
A Wildfire Smoke Detection System Using Unmanned Aerial Vehicle Images Based on the Optimized YOLOv5


Abstract
:1. Introduction
- A fully automated wildfire smoke detection and notification system was developed to reduce natural catastrophes and the loss of forest resources;
- A large wildfire smoke image dataset was collected using UAV and wildland images of wildfire smoke scenes to improve the accuracy of the deep CNN model;
- Anchor-box clustering of the backbone was improved using the K-mean++ technique to reduce the classification error;
- The spatial pyramid pooling fast (SPPF) layer of the backbone part was optimized to focus on small wildfire smoke;
- The neck part was adjusted using a bidirectional feature pyramid network (Bi-FPN) module to balance multi-scale feature fusion;
- Finally, network pruning and transfer learning techniques were used during training to improve the network architecture, detection accuracy, and speed.
2. Related Works
2.1. Conventional Image-Based Methods
2.2. Deep Learning and UAV-Based Wildfire Smoke Detection
3. Materials and Methods
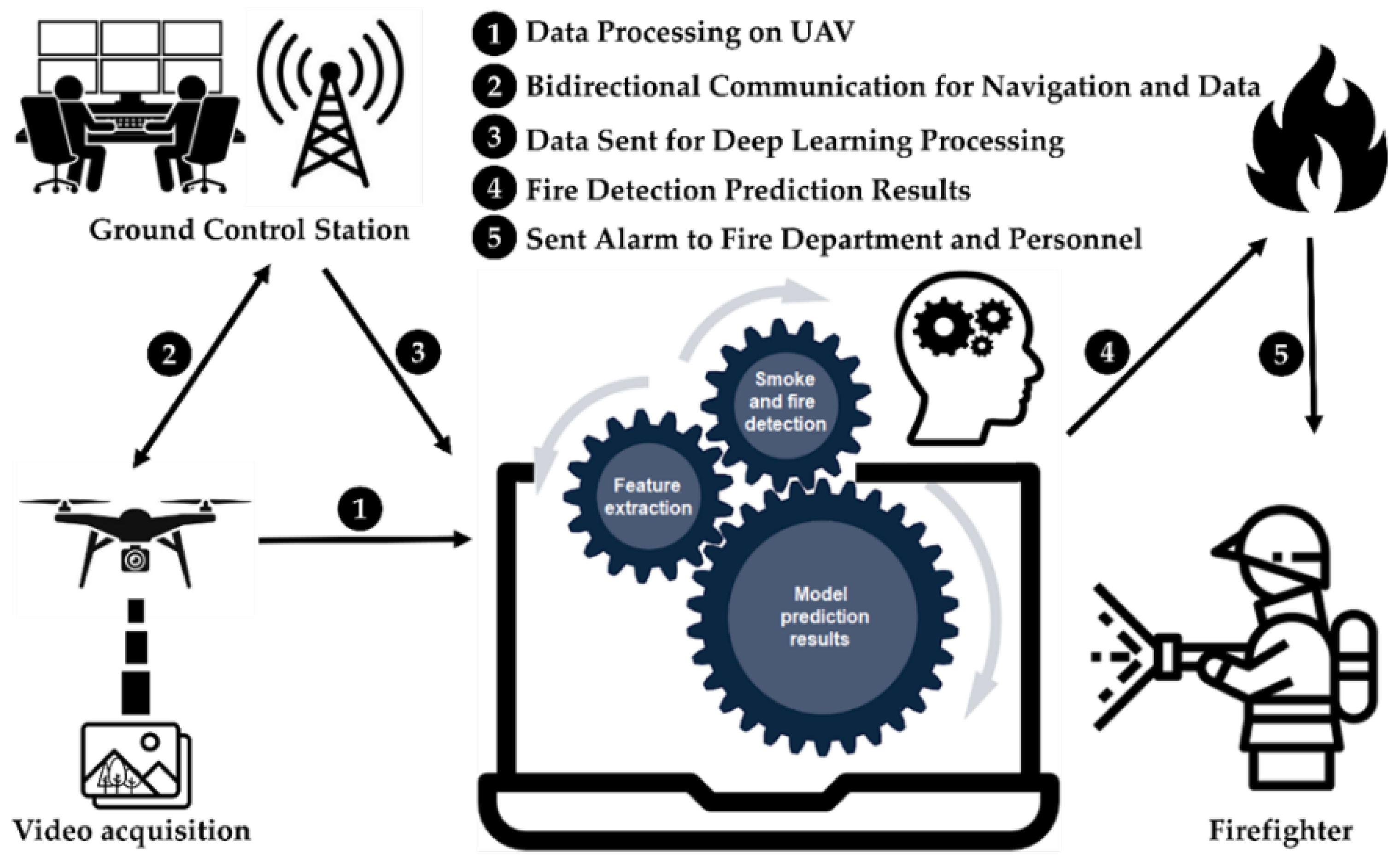
3.1. Overview of the UAV-Based Wildfire Detection System
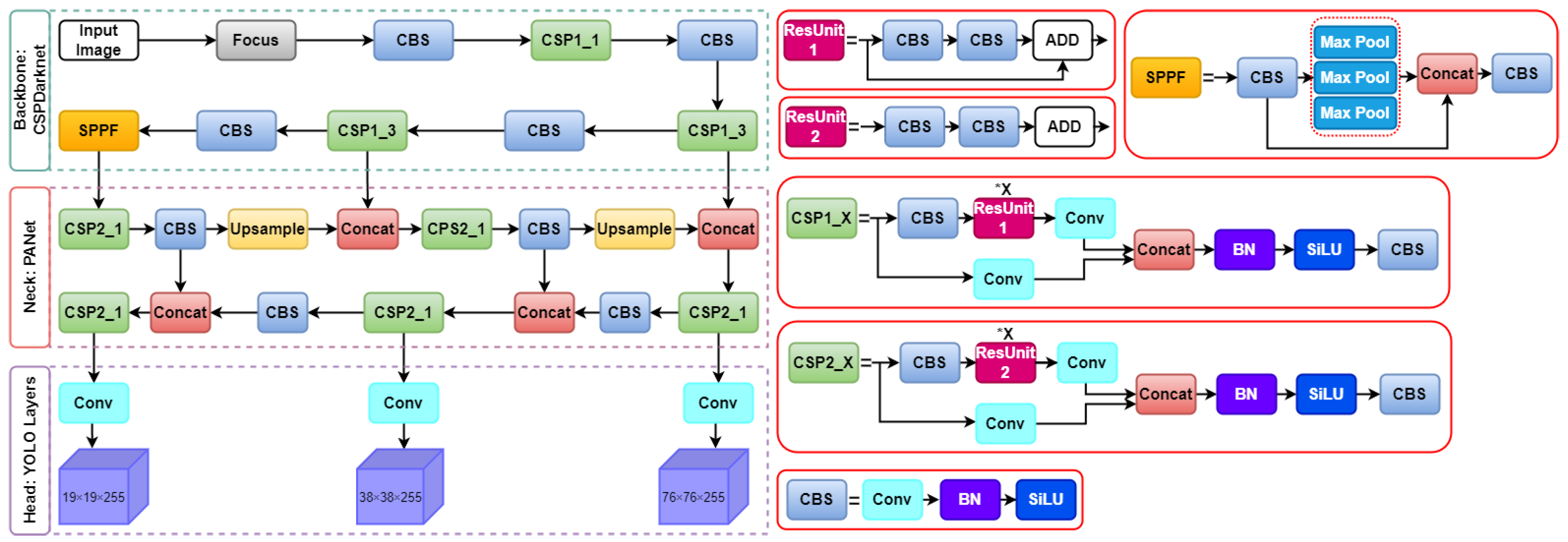
3.2. Proposed Wildfire Smoke Detection Method
3.2.1. Original YOLOv5 Model
3.2.2. K-Means++ Clustering Technique for Determining Anchor Boxes
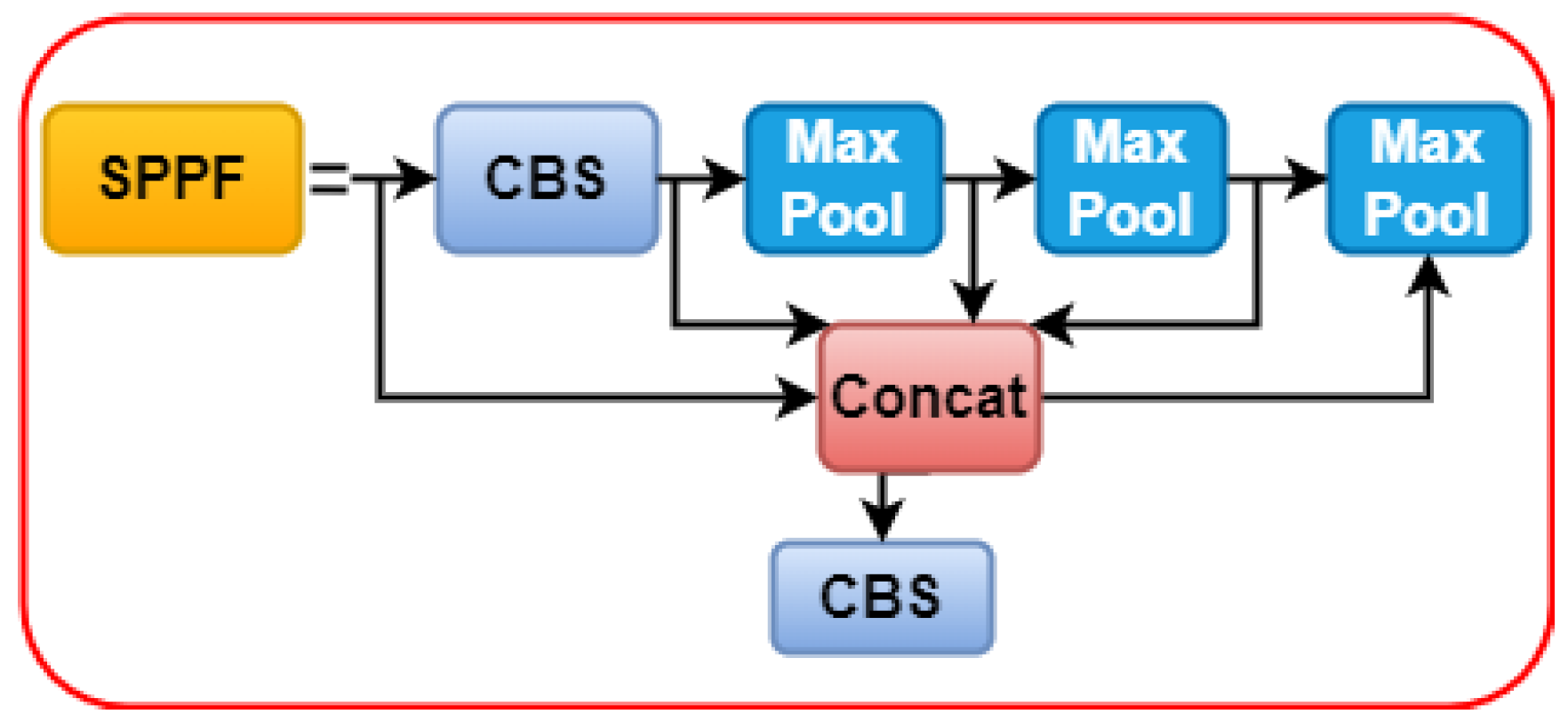
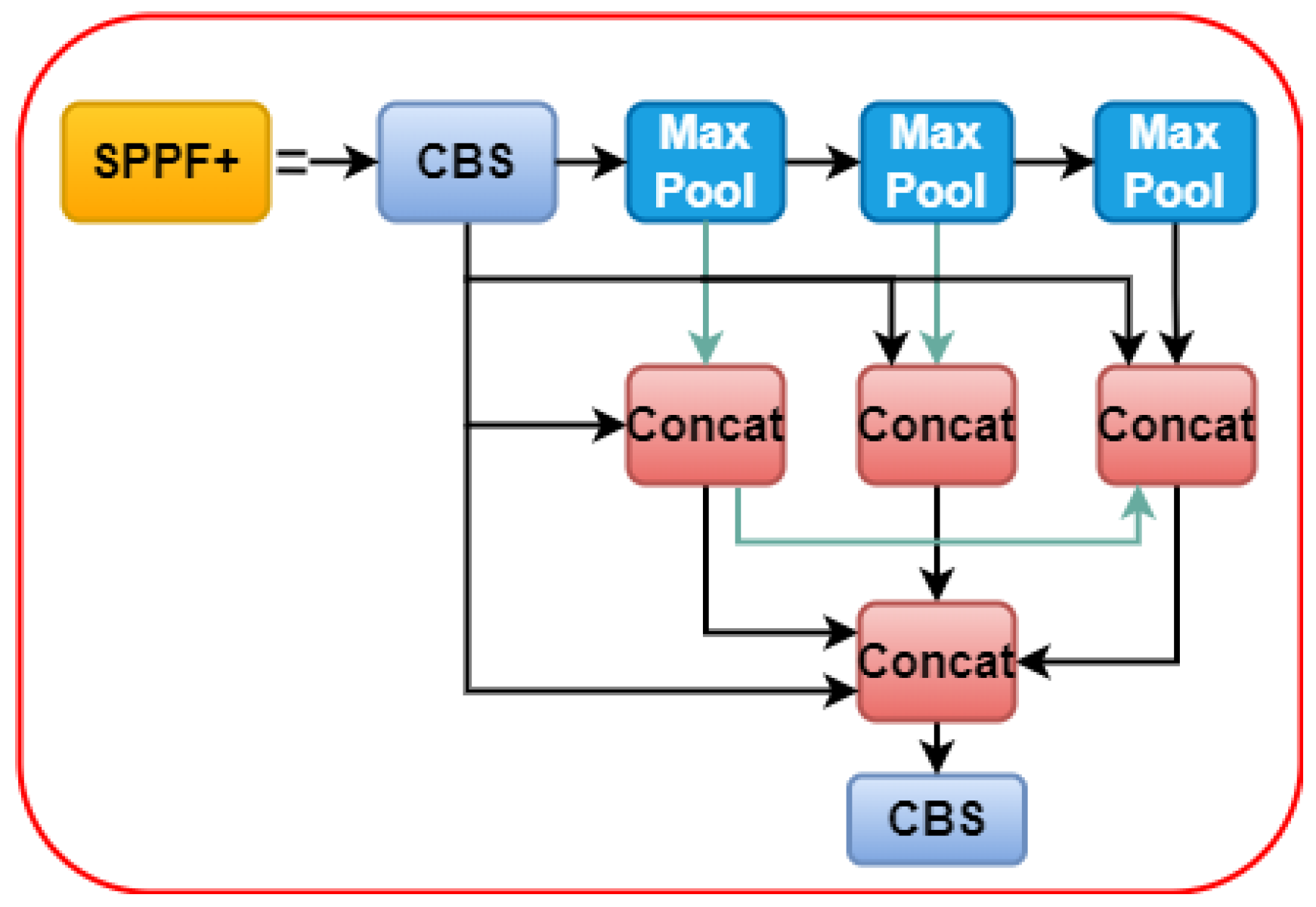
3.2.3. Spatial Pyramid Pooling Fast
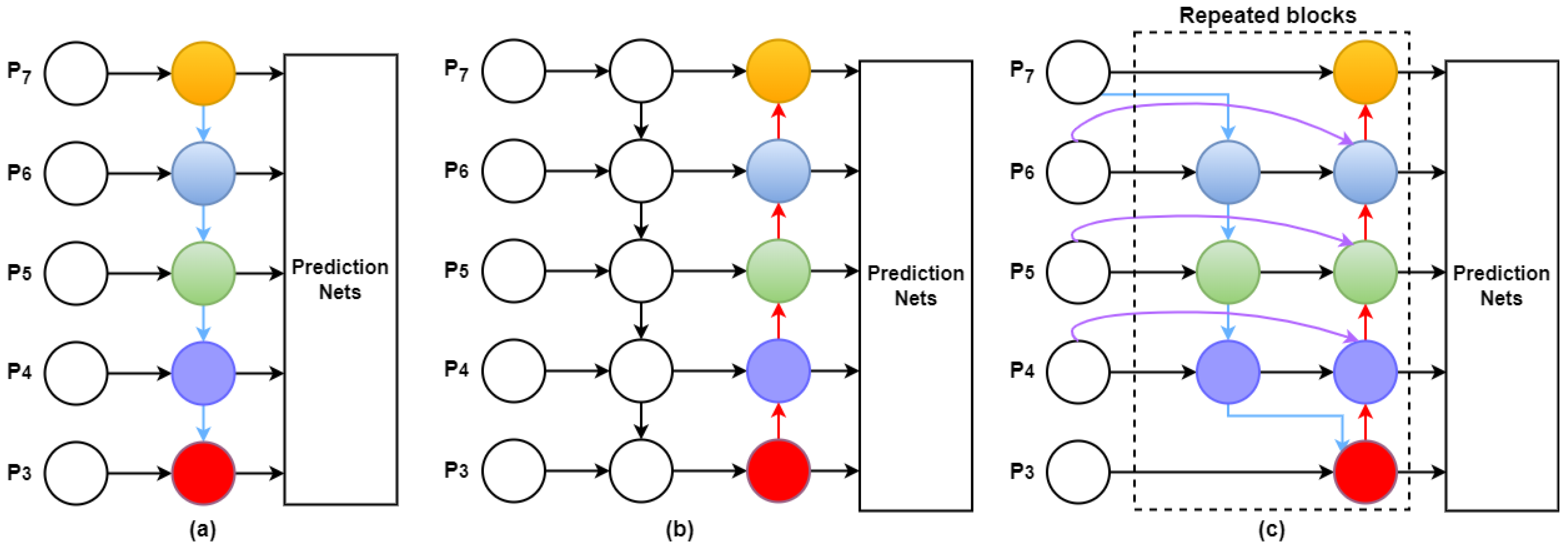
3.2.4. Bi-Directional Feature Pyramid Network
3.2.5. Network Pruning
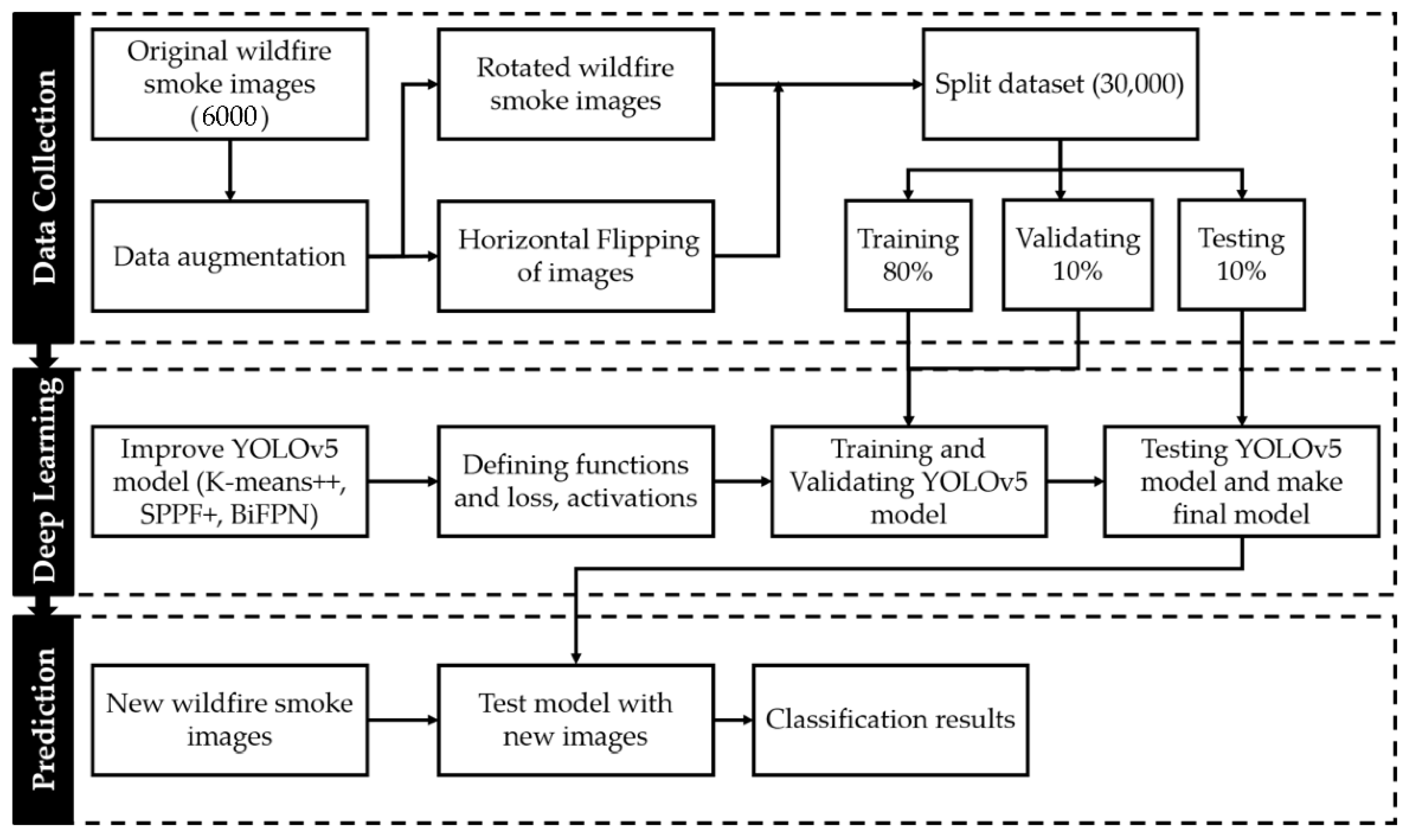
3.3. Wildfire Smoke Detection Dataset
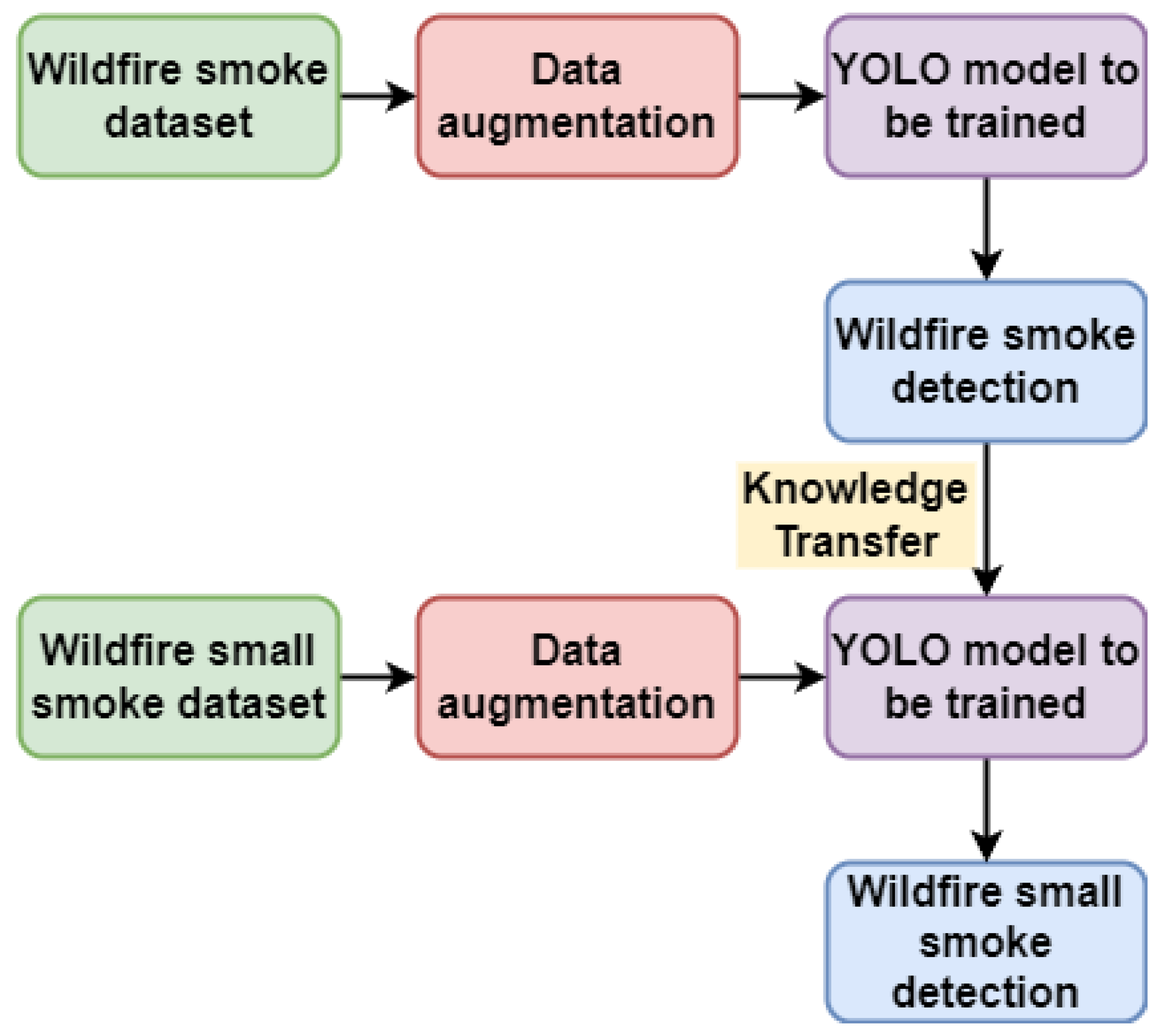
3.4. Transfer Learning
3.5. Evaluation Metrics
4. Experimental Results
4.1. Qualitative Evaluation
4.2. Quantitative Evaluation
4.3. Ablation Study
5. Analysis of Wildfire Smoke Detection Based on Various Systems
6. Limitations and Future Research
