
Image Classification Method Based on Multi-Agent Reinforcement Learning for Defects Detection for Casting


Abstract
:1. Introduction
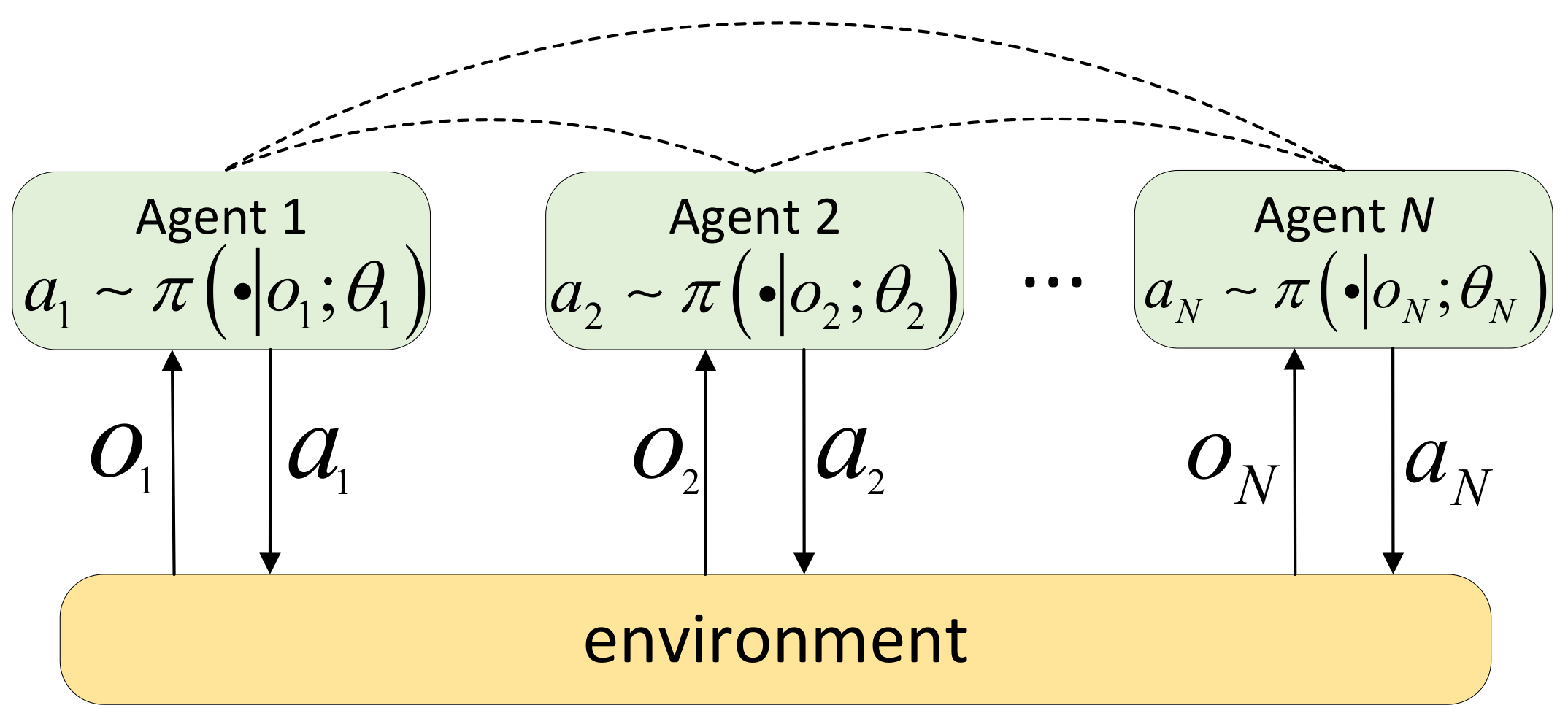
2. Multi-Agent Reinforcement Learning
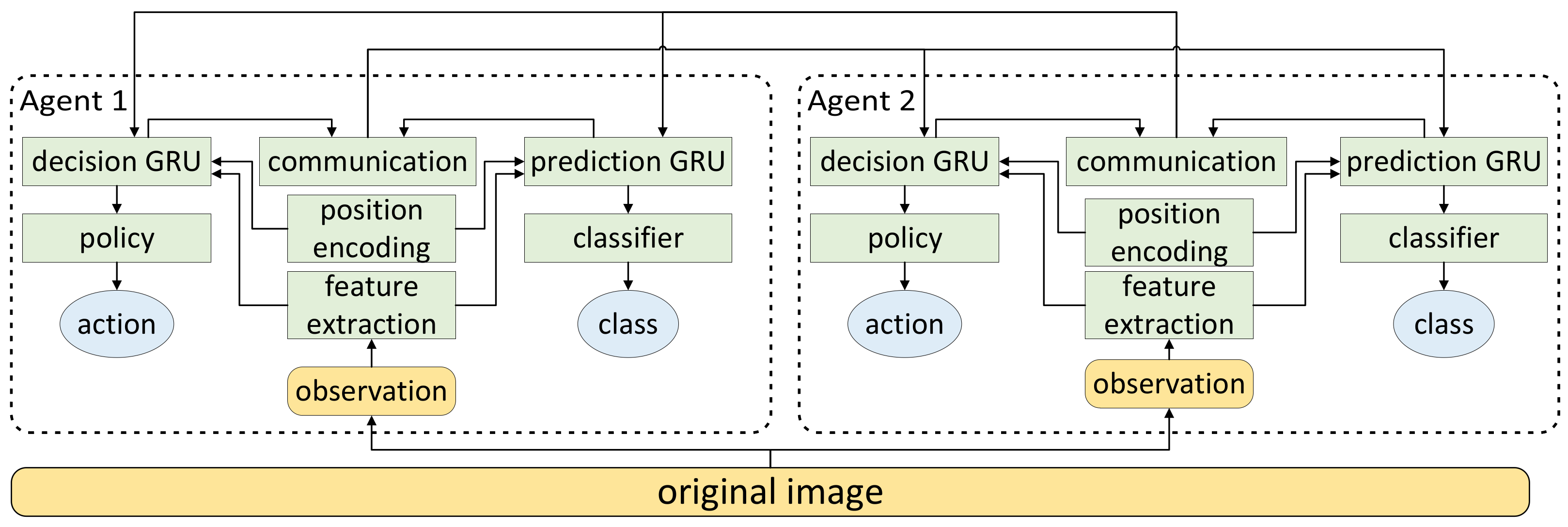
3. Network Structure and Training Method
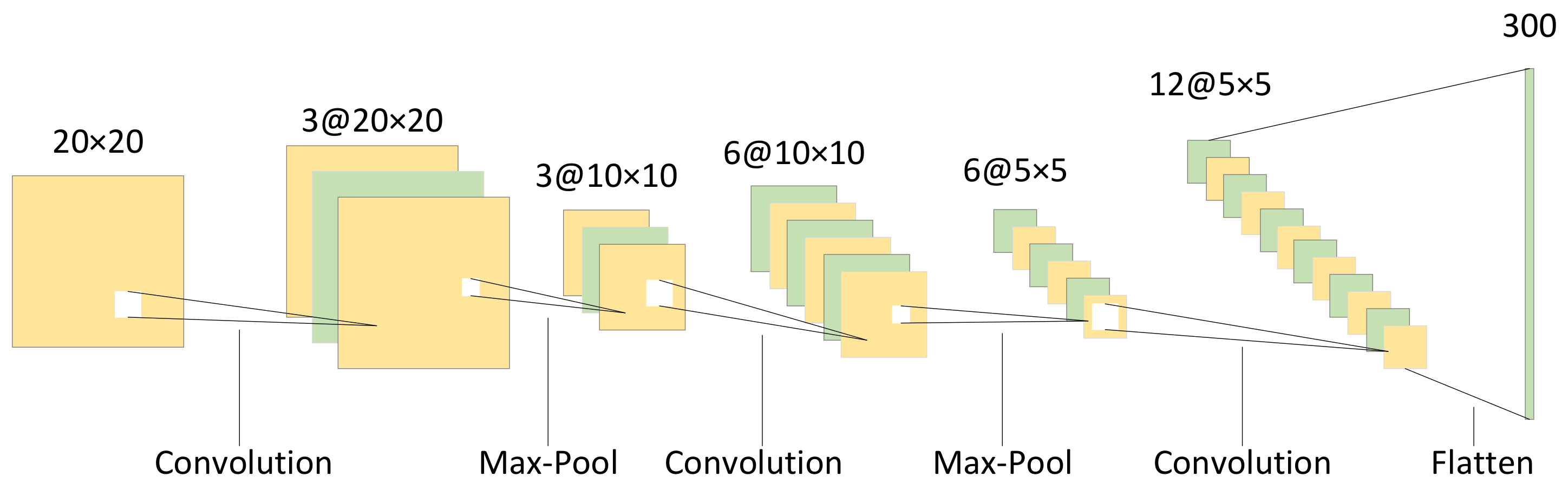
3.1. Feature Extraction Module
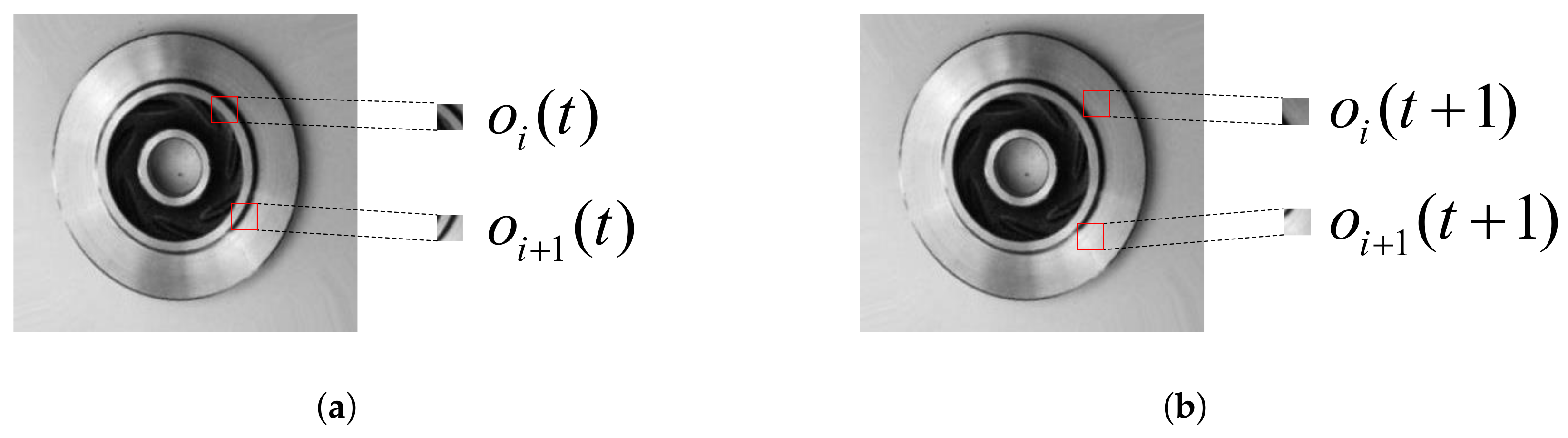
3.2. Position Encoding Module
3.3. Prediction Module
3.4. Resolution Module
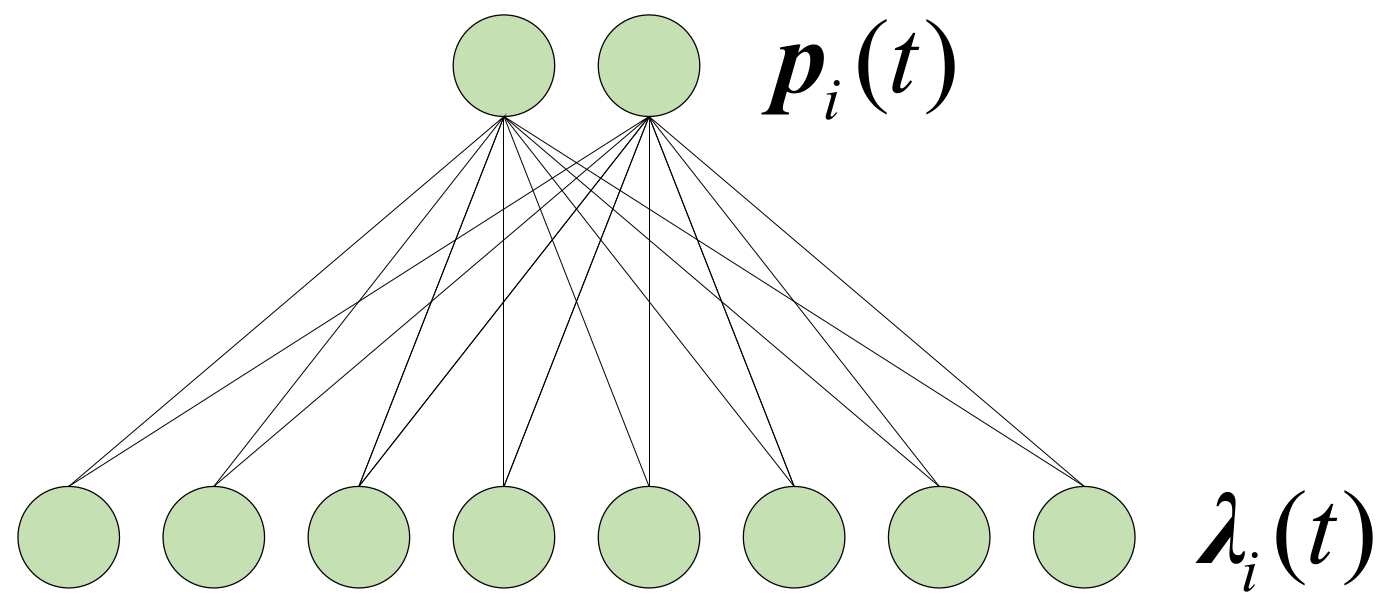
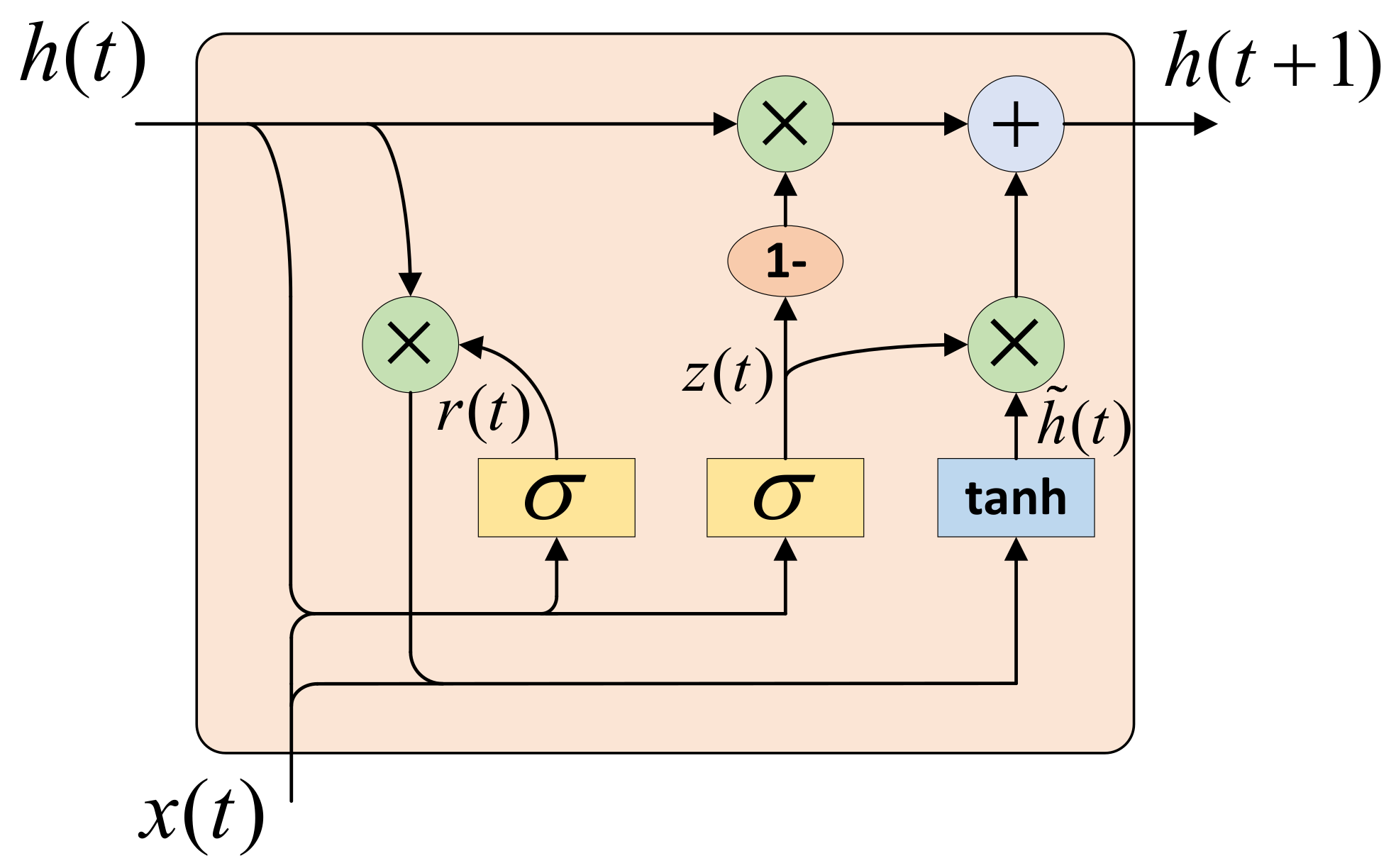
3.5. Communication Module
3.6. Prediction Process and Training Method
| Algorithm 1:Multi-agent prediction of image classes |
 |
4. Experiment Results and Discussion
4.1. Dataset and Setups
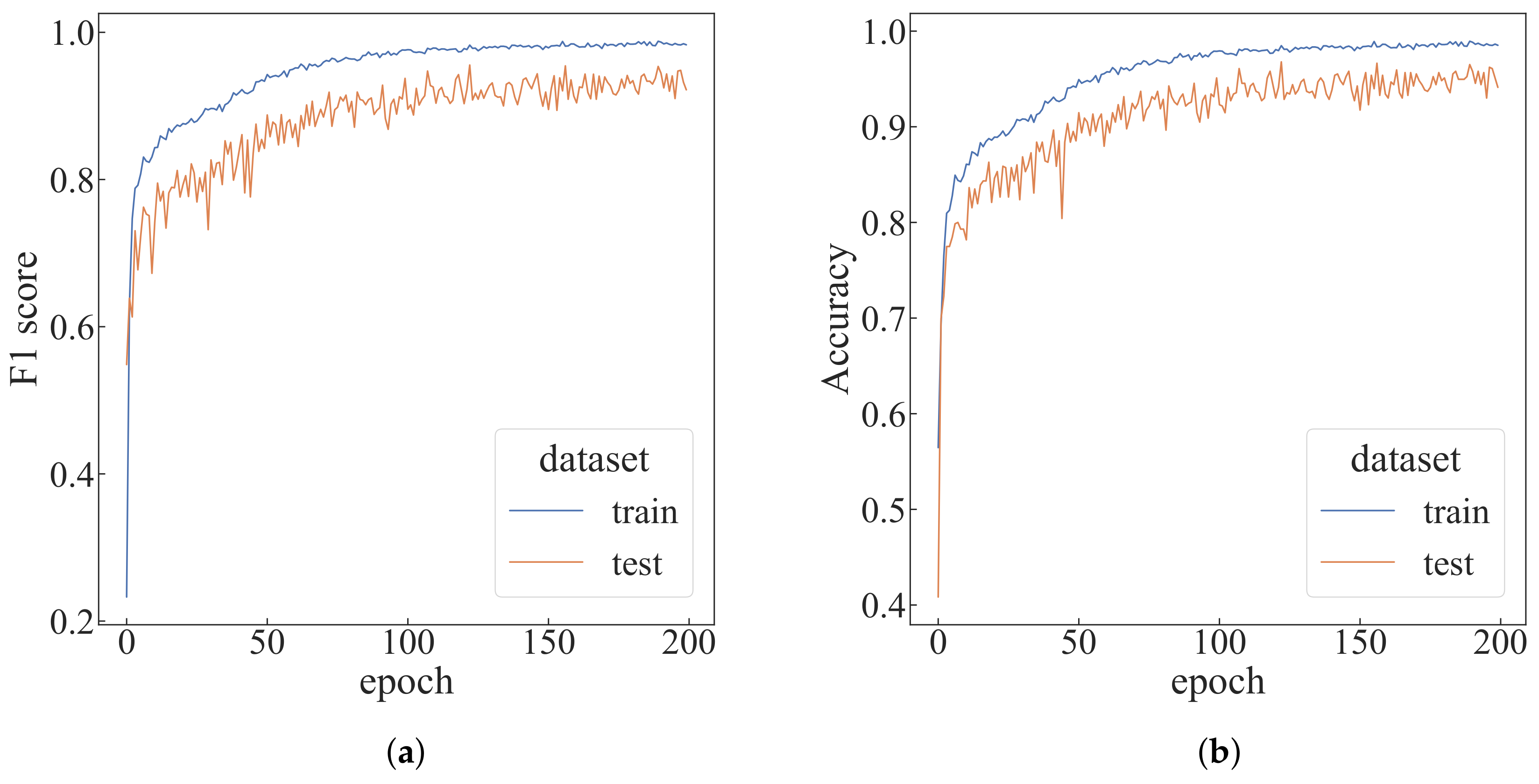
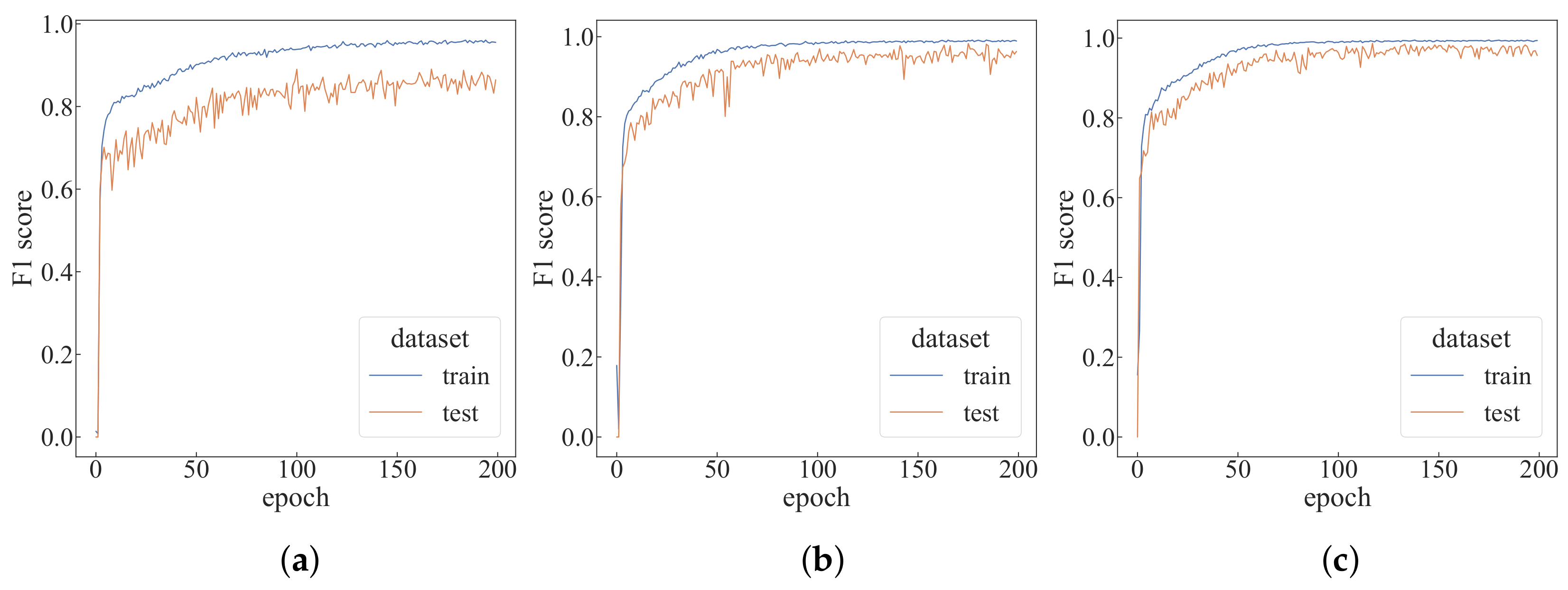
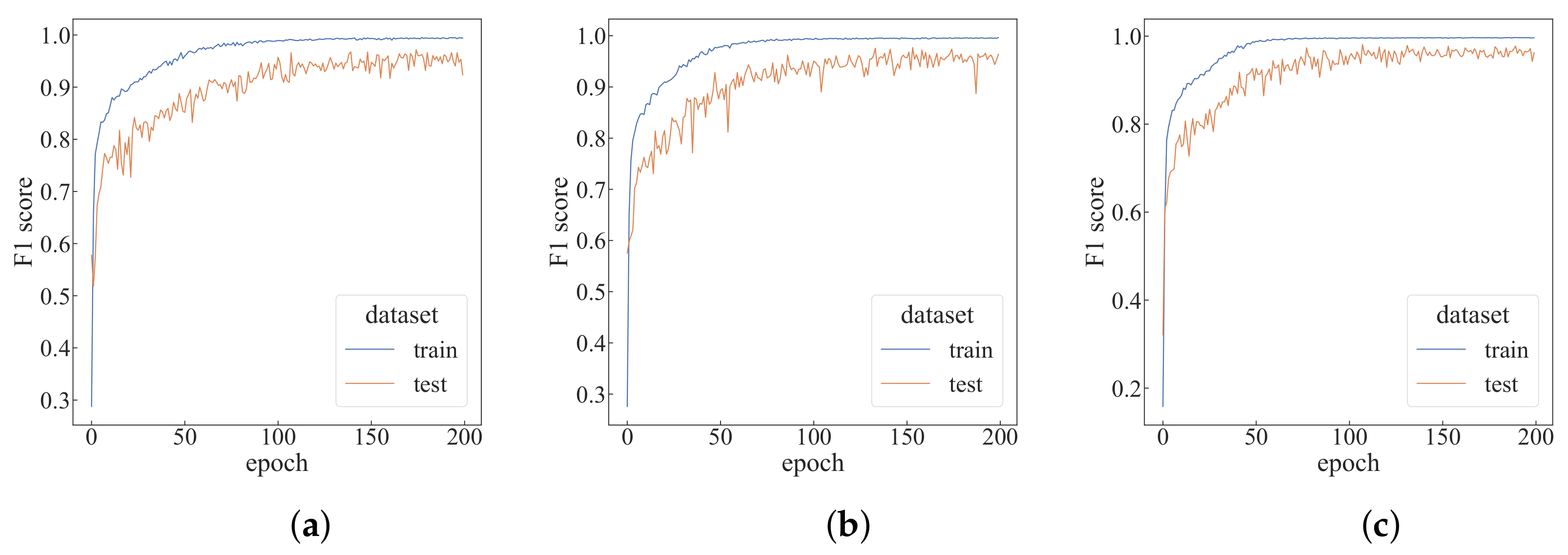
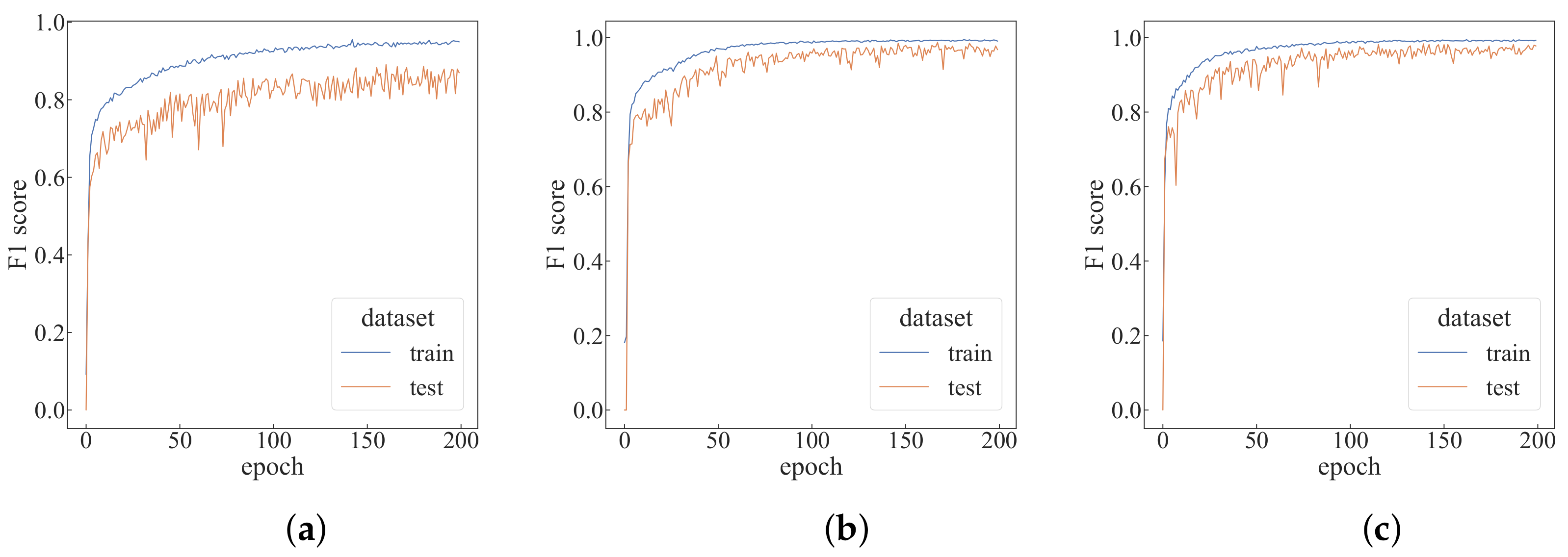
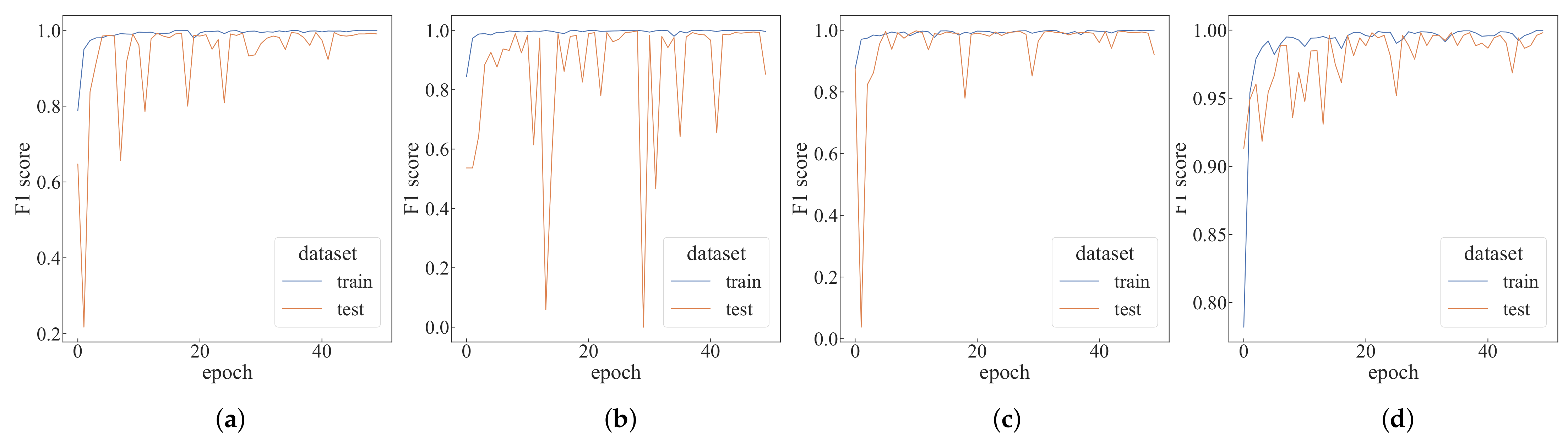
4.2. Performance Analysis under Different Parameters
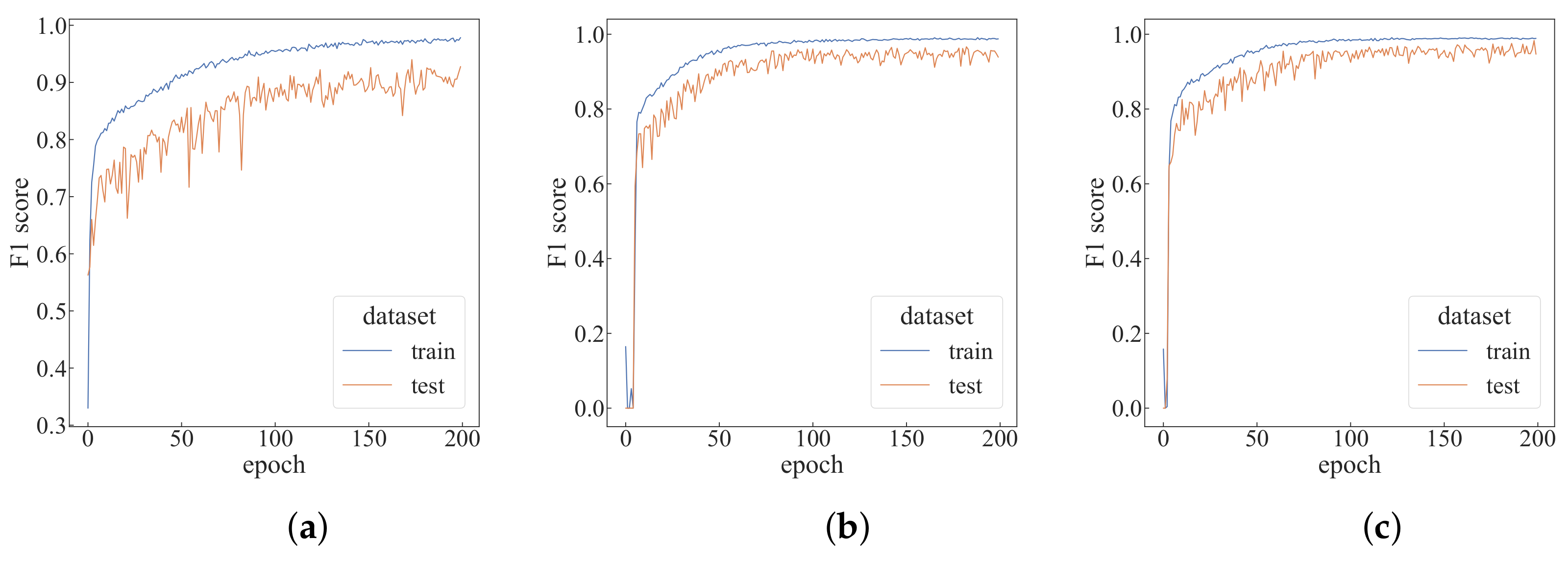
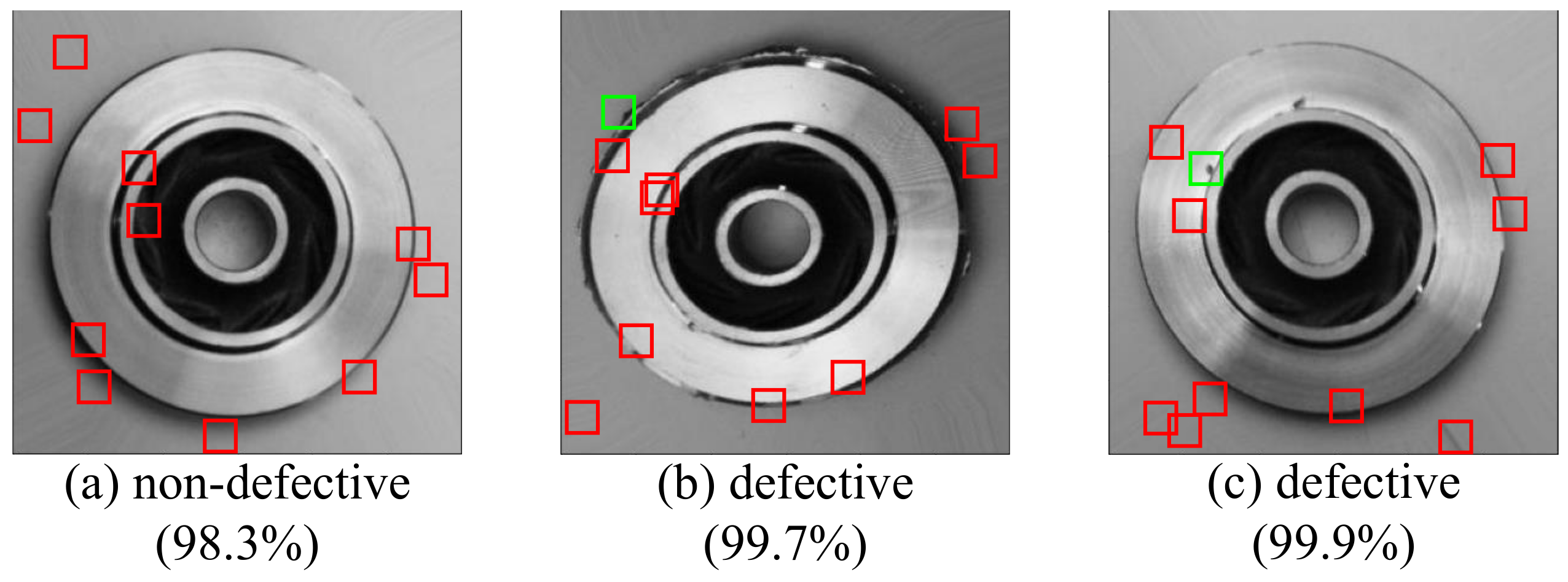
4.3. Comparative Experiments
5. Conclusions and Future Works
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Jiang, X.; Feng Wang, X.; Chen, D. Research on Defect Detection of Castings Based on Deep Residual Network. In Proceedings of the 2018 IEEE 11th International Congress on Image and Signal Processing, BioMedical Engineering and Informatics (CISP-BMEI), Beijing, China, 13–15 October 2018; pp. 1–6. [Google Scholar]
