
Online Anomaly Detection for Smartphone-Based Multivariate Behavioral Time Series Data


Abstract
:1. Introduction
2. Materials and Methods
2.1. Offline Anomaly Detection Method
2.2. Online Anomaly Detection Method
2.2.1. Updating the General Trend and Periodic Terms
2.2.2. Sorting the Errors
2.2.3. Updating the Covariance Matrix
2.2.4. Incorporating the between-Individual Comparison
2.2.5. Software Implementation
3. Results
3.1. Simulation with Synthetic Data
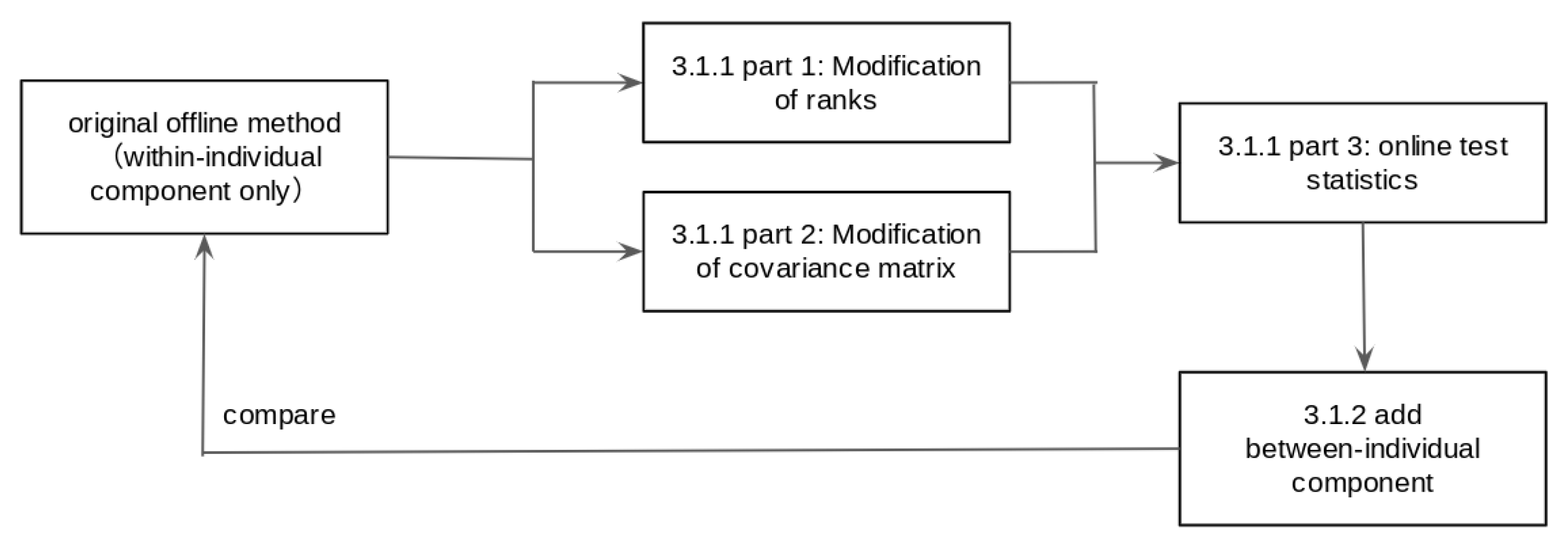
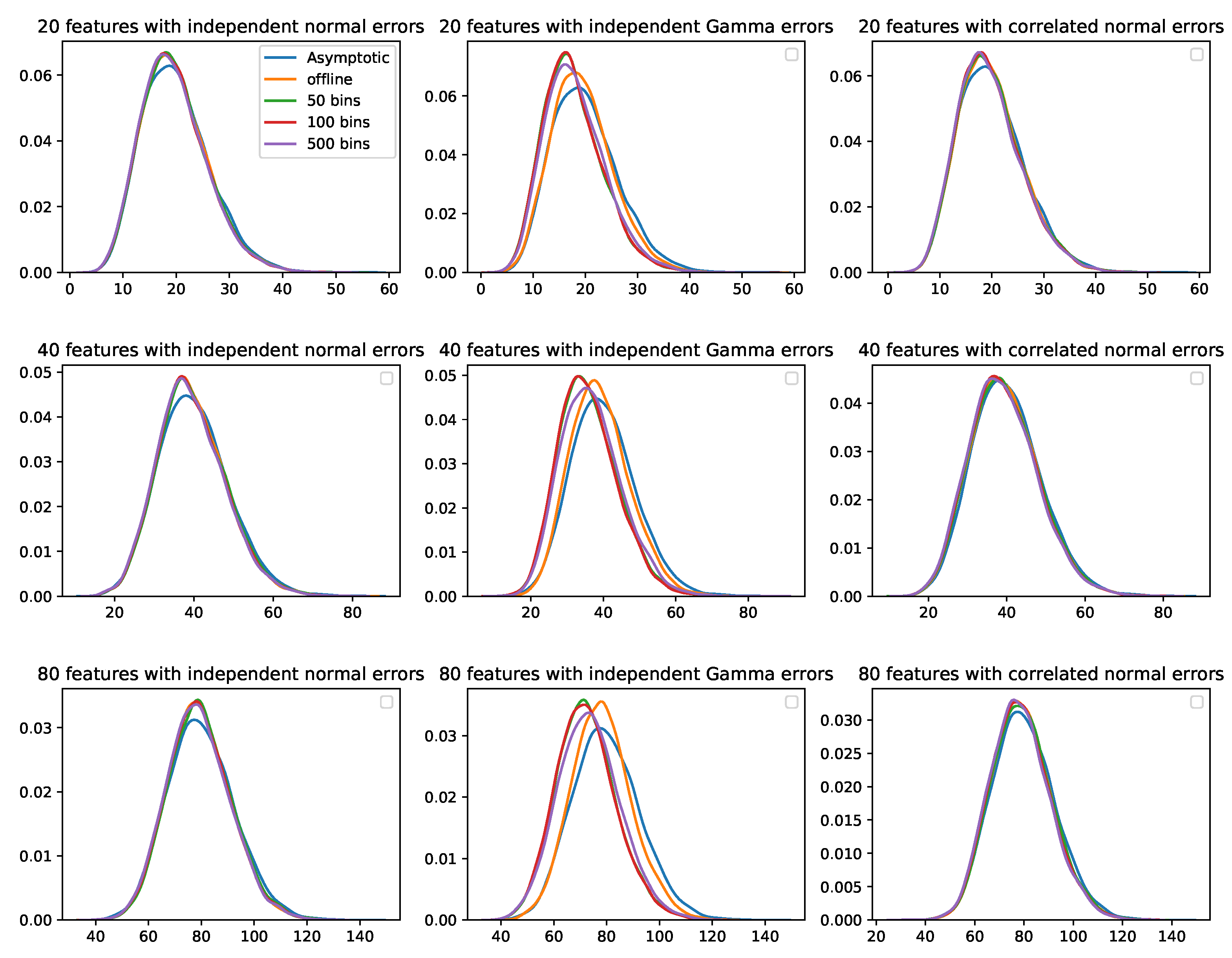
3.1.1. Comparison of the within-Individual Component of the Online Test Statistic and the Offline Test Statistic
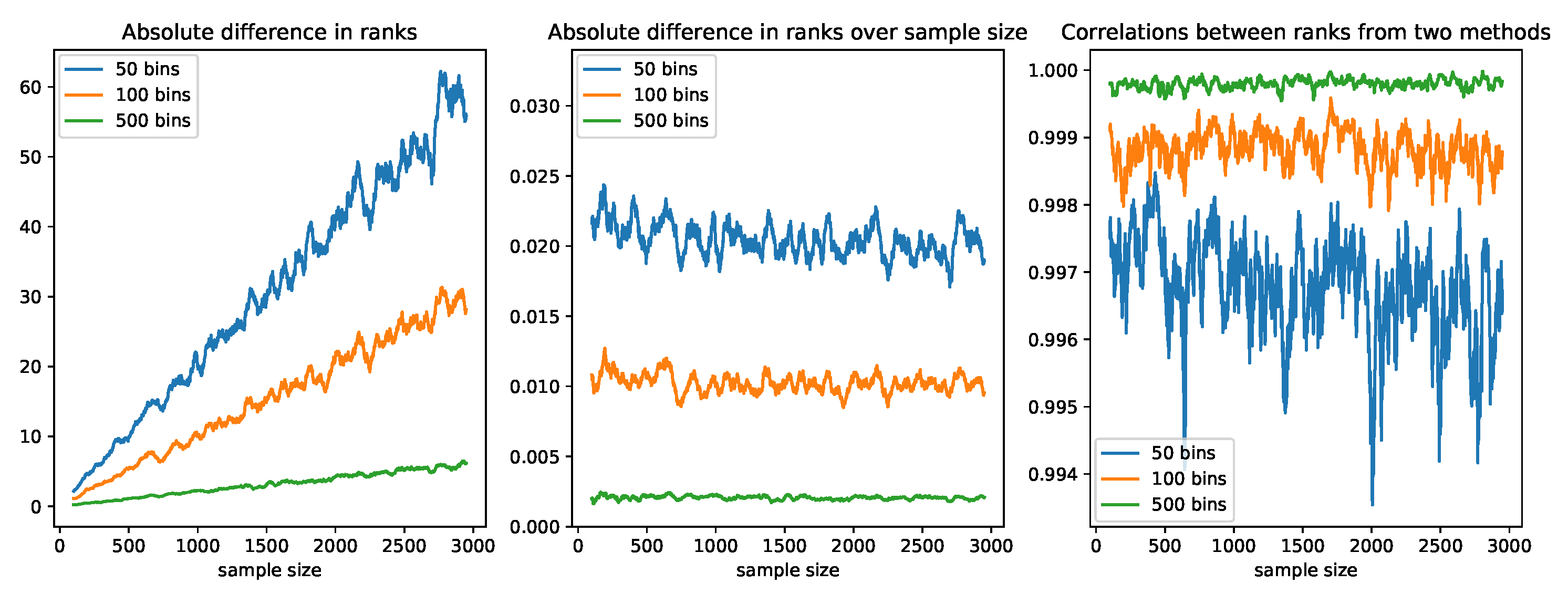
Comparison of Ranks
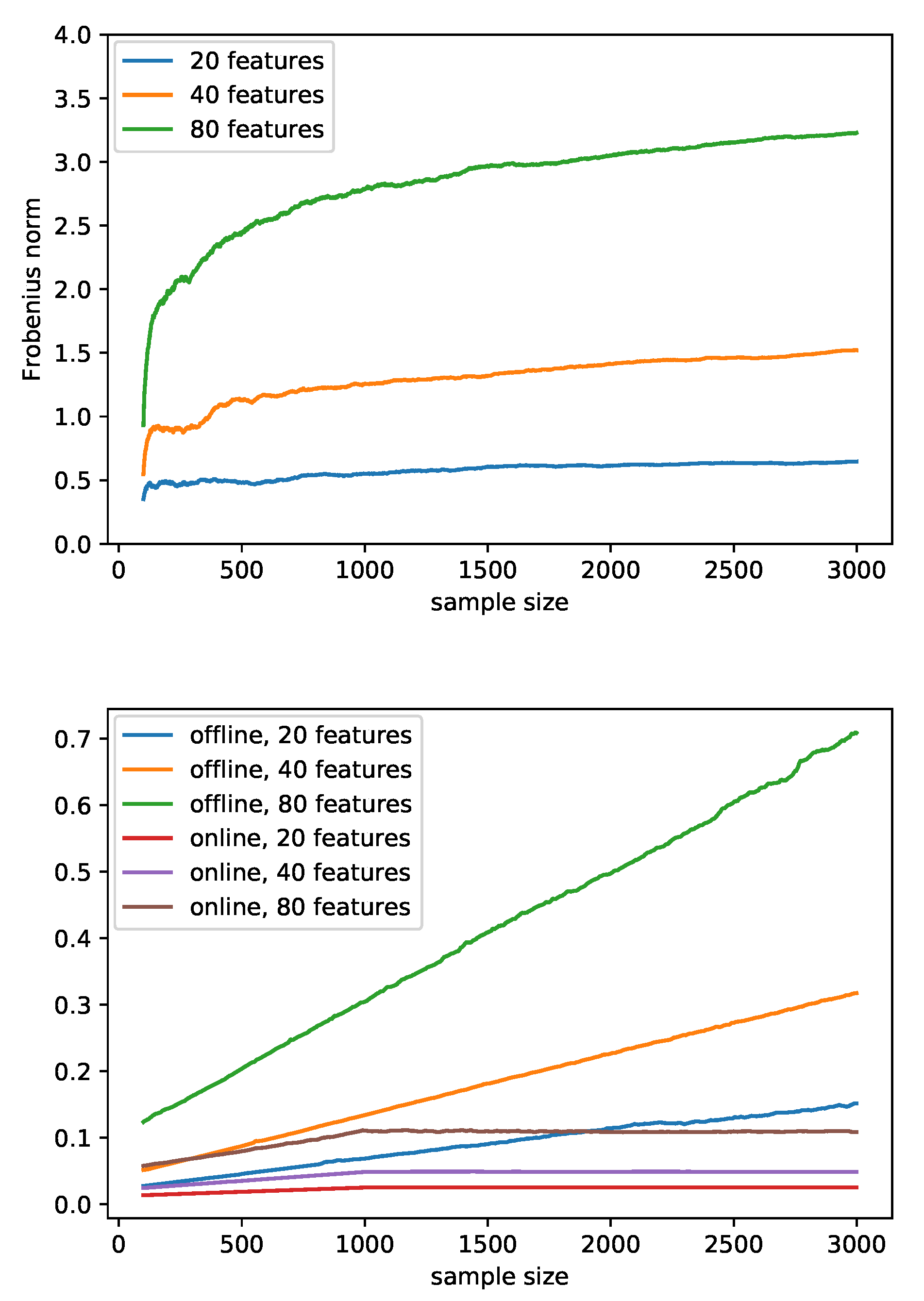
Comparison between Covariance Matrices
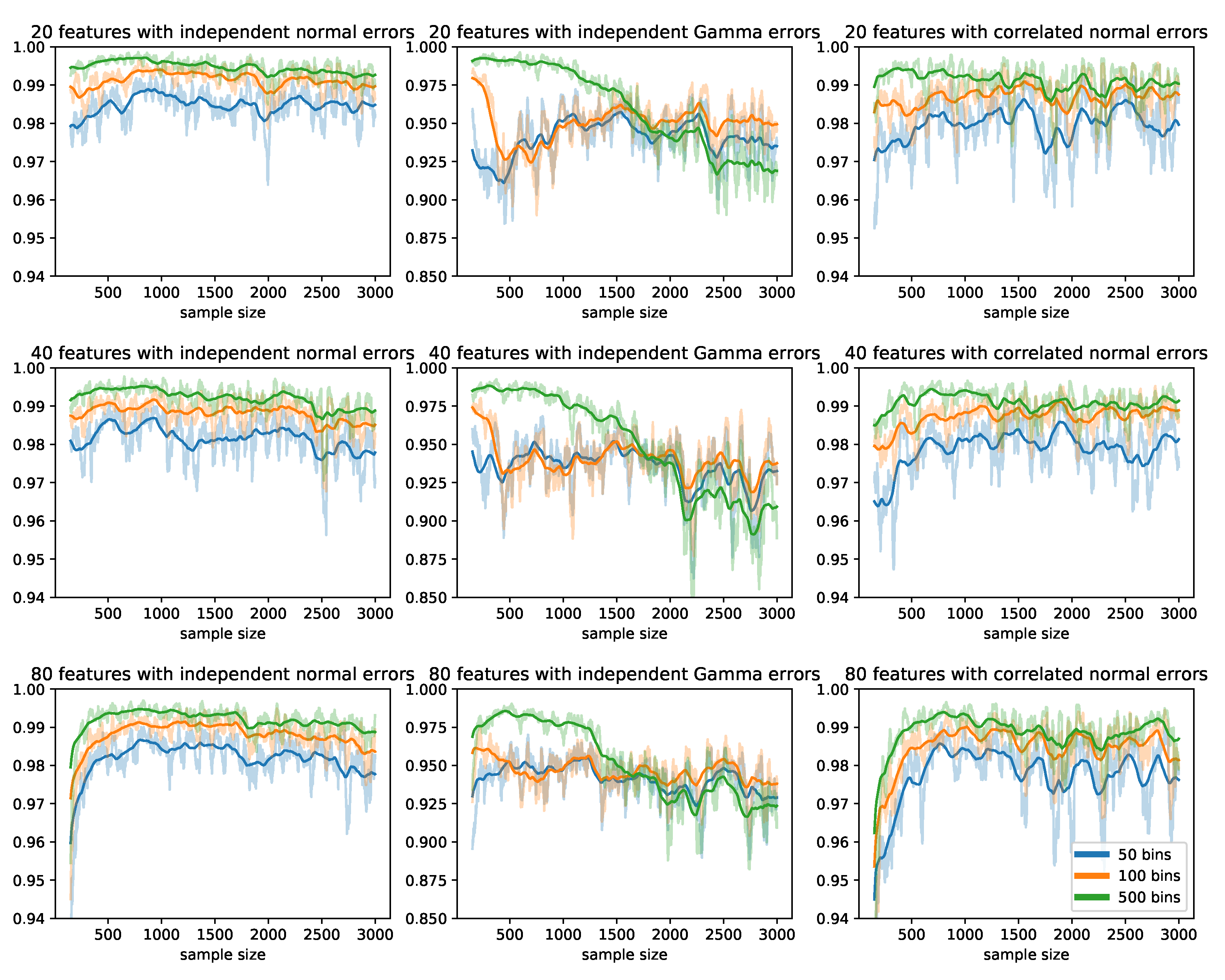
Comparison of the Test Statistics
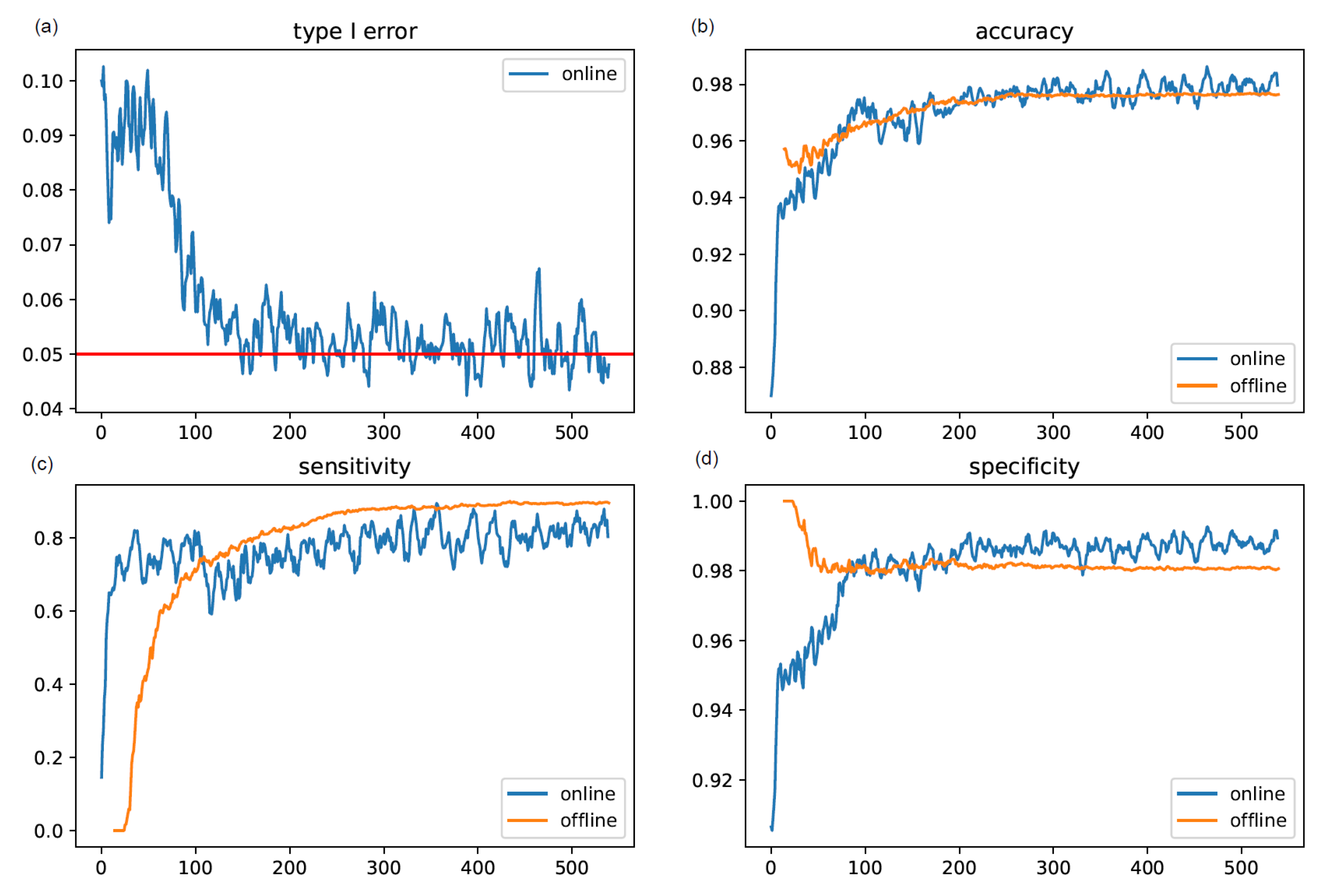
3.1.2. Comparison of the Performance of the Online Method with the Weighted Test Statistic and the Offline Method
3.2. Simulation with Pseudo-Data
4. Discussion and Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Onnela, J.P.; Rauch, S.L. Harnessing Smartphone-Based Digital Phenotyping to Enhance Behavioral and Mental Health. Neuropsychopharmacology 2016, 41, 1691–1696. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Torous, J.; Kiang, M.V.; Lorme, J.; Onnela, J.P. New Tools for New Research in Psychiatry: A Scalable and Customizable Platform to Empower Data Driven Smartphone Research. JMIR Ment. Health 2016, 3, e16. [Google Scholar] [CrossRef] [PubMed]
- Barnett, I.; Torous, J.; Staples, P.S.; Oval, L.; Keshavan, M.; Onnela, J.P. Relapse prediction in schizophrenia through digital phenotyping: A pilot study. Neuropsychopharmacology 2018, 43, 1660–1666. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ben-Zeev, D.; Brian, R.; Wang, R.; Wang, W.; Campbell, A.T.; Aung, M.S.; Merrill, M.; Tseng, V.W.; Choudhury, T.; Hauser, M.; et al. Tseng and Tanzeem Choudhury and Marta Hauser and John M. Kane and Emily A. Scherer, CrossCheck: Integrating self-report, behavioral sensing, and smartphone use to identify digital indicators of psychotic relapse. Psychiatr. Rehabil. J. 2017, 40, 266–275. [Google Scholar] [CrossRef] [PubMed]