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Vargo, J.A. Time series of potential US wildland fire smoke exposures. Front. Public Health 2020, 8, 126. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Papathoma-Köhle, M.; Schlögl, M.; Garlichs, C.; Diakakis, M.; Mavroulis, S.; Fuchs, S. A wildfire vulnerability index for buildings. Sci. Rep. 2022, 12, 1–15. [Google Scholar] [CrossRef]
- Luo, S.; Zhang, X.; Wang, M.; Xu, J.H.; Zhang, X. A slight smoke perceptual network. IEEE Access 2017, 7, 42889–42896. [Google Scholar] [CrossRef]
- Ahmad, S.; Jamil, F.; Khudoyberdiev, A.; Kim, D.-H. Accident risk prediction and avoidance in intelligent semi-autonomous vehicles based on road safety data and driver biological behaviours. J. Intell. Fuzzy Syst. 2020, 38, 4591–4601. [Google Scholar] [CrossRef]
- Clarke, H.; Cirulis, B.; Penman, T.; Price, O.; Boer, M.M.; Bradstock, R. The 2019–2020 Australian forest fires are a harbinger of decreased prescribed burning effectiveness under rising extreme conditions. Sci. Rep. 2022, 12, 1–10. [Google Scholar] [CrossRef]
- Adhikari, R.K.; Grala, R.K.; Grado, S.C.; Grebner, D.L.; Petrolia, R. Landowner concerns related to availability of ecosystem services and environmental issues in the southern United States. Ecosyst. Serv. 2021, 49, 101283. [Google Scholar] [CrossRef]
- Mockrin, M.H.; Fishler, H.K.; Stewart, S.I. After the fire: Perceptions of land use planning to reduce wildfire risk in eight communities across the United States. Int. J. Disaster Risk Reduct. 2020, 45, 101444. [Google Scholar] [CrossRef]
- Bouguettaya, A.; Zarzour, H.; Taberkit, A.M.; Kechida, A. A review on early wildfire detection from unmanned aerial vehicles using deep learning-based computer vision algorithms. Signal Proc. 2022, 190, 108309. [Google Scholar] [CrossRef]
- Boylan, J.L.; Lawrence, C. The development and validation of the bushfire psychological preparedness scale. Int. J. Disaster Risk Reduct. 2020, 47, 101530. [Google Scholar] [CrossRef]
- Shakhnoza, M.; Sabina, U.; Sevara, M.; Cho, Y.-I. Novel Video Surveillance-Based Fire and Smoke Classification Using Attentional Feature Map in Capsule Networks. Sensors 2022, 22, 98. [Google Scholar] [CrossRef]
