
A Virtual Sensing Concept for Nitrogen and Phosphorus Monitoring Using Machine Learning Techniques

Abstract
:1. Introduction
1.1. Background and Motivation
1.2. Literature Review
1.3. Work Objectives
- To present a specification book for virtual sensor-based N and P monitoring. The specification book (i) proposes more effective baseline models, (ii) recommends performance metrics to enable adequate model comparison, (iii) recommends the different levels of predictive accuracy benchmarks based on the requirements of data quality objectives, and (iv) proposes the benchmark datasets;
- To assess the effect of different scalers (Standard, MinMax, MaxAbs, and Robust Scaler) and transformers (Quantile and Power Transformer) on ML algorithms and virtual sensor performance on WQ data with outliers;
- To assess the effect of univariate, multivariate, and nearest neighbor imputation methods in the prediction of N and P concentrations.
2. Materials and Methods
2.1. Description of Study Areas and Water Quality Data
2.2. Data Analysis Frameworks
- Pandas (1.0.5): Used for data analysis and manipulation;
- NumPy (1.18.5): Used for array computations;
- SciPy (1.5.0): Used for statistical tests;
- XGBoost (2.0.0): An optimized distributed gradient boosting library that implements ML algorithms under the gradient boosting framework;
- LightGBM (3.3.2): A gradient boosting ML framework that uses tree-based learning algorithms;
- SHAP (0.41.0): Used to explain individual predictions;
- Scikit-Learn(1.1.0): A library for ML in Python programming language;
- Python (3.8.3): Chosen because of its growing usage in academic and industrial settings [26].
2.3. Exploratory Data Analysis and Preprocessing
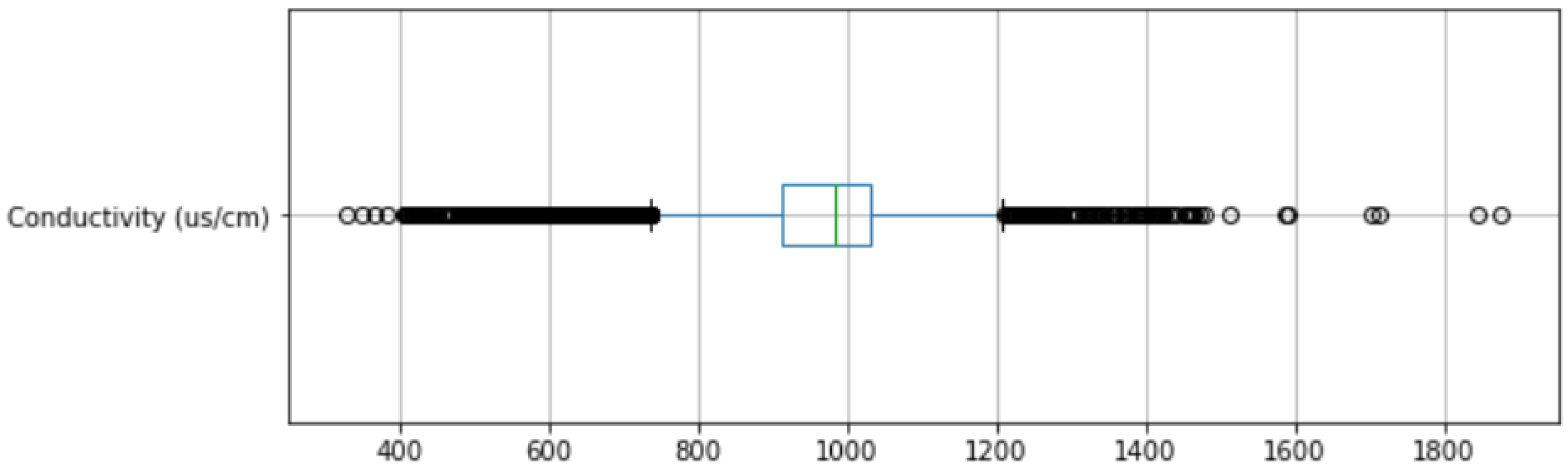
2.3.1. Box and Whisker Plot Analysis: Outlier Detection
2.3.2. Data Transformation
2.3.3. Data Scaling
2.4. Virtual Sensor Development: Best Practices
2.4.1. Selection of Input Variables
2.4.2. Cross Validation
2.4.3. Hyperparameter Tuning
2.4.4. Avoiding Data Leakage
2.4.5. Imputation of Missing Values
3. Results and Discussion
3.1. A Specification Book
3.1.1. Standard or Benchmark Datasets
3.1.2. Model Performance Evaluation
- Estimating the predictive and generalization performance of the model on unseen (future) data;
- Providing a basis for evaluating improvements in the predictive performance when adjusting (or tweaking) model parameter values;
- Identifying the best ML algorithm for the problem at hand by comparing different algorithms or current modeling efforts with peer-reviewed literature results.
