1. Introduction
Massive Multiple-Input Multiple-Output (MIMO) and millimeter wave (mmWave) technologies are promising candidates to satisfy the demands of future wideband wireless communication systems. A common feature of these technologies is the deployment of antenna arrays with a large number of elements while keeping the size of the antenna aperture small. This way, advantages such as large beamforming gains necessary to compensate the propagation losses at mmWave frequencies, or the ability to support many spatially multiplexed streams, are efficiently achieved [
1,
2]. In addition, it has been shown that in multi-cell massive MIMO systems the capacity increases without bound as the number of antennas increases, even under pilot contamination, if the channel covariance matrices of the contaminating users are asymptotically linearly independent [
3]. Measurements campaigns have proved that this is usually the case in practice [
4].
Deploying massive antenna arrays raises concerns in terms of hardware cost and power consumption, especially at mmWave frequencies. To alleviate these requirements, hybrid architectures with an analog preprocessing network operating in the Radio Frequency (RF) domain have been proposed to reduce the number of complete RF chains [
2]. Hybrid approaches imply stringent limitations, such as the reduced spatial dimensionality and the lack of flexibility of the analog part, usually implemented with a Phase Shifter (PS) network. Thus, results obtained for fully digital scenarios are not applicable to the hybrid case in general, and new precoding or combining solutions are needed.
The benefits of large antenna arrays rely on the accuracy of the Channel State Information (CSI). Considering wideband systems with multicarrier modulations, this information should be acquired for the whole frequency band. However, acquiring the CSI is challenging in this scenario, especially when the system operates in Frequency-Division Duplex (FDD) mode. In this case, if the channel is sounded in the downlink, the length of the training sequence depends on the number of transmit antennas [
5]. Thus, most prior art on channel estimation focused on systems operating on Time-Division Duplex (TDD) mode [
6]. Moreover, the aforementioned restrictions related to hybrid architectures are even more challenging on wideband scenarios, since the analog network is frequency-flat [
7]. This‘is incompatible with methods independently designing the spatial signature of the training sequences for each subcarrier, such as those employed in [
8,
9], or fully digital narrowband solutions. Therefore, hybrid approaches usually compensate these limitations with longer training overheads [
10]. This problem is even more relevant if large bandwidths are considereddue to the beam squint effect [
11], which causes that the channel statistics change in each subcarrier.
A common approach to reduce the training overhead is to as sume that the channel is sparse [
12,
13,
14,
15]. Some authors conducting measurement experiments reported sparsity at mmWave frequencies, with a few channel propagation paths and small angular spreads [
16,
17]. Nevertheless, measurement campaigns on sub-6 GHz frequencies with local scatterers around the Base Station (BS) show that these channels are not sparse in general [
10,
18]. As a consequence, dropping the sparsity as sumption enables a wider applicability, and allows us to circumvent the power leakage typically arisingdue to basis mismatching.
Other authors consider that the channel second order statistics are known in a dvance. Unfortunately, these channel statistics have to be acquired too in practical settings. In case the channel is almost spatially uncorrelated or Rician-distributed, it has been proved that it is a good approximation to estimate only the diagonal elements of the covariance matrix of the channel [
19,
20]. Under correlated channels with Rayleigh fading, the training sequences are designed according to the main eigenvectors of the downlink channel covariance [
21,
22]. However, these training sequences cannot be used in hybrid architectures given their hardware constraints. In TDD scenarios, this covariance can be computed from the uplink [
23,
24] and extrapolated to the downlink by means of channel reciprocity. However, uplink and downlink channels are different in FDD mode, and in that case angular reciprocity is assumed [
25,
26,
27,
28,
29]. However, the computational complexity of these solutions for fully-digital narrowband scenarios is high, and they require an additional training period in the downlink to obtain the instantaneous channel realizations.
Channel covariance estimation techniques usually rely on the assumption of Toeplitz covariance matrices, a circumstance that occurs in usual antenna arrangements, such as Uniform Linear Array (ULA), and channel as sumptions, such as Rayleigh fading and the one-ring channel model [
19,
21,
27]. This structure can be exploited to design short training sequences based on sparse rulers. Previous works designed these rulers using coprime arrays [
30,
31], but this strategy cannot attain the shortest possible training lengths for any number of antennas. There are works that consider more efficient ruler designs for small covariance matrices [
32,
33], but they lack an efficient method to design these training sequences for an arbitrary number of antennas.
Regarding frequency selective channels, solutions have been proposed [
15,
34,
35]. In [
34], authors address covariance estimation in TDD mode for hybrid architectures. The proposed algorithm is an application of Orthogonal Matching Pursuit (OMP) and solves the Multiple Measurement Vector (MMV) problem by allowing for a dynamic sensing matrix. In addition, this method is extended to wideband scenarios under the assumption of common subcarrier support, as done in [
8,
14,
15]. Conversely, authors consider approximately frequency flat second order channel statistics in [
35]. These as sumptions are impractical for scenarios where the signal bandwidth is as large as several GHz [
10] because of the beam squint effect. Recently, refs. [
28,
29] considered the wideband scenario under beam squint and relied on angle reciprocity and channel sparsity to estimate the downlink channel in FDD. However, this approach shares the same drawbacks as other works based on similar as sumptions, namely, large computational complexity and additional training in the downlink, as explained above.
