

A Comprehensive “Real-World Constraints”-Aware Requirements Engineering Related Assessment and a Critical State-of-the-Art Review of the Monitoring of Humans in Bed
 ,
,
Abstract
:1. Introduction
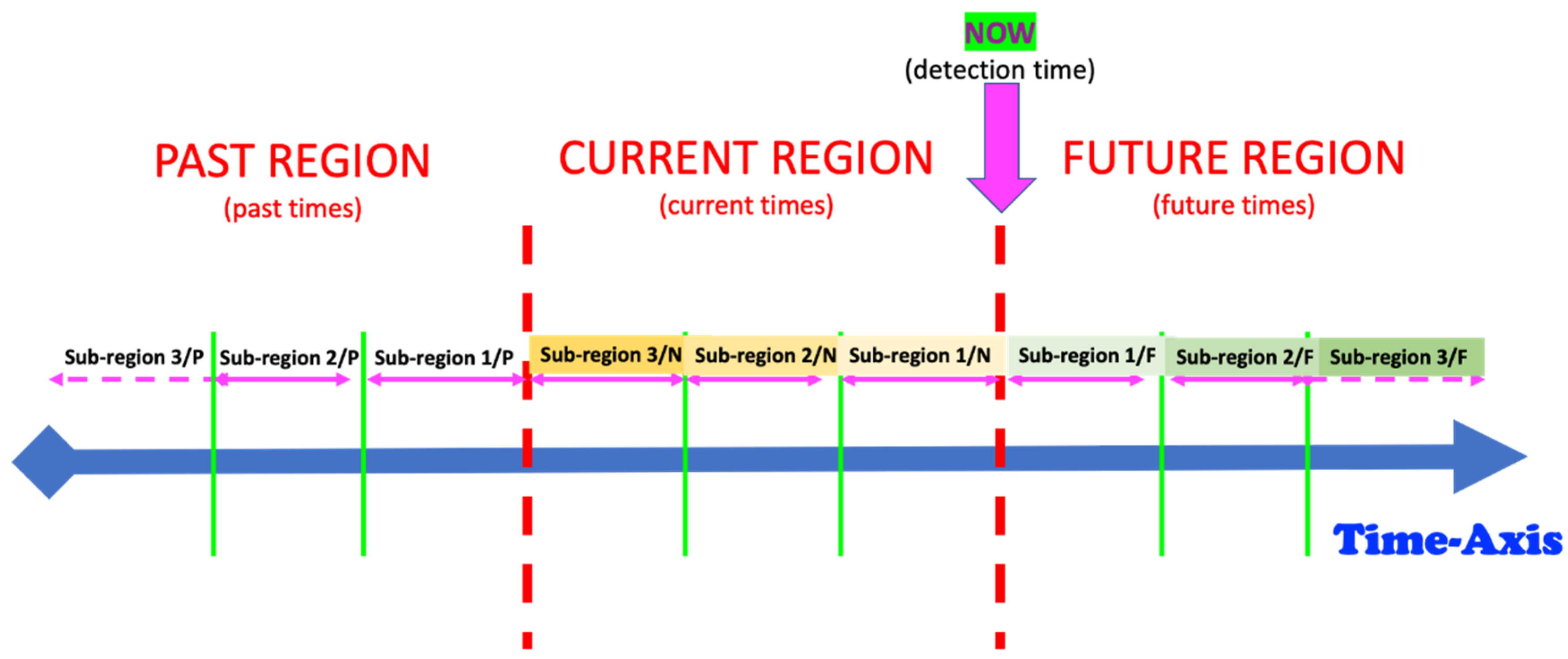
- Time Case 1—Posterior anomaly detection: the anomaly happened in the past (in one of the different sub-regions of the past), but it is detected now. Here, the detection of posterior is the anomaly occurrence;
- Time Case 2—Online or simultaneous detection: the anomaly happens in the current time, now (in one of the different sub-regions of now), and it is detected now. Here, the detection and anomaly occurrence are both in the current time, now;
- Time Case 3—Forecasting or anterior anomaly detection: the anomaly will happen in the future (in one of the different sub-regions of the future), but it is detected now. Here, the detection of anterior is the anomaly occurrence.
- Briefly describe the basic settings and the general architecture of the monitoring context of a human in bed;
- Identify the currently poor definition of the “anomaly” concept and suggest a comprehensive and coherent definition that is consistent with systems engineering-related practical requirements. A comprehensive definition of the anomaly concepts shall include all important dimensions of its complexity. A clear differentiation to other closely related and/or coexistent concepts is provided;
- Furthermore, provide a comprehensive explanation of a series of relevant characteristics of a robust and real-world mature anomaly detection endeavor. For example, the following: subject-dependency; use-case dependency; activity/event attributes/features; anomaly score; uncertainty quantification; unsupervised learning versus semi-supervised learning versus supervised learning; the complex and time dynamic and/or structural relationship between events (at/of different levels of the data-processing hierarchy), events sequences and anomalies; the relative timing between detection and occurrence; the observation perspectives of the anomaly phenomenon, which are, amongst others the following: (a) “condition/entity/event-type related anomaly”, (b) “time-window related anomaly”, (c) “multiple time-windows related anomaly”, (d) “conditions/entity/event-sequence related anomaly”, etc.; adaptivity based on data aging, data dissimilarity forgetting factors and novelty detection;
- Formulate a comprehensive requirements engineering dossier for a robust and practically useful anomaly detection system. A subsequent representative specification book shall be presented. The specification shall distinguish three classes of requirements: the MUST-HAVE requirements, the NICE-TO-HAVE requirements and the NEVER HAVE/DO NOT requirements;
- Comprehensively discuss the verification and validation of the challenge of a robust and real-world mature anomaly detection system in the context of the monitoring of humans in bed. Hereby, amongst other concerns, the appropriate setting and availability of reference datasets are discussed;
- Then, a comprehensive critical review, identifying respective limitations, of how far the major schemes/approaches for anomaly detection as per the current state-of-the-art are capable or not to fully satisfying the major requirements described for the robust and real-world mature anomaly detection system;
- Finally, the suggestion and discussion of a tentative general and strategic architecture of a truly robust anomaly detection scheme, which has the potential of fully satisfying all of the MUST-HAVE requirements of the formulated comprehensive specification book. The bricks of this architecture, which have capabilities going beyond those of competing schemes from the current state-of-the-art (see also the reference system described in Section 2), are briefly discussed.
2. General Context Description of the Monitoring of Humans in Bed, One Illustrative Example from the Practice
3. A General Comprehensive Discussion of the “Abnormality Concept” in General and in Particular w.r.t. the Monitoring Context of Humans in Bed
- Hierarchy levels (data-processing related) of the behavioral entities;
- Form-type related anomaly classification;
- Observation-context perspective related anomaly classification;
- Learning strategy and learning context-related perspective. Examples: “black” versus “white” versus “gray” versus “subject-dependent” versus “use-case dependent” modeling and identification of anomalies;
- Novelty-related anomaly classification (see “novelty” detection; see also continual learning);
- Subject-dependency-related anomaly detection.
3.1. Consider the Hierarchy Levels (Data-Processing Related) of the Behavioral Entities
3.2. Consider the Form-Type Related Anomaly Classification
- Attribute 0: It is a binary attribute indicating whether this entity is new (see novelty detection) or it was already encountered once in the past;
- Attribute 1: Relative occurrence-time difference(s) w.r.t. to one or more of the latest occurrence(s) of the same entity at a given level;
- Attribute 2: Relative occurrence-time difference(s) w.r.t. to one or more of the latest occurrences of other entities of the same given level;
- Attribute 3: Time duration of the current occurrence of the same entity;
- Attribute 4: Selected time-duration-related metadata related to the current and previous occurrences of the same entity;
- Attribute 5: Number of occurrences of the entity with a given time window;
- Attribute 6: Relative number of occurrences of the same entity with a given time window w.r.t. one or more other entities of the same level;
- Attribute 7: Selected metadata w.r.t. one or more of the previous attributes (i.e., Attribute 1 up to Attribute 6);
- Etc.
3.3. Consider the Observation-Context Perspective Related Anomaly Classification
- OCP 1: “Condition-type” or better “entity type”-related anomaly. See the entities of the four upper levels of the hierarchy presented in Figure 3. Each of those entities at different levels does define a particular system condition. Indeed, every single time, the system state is represented by a particular entity at each of the four upper hierarchy levels in Figure 3. The condition may be current, past or future; see OCP 5;
- OCP 2: “Conditions-sequence”-related anomaly. The conditions-sequence may be current, past or future; see OCP 5;
- OCP 3: “Single time-window”-related anomaly. Notice that the time window may be current, future or past (see OCP 5);
- OCP 4: “Multiple time-windows”-related anomaly. Notice that some of these time windows may be current, future or past (see OCP 5).;
- OCP 5: “Time-Case“ perspective of anomaly detection. The “Time-Case” concept was defined in Section 1 above. Indeed, this is an additional context feature to be combined with each of the four previous observation context perspectives. Let us recall here those in Section 1 already explained three time cases: (a) Time case 1, the posterior anomaly detection; (b) Time case 2, the online or simultaneous anomaly detection; (c) Time case 3, the forecasting or anterior anomaly detection.
