
SDFormer: A Novel Transformer Neural Network for Structural Damage Identification by Segmenting the Strain Field Map



Abstract
:1. Introduction
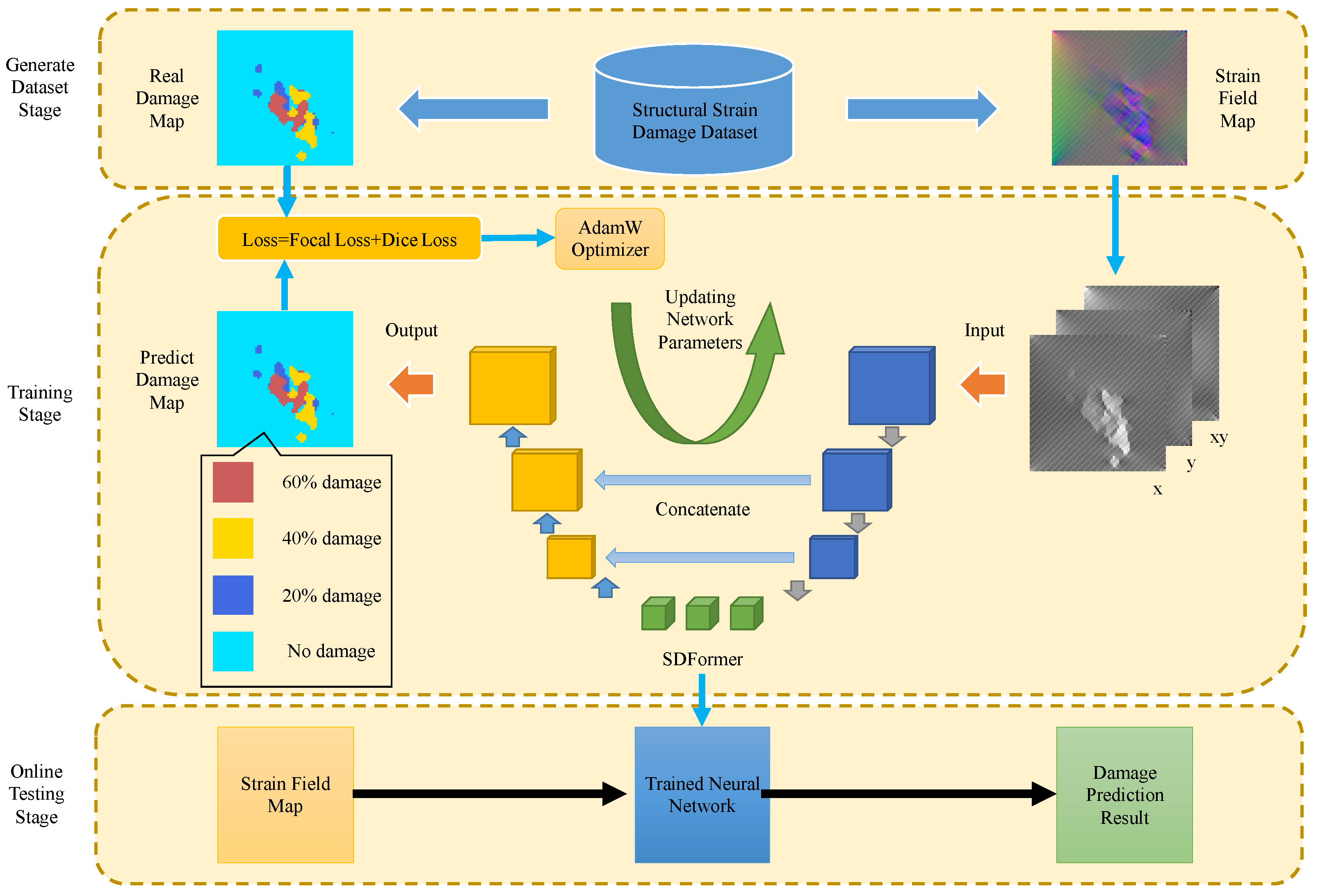
2. Proposed Method
2.1. Overall Architecture
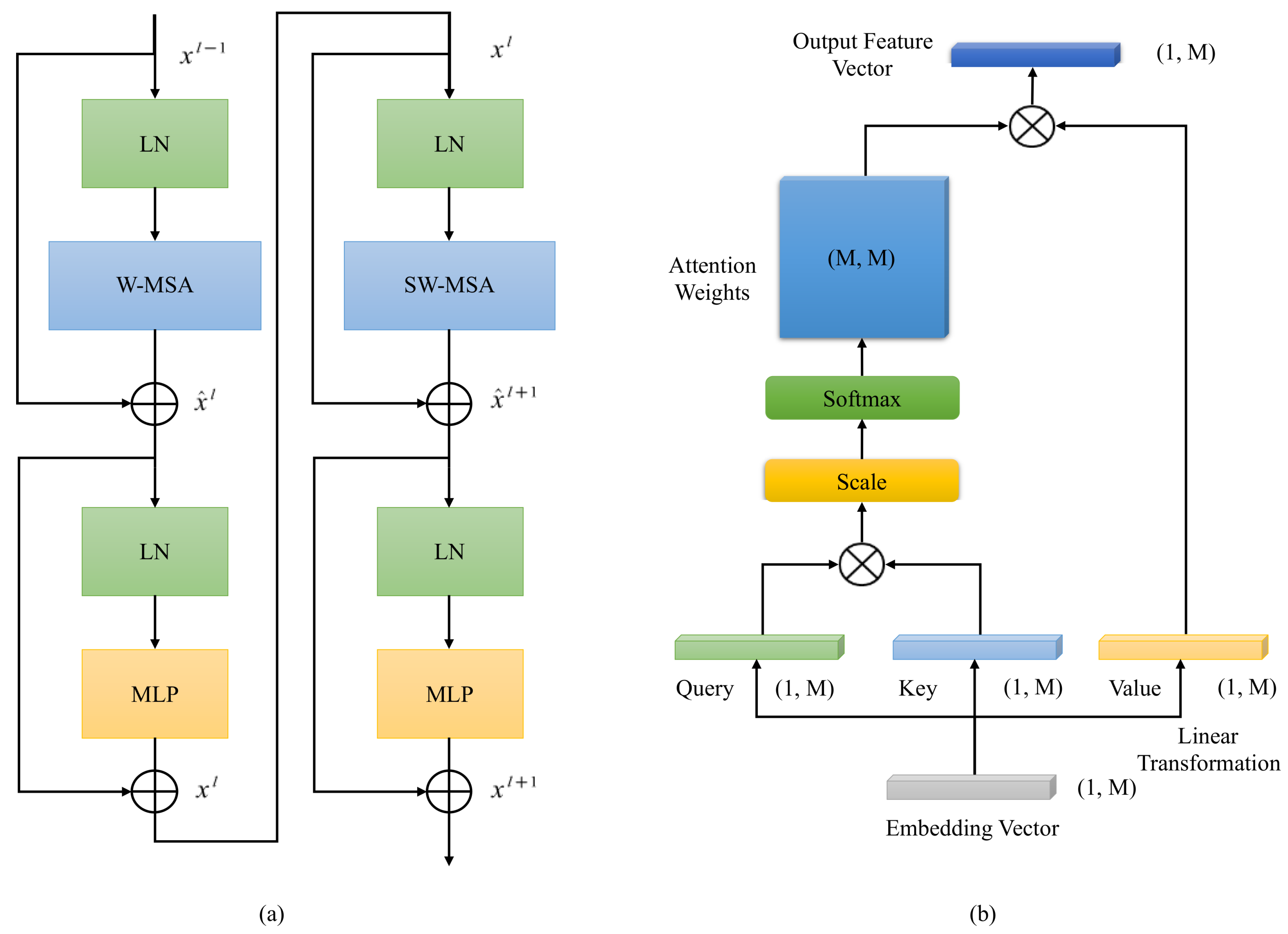
2.2. SDFormer
2.2.1. Patch Block and Patch Merging
2.2.2. Pixel Shuffle
2.2.3. Swin Transformer Block
2.3. Loss and Optimizer
3. Numerical Experiments and Results
3.1. Numerical Experiments Setup
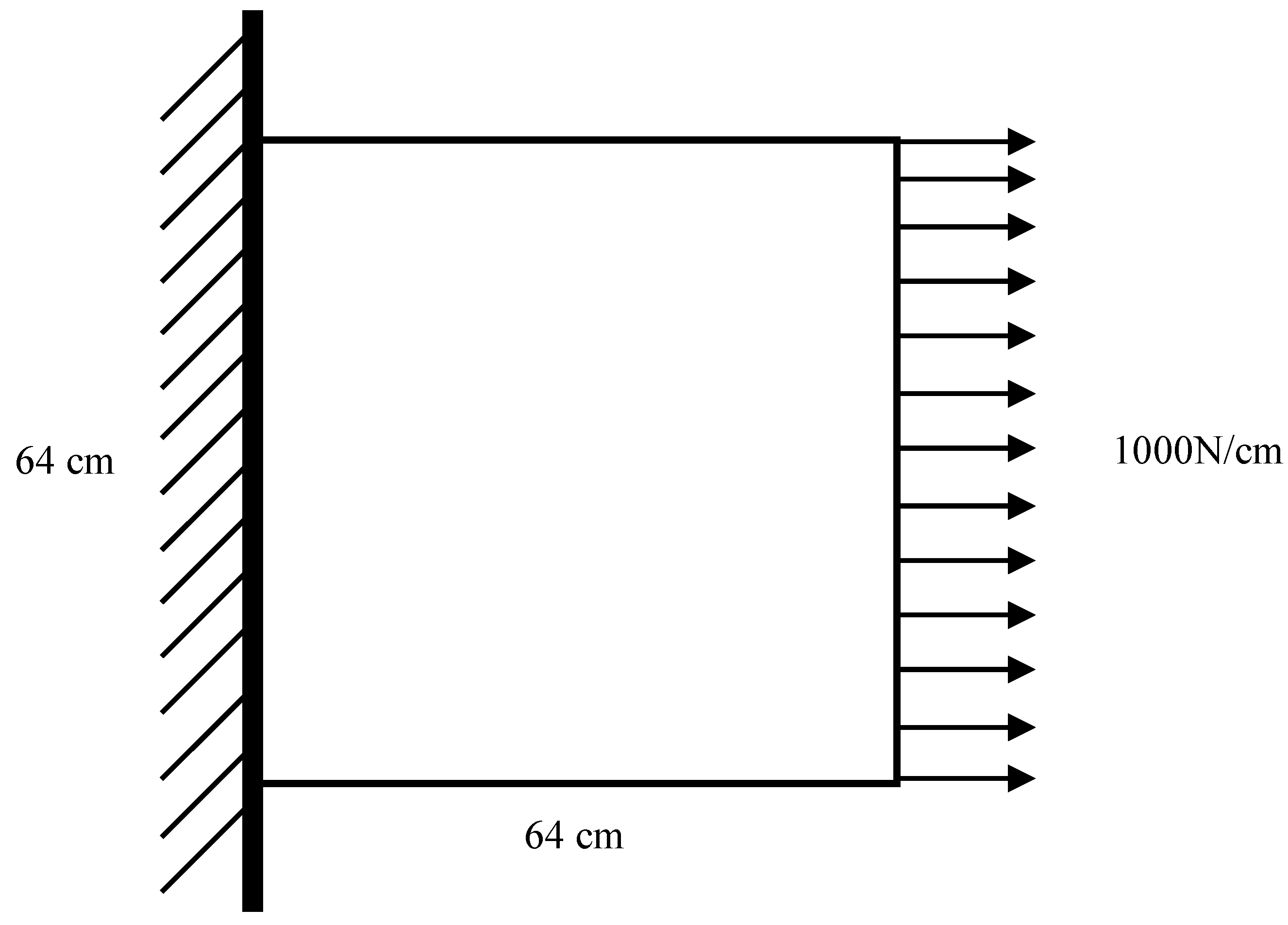
3.1.1. Damage Simulation
- For the structural component S, the material of S and the corresponding elastic modulus E are known. The preset damage level defines four materials (three damaged materials and one undamaged material), in which the undamaged material corresponds to , the elastic modulus of the three damaged materials is set as , according to Formula (21), and other material properties are consistent with .
- Mesh S, and randomly select an area not exceeding 5% of the total area of the structure for each damaged material. If the selected area of two damaged materials overlaps, the one set later is the material of the overlapping area. In addition, other conditions are consistent, and a damage sample finite element model is obtained.
- The damage map and corresponding strain field data in X, Y, and XY directions are obtained by solving the finite element model obtained in step 2.
- Repeat steps 2 and 3 until enough data samples are obtained to construct the structural strain damage dataset.
3.1.2. Case 1
3.1.3. Case 2
3.1.4. Evaluation Metrics
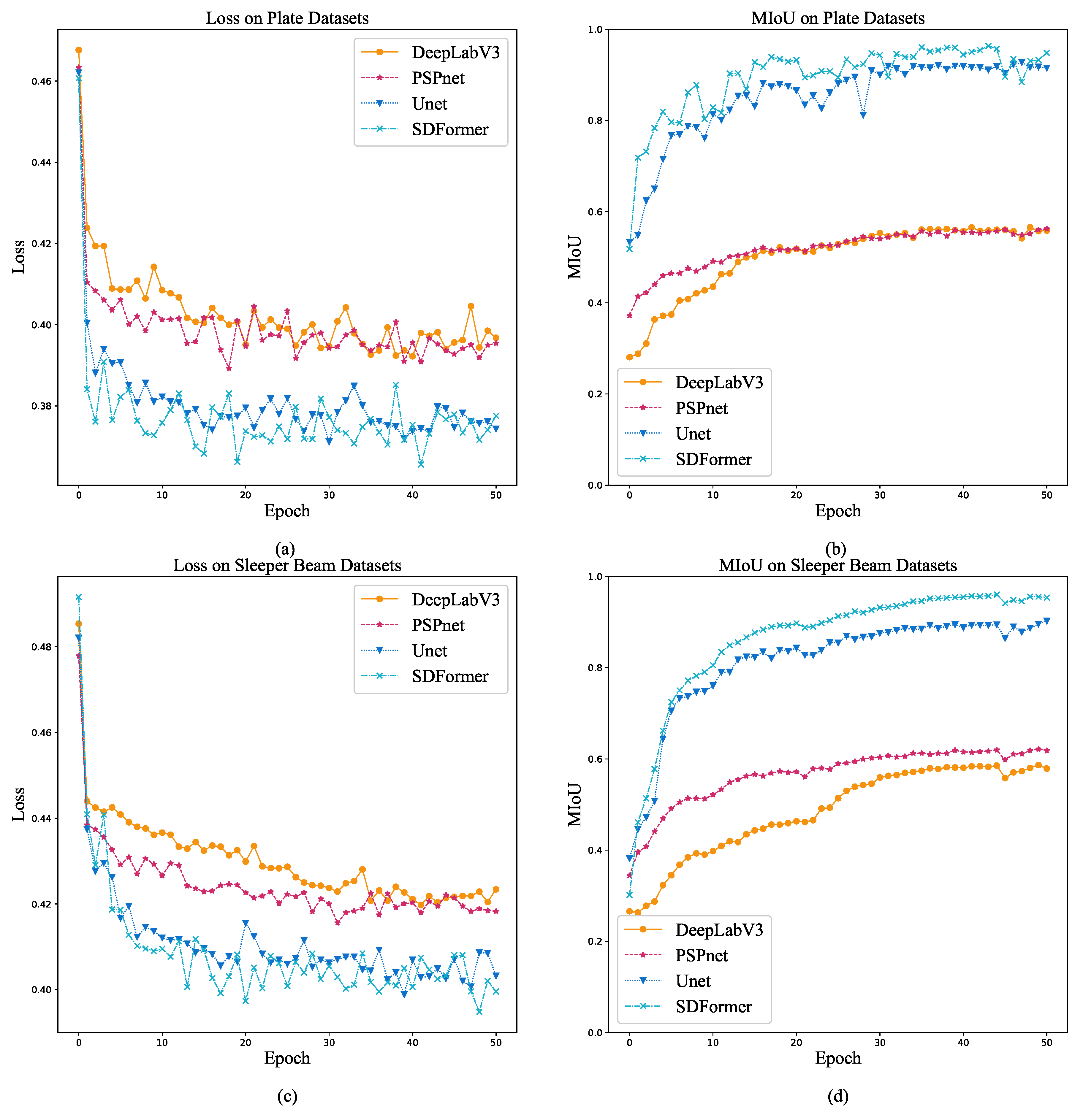
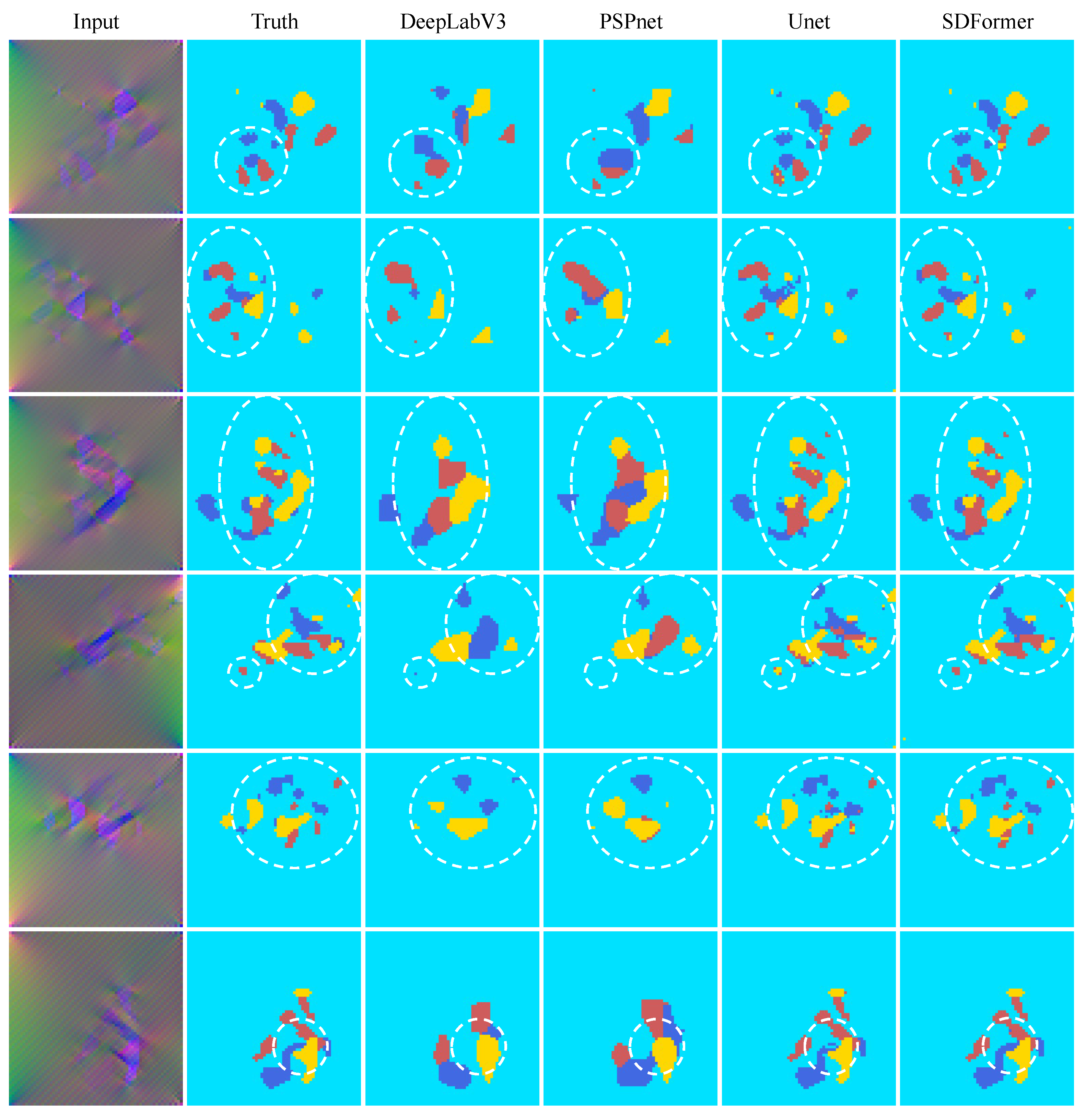
3.2. Result
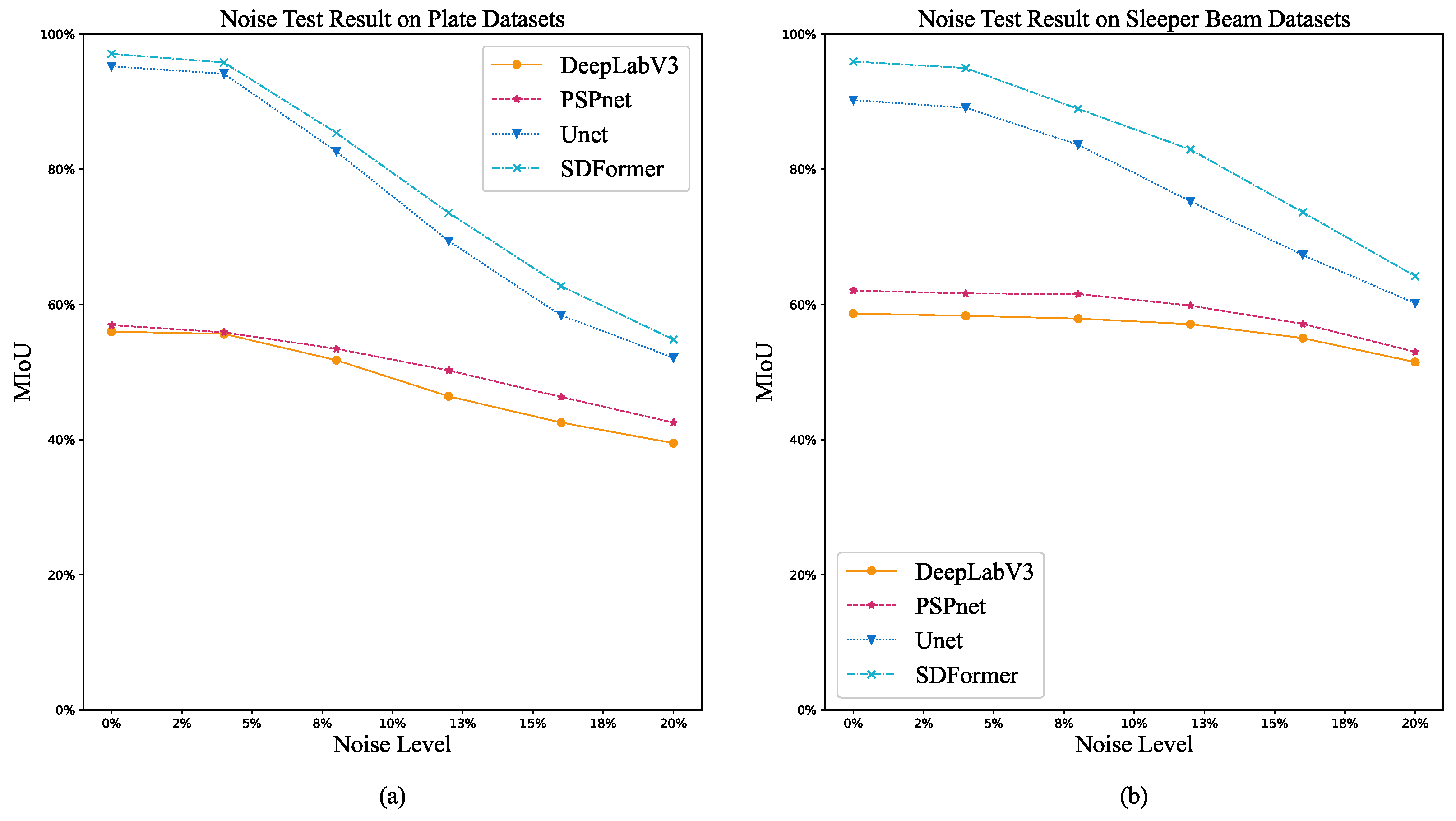
3.3. Anti-Noise Experiment Setup
3.4. Anti-Noise Result
4. Discussion
5. Conclusions
- A novel structural strain damage identification strategy is proposed in this paper. This strategy takes the strain field map of the structure as the input, and uses the image segmentation algorithm to identify the damage location and level. This damage identification process is simple and there is no need for complex damage index design. On the premise of ensuring the accuracy, it can greatly simplify the process of damage identification and improve the efficiency.
- According to the results of numerical experiments, compared with the advanced convolutional neural network, the SDFormer can achieve better damage identification performance with fewer parameters. The damage identification results of SDFormer are closer to the real damage map than those of the comparison model, which shows that SDFormer has excellent structural strain damage identification performance.
- The results of anti-noise experiment show that SDFormer can still maintain better identification performance than that of the comparison models, although the identification performance of SDFormer decreases under the influence of different noise levels, which illustrates that the SDFormer has good noise resistance and robustness.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Eisenmann, D.J.; Enyart, D.; Lo, C.; Brasche, L. Review of Progress in Magnetic Particle Inspection. In 40th Annual Review of Progress in Quantitative Nondestructive Evaluation: Incorporating the 10th International Conference on Barkhausen Noise and Micromagnetic Testing, VOLS 33A & 33B; American Institute of Physics: College Park, MD, USA, 2014. [Google Scholar]
- Marcantonio, V.; Monarca, D.; Colantoni, A.; Cecchini, M. Ultrasonic waves for materials evaluation in fatigue, thermal and corrosion damage: A review. Mech. Syst. Signal Process. 2019, 120, 32–42. [Google Scholar] [CrossRef]
- Withers, P.J.; Preuss, M. Fatigue and Damage in Structural Materials Studied by X-ray Tomography. Annu. Rev. Mater. Res. 2012, 42, 81–103. [Google Scholar] [CrossRef]
- Sophian, A.; Tian, G.; Fan, M. Pulsed Eddy Current Non-destructive Testing and Evaluation: A Review. Chin. J. Mech. Eng. 2017, 30, 500–514. [Google Scholar] [CrossRef] [Green Version]
- Campanella, C.E.; Cuccovillo, A.; Campanella, C.; Yurt, A.; Passaro, V.M.N. Fibre Bragg Grating Based Strain Sensors: Review of Technology and Applications. Sensors 2018, 18, 3115. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Yang, L.; Xie, X.; Zhu, L.; Wu, S.; Wang, Y. Review of Electronic Speckle Pattern Interferometry (ESPI) for Three Dimensional Displacement Measurement. Chin. J. Mech. Eng. 2014, 27, 1–13. [Google Scholar] [CrossRef]
- Kaewunruen, S.; Janeliukstis, R.; Freimanis, A.; Goto, K. Normalised curvature square ratio for detection of ballast voids and pockets under rail track sleepers. J. Phys. Conf. Ser. 2018, 1106, 012002. [Google Scholar] [CrossRef] [Green Version]
- Bayissa, W.L.; Haritos, N. Structural damage identification in plates using spectral strain energy analysis. J. Sound Vib. 2007, 307, 226–249. [Google Scholar] [CrossRef]
- Shadan, F.; Khoshnoudian, F.; Esfandiari, A. Structural Damage Identification Based on Strain Frequency Response Functions. Int. J. Struct. Stab. Dyn. 2018, 18, 1850159. [Google Scholar] [CrossRef]
- Abdeljaber, O.; Avci, O.; Kiranyaz, S.; Gabbouj, M.; Inman, D.J. Real-time vibration-based structural damage detection using one-dimensional convolutional neural networks. J. Sound Vib. 2017, 388, 154–170. [Google Scholar] [CrossRef]
- Kim, S.; Choi, J.H. Convolutional neural network for gear fault diagnosis based on signal segmentation approach. Struct. Health Monit. Int. J. 2019, 18, 1401–1415. [Google Scholar] [CrossRef]
- Bao, Y.; Tang, Z.; Li, H.; Zhang, Y. Computer vision and deep learning-based data anomaly detection method for structural health monitoring. Struct. Health Monit. Int. J. 2019, 18, 401–421. [Google Scholar] [CrossRef]
