
Deep Learning for Encrypted Traffic Classification and Unknown Data Detection



Abstract
:1. Introduction
- There is a wide variety of app categories, from social networking to lifestyle, games, entertainment, health, education, finance, etc. It is impractical to train ML algorithms for such a wide range and for each in-app activity in those applications. When deploying an in-app activity classification framework in a real-world setting, the framework needs to identify a set of applications and activities within those applications while earmarking previously untrained activities as unknown data traffic. In the majority of the existing literature, ML algorithms were trained and tested on the same set of applications, which renders them unfit for filtering previously unknown traffic. The proposed framework in our work is capable of handling network traffic analysis accurately in the presence of noise generated by unknown traffic, thereby making this a desirable approach that can adapt to new environments and data streams with little or no training.
- In an attempt to detect in-app activities, there may be instances where an eavesdropper captures the network traffic partially rather than the entire transaction, as user activity may well be already underway [6]. In those cases, most existing work in literature fails to detect an activity if its signature does not fall into the captured window. The proposed framework can identify fine-grained in-app activities even by observing a subset of an activity’s traffic.
- Existing work focuses on either coarse-grained activities such as browsing, downloading, uploading, etc. [7] or generic activities such as posting on Instagram, messaging on WhatsApp, etc. [8,9,10]. Our research advances the state-of-the-art by identifying fine-grained user-in-app activities in encrypted network traffic. As such, e.g., when a generic WhatsApp activity such as ‘sending a message’ is considered, it can determine whether this message is a long text, short text, image, video, or voice recording. This level of classification is challenging when performed using metadata in an encrypted domain as it requires deep traffic pattern inspection. However, it