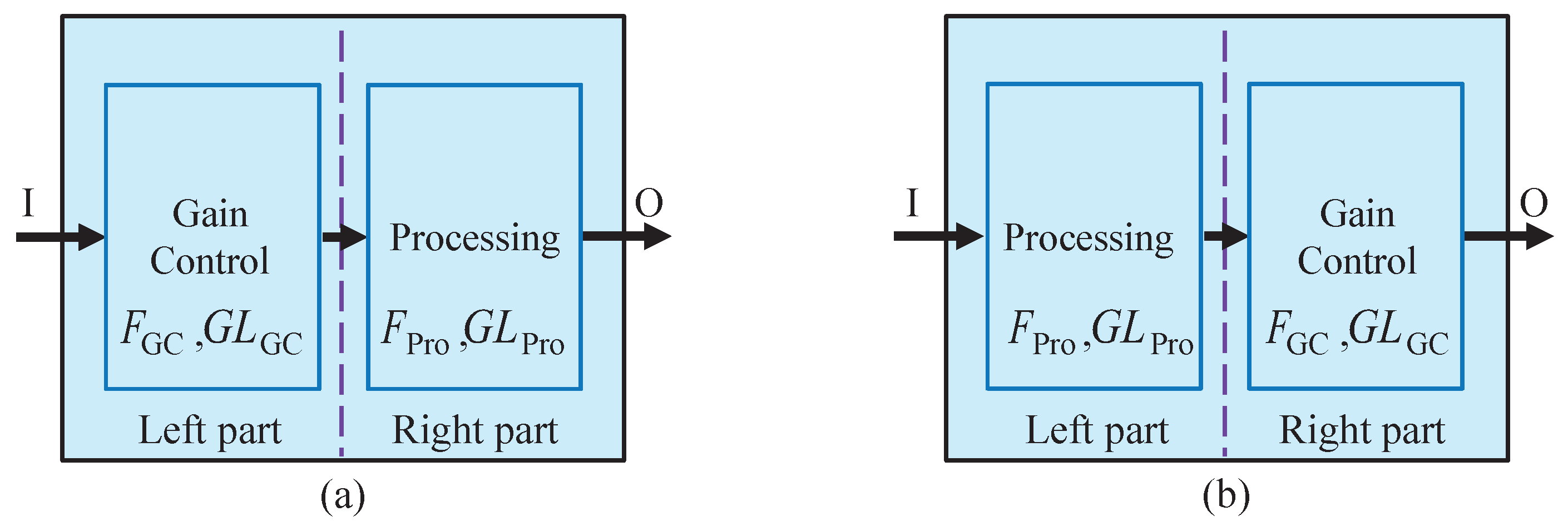
3.1. Proposed Gain Control Strategy
- From the perspective of different units, assume that a gain of −3 dB is required in the recognition unit. For the current gain control strategy, the execution position of the gain of −3 dB is unconstrained, and it can be performed at the output of the receiving unit, or −1 dB at each middle unit, etc. On the contrary, the proposed MOST gain control strategy means that the −3 dB gain must be performed at the output of the last middle unit;
- From the perspective of a specific unit, assume that the middle unit of pre-processing needs a −2 dB gain control. Ensuring the −2 dB gain control is only performed on this middle unit does not satisfy the constraint. Because this middle unit probably consists of many smaller software function units, the gain control also has an execution order among these smaller function units. Thus, the −2 dB gain control should be placed as close to the end of these smaller function units.
- Transmission channel for gain control commands represented by the arrow between units, which can be wired or wireless, together or independently;
- Gain control logic on the right side of the dotted line in each unit. The double pole double throw is critical, because it maps the switch control command into the corresponding gain control logic.
- Wait for a handshake signal at the input. If the handshake signal is received, return the ACK signal to the former unit;
- Send handshake signals periodically on the output and check for the ACK signal. If received, return the ACK signal to the switch control module.