3.4. Consider the Learning Strategy and Learning Context Related Perspective for Anomaly Perception
- Unsupervised learning and related system behavior identification, i.e., a “blind” approach;
- Semi-supervised learning and related system behavior identification, i.e., a “gray” approach;
- Supervised learning and related system behavior identification, i.e., a “white” approach;
- The subject-dependency concern w.r.t. behavior identification; there may be some interlinking to either “blind” or “white” approaches;
- The monitoring use-case dependency; there may be some interlinking to either “blind” or “white” approaches;
3.5. Consider the “Novelty Related Anomaly” Perception
3.6. Subject-Dependency Related Anomaly Perception, Detection and Related Nuances
- (a)
- Reference Clusters for behavior segments of length 1 h: each cluster shall be considered as a class, examples: 1HC1, 1HC2, 1HC3; …; 1HCN1. Hereby, N1 is the total number of classes of length 1 h;
- (b)
- Reference Clusters for behavior segments of length 6 h: each cluster shall be considered as a class, examples: 6HC1, 6HC2, 6HC3; …; 6HCN2. Hereby, N2 is the total number of classes of length 6 h;
- (c)
- Reference Clusters for behavior segments of length 12 h: each cluster shall be considered as a class, examples: 12HC1, 12HC2, 12HC3; …; 12HCN3. Hereby, N3 is the total number of classes of length 12 h;
- (d)
- Reference Clusters for behavior segments of length 1 day: each cluster shall be considered as a class, examples: 1DC1, 1DC2, 1DC3; …; 1DCN4. Hereby, N4 is the total number of classes of length 1 day;
- (e)
- Reference Clusters for behavior segments of length 3 days: each cluster shall be considered as a class, examples: 3DC1, 3DC2, 3DC3; …; 3DCN5. Hereby, N5 is the total number of classes of length 3 days;
- (f)
- Reference Clusters for behavior segments of length 7 days: each cluster shall be considered as a class, examples: 7DC1, 7DC2, 7DC3; …; 7DCN6. Hereby, N6 is the total number of classes of length 7 days.
- (g)
- Etc.
4. Comprehensive Discussions of Selected Key Advanced Characteristics of Robust and Real-World Mature Anomaly Detection Schemes
5. Comprehensive Requirements Engineering Dossier for a Robust Anomaly Detection System
6. Comprehensive Verification and Validation Challenge for a Robust Anomaly Detection System
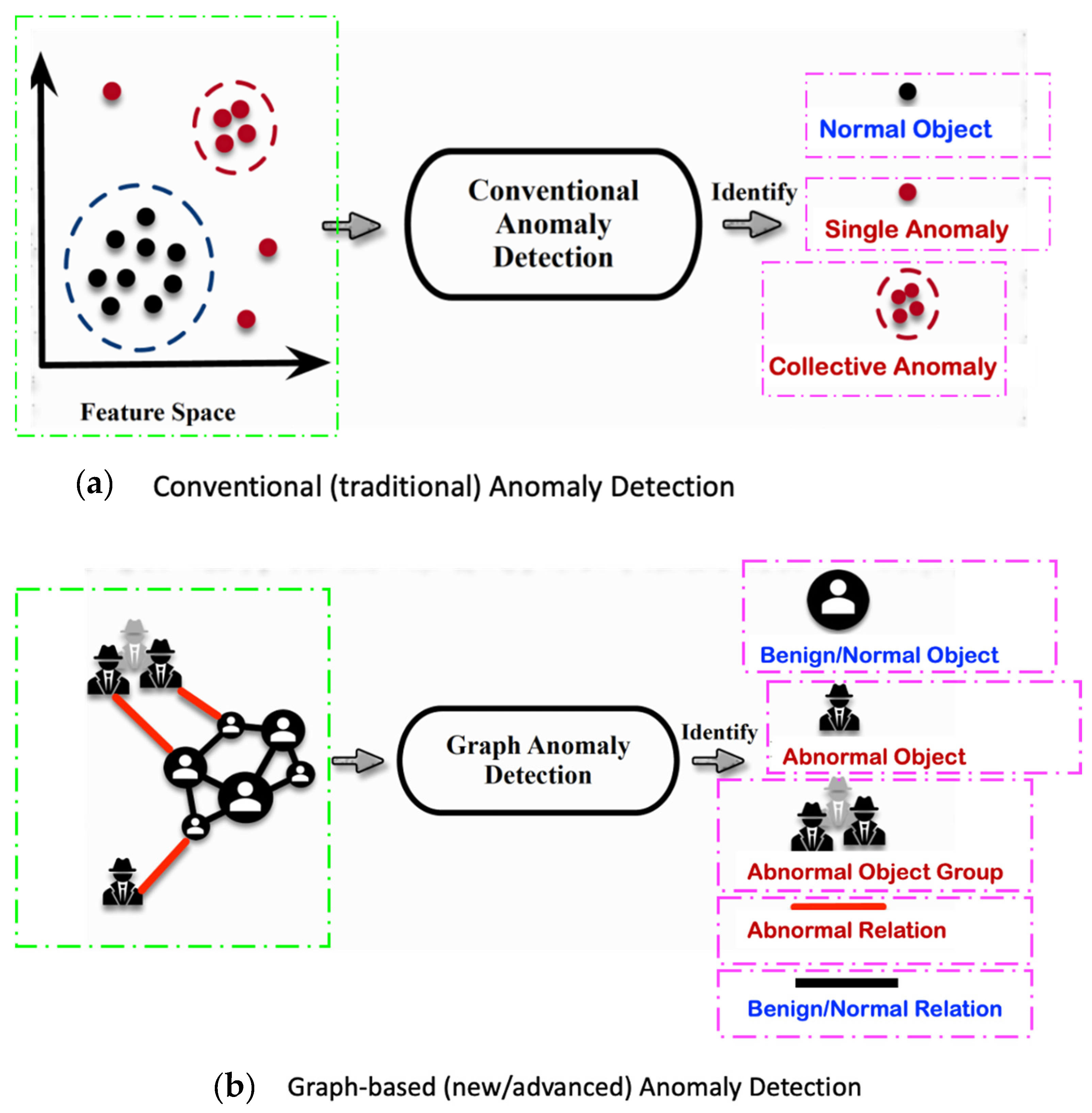
7. Modelling the Basic Infrastructure of the “Monitoring System of Humans-in-Bed” in the form of a Graph Network
- (a)
- Node-related anomalies, which can be either local or global. A node that is labeled globally abnormal is thereby compared to all other nodes of the whole graph. However, a node may also be locally abnormal when it is compared to the other nodes belonging to a local sub-graph (around a given node) of the whole graph;
- (b)
- Structure-related anomalies. Structural information focuses on the relationships amongst objects/entities, which are represented by the edges connecting the nodes in the whole graph. Here, the abnormality is related to the different connection patterns. Evidently, the abnormality of an edge does also affect the involved nodes;
- (c)
- Community anomalies. Here, one considers a sub-graph of the whole graph that is called abnormal. Hereby, information related to both node attributes and edge attributes is involved in the assessment of the status “abnormal” for a given sub-graph.
8. Comprehensive Critical State-of-the-Art Review of Core Approaches Usable to Construct a Robust Anomaly Detection System
8.1. Brief Description of the Quintessence of the Four Major Usable Approaches/Avenues/Paradigms (i.e., Anomaly Detection Paradigms) for Human Activity Monitoring
- MAJA 1: Statistical- or “stochastic processes”-based methods;
- MAJA 2: Deep-learning- and neural network-based methods;
- MAJA 3: Graph-network-based methods, combined with either traditional ML (machine learning) methods or MAJA 1;
- MAJA 4: Graph neural network (or Graph-based DL) based methods.
8.2. Assessment of How Far the Four Major Approaches/Avenues Do Fulfil or Not the Comprehensive Real-World Requirements Formulated in Section 5 (see Table 4)
9. Discussion of a Tentative General Strategic System Architecture Potentially Satisfying the Formulated Hard Requirements
10. Conclusions and Outlook
Author Contributions
Funding
Conflicts of Interest
References
- Apple. Available online: https://www.apple.com/at/shop/product/MVF02ZM/A/beddit-schlafmonitor (accessed on 20 July 2021).
- Sleepace. Available online: http://www.sleepace.com (accessed on 24 September 2021).
- Emfit. Available online: www.emfit.com (accessed on 12 December 2021).
- Early Sense. Available online: https://earlysense.com/solutions/ (accessed on 12 December 2021).
- Sleeptracker-AI. Available online: https://www.sleeptracker.com/ (accessed on 27 July 2022).
- Bucinator. Available online: https://bucinator.at/ (accessed on 12 December 2021).
- Eight. Available online: https://www.eightsleep.com/pod-mattress (accessed on 23 November 2021).
- Malsch. Available online: https://bettenmalsch.com/de/pflegebetten/premium-pflegebett-aura.html (accessed on 24 September 2021).