provides valuable information for an analyst to identify the users, where confidential information is retained. The proposed framework can identify 92 in-app activities from eight distinct applications.
- A comprehensive dataset was created by performing a series of actions on apps such as Facebook, Instagram, WhatsApp, Viber, Messenger, Gmail, Skype, and YouTube. To foster new studies and allow the reproduction of the results presented, the dataset is shared openly with the research community.
2. Literature Review
3. Proposed Methodology
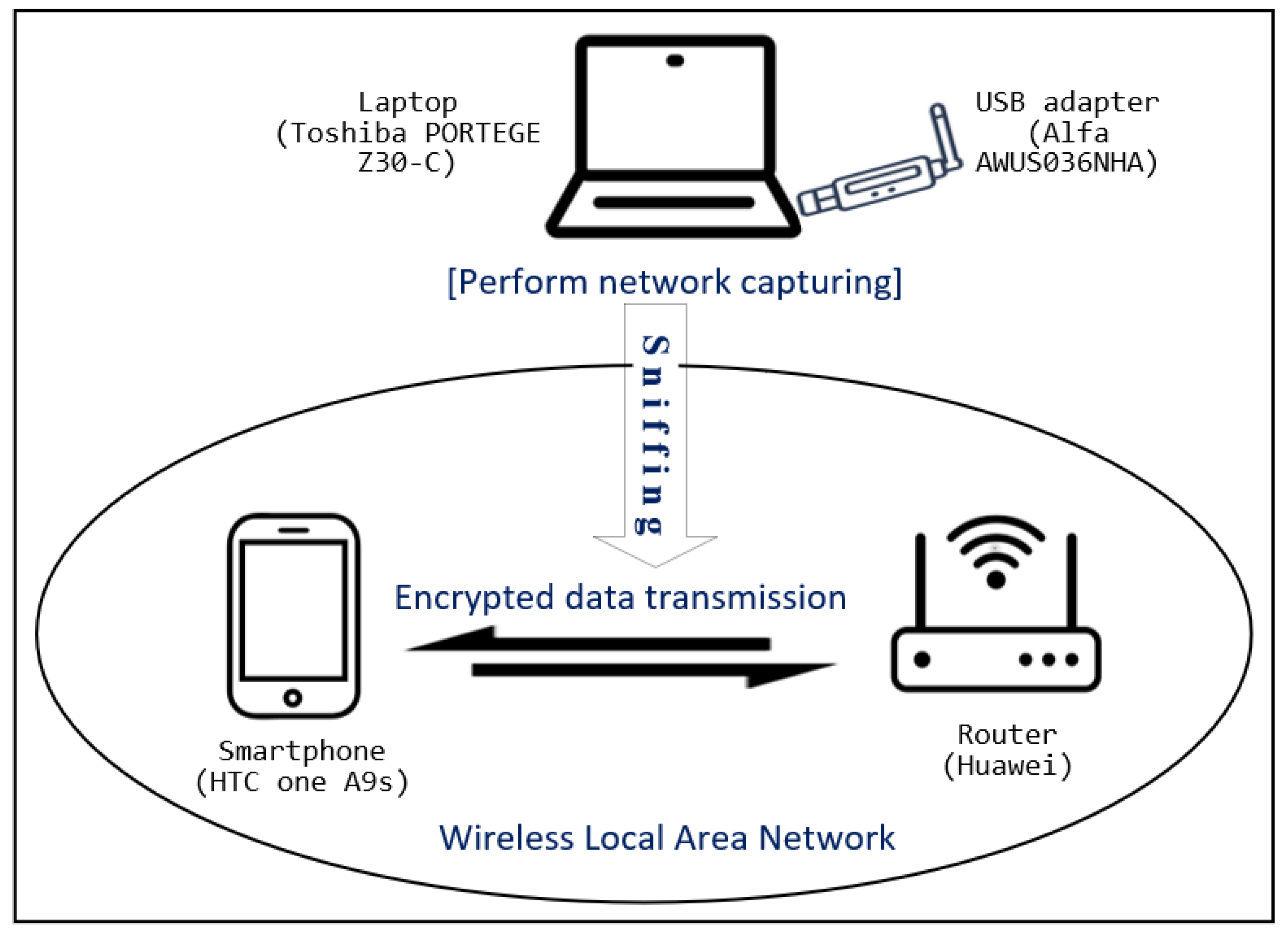
3.1. Data Collection
3.2. Data Pre-Processing
- (a)
- Data frame filtering
- (b)
- Obtaining error-free frames
- (c)
- Data normalization
- (d)
- Traffic Segmentation
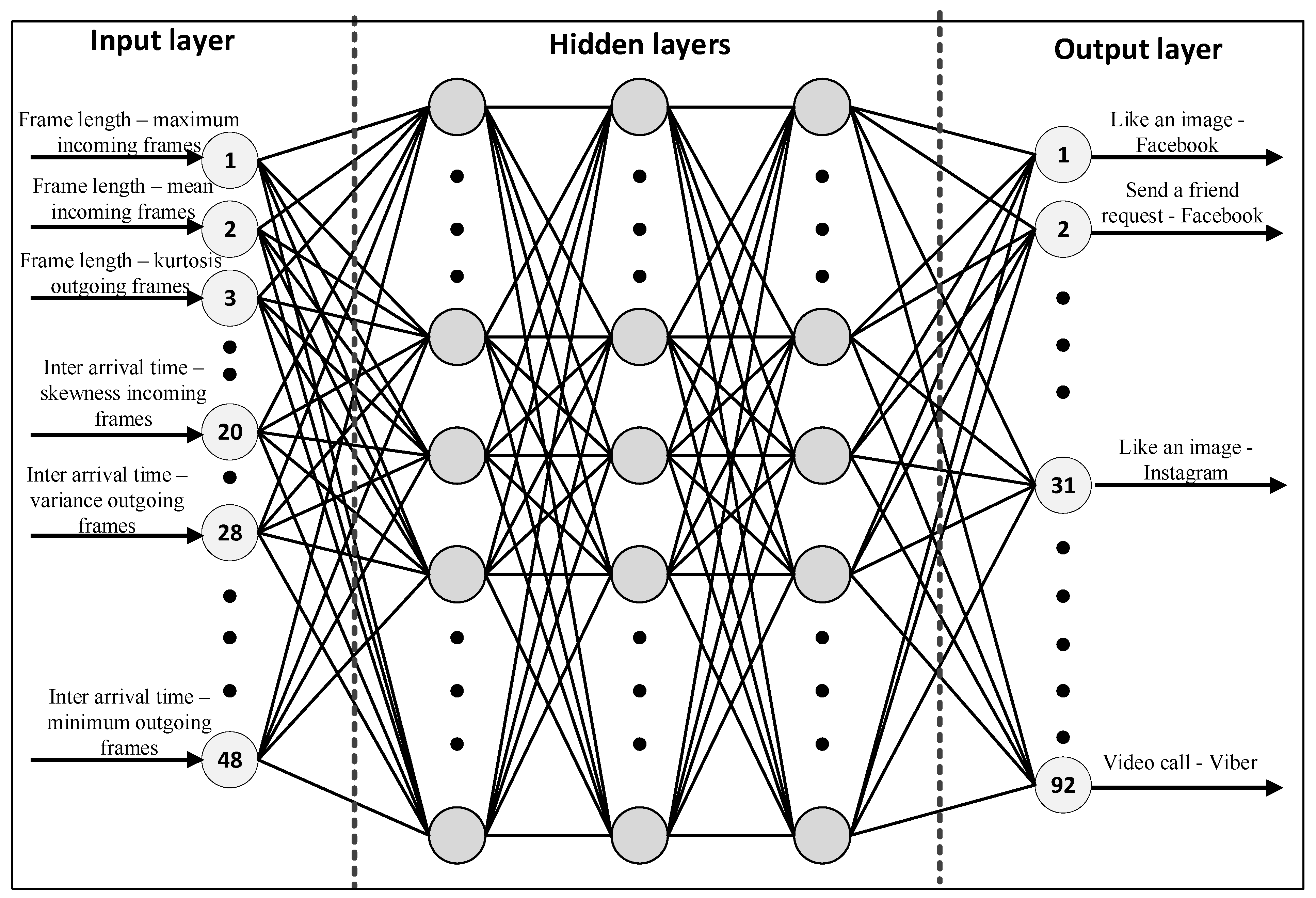
3.3. Neural Network Architecture
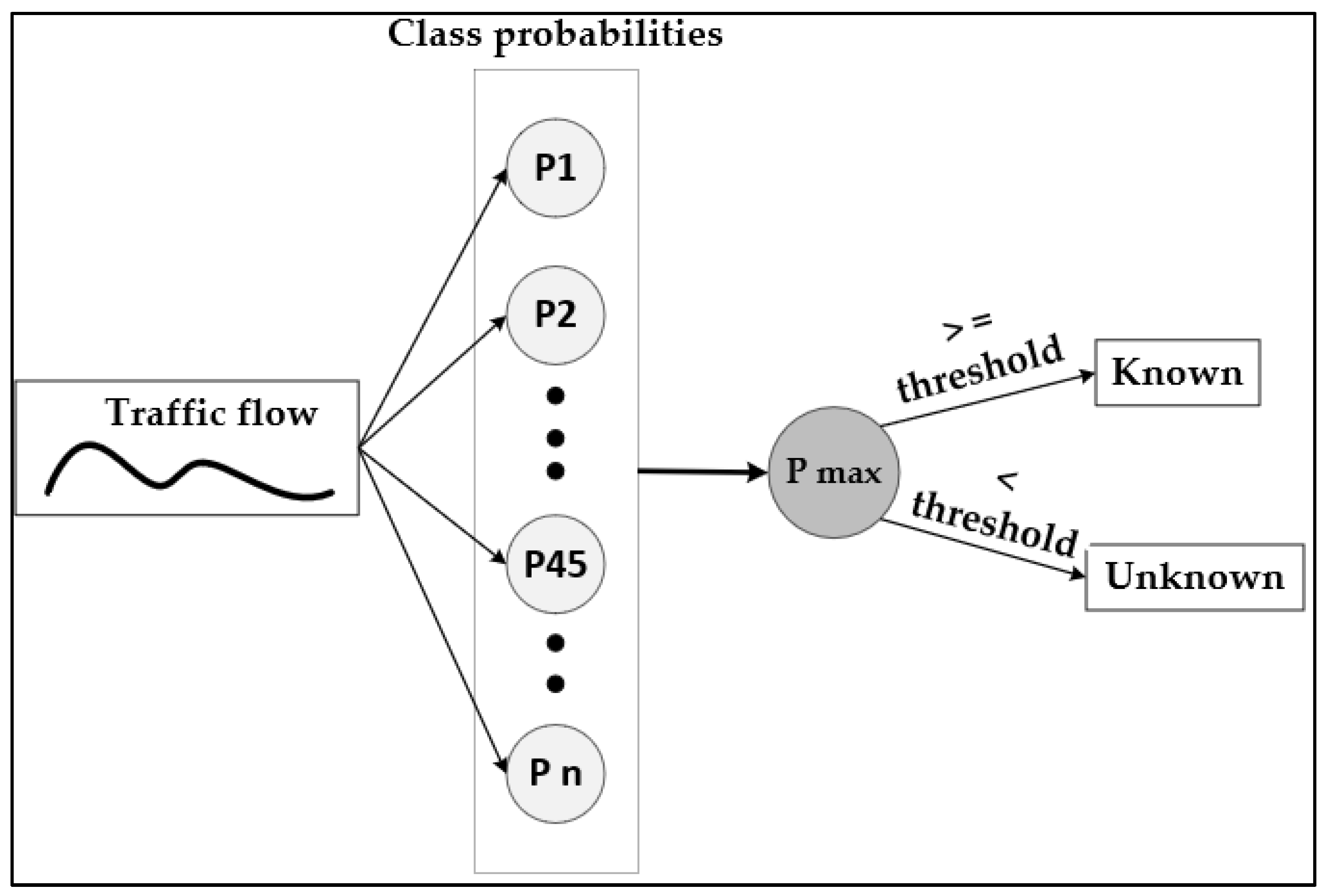
3.4. Classification Technique to Identify Untrained In-App Activities
4. Experimental Results and Discussions
- When previously trained in-app activities are input into the model, it should be able to detect them accurately.