- Faherty, L.J.; Hantsoo, L.; Appleby, D.; Sammel, M.D.; Bennett, I.M.; Wiebe, D.J. Movement patterns in women at risk for perinatal depression: Use of a mood-monitoring mobile application in pregnancy. J. Am. Med. Inform. Assoc. 2017, 24, 746–753. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Henson, P.; D’Mello, R.; Vaidyam, A.; Keshavan, M.; Torous, J. Anomaly detection to predict relapse risk in schizophrenia. Transl. Psychiatry 2021, 11, 1–6. [Google Scholar] [CrossRef] [PubMed]
- Forster, A.J.; Murff, H.J.; Peterson, J.F.; Gandhi, T.K.; Bates, D.W. The Incidence and Severity of Adverse Events Affecting Patients after Discharge from the Hospital. Ann. Intern. Med. 2003, 138, 161. [Google Scholar] [CrossRef] [PubMed]
- Chung, D.T.; Ryan, C.J.; Hadzi-Pavlovic, D.; Singh, S.P.; Stanton, C.; Large, M.M. Suicide Rates After Discharge from Psychiatric Facilities. JAMA Psychiatry 2017, 74, 694. [Google Scholar] [CrossRef] [PubMed]
- Meehan, J.; Kapur, N.; Hunt, I.M.; Turnbull, P.; Robinson, J.; Bickley, H.; Parsons, R.; Flynn, S.; Burns, J.; Amos, T. Suicide in mental health in-patients and within 3 months of discharge. Br. J. Psychiatry 2006, 188, 129–134. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Bickley, H.; Hunt, I.M.; Windfuhr, K.; Shaw, J.; Appleby, L.; Kapur, N. Suicide Within Two Weeks of Discharge From Psychiatric Inpatient Care: A Case-Control Study. Psychiatr. Serv. 2013, 64, 653–659. [Google Scholar] [CrossRef] [PubMed]
- Hsieh, R.J.; Chou, J.; Ho, C.H. Unsupervised Online Anomaly Detection on Multivariate Sensing Time Series Data for Smart Manufacturing. In Proceedings of the 2019 IEEE 12th Conference on Service-Oriented Computing and Applications (SOCA), Kaohsiung, Taiwan, 18–21 November 2019. [Google Scholar]
- Aminanto, M.E.; Zhu, L.; Ban, T.; Isawa, R.; Takahashi, T.; Inoue, D. Combating Threat-Alert Fatigue with Online Anomaly Detection Using Isolation Forest. In Proceedings of the International Conference on Neural Information Processing, Sydney, NSW, Australia, 12–15 December 2019; pp. 756–765. [Google Scholar]
