Improved Handwritten Digit Recognition Using Convolutional Neural Networks (CNN)



Abstract
:1. Introduction
2. Related Work
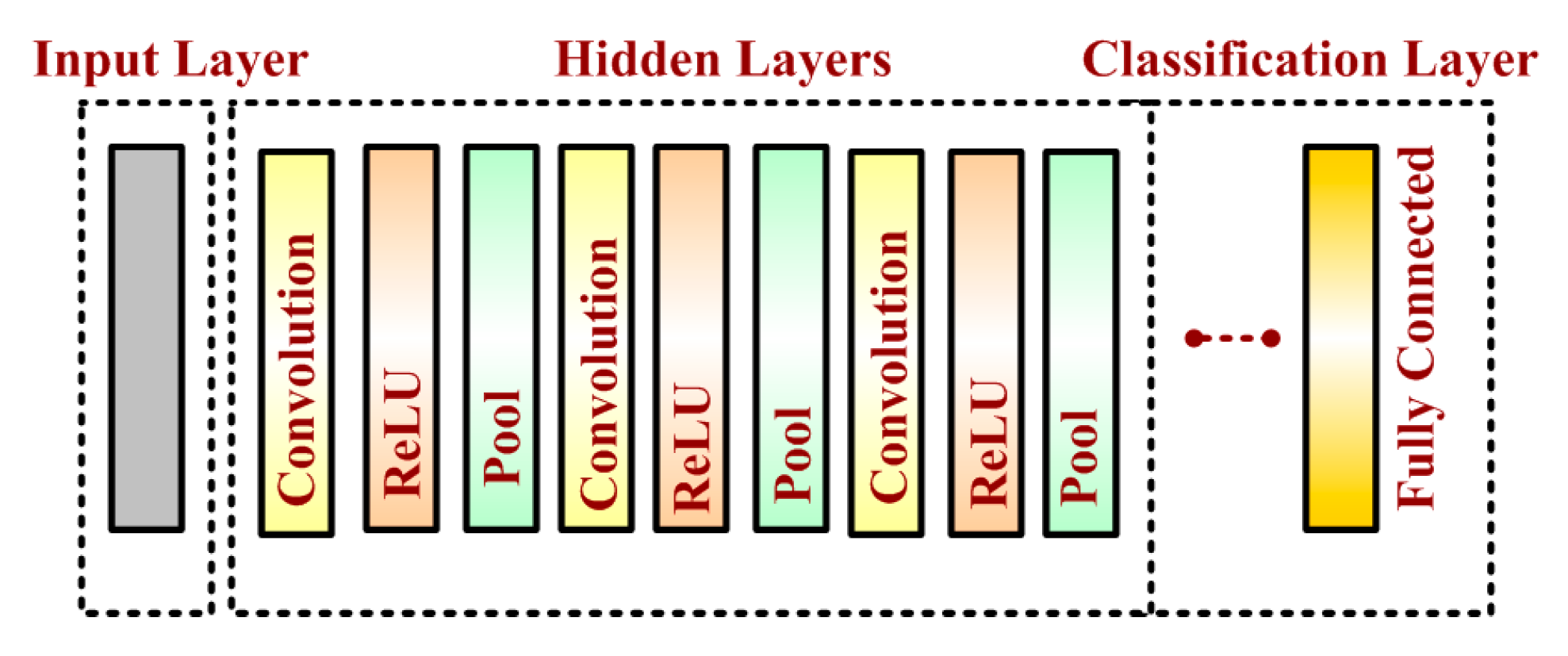
3. Convolutional Neural Network Architecture
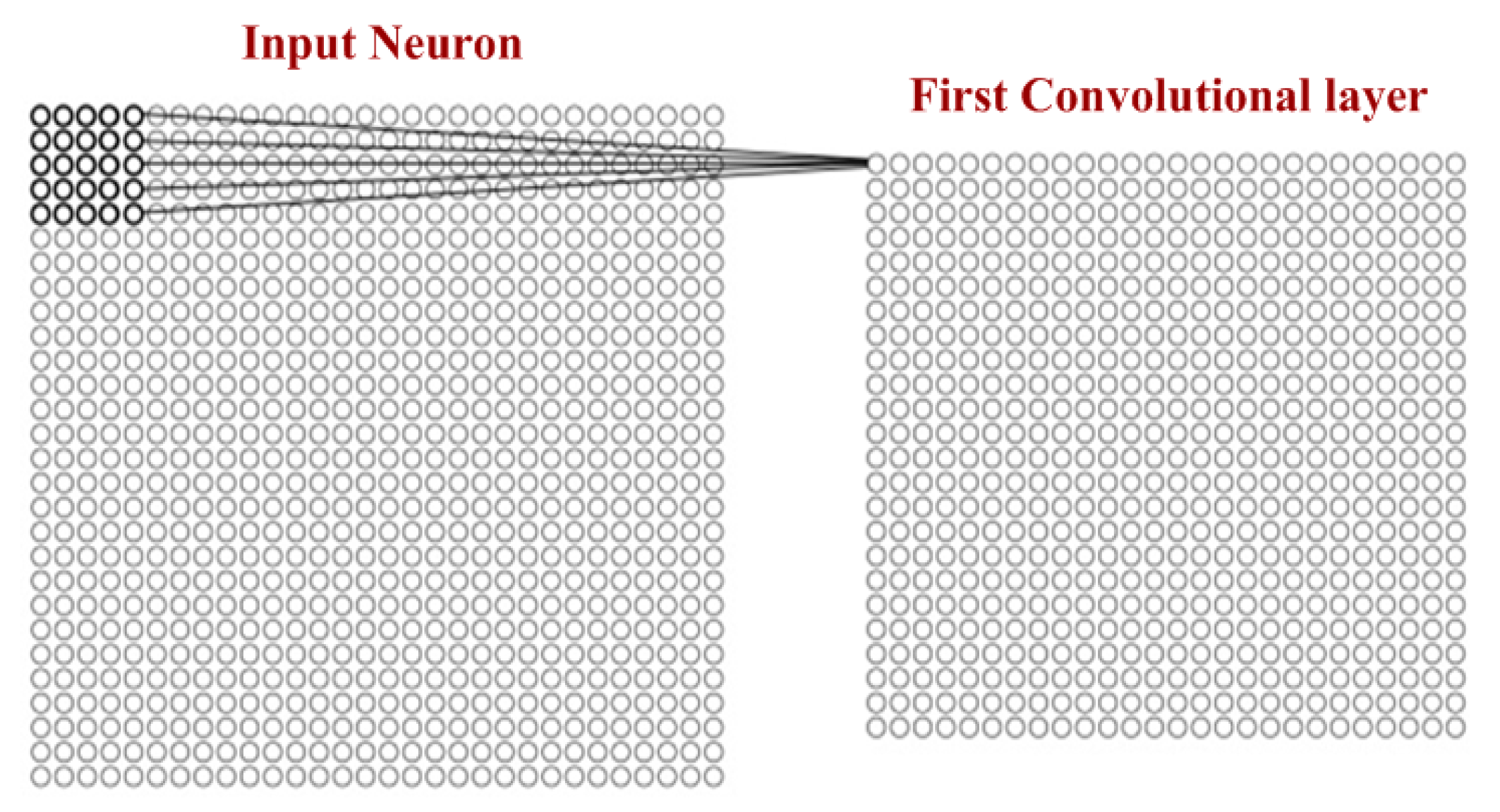
3.1. Input Layer
3.2. Hidden Layer
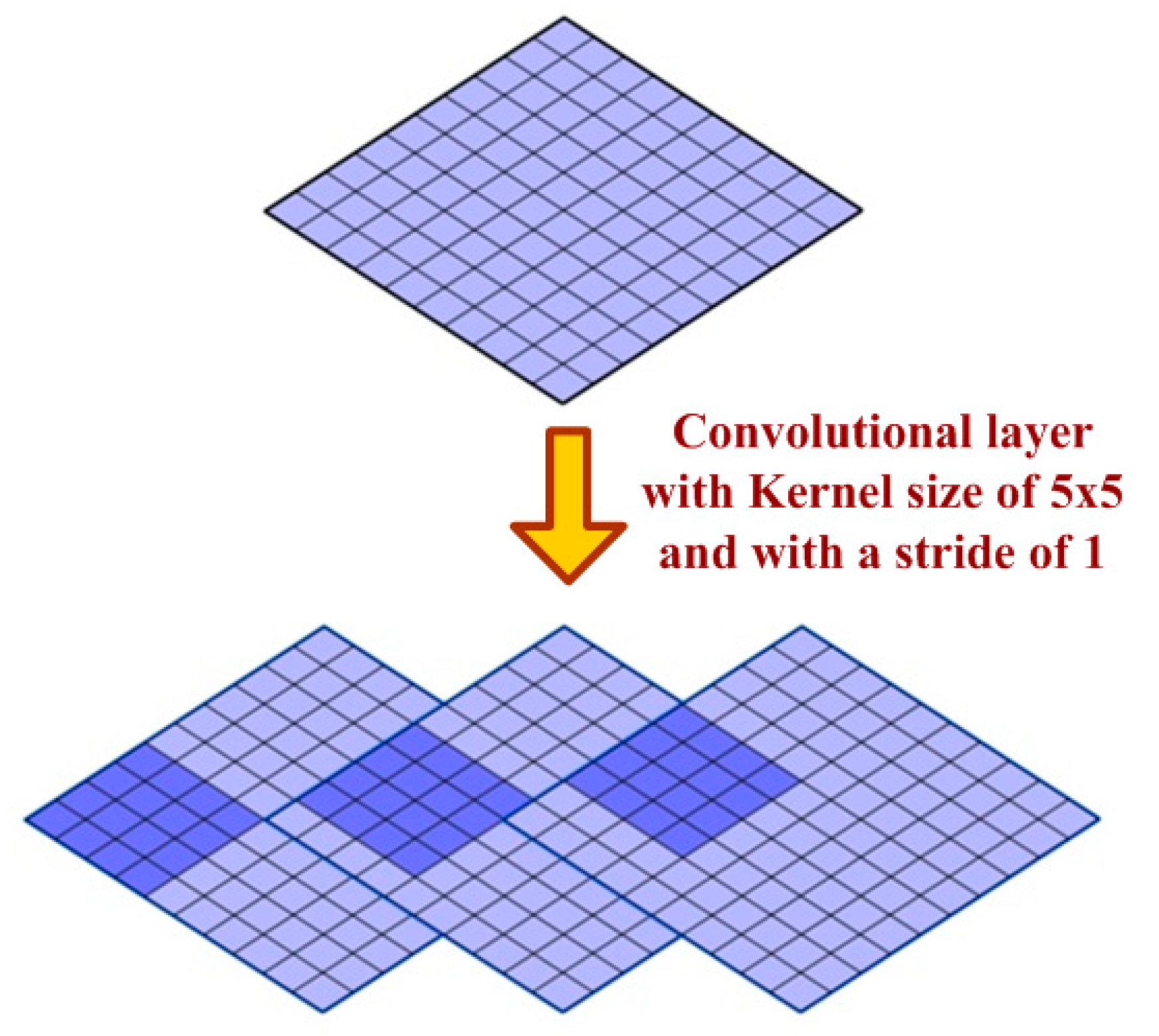
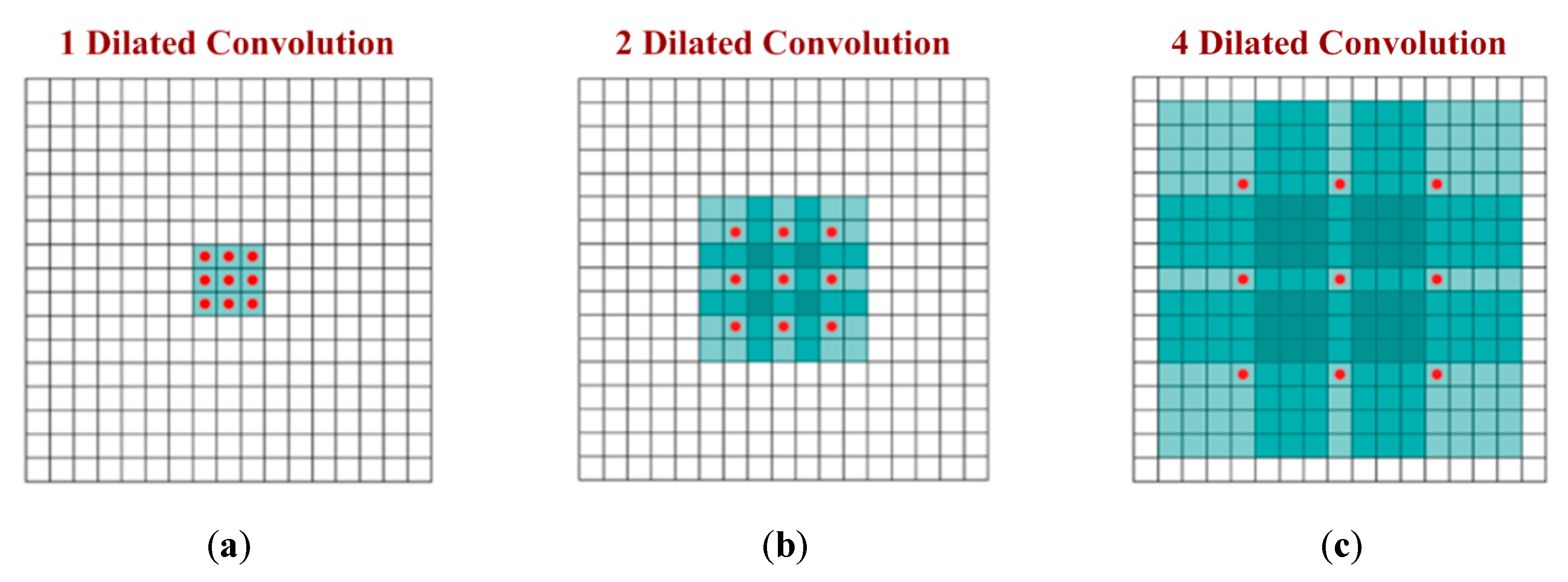
3.3. Convolutional Layer
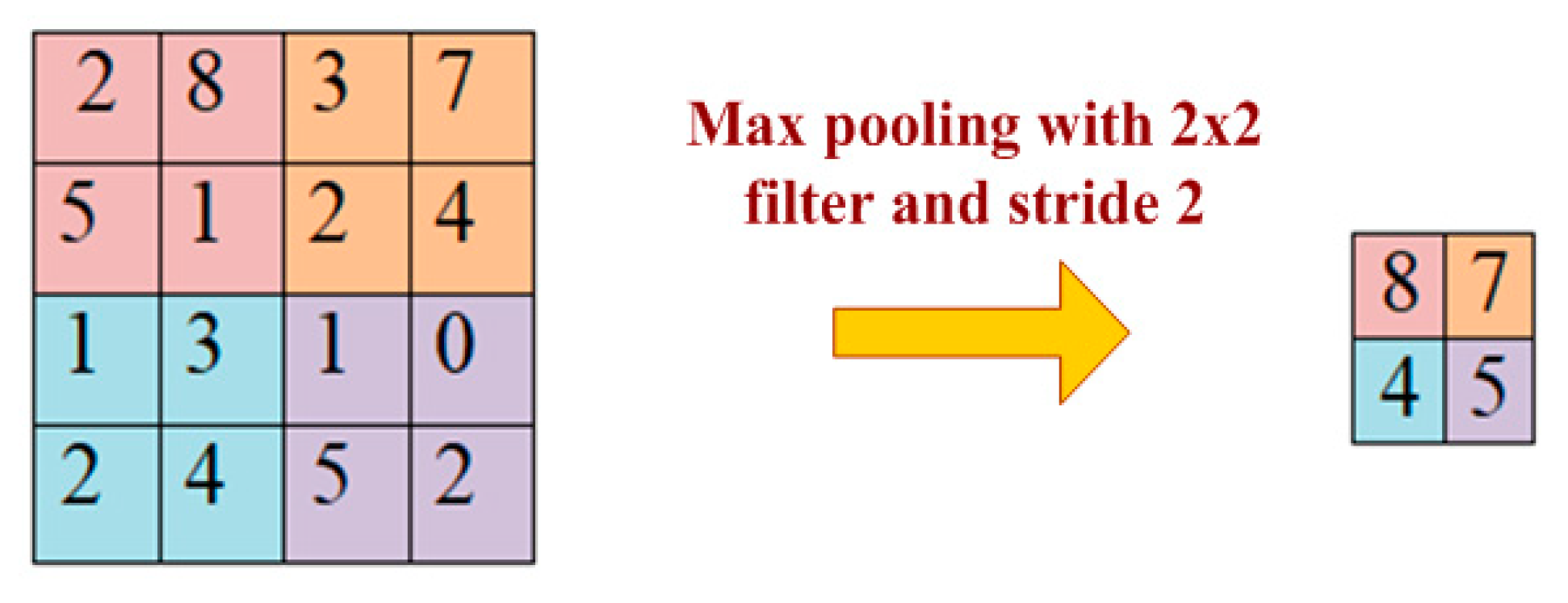
3.4. Pooling Layer
3.5. Activation Layer
3.6. Classification Layer
3.7. Gradient Descent Optimization Algorithm
| Algorithm 1 Learning Parameters Update Mechanism |
| 1: Input: as training data; as learning rate; is a gradient of loss (error) function with respect to the parameter; momentum factor () 2: Output: For each training pair, update the learning parameters using the equation θ=θ-η.∇E(θ;x(i);y(i)) 3: if stopping condition is met 4: return parameter θ. |
4. Experimental Setup
- To acquire or collect the MNIST handwritten digit images.
- To divide the input images into training and test images.
- To apply the pre-processing technique to both the training dataset and the test dataset.
- To normalize the data so that it ranges from 0 to 1.
- To divide the training dataset into batches of a suitable size.
- To train the CNN model and its variants using the labelled data.