- Park, H.S.; An, J.H.; Park, Y.J.; Oh, B.K. Convolutional neural network-based safety evaluation method for structures with dynamic responses. Expert Syst. Appl. 2020, 158, 113634. [Google Scholar] [CrossRef]
- Lin, J.; Yu, Y.; Lin, M.; Wang, Y. Detection of a casting defect tracked by deep convolution neural network. Int. J. Adv. Manuf. Technol. 2018, 97, 573–581. [Google Scholar] [CrossRef]
- Zhang, K.; Cheng, H.D.; Zhang, B. Unified Approach to Pavement Crack and Sealed Crack Detection Using Preclassification Based on Transfer Learning. J. Comput. Civ. Eng. 2018, 32, 04018001. [Google Scholar] [CrossRef]
- Kumar, R.; Cirrincione, G.; Cirrincione, M.; Tortella, A.; Andriollo, M. Induction Machine Fault Detection and Classification Using Non-Parametric, Statistical-Frequency Features and Shallow Neural Networks. IEEE Trans. Energy Convers. 2020, 36, 1070–1080. [Google Scholar] [CrossRef]
- Jin, C.; Chen, X. An end-to-end framework combining time-frequency expert knowledge and modified transformer networks for vibration signal classification. Expert Syst. Appl. 2021, 171, 114570. [Google Scholar] [CrossRef]
- Shelhamer, E.; Long, J.; Darrell, T. Fully Convolutional Networks for Semantic Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 39, 640–651. [Google Scholar] [CrossRef]
- Chen, L.; Papandreou, G.; Schroff, F.; Adam, H. Rethinking Atrous Convolution for Semantic Image Segmentation. arXiv 2017, arXiv:1706.05587. [Google Scholar]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid Scene Parsing Network. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 6230–6239. [Google Scholar] [CrossRef] [Green Version]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar] [CrossRef] [Green Version]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image is Worth 16 × 16 Words: Transformers for Image Recognition at Scale. arXiv 2021, arXiv:2010.11929. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical Vision Transformer using Shifted Windows. arXiv 2021, arXiv:2103.14030. [Google Scholar]