3.1.3. Accuracy Requirements
3.1.4. A Baseline Model
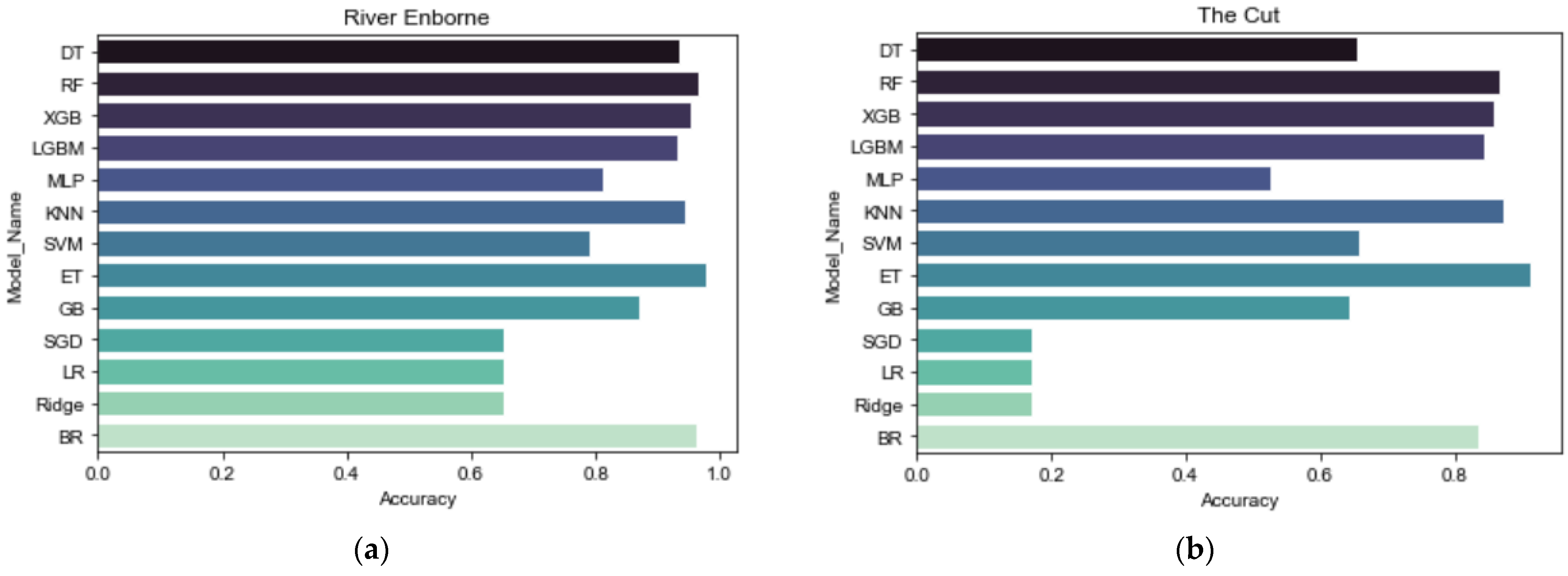
3.2. Selected Models from Spot Checking
3.3. The Effect of Different Scalers
3.4. Missing Values Handling
3.5. Sensitivity Analysis
3.6. Performance Results of Our Approach: A Comparative Analysis
4. Conclusions
- This study presented a specification book and best practices for developing virtual sensors for nutrient monitoring. These concepts will aid in developing robust and interpretable virtual sensors whose performance can be independently verified;
- The effect of various scalers and transformers on WQ data with outliers is assessed. Although this is usually overlooked in WQ monitoring studies, the present work proved its importance. For instance, the most effective scaler was the MinMax scaler and not the commonly applied standard scaler;
- Even though missing data is a common problem in WQ data, it is often overlooked in WQ monitoring studies. Therefore, this study assessed the impact of missing value imputation in predicting N and P concentrations where RF and LGBM-based multivariate imputers were the most effective.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Ndlela, L.L.; Oberholster, P.J.; van Wyk, J.H.; Cheng, P.H. An overview of cyanobacterial bloom occurrences and research in Africa over the last decade. Harmful Algae 2016, 60, 11–26. [Google Scholar] [CrossRef] [PubMed]
- Sagan, V.; Peterson, K.T.; Maimaitijiang, M.; Sidike, P.; Sloan, J.; Greeling, B.A.; Maalouf, S.; Adams, C. Monitoring inland water quality using remote sensing: Potential and limitations of spectral indices, bio-optical simulations, machine learning, and cloud computing. Earth-Sci. Rev. 2020, 205, 103187. [Google Scholar] [CrossRef]
- Ha, N.T.; Nguyen, H.Q.; Truong, N.C.Q.; Le, T.L.; Thai, V.N.; Pham, T.L. Estimation of nitrogen and phosphorus concentrations from water quality surrogates using machine learning in the Tri An Reservoir, Vietnam. Environ. Monit. Assess. 2020, 192, 789. [Google Scholar] [CrossRef] [PubMed]
- Van Ginkel, C.E. Eutrophication: Present reality and future challenges for South Africa. Water SA 2011, 37, 693–702. [Google Scholar] [CrossRef]
- Carmichael, W.W.; Boyer, G.L. Health impacts from cyanobacteria harmful algae blooms: Implications for the North American Great Lakes. Harmful Algae 2016, 54, 194–212. [Google Scholar] [CrossRef] [PubMed]
- Matthews, M.W.; Bernard, S. Eutrophication and cyanobacteria in South Africa’s standing water bodies: A view from space. S. Afr. J. Sci. 2015, 111, 1–8. [Google Scholar] [CrossRef]
- Pretty, J.N.; Mason, C.F.; Nedwell, D.B.; Hine, R.E.; Leaf, S.; Dils, R. Environmental costs of freshwater eutrophication in England and Wales. Environ. Sci. Technol. 2003, 37, 201–208. [Google Scholar] [CrossRef]
- Dodds, W.K.; Bouska, W.W.; Eitzmann, J.L.; Pilger, T.J.; Pitts, K.L.; Riley, A.J.; Schloesser, J.T.; Thornbrugh, D.J. Eutrophication of U. S. freshwaters: Analysis of potential economic damages. Environ. Sci. Technol. 2009, 43, 12–19. [Google Scholar] [CrossRef]
- Castrillo, M.; García, Á.L. Estimation of high frequency nutrient concentrations from water quality surrogates using machine learning methods. Water Res. 2020, 172, 115490. [Google Scholar] [CrossRef]
- Djerioui, M.; Bouamar, M.; Ladjal, M.; Zerguine, A. Chlorine Soft Sensor Based on Extreme Learning Machine for Water Quality Monitoring. Arab. J. Sci. Eng. 2019, 44, 2033–2044. [Google Scholar] [CrossRef]
