
Identification of Specific Substances in the FAIMS Spectra of Complex Mixtures Using Deep Learning


Abstract
:1. Introduction
2. Materials and Methods
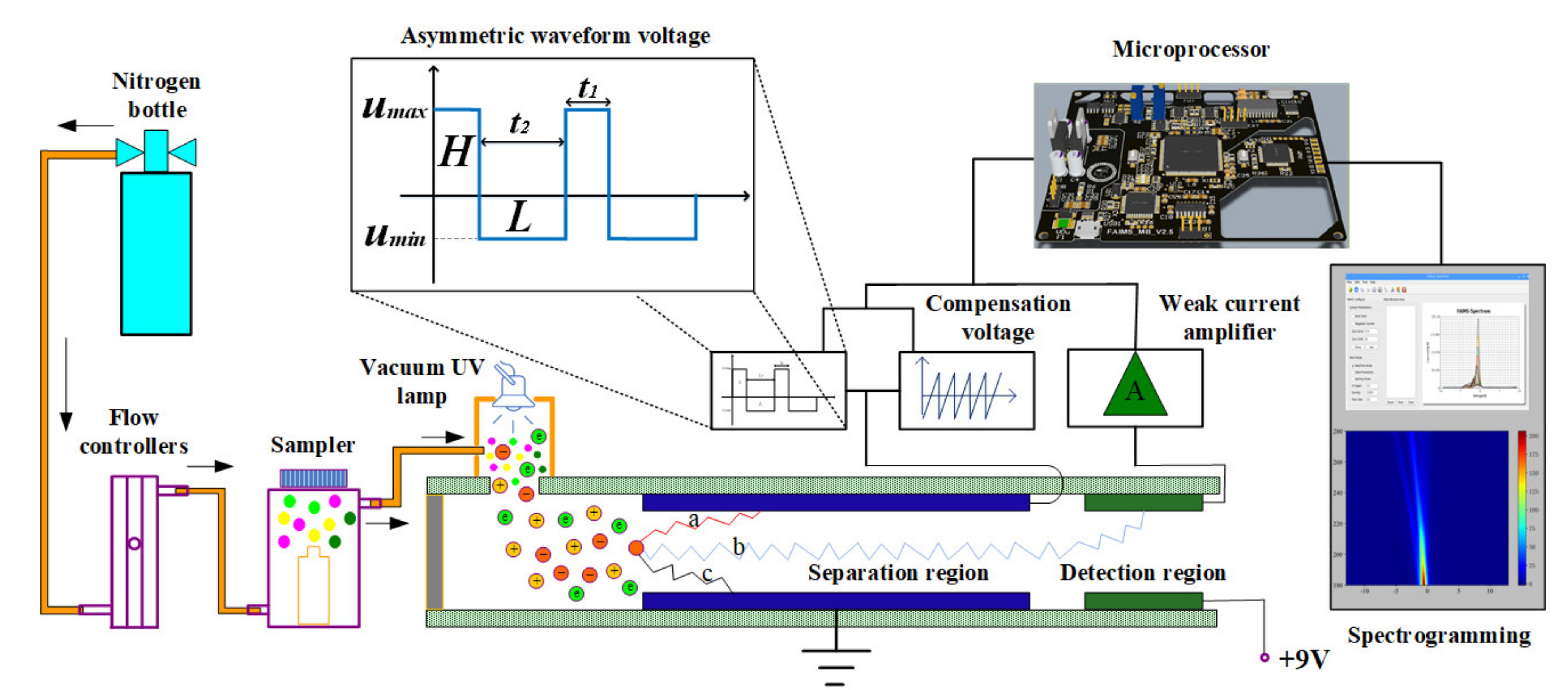
2.1. FAIMS System
2.2. Sample Information
2.3. Experimental Protocol
2.4. Principal Component Analysis and Support Vector Machine
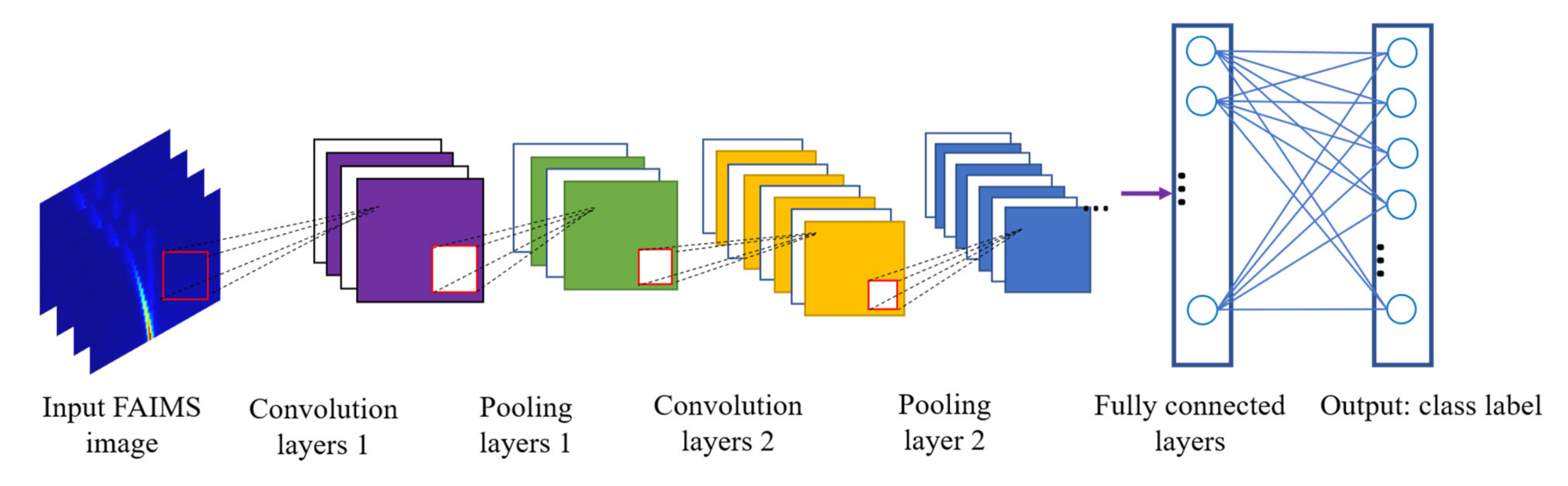
2.5. Deep Learning Network
3. Results and Discussion
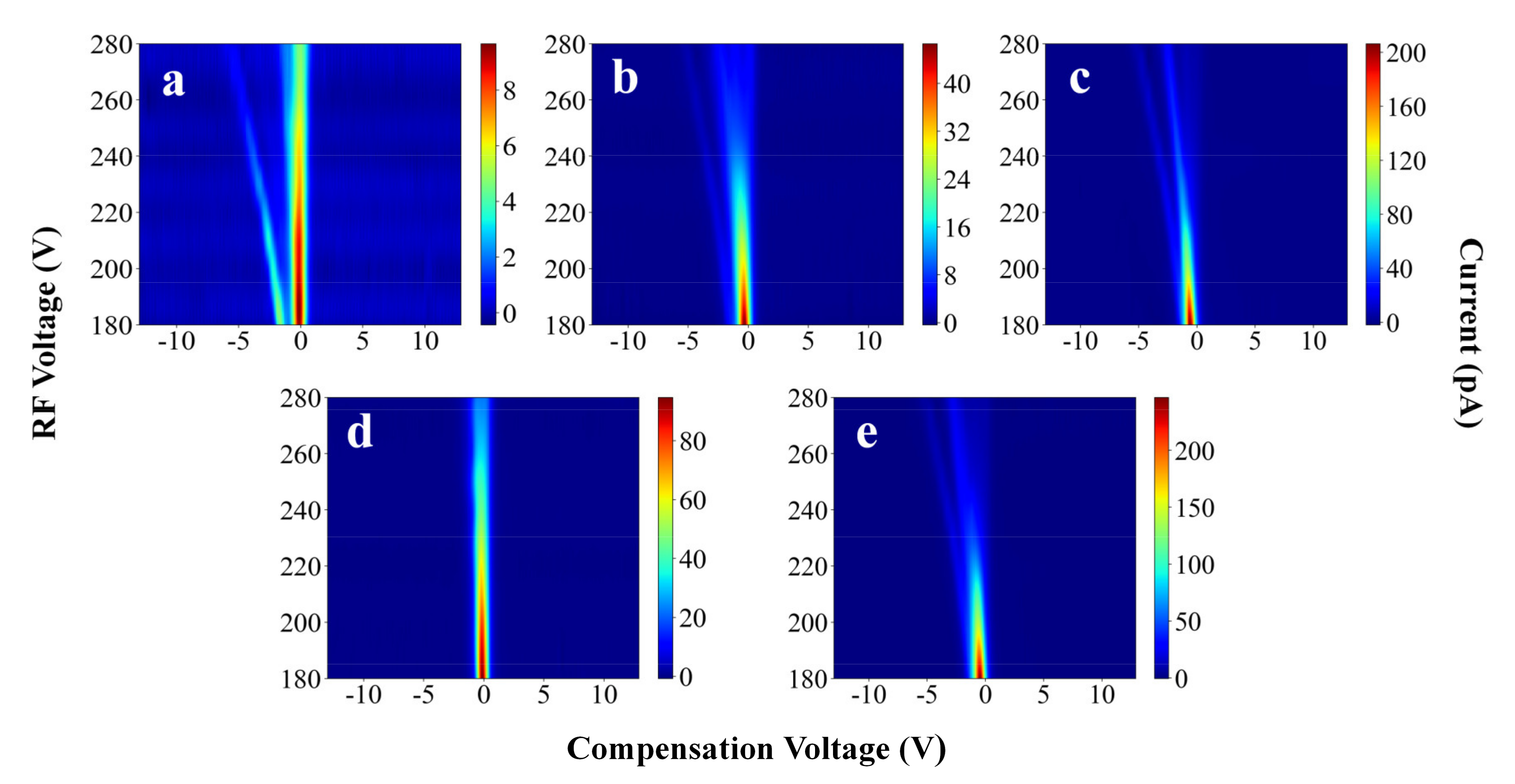
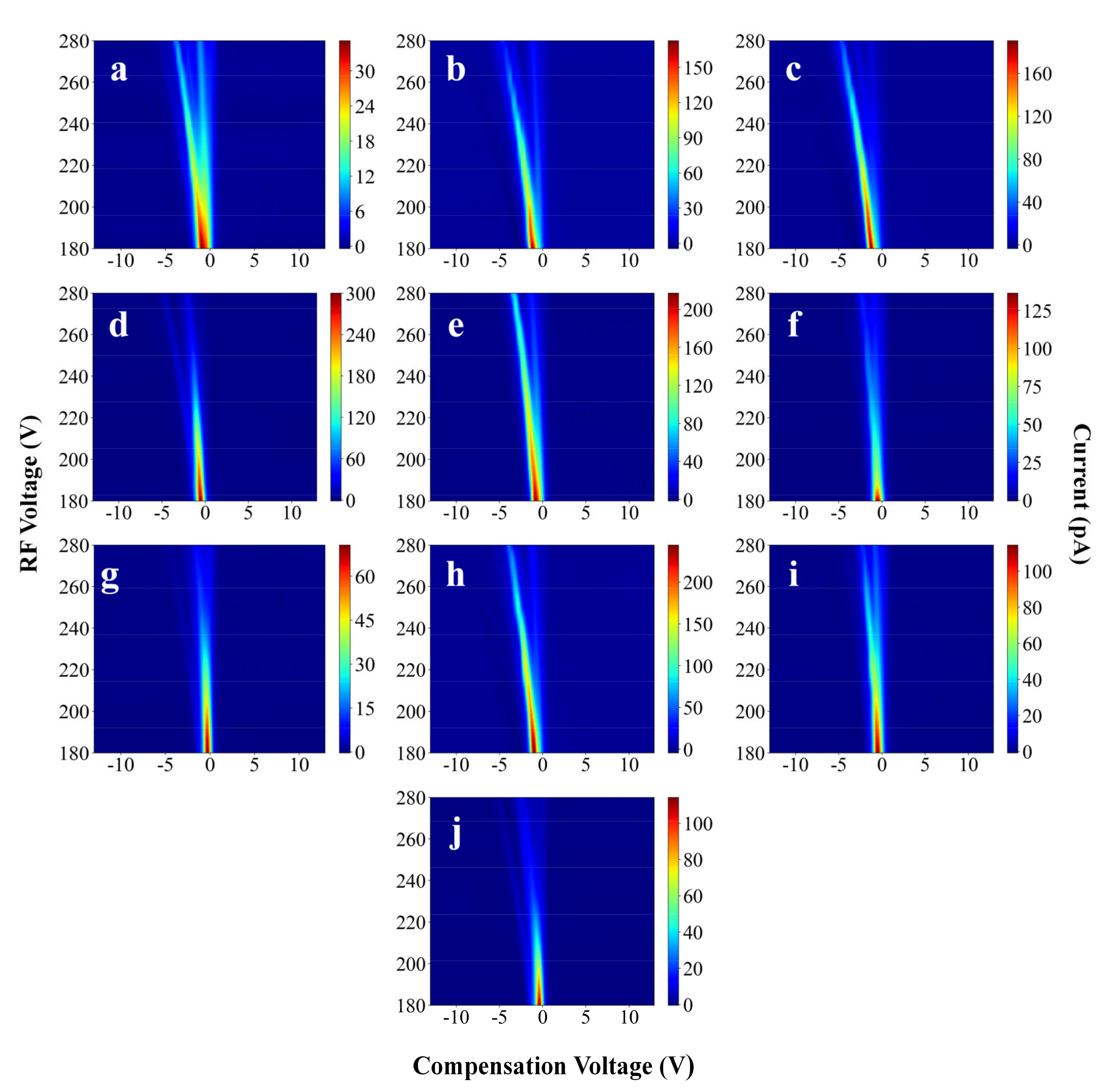
3.1. FAIMS Spectra
3.2. CNNs and FAIMS Spectra
3.3. Experimental Results
3.4. Application
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Maziejuk, M.; Szczurek, A.; Maciejewska, M.; Pietrucha, T.; Szyposzyńska, M. Determination of Benzene, Toluene and Xylene Concentration in Humid Air Using Differential Ion Mobility Spectrometry and Partial Least Squares Regression. Talanta 2016, 152, 137–146. [Google Scholar] [CrossRef]
- Arasaradnam, R.P.; Ouaret, N.; Thomas, M.G.; Gold, P.; Quraishi, M.N.; Nwokolo, C.U.; Bardhan, K.D.; Covington, J.A. Evaluation of gut bacterial populations using an electronic e-nose and field asymmetric ion mobility spectrometry: Further insights into ‘fermentonomics’. J. Med. Eng. Technol. 2012, 36, 333–337. [Google Scholar] [CrossRef]
- Guevremont, R. High-field asymmetric waveform ion mobility spectrometry: A new tool for mass spectrometry. J. Chromatogr. A 2004, 1058, 3–19. [Google Scholar] [CrossRef]
- Schweppe, D.K.; Prasad, S.; Belford, M.W.; Navarrete-Perea, J.; Bailey, D.J.; Huguet, R.; Jedrychowski, M.P.; Rad, R.; McAlister, G.; Abbatiello, S.E.; et al. Characterization and Optimization of Multiplexed Quantitative Analyses Using High-Field Asymmetric-Waveform Ion Mobility Mass Spectrometry. Anal. Chem. 2019, 91, 4010–4016. [Google Scholar] [CrossRef]
- Krylov, E.V.; Coy, S.L.; Vandermey, J.; Schneider, B.B.; Covey, T.R.; Nazarov, E.G. Selection and generation of waveforms for differential mobility spectrometry. Rev. Sci. Instrum. 2010, 81, 24101. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Krebs, M.D.; Zapata, A.M.; Nazarov, E.G.; Miller, R.A.; Costa, I.S.; Sonenshein, A.L.; Davis, C.E. Detection of biological and chemical agents using differential mobility spectrometry (dms) technology. IEEE Sens. J. 2005, 5, 696–703. [Google Scholar] [CrossRef]
