
Adaptive Points Sampling for Implicit Field Reconstruction of Industrial Digital Twin
Abstract
:1. Introduction
- We leverage SVR technology to model physical industrial products in digital space using only one image. Experiments on industrial datasets show that implicit-field-based reconstruction methods have great potential for the digital twin field.
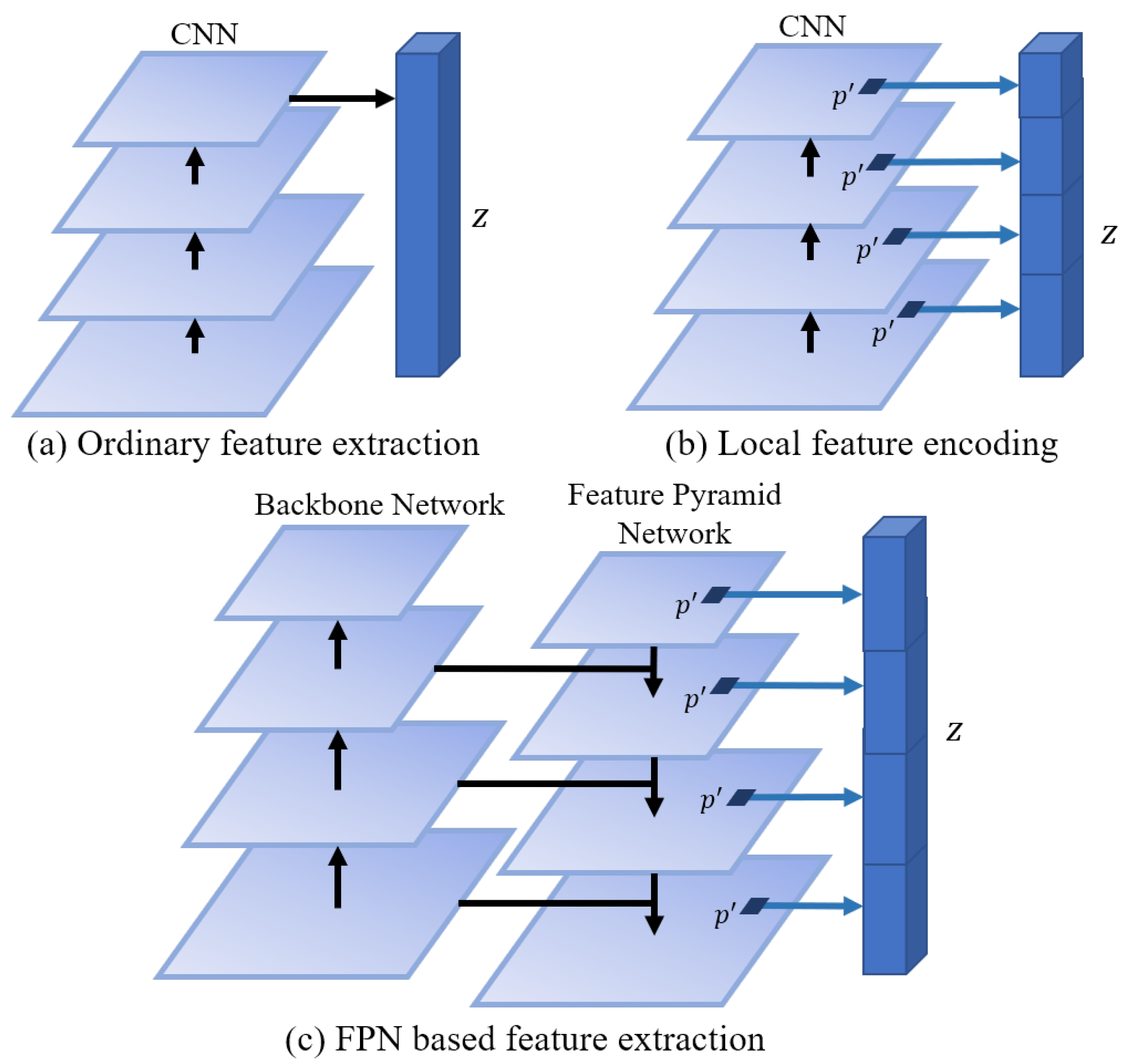
- We propose a feature extractor network for implicit field learning. An extra network is used to take advantage of FPN architecture that combines multi-level feature maps to extract feature vectors with rich semantics and texture information.