- Du, W.; Shen, H.; Fu, J.; Zhang, G.; He, Q. Approaches for improvement of the X-ray image defect detection of automobile casting aluminum parts based on deep learning. NDT Int. 2019, 107, 102144. [Google Scholar] [CrossRef]
- Duan, L.; Yang, K.; Ruan, L. Research on automatic recognition of casting defects based on deep learning. IEEE Access 2020, 9, 12209–12216. [Google Scholar] [CrossRef]
- Ferguson, M.; Ak, R.; Lee, Y.T.T.; Law, K.H. Automatic localization of casting defects with convolutional neural networks. In Proceedings of the 2017 IEEE International Conference on Big Data (Big Data), Boston, MA, USA, 11–14 December 2017; pp. 1726–1735. [Google Scholar]
- Lee, J.H.; Oh, H.M.; Kim, M.Y. Deep learning based 3D defect detection system using photometric stereo illumination. In Proceedings of the 2019 IEEE International Conference on Artificial Intelligence in Information and Communication (ICAIIC), Okinawa, Japan, 11–13 February 2019; pp. 484–487. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. In Advances in Neural Information Processing Systems; MIT Press: Cambridge, MA, USA, 2012; Volume 25. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Chen, L.; Li, S.; Bai, Q.; Yang, J.; Jiang, S.; Miao, Y. Review of Image Classification Algorithms Based on Convolutional Neural Networks. Remote Sens. 2021, 13, 4712. [Google Scholar] [CrossRef]