- Resmed. Available online: https://www.resmed.com/en-us/sleep-apnea/cpap-products/cpap-equipment-the-complete-system/ (accessed on 11 December 2021).
- Grasel, S. Available online: https://www.trendingtopics.eu/cogvis-fearless-wiener-startup-befreit-senioren-von-notruf-armbaendern/ (accessed on 13 December 2021).
- Hisense. Available online: https://www.hisense.co.il/ (accessed on 22 September 2021).
- Danish Care. Available online: https://danishcaretechnology.de/ (accessed on 20 September 2021).
- Costin, M.; Baltag, O.; Ciobanu, A.; Stefanescu, C.; Costandache, D. Improving Noninvasive Monitoring in Medical Care. In Proceedings of the IEEE International Conference on Computational Cybernetics, Gammarth, Tunisia, 19–21 October 2007. [Google Scholar]
- Wang, S.; Pohl, A.; Jaeschke, T.; Czaplik, M.; Köny, M.; Leonhardt, S.; Pohl, N. A novel ultra-wideband 80 GHz FMCW radar system for contactless monitoring of vital signs. In Proceedings of the 37th Annual International Conference of the IEEE EMBC, Milano, Italy, 25–29 August 2015. [Google Scholar]
- Shin, J.H.; Chee, Y.J.; Jeong, D.U.; Park, K.S. Nonconstrained Sleep Monitoring System and Algorithms Using Air-Mattress With Balancing Tube Method. IEEE Trans. Inf. Technol. Biomed. 2010, 14, 147–156. [Google Scholar] [CrossRef] [PubMed]
- Watanabe, K.; Kurihara, Y.; Tanaka, H. Ubiquitous Health Monitoring at Home—Sensing of Human Biosignals on Flooring, on Tatami Mat, in the Bathtub, and in the Lavatory. IEEE S. J. 2009, 9, 1847–1855. [Google Scholar] [CrossRef]
- Sardini, E.; Serpelloni, M.; Ometto, M. Multi-parameters wireless shirt for physiological monitoring. In Proceedings of the IEEE International Workshop on Medical Measurements and Applications Proceedings (MeMeA), Bari, Italy, 30–31 May 2011. [Google Scholar]
- Wu, K.F.; Zhang, Y.T. Contactless and continuous monitoring of heart electric activities through clothes on a sleeping bed. In Proceedings of the 2008 International Conference on Information Technology and Applications in Biomedicine, Shenzhen, China, 30–31 May 2008. [Google Scholar]
- Wong, M.Y.M.; Leung, H.K.; Pickwell-MacPherson, E.; Gu, W.B.; Zhang, Y.T. Contactless Recording of Photoplethysmogram on a Sleeping Bed. In Proceedings of the 31st Annual International Conference of the IEEE EMBS, Minneapolis, MA, USA, 2–6 September 2009. [Google Scholar]
- Guettari, T.; Istrate, D.; Boudy, J.; Benkelfat, B.E.; Fumel, B.; Daviet, J.C. Design and First Evaluation of a Sleep Characterization Monitoring System Using a Remote Contactless Sensor. IEEE J. Biomed. Health Inform. 2016, 21, 1511–1523. [Google Scholar] [CrossRef] [PubMed]
- Shino, T.; Watanabe, K.; Kobayashi, K.; Suzuki, K.; Kurihara, Y. Noninvasive biosignal measurement of a subject in bed using ceramic sensors. In Proceedings of the SICE Annual Conference 2010, Taipei, Taiwan, 18–21 August 2010. [Google Scholar]
- Kurihara, Y.; Kaburagi, T.; Watanabe, K. Yosuke Kurihara. Sensing Method of Patient’s Body Movement Without Attaching Sensors on the Patient’s. IEEE S. J. 2016, 16, 8271–8278. [Google Scholar]
- Sivanantham, A. Measurement of heartbeat, respiration and movements detection using Smart Bed. In Proceedings of the 2015 IEEE Recent Advances in Intelligent Computational Systems (RAICS), Kerala, India, 10–12 December 2015. [Google Scholar]
- van Harxen, T.R.E. Be at the Right Place, at the Right Time. In Smart Living Forum & Lounge; Villach, Austria, 2019; Available online: https://www.ldoceonline.com/dictionary/be-in-the-right-place-at-the-right-time (accessed on 16 August 2022).
- P.SYS caring systems GmbH. Available online: https://www.psys-care.com/en/index.htm (accessed on 30 March 2022).
- Forkan, A.R.M.; Khalil, I.; Tari, Z.; Foufou, S.; Bouras, A. A context-aware approach for long-term behavioural change detection and abnormality prediction in ambient assisted living. Pattern Recognit. 2015, 48, 628–641. [Google Scholar] [CrossRef]
- Demrozi, F.; Pravadelli, G.; Bihorac, A.; Rashidi, P. Human Activity Recognition Using Inertial, Physiological and Environmental Sensors: A Comprehensive Survey. IEEE Access 2020, 8, 210816–210836. [Google Scholar] [CrossRef]
- Xia, K.; Huang, J.; Wang, H. LSTM-CNN Architecture for Human Activity Recognition. IEEE Access 2020, 8, 56855–56866. [Google Scholar] [CrossRef]
- Goodfellow, I. NIPS 2016 Tutorial: Generative Adversarial Networks. arXiv 2017, arXiv:1701.00160. [Google Scholar]
- Makhzani, A.; Shlens, J.; Jaitly, N.; Goodfellow, I.J. Adversarial Autoencoders. In Proceedings of the International Conference on Learning Representations, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Fawaz, H.I.; Forestier, G.; Weber, J.; Idoumghar, L.; Muller, P.A. Transfer learning for time series classification. In Proceedings of the 2018 IEEE International Conference on Big Data (Big Data), Seattle, WA, USA, 10–13 December 2018; pp. 1367–1376. [Google Scholar]
- Fu, Z.; He, X.; Wang, E.; Huo, J.; Huang, J.; Wu, D. Personalized Human Activity Recognition Based on Integrated Wearable Sensor and Transfer Learning. Sensors 2021, 21, 885. [Google Scholar] [CrossRef]
- Renjie, D.; Li, X.; Lanshun, N.; Jiazhen, L.; Xiandong, S.; Dianhui, C.; Guozhong, L.; Dechen, Z. Empirical Study and Improvement on Deep Transfer Learning for Human Activity Recognition. Sensors 2018, 19, 57. [Google Scholar]
- Zhang, J.; Wu, F.; Wei, B.; Zhang, Q.; Huang, H.; Shah, S.W.; Cheng, J. Data Augmentation and Dense-LSTM for Human Activity Recognition Using WiFi Signal. IEEE Internet Things J. 2021, 8, 4628–4641. [Google Scholar] [CrossRef]
- Alnujaim, I.; Oh, D.; Kim, Y. Generative Adversarial Networks to Augment Micro-Doppler Signatures for the Classification of Human Activity. In Proceedings of the IGARSS 2019 IEEE International Geoscience and Remote Sensing Symposium, Yokohama, Japan, 28 July–2 August 2019; pp. 9459–9461. [Google Scholar]
- Pimentel, M.A.F.; Clifton, D.A.; Clifton, L.; Tarassenko, L. A review of novelty detection. Signal Process. 2014, 99, 215–249. [Google Scholar] [CrossRef]
- Gruhl, C.; Sick, B.; Tomforde, S. Novelty detection in continuously changing environments. Future Gener. Comput. Syst. 2021, 114, 138–154. [Google Scholar] [CrossRef]
- Li, X.A.; Luo, J.; Younes, R. ActivityGAN: Generative Adversarial Networks for Data Augmentation in Sensor-Based Human Activity Recognition. In Adjunct Proceedings of the 2020 ACM International Joint Conference on Pervasive and Ubiquitous Computing and Proceedings of the 2020 ACM International Symposium on Wearable Computers; Association for Computing Machinery: New York, NY, USA, 2020; pp. 249–254. [Google Scholar]
- Hoelzemann, A.; Sorathiya, N.; van Laerhoven, K. Data Augmentation Strategies for Human Activity Data Using Generative Adversarial Neural Networks. In Proceedings of the 2021 IEEE International Conference on Pervasive Computing and Communications Workshops and other Affiliated Events (PerCom Workshops), Kassel, Germany, 22–26 March 2021; pp. 8–13. [Google Scholar]
- Soleimani, E.; Nazerfard, E. Cross-subject transfer learning in human activity recognition systems using generative adversarial networks. Neurocomputing 2021, 426, 26–34. [Google Scholar] [CrossRef]
- Yahaya, S.W.; Lotfi, A.; Mahmud, M. Towards a data-driven adaptive anomaly detection system for human activity. Pattern Recognit. Lett. 2021, 145, 200–207. [Google Scholar] [CrossRef]
- Dahmen, J.; Cook, D.J. Indirectly supervised anomaly detection of clinically meaningful health events from smart home data. ACM Trans. Intell. Syst. Technol. 2021, 12, 1–18. [Google Scholar] [CrossRef]
- Rezaee, K.; Rezakhani, S.M.; Khosravi, M.R. A survey on deep learning-based real-time crowd anomaly detection for secure distributed video surveillance. Pers. Ubiquitous Comput. 2021, 1–17. [Google Scholar] [CrossRef]
- Nayak, R.; Pati, U.C.; Das, S.K. A comprehensive review on deep learning-based methods for video anomaly detection. Image Vis. Comput. 2021, 106, 104078. [Google Scholar] [CrossRef]
- Choi, S.; Kim, C.; Kang, Y.-S.; Youm, S. Human behavioral pattern analysis-based anomaly detection system in residential space. J. Supercomput. 2021, 77, 9248–9265. [Google Scholar] [CrossRef]
- Hines, J.W.; Garvey, D.R. Development and Application of Fault Detectability Performance Metrics for Instrument Calibration Verification and Anomaly Detection. J. Pattern Recognit. Res. 2006, 1, 2–15. [Google Scholar] [CrossRef] [Green Version]
- Ma, X.; Wu, J.; Xue, S.; Yang, J.; Zhou, C.; Sheng, Q.; Xiong, H.; Akoglu, L. A Comprehensive Survey on Graph Anomaly Detection with Deep Learning. IEEE Trans. Knowl. Data Eng. 2021. [Google Scholar] [CrossRef]
- Akoglu, L.; Tong, H.; Koutra, D. Graph-based Anomaly Detection and Description: A Survey. Data Min. Knowl. Discov. 2015, 29, 626–688. [Google Scholar] [CrossRef] [Green Version]
- Goyal, P.; Chhetri, S.R.; Canedo, A. Dyngraph2vec: Capturing network dynamics using dynamic graph representation learning. Knowl. Based Syst. 2020, 187, 104816. [Google Scholar] [CrossRef]
- Zhou, L.; Yang, Y.; Ren, X.; Wu, F.; Zhuang, Y. Dynamic Network Embedding by Modeling Triadic Closure Process. In Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence (AAAI-18), New Orleans, LA, USA, 2–7 February 2018. [Google Scholar]
