



Design and Implementation of a Cloud PACS Architecture
 , , , ,
, , , ,
Abstract
:1. Introduction
1.1. Evolution of Cloud PACS
1.2. Cloud-Native Systems
1.3. Contribution
2. Materials and Methods
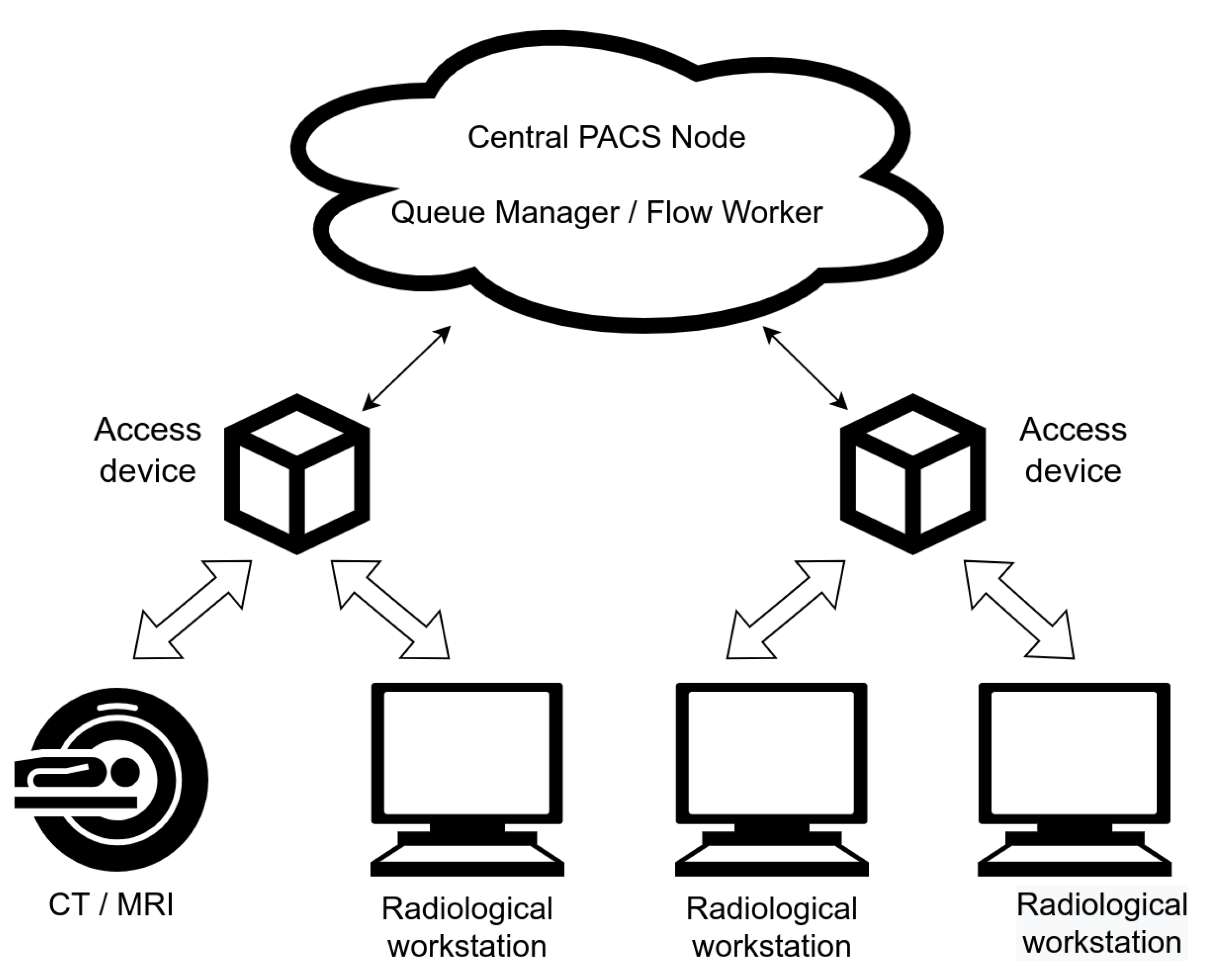
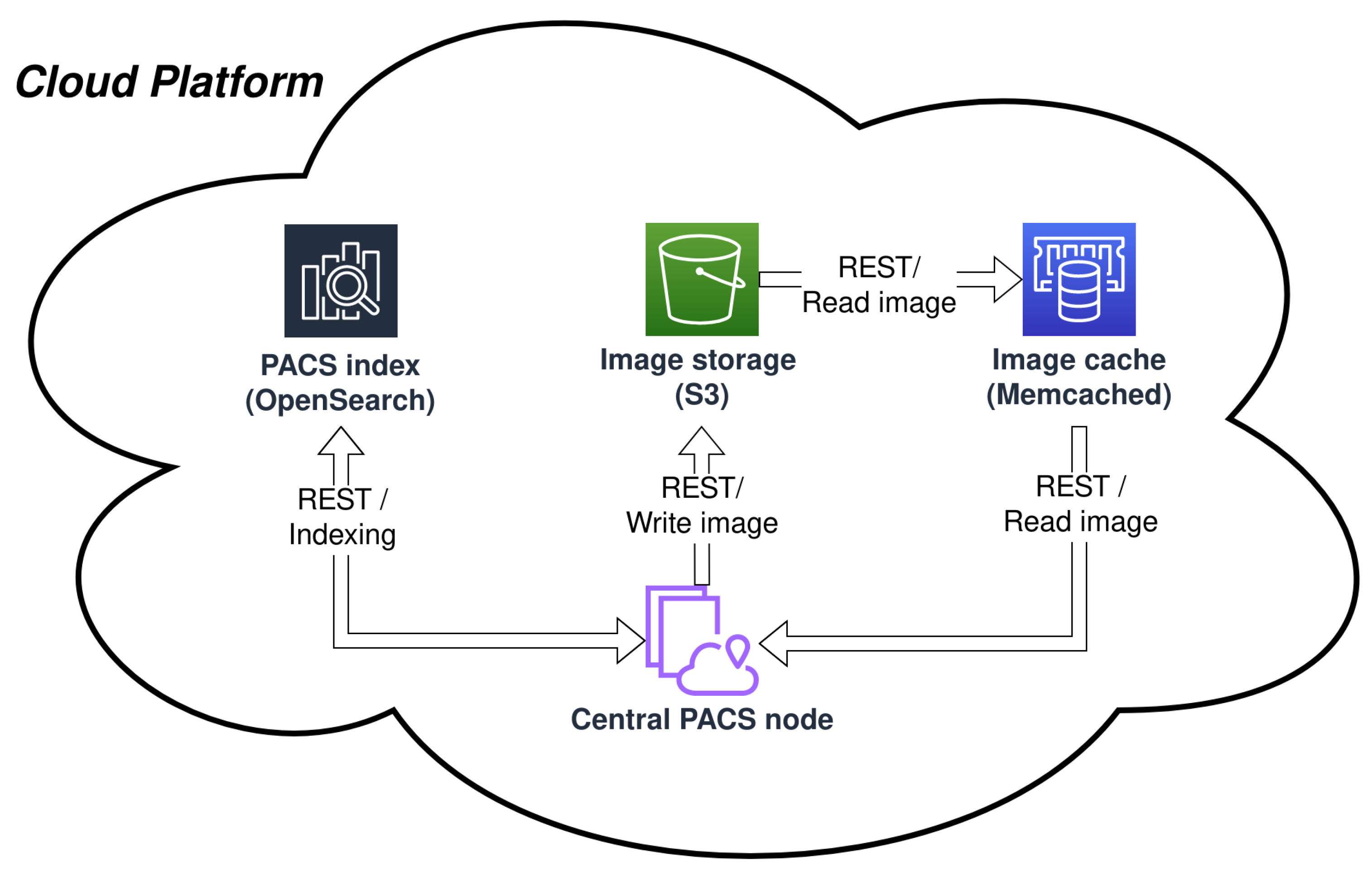
2.1. Central PACS Node
- DICOM, DIMSE (DICOM message service element)-based interface, featuring a set of basic C-STORE, C-FIND, C-MOVE operations;
- Native DICOMweb interface, featuring STOW-RS, QIDO-RS, WADO-RS—web services providing access to storing, querying, and retrieving DICOM objects;
- Custom REST (Representational state transfer) API providing additional capabilities.
