
A Novel Reinforcement Learning Collision Avoidance Algorithm for USVs Based on Maneuvering Characteristics and COLREGs


Abstract
:1. Introduction
- (1)
- The COLREGs need to be followed, which divide the responsibilities and restrict the behaviors when encountering other USVs;
- (2)
- The collision avoidance algorithm should be able to work stably and reliably for a long time;
- (3)
- The algorithm for multi-USV collision avoidance is critical;
- (4)
- The algorithm should have a tremendous real-time performance to face the real-time changes of the marine environment.
- (1)
- A characteristic Markov decision process for USV collision avoidance that fully considers the COLREGs and maneuverability of USVs was built. Remarkably, the agent realizes the training process without learning the coordinate information of the longitude and latitude. This makes the algorithm more realistic;
- (2)
- The double-DQN method was used to reduce the overestimation in the training process. The architecture of the deep Q network was improved by the dueling architecture; it can describe the value function in more detail. Furthermore, the way of storing training transitions was improved;
- (3)
- To solve the exploration problem of the agent, an optimized exploration method called category-based exploration suitable for the characteristics of the USV is proposed, which can effectively improve the exploration ability of the USV agents;
- (4)
- The RLCA algorithm can achieve an outstanding collision avoidance effect in many typical encounter situations. Specifically, the RLCA agent can obtain a higher average reward in training and has good engineering prospects.
2. Mathematical Model and COLREGs
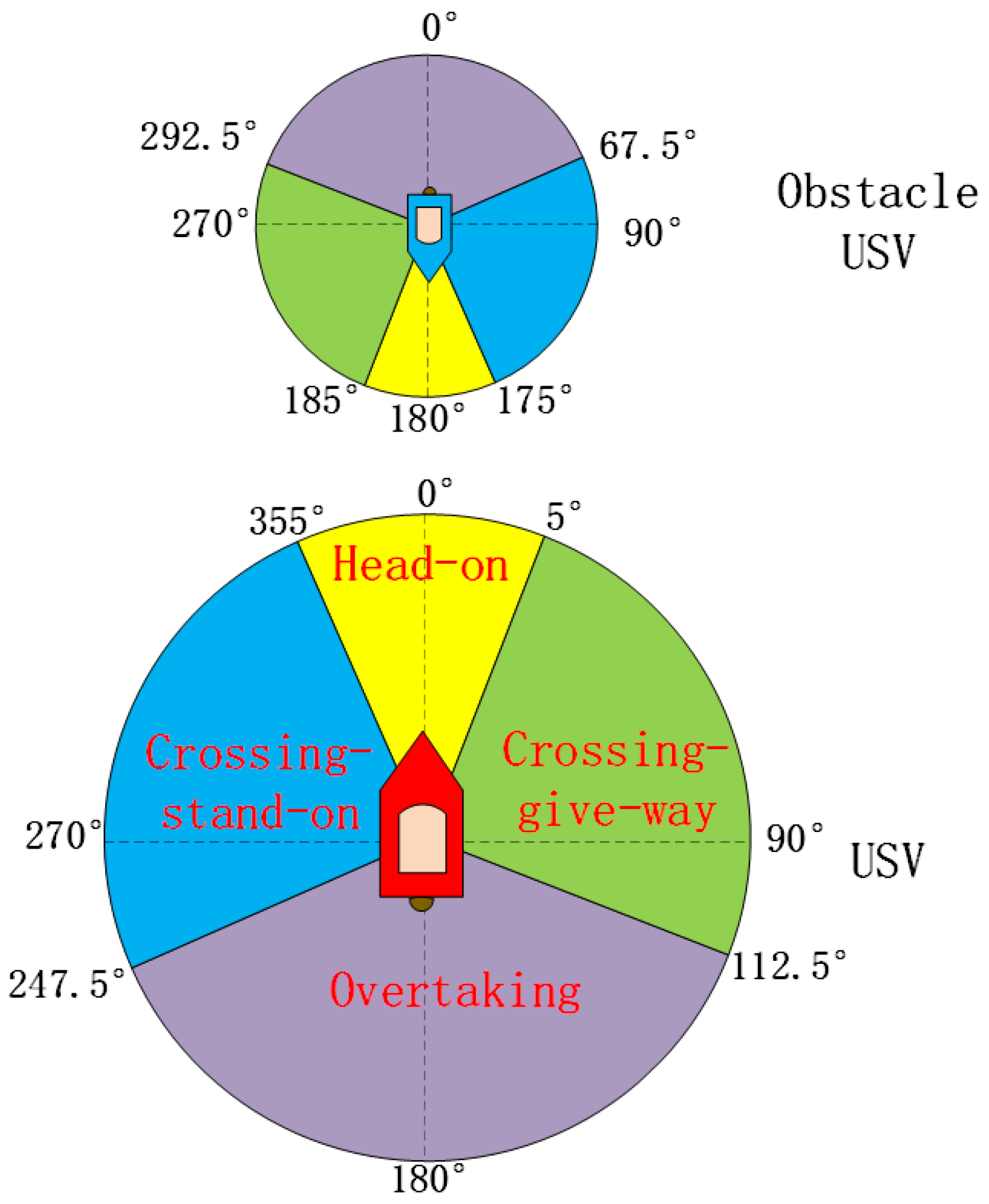
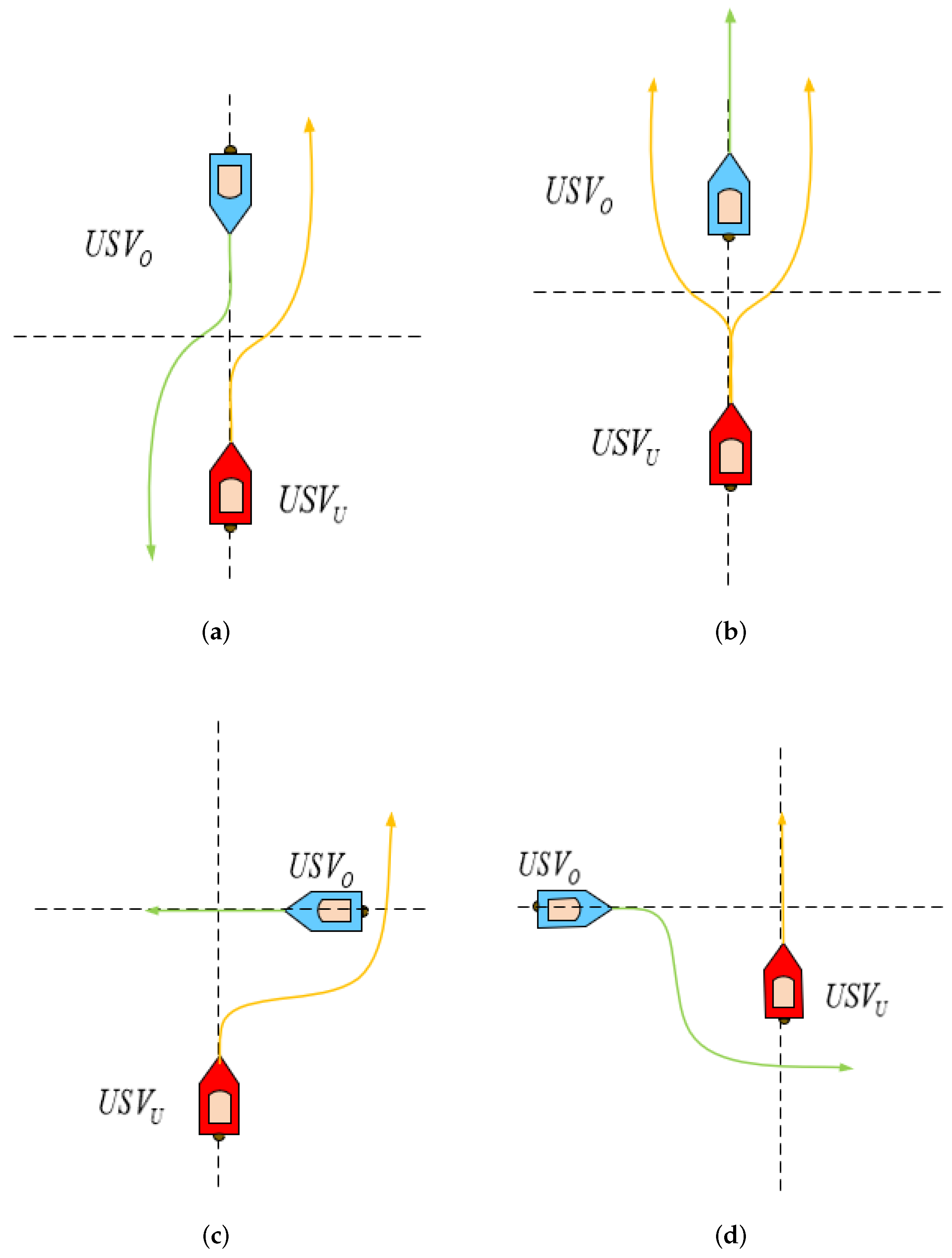
2.1. The COLREGs for USVs
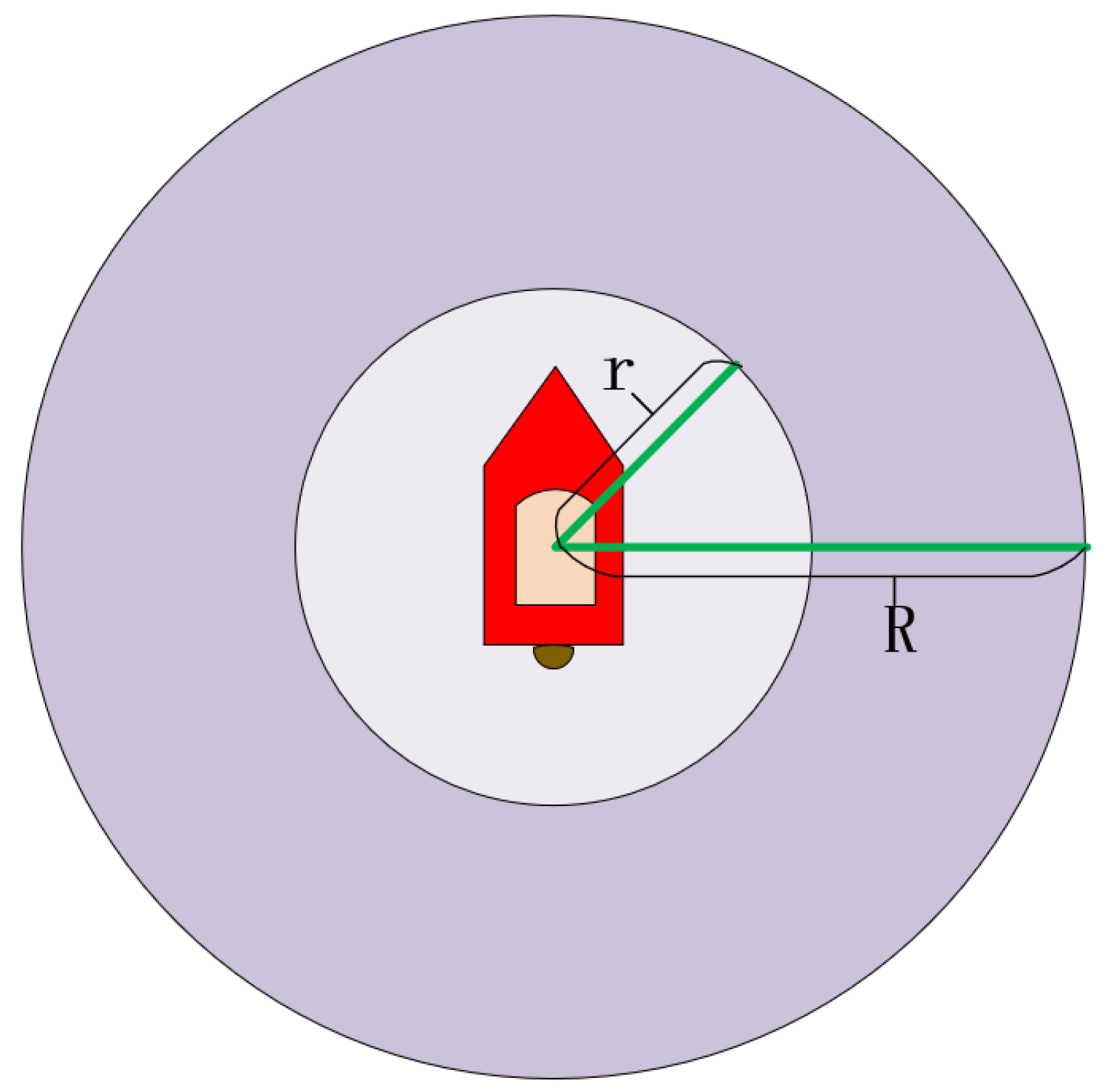
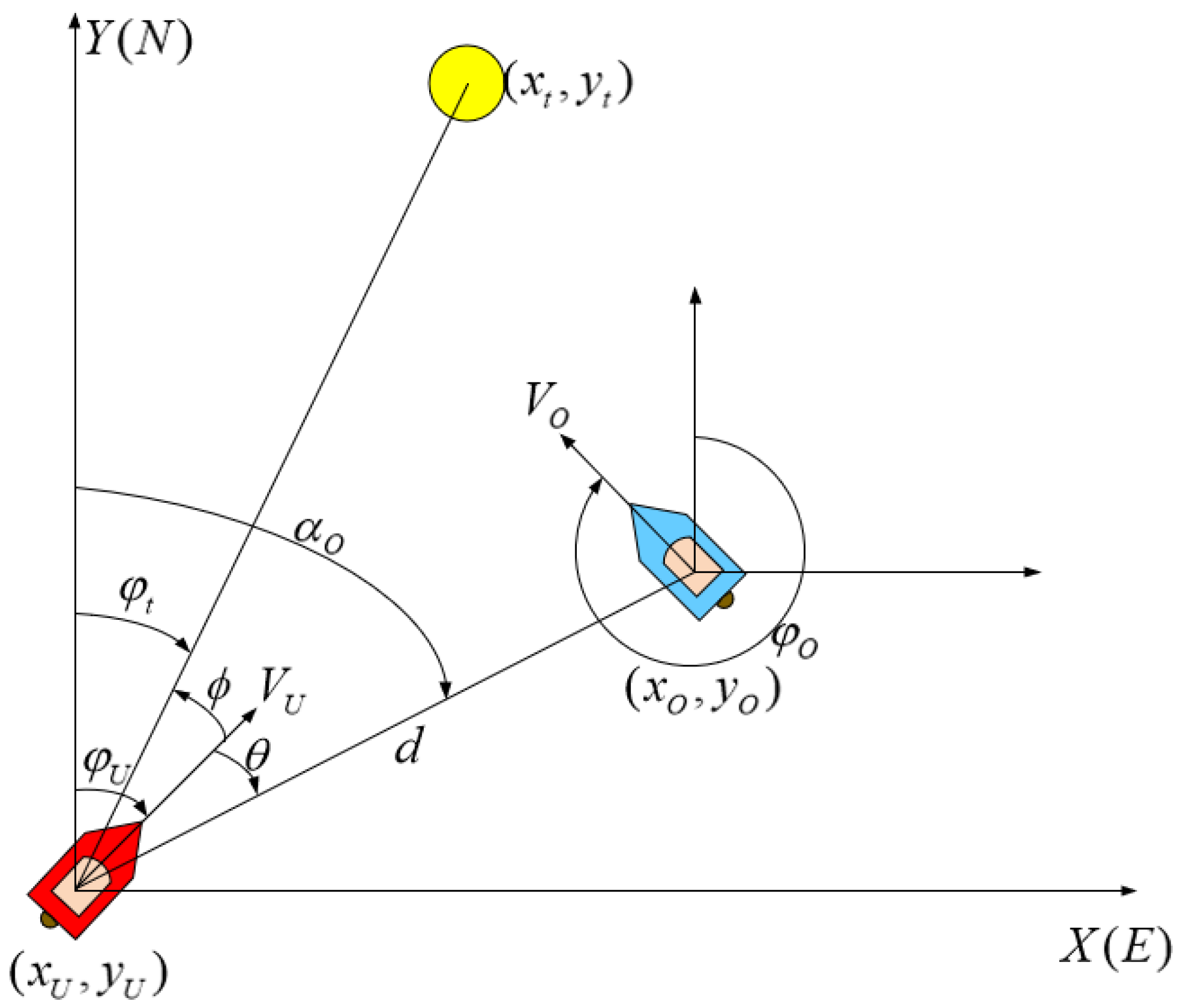
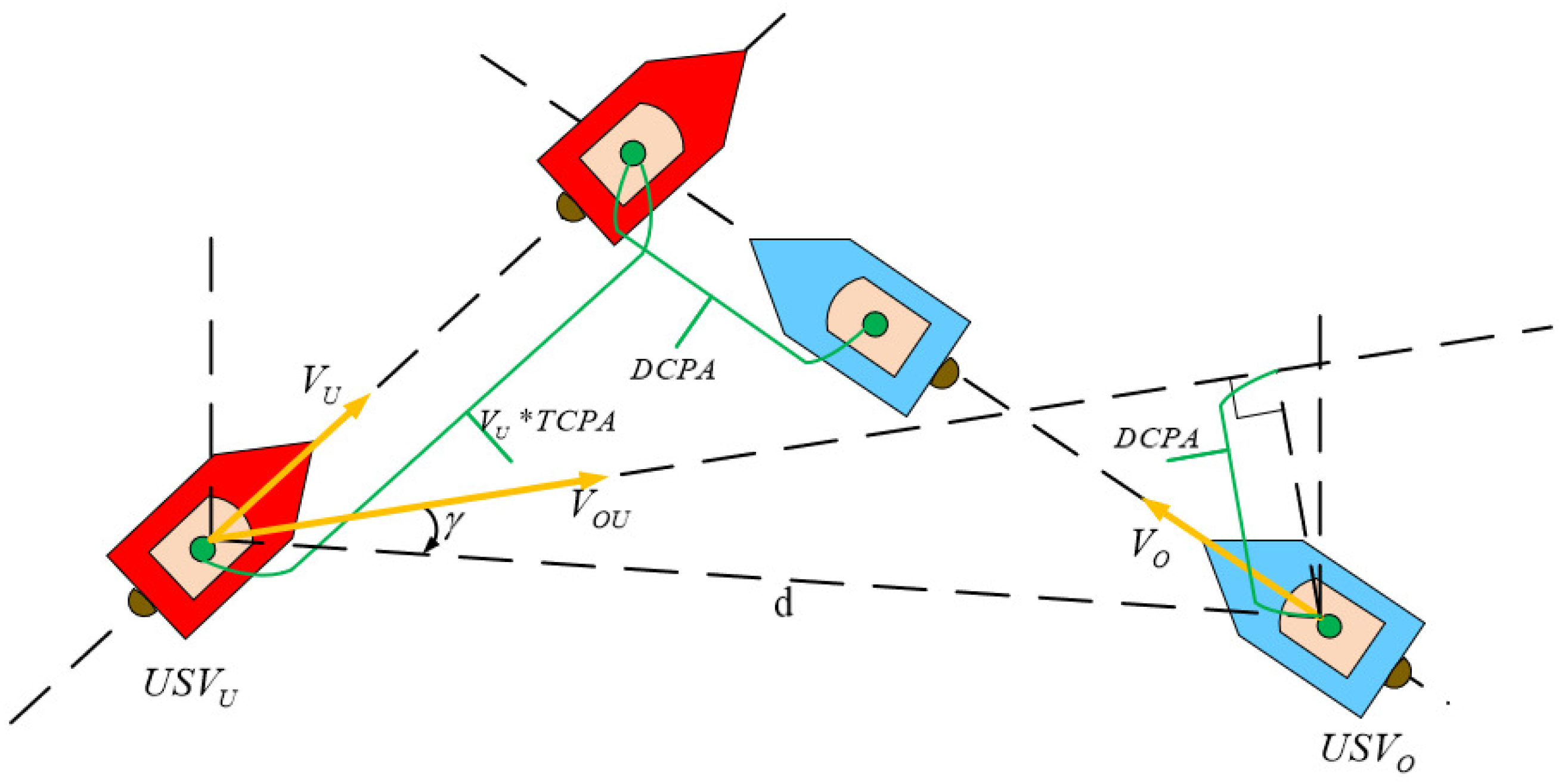
2.2. USV Motion Variables
2.3. USV Mathematical Model
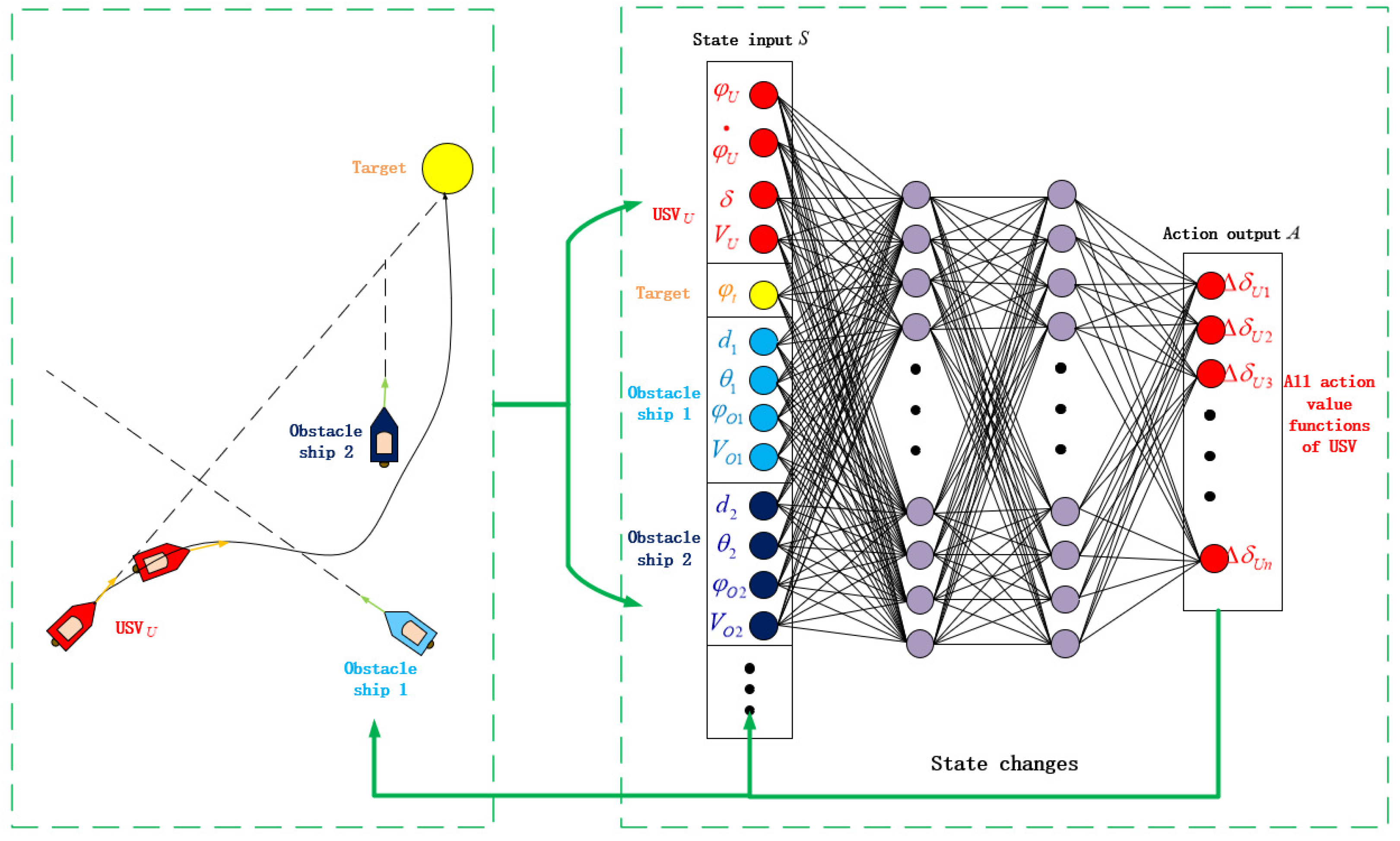
3. Reinforcement Learning Collision Avoidance Algorithm
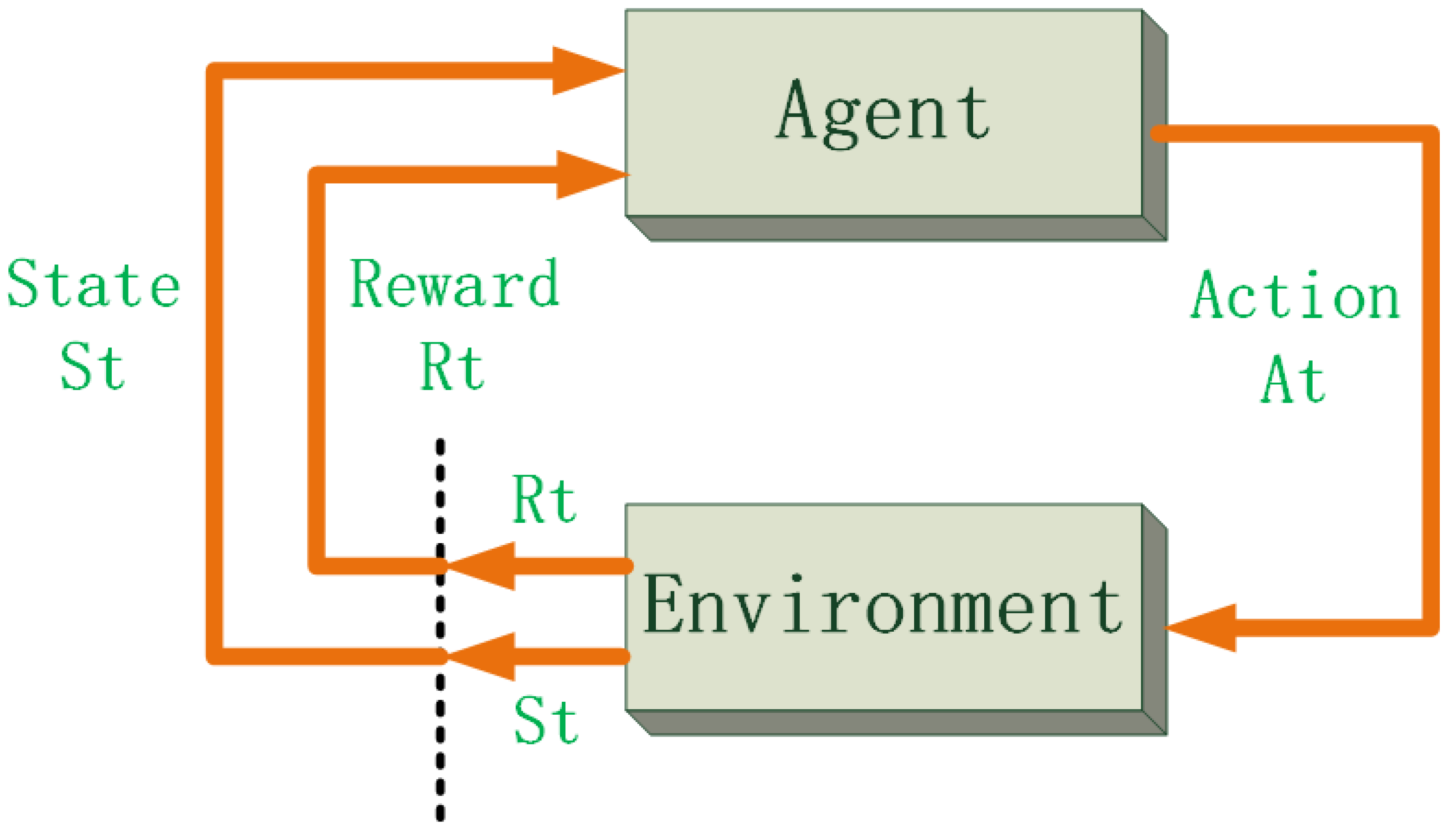
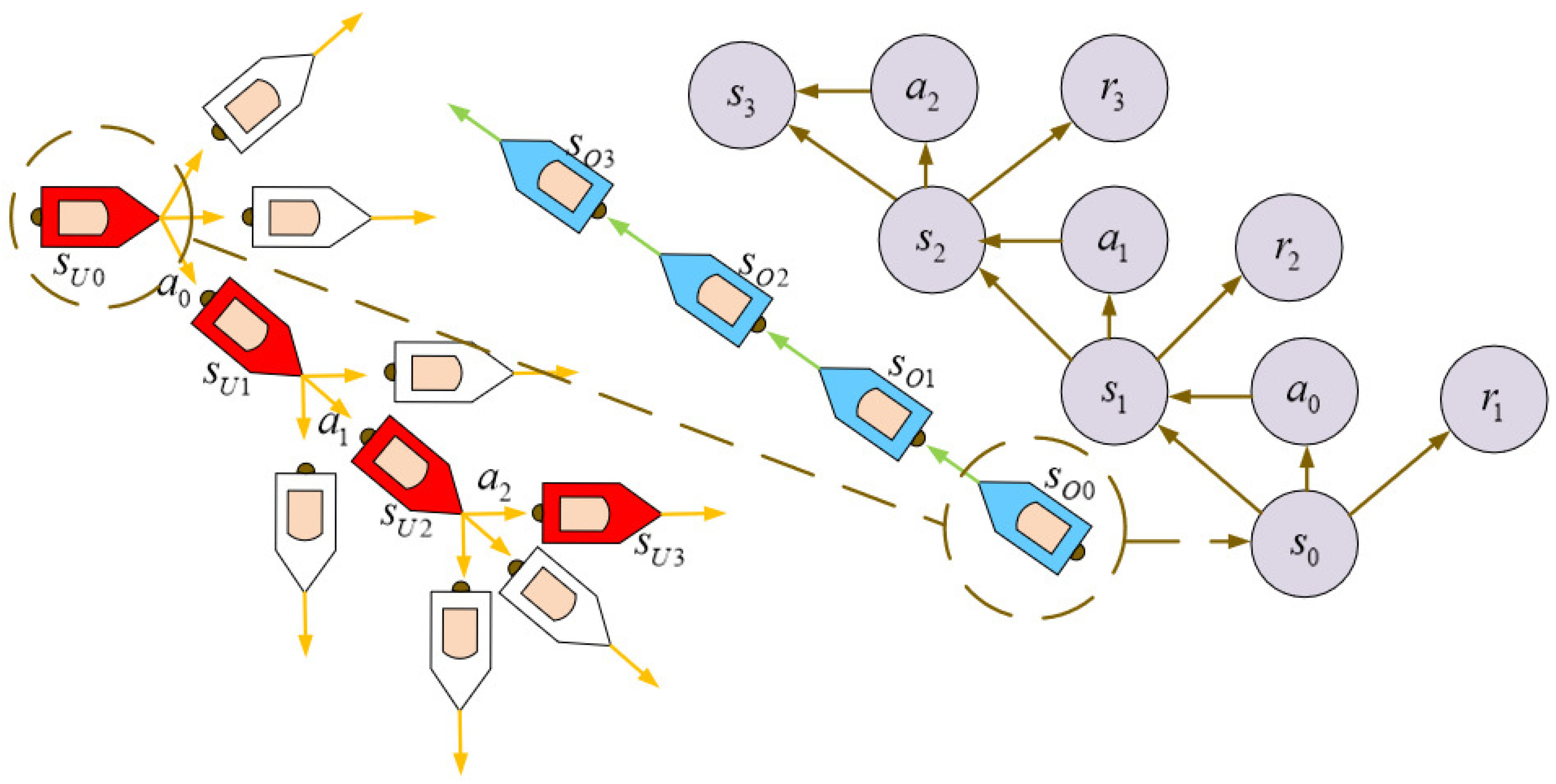
3.1. Reinforcement Learning and the Finite Markov Decision Process
3.2. Q Learning
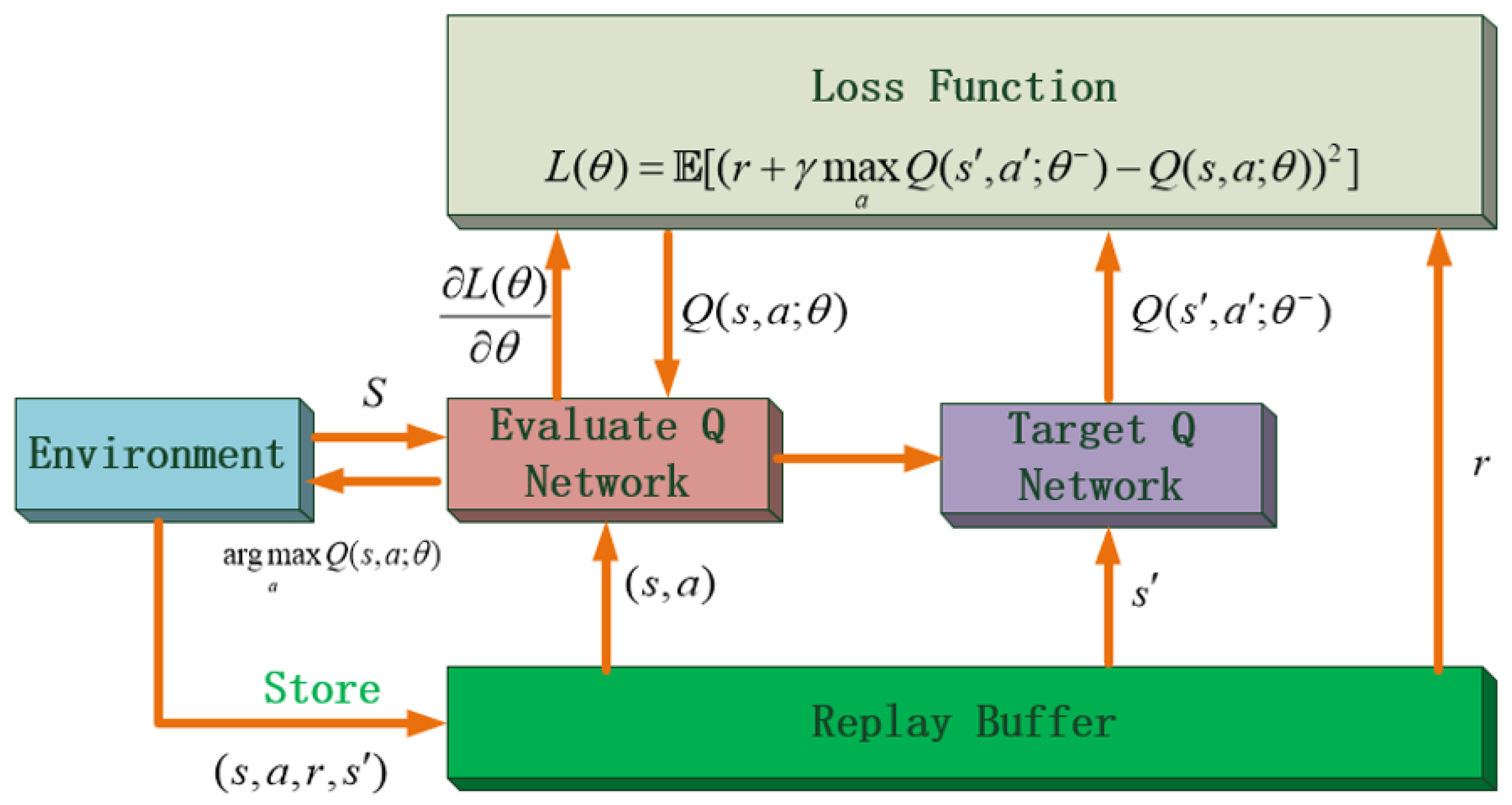
3.3. Deep Q Network
3.4. Collision Avoidance Algorithm with RL
- (1)
- The terminal is the position where the USV is expected to arrive at the end, and the terminal reward can guide the agent to the terminal position well. Therefore, the reward for reaching the terminal position is,
- (2)
- The most considerable thing in the collision avoidance of USVs is avoiding collision with the obstacle USVs. Therefore, the design of the collision reward can constrain the collision avoidance behavior strongly. The reward design for collisions is,
- (3)
- It is expected that the algorithm for the autonomous collision avoidance of USVs conforms to the actual COLREGs. As a consequence, it needs to make positive rewards for actions that follow the COLREGs and earn negative rewards for actions that are against the COLREGs. This kind of reward function can better constrain the USV behaviors following the COLREGs in different encounter situations. When the obstacle USV enters the dynamic area and with the danger of collision, according to the COLREGs, the actions of unreasonable rudder angle changes should be punished. Therefore, the reward function of the COLREGs is as follows.When ,When ,is the scale factor, and is the collision risk.