- To use a trained model for the classification.
- To analyze the recognition accuracy and processing time for all the variants.
5. Results and Discussion
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Dalal, N.; Triggs, B. Histograms of oriented gradients for human detection. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR ’05), San Diego, CA, USA, 20–26 June 2005; Volume 1, pp. 886–893. [Google Scholar]
- Lowe, D.G. Distinctive image features from scale-invariant keypoints. Int. J. Comput. Vis. 2004, 60, 2. [Google Scholar] [CrossRef]
- Xiao, J.; Xuehong, Z.; Chuangxia, H.; Xiaoguang, Y.; Fenghua, W.; Zhong, M. A new approach for stock price analysis and prediction based on SSA and SVM. Int. J. Inf. Technol. Decis. Making 2019, 18, 287–310. [Google Scholar] [CrossRef]
- Wang, D.; Lihong, H.; Longkun, T. Dissipativity and synchronization of generalized BAM neural networks with multivariate discontinuous activations. IEEE Trans. Neural Netw. Learn. Syst. 2017, 29, 3815–3827. [Google Scholar] [PubMed]
- Kuang, F.; Siyang, Z.; Zhong, J.; Weihong, X. A novel SVM by combining kernel principal component analysis and improved chaotic particle swarm optimization for intrusion detection. Soft Comput. 2015, 19, 1187–1199. [Google Scholar] [CrossRef]
- Choudhary, A.; Ahlawat, S.; Rishi, R. A binarization feature extraction approach to OCR: MLP vs. RBF. In Proceedings of the International Conference on Distributed Computing and Technology ICDCIT, Bhubaneswar, India, 6–9 February 2014; Springer: Cham, Switzerland, 2014; pp. 341–346. [Google Scholar]
- Fukushima, K. Neocognitron: A self-organizing neural network model for a mechanism of pattern recognition unaffected by shift in position. Biol. Cybern. 1980, 36, 193–202. [Google Scholar] [CrossRef]
- Jarrett, K.; Kavukcuoglu, K.; Ranzato, M.; LeCun, Y. What is the best multi-stage architecture for object recognition. In Proceedings of the IEEE 12th International Conference on Computer Vision (ICCV), Kyoto, Japam, 29 September–2 October 2009. [Google Scholar]
- Ciresan, D.C.; Meier, U.; Masci, J.; Gambardella, L.M.; Schmidhuber, J. High-performance neural networks for visual object classification. arXiv 2011, arXiv:1102.0183v1. [Google Scholar]
- Ciresan, D.C.; Meier, U.; Schmidhuber, J. Multi-column deep neural networks for image classification. arXiv 2012, arXiv:1202.2745. [Google Scholar]
- Niu, X.X.; Suen, C.Y. A novel hybrid CNN–SVM classifier for recognizing handwritten digits. Pattern Recognit. 2012, 45, 1318–1325. [Google Scholar] [CrossRef]
- Qu, X.; Wang, W.; Lu, K.; Zhou, J. Data augmentation and directional feature maps extraction for in-air handwritten Chinese character recognition based on convolutional neural network. Pattern Recognit. Lett. 2018, 111, 9–15. [Google Scholar] [CrossRef]
- Alvear-Sandoval, R.; Figueiras-Vidal, A. On building ensembles of stacked denoising auto-encoding classifiers and their further improvement. Inf. Fusion 2018, 39, 41–52. [Google Scholar] [CrossRef] [Green Version]
- Demir, C.; Alpaydin, E. Cost-conscious classifier ensembles. Pattern Recognit. Lett. 2005, 26, 2206–2214. [Google Scholar] [CrossRef]
- Choudhary, A.; Ahlawat, S.; Rishi, R. A neural approach to cursive handwritten character recognition using features extracted from binarization technique. Complex Syst. Model. Control Intell. Soft Comput. 2015, 319, 745–771. [Google Scholar]
- Choudhary, A.; Rishi, R.; Ahlawat, S. Handwritten numeral recognition using modified BP ANN structure. In Proceedings of the Communication in Computer and Information Sciences (CCIS-133), Advanced Computing, CCSIT 2011, Royal Orchid Central, Bangalore, India, 2–4 January 2011; Springer: Berling/Heildelberg, Germany, 2011; pp. 56–65. [Google Scholar]
- Cai, Z.W.; Li-Hong, H. Finite-time synchronization by switching state-feedback control for discontinuous Cohen–Grossberg neural networks with mixed delays. Int. J. Mach. Learn. Cybern. 2018, 9, 1683–1695. [Google Scholar] [CrossRef]
- Zeng, D.; Dai, Y.; Li, F.; Sherratt, R.S.; Wang, J. Adversarial learning for distant supervised relation extraction. Comput. Mater. Contin. 2018, 55, 121–136. [Google Scholar]
- Long, M.; Yan, Z. Detecting iris liveness with batch normalized convolutional neural network. Comput. Mater. Contin. 2019, 58, 493–504. [Google Scholar] [CrossRef]
