
Comparing YOLOv3, YOLOv4 and YOLOv5 for Autonomous Landing Spot Detection in Faulty UAVs


Abstract
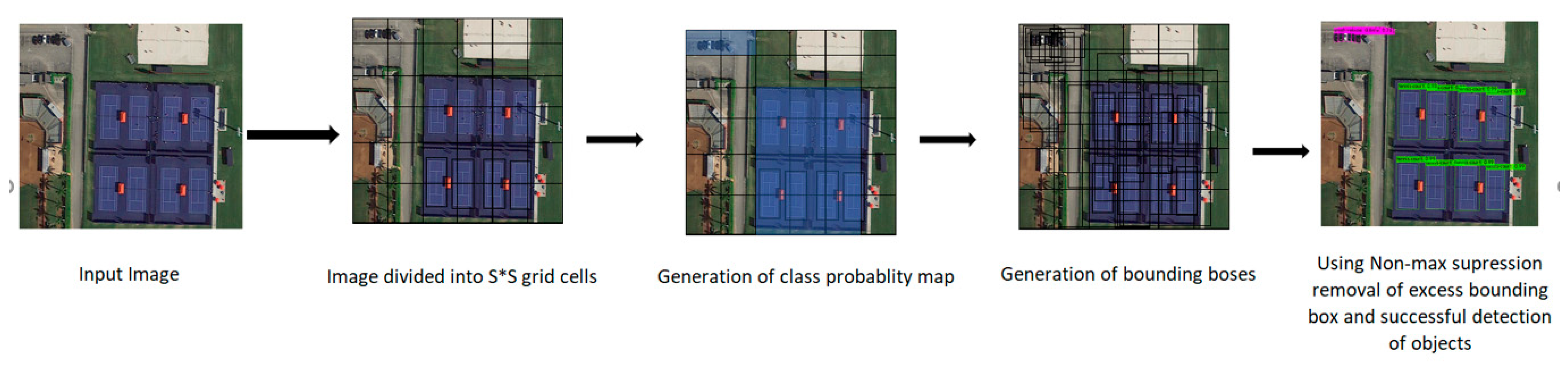
:1. Introduction and Related Works
2. Theoretical Overview
2.1. YOLOv4 Architecture
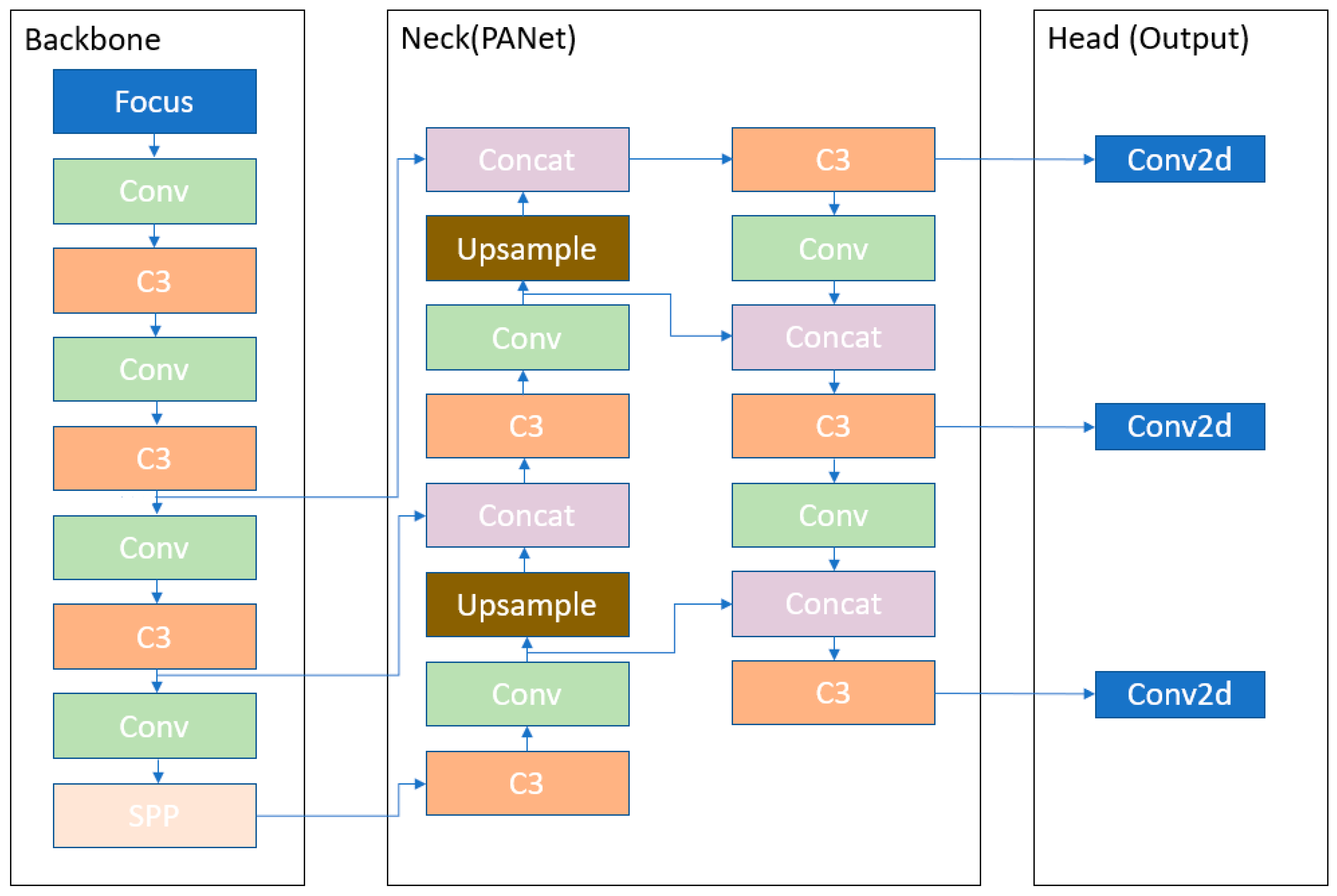
2.2. YOLOv5 Architecture
3. Results and Discussion
3.1. Evaluation Metrics
3.2. Training and Comparing the Algorithms
- CPU: 10th Gen. Intel® Core™ i7-10750H Processor.
- GPU: NVIDIA® GeForce® RTX 2070 SUPER™ Turing™ architecture with 8 GB GDDR6.
- RAM: 32 GB DDR4.
- Storage: 1TB NVMe SSD.
- Operating System: UBUNTU 18.04.
- Model: Jetson Xavier NX.
- CPU: 6-core NVIDIA Carmel ARM®v8.2 64-bit CPU 6MB L2 + 4 MB L3.
- GPU: NVIDIA Volta™ architecture with 384 NVIDIA®CUDA® cores and 48 Tenor cores.
- RAM: 8 GB 128-bit LPDDR4x 59.7 GB/s.
- Storage: 500 GB NVMe SSD and.
- Operating System: linux4tegra operating system (an Ubuntu derived OS).
3.3. Embedded Platform Results
4. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Label | YOLOv3 Average Precision | YOLOv4 Average Precision | YOLOv5l Average Precision |
|---|---|---|---|
| Small-Vehicle | 29.25 | 39.62 | 44.8 |
| Large-Vehicle | 55.84 | 73.43 | 70.1 |
| Plane | 83.06 | 90.39 | 91.3 |
| Storage-tank | 44.69 | 61.52 | 63 |
| Ship | 71.19 | 82.67 | 78.6 |
| Harbor | 67.94 | 80.35 | 82.7 |
| Ground-track-field | 36.12 | 67.32 | 65.7 |
| Soccer-ballfield | 36.82 | 54.24 | 59.8 |
| Tennis-court | 87.30 | 92.57 | 92.7 |
| Swimming-pool | 39.76 | 57.57 | 65.4 |
| baseball | 61.35 | 76.62 | 75.8 |
| roundabout | 44.14 | 55.98 | 55.9 |
| Basketball-court | 37.79 | 63.04 | 64.5 |
| bridge | 26.65 | 42.41 | 50.1 |
| helicopter | 15.84 | 34.54 | 48.2 |
References
- Corcoran, M. Drone Journalism: Newsgathering applications of Unmanned Aerial Vehicles (UAVs) in covering conflict, civil unrest and disaster. Flinders Univ. Adelaide 2014, 201, 202014. [Google Scholar]
- Osco, L.P.; Junior, J.M.; Ramos, A.P.M.; de Castro Jorge, L.A.; Fatholahi, S.N.; de Andrade Silva, J.; Matsubara, E.T.; Pistori, H.; Gonçalves, W.N.; Li, J. A review on deep learning in UAV remote sensing. arXiv 2021, arXiv:2101.10861. [Google Scholar] [CrossRef]
- Yang, K.; Yu, Z.; Luo, Y.; Zhou, X.; Shang, C. Spatial-temporal variation of lake surface water temperature and its driving factors in Yunnan-Guizhou Plateau. Water Resour. Res. 2019, 55, 4688–4703. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7263–7271. [Google Scholar]
- Bochkovskiy, A.; Wang, C.-Y.; Liao, H.-Y.M. YOLOv4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Ding, J.; Xue, N.; Xia, G.-S.; Bai, X.; Yang, W.; Yang, M.Y.; Belongie, S.; Luo, J.; Datcu, M.; Pelillo, M. Object detection in aerial images: A large-scale benchmark and challenges. arXiv 2021, arXiv:2102.12219. [Google Scholar] [CrossRef] [PubMed]
- Xia, G.-S.; Bai, X.; Ding, J.; Zhu, Z.; Belongie, S.; Luo, J.; Datcu, M.; Pelillo, M.; Zhang, L. DOTA: A large-scale dataset for object detection in aerial images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 3974–3983. [Google Scholar]
- Ding, J.; Xue, N.; Long, Y.; Xia, G.-S.; Lu, Q. Learning RoI transformer for detecting oriented objects in aerial images. arXiv 2018, arXiv:1812.00155. [Google Scholar]
- Viraktamath, D.S.; Navalgi, P.; Neelopant, A. Comparison of YOLOv3 and SSD Algorithms. Int. J. Eng. Res. Technol. 2021, 10, 1156–1160. [Google Scholar]
- Benjdira, B.; Khursheed, T.; Koubaa, A.; Ammar, A.; Ouni, K. Car detection using unmanned aerial vehicles: Comparison between faster r-cnn and yolov3. In Proceedings of the 2019 1st International Conference on Unmanned Vehicle Systems-Oman (UVS), Muscat, Oman, 5–7 February 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 1–6. [Google Scholar]
- Rahman, E.U.; Zhang, Y.; Ahmad, S.; Ahmad, H.I.; Jobaer, S. Autonomous vision-based primary distribution systems porcelain insulators inspection using UAVs. Sensors 2021, 21, 974. [Google Scholar] [CrossRef] [PubMed]
- Ge, Z.; Liu, S.; Wang, F.; Li, Z.; Sun, J. Yolox: Exceeding yolo series in 2021. arXiv 2021, arXiv:2107.08430. [Google Scholar]
- Maxwell, A.E.; Warner, T.A.; Guillén, L.A. Accuracy assessment in convolutional neural network-based deep learning remote sensing studies—part 1: Literature review. Remote Sens. 2021, 13, 2450. [Google Scholar] [CrossRef]
