
A Study on the Geometric and Kinematic Descriptors of Trajectories in the Classification of Ship Types


Abstract
:1. Introduction
- The examination of a wide range of ship classification problems using comprehensive sets of geometric and kinematic descriptors and a quantitative determination of the problems for which geometric or kinematic descriptors can deliver acceptable results on their own and those that rely on both sets of descriptors;
- The uncovering of the potential of geometric and kinematic descriptors as stand-alone attributes in movement characterization, along with the identification and analysis of the complex movements of certain ship classes for which neither set is enough for movement characterization;
- The verification of the conjecture that similar descriptors in ship classification emerge in line with a geometric–kinematic taxonomy and the development of a comprehensive set of descriptors.
2. Materials and Methods
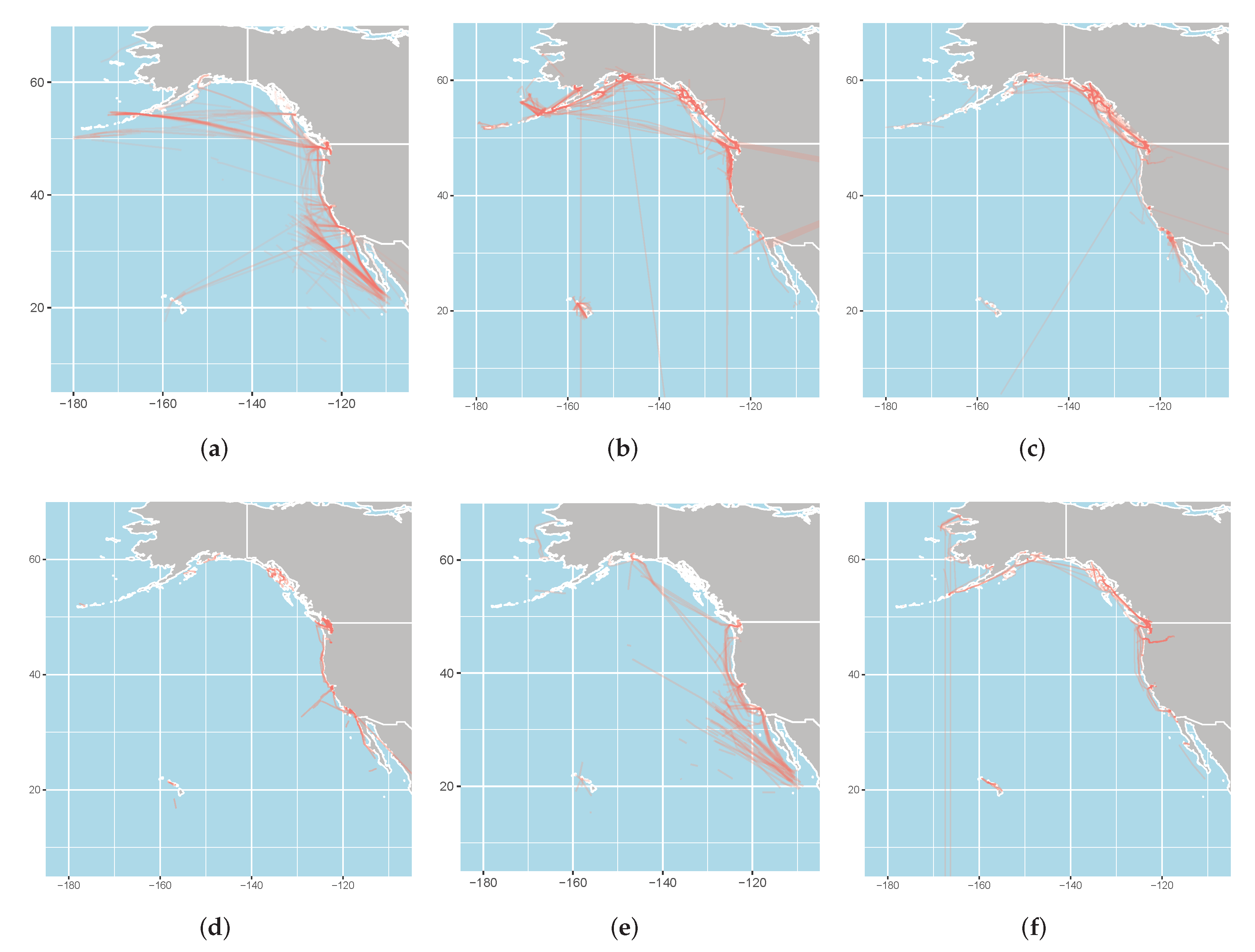
2.1. Data
2.2. Classification Problems
2.3. Descriptors
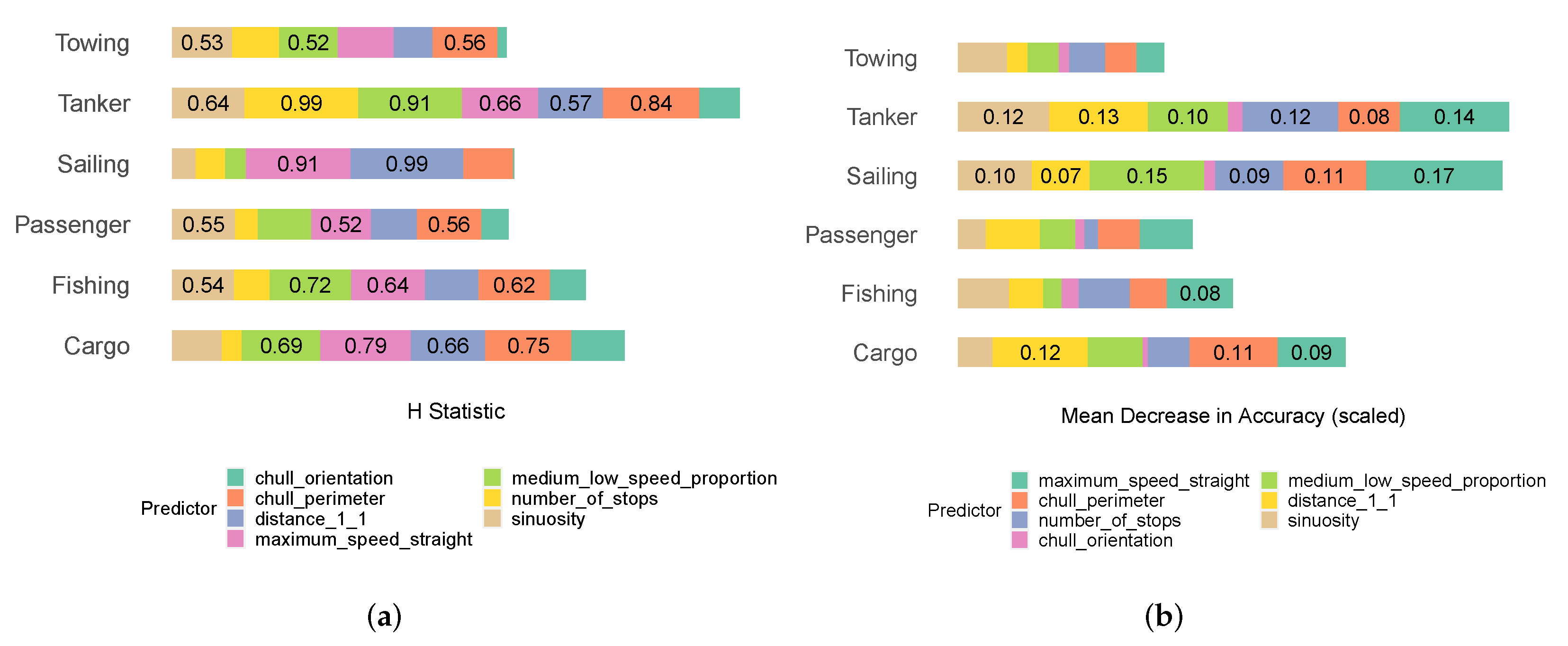
2.4. Investigation into the Predictive Performances of Geometric and Kinematic Descriptors (RQ1)
- Since our approach involved hundreds of models, tuning could become a bottleneck;
- The performance assessment of so many models was time-consuming;
- The modeling method had to guarantee that the models that were based on both geometric and kinematic predictors (in this paper, we refer to descriptors as predictors in the context of modeling), as the benchmark, did not underperform the models that were solely based on either geometric or kinematic descriptors as not all the modeling methods meet this requirement: some modeling methods perform worse in the presence of multicolinearity between additional predictors and some perform worse when additional predictors contain irrelevant predictors.