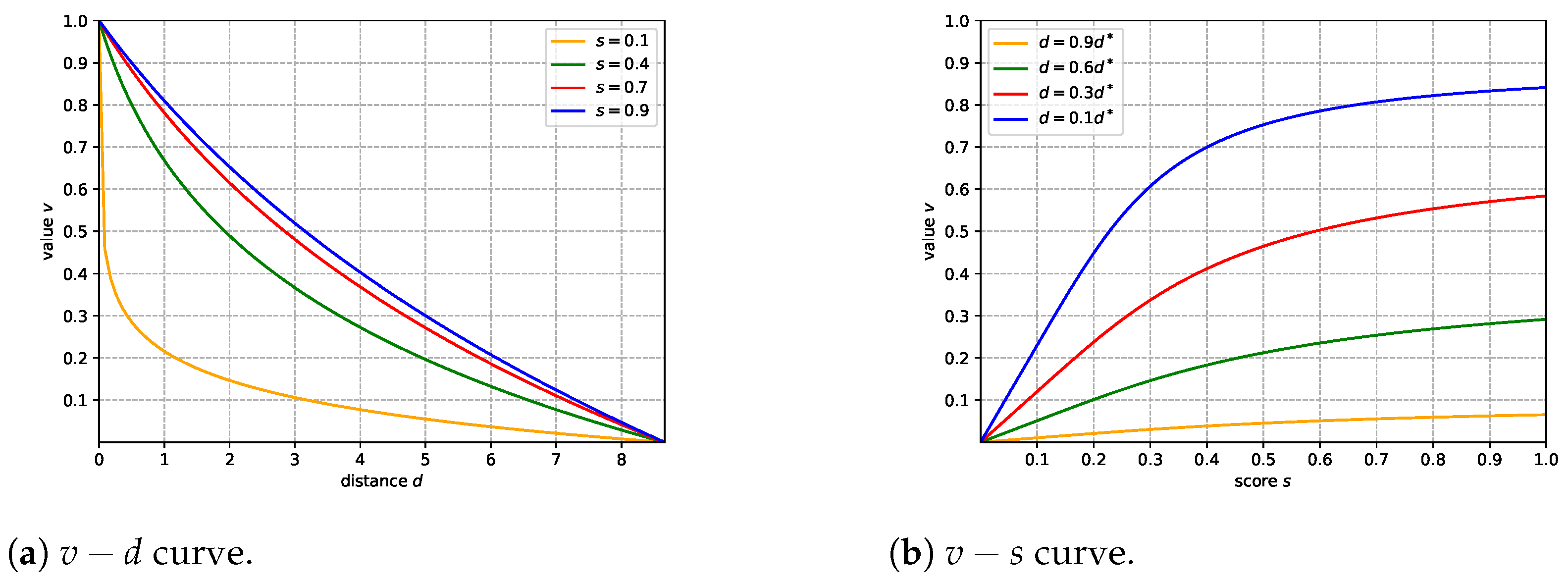
- A novel adaptive data-sampling strategy is proposed to accelerate and stabilize the training of the network and improve the performance of the reconstruction.
2. Related Work
2.1. Digital Twin Technology
2.2. Implicit-Field-Based SVR Methods
2.3. Detail Reconstruction with SVR
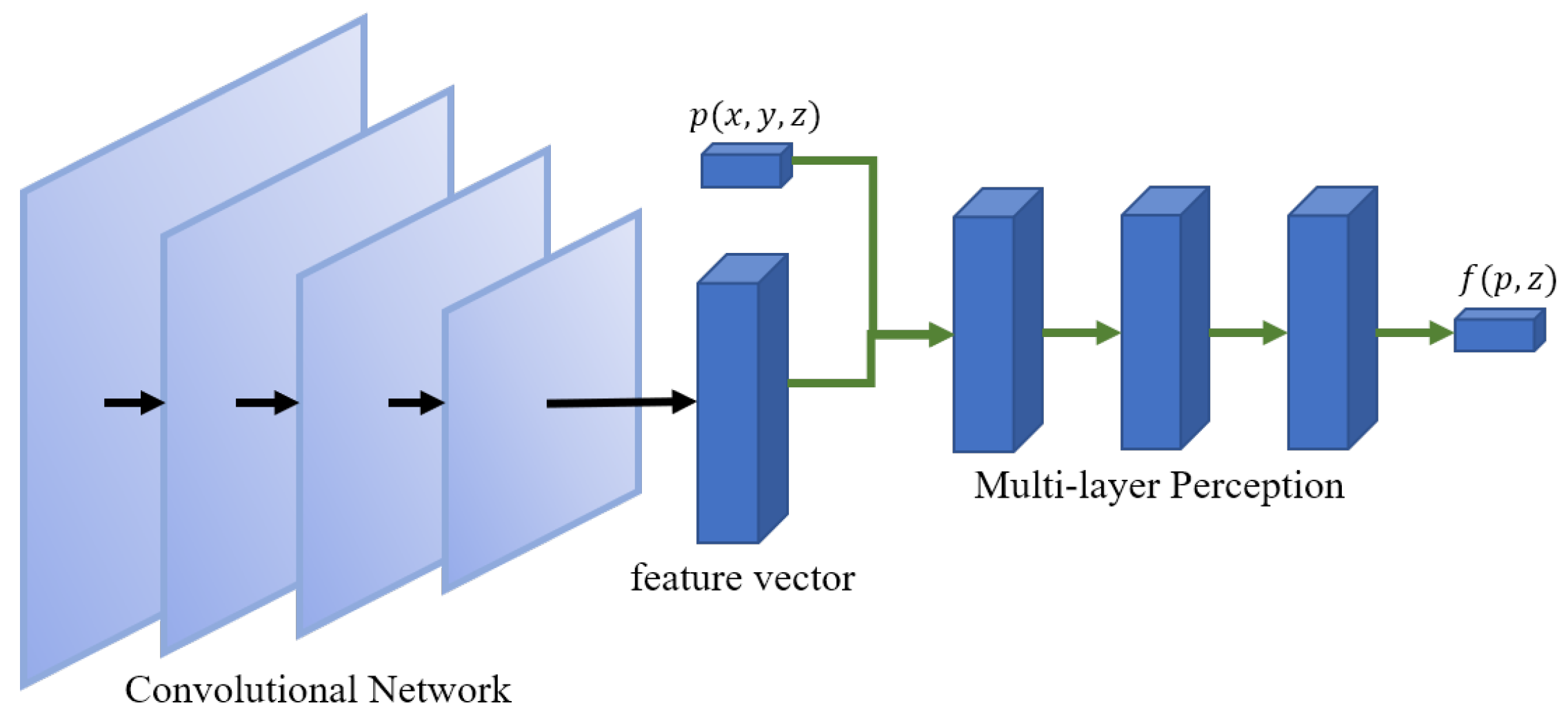
3. Overview of Implicit Field Learning
3.1. Problem Definition
3.2. Overview of the SVR Pipeline
4. Method
4.1. Feature Extractor Network
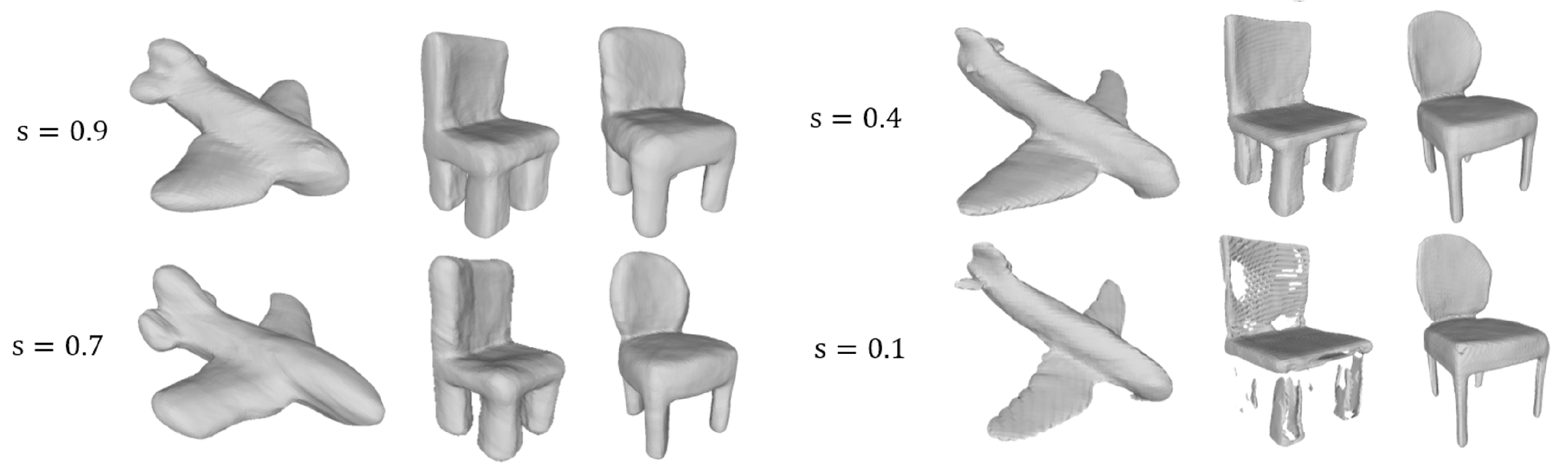
4.2. Adaptive Data Sampling Strategy
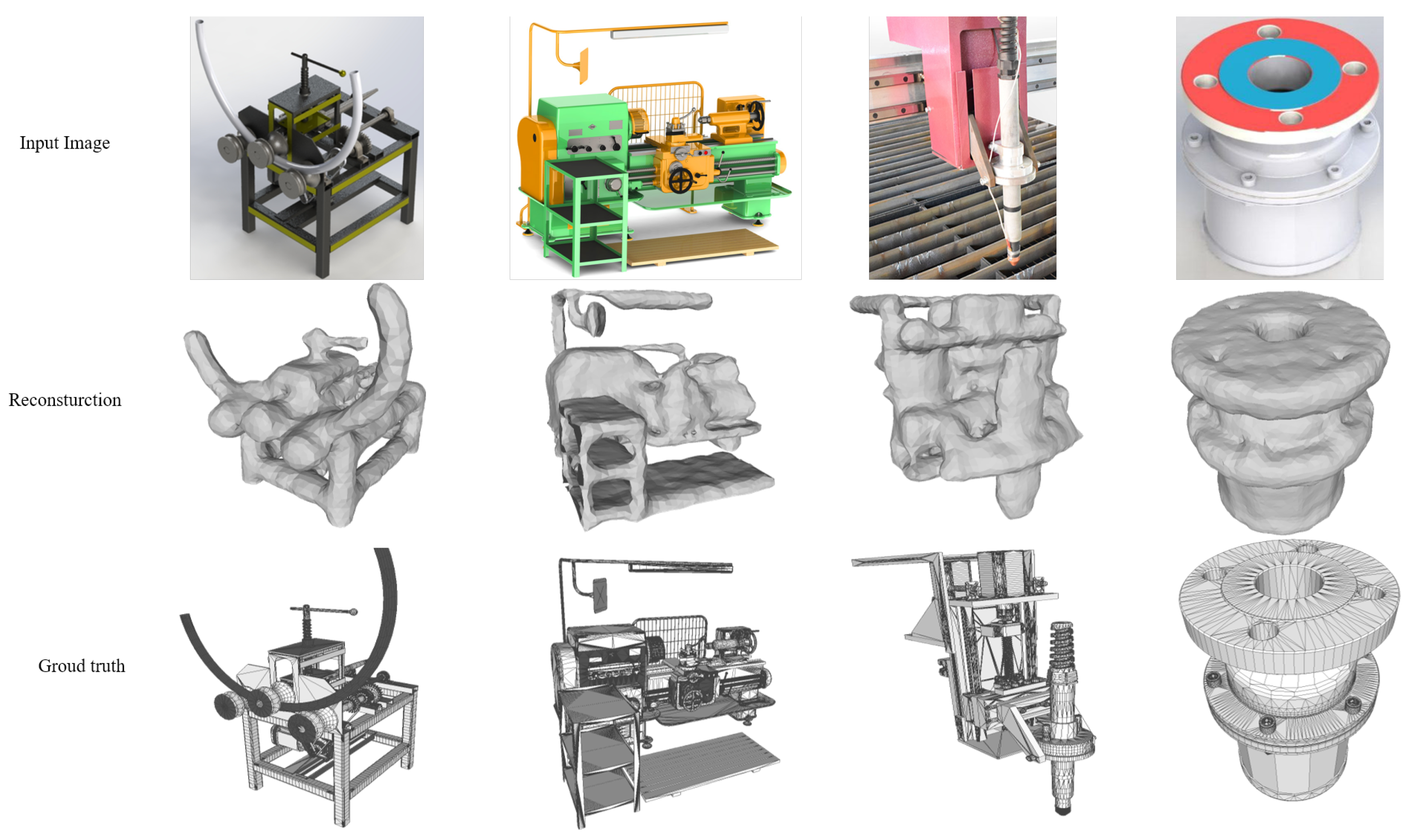
5. Experiments
5.1. Implementation Details
5.2. Dataset and Metrics
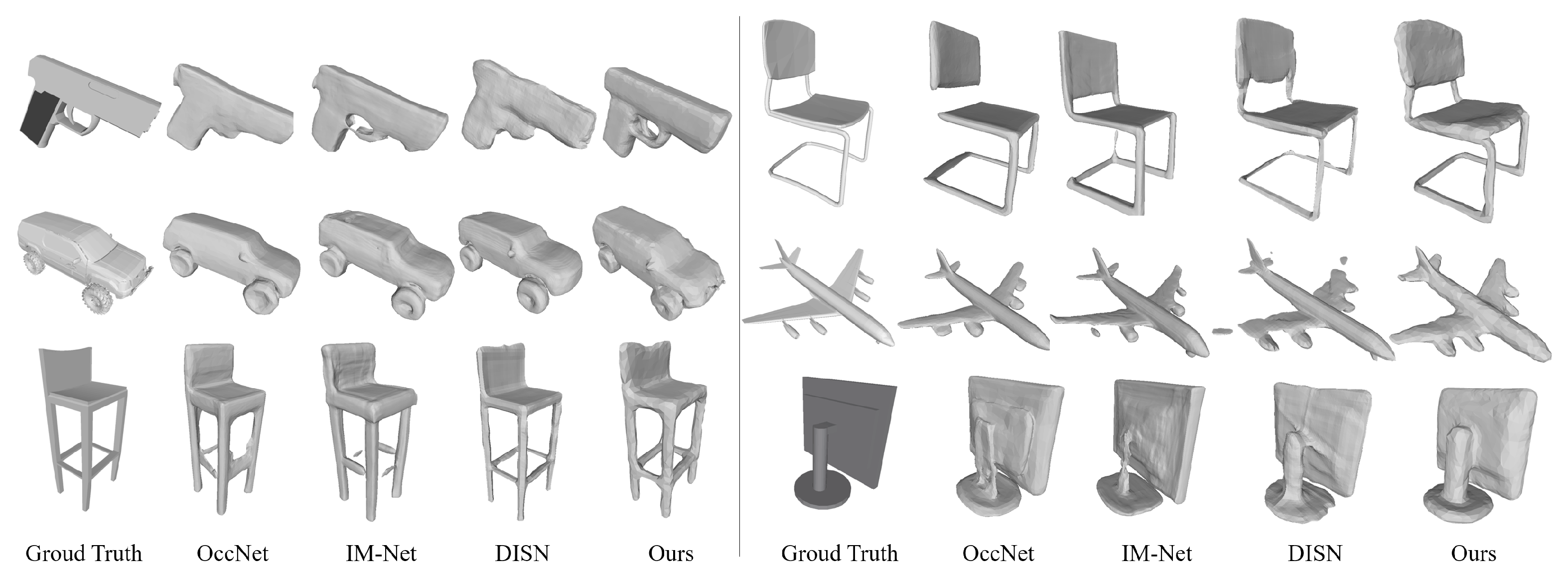
5.3. Experiments on General Objects
5.4. Experiments on Industrial Machines
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Tao, F.; Zhang, H.; Liu, A.; Nee, A.Y.C. Digital Twin in Industry: State-of-the-Art. IEEE Trans. Ind. Inform. 2019, 15, 2405–2415. [Google Scholar] [CrossRef]
- Tao, F.; Cheng, J.; Qi, Q.; Zhang, M.; Zhang, H.; Sui, F. Digital twin-driven product design, manufacturing and service with big data. Int. J. Adv. Manuf. Technol. 2018, 94, 3563–3576. [Google Scholar] [CrossRef]
- Gehrmann, C.; Gunnarsson, M. A Digital Twin Based Industrial Automation and Control System Security Architecture. IEEE Trans. Ind. Inform. 2020, 16, 669–680. [Google Scholar] [CrossRef]
- Tao, F.; Zhang, M. Digital Twin Shop-Floor: A New Shop-Floor Paradigm Towards Smart Manufacturing. IEEE Access 2017, 5, 20418–20427. [Google Scholar] [CrossRef]
- Yang, H.; Li, Y.; Yao, K.; Sun, T.; Zhou, C. A Systematic Network Traffic Emulation Framework for Digital Twin Network. In Proceedings of the 2021 IEEE 1st International Conference on Digital Twins and Parallel Intelligence (DTPI), Beijing, China, 15 July–15 August 2021; pp. 94–97. [Google Scholar] [CrossRef]
- Viola, J.; Chen, Y. Parallel Self Optimizing Control Framework for Digital Twin Enabled Smart Control Engineering. In Proceedings of the 2021 IEEE 1st International Conference on Digital Twins and Parallel Intelligence (DTPI), Beijing, China, 15 July–15 August 2021; pp. 358–361. [Google Scholar] [CrossRef]