3.2. Modeling of Gain Control in ASR Systems
3.3. Analysis and Proof
4. Experiment
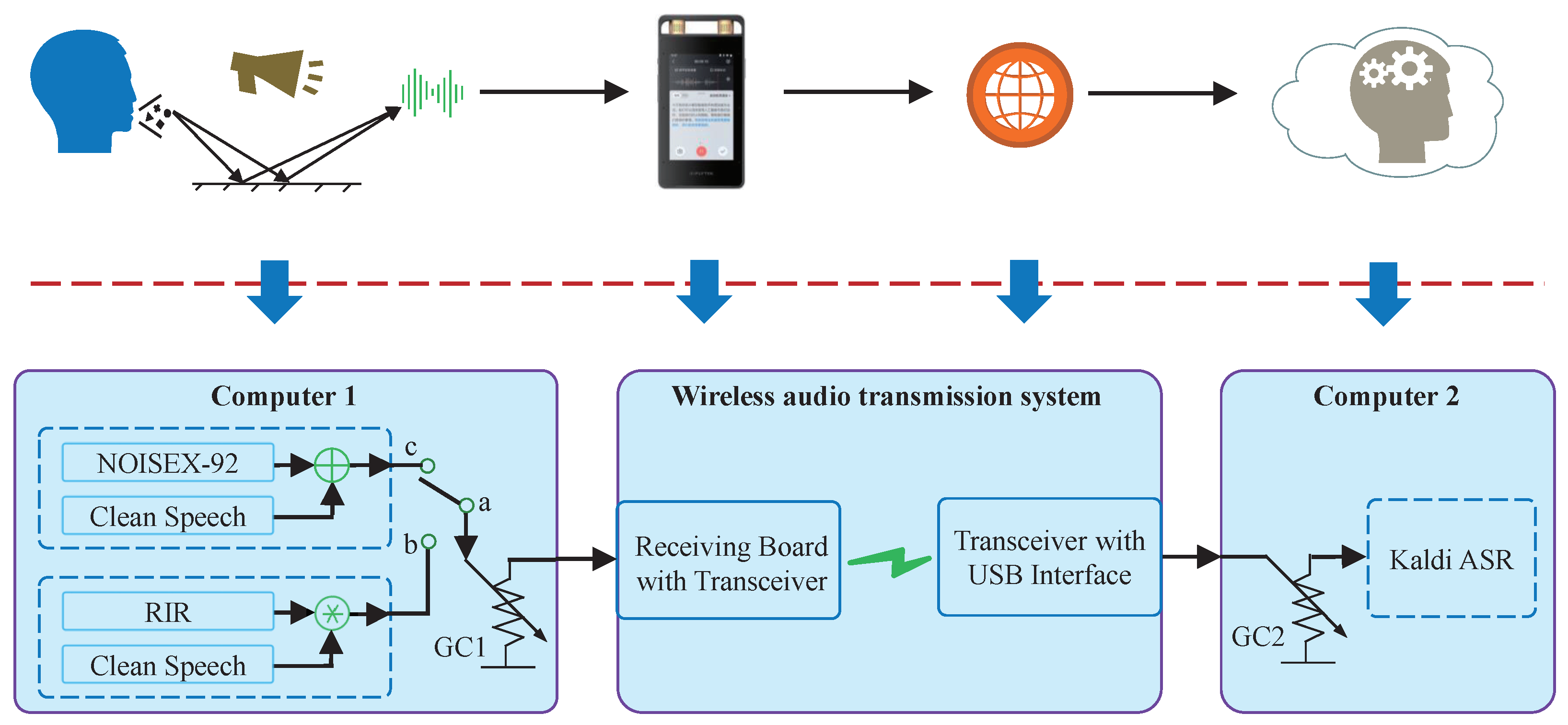
4.1. Experimental Setup Overview
- The test utterances were generated on computer 1 to make the reverberation degree and noise level of the experimental speech signal more controllable and quantitatively modified;
- The wireless audio transmission system contained a receiving board and a transceiver with a USB interface; the details are in Appendix A. The user-end device corresponded to the receiving board, within which, the filtering and other processing were integrated to simulate the actual noises induced by the hardware. The wireless transceiver was designed to simulate the actual network transmission of the voice recorder;
- The ASR function in the cloud was simulated through a locally installed Kaldi ASR module on computer 2.