- Bo, M.; Mercalli, L.; Pognan, F.; Berro, D.C.; Clerico, M. Urban air pollution, climate change and wildfires: The case study of an extended forest fire episode in northern Italy favoured by drought and warm weather conditions. Energy Rep. 2020, 6, 781–786. [Google Scholar] [CrossRef]
- Vardoulakis, S.; Marks, G.; Abramson, M.J. Lessons learned from the Australian bushfires: Climate change, air pollution, and public health. JAMA Intern. 2020, 180, 635–636. [Google Scholar] [CrossRef] [PubMed]
- Valikhujaev, Y.; Abdusalomov, A.; Cho, Y.I. Automatic fire and smoke detection method for surveillance systems based on dilated CNNs. Atmosphere 2020, 11, 1241. [Google Scholar] [CrossRef]
- Ba, R.; Chen, C.; Yuan, J.; Song, W.; Lo, S. Smokenet: Satellite smoke scene detection using convolutional neural network with spatial and channel-wise attention. Remote Sens. 2019, 11, 1702. [Google Scholar] [CrossRef] [Green Version]
- Zhao, L.; Liu, J.; Peters, S.; Li, J.; Oliver, S.; Mueller, N. Investigating the Impact of Using IR Bands on Early Fire Smoke Detection from Landsat Imagery with a Lightweight CNN Model. Remote Sens. 2022, 14, 3047. [Google Scholar] [CrossRef]
- Akhloufi, M.A.; Couturier, A.; Castro, N.A. Unmanned Aerial Vehicles for Wildland Fires: Sensing, Perception, Cooperation and Assistance. Drones 2021, 5, 15. [Google Scholar] [CrossRef]
- Ghali, R.; Akhloufi, M.A.; Mseddi, W.S. Deep Learning and Transformer Approaches for UAV-Based Wildfire Detection and Segmentation. Sensors 2022, 22, 1977. [Google Scholar] [CrossRef]
- Abdusalomov, A.; Baratov, N.; Kutlimuratov, A.; Whangbo, T.K. An improvement of the fire detection and classification method using YOLOv3 for surveillance systems. Sensors 2021, 21, 6519. [Google Scholar] [CrossRef]
- Avazov, K.; Mukhiddinov, M.; Makhmudov, F.; Cho, Y.I. Fire Detection Method in Smart City Environments Using a Deep-Learning-Based Approach. Electronics 2021, 1, 73. [Google Scholar] [CrossRef]