- Rawat, W.; Wang, Z. Deep convolutional neural networks for image classification: A comprehensive review. Neural Comput. 2017, 29, 2352–2449. [Google Scholar] [CrossRef] [PubMed]
- Gupta, S.K. Reinforcement based learning on classification task could yield better generalization and adversarial accuracy. arXiv 2020, arXiv:2012.04353. [Google Scholar]
- Sutton, R.S.; McAllester, D.; Singh, S.; Mansour, Y. Policy gradient methods for reinforcement learning with function approximation. In Advances in Neural Information Processing Systems; MIT Press: Cambridge, MA, USA, 1999; Volume 12. [Google Scholar]
- Mansour, R.F.; Escorcia-Gutierrez, J.; Gamarra, M.; Villanueva, J.A.; Leal, N. Intelligent video anomaly detection and classification using faster RCNN with deep reinforcement learning model. Image Vis. Comput. 2021, 112, 104229. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. In Advances in Neural Information Processing Systems; MIT Press: Cambridge, MA, USA, 2015; Volume 28. [Google Scholar]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Graves, A.; Antonoglou, I.; Wierstra, D.; Riedmiller, M. Playing atari with deep reinforcement learning. arXiv 2013, arXiv:1312.5602. [Google Scholar]
- Zhao, D.; Chen, Y.; Lv, L. Deep reinforcement learning with visual attention for vehicle classification. IEEE Trans. Cogn. Dev. Syst. 2016, 9, 356–367. [Google Scholar] [CrossRef]
