
Group Emotion Detection Based on Social Robot Perception




Abstract
:1. Introduction
2. Related Work
2.1. Group Emotion Recognition
2.1.1. Pre-Processing of Images
2.1.2. Feature Extraction
2.1.3. Fusion Methods and Evaluation
2.1.4. Comparative Evaluation
2.2. Emotion Recognition for Social Robots
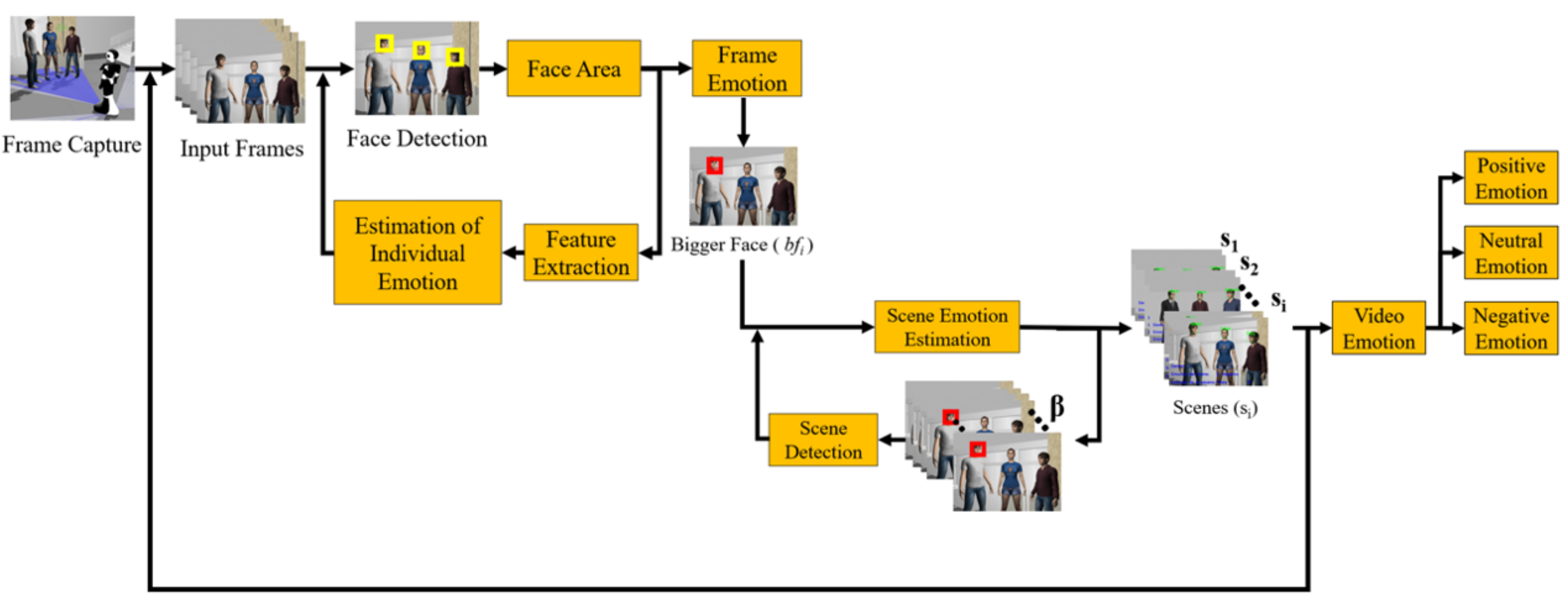
3. Group Emotion Detection: The Proposal
- Video (V): This is a recording of a sequence of images (frames) of an indoor space, taken from the robot sensors. While the robot is moving around the room, it records what it sees, with the aim of detecting groups of people (scenes).
- Frame (f): This is an image of the set of images in a video. In this case, the frames with people are the targeted frames for the robots, in which an emotion is recognised, denoted as .
- Scene (s): This is a sequence of frames (short video) in which a group of persons is detected. In each scene, an emotion is recognised, denoted as .
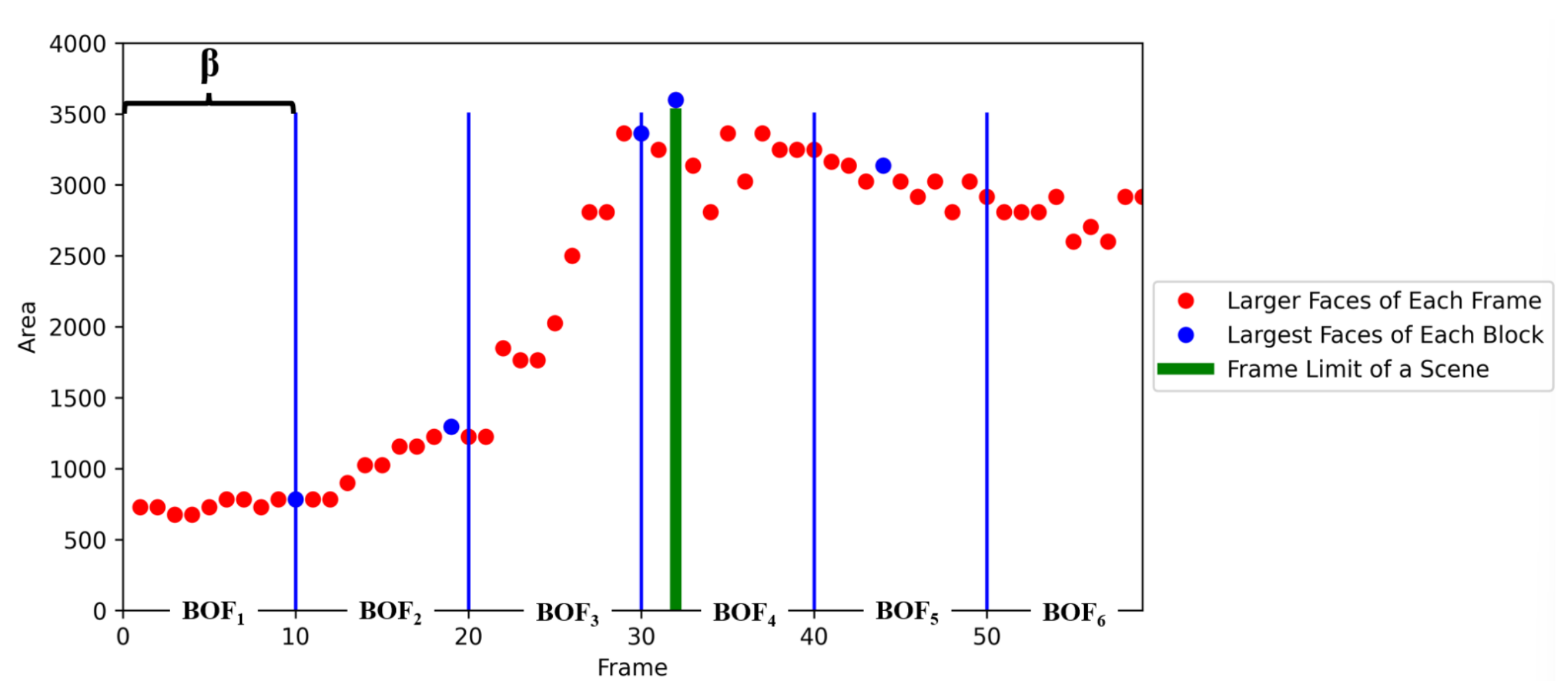
- Blocks of frames in a video (): A video is divided into blocks of frames (), each one conformed by frames. The parameter is provided by the users and defines the windows to identify scenes (i.e., the number of frames that a robot should analyse to detect scenes in the video). If the video has n frames, the video is divided into k, where ; hence, , where and is the frame i of .
- Set of biggest faces per (): For each , the area of the biggest face among the frames in is extracted, such that , where is the area of the biggest face found in .
- A can contain two scenes at a maximum, since the start of a scene is marked by the (the biggest face in ) if the is smaller than , or several might belong to the same scene, if is smaller than . Hence, a video contains one or more scenes, such that , where is the scene i in the video V and .