- (1)
- At each step, the agent will reach another state and obtain some specific stage rewards. This makes the agent able to obtain plentiful rewards during the exploration process, which guide the agent to achieve the terminal better. Therefore, certain rewards for the course were designed. The reward of the course is,where is a scale factor, and is a value distinguishing positive and negative rewards in the training environment;
- (2)
- It is desirable that the course of the USV be closer to , so the rewards of the course changes are as follows.If becomes smaller,If becomes bigger,If remains unchanged,The total reward function can be written as,
4. Improvement of the DQN Algorithm
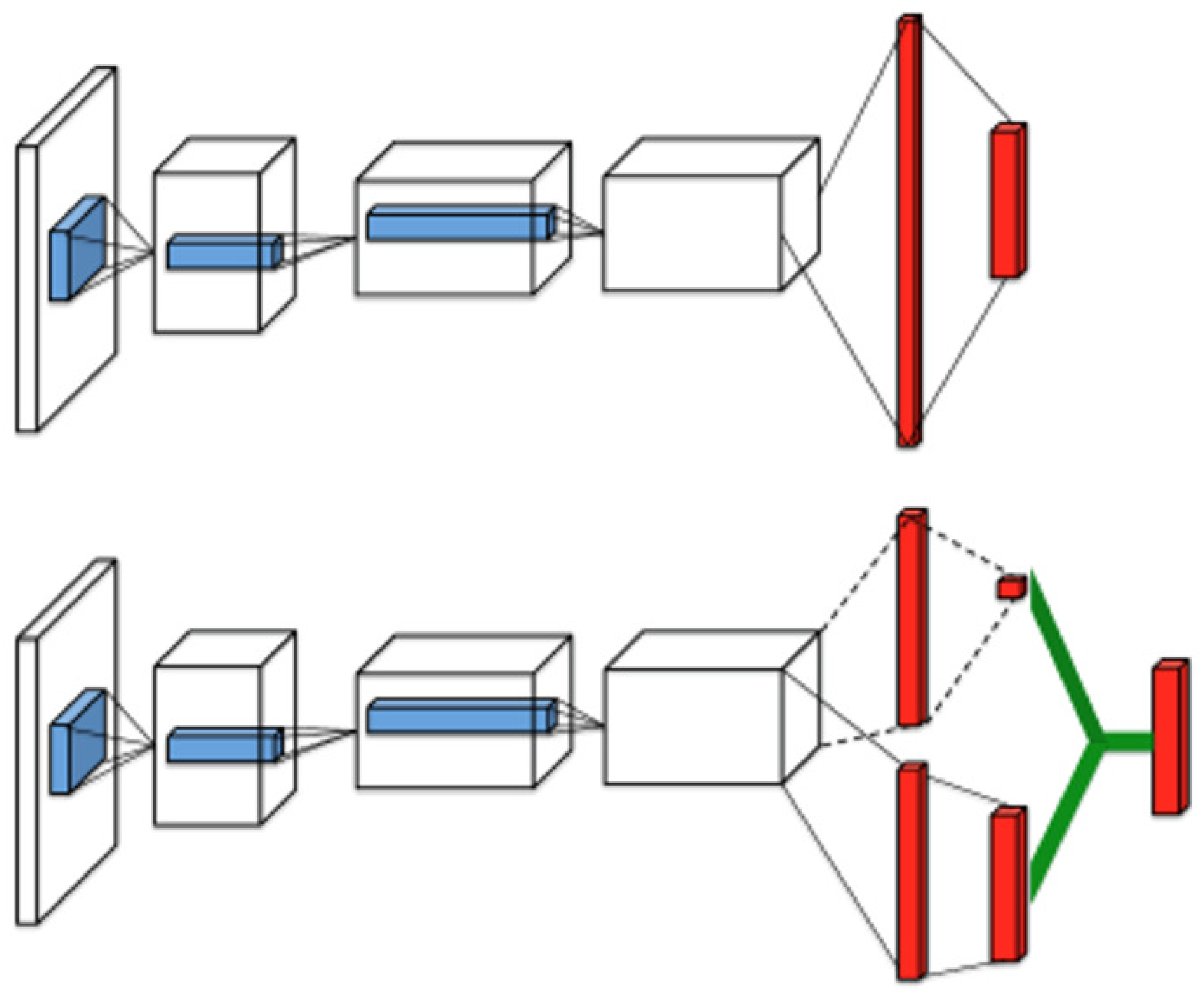
4.1. D3QN Algorithm
4.2. Category-Based Exploration Method
| Algorithm 1 RLCA algorithm code |
Initialize the training environment Initialize the replay memory buffer to capacity D Initialize the evaluate network with random weight Initialize the target network with random weight For episode = 1, M do Initialize the initial position of the own USV and the obstacle USVs While true update the training environment With probability , select USV action Otherwise, select USV action Execute action in the training environment, and obtain Obtain reward via maneuvering and the COLREGs Obtain the category, and add one in by the method of category-based exploration Obtain a reward based on category-based exploration Obtain the total reward Store transition in replay memory buffer D Sample the random minibatch of transitions from D Obtain Update the evaluate network parameters with gradient descent If the number of steps reaches the update step N update the target network with weight End if The number of steps plus 1 End while End while Return the weight |
4.3. Some Algorithm Details
5. Experiments
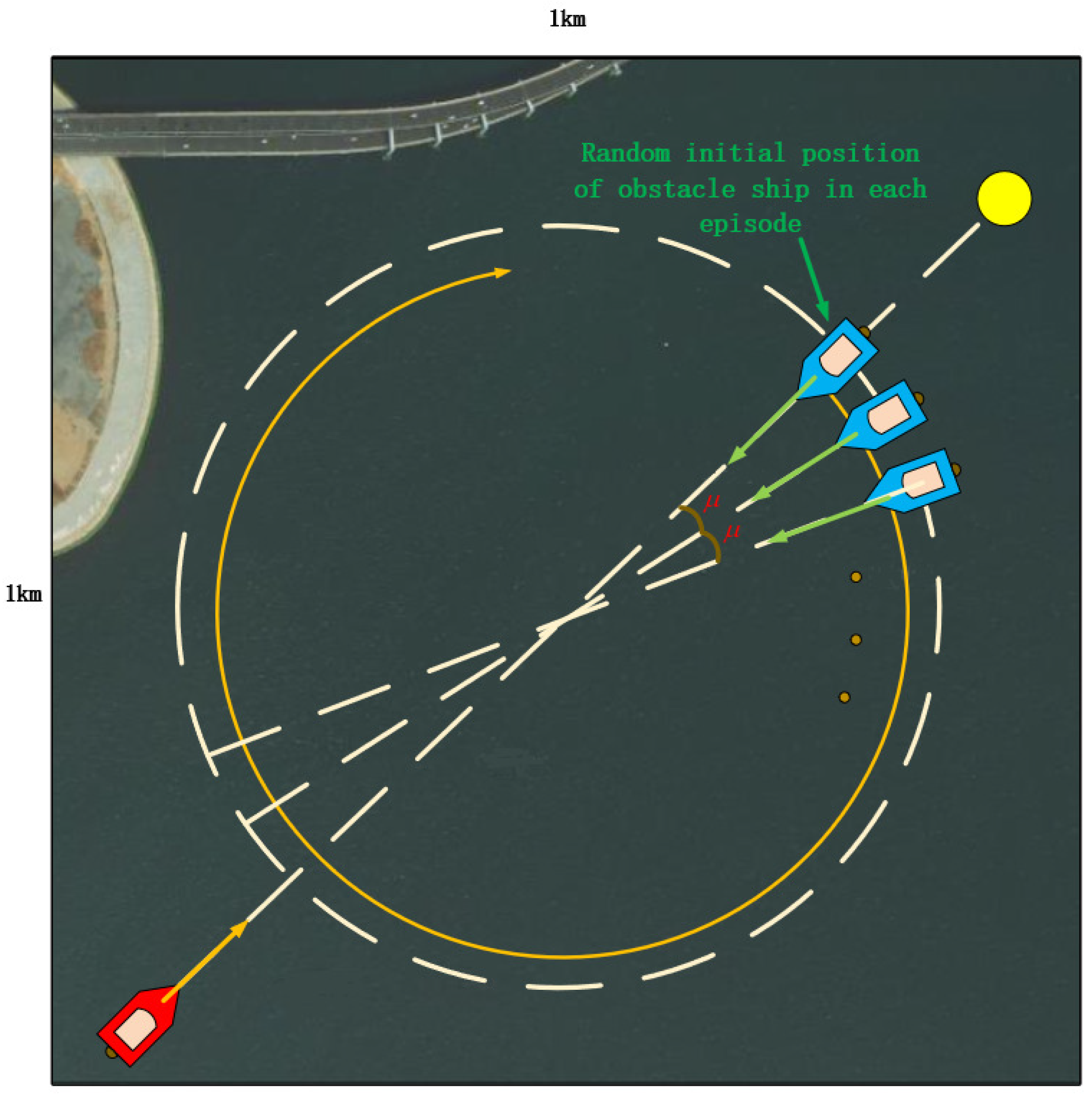
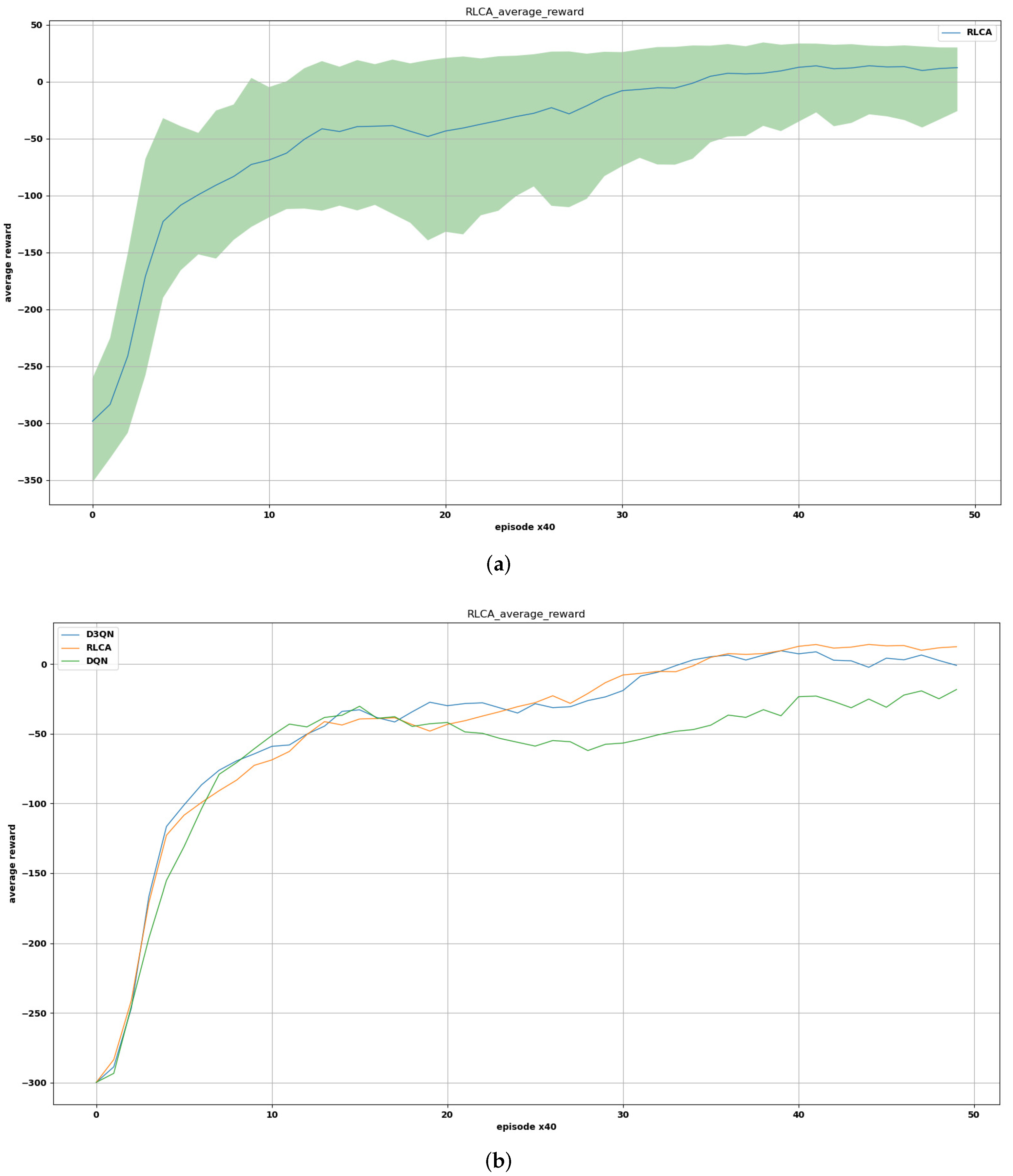
5.1. Training and Parameter Setting
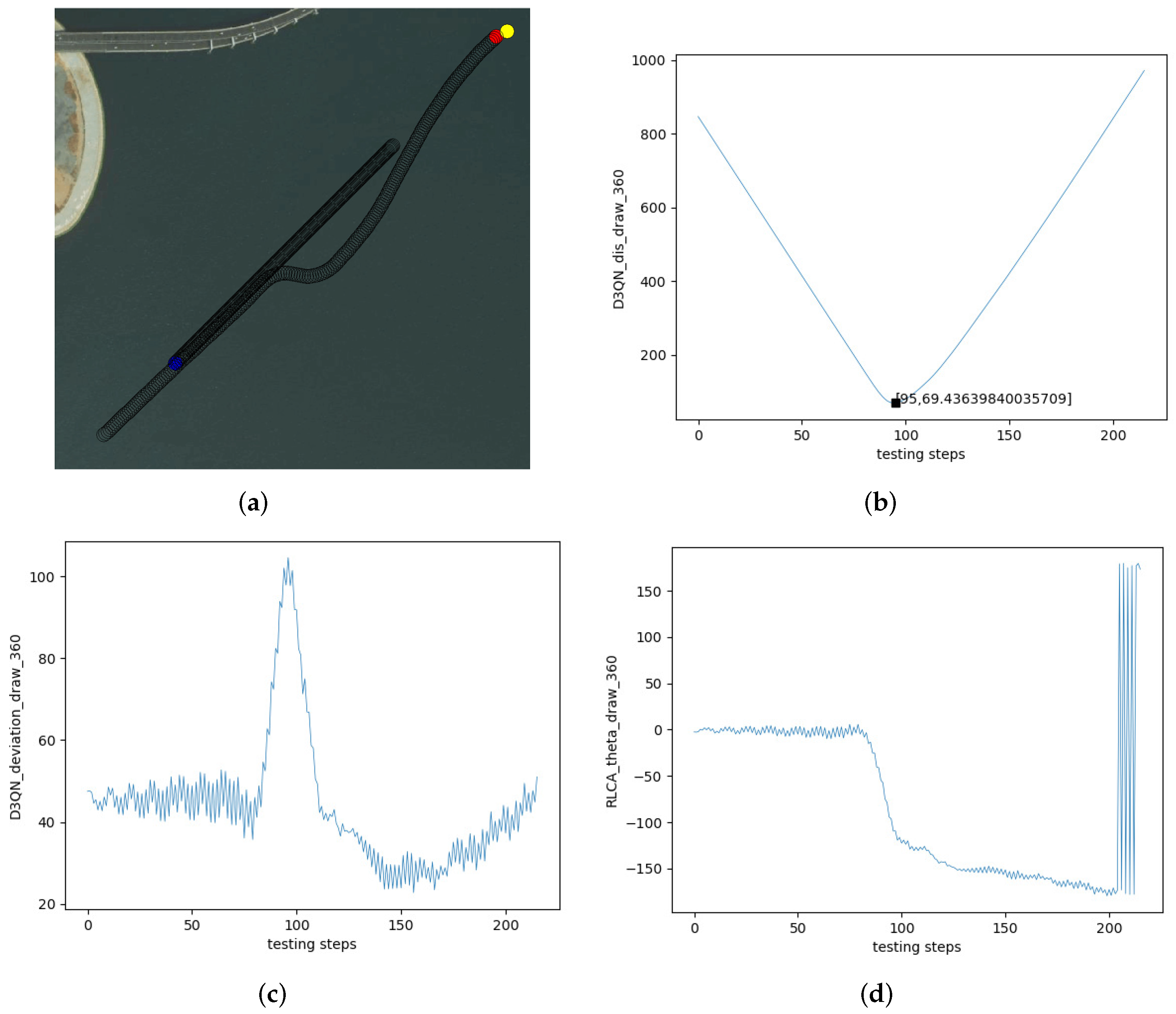
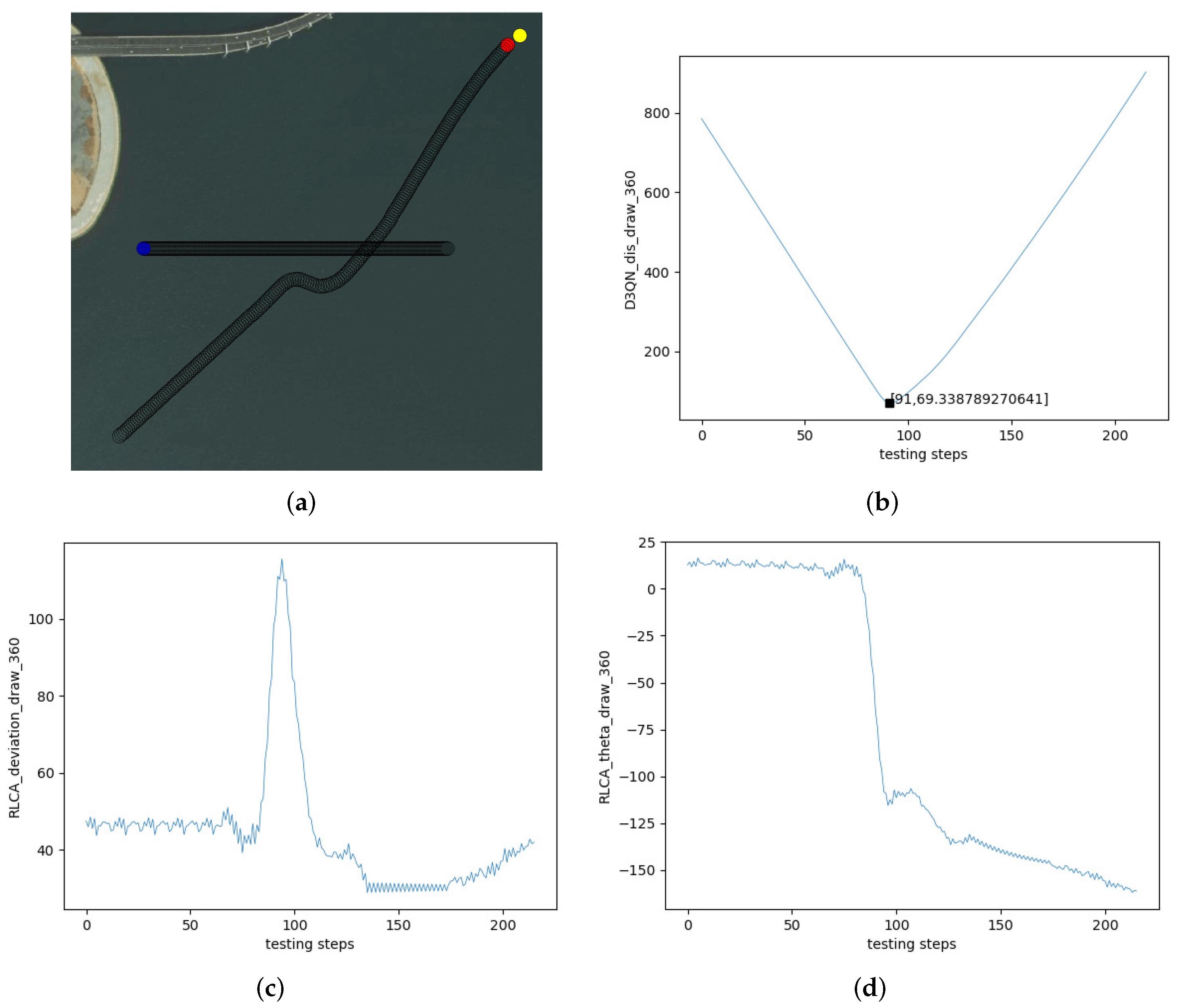
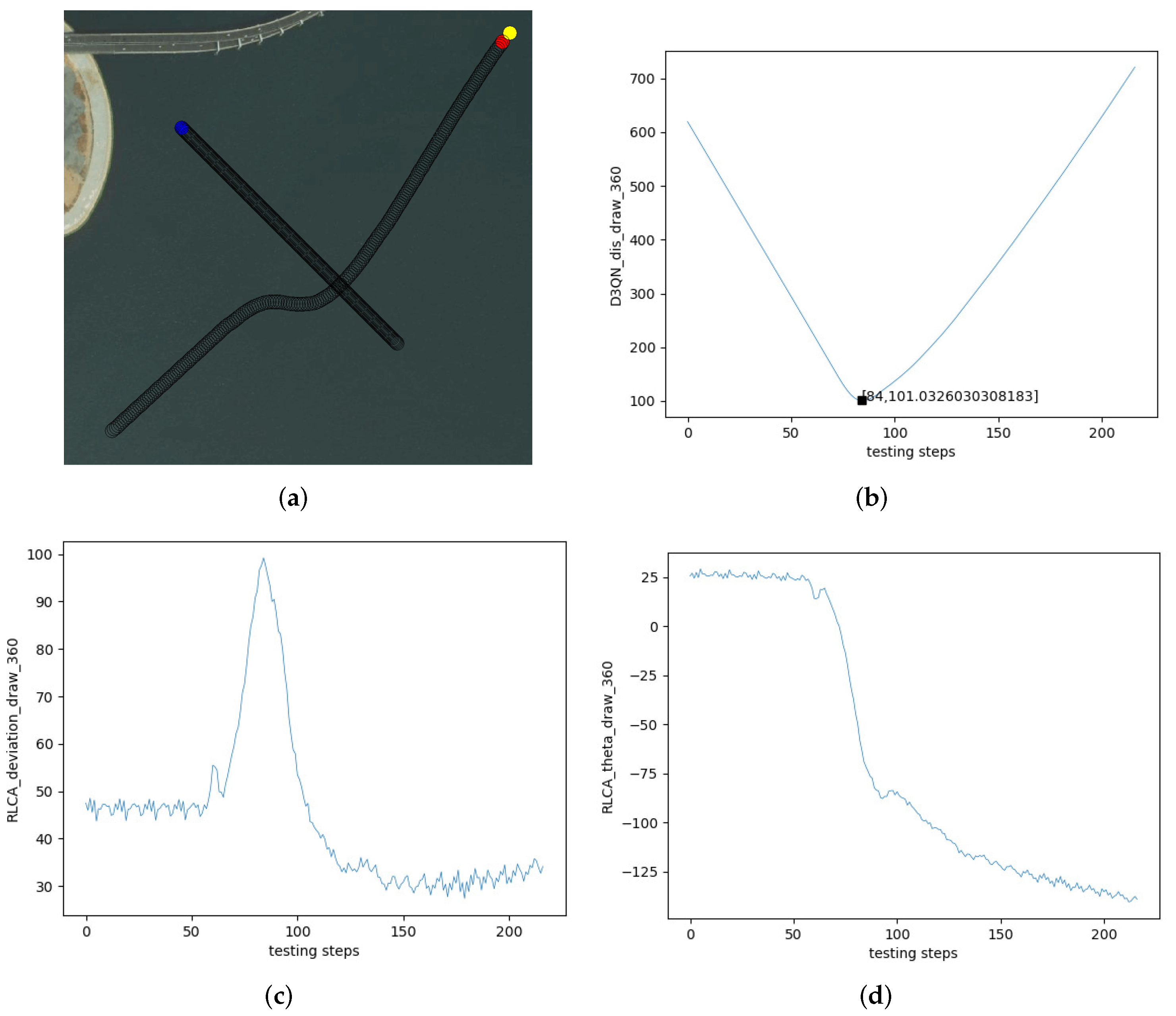
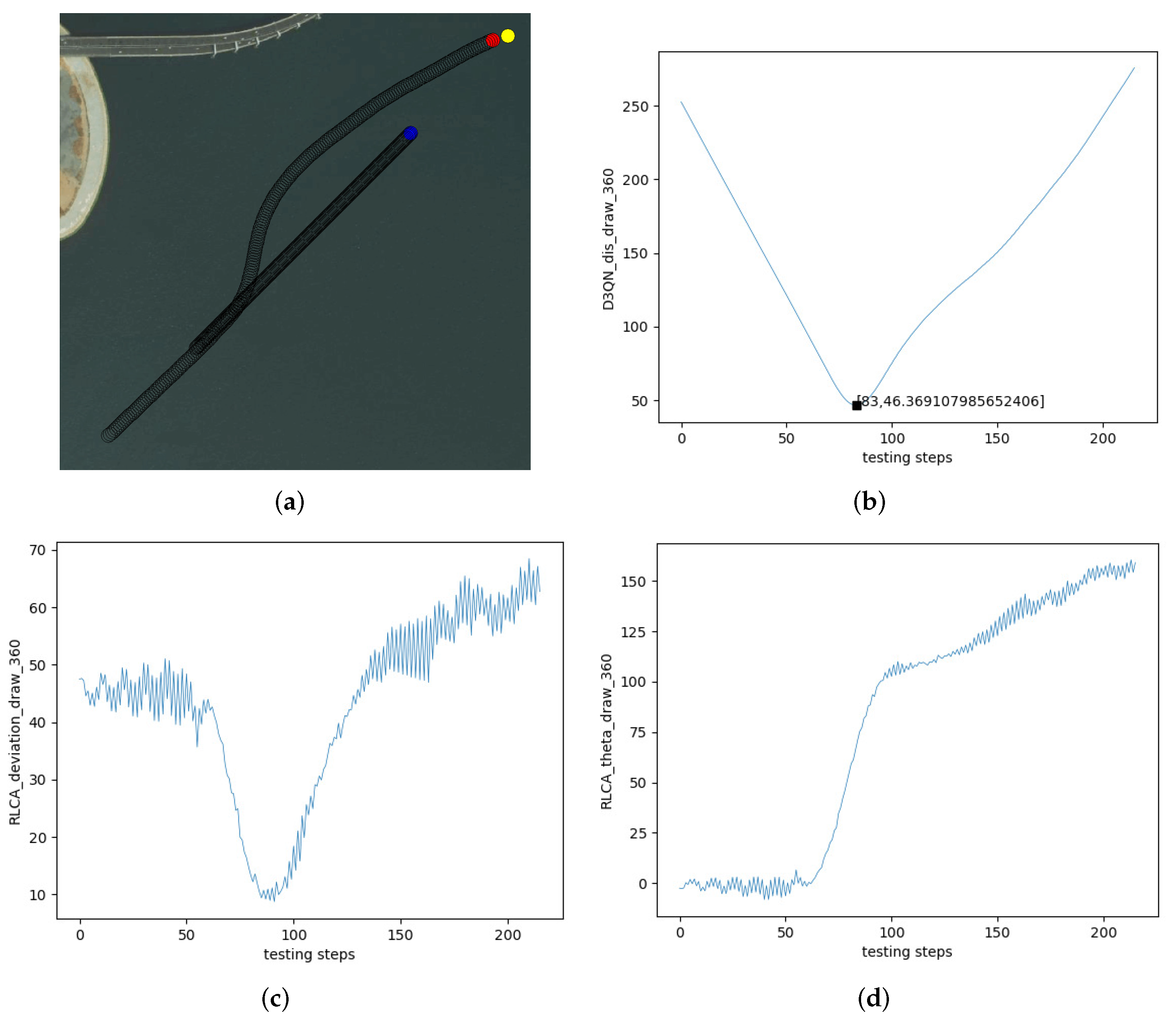
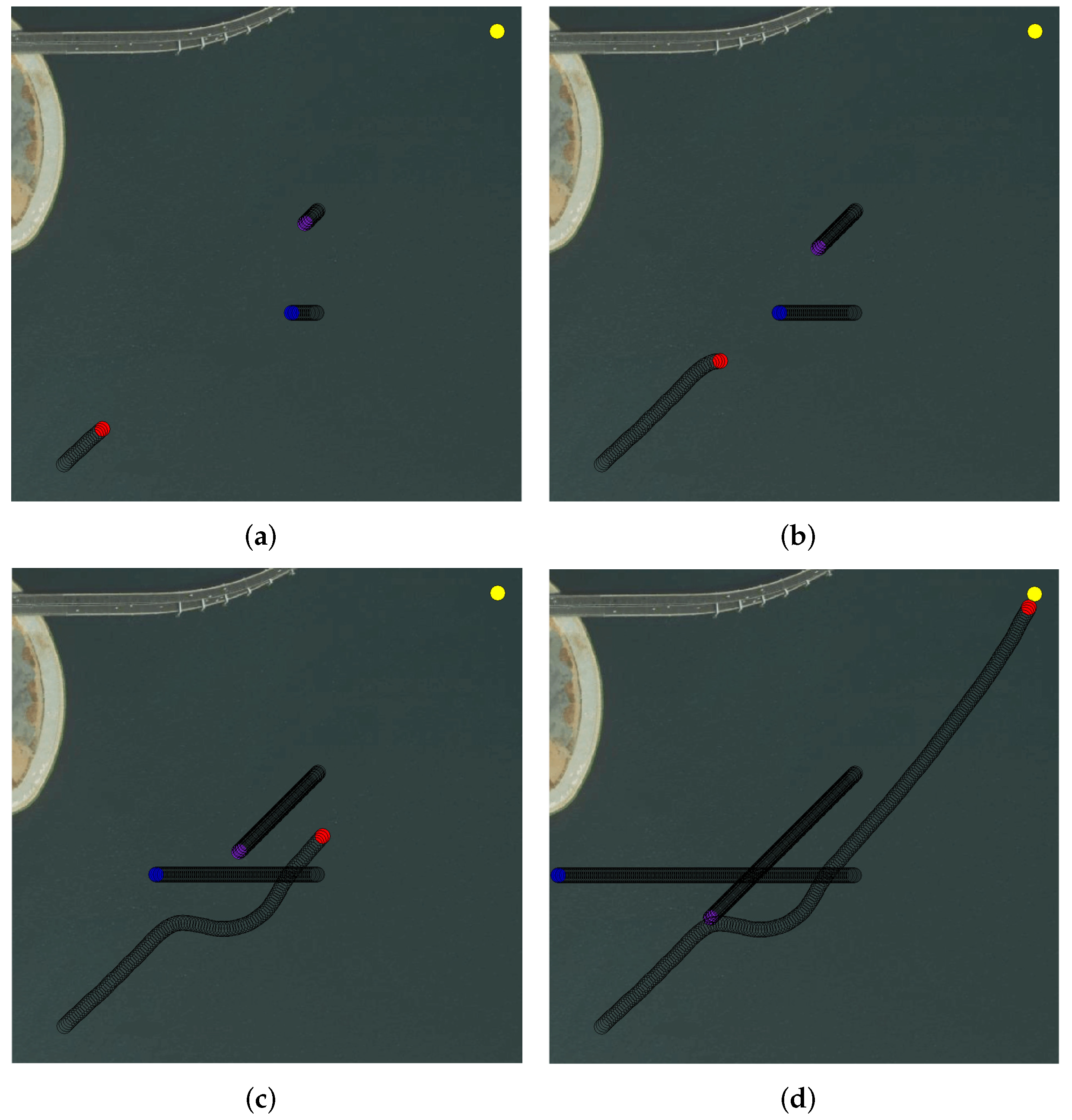
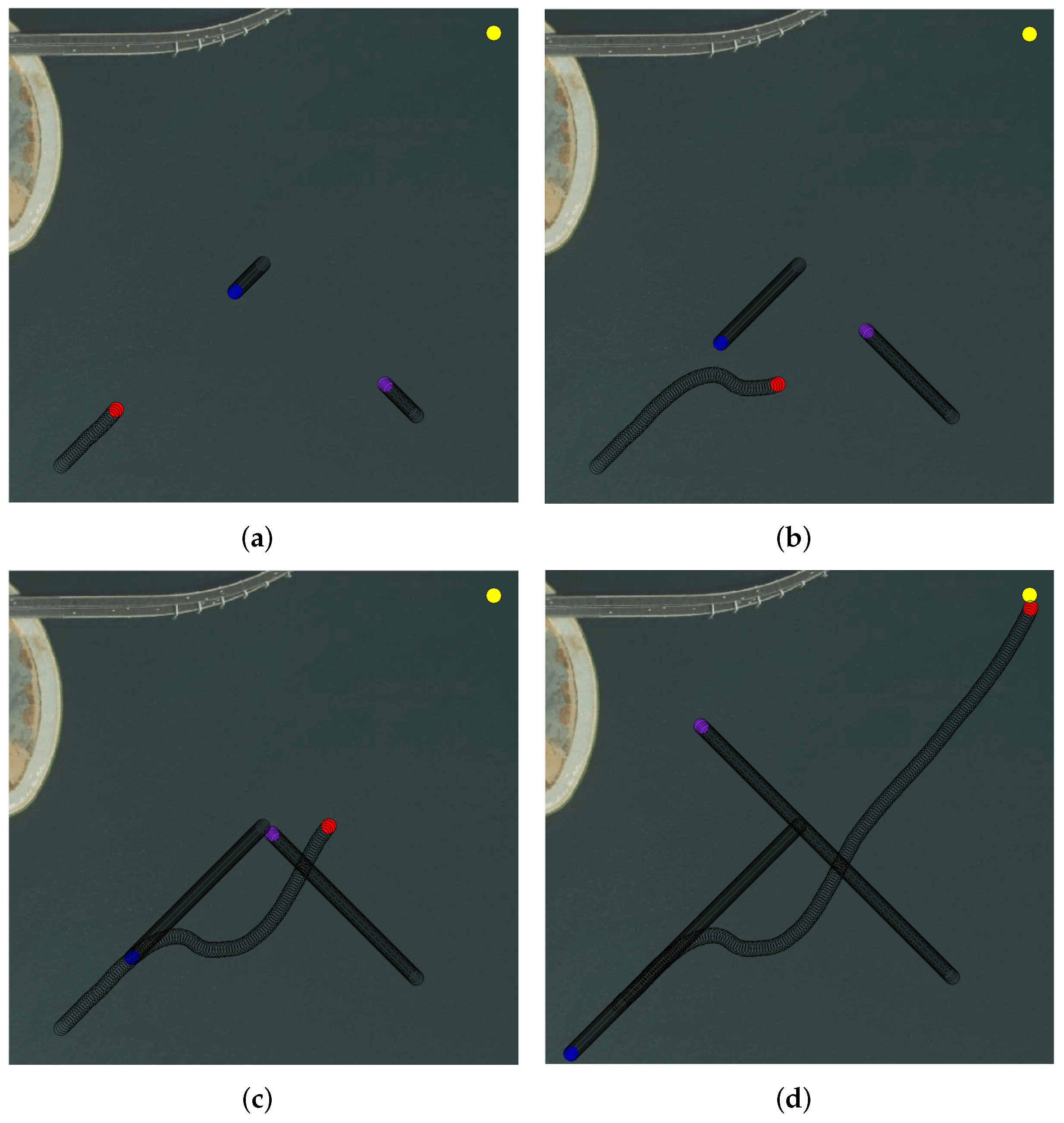
5.2. The Experiments on Multi-USV Collision Avoidance
6. Conclusions and Prospects
- (1)
- More factors in the training process should be considered, such as environmental interference and a more accurate USV mathematical model. This would make the trained agent more realistic;
- (2)
- The sampling method and network architecture will be further improved to obtain better training results;
- (3)
- Multi-agent reinforcement learning methods will be considered coping with the collaborative collision avoidance of multiple USVs;
- (4)
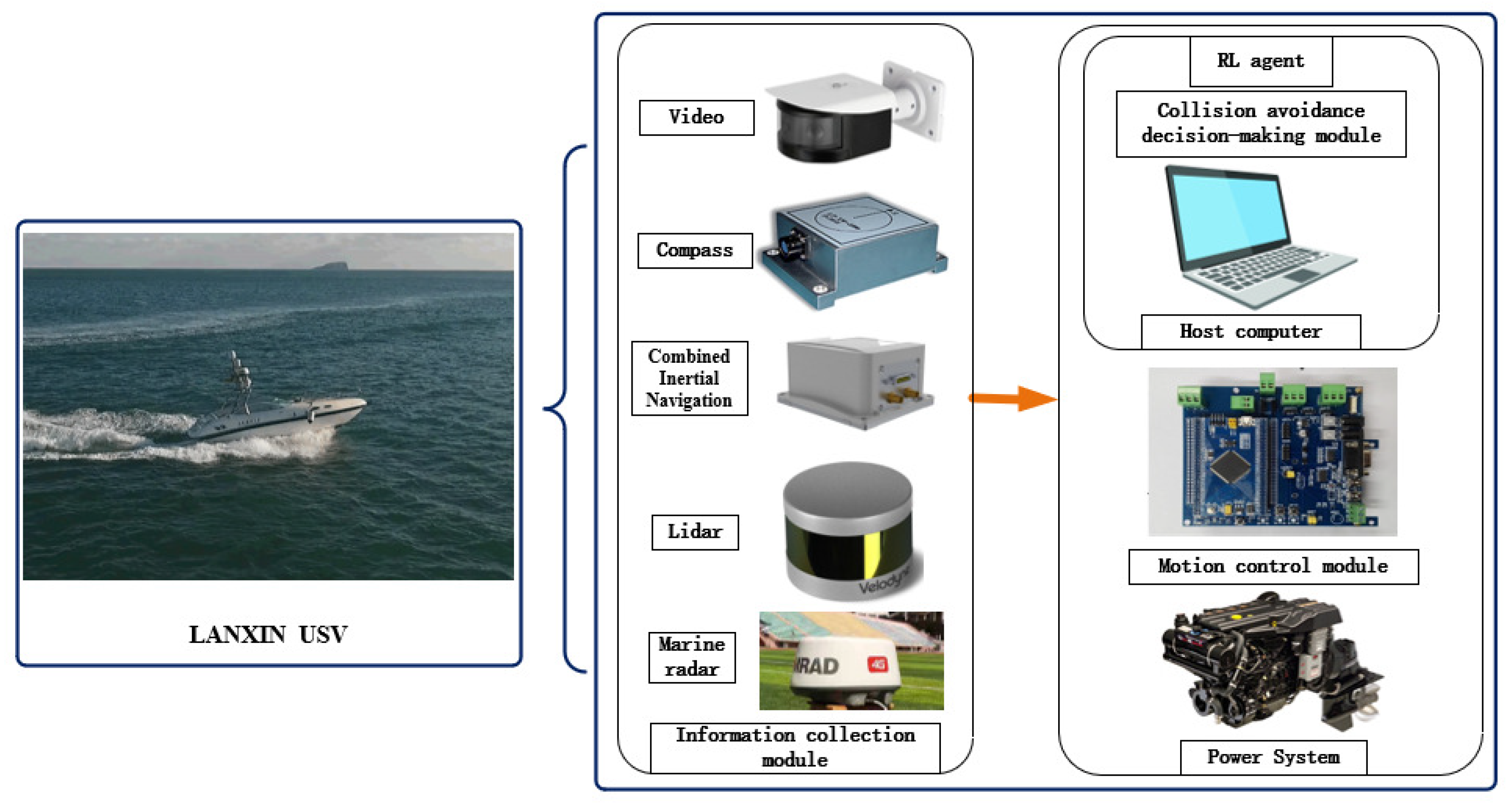