- Goyal, P.; Kamra, N.; He, X.; Liu, Y. DynGEM: Deep Embedding Method for Dynamic Graphs. arXiv 2018, arXiv:1805.11273. [Google Scholar]
- Zhao, T.; Jiang, T.; Shah, N.; Jiang, M. A Synergistic Approach for Graph Anomaly Detection With Pattern Mining and Feature Learning. IEEE Trans. Neural Netw. Learn. Syst. 2022, 33, 2393–2405. [Google Scholar] [CrossRef]
- Girdhar, M.; Hong, J.; Lee, H.; Song, T.J. Hidden Markov Models based Anomaly Correlations for the Cyber-Physical Security of EV Charging Stations. IEEE Trans. Smart Grid 2021. [Google Scholar] [CrossRef]
- Choi, K.; Yi, J.; Park, C.; Yoon, S. Deep Learning for Anomaly Detection in Time-Series Data: Review, Analysis, and Guidelines. IEEE Access 2021, 9, 120043–120065. [Google Scholar] [CrossRef]
- Ding, N.; Gao, H.; Bu, H.; Ma, H. RADM: Real-Time Anomaly Detection in Multivariate Time Series Based on Bayesian Network. In Proceedings of the IEEE International Conference on Smart Internet of Things (SmartIoT), Xi’an, China, 17–19 August 2018; pp. 129–134. [Google Scholar]
- Pang, G.; Shen, C.; Cao, L.; van den Hengel, A. Deep Learning for Anomaly Detection: A Review. ACM Comput. Surv. 2021, 54, 1–38. [Google Scholar] [CrossRef]
- Caccia, M.; Rodriguez, P.; Ostapenko, O.; Normandin, F.; Lin, M.; Caccia, L.; Laradji, I.; Rish, I.; Lacoste, A.; Vazquez, D.; et al. Online fast adaptation and knowledge accumulation: A new approach to continual learning. arXiv 2020, arXiv:2003.05856. [Google Scholar]
- Sadhu, S.; Hermansky, H. Continual Learning in Automatic Speech Recognition. In Proceedings of the Interspeech 2020, Shanghai, China, 25–29 October 2020; pp. 1246–1250. [Google Scholar]
- Zhang, J.; Zhou, D.; Chen, M.; Hong, X. Continual Learning for Multimode Dynamic Process Monitoring with Applications to an Ultra-Supercritical Thermal Power Plant. IEEE Trans. Autom. Sci. Eng. 2022. [Google Scholar] [CrossRef]
- Titsias, M.K.; Schwarz, J.; Matthews, A.G.D.G.; Pascanu, R.; Teh, Y.W. Functional regularisation for con-tinual learning with gaussian processes. arXiv 2019, arXiv:1901.11356. [Google Scholar]
- Abreu, M.; Barandas, M.; Leonardo, R.; Gamboa, H. Detailed Human Activity Recognition based on Multiple HMM. In Proceedings of the 12th International Conference on Bio-inspired Systems and Signal, Prague, Czech Republic, 22–24 February 2019; pp. 171–178. [Google Scholar]
- Lesort, T.; Caccia, M.; Rish, I. Understanding continual learning settings with data distribution drift analysis. arXiv 2021, arXiv:2104.01678. [Google Scholar]
- Thrun, S.; Pratt, L. Learning to Learn; Springer: Berlin/Heidelberg, Germany, 1998. [Google Scholar]
- Hadsell, R.; Rao, D.; Rusu, A.A.; Pascanu, R. Embracing change: Continual learning in deep neural networks. Trends Cogn. Sci. 2020, 24, 1028–1040. [Google Scholar] [CrossRef] [PubMed]
- Ashfahani, A.; Pratama, M. Autonomous deep learning: Continual learning approach for dynamic environments. In Proceedings of the 2019 SIAM International Conference on Data Mining, Society for Industrial and Applied Mathematics, Calgary, Canada, 2–4 May 2019; pp. 666–674. [Google Scholar]
- Nguyen, C.V.; Li, Y.; Bui, T.D.; Turner, R.E. Variational continual learning. arXiv 2017, arXiv:1710.10628. [Google Scholar]
- Doshi, K.; Yilmaz, Y. Rethinking Video Anomaly Detection—A Continual Learning Approach. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 4–8 January 2022; pp. 3961–3970. [Google Scholar]
- Irfan, M.; Jiangbin, Z.; Iqbal, M.; Masood, Z.; Arif, M.H. Knowledge extraction and retention based continual learning by using convolutional autoencoder-based learning classifier system. Inf. Sci. 2022, 591, 287–305. [Google Scholar] [CrossRef]
- Mundt, M.; Pliushch, I.; Majumder, S.; Hong, Y.; Ramesh, V. Unified probabilistic deep continual learning through generative replay and open set recognition. J. Imaging 2022, 8, 93. [Google Scholar] [CrossRef]
- Han, R.; Yan, H.; Li, J.; Wang, S.; Feng, W.; Wang, S. Panoramic Human Activity Recognition. arXiv 2022, arXiv:2203.03806. [Google Scholar]
- Ranshous, S.; Shen, S.; Koutra, D.; Harenberg, S.; Faloutsos, C.; Samatova, N.F. Anomaly detection in dynamic networks: A survey. Wiley Interdiscip. Rev. Comput. Stat. 2015, 7, 223–247. [Google Scholar] [CrossRef]
- Daruna, A.; Gupta, M.; Sridharan, M.; Chernova, S. Continual learning of knowledge graph embeddings. IEEE Robot. Autom. Lett. 2021, 6, 1128–1135. [Google Scholar] [CrossRef]
- Tang, B.; Matteson, D.S. Graph-based continual learning. arXiv 2020, arXiv:2007.04813. [Google Scholar]
- Han, Y.; Karunasekera, S.; Leckie, C. Graph neural networks with continual learning for fake news detection from social media. arXiv 2020, arXiv:2007.03316. [Google Scholar]
- Song, H.H.; Park, S. Enriching translation-based knowledge graph embeddings through continual learning. IEEE Access 2018, 6, 60489–60497. [Google Scholar] [CrossRef]
- Pidhorskyi, S.; Almohsen, R.; Doretto, G. Generative probabilistic novelty detection with adversarial autoencoders. In Proceedings of the NIPS 2018: The Thirty-second Annual Conference on Neural Information Processing Systems, Montréal, QC, Canada, 3–8 December 2018. [Google Scholar]
- Yang, P.; Yang, C.; Lanfranchi, V.; Ciravegna, F. Activity Graph based Convolutional Neural Network for Physical Activity Recognition using Acceleration and Gyroscope Data. IEEE Trans. Ind. Inform. 2022, 18, 6619–6630. [Google Scholar] [CrossRef]
- Liu, W.; Fu, S.; Zhou, Y.; Zha, Z.-J.; Nie, L. Human activity recognition by manifold regularization based dynamic graph convolutional networks. Neurocomputing 2021, 444, 217–225. [Google Scholar] [CrossRef]
- Zhou, F.; Cao, C. Overcoming Catastrophic Forgetting in Graph Neural Networks with Experience Re-play. arXiv 2021, arXiv:2003.09908. [Google Scholar]
- Aouichaoui, A.R.; Mansouri, S.S.; Abildskov, J.; Sin, G. Uncertainty estimation in deep learn-ing-based property models: Graph neural networks applied to the critical properties. AIChE J. 2022, 68, 17696. [Google Scholar] [CrossRef]
- Carr, A.; Wingate, D. Graph neural processes: Towards Bayesian graph neural networks. arXiv 2019, arXiv:1902.10042. [Google Scholar]
- Feng, B.; Wang, Y.; Ding, Y. Uncertainty-aware attention graph neural network for defending adversarial attacks. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtual, 2–9 February 2021; pp. 7404–7412. [Google Scholar]
- Song, T.; Chen, L.; Zheng, W.; Ji, Q. Uncertain graph neural networks for facial action unit detection. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtual, 2–9 February 2021. [Google Scholar]
- Sun, L.; Zhang, Z.; Zhang, J.; Wang, F.; Peng, H.; Su, S.; Philip, S.Y. Hyperbolic variational graph neural network for modeling dynamic graphs. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtual, 2–9 February 2021; pp. 4375–4383. [Google Scholar]
- Zhong, F.; Liu, Y.; Liu, L.; Zhang, G.; Duan, S. DEDGCN: Dual Evolving Dynamic Graph Convolutional Network. Secur. Commun. Netw. 2022, 2022, 6945397. [Google Scholar] [CrossRef]
- Wu, B.; Liang, X.; Zheng, X.; Guo, Y.; Tang, H. Improving Dynamic Graph Convolutional Network with Fine-Grained Attention Mechanism. In Proceedings of the ICASSP 2022-2022 IEEE International Conference on Acoustics, Speech and Signal Processing, Singapore, 22–27 May 2022; pp. 3938–3942. [Google Scholar]
- Lan, L.; Li, J.; Fu, Y.-G. Developing GCN: Graph Convolutional Network with Evolving Parameters for Dynamic Graphs. In International Conference on Neural Information Processing; Springer: Berlin/Heidelberg, Germany, 2021; pp. 369–376. [Google Scholar]
- Gao, C.; Zhu, J.; Zhang, F.; Wang, Z.; Li, X. A novel representation learning for dynamic graphs based on graph convolutional networks. IEEE Trans. Cybern. 2022. [Google Scholar] [CrossRef]
- Rida, A.A.; Amhaz, R.; Parrend, P. Anomaly Detection on Static and Dynamic Graphs Using Graph Convolutional Neural Networks. In Robotics and AI for Cybersecurity and Critical Infrastructure in Smart Cities; Springer: Berlin/Heidelberg, Germany, 2022; pp. 227–248. [Google Scholar]
- Zhang, M.; Wu, S.; Yu, X.; Liu, Q.; Wang, L. Dynamic graph neural networks for sequential recommendation. IEEE Trans. Knowl. Data Eng. 2022. [Google Scholar] [CrossRef]
- Peng, L.; Hu, R.; Kong, F.; Gan, J.; Mo, Y.; Shi, X.; Zhu, X. Reverse graph learning for graph neural network. IEEE Trans. Neural Netw. Learn. Syst. 2022. [Google Scholar] [CrossRef] [PubMed]
- Zhao, K.; Duka, B.; Xie, H.; Oathes, D.J.; Calhoun, V.; Zhang, Y. A dynamic graph convolutional neural network framework reveals new insights into connectome dysfunctions in ADHD. NeuroImage 2021, 246, 118774. [Google Scholar] [CrossRef]
- Zheng, P.; Xia, L.; Li, C.; Li, X.; Liu, B. Towards Self-X cognitive manufacturing network: An industrial knowledge graph-based multi-agent reinforcement learning approach. J. Manuf. Syst. 2021, 61, 16–26. [Google Scholar] [CrossRef]
- Markus, A.F.; Kors, J.A.; Rijnbeek, P.R. The role of explainability in creating trustworthy artificial intelligence for health care: A comprehensive survey of the terminology, design choices, and evaluation strategies. J. Biomed. Inform. 2020, 113, 103655. [Google Scholar] [CrossRef] [PubMed]
- Li, W.; Hu, W.; Chen, N.; Feng, C. Stacking VAE with graph neural networks for effective and interpretable time series anomaly detection. arXiv 2021, arXiv:2105.08397. [Google Scholar]