- Furuta, R.; Inoue, N.; Yamasaki, T. Pixelrl: Fully convolutional network with reinforcement learning for image processing. IEEE Trans. Multimed. 2019, 22, 1704–1719. [Google Scholar] [CrossRef] [Green Version]
- Mnih, V.; Badia, A.P.; Mirza, M.; Graves, A.; Lillicrap, T.; Harley, T.; Silver, D.; Kavukcuoglu, K. Asynchronous methods for deep reinforcement learning. In Proceedings of the International Conference on Machine Learning, PMLR, New York, NY, USA, 20–22 June 2016; pp. 1928–1937. [Google Scholar]
- Fan, L.; Zhang, F.; Fan, H.; Zhang, C. Brief review of image denoising techniques. Vis. Comput. Ind. Biomed. Art 2019, 2, 1–12. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Park, J.; Lee, J.Y.; Yoo, D.; Kweon, I.S. Distort-and-recover: Color enhancement using deep reinforcement learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 5928–5936. [Google Scholar]
- Mousavi, H.K.; Nazari, M.; Takáč, M.; Motee, N. Multi-agent image classification via reinforcement learning. In Proceedings of the 2019 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Macau, China, 3–8 November 2019; pp. 5020–5027. [Google Scholar]
- Cho, K.; Van Merriënboer, B.; Gulcehre, C.; Bahdanau, D.; Bougares, F.; Schwenk, H.; Bengio, Y. Learning phrase representations using RNN encoder-decoder for statistical machine translation. arXiv 2014, arXiv:1406.1078. [Google Scholar]