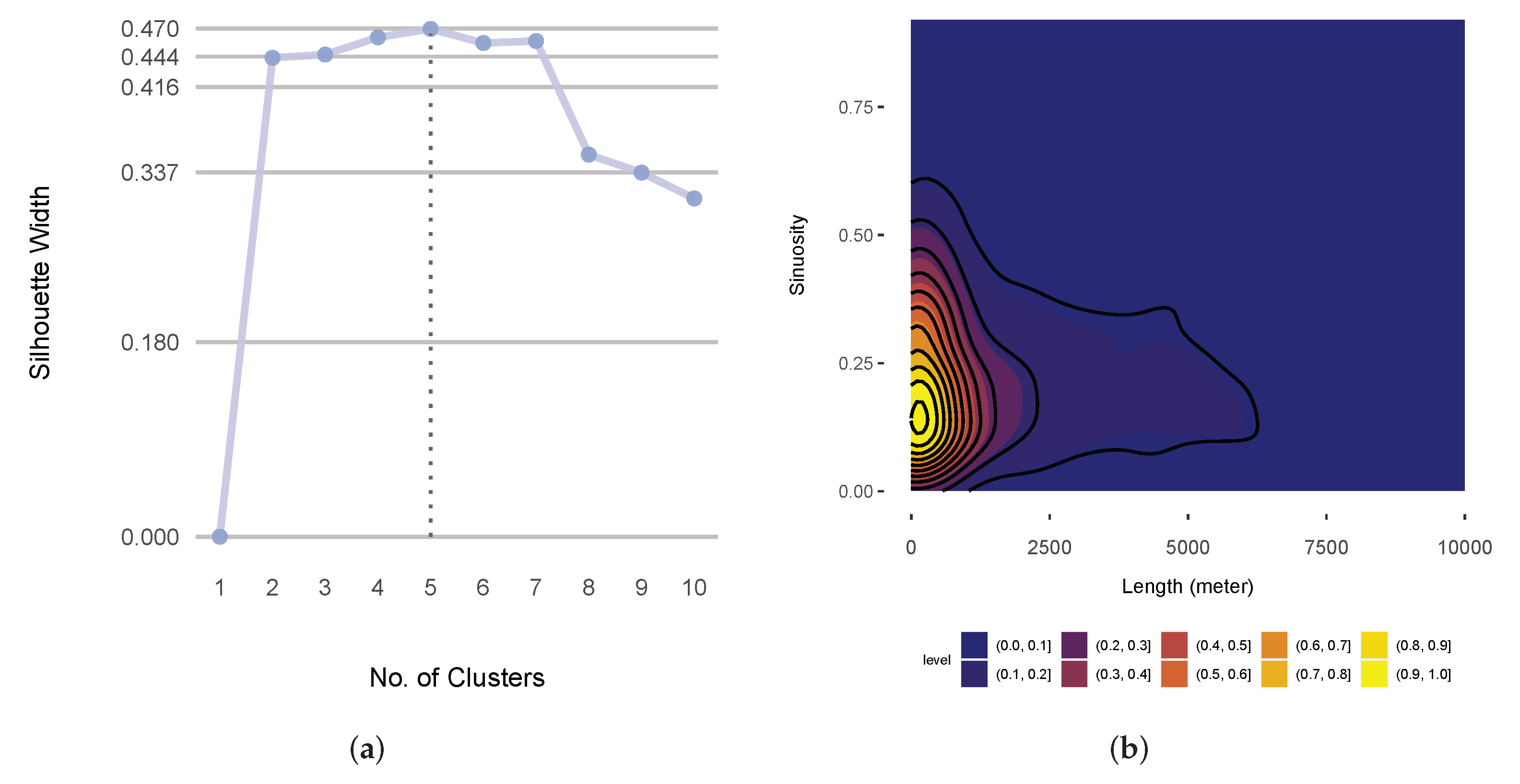
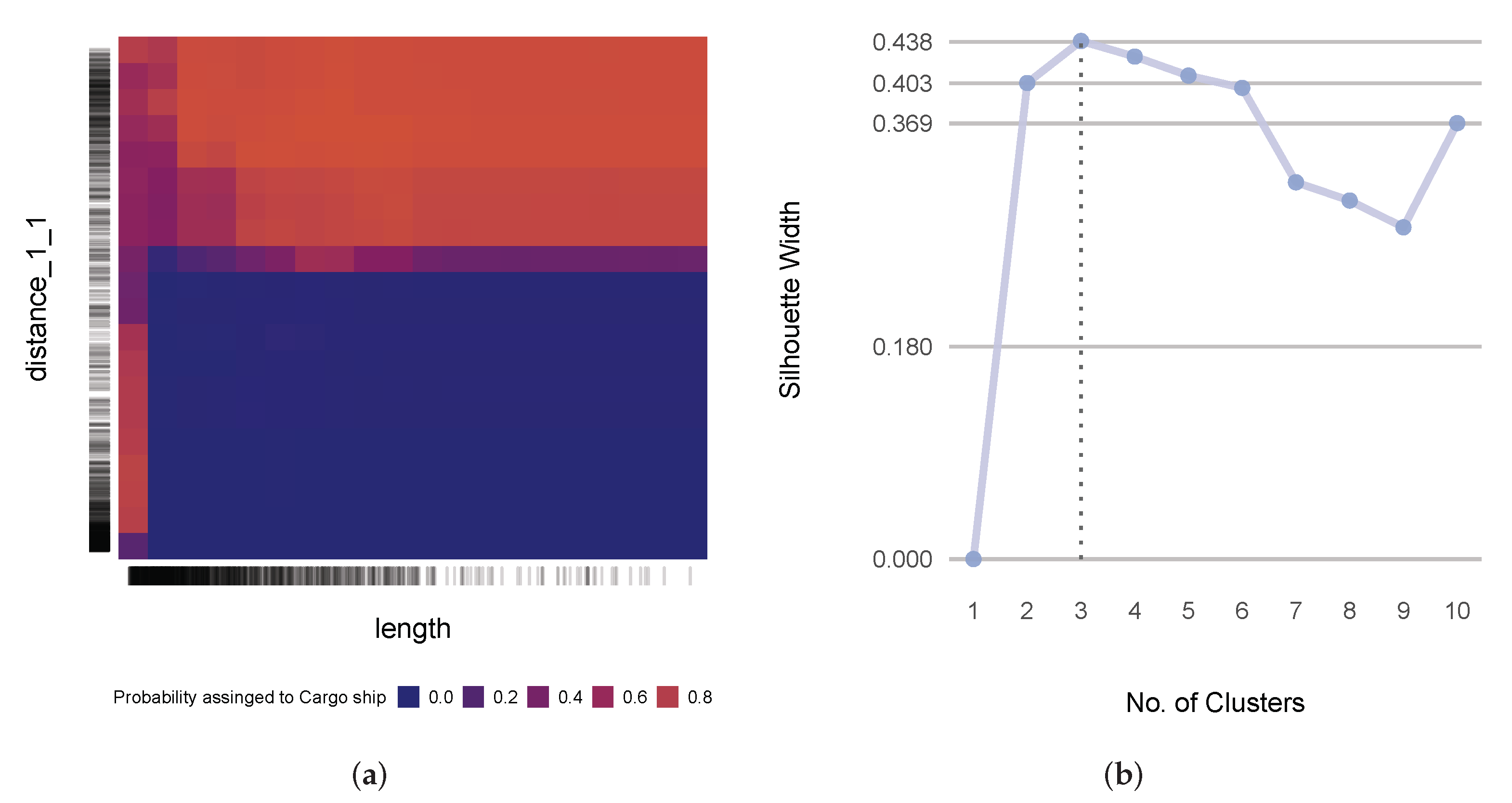
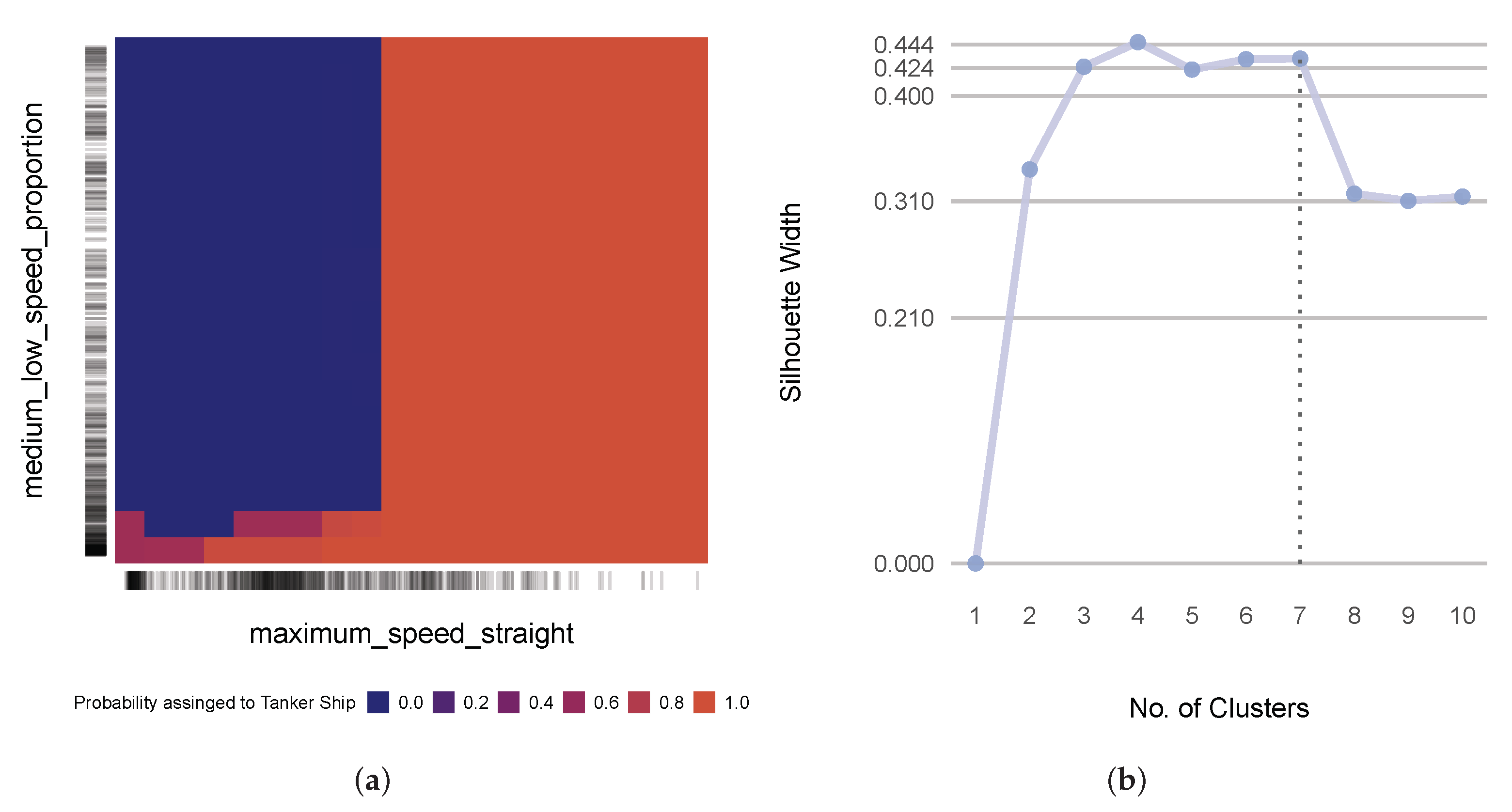
2.5. Investigation into the Capabilities of Geometric and Kinematic Descriptors for Movement Characterization (RQ2)
- To ensure that the representatives well encapsulated the characteristics of the cluster and not the other clusters, the representatives needed to manifest strong similarity bonds to the rest of the host cluster and weak similarity bonds to the predictors in foreign clusters as much as possible;
- Weak models have weak ties to the ground truth; so, representatives that led to even higher performance models produced more reliable interpretations and thus, took precedence over the others;
- A predictor could take precedence over the others when its definition was more intuitive and hence, interpretable;
- Where applicable, we wanted both geometric and kinematic predictors to be well represented in the selected set of predictors.