3.1. Face Detection
3.2. Feature Extraction
3.3. Estimation of Individual Emotion
3.4. Estimation of Emotion in Each Frame, Scene, and Video
3.5. Scene Detection
| Algorithm 1:Scene and Emotion Detection for a Video |
Input:V = the video; = number of frames per block; n = number of frames in the video. Output:S = array of scenes, F = pairs of frames that delimit each scene. 1. , // First scene, first frame of the first scene. 2. // Number of BOF to analyse. 3. for tok do 4. for to do 5. determine the emotion of the frame 6. end for 7. determine the largest face of block . 8. end for 9. for to do 10. if then 11. add a new scene . 12. frame where is located. 13. // first and last frame that form the scene . 14. 15. 16. end if 17. end for 18. for to do 19. detect scene emotion in S 20. end for 21. determine emotion of video V from S 22. return V.emotion, S, F // Video and scenes detected with their emotions tagged. |
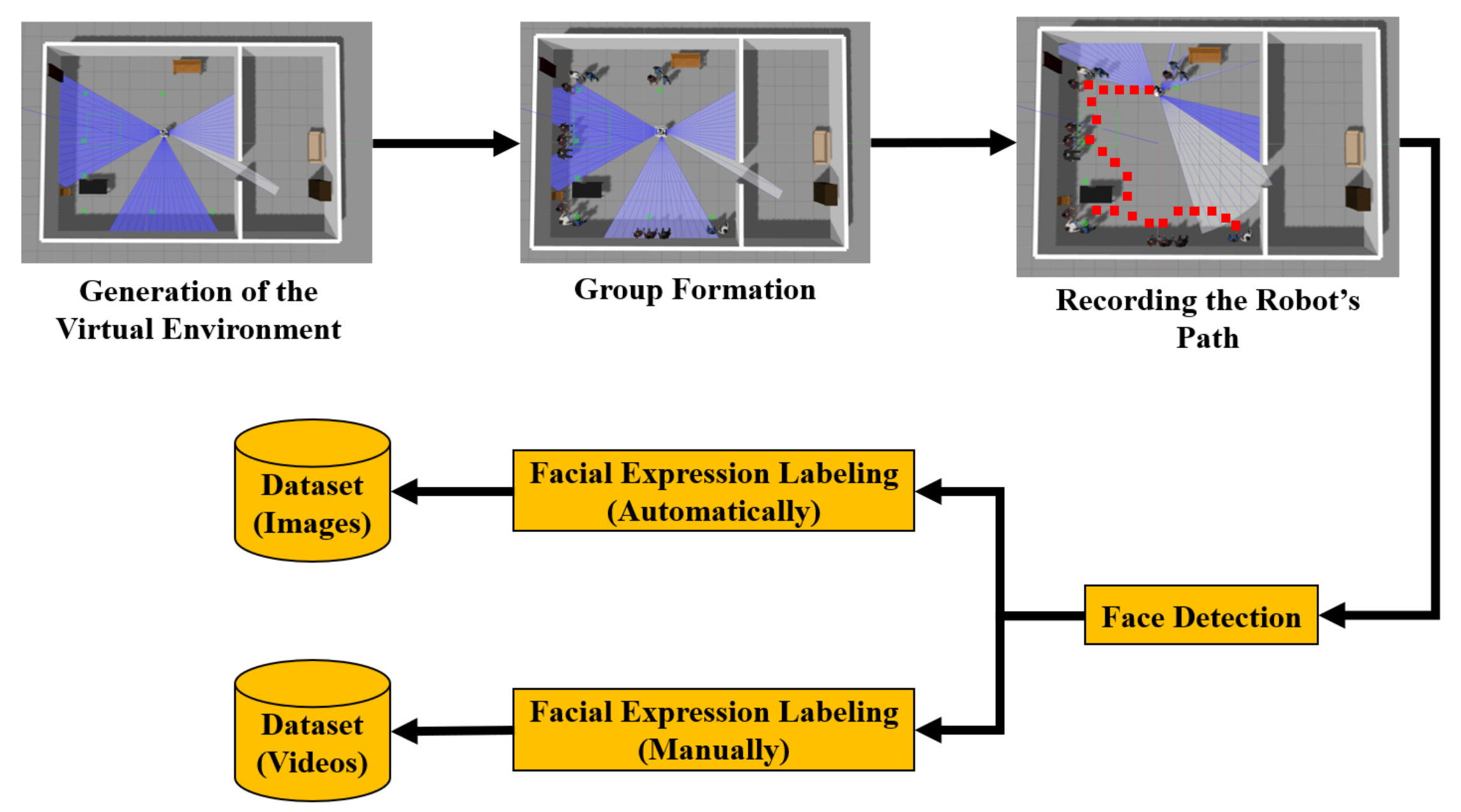
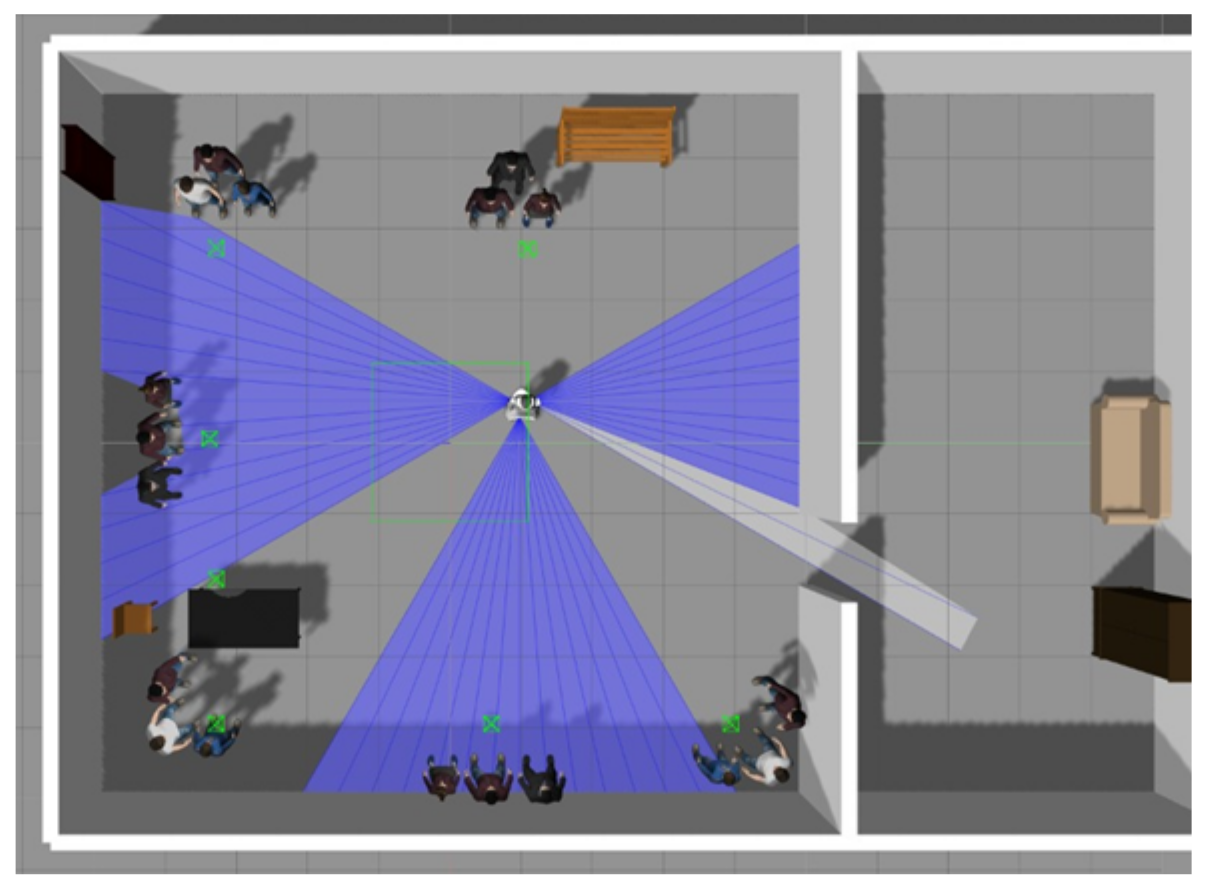
4. Generation of Datasets
4.1. Images Dataset
4.2. Videos Dataset
5. Simulations and Results
5.1. Simulation Environment
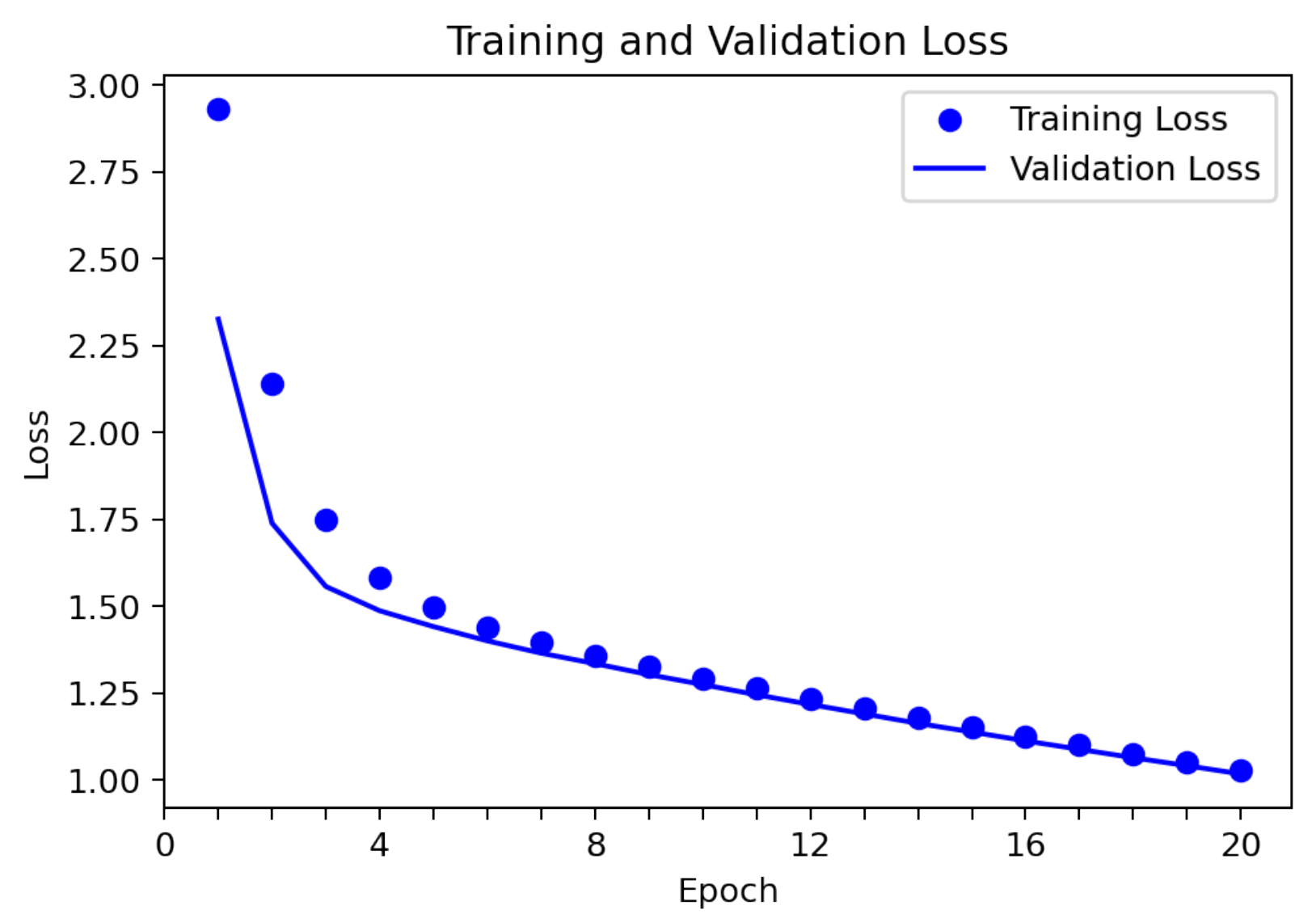
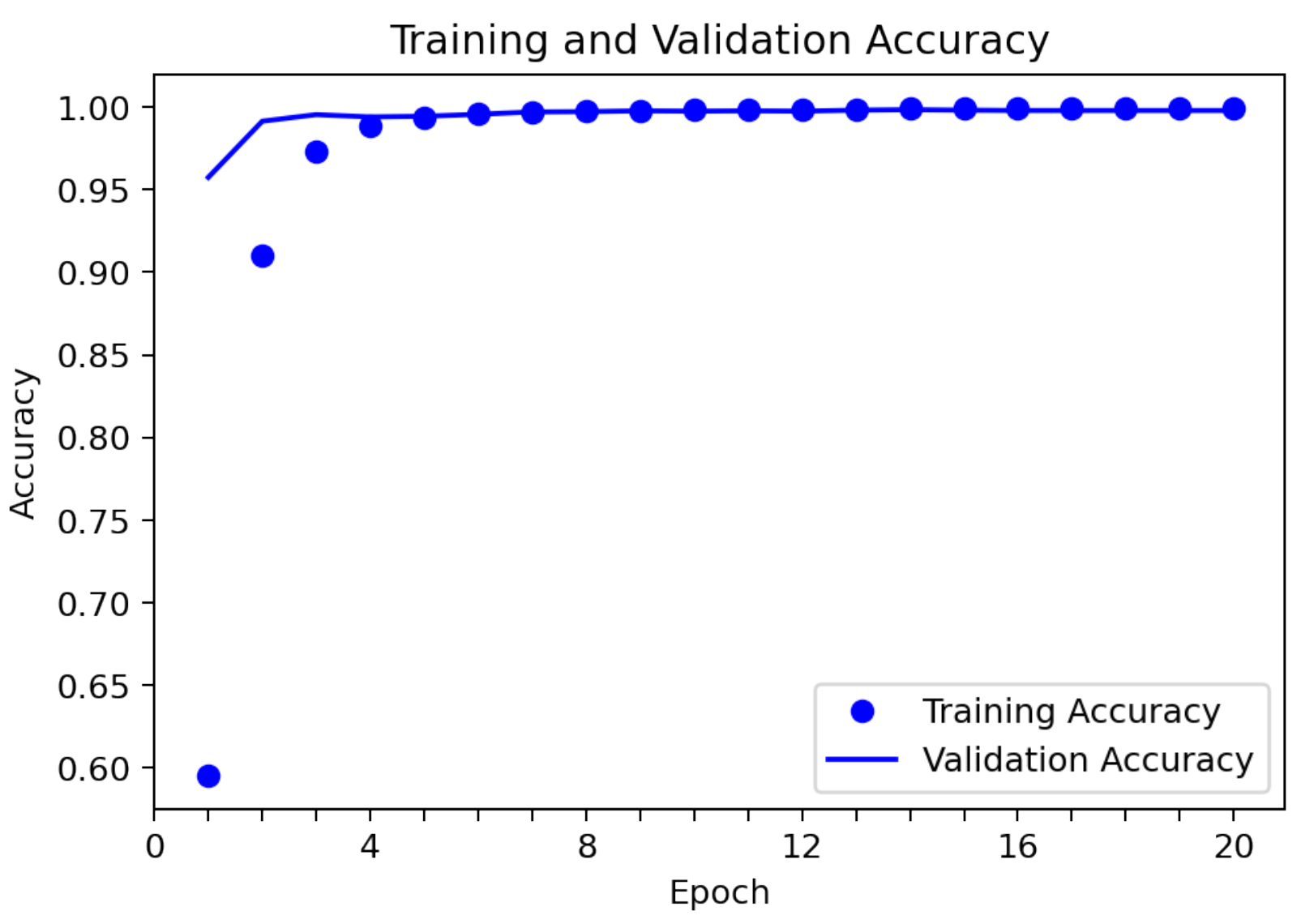
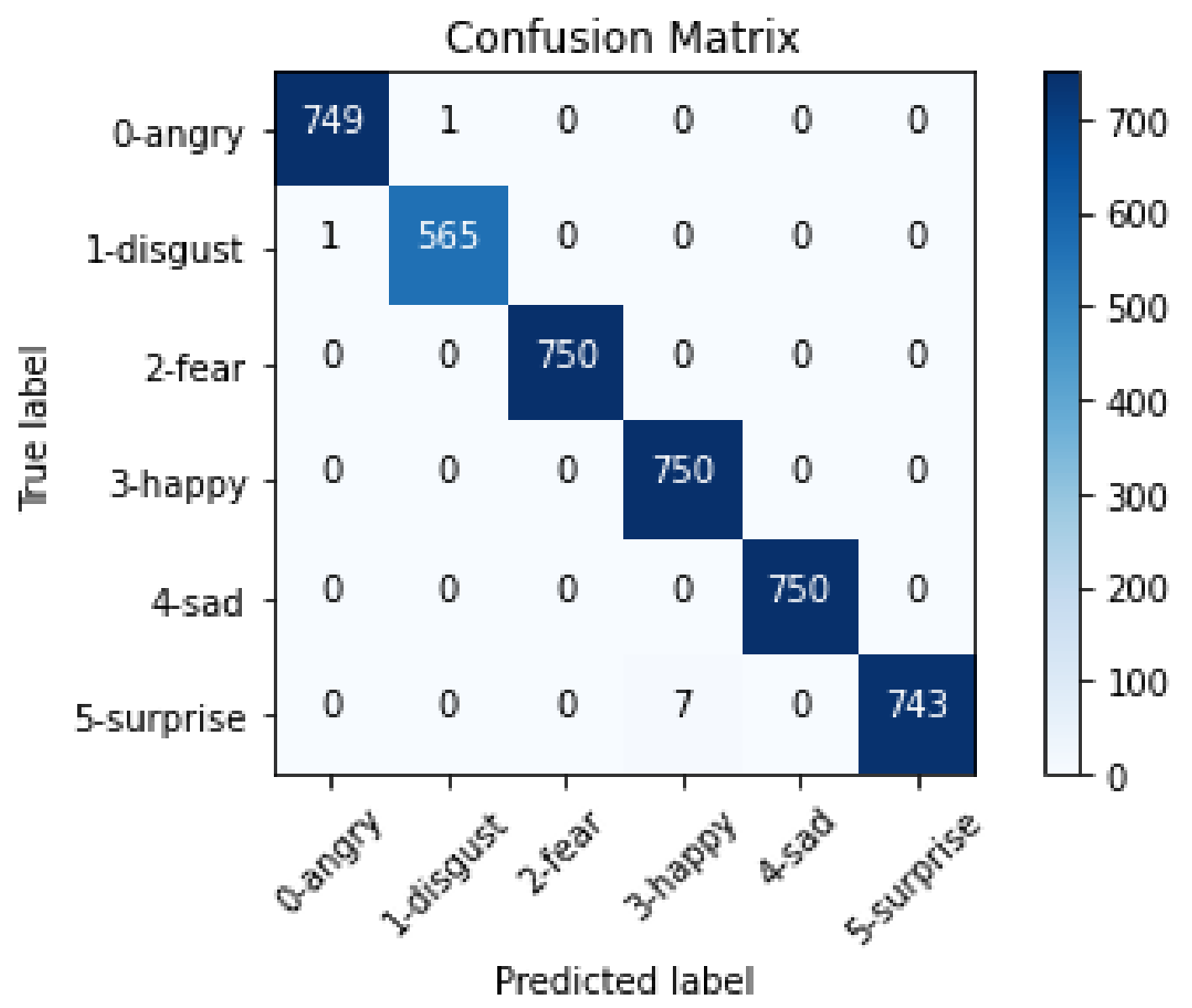