- Littman, M.L. Markov games as a framework for multi-agent reinforcement learning. In Machine Learning Proceedings 1994; Morgan Kaufmann: Burlington, MA, USA, 1994; pp. 157–163. [Google Scholar]
- Tian, Y.; Wang, Y.; Yu, T.; Sra, S. Online learning in unknown markov games. In Proceedings of the International Conference on Machine Learning, PMLR, Virtual Event, 13–14 August 2021; pp. 10279–10288. [Google Scholar]
- Pajarinen, J.; Peltonen, J. Periodic finite state controllers for efficient POMDP and DEC-POMDP planning. In Advances in Neural Information Processing Systems; MIT Press: Cambridge, MA, USA, 2011; Volume 24. [Google Scholar]
- Aşık, O.; Akın, H.L. Solving multi-agent decision problems modeled as dec-pomdp: A robot soccer case study. In Robot Soccer World Cup; Springer: Berlin/Heidelberg, Germany, 2012; pp. 130–140. [Google Scholar]
- Kumar, A.; Mostafa, H.; Zilberstein, S. Dual formulations for optimizing Dec-POMDP controllers. In Proceedings of the Twenty-Sixth International Conference on Automated Planning and Scheduling, London, UK, 12–17 June 2016. [Google Scholar]
- Gronauer, S.; Diepold, K. Multi-agent deep reinforcement learning: A survey. Artif. Intell. Rev. 2022, 55, 895–943. [Google Scholar] [CrossRef]
- Li, M.L.; Chen, S.; Chen, J. Adaptive learning: A new decentralized reinforcement learning approach for cooperative multiagent systems. IEEE Access 2020, 8, 99404–99421. [Google Scholar] [CrossRef]