- Shen, L.Q.; Amatulli, G.; Sethi, T.; Raymond, P.; Domisch, S. Estimating nitrogen and phosphorus concentrations in streams and rivers, within a machine learning framework. Sci. Data 2020, 7, 161. [Google Scholar] [CrossRef] [PubMed]
- Harrison, J.W.; Lucius, M.A.; Farrell, J.L.; Eichler, L.W.; Relyea, R.A. Prediction of stream nitrogen and phosphorus concentrations from high-frequency sensors using Random Forests Regression. Sci. Total Environ. 2021, 763, 143005. [Google Scholar] [CrossRef] [PubMed]
- Paepae, T.; Bokoro, P.N.; Kyamakya, K. From fully physical to virtual sensing for water quality assessment: A comprehensive review of the relevant state-of-the-art. Sensors 2021, 21, 6971. [Google Scholar] [CrossRef] [PubMed]
- Pellerin, B.A.; Stauffer, B.A.; Young, D.A.; Sullivan, D.J.; Bricker, S.B.; Walbridge, M.R.; Clyde, G.A., Jr.; Shaw, D.M. Emerging Tools for Continuous Nutrient Monitoring Networks: Sensors Advancing Science and Water Resources Protection. J. Am. Water Resour. Assoc. 2016, 52, 993–1008. [Google Scholar] [CrossRef]
- Pattanayak, A.S.; Pattnaik, B.S.; Udgata, S.K.; Panda, A.K. Development of Chemical Oxygen on Demand (COD) Soft Sensor Using Edge Intelligence. IEEE Sens. J. 2020, 20, 14892–14902. [Google Scholar] [CrossRef]
- Pattnaik, B.S.; Pattanayak, A.S.; Udgata, S.K.; Panda, A.K. Machine learning based soft sensor model for BOD estimation using intelligence at edge. Complex Intell. Syst. 2021, 7, 961–976. [Google Scholar] [CrossRef]
- Wen, X.; Hou, D.; Tu, D.; Zhu, N.; Huang, P.; Zhang, G.; Zhang, H. Application of least-squares support vector machines for quantitative evaluation of known contaminant in water distribution system using online water quality parameters. Sensors 2018, 18, 938. [Google Scholar] [CrossRef]
- Bhattarai, A.; Dhakal, S.; Gautam, Y.; Bhattarai, R. Prediction of nitrate and phosphorus concentrations using machine learning algorithms in watersheds with different landuse. Water 2021, 13, 3096. [Google Scholar] [CrossRef]
- Geurts, P.; Ernst, D.; Wehenkel, L. Extremely randomized trees. Mach. Learn. 2006, 63, 3–42. [Google Scholar] [CrossRef]
- Wu, W.; Dandy, G.C.; Maier, H.R. Protocol for developing ANN models and its application to the assessment of the quality of the ANN model development process in drinking water quality modelling. Environ. Model. Softw. 2014, 54, 108–127. [Google Scholar] [CrossRef]
- Di Blasi, J.I.P.; Torres, J.M.; Nieto, P.J.G.; Fernández, J.R.A.; Muñiz, C.D.; Taboada, J. Analysis and detection of functional outliers in water quality parameters from different automated monitoring stations in the Nalón River Basin (Northern spain). Environ. Sci. Pollut. Res. 2014, 22, 387–396. [Google Scholar] [CrossRef] [PubMed]
- Ma, J.; Ding, Y.; Cheng, J.C.P.; Jiang, F.; Xu, Z. Soft detection of 5-day BOD with sparse matrix in city harbor water using deep learning techniques. Water Res. 2020, 170, 115350. [Google Scholar] [CrossRef] [PubMed]
- Robinson, R.B.; Cox, C.D.; Odom, K. Identifying Outliers in Correlated Water Quality Data. J. Environ. Eng. 2005, 131, 651–657. [Google Scholar] [CrossRef]
- Cruz, M.A.S.; Gonçalves, A.D.A.; de Aragão, R.; de Amorim, J.R.A.; da Mota, P.V.M.; Srinivasan, V.S.; Garcia, C.A.B.; de Figueiredo, E.E. Spatial and seasonal variability of the water quality characteristics of a river in Northeast Brazil. Environ. Earth Sci. 2019, 78, 68. [Google Scholar] [CrossRef]
- Ahsan, M.M.; Mahmud, M.A.P.; Saha, P.K.; Gupta, K.D.; Siddique, Z. Effect of Data Scaling Methods on Machine Learning Algorithms and Model Performance. Technologies 2021, 9, 52. [Google Scholar] [CrossRef]