- When previously untrained in-app activities are input into the model, it should be able to identify them as unknown data.
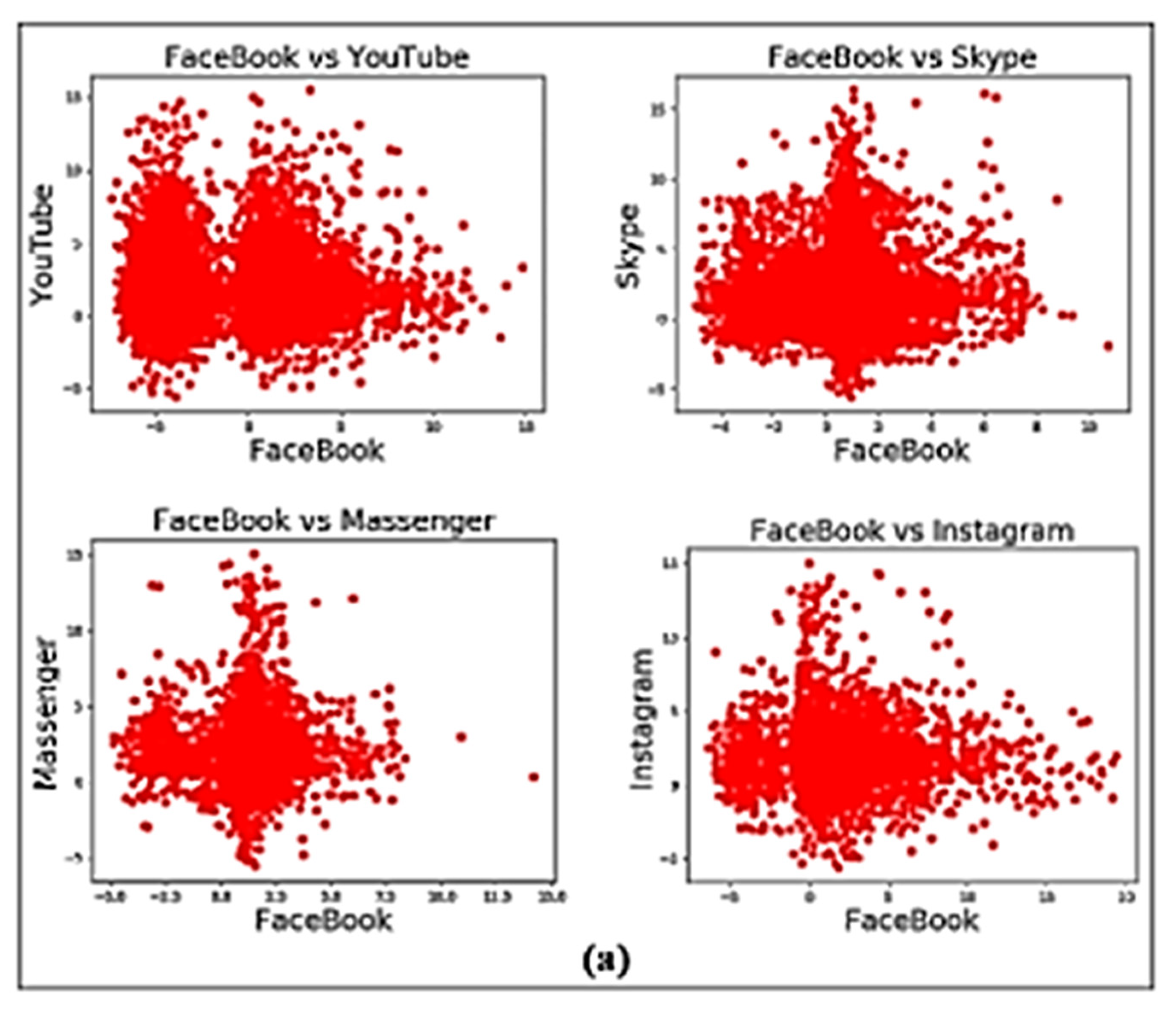
4.1. In-App Activity Detection
4.2. Unknown In-App Activities Detection
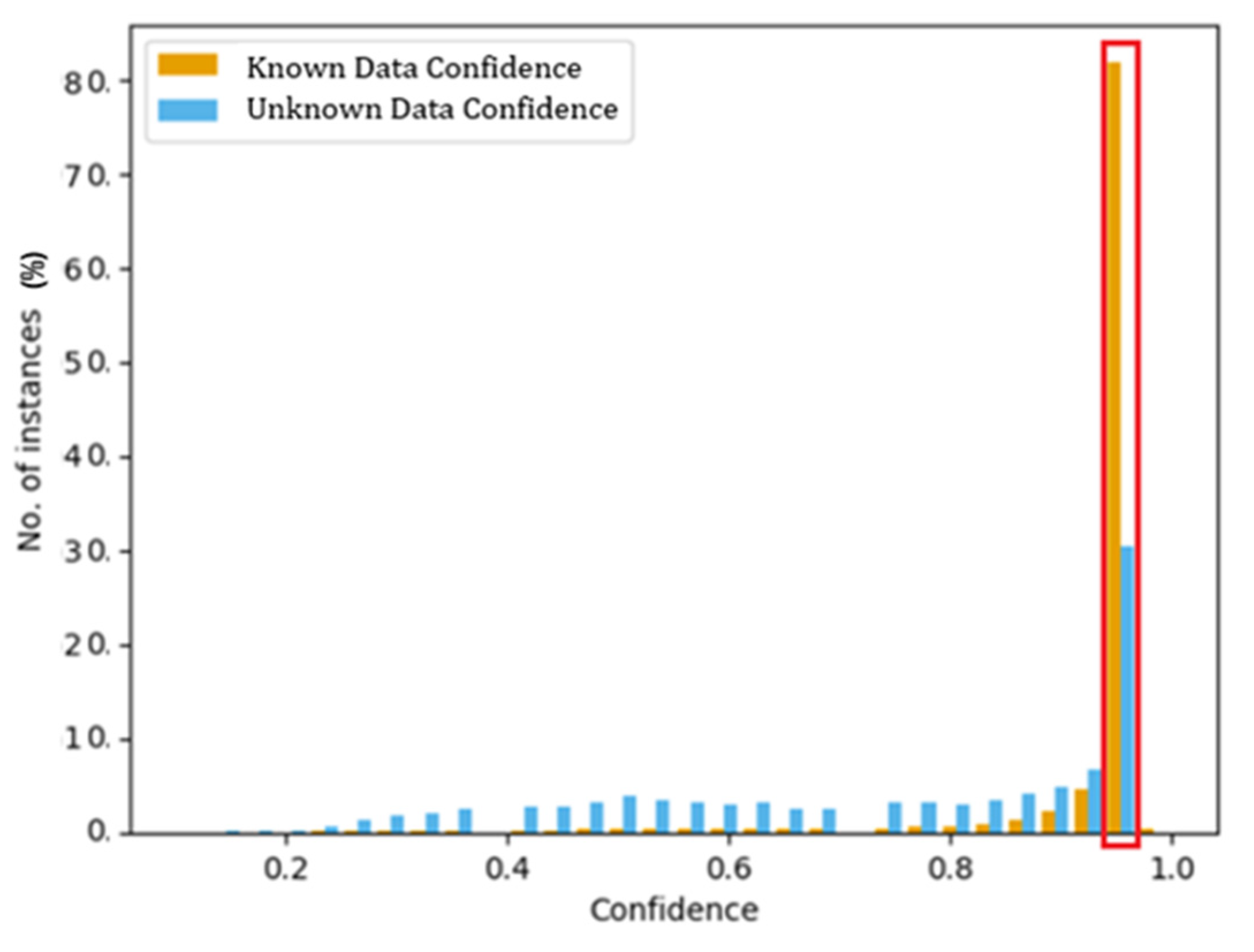
4.3. Threshold Selection
4.4. Performance Comparison with the State-of-the-Art
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Flurry Analytics, ComScore, Pandora, Facebook, NetMarketShare. 2015. Available online: https://www.marketingcharts.com/industries/media-and-entertain-ment58693/attachment/flurry-share-time-spent-mobile-devices-sept (accessed on 15 December 2021).
- Al-Mejibli, I.S.; Alharbe, N.R. Analyzing and evaluating the security standards in wireless network: A review study. Iraqi J. Comput. Inform. 2020, 46, 32–39. [Google Scholar] [CrossRef]
- Taylor, V.F.; Spolaor, R.; Conti, M.; Martinovic, I. Robust smartphone app identification via encrypted network traffic analysis. IEEE Trans. Inf. Forensics Secur. 2017, 13, 63–78. [Google Scholar] [CrossRef] [Green Version]
- Aceto, G.; Ciuonzo, D.; Montieri, A.; Pescape, A. Mobile Encrypted Traffic Classification Using Deep Learning. In Proceedings of the Network Traffic Measurement and Analysis Conference (TMA), Vienna, Austria, 26–29 June 2018; pp. 1–8. [Google Scholar] [CrossRef]
- Wang, W.; Zhu, M.; Wang, J.; Zeng, X.; Yang, Z. End-to-end encrypted traffic classification with one-dimensional convolution neural networks. In Proceedings of the IEEE International Conference on Intelligence and Security Informatics (ISI), Beijing, China, 22–24 July 2017; pp. 43–48. [Google Scholar] [CrossRef]
- Pathmaperuma, M.H.; Rahulamathavan, Y.; Dogan, S.; Kondoz, A.M. In-App Activity Recognition from Wi-Fi Encrypted Traffic. In Intelligent Computing. SAI 2020; Arai, K., Kapoor, S., Bhatia, R., Eds.; Advances in Intelligent Systems and Computing; Springer: Cham, Switzerland, 2020; Volume 1228. [Google Scholar] [CrossRef]
- Zhang, F.; He, W.; Liu, X.; Bridges, P.G. Inferring users’ online activities through traffic analysis. In Proceedings of the ACM Conference on Wireless Network Security, Hamburg, Germany, 14–17 June 2011. [Google Scholar]
- Conti, M.; Mancini, L.V.; Spolaor, R.; Verde, N.V. Analyzing Android encrypted network traffic to identify user actions. IEEE Inf. Forensics Secur. 2016, 11, 114–125. [Google Scholar] [CrossRef]
- Park, K.; Kim, H. Encryption is not enough: Inferring user activities on KakaoTalk with traffic analysis. In 16th International Workshop on Information Security Applications; Kim, H.-W., Choi, D., Eds.; ser. WISA ’15; Springer: Berlin/Heidelberg, Germany, 2015; pp. 254–265. [Google Scholar]
- Saltaformaggio, B.; Choi, H.; Johnson, K.; Kwon, Y.; Zhang, Q.; Zhang, X.; Xu, D.; Qian, J. Eavesdropping on fine-grained user activities within smartphone apps over encrypted network traffic. In WOOT’16 Proceedings of the 10th USENIX Conference on Offensive Technologies; USENIX Association: Berkeley, CA, USA, 2016; pp. 69–78. [Google Scholar]
- Taylor, V.F.; Spolaor, R.; Conti, M.; Martinovic, I. AppScanner: Automatic Fingerprinting of Smartphone Apps from Encrypted Network Traffic. In Proceedings of the IEEE European Symposium on Security and Privacy (Euro S&P), Saarbruecken, Germany, 21–24 March 2016; pp. 439–454. [Google Scholar]
- Lotfollahi, M.; Zade, R.S.H.; Siavoshani, M.J.; Saberian, M. Deep packet: A novel approach for encrypted traffic classification using deep learning. Soft Comput. 2020, 24, 1999–2012. [Google Scholar] [CrossRef] [Green Version]
- Draper-Gil, G.; Lashkari, A.H.; Mamun, M.S.I.; Ghorbani, A. Characterization of encrypted and VPN traffic using time-related features. In Proceedings of the ICISSP, Rome, Italy, 19–21 February 2016; pp. 407–414. [Google Scholar]
- Lopez-Martin, M.; Carro, B.; Sanchez-Esguevillas, A.; Lloret, J. Net-work traffic classifier with convolutional and recurrent neural networks for internet of things. IEEE Access 2017, 5, 18042–18050. [Google Scholar] [CrossRef]
- Wang, P.; Ye, F.; Chen, X.; Qian, Y. DataNet: Deep learning based en-crypted network traffic classification in SDN home gateway. IEEE Access 2018, 6, 55380–55391. [Google Scholar] [CrossRef]
- Bayat, N.; Jackson, W.; Liu, D. Deep Learning for Network Traffic Classification. arXiv 2021, arXiv:2106.12693. [Google Scholar]
- Aceto, G.; Ciuonzo, D.; Montieri, A.; Pescapé, A. MIMETIC: Mobile encrypted traffic classification using multimodal deep learning. Comput. Netw. 2019, 165, 106944. [Google Scholar] [CrossRef]
- Aceto, G.; Ciuonzo, D.; Montieri, A.; Pescapé, A. DISTILLER: Encrypted traffic classification via multimodal multitask deep learning. J. Netw. Comput. Appl. 2021, 183, 102985. [Google Scholar] [CrossRef]
- Liu, C.; He, L.; Xiong, G.; Cao, Z.; Li, Z. FS-Net: A Flow Sequence Network for Encrypted Traffic Classification. In Proceedings of the IEEE Conference on Computer Communications (INFOCOM), Paris, France, 29 April–2 May 2019; pp. 1171–1179. [Google Scholar]
- Tong, V.; Tran, H.-A.; Souihi, S.; Mellouk, A. A novel QUIC traffic classifier based on convolutional neural networks. In Proceedings of the 2018 IEEE Global Communications Conference (GLOBECOM), Abu Dhabi, United Arab Emirates, 9–13 December 2018; pp. 1–6. [Google Scholar]
- Li, D.; Li, W.; Wang, X.; Nguyen, C.T.; Lu, S. App trajectory recognition over encrypted internet traffic based on deep neural network. Comput. Netw. 2020, 179, 107372. [Google Scholar] [CrossRef]
- Shapira, T.; Shavitt, Y. FlowPic: Encrypted internet traffic classification is as easy as image recognition. In Proceedings of the IEEE INFOCOM 2019-IEEE Conference on Computer Communications Workshops (INFOCOM WKSHPS), Paris, France, 29 April–2 May 2019; pp. 680–687. [Google Scholar] [CrossRef]
- WWang, W.; Zhu, M.; Zeng, X.; Ye, X.; Sheng, Y. Malware traffic classification using convolutional neural network for representation learning. In Proceedings of the 2017 International Conference on Information Networking (ICOIN), IEEE, Da Nang, Vietnam, 11–13 January 2017; pp. 712–717. [Google Scholar]
- Zhao, M.; Chang, C.H.; Xie, W.; Xie, Z.; Hu, J. Cloud shape classification system based on multi-channel cnn and improved fdm. IEEE Access 2020, 8, 44111–44124. [Google Scholar] [CrossRef]
- Jin, B.; Cruz, L.; Goncalves, N. Pseudo RGB-D Face Recognition. IEEE Sens. J. 2022, 1-1. [Google Scholar] [CrossRef]
- Zheng, Q.; Yang, M.; Yang, J.; Zhang, Q.; Zhang, X. Improvement of generalization ability of deep CNN via implicit regularization in two-stage training process. IEEE Access 2018, 6, 15844–15869. [Google Scholar] [CrossRef]
- Aircrack-ng. Available online: https://www.aircrack-ng.org/ (accessed on 1 December 2021).
- Rodrig, M.; Reis, C.; Mahajan, R.; Wetherall, D.; Zahorjan, J. Measurement-based characterization of 802.11 in a hotspot setting. In Proceedings of the ACM SIGCOMM Workshop on Experimental Approaches to Wireless Network Design and Analysis, Philadelphia, PA, USA, 22 August 2005; pp. 5–10. [Google Scholar]
- Rezaei, S.; Liu, X. Deep Learning for Encrypted Traffic Classification: An Overview. IEEE Commun. Mag. 2019, 57, 76–81. [Google Scholar] [CrossRef] [Green Version]
- Sklearn.preprocessing. StandardScaler. Available online: https://scikit-learn.org/stable/modules/generated/sklearn.preprocessing.StandardScaler.html (accessed on 11 November 2021).
- McKinney, W. Data Structures for Statistical Computing in Python. In Proceedings of the 9th Python in Science Conference, Austin, TX, USA, 28 June–3 July 2010; pp. 51–56. [Google Scholar]
- Chollet, F. Keras. Available online: https://github.com/fchollet/keras (accessed on 1 April 2022).