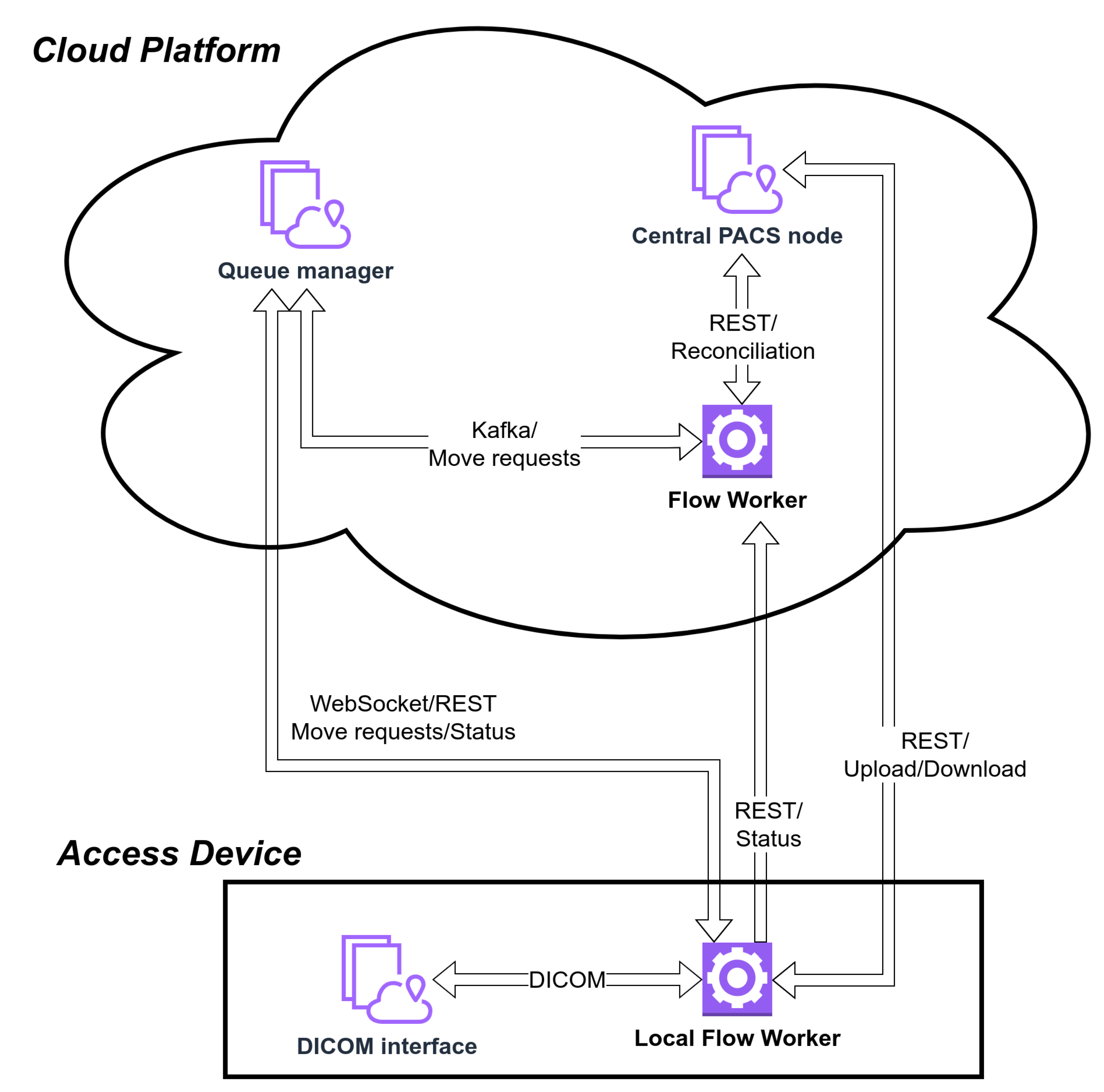
2.2. Queue Manager and Flow Workers
2.3. Access Devices
2.3.1. DICOM Interface
2.3.2. Local Flow Worker
2.4. Supporting Services
- Single Sign On, responsible for credential validation and JWT token distribution;
- Proxy layer, responsible for authentication and redirection of external requests. For example, the proxy layer permits access device communication with internal cloud services;
- The provisioning module monitors access devices’ state and deploys updates.