- Pedregosa, F.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; Vanderplas, J.; Passos, A.; Cournapeau, D. Scikit-learn: Machine learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Halliday, S.J.; Skeffington, R.A.; Bowes, M.J.; Gozzard, E.; Newman, J.R.; Loewenthal, M.; Palmer-Felgate, E.J.; Jarvie, H.P.; Wade, A.J. The water quality of the River Enborne, UK: Observations from high-frequency monitoring in a rural, lowland river system. Water 2014, 6, 150–180. [Google Scholar] [CrossRef]
- Halliday, S.J.; Skeffington, R.A.; Wade, A.J.; Bowes, M.J.; Gozzard, E.; Newman, J.R.; Loewenthal, M.; Palmer-Felgate, E.J.; Jarvie, H.P. High-frequency water quality monitoring in an urban catchment: Hydrochemical dynamics, primary production and implications for the Water Framework Directive. Hydrol. Process. 2015, 29, 3388–3407. [Google Scholar] [CrossRef]
- Wade, A.J.; Palmer-Felgate, E.J.; Halliday, S.J.; Skeffington, R.A.; Loewenthal, M.; Jarvie, H.P.; Bowes, M.J.; Greenway, G.M.; Haswell, S.J.; Bell, I.M.; et al. Hydrochemical processes in lowland rivers: Insights from in situ, high-resolution monitoring. Hydrol. Earth Syst. Sci. 2012, 16, 4323–4342. [Google Scholar] [CrossRef]
- Zanoni, M.G.; Majone, B.; Bellin, A. A catchment-scale model of river water quality by Machine Learning. Sci. Total Environ. 2022, 838, 156377. [Google Scholar] [CrossRef]
- Raymaekers, J.; Rousseeuw, P.J. Transforming variables to central normality. Mach. Learn. 2021, 1–23. [Google Scholar] [CrossRef]
- Linklater, N.; Örmeci, B. Real-Time and Near Real-Time Monitoring Options for Water Quality; Elsevier B.V.: Amsterdam, The Netherlands, 2013. [Google Scholar]
- Murphy, K.; Heery, B.; Sullivan, T.; Zhang, D.; Paludetti, L.; Lau, K.T.; Diamond, D.; Costa, E.J.X.; O’connor, N.; Regan, F. A low-cost autonomous optical sensor for water quality monitoring. Talanta 2015, 132, 520–527. [Google Scholar] [CrossRef]
- Lundberg, S.M.; Lee, S.-I. A Unified Approach to Interpreting Model Predictions. Adv. Neural Inf. 2017, 30. [Google Scholar] [CrossRef]
- Badiru, A.B.; Racz, L. Handbook of Measurements: Benchmarks for Systems Accuracy and Precision; CRC Press: Boca Raton, FL, USA, 2018; Volume 53. [Google Scholar]
- Scheuerman, M.K.; Hanna, A.; Denton, E. Do Datasets Have Politics? Disciplinary Values in Computer Vision Dataset Development. Proc. ACM Hum.-Comput. Interact. 2021, 5, 1–37. [Google Scholar] [CrossRef]
- Paullada, A.; Raji, I.D.; Bender, E.M.; Denton, E.; Hanna, A. Data and its (dis)contents: A survey of dataset development and use in machine learning research. Patterns 2021, 2, 100336. [Google Scholar] [CrossRef]
- Olson, R.S.; la Cava, W.; Orzechowski, P.; Urbanowicz, R.J.; Moore, J.H. PMLB: A large benchmark suite for machine learning evaluation and comparison. BioData Min. 2017, 10, 36. [Google Scholar] [CrossRef]
- Krause, P.; Boyle, D.P.; Bäse, F. Comparison of different efficiency criteria for hydrological model assessment. Adv. Geosci. 2005, 5, 89–97. [Google Scholar] [CrossRef]
- Moriasi, D.N.; Arnold, J.G.; van Liew, M.W.; Bingner, R.L.; Harmel, R.D.; Veith, T.L. Model evaluation guidelines for systematic quantification of accuracy in watershed simulations. Trans. ASABE 2007, 50, 885–900. [Google Scholar] [CrossRef]
- Moriasi, D.N.; Gitau, M.W.; Pai, N.; Daggupati, P. Hydrologic and water quality models: Performance measures and evaluation criteria. Trans. ASABE 2015, 58, 1763–1785. [Google Scholar] [CrossRef]
- Terblanche, A.P.S. Health hazards of nitrate in drinking water. Water SA 1991, 17, 77–82. [Google Scholar]