- An, D.; Chen, Y. Digital Twin Enabled Methane Emission Abatement Using Networked Mobile Sensing and Mobile Actuation. In Proceedings of the 2021 IEEE 1st International Conference on Digital Twins and Parallel Intelligence (DTPI), Beijing, China, 15 July–15 August 2021; pp. 354–357. [Google Scholar] [CrossRef]
- Zhang, Z.; Lu, J.; Xia, L.; Wang, S.; Zhang, H.; Zhao, R. Digital twin system design for dual-manipulator cooperation unit. In Proceedings of the 2020 IEEE 4th Information Technology, Networking, Electronic and Automation Control Conference (ITNEC), Chongqing, China, 12–14 June 2020; Volume 1, pp. 1431–1434. [Google Scholar] [CrossRef]
- Ji, G.; Hao, J.g.; Gao, J.l.; Lu, C.z. Digital Twin Modeling Method for Individual Combat Quadrotor UAV. In Proceedings of the 2021 IEEE 1st International Conference on Digital Twins and Parallel Intelligence (DTPI), Beijing, China, 15 July–15 August 2021; pp. 1–4. [Google Scholar] [CrossRef]
- Mescheder, L.M.; Oechsle, M.; Niemeyer, M.; Nowozin, S.; Geiger, A. Occupancy Networks: Learning 3D Reconstruction in Function Space. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2019, Long Beach, CA, USA, 16–20 June 2019; pp. 4460–4470. [Google Scholar] [CrossRef] [Green Version]
- Chen, Z.; Zhang, H. Learning Implicit Fields for Generative Shape Modeling. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2019, Long Beach, CA, USA, 16–20 June 2019; pp. 5939–5948. [Google Scholar] [CrossRef]
- Park, J.J.; Florence, P.; Straub, J.; Newcombe, R.A.; Lovegrove, S. DeepSDF: Learning Continuous Signed Distance Functions for Shape Representation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2019, Long Beach, CA, USA, 16–20 June 2019; pp. 165–174. [Google Scholar] [CrossRef]
- Chen, Z.; Tagliasacchi, A.; Zhang, H. BSP-Net: Generating Compact Meshes via Binary Space Partitioning. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2020, Seattle, WA, USA, 13–19 June 2020; pp. 42–51. [Google Scholar] [CrossRef]
- Xu, Q.; Wang, W.; Ceylan, D.; Mech, R.; Neumann, U. DISN: Deep Implicit Surface Network for High-quality Single-view 3D Reconstruction. In Proceedings of the Advances in Neural Information Processing Systems 32: Annual Conference on Neural Information Processing Systems 2019, NeurIPS 2019, Vancouver, BC, Canada, 8–14 December 2019; Wallach, H.M., Larochelle, H., Beygelzimer, A., d’Alché-Buc, F., Fox, E.B., Garnett, R., Eds.; MIT Press: Cambridge, MA, USA, 2019; pp. 490–500. [Google Scholar]