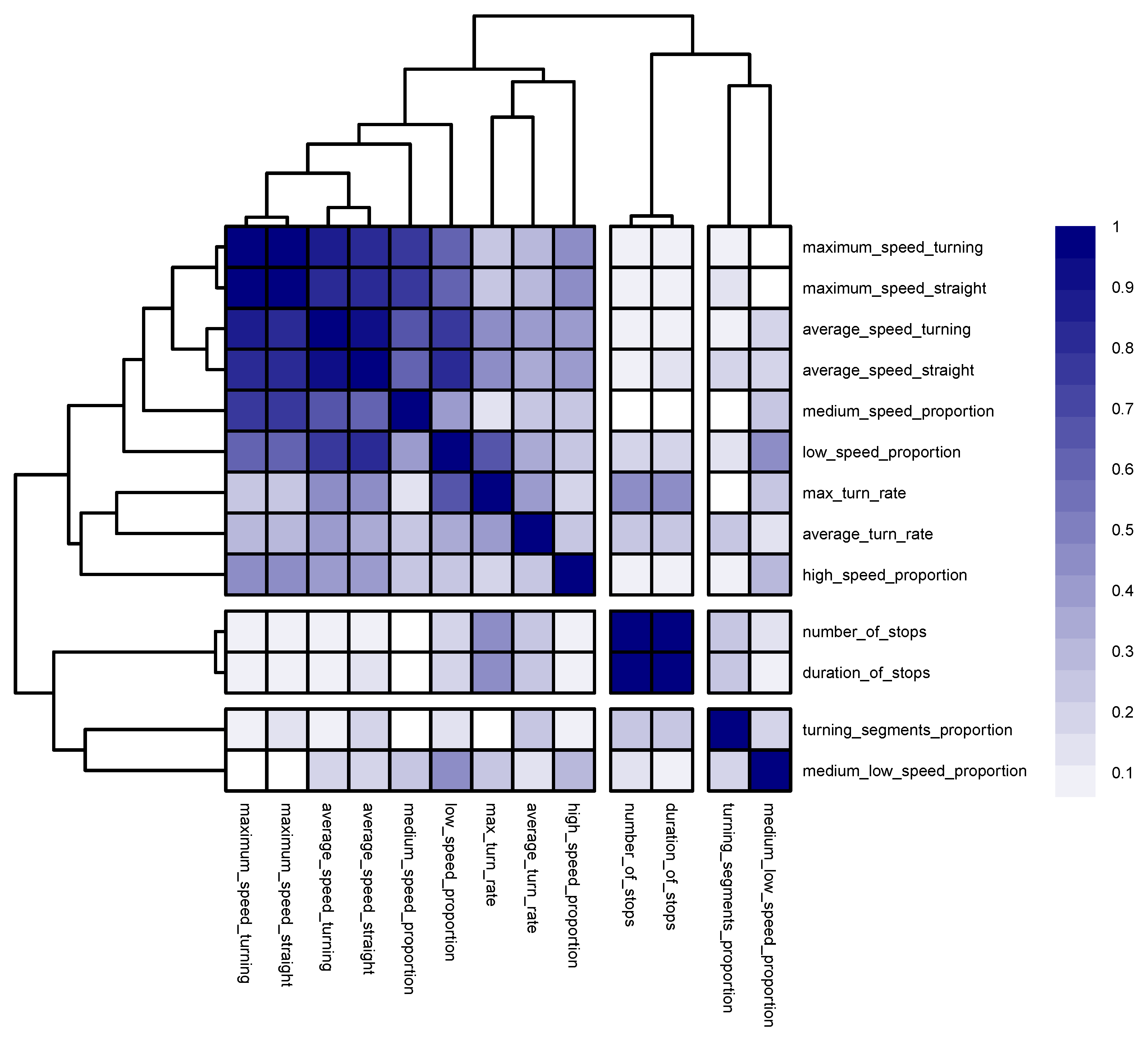
2.6. Investigation into the Group Similarity Induced by Geometric and Kinematic Descriptors (RQ3)
3. Results
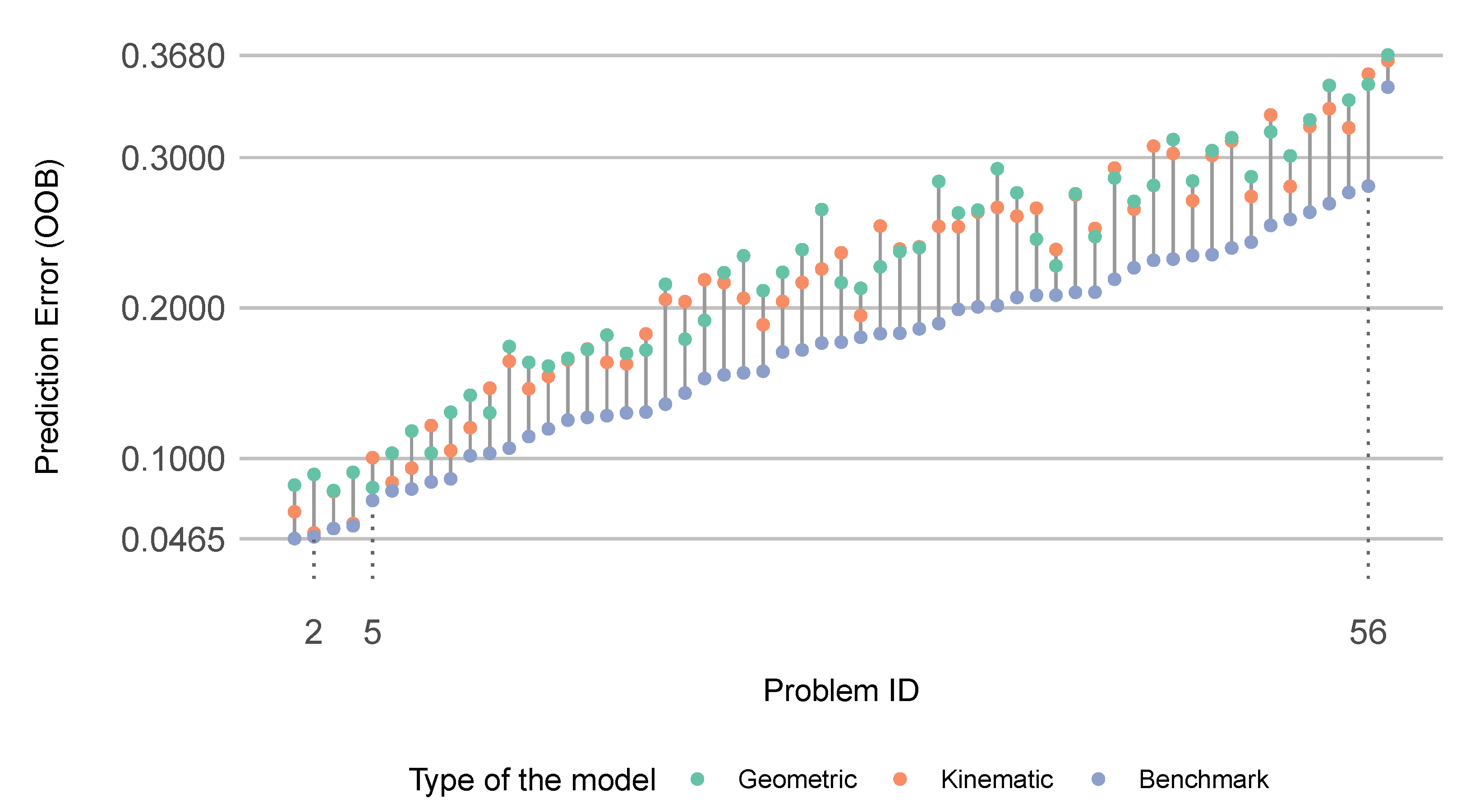
3.1. The Predictive Performance of Geometric and Kinematic Descriptors (RQ1)
3.2. The Interpretive Performance of Geometric and Kinematic Descriptors (RQ2)
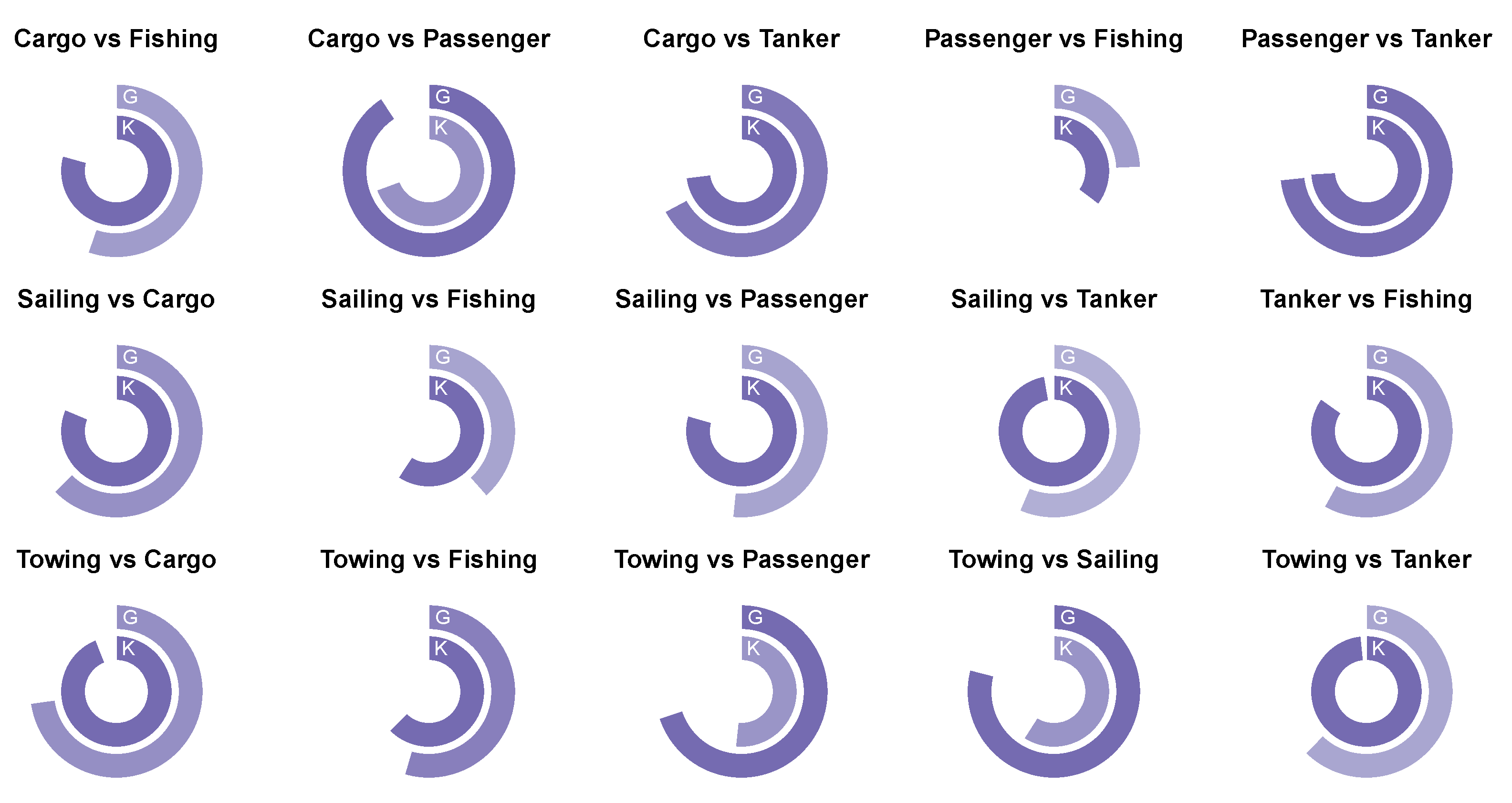
3.3. Universal Similarity among Geometric and Kinematic Descriptors (RQ3)
4. Discussion and Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Moreau, H.; Vassilev, A.; Chen, L. The Devil Is in the Details: An Efficient Convolutional Neural Network for Transport Mode Detection. IEEE Trans. Intell. Transp. Syst. 2021. [Google Scholar] [CrossRef]
- Laube, P. Computational Movement Analysis; SpringerBriefs in Computer Science; Springer International Publishing: Cham, Switzerland, 2014. [Google Scholar]
- Rintoul, M.D.; Jones, J.L.; Newton, B.D.; Wisniewski, K.L.; Wilson, A.T.; Ginaldi, M.J.; Waddell, C.A.; Goss, K.; Ward, K.J. Large-Scale Trajectory Analysis via Feature Vectors; Technical Report; Office of Scientific and Technical Information (OSTI): Oak Ridge, TN, USA, 2021. [CrossRef]
- Soleymani, A.; Cachat, J.; Robinson, K.; Dodge, S.; Kalueff, A.; Weibel, R. Integrating cross-scale analysis in the spatial and temporal domains for classification of behavioral movement. J. Spat. Inf. Sci. 2014, 2014, 1–25. [Google Scholar] [CrossRef]
- Andrienko, G.; Andrienko, N.; Bak, P.; Keim, D.; Wrobel, S. Transformations of Movement Data. In Visual Analytics of Movement; Springer: Berlin/Heidelberg, Germany, 2013; pp. 73–101. [Google Scholar] [CrossRef]
- Fu, P.; Wang, H.; Liu, K.; Hu, X.; Zhang, H. Finding Abnormal Vessel Trajectories Using Feature Learning. IEEE Access 2017, 5, 7898–7909. [Google Scholar] [CrossRef]
- Guo, W.; Zhao, Z.; Zheng, Z.; Xu, Y. A Cloud-based Approach for Ship Stay Behavior Classification using Massive Trajectory Data. In Proceedings of the 2020 International Conference on Service Science (ICSS), Xining, China, 24–26 August 2020; pp. 82–89. [Google Scholar] [CrossRef]
- Mazimpaka, J.D.; Timpf, S. Trajectory data mining: A review of methods and applications. J. Spat. Inf. Sci. 2016, 2016, 61–99. [Google Scholar] [CrossRef]
- Rintoul, M.D.; Wilson, A.T. Trajectory analysis via a geometric feature space approach. Stat. Anal. Data Min. 2015, 8, 287–301. [Google Scholar] [CrossRef]
- Wilson, A.T.; Rintoul, M.D.; Valicka, C.G. Exploratory Trajectory Clustering with Distance Geometry. In Foundations of Augmented Cognition: Neuroergonomics and Operational Neuroscience, Proceedings of the 10th International Conference AC 2016, Toronto, ON, Canada, 17–22 July 2016; Lecture Notes in Computer Science; Springer International Publishing: Cham, Switzerland, 2016; pp. 263–274. [Google Scholar]
- Bhuyan, M.; Ghosh, D.; Bora, P. Feature Extraction from 2D Gesture Trajectory in Dynamic Hand Gesture Recognition. In Proceedings of the 2006 IEEE Conference on Cybernetics and Intelligent Systems, Bangkok, Thailand, 7–9 June 2006; pp. 1–6. [Google Scholar]
- Wang, W.; Chu, X.; Jiang, Z.; Liu, L. Classification of Ship Trajectories by Using Naive Bayesian algorithm. In Proceedings of the 2019 5th International Conference on Transportation Information and Safety (ICTIS), Liverpool, UK, 14–17 July 2019; pp. 466–470. [Google Scholar]
