
Life Science—Microbial Culture Collections Data Integration Tasks

Abstract
:1. Introduction
- -
- mBRCs are long-term preservation facilities, and they provide well-characterized microorganisms as well as related data. By doing so, the mBRCs constitute the foundations of cumulative research because they ensure that experiments involving microorganisms can be repeated or exploited to generate new knowledge by any person that is skilled in the field;
- -
- mBRCs are a professional source of taxonomy information, and they contribute to resolve nomenclatural issues related to microorganisms;
- -
- mBRCs keep and study specific strains with unique characteristics, and these well-documented strains constitute libraries of strain-specific characters that are functionally useful in biotechnology.
- Databases;
- Publications;
- Datasets.
- -
- on Life Science side—to find the organism presented in a database several years ago so as to verify its properties and to do more advanced research,
- -
- on mBRCs side—to select the most needful organisms to be preserved, the storage technology for them, to do appropriate microbial research and services for specific organisms kept.Forbes (https://www.forbes.com/sites/johncumbers/2022/09/12/white-house-inks-strategy-to-grow-trillion-dollar-us-bioeconomy/?sh=61e9bfa735e1 (accessed on 30 October 2022)) estimated that the USA bioeconomy was worth approximately USD 1 trillion in 2022 and that it will be worth over USD 30 trillion globally in the next two decades (message published on 12 September 2022, accessed on 10 December 2022). There are arguments that microbial systems comprise a big fraction of the bioeconomy, and the positive effect of the database integration task presented here could be estimated to be worth USD 1 billion per year, at least.
2. Materials and Methods
2.1. Life Science Databases That Were Inspected
- FAIRsharing (1933 databases (https://fairsharing.org (accessed on 30 October 2022)), which were analyzed till October 2022);
- MB (1802 entries (http://metadatabase.org (accessed on 30 October 2022)), the last analysis was complited on 26 December 2015);
- Biosharing (724 databases, (https://www.biosharing.org/ (accessed on 30 October 2022)), 26 December 2015);
- BioMedBriges (814 databases, (http://wwwdev.ebi.ac.uk/fgpt/toolsui/ (accessed on 30 October 2022)), 27 December 2015);
- Pathguide (363 database names, 2013) (http://www.pathguide.org/ (accessed on 30 October 2022))
- ELIXIR list (579 entries, (https://bio.tools/?q=database (accessed on 30 October 2022)), 28 January 2016);
- ExPASy (85 + 665 databases, (http://www.expasy.org/old_links (accessed on 30 October 2022)), 12 February 2016;
- Bioinformatics Links Directory (621 databases);
- OBRC (http://www.hsls.pitt.edu/obrc/ (accessed on 30 October 2022)) (30 March 2017).
2.2. Research Procedure
- A unique identifier. For example: BIODBCORE-000438.
- A database acronym that is used by the database producer. For example: dbSNP.
- A database name that is used by the database producer. For example: The Database of short genetic variation (single nucleotide polymorphism).
- A database URL. For example: http://www.ncbi.nlm.nih.gov/SNP/ (accessed on 30 October 2022)
- The access level. “Open” if the database records are available to read for free for anybody, but the “Restricted” otherwise.
- The year of the last correction. It could be the last year presented in records of the database or in the news messages or in copyright. It could be also the current year if there is a clear message that this database is still being curated. For example: 2022.
- The developer/Owner. For example: USA, NCBI; USA, National Library of Medicine, National Institutes of Health.
- A comment. For example: Escherichia coli.
- A practical domain. Here the used values refer to: patent, health (mostly human), pharmacology, agriculture, bioremediation/biodegradation, veterinary, food preparation, winemaking, baking, brewing, biofuel, and other kinds of biotechnology. These help in navigating the collected databases.
- The microbial level. Here the used values refer to: MO, SP, and ST. The value ST is used if at least one database message provides information on a specific microorganism strain. The value SP is used if there are no strains, but there is information on at least one microorganism species discovered. The value MO is used if there are no species, but there is some kind of information on the microorganisms discovered.
- The properties. This shows the types of data discovered in this database. The used values include: cell, chemistry, disease, DNA, drugs, enzyme, gene, genome, image, immunology, interactome, lipid, metabolite, microbiome, molecules, pathogen, pathways, peptide, proteomics, publications, RNA, taxonomy, and toxicology. On average, the number of properties and keywords assigned to a database is between six and seven. For example: DNA, gene, genome, proteomics, publications, and RNA.