- Li, M.; Zhang, H. D2IM-Net: Learning Detail Disentangled Implicit Fields From Single Images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2021, Virtual, 19–25 June 2021; pp. 10246–10255. [Google Scholar] [CrossRef]
- Lin, T.; Dollár, P.; Girshick, R.B.; He, K.; Hariharan, B.; Belongie, S.J. Feature Pyramid Networks for Object Detection. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2017, Honolulu, HI, USA, 21–26 July 2017; IEEE Computer Society: Washington, DC, USA, 2017; pp. 936–944. [Google Scholar] [CrossRef]
- Cai, Y.; Starly, B.; Cohen, P.; Lee, Y.S. Sensor data and information fusion to construct digital-twins virtual machine tools for cyber-physical manufacturing. Procedia Manuf. 2017, 10, 1031–1042. [Google Scholar] [CrossRef]
- Schluse, M.; Priggemeyer, M.; Atorf, L.; Rossmann, J. Experimentable Digital Twins—Streamlining Simulation-Based Systems Engineering for Industry 4.0. IEEE Trans. Ind. Inform. 2018, 14, 1722–1731. [Google Scholar] [CrossRef]
- Zhou, J.; Zhou, Y.; Wang, B.; Zang, J. Human–Cyber–Physical Systems (HCPSs) in the Context of New-Generation Intelligent Manufacturing. Engineering 2019, 5, 624–636. [Google Scholar] [CrossRef]
- Zhou, X.; Xu, X.; Liang, W.; Zeng, Z.; Shimizu, S.; Yang, L.T.; Jin, Q. Intelligent Small Object Detection for Digital Twin in Smart Manufacturing With Industrial Cyber-Physical Systems. IEEE Trans. Ind. Inform. 2022, 18, 1377–1386. [Google Scholar] [CrossRef]
- Zhang, C.; Zhou, G.; Li, H.; Cao, Y. Manufacturing Blockchain of Things for the Configuration of a Data- and Knowledge-Driven Digital Twin Manufacturing Cell. IEEE Internet Things J. 2020, 7, 11884–11894. [Google Scholar] [CrossRef]
- Leng, J.; Yan, D.; Liu, Q.; Xu, K.; Zhao, J.L.; Shi, R.; Wei, L.; Zhang, D.; Chen, X. ManuChain: Combining Permissioned Blockchain With a Holistic Optimization Model as Bi-Level Intelligence for Smart Manufacturing. IEEE Trans. Syst. Man Cybern. Syst. 2020, 50, 182–192. [Google Scholar] [CrossRef]
- Groueix, T.; Fisher, M.; Kim, V.G.; Russell, B.C.; Aubry, M. AtlasNet: A Papier-Mâché Approach to Learning 3D Surface Generation. CoRR 2018. Available online: http://xxx.lanl.gov/abs/1802.05384 (accessed on 15 February 2018).