5.2. Individual Emotion
5.3. Emotion of Videos
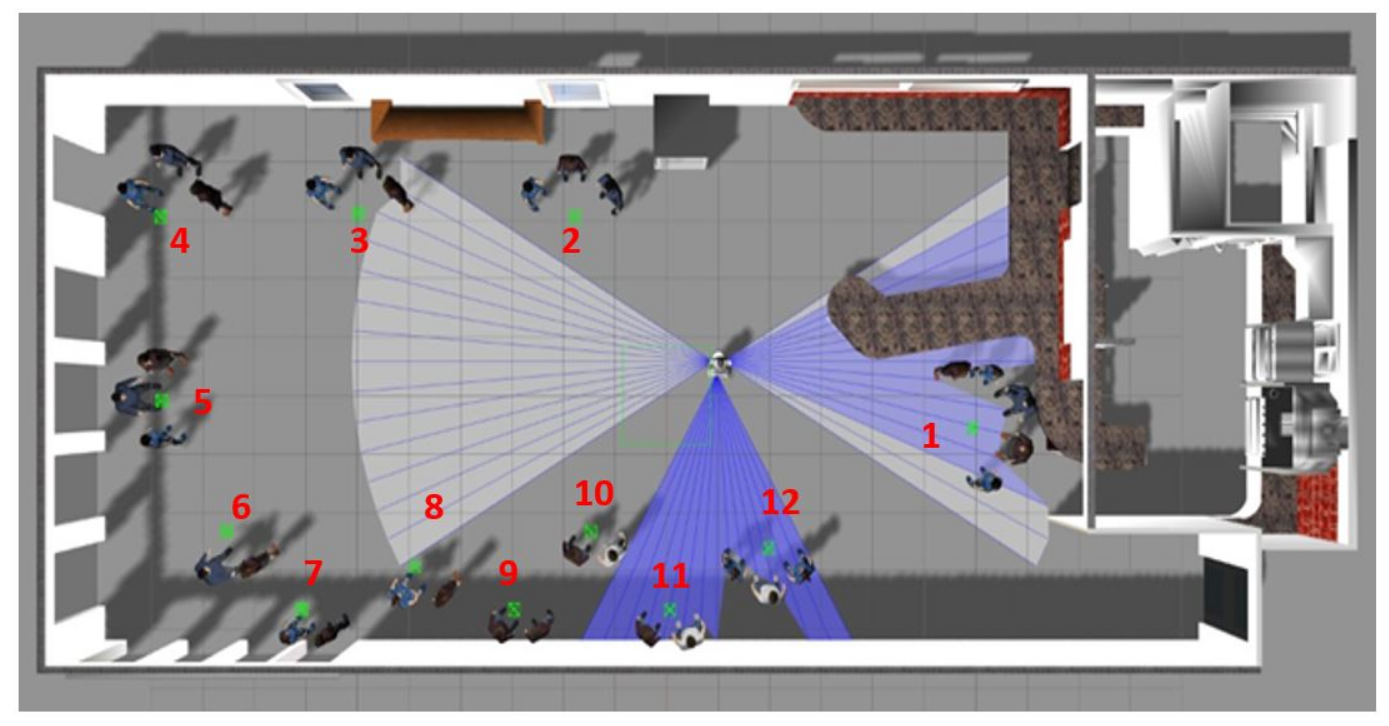
5.3.1. Videos Recorded in the Museum
5.3.2. Videos Recorded in the Cafeteria
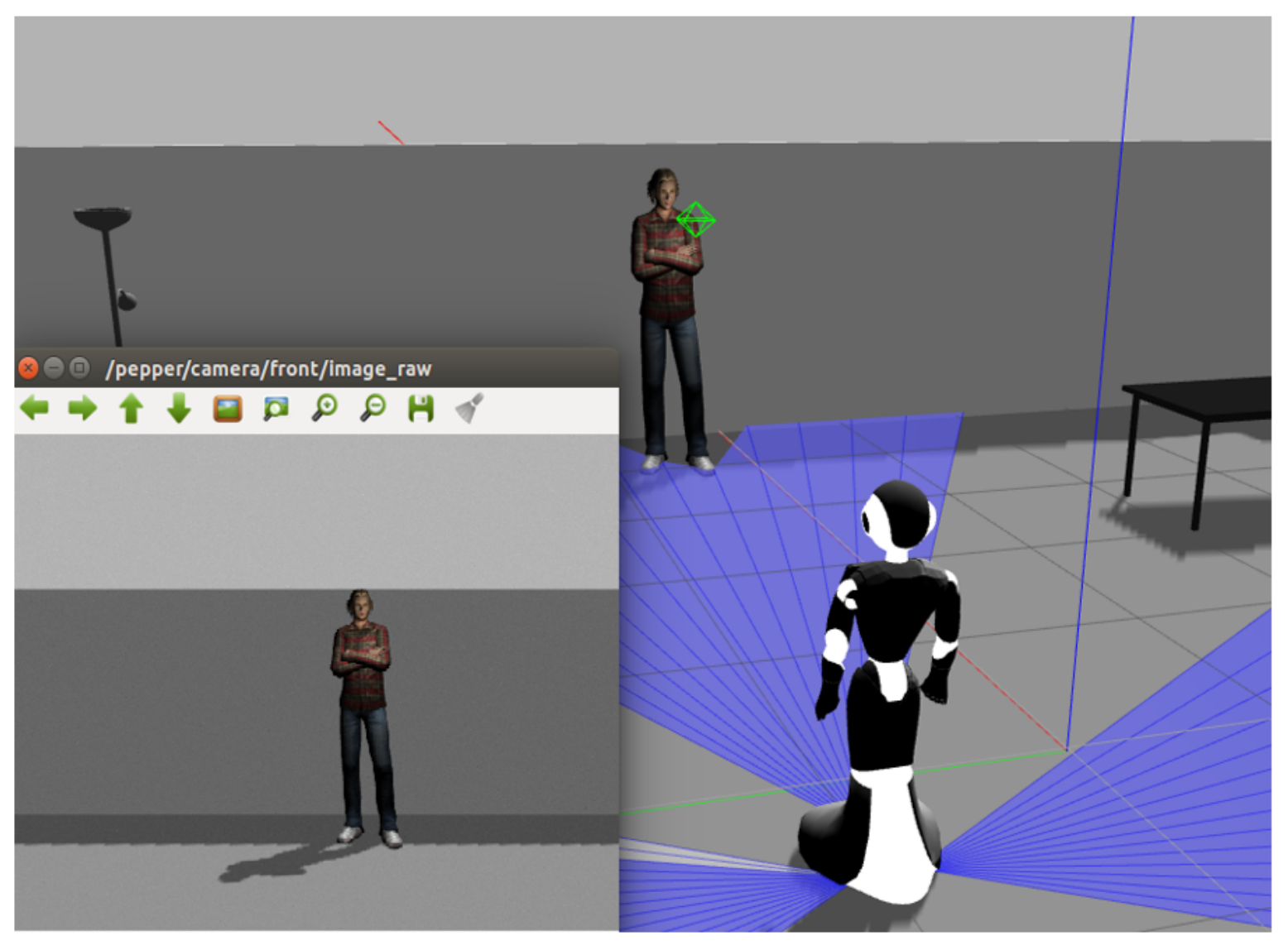
5.4. Simulation in ROS/Gazebo
6. Discussion
6.1. Datasets with Robocentric Perspective and Group Emotion Detection
6.2. Emotion of a Scene
6.3. Applicability
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Duffy, B.R.; Rooney, C.; O’Hare, G.M.; O’Donoghue, R. What is a social robot? In Proceedings of the 10th Irish Conference on Artificial Intelligence & Cognitive Science, Cork, Ireland, 1–3 September 1999.