4.1.1. ASR Module and Dataset Selection
4.1.2. Noise Setup
4.1.3. Reverberation Setup
4.2. Results and Analysis
4.2.1. WER Analysis
- The proposed MOST gain control strategy showed advantages over the current strategies under the 18 sets of comparison test conditions in Figure 8 and Figure 9, except for the penultimate set indicated by the red circle in the right down position of Figure 9. The abnormal results corresponded to the conditions of RT60 = 1 s, d = 4 m, and the gain setting of −3 dB, within which the proposed MOST gain control strategy was slightly higher by 1%. The abnormal WER results exceeded 70%. The reason is likely that such a harsh reverberation condition is close to the working limitation of the experimental ASR system; thus, the WER performance of the ASR system is no longer positively related to distance;
- For a certain noise type shown in Figure 8, the power ratio of the clean speech to the selected noise is negatively correlated to the performance improvement of the proposed MOST gain control strategy.
4.2.2. Absolute WER Reduction Analysis
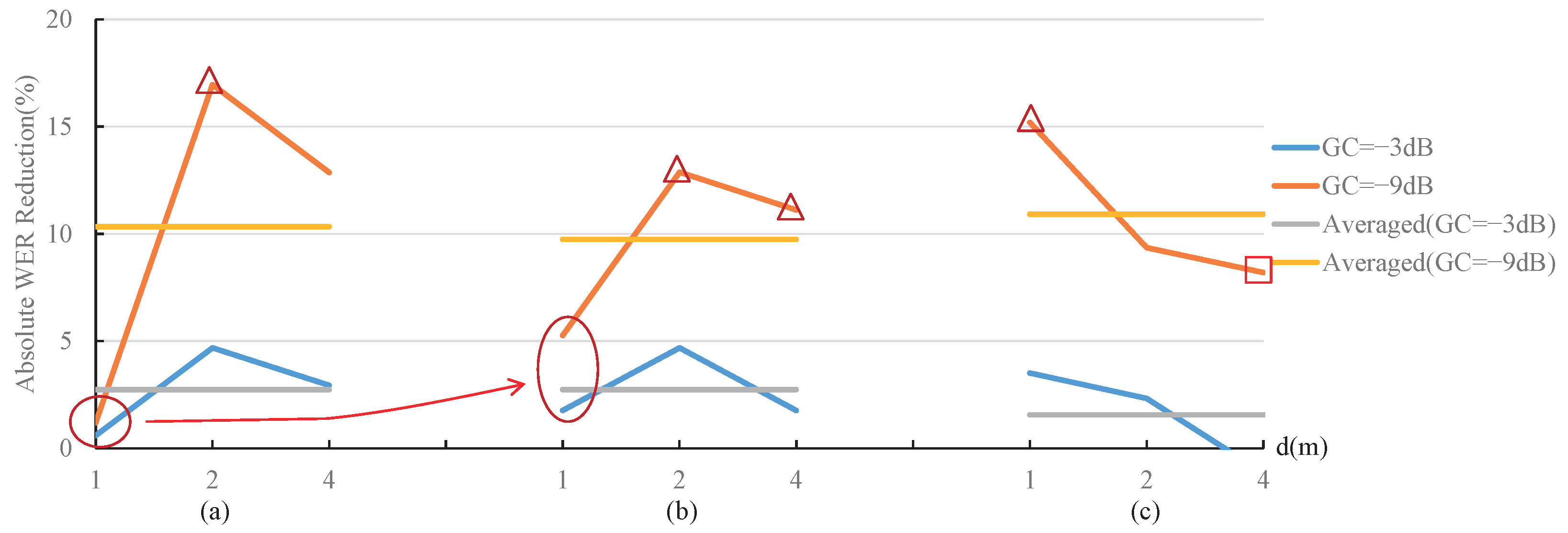
- The gain control strategy dramatically influences the performance improvement degree of the proposed MOST gain control strategy, and the noise type, signal-to-noise ratio, RT60, and distance factors have a relatively small influence. The average performance improvement of the proposed MOST gain control strategy was around 10% under the −9 dB gain condition, while it was about 2% under −3 dB gain condition;
- The performance improvement degree of the proposed MOST gain control strategy is rather effective under a lower gain. In the case of −9 dB gain, 8 of the 18 sets of the proposed MOST gain control strategy offered a WER reduction of more than 10%, as shown with the △ symbols in Figure 10 and Figure 11;
- The proposed MOST gain control strategy has a smaller performance improvement if the utterances are less affected by the noises or reverberations. (1) The WER reduction is relatively small for the test utterances with high SNRs, corresponding to the two circle positions in Figure 10. The reason is that such a high SNR provides enough features for the test utterance signal to be recognized by ASR; thus, the current strategies and our MOST gain control strategy both obtained better WER results, as shown in the two right sets of results in Figure 8b,c. (2) The WER reduction is not obvious under weak reverberation conditions, as shown in Figure 11. When the distance is very close (1 m) and RT60 is small (0.5 s) (corresponding to the two circle positions in Figure 11), the improvement effect is not apparent; therefore, all strategies can obtain good WER results, as shown in the two left sets of results in Figure 9a,b;
- The performance improvement degree of the proposed MOST gain control strategy becomes evident as the reverberation condition becomes severe. The increase in the vertical distance of the circles in Figure 11 shows that, as increasing the adverse effects of the environment become more serious, the improvement effect of the proposed MOST gain control strategy gradually emerges;