- Abadi, M.; Agarwal, A.; Barham, P.; Brevdo, E.; Chen, Z.; Citro, C.; Corrado, G.S.; Davis, A.; Dean, J.; Devin, M.; et al. TensorFlow: Large-scale machine learning on hetero-geneous systems. arXiv 2015. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Research Article | Encrypted Traffic | Unknown Data Detection | Classification Type | Classification Based on Subset of Traffic | Results Compared with the State-of-the-Art Methods | Dataset Type | Accuracy |
|---|---|---|---|---|---|---|---|
| [12] |  |  | Traffic characterization and application | | But not DL methods | ISCX | Traffic characterization 94%, app identification 98% |
| [14] | | | Service (HTTP, DNS, Telnet, etc.) | First 20 packets | | RedIRIS | 96% |
| [5] | | | Traffic characterization | First 784 bytes of a flow session | But not DL methods | ISCX | 86% |
| [15] | | | Application | | | ISCX | 93–98% precision. accuracy not given |
| [16] | | | SNI | Sequence length 25 | | Private | 82.3% |
| [17] | | | Application | | | 3 Private datasets | 79.98%, 89.49%, 89.14% |
| [18] | | | Traffic type and application | | | ISCX | 93.75% |
| [19] | | | Application | | | MaMPF | 99.14% True positive rate |
| [20] | | | QUIC based services | | | Private | 99% |
| [21] | | | App trajectory | | But not DL methods | Private | 79.65% |
| This paper | | | Application and activity | | | Openly shared | 90% to 95% |
| App | Category | Number of Activities | Number of Samples |
|---|---|---|---|
| Social networking | 22 | 19,944 | |
| Photo and video | 20 | 6818 | |
| YouTube | Photo and video | 9 | 14,501 |
| Social networking | 9 | 436 | |
| Viber | Social networking | 9 | 690 |
| Gmail | Productivity | 5 | 1036 |
| Skype | Social networking | 8 | 15,703 |
| Messenger | Social networking | 10 | 6061 |
| Total: 8 apps | 92 | 65,189 | |
| Parameter | Values |
|---|---|
| Number of hidden layers | 4 |
| Number of nodes in each layer | [128, 256, 512, 1024] |
| Activation functions | Hidden layers—Tanh Output layer—Softmax |
| Loss function | Categorical cross entropy |
| Optimizer | Adam |
| Batch size | 2048 |
| Number of epochs | 100 |
| Window Size | Total Samples | Training Accuracy | Validation Accuracy |
|---|---|---|---|
| 0.5 sec | 65,189 | 97% | 93% |
| 0.2 sec | 231,824 | 97% | 95% |
| 0.05 sec | 1876,624 | 94% | 91% |
| 0.02 sec | 7067,363 | 93% | 90% |
| Test No. | The Apps Used to Train the DNN Model | The App Not Used in Model Training | Noise Detection |
|---|---|---|---|
| T1 | I, Y, G, M, S, W, V | F | 88% |
| T2 | F, I, G, M, S, W, V | Y | 62% |
| T3 | F, Y, G, M, S, W, V | I | 75% |
| T4 | F, I, Y, M, S, W, V | G | 91% |
| T5 | F, I, Y, G, S, W, V | M | 75% |
| T6 | F, I, Y, G, M, W, V | S | 63% |
| T7 | F, I, Y, G, M, S, W | V | 91% |
| T8 | F, I, Y, G, M, S, V | W | 85% |
| Average noise detection rate | 79% | ||
| Test App | F | I | Y | G | M | S | W | V |
|---|---|---|---|---|---|---|---|---|
| F | 15 | 33 | 2 | 13 | 34 | 1 | 2 | |
| I | 34 | 25 | 2 | 10 | 27 | 1 | 1 | |
| Y | 41 | 11 | 2 | 12 | 31 | 1 | 2 | |
| G | 31 | 10 | 22 | 10 | 25 | 1 | 1 | |
| M | 35 | 11 | 24 | 2 | 26 | 1 | 1 | |
| S | 41 | 13 | 29 | 2 | 12 | 1 | 2 | |
| W | 31 | 11 | 22 | 2 | 9 | 24 | 1 | |
| V | 31 | 10 | 22 | 2 | 9 | 25 | 1 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Pathmaperuma, M.H.; Rahulamathavan, Y.; Dogan, S.; Kondoz, A.M. Deep Learning for Encrypted Traffic Classification and Unknown Data Detection. Sensors 2022, 22, 7643. https://doi.org/10.3390/s22197643
Pathmaperuma MH, Rahulamathavan Y, Dogan S, Kondoz AM. Deep Learning for Encrypted Traffic Classification and Unknown Data Detection. Sensors. 2022; 22(19):7643. https://doi.org/10.3390/s22197643
Chicago/Turabian StylePathmaperuma, Madushi H., Yogachandran Rahulamathavan, Safak Dogan, and Ahmet M. Kondoz. 2022. "Deep Learning for Encrypted Traffic Classification and Unknown Data Detection" Sensors 22, no. 19: 7643. https://doi.org/10.3390/s22197643