- Yang, K.; Yu, Z.; Luo, Y.; Yang, Y.; Zhao, L.; Zhou, X. Spatial and temporal variations in the relationship between lake water surface temperatures and water quality-A case study of Dianchi Lake. Sci. Total Environ. 2018, 624, 859–871. [Google Scholar] [CrossRef] [PubMed]
- Eslamiat, H.; Li, Y.; Wang, N.; Sanyal, A.K.; Qiu, Q. Autonomous waypoint planning, optimal trajectory generation and nonlinear tracking control for multi-rotor UAVS. In Proceedings of the 2019 18th European Control Conference (ECC), Naples, Italy, 25–28 June 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 2695–2700. [Google Scholar]
- Li, Y.; Eslamiat, H.; Wang, N.; Zhao, Z.; Sanyal, A.K.; Qiu, Q. Autonomous waypoints planning and trajectory generation for multi-rotor UAVs. In Proceedings of the Workshop on Design Automation for CPS and IoT, New York, NY, USA, 15 April 2019; 2019; pp. 31–40. [Google Scholar]
- Madiajagan, M.; Raj, S.S. Parallel computing, graphics processing unit (GPU) and new hardware for deep learning in computational intelligence research. In Deep Learning and Parallel Computing Environment for Bioengineering Systems; Elsevier: Amsterdam, The Netherlands, 2019; pp. 1–15. [Google Scholar]
- Albawi, S.; Mohammed, T.A.; Al-Zawi, S. Understanding of a convolutional neural network. In Proceedings of the 2017 International Conference on Engineering and Technology (ICET), Antalya, Turkey, 21–23 August 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 1–6. [Google Scholar]
- Girshick, R. Fast R-CNN. In Proceedings of the IEEE International Conference on Computer Vision, Washington, DC, USA, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask R-CNN. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Noble, W.S. What is a support vector machine? Nat. Biotechnol. 2006, 24, 1565–1567. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. Adv. Neural Inf. Processing Syst. 2015, 28, 91–99. [Google Scholar] [CrossRef] [Green Version]