In this work, we propose a downlink channel estimation method for wideband massive MIMO systems over hybrid architectures based on the explicit acquisition of the channel covariance matrix. With the aim of achieving low training overheads, the proposed method employs training sequences based on sparse rulers. The considered setup typically arises in mmWave frequencies, but the proposed framework is general enough to be applicable in sub-6 GHz bands since channel sparsity is not required. Indeed, our approach only as sumes (1) the channel is wide-sense stationary over a period of time, and (2) the channel covariance matrix has a Toeplitz structure. Moreover, we consider the nonlinear spatial transformation caused by the beam squint effect. In the following, we summarize the contributions of our work:
We propose a wideband downlink channel covariance estimation method for hybrid FDD massive MIMO systems that can be utilized for mmWave frequencies. The covariance matrices for different subcarriers lie in distinct subspacesdue to the beam squint effect. The proposed covariance estimation algorithm implements dictionary rotations to overcome this difficulty and exploit the common structure of the wideband covariance matrices.
Differently from the prior art, and with the aim of reducing the training overhead, Wichmann sparse rulers [
36] are used to design the training sequences. Prior work made use of coprime arrays, but this solution cannot attain the lowest training lengths for a given number of transmit antennas. Other works that relied on sparse rulers did not provide methods to design the training sequences for a number of antennas arbitrarily large.
We analyze the limitations of the proposed method based on MUltiple SIgnal Classification (MUSIC): (1) The low rank characteristic of the sample covariance matrices limits the applicability of MUSIC-like techniques. The use of sparse rulers make it possible to extend the proposed method using spatial smoothing techniques and allows for even shorter training sequences; (2) Prior knowledge on the number of channel paths. We show numerically that the number of channel paths can be estimated without significant performance losses and negligible computational cost. (3) The dictionary dependency. We provide a discussion on dictionary sizes, posing that moderated sizes provide enough angular resolution. Furthermore, since sparsity is not a requirement for the proposed method, we show empirically how to avoid the power leakage arising when the Angle of Departures (AoDs) do not lie on the dictionary.
We propose a low complexity channel estimator, leveraging on the structure of the wideband channels to avoid the individual per-subcarrier procedure. This estimator obtains the delays and gains corresponding to each channel propagation path exploiting underlying the common information for all the subcarriers. Moreover, the estimation is performed using the training sequence employed for the acquisition of the covariance matrices, and it does not require an additional training stage.
Notation
In this work, scalars are represented by lower case letters, vectors by bold lower case letters, and matrices by bold capital letters. The superscripts and are the transpose and the Hermitian operators, respectively. The operator with a scalar argument represents the absolute value, with a vector argument represents its norm and with a matrix argument the Frobenius norm. The operator represents the element-wise floor operation. is the Kronecker product of matrices and , and the Khatri–Rao product (or the column-wise Kronecker product) of matrices and . is the diagonal matrix with the arguments in its main diagonal, and constructs a diagonal supermatrix in which the diagonal elements are given by the matrices in the argument, and the off-diagonal elements are zero matrices. and denote the vectors of zeros and ones of the right dimension, respectively. The constant c is the speed of light.
2. System Model
We consider a hybrid FDD massive MIMO system with M transmit antennas and RF chains communicating with several single-antenna users over a multipath channel. To overcome the channel frequency selectivity, we assume an Orthogonal Frequency-Division Multiplexing (OFDM) modulation with subcarriers and a cyclic prefix large enough to avoid intercarrier and intersymbol interference. One of the aims of this work is to estimate the downlink channel covariance; hence, as suming that the channel is locally stationary, we will consider several blocks with the duration of the channel coherence time. At the beginning of each block, the BS transmits a training sequence of length OFDM symbols to sound both the covariance and the channel. The remaining time is devoted to data transmission. That is, we collect K wideband observations of size during K training periods. Since the block duration is limited by the channel coherence time, the training sequence length must satisfy due to the large antenna array deployed at the BS. Indeed, we circumvent the requirement of training sequence lengths larger than the number of paths L, i.e., we propose solutions to the scenario .
Finally, we will as sume that the users feed the observations back to the BS using, e.g., scalar quantization [
8,
37]. With the received feedback, the BS estimates the channel covariance matrices for all users and frequency subcarriers. This scheme allows for tracking the channel covariance matrices using subsequent received feedbackdue to the slow variation of the channel statistics. As previously mentioned, these slow changes make channel covariance acquisition simpler than estimating the channel itself. Next, with the aid of the obtained channel covariance matrices, we estimate the wideband channels employing the
K aforementioned observations.
2.1. Channel Model
We represent the channel response to an arbitrary user using a model similar to that in [
34,
38]. We as sume a multipath channel model with
N taps, where the gains for all antennas in the
f-th subcarrier during the
k-th coherence block are given by
where
are the channel coefficients of the
n-th tap of the channel. Each tap, in turn, is decomposed into
L paths as
where the
are the steering vectors for the AoD of the
l-th path
,
and
are the complex channel gain and the relative delay corresponding to the
l-th path, respectively, and
is the transmit filter as sociated with the Digital to Analog Converter (DAC) sampled with time interval
. We as sume that the channel gains for different paths are statistically independent, i.e.,
.