- The performance improvement degree of the proposed MOST gain control strategy decreases under extremely severe reverberation conditions. When the distance is extremely long (4 m) and RT60 is large (1.0 s) (corresponding to the position of the box in Figure 11), the ASR system can hardly work normally, so the WER results of the current strategies and MOST gain control strategy are both very poor, as shown in the two right sets of the results in Figure 9c.
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| ASR | automatic speech recognition |
| ACK | acknowledgement |
| ASRC | asynchronous sampling rate converter |
| AM | acoustic model |
| ADC | analog to digital converter |
| ANN | artificial neural network |
| aptX | audio delivers premium sound wirelessly via Bluetooth |
| aptX HD | aptX High Definition |
| aptX LL | aptX Low Latency |
| BT SBC | Bluetooth subband codec |
| DSP | digital signal processor/processing |
| DNN | deep neural network |
| FNN | fuzzy neural network |
| HMM | hidden Markov model |
| GUI | graphical user interface |
| GC | gain control |
| LM | language model |
| LNA | low noise amplifier |
| LDAC | a proprietary audio coding technology developed by Sony |
| MCU | micro control unit |
| MFCC | Mel-frequency cepstral coefficients |
| ML | machine learning |
| MOST | maximized original signal transmission |
| MUX | multiplexer |
| mic | microphone |
| NW | network |
| PP | preprocessing |
| PM | pronunciation model |
| RF | radio frequency |
| RNN | Recurrent neural network |
| RIR | room impulse responses |
| RT60 | metric reverberation time 60 |
| SVM | support vector machines |
| SOC | System on chip |
| spk | speaker |
| TDNN | time delay neural network |
| THCHS-30 | an open Chinese speech database published at Tsinghua University |
| THD + N | total harmonic distortion and noise |
| VUI | voice user interface |
| WER | word error rate |
| d | speaker to microphone distance |
| F | noise figure |
| noise figure of ideal gain control | |
| noise figure of actual gain control | |
| noise figure of gain control part of the basic unit model | |
| overall noise figure of ASR system | |
| noise figure of processing part of the basic unit model | |
| noise figure of left part of 1th, 2th, …basic unit model | |
| noise figure of right part of 1th, 2th, …basic unit model | |
| gain requirement in logarithmic form | |
| Linear gain | |
| linear gain of gain control part of basic unit model | |
| linear gain of processing part of basic unit model | |
| linear gain of left part of 1th, 2th, …basic unit model | |
| linear gain of right part of 1th, 2th, …basic unit model | |
| power of speech signal | |
| power of noise | |
| power of the noise floor | |
| Signal to noise ratio | |
| signal to noise ratio at the input port | |
| signal to noise ratio at the output port | |
| absolute WER reduction | |
| WER corresponds to current gain control strategy | |
| WER corresponds to proposed MOST gain control strategy |
Appendix A. Experimental Hardware