- Li, M.; Zhang, Z.; Lei, L.; Wang, X.; Guo, X. Agricultural greenhouses detection in high-resolution satellite images based on convolutional neural networks: Comparison of Faster R-CNN, YOLOv3 and SSD. Sensors 2020, 20, 4938. [Google Scholar] [CrossRef] [PubMed]
- Zhao, K.; Ren, X. Small aircraft detection in remote sensing images based on YOLOv3. In Proceedings of the IOP Conference Series: Materials Science and Engineering, Guangzhou, China, 12–14 January 2019. [Google Scholar]
- Dorrer, M.; Tolmacheva, A. Comparison of the YOLOv3 and Mask R-CNN architectures’ efficiency in the smart refrigerator’s computer vision. J. Phys. Conf. Ser. 2020, 1679, 042022. [Google Scholar] [CrossRef]
- Kim, J.-A.; Sung, J.-Y.; Park, S.-H. Comparison of Faster-RCNN, YOLO, and SSD for real-time vehicle type recognition. In Proceedings of the 2020 IEEE International Conference on Consumer Electronics-Asia (ICCE-Asia), Seoul, Korea, 1–3 November 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 1–4. [Google Scholar]
- Long, X.; Deng, K.; Wang, G.; Zhang, Y.; Dang, Q.; Gao, Y.; Shen, H.; Ren, J.; Han, S.; Ding, E. PP-YOLO: An effective and efficient implementation of object detector. arXiv 2020, arXiv:2007.12099. [Google Scholar]
- Redmon, J. Darknet: Open Source Neural Networks in C; 2013–2016. Available online: https://pjreddie.com/darknet/ (accessed on 20 October 2021).
- Lin, T.-Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Iandola, F.; Moskewicz, M.; Karayev, S.; Girshick, R.; Darrell, T.; Keutzer, K. Densenet: Implementing efficient convnet descriptor pyramids. arXiv 2014, arXiv:1404.1869. [Google Scholar]
- Zhang, Z.; He, T.; Zhang, H.; Zhang, Z.; Xie, J.; Li, M. Bag of freebies for training object detection neural networks. arXiv 2019, arXiv:1902.04103. [Google Scholar]
- Zheng, Z.; Wang, P.; Liu, W.; Li, J.; Ye, R.; Ren, D. Distance-IoU loss: Faster and better learning for bounding box regression. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020. [Google Scholar]
- glenn-jocher, YOLOv5 Focus() Layer #3181. In Ultralytics: Github; 2021; Available online: https://github.com/ultralytics/yolov5/discussions/3181m1 (accessed on 20 October 2021).