- Arasaradnam, R.P.; Ouaret, N.; Thomas, M.G.; Quraishi, N.; Heatherington, E.; Nwokolo, C.U.; Bardhan, K.D.; Covington, J.A. A Novel Tool for Noninvasive Diagnosis and Tracking of Patients with Inflammatory Bowel Disease. Inflamm. Bowel Dis. 2013, 19, 999–1003. [Google Scholar] [CrossRef]
- Martinez-Vernon, A.S.; Covington, J.A.; Arasaradnam, R.P.; Esfahani, S.; O’Connell, N.; Kyrou, I.; Savage, R.S. An Improved Machine Learning Pipeline for Urinary Volatiles Disease Detection: Diagnosing Diabetes. PLoS ONE 2018, 13, e0204425. [Google Scholar] [CrossRef]
- Covington, J.; Westenbrink, E.; Ouaret, N.; Harbord, R.; Bailey, C.; O’Connell, N.; Cullis, J.; Williams, N.; Nwokolo, C.; Bardhan, K.; et al. Application of a Novel Tool for Diagnosing Bile Acid Diarrhoea. Sensors 2013, 13, 11899–11912. [Google Scholar] [CrossRef] [PubMed]
- Sinha, R.; Khot, L.R.; Schroeder, B.K. FAIMS based sensing of Burkholderia cepacia caused sour skin in onions under bulk storage condition. Food Meas. 2017, 11, 1578–1585. [Google Scholar] [CrossRef]
- Li, J.; Gutierrez-Osuna, R.; Hodges, R.D.; Luckey, G.; Crowell, J. Odor Assessment of Automobile Interior Components Using Ion Mobility Spectrometry. In Proceedings of the IEEE Sensors, Orlando, FL, USA, 30 October–2 November 2016. [Google Scholar]
- Li, J.; Gutierrez-Osuna, R.; Hodges, R.D.; Luckey, G.; Crowell, J.; Schiffman, S.S.; Nagle, H.T. Using Field Asymmetric Ion Mobility Spectrometry for Odor Assessment of Automobile Interior Components. IEEE Sens. J. 2016, 16, 5747–5756. [Google Scholar] [CrossRef]