- Wang, N.; Zhang, Y.; Li, Z.; Fu, Y.; Liu, W.; Jiang, Y.G. Pixel2mesh: Generating 3d mesh models from single rgb images. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 52–67. [Google Scholar]
- Choy, C.B.; Xu, D.; Gwak, J.; Chen, K.; Savarese, S. 3D-R2N2: A Unified Approach for Single and Multi-view 3D Object Reconstruction. In Proceedings of the Computer Vision—ECCV 2016—14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Proceedings, Part VIII. Leibe, B., Matas, J., Sebe, N., Welling, M., Eds.; Springer: Berlin/Heidelberg, Germany, 2016; Volume 9912, Lecture Notes in Computer Science. pp. 628–644. [Google Scholar] [CrossRef]
- Xie, H.; Yao, H.; Sun, X.; Zhou, S.; Zhang, S. Pix2Vox: Context-Aware 3D Reconstruction From Single and Multi-View Images. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision, ICCV 2019, Seoul, Korea, 27 October–2 November 2019; pp. 2690–2698. [Google Scholar] [CrossRef]
- Yang, G.; Huang, X.; Hao, Z.; Liu, M.; Belongie, S.J.; Hariharan, B. PointFlow: 3D Point Cloud Generation With Continuous Normalizing Flows. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision, ICCV 2019, Seoul, Korea, 27 October–2 November 2019; pp. 4540–4549. [Google Scholar] [CrossRef]
- Tchapmi, L.P.; Kosaraju, V.; Rezatofighi, H.; Reid, I.D.; Savarese, S. TopNet: Structural Point Cloud Decoder. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2019, Long Beach, CA, USA, 16–20 June 2019; pp. 383–392. [Google Scholar] [CrossRef]
- Bechtold, J.; Tatarchenko, M.; Fischer, V.; Brox, T. Fostering Generalization in Single-View 3D Reconstruction by Learning a Hierarchy of Local and Global Shape Priors. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2021, Virtual, 19–25 June 2021; Computer Vision Foundation/IEEE. pp. 15880–15889. [Google Scholar] [CrossRef]
- Saito, S.; Huang, Z.; Natsume, R.; Morishima, S.; Li, H.; Kanazawa, A. PIFu: Pixel-Aligned Implicit Function for High-Resolution Clothed Human Digitization. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision, ICCV 2019, Seoul, Korea, 27 October–2 November 2019; pp. 2304–2314. [Google Scholar] [CrossRef]