- Davis, J.; Goadrich, M. The relationship between Precision-Recall and ROC curves. In Proceedings of the 23rd International Conference on Machine Learning, New York, NY, USA, 25–29 June 2006; pp. 233–240. [Google Scholar]
- Mseddi, W.S.; Sedrine, M.A.; Attia, R. YOLOv5 Based Visual Localization for Autonomous Vehicles. In Proceedings of the 2021 29th European Signal Processing Conference (EUSIPCO), Dublin, Ireland, 23–27 August 2021; IEEE: Piscataway, NJ, USA; pp. 746–750. [Google Scholar]
- Hao, W.; Zhili, S. Improved Mosaic: Algorithms for more Complex Images. J. Phys. Conf. Ser. 2020, 1684, 012094. [Google Scholar] [CrossRef]





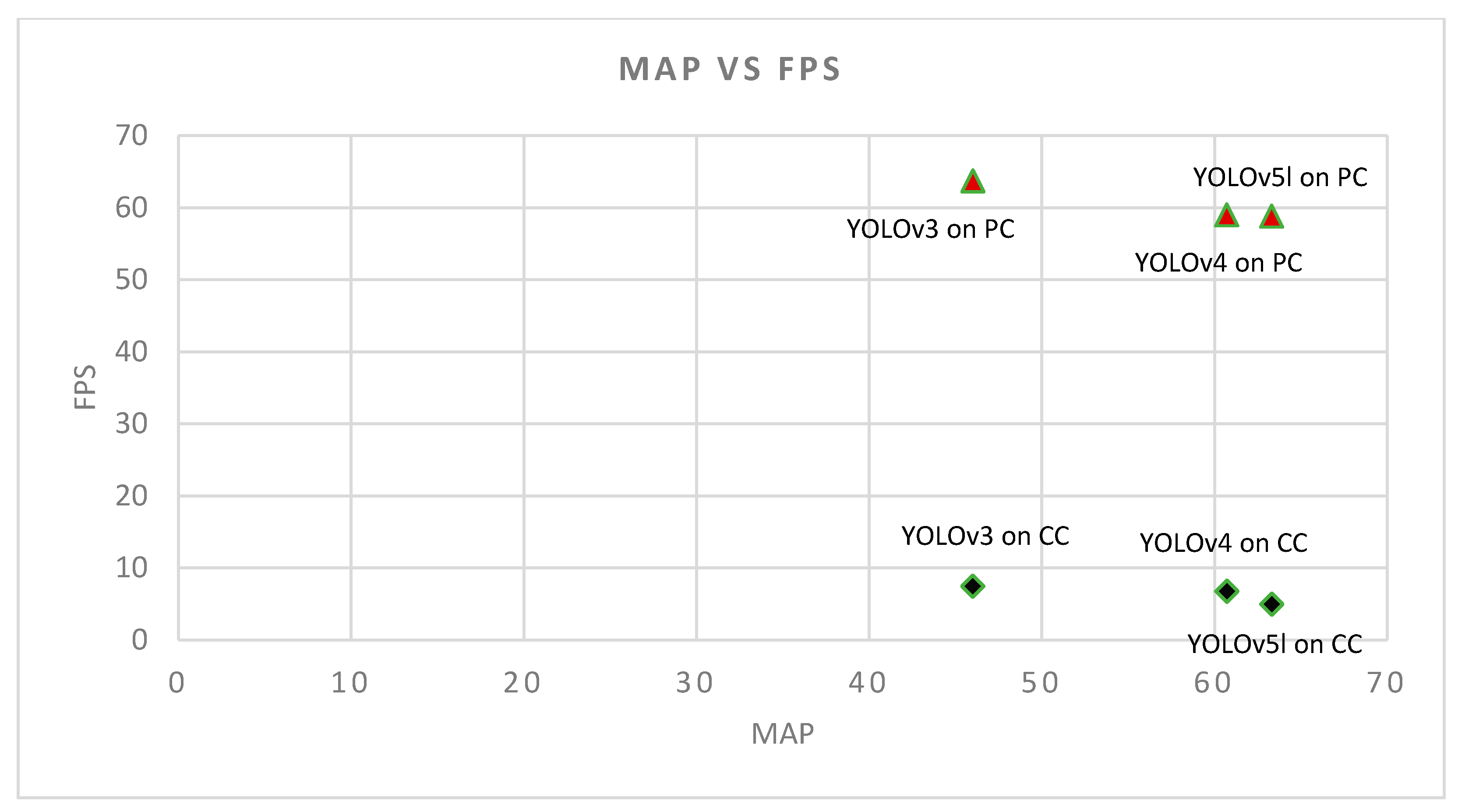
 ) and Companion Computer (CC) (
) and Companion Computer (CC) (  ). This figure shows that the accuracy of YOLOv5l is higher than YOLOv4 and YOLOv3 with a negligible drop in speed compared to YOLOv4 and YOLOv3.
) and Companion Computer (CC) ( ). This figure shows that the accuracy of YOLOv5l is higher than YOLOv4 and YOLOv3 with a negligible drop in speed compared to YOLOv4 and YOLOv3.
). This figure shows that the accuracy of YOLOv5l is higher than YOLOv4 and YOLOv3 with a negligible drop in speed compared to YOLOv4 and YOLOv3.