Regarding the steering vectors, we consider a ULA configuration together with the so-called beam squint effect that arises for the typical antenna apertures in massive MIMO and large relative signal bandwidths
[
11]. We express this effect as a rotation of the steering vectors with respect to the central frequency
, i.e.,
where
is the steering vector for
in a ULA, whose elements are
with
d is the distance between two consecutive array elements,
is the carrier wavelength, and
is a diagonal matrix with the beam squint rotation coefficients. Under the common as sumption of inter-antenna distance
, the elements of
read as
where
is the frequency offset of the
f-th subcarrier with respect to
, and
is its relative position to the central one. This frequency-dependent rotations allows for exploiting the common structure of the wideband covariance matrices, since the beam squint effect for the subcarriers is isolated as a rotation of the frequency-independent vectors
.
Combining Equations (
1) and (
2), the channel frequency response for the
f-th subcarrier reads as
where
N is the number of delay taps and
.
Since the actual AoD of the channel are unknown, the linear combination of steering vectors in (
5) can be approximated by means of the steering vectors as sociated with
G predefined angles
comprised in a frequency-dependent dictionary
, that is,
where
is a vector with
L non-zero entries in the positions corresponding to the AoDs, i.e.,
with
, and
. Note that equality holds for (
6) if the AoDs lie on the dictionary. According to the assumptions regarding the channel statistics, we obtain
. Moreover, we use the approximation in (
6) yielding
with
being Toeplitz, and
the effective gains for the
f-th subcarrier. In the following, we will consider that the AoDs belong to the dictionary, i.e., we as sume
. The consequences of this as sumption are discussed in
Section 4.4.
2.2. Channel Observations
We aim to estimate the channel response using hybrid architectures to reduce the power consumption and implementation costs. This is achieved by using a number of RF chains significantly lower than the number of antennas, i.e.,
. As a counterpart, the feasible hybrid precoding vectors are restricted to the subspace imposed by the hardware limitations. Considering hybrid precoding, the signal received by the users during the
k-th training block in the
f-th subcarrier is
where
is the noise,
is a matrix whose rows are the training vectors for each of the
training channel uses, such that
,
,
contains the transmitted pilot symbols in the
f-subcarrier satisfying
, and
is the hybrid precoder. Therefore, each of these training vectors is the result of the product
where
is the configuration of the precoders during the
t-th training period of
k-th training block, and
and
denote the analog and digital precoding matrices. Recall that
is flat in the frequency domain. Hence, it is not possible to design independent training sequences for each subcarrier.
After the transmission of the
vectors and the subsequent feedback stage, the channel observation
of the
k-th training period will be available at the BS. Since the channel and the noise vectors are statistically independent, the covariance of the observations is given by
By considering the channel covariance matrix model in (
7), we rewrite the previous equation as
where we introduce the measurement matrices
. When the
K samples of the random variable of (
8) are available at the BS,
is estimated. Furthermore, given that both
and
are known, determining
is equivalent to estimating
.
3. Training Design
This section is devoted to the design of training sequences to estimate the channel covariance, together with bounds on their length to guarantee its correct identification under the assumption of a Toeplitz structure.
Toeplitz covariance matrices of size
have
M different coefficients and a training sequence of length
allows for defining
equations. This establishes the following trivial lower bound on the training length:
. A necessary condition to achieve this bound is that the training sequence should allow for measuring the correlation between pairs of antennas for any separation. This has a strong connection with complete sparse rulers, defined mathematically as an ordered integer sequence of with
T elements
, such that
and any
can be written as
for some
. In this case, we speak of a complete sparse ruler of length
, and a perfect ruler is a complete ruler that contains the minimum possible number of elements for a given
. It has been shown that a training sequence built from a perfect sparse ruler is sufficient for determining Toeplitz covariance matrices [
32,
33]. In that case, the length of the training sequence is equal to the number of elements of the ruler, i.e.,
, and the last element of the ruler is
.
In the following, we summarize some results found in the literature for sparse rulers. First, there exist bounds on the size of perfect rulers for a given length [
39].
Theorem 1. (see [39]) Denoting as the minimum number of marks of a complete sparse ruler of length r, exists and Hence, it is possible to identify a Toeplitz covariance matrix using sparse rulers with a training length that satisfies when M approaches infinity.r.