- Yeap, D.; Hichwa, P.T.; Rajapakse, M.Y.; Peirano, D.J.; McCartney, M.M.; Kenyon, N.J.; Davis, C.E. Machine Vision Methods, Natural Language Processing, and Machine Learning Algorithms for Automated Dispersion Plot Analysis and Chemical Identification from Complex Mixtures. Anal. Chem. 2019, 91, 10509–10517. [Google Scholar] [CrossRef] [PubMed]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet Classification with Deep Convolutional Neural Networks. Adv. Neural Inf. Process. Syst. 2012, 25, 1097–1105. [Google Scholar] [CrossRef]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going Deeper with Convolutions. arXiv 2014, arXiv:1409.4842. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2015, arXiv:1409.1556. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Cho, K.; van Merrienboer, B.; Gulcehre, C.; Bahdanau, D.; Bougares, F.; Schwenk, H.; Bengio, Y. Learning Phrase Representations Using RNN Encoder-Decoder for Statistical Machine Translation. arXiv 2014, arXiv:1406.1078. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long Short-Term Memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Xingjian, S.; Chen, Z.; Wang, H.; Yeung, D.-Y.; Wong, W.-K.; Woo, W. Convolutional LSTM Network: A Machine Learning Approach for Precipitation Nowcasting. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 7–12 December 2015; pp. 802–810. [Google Scholar]
- Cai, L.; Gao, J.; Zhao, D. A Review of the Application of Deep Learning in Medical Image Classification and Segmentation. Ann. Transl. Med. 2020, 8, 713. [Google Scholar] [CrossRef]
- Litjens, G.; Kooi, T.; Bejnordi, B.E.; Setio, A.A.A.; Ciompi, F.; Ghafoorian, M.; Van Der Laak, J.A.; Van Ginneken, B.; Sánchez, C.I. A Survey on Deep Learning in Medical Image Analysis. Med. Image Anal. 2017, 42, 60–88. [Google Scholar] [CrossRef] [Green Version]
- Shen, D.; Wu, G.; Suk, H.-I. Deep Learning in Medical Image Analysis. Annu. Rev. Biomed. Eng. 2017, 19, 221–248. [Google Scholar] [CrossRef] [Green Version]
- He, X.; Yang, X.; Zhang, S.; Zhao, J.; Zhang, Y.; Xing, E.; Xie, P. Sample-Efficient Deep Learning for COVID-19 Diagnosis Based on CT Scans; Health Informatics: New York, NY, USA, 2020. [Google Scholar]
- Delnevo, G.; Girau, R.; Ceccarini, C.; Prandi, C. A Deep Learning and Social IoT Approach for Plants Disease Prediction toward a Sustainable Agriculture. IEEE Internet Things J. 2021, 1. [Google Scholar] [CrossRef]
