1. Introduction
In the context of distributed defense [
1], sensors are deployed in a decentralized manner. Multi-sensor collaborative scheduling is a multi-sensor resource management problem. Traditional multi-sensor scheduling research is often aimed at static problems. However, with the development of science and technology, the goal is gradually with the characteristics of high mobility, stealth and changeable tactics, the real battlefield is often complex and changeable, which makes the multi-sensor scheduling process more complicated.
Therefore, how to reasonably schedule multi-sensors in a dynamically changing battlefield and continuously detect and track targets with high precision has become a research hotspot.
In terms of the sensor scheduling model, Vikram et al. for example, used the hidden Markov principle to build a sensor network scheduling model for the target detection problem, and used stochastic dynamic programming to solve the optimal scheduling strategy [
2]. Atiyeh et al. used interactive multi-model and particle filter algorithms for maneuvering targets to solve the sensor scheduling selection problem in the target tracking process [
3]. Ying He et al. solved the sensor scheduling problem in the target tracking process by using the Monte Carlo sampling method based on the Markov decision principle [
4]. Wendong Xiao et al. saved energy consumption on the premise of ensuring target tracking accuracy, and proposed a new adaptive sensor scheduling method [
5]. In the process of studying sensor network scheduling, Bo Hu et al. proposed an approximate solution algorithm C-QMDP based on the POMDP model, which reduced the cumulative loss and online computation [
6]. Using POMDP and FISST theory, Wei Li et al. proposed a dual-sensor control scheme to maximize the overall utility of the monitoring system [
7]. For decentralized large-scale multi-target tracking under the RFS framework, Feng Lian et al. proposed a new sensor selection optimization algorithm based on the marginalized delta-generalized labeled multi-Bernoulli RFS to reduce the computational cost of sensor selection and the accuracy of MTT [
8]. Gongguo Xu et al. constructed a sensor scheduling model based on Bayesian theory, and transformed the sensor movement selection problem into a decision tree problem to obtain the optimal sensor combination and effectively solve the sensor scheduling problem [
9].
In terms of target tracking, the basic idea is to use the tracking filter algorithm to update the state of the system. At present, the commonly used filtering algorithms mainly include Kalman filter, extended Kalman filter, unscented Kalman filter, particle filter and their improved algorithms. For example, Xiaofei Zhang et al. used the Kalman filter based on the interactive multi-model to process dynamic tracking data, which has a stronger tracking adaptability than a single-model Kalman filter [
10]. Bo Lv et al. improved the extended Kalman filter by using innovation theory, an emerging orbit prediction model was built, which effectively reduced the error caused by noise and improved the prediction accuracy of the real-time motion state of the target [
11]. In different parts of the unscented Kalman filter algorithm, Bo Chen et al. used statistics and analysis principles to linearize the state estimation, which enhanced the ability to deal with nonlinear problems and improved the tracking effect of the algorithm [
12]. Jianyang Hu et al. used the particle swarm optimization algorithm to improve the particle degradation phenomenon, effectively improving the accuracy of target tracking [
13].
In terms of resource allocation, with the development of intelligent optimization algorithms, its applications in sensor scheduling problems are becoming more and more extensive. For example, for the sensor scheduling problem of target detection, Lei An et al. compared and analyzed the solution strategies of various intelligent optimization algorithms based on part of the objective Markov decision process, and proved the superiority of the intelligent optimization algorithm [
14]. Bans E et al. used a genetic algorithm for a policy search to solve the multi-agent planning problem under the partially observable Markov model [
15]. Bo Wang et al. proposed a sensor management method based on real-valued particle swarm optimization algorithm, which could perform sensor-target management more effectively [
16]. Ganlin Shan et al. proposed a sensor scheduling method for multi-target detection based on risk theory, and used the improved artificial bee colony algorithm to solve the scheme, which proved the feasibility of the model and the effectiveness of the algorithm [
17]. Xiaojuan Zhu et al. proposed an energy-minimizing dynamic task-scheduling algorithm. The improved ant colony algorithm was used to solve the problem, which effectively reduced the task allocation time and energy consumption [
18]. For high-threat targets, Yuqi Lan used the binary particle swarm optimization algorithm to solve the multi-sensor multi-target model, which effectively improved the allocation efficiency of sensor resources to targets with different threats [
19].
With the development of technologies such as 5G, 6G, and the Internet of Things (IoT), another idea is to improve the sensor communication level based on the existing model. By applying 5G, 6G and other technologies to sensor networks, the intelligence level, collaborative detection accuracy, and anti-jamming capabilities of sensor networks can be improved, and the energy consumption of the network can be reduced to achieve the purpose of optimizing operations. For example, Manzoor Ahmed et al. combined non-orthogonal multiple access (NOMA) with backscatter sensor communication (BSC) and connected them with IoT technology, and proposed a new IoT optimization framework, which optimized the power distribution and effectively improved the network performance under imperfect successive interference cancellation (SIC) [
20]. In the case of channel uncertainty, Asim Ihsan et al. proposed a two-stage alternating optimization algorithm to maximize the sensor network energy efficiency (EE) with low complexity by optimizing the transmit power of carrier emitter (CE) and the RCs of RSs [
21]. Under the conditions of future high and new technology, these ideas have reference significance for improving the task planning capability of sensor networks under complex conditions.
In distributed cooperative air defense operations, sensors are required to track targets continuously, accurately and quickly, and the scheduling process must be continuous, accurate and fast. Most of the existing research analyzes a certain aspect, which makes the performance of the model and algorithm not comprehensive, and it is difficult to meet the requirements of the battlefield for the model and algorithm, so it is difficult to truly adapt to the real battlefield environment.
Therefore, this paper proposes a distributed multi-sensor cooperative detection model based on the partially observable Markov decision process. The core of this paper is divided into three parts. The first part is the model. Because the target has complex uncertainties such as maneuvering and stealth, the sensors are often incompletely observed; at the same time, in the process of target detection, the scheduling strategy of the sensor at the current moment will affect the observation results of the sensor on the target, the observation results will affect the current estimation of the target state, and the state estimation will affect the scheduling strategy of the sensor at the next moment, which determines that the scheduling problem of the multi-sensor is a sequential decision-making problem in an uncertain environment and with incomplete information. It is necessary to use timely information to decide the current detection scheme. The partially observable Markov decision process (POMDP) model is a theoretical tool for studying multi-stage decision-making in random environments, and provides a complete description framework for the multi-sensor scheduling problem in this paper. Posterior Cramer–Rao lower bound (PCRLB), as a measure of the optimal tracking accuracy of the system, is used to measure the detection accuracy of the sensor, so as to participate in the construction of the objective function.