Utilizing the bounds provided by (
12), we evaluate the efficiency of the training sequences employed in previous works on AoD estimation [
30,
31]. Let us start by introducing a trivial example of a complete sparse ruler of length
, for any arbitrary
m. Using the
marks
provides a length of
different differences. This complete ruler achieves a value of
, larger than the bound of (
12). A similar result is obtained with the use of coprime arrays [
30,
31]. This method is based on two co-prime numbers
p and
q, i.e.,
, and on generating the ruler as the set
. This method achieves a training length of
and allows for identifying
different lags. Thus, the limiting function reads as
. Setting
provides the bound
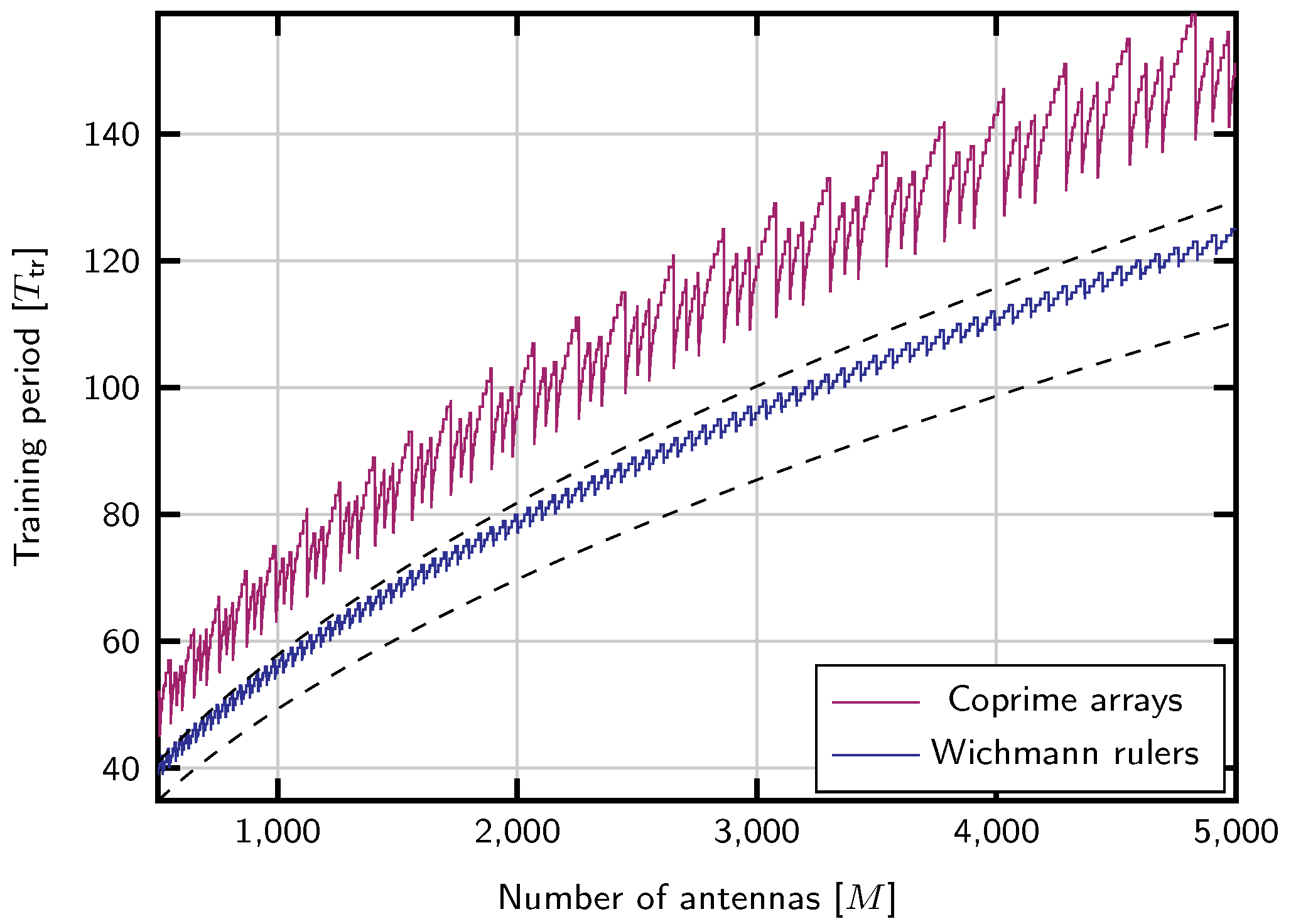
. Hence, coprime arrays cannot improve the asymptotic efficiency of the previous trivial complete ruler.
In the literature, we can find some techniques to build sparse rulers for arbitrary lengths satisfying the bound in (
12). The following section summarizes a method to obtain rulers that are close to that bounds with very low computational complexity.
3.1. Wichmann Rulers
Wichmann [
36] proposed a direct method to obtain sparse rulers of any size that, denoted as the differences between consecutive terms, have the form
for some positive integers
r and
s such that
. The number of elements of this ruler is
and its length
. Hence, if the elements of
are denoted as
, the sparse ruler is
with
and
.
With a change of variable
, the length expression changes to
The parameter r roughly adjusts the length to intervals starting at . Then, for each r value, the parameter finely adjusts length in steps of size . This allows for finding parameters r and that generate a sparse ruler whose length is as close as possible to a given value.
Finally, the ruler can be completed up to the desired length, relying on the following observation: it is always possible to build a ruler that contains all differences in the interval with a set of the form , with . The cardinality of this set is at most . In this case, given a Wichmann ruler of length , and a set that contains all differences in the interval , a new ruler extended to length M can be found by .
3.2. Training Based on Sparse Rulers
A training sequence to estimate a Toeplitz covariance matrix can be built from a sparse ruler. In that case, the length of the ruler must be equal to , the number of correlation coefficients. Given a sparse ruler of length with elements , a training sequence for a Toeplitz covariance matrix can be designed as , where is the M-length indicator column vector of zeros and a one in the i-th element.
In the case of Wichmann rulers, it is not possible to obtain them for arbitrary lengths, but instead a length close to a given value. Hence, to obtain a ruler close to length
, the
r parameter can be found as the largest such that
, which is
. The other parameter is the largest
such that
, implying that
. The length of the ruler can be completed up to
by the method detailed in the previous section. Since the Wichmann rulers always contain entries from 0 to
r, and the
s parameter increases length in steps of
, this completion procedure will add always at most
marks to the ruler, and the minimum training period will be in the interval
.