- Zhang, Q.; Liu, Y.; Gong, C.; Chen, Y.; Yu, H. Applications of Deep Learning for Dense Scenes Analysis in Agriculture: A Review. Sensors 2020, 20, 1520. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kamilaris, A.; Prenafeta-Boldú, F.X. Deep Learning in Agriculture: A Survey. Comput. Electron. Agric. 2018, 147, 70–90. [Google Scholar] [CrossRef] [Green Version]
- Zou, J.; Huss, M.; Abid, A.; Mohammadi, P.; Torkamani, A.; Telenti, A. A Primer on Deep Learning in Genomics. Nat. Genet. 2019, 51, 12–18. [Google Scholar] [CrossRef]
- Kopp, W.; Monti, R.; Tamburrini, A.; Ohler, U.; Akalin, A. Deep Learning for Genomics Using Janggu. Nat. Commun. 2020, 11, 3488. [Google Scholar] [CrossRef]
- Eraslan, G.; Avsec, Ž.; Gagneur, J.; Theis, F.J. Deep Learning: New Computational Modelling Techniques for Genomics. Nat. Rev. Genet. 2019, 20, 389–403. [Google Scholar] [CrossRef]
- Wang, X.; Kou, L.; Sugumaran, V.; Luo, X.; Zhang, H. Emotion correlation mining through deep learning models on natural language text. IEEE Trans. Cybern. 2020, 1–14. [Google Scholar] [CrossRef]
- Khalil, R.A.; Jones, E.; Babar, M.I.; Jan, T.; Zafar, M.H.; Alhussain, T. Speech Emotion Recognition Using Deep Learning Techniques: A Review. IEEE Access 2019, 7, 117327–117345. [Google Scholar] [CrossRef]
- Tian, Y.; Luo, P.; Wang, X.; Tang, X. Pedestrian Detection Aided by Deep Learning Semantic Tasks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Zhang, L.; Wang, S.; Liu, B. Deep Learning for Sentiment Analysis: A Survey. WIREs Data Min. Knowl. Discov. 2018, 8, e1253. [Google Scholar] [CrossRef] [Green Version]
- Chen, X.; Jia, S.; Xiang, Y. A Review: Knowledge Reasoning over Knowledge Graph. Expert Syst. Appl. 2020, 141, 112948. [Google Scholar] [CrossRef]
- Xu, J.; Kim, S.; Song, M.; Jeong, M.; Kim, D.; Kang, J.; Rousseau, J.F.; Li, X.; Xu, W.; Torvik, V.I.; et al. Building a PubMed Knowledge Graph. Sci. Data 2020, 7, 205. [Google Scholar] [CrossRef] [PubMed]
- Xiong, W.; Hoang, T.; Wang, W.Y. DeepPath: A Reinforcement Learning Method for Knowledge Graph Reasoning. arXiv 2018, arXiv:1707.06690. [Google Scholar]
- Covington, J.A.; van der Schee, M.P.; Edge, A.S.L.; Boyle, B.; Savage, R.S.; Arasaradnam, R.P. The Application of FAIMS Gas Analysis in Medical Diagnostics. Analyst 2015, 140, 6775–6781. [Google Scholar] [CrossRef]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. PyTorch: An Imperative Style, High-Performance Deep Learning Library. arXiv 2019, arXiv:1912.01703. [Google Scholar]
- Qi, J.; Jiang, G.; Li, G.; Sun, Y.; Tao, B. Surface EMG Hand Gesture Recognition System Based on PCA and GRNN. Neural Comput. Applic. 2020, 32, 6343–6351. [Google Scholar] [CrossRef]
- McCartney, M.M.; Spitulski, S.L.; Pasamontes, A.; Peirano, D.J.; Schirle, M.J.; Cumeras, R.; Simmons, J.D.; Ware, J.L.; Brown, J.F.; Poh, A.J.Y.; et al. Coupling a Branch Enclosure with Differential Mobility Spectrometry to Isolate and Measure Plant Volatiles in Contained Greenhouse Settings. Talanta 2016, 146, 148–154. [Google Scholar] [CrossRef] [Green Version]
- Yang, J.; Zhang, D.; Frangi, A.F.; Yang, J. Two-Dimensional PCA: A New Approach to Appearance-Based Face Representation and Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2004, 26, 131–137. [Google Scholar] [CrossRef] [Green Version]
- Kaucha, D.P.; Prasad, P.W.C.; Alsadoon, A.; Elchouemi, A.; Sreedharan, S. Early Detection of Lung Cancer Using SVM Classifier in Biomedical Image Processing. In Proceedings of the 2017 IEEE International Conference on Power, Control, Signals and Instrumentation Engineering (ICPCSI), Chennai, India, 21–22 September 2017; pp. 3143–3148. [Google Scholar]
- Strack, R.; Kecman, V. Minimal Norm Support Vector Machines for Large Classification Tasks. In Proceedings of the 2012 11th International Conference on Machine Learning and Applications, Boca Raton, FL, USA, 12–15 December 2012; pp. 209–214. [Google Scholar]
- Cortes, C.; Vapnik, V. Support-Vector Networks. Mach Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Lecun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-Based Learning Applied to Document Recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef] [Green Version]
- Zeiler, M.D.; Fergus, R. Visualizing and Understanding Convolutional Networks. In Proceedings of the Computer Vision—ECCV 2014; Fleet, D., Pajdla, T., Schiele, B., Tuytelaars, T., Eds.; Springer International Publishing: Cham, Germany, 2014; pp. 818–833. [Google Scholar]
- Tan, M.; Le, Q. EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks. In Proceedings of the International Conference on Machine Learning, Long Beach, CA, USA, 24 May 2019; pp. 6105–6114. [Google Scholar]
- Tan, M.; Le, Q.V. EfficientNetV2: Smaller Models and Faster Training. arXiv 2021, arXiv:2104.00298. [Google Scholar]
- Duong, L.T.; Nguyen, P.T.; Di Sipio, C.; Di Ruscio, D. Automated Fruit Recognition Using EfficientNet and MixNet. Comput. Electron. Agric. 2020, 171, 105326. [Google Scholar] [CrossRef]
- Marques, G.; Agarwal, D.; de la Torre Díez, I. Automated Medical Diagnosis of COVID-19 through EfficientNet Convolutional Neural Network. Appl. Soft Comput. 2020, 96, 106691. [Google Scholar] [CrossRef]
- Alhichri, H.; Alswayed, A.S.; Bazi, Y.; Ammour, N.; Alajlan, N.A. Classification of Remote Sensing Images Using EfficientNet-B3 CNN Model With Attention. IEEE Access 2021, 9, 14078–14094. [Google Scholar] [CrossRef]
- Chowdhury, N.K.; Kabir, M.A.; Rahman, M.d.M.; Rezoana, N. ECOVNet: A Highly Effective Ensemble Based Deep Learning Model for Detecting COVID-19. PeerJ Comput. Sci. 2021, 7, e551. [Google Scholar] [CrossRef]
- Atila, Ü.; Uçar, M.; Akyol, K.; Uçar, E. Plant Leaf Disease Classification Using EfficientNet Deep Learning Model. Ecol. Inform. 2021, 61, 101182. [Google Scholar] [CrossRef]
- Pan, S.J.; Yang, Q. A Survey on Transfer Learning. IEEE Trans. Knowl. Data Eng. 2010, 22, 1345–1359. [Google Scholar] [CrossRef]
- Tajbakhsh, N.; Shin, J.Y.; Gurudu, S.R.; Hurst, R.T.; Kendall, C.B.; Gotway, M.B.; Liang, J. Convolutional Neural Networks for Medical Image Analysis: Full Training or Fine Tuning? IEEE Trans. Med. Imaging 2016, 35, 1299–1312. [Google Scholar] [CrossRef] [Green Version]
- Anttalainen, A.; Mäkelä, M.; Kumpulainen, P.; Vehkaoja, A.; Anttalainen, O.; Oksala, N.; Roine, A. Predicting Lecithin Concentration from Differential Mobility Spectrometry Measurements with Linear Regression Models and Neural Networks. Talanta 2021, 225, 121926. [Google Scholar] [CrossRef]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; MIT Press: Cambridge, MA, USA, 2016. [Google Scholar]
- Wong, T.-T. Performance Evaluation of Classification Algorithms by K-Fold and Leave-One-out Cross Validation. Pattern Recognit. 2015, 48, 2839–2846. [Google Scholar] [CrossRef]
- Righettoni, M.; Tricoli, A.; Gass, S.; Schmid, A.; Amann, A.; Pratsinis, S.E. Breath Acetone Monitoring by Portable Si: WO3 Gas Sensors. Anal. Chim. Acta 2012, 738, 69–75. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wang, Z.; Wang, C. Is Breath Acetone a Biomarker of Diabetes? A Historical Review on Breath Acetone Measurements. J. Breath Res. 2013, 7, 37109. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ubeda, C.; Lepe-Balsalobre, E.; Ariza-Astolfi, C.; Ubeda-Ontiveros, J.M. Identification of Volatile Biomarkers of Giardia Duodenalis Infection in Children with Persistent Diarrhoea. Parasitol. Res. 2019, 118, 3139–3147. [Google Scholar] [CrossRef] [PubMed]
- Garner, C.E.; Smith, S.; Bardhan, P.K.; Ratcliffe, N.M.; Probert, C.S.J. A Pilot Study of Faecal Volatile Organic Compounds in Faeces from Cholera Patients in Bangladesh to Determine Their Utility in Disease Diagnosis. Trans. R. Soc. Trop. Med. Hyg. 2009, 103, 1171–1173. [Google Scholar] [CrossRef] [PubMed]
- Schmidt, A.C.; Leroux, J.-C. Treatments of Trimethylaminuria: Where We Are and Where We Might Be Heading. Drug Discov. Today 2020, 25, 1710–1717. [Google Scholar] [CrossRef]
- Mackay, R.J.; McEntyre, C.J.; Henderson, C.; Lever, M.; George, P.M. Trimethylaminuria: Causes and Diagnosis of a Socially Distressing Condition. Clin. Biochem. Rev. 2011, 32, 33–43. [Google Scholar] [PubMed]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
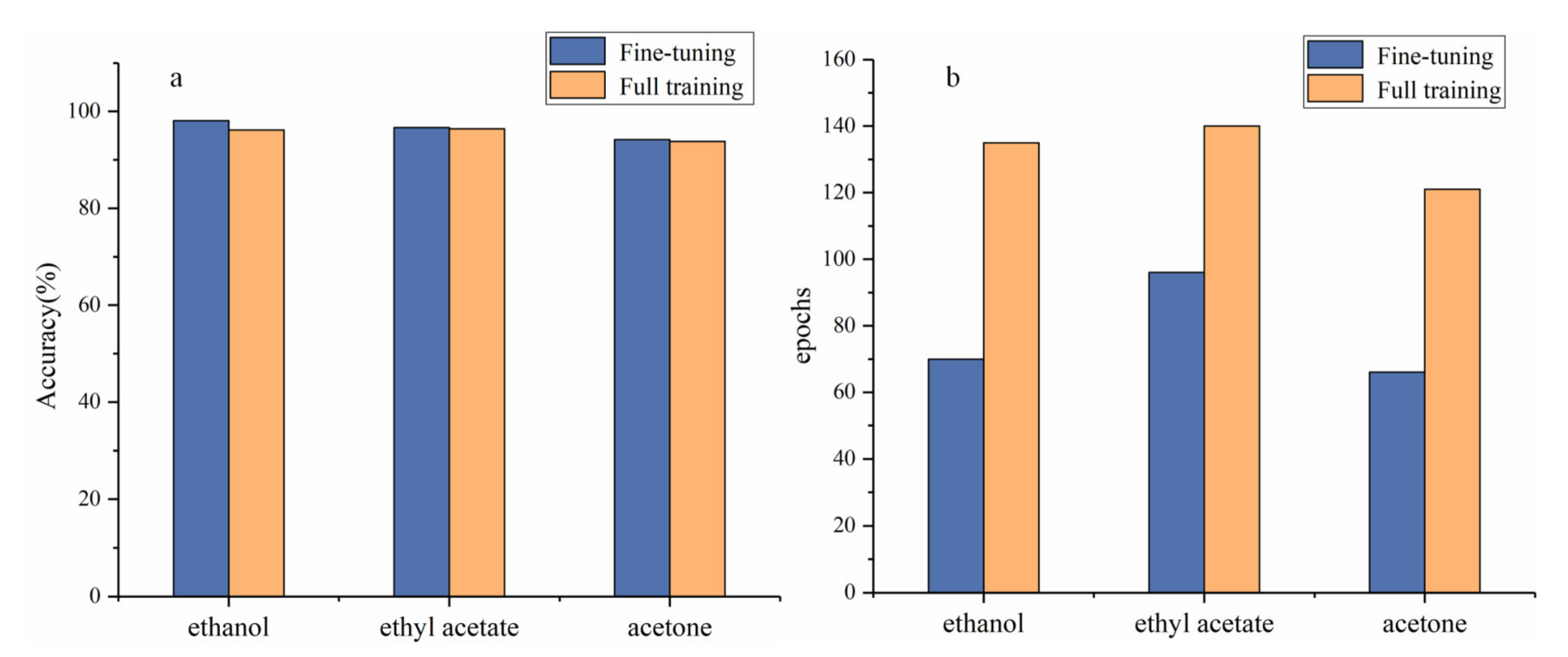{kind=link}
| Serial Number | Sample | Model Dataset Number | Blind Test Set Number |