- The orientation. If the database is focused on some kind of microorganisms. For example: fungi.
- Search by. Data types used in indexing between database partners. It makes a tools in integration technology. With these tools two big communities of Life Science databases were discovered, each interconnected inside like, such as in a LOD Cloud but with no obligation to be open.
- Ontologies list. For example: SO.
- Partner databases. Shows integration of this specific database into the other databases. The external database obtains partner status for this specific database for the following:
- (1)
- It is mentioned on its WEB pages in data interchange;
- (2)
- If this specific database use some data from that external database as a data source;
- (3)
- There are messages with fields values from this external database;
- (4)
- There is a message that this is the database partner;
- (5)
- When these databases have common datacuration. Example: Assembly, BioProject, BioSample, ClinVar, dbGaP, dbMHC, dbSTS, dbVar, Ensembl, GenBank, Homologene, IGSR, MapViewer, NCBI Gene, Nucleotide, OMIM, PMC, Protein, PubChem Substance, PubMed, RDP, RefSeq, UniGene, UniProtKB.
- Program interface. Mostly according to descriptions in documents of this specific database. Example: ELIXIR WEB UI, Entrez Programming Utilities (E-Utils). It makes the tools in integration technology.
3. Results
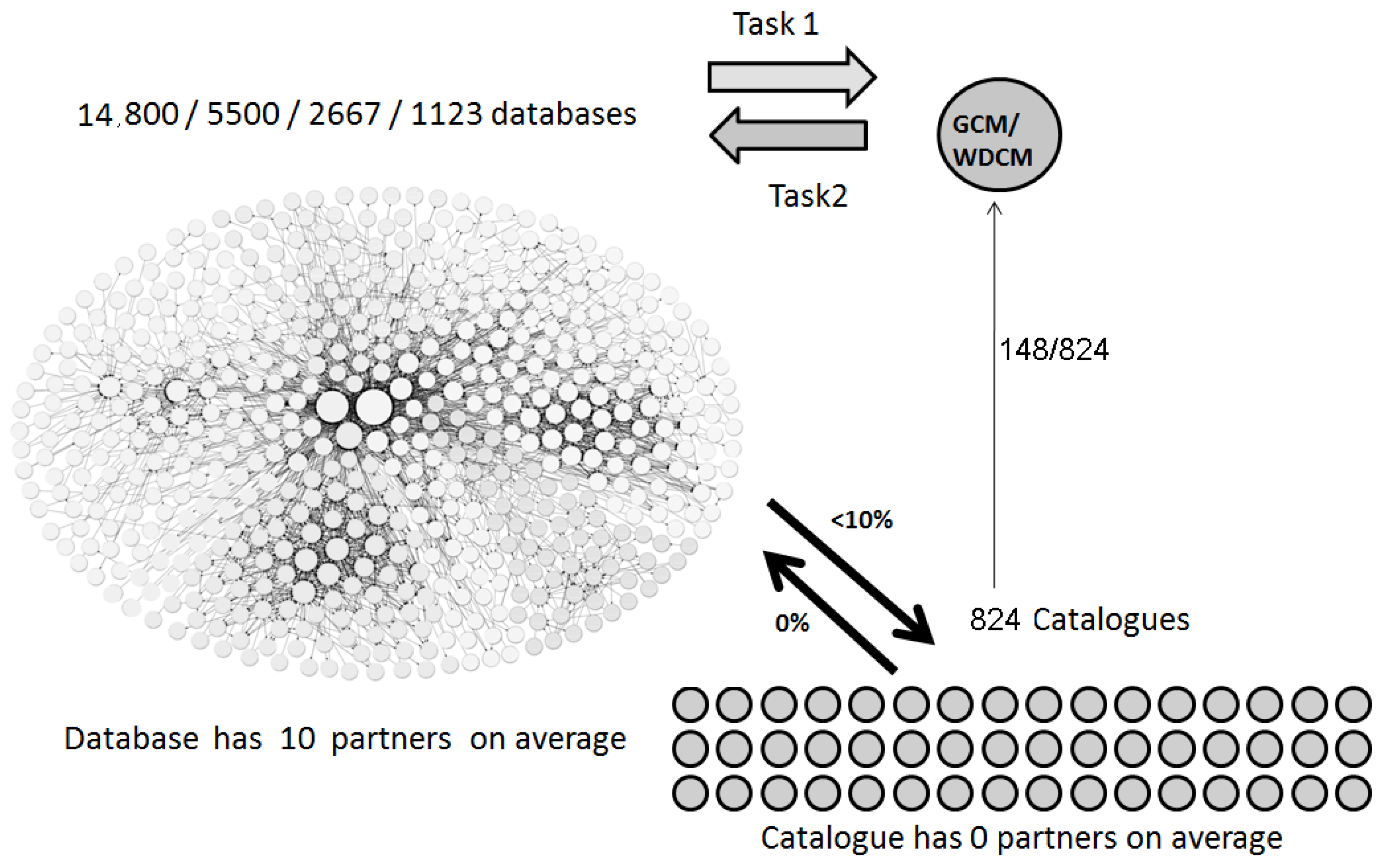
3.1. Microbial Databases—Microbial Culture Collection (CC) Interconnection
- -
- There were mostly no links to microbial catalogs,
- -
- The strains interconnection service called Histri in the former Straininfo system was currently not available.