Figure 1 shows the training length obtained with this strategy compared to the upper and lower bounds in (
12). It also shows the length achieved with the coprime arrays strategy.
In the following, we show that the mild as sumption
is enough to obtain the sparse ruler training sequence
according to (
9). Let
,
be blueeligible arbitrary phases for the PS
s in the analog processing network, and
, with the
is the
m-th row of the analog precoding matrix for the
t-th channel training use. Since the desired training based on sparse rulers must satisfy
, we obtain
as
with the digital part as
. Note that only two elements of
are employed to achieve
. Indeed,
is enough to apply (
15).
5. Delay-Gain Channel Estimator
As a means to estimate the channel, we propose a (DG) Delay-Gains estimator that exploits the structure of the wideband channels. This method employs the observations for all the subcarriers
to estimate the frequency independent gains of each propagation path
(cf. (
6)). Thus, even in the case where certain frequencies present very poor SNR, their corresponding channels can be estimated by using the information from the remaining frequencies.
The covariance estimation procedure provides the measurement matrix and the estimated gain variances for all the frequencies. Using this information, we estimate the delay matrices and the gain vector from the observations gathered in the covariance estimation stage. Next, a robust low complexity estimator is calculated for the frequency selective channels.
First, notice that the observations in (
8) can be rewritten as
, where
was introduced in
Section 4.2,
and
contains the gains for the positions
of
. Then, we focus on the unknown vector
that contains the channel gains affected by the shaping pulse. Accordingly, the linear Minimum Mean Squared Error (MMSE) estimator of
reads as
Once
is determined, we have to identify the matrices
before performing the estimation of
jointly using the vectors
for all the frequencies. Since
contains samples of the shaping filter
in the frequency domain, we obtain
by estimating the delays corresponding to the
L channel paths. In particular, to determine delay for the
l-th path
, we collect the entries as sociated with the
l-th path for all the frequencies, i.e.,
for
, in a vector. Then, we multiply this vector times the first
N columns of the Discrete Fourier Transform (DFT) matrix,
, that is
Observe now that
contains the aforementioned
N stacked pulse samples
, and the estimation noise
. Unfortunately, these samples are scaled by the unknown complex-valued channel gain
of (
2). Note that we assume that the error is statistically independent for different frequencies. Hence, for given shaping filter
, we propose the following estimator function for
where
contains the pulse samples for the delay
. Unfortunately,
is a non-monotonic function. Thus, we minimize
over
, e.g., by linear search over
to obtain the delay estimate
. In the high SNR regime, it is enough to sound within the interval corresponding to the two samples of
with larger absolute values.
Recall that the channel gains are multiplied times
in the unknown vector
of (
24). Thus, employing the estimated delays
, we compute
for all frequencies (see (
6)). To eventually estimate the channel gains
, we compute the minimum variance unbiased estimator [
47] using information from all the frequencies, i.e.,
, where
and
. Finally, by invoking (
6), the estimated channel yields
6. Simulation Results
The following setup is considered for the numerical experiments. We as sume a training sequence
generated from a Wichmann ruler of length
. The number of transmit antennas is
, while we consider a hybrid architecture using
RF chains,
subcarriers, and a dictionary of size
with equally spaced angles within the range
. We consider the channel covariance model of (
6) with
L propagation paths uniformly distributed in
; different number of training periods
K, and
random delay taps uniformly distributed in
, with
. The numerical results are averaged over 200 channel covariance realizations for independent users, and over the different subcarriers
. To evaluate the accuracy of the covariance identification, we employ the Normalized Mean Squared Error (NMSE) metric defined as
with the Frobenius norm
. In the case of channel estimation, we use the efficiency
given by
, which is similar to the figures of merit in e.g., [
26,
34,
48]. This insightful metric evaluates the signal power lost by beamforming using the estimated channels. Note that this metric is averaged over the number of channel blocks.
As a benchmark, we include an LS (known
) curve that individually estimates the gain variances for each subcarrier using (
18) as suming that the channel angles are known. That is, it does not exploit the symmetry with respect to the central frequency of (
19) to estimate the variance gain.