- The wireless audio transmission system demonstrates an application example of the proposed MOST gain control strategy;
- Parts of the wireless audio transmission system are adopted to simulate the user-end device in Figure 7 and transmission parts in the ASR experiment.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
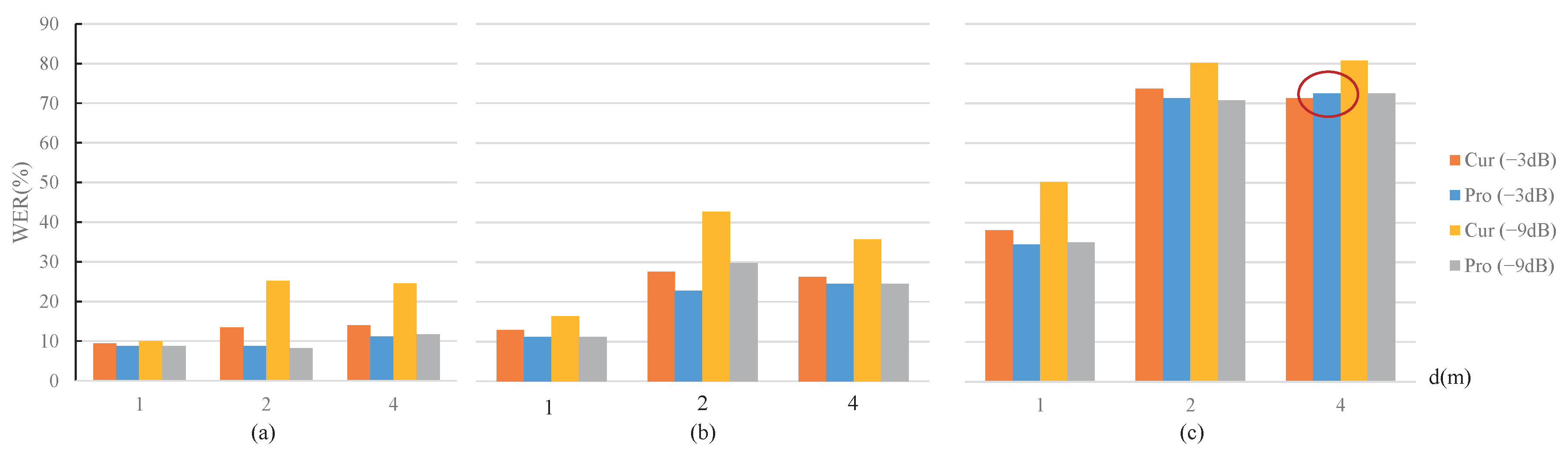{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Index | BT SBC | aptX | aptX HD | aptX LL | LDAC | Ours’ |
|---|---|---|---|---|---|---|
| Data rate/Mbps | 0.328 | 0.384/0.325 | 0.576 | 0.352 | 0.99 | 5.0 |
| Latency/ms | 220 | 130 | 220 | 40 | >80 | 10.7–40 |
Appendix B. Experimental Reverberation Conditions

References
- Wang, Z. Future Challenges in the Next Generation of Voice User Interface. In Proceedings of the 2020 International Conference on Computing and Data Science (CDS), Stanford, CA, USA, 1–2 August 2020; pp. 191–193. [Google Scholar] [CrossRef]
- Abdelhamid, A.A.; Alotaibi, S.R. Robust voice user interface for internet-of-things. J. Intell. Fuzzy Syst. 2021, 41, 5887–5902. [Google Scholar] [CrossRef]
- Aloufi, R.; Haddadi, H.; Boyle, D. Privacy-preserving voice analysis via disentangled representations. In Proceedings of the 2020 ACM SIGSAC Conference on Cloud Computing Security Workshop, Virtual Event, USA, 9 November 2020; pp. 1–14. [Google Scholar]
- Gondala, S.; Verwimp, L.; Pusateri, E.; Tsagkias, M.; Van Gysel, C. Error-driven pruning of language models for virtual assistants. In Proceedings of the ICASSP 2021—2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Toronto, ON, Canada, 6–11 June 2021; pp. 7413–7417. [Google Scholar]
- Kashevnik, A.; Lashkov, I.; Axyonov, A.; Ivanko, D.; Ryumin, D.; Kolchin, A.; Karpov, A. Multimodal Corpus Design for Audio-Visual Speech Recognition in Vehicle Cabin. IEEE Access 2021, 9, 34986–35003. [Google Scholar] [CrossRef]
- Yu, D.; Deng, L. Automatic Speech Recognition, 1st ed.; Springer: New York, NY, USA, 2016. [Google Scholar]
- Huang, C.H.; Wen, C.; Chang, K.C.; Hsiao, C.L. Design of smart volume controller for televisions. IEEE Trans. Consum. Electron. 2013, 59, 623–628. [Google Scholar] [CrossRef]
- Felber, F. An automatic volume control for preserving intelligibility. In Proceedings of the 34th IEEE Sarnoff Symposium, Princeton, NJ, USA, 3–4 May 2011; IEEE: New York, NY, USA, 2011; pp. 1–5. [Google Scholar] [CrossRef] [Green Version]
- Bui, H.D.; Chong, N.Y. Autonomous Speech Volume Control for Social Robots in a Noisy Environment Using Deep Reinforcement Learning. In Proceedings of the 2019 IEEE International Conference on Robotics and Biomimetics (ROBIO), Dali, China, 6–8 December 2019; IEEE: New York, NY, USA, 2019; pp. 1263–1268. [Google Scholar] [CrossRef]
- Yoon, D.; Chen, N.; Guimbretière, F.; Sellen, A. RichReview: Blending Ink, Speech, and Gesture to Support Collaborative Document Review; Association for Computing Machinery: New York, NY, USA, 2014; pp. 481–490. [Google Scholar] [CrossRef]
- Sidner, C. Creating interfaces founded on principles of discourse communication and collaboration. In More Than Screen Deep: Toward Every-Citizen Interfaces to the Nation’s Information Infrastructure; National Research Council, Ed.; National Academies Press: Washington, DC, USA, 1997; pp. 315–321. [Google Scholar]