- Tran-Ngoc, H.; Khatir, S.; Ho-Khac, H.; De Roeck, G.; Bui-Tien, T.; Abdel Wahab, M. Efficient Artificial neural networks based on a hybrid metaheuristic optimization algorithm for damage detection in laminated composite structures. Compos. Struct. 2021, 262, 113339. [Google Scholar] [CrossRef]
- Khatir, S.; Tiachacht, S.; Le Thanh, C.; Ghandourah, E.; Mirjalili, S.; Abdel Wahab, M. An improved Artificial Neural Network using Arithmetic Optimization Algorithm for damage assessment in FGM composite plates. Compos. Struct. 2021, 273, 114287. [Google Scholar] [CrossRef]
- Loshchilov, I.; Hutter, F. Decoupled Weight Decay Regularization. In Proceedings of the International Conference on Learning Representations, New Orleans, LA, USA, 6–9 May 2019. [Google Scholar]
- Shi, W.; Caballero, J.; Huszár, F.; Totz, J.; Aitken, A.P.; Bishop, R.; Rueckert, D.; Wang, Z. Real-Time Single Image and Video Super-Resolution Using an Efficient Sub-Pixel Convolutional Neural Network. arXiv 2016, arXiv:1609.05158. [Google Scholar]
- Han, H.; Gu, J.; Zheng, Z.; Dai, J.; Wei, Y. Relation Networks for Object Detection. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 3588–3597. [Google Scholar]
- Hu, H.; Zhang, Z.; Xie, Z.; Lin, S. Local Relation Networks for Image Recognition. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 3464–3473. [Google Scholar]
- Milletari, F.; Navab, N.; Ahmadi, S.A. V-Net: Fully Convolutional Neural Networks for Volumetric Medical Image Segmentation. In Proceedings of the 2016 Fourth International Conference on 3D Vision (3DV), Stanford, CA, USA, 25–28 October 2016; pp. 565–571. [Google Scholar] [CrossRef] [Green Version]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal Loss for Dense Object Detection. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 318–327. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kingma, D.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Medical Image Computing and Computer-Assisted Intervention—MICCAI 2015; Springer International Publishing: Cham, Switzerland, 2015; pp. 234–241. [Google Scholar]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | Backbone | Input Size | MIoU. () | FLOPs | Params. (M) |