6.1. Wideband Covariance Estimation
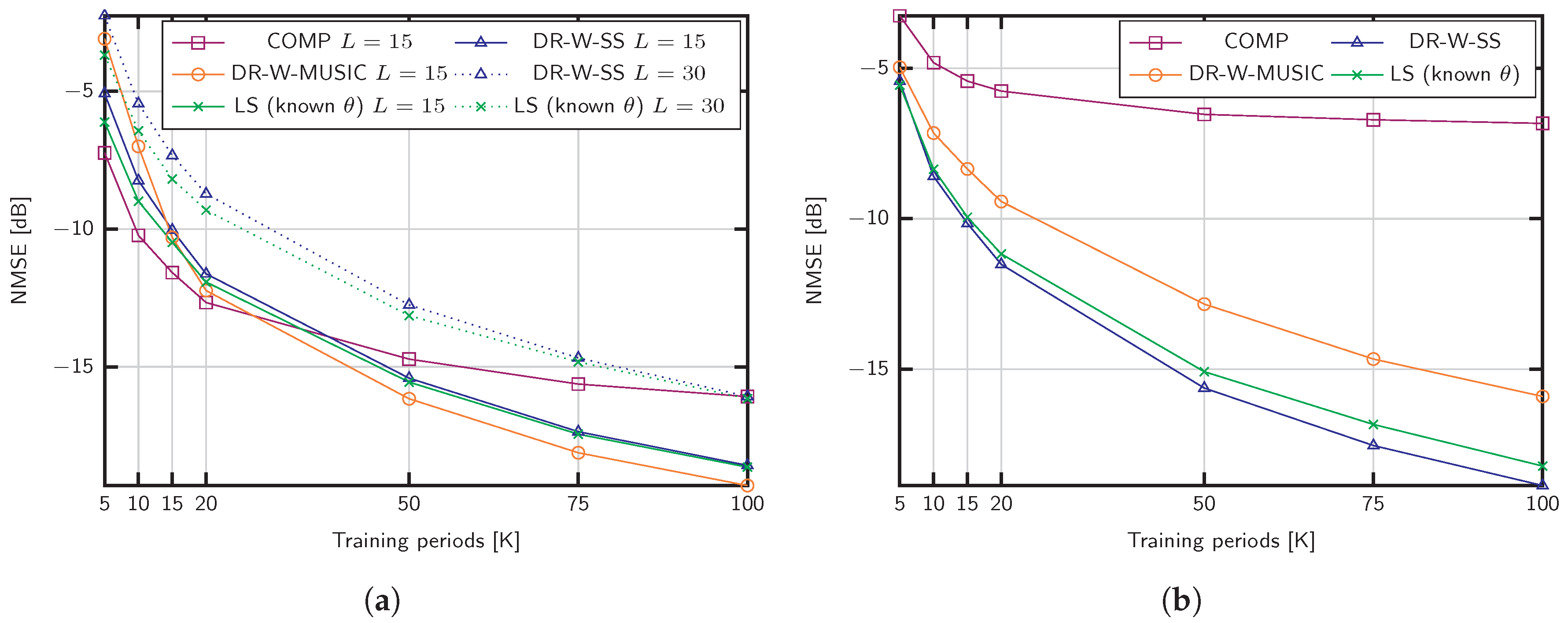
Figure 3a shows the NMSE obtained with the proposed algorithms. The training sequence length is set to
and the channel parameters are adjusted according to massive MIMO settings with
GHz,
MHz,
channel propagation paths, and a SNR of 15 dB. Using the same training sequence, we compare our methods with COMP in [
34], which supports wideband estimation in the absence of beam squint. For
, the proposed methods achieve better performance than COMP when the number of training blocks
K is large, but the accuracy of the estimation deteriorates when
. This behavior is motivated by the lack of similarity between the sample covariance matrix
and the actual channel covariance matrix
that makes difficult the discrimination of the signal and noise subspaces (see Algorithm 1). Nevertheless, values of
K above 50 are feasible in practical settings, since
K is not restricted by the channel coherence time. We also include the case of
channel paths in
Figure 3a. Under such as sumption, COMP and DR-W-MUSIC do not applydue to the lack of angular sparsity, and the limited rank of the sample covariance matrices, respectively. Conversely, the DR-W-SS approach performs close to the benchmark with known angles, denoted by LS (known
).
Figure 3a shows the NMSE for a mmWave setup with
, SNR
dB, a small signal bandwidth
MHz and
GHz. The robustness against the noise of the proposed strategies is remarkable, especially in the case of DR-W-SS. On the contrary, COMP does not achieve good performance results in this SNR regime compared to the proposed methods.