- Chuangxia, H.; Liu, B. New studies on dynamic analysis of inertial neural networks involving non-reduced order method. Neurocomputing 2019, 325, 283–287. [Google Scholar]
- Xiang, L.; Li, Y.; Hao, W.; Yang, P.; Shen, X. Reversible natural language watermarking using synonym substitution and arithmetic coding. Comput. Mater. Contin. 2018, 55, 541–559. [Google Scholar]
- Huang, Y.S.; Wang, Z.Y. Decentralized adaptive fuzzy control for a class of large-scale MIMO nonlinear systems with strong interconnection and its application to automated highway systems. Inf. Sci. 2014, 274, 210–224. [Google Scholar] [CrossRef]
- Choudhary, A.; Rishi, R. Improving the character recognition efficiency of feed forward bp neural network. Int. J. Comput. Sci. Inf. Technol. 2011, 3, 85–96. [Google Scholar] [CrossRef]
- Ahlawat, S.; Rishi, R. A genetic algorithm based feature selection for handwritten digit recognition. Recent Pat. Comput. Sci. 2019, 12, 304–316. [Google Scholar] [CrossRef]
- Hinton, G.E.; Osindero, S.; Teh, Y.W. A fast learning algorithm for deep belief nets. Neural Comput. 2006, 18, 1527–1554. [Google Scholar] [CrossRef]
- Pham, V.; Bluche, T.; Kermorvant, C.; Louradour, J. Dropout improves recurrent neural networks for handwriting recognition. In Proceedings of the 14th Int. Conf. on Frontiers in Handwriting Recognition, Heraklion, Greece, 1–4 September 2014. [Google Scholar]
- Tabik, S.; Alvear-Sandoval, R.F.; Ruiz, M.M.; Sancho-Gómez, J.L.; Figueiras-Vidal, A.R.; Herrera, F. MNIST-NET10: A heterogeneous deep networks fusion based on the degree of certainty to reach 0.1% error rate. Ensembles Overv. Proposal Inf. Fusion 2020, 62, 73–80. [Google Scholar] [CrossRef]
- Lang, G.; Qingguo, L.; Mingjie, C.; Tian, Y.; Qimei, X. Incremental approaches to knowledge reduction based on characteristic matrices. Int. J. Mach. Learn. Cybern. 2017, 8, 203–222. [Google Scholar] [CrossRef]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. SegNet: A Deep convolutional encoder-decoder architecture for image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef]
- He, S.; Zeng, W.; Xie, K.; Yang, H.; Lai, M.; Su, X. PPNC: Privacy preserving scheme for random linear network coding in smart grid. KSII Trans. Internet Inf. Syst. 2017, 11, 1510–1532. [Google Scholar]
- Sueiras, J.; Ruiz, V.; Sanchez, A.; Velez, J.F. Offline continuous handwriting recognition using sequence to sequence neural networks. Neurocomputing. 2018, 289, 119–128. [Google Scholar] [CrossRef]
- Liang, T.; Xu, X.; Xiao, P. A new image classification method based on modified condensed nearest neighbor and convolutional neural networks. Pattern Recognit. Lett. 2017, 94, 105–111. [Google Scholar] [CrossRef]
- Simard, P.Y.; Steinkraus, D.; Platt, J.C. Best practice for convolutional neural networks applied to visual document analysis. In Proceedings of the Seventh International Conference on Document Analysis and Recognition (ICDAR 2003), Edinburgh, UK, 3–6 August 2003. [Google Scholar]
- Wang, T.; Wu, D.J.; Coates, A.; Ng, A.Y. End-to-end text recognition with convolutional neural networks. In Proceedings of the 21st International Conference on Pattern Recognition (ICPR2012), Tsukuba, Japan, 11–15 November 2012. [Google Scholar]
- Shi, B.; Bai, X.; Yao, C. An End-to-end trainable neural network for image-based sequence recognition and its application to scene text recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2298–2304. [Google Scholar] [CrossRef] [Green Version]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Chen, L.-C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. DeepLab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected CRFs. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 834–848. [Google Scholar] [CrossRef]
- Noh, H.; Hong, S.; Han, B. Learning deconvolution network for semantic segmentation. In Proceedings of the IEEE International Conference on Computer Vision, Araucano Park, Las Condes, Chille, 11–18 December 2015. [Google Scholar]
- Boufenar, C.; Kerboua, A.; Batouche, M. Investigation on deep learning for off-line handwritten Arabic character recognition. Cogn. Syst. Res. 2018, 50, 180–195. [Google Scholar] [CrossRef]
- Kavitha, B.; Srimathi, C. Benchmarking on offline Handwritten Tamil Character Recognition using convolutional neural networks. J. King Saud Univ. Comput. Inf. Sci. 2019. [Google Scholar] [CrossRef]