3. Data Flow
3.1. CT to Cloud
3.2. Local Archive to the Workstation
3.3. Cloud to Workstation
3.4. Between PACS Nodes
4. Results
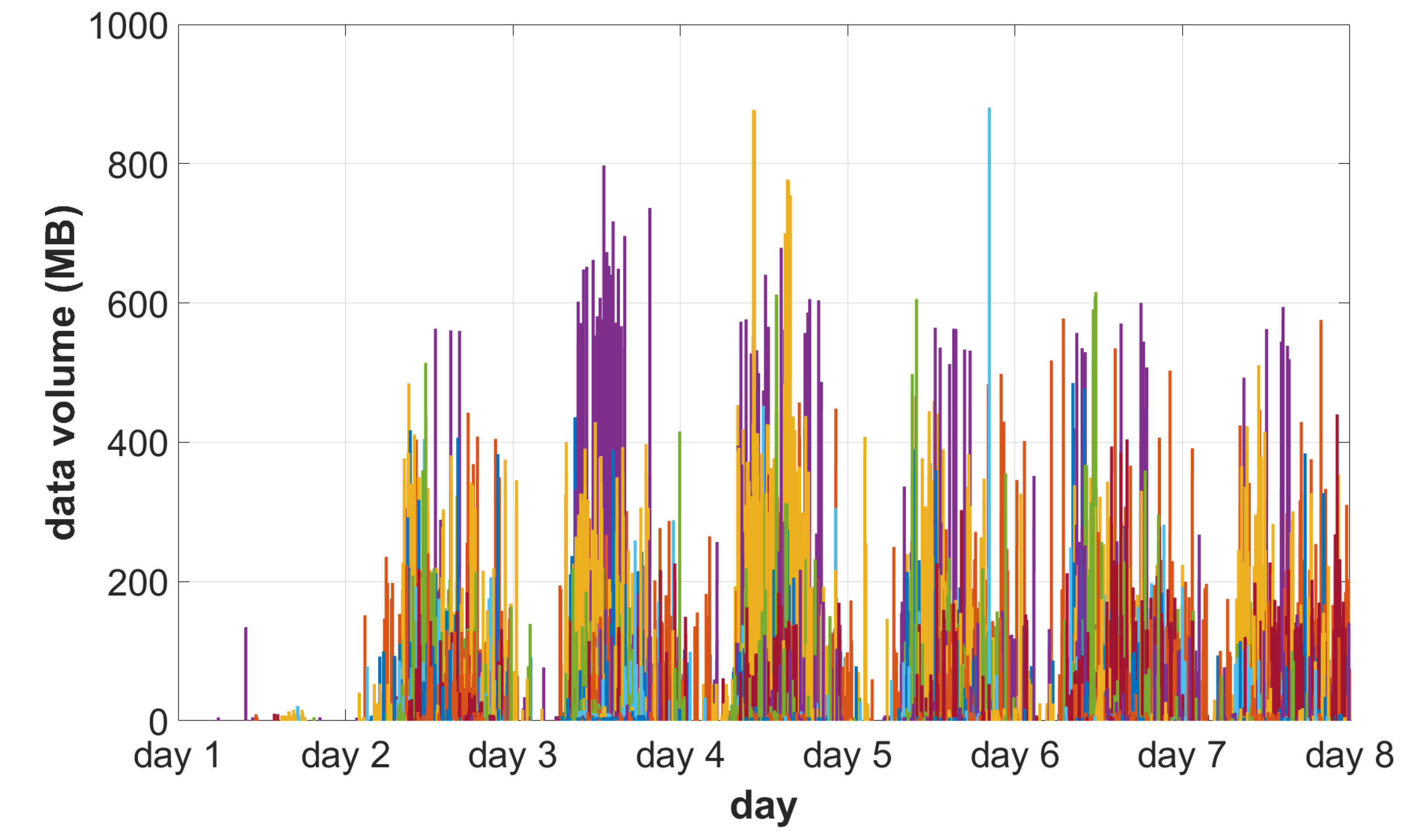
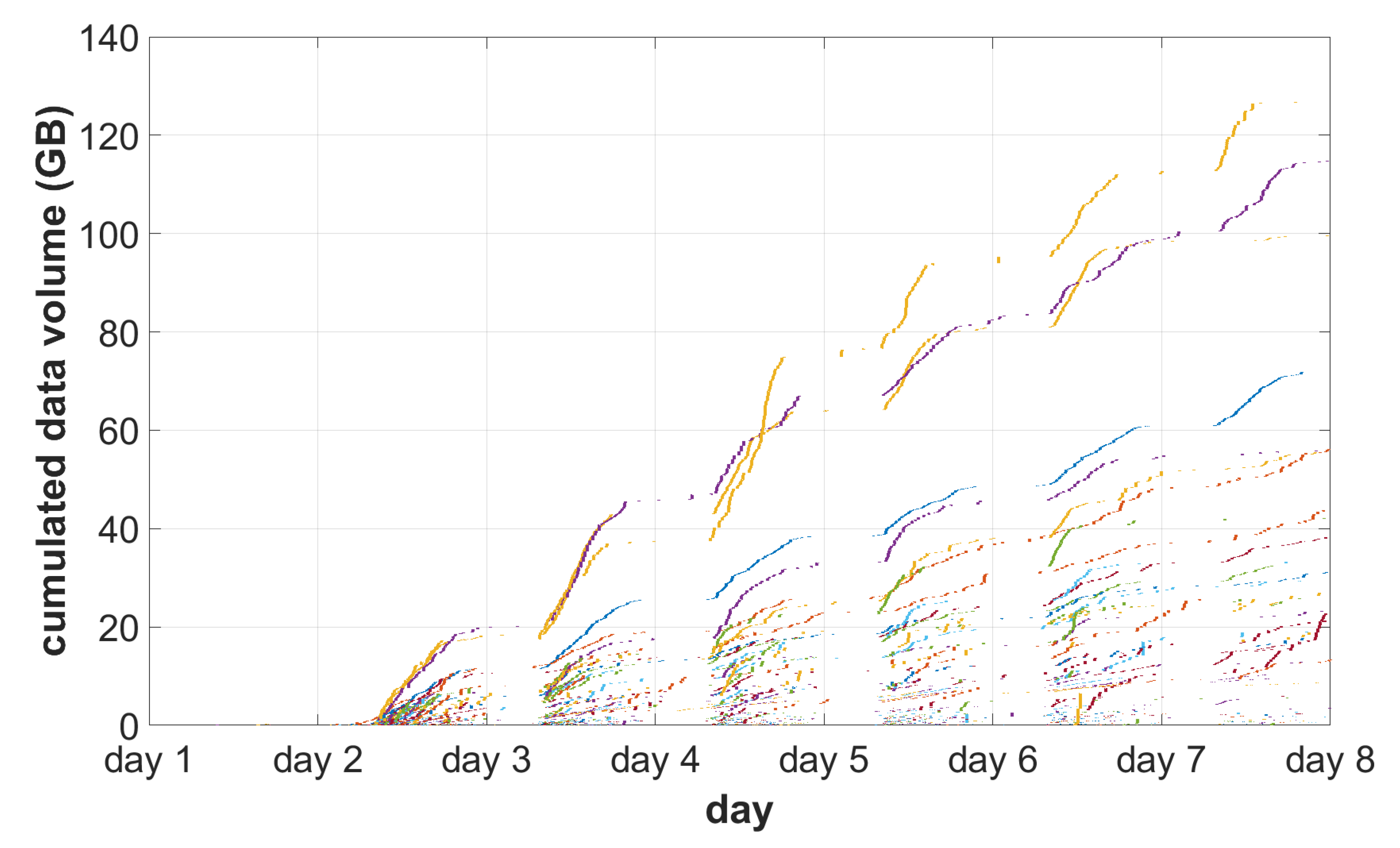
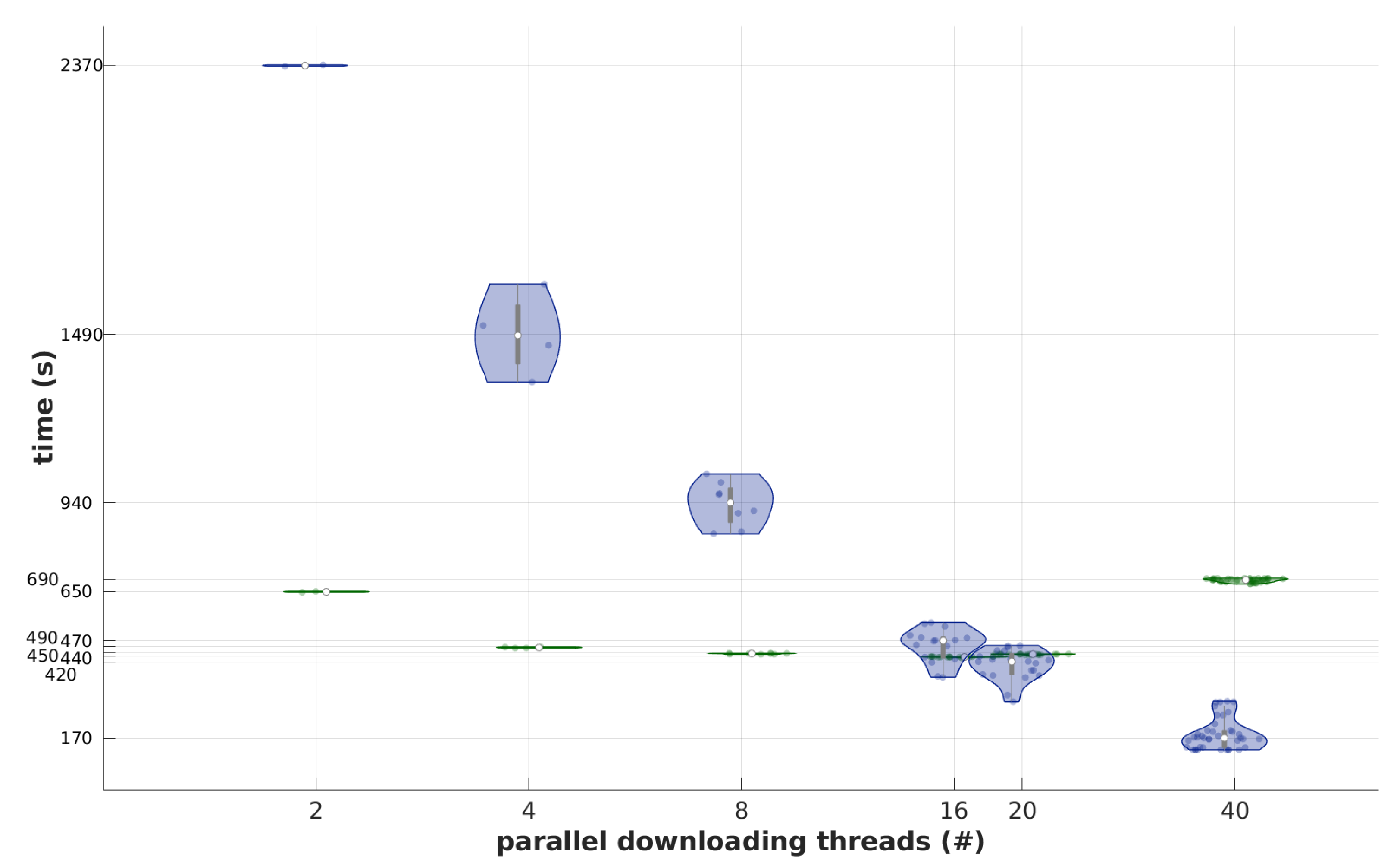
4.1. The Behavior of the System under Simulated Load
- Four central PACS nodes have been set up on separate c5d.large AWS instances; on each host, the container network is bridged to the host network and the PACS node is the only microservice running; the Docker swarm system supervises the cluster;
- Eight cache hosts (Memcached) have been set up using r5a.large EC machines and connected to S3 storage;
- Elasticsearch (OpenSearch) index is initialized;
- Twenty access devices are connected to the system using a broadband connection (20–100 Mbps).
- Day 1: initial eight devices;
- Days 2–7: remaining devices.
- Created on each day of the test;
- Created at 8 am.
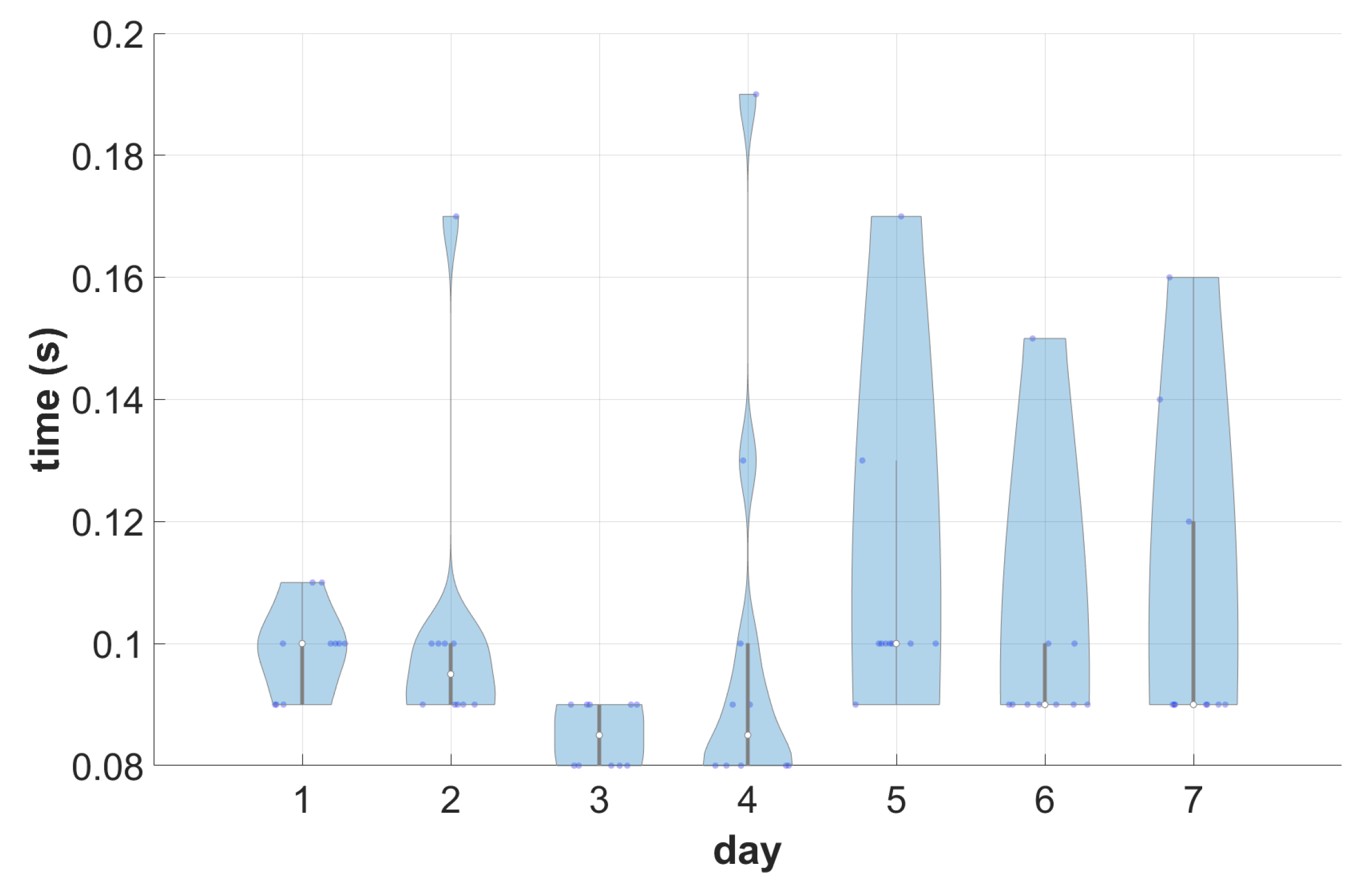
4.2. Comparison of Data Retrieval and Search in the Monolithic and Cloud PACS
- A single, monolithic Dcm4chee 2.18.3 server was installed on an m5n.xlarge virtual instance (four logical processors, 16 GB RAM, Elastic Block Store (EBS) with 3.5 Gbps capacity and 25 Gbps bandwidth network). The server was configured to use the EBS storage local to the machine, external index in PostgreSQL database, accept and send 64 kB DICOM PDUs (protocol data units), and allow up to 128 simultaneous connections without a limit on underlying asynchronous operations;
- A cluster of two central PACS nodes was set up on two m5n.xlarge instances. Between nodes, traffic was balanced using the Application Load Balancer service on c6gn.large instance (two virtual processors, 10Gbps bandwidth network). A cluster was attached to the S3 storage and OpenSearch index. Central PACS nodes were configured to handle DICOM connections in a serial manner (e.g., in the case of C-MOVE operation, all instances were sent one after another). Four Memcached nodes were configured. 64 kB DICOM PDUs were allowed;
- A testing machine was configured. An m5n.large instance was configured with Ubuntu 20.04.5 system, equipped with dcmtk toolkit, and put under netdata service monitoring;
- A DICOM dataset was generated consisting of 500 studies of 10 patients. Each study consisted of five series with 104 uncompressed (Little Ending Explicit) CT instances embedding the same image content. The size of a single instance was ca. 202 kB, accounting for a volume of a single study being ca. 205 MB and the total volume of the dataset being 100 GB. The dataset was uploaded to both DICOM servers on the day preceding the testing.
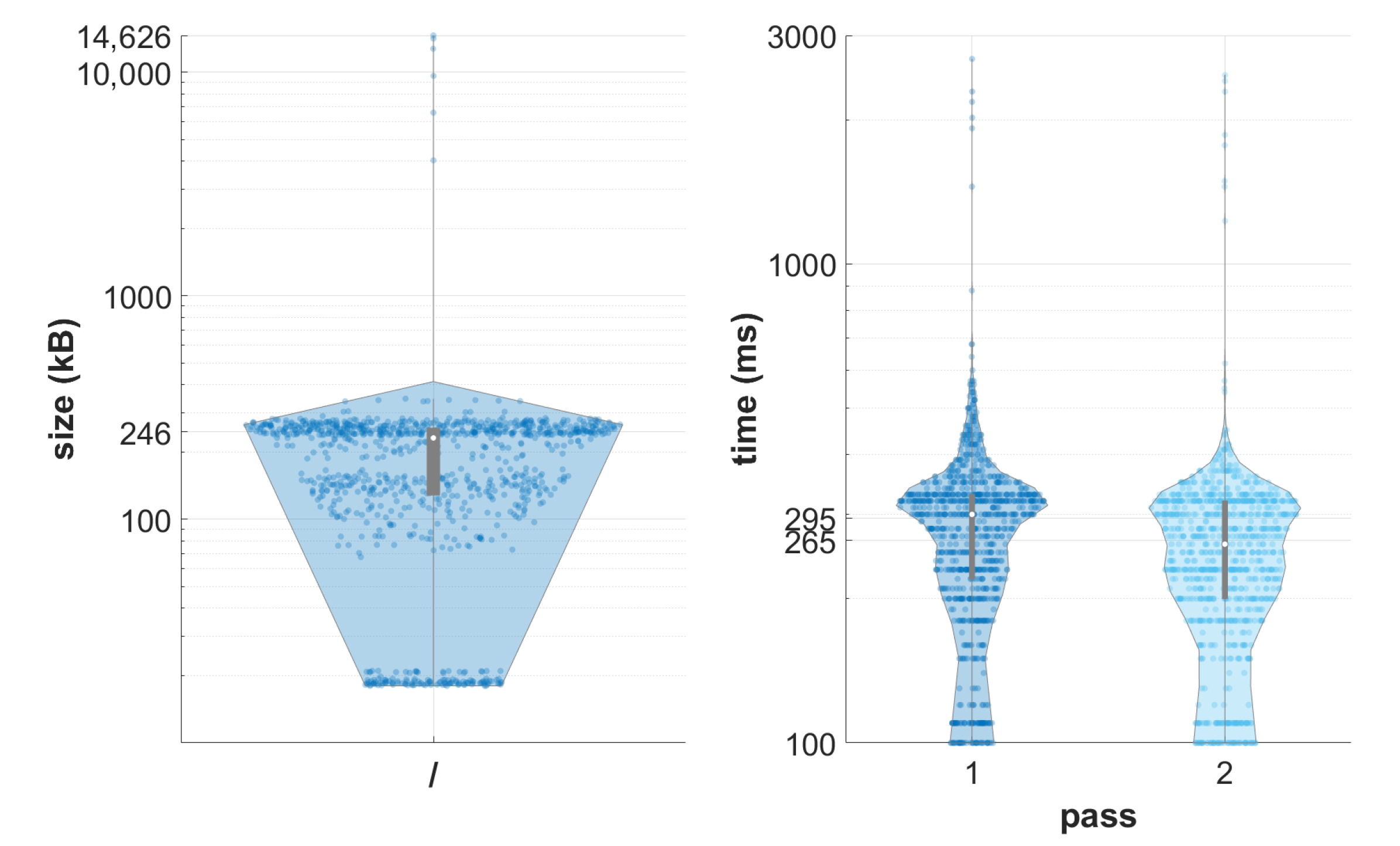
4.3. Performance Analysis for Different Loads and Study Sizes
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| ACR | American College of Radiology |
| AI | Artificial Intelligence |
| API | Application Programming Interface |
| CAD | Computer-Aided Diagnosis |
| DICOM | Digital Imaging and Communications in Medicine |
| EBS | Elastic Block Store |
| HTTP | Hypertext Transfer Protocol |
| JWT | JSON Web Token |
| LAN | Local Area Network |
| NEMA | National Electrical Manufacturers Association |
| PACS | Picture Archiving and Communication System |
| PDU | Protocol Data Unit |
| REST | Representational State Transfer |
| SSL | Secure Socket Layer |
| VNA | Vendor Neutral Archive |
| VPN | Virtual Private Network |
| WAN | Wide Area Network |
References
- Fennell, N.; Ralston, M.D.; Coleman, R.M. PACS and Other Image Management Systems. In Practical Imaging Informatics: Foundations and Applications for Medical Imaging; Branstetter, B.F., IV, Ed.; Springer: New York, NY, USA, 2021; pp. 131–142. [Google Scholar] [CrossRef]
- Huang, H. PACS and Imaging Informatics: Basic Principles and Applications; John Wiley & Sons, Inc.: Hoboken, NJ, USA, 2010. [Google Scholar]
- Armbrust, L.J. PACS and Image Storage. Vet. Clin. N. Am.-Small 2009, 39, 711–718. [Google Scholar] [CrossRef] [PubMed]
- Agarwal, T.K.; Sanjeev. Vendor Neutral Archive in PACS. Indian J. Radiol. Imaging 2012, 22, 242–245. [Google Scholar] [CrossRef] [PubMed]
- Bidgood, W.D.; Horii, S.C. Introduction to the ACR-NEMA DICOM Standard. RadioGraphics 1992, 12, 345–355. [Google Scholar] [CrossRef] [PubMed]
- Pianykh, O.S. Digital Imaging and Communications in Medicine (DICOM), 1st ed.; Springer: Berlin/Heidelberg, Germany, 2012. [Google Scholar] [CrossRef]
- Bergh, B. Enterprise imaging and multi-departmental PACS. Eur. Radiol. 2006, 16, 2775–2791. [Google Scholar] [CrossRef]
- Costa, C.; Silva, A.; Oliveira, J.L. Current Perspectives on PACS and a Cardiology Case Study. In Advanced Computational Intelligence Paradigms in Healthcare-2; Springer: Berlin/Heidelberg, Germany, 2007; pp. 79–108. [Google Scholar] [CrossRef]
- Herrmann, M.D.; Clunie, D.A.; Fedorov, A.; Doyle, S.W.; Pieper, S.; Klepeis, V.; Le, L.P.; Mutter, G.L.; Milstone, D.S.; Schultz, T.J.; et al. Implementing the DICOM Standard for Digital Pathology. J. Pathol. Inform. 2018, 9, 37. [Google Scholar] [CrossRef]
- Duncan, L.D.; Gray, K.; Lewis, J.M.; Bell, J.L.; Bigge, J.; McKinney, J.M. Clinical Integration of Picture Archiving and Communication Systems with Pathology and Hospital Information System in Oncology. Am. Surg. 2010, 76, 982–986. [Google Scholar] [CrossRef]
- Rybak, G.; Strzecha, K.; Krakós, M. A New Digital Platform for Collecting Measurement Data from the Novel Imaging Sensors in Urology. Sensors 2022, 22, 1539. [Google Scholar] [CrossRef]
- Halford, J.J.; Clunie, D.A.; Brinkmann, B.H.; Krefting, D.; Rémi, J.; Rosenow, F.; Husain, A.; Fürbass, F.; Ehrenberg, J.A.; Winkler, S. Standardization of neurophysiology signal data into the DICOM® standard. Clin. Neurophysiol. 2021, 132, 993–997. [Google Scholar] [CrossRef]
- Gupta, Y.; Costa, C.; Pinho, E.; Silva, L.B. DICOMization of Proprietary Files Obtained from Confocal, Whole-Slide, and FIB-SEM Microscope Scanners. Sensors 2022, 22, 2322. [Google Scholar] [CrossRef]
- Faggioni, L.; Neri, E.; Castellana, C.; Caramella, D.; Bartolozzi, C. The Future of PACS in Healthcare Enterprises. Eur. J. Radiol. 2011, 78, 253–258. [Google Scholar] [CrossRef]
- Cawthra, J.; Hodges, B.; Kuruvilla, J.; Littlefield, K.; Niemeyer, B.; Peloquin, C.; Wang, S.; Williams, R.; Zheng, K. Securing Picture Archiving and Communication System (PACS) Cybersecurity for the Healthcare Sector; Technical Report; U.S. Department of Commerce: Washington, DC, USA, 2020. [CrossRef]
- Cordero, D.; Barría, C. Cybersecurity Analysis in Nodes That Work on the DICOM Protocol, a Case Study. In ITNG 2021 18th International Conference on Information Technology-New Generations; Latifi, S., Ed.; Springer International Publishing: Cham, Switzerland, 2021; pp. 69–76. [Google Scholar] [CrossRef]
- Huang, H.K.; Zhang, A.; Liu, B.; Zhou, Z.; Documet, J.; King, N.; Chan, L.W.C. Data grid for large-scale medical image archive and analysis. In Proceedings of the 13th annual ACM international conference on Multimedia—MULTIMEDIA ’05, Singapore, 28 November–30 December 2005; ACM Press: New York, NY, USA, 2005. [Google Scholar] [CrossRef]
- Kagadis, G.C.; Kloukinas, C.; Moore, K.; Philbin, J.; Papadimitroulas, P.; Alexakos, C.; Nagy, P.G.; Visvikis, D.; Hendee, W.R. Cloud computing in medical imaging. Med. Phys. 2013, 40, 070901. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Khajouei, R.; Jahromi, M.E.; Ameri, A. Challenges of Implementing Picture Archiving and Communication System in Multiple Hospitals: Perspectives of Involved Staff and Users. J. Med. Syst. 2019, 43, 182. [Google Scholar] [CrossRef] [PubMed]
- Fridell, K.; Aspelin, P.; Edgren, L.; Lindsköld, L.; Lundberg, N. PACS influence the radiographer’s work. Radiography 2009, 15, 121–133. [Google Scholar] [CrossRef]
- Yu, T.Y.; Ho, H.H. The design and development of a physician-oriented PACS for the enhancement of e-hospital facilities. Int. J. Med. Inform. 2008, 77, 836–847. [Google Scholar] [CrossRef] [PubMed]
- European Society of Radiology (ESR). Organisation and practice of radiological ultrasound in Europe: A survey by the ESR Working Group on Ultrasound. Insights Imaging 2013, 4, 401–407. [Google Scholar] [CrossRef] [Green Version]
- European Society of Radiology (ESR). Position statement and best practice recommendations on the imaging use of ultrasound from the European Society of Radiology ultrasound subcommittee. Insights Imaging 2020, 11, 115. [Google Scholar] [CrossRef]
- Ratib, O. From PACS to the Clouds. Eur. J. Radiol. 2011, 78, 161–162. [Google Scholar] [CrossRef]
- Philbin, J.; Prior, F.; Nagy, P. Will the Next Generation of PACS Be Sitting on a Cloud? J. Digit. Imaging 2011, 24, 179–183. [Google Scholar] [CrossRef] [Green Version]
- Kratzke, N.; Quint, P.C. Understanding cloud-native applications after 10 years of cloud computing—A systematic mapping study. J. Syst. Softw. 2017, 126, 1–16. [Google Scholar] [CrossRef]
- Langer, S.G. Challenges for Data Storage in Medical Imaging Research. J. Digit. Imaging 2011, 24, 203–207. [Google Scholar] [CrossRef] [Green Version]
- Shini, S.G.; Thomas, T.; Chithraranjan, K. Cloud Based Medical Image Exchange—Security Challenges. Procedia Eng. 2012, 38, 3454–3461. [Google Scholar] [CrossRef] [Green Version]
- Savaris, A.; Gimenes Marquez Filho, A.A.; Rodrigues Pires de Mello, R.; Colonetti, G.B.; Von Wangenheim, A.; Krechel, D. Integrating a PACS Network to a Statewide Telemedicine System: A Case Study of the Santa Catarina State Integrated Telemedicine and Telehealth System. In Proceedings of the 2017 IEEE 30th International Symposium on Computer-Based Medical Systems (CBMS), Thessaloniki, Greece, 22–24 June 2017; pp. 356–357. [Google Scholar] [CrossRef]
- Berkowitz, S.J.; Wei, J.L.; Halabi, S. Migrating to the Modern PACS: Challenges and Opportunities. RadioGraphics 2018, 38, 1761–1772. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Dikici, E.; Bigelow, M.; Prevedello, L.M.; White, R.D.; Erdal, B.S. Integrating AI into radiology workflow: Levels of research, production, and feedback maturity. J. Med. Imag. 2020, 7, 1. [Google Scholar] [CrossRef] [PubMed]
- Horii, S.C.; Behlen, F.M. PACS Readiness and PACS Migration. In Practical Imaging Informatics: Foundations and Applications for Medical Imaging; Branstetter, B.F., IV, Ed.; Springer: New York, NY, USA, 2021; pp. 553–584. [Google Scholar] [CrossRef]
- Valente, F.; Viana-Ferreira, C.; Costa, C.; Oliveira, J.L. A RESTful Image Gateway for Multiple Medical Image Repositories. IEEE Ttans. Inf. Technol. Biomed. 2012, 16, 356–364. [Google Scholar] [CrossRef] [PubMed]
- Álvarez, R.; Legarreta, J.H.; Kabongo, L.; Epelde, G.; Macía, I. Towards a Deconstructed PACS-as-a-Service System. In International Conference on Innovation in Medicine and Healthcare; Springer: Cham, Switzerland, 2017; pp. 234–243. [Google Scholar] [CrossRef]
- Jodogne, S. The Orthanc Ecosystem for Medical Imaging. J. Digit. Imaging 2018, 31, 341–352. [Google Scholar] [CrossRef] [Green Version]
- Sohn, J.H.; Chillakuru, Y.R.; Lee, S.; Lee, A.Y.; Kelil, T.; Hess, C.P.; Seo, Y.; Vu, T.; Joe, B.N. An Open-Source, Vender Agnostic Hardware and Software Pipeline for Integration of Artificial Intelligence in Radiology Workflow. J. Digit. Imaging 2020, 33, 1041–1046. [Google Scholar] [CrossRef]
- Warnock, M.J.; Toland, C.; Evans, D.; Wallace, B.; Nagy, P. Benefits of Using the DCM4CHE DICOM Archive. J. Digit. Imaging 2007, 20, 125–129. [Google Scholar] [CrossRef] [Green Version]
- Costa, C.; Ferreira, C.; Bastião, L.; Ribeiro, L.; Silva, A.; Oliveira, J.L. Dicoogle—An Open Source Peer-to-Peer PACS. J. Digit. Imaging 2011, 24, 848–856. [Google Scholar] [CrossRef] [Green Version]
- Ribeiro, L.S.; Costa, C.; Oliveira, J.L. Clustering of Distinct PACS Archives Using a Cooperative Peer-to-Peer Network. Comput. Meth. Prog. Biomed. 2012, 108, 1002–1011. [Google Scholar] [CrossRef]
- Valente, F.; Silva, L.A.B.; Godinho, T.M.; Costa, C. Anatomy of an Extensible Open Source PACS. J. Digit. Imaging 2016, 29, 284–296. [Google Scholar] [CrossRef] [Green Version]
- Lebre, R.; Silva, L.B.; Costa, C. Decentralizing the Storage of a DICOM Compliant PACS. In Proceedings of the 2021 IEEE International Conference on Bioinformatics and Biomedicine (BIBM), Houston, TX, USA, 9–12 December 2021; pp. 2749–2756. [Google Scholar] [CrossRef]
- Lebre, R.; Pinho, E.; Silva, J.M.; Costa, C. Dicoogle Framework for Medical Imaging Teaching and Research. In Proceedings of the 2020 IEEE Symposium on Computers and Communications (ISCC), Rennes, France, 7–10 July 2020; pp. 1–7. [Google Scholar] [CrossRef]
- Faggioni, L.; Neri, E.; Cerri, F.; Turini, F.; Bartolozzi, C. Integrating Image Processing in PACS. Eur. J. Radiol. 2011, 78, 210–224. [Google Scholar] [CrossRef] [PubMed]
- Pietka, E.; Kawa, J.; Spinczyk, D.; Badura, P.; Wieclawek, W.; Czajkowska, J.; Rudzki, M. Role of radiologists in CAD life-cycle. Eur. J. Radiol. 2011, 78, 225–233. [Google Scholar] [CrossRef] [PubMed]
- Lui, Y.W.; Geras, K.; Block, K.T.; Parente, M.; Hood, J.; Recht, M.P. How to Implement AI in the Clinical Enterprise: Opportunities and Lessons Learned. J. Am. Coll. Radiol. 2020, 17, 1394–1397. [Google Scholar] [CrossRef] [PubMed]
- Kotter, E.; Ranschaert, E. Challenges and solutions for introducing artificial intelligence (AI) in daily clinical workflow. Eur. Radiol. 2020, 31, 5–7. [Google Scholar] [CrossRef]
- Ranschaert, E.; Topff, L.; Pianykh, O. Optimization of Radiology Workflow with Artificial Intelligence. Radiol. Clin. N. Am. 2021, 59, 955–966. [Google Scholar] [CrossRef]
- Jiang, L.; Wu, Z.; Xu, X.; Zhan, Y.; Jin, X.; Wang, L.; Qiu, Y. Opportunities and challenges of artificial intelligence in the medical field: Current application, emerging problems, and problem-solving strategies. J. Int. Med. Res. 2021, 49, 030006052110001. [Google Scholar] [CrossRef]
- Gannon, D.; Barga, R.; Sundaresan, N. Cloud-Native Applications. IEEE Cloud Comput. 2017, 4, 16–21. [Google Scholar] [CrossRef] [Green Version]
- Jamshidi, P.; Pahl, C.; Mendonca, N.C.; Lewis, J.; Tilkov, S. Microservices: The Journey So Far and Challenges Ahead. IEEE Softw. 2018, 35, 24–35. [Google Scholar] [CrossRef] [Green Version]
- Plecinski, P.; Bokla, N.; Klymkovych, T.; Melnyk, M.; Zabierowski, W. Comparison of Representative Microservices Technologies in Terms of Performance for Use for Projects Based on Sensor Networks. Sensors 2022, 22, 7759. [Google Scholar] [CrossRef]
- Bushong, V.; Abdelfattah, A.S.; Maruf, A.A.; Das, D.; Lehman, A.; Jaroszewski, E.; Coffey, M.; Cerny, T.; Frajtak, K.; Tisnovsky, P.; et al. On Microservice Analysis and Architecture Evolution: A Systematic Mapping Study. Appl. Sci. 2021, 11, 7856. [Google Scholar] [CrossRef]
- Szalay, M.; Mátray, P.; Toka, L. State Management for Cloud-Native Applications. Electronics 2021, 10, 423. [Google Scholar] [CrossRef]
- Linthicum, D.S. Cloud-Native Applications and Cloud Migration: The Good, the Bad, and the Points Between. IEEE Cloud Comput. 2017, 4, 12–14. [Google Scholar] [CrossRef]
- Kawa, J. DICOM Traffic Record from Different Medical Imaging Devices. Mendeley Data. Available online: https://data.mendeley.com/datasets/n8mssthhnm (accessed on 13 September 2022). [CrossRef]
- Alzakholi, O.; Haji, L.; Shukur, H.; Zebari, R.; Abas, S.; Sadeeq, M. Comparison Among Cloud Technologies and Cloud Performance. J. Appl. Sci. Technol. Trends 2020, 1, 40–47. [Google Scholar] [CrossRef] [Green Version]
- Pyciński, B.; Kawa, J.; Bożek, P.; Smoliński, M.; Bieńkowska, M. Performance of Medical Image Transfer in High Bandwidth Networks. In Innovations in Biomedical Engineering; Advances in Intelligent Systems and Computing; Springer International Publishing: Cham, Switzerland, 2019; Volume 925, pp. 28–35. [Google Scholar] [CrossRef]
- Silva, L.A.B.; Beroud, L.; Costa, C.; Oliveira, J.L. Medical Imaging Archiving: A Comparison between Several NoSQL Solutions. In Proceedings of the IEEE-EMBS International Conference on Biomedical and Health Informatics (BHI), Valencia, Spain, 1–4 June 2014; pp. 65–68. [Google Scholar] [CrossRef]
- Van Ooijen, P.M.A.; Aryanto, K.Y.; Broekema, A.; Horii, S. DICOM Data Migration for PACS Transition: Procedure and Pitfalls. Int. J. Comput. Assist. Rad. 2015, 10, 1055–1064. [Google Scholar] [CrossRef]
- Cohen, R.Y.; Sodickson, A.D. An Orchestration Platform that Puts Radiologists in the Driver’s Seat of AI Innovation: A Methodological Approach. arXiv 2021, arXiv:2107.04409. [Google Scholar] [CrossRef]
- Tang, A.; Tam, R.; Cadrin-Chênevert, A.; Guest, W.; Chong, J.; Barfett, J.; Chepelev, L.; Cairns, R.; Mitchell, J.R.; Cicero, M.D.; et al. Canadian Association of Radiologists White Paper on Artificial Intelligence in Radiology. Can. Assoc. Radiol. J. 2018, 69, 120–135. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| First Author and Year | Description | Advantages | Drawbacks |
|---|---|---|---|
| Warnock 2007 [37] | Dcm4chee PACS | Well known, fully featured PACS; wide usage | Heavyweight, no efficient scalability in 2.x series |
| Valente 2012 [33] | REST front-end to Dcm4chee; proof of concept | Modern network technology | Solely front-end |
| Ribeiro 2012 [39] | Dcm4chee based peer-to-peer PACS architecture | Improved performance regarding the transfer rate of DICOM objects | Shared-everything architecture |
| Valente 2016 [40] | Dicoogle PACS | Support for plugins for storage and index | Lack of integration with electronic health record systems |
| Álvarez 2017 [34] | Proof of concept of a distributed “PACS-as-a-service” | Modular architecture: a client-side, a server and a storage | lack of DICOM communication |
| Jodogne 2018 [35] | Orthanc PACS | Modular, lightweight | Designed as front-end to PACS; performance decreases with amount of stored data |
| Lebre 2021 [41] | Dicoogle-driven proof of concept of peer-to-peer storage | Automatic data redundancy | Unknown performance in production environment |
| this work | Presented system | High scalability | Overly complex for on-premise development |
| Parameter | Value |
|---|---|
| Total storage | 490 TB |
| Total studies | 4 M |
| Total series | 23.3 M |
| Instance count | 1.35 G |
| Registered access devices | 415 |
| New data per month * | 33 TB |
| Central node instances | 6 |
| No. | Modality | Count | |
|---|---|---|---|
| 1 | CT | Computed tomography | 37 |
| 2 | DX | Digital radiography | 29 |
| 3 | CR | Computed radiography | 27 |
| 4 | MR | Magnetic resonance | 21 |
| 5 | MG | Mammography | 2 |
| 6 | XA | X-ray angiography | 1 |
| Four Retrieving Threads | |||
| Size of | Instances | Seconds per | Throughput |
| Study (MB) | per Second | 100 Instances | (Mbps) |
| 2 | 23–24 | 4.2–4.3 | 93–96 |
| 4 | 25 | 3.9–4.0 | 100–102 |
| 8 | 22–23 | 4.4–4.5 | 89–92 |
| 16 | 22–23 | 4.3–4.6 | 87–93 |
| 32 | 22–23 | 4.4–4.6 | 88–90 |
| 64 | 23–25 | 3.9–4.3 | 93–102 |
| 128 | 26 | 3.8–3.9 | 104–106 |
| 256 | 26–28 | 3.5–3.8 | 105–114 |
| 512 | 31 | 3.2 | 124–126 |
| 1024 | 28 | 3.6 | 112–113 |
| Eight Retrieving Threads | |||
| Size of | Instances | Seconds per | Throughput |
| Study (MB) | per Second | 100 Instances | (Mbps) |
| 2 | 48–67 | 1.5–2.1 | 193–269 |
| 4 | 57–73 | 1.4–1.8 | 229–293 |
| 8 | 48–68 | 1.5–2.1 | 194–273 |
| 16 | 49–65 | 1.5–2.0 | 197–262 |
| 32 | 48–61 | 1.7–2.1 | 192–243 |
| 64 | 45–57 | 1.7–2.2 | 181–230 |
| 128 | 51–53 | 1.9–2.0 | 204–213 |
| 256 | 48–51 | 2.0–2.1 | 194–205 |
| 512 | 48–54 | 1.8–2.1 | 193–218 |
| 1024 | 48 | 2.1–2.1 | 193–194 |
| Sixteen Retrieving Threads | |||
| Size of | Instances | Seconds per | Throughput |
| Study (MB) | per Second | 100 Instances | (Mbps) |
| 2 | 71–85 | 1.2–1.4 | 284–343 |
| 4 | 79–112 | 0.9–1.3 | 316–449 |
| 8 | 81–102 | 1.0–1.2 | 325–409 |
| 16 | 84–109 | 0.9–1.2 | 336–437 |
| 32 | 82–104 | 1.0–1.2 | 328–418 |
| 64 | 77–104 | 1.0–1.3 | 310–420 |
| 128 | 84–92 | 1.1–1.2 | 335–370 |
| 256 | 85–91 | 1.1–1.2 | 339–367 |
| 512 | 86–93 | 1.1–1.2 | 347–373 |
| 1024 | 81–88 | 1.1–1.2 | 325–353 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kawa, J.; Pyciński, B.; Smoliński, M.; Bożek, P.; Kwasecki, M.; Pietrzyk, B.; Szymański, D. Design and Implementation of a Cloud PACS Architecture. Sensors 2022, 22, 8569. https://doi.org/10.3390/s22218569
Kawa J, Pyciński B, Smoliński M, Bożek P, Kwasecki M, Pietrzyk B, Szymański D. Design and Implementation of a Cloud PACS Architecture. Sensors. 2022; 22(21):8569. https://doi.org/10.3390/s22218569
Chicago/Turabian StyleKawa, Jacek, Bartłomiej Pyciński, Michał Smoliński, Paweł Bożek, Marek Kwasecki, Bartosz Pietrzyk, and Dariusz Szymański. 2022. "Design and Implementation of a Cloud PACS Architecture" Sensors 22, no. 21: 8569. https://doi.org/10.3390/s22218569