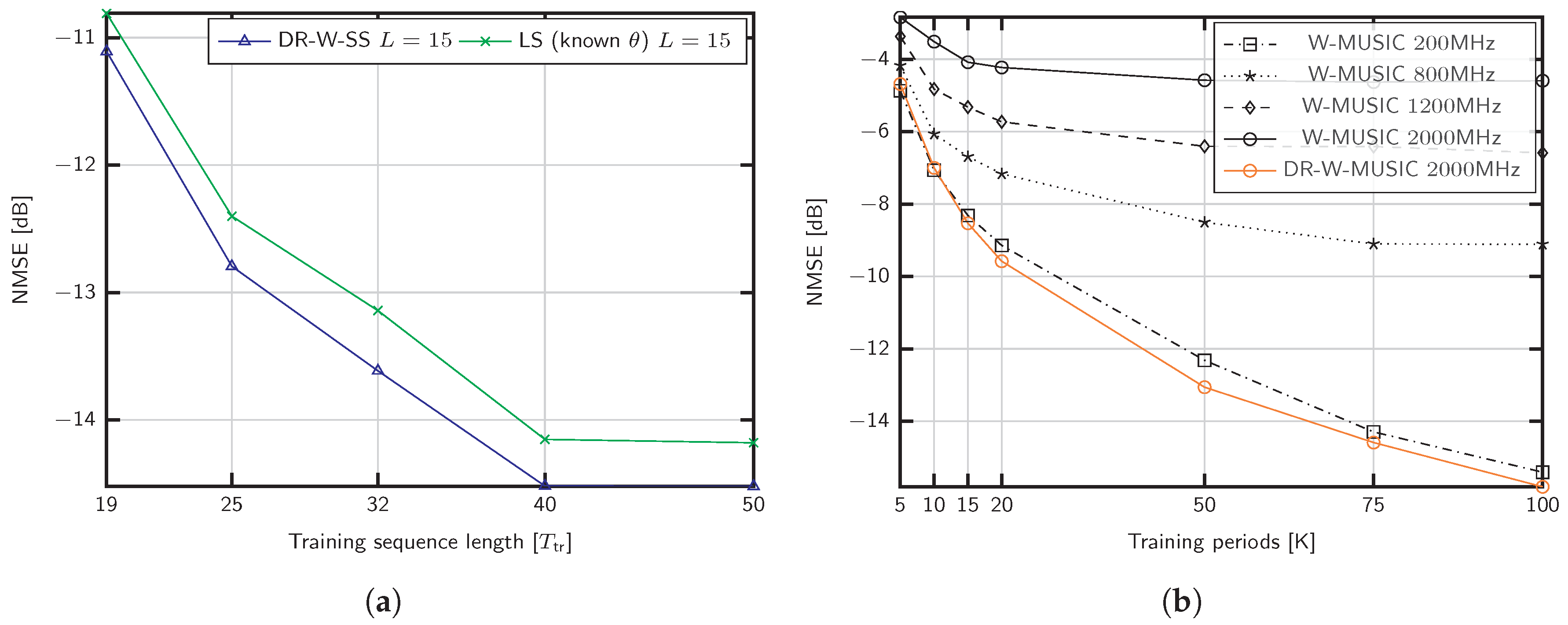
To evaluate the performance impact of the training sequence length
, we fix the parameters to
,
, SNR
dB and
in
Figure 4a. The training sequence is shorter than the number of paths and takes the values 19, 25, 32, 40, 50, to show the capability of DR-W-SS in the challenging scenario
. As shown, the proposed method performs better than the LS benchmark with known support
.
We now evaluate the consequences of neglecting the beam squint effect for the setup considered in
Figure 3a, that is,
GHz and different signal bandwidths,
MHz. The methods referred to as W-MUSIC consist of Algorithm 1 ignoring the dictionary rotation.
Figure 4b exhibits the performance impact of beam squintdue to the lack of a common subspace for different frequencies. As shown, the proposed dictionary rotation is able to exploit the structure even in the case of
MHz.
6.2. Covariance Subspace Estimation
In the previous numerical examples, the number of paths
L was as sumed to be known. Subspace estimation methods, like the one in [
49], can be used to estimate
L by comparing the differences between consecutive eigenvalues of the sample covariance matrix with a threshold
. In the wideband case, we employ the information of all frequencies jointly, to increase the detection accuracy. Moreover, the computational cost over DR-W-MUSIC and DR-W-SS is negligible while it is significant for other approaches not performing a subspace discrimination.
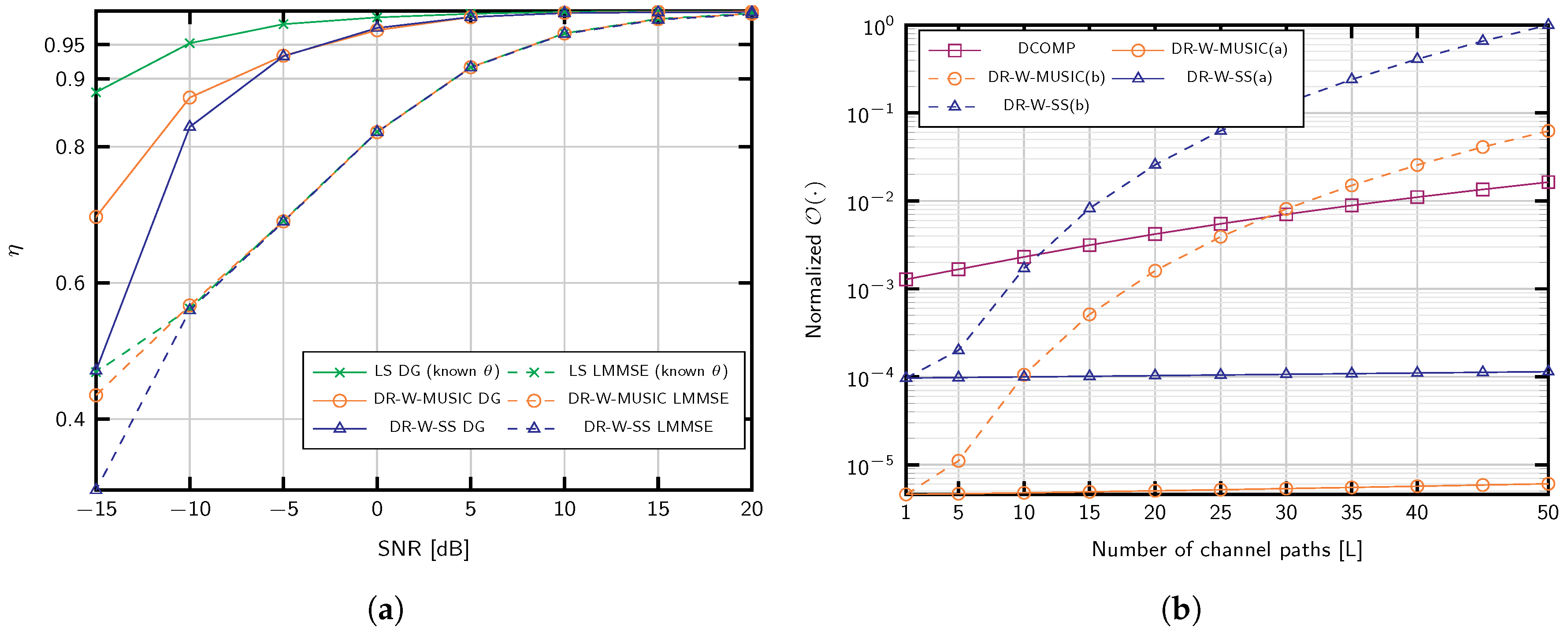
Figure 5a shows the robustness against uncertainty in the number of channel propagation paths
L. We employ Algorithm 2 in [
49] and empirically adjust the parameter
for the different estimation methods. For the considered scenario with SNR = 0 dB, we set the threshold as
for DR-W-MUSIC and
for DR-W-SS. Remarkably, the performance obtained with subspace estimation for DR-W-SS is similar to that of the strategies with known
L. In particular, for DR-W-MUSIC, overestimating the number of channel paths
L improves the performance. This observation reveals that the support identified by Algorithm 1 with known
L was incorrect. Recall that the support
comprises the angles corresponding to the
L larger values on the estimator function
. Under the strong noise conditions considered in
Figure 5a, some angles belonging to the covariance support might be ignored (see line 14 of Algorithm 1). Instead, step 14 selects angles in the dictionary whose steering vectors are linearly dependent. Thus, overestimating
L enables a better detection of the channel covariance subspace where angles with lower
are included in
. In addition, we compare the effect of discarding the repeated distances in DR-W-SS, as performed in conventional SS [
44]. In
Figure 5a, this strategy is labeled DR-W-SS Discard. As shown, for
, the performance loss is significant.
In
Section 4.4, we discussed the advantages and practical orientation of moderate dictionary sizes. Nevertheless, we investigate the effect of off-grid AoDs in
Figure 5b for the mmWave setup and
MHz. The error floordue to basis mismatch is clear. As an alternative to increase
G, we propose to compensate the basis inaccuracy by overestimating the number of channel paths