- Zimmer, M.; Glanois, C.; Siddique, U.; Weng, P. Learning fair policies in decentralized cooperative multi-agent reinforcement learning. In Proceedings of the International Conference on Machine Learning, PMLR, Virtual Event, 18–24 July 2021; pp. 12967–12978. [Google Scholar]
- Lowe, R.; Wu, Y.I.; Tamar, A.; Harb, J.; Pieter Abbeel, O.; Mordatch, I. Multi-agent actor-critic for mixed cooperative-competitive environments. In Advances in Neural Information Processing Systems; MIT Press: Cambridge, MA, USA, 2017; Volume 30. [Google Scholar]
- Rashid, T.; Samvelyan, M.; Schroeder, C.; Farquhar, G.; Foerster, J.; Whiteson, S. Qmix: Monotonic value function factorisation for deep multi-agent reinforcement learning. In Proceedings of the International Conference on Machine Learning, PMLR, Stockholm, Sweden, 10–15 July 2018; pp. 4295–4304. [Google Scholar]
- Zhang, Q.; Zhao, D.; Zhu, Y. Data-driven adaptive dynamic programming for continuous-time fully cooperative games with partially constrained inputs. Neurocomputing 2017, 238, 377–386. [Google Scholar] [CrossRef]
- Park, Y.J.; Cho, Y.S.; Kim, S.B. Multi-agent reinforcement learning with approximate model learning for competitive games. PLoS ONE 2019, 14, e0222215. [Google Scholar] [CrossRef] [PubMed]
- He, J.; Li, Y.; Li, H.; Tong, H.; Yuan, Z.; Yang, X.; Huang, W. Application of game theory in integrated energy system systems: A review. IEEE Access 2020, 8, 93380–93397. [Google Scholar] [CrossRef]