- Barceló, P.; Kostylev, E.; Monet, M.; Pérez, J.; Reutter, J.; Silva, J.P. The logical expressiveness of graph neural networks. In Proceedings of the 8th International Conference on Learning Representations (ICLR 2020), Addis Ababa, Ethiopia, 26–30 April 2020. [Google Scholar]
- Knyazev, B.; Taylor, G.W.; Amer, M. Understanding attention and generalization in graph neural networks. In Proceedings of the NIPS 2019: The Thirty-second Annual Conference on Neural Information Processing Systems, Vancouver, BC, Canada, 8–14 December 2019. [Google Scholar]
- Sinha, K.; Sodhani, S.; Pineau, J.; Hamilton, W.L. Evaluating logical generalization in graph neural net-works. arXiv 2020, arXiv:2003.06560. [Google Scholar]
- Sinha, K.; Sodhani, S.; Pineau, J.; Hamilton, W.L. GraphLog: A Benchmark for Measuring Logical Generalization in Graph Neural Networks. In Proceedings of the ICLR 2021 Conference, Virtual Event, Austria, 3–7 May 2021. [Google Scholar]
- Wang, X.; Wu, Y.; Zhang, A.; He, X.; Chua, T.S. Towards Multi-Grained Explainability for Graph Neural Net-works. Adv. Neural Inf. Processing Syst. 2021, 34, 18446–18458. [Google Scholar]
- Pope, P.E.; Kolouri, S.; Rostami, M.; Martin, C.E.; Hoffmann, H. Explainability methods for graph convolutional neural networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 10772–10781. [Google Scholar]
- Holzinger, A.; Malle, B.; Saranti, A.; Pfeifer, B. Towards multi-modal causability with Graph Neural Net-works enabling information fusion for explainable AI. Inf. Fusion 2021, 71, 28–37. [Google Scholar] [CrossRef]
- Yuan, H.; Yu, H.; Wang, J.; Li, K.; Ji, S. On explainability of graph neural networks via subgraph explorations. Int. Conf. Mach. Learn. 2021, 139, 12241–12252. [Google Scholar]
- Meirom, E.; Maron, H.; Mannor, S.; Chechik, G. Controlling graph dynamics with reinforcement learning and graph neural networks. Int. Conf. Mach. Learn. 2021, 139, 7565–7577. [Google Scholar]
- Hart, P.; Knoll, A. Graph neural networks and reinforcement learning for behavior generation in semantic environments. In Proceedings of the 2020 IEEE Intelligent Vehicles Symposium, Las Vegas, NV, USA, 19 October–13 November 2020; pp. 1589–1594. [Google Scholar]
- Shan, C.; Shen, Y.; Zhang, Y.; Li, X.; Li, D. Reinforcement Learning Enhanced Explainer for Graph Neural Networks. In Proceedings of the NIPS 2021: The Thirty-second Annual Conference on Neural Information Processing Systems, Virtual, 28 November–9 December 2021. [Google Scholar]
- Zhang, L.; Liu, P.; Choi, Y.; Chen, P. Semantics-preserving Reinforcement Learning Attack Against Graph Neural Networks for Malware Detection. IEEE Trans. Dependable Secur. Comput. 2022. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Anomaly Pattern Name and ID | Point Observation vs. Burst Observation Versus Interval Observation | Related Illustrative Graphical Illustration | Remarks and Other Useful Hints and/or Considerations |
|---|---|---|---|
| Outlier (AN-1) | Point observation |  | It is generally a stochastically described irregularity. Indeed, probability densities are calculated for target parameters, and defined percentiles are declared as outliers and thereby as anomalies of a certain degree. |
| Collective anomaly (AN-2) | Burst observation |  | Collective anomalies are data points that are considered anomalies when viewed with other data points against the rest of the data set. |
| Contextual anomaly (AN-3) | Point observation |  | Context anomalies are data points that are considered abnormal when viewed against meta-information associated with the data points. |
| Missing signal/data anomaly (AN-4) | Time interval observation |  | Here, most of the data are missing, and the time/frequency response is zero. This anomaly type is more relevant for Level 0 of Figure 3. |
| Minor data/ signal (AN-5) | Time interval observation |  | Here, compared to the ground truth values, the observed amplitude is very small. |
| Multiple outlier pattern (AN-6) | Time interval observation |  | Here, one or more appear in the observed data. |
| Square pattern (AN-7) | Time interval observation |  | Here, the time response oscillates within a limited range, such as a square signal. |
| Trend pattern (AN-8) | Time interval observation |  | Here, the observed data/signal has an obvious non-stationary and monotonous trend. |
| Drift data pattern (AN-9) | Time interval observation |  | Here, the observed data signal is non-stationary with a random drift. |
| Time of the Detection Process | Location (in the Time Dimension) of the Element to Be Assessed (See OCP 1 to OCP 4) | Time Case Labelling | Remarks and Eventual Comments |
|---|---|---|---|
| NOW (see Figure 4) | Sub-region 1/N | Online detection (Time case 2/a) | Here, the processing speed of the detection algorithm is critical. This depends on the computing infrastructure, namely embedded systems or processing in the cloud. |
| NOW (see Figure 4) | Sub-region 2/N | Near to online detection (Time case 2/b) | |
| NOW (see Figure 4) | Sub-region 3/N | Late online detection (Time case 2/c) | |
| NOW (see Figure 4) | Sub-region 1/P | Closest posterior detection (Time case 1/a) | This may be a new re-assessment of those past elements. This may be necessary in view of the time-varying system dynamics of the human under observation. It is theoretically possible that events that were perceived normal become later perceived abnormal after the system dynamics have evolved, and vice-versa. |
| NOW (see Figure 4) | Sub-region 2/P | Close posterior detection (Time case 1/b) | |
| NOW (see Figure 4) | Sub-region 3/P | Late posterior detection (Time case 1/c) | |
| NOW (see Figure 4) | Sub-region 1/F | Nearest anterior detection (Time case 3/a) | Here, one is looking into the future. In case one can see anomalies in that future, one has then a case of early warning: from a “close” early warning up to a “far” early warning situation. The elements to be assessed are coming from forecasting of the future system behavior at all levels in Figure 3. |
| NOW (see Figure 4) | Sub-region 2/F | Close anterior detection (Time case 3/b) | |
| NOW (see Figure 4) | Sub-region 3/F | Far anterior detection (Time case 3/c) |
| Novelty Pattern Name and ID | Related Illustrative Graphical Illustration | Remarks |
|---|---|---|
| NOV 1: Sudden novelty |  | A sudden drift is characterized by an abrupt change in the underlying process (the one guiding the occurrence of anomalies over the time window observed). |
| NOV 2: Gradual drift |  | A gradual drift happens over time, and observations from one or more processes may be observed with changing frequency. |
| NOV 3: Incremental drift |  | The incremental drift also happens over time but also involves one or more processes. |
| NOV 4: Reoccurring behavior/concept |  | The reoccurring concept/behavior describes processes that cease to exist at one point and time but reappear later in time. |
| Selected Advanced Characteristics and Their Naming | Importance of a Real-World Mature Monitoring System | Remarks |
|---|---|---|
| REQ 1: Self-learning and continual learning capability, for either single individuals or groups of individuals | Very high | Continual learning can be understood as a concept of learning a model for a large number of “tasks” sequentially without forgetting knowledge obtained from the preceding tasks, whereby the data in/of the old tasks are not available anymore while training new ones. The learning relates to either the behavior of an individual person currently under monitoring or to the behavior of an individual person within the contextual background of the behaviors of several other persons (a group of persons) who have been priorly monitored. |
| REQ 2: Identification of and adaptivity to novelty/evolution | Very high | After the novelty has been identified, the model adapts to the confirmed behavior change. This means essentially adjusting to change over time. |
| REQ 3: Comprehensive uncertainty model/assessment for all subtasks (A–E) described in Section 3.4. | Very high | Anomaly detection in the case of monitoring a human in bed requires a high level of trust in its results. A key to this trust is the ability to assess the uncertainty of the computed results appropriately. |
| REQ 4: Prediction capability of the system status at levels 1 to 4 of Figure 3 for one or more future time sub-regions | Very high | See Subtask E described in Section 3.4. |
| REQ 5: Reconfigurability w.r.t. USPs (user-specific perspectives) | Very high | Since the USP are practically of high relevance, related reconfigurability of the intelligent system is needed. |
| REQ 6: Reconfigurability w.r.t. OCPs (observation context perspectives) | Very high | Since the OCP are practically of high relevance, related reconfigurability of the intelligent system is needed. |
| REQ 7: Explainability of the identification of entities at levels 1–4 of Figure 3 | Very high/MUST | To avoid the lack of interpretability, this characteristic is needed. |
| REQ 8: Explainability of the anomaly detection (considering USPs and OCPs) | Very high | To avoid the lack of interpretability, this characteristic is needed. |
| REQ 9: Explainability of the evolution detection | Very high | To avoid the lack of interpretability, this characteristic is needed. |