- -
- 1a: to make mBRC data visible and accessible via partners of Life Science databases for human access.
- -
- 1b: to make mBRC data visible and accessible via partners of Life Science databases for computer programs.
- -
- 2a: to make the records for specific microorganisms stored by partners of the Life Science database visible and accessible for human access.
- -
- 2b: to make the records for specific microorganisms stored by partners of the Life Science database visible and accessible by computer.
- Tier 1 databases: EcoCyc, MetaCyc, HumanCyc, AraCyc, YeastCyc.
- Tier 2 had 63 databases generated by the PathoLogic program, with subsequent curation conducted manually.
- Tier 3 had 19,936 databases generated by the PathoLogic program with no manual review of the pathway predictions, nor subsequent curation.
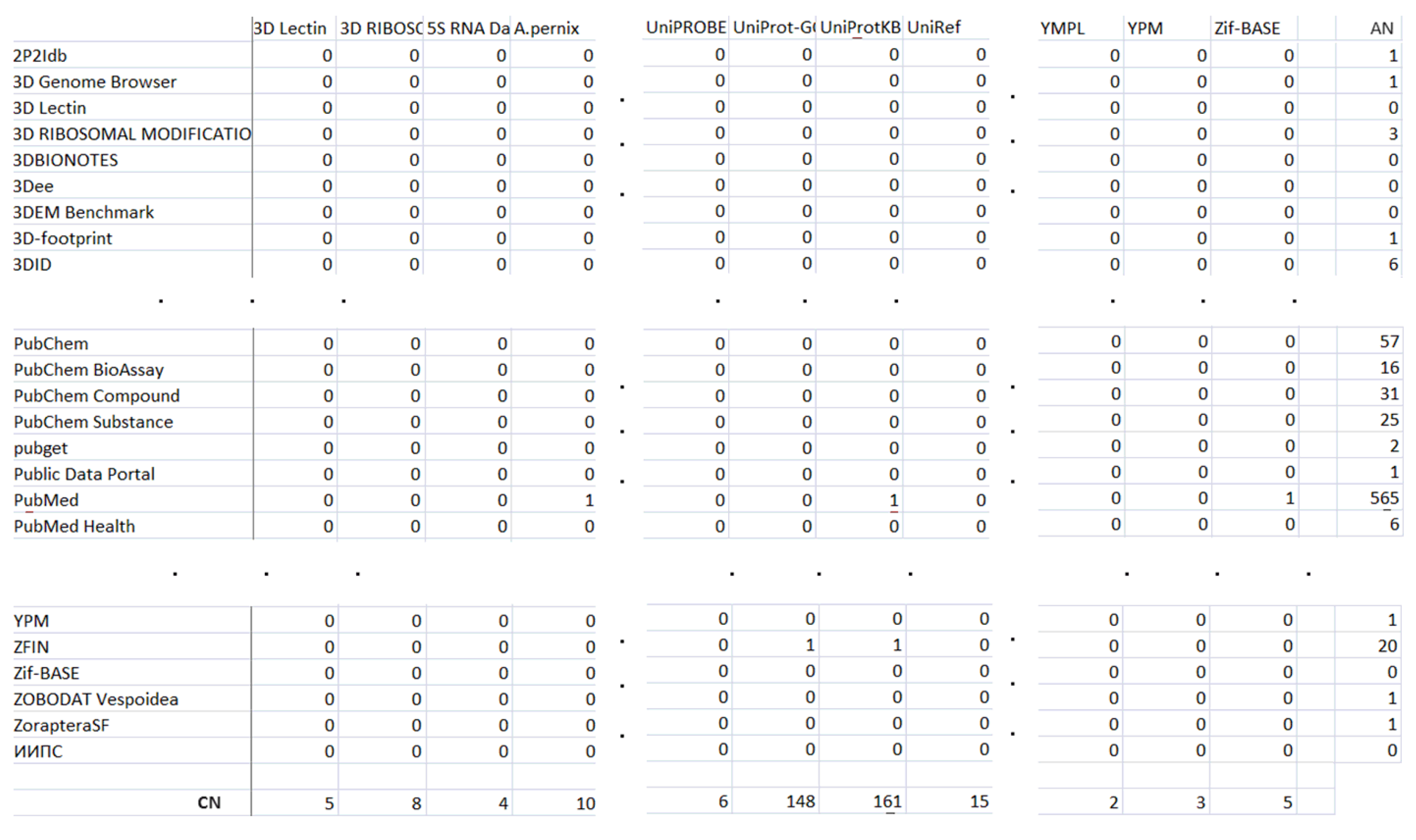
- The connection number—CN—the number of database partners found in each microbial Life Science database,