- Kaur, J.; Singh, A.; Kadyan, V. Automatic speech recognition system for tonal languages: State-of-the-art survey. Arch. Comput. Methods Eng. 2021, 28, 1039–1068. [Google Scholar] [CrossRef]
- Tsiakoulis, P.; Potamianos, A.; Dimitriadis, D. Spectral moment features augmented by low order cepstral coefficients for robust ASR. IEEE Signal Process. Lett. 2010, 17, 551–554. [Google Scholar] [CrossRef]
- Bai, Y.; Yi, J.; Tao, J.; Tian, Z.; Wen, Z.; Zhang, S. Fast End-to-End Speech Recognition Via Non-Autoregressive Models and Cross-Modal Knowledge Transferring From BERT. IEEE/ACM Trans. Audio Speech Lang. Process. 2021, 29, 1897–1911. [Google Scholar] [CrossRef]
- Deng, L.; O’Shaughnessy, D. Speech Recognition. In Speech Processing; CRC Press: Boca Raton, FL, USA, 2018; pp. 459–468. [Google Scholar]
- Schröter, H.; Rosenkranz, T.; Escalante-B, A.N.; Maier, A. LACOPE: Latency-Constrained Pitch Estimation for Speech Enhancement. In Proceedings of the Interspeech 2021, Brno, Czechia, 30 August 2021; pp. 656–660. [Google Scholar]
- Ambeth Kumar, V.D.; Malathi, S.; Kumar, A.; Veluvolu, K.C. Active Volume Control in Smart Phones Based on User Activity and Ambient Noise. Sensors 2020, 20, 4117. [Google Scholar] [CrossRef]
- Petkov, P.N.; Stylianou, Y. Adaptive gain control and time warp for enhanced speech intelligibility under reverberation. In Proceedings of the 2017 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), New Orleans, LA, USA, 5–9 March 2017; IEEE: New York, NY, USA, 2017; pp. 691–695. [Google Scholar] [CrossRef]
- Heitkamper, P.; Walker, M. Adaptive gain control for speech quality improvement and echo suppression. In Proceedings of the 1993 IEEE International Symposium on Circuits and Systems, Chicago, IL, USA, 3–6 May 1993; IEEE: New York, NY, USA, 1993; pp. 455–458. [Google Scholar] [CrossRef]
- Braun, S.; Habets, E.A. Linear prediction-based online dereverberation and noise reduction using alternating Kalman filters. IEEE/ACM Trans. Audio Speech Lang. Process. 2018, 26, 1119–1129. [Google Scholar] [CrossRef]
- Dietzen, T.; Doclo, S.; Moonen, M.; van Waterschoot, T. Integrated sidelobe cancellation and linear prediction Kalman filter for joint multi-microphone speech dereverberation, interfering speech cancellation, and noise reduction. IEEE/ACM Trans. Audio Speech Lang. Process. 2020, 28, 740–754. [Google Scholar] [CrossRef] [Green Version]
- Motchenbacher, C.D.; Connelly, J.A. Low Noise Electronic System Design, 1st ed.; Wiley: New York, NY, USA, 1993. [Google Scholar]
- Green, S. Increasing ADC Dynamic Range with Channel Summation; Technical Report; Cirrus Logic, Inc.: Austin, TX, USA, 2008. [Google Scholar]
- Huang, C.M.; Lin, C.W.; Chuang, C.Y. A multilayered audiovisual streaming system using the network bandwidth adaptation and the two-phase synchronization. IEEE Trans. Multimed. 2009, 11, 797–809. [Google Scholar] [CrossRef]