- Sanchez Pedroche, D.; Amigo, D.; Garcia, J.; Molina, J.M. Architecture for Trajectory-Based Fishing Ship Classification with AIS Data. Sensors 2020, 20, 3782. [Google Scholar] [CrossRef]
- Sheng, K.; Liu, Z.; Zhou, D.; He, A.; Feng, C. Research on Ship Classification Based on Trajectory Features. J. Navig. 2018, 71, 100–116. [Google Scholar] [CrossRef]
- Liang, M.; Zhan, Y.; Liu, R.W. MVFFNet: Multi-view feature fusion network for imbalanced ship classification. Pattern Recognit. Lett. 2021, 151, 26–32. [Google Scholar] [CrossRef]
- Zhang, T.; Zhao, S.; Chen, J. Research on Ship Classification Based on Trajectory Association. In Proceedings of the International Conference on Knowledge Science, Engineering and Management (KSEM 2019), Athens, Greece, 28–30 August 2019; Lecture Notes in Computer Science. Springer International Publishing: Cham, Switzerland, 2019; pp. 327–340. [Google Scholar]
- Pipanmekaporn, L.; Kamonsantiroj, S. A Deep Learning Approach for Fishing Vessel Classification from VMS Trajectories Using Recurrent Neural Networks. In Proceedings of the 2nd International Conference on Human Interaction, Emerging Technologies and Future Applications II (IHIET–AI 2020), Lausanne, Switzerland, 23–25 April 2020; Advances in Intelligent Systems and Computing. Springer International Publishing: Cham, Switzerland, 2020; pp. 135–141. [Google Scholar]
- Kraus, P.; Mohrdieck, C.; Schwenker, F. Ship classification based on trajectory data with machine-learning methods. In Proceedings of the 2018 19th International Radar Symposium (IRS), Bonn, Germany, 20–22 June 2018; pp. 1–10. [Google Scholar] [CrossRef]
- Li, X. Using Complexity Measures of Movement for Automatically Detecting Movement Types of Unknown GPS Trajectories. Am. J. Geogr. Inf. Syst. 2014, 3, 63–74. [Google Scholar] [CrossRef]
- Beyan, C.; Fisher, R. Detection of Abnormal Fish Trajectories Using a Clustering Based Hierarchical Classifier. In Proceedings of the British Machine Vision Conference, Bristol, UK, 9–13 September 2013; British Machine Vision Association (BMVA) Press: Durham, UK, 2013. [Google Scholar] [CrossRef] [Green Version]
- Yang, X.; Stewart, K.; Tang, L.; Xie, Z.; Li, Q. A Review of GPS Trajectories Classification Based on Transportation Mode. Sensors 2018, 18, 3741. [Google Scholar] [CrossRef] [Green Version]
- Shen, W.; Lin, Y.; Chen, S.; Xue, F.; Yang, Y.; Hong, W. Apparent Trace Analysis of Moving Target with Linear Motion in Circular SAR Imagery. In Proceedings of the 12th European Conference on Synthetic Aperture Radar (EUSAR 2018), Aachen, Germany, 4–7 June 2018; pp. 1–4. [Google Scholar]
- Shen, W.; Hong, W.; Han, B.; Wang, Y.; Lin, Y. Moving Target Detection with Modified Logarithm Background Subtraction and Its Application to the GF-3 Spotlight Mode. Remote Sens. 2019, 11, 1190. [Google Scholar] [CrossRef] [Green Version]
- Abimanyu, A.; Pranowo, W.S.; Faizal, I.; Afandi, N.K.; Purba, N.P. Reconstruction of oil spill trajectory in the Java Sea, Indonesia using sar imagery. Geogr. Environ. Sustain. 2021, 14, 177–184. [Google Scholar] [CrossRef]
- Li, H.; Chen, L.; Li, F.; Huang, M. Ship detection and tracking method for satellite video based on multiscale saliency and surrounding contrast analysis. J. Appl. Remote Sens. 2019, 13, 026511. [Google Scholar] [CrossRef]
- Protopapadakis, E.; Voulodimos, A.; Doulamis, A.; Doulamis, N.; Dres, D.; Bimpas, M. Stacked Autoencoders for Outlier Detection in Over-the-Horizon Radar Signals. Comput. Intell. Neurosci. 2017, 2017, 5891417. [Google Scholar] [CrossRef]