- The attraction number—AN—The number of microbial databases indicating this database to be a partner.
3.2. Microbial Databases with the Largest Number of Partners
3.3. Connection Strategy
- -
- ArrayExpress, Assembly;
- -
- BioModels, BioProject, BioSample, BioSamples, BioSystems, Bookshelf;
- -
- CDD, Cellosaurus, ChEBI, ChEMBL, COGs, CSA;
- -
- dbEST, dbProbe, dbSNP, Dengue virus database, DNAtraffic, DrugPort;
- -
- e!Ensembl, e!Ensembl Saccharomyces cerevisiae, e!EnsemblBacteria, e!EnsemblFungi, e!EnsemblGenomes, e!EnsemblProtists, EMBL, EMBL-EBI, EMDB, ENA, Ensembl, ENZYME, Enzyme Structures, EPD, EVA, Expression Atlas;
- -
- Genbank, Gene, GeneDB, Genetic Codes, Genome, GEO, GEO DataSets, GEO Profiles, GSS;
- -
- HAMAP, Hits, HIV-1, Homologene;
- -
- IMEx, Influenza Virus Resource, IntAct, InterPro;
- -
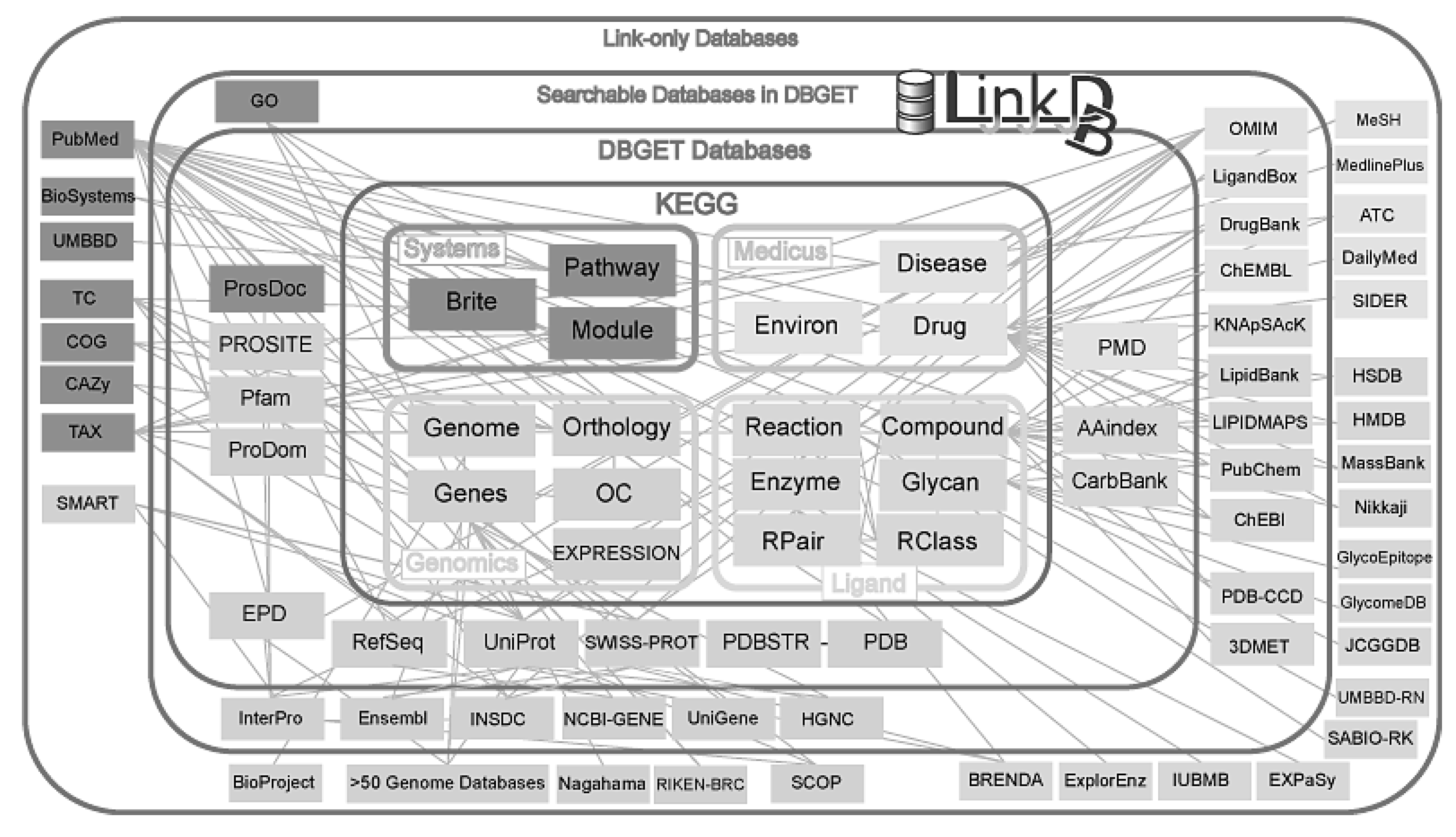