The second part is the tracking algorithm, the particle filter (PF) is used to update the belief state in the model process to maintain its Markov property. At the same time, the optimization process of the beetle swarm optimization (BSO) is used to replace the resampling process of the PF algorithm to overcome the particle depletion problems of the PF algorithm, so as to improve the performance of the algorithm and the accuracy of filtering.
The third part is the solution algorithm, which uses the elephant herding optimization (EHO) to solve the solution, and by researching and improving the initialization stage, update stage and separation stage of the EHO, the performance of the algorithm is improved, and the speed and quality of the solution are improved.
2. Analysis of Multi-Sensor Cooperative Scheduling Model Based on POMDP
2.1. Framework Composition and Function
In the context of distributed defense, the multi-sensor scheduling process can be described as a Markov decision process. In a task cycle, the sensor detects the target at time , obtains the measurement value , and then formulates the sensor scheduling action for the current step according to the obtained measurement value and the corresponding constraints, so as to maximize the detection performance of the sensor and the ratio of accuracy and energy consumption, or maximize the expected return such as the minimum probability of target loss, and perform the same operation at time to achieve continuous and high-precision tracking of the target.
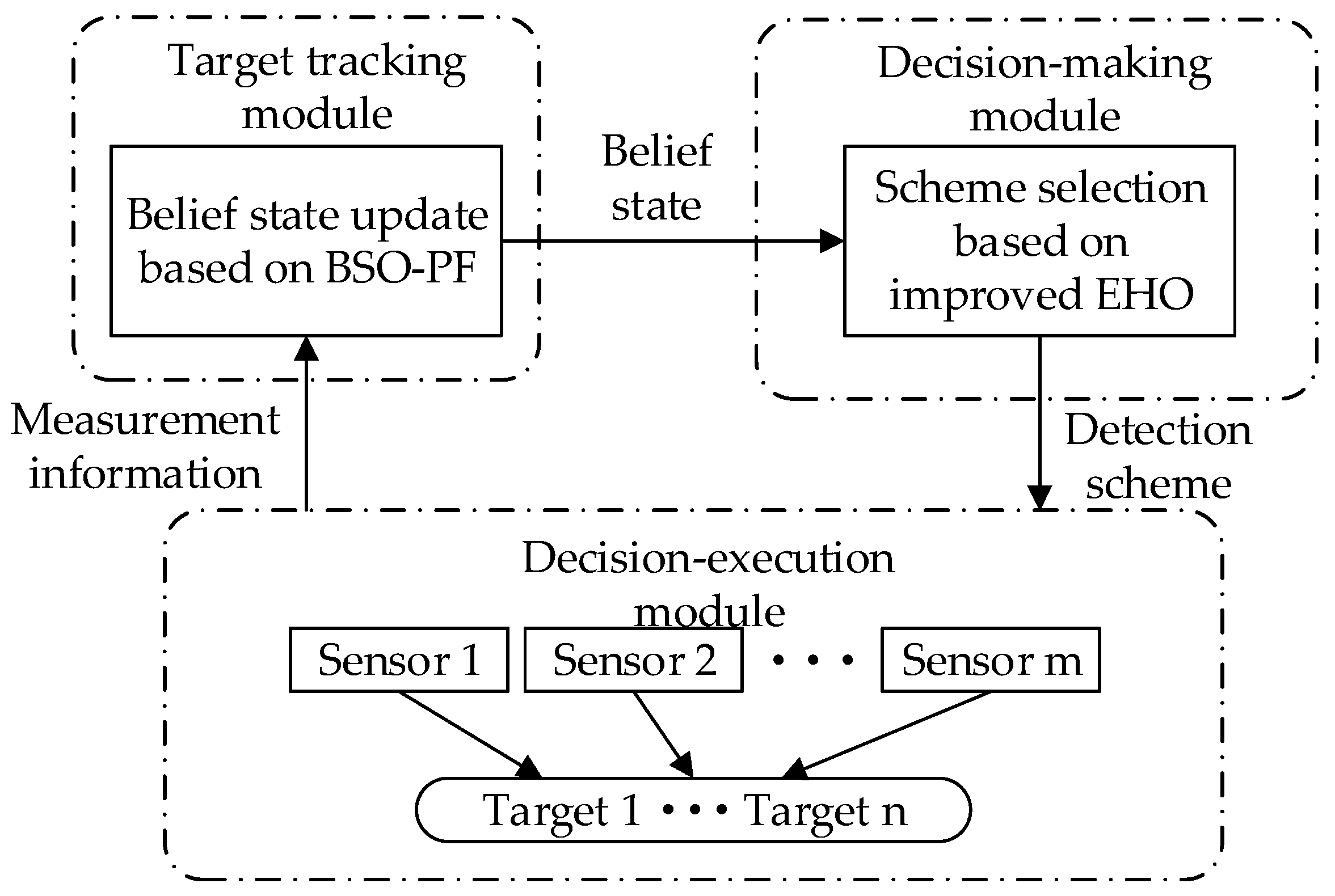
The multi-sensor collaborative scheduling framework can be composed of three modules, namely the target tracking module, the plan formulation module and the plan execution module. The target tracking module is responsible for receiving the measurement information of the sensors and outputting the belief state, the scheme formulation module accepts the belief status and outputs the detection scheme, the scheme execution module receives and executes the detection scheme and outputs the measurement information. The three cooperate with each other to complete the target detection task. The multi-sensor cooperative scheduling framework is shown in
Figure 1.
The target tracking module is mainly used to update the belief state, which is the source of the target belief state and one of the bases for action selection. The accuracy of target tracking is the foundation of the sensor scheduling scheme. The key point of target tracking is the prediction of the target state. However, in the actual sensor detection process, due to the performance constraints of the sensor, the high performance of the target and its complex tactical tactics, the observation of the target state is often uncertain. As a result, the state of the system is often not completely observable, and only with noise can be obtained, which cannot be directly used in the decision-making process, and it is difficult to support the subsequent attack process. Therefore, using the POMDP principle, by introducing the belief state to fully count the historical observations and actions , and continuously updating them, the basic idea is to use the new tracking filtering algorithm to update the posterior probability distribution of the system state. It also guarantees the Markov property of the decision-making process. Therefore, the scheduling process becomes a continuous cycle of observation-belief state update-action-observation. In this paper, the PF algorithm is used to update the belief state, and the BSO algorithm is used to improve the performance of the PF algorithm and improve the tracking performance of the algorithm, which is suitable for any nonlinear system.
The program formulation module is the process of generating the sensor scheduling program. According to the detection accuracy of the target, the energy consumption of the sensor and the optimization target of the scheme, the module formulates the optimal target tracking scheme at the current moment under certain constraints. In this paper, an improved elephant herding optimization algorithm is used to solve the scheduling scheme selection problem.