- Latif, S.D.; Birima, A.H.; Ahmed, A.N.; Hatem, D.M.; Al-Ansari, N.; Fai, C.M.; El-Shafie, A. Development of prediction model for phosphate in reservoir water system based machine learning algorithms. Ain Shams Eng. J. 2022, 13, 101523. [Google Scholar] [CrossRef]
- Nour, M.H.; Smith, D.W.; El-Din, M.G.; Prepas, E.E. The application of artificial neural networks to flow and phosphorus dynamics in small streams on the Boreal Plain, with emphasis on the role of wetlands. Ecol. Modell. 2006, 191, 19–32. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
| Predictors | Formula | The Cut | Enborne | Description |
|---|---|---|---|---|
| pH | N/A | • | • | A measure of water’s acidity or basicity. A changing stream pH indicates an increase in water pollution. |
| Flow rate | N/A | • | • | The volume of water flowing past a point per unit time. Streamflow and runoff drive the generation and delivery of various diffuse (non-point) pollutants; therefore, the knowledge of streamflow enables the determination of pollutant loads. |
| Turbidity | N/A | • | • | A measure of water’s relative clarity. It is an optical characteristic that indicates the presence of bacteria, pathogens, and other harmful contaminants. |
| Chlorophyll | C55H72O5N4Mg | • | • | A measure of how much algae is growing in a water body. It is usually used to classify the water body’s trophic condition. |
| Temperature | N/A | • | • | A property that expresses how cold or hot the water is. It influences various other variables and can alter water’s chemical and physical properties. |
| Conductivity | N/A | • | • | A measure of water’s ability to conduct electricity. Its increase may indicate that a discharge has decreased the water body’s relative health or condition. |
| Dissolved oxygen | O2 | • | • | A measure of how much non-compound oxygen is available in the water. It is a direct indicator of the water body’s ability to support aquatic life. |
| Nitrogen as nitrate | NO3 | • | Nitrates are one form of nitrogen found in aquatic environments. Although nitrates are vital plant nutrients, their excess amounts can accelerate eutrophication. | |
| Nitrogen as ammonium | NH4 | • | Ammonium is another form of nitrogen found in water bodies. It has toxic effects on aquatic life at elevated concentrations. | |
| Total phosphorus | P | • | Total phosphorus is more stable and, therefore, a more reliable index of the phosphorus status in water bodies. Similar to nitrates, excess amounts of phosphorus lead to eutrophication and harmful algal growth. | |
| Total reactive phosphorus | PO43− | • | • | Total reactive phosphorus (orthophosphate) is regarded as the best indicator of the nutrient status of water bodies. It has similar effects to nitrates and ammonium in excess amounts. |
| Variable | Transformation | |
|---|---|---|
| The Cut | River Enborne | |
| Flow rate (Flow) | Reciprocal | Logarithm |
| Chlorophyll (Chl) | Logarithm | Logarithm |
| Dissolved oxygen (DO) | Square root | Logarithm |
| Nitrate (as NH4 or NO3) | Cube root | Cube root |
| Turbidity (Turb) | Reciprocal | Reciprocal |
| Total Reactive Phosphorus (TRP) | None | Cube root |
| pH | None | Reciprocal |
| Conductivity (EC) | None | None |
| Temperature (Temp) | None | None |
| Total Phosphorus (TP) | Square root | |
| Predictors in RF and ET Models | RF: [9] | ET: Our Work | Improvement (%) |
|---|---|---|---|
| RMSE ± Std | RMSE ± Std | ||
| NO3 in River Enborne | |||
| EC | 0.458 ± 0.286 | 0.062 ± 0.002 | 86% |
| EC, pH | 0.343 ± 0.229 | 0.050 ± 0.002 | 85% |
| EC, pH, Flow | 0.254 ± 0.186 | 0.027 ± 0.001 | 89% |