- KEGG, KEGG BRITE, KEGG DISEASE, KEGG GENES, KEGG GENOME, KEGG GLYCAN, KEGG LIGAND, KEGG MEDICUS, KEGG MODULE, KEGG Organisms, KEGG ORTHOLOGY, KEGG PATHWAY;
- -
- MACiE, MapViewer, MedGen, MEDLINE, MEROPS, MeSH, MetaboLights, MIAPEGelDB, MMDB, MTBLS;
- -
- NCBI, NCBI taxonomy, NCBI Trace Archives, neXtProt, NLM Catalog, Nucleotide;
- -
- OMA, OMIM, OpenFlu, Organelle genomes;
- -
- PathComp, PathPred, PathSearch, PaxDB, PDBe, PDBe EM Resources, PDBsum, Pfam, PICR, PMC, PMP, PomBase, PopSet, PRIDE, Probe, PROSITE, Protein, Protein Clusters, Protein Spotlight, Proteomes, PubChem, PubChem BioAssay, PubChem Compound, PubChem Substance, PubMed, PubMed Health;
- -
- Reactome, RefSeq, RefSeqGene, Retroviruses, Rfam, Rhea, RNAcentral;
- -
- SPARCLE, SpliceInfo, SRA, Structure, SugarBind, SWISS-2DPAGE, SWISS-MODEL, SwissVar;
- -
- UniGene, UniProt-GOA, UniProtKB, UniRef;
- -
- Viral genomes, ViralZone, Virus Variation.