- Dewan, S.; Chakravarthy, S. A system for offline character recognition using auto-encoder networks. In Proceedings of the International Conference on Neural Information Processing, Doha, Qatar, 12–15 November 2012. [Google Scholar]
- Ahmed, S.; Naz, S.; Swati, S.; Razzak, M.I. Handwritten Urdu character recognition using one-dimensional BLSTM classifier. Neural Comput. Appl. 2019, 31, 1143–1151. [Google Scholar] [CrossRef]
- Husnain, M.; Saad Missen, M.; Mumtaz, S.; Jhanidr, M.Z.; Coustaty, M.; Luqman, M.M.; Ogier, J.-M.; Choi, G.S. Recognition of urdu handwritten characters using convolutional neural network. Appl. Sci. 2019, 9, 2758. [Google Scholar] [CrossRef] [Green Version]
- Sarkhel, R.; Das, N.; Das, A.; Kundu, M.; Nasipuri, M. A multi-scale deep quad tree based feature extraction method for the recognition of isolated handwritten characters of popular indic scripts. Pattern Recognit. 2017, 71, 78–93. [Google Scholar] [CrossRef]
- Xie, Z.; Sun, Z.; Jin, L.; Feng, Z.; Zhang, S. Fully convolutional recurrent network for handwritten chinese text recognition. In Proceedings of the 23rd International Conference on Pattern Recognition (ICPR 2016), Cancun, Mexico, 4–8 December 2016. [Google Scholar]
- Liu, C.; Yin, F.; Wang, D.; Wang, Q.-F. Online and offline handwritten Chinese character recognition: Benchmarking on new databases. Pattern Recognit. 2013, 46, 155–162. [Google Scholar] [CrossRef]
- Wu, Y.-C.; Yin, F.; Liu, C.-L. Improving handwritten chinese text recognition using neural network language models and convolutional neural network shape models. Pattern Recognit. 2017, 65, 251–264. [Google Scholar] [CrossRef]
- Gupta, A.; Sarkhel, R.; Das, N.; Kundu, M. Multiobjective optimization for recognition of isolated handwritten Indic scripts. Pattern Recognit. Lett. 2019, 128, 318–325. [Google Scholar] [CrossRef]
- Nguyen, C.T.; Khuong, V.T.M.; Nguyen, H.T.; Nakagawa, M. CNN based spatial classification features for clustering offline handwritten mathematical expressions. Pattern Recognit. Lett. 2019. [Google Scholar] [CrossRef]
- Ziran, Z.; Pic, X.; Innocenti, S.U.; Mugnai, D.; Marinai, S. Text alignment in early printed books combining deep learning and dynamic programming. Pattern Recognit. Lett. 2020, 133, 109–115. [Google Scholar] [CrossRef]
- Ptucha, R.; Such, F.; Pillai, S.; Brokler, F.; Singh, V.; Hutkowski, P. Intelligent character recognition using fully convolutional neural networks. Pattern Recognit. 2019, 88, 604–613. [Google Scholar] [CrossRef]
- Cui, H.; Bai, J. A new hyperparameters optimization method for convolutional neural networks. Pattern Recognit. Lett. 2019, 125, 828–834. [Google Scholar] [CrossRef]
- Tso, W.W.; Burnak, B.; Pistikopoulos, E.N. HY-POP: Hyperparameter optimization of machine learning models through parametric programming. Comput. Chem. Eng. 2020, 139, 106902. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016. [Google Scholar]
- Christian, S.; Wei, L.; Yangqing, J.; Pierre, S.; Scott, R.; Dragomir, A.; Andrew, R. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. In Proceedings of the International Conference on Learning Representations, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 2012, 25, 1097–1105. [Google Scholar] [CrossRef]
- Eickenberg, M.; Gramfort, A.; Varoquaux, G.; Thirion, B. Seeing it all: Convolutional network layers map the function of the human visual system. NeuroImage 2017, 152, 184–194. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Le, H.; Borji, A. What are the receptive, effective receptive, and projective fields of neurons in convolutional neural networks? arXiv 2018, arXiv:1705.07049. [Google Scholar]
- Luo, W.; Li, Y.; Urtasun, R.; Zemel, R. Understanding the effective receptive field in deep convolutional neural networks. arXiv 2017, arXiv:1701.04128. [Google Scholar]
- Lin, G.; Wu, Q.; Qiu, L.; Huang, X. Image super-resolution using a dilated convolutional neural network. Neurocomputing 2018, 275, 1219–1230. [Google Scholar] [CrossRef]
- Scherer, D.; Muller, A.; Behnke, S. Evaluation of pooling operations in convolutional architectures for object recognition. In Proceedings of the International Conference on Artificial Neural Networks, Thessaloniki, Greece, 15–18 September 2010. [Google Scholar]
- Shi, Z.; Ye, Y.; Wu, Y. Rank-based pooling for deep convolutional neural networks. Neural Netw. 2016, 83, 21–31. [Google Scholar] [CrossRef]