The scheme execution module is mainly used by the sensor network to perform the detection task according to the established detection scheme, and obtain the measurement information of the target to support the update of the belief state and maintain the cycle of the detection process.
2.2. Model Elements Analysis
(1) Sensor action
Assuming that the defender deploys
sensors dispersedly according to a certain principle, at time
, there are
airborne targets. Due to the energy consumption constraints of the sensors, all sensors cannot work at the same time. Then construct the action matrix
, its elements:
(2) System state space
Define moment , the system state is , and the element is denoted as . , , , and represent the vector components of the target in position and velocity.
(3) System observation set
Define time , the system observation is the set of the measurement values of sensor to the target, element is represented as , represents the measurement value of sensor to target at time , , where and represent the azimuth and oblique distance of target relative to sensor . The working mode of the sensor can adopt the classic AOA angle measurement mode and RSSI ranging mode.
(4) State transition law
The state transition law is determined by the state transition equation of the target. At time
, the state transition equation of target
is:
in the formula,
is the state transition matrix of target
, and
is Gaussian noise with the mean of 0 and the variance of
. Then the system state transition rate is:
in the formula,
is the system transition matrix, expressed as
,
is the system transition noise, expressed as
, and its variance matrix is
.
(5) Systematic observation law
The observation law of the system is determined by the measurement equation of the sensor. At time
, the measurement equation of the sensor
to the target
is:
in the formula,
represents the measurement equation of the sensor to the target, and
represents the Gaussian noise with the mean of 0 and the variance of
. Then the observation law of the system is:
in the formula,
represents the sensor measurement equation,
is the observation noise, expressed as
, and its variance matrix is
.
2.3. Optimization Goal
The purpose of sensor cooperative detection is to continuously detect the target with high precision, and at the same time, the energy consumption of the sensor network is minimized, and the selected scheme has the largest ratio of accuracy to energy consumption.
2.3.1. Detection Accuracy Model Based on PCRLB
When a sensor detects the state of the target, there will be a certain error, and there will be an error every time a prediction is made. After multiple predictions, an unbiased estimator will be generated, and at the same time, along with the variance, the minimum variance will change continuously with the number of detections. The higher the detection accuracy, the smaller the variance. In contrast, the smaller the detection variance that the sensor detection can achieve, the higher the accuracy. Therefore, in order to effectively measure the detection accuracy value of the sensor, PCRLB is used as the measurement standard [
22,
23]. PCRLB represents the lower bound of the variance of the unbiased estimator of the system. The smaller the lower bound, the higher the detection accuracy. PCRLB usually utilizes the inverse representation of Fisher information matrix (FIM):
in the formula,
represents the real state of the target, and
represents the motion state of the target.
is the PCRLB of the system,
is the Fisher information matrix of the target state, expressed as:
represents the a priori information FIM of the target state, which can be obtained iteratively by Equation (8).
in the formula,
,
,
,
can be expressed as:
Therefore, it can be obtained:
represents the FIM of the measurement information, expressed as:
in the formula,
is the measurement array of the sensor, which represents the Jacobian matrix of
pairs of state
, which is determined by the working mode of the sensor.
In summary, the PCRLB can be obtained as:
Using the trace of
at each moment as the accuracy index, it is expressed as:
2.3.2. Energy Consumption Model
Sensors will consume energy during detection. In order to maximize the continuous combat capability, the energy consumption indicator is added. Assuming that the energy consumption of the sensor scheme at time