- Barron, J.T. Continuously differentiable exponential linear units. arXiv 2017, arXiv:1704.07483. [Google Scholar]
- Han, K.; Wang, Y.; Tian, Q.; Guo, J.; Xu, C.; Xu, C. Ghostnet: More features from cheap operations. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 1580–1589. [Google Scholar]
- Howard, A.; Sandler, M.; Chu, G.; Chen, L.C.; Chen, B.; Tan, M.; Wang, W.; Zhu, Y.; Pang, R.; Vasudevan, V.; et al. Searching for mobilenetv3. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27–28 October 2019; pp. 1314–1324. [Google Scholar]
- Gao, S.H.; Cheng, M.M.; Zhao, K.; Zhang, X.Y.; Yang, M.H.; Torr, P. Res2net: A new multi-scale backbone architecture. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 43, 652–662. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ma, N.; Zhang, X.; Zheng, H.T.; Sun, J. Shufflenet v2: Practical guidelines for efficient cnn architecture design. In Proceedings of the European conference on computer vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 116–131. [Google Scholar]
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameters | Top-1 Training -Score | Top-1 Test -Score | Average Training Time Per Epoch (s) | Average Test Time Per Epoch (s) |
|---|---|---|---|---|
| , , , | 0.96077 | 0.89051 | 39.58 | 1.68 |
| , , , | 0.97834 | 0.93985 | 30.62 | 1.67 |
| , , , | 0.95514 | 0.89051 | 44.80 | 1.84 |
| , , , | 0.98789 | 0.95551 | 44.85 | 1.84 |