- Duan, Y.; Zhu, H.; Wang, H.; Yi, L.; Nevatia, R.; Guibas, L.J. Curriculum DeepSDF. In Proceedings of the Computer Vision—ECCV 2020—16th European Conference, Glasgow, UK, 23–28 August 2020; Proceedings, Part VIII. Vedaldi, A., Bischof, H., Brox, T., Frahm, J., Eds.; Springer: Berlin/Heidelberg, Germany, 2020; Volume 12353, Lecture Notes in Computer Science. pp. 51–67. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. In Proceedings of the 3rd International Conference on Learning Representations, ICLR 2015, San Diego, CA, USA, 7–9 May 2015; Conference Track Proceedings. Bengio, Y., LeCun, Y., Eds.; [Google Scholar]
- Lorensen, W.E.; Cline, H.E. Marching cubes: A high resolution 3D surface construction algorithm. In Proceedings of the Proceedings of the 14th Annual Conference on Computer Graphics and Interactive Techniques, SIGGRAPH 1987, Anaheim, CA, USA, 27–31 July 1987; Stone, M.C., Ed.; ACM: New York, NY, USA, 1987; pp. 163–169. [Google Scholar] [CrossRef]
- Kuhn, M.; Johnson, K. Applied Predictive Modeling; Springer: Berlin/Heidelberg, Germany, 2013; Volume 26. [Google Scholar]
- Chang, A.X.; Funkhouser, T.A.; Guibas, L.J.; Hanrahan, P.; Huang, Q.; Li, Z.; Savarese, S.; Savva, M.; Song, S.; Su, H.; et al. ShapeNet: An Information-Rich 3D Model Repository. CoRR 2015, abs/1512.03012. Available online: http://xxx.lanl.gov/abs/1512.03012 (accessed on 9 December 2015).
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2016, Las Vegas, NV, USA, 27–30 June 2016; IEEE Computer Society: Washington, DC, USA, 2016; pp. 770–778. [Google Scholar] [CrossRef] [Green Version]
- Xu, B.; Wang, N.; Chen, T.; Li, M. Empirical Evaluation of Rectified Activations in Convolutional Network. CoRR 2015, abs/1505.00853. Available online: http://xxx.lanl.gov/abs/1505.00853 (accessed on 5 May 2015).
- Ioffe, S.; Szegedy, C. Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift. In Proceedings of the 32nd International Conference on Machine Learning, ICML 2015, Lille, France, 6–11 July 2015; Bach, F.R., Blei, D.M., Eds.; JMLR.org, JMLR Workshop and Conference Proceedings. 2015; Volume 37, pp. 448–456. [Google Scholar]
- Hane, C.; Tulsiani, S.; Malik, J. Hierarchical Surface Prediction for 3D Object Reconstruction. In Proceedings of the 2017 International Conference on 3D Vision, 3DV 2017, Qingdao, China, 10–12 October 2017; IEEE Computer Society: Washington, DC, USA; pp. 412–420. [Google Scholar] [CrossRef]