can be expressed as:
in the formula,
represents the energy consumed by the sensor
to perform a detection task.
2.3.3. Fitness Function
Assuming a multi-sensor multi-target background, the sensor can detect targets in one-to-one, one-to-many, and many-to-one modes, and one sensor can accurately track at most two targets at the same time.
Let
denote the detection accuracy of the sensor scheme for target
at time
and be the reciprocal of
, expressed as:
The tracking number constraint is:
Then, at time
, the fitness function of the sensor scheme can be expressed as:
Then, the optimization objective is:
2.4. Task Scheduling Cycle
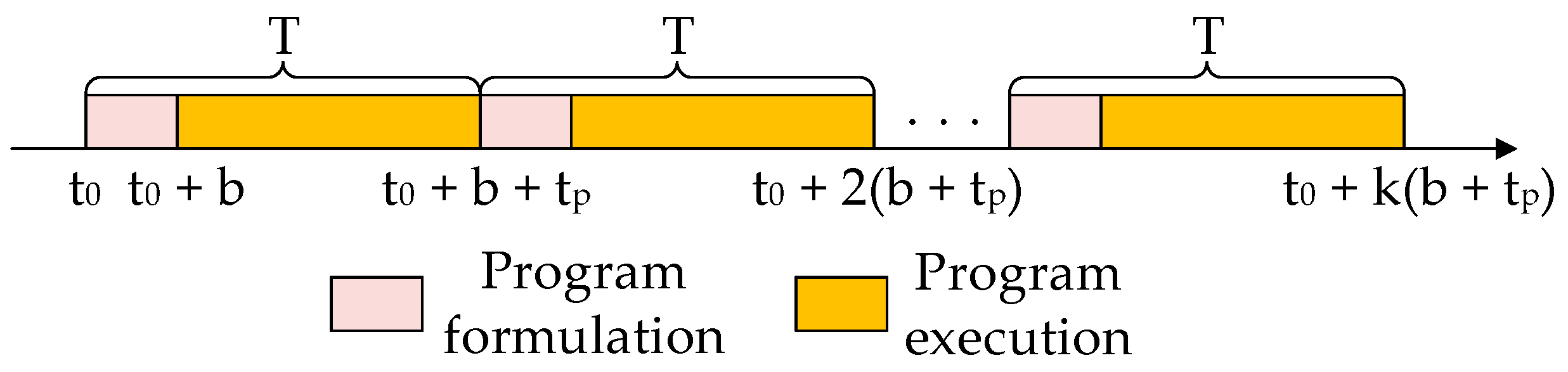
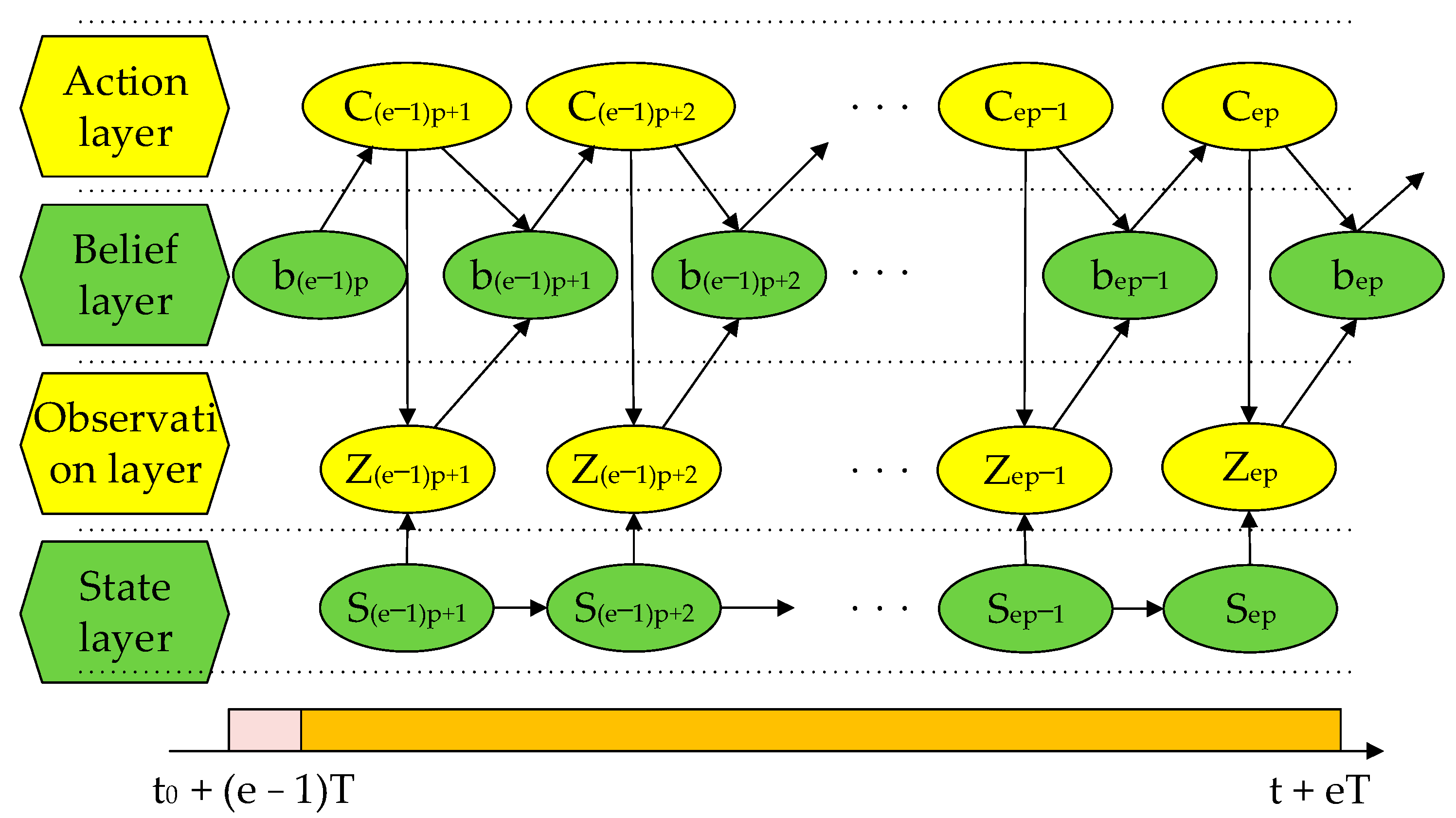
Different from the offline scheduling process, online scheduling is a real-time continuous process. Therefore, the entire combat process is divided into
cycles
, including the program formulation and program execution stages,
sampling per cycle, the single sampling time is
, the total sampling time is
, and the decision time is
, then the online scheduling process is shown in
Figure 2, and the scheduling process of a single task cycle is shown in
Figure 3.
3. A Belief State Update Method Based on Improved Particle Filter Algorithm
The particle filter algorithm [
24,
25] is suitable for any nonlinear system, and has higher accuracy and stability than other filtering algorithms, so this paper uses the PF algorithm to update the belief state. However, at the same time, it also has the problem of particle depletion caused by resampling. The introduction of an intelligent optimization algorithm can significantly improve this phenomenon [
26,
27,
28]. Therefore, this paper uses the optimization process of the beetle swarm optimization algorithm to replace the particle resampling process to maintain the diversity of particles and further improve the filtering effect and stability.
3.1. Basic PF Algorithm
(1) Initialize the particle set
Sampling is performed according to the prior probability density function (system equation) and the importance probability density function (probability density function of normal distribution), and sampled particles are obtained.
(2) Calculate particle weight
The weight calculation formula is:
(3) Particle resampling
Using the method of systematic resampling, the sampled particles are:
(4) Status output
Weighted summation of particles to get the state at the next moment:
3.2. BSO-PF Algorithm
The beetle swarm optimization algorithm [
29] is a new intelligent optimization algorithm proposed in recent years. It has the advantages of fast calculation speed, low complexity and strong search ability in dealing with low-dimensional problems. Therefore, in the resampling stage of the PF algorithm, using the BSO performs process substitution.
Each beetle represents a particle, and the global optimization idea of the beetle swarm optimization algorithm is used to make the particle adjust its position according to the optimal information, and then change the particle distribution to move the particles to the region with high-likelihood probability, so as to achieve the purpose of optimizing the weights on the premise of maintaining the diversity of particles. The basic process of the algorithm is:
(1) Initialize the beetle swarm
Each beetle is defined as a particle, and sampling is performed according to the initialization stage of the basic particle filter algorithm.
(2) The fitness function defining the location of the beetle
in the formula,
is the observation noise,
is the observed value of the system, and
is the predicted value of the system.
(3) Update beetle location
It is defined that the individual extreme value of the beetle swarm is
, and the group extreme value is
. Then the speed update formula is:
The location update formula is:
The position increment factor
is:
The step size
update formula is:
The search and update formula for the left and right whiskers of the beetle are:
The distance between the left and right whiskers of the beetle
is:
in the formula,
and
are learning factors,
and
are random numbers uniformly distributed between
,
is a constant, and
and
are recursive factors, which are constants.