- Amir, Y.; Danilov, C.; Goose, S.; Hedqvist, D.; Terzis, A. An overlay architecture for high-quality VoIP streams. IEEE Trans. Multimed. 2006, 8, 1250–1262. [Google Scholar] [CrossRef] [Green Version]
- Simrock, S.; Geng, Z. Noise in RF Systems. In Low-Level Radio Frequency Systems; Springer International Publishing: Cham, Switzerland, 2022; pp. 183–264. [Google Scholar] [CrossRef]
- Yang, J.; Hilmes, P.; Adair, B.; Krueger, D.W. Deep learning based automatic volume control and limiter system. In Proceedings of the 2017 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), New Orleans, LA, USA, 5–9 March 2017; IEEE: New York, NY, USA, 2017; pp. 2177–2181. [Google Scholar]
- Prabhavalkar, R.; Alvarez, R.; Parada, C.; Nakkiran, P.; Sainath, T.N. Automatic gain control and multi-style training for robust small-footprint keyword spotting with deep neural networks. In Proceedings of the 2015 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), South Brisbane, QLD, Australia, 19–24 April 2015; IEEE: New York, NY, USA, 2015; pp. 4704–4708. [Google Scholar] [CrossRef]
- Friis, H.T. Noise figures of radio receivers. Proc. IRE 1944, 32, 419–422. [Google Scholar] [CrossRef]
- Dionelis, N.; Brookes, M. Modulation-domain Kalman filtering for monaural blind speech denoising and dereverberation. IEEE/ACM Trans. Audio Speech Lang. Process. 2019, 27, 799–814. [Google Scholar] [CrossRef] [Green Version]
- van Waterschoot, T.; Defraene, B.; Diehl, M.; Moonen, M. Embedded optimization algorithms for multi-microphone dereverberation. In Proceedings of the 21st European Signal Processing Conference (EUSIPCO 2013), Marrakech, Morocco, 9–13 September 2013; IEEE: New York, NY, USA, 2013; pp. 1–5. [Google Scholar]
- Malik, M.; Malik, M.K.; Mehmood, K.; Makhdoom, I. Automatic speech recognition: A survey. Multimed. Tools Appl. 2021, 80, 9411–9457. [Google Scholar] [CrossRef]
- Khan, A.; Sohail, A.; Zahoora, U.; Qureshi, A.S. A survey of the recent architectures of deep convolutional neural networks. Artif. Intell. Rev. 2020, 53, 5455–5516. [Google Scholar] [CrossRef] [Green Version]
- Shahamiri, S.R.; Salim, S.S.B. Real-time frequency-based noise-robust Automatic Speech Recognition using Multi-Nets Artificial Neural Networks: A multi-views multi-learners approach. Neurocomputing 2014, 129, 199–207. [Google Scholar] [CrossRef]
- Makino, T.; Liao, H.; Assael, Y.; Shillingford, B.; Garcia, B.; Braga, O.; Siohan, O. Recurrent Neural Network Transducer for Audio-Visual Speech Recognition. In Proceedings of the 2019 IEEE Automatic Speech Recognition and Understanding Workshop (ASRU), Singapore, 14–18 December 2019; pp. 905–912. [Google Scholar] [CrossRef] [Green Version]
- Toshniwal, S.; Sainath, T.N.; Weiss, R.J.; Li, B.; Moreno, P.; Weinstein, E.; Rao, K. Multilingual Speech Recognition with a Single End-to-End Model. In Proceedings of the 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, AB, Canada, 15–20 April 2018; pp. 4904–4908. [Google Scholar] [CrossRef] [Green Version]