- Yu, G.; Cai, Z.; Wang, S.; Chen, H.; Liu, F.; Liu, A. Unsupervised Online Anomaly Detection With Parameter Adaptation for KPI Abrupt Changes. IEEE Trans. Netw. Serv. Manag. 2020, 17, 1294–1308. [Google Scholar] [CrossRef]
- Karaahmetoglu, O.; Ilhan, F.; Balaban, I.; Kozat, S.S. Unsupervised Online Anomaly Detection On Irregularly Sampled Or Missing Valued Time-Series Data Using LSTM Networks. arXiv 2020, arXiv:2005.12005. [Google Scholar]
- Hwang, R.H.; Peng, M.C.; Huang, C.W.; Lin, P.C.; Nguyen, V.L. An Unsupervised Deep Learning Model for Early Network Traffic Anomaly Detection. IEEE Access 2020, 8, 30387–30399. [Google Scholar] [CrossRef]
- Jones, C.B.; Chavez, A.; Hossain-McKenzie, S.; Jacobs, N.; Summers, A.; Wright, B. Unsupervised Online Anomaly Detection to Identify Cyber-Attacks on Internet Connected Photovoltaic System Inverters. In Proceedings of the 2021 IEEE Power and Energy Conference at Illinois (PECI), Urbana, IL, USA, 1–2 April 2021. [Google Scholar]