| REQ 10: Explainability of the uncertainty grade or confidence level for all Sub-tasks (A–E) described in Section 3 | Very high/MUST | To avoid the lack of interpretability, this characteristic is needed. |
| REQ 11: The possibility of a performance tuning/improvement through either partial human assistance (via some form of feedback) or evolutive/reinforced learning or involving artificially generated data out of some reliable “generative adversarial” process or a combination of some or of all of the above. | Very high/MUST | The trained personnel that operates the advanced intelligent monitoring system can, through an appropriate human–machine interface, confirm or inform some of the predictions/detections. Alternatively, self-learning triggered reinforcement learning can also be used. |
| REQ 12: The reconfigurability w.r.t. tolerance level/grade/margin related to the abnormality assessment (or, in other words, related to the anomaly detectability). The operators of the intelligent system for anomaly detection in the monitoring of “human in bed” is able to modify, even dynamically, the tolerance level/margin of the anomaly detection. This characteristic complements the so-called USPs described in Section 3.4; see also REQ 5. | Very high/MUST | For most technical systems, the acceptable tolerance level w.r.t. key system parameters is very important and very sensitive from a practical point of view. Indeed, in real-world applications and practice, in general, a low tolerance margin may result in a significantly much more expensive system. A bigger tolerance is thus resulting in a more interesting cost/benefit ratio. It is evident that the abnormality detection endeavor can therefore not ignore the tolerance level dimension. This is especially very sensitive in view of two critical facts related to the human monitoring scenario: (a) the sensor data obtained from the Level 0 of the architecture shown in Figure 3 are surely never perfect and thus full of uncertainties originating from various pure sensor systems related imperfections and disturbances; (b) the time-variant and stochastic physical activity related behavior pattern of the system “human in bed”; (c) the variance w.r.t. behavior pattern amongst different samples of the system under observation (i.e., the “human in bed”). This characteristic surely also impacts the interpretation of the anomaly score. In practice, the use-case engineer should know or at least be able to fix how much tolerance margin is really needed. Indeed, it makes no sense to fix/set a very small tolerance margin (which is very expensive to realize), although the given use-case can well be satisfied by a much bigger tolerance margin. In the various and extensive experimentation in the frame of a comprehensive verification process, it is worth closely studying the sensitivity of the tolerance margin w.r.t. the robustness of the intelligent anomaly detection system. |
| REQ 13: Tolerance to non-ideal training data | VERY HIGH/MUST | This is one practical requirement expressed by P.SYS. Essentially, data imperfection have several faces: (a) sensors related imperfections such as low update rate, low accuracy, noise and/or bias in the data, signal-related faults, etc.; (b) sensor’s drifts and/or other nonlinear, eventually time-varying disturbing phenomena; (c) data size related imperfections (this may be related to the effective (short) duration of the data recordings (i.e., observations and/or to the number of human samples involved, etc.; (d) involving only one of maximum two sensor modes or types (e.g., solely piezo-electric sensor and vibration sensors). |
| REQ 14: The complete intelligent system is capable of running fully on COTS embedded platforms (i.e., the intelligent system is fully Embedded AI), which are essentially low-computing power; this to ensure both low cost and data security while satisfying use-case specific real-time processing deadlines. | HIGH or LOW/MUST (A) VERY HIGH for a significant part of the target application scenarios. (B) “LOW” for application scenarios that wish or must involve IoT technologies | This requirement ensures that the intelligent system is low cost, has a relatively low power consumption, is application-scenario-dependently real-time capable and can operate almost self-sufficiently without involving remote computing infrastructure(s) and/or data. However, in the age of Cloud Computing and IoT, another part of the application scenarios may wish to enjoy the benefits of these recent, very advanced infrastructures. For these parts of the applications universe, the importance and criticality of this requirement (REQ 14) are rather low. Under the hypothesis (which is, however, not yet fulfilled at present) that “data security” is well and strong-reliably ensured in an “IoT and cloud computing” based networked universe, the core benefits of the “fully embedded system” version (which are essentially: low cost, low power consumption (by the end devices), real-time processing) become also fully satisfied by an Intelligent System architecture involving IoT and Cloud computing. |
| REQ 15: Short learning duration and/or fast detection of/and adaptation to behavior changes | VERY HIGH/MUST | This requirement also integrates, additionally, the fast detection of behavior change. It factually complements REQ 2. An issue here is, however, to clearly specify what “short” or “fast” means in the context of this requirement. This may be use-case dependent, as the use-case determines the basic time constant of the system. For example, some hours, some days, some weeks, etc. The effective “learning duration” length may/shall impact or strongly correlate with the performance metrics “Anomaly Detectability (MET-4)” that is described further below in Table 5. |
| Metric Name and ID | Metric Description | Remarks |
|---|---|---|
| MET 1: Accuracy | It is simply defined as the mean squared error (MSE) between the model’s predictions and the target values. | Although this metric is named “accuracy”, it is actually a measure of error, and a low value is desired. |
| MET 2: Self-sensitivity | For self-associative empirical models, a robust model does/shall produce small changes in all of its outputs for (in the face of) small errors in the (model) inputs. | The self-sensitivity is a measure of an empirical model’s ability to make correct anomaly predictions when the respective anomaly-related score value is incorrect due to some sort of uncertainty (or fault). |
| MET 3: Cross-sensitivity | Cross-sensitivity measures the effect a faulty (model) input has on the other (model) predictions. | |
| MET 4: Anomaly detectability | This metric help to determine the smallest drift (in the relevant input data values of the detection system) that can be identified. Therefore, this anomaly detection performance metric is used to determine the smallest process parameter change that can be detected. | |
| MET 5: Precision | The precision answers the question: “What proportion of identified anomalies are true anomalies?” | This is a classical metric |
| MET 6: Recall | The recall is used to answer the question: “What proportion of true anomalies was identified?” | This is a classical metric |
| MET 7: F1 Score | The F1 score identifies the overall performance of the anomaly detection model by combining both recall and precision, using the harmonic mean. | This is a classical metric |
| Reason Supporting the Use of Graph Networks | Explanation | How Far Is It Relevant for Our Target Context of Monitoring a Human in Bed |
|---|---|---|
| Strong inter-dependence between entities and data | Data objects are often related to each other and exhibit dependencies. In fact, most relational data can be thought of as inter-dependent, which necessitates accounting for related objects in finding anomalies. | Highly relevant |
| Powerful representation ability | Graphs naturally represent the inter-dependencies by the introduction of links (or edges) between the related objects. The multiple paths lying between these related objects effectively capture their long-range correlations. Moreover, a graph representation facilitates the representation of rich datasets enabling the incorporation of node and edge attributes/types. | Highly relevant |
| The relational nature of problem domains | The nature of anomalies could exhibit itself as relational. An illustration example can be given from the performance monitoring domain, where the failure of a machine could cause the malfunction of the machines dependent on it. Similarly, the failure of a machine could be a good indicator of the possible other failures of machines in close spatial proximity to it (e.g., due to an excessive increase in humidity in that particular region of a warehouse). | Highly relevant |
| Graphs are a robust machinery | One could argue that graphs serve as more adversarial robust tools. For example, in fraud detection systems, behavioral clues such as log-in times and locations (e.g., IP addresses) can be easily altered or faked by advanced fraudsters. On the other hand, it may be reasonable to argue that the fraudsters could not have a global view of the entire network (e.g., money transfer, telecommunication, email, review network) that they are operating. As such, it would be harder for a fraudster to fit into this network as good as possible without knowing its entire characteristic structure and dynamic operations. | Highly relevant |