- Chen, X.; Qi, L.; Yang, Y.; Luo, Q.; Postolache, O.; Tang, J.; Wu, H. Video-Based Detection Infrastructure Enhancement for Automated Ship Recognition and Behavior Analysis. J. Adv. Transp. 2020, 2020, 1–12. [Google Scholar] [CrossRef] [Green Version]
- Yu, J.G.; Selby, B.; Vlahos, N.; Yadav, V.; Lemp, J. A feature-oriented vehicle trajectory data processing scheme for data mining: A case study for Statewide truck parking behaviors. Transp. Res. Interdiscip. Perspect. 2021, 11, 100401. [Google Scholar] [CrossRef]
- Bolbol, A.; Cheng, T.; Tsapakis, I.; Haworth, J. Inferring hybrid transportation modes from sparse GPS data using a moving window SVM classification. Comput. Environ. Urban Syst. 2012, 36, 526–537. [Google Scholar] [CrossRef] [Green Version]
- Kontopoulos, I.; Chatzikokolakis, K.; Tserpes, K.; Zissis, D. Classification of vessel activity in streaming data. In Proceedings of the 14th ACM International Conference on Distributed and Event-Based Systems (DEBS ’20), Montreal, QC, Canada, 13–17 July 2020; pp. 153–164. [Google Scholar]
- Liu, H.; Motoda, H. (Eds.) Computational Methods of Feature Selection; Taylor & Francis Group, LLC: New York, NY, USA, 2007. [Google Scholar] [CrossRef]
- Kuhn, M. Feature Engineering and Selection: A Practical Approach for Predictive Models; CRC Press, LLC: Milton, UK, 2019. [Google Scholar]
- Liu, H.; Motoda, H. Feature Selection for Knowledge Discovery and Data Mining, 1st ed.; The Springer International Series in Engineering and Computer Science; Springer: New York, NY, USA, 1998; Volume 454. [Google Scholar]
- Dong, G.; Liu, H. (Eds.) Feature Engineering for Machine Learning and Data Analytics, 1st ed.; Chapman & Hall/CRC Data Mining and Knowledge Discovery Series; CRC Press/Taylor & Francis Group: Boca Raton, FL, USA, 2018. [Google Scholar]
- Liu, H.; Zhao, Z.A. Spectral Feature Selection for Data Mining; Chapman & Hall/CRC Data Mining and Knowledge Discovery Series; CRC Press: London, UK, 2012. [Google Scholar]
- Liu, H.; Motoda, H. Feature Extraction, Construction and Selection: A Data Mining Perspective; The Springer International Series in Engineering and Computer Science; Springer: New York, NY, USA, 1998; Volume 453. [Google Scholar]
- Dodge, S.; Weibel, R.; Forootan, E. Revealing the physics of movement: Comparing the similarity of movement characteristics of different types of moving objects. Comput. Environ. Urban Syst. 2009, 33, 419–434. [Google Scholar] [CrossRef] [Green Version]
- Cheung, A.; Zhang, S.; Stricker, C.; Srinivasan, M.V. Animal navigation: The difficulty of moving in a straight line. Biol. Cybern. 2007, 97, 47–61. [Google Scholar] [CrossRef]
- Kareiva, P.M.; Shigesada, N. Analyzing insect movement as a correlated random walk. Oecologia 1983, 56, 234–238. [Google Scholar] [CrossRef]
- Hooker, G.; Mentch, L. Comments on: A random forest guided tour. Test 2016, 25, 254–260. [Google Scholar] [CrossRef]
- Svetnik, V.; Liaw, A.; Tong, C.; Wang, T. Application of Breiman’s Random Forest to Modeling Structure-Activity Relationships of Pharmaceutical Molecules. In Proceedings of the 5th International Workshop Multiple Classifier Systems (MCS 2004), Cagliari, Italy, 9–11 June 2004; Lecture Notes in Computer Science. Springer: Berlin/Heidelberg, Germany, 2004; pp. 334–343. [Google Scholar]