| EC, pH, Flow, Temp | 0.194 ± 0.138 | 0.017 ± 0.001 | 91% |
| TRP in River Enborne | |||
| EC | 0.061 ± 0.043 | 0.066 ± 0.002 | −8% |
| EC, Flow | 0.043 ± 0.035 | 0.051 ± 0.001 | −19% |
| EC, Flow, Temp | 0.030 ± 0.025 | 0.027 ± 0.001 | 10% |
| EC, Flow, Temp, Turb | 0.025 ± 0.021 | 0.020 ± 0.001 | 20% |
| NH4 in The Cut | |||
| Chl | 0.210 ± 0.144 | 0.130 ± 0.004 | 38% |
| Chl, Temp | 0.190 ± 0.123 | 0.135 ± 0.003 | 29% |
| Chl, Temp, Turb | 0.150 ± 0.104 | 0.091 ± 0.004 | 39% |
| Chl, Temp, Turb, pH | 0.128 ± 0.095 | 0.067 ± 0.004 | 48% |
| Chl, Temp, Turb, pH, EC | 0.107 ± 0.077 | 0.051 ± 0.003 | 52% |
| TRP in The Cut | |||
| EC | 0.199 ± 0.115 | 0.196 ± 0.005 | 2% |
| EC, Turb | 0.180 ± 0.112 | 0.205 ± 0.007 | −14% |
| EC, Turb, Temp | 0.141 ± 0.099 | 0.142 ± 0.003 | −1% |
| EC, Turb, Temp, pH | 0.117 ± 0.088 | 0.107 ± 0.005 | 9% |
| EC, Turb, Temp, pH, Flow | 0.107 ± 0.078 | 0.088 ± 0.004 | 18% |
| TP in The Cut | |||
| EC | 0.192 ± 0.114 | 0.122 ± 0.003 | 36% |
| EC, Turb | 0.173 ± 0.116 | 0.128 ± 0.004 | 26% |
| EC, Turb, Temp | 0.153 ± 0.104 | 0.088 ± 0.002 | 42% |
| EC, Turb, Temp, pH | 0.119 ± 0.087 | 0.067 ± 0.003 | 44% |
| EC, Turb, Temp, pH, Flow | 0.110 ± 0.081 | 0.055 ± 0.002 | 50% |
| Scaling Method | RF | XGB | LGBM | kNN | ET | BR | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| RMSE | R2 | RMSE | R2 | RMSE | R2 | RMSE | R2 | RMSE | R2 | RMSE | R2 | |
| No scaling | 0.0211 | 0.9544 | 0.0246 | 0.9382 | 0.0279 | 0.9200 | 0.0534 | 0.7085 | 0.0176 | 0.9682 | 0.0229 | 0.9465 |
| Robust scaler | 0.0211 | 0.9547 | 0.0241 | 0.9405 | 0.0280 | 0.9198 | 0.0257 | 0.9322 | 0.0176 | 0.9684 | 0.0226 | 0.9469 |
| MaxAbs scaler | 0.0211 | 0.9546 | 0.0246 | 0.9378 | 0.0279 | 0.9200 | 0.0292 | 0.9125 | 0.0176 | 0.9681 | 0.0224 | 0.9466 |
| MinMax scaler | 0.0211 | 0.9548 | 0.0241 | 0.9403 | 0.0279 | 0.9200 | 0.0210 | 0.9548 | 0.0176 | 0.9683 | 0.0226 | 0.9467 |
| Standard scaler | 0.0210 | 0.9546 | 0.0243 | 0.9397 | 0.0278 | 0.9207 | 0.0236 | 0.9427 | 0.0176 | 0.9683 | 0.0226 | 0.9459 |
| Power transformer | 0.0211 | 0.9545 | 0.0242 | 0.9398 | 0.0279 | 0.9200 | 0.0234 | 0.9440 | 0.0176 | 0.9684 | 0.0227 | 0.9494 |
| Quantile transformer | 0.0223 | 0.9487 | 0.0313 | 0.8999 | 0.0315 | 0.8984 | 0.0253 | 0.9344 | 0.0199 | 0.9596 | 0.0236 | 0.9429 |
| Scaling Method | RF | XGB | LGBM | kNN | ET | BR | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| RMSE | R2 | RMSE | R2 | RMSE | R2 | RMSE | R2 | RMSE | R2 | RMSE | R2 | |
| No scaling | 0.0268 | 0.9386 | 0.0298 | 0.9240 | 0.0322 | 0.9112 | 0.0565 | 0.7268 | 0.0243 | 0.9498 | 0.0284 | 0.9318 |
| Robust scaler | 0.0269 | 0.9377 | 0.0299 | 0.9234 | 0.0323 | 0.9108 | 0.0311 | 0.9170 | 0.0243 | 0.9497 | 0.0285 | 0.9282 |
| MaxAbs scaler | 0.0268 | 0.9383 | 0.0297 | 0.9244 | 0.0322 | 0.9112 | 0.0331 | 0.9065 | 0.0243 | 0.9495 | 0.0283 | 0.9295 |
| MinMax scaler | 0.0269 | 0.9381 | 0.0299 | 0.9234 | 0.0324 | 0.9103 | 0.0270 | 0.9377 | 0.0242 | 0.9498 | 0.0287 | 0.9302 |
| Standard scaler | 0.0268 | 0.9379 | 0.0298 | 0.9242 | 0.0325 | 0.9099 | 0.0294 | 0.9260 | 0.0241 | 0.9498 | 0.0290 | 0.9299 |
| Power transformer | 0.0269 | 0.9385 | 0.0299 | 0.9237 | 0.0324 | 0.9102 | 0.0294 | 0.9258 | 0.0241 | 0.9490 | 0.0287 | 0.9300 |
| Quantile transformer | 0.0293 | 0.9269 | 0.0354 | 0.8926 | 0.0360 | 0.8892 | 0.0316 | 0.9145 | 0.0276 | 0.9343 | 0.0302 | 0.9222 |
| Scaling Method | RF | XGB | LGBM | kNN | ET | BR | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| RMSE | R2 | RMSE | R2 | RMSE | R2 | RMSE | R2 | RMSE | R2 | RMSE | R2 | |