| Dynamic Graphs offer unique capabilities for anomaly detection | The anomaly detection in dynamic graphs can be based on the following situations: feature-based events, decomposition-based events, community or clustering-based events and window-based events. | Highly relevant(for example, see some of the OCPs) |
| Strong graph-based anomaly description capability | This is underscored by the following capabilities that are well documented in the relevant literature: (a) interpretation-friendly graph anomaly detection; (b) interactive graph querying and sense-making. | Highly relevant (see REQ 7 to REQ 10 in Table 4) |
| Several proven application examples of graph-based anomaly detection in highly complex real-world applications | Following applications examples can be found in the relevant literature: anomalies in telecom networks; anomalies in opinion networks; anomalies in auction networks; anomalies in the web network; anomalies in account networks; anomalies in social networks; anomalies in security networks; anomalies in computer networks; anomalies in financial networks | Highly relevant |
| Paradigm- Identifi-Cation | Core Quintessence of the Paradigm | Selected Representative Related Works Related to Anomaly Detection and/or Prediction |
|---|---|---|
| MAJA 1: Statistical or “stochastic processes” based methods | A good representative of these methods are the so-called hidden Markov models (HMM). HMMs are statistical models to capture hidden information from observable sequential symbols/values. In an HMM, the system being modeled is assumed to be a Markov process with unknown parameters, and the challenge thereby is to determine the hidden parameters from the observable parameters. HMMs are sequence models. Thus, given a sequence of inputs, an HMM computes a sequence of outputs of the same length. An HMM model is a graph where nodes are probability distributions over labels, and edges give the probability of transitioning from one node to the other. Together, these can be used to compute the probability of a label sequence given the input sequence. By using HMM, it is possible to predict future states based on the current observations as well as the sequence of states from an observed sequence. For a process under observation over time, the possible states, which are hidden parameters, are generally “normal”, “abnormal” and “critical”. | Forkan et al. (2014) [26]; Girdhar, Mansi, et al. (2021) [53] Note: After appropriate tuning, the concept presented in these selected references can be used to model the scene described in Figure 3, at least for some of the defined OCPs and USPs. Each OCP is displayed by a different HMM model. Multiple OCPs can be considered simultaneously, resulting in much more complex HMM architectures. |
| MAJA 2: Deep-learning and neural networks (DL) based methods | Deep-learning (DL) concepts use complex neural networks for modeling time series and are thereby capable of detecting and/or predicting anomalies. DL models are very good at modeling the “temporal context” of a dynamically evolving system. The family of DL concepts of relevance for anomaly detection/prediction is well represented by five core models, which are: RNN (recurrent neural network), CNN (convolutional neural network), HYBRID (that is, a merging of the two previous ones), ATTENTION (refers to the so-called attention-based models), HTM (hierarchical temporal memory) and HTM. Each of these models displays specific interesting features w.r.t. the capability to capture the temporal context: (a) CNN: recognizes pattern sequences and predicts expected values, determines anomalies by identifying the differences between the predicted and actual signals, learns long-term dependencies by determining the number of previous states to keep or forget at every time step, extract multi-scale features while modeling long-term dependencies. CNN: instead of explicitly capturing the temporal context, it learns patterns in segmented time series; in order to comprehend behaviors appearing over a long period, a temporal convolution is used; three properties of the temporal convolutions: (i) they are causal, meaning that they ensure no information leakage from the future to the past; (ii) they can take a sequence of any length, just as with an RNN; (iii) they can look quite far into the past to forecast futures. HYBRID: when monitoring time-series data with a sliding window, the detectable anomaly pattern varies according to the window size; it considers the spatial information and temporal dependencies simultaneously; it solves the solve the spatiotemporal sequence-forecasting problem; eventually, a temporal “attention mechanism” adjusts the contribution of the previous feature maps to update the current one. The so-called “attention mechanism” was introduced to improve the performance (this it is a tuning) of the encoder-decoder model for machine translation. The idea behind the attention mechanism was to permit the decoder to utilize the most relevant parts of the input sequence in a flexible manner by a weighted combination of all of the encoded input vectors, whereby the most relevant vectors are attributed the highest weights. ATTENTION: by paying attention to the input weights that contribute more to the output, the so-called attention-based models can capture a very long-range dependence with relative importance to each data point; its remarkable achievements in NLP (natural language processing) motivated an application also in the time-series anomaly detection domain. HTM: it can reliably capture and predict sequence patterns and thus is beneficial to anomaly detection in time-series data; it is considered to be one of the most promising next-generation deep learning approaches; it is especially unique in that it does continuously learn temporal patterns from streaming data without backpropagation. | A sufficiently exhaustive inventory of schemes within this family of (DL-based) methods is provided in the survey by Kukjin Choi et al. (2021) [54]. Consider RNN, two examples of models: (a) LSTM family (e.g., LSTM-VAE, SPREAD, MAD-GAN), (b) GRU-gated recurrent unit) family (e.g., THOC, GGM-VAE, S-RNN). Consider CNN, two examples of models: (a) traditional CNN family (e.g., MU-Net, BeatGAN), (b) Temporal Convolutional Networks (TCU) family (e.g., HS-TCN, TCN-GMM). Consider HYBRID, one example of model: the Convolutional LSTM (ConvLSTM) family (e.g., MSCRED, RSM-GAN). Consider ATTENTION, one example of models: the self-attention or transformer family (e.g., MTSM, GAT). Consider HTM: one example of a model: RADM, a concept that integrates HTM and a Bayesian network [55]. |
| MAJA 3: Graph-network-based methods, combined with either traditional ML (machine learning) methods or MAJA 1 | Data objects representing a scene like the one in Figure 3 cannot always be treated as points lying in a multi-dimensional space independently. In contrast, they may exhibit inter-dependencies that should be accounted for during the anomaly detection process. Indeed, graphs provide powerful machinery for effectively capturing these long-range correlations amongst inter-dependent data objects. Anomaly detection methods for static graph data concern both unlabeled (plain) and labeled (attributed) graphs. Moreover, change or event detection approaches for time-varying or dynamic graph data, based for, e.g., on edit distances and connectivity structure, are available. Of particular interest is the so-called “anomaly attribution”, which consists of revealing the root cause of the detected anomalies and presenting anomalies in a user-friendly form. This provides tools that could/do enable/facilitate the post-analysis of detected anomalies for the crucial task of sense-making. Indeed, qualitative analysis techniques for the sense-making of spotted anomalies are very important and needed. | A sufficiently exhaustive inventory of schemes within this family of (graph-based) methods is provided in the survey by Leman Akoglu et al. (2015) [48] |