- Scaranti, G.F.; Carvalho, L.F.; Junior, S.B.; Lloret, J.; Proença, M.L., Jr. Unsupervised online anomaly detection in Software Defined Network environments. Expert Syst. Appl. 2021, 191, 116225. [Google Scholar] [CrossRef]
- Knuth, D.E. The Art of Computer Programming; Pearson Education: London, UK, 1997. [Google Scholar]
- Beiwe Research Platform. Available online: www.beiwe.org (accessed on 27 May 2021).
- General Data Protection Regulation. Available online: https://gdpr-info.eu (accessed on 18 May 2021).
- GitHub Source Code. Available online: https://github.com/onnela-lab/forest/tree/master/forest (accessed on 7 October 2021).
- Panda, N.; Solsky, I.; Huang, E.J.; Lipsitz, S.; Pradarelli, J.C.; Delisle, M.; Cusack, J.C.; Gadd, M.A.; Lubitz, C.C.; Mullen, J.T.; et al. Gawande and Jukka-Pekka Onnela and Alex B. Haynes, Using Smartphones to Capture Novel Recovery Metrics After Cancer Surgery. JAMA Surg. 2020, 155, 123. [Google Scholar] [CrossRef] [PubMed]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| z\Day | 1–30 | 31–60 | 61–90 | 91–120 | 121–150 | 151–180 |
|---|---|---|---|---|---|---|
| 1 | 0.0566 | 0.0547 | 0.0514 | 0.0501 | 0.0492 | 0.0490 |