- Jin, J.; Patil, A.G.; Xiong, Z.; Zhang, H.R. DR-KFS: A Differentiable Visual Similarity Metric for 3D Shape Reconstruction. In Proceedings of the Computer Vision—ECCV 2020—16th European Conference, Glasgow, UK, 23–28 August 2020; Proceedings, Part XXI. Vedaldi, A., Bischof, H., Brox, T., Frahm, J., Eds.; Springer: Berlin/Heidelberg, Germany, 2020; Volume 12366, Lecture Notes in Computer Science. pp. 295–311. [Google Scholar] [CrossRef]
- Vakalopoulou, M.; Chassagnon, G.; Bus, N.; Marini, R.; Zacharaki, E.I.; Revel, M.P.; Paragios, N. AtlasNet: Multi-atlas non-linear deep networks for medical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Granada, Spain, 16–20 September 2018; Springer: Berlin/Heidelberg, Germany, 2018; pp. 658–666. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Airplane | Car | Chair | Display | Lamp | Rifle | Table | Mean | |
|---|---|---|---|---|---|---|---|---|---|
| IOU(↑) | Pixel2Mesh | 0.423 | 0.524 | 0.311 | 0.475 | 0.238 | 0.429 | 0.408 | 0.401 |
| AtlasNet | 0.451 | 0.535 | 0.366 | 0.480 | 0.217 | 0.455 | 0.430 | 0.419 | |
| OccNET | 0.480 | 0.570 | 0.358 | 0.439 | 0.254 | 0.427 | 0.461 | 0.461 | |
| IM-NET | 0.379 | 0.674 | 0.487 | 0.514 | 0.336 | 0.468 | 0.484 | 0.527 | |
| DISN | 0.328 | 0.672 | 0.301 | 0.358 | 0.189 | 0.197 | 0.105 | 0.360 | |
| Ours | 0.443 | 0.710 | 0.532 | 0.552 | 0.295 | 0.671 | 0.505 | 0.592 | |
| CD(↓) | Pixel2Mesh | 0.587 | 0.414 | 0.662 | 0.641 | 0.702 | 0.521 | 0.796 | 0.617 |
| AtlasNet | 0.592 | 0.440 | 0.651 | 0.632 | 0.695 | 0.438 | 0.701 | 0.593 | |
| OccNET | 0.461 | 0.368 | 0.639 | 0.636 | 0.683 | 0.414 | 0.763 | 0.587 | |
| IM-NET | 0.574 | 0.650 | 0.919 | 0.907 | 0.802 | 0.556 | 0.979 | 0.797 | |
| DISN | 0.572 | 0.645 | 0.907 | 0.906 | 0.800 | 0.578 | 0.972 | 0.794 | |
| Ours | 0.562 | 0.344 | 0.597 | 0.613 | 0.637 | 0.325 | 0.653 | 0.552 | |
| ECD(↓) | Pixel2Mesh | 0.565 | 0.477 | 0.589 | 0.582 | 0.677 | 0.430 | 0.742 | 0.580 |
| AtlasNet | 0.601 | 0.397 | 0.506 | 0.658 | 0.679 | 0.426 | 0.688 | 0.565 | |
| OccNET | 0.423 | 0.288 | 0.465 | 0.475 | 0.581 | 0.321 | 0.594 | 0.473 | |