| No scaling | 0.0494 | 0.8552 | 0.0554 | 0.8183 | 0.0560 | 0.8140 | 0.1157 | 0.2085 | 0.0436 | 0.8856 | 0.0538 | 0.8299 |
| Robust scaler | 0.0494 | 0.8540 | 0.0548 | 0.8218 | 0.0558 | 0.8157 | 0.0501 | 0.8508 | 0.0438 | 0.8852 | 0.0529 | 0.8275 |
| MaxAbs scaler | 0.0497 | 0.8538 | 0.0554 | 0.8183 | 0.0560 | 0.8140 | 0.0536 | 0.8287 | 0.0440 | 0.8850 | 0.0543 | 0.8309 |
| MinMax scaler | 0.0495 | 0.8520 | 0.0540 | 0.8275 | 0.0559 | 0.8151 | 0.0445 | 0.8821 | 0.0438 | 0.8859 | 0.0537 | 0.8298 |
| Standard scaler | 0.0496 | 0.8544 | 0.0550 | 0.8208 | 0.0560 | 0.8141 | 0.0463 | 0.8726 | 0.0440 | 0.8842 | 0.0524 | 0.8312 |
| Power transformer | 0.0567 | 0.8093 | 0.0577 | 0.8024 | 0.0590 | 0.7934 | 0.0549 | 0.8183 | 0.0514 | 0.8385 | 0.0599 | 0.7903 |
| Quantile transformer | 0.0631 | 0.7611 | 0.0732 | 0.6832 | 0.0767 | 0.6524 | 0.0562 | 0.8118 | 0.0627 | 0.7678 | 0.0642 | 0.7670 |
| Scaling Method | RF | XGB | LGBM | kNN | ET | BR | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| RMSE | R2 | RMSE | R2 | RMSE | R2 | RMSE | R2 | RMSE | R2 | RMSE | R2 | |
| No scaling | 0.0954 | 0.8058 | 0.1040 | 0.7675 | 0.1079 | 0.7498 | 0.1723 | 0.3623 | 0.0904 | 0.8229 | 0.1022 | 0.7805 |
| Robust scaler | 0.0950 | 0.8059 | 0.1042 | 0.7667 | 0.1080 | 0.7496 | 0.1044 | 0.7660 | 0.0909 | 0.8227 | 0.1019 | 0.7784 |
| MaxAbs scaler | 0.0956 | 0.8047 | 0.1045 | 0.7651 | 0.1079 | 0.7498 | 0.1085 | 0.7471 | 0.0904 | 0.8229 | 0.1019 | 0.7782 |
| MinMax scaler | 0.0951 | 0.8041 | 0.1044 | 0.7657 | 0.1079 | 0.7499 | 0.0983 | 0.7926 | 0.0906 | 0.8221 | 0.1009 | 0.7795 |
| Standard scaler | 0.0952 | 0.8041 | 0.1037 | 0.7687 | 0.1082 | 0.7486 | 0.1000 | 0.7849 | 0.0909 | 0.8222 | 0.1014 | 0.7798 |
| Power transformer | 0.1017 | 0.7792 | 0.1054 | 0.7612 | 0.1080 | 0.7493 | 0.1069 | 0.7538 | 0.0974 | 0.7951 | 0.1090 | 0.7529 |
| Quantile transformer | 0.1006 | 0.7820 | 0.1110 | 0.7353 | 0.1133 | 0.7242 | 0.1038 | 0.7684 | 0.1005 | 0.7837 | 0.1051 | 0.7564 |
| Type | Method(s) | River Enborne | The Cut | ||||||
|---|---|---|---|---|---|---|---|---|---|
| NO3 | TRP | NH4 | TRP | ||||||
| RMSE | R2 | RMSE | R2 | RMSE | R2 | RMSE | R2 | ||
| Deletion | Listwise | 0.0176 | 0.9683 | 0.0242 | 0.9498 | 0.0438 | 0.8859 | 0.0906 | 0.8221 |
| Univariate | Mean | 0.0282 | 0.9018 | 0.0335 | 0.8624 | 0.0427 | 0.9053 | 0.0783 | 0.7794 |
| Mode | 0.0285 | 0.9004 | 0.0461 | 0.8141 | 0.0426 | 0.9054 | 0.0781 | 0.7853 | |
| Median | 0.0282 | 0.9010 | 0.0337 | 0.8629 | 0.0424 | 0.9057 | 0.0780 | 0.7775 | |
| Multivariate | Bayesian ridge | 0.0215 | 0.9463 | 0.0245 | 0.9370 | 0.0430 | 0.9033 | 0.0760 | 0.7957 |
| RF | 0.0176 | 0.9649 | 0.0208 | 0.9580 | 0.0429 | 0.9058 | 0.0798 | 0.7948 | |
| BR | 0.0178 | 0.9635 | 0.0217 | 0.9542 | 0.0427 | 0.9051 | 0.0819 | 0.7893 | |
| XGB | 0.0183 | 0.9687 | 0.0217 | 0.9548 | 0.0428 | 0.9040 | 0.0794 | 0.7904 | |
| LGBM | 0.0181 | 0.9678 | 0.0212 | 0.9555 | 0.0426 | 0.9098 | 0.0763 | 0.8009 | |
| Nearest neighbors | kNN | 0.0238 | 0.9328 | 0.0320 | 0.8884 | 0.0436 | 0.9017 | 0.0853 | 0.7949 |
| Predictors in the ET Model | RMSE | R2 |
|---|---|---|
| NO3 in River Enborne | ||
| EC | 0.0617 | 0.6107 |
| EC, Temp | 0.0559 | 0.6818 |
| EC, Temp, pH | 0.0274 | 0.9223 |
| EC, Temp, pH, DO | 0.0205 | 0.9566 |
| EC, Temp, pH, DO, Turb | 0.0172 | 0.9695 |
| EC, Temp, pH, DO, Turb, Chl | 0.0177 | 0.9681 |
| TRP in River Enborne | ||
| EC | 0.0666 | 0.5637 |
| EC, DO | 0.0608 | 0.6355 |
| EC, DO, Temp | 0.0343 | 0.8848 |
| EC, DO, Temp, Turb | 0.0257 | 0.9345 |
| EC, DO, Temp, Turb, pH | 0.0213 | 0.9559 |
| EC, DO, Temp, Turb, pH, Chl | 0.0212 | 0.9558 |