| , , , | 0.99515 | 0.97164 | 67.28 | 1.85 |
| , , , | 0.99653 | 0.97692 | 94.18 | 1.83 |
| , , , | 0.99688 | 0.98099 | 117.51 | 1.86 |
| , , , | 0.99463 | 0.98667 | 44.89 | 1.85 |
| , , , | 0.99446 | 0.98305 | 46.25 | 1.88 |
| , , , | 0.99084 | 0.96629 | 59.79 | 2.41 |
| , , , | 0.99084 | 0.98299 | 75.76 | 2.64 |
| , , , | 0.99153 | 0.98292 | 52.58 | 2.05 |
| , , , | 0.99498 | 0.98677 | 58.46 | 2.24 |
| Models | Top-1 Training F1-Score | Top-1 Test F1-Score | Average Training Time Per Epoch (s) | Average Test Time Per Epoch (s) |
|---|---|---|---|---|
| GhostNet | 1 | 0.99431 | 110.93 | 10.90 |
| MobileNetV3 Small | 1 | 0.99809 | 129.54 | 13.59 |
| Res2Net-50 | 0.99965 | 0.99809 | 185.67 | 12.81 |
| ShuffleNetV2 | 0.99983 | 0.99809 | 126.63 | 13.64 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, C.; Zhang, Y.; Mao, S. Image Classification Method Based on Multi-Agent Reinforcement Learning for Defects Detection for Casting. Sensors 2022, 22, 5143. https://doi.org/10.3390/s22145143
Liu C, Zhang Y, Mao S. Image Classification Method Based on Multi-Agent Reinforcement Learning for Defects Detection for Casting. Sensors. 2022; 22(14):5143. https://doi.org/10.3390/s22145143
Chicago/Turabian StyleLiu, Chaoyue, Yulai Zhang, and Sijia Mao. 2022. "Image Classification Method Based on Multi-Agent Reinforcement Learning for Defects Detection for Casting" Sensors 22, no. 14: 5143. https://doi.org/10.3390/s22145143