) and Companion Computer (CC) ( ). This figure shows that the accuracy of YOLOv5l is higher than YOLOv4 and YOLOv3 with a negligible drop in speed compared to YOLOv4 and YOLOv3.
| Reference | Dataset Used | Algorithms | Findings |
|---|---|---|---|
| Li et al., 2021 [26] | Remote sensing images collected from GF-1 and GF-2 satellites. Training: 826 images. Testing: 275 images. Resolution: 300 × 300, 416 × 416, 500 × 500, 800 × 800, 1000 × 1000 | Faster R-CNN YOLO v3 SSD | YOLOv3 has higher mAP and FPS than SSD and Faster R-CNN algorithms. |
| Benjdira et al., 2019 [12] | UAV dataset Training: 218 Images Test: 52 Images Resolution: 600 × 600 to 1024 × 1024 | Faster R-CNN YOLOv3 | YOLOv3 has higher F1 score and FPS than Faster R-CNN. |
| Zhao et al., 2019 [27] | Google Earth and DOTA datasetTraining: 224 Images Test: 56 Images Resolution: 600 × 600 to 1500 × 1500 | SSD Faster R-CNN YOLOv3 | YOLOv3 has higher mAP and FPS than Faster R-CNN and SSD. |
| Kim et al., 2020 [29] | Korea expressway dataset Training: 2620 Test: 568 Resolution: NA | YOLOv4 SSD Faster R-CNN | YOLOv4 has higher accuracy SSD has higher detection speed |
| Dorrer et al., [28] | Custom Refrigerator images Training: 800 Images Test: 70 Images Resolution: NA | Mask RCNN YOLOv3 | The detection of YOLOv3 was 3 times higher but the accuracy of Mask RCNN was higher. |
| Rahman et al., [13] | Custom Electrical dataset Training: 5939 Test: 1400 Resolution: NA | YOLOv4 YOLOv5l | YOLOv4 has higher mAP compared to YOLOv5l algorithms |
| Long et al., [30] | MS COCO dataset Training: 118,000 Test: 5000 Resolution: NA | YOLOv3 YOLOv4 | YOLOv4 has higher mAP compared to YOLOv3 |
| Bochkovskiy et al., [7] | MS COCO dataset Training: 118,000 Test: 5000 Resolution: NA | YOLOv3 YOLOv4 | YOLOv4 has higher mAP and fps than YOLOv3 |
| Ge et al., [14] | MS COCO dataset Training: 118,000 Test: 5000 Resolution: NA | YOLOv3 YOLOv4 YOLOv5 | YOLOv5 has higher mAP than YOLOv3 and YOLOv5l YOLOv3 has higher FPS than YOLOv4 and YOLOv5l |
| YOLOv3 | YOLOv4 | YOLOv5 | |
|---|---|---|---|
| Neural Network Type | Fully convolution | Fully convolution | Fully convolution |
| Backbone Feature Extractor | Darknet-53 | CSPDarknet53 | CSPDarknet53 |
| Loss Function | Binary cross entropy | Binary cross entropy | Binary cross entropy and Logits loss function |
| Neck | FPN | SSP and PANet | PANet |
| Head | YOLO layer | YOLO layer | YOLO layer |
| Measure | YOLOv3 | YOLOv4 | YOLOv5l |
|---|---|---|---|
| Precision | 0.73 | 0.69 | 0.707 |
| Recall | 0.41 | 0.57 | 0.611 |
| F1 Score | 0.53 | 0.63 | 0.655 |
| mAP | 0.46 | 0.607 | 0.633 |
| PC Speed (FPS) | 63.7 | 59 | 58.82 |
| Jetson Speed (FPS) | 7.5 | 6.8 | 5 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Nepal, U.; Eslamiat, H. Comparing YOLOv3, YOLOv4 and YOLOv5 for Autonomous Landing Spot Detection in Faulty UAVs. Sensors 2022, 22, 464. https://doi.org/10.3390/s22020464
Nepal U, Eslamiat H. Comparing YOLOv3, YOLOv4 and YOLOv5 for Autonomous Landing Spot Detection in Faulty UAVs. Sensors. 2022; 22(2):464. https://doi.org/10.3390/s22020464
Chicago/Turabian StyleNepal, Upesh, and Hossein Eslamiat. 2022. "Comparing YOLOv3, YOLOv4 and YOLOv5 for Autonomous Landing Spot Detection in Faulty UAVs" Sensors 22, no. 2: 464. https://doi.org/10.3390/s22020464