- Wu, H.; Gu, X. Towards dropout training for convolutional neural networks. Neural Netw. 2015, 71, 1–10. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Saeed, F.; Paul, A.; Karthigaikumar, P.; Nayyar, A. Convolutional neural network based early fire detection. Multimed. Tools Appl. 2019, 1–17. [Google Scholar] [CrossRef]
- Alzubi, J.; Nayyar, A.; Kumar, A. Machine learning from theory to algorithms: An overview. J. Phys. Conf. Series 2018, 1142, 012012. [Google Scholar] [CrossRef]
- Duchi, J.; Hazen, E.; Singer, Y. Adaptive subgradient methods for online learning and stochastic optimization. J. Mach. Learn. Res. 2011, 12, 2121–2159. [Google Scholar]
- Zeiler, M.D. ADADELTA: An Adaptive Learning Rate Method. arXiv 2012, arXiv:abs/1212.5701. [Google Scholar]
- Kingma, D.; Ba, J. Adam: A method for stochastic optimization. In Proceedings of the International Conference on Learning Representations, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Bartlett, P.; Hazan, E.; Rakhlin, A. Adaptive online gradient descent. In Proceedings of the NIPS, Vancuver, BC, Canada, 8–11 December 2008. [Google Scholar]
- Do, C.B.; Le, Q.V.; Foo, C.S. Proximal regularization for online and batch learning. In Proceedings of the ICML, Montreal, QC, Canada, 14–18 June 2009. [Google Scholar]
- Hinton, G.E.; Salakhutdinov, R.R. Reducing the dimensionality of data with neural networks. Science 2006. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Shalev-Shwartz, S.; Singer, Y.; Srebro, N. Pegasos: Primal estimated sub-gradient solver for svm. In Proceedings of the ICML, Corvallis, OR, USA, 20–24 June 2007. [Google Scholar]
- Zinkevich, M.; Weimer, M.; Smola, A.; Li, L. Parallelized stochastic gradient descent. NIPS 2010, 2, 2595–2603. [Google Scholar]
- LeCun, Y.; Boser, B.; Denker, J.S.; Henderson, D. Backpropagation applied to handwritten zip code recognition. Neural Comput. 1989, 1, 541–551. [Google Scholar] [CrossRef]
- Dietterich, T.; Bakiri, G. Solving multiclass learning problems via error-correcting output codes. J. Artif. Intell. Res. 1995, 1, 263–286. [Google Scholar] [CrossRef] [Green Version]
- Wan, L.; Zeiler, M.; Zhang, S.; Le Cun, Y.; Fergus, R. Regularization of neural networks using DropConnect. In Proceedings of the 30th International Conference on Machine Learning (PMLR), Atlanta, GA, USA, 16–21 June 2013. [Google Scholar]
- Loquercio, A.; Della Torre, A.; Buscema, M. Computational Eco-Systems for handwritten digits recognition. arXiv 2017, arXiv:1703.01872v1. [Google Scholar]
- Soomro, M.; Farooq, M.A.; Raza, M.A. Performance evaluation of advanced deep learning architectures for offline handwritten character recognition. In Proceedings of the International Conference on Frontiers of Information Technology (FIT), Islamabad, Pakistan, 18–20 December 2017; pp. 362–367. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Factors | Shallow Neural Network (SNN) | Deep Neural Network (DNN) |
|---|---|---|
| Number of hidden layers | - single hidden layer (need to be fully connected). | - multiple hidden layers (not necessarily fully connected). |
| Feature Engineering | - requires a separate feature extraction process. - some of the famous features used in the literature include local binary patterns (LBPs), histogram of oriented gradients (HOGs), speeded up robust features (SURFs), and scale-invariant feature transform (SIFT). | - supersedes the handcrafted features and works directly on the whole image. - useful in computing complex pattern recognition problems. - can capture complexities inherent in the data. |
| Requirements | - emphasizes the quality of features and their extraction process. - networks are more dependent on the expert skills of researchers. | - able to automatically detect the important features of an object (here an object can be an image, a handwritten character, a face, etc.) without any human supervision or intervention. |
| Dependency on data volume | - requires small amount of data. | - requires large amount of data. |
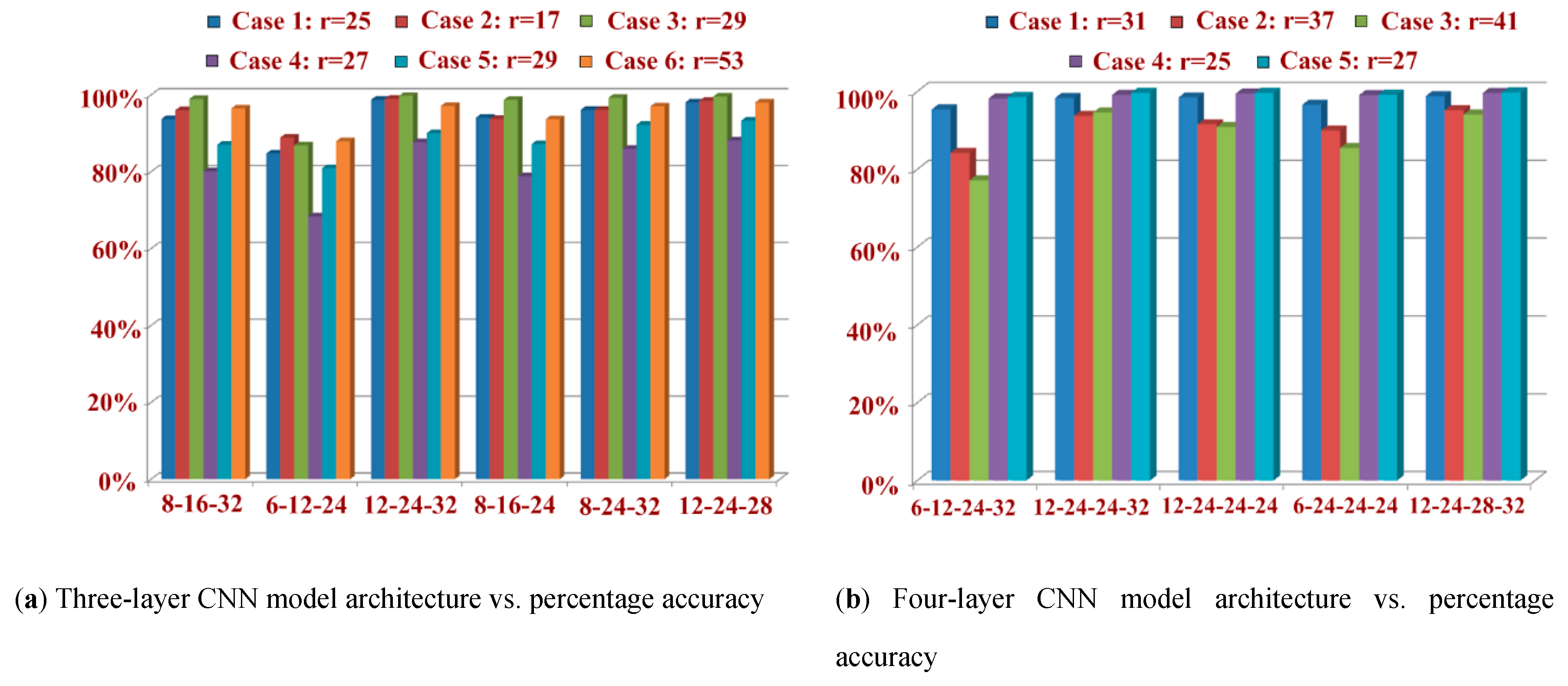
| Model | Layer | k | s | d | p | i/p | o/p | r | Recognition Accuracy (%) and Total Time Elapsed | |||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 8-16-32 | 6-12-24 | 12-24-32 | 8-16-24 | 8-24-32 | 12-24-28 | |||||||||
| Case 1 | Layer 1 | 5 | 2 | 2 | 2 | 28 | 14 | 5 | 93.76% (20 s) | 84.76% (42 s) | 98.76% (45 s) | 94.08% (46 s) | 96.12% (42 s) | 98.08% (44 s) |
| Layer 2 | 5 | 2 | 1 | 2 | 14 | 7 | 9 | |||||||