(4) Set the algorithm termination condition
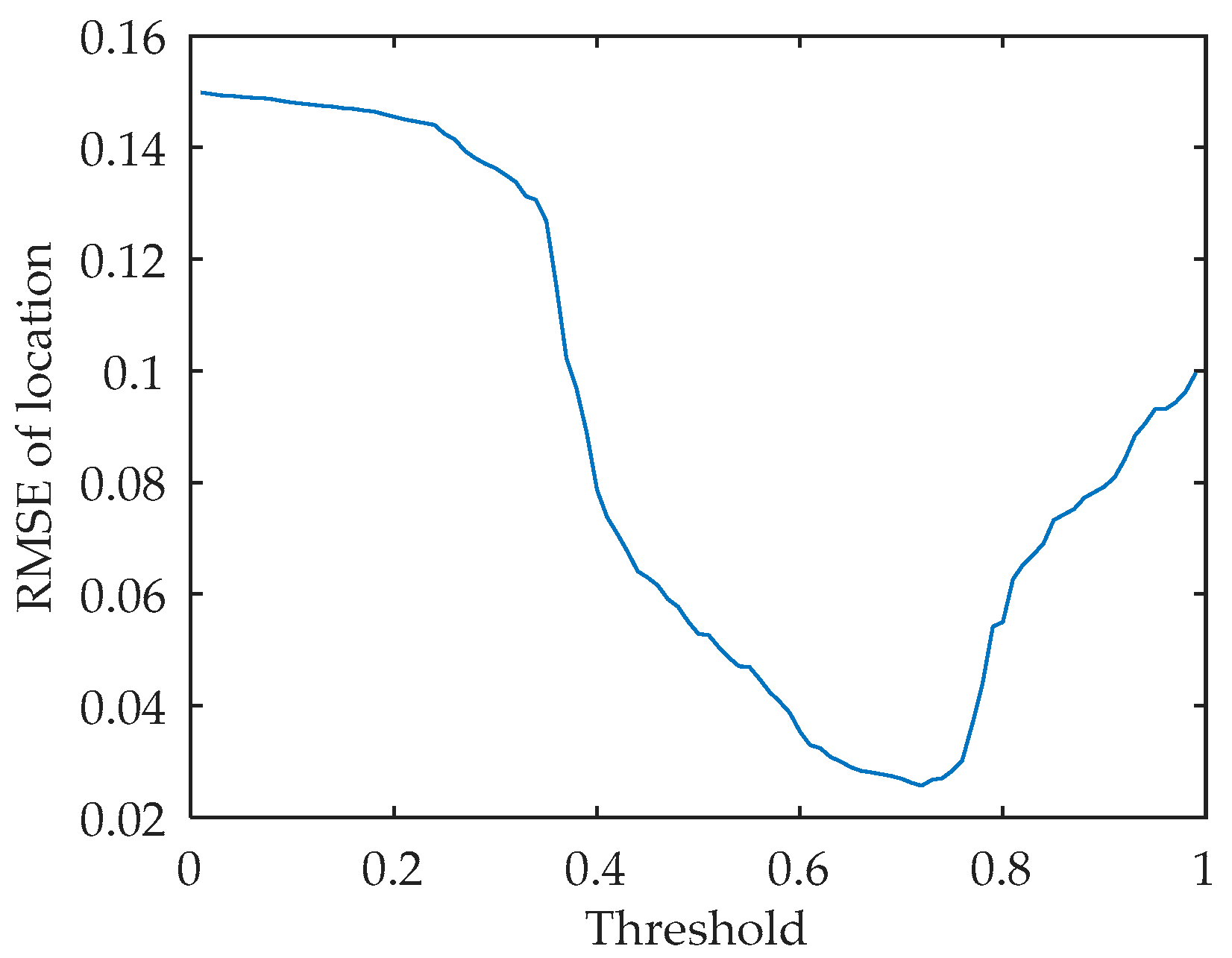
It can be seen from Equation (23) that the fitness value of beetles is inversely proportional to the difference between and . Therefore, in order to avoid the final convergence of the algorithm, the termination fitness threshold is set. If the current function value is greater than , the algorithm terminates. At this time, the particles have been gathered near the real value, so as to achieve the purpose of moving the particles to the high-likelihood probability area, and at the same time reduce the amount of calculation. If all particles are concentrated near the true value, it will reduce the diversity of particles, so that the concept of distribution density function is lost. If the function value does not reach , iteratively update to the maximum number of times. After many experiments, the threshold is set to 0.73 in this paper, and the experimental results are shown in the simulation analysis section.
(5) Weight update
After the optimization of the beetle swarm optimization algorithm, the particle gradually approximates the posterior probability distribution of the particle, but the particle only relies on the difference between its own fitness value and the optimal fitness value to update the position during the optimization process, which results in the particle distribution no longer obeying
, and does not conform to the basis of Bayesian filtering theory, and these particles are not suitable for direct particle filtering. So these particles are not suitable for direct particle filtering. Therefore, it is necessary to modify the weights:
In this way, the particle distribution theoretically does not change the probability model, and the sampling effect is improved.
3.3. Complexity Analysis
Computational complexity analysis: compared with standard PF, the BSO optimization step replaces the resampling step in BSO-PF. Suppose the number of particles is and the maximum number of iterations is . The position of each particle in BSO is the same, which is independent and identically distributed, and the time complexity of updating the position of each particle is . Therefore, for one iteration, the time complexity of the position update of all particles is , then with the maximum number of iterations , the computational complexity of BSO-PF can be obtained as , the PF resampling process involves the interactive comparison of particles, and its computational complexity is .
Due to the setting of the threshold and the maximum number of iterations, the computational complexity of BSO-PF is at most
. Compared with the complexity of resampling, the optimization steps are more complicated. BSO-PF is higher than PF in operation time. By increasing the fitness threshold, the number of iterations
is moderately reduced, and the complexity is reduced. Finally, the experiment is supplemented, and the operation time of BSO-PF, basic PF, EKF and PSO-PF is compared and analyzed under the set initial conditions, which is consistent with the complexity analysis. The results are shown in
Table 1.
6. Summarize
This paper proposes a multi-sensor cooperative scheduling model based on POMDP. Firstly, for the multi-sensor multi-objective cooperative scheduling process, a sensor cooperative scheduling framework and various model elements based on POMDP were established, so that the utilization of uncertain and incomplete target states was realized. At the same time, a PCRLB-based precision consumption ratio model was established for the optimization objective function, using PCRLB to define the detection accuracy of the sensor, it had good tracking performance and could meet the accuracy requirements to participate in the construction of the optimization objective function. In terms of algorithms, the PF tracking algorithm was used to update the belief state, and the BSO was used to improve the PF, which overcame the particle depletion problem of PF, enhanced the performance of the algorithm, and improved the accuracy of target detection. The elephant swarm optimization algorithm was used to solve the plan, and improve the basic elephant group optimization algorithm to improve the solution speed and quality of the algorithm, and further improve the speed and accuracy of the scheduling plan.