- Chaturvedi, S.; Khanna, P.; Ojha, A. A survey on vision-based outdoor smoke detection techniques for environmental safety. ISPRS J. Photogramm. Remote Sens. 2022, 185, 158–187. [Google Scholar] [CrossRef]
- Han, X.F.; Jin, J.S.; Wang, M.J.; Jiang, W.; Gao, L.; Xiao, L.P. Video fire detection based on Gaussian mixture model and multi-color features. Signal Image Video Process. 2017, 11, 1419–1425. [Google Scholar] [CrossRef]
- Zhao, Y.; Ma, J.; Li, X.; Zhang, J. Saliency detection and deep learning-based wildfire identification in UAV imagery. Sensors 2018, 18, 712. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Li, T.; Zhao, E.; Zhang, J.; Hu, C. Detection of wildfire smoke images based on a densely dilated convolutional network. Electronics 2019, 8, 1131. [Google Scholar] [CrossRef] [Green Version]
- Kanand, T.; Kemper, G.; König, R.; Kemper, H. Wildfire detection and disaster monitoring system using UAS and sensor fusion technologies. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2020, 43, 1671–1675. [Google Scholar] [CrossRef]
- Rahman, E.U.; Kha, M.A.; Algarni, F.; Zhang, Y.; Irfan Uddin, M.; Ullah, I.; Ahmad, H.I. Computer vision-based wildfire smoke detection using UAVs. Math. Probl. Eng. 2021, 2021, 9977939. [Google Scholar] [CrossRef]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. Yolov4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-CNN: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [Green Version]
- Xie, X.; Cheng, G.; Wang, J.; Yao, X.; Han, J. Oriented R-CNN for object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 3520–3529. [Google Scholar]
- Nguyen, A.Q.; Nguyen, H.T.; Tran, V.C.; Pham, H.X.; Pestana, J. A visual real-time fire detection using single shot multibox detector for uav-based fire surveillance. In Proceedings of the 2020 IEEE Eighth International Conference on Communications and Electronics (ICCE), Phu Quoc Island, Vietnam, 13–15 January 2021; pp. 338–343. [Google Scholar]
- Rashkovetsky, D.; Mauracher, F.; Langer, M.; Schmitt, M. Wildfire detection from multisensor satellite imagery using deep semantic segmentation. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 7001–7016. [Google Scholar] [CrossRef]
- Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. IEEE Trans. Pattern Anal. 2018, 40, 834–848. [Google Scholar]
- Jeong, M.; Park, M.; Nam, J.; Ko, B.C. Light-weight student LSTM for real-time wildfire smoke detection. Sensors 2020, 20, 5508. [Google Scholar] [CrossRef] [PubMed]
- Sheng, D.; Deng, J.; Zhang, W.; Cai, J.; Zhao, W.; Xiang, J. A statistical image feature-based deep belief network for fire detection. Complexity 2021, 2021, 5554316. [Google Scholar] [CrossRef]
- Park, M.; Tran, D.Q.; Jung, D.; Park, S. Wildfire-detection method using DenseNet and CycleGAN data augmentation-based remote camera imagery. Remote Sens. 2020, 12, 3715. [Google Scholar] [CrossRef]
- Hu, Y.; Zhan, J.; Zhou, G.; Chen, A.; Cai, W.; Guo, K.; Hu, Y.; Li, L. Fast forest fire smoke detection using MVMNet. Knowl. Based Syst. 2022, 241, 108219. [Google Scholar] [CrossRef]
- Guan, Z.; Min, F.; He, W.; Fang, W.; Lu, T. Forest fire detection via feature entropy guided neural network. Entropy 2022, 24, 128. [Google Scholar] [CrossRef] [PubMed]
- Fan, R.; Pei, M. Lightweight forest fire detection based on deep learning. In Proceedings of the 2021 IEEE 31st International Workshop on Machine Learning for Signal Processing (MLSP), Gold Coast, QC, Australia, 25–28 October 2021; pp. 1–6. [Google Scholar]
- Guede-Fernández, F.; Martins, L.; Almeida, R.V.; Gamboa, H.; Vieira, P. A deep learning based object identification system for forest fire detection. Fire 2021, 4, 75. [Google Scholar] [CrossRef]
- Zhang, L.; Wang, M.; Fu, Y.; Ding, Y. A Forest Fire Recognition Method Using UAV Images Based on Transfer Learning. Forests 2022, 13, 975. [Google Scholar] [CrossRef]
- Mukhiddinov, M.; Cho, J. Smart Glass System Using Deep Learning for the Blind and Visually Impaired. Electronics 2021, 10, 2756. [Google Scholar] [CrossRef]
- Jocher, G. YOLOv5. Ultralytics: Github. 2022. Available online: https://github.com/ultralytics/yolov5 (accessed on 20 August 2022).