- Casas, J.; Gomez, N.C.; Senft, E.; Irfan, B.; Gutiérrez, L.F.; Rincón, M.; Múnera, M.; Belpaeme, T.; Cifuentes, C.A. Architecture for a social assistive robot in cardiac rehabilitation. In Proceedings of the Colombian Conference on Robotics and Automation (CCRA), Barranquilla, Colombia, 1–3 November 2018; pp. 1–6. [Google Scholar]
- Cooper, S.; Di Fava, A.; Vivas, C.; Marchionni, L.; Ferro, F. ARI: The social assistive robot and companion. In Proceedings of the International Conference on Robot and Human Interactive Communication (RO-MAN), Naples, Italy, 31 August–4 September 2020; pp. 745–751. [Google Scholar]
- Nocentini, O.; Fiorini, L.; Acerbi, G.; Sorrentino, A.; Mancioppi, G.; Cavallo, F. A survey of behavioural models for social robots. Robotics 2019, 8, 54. [Google Scholar] [CrossRef] [Green Version]
- Hong, A.; Lunscher, N.; Hu, T.; Tsuboi, Y.; Zhang, X.; dos Reis Alves, S.F.; Nejat, G.; Benhabib, B. A Multimodal Emotional Human-Robot Interaction Architecture for Social Robots Engaged in Bidirectional Communication. IEEE Trans. Cybern. 2020, 51, 5954–5968. [Google Scholar] [CrossRef] [PubMed]
- Liu, Z.; Wu, M.; Cao, W.; Chen, L.; Xu, J.; Zhang, R.; Zhou, M.; Mao, J. A facial expression emotion recognition based human–robot interaction system. IEEE/CAA J. Autom. Sin. 2017, 4, 668–676. [Google Scholar] [CrossRef]
- Lopez-Rincon, A. Emotion recognition using facial expressions in children using the NAO Robot. In Proceedings of the International Conference on Electronics, Communications and Computers (CONIELECOMP), Cholula, Mexico, 27 February–1 March 2019; pp. 146–153. [Google Scholar]
- Cavallo, F.; Semeraro, F.; Fiorini, L.; Magyar, G.; Sinčák, P.; Dario, P. Emotion modelling for social robotics applications: A review. J. Bionic Eng. 2018, 15, 185–203. [Google Scholar] [CrossRef]
- Mohammed, S.N.; Hassan, A.K.A. A Survey on Emotion Recognition for Human Robot Interaction. J. Comput. Inf. Technol. 2020, 28, 125–146. [Google Scholar]
- Yan, F.; Iliyasu, A.M.; Hirota, K. Emotion space modelling for social robots. Eng. Appl. Artif. Intell. 2021, 100, 104178. [Google Scholar] [CrossRef]
- Bandini, A.; Zariffa, J. Analysis of the hands in egocentric vision: A survey. IEEE Trans. Pattern Anal. Mach. Intell. 2020. [Google Scholar] [CrossRef] [Green Version]
- Pathi, S.K.; Kiselev, A.; Loutfi, A. Detecting Groups and Estimating F-Formations for Social Human–Robot Interactions. Multimodal Technol. Interact. 2022, 6, 18. [Google Scholar] [CrossRef]
- Kivrak, H.; Cakmak, F.; Kose, H.; Yavuz, S. Social navigation framework for assistive robots in human inhabited unknown environments. Eng. Sci. Technol. Int. J. 2021, 24, 284–298. [Google Scholar] [CrossRef]
- Liu, S.; Chang, P.; Huang, Z.; Chakraborty, N.; Liang, W.; Geng, J.; Driggs-Campbell, K. Socially Aware Robot Crowd Navigation with Interaction Graphs and Human Trajectory Prediction. arXiv 2022, arXiv:2203.01821. [Google Scholar]
- Bera, A.; Randhavane, T.; Prinja, R.; Kapsaskis, K.; Wang, A.; Gray, K.; Manocha, D. The emotionally intelligent robot: Improving social navigation in crowded environments. arXiv 2019, arXiv:1903.03217. [Google Scholar]
- Sathyamoorthy, A.J.; Patel, U.; Paul, M.; Kumar, N.K.S.; Savle, Y.; Manocha, D. CoMet: Modeling group cohesion for socially compliant robot navigation in crowded scenes. Robot. Autom. Lett. 2021, 7, 1008–1015. [Google Scholar] [CrossRef]
- Guo, X.; Polanía, L.F.; Barner, K.E. Group-level emotion recognition using deep models on image scene, faces, and skeletons. In Proceedings of the ACM International Conference on Multimodal Interaction, Glasgow, UK, 13–17 November 2017; pp. 603–608. [Google Scholar]
- Guo, X.; Zhu, B.; Polanía, L.F.; Boncelet, C.; Barner, K.E. Group-level emotion recognition using hybrid deep models based on faces, scenes, skeletons and visual attentions. In Proceedings of the ACM International Conference on Multimodal Interaction, Boulder, CO, USA, 16–20 October 2018; pp. 635–639. [Google Scholar]
- Xuan Dang, T.; Kim, S.H.; Yang, H.J.; Lee, G.S.; Vo, T.H. Group-level Cohesion Prediction using Deep Learning Models with A Multi-stream Hybrid Network. In Proceedings of the International Conference on Multimodal Interaction, Suzhou, China, 14–18 October 2019; pp. 572–576. [Google Scholar]
- Tien, D.X.; Yang, H.J.; Lee, G.S.; Kim, S.H. D2C-Based Hybrid Network for Predicting Group Cohesion Scores. IEEE Access 2021, 9, 84356–84363. [Google Scholar] [CrossRef]
- Quach, K.G.; Le, N.; Duong, C.N.; Jalata, I.; Roy, K.; Luu, K. Non-Volume Preserving-based Fusion to Group-Level Emotion Recognition on Crowd Videos. Pattern Recognit. 2022, 128, 108646. [Google Scholar] [CrossRef]
- Zhang, K.; Zhang, Z.; Li, Z.; Qiao, Y. Joint face detection and alignment using multitask cascaded convolutional networks. Signal Process. Lett. 2016, 23, 1499–1503. [Google Scholar] [CrossRef] [Green Version]
- Zhu, B.; Guo, X.; Barner, K.; Boncelet, C. Automatic group cohesiveness detection with multi-modal features. In Proceedings of the International Conference on Multimodal Interaction, Suzhou, China, 14–18 October 2019; pp. 577–581. [Google Scholar]
- Tan, L.; Zhang, K.; Wang, K.; Zeng, X.; Peng, X.; Qiao, Y. Group emotion recognition with individual facial emotion CNNs and global image based CNNs. In Proceedings of the ACM International Conference on Multimodal Interaction, Glasgow, UK, 13–17 November 2017; pp. 549–552. [Google Scholar]
- Wang, K.; Zeng, X.; Yang, J.; Meng, D.; Zhang, K.; Peng, X.; Qiao, Y. Cascade attention networks for group emotion recognition with face, body and image cues. In Proceedings of the ACM International Conference on Multimodal Interaction, Boulder, CO, USA, 16–20 October 2018; pp. 640–645. [Google Scholar]