| IM-NET | 0.522 | 0.370 | 0.627 | 0.641 | 0.695 | 0.478 | 0.750 | 0.589 | |
| DISN | 0.554 | 0.412 | 0.732 | 0.653 | 0.733 | 0.565 | 0.844 | 0.655 | |
| Ours | 0.447 | 0.313 | 0.385 | 0.469 | 0.547 | 0.296 | 0.536 | 0.452 | |
| DR-KFS(↓) | Pixel2Mesh | 0.338 | 0.490 | 0.551 | 0.568 | 0.592 | 0.487 | 0.605 | 0.519 |
| AtlasNet | 0.299 | 0.401 | 0.499 | 0.524 | 0.559 | 0.463 | 0.592 | 0.425 | |
| OccNET | 0.296 | 0.239 | 0.325 | 0.366 | 0.402 | 0.291 | 0.438 | 0.337 | |
| IM-NET | 0.337 | 0.308 | 0.375 | 0.386 | 0.398 | 0.269 | 0.512 | 0.367 | |
| DISN | 0.324 | 0.313 | 0.392 | 0.403 | 0.422 | 0.401 | 0.524 | 0.397 | |
| Ours | 0.320 | 0.274 | 0.314 | 0.361 | 0.374 | 0.258 | 0.373 | 0.288 |
| CNN | CNN + FPN | CNN + FPN | CNN + FPN | |
|---|---|---|---|---|
| Binary | Binary | v(d,0.5) | v(d,s) | |
| IOU | 0.524 | 0.553 | 0.567 | 0.592 |
| CD | 0.813 | 0.664 | 0.560 | 0.552 |
| ECD | 0.576 | 0.538 | 0.457 | 0.452 |
| Method | Machines | Components | Buildings | Cartoons | Mean | |
|---|---|---|---|---|---|---|
| ECD(↓) | Pixel2Mesh | 0.828 | 0.801 | 0.874 | 0.853 | 0.839 |
| AtlasNet | 0.802 | 0.783 | 0.859 | 0.848 | 0.823 | |
| OccNET | 0.795 | 0.763 | 0.848 | 0.820 | 0.806 | |
| IM-NET | 0.789 | 0.771 | 0.852 | 0.810 | 0.805 | |
| DISN | 0.798 | 0.784 | 0.851 | 0.816 | 0.812 | |
| Ours | 0.724 | 0.712 | 0.801 | 0.790 | 0.757 | |
| DR-KFS(↓) | Pixel2Mesh | 0.742 | 0.709 | 0.885 | 0.838 | 0.793 |
| AtlasNet | 0.757 | 0.701 | 0.873 | 0.850 | 0.795 | |
| OccNET | 0.695 | 0.673 | 0.794 | 0.771 | 0.733 | |
| IM-NET | 0.662 | 0.649 | 0.781 | 0.744 | 0.709 | |
| DISN | 0.678 | 0.641 | 0.790 | 0.724 | 0.724 | |
| Ours | 0.589 | 0.576 | 0.703 | 0.699 | 0.641 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jin, J.; Xu, H.; Leng, B. Adaptive Points Sampling for Implicit Field Reconstruction of Industrial Digital Twin. Sensors 2022, 22, 6630. https://doi.org/10.3390/s22176630
Jin J, Xu H, Leng B. Adaptive Points Sampling for Implicit Field Reconstruction of Industrial Digital Twin. Sensors. 2022; 22(17):6630. https://doi.org/10.3390/s22176630
Chicago/Turabian StyleJin, Jiongchao, Huanqiang Xu, and Biao Leng. 2022. "Adaptive Points Sampling for Implicit Field Reconstruction of Industrial Digital Twin" Sensors 22, no. 17: 6630. https://doi.org/10.3390/s22176630