- Abdusalomov, A.B.; Mukhiddinov, M.; Kutlimuratov, A.; Whangbo, T.K. Improved Real-Time Fire Warning System Based on Advanced Technologies for Visually Impaired People. Sensors 2022, 22, 7305. [Google Scholar] [CrossRef]
- Mukhamadiyev, A.; Khujayarov, I.; Djuraev, O.; Cho, J. Automatic Speech Recognition Method Based on Deep Learning Approaches for Uzbek Language. Sensors 2022, 22, 3683. [Google Scholar] [CrossRef]
- Mukhiddinov, M.; Kim, S.Y. A Systematic Literature Review on the Automatic Creation of Tactile Graphics for the Blind and Visually Impaired. Processes 2021, 9, 1726. [Google Scholar] [CrossRef]
- Calderara, S.; Piccinini, P.; Cucchiara, R. Vision based smoke detection system using image energy and color information. Mach. Vis. Appl. 2011, 22, 705–719. [Google Scholar] [CrossRef]
- Xuehui, W.; Xiaobo, L.; Leung, H. A video based fire smoke detection using Robust AdaBoost. Sensors 2018, 8, 3780. [Google Scholar]
- Ye, W.; Zhao, J.; Wang, S.; Wang, Y.; Zhang, D.; Yuan, Z. Dynamic texture based smoke detection using surfacelet transform and HMT model. Fire Saf. J. 2015, 73, 91–101. [Google Scholar] [CrossRef]
- Ye, S.; Bai, Z.; Chen, H.; Bohush, R.; Ablameyko, S. An effective algorithm to detect both smoke and flame using color and wavelet analysis. Pattern Recognit. Image Anal. 2017, 27, 131–138. [Google Scholar] [CrossRef]
- Islam, M.R.; Amiruzzaman, M.; Nasim, S.; Shin, J. Smoke Object Segmentation and the Dynamic Growth Feature Model for Video-Based Smoke Detection Systems. Symmetry 2020, 12, 1075. [Google Scholar] [CrossRef]
- Khalil, A.; Rahman, S.U.; Alam, F.; Ahmad, I.; Khalil, I. Fire Detection Using Multi Color Space and Background Modeling. Fire Technol. 2021, 57, 1221–1239. [Google Scholar] [CrossRef]
- Phan, T.C.; Quach, N.D.K.; Nguyen, T.T.; Nguyen, T.T.; Jo, J.; Nguyen, Q.V.H. Real-time wildfire detection with semantic explanations. Expert Syst. Appl. 2022, 201, 117007. [Google Scholar] [CrossRef]
- Rocha, A.M.; Casau, P.; Cunha, R. A Control Algorithm for Early Wildfire Detection Using Aerial Sensor Networks: Modeling and Simulation. Drones 2022, 6, 44. [Google Scholar] [CrossRef]
- Yazdi, A.; Qin, H.; Jordan, C.B.; Yang, L.; Yan, F. Nemo: An Open-Source Transformer-Supercharged Benchmark for Fine-Grained Wildfire Smoke Detection. Remote Sens. 2022, 14, 3979. [Google Scholar] [CrossRef]
- Dewangan, A.; Pande, Y.; Braun, H.W.; Vernon, F.; Perez, I.; Altintas, I.; Cottrell, G.W.; Nguyen, M.H. FIgLib & SmokeyNet: Dataset and Deep Learning Model for Real-Time Wildland Fire Smoke Detection. Remote Sens. 2022, 14, 1007. [Google Scholar]
- Seydi, S.T.; Saeidi, V.; Kalantar, B.; Ueda, N.; Halin, A.A. Fire-Net: A deep learning framework for active forest fire detection. J. Sens. 2022, 2022, 8044390. [Google Scholar] [CrossRef]
- Hossain, F.A.; Zhang, Y.M.; Tonima, M.A. Forest fire flame and smoke detection from UAV-captured images using fire-specific color features and multi-color space local binary pattern. J. Unmanned Veh. Syst. 2020, 8, 285–309. [Google Scholar] [CrossRef]
- Sudhakar, S.; Vijayakumar, V.; Kumar, C.S.; Priya, V.; Ravi, L.; Subramaniyaswamy, V. Unmanned Aerial Vehicle (UAV) based Forest Fire Detection and monitoring for reducing false alarms in forest-fires. Comput. Commun. 2020, 149, 1–6. [Google Scholar] [CrossRef]
- Almeida, J.S.; Huang, C.; Nogueira, F.G.; Bhatia, S.; de Albuquerque, V.H.C. EdgeFireSmoke: A Novel Lightweight CNN Model for Real-Time Video Fire–Smoke Detection. IEEE Trans. Ind. Inform. 2022, 18, 7889–7898. [Google Scholar] [CrossRef]
- Wang, C.Y.; Liao, H.Y.M.; Wu, Y.H.; Chen, P.Y.; Hsieh, J.W.; Yeh, I.H. CSPNet: A new backbone that can enhance learning capability of CNN. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR 2020), Washington, DC, USA, 14–19 June 2020; pp. 390–391. [Google Scholar]
- Liu, S.; Qi, L.; Qin, H.; Shi, J.; Jia, J. Path aggregation network for instance segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8759–8768. [Google Scholar]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar]
- Tan, M.; Pang, R.; Le, Q.V. Efficientdet: Scalable and efficient object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 10781–10790. [Google Scholar]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision, Honolulu, HI, USA, 21–26 July 2017; pp. 2980–2988. [Google Scholar]
- Research, A.T.H.P.W. Education Network University of California San Diego. HPWREN Dataset. 2020. Available online: http://hpwren.ucsd.edu/HPWREN-FIgLib/ (accessed on 20 August 2022).