| NH4 in The Cut | ||
| Temp | 0.1312 | 0.1620 |
| Temp, Chl | 0.1342 | 0.1220 |
| Temp, Chl, Turb | 0.0907 | 0.5986 |
| Temp, Chl, Turb, EC | 0.0655 | 0.7895 |
| Temp, Chl, Turb, EC, DO | 0.0526 | 0.8647 |
| Temp, Chl, Turb, EC, DO, pH | 0.0429 | 0.9101 |
| TRP in The Cut | ||
| EC | 0.1952 | 0.1820 |
| EC, Turb | 0.2037 | 0.1072 |
| EC, Turb, DO | 0.1554 | 0.4813 |
| EC, Turb, DO, Temp | 0.1101 | 0.7401 |
| EC, Turb, DO, Temp, Chl | 0.0999 | 0.7864 |
| EC, Turb, DO, Temp, Chl, pH | 0.0907 | 0.8219 |
| TP in The Cut | ||
| EC | 0.1213 | 0.1697 |
| EC, DO | 0.1291 | 0.0593 |
| EC, DO, Turb | 0.0956 | 0.4853 |
| EC, DO, Turb, Temp | 0.0680 | 0.7382 |
| EC, DO, Turb, Temp, Chl | 0.0610 | 0.7880 |
| EC, DO, Turb, Temp, Chl, pH | 0.0556 | 0.8253 |
| Step | [3] | [9] | [12] | Our Work | Remark |
|---|---|---|---|---|---|
| Data transformation | N/S | Cubic Logarithm | N/S | Cubic Logarithm Reciprocal Square root | Even though water quality data is usually skewed, only [9] performed feature transformation, although sub-optimally on three features. |
| Data scaling | N/S | Standard scaler | N/S | Standard scaler MinMax scaler MaxAbs scaler Robust scaler Power transformer Quantile transformer | Only one study [9] scaled the data before evaluating the MLR model. However, MinMax scaler is the best scaling technique in this case. While the other two studies did not scale the data, the impact on their model (RF) would have been minimal. |
| Missing values handling | N/S | Listwise deletion | Median imputation | Listwise deletion kNN imputation Univariate imputation Multivariate imputation | Amongst the various missing data handling methods, our work showed that multivariate imputation, which was not implemented in the three reference studies, results in best-performing models on average. |
| ML models | RF, MLR | RF, MLR | RF | RF, DT, XGB, LGBM, BR, MLP, kNN, SVM, ET, GB, SGD, MLR, Ridge | Although the commonly used RF performed competitively, the extensive analysis in our work showed that ET performs better. |
| Input variable selection | N/S | Stepwise selection | Stepwise selection | SHAP | Contrary to the commonly used stepwise selection method, we applied SHAP in this work because it satisfies the interpretability requirements, which are essential for sensitive applications like public health. |
| Method | NO3 | TRP | TP | |||
|---|---|---|---|---|---|---|
| RMSE | NSE/R2 | RMSE | NSE/R2 | RMSE | NSE/R2 | |
| Random forest [3] | 0.059 | 0.89 | 0.005 | 0.903 | - | - |
| Random forest [9] | 0.194 | - | 0.025 | - | 0.110 | - |
| Random forest [12] | 0.120 | 0.89 | 2.000 | 0.320 | 11.00 | 0.740 |
| Extra trees [our work] | 0.017 | 0.97 | 0.021 | 0.956 | 0.056 | 0.825 |
| Accuracy Metric | Accuracy Ratings | |||
|---|---|---|---|---|
| Target | Acceptable | Tolerable | Poor | |
| R2 | 95–100% | 90–94% | 85–89% | 80–84% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Paepae, T.; Bokoro, P.N.; Kyamakya, K. A Virtual Sensing Concept for Nitrogen and Phosphorus Monitoring Using Machine Learning Techniques. Sensors 2022, 22, 7338. https://doi.org/10.3390/s22197338
Paepae T, Bokoro PN, Kyamakya K. A Virtual Sensing Concept for Nitrogen and Phosphorus Monitoring Using Machine Learning Techniques. Sensors. 2022; 22(19):7338. https://doi.org/10.3390/s22197338
Chicago/Turabian StylePaepae, Thulane, Pitshou N. Bokoro, and Kyandoghere Kyamakya. 2022. "A Virtual Sensing Concept for Nitrogen and Phosphorus Monitoring Using Machine Learning Techniques" Sensors 22, no. 19: 7338. https://doi.org/10.3390/s22197338