- Although reinforcement learning methods have been used in many research works on USV collision avoidance, their applications have been limited to experiments in simulation environments. In the subsequent works, the proposed autonomous collision avoidance algorithm for USVs will be applied to and experimented on real USVs. As shown in Figure 23, this will be the reinforcement learning autonomous collision avoidance control structure of the Lan Xin USV. It includes many modules for information collection, collision avoidance decision-making, and motion control, which maintain the operation of the collision avoidance system. It is certain that the applications of collision avoidance for USVs based on reinforcement learning algorithms will be bound to become more and more widespread;
- (5)
- The COLREGs are behavioral constraints for vessels commanded by humans. Because there are still few unmanned ships at sea today, the USVs trained under the COLREGs can coexist more easily with vessels commanded by humans. This is why the COLREGs were chosen in this paper. This is an attempt and not necessarily the best rule. How to design more suitable collision avoidance rules for USVs will be studied.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| USV | unmanned surface vehicle |
| RL | reinforcement learning |
| MDP | Markovian decision process |
| DOF | degree of freedom |
| COLREGs | international regulations for preventing collisions at sea |
| RLCA | reinforcement learning collision avoidance |
| D3QN | dueling double-deep Q network |
| DQN | deep Q network |
References
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Rusu, A.A.; Veness, J.; Bellemare, M.G.; Graves, A.; Riedmiller, M.; Fidjeland, A.K.; Ostrovski, G.; et al. Human-level control through deep reinforcement learning. Nature 2015, 518, 529–533. [Google Scholar] [CrossRef] [PubMed]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Graves, A.; Antonoglou, I.; Wierstra, D.; Riedmiller, M. Playing atari with deep reinforcement learning. arXiv 2013, arXiv:1312.5602. [Google Scholar]
- Vinyals, O.; Babuschkin, I.; Czarnecki, W.M.; Mathieu, M.; Dudzik, A.; Chung, J.; Choi, D.H.; Powell, R.; Ewalds, T.; Georgiev, P.; et al. Grandmaster level in StarCraft II using multi-agent reinforcement learning. Nature 2019, 575, 350–354. [Google Scholar] [CrossRef] [PubMed]
- Silver, D.; Schrittwieser, J.; Simonyan, K.; Antonoglou, I.; Huang, A.; Guez, A.; Hubert, T.; Baker, L.; Lai, M.; Bolton, A.; et al. Mastering the game of go without human knowledge. Nature 2017, 550, 354–359. [Google Scholar] [CrossRef] [PubMed]
- Liu, Z.; Zhang, Y.; Yu, X.; Yuan, C. Unmanned surface vehicles: An overview of developments and challenges. Annu. Rev. Control. 2016, 41, 71–93. [Google Scholar] [CrossRef]