L. This way, part of the power leakage is recovered with the additional AoDs. These approaches are denoted DR-W-MUSIC Overestimated
L and DR-W-SS Overestimated
L. For the LS estimator with known angles, we choose the closest dictionary angles to the real ones.
6.3. Wideband Channel Estimation
Figure 6a shows the performance of the channel estimator with the covariance identified and the two different channel estimation methods: LMMSE [
21,
25,
47]
and the proposed DG estimator of (
27). The number of channel blocks is set to
, and the number of delay candidates
considered in (
26) is 20
N. Since the proposed DG method uses the information of all the subcarriers to produce the estimates, it is very robust against noise and results in a considerable performance gain. Indeed, more than
of the signal power is captured at
dB with the proposed strategies.
6.4. Computational Complexity
Table 1 summarizes the computational complexity of the proposed methods. Recall that a fast covariance estimation is important, but not as critical as the actual channel estimation. Indeed, we only employ a training stage contrarily to other approaches like [
21,
37].
For the favorable scenario, DR-W-MUSIC(a) and DR-W-SS(a), the gain variances are estimated using well-conditioned measurement matrices, while (
18) with the Khatri–Rao product is considered for MUSIC(b) and DR-W-SS(b). The complexities have been calculated as suming
for DR-W-MUSIC and COMP. It is noticeable that neither DR-W-MUSIC nor COMP depend on the number of antennas, although both of them linearly depend on the dictionary size
G. The number of channel taps
N is also relatively small, and
T is the number of
candidates evaluated to estimate the delays using (
26). Since COMP and DR-W-MUSIC apply to scenarios where
L and
are very small compared to
M or
G, the complexity of the latter is smaller in general. Furthermore, the number of steps performed by COMP is larger, and its computational burden depends on the number of training periods
K.
When
, the computational complexity virtually depends on the number of antennas. Hence, DR-W-SS and DR-W-MUSIC establish a trade-off among
,
L and
M, since we could use the less complex option by adjusting
and
K. The effect of increasing
L is depicted in
Figure 6b. Interestingly, in the region where the channel is sparse and Dynamic COMP (DCOMP) applies,
, the computational complexity of the proposed approaches is lower than that of DCOMP.
We now differentiate between the operations computed once using the estimated covariance matrix, referred to as “Computing Estimator”, and the channel estimation for each observation, referred to as “Channel Estimation”. Remarkably, the complexity of computing the proposed estimator (DG) linearly depends on
M, cf. (
24)–(
26) whereas for the LMMSE estimator this dependency is quadratic.
Regarding the actual channel estimation, in scenarios suitable for DR-W-MUSIC with
, DG channel estimation is more efficient. This applies to mmWave frequencies and other massive MIMO scenarios, e.g., [
8,
37,
50,
51,
52,
53]. Conversely, LMMSE estimator might be less complex for large number of channel propagation paths, i.e.,
.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}