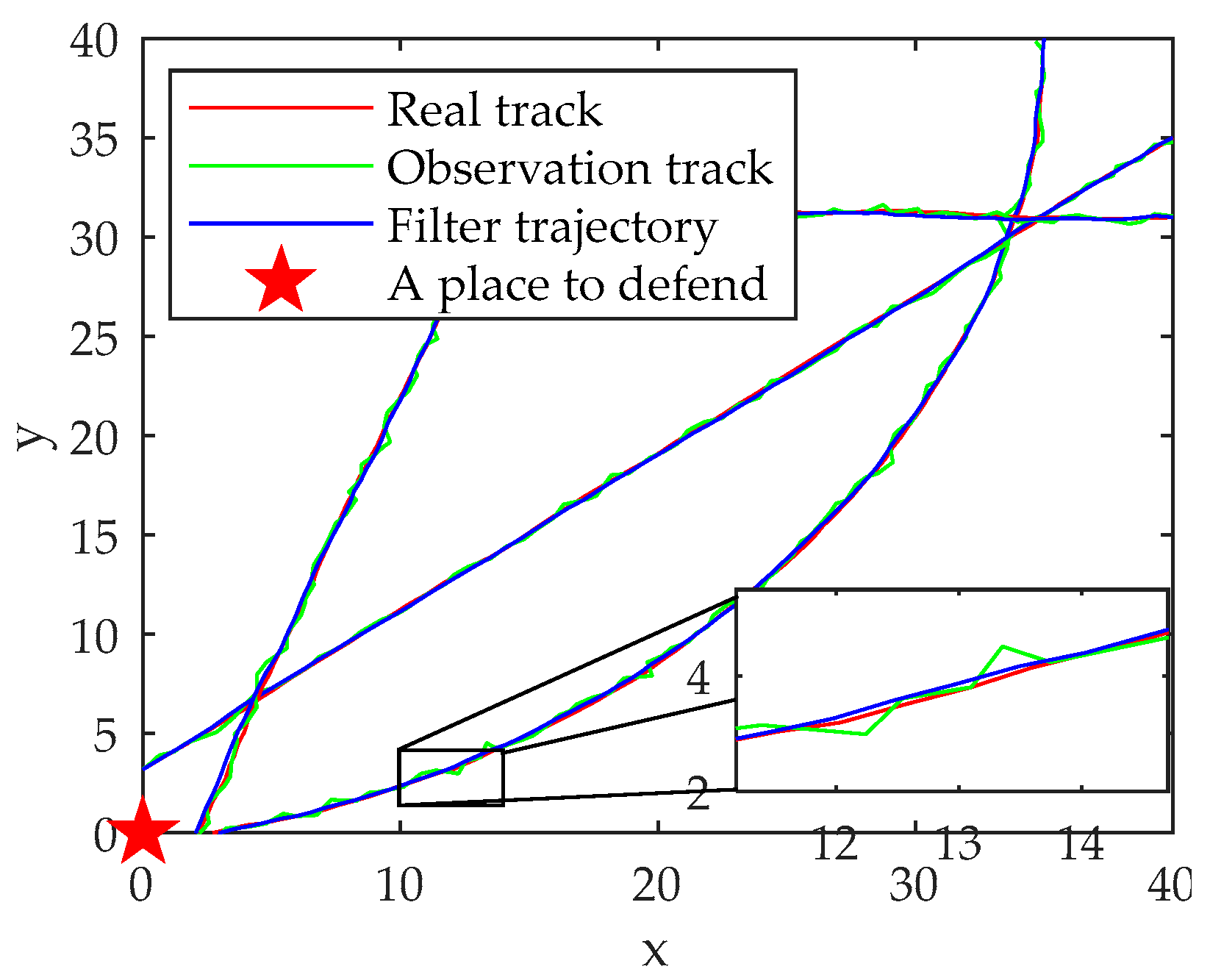
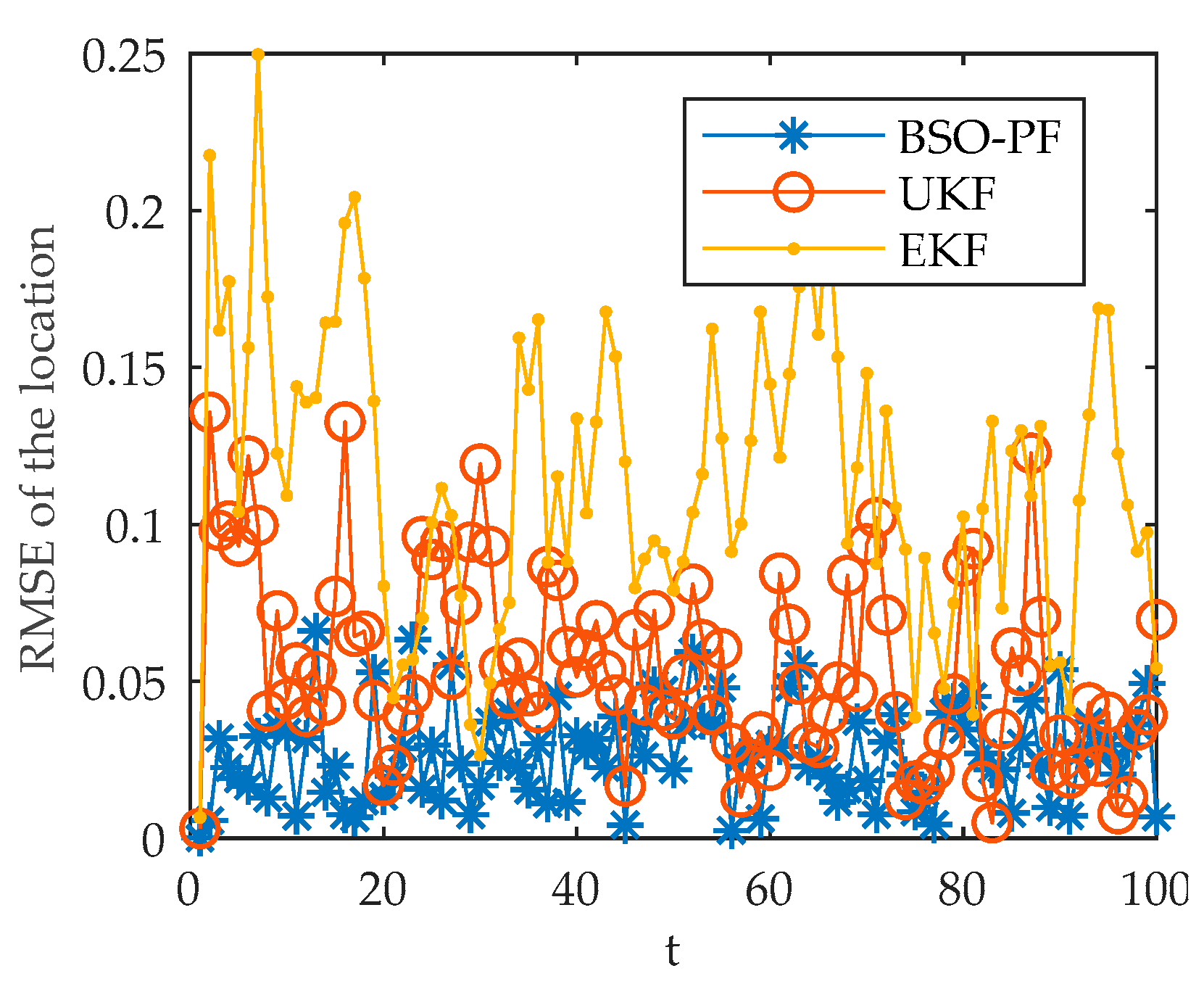
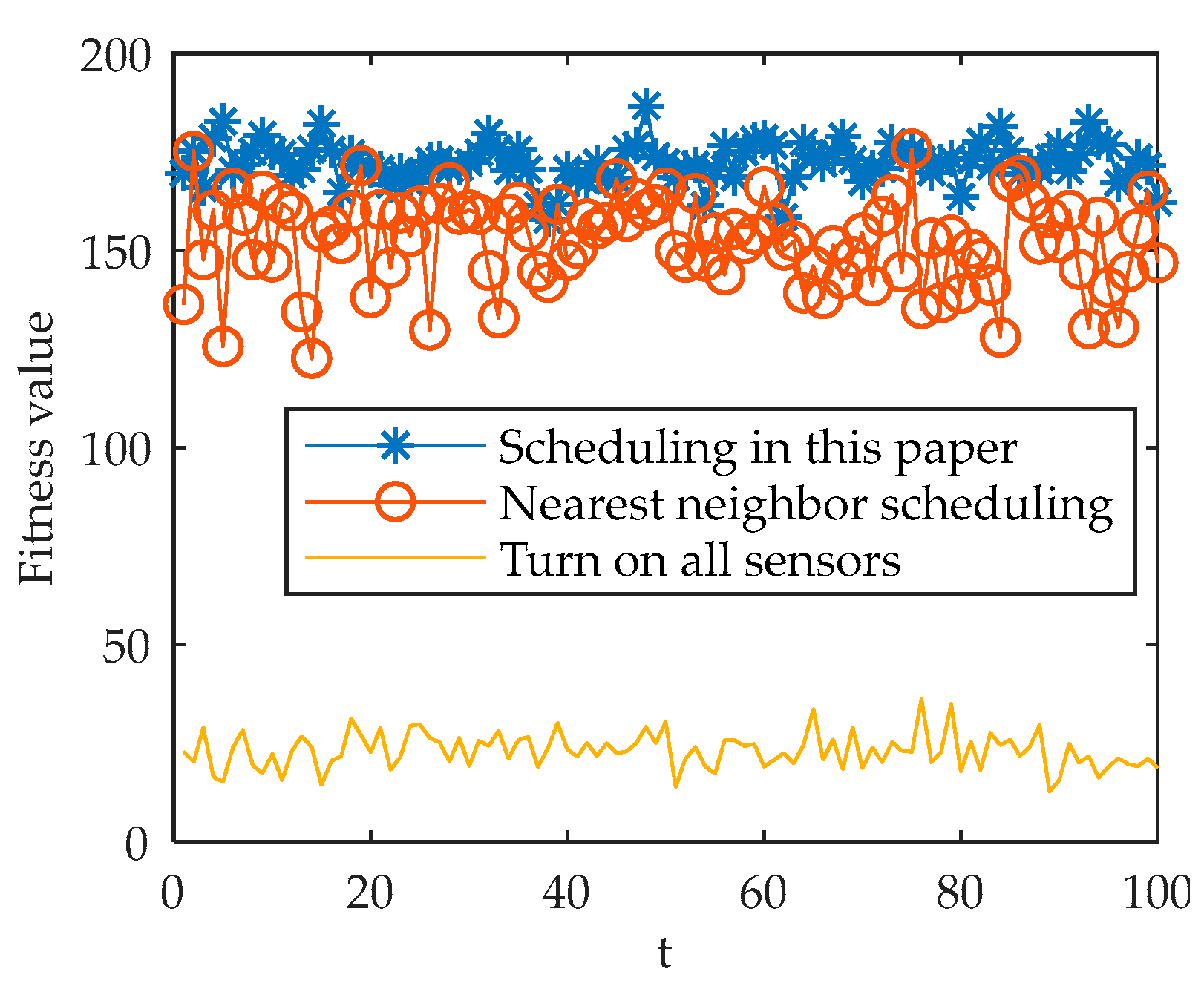
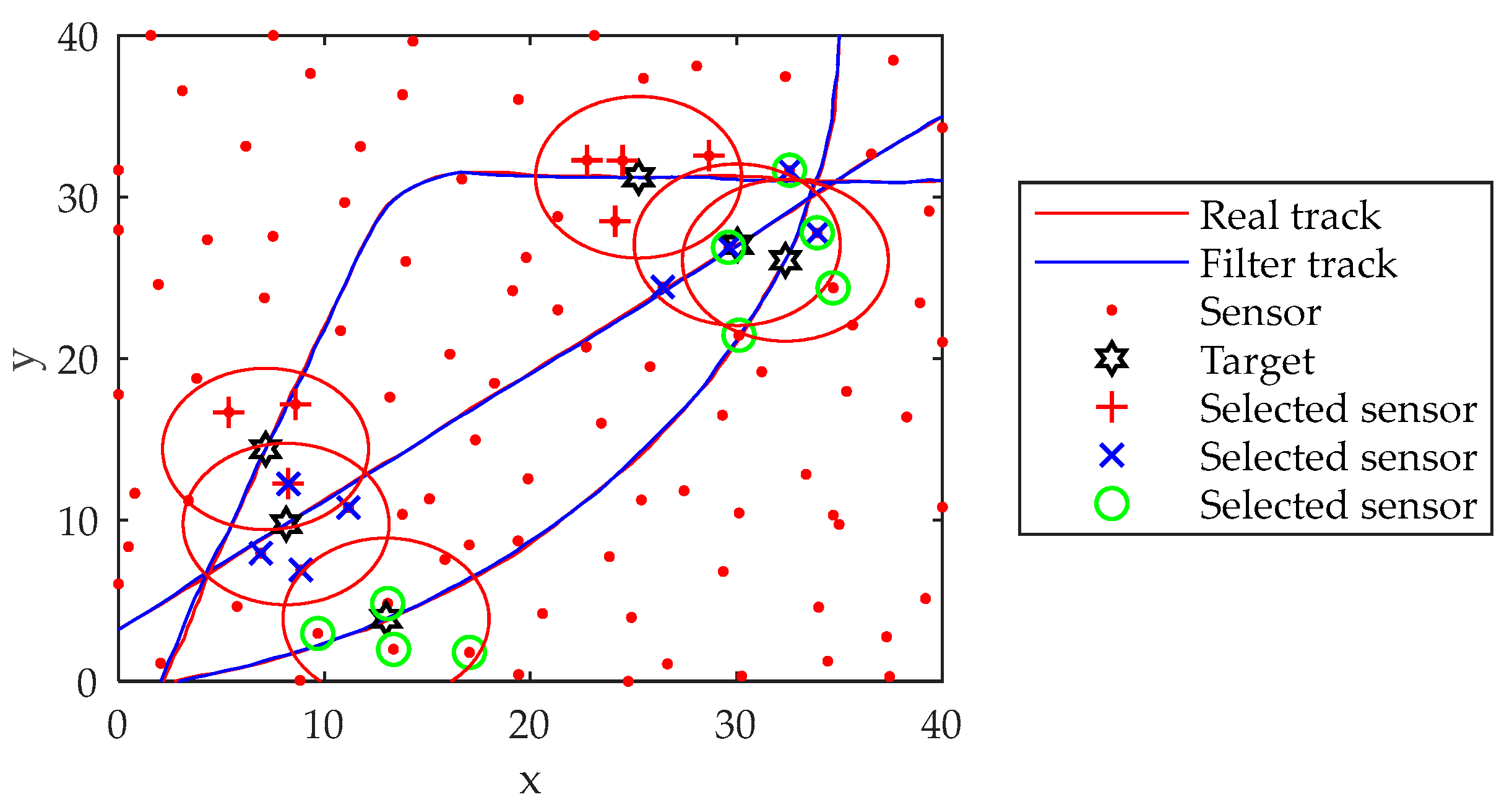
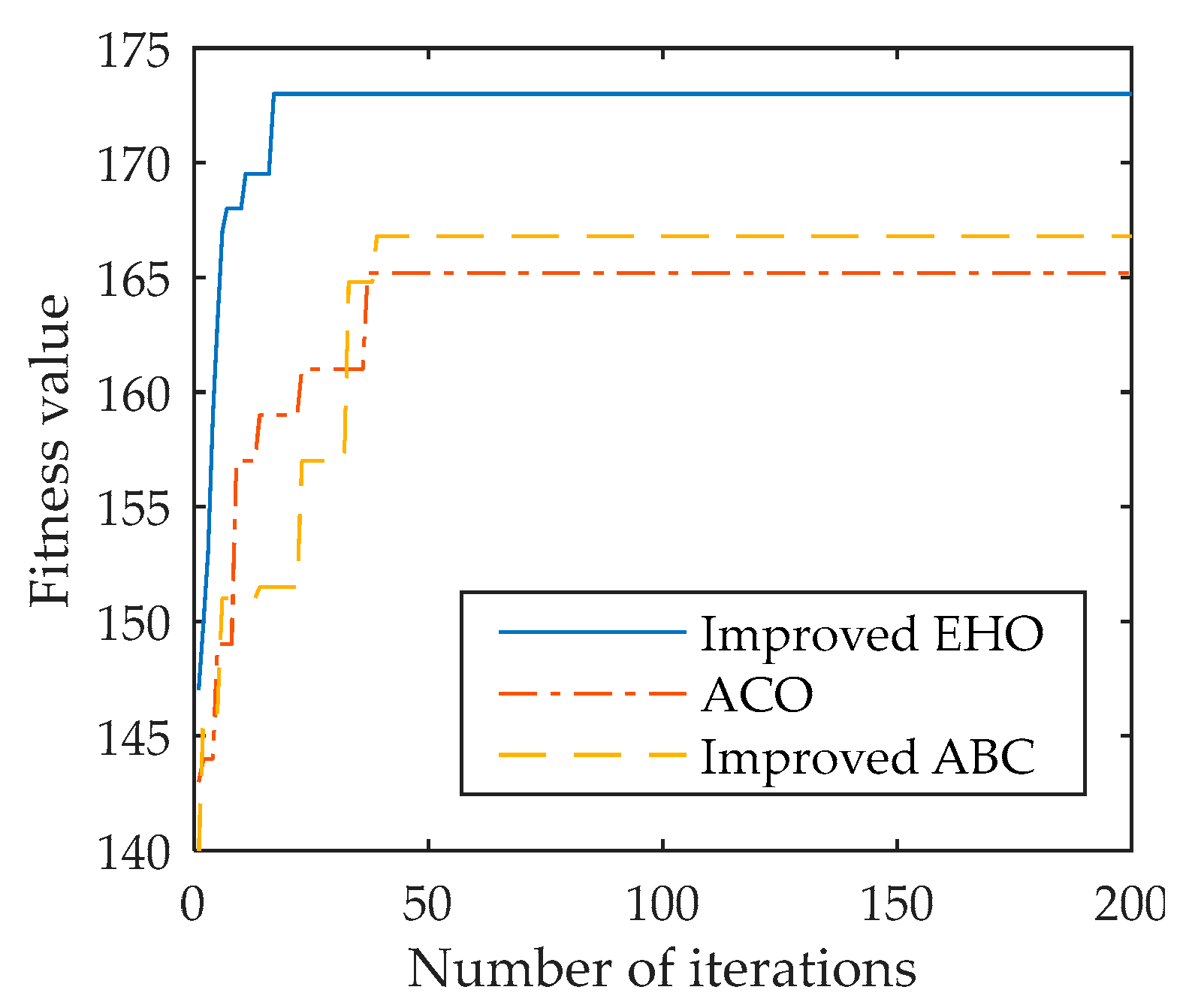
The simulation results show that the proposed model and algorithm can be well adapted to the multi-sensor multi-target scheduling problem under the background of distributed defense. The proposed improved algorithm has better performance, can adapt to the dynamically changing battlefield environment, and can achieve continuous, accurate and fast tracking of maneuvering targets, which has certain reference significance.
The next step will be to study the sensor-fire coordinated strike mechanism, model and algorithm in the context of distributed defense. Research into the firepower–target allocation model and high-performance algorithms is needed, focusing on exploring the matching of sensors and firepower units, guidance models and algorithms in complex and changeable environments, in order to achieve the best launch of the fire unit by using the sensor under the background of distributed defense for the purpose of intercepting as soon as possible and as far as possible. At the same time, based on the existing sensor scheduling model, trying to apply technologies such as 5G, 6G and the IoT to the sensor network, and explore new models and new algorithms that can improve the intelligence level, collaborative detection accuracy, and anti-interference ability of sensor networks, while reducing network energy consumption.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}