3.4. Possible Tasks 1 and 2 Solutions
| Penicillium cyaneofulvum | |
| Summary: | Penicillium cyaneofulvum Biourge, La Cellule 33: 174 (1923) |
| Synonymy: | =Penicillium brunneorubrum Dierckx, Annales de la Société Scientifique de Bruxelles 25 (1): 88 (1901) =Penicillium griseoroseum Dierckx, Annales de la Société Scientifique de Bruxelles 25 (1): 86 (1901) =Penicillium chrysogenum Thom, U.S.D.A. Bureau of Animal Industry Bulletin 118: 58 (1910) =Penicillium baculatum Westling, Svensk Botanisk Tidskrift 4: 139 (1910) =Penicillium notatum Westling, Arkiv før Botanik 11 (1): 95 (1911) =Penicillium chlorophaeum Biourge, La Cellule 33: 271 (1923) =Penicillium meleagrinum Biourge, La Cellule 33: 147 (1923) =Penicillium roseocitreum Biourge, La Cellule 33: 184 (1923) =Penicillium flavidomarginatum Biourge, La Cellule 33: 150 (1923) =Penicillium fluorescens Laxa, Zentralblatt für Bakteriologie und Parasitenkunde Abteilung 2 86 (5–7): 160–165 (1932) =Penicillium camerunense R. Heim, Bull. Acad. R. Belg. Cl. Sci.: 42 (1949) =Penicillium aromaticum f. microsporum Romankova, Uchenn. Zap. Leningr. Univ. Zhadanov: 102 (1955) =Penicillium harmonense Baghd., Novosti Sistematiki Nizshikh Rastenii 5: 102 (1968) |
| Current name: | Penicillium chrysogenum Thom, U.S.D.A. Bureau of Animal Industry Bulletin 118: 58 (1910) |
| Classification: | Fungi, Dikarya, Ascomycota, Pezizomycotina, Eurotiomycetes, Eurotiomycetidae, Eurotiales, Trichocomaceae, Penicillium |
- -
- NCBI—Entrez Programming Utilities (E-Utils);
- -
- EMBL-EBI—RESTful Web Services interface, Semantic WEB, RDF, SPARQL endpoint;
- -
- SIB—RESTful Web Services interface, Semantic WEB;
- -
- Kyoto University—KEGG API, LinkDB.
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| BESC | BioEnergy Science Center |
| CABRI | Common Access to Biological Resources and Information |
| CC | microbial Culture Collection |
| CCINFO | Culture Collections Information Worldwide |
| EMBL-EBI | The European Bioinformatics Institute |
| GCM | Global Catalog of Microorganisms |
| LPSN | List of Prokaryotic names with standing in nomenclature |
| LS | Life Science |
| Mbrc | Microbial Biological Resources Centre |
| NAR | Nucleic Acids Research journal |
| NCBI | National Center for Biotechnology Information |
| SIB | Swiss Institute of Bioinformatics |
| URL | Uniform Resource Locator |
| VKM | All-Russian Collection of Microorganisms |
| WDCM | World Data Center for Microorganisms |
References
- Biological Resource Centres Underpinning the future of Life Sciences and Biotechnology. OECD, Paris, France. 2001. Available online: https://read.oecd-ilibrary.org/science-and-technology/biological-resource-centres_9789264193550-en#page1 (accessed on 25 October 2022).
- Wu, L.; Sun, Q.; Desmeth, P.; Sugawara, H.; McCluskey, K.; Smith, D.; Vasilenko, A.; Lima, N.; Ohkuma, M.; Robert, V.; et al. World data centre for microorganisms: An information infrastructure for the exploration and utilization of microbial strains preserved worldwide. Nucleic Acids Res. 2017, 45, D611–D618. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Vasilenko, A.N.; Stupar, O.S.; Kochkina, G.A.; Ivanushkina, N.E.; Ozerskaya, S.M. Comparison of Microbial Diversity in Life Science Databases and in the Culture Collection. Microbiology 2023, 92, 94–95, in press. [Google Scholar]
- Verslyppe, B. StrainInfo: From Microbial Information to Microbiological Knowledge; Ghent University, Faculty of Sciences: Ghent, Belgium, 2012; Available online: http://hdl.handle.net/1854/LU-4337118 (accessed on 25 October 2022).
- Romano, P.; Kracht, M.; Manniello, M.A.; Stegehuis, G.; Fritze, D. The role of informatics in the coordinated management of biological resources collections. Appl. Bioinform. 2005, 4, 175–186. [Google Scholar] [CrossRef] [PubMed]
- Dijkstra, E.W. Notes on Structured Programming. In EUT Report. WSK, Dept. of Mathematics and Computing Science, Report 70-WSK-03, 2nd ed.; Technische Hogeschool Eindhoven: Eindhoven, The Netherlands, 1970. [Google Scholar]
- Sakkas, N.; Yfanti, S. Open data or open access? The case of building data. Acad. Lett. 2021, 3629. [Google Scholar] [CrossRef]
- What Is Open? Available online: https://okfn.org/opendata/ (accessed on 25 October 2022).