- Khan, A.S.; Li, Z.; Cai, J.; Meng, Z.; O’Reilly, J.; Tong, Y. Group-level emotion recognition using deep models with a four-stream hybrid network. In Proceedings of the ACM International Conference on Multimodal Interaction, Boulder, CO, USA, 16–20 October 2018; pp. 623–629. [Google Scholar]
- Gupta, A.; Agrawal, D.; Chauhan, H.; Dolz, J.; Pedersoli, M. An attention model for group-level emotion recognition. In Proceedings of the ACM International Conference on Multimodal Interaction, Boulder, CO, USA, 16–20 October 2018; pp. 611–615. [Google Scholar]
- Guo, X.; Polania, L.; Zhu, B.; Boncelet, C.; Barner, K. Graph neural networks for image understanding based on multiple cues: Group emotion recognition and event recognition as use cases. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Snowmass Village, CO, USA, 1–5 March 2020; pp. 2921–2930. [Google Scholar]
- Khan, A.S.; Li, Z.; Cai, J.; Tong, Y. Regional Attention Networks with Context-aware Fusion for Group Emotion Recognition. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 4–8 January 2021; pp. 1150–1159. [Google Scholar]
- Sun, M.; Li, J.; Feng, H.; Gou, W.; Shen, H.; Tang, J.; Yang, Y.; Ye, J. Multi-Modal Fusion Using Spatio-Temporal and Static Features for Group Emotion Recognition. In Proceedings of the International Conference on Multimodal Interaction, Online, 25–29 October 2020; pp. 835–840. [Google Scholar]
- Balaji, B.; Oruganti, V.R.M. Multi-level feature fusion for group-level emotion recognition. In Proceedings of the ACM International Conference on Multimodal Interaction, Glasgow, UK, 13–17 November 2017; pp. 583–586. [Google Scholar]
- Guo, D.; Wang, K.; Yang, J.; Zhang, K.; Peng, X.; Qiao, Y. Exploring Regularizations with Face, Body and Image Cues for Group Cohesion Prediction. In Proceedings of the International Conference on Multimodal Interaction, Suzhou, China, 14–18 October 2019; pp. 557–561. [Google Scholar]
- Viola, P.; Jones, M. Rapid object detection using a boosted cascade of simple features. In Proceedings of the Computer Society Conference on Computer Vision and Pattern Recognition, Kauai, HI, USA, 8–14 December 2001; Volume 1, p. 1. [Google Scholar]
- Rassadin, A.; Gruzdev, A.; Savchenko, A. Group-level emotion recognition using transfer learning from face identification. In Proceedings of the ACM International Conference on Multimodal Interaction, Glasgow, UK, 13–17 November 2017; pp. 544–548. [Google Scholar]
- Wei, Q.; Zhao, Y.; Xu, Q.; Li, L.; He, J.; Yu, L.; Sun, B. A new deep-learning framework for group emotion recognition. In Proceedings of the ACM International Conference on Multimodal Interaction, Glasgow, UK, 13–17 November 2017; pp. 587–592. [Google Scholar]
- Sun, B.; Wei, Q.; Li, L.; Xu, Q.; He, J.; Yu, L. LSTM for dynamic emotion and group emotion recognition in the wild. In Proceedings of the ACM International Conference on Multimodal Interaction, Tokyo, Japan, 12–16 November 2016; pp. 451–457. [Google Scholar]
- Abbas, A.; Chalup, S.K. Group emotion recognition in the wild by combining deep neural networks for facial expression classification and scene-context analysis. In Proceedings of the ACM International Conference on Multimodal Interaction, Glasgow, UK, 13–17 November 2017; pp. 561–568. [Google Scholar]
- Hassner, T.; Harel, S.; Paz, E.; Enbar, R. Effective face frontalization in unconstrained images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 4295–4304. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Yu, D.; Xingyu, L.; Shuzhan, D.; Lei, Y. Group emotion recognition based on global and local features. IEEE Access 2019, 7, 111617–111624. [Google Scholar] [CrossRef]
- Savery, R.; Weinberg, G. A Survey of Robotics and Emotion: Classifications and Models of Emotional Interaction. In Proceedings of the International Conference on Robot and Human Interactive Communication (RO-MAN), Naples, Italy, 31 August–4 September 2020; pp. 986–993. [Google Scholar]
- Stock-Homburg, R. Survey of Emotions in Human–Robot Interactions: Perspectives from Robotic Psychology on 20 Years of Research. Int. J. Soc. Rob. 2021, 14, 1–23. [Google Scholar] [CrossRef]
- Bhagya, S.; Samarakoon, P.; Viraj, M.; Muthugala, J.; Buddhika, A.; Jayasekara, P.; Elara, M.R. An exploratory study on proxemics preferences of humans in accordance with attributes of service robots. In Proceedings of the International Conference on Robot and Human Interactive Communication (RO-MAN), New Delhi, India, 14–18 October 2019; pp. 1–7. [Google Scholar]
- Ginés, J.; Martín, F.; Vargas, D.; Rodríguez, F.J.; Matellán, V. Social navigation in a cognitive architecture using dynamic proxemic zones. Sensors 2019, 19, 5189. [Google Scholar] [CrossRef] [Green Version]
- Rawal, N.; Stock-Homburg, R.M. Facial emotion expressions in human–robot interaction: A survey. arXiv 2021, arXiv:2103.07169. [Google Scholar]
- Yu, C.; Tapus, A. Interactive Robot Learning for Multimodal Emotion Recognition. In Social Robotics; Springer: Berlin/Heidelberg, Germany, 2019; pp. 633–642. [Google Scholar]
- Kashii, A.; Takashio, K.; Tokuda, H. Ex-amp robot: Expressive robotic avatar with multimodal emotion detection to enhance communication of users with motor disabilities. In Proceedings of the 26th International Symposium on Robot and Human Interactive Communication (RO-MAN), Lisbon, Portugal, 28–31 August 2017; pp. 864–870. [Google Scholar]
- Lui, J.H.; Samani, H.; Tien, K.Y. An affective mood booster robot based on emotional processing unit. In Proceedings of the International Automatic Control Conference (CACS), Keelung, Taiwan, 13–16 November 2017; pp. 1–6. [Google Scholar]