- Abdullah-Al-Kafi, M.; Tasnova, I.J.; Wadud Islam, M.; Banshal, S.K. Performances of Different Approaches for Fake News Classification: An Analytical Study. In Proceedings of the 1st International Conference Advanced Network Technologies and Intelligent Computing (ANTIC 2021), Varanasi, India, 17–18 December 2021; Woungang, I., Dhurandher, S.K., Pattanaik, K.K., Verma, A., Verma, P., Eds.; Springer International Publishing: Cham, Switzerland, 2022; pp. 700–714. [Google Scholar]
- Bolón-Canedo, V.; Sánchez-Maroño, N.; Alonso-Betanzos, A. Feature Selection for High-Dimensional Data; Artificial Intelligence: Foundations, Theory, and Algorithms; Springer International Publishing: Cham, Switzerland, 2015. [Google Scholar]
- Skillings, J.H.; Weber, D. A First Course in the Design of Experiments: A Linear Models Approach; Routledge: Boca Raton, FL, USA, 2018. [Google Scholar]
- Williams, R.B.G. Introduction to Statistics for Geographers and Earth Scientists; Macmillan: London, UK, 1984. [Google Scholar]
- Bishara, A.J.; Hittner, J.B. Confidence intervals for correlations when data are not normal. Behav. Res. Methods 2016, 49, 294–309. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Moreira, J.; Carvalho, A.; Horvath, T. A General Introduction to Data Analytics; Wiley: Hoboken, NJ, USA, 2018. [Google Scholar]
- Altmann, A.; Toloşi, L.; Sander, O.; Lengauer, T. Permutation importance: A corrected feature importance measure. Bioinformatics 2010, 26, 1340–1347. [Google Scholar] [CrossRef] [PubMed]
- Kamath, U.; Liu, J. Explainable Artificial Intelligence: An Introduction to Interpretable Machine Learning, 1st ed.; Springer International Publishing: Cham, Switzerland, 2021. [Google Scholar]
- Thampi, A. Interpretable AI: Building Explainable Machine Learning Systems; Manning: Shelter Island, NY, USA, 2022. [Google Scholar]
- Montáns, F.J.; Chinesta, F.; Gómez-Bombarelli, R.; Kutz, J.N. Data-driven modeling and learning in science and engineering. Comptes Rendus Mécanique 2019, 347, 845–855. [Google Scholar] [CrossRef]
- Aggarwal, C.C. Data Mining; Springer International Publishing: Cham, Switzerland, 2015. [Google Scholar]
- Goshtasby, A.A. Similarity and dissimilarity measures. In Image Registration: Principles, Tools and Methods; Springer: London, UK, 2012; pp. 7–66. [Google Scholar]
- Zhu, F.; Ma, Z. Ship Trajectory Online Compression Algorithm Considering Handling Patterns. IEEE Access 2021, 9, 70182–70191. [Google Scholar] [CrossRef]
- Zhang, C.; Zhang, S. Association Rule Mining: Models and Algorithms; Springer: Berlin/Heidelberg, Germany, 2002; p. 238. [Google Scholar]
- Wiratma, L.; van Kreveld, M.; Löffler, M. On Measures for Groups of Trajectories. In Societal Geo-Innovation, Proceedings of the 20th AGILE Conference on Geographic Information Science, Wageningen, The Netherlands, 9–12 May 2017; Lecture Notes in Geoinformation and Cartography; Springer International Publishing: Cham, Switzerland, 2017; pp. 311–330. [Google Scholar]










 geometric predictors;
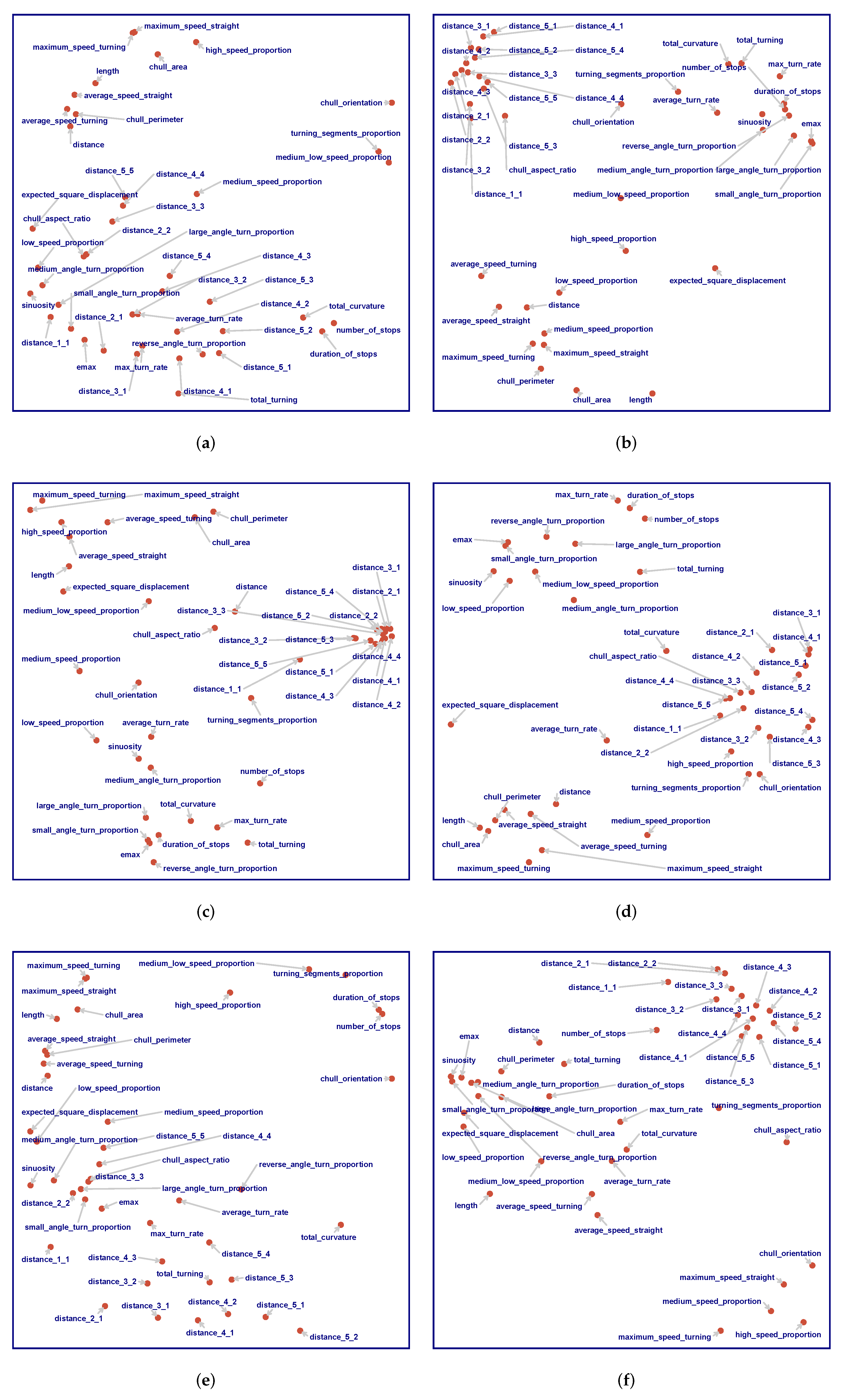
geometric predictors;  kinematic predictors. The similarity index for a pair of descriptors is between 0 and 1.
geometric predictors; kinematic predictors. The similarity index for a pair of descriptors is between 0 and 1.
kinematic predictors. The similarity index for a pair of descriptors is between 0 and 1.