- Cheng, Y.; Zhang, W. Concise deep reinforcement learning obstacle avoidance for underactuated unmanned marine vessels. Neurocomputing 2018, 272, 63–73. [Google Scholar] [CrossRef]
- Chun, D.; Roh, M.; Lee, H.; Ha, J.; Yu, D. Deep reinforcement learning-based collision avoidance for an autonomous ship. Ocean Eng. 2021, 234, 109216. [Google Scholar] [CrossRef]
- Schulman, J.; Wolski, F.; Dhariwal, P.; Radford, A.; Klimov, O. Proximal policy optimization algorithms. arXiv 2017, arXiv:1707.06347. [Google Scholar]
- Li, L.; Wu, D.; Huang, Y.; Yuan, Z. A path planning strategy unified with a COLREGS collision avoidance function based on deep reinforcement learning and artificial potential field. Appl. Ocean Res. 2021, 113, 102759. [Google Scholar] [CrossRef]
- Xie, S.; Chu, X.; Zheng, M.; Liu, C. A composite learning method for multi-ship collision avoidance based on reinforcement learning and inverse control. Neurocomputing 2020, 411, 375–392. [Google Scholar] [CrossRef]
- Mnih, V.; Badia, A.P.; Mirza, M.; Graves, A.; Lillicrap, T.; Harley, T.; Silver, D.; Kavukcuoglu, K. Asynchronous methods for deep reinforcement learning. Int. Conf. Mach. Learn. 2016, 1928–1937. [Google Scholar]
- Wu, X.; Chen, H.; Chen, C.; Zhong, M.; Xie, S.; Guo, Y.; Fujita, H. The autonomous navigation and obstacle avoidance for USVs with ANOA deep reinforcement learning method. Knowl.-Based Syst. 2020, 196, 105210. [Google Scholar] [CrossRef]
- Rummery, G.A.; Niranjan, M. On-Line Q-Learning Using Connectionist Systems; Citeseer: Princeton, NJ, USA, 1994. [Google Scholar]
- Andrecut, M.; ALI, M.K. Deep-Sarsa: A reinforcement learning algorithm for autonomous navigation. Int. J. Mod. Phys. C 2001, 12, 1513–1523. [Google Scholar] [CrossRef]
- Guo, S.; Zhang, X.; Zheng, Y.; Du, Y. An autonomous path planning model for unmanned ships based on deep reinforcement learning. Sensors 2020, 20, 426. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Lillicrap, T.P.; Hunt, J.J.; Pritzel, A.; Heess, N.; Erez, T.; Tassa, Y.; Silver, D.; Wierstra, D. Continuous control with deep reinforcement learning. arXiv 2015, arXiv:1509.02971. [Google Scholar]
- Woo, J.; Kim, N. Collision avoidance for an unmanned surface vehicle using deep reinforcement learning. Ocean Eng. 2020, 199, 107001. [Google Scholar] [CrossRef]
- Xu, X.; Lu, Y.; Liu, X.; Zhang, W. Intelligent collision avoidance algorithms for USVs via deep reinforcement learning under COLREGs. Ocean Eng. 2020, 217, 107704. [Google Scholar] [CrossRef]
- Fossen, T.I. Handbook of Marine Craft Hydrodynamics and Motion Control; John Wiley & Sons: Hoboken, NJ, USA, 2011. [Google Scholar]
- Zhao, L.; Roh, M. COLREGs-compliant multiship collision avoidance based on deep reinforcement learning. Ocean Eng. 2019, 191, 106436. [Google Scholar] [CrossRef]
- Zhang, X.; Wang, C.; Liu, Y.; Chen, X. Decision-making for the autonomous navigation of maritime autonomous surface ships based on scene division and deep reinforcement learning. Sensors 2019, 19, 4055. [Google Scholar] [CrossRef] [Green Version]
- Shen, H.; Hashimoto, H.; Matsuda, A.; Taniguchi, Y.; Terada, D.; Guo, C. Automatic collision avoidance of multiple ships based on deep Q-learning. Appl. Ocean Res. 2019, 86, 268–288. [Google Scholar] [CrossRef]
- Zhou, X.; Wu, P.; Zhang, H.; Guo, W.; Liu, Y. Learn to navigate: Cooperative path planning for unmanned surface vehicles using deep reinforcement learning. IEEE Access 2019, 7, 165262–165278. [Google Scholar] [CrossRef]
- Sun, X.; Wang, G.; Fan, Y.; Mu, D.; Qiu, B. A formation autonomous navigation system for unmanned surface vehicles with distributed control strategy. IEEE Trans. Intell. Transp. Syst. 2020, 22, 2834–2845. [Google Scholar] [CrossRef]
- Szlapczynski, R.; Szlapczynska, J. Review of ship safety domains: Models and applications. Ocean Eng. 2017, 145, 277–289. [Google Scholar] [CrossRef]
- Li, L.; Zhou, Z.; Wang, B.; Miao, L.; An, Z.; Xiao, X. Domain Adaptive Ship Detection in Optical Remote Sensing Images. Remote Sens. 2021, 13, 3168. [Google Scholar] [CrossRef]
- Norrbin, N.H. Theory and observations on the use of a mathematical model for ship manoeuvring in deep and confined waters. SSPA Rep. Nr 1971, 68, 807–905. [Google Scholar]
- Sutton, R.S.; Barto, A.G. Reinforcement Learning: An Introduction; MIT Press: Cambridge, MA, USA, 2018. [Google Scholar]
- Schrittwieser, J.; Antonoglou, I.; Hubert, T.; Simonyan, K.; Sifre, L.; Schmitt, S.; Guez, A.; Lockhart, E.; Hassabis, D.; Graepel, T.; et al. Mastering atari, go, chess and shogi by planning with a learned model. Nature 1992, 588, 604–609. [Google Scholar] [CrossRef] [PubMed]
- Watkins, C.J.C.H. Learning from Delayed Rewards; University of Cambridge: Cambridge, UK, 1989. [Google Scholar]
- Sutton, R.S.; McAllester, D.A.; Singh, S.P.; Mansour, Y. Policy gradient methods for reinforcement learning with function approximation. Adv. Neural Inf. Process. Syst. 2000, 12, 1057–1063. [Google Scholar]
- Silver, D.; Lever, G.; Heess, N.; Degris, T.; Wierstra, D.; Riedmiller, M. Deterministic policy gradient algorithms. Int. Conf. Mach. Learn. 2014, 32, 387–395. [Google Scholar]
- Sutton, R.S. Learning to predict by the methods of temporal differences. Mach. Learn. 1988, 3, 9–44. [Google Scholar] [CrossRef]
- Watkins, C.J.; Dayan, P. Q-learning. Mach. Learn. 1992, 8, 279–292. [Google Scholar] [CrossRef]
- Bengio, Y. Learning deep architectures for Al. Found. Trends Mach. 2007, 2, 1–127. [Google Scholar]
- Tesauro, G. Practical issues in temporal difference learning. Mach. Learn. 1992, 8, 257–277. [Google Scholar] [CrossRef] [Green Version]