- De Carolis, B.; Ferilli, S.; Palestra, G. Simulating empathic behaviour in a social assistive robot. Multimed. Tools Appl. 2017, 76, 5073–5094. [Google Scholar] [CrossRef]
- Castillo, J.C.; Castro-González, Á.; Alonso-Martín, F.; Fernández-Caballero, A.; Salichs, M.Á. Emotion detection and regulation from personal assistant robot in smart environment. In Personal Assistants: Emerging Computational Technologies; Springer: Berlin/Heidelberg, Germany, 2018; pp. 179–195. [Google Scholar]
- Adiga, S.; Vaishnavi, D.V.; Saxena, S.; Tripathi, S. Multimodal Emotion Recognition for Human Robot Interaction. In Proceedings of the 7th International Conference on Soft Computing & Machine Intelligence (ISCMI), Stockholm, Sweden, 14–15 November 2020; pp. 197–203. [Google Scholar]
- Chen, L.; Liu, Z.; Wu, M.; Hirota, K.; Pedrycz, W. Multimodal Emotion Recognition and Intention Understanding in Human-Robot Interaction. Dev. Adv. Control. Intell. Autom. Complex Syst. 2021, 329, 255–288. [Google Scholar]
- Heredia, J.; Lopes-Silva, E.; Cardinale, Y.; Diaz-Amado, J.; Dongo, I.; Graterol, W.; Aguilera, A. Adaptive Multimodal Emotion Detection Architecture for Social Robots. IEEE Access 2022, 10, 20727–20744. [Google Scholar] [CrossRef]
- Graterol, W.; Diaz-Amado, J.; Cardinale, Y.; Dongo, I.; Lopes-Silva, E.; Santos-Libarino, C. Emotion Detection for Social Robots Based on NLP Transformers and an Emotion Ontology. Sensors 2021, 21, 1322. [Google Scholar] [CrossRef]
- Spezialetti, M.; Placidi, G.; Rossi, S. Emotion Recognition for Human-Robot Interaction: Recent Advances and Future Perspectives. Front. Robot. AI 2020, 7, 532279. [Google Scholar] [CrossRef] [PubMed]
- Du, Y.; Hetherington, N.J.; Oon, C.L.; Chan, W.P.; Quintero, C.P.; Croft, E.; Van der Loos, H.M. Group surfing: A pedestrian-based approach to sidewalk robot navigation. In Proceedings of the International Conference on Robotics and Automation (ICRA), Montreal, QC, Canada, 20–24 May 2019; pp. 6518–6524. [Google Scholar]
- Yang, F.; Peters, C. Appgan: Generative adversarial networks for generating robot approach behaviours into small groups of people. In Proceedings of the International Conference on Robot and Human Interactive Communication (RO-MAN), New Delhi, India, 14–18 October 2019; pp. 1–8. [Google Scholar]
- Taylor, A.; Chan, D.M.; Riek, L.D. Robot-centric perception of human groups. ACM Trans. Hum.-Robot Interact. 2020, 9, 1–21. [Google Scholar] [CrossRef]
- Vázquez, M.; Carter, E.J.; McDorman, B.; Forlizzi, J.; Steinfeld, A.; Hudson, S.E. Towards robot autonomy in group conversations: Understanding the effects of body orientation and gaze. In Proceedings of the ACM/IEEE International Conference on Human-Robot Interaction (HRI), Vienna, Austria, 6–9 March 2017; pp. 42–52. [Google Scholar]
- Hayamizu, T.; Mutsuo, S.; Miyawaki, K.; Mori, H.; Nishiguchi, S.; Yamashita, N. Group emotion estimation using Bayesian network based on facial expression and prosodic information. In Proceedings of the International Conference on Control System, Computing and Engineering, Penang, Malaysia, 23–25 November 2012; pp. 177–182. [Google Scholar]
- Choi, S.G.; Cho, S.B. Bayesian networks+ reinforcement learning: Controlling group emotion from sensory stimuli. Neurocomputing 2020, 391, 355–364. [Google Scholar] [CrossRef]
- Cosentino, S.; Randria, E.I.; Lin, J.Y.; Pellegrini, T.; Sessa, S.; Takanishi, A. Group emotion recognition strategies for entertainment robots. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Madrid, Spain, 1–5 October 2018; pp. 813–818. [Google Scholar]
- Oliveira, R.; Arriaga, P.; Paiva, A. Human-robot interaction in groups: Methodological and research practices. Multimodal Technol. Interact. 2021, 5, 59. [Google Scholar] [CrossRef]
- Schmuck, V.; Celiktutan, O. RICA: Robocentric Indoor Crowd Analysis Dataset. In Proceedings of the Conference for PhD Students & Early Career Researcher, Lincoln, UK, 14–17 April 2020; pp. 31–172. [Google Scholar]
- Ekman, P. An argument for basic emotions. Cogn. Emot. 1992, 6, 169–200. [Google Scholar] [CrossRef]
- Plutchik, R. Emotions: A general psychoevolutionary theory. Approaches Emot. 1984, 1984, 197–219. [Google Scholar]
- Johnson-Laird, P.N.; Oatley, K. The language of emotions: An analysis of a semantic field. Cogn. Emot. 1989, 3, 81–123. [Google Scholar] [CrossRef]
- Schmuck, V.; Sheng, T.; Celiktutan, O. Robocentric Conversational Group Discovery. In Proceedings of the International Conference on Robot and Human Interactive Communication (RO-MAN), Naples, Italy, 31 August–4 September 2020; pp. 1288–1293. [Google Scholar]
- Schmuck, V.; Celiktutan, O. GROWL: Group Detection With Link Prediction. In Proceedings of the International Conference on Automatic Face and Gesture Recognition, Jodhpur, India, 15–18 December 2021; pp. 1–8. [Google Scholar]
- Taylor, A.; Riek, L.D. REGROUP: A Robot-Centric Group Detection and Tracking System. In Proceedings of the ACM/IEEE International Conference on Human-Robot Interaction, Hokkaido, Japan, 7–10 March 2022; pp. 412–421. [Google Scholar]
- Azagra, P.; Golemo, F.; Mollard, Y.; Lopes, M.; Civera, J.; Murillo, A.C. A multimodal dataset for object model learning from natural human–robot interaction. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Vancouver, BC, Canada, 24–28 September 2017; pp. 6134–6141. [Google Scholar]
- Bloesch, M.; Omari, S.; Hutter, M.; Siegwart, R. Robust visual inertial odometry using a direct EKF-based approach. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Hamburg, Germany, 28 September–3 October 2015; pp. 298–304. [Google Scholar]