- Auer, S.R.; Bizer, C.; Kobilarov, G.; Lehmann, J.; Cyganiak, R.; Ives, Z. DBpedia: A Nucleus for a Web of Open Data. Semant. Web 2007, 4825, 722–735. [Google Scholar] [CrossRef] [Green Version]
- Kassen, M. A promising phenomenon of open data: A case study of the Chicago open data project. Gov. Inf. Q. 2013, 30, 508–513. [Google Scholar] [CrossRef]
- Science Commons. Available online: https://creativecommons.org/about/program-areas/open-science (accessed on 25 October 2022).
- Lehmann, J.; Isele, R.; Jakob, M.; Jentzsch, A.; Kontokostas, D.; Mendes, P.N.; Hellmann, S.; Morsey, M.; van Kleef, P.; Auer, S.; et al. DBpedia: A large-scale, multilingual knowledge base extracted from Wikipedia. Semant. Web 2015, 6, 167–195. [Google Scholar] [CrossRef] [Green Version]
- Wilkinson, M.D.; Dumontier, M.; Aalbersberg, I.J.; Appleton, G.; Axton, M.; Baak, A.; Blomberg, N.; Boiten, J.W.; da Silva Santos, L.B.; Bourne, P.E.; et al. The FAIR Guiding Principles for scientific data management and stewardship. Sci. Data 2016, 3, 160018. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Collins, S.; Genova, F.; Harrower, N.; Hodson, S.; Jones, S.; Laaksonen, L.; Mietchen, D.; Petrauskaité, R.; Wittenburg, P. Turning FAIR into Reality–Final Report and Action Plan from the European Commission Expert Group on FAIR Data; Report; Publications Office of the European Union: Brussel, Belgium, 2018. [Google Scholar]
- Vasilenko, A.; Stupar, O.; Kochkina, G.; Ozerskaya, S. Data Intergration with Life Science Databases: Gathering of Technology. In Proceedings of the Conference Proceedings of XXXVII Annual Meeting of the European Culture Collections’ Organisation (ECCO); Moscow, Russia, 13–15 September 2018, p. 125.
- Vasilenko, A.; Robert, V.; Coronado, J.M.L.; Stupar, O.; Kochkina, G.; Ozerskaya, S.; Casaregola, S. FAIR options in mBRC specifics. In Proceedings of the Conference Proceedings of XXXVIII Annual Meeting of the European Culture Collections’ Organisation (ECCO), Turin, Italy, 12–14 June 2019; pp. 57–58. [Google Scholar]
- Berners-Lee, T.; Hendler, J.; Lassila, O. The Semantic Web: A new form of Web content that is meaningful to computers will unleash a revolution of new possibilities. Sci. Am 2001. Available online: http://web.dfc.unibo.it/buzzetti/IUcorso2006-07/materiali/bl-engl.pdf (accessed on 30 October 2022). [CrossRef]
- Vasilenko, A.; Ozerskaya, S.; Stupar, O.; Romano, P.; Wu, L.; Evtushenko, L.; Smith, D.; Ma, J. Life Science Databases Interconnection Data Specifications. In Proceedings of the Abstract book of IUMS 2017, 15th International Congress of Bacteriology and Applied Microbiology, Singapore, 17–21 June 2017; p. 164. [Google Scholar]
- Vasilenko, A.; Ozerskaya, S.; Stupar, O.; Romano, P.; Wu, L.; Evtushenko, L.; Smith, D.; Ma, J. Data Integration Opportunities for BRC Catalogs and Life Science Databases. In Proceedings of the Abstract book of 14th International conference on culture collections. ICCC14, Singapore, 17–22 July 2017; p. 12. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Specific Type of Data | How Many Databases Have It |
|---|---|
| Gene | 826 |
| Proteomics | 716 |
| Publications | 625 |