| MAJA 4: Graph neural network (Graph-DL) based methods | A very significant change in the last years is that graph anomaly detection (see MAJA 3) has evolved from relying heavily on the domain knowledge of human experts towards rather machine learning techniques that eliminate human intervention and, more recently, various deep learning technologies. These deep learning techniques are not only capable of identifying potential anomalies in graphs far more accurately than ever before, but they can also do so in real-time. Consequently, MAJA 4 can be viewed as a synergetic merging of MAJA 3 and MAJA 2. Moreover, certain bricks of MAJA 1 and of fuzzy logic may be easily casually integrated (e.g., Bayesian networks, certain HMM architectures, etc.). Conventional techniques (see MAJA 1 and MAJA 2) typically represent real-world objects as feature vectors and then detect outlying data points in the vector space. Although these techniques (see MAJA 1 and MAJA 2) showed power in locating deviating data points under tabulated data format, they inherently discard the complex relationships between objects. This discarding of relationships is a significant limitation especially, amongst others, from the perspective of “explainable anomaly detection and prediction” on hand and of the capability to model/map appropriately the complex scene of “monitoring a human in bed”, as was described in Figure 3 (while additionally considering the above so-called OCPs and USPs) on the other hand. Moreover, in real-world scenarios, many objects have rich relationships with each other, which can provide valuable complementary or dedicated special information for anomaly detection. Or the observation perspective from which the anomaly is detected can change even dynamically over time (see the above so-called USPs and OCPs). It is well known that non-deep-learning-based techniques (see MAJ-1 and MAJ-3) generally/essentially lack the capability to capture the non-linear properties of real objects [56]. Consequently, the representations of objects learned by them are not expressive enough to fully support a robust anomaly detection capability. In order to tackle these limitations, more recent studies seek the potential of adopting deep learning techniques to identify anomalous graph objects. By extracting expressive representations such that graph anomalies and normal objects can be easily separated, or the deviating patterns of anomalies can be learned directly through deep learning techniques, graph anomaly detection with deep learning is starting to take the lead in the forefront of anomaly detection. As a frontier technology, graph anomaly detection through integrated deep learning, hence, is expected to generate more fruitful results w.r.t. accuracy and robustness in detecting anomalies. | A sufficiently exhaustive inventory of schemes within this family of (graph DL-based) methods is provided in the survey by Xiaoxiao Ma et al. (2021) [47]. |
| Requirement ID and Description | Capability of MAJA 1 to Fulfil the Requirement [57,58,59,60,61,62,63] | Capability of MAJA 2 to Fulfil the Requirement [64,65,66,67,68,69] | Capability of MAJA 3 to Fulfil the Requirement [48,70,71] | Capability of MAJA 4 to Fulfil the Requirement [69,72,73,74,75] | Remarks |
|---|---|---|---|---|---|
| REQ 1: Self-learning and continual learning capability, for either single individuals or groups of individuals | Possible but relatively/ eventually limited | Possible | Possible but relatively limited | Possible | All approaches can handle this requirement |
| REQ 2: Identification of and adaptivity to novelty/evolution | Possible but relatively/ eventually limited [26,37] | Possible [41,76] | Possible but relatively/ eventually limited [77] | Possible (a) [78] (b) [79] | All approaches can handle these requirements, whereby DL involving ones are better |
| REQ 3: Comprehensive uncertainty model/assessment for all subtasks (A–E) described in Section 3.4. | Not possible | Not possible | Possible but relatively/ eventually limited | Possible [80,81,82,83,84] | Only graph-based approaches can handle this requirement |
| REQ 4: Prediction capability of the system status at levels 1 to 4 of Figure 3 for one or more future time sub-regions | Possible but relatively/ eventually limited | Possible | Possible but relatively/ eventually limited | Possible [85,86,87,88,89] | All approaches can handle these requirements, whereby DL involving ones are better |
| REQ 5: Reconfigurability w.r.t. USPs (user-specific perspectives) | Not possible | Not possible | Eventually possible but very limited | Possible [90,91,92,93] | Only graph-based approaches can handle this requirement |
| REQ 6: Reconfigurability w.r.t. OCPs (observation context perspectives) | Not possible | Not possible | Eventually possible but very limited | Possible [90,91,92,93] | Only graph-based approaches can handle this requirement |
| REQ 7: Explainability [94] of the identification of entities at levels 1–4 of Figure 3 | Not possible | Eventually possible but very limited | Eventually possible but very limited | Possible [95,96,97,98,99,100,101,102,103] | Only graph and/or DL-based approaches can handle this requirement |
| REQ 8: Explainability of the anomaly detection (considering USPs and OCPs) | Not possible | Not possible | Eventually possible but very limited | Possible | Only graph and/or DL-based approaches can handle this requirement |
| REQ 9: Explainability of the evolution detection | Not possible | Eventually possible but very limited | Eventually possible but very limited | Possible | Only graph and/or DL-based approaches can handle this requirement |
| REQ 10: Explainability of the uncertainty grade or confidence level for all subtasks (A–E) described in Section 3 | Not possible | Eventually possible but very limited | Eventually possible but very limited | Possible | Only graph and/or DL-based approaches can handle this requirement |
| REQ 11: The possibility of a performance tuning/improvement through either partial human assistance (via some form of feedback) or evolutive/reinforced learning or involving artificially generated data out of some reliable “generative adversarial” process or a combination of some or all of the above. | Not possible | Eventually possible but very limited | Eventually possible but very limited | Possible [104,105,106,107] | Only graph and/or DL-based approaches can handle this requirement |
| REQ 12: The reconfigurability w.r.t. the tolerance level/grade/ margin related to the abnormality assessment (or, in other words, related to the anomaly detectability). The operators of the intelligent system for anomaly detection in the monitoring of “human in bed” shall able to modify, even dynamically, the tolerance level/margin of the anomaly detection. | Not possible | Eventually possible but very limited | Eventually possible but very limited | Possible | Only graph and/or DL-based approaches can handle this requirement |
| REQ 13: Tolerance to non-ideal training data | Possible (however, some adaptations may be necessary) | Possible (however, some adaptations (e.g., in the form of pre-processing layers or dataset augmentations) may be necessary) | Eventually possible but after adaptations | Surely possible | Almost all approaches can handle this requirement, although adaptations, which may be very substantial, may be necessary |
| REQ 14: The complete intelligent system shall be capable of running fully on COTS embedded platforms (i.e., the intelligent system shall be fully Embedded AI), which are essentially low-computing power; this is to ensure both low cost and data security while satisfying use-case specific real-time processing deadlines. | Possible (however, some adaptations may be necessary) | Possible (however, some significant architecture and pipeline adaptations may be necessary) | Eventually possible (however, some significant architecture and pipeline adaptations may be necessary) | Eventually possible (however, some significant architecture and pipeline adaptations may be necessary) | For this requirement, the approaches involving DL are not superior to the intelligent system version that is “fully embedded”. For this system version, MAJA 1 is potentially superior. However, the situation significantly changes for the case of an intelligent system that can/does involve IoT and related infrastructure such as Cloud Computing |
| REQ 15: Short learning duration and/or fast detection of/and adaptation to behavior changes | Possible (however, some adaptations may be necessary) | Possible (however, some significant architecture and pipeline adaptations may be necessary) | Possible (however, some significant architecture and pipeline adaptations may be necessary) | Possible (however, some significant architecture and pipeline adaptations may be necessary). However, more flexible in the presence of reconfigurability needs w.r.t. REQ 11 and REQ 12 | The performance metric MET 4 (see Table 5) can influence (subject-dependently) this requirement. For non-reconfigurable setups, MAJA 1 appears potentially superior. However, in the face of reconfigurability needs, MAJA 4 becomes evidently the superior one. |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kyamakya, K.; Tavakkoli, V.; McClatchie, S.; Arbeiter, M.; Scholte van Mast, B.G. A Comprehensive “Real-World Constraints”-Aware Requirements Engineering Related Assessment and a Critical State-of-the-Art Review of the Monitoring of Humans in Bed. Sensors 2022, 22, 6279. https://doi.org/10.3390/s22166279
Kyamakya K, Tavakkoli V, McClatchie S, Arbeiter M, Scholte van Mast BG. A Comprehensive “Real-World Constraints”-Aware Requirements Engineering Related Assessment and a Critical State-of-the-Art Review of the Monitoring of Humans in Bed. Sensors. 2022; 22(16):6279. https://doi.org/10.3390/s22166279
Chicago/Turabian StyleKyamakya, Kyandoghere, Vahid Tavakkoli, Simon McClatchie, Maximilian Arbeiter, and Bart G. Scholte van Mast. 2022. "A Comprehensive “Real-World Constraints”-Aware Requirements Engineering Related Assessment and a Critical State-of-the-Art Review of the Monitoring of Humans in Bed" Sensors 22, no. 16: 6279. https://doi.org/10.3390/s22166279