- Huai, Z.; Huang, G. Robocentric visual-inertial odometry. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Madrid, Spain, 1–5 October 2018; pp. 6319–6326. [Google Scholar]
- Wagstaff, B.; Wise, E.; Kelly, J. A Self-Supervised, Differentiable Kalman Filter for Uncertainty-Aware Visual-Inertial Odometry. arXiv 2022, arXiv:2203.07207. [Google Scholar]
- Heredia, J.; Cardinale, Y.; Dongo, I.; Díaz-Amado, J. A multi-modal visual emotion recognition method to instantiate an ontology. In Proceedings of the 16th International Conference on Software Technologies, Online, 6–8 July 2021; pp. 453–464. [Google Scholar]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Reference | Pre-Processing for Face Detection | Individual Emotion Detection Model | Fusion Method |
|---|---|---|---|
| Sun et al., 2016 [36] | Intraface | AlexNet | LSTM |
| Tan et al., 2017 [24] | MTCNN | ResNet-64 and ResNet-34 | Average |
| Guo et al., 2017 [17] | Regression Trees and Viola–Jones | VGGFace | Weighted Sum |
| Wei et al., 2017 [35] | Seetaface | VGGFace with LSTM and DCNN with LSTM | LSTM |
| Rassadin et al., 2017 [34] | HOG and Viola–Jones | VGGFace | Unmentioned |
| Abbas and Chalup, 2017 [37] | Mixtures of Trees Method | CNN | Unmentioned |
| Balaji and Oruganti, 2017 [31] | TinyFace | VGGFace | Unmentioned |
| Guo et al., 2018 [18] | MTCNN | VGGFace and VGG2-SENet-ft-FACE | Weighted Sum |
| Wang et al., 2018 [25] | MTCNN | ResNet64, VGGFace, ResNet-34 and SENet154 | Cascade Attention Networks |
| Khan et al., 2018 [26] | MTCNN | ResNet-18 and ResNet-34 | Average |
| Gupta et al., 2018 [27] | MTCNN | Deep Hypersphere Embedding for Face Recognition | Attention Mechanisms |
| Xuan Dang et al., 2019 [19] | PyramidBox and TinyFace | ResNet50, Inception-ResNet-v2 and DenseNet201 | Combination of Feature Vectors |
| Guo et al., 2019 [32] | S3FD and MTCNN | ResNet18 | Cascade Attention Networks |
| Zhu et al., 2019 [23] | MTCNN | VGGFace | Average |
| Yu et al., 2019 [40] | Unmentioned | VGG-16, MobileNet-v1 | Bi-directional LSTM |
| Guo et al., 2020 [28] | MTCNN | VGGFace and GNN | Unmentioned |
| Sun et al., 2020 [30] | RetinaFace | ResNet and BNInception | FAN Model |
| Tien et al., 2021 [20] | TinyFace | ResNet50 | MLP network with D2C block |
| Khan et al., 2021 [29] | MTCNN | VGGFace and GNN | Context-aware Fusion |
| Quach et al., 2022 [21] | RetinaFace | EmoNet | NVPF |
| Layer (Type) | Output Shape |
|---|---|
| fc8 (Dense) | (None, 512) |
| d1 (Dropout) | (None, 512) |
| fc7 (Dense) | (None, 512) |
| d2 (Dropout) | (None, 512) |
| fc6 (Dense) | (None, 6) |
| Positive Emotions | Neutral Emotions | Negative Emotions |
|---|---|---|
| Happy | Surprise | Sad, Fear, Disgust, and Angry |
| Emotions | Happy | Sad | Angry | Disgust | Surprise | Fear |
|---|---|---|---|---|---|---|
| Training Data | 3371 | 3145 | 3363 | 2872 | 3179 | 2976 |
| Test Data | 750 | 750 | 750 | 566 | 750 | 750 |
| Total | 4121 | 3895 | 4113 | 3438 | 3929 | 3726 |
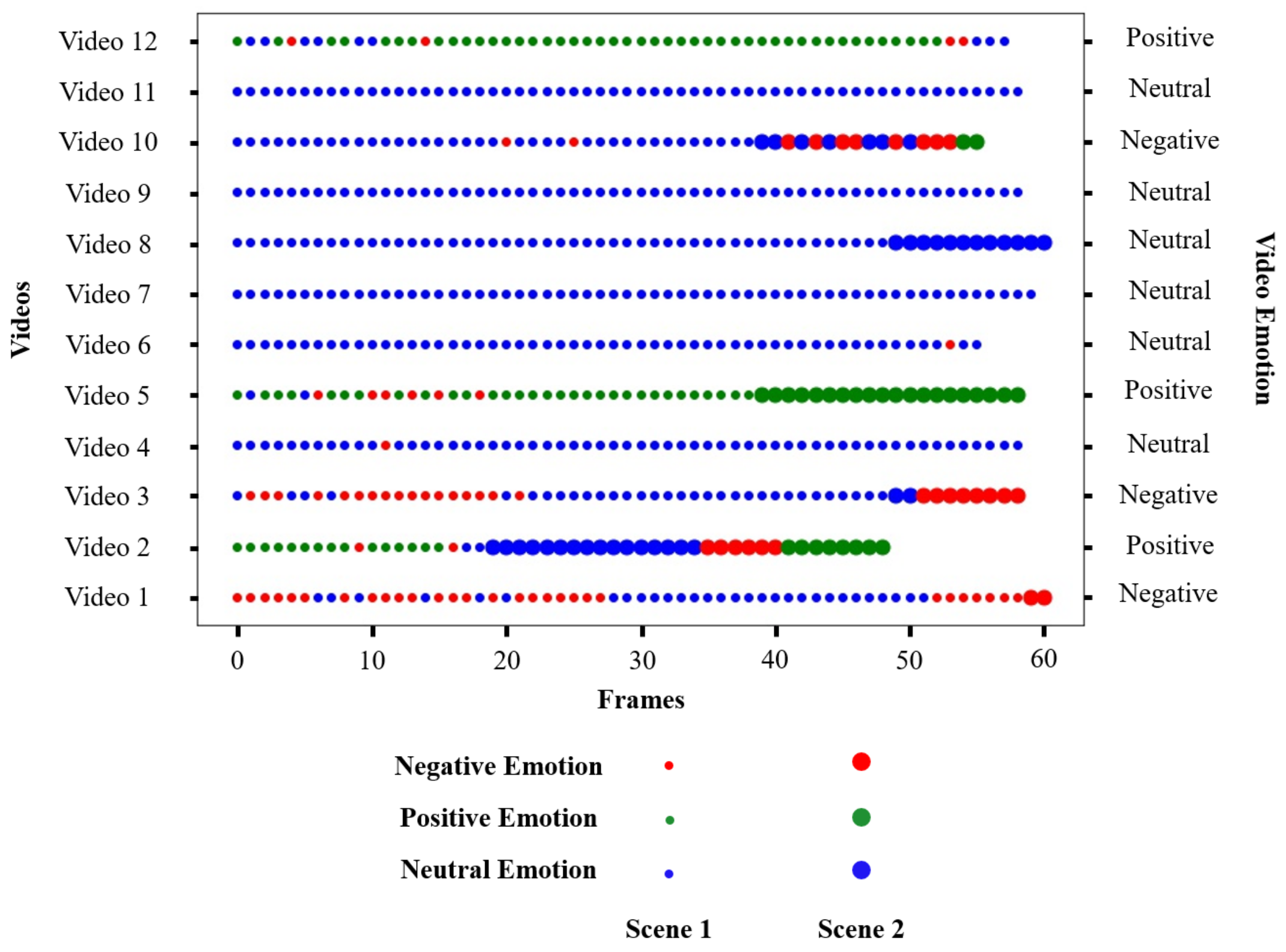
| Video | Emotion of the Scene | Emotion of the Video | Accuracy |
|---|---|---|---|
| Video 1 | Neutral Emotion | Negative Emotion | 1.0000 |
| Negative Emotion | |||
| Video 2 | Positive Emotion | Positive Emotion | 1.0000 |
| Neutral Emotion | |||
| Video 3 | Neutral Emotion | Negative Emotion | 0.5094 |
| Negative Emotion | |||
| Video 4 | Neutral Emotion | Neutral Emotion | 0.7736 |
| Video 5 | Positive Emotion | Positive Emotion | 0.8113 |
| Positive Emotion | |||
| Video 6 | Neutral Emotion | Neutral Emotion | 0.9811 |
| Video 7 | Neutral Emotion | Neutral Emotion | 1.0000 |
| Video 8 | Neutral Emotion | Neutral Emotion | 0.9811 |
| Neutral Emotion | |||
| Video 9 | Neutral Emotion | Neutral Emotion | 1.0000 |
| Video 10 | Neutral Emotion | Negative Emotion | 0.7924 |
| Negative Emotion | |||
| Video 11 | Neutral Emotion | Neutral Emotion | 0.9811 |
| Video 12 | Positive Emotion | Positive Emotion | 0.9434 |
| Average Accuracy | - | - | 0.8978 |
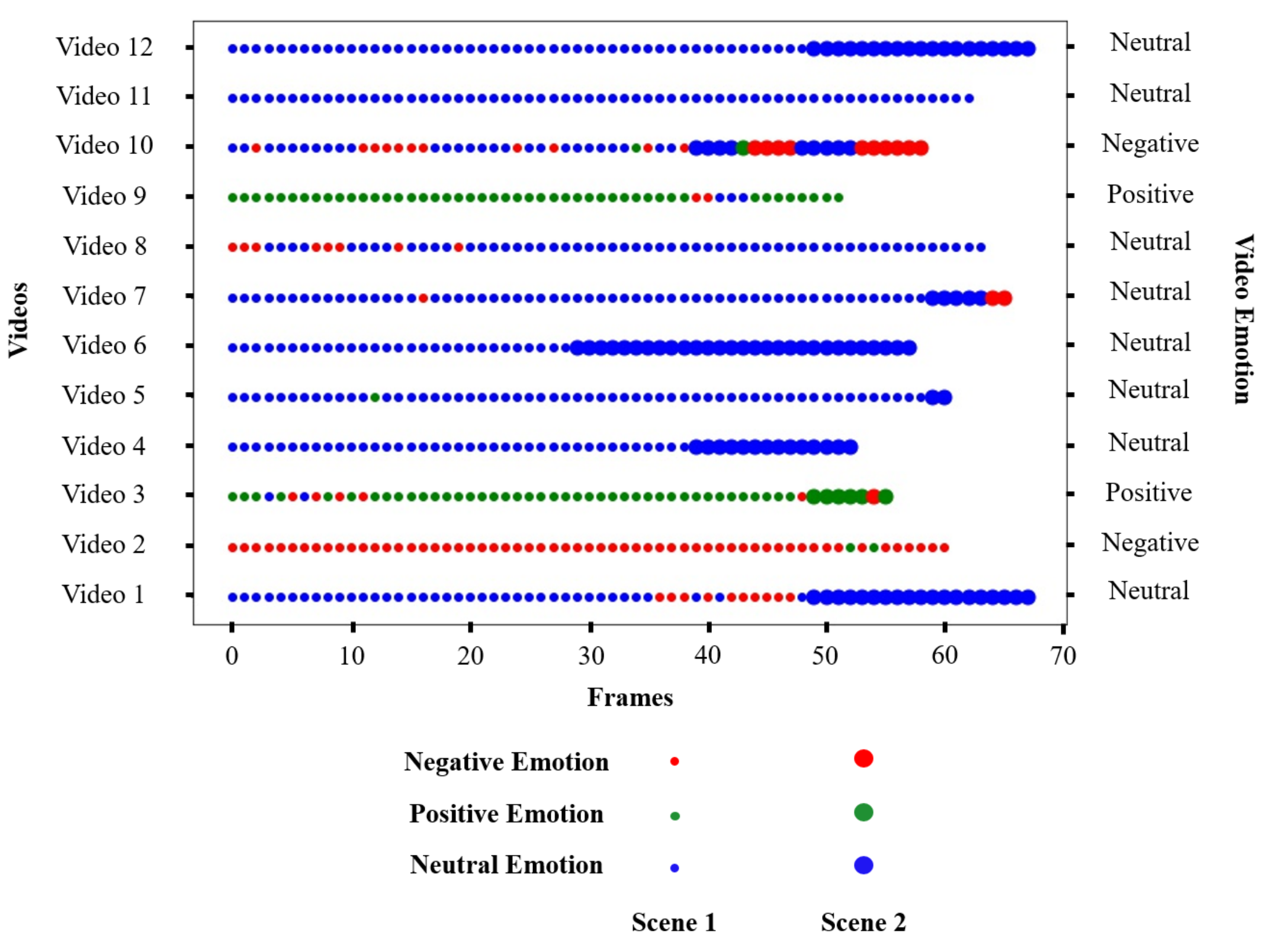
| Video | Emotion of the Scene | Emotion of the Video | Accuracy |
|---|---|---|---|
| Video 1 | Neutral Emotion | Neutral Emotion | 0.9559 |
| Neutral Emotion | |||
| Video 2 | Negative Emotion | Negative Emotion | 1.0000 |
| Video 3 | Positive Emotion | Positive Emotion | 0.7544 |
| Positive Emotion | |||
| Video 4 | Neutral Emotion | Neutral Emotion | 1.0000 |
| Neutral Emotion | |||
| Video 5 | Neutral Emotion | Neutral Emotion | 1.0000 |
| Neutral Emotion | |||
| Video 6 | Neutral Emotion | Neutral Emotion | 1.0000 |
| Neutral Emotion | |||
| Video 7 | Neutral Emotion | Neutral Emotion | 1.0000 |
| Neutral Emotion | |||
| Video 8 | Neutral Emotion | Neutral Emotion | 0.7813 |
| Video 9 | Positive Emotion | Neutral Emotion | 0.9811 |
| Video 10 | Neutral Emotion | Negative Emotion | 0.4286 |
| Negative Emotion | |||
| Video 11 | Neutral Emotion | Neutral Emotion | 1.0000 |
| Video 12 | Neutral Emotion | Neutral Emotion | 1.0000 |
| Neutral Emotion | |||
| Average Accuracy | - | - | 0.9084 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Quiroz, M.; Patiño, R.; Diaz-Amado, J.; Cardinale, Y. Group Emotion Detection Based on Social Robot Perception. Sensors 2022, 22, 3749. https://doi.org/10.3390/s22103749
Quiroz M, Patiño R, Diaz-Amado J, Cardinale Y. Group Emotion Detection Based on Social Robot Perception. Sensors. 2022; 22(10):3749. https://doi.org/10.3390/s22103749
Chicago/Turabian StyleQuiroz, Marco, Raquel Patiño, José Diaz-Amado, and Yudith Cardinale. 2022. "Group Emotion Detection Based on Social Robot Perception" Sensors 22, no. 10: 3749. https://doi.org/10.3390/s22103749