
Local Phase Transitions in a Model of Multiplex Networks with Heterogeneous Degrees and Inter-Layer Coupling

1
Lorentz Institute for Theoretical Physics, University of Leiden, 2333 CA Leiden, The Netherlands
2
IMT School of Advanced Studies Lucca, 55100 Lucca, Italy
3
INdAM-GNAMPA Istituto Nazionale di Alta Matematica, 00185 Rome, Italy
*
Author to whom correspondence should be addressed.
Entropy 2023, 25(5), 828; https://doi.org/10.3390/e25050828
Submission received: 1 March 2023
/
Revised: 6 May 2023
/
Accepted: 9 May 2023
/
Published: 22 May 2023
(This article belongs to the Special Issue Recent Trends and Developments in Econophysics)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:Multilayer networks represent multiple types of connections between the same set of nodes. Clearly, a multilayer description of a system adds value only if the multiplex does not merely consist of independent layers. In real-world multiplexes, it is expected that the observed inter-layer overlap may result partly from spurious correlations arising from the heterogeneity of nodes, and partly from true inter-layer dependencies. It is therefore important to consider rigorous ways to disentangle these two effects. In this paper, we introduce an unbiased maximum entropy model of multiplexes with controllable intra-layer node degrees and controllable inter-layer overlap. The model can be mapped to a generalized Ising model, where the combination of node heterogeneity and inter-layer coupling leads to the possibility of local phase transitions. In particular, we find that node heterogeneity favors the splitting of critical points characterizing different pairs of nodes, leading to link-specific phase transitions that may, in turn, increase the overlap. By quantifying how the overlap can be increased by increasing either the intra-layer node heterogeneity (spurious correlation) or the strength of the inter-layer coupling (true correlation), the model allows us to disentangle the two effects. As an application, we show that the empirical overlap observed in the International Trade Multiplex genuinely requires a nonzero inter-layer coupling in its modeling, as it is not merely a spurious result of the correlation between node degrees across different layers.
1. Introduction
The wide variety of different phenomena that occur around us are often the result of systems that emerge and (self-)organize dynamically. These systems consist of a multitude of basic constituents interacting with each other in complicated ways and forming complex patterns. Many of these systems can be represented as networks sustaining various processes. Examples of such systems include social networks, transportation networks, biological networks, financial networks, and technological networks. In particular, social, financial, and economic networks are an important class of systems that, in the wake of recent global crises (such as the 2007–2008 financial crisis, the COVID-19 pandemic, and the ongoing Ukraine crisis), have been attracting attention given the possibility of studying the propagation of shocks among their constituents. Generally, individuals, banks, firms, or countries can be represented as nodes, and the relationships among them can be represented as links [1,2,3]. Other types of economic and financial networks are obtained as some form of projection from time series data [3,4,5,6,7]. The study of these networks may increase our understanding of a variety of processes that take place through them, such as the spreading of diseases, the diffusion of (mis)information, the stability of financial markets, and the resilience of the economy.
The simplest approach is to map each constituent within a system onto a single node and to map each interaction between pairs of constituents onto a link of a single type, regardless of the nature of the interaction. In this approach, all the links in a network are treated on an equal footing, making it a single-layer network representation, which might, however, lead to an oversimplification that fails to capture the details of a multirelational system. For instance, production and trade networks are the result of the functioning of global supply chains, involving the exchange of multiple products between firms and countries, which determines nontrivial dependencies between product-specific layers of the network. In order to realistically follow the propagation of shocks in the economy, knowledge of the nature of the links is essential. The inability to properly represent multirelational systems using single-layer networks has lead to the introduction of so-called multilayer networks [8,9,10,11,12]. Multilayer networks allow us to describe multirelational systems by representing each type of relationship in a separate layer of the network, where each node is present in all layers, and the different types of connections are reported in the corresponding layers. Returning to the example of social networks, the different types of relationships between people, such as kinship, friendship, coworkership, etc., would each be represented by links in a different layer [13], and could be analyzed in their mutual dependencies.
However, in order to assess true dependencies across layers, one should use proper null models. In recent years, there has been an increase in attention towards null models of networks constructed as random graph ensembles [14,15,16,17,18,19,20]. A class of such models is the so-called Exponential Random Graph Models (ERGMs) [17,18,19,20,21,22,23,24,25,26,27]. ERGMs are used commonly within the social network analysis community, and have been more recently re-derived within a statistical physics maximum entropy framework [19,20,27]. This has allowed researchers to utilize techniques that are common in statistical physics. In the ERGM framework, one chooses the probability distribution on graphs such that it maximizes the entropy. This maximization is performed while the expected values of certain chosen graph properties are constrained to be equal to desired values.
Real-world multilayer networks have been compared against null ERGMs with independent layers [28,29]. This comparison has highlighted various properties of real multilayer networks that result from the interdependence of layers. Two such properties are the overlap and the multiplexity [9,28]. The overlap and the multiplexity essentially contain similar information and capture the correlation of a node’s connectivity across two or more layers. For example, in a social network, people may communicate with their friends through multiple means of communication, such as talking on the phone, sending emails, or sending instant text messages. In this example, the layer that represents communication through email has a significant overlap with the layer of communication through text messages. A more specific example is a study of the so-called World Trade Multiplