2.1. Literature Review
This section presents various algorithms, methods and techniques that were proposed and used by different authors regarding fruit detection, more specifically the tomato (
Table 1).
In recent years, machine learning, and especially deep learning, techniques in fruit detection has been increasingly used and tested [
9,
16,
17,
18,
19,
20,
21,
22,
23,
24,
25,
26,
27,
28,
29,
30,
31,
32,
33]. Unlike conventional methods, machine learning is a more robust and accurate alternative with a better response to problems such as occlusion and green tomato detection. The problem of green tomato detection is rarely studied due to the difficulty of segmentation and differentiating it from the background, as they have similar colours. This can be observed by the comparison made by E Alam Siddiquee et al. [
34]. They compared a machine learning method, known as the “cascaded object detector”, with a system that combines more traditional methods of image processing: “colour transformation”, “colour segmentation”, and “circular Hough transformation”, in the detection of ripe tomatoes. The results showed that the accuracy of the machine learning method is 95% better than conventional methods.
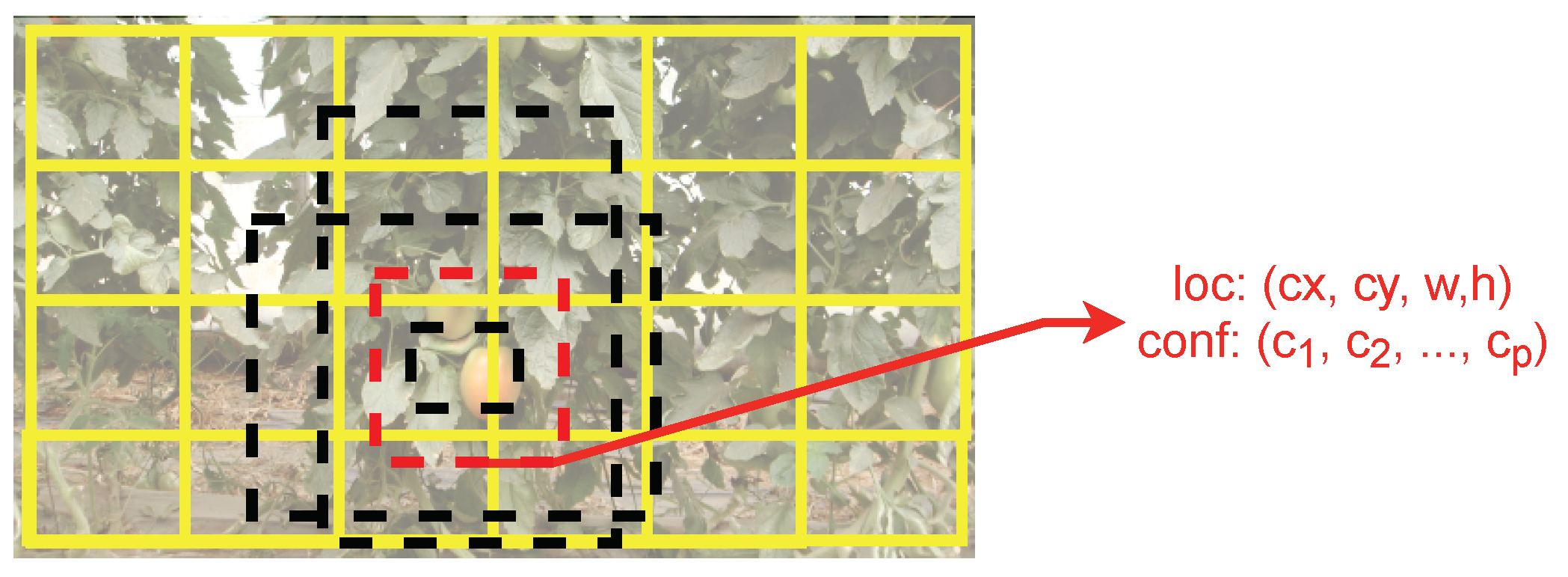
For the detection and segmentation purposes of tomatoes in plants, authors usually consider the plants’ canopy as the Region of Interest (RoI) (see Figure 7). In this RoI, besides the fruits, other structures may be seen that make the fruits’ detection difficult—relevant to estimate the fruit location. These other structures may occlude or overlap the tomato/fruit, and this creates some challenges for the algorithms or processes that are responsible for the fruit detection and segmentation. These challenges become greater in the early ripening stages, due to the high colour correlation between leaves and tomatoes. Despite this fact, the most common and relevant research found in the literature considers the harvesting period in the late maturation stage of tomatoes (where the tomato is already red), so the colour is therefore a feature used recurrently to differentiate the objects to be detected [
16,
17,
18,
19,
20,
21,
25,
35]. Considering the case of fruit detection and segmentation, the authors try to distinguish it from everything external and the background, which at the crop level, can be very complex. Several colour spaces such as Hue, Saturation and Intensity (HSI) [
18,
19], CIELAB (or L*a*b*) [
16,
17,
25] and RGB [
18,
19,
20,
35] are used to extract this feature. Besides, mathematical morphology approaches [
36] combined with machine learning techniques have also been used in fruit detection in occlusion and overlap situations [
9,
16,
17,
18,
19,
20,
21,
22,
23,
24,
25,
26,
27].
For developing a harvesting robot in greenhouses, Yin et al. [
16] segmented ripe tomatoes through K-means clustering using the CIELAB colour space, recording an average task execution time of 10.14
. Huang et al. [
17] used the CIELAB colour space to segment and localise ripe tomatoes in a greenhouse and bi-level partition fuzzy logic entropy to discriminate the fruits from the background. They did not evaluate the performance of the algorithm. Zhao et al. [
25] developed a detection algorithm capable of recognising green, or intermediate, and ripe tomatoes. First, the images of component a* and the images of component L* were extracted from the colour space L*a*b* and the luminance of the Quadrature-phase (YIQ) colour space, respectively. Then, wavelet transformation was adopted to merge the images at the pixel level, which combined the information from the two original images. Finally, to differentiate the fruits from the background, an adaptive threshold algorithm was used to obtain the optimal threshold. The evaluation tests proved a detection rate of 93% of tomatoes.
Arefi et al. [
18] proposed an algorithm for the recognition of ripe tomatoes through a combination of the RGB, HSI and YIQ colour spaces and the morphological characteristics of the image. The algorithm obtained a total accuracy of 96.36% when tested in a greenhouse with artificial lighting. Feng et al. [
35] developed a ripe tomato harvesting robot for a greenhouse, whose identification and location of fruits consisted of the transformation of the RGB colour space images into an HSI colour model to identify and locate the fruits. The robot performed this task in 4
, and the harvest process had a success rate of 83.9%. Zhang [
19], aiming to detect ripe tomatoes, also converted the RGB colour space into an HSI colour space. The ripe tomato region was cut based on the grey distribution of the H component using the threshold method. The Canny operator [
37] was used to detect the edges. After a corrosive expansion, the coordinates of the centre of the tomato were marked. The results were not quantified. Benavides et al. [
20] designed a computer vision system for the detection of ripe tomatoes in greenhouses. The segmentation of the fruit was mainly done based on the colour and edges of the fruit, using the R component of the RGB images and the Sobel operator [
38], respectively. Clustered tomatoes were detected with a precision of 87.5% and beef tomatoes with 80.8%. Malik et al. [
21] presented a ripe tomato detection algorithm based on the HSV (Hue, Saturation, Value) colour space and the watershed segmentation method. For removing the background and detecting only ripe tomatoes, the HSV colour space was used, and through morphological operations, it was possible to modify the detected fruits. The watershed segmentation algorithm was implemented to “separate” the clustered fruits. The combination of these two methods led to a precision of 81.6%.
Zhu et al. [
22] combined the mathematical morphology with a Fuzzy C-Means (FCM)-based method for the detection of ripe tomatoes in a greenhouse, with no results reported. Based on the mathematical morphology, Xiang et al. [
23] tested a ripe cluster tomato recognition algorithm. The algorithm was divided into four fundamental steps: tomato image segmentation, performed based on a normalised colour difference; recognition of the clustered region according to the length of the longest edge of the minimum enclosing rectangle of the tomato region; clustered regions, in a binary image, were processed by an iterative erosion course to separate each tomato in this clustered region, and every seed region in the clustered region acquired by the iterative erosion was restored using a circulatory dilation operation. At a distance of 500
, they achieved a detection rate of 87.5%, while from 300
to 700
, the rate dropped to 58.4%.
Yamamoto et al. [
24] used different machine learning techniques to detect and distinguish the different stages of tomato ripeness. The proposed method consisted of three steps: pixel-based segmentation conducted to roughly segment the pixels of the images into classes composed of fruits, leaves, stems, and background; blob-based segmentation to eliminate the wrong classifications generated in the first step; and finally, X-means clustering was applied to detect fruits individually in a fruit cluster. The results indicated a precision of 88%. Zhao et al. [
39], to detect ripe tomatoes, extracted the Haar-like features of the grey-scale image, classifying them with the AdaBoost classifier. The false negatives that derived from this classification were eliminated using a colour analysis approach based on the average pixel value (APV). The results showed that the combination of AdaBoost classification with the colour analysis allowed a 96% detection rate, although 10% were false negatives and 3.5% of the fruits were not detected. Liu et al. [
9] proposed an algorithm for the detection of greenhouse ripe tomatoes, where the Histogram of Oriented Gradients (HOG) descriptor was used to train a Support Vector Machine (SVM) classifier. A coarse-to-fine scanning method was developed to detect the fruit, followed by the proposed False Colour Removal (FCR) method to eliminate false-positive detections. The Non-Maximum Suppression (NMS) method was finally used in order to merge the overlapping results. The algorithm was able to detect the fruits with an accuracy of 94.41%. Wu et al. [
26] developed a greenhouse ripe tomato detection algorithm for a harvesting robot, through a method that combines the analysis and selection of multiple features, a Relevance Vector Machine (RVM) classifier and a bi-layer classification strategy. The algorithm demonstrated an accuracy of 94.90%. Lili et al. [
27], developing a greenhouse harvest robot for tomatoes, used the Otsu segmentation algorithm [
40] for the automatic detection of ripe tomatoes, obtaining success rates of 99.3%.
In the most recent SoA, the interest in DL strategies has been growing [
28,
29,
30,
31,
32,
33]. This interest is due to the higher computability rate of the most recent computers and new edge computing devices dedicated to running DL models, as the TPU. Among the different DL architectures, the You Only Look Once (YOLO) models [
41,
42] seem to be the most common ones [
28,
29]. However, Convolutional Neural Network (CNN) structures also have their place due to their high accuracy, besides the long inference time [
11]. This issue allows the appearance and use of the SSD adaptation of these models [
11]. Among these adaptations, we can find the insertion of new layers (to increase the network resolution) and pruning of the output layers to fit the network classes, change the detection or feature extraction layers.
Xu et al. [
28] improved the YOLOv3-tiny method to obtain a faster and more accurate detection of ripe tomatoes. The accuracy of the model was increased by improving the backbone network, and the image enhancement allowed better detection in more complex scenarios. The results obtained showed that the F1-score of the proposed model was 91.92%, which was 12% higher than the unmodified YOLOv3-tiny method. Liu et al. [
29] used the YOLOv3 detection model to create the YOLOTomato model, which was possible to achieve due to the incorporation of the dense architecture for feature extraction and the replacement of the traditional R-box by the proposed C-box. In scenarios with moderate occlusions, the model obtained a detection rate of 94.58%, 4% more than in scenarios with severe occlusions. In order to overcome overlaps and occlusions, Sun et al. [
30] developed a detection method based on CNN, more specifically the feature pyramid network method. By comparing this method with traditional Faster Region-based Convolutional Neural Network (R-CNN) models, the proposed method improved the detection rate from 90.7% to 99.5%. Mu et al. [
31] built a tomato detection model capable of detecting green tomatoes in greenhouses, regardless of possible occlusions. The model uses a pre-trained Faster R-CNN structure with the deep convolutional neural network ResNet-101 based on the Common Objects in Context (COCO) dataset, which was then fine-tuned for tomato detection, reaching an accuracy of 87.83%.
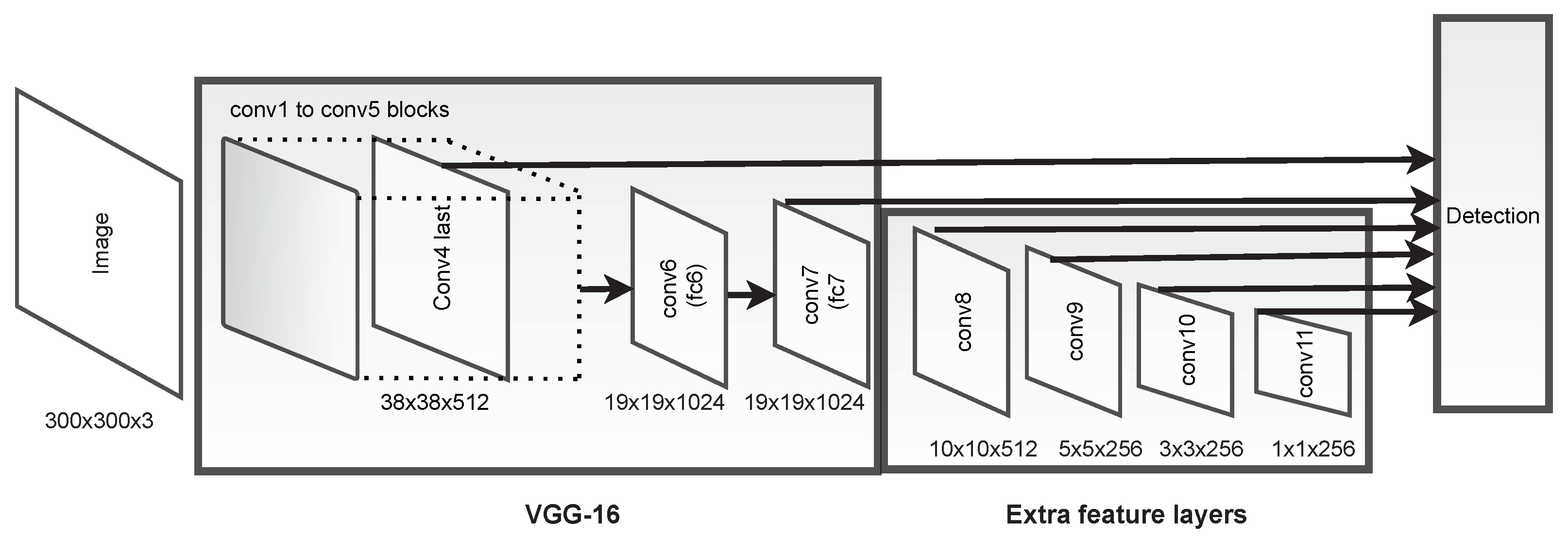
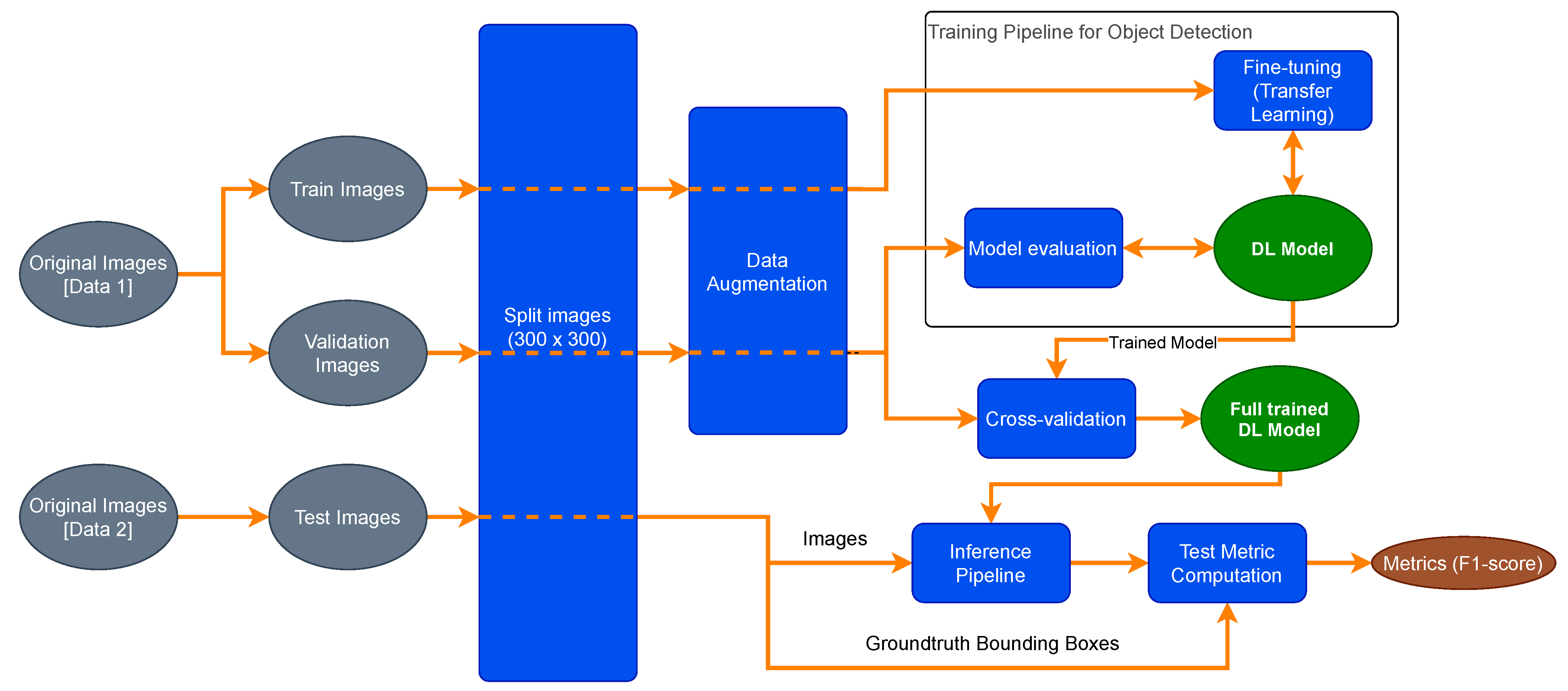
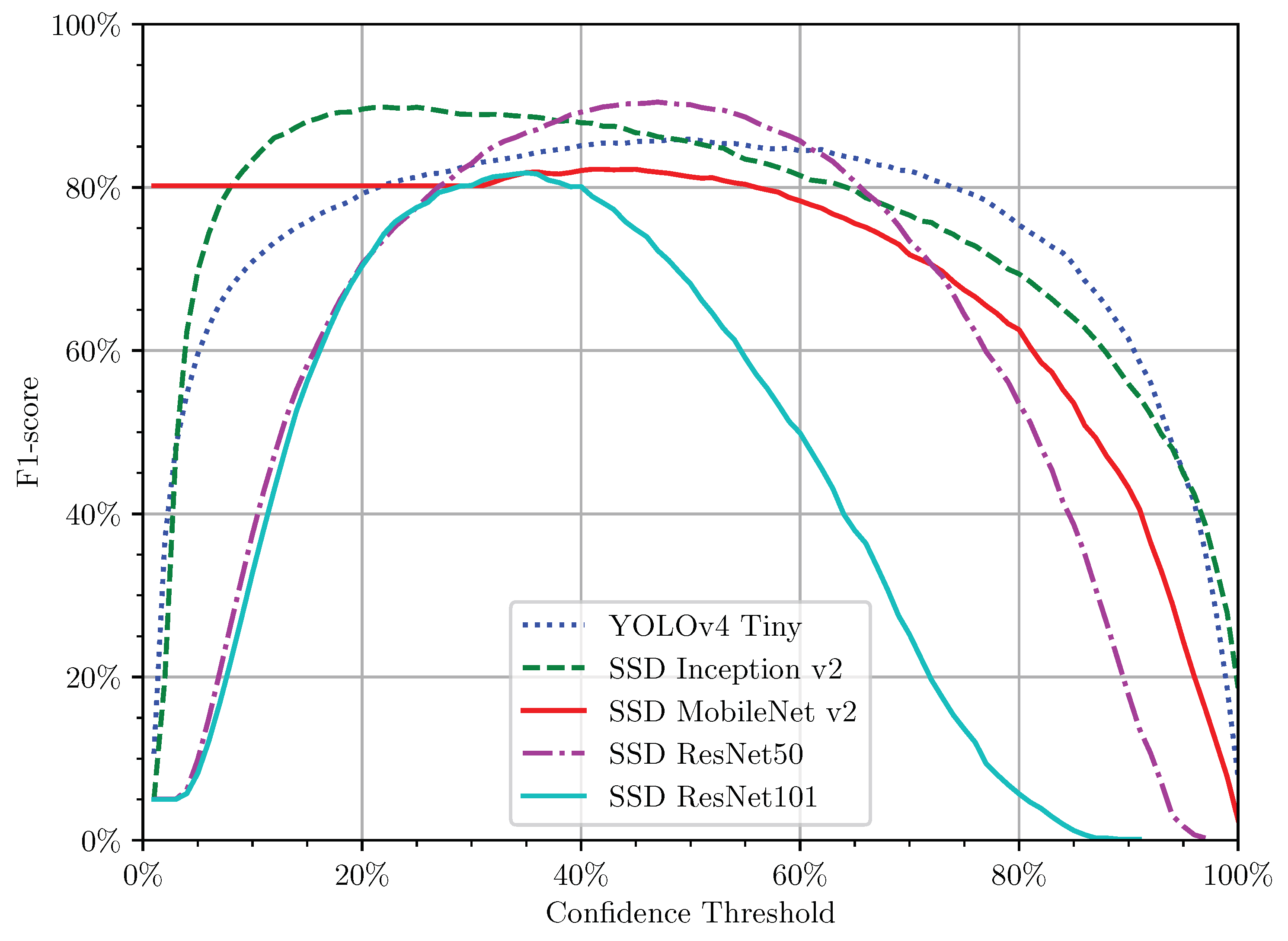
As will be studied in this paper, the Deep Learning Single-Shot Multibox Detector (SSD) model promises a substantial improvement in fruit detection. Therefore, it has been increasingly studied, since it can capture the information of an object and its anti-interference, as well as directly complete the localisation and the classification task in just one step.
This improvement was demonstrated by de Luna et al. [
32] who designed a computer visualisation system to evaluate the growth of tomato plants through the detection of fruits and flowers. Two deep learning models were used: R-CNN and SSD. The fruit detection accuracy of the R-CNN model was only 19.48%, while the SSD model showed a much higher detection rate of 95.99%. To detect cherry tomatoes in greenhouses, whether ripe, green or intermediate, Yuan et al. [
33] developed an SSD-based algorithm. After building the datasets, they were used to train and develop network models. For studying the effect of the base network, one of the experiments was tested on different networks, such as VGG16, MobileNet and Inception V2. The results indicated that the Inception V2 network obtained the best performance with an accuracy of 98.85%.


 ,
, 




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}