| Layer 3 | 5 | 2 | 1 | 2 | 7 | 4 | 25 | |||||||
| Case 2 | Layer 1 | 5 | 2 | 1 | 2 | 28 | 14 | 5 | 96.04% (37 s) | 88.91% (27 s) | 99% (37 s) | 93.80% (37 s) | 96.12% (37 s) | 98.48% (17 s) |
| Layer 2 | 3 | 2 | 1 | 2 | 14 | 7 | 9 | |||||||
| Layer 3 | 3 | 2 | 1 | 2 | 7 | 4 | 17 | |||||||
| Case 3 | Layer 1 | 5 | 2 | 1 | 2 | 28 | 14 | 5 | 98.96% (27 s) | 86.88% (27 s) | 99.7% (29 s) | 98.72% (39 s) | 99.28% (31 s) | 99.60% (53 s) |
| Layer 2 | 5 | 2 | 1 | 2 | 14 | 7 | 13 | |||||||
| Layer 3 | 5 | 2 | 1 | 2 | 7 | 4 | 29 | |||||||
| Case 4 | Layer 1 | 3 | 3 | 1 | 1 | 28 | 10 | 3 | 80.16% (48 s) | 68.40% (29 s) | 87.72% (29 s) | 78.84% (29 s) | 85.96% (51 s) | 88.16% (29 s) |
| Layer 2 | 3 | 3 | 1 | 1 | 10 | 4 | 9 | |||||||
| Layer 3 | 3 | 3 | 1 | 1 | 4 | 2 | 27 | |||||||
| Case 5 | Layer 1 | 5 | 3 | 1 | 2 | 28 | 10 | 5 | 87.08% (52 s) | 80.96% (30 s) | 90.08% (24 s) | 87.22% (24 s) | 92.24% (24 s) | 93.32% (24 s) |
| Layer 2 | 3 | 3 | 1 | 1 | 10 | 4 | 11 | |||||||
| Layer 3 | 3 | 3 | 1 | 1 | 4 | 2 | 29 | |||||||
| Case 6 | Layer 1 | 5 | 3 | 1 | 2 | 28 | 10 | 5 | 96.48% (23 s) | 87.96% (23 s) | 97.16% (23 s) | 93.68% (24 s) | 97.04% (24 s) | 98.06% (24 s) |
| Layer 2 | 5 | 3 | 1 | 2 | 10 | 4 | 17 | |||||||
| Layer 3 | 5 | 3 | 1 | 2 | 4 | 2 | 53 | |||||||
| Model | Layer | k | s | d | p | i/p | o/p | r | Recognition Accuracy (%) and Total Time Elapsed | ||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 6-12-24-32 | 12-24-24-32 | 12-24-24-24 | 6-24-24-24 | 12-24-28-32 | |||||||||
| Case 1 | Layer 1 | 3 | 2 | 1 | 1 | 28 | 14 | 3 | 95.36% (56 s) | 98.34% (31 s) | 98.48% (53 s) | 96.56% (44 s) | 98.80% (31 s) |
| Layer 2 | 3 | 2 | 1 | 1 | 14 | 7 | 7 | ||||||
| Layer 3 | 3 | 2 | 1 | 1 | 7 | 4 | 15 | ||||||
| Layer 4 | 3 | 2 | 1 | 1 | 4 | 2 | 31 | ||||||
| Case 2 | Layer 1 | 3 | 2 | 2 | 2 | 28 | 14 | 5 | 84.20% (26 s) | 93.72% (30 s) | 91.56% (24 s) | 89.96% (26 s) | 95.16% (25 s) |
| Layer 2 | 3 | 2 | 2 | 2 | 14 | 7 | 13 | ||||||
| Layer 3 | 3 | 2 | 1 | 1 | 7 | 4 | 21 | ||||||
| Layer 4 | 3 | 2 | 1 | 1 | 4 | 2 | 37 | ||||||
| Case 3 | Layer 1 | 5 | 2 | 2 | 2 | 28 | 14 | 9 | 77.16% (32 s) | 94.60% (25 s) | 90.88% (26 s) | 85.48% (25 s) | 94.04% (26 s) |
| Layer 2 | 3 | 2 | 2 | 2 | 14 | 7 | 17 | ||||||
| Layer 3 | 3 | 2 | 1 | 1 | 7 | 4 | 25 | ||||||
| Layer 4 | 3 | 2 | 1 | 1 | 4 | 2 | 41 | ||||||
| Case 4 | Layer 1 | 5 | 1 | 2 | 2 | 28 | 17 | 9 | 98.20% (30 s) | 99.12% (29 s) | 99.44% (25 s) | 99.04% (22 s) | 99.60% (29 s) |
| Layer 2 | 3 | 2 | 2 | 2 | 17 | 7 | 13 | ||||||
| Layer 3 | 3 | 2 | 1 | 1 | 7 | 4 | 17 | ||||||
| Layer 4 | 3 | 2 | 1 | 1 | 4 | 2 | 25 | ||||||
| Case 5 | Layer 1 | 5 | 1 | 2 | 2 | 28 | 28 | 9 | 98.60% (27 s) | 99.64% (27 s) | 99.64% (27 s) | 99.20% (27 s) | 99.76% (43 s) |
| Layer 2 | 5 | 2 | 1 | 2 | 28 | 14 | 13 | ||||||
| Layer 3 | 3 | 2 | 1 | 1 | 14 | 7 | 17 | ||||||
| Layer 4 | 3 | 2 | 1 | 1 | 7 | 4 | 27 | ||||||
| Model | Recognition Accuracy (%) | |||
|---|---|---|---|---|
| Momentum (Sgdm) | Adam | Adagrad | Adadelta | |
| CNN_3L | 99.76% | 99.89 | 98.67 | 99.77 |
| CNN_4L | 99.76% | 99.35 | 98 | 99.73 |
| Handwritten Numeral Recognition | ||||
|---|---|---|---|---|
| Reference | Approach | Database | Features | Accuracy (%)/Error Rate |
| [75] | CNN | MNIST | Pixel based | 0.23% |
| [76] | CNN | MNIST | Pixel based | 0.19% |
| [8] | CNN | MNIST | Pixel based | 0.53% |
| [77] | CNN | MNIST | Pixel based | 0.21% |
| [78] | CNN | MNIST | Pixel based | 0.17% |
| [79] | Deep Learning | The Chars74K | Pixel based | 88.89% (GoogleNet) 77.77% (Alexnet) |
| [43] | CNN | Urdu Nasta’liq handwritten dataset (UNHD) | Pixel and geometrical based | 98.3% |
| Proposed approach | CNN | MNIST | Pixel and geometrical based | 99.89% |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ahlawat, S.; Choudhary, A.; Nayyar, A.; Singh, S.; Yoon, B. Improved Handwritten Digit Recognition Using Convolutional Neural Networks (CNN). Sensors 2020, 20, 3344. https://doi.org/10.3390/s20123344
Ahlawat S, Choudhary A, Nayyar A, Singh S, Yoon B. Improved Handwritten Digit Recognition Using Convolutional Neural Networks (CNN). Sensors. 2020; 20(12):3344. https://doi.org/10.3390/s20123344
Chicago/Turabian StyleAhlawat, Savita, Amit Choudhary, Anand Nayyar, Saurabh Singh, and Byungun Yoon. 2020. "Improved Handwritten Digit Recognition Using Convolutional Neural Networks (CNN)" Sensors 20, no. 12: 3344. https://doi.org/10.3390/s20123344