| 2 | 0.3765 | 0.4204 | 0.4143 | 0.4305 | 0.4254 | 0.4352 |
| 3 | 0.4505 | 0.4949 | 0.4849 | 0.4858 | 0.4915 | 0.4986 |
| 4 | 0.4558 | 0.5079 | 0.5071 | 0.5216 | 0.5355 | 0.5393 |
| z\Day | 1–30 | 31–60 | 61–90 | 91–120 | 121–150 | 151–180 |
|---|---|---|---|---|---|---|
| 1 | 0.8916 | 0.8945 | 0.9016 | 0.9007 | 0.8998 | 0.9023 |
| 2 | 0.9405 | 0.9446 | 0.9482 | 0.9489 | 0.9485 | 0.9451 |
| 3 | 0.9482 | 0.9533 | 0.9556 | 0.9577 | 0.9586 | 0.9589 |
| 4 | 0.9490 | 0.9551 | 0.9586 | 0.9609 | 0.9646 | 0.9648 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, G.; Onnela, J.-P. Online Anomaly Detection for Smartphone-Based Multivariate Behavioral Time Series Data. Sensors 2022, 22, 2110. https://doi.org/10.3390/s22062110
Liu G, Onnela J-P. Online Anomaly Detection for Smartphone-Based Multivariate Behavioral Time Series Data. Sensors. 2022; 22(6):2110. https://doi.org/10.3390/s22062110
Chicago/Turabian StyleLiu, Gang, and Jukka-Pekka Onnela. 2022. "Online Anomaly Detection for Smartphone-Based Multivariate Behavioral Time Series Data" Sensors 22, no. 6: 2110. https://doi.org/10.3390/s22062110