|---|---|---|---|
| 1 | ethanol | 18 | 2 |
| 2 | ethyl acetate | 13 | 2 |
| 3 | acetone | 18 | 2 |
| 4 | 4-methyl-2-pentanone | 18 | 2 |
| 5 | 2-butanone | 19 | 2 |
| 6 | ethanol + ethyl acetate | 18 | 2 |
| 7 | ethanol + acetone | 18 | 2 |
| 8 | ethanol + acetone + ethyl acetate | 18 | 2 |
| 9 | acetone + ethyl acetate | 17 | 2 |
| 10 | ethanol + 4-methyl-2-pentanone | 18 | 2 |
| 11 | ethanol + 4-methyl-2-pentanone + ethyl acetate | 18 | 2 |
| 12 | 4-methyl-2-pentanone + ethyl acetate | 17 | 2 |
| 13 | ethanol + 2-butanone | 19 | 2 |
| 14 | ethanol + 2-butanone + ethyl acetate | 18 | 2 |
| 15 | 2-butanone + ethyl acetate | 18 | 2 |
| Total | 265 | 30 |
| Sample | Number of Class 1 Samples * | Number of Class 2 Samples | Total |
|---|---|---|---|
| ethanol | 145 | 120 | 265 |
| ethyl acetate | 137 | 126 | 265 |
| acetone | 71 | 194 | 265 |
| Blind Test Set | Number of Real Labels | Number of Predicted Labels | Accuracy | |
|---|---|---|---|---|
| 1 | other | 14 | 14 | 100% |
| ethanol | 16 | 16 | ||
| 2 | other | 14 | 13 | 96.7% |
| ethyl acetate | 16 | 17 | ||
| 3 | other | 22 | 18 | 86.7% |
| acetone | 8 | 12 | ||
| Sample | Training Set | Validation Set | Blind Dataset |
|---|---|---|---|
| ethanol | 74.5% | 79.2% | 70.0% |
| ethyl acetate | 81.5% | 75.0% | 66.7% |
| acetone | 85.4% | 78.8% | 80.0% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, H.; Pan, J.; Zeng, H.; Chen, Z.; Du, X.; Xiao, W. Identification of Specific Substances in the FAIMS Spectra of Complex Mixtures Using Deep Learning. Sensors 2021, 21, 6160. https://doi.org/10.3390/s21186160
Li H, Pan J, Zeng H, Chen Z, Du X, Xiao W. Identification of Specific Substances in the FAIMS Spectra of Complex Mixtures Using Deep Learning. Sensors. 2021; 21(18):6160. https://doi.org/10.3390/s21186160
Chicago/Turabian StyleLi, Hua, Jiakai Pan, Hongda Zeng, Zhencheng Chen, Xiaoxia Du, and Wenxiang Xiao. 2021. "Identification of Specific Substances in the FAIMS Spectra of Complex Mixtures Using Deep Learning" Sensors 21, no. 18: 6160. https://doi.org/10.3390/s21186160