- Schmidhuber, J. Deep learning in neural networks: An overview. Neural Netw. 2015, 61, 85–117. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Van, H.H. Double Q-learning. Adv. Neural Inf. Process. Syst. 2010, 23, 2613–2621. [Google Scholar]
- Sutton, R.S. Generalization in reinforcement learning: Successful examples using sparse coarse coding. Adv. Neural Inf. Process. Syst. 1996, 8, 1038–1044. [Google Scholar]
- Van, H.H.; Guez, A.; Silver, D. Deep reinforcement learning with double q-learning. Proc. AAAI Conf. Artif. Intell. 2016, 30, 1. [Google Scholar]
- Wang, Z.; Schaul, T.; Hessel, M.; Hasselt, H.; Lanctot, M.; Freitas, N. Dueling network architectures for deep reinforcement learning. Int. Conf. Mach. Learn. 2016, 48, 1995–2003. [Google Scholar]
- Ecoffet, A.; Huizinga, J.; Lehman, J.; Stanley, K.O.; Clune, J. First return, then explore. Nature 2021, 590, 580–586. [Google Scholar] [CrossRef]
- Bellemare, M.; Srinivasan, S.; Ostrovski, G.; Schaul, T.; Schaul, D.; Munos, R. Unifying count-based exploration and intrinsic motivation. Adv. Neural Inf. Process. Syst. 2016, 29, 1471–1479. [Google Scholar]
- Ostrovski, G.; Bellemare, M.G.; Oord, A.V.D.; Munos, R. Count-based exploration with neural density models. Int. Conf. Mach. Learn. 2017, 70, 2721–2730. [Google Scholar]
- Tang, H.; Houthooft, R.; Foote, D.; Stooke, A.; Chen, X.; Duan, Y.; Schulman, J.; De, T.F.; Abbeel, P. Exploration: A study of count-based exploration for deep reinforcement learning. Conf. Neural Inf. Process. Syst. 2017, 30, 1–18. [Google Scholar]
























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameters | Value |
|---|---|
| Length Between Perpendiculars | 7.02 m |
| Breadth | 2.60 m |
| Speed | ≤35 kn |
| Draft (Full Load) | 0.32 m |
| Block Coefficient | 0.6976 |
| Displacement (Full Load) | 2.73 |
| Rudder Area | 0.2091 |
| Distance Between Barycenter and Center | 0.35 m |
| Hyperparameter | Value |
|---|---|
| Batch Size | 600 |
| Replay Memory Size | 350,000 |
| Target Network Update Frequency | 5360 |
| Learning Rate | |
| Discount Factor | |
| Initial Exploration | 1 |
| Final Exploration | |
| Final Exploration Frame | 30,000 |
| Replay Start Size | 2000 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Fan, Y.; Sun, Z.; Wang, G. A Novel Reinforcement Learning Collision Avoidance Algorithm for USVs Based on Maneuvering Characteristics and COLREGs. Sensors 2022, 22, 2099. https://doi.org/10.3390/s22062099
Fan Y, Sun Z, Wang G. A Novel Reinforcement Learning Collision Avoidance Algorithm for USVs Based on Maneuvering Characteristics and COLREGs. Sensors. 2022; 22(6):2099. https://doi.org/10.3390/s22062099
Chicago/Turabian StyleFan, Yunsheng, Zhe Sun, and Guofeng Wang. 2022. "A Novel Reinforcement Learning Collision Avoidance Algorithm for USVs Based on Maneuvering Characteristics and COLREGs" Sensors 22, no. 6: 2099. https://doi.org/10.3390/s22062099