| Image | 517 |
| RNA | 389 |
| DNA | 395 |
| Genome | 355 |
| Enzyme | 361 |
| Cell | 316 |
| Chemistry | 297 |
| Pathways | 270 |
| Disease | 263 |
| Interactome | 226 |
| Taxonomy | 219 |
| Drugs | 195 |
| Peptide | 195 |
| Molecular data | 183 |
| Immunology | 167 |
| Metabolite | 166 |
| Toxicology | 156 |
| Pathogen | 151 |
| Lipids | 132 |
| Microbiome | 45 |
| Database Name | Number of Its Partners |
|---|---|
| Pathguide | 364 |
| UniProtKB | 161 |
| iProClass | 159 |
| COL | 153 |
| UniProt-GOA | 148 |
| OReFiL | 143 |
| EcoliWiki | 129 |
| GeneCards | 128 |
| PIR | 91 |
| UCD 2D-PAGE | 73 |
| Hits | 63 |
| SWISS 2DPage | 61 |
| PubChem | 57 |
| PubChem BioAssay | 57 |
| PubChem Compound | 57 |
| PubChem Substance | 57 |
| dbProbe | 55 |
| NCBI | 55 |
| PiroplasmsDB | 53 |
| E!EnsemblGenomes | 52 |
| EMBL | 49 |
| ENA | 49 |
| SBKB | 49 |
| EcoGene | 46 |
| SGD | 46 |
| Gene | 45 |
| InterMitoBase | 44 |
| EMBL-EBI | 43 |
| OMIM | 43 |
| MetaCyc | 42 |
| Guide to Pharmacology | 40 |
| MalaCards | 40 |
| NCBI Taxonomy | 38 |
| OpenHelix | 38 |
| ViralZone | 38 |
| Database Name | Number of Databases That Refer to It |
|---|---|
| PubMed | 565 |
| UniProtKB | 501 |
| NCBI Taxonomy | 275 |
| RCSB PDB | 255 |
| Genbank | 239 |
| Gene | 229 |
| KEGG | 199 |
| RefSeq | 193 |
| EC | 187 |
| Pfam | 182 |
| InterPro | 160 |
| Protein | 157 |
| Ensembl | 152 |
| Nucleotide | 125 |
| OMIM | 109 |
| SGD | 99 |
| ENA | 80 |
| HGNC | 80 |
| PROSITE | 76 |
| CAS | 71 |
| IntAct | 71 |
| Reactome | 70 |
| ChEBI | 69 |
| FlyBase | 63 |
| MEDLINE | 61 |
| UniGene | 61 |
| BioGRID | 59 |
| PubChem | 57 |
| GEO | 56 |
| NCBI | 56 |
| SMART | 56 |
| DrugBank | 55 |
| MGI | 55 |
| PIR | 55 |
| PMC | 55 |
| SCOP | 55 |
| COGs | 54 |
| Genome | 53 |
| DIP | 51 |
| STRING | 51 |
| ENZYME | 50 |
| KEGG Pathway | 49 |
| HPRD | 48 |
| WormBase | 48 |
| BioProject | 47 |
| Priority No | Producer | Databases | AN |
|---|---|---|---|
| 1 | NCBI | 70 | 2909 |
| 2 | EMBL-EBI | 97 | 1209 |
| 3 | SIB | 37 | 762 |
| 4 | Kyoto University | 19 | 348 |
| 5 | Instute Paster | 18 | 148 |
| 6 | BioCyc | 9378 | 133 |
| 7 | InterMine | 16 | 20 |
| 1 + 2 + 3 + 4 | 133 | 5228 | |
| 1 + 3 + 4 | 92 | 4019 | |
| 2 + 3 + 4 | 78 | 2319 | |
| Total | 1116 | 8870 | |
| Taxonomy | References in the | |
|---|---|---|
| Databases with Taxonomical Data | Databases with Microbial Data | |
| NCBI | 115 | 267 |
| GBIF | 16 | 16 |
| IF | 7 | 9 |
| COL | 6 | 6 |
| LPSN | 2 | 2 |
| MycoBank | 2 | 5 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Vasilenko, A.; Kochkina, G.; Ivanushkina, N.; Ozerskaya, S. Life Science—Microbial Culture Collections Data Integration Tasks. Diversity 2023, 15, 17. https://doi.org/10.3390/d15010017
Vasilenko A, Kochkina G, Ivanushkina N, Ozerskaya S. Life Science—Microbial Culture Collections Data Integration Tasks. Diversity. 2023; 15(1):17. https://doi.org/10.3390/d15010017
Chicago/Turabian StyleVasilenko, Alexander, Galina Kochkina, Natalya Ivanushkina, and Svetlana Ozerskaya. 2023. "Life Science—Microbial Culture Collections Data Integration Tasks" Diversity 15, no. 1: 17. https://doi.org/10.3390/d15010017