- Jeong, C.; Jang, S.-E.; Na, S.; Kim, J. Korean Tourist Spot Multi-Modal Dataset for Deep Learning Applications. Data 2019, 4, 139. [Google Scholar] [CrossRef] [Green Version]
- Khalifa, N.E.; Loey, M.; Mirjalili, S. A comprehensive survey of recent trends in deep learning for digital images augmentation. Artif. Intell. Rev. 2021, 55, 2351–2377. [Google Scholar] [CrossRef]
- Tang, Y.; Li, B.; Liu, M.; Chen, B.; Wang, Y.; Ouyang, W. Autopedestrian: An automatic data augmentation and loss function search scheme for pedestrian detection. IEEE Trans. Image Proc. 2021, 30, 8483–8496. [Google Scholar] [CrossRef]
- Avazov, K.; Abdusalomov, A.; Mukhiddinov, M.; Baratov, N.; Makhmudov, F.; Cho, Y.I. An improvement for the automatic classification method for ultrasound images used on CNN. Int. J. Wavelets Multiresolution Inf. Proc. 2022, 20, 2150054. [Google Scholar] [CrossRef]
- Makhmudov, F.; Mukhiddinov, M.; Abdusalomov, A.; Avazov, K.; Khamdamov, U.; Cho, Y.I. Improvement of the end-to-end scene text recognition method for “text-to-speech” conversion. Int. J. Wavelets Multiresolution Inf. Proc. 2020, 18, 2050052. [Google Scholar] [CrossRef]
- Abdusalomov, A.; Mukhiddinov, M.; Djuraev, O.; Khamdamov, U.; Whangbo, T.K. Automatic salient object extraction based on locally adaptive thresholding to generate tactile graphics. Appl. Sci. 2020, 10, 3350. [Google Scholar] [CrossRef]
- Mukhriddin, M.; Jeong, R.; Cho, J. Saliency cuts: Salient region extraction based on local adaptive thresholding for image information recognition of the visually impaired. Int. Arab J. Inf. Technol. 2020, 17, 713–720. [Google Scholar]
- Mukhiddinov, M.; Muminov, A.; Cho, J. Improved Classification Approach for Fruits and Vegetables Freshness Based on Deep Learning. Sensors 2022, 22, 8192. [Google Scholar] [CrossRef] [PubMed]
- Tychsen-Smith, L.; Petersson, L. Denet: Scalable real-time object detection with directed sparse sampling. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 428–436. [Google Scholar]
- Zhu, Y.; Zhao, C.; Wang, J.; Zhao, X.; Wu, Y.; Lu, H. Couplenet: Coupling global structure with local parts for object detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 4126–4134. [Google Scholar]
- Girshick, R. Fast R-CNN. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. Adv. Neural Inf. Proc. Syst. 2015, 28. [Google Scholar] [CrossRef] [Green Version]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask R-CNN. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Cai, Z.; Vasconcelos, N. Cascade r-cnn: Delving into high quality object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6154–6162. [Google Scholar]
- Songtao, L.; Huang, D.; Wang, Y. Receptive field block net for accurate and fast object detection. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 385–400. [Google Scholar]
- Wei, L.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.-Y.; Berg, A.C. SSD: Single shot multibox detector. In Proceedings of the European Conference on Computer Vision (ECCV), Amsterdam, The Netherlands, 11–14 October 2016; pp. 21–37. [Google Scholar]
- Zhang, S.; Wen, L.; Bian, X.; Lei, Z.; Li, S.Z. Single-shot refinement neural network for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 4203–4212. [Google Scholar]
- Khan, S.; Muhammad, K.; Hussain, T.; Del Ser, J.; Cuzzolin, F.; Bhattacharyya, S.; Akhtar, Z.; de Albuquerque, V.H. Deepsmoke: Deep learning model for smoke detection and segmentation in outdoor environments. Expert Syst. Appl. 2021, 182, 115125. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE conference on computer vision and pattern recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the IEEE conference on computer vision and pattern recognition, Honolulu, HI, USA, 21–26 July; pp. 7263–7271.
- Shukla, B.P.; Pal, P.K. Automatic smoke detection using satellite imagery: Preparatory to smoke detection from Insat-3D. Int. J. Remote Sens. 2009, 30, 9–22. [Google Scholar] [CrossRef]
- Vani, K. Deep Learning Based Forest Fire Classification and Detection in Satellite Images. In Proceedings of the 2019 11th International Conference on Advanced Computing (ICoAC), Chennai, India, 18–20 December 2019; pp. 61–65. [Google Scholar]
- Larsen, A.; Hanigan, I.; Reich, B.J.; Qin, Y.; Cope, M.; Morgan, G.; Rappold, A.G. A deep learning approach to identify smoke plumes in satellite imagery in near-real time for health risk communication. J. Expo. Sci. Environ. Epidemiol. 2020, 31, 170–176. [Google Scholar] [CrossRef]
- Shah, S.B.; Grübler, T.; Krempel, L.; Ernst, S.; Mauracher, F.; Contractor, S. Real-time wildfire detection from space—A trade-off between sensor quality, physical limitations and payload size. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2019, 42, 209–213. [Google Scholar] [CrossRef] [Green Version]
- Agirman, A.K.; Tasdemir, K. BLSTM based night-time wildfire detection from video. PLoS ONE 2022, 17, e0269161. [Google Scholar] [CrossRef]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Name of Dataset | Number of Smoke Images (3285) | Number of Non-Smoke Images (2715) | Total | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Kaggle | Bing | Flickr | Kaggle | Bing | Flickr | ||||
| Wildfire Smoke | 2580 | 250 | 300 | 155 | 2460 | 100 | 105 | 50 | 6000 |
| Wildfire Smoke Detection Dataset | Number of Training Images | Number of Testing Images | Total | ||
|---|---|---|---|---|---|
| Original Images | Image Rotation | Image Flipping | Original Images | ||
| Wildfire smoke images | 2628 | 5256 | 7884 | 657 | 16,425 |
| Non-smoke images | 2172 | 4344 | 6516 | 543 | 13,575 |
| Total | 4800 | 9600 | 14,400 | 1200 | 30,000 |
| AP | AP50 | AP at IoU = 0.5 |
| AP | AP75 | AP at IoU = 0.75 |
| AP at various levels | APS | AP0.5 for small regions: area < 322 |
| APM | AP0.5 for medium regions: 322 < area < 962 | |
| APL | AP0.5 for large regions: area > 962 |
| Hardware Parts | Detailed Specifications |
|---|---|
| Storage | SSD: 512 GB HDD: 2 TB (2 are installed) |
| Motherboard | ASUS PRIME Z390-A |
| Operating System | Ubuntu Desktop |
| Graphic Processing Unit | GeForce RTX 2080 Ti 11 GB (2 are installed) |
| Central Processing Unit | Intel Core 9 Gen i7-9700k (4.90 GHz) |
| Random Access Memory | DDR4 16 GB (4 are installed) |
| Local Area Network | Internal port—10/100 Mbps External port—10/100 Mbps |
| Power | 1000 W (+12 V Single Rail) |
| Models | AP 0.5:0.95 | AP 0.5 | Speed CPU (ms) | Speed GPU (ms) | Parameters (million) | FLOPS (b) | Iteration number |
|---|---|---|---|---|---|---|---|
| YOLOv5n | 28.0 | 45.7 | 45 | 6.3 | 1.9 | 4.5 | 300 |
| YOLOv5s | 37.4 | 56.8 | 98 | 6.4 | 7.2 | 16.5 | |
| YOLOv5m | 45.4 | 64.1 | 224 | 8.2 | 21.2 | 49.0 | |
| YOLOv5l | 49.0 | 67.3 | 430 | 10.1 | 46.5 | 109.1 | |
| YOLOv5x | 50.7 | 68.9 | 766 | 12.1 | 86.7 | 205.7 |
| Model | Input Size | Training (AP50) | Training Time | Weight Size | |||
|---|---|---|---|---|---|---|---|
| Before DA | After DA | Before DA | After DA | Before DA | After DA | ||
| Improved YOLOv5m | 640 × 640 | 75.6 | 82.7 | 46 h | 85 h | 68 MB | 93 MB |
| Models | Training Input Size | Training (AP50) | Testing Input Size | Testing (AP50) | Iteration Number |
|---|---|---|---|---|---|
| YOLOv3 [26] | 416 × 416 | 65.6 | 640 × 640 | 63.5 | 300 |
| YOLOv4 [27] | 608 × 608 | 71.3 | 68.6 | ||
| YOLOv5m [42] | 640 × 640 | 73.5 | 70.8 | ||
| Improved YOLOv5m | 640 × 640 | 75.6 | 72.4 |
| Models | Training Input Size | Training (AP50) | Testing Input Size | Testing (AP50) | Iteration Number |
|---|---|---|---|---|---|
| YOLOv3 [26] | 416 × 416 | 73.5 | 640 × 640 | 69.8 | 300 |
| YOLOv4 [27] | 608 × 608 | 78.1 | 73.9 | ||
| YOLOv5m [42] | 640 × 640 | 79.6 | 75.4 | ||
| Improved YOLOv5m | 640 × 640 | 82.7 | 79.3 |
| Model | Backbone | AP | AP50 | AP75 | APS | APM | APL |
|---|---|---|---|---|---|---|---|
| DeNet [75] | ResNet-101 | 55.4 | 63.7 | 58.2 | 46.3 | 55.8 | 61.5 |
| CoupleNet [76] | ResNet-101 | 58.6 | 65.2 | 60.7 | 48.6 | 58.4 | 63.7 |
| Fast R-CNN [77] | ResNet-101 | 61.5 | 68.3 | 62.4 | 51.8 | 60.4 | 66.1 |
| Faster R-CNN [78] | ResNet-101 | 63.7 | 70.6 | 65.7 | 54.3 | 62.6 | 68.2 |
| Mask R-CNN [79] | ResNet-101 | 67.5 | 75.8 | 70.9 | 59.4 | 66.3 | 73.1 |
| Cascade R-CNN [80] | ResNet-101 | 70.2 | 78.4 | 74.3 | 62.8 | 69.1 | 75.6 |
| Improved YOLOv5m | CSPDarknet-53 | 73.6 | 81.5 | 76.3 | 65.7 | 72.4 | 78.6 |
| Model | Backbone | AP | AP50 | AP75 | APS | APM | APL |
|---|---|---|---|---|---|---|---|
| RFBNet [81] | VGG-16 | 62.4 | 68.5 | 63.7 | 51.2 | 59.6 | 72.8 |
| SSD [82] | VGG-16 | 63.7 | 71.3 | 65.8 | 54.7 | 63.1 | 76.4 |
| RefineDet [83] | VGG-16 | 68.3 | 75.8 | 70.6 | 59.8 | 66.3 | 81.7 |
| EfficientDet [63] | EfficientNet | 70.6 | 77.4 | 73.1 | 62.5 | 69.0 | 82.9 |
| DeepSmoke [84] | EfficientNet | 71.4 | 78.6 | 74.5 | 63.4 | 70.5 | 85.3 |
| YOLO [85] | GoogleNet | 56.3 | 62.6 | 54.8 | 46.2 | 55.7 | 68.1 |
| YOLOv2 [86] | Darknet-19 | 64.8 | 71.7 | 65.2 | 55.6 | 64.3 | 75.4 |
| YOLOv3 [26] | Darknet-53 | 67.2 | 75.4 | 68.5 | 59.1 | 66.7 | 78.6 |
| YOLOv4 [27] | CSPDarknet-53 | 69.7 | 77.5 | 71.6 | 60.4 | 68.2 | 81.8 |
| YOLOv5m [42] | CSPDarknet-53 | 70.9 | 78.2 | 72.4 | 62.8 | 69.5 | 83.6 |
| Improved YOLOv5m | CSPDarknet-53 | 73.6 | 81.5 | 76.3 | 65.7 | 72.4 | 87.2 |
| Model | AP | AP50 | AP75 | APS | APM | APL |
|---|---|---|---|---|---|---|
| YOLOv5m | 70.9 | 78.2 | 72.4 | 62.8 | 69.5 | 83.6 |
| YOLOv5m+SPPF+ | 71.6 | 78.5 | 73.2 | 63.7 | 70.4 | 84.7 |
| YOLOv5m+BiFPN | 72.4 | 79.2 | 74.5 | 64.6 | 71.3 | 86.1 |
| YOLOv5m+(SPPF+)+BiFPN | 73.6 | 81.5 | 76.3 | 65.7 | 72.4 | 87.2 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mukhiddinov, M.; Abdusalomov, A.B.; Cho, J. A Wildfire Smoke Detection System Using Unmanned Aerial Vehicle Images Based on the Optimized YOLOv5. Sensors 2022, 22, 9384. https://doi.org/10.3390/s22239384
Mukhiddinov M, Abdusalomov AB, Cho J. A Wildfire Smoke Detection System Using Unmanned Aerial Vehicle Images Based on the Optimized YOLOv5. Sensors. 2022; 22(23):9384. https://doi.org/10.3390/s22239384
Chicago/Turabian StyleMukhiddinov, Mukhriddin, Akmalbek Bobomirzaevich Abdusalomov, and Jinsoo Cho. 2022. "A Wildfire Smoke Detection System Using Unmanned Aerial Vehicle Images Based on the Optimized YOLOv5" Sensors 22, no. 23: 9384. https://doi.org/10.3390/s22239384