|---|---|---|---|---|---|
| DeepLabV3 | ResNet-50 | 55.97 | 2561 M | 39.63 | |
| PSPnet | ResNet-50 | 56.93 | 161 M | 1.75 | |
| UNet | ResNet-50 | 95.21 | 669 M | 32.5 | |
| SDFormer(ours) | - | 97.07 | 1807 M | 18.8 |
| Methods | Backbone | Input Size | MIoU. () | FLOPs | Params. (M) |
|---|---|---|---|---|---|
| DeepLabV3 | ResNet-50 | 58.65 | 102.41 G | 39.63 | |
| PSPnet | ResNet-50 | 62.05 | 6.51 G | 1.75 | |
| UNet | ResNet-50 | 90.21 | 26.74 G | 32.5 | |
| SDFormer(ours) | - | 95.93 | 72.29 G | 18.8 |
| Methods | ||||||
|---|---|---|---|---|---|---|
| DeepLabV3 | 55.97 | 55.63 | 51.74 | 46.40 | 42.51 | 39.48 |
| PSPnet | 56.93 | 55.86 | 53.43 | 50.23 | 46.31 | 42.51 |
| UNet | 95.21 | 94.13 | 82.61 | 69.38 | 58.37 | 52.11 |
| SDFormer(ours) | 97.07 | 95.78 | 85.37 | 73.56 | 62.71 | 54.79 |
| Methods | ||||||
|---|---|---|---|---|---|---|
| DeepLabV3 | 58.65 | 58.31 | 57.89 | 57.08 | 55.01 | 51.46 |
| PSPnet | 62.05 | 61.61 | 61.54 | 59.82 | 57.11 | 52.98 |
| UNet | 90.21 | 89.09 | 83.60 | 75.25 | 67.29 | 60.17 |
| SDFormer(ours) | 95.93 | 94.96 | 88.93 | 82.91 | 73.62 | 64.17 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, Z.; Xu, P.; Xing, J.; Yang, C. SDFormer: A Novel Transformer Neural Network for Structural Damage Identification by Segmenting the Strain Field Map. Sensors 2022, 22, 2358. https://doi.org/10.3390/s22062358
Li Z, Xu P, Xing J, Yang C. SDFormer: A Novel Transformer Neural Network for Structural Damage Identification by Segmenting the Strain Field Map. Sensors. 2022; 22(6):2358. https://doi.org/10.3390/s22062358
Chicago/Turabian StyleLi, Zhaoyang, Ping Xu, Jie Xing, and Chengxing Yang. 2022. "SDFormer: A Novel Transformer Neural Network for Structural Damage Identification by Segmenting the Strain Field Map" Sensors 22, no. 6: 2358. https://doi.org/10.3390/s22062358