geometric predictors; kinematic predictors. The similarity index for a pair of descriptors is between 0 and 1.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Ship Type | Number of AIS Messages | Number of Trajectories |
|---|---|---|
| Cargo | 5,778,529 | 933 |
| Tanker | 3,313,088 | 731 |
| Towing | 14,460,834 | 1010 |
| Fishing | 14,385,974 | 1025 |
| Passenger | 3,935,171 | 753 |
| Sailing | 1,343,775 | 1027 |
| Total | 43,217,371 | 5479 |
| Descriptor | Identifier | Comment |
|---|---|---|
| Sinuosity | sinuosity | , where is the standard deviation of trajectory turning angles at each step and q is the mean step length |
| Distance geometries | distance_i_j for and | A group of 1 + 2 + 3 + 4 + 5 = 15 descriptors that measure tortuosity as the effective distance (the ratio of the distance between the start and end points of a segment to the length of the segment); each term of the summation, which we call a signature, measures the tortuosity of the trajectory in progressively finer frequencies and then, the signatures together define the shape of a trajectory; therefore, the first signature consists of one descriptor and is the effective length of the entire trajectory, the second signature consists of two descriptors (the first being the effective length of the first segment and the second being the effective distance of the second segment), etc.; although the authors of [9] suggested the use of four signatures to capture enough variations, we opted for five to capture even more nuanced shapes |
| Distance | distance | Distance between the start and end points of trajectory |
| Maximum expected displacement of trajectory | emax | A dimensionless and scale-independent measure of trajectory straightness, as proposed by [38]; values closer to 0 indicate higher degrees of tortuosity, while larger values (approaching infinity) indicate lower degrees of tortuosity |
| Expected displacement of trajectory | expected_square_displacement | Values closer to 0 indicate a lower density of turning angles, while larger values (approaching infinity) indicate a higher density of turning angles [39] |
| Length of trajectory | length | The cumulative distance traveled along trajectory |
| Sum of absolute values of trajectory angles | total_curvature | Values closer to 0 indicate small course variations, while larger values (approaching infinity) indicate larger course variations |
| Sum of trajectory angles | total_turning | The sum of trajectory angles at each step |
| Proportion of small angles to total number of angles | small_angle_turn_proportion | Small angles constitute angles between and |
| Proportion of medium angles to total number of angles | medium_angle_turn_proportion | Medium angles constitute angles between and |
| Proportion of large angles to total number of angles | large_angle_turn_proportion | Large angles constitute angles between and |
| Proportion of reverse angles to total number of angles | reverse_angle_turn_proportion | Reverse angles constitute angles between and |
| Perimeter of convex hull of trajectory | chull_perimeter | Larger values imply longer trajectories; the convex hull of a trajectory is the smallest convex polygon within the trajectory |
| Area of convex hull of trajectory | chull_area | Larger values imply that the trajectory deviates more from the shortest path between the start point and end point of the trajectory; the convex hull of a trajectory is the smallest convex polygon within the trajectory |
| Ratio of shortest to longest axis of convex hull of trajectory | chull_aspect_ratio | The distance between the centroid of the convex hull and the nearest point on the convex hull and the longest axis is the distance between the centroid of the convex hull and the farthest vertex of the convex hull; smaller values imply more stretched out convex hulls |
| Orientation of convex hull of trajectory (with reference to hull’s longest axis) | chull_orientation | The longest axis is the distance between the centroid of the convex hull and the farthest vertex of the convex hull; we regarded the supplementary angles (adding up to ) as identical, so the orientation of the convex hull could be represented by a value between and |
| Descriptor | Identifier | Comment |
|---|---|---|
| Average speed of turning | average_speed_turning | Average speed of the ship when it is turning |
| Maximum speed of turning | max_speed_turning | Maximum speed of the ship when it is turning |
| Average speed of straight sailing | average_speed_straight | Average speed of the ship when it is sailing straight |
| Maximum speed of straight sailing | max_speed_straight | Maximum speed of the ship when it is sailing straight |
| Maximum rate of turn | max_turn_rate | Rate as degrees per minute |
| Average rate of turn | average_turn_rate | Rate as degrees per minute |
| Proportion of trajectory in which the ship is turning with respect to entire trajectory | turning_segments_proportion | A value between 0 and 1 that indicates the ratio of accumulative duration of segments in which the ship is turning to entire duration of trajectory |
| Proportion of trajectory in which the ship is moving at up to 4 knots with respect to entire trajectory | low_speed_proportion | Based on [14], a value between 0 and 1 that indicates the ratio of accumulative duration of segments in which the ship is moving slower than 4 knots to entire duration of trajectory |
| Proportion of trajectory in which the ship is moving at 4 to 10 knots with respect to entire trajectory | medium_low_speed_proportion | Based on [14], a value between 0 and 1 that indicates the ratio of accumulative duration of segments in which the ship is moving between 4 to 10 knots to entire duration of trajectory |
| Proportion of trajectory in which the ship is moving at 10 to 18 knots with respect to entire trajectory | medium_speed_proportion | Based on [14], a value between 0 and 1 that indicates the ratio of accumulative duration of segments in which the ship is moving between 10 to 18 knots to entire duration of trajectory |
| Proportion of trajectory in which the ship is moving at more than 18 knots | high_speed_proportion | Based on [14], a value between 0 and 1 that indicates the ratio of accumulative duration of the segments in which the ship is moving faster than 18 knots to entire duration of trajectory |
| Number of anchored off segments | no_of_stops | An integer greater than or equal to 0 that counts the number of trajectory segments that are classed as anchored off; this descriptor can appear to be geometric at the first sight, but in the case of free-floating vessels, kinematic parameters determine whether the vessel is anchored off; in accordance with [14], in this study, when the location of the ship did not change for a certain period and the speed of the ship did not surpass a certain threshold, we then regarded the status of the ship as anchored off |
| Total time of anchored off segments | duration_of_stops | A value that is greater than or equal to 0, which is the sum of all duration values of each trajectory segment that are classed as anchored off; following the same argument as that presented for the previous descriptor, this descriptor is essentially kinematic in nature |
| Row No. | Min. | 1st Qu. | Median | Mean | 3rd Qu. | Max. | Description |
|---|---|---|---|---|---|---|---|
| 1 | 0.0086 | 0.0387 | 0.0493 | 0.0512 | 0.0667 | 0.0945 | The OOB errors produced by Geometric models minus those produced by the benchmark models. |
| 2 | 0.0015 | 0.0309 | 0.0456 | 0.0452 | 0.0630 | 0.0760 | The OOB errors produced by Kinematic models minus those produced by the benchmark models. |
| 3 | 0.0214 | 0.0418 | 0.0545 | 0.0558 | 0.0693 | 0.0945 | The OOB errors produced by the best alternative model (either Kinematic or Geometric) minus those produced by the benchmark models. |
| 4 | −0.0272 | −0.0055 | 0.0069 | 0.0060 | 0.0184 | 0.0395 | The OOB errors produced by the Geometric models minus those produced by the Kinematic models. |
| Min. | 1st Qu. | Median | Mean | 3rd Qu. | Max. |
|---|---|---|---|---|---|
| 0.5700 | 0.6736 | 0.7231 | 0.7308 | 0.7636 | 0.9443 |
| Row No. | Min. | 1st Qu. | Median | Mean | 3rd Qu. | Max. | Description |
|---|---|---|---|---|---|---|---|
| 1 | 0.7764 | 0.8159 | 0.8837 | 0.8763 | 0.9325 | 0.9754 | Similarities pertaining to the first cluster of the hybrid problem. |
| 2 | 0.6791 | 0.6799 | 0.7036 | 0.7286 | 0.7758 | 0.8296 | Similarities pertaining to the second cluster of the hybrid problem. |
| 3 | 0.4843 | 0.5600 | 0.6201 | 0.6511 | 0.7270 | 0.9556 | Similarities pertaining to the third cluster of the hybrid problem. |
| 4 | 0.4842 | 0.6628 | 0.6907 | 0.7221 | 0.8246 | 0.9678 | Similarities pertaining to the fourth cluster of the hybrid problem. |
| 5 | 0.2795 | 0.6116 | 0.6800 | 0.6560 | 0.7422 | 0.9425 | Similarities pertaining to the fifth cluster of the hybrid problem. |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tavakoli, Y.; Peña-Castillo, L.; Soares, A. A Study on the Geometric and Kinematic Descriptors of Trajectories in the Classification of Ship Types. Sensors 2022, 22, 5588. https://doi.org/10.3390/s22155588
Tavakoli Y, Peña-Castillo L, Soares A. A Study on the Geometric and Kinematic Descriptors of Trajectories in the Classification of Ship Types. Sensors. 2022; 22(15):5588. https://doi.org/10.3390/s22155588
Chicago/Turabian StyleTavakoli, Yashar, Lourdes Peña-Castillo, and Amilcar Soares. 2022. "A Study on the Geometric and Kinematic Descriptors of Trajectories in the Classification of Ship Types" Sensors 22, no. 15: 5588. https://doi.org/10.3390/s22155588