- O’ Brien, M.G.; Derwing, T.M.; Cucchiarini, C.; Hardison, D.M.; Mixdorff, H.; Thomson, R.I.; Strik, H.; Levis, J.M.; Munro, M.J.; Foote, J.A.; et al. Directions for the future of technology in pronunciation research and teaching. J. Second. Lang. Pronunciation 2018, 4, 182–207. [Google Scholar] [CrossRef] [Green Version]
- Tejedor-García, C.; Cardeñoso-Payo, V.; Escudero-Mancebo, D. Automatic Speech Recognition (ASR) Systems Applied to Pronunciation Assessment of L2 Spanish for Japanese Speakers. Appl. Sci. 2021, 11, 6695. [Google Scholar] [CrossRef]
- Nagata, Y.; Fujioka, T.; Abe, M. Speech enhancement based on auto gain control. IEEE Trans. Audio Speech Lang. Process. 2005, 14, 177–190. [Google Scholar] [CrossRef] [Green Version]
- Stolbov, M.; Koval, S.; Khitrov, M. Parametric Multi-Band Automatic Gain Control for Noisy Speech Enhancement. In Proceedings of the Eighth European Conference on Speech Communication and Technology, Geneva, Switzerland, 1 September 2003; pp. 561–564. [Google Scholar]
- Nielsen, J.K.; Jensen, T.L.; Jensen, J.R.; Christensen, M.G.; Jensen, S.H. Fast fundamental frequency estimation: Making a statistically efficient estimator computationally efficient. Signal Process. 2017, 135, 188–197. [Google Scholar] [CrossRef] [Green Version]
- Heller, E.J. Why You Hear What You Hear: An Experiential Approach to Sound, Music, and Psychoacoustics; Princeton University Press: Princeton, NJ, USA, 2013. [Google Scholar]
- Povey, D.; Ghoshal, A.; Boulianne, G.; Burget, L.; Glembek, O.; Goel, N.; Hannemann, M.; Motlicek, P.; Qian, Y.; Schwarz, P.; et al. The Kaldi speech recognition toolkit. In Proceedings of the IEEE 2011 Workshop on Automatic Speech Recognition and Understanding, Big Island, HI, USA, 11 December 2011; IEEE Signal Processing Society: New York, NY, USA, 2011. [Google Scholar]
- Wang, D.; Zhang, X. THCHS-30: A free Chinese speech corpus. arXiv 2015, arXiv:1512.01882. [Google Scholar]
- Varga, A.; Steeneken, H.J. Assessment for automatic speech recognition: II. NOISEX-92: A database and an experiment to study the effect of additive noise on speech recognition systems. Speech Commun. 1993, 12, 247–251. [Google Scholar] [CrossRef]
- Allen, J.B.; Berkley, D.A. Image method for efficiently simulating small-room acoustics. J. Acoust. Soc. Am. 1979, 65, 943–950. [Google Scholar] [CrossRef]











| Category | Reverberation | Noise | ||
|---|---|---|---|---|
| Gain (dB) | −3 | −9 | −3 | −9 |
| Averaged absolute WER reduction (%) | 2.3 | 10.3 | 1.1 | 9.0 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, D.; Wei, Y.; Zhang, K.; Ji, D.; Wang, Y. Automatic Speech Recognition Performance Improvement for Mandarin Based on Optimizing Gain Control Strategy. Sensors 2022, 22, 3027. https://doi.org/10.3390/s22083027
Wang D, Wei Y, Zhang K, Ji D, Wang Y. Automatic Speech Recognition Performance Improvement for Mandarin Based on Optimizing Gain Control Strategy. Sensors. 2022; 22(8):3027. https://doi.org/10.3390/s22083027
Chicago/Turabian StyleWang, Desheng, Yangjie Wei, Ke Zhang, Dong Ji, and Yi Wang. 2022. "Automatic Speech Recognition Performance Improvement for Mandarin Based on Optimizing Gain Control Strategy" Sensors 22, no. 8: 3027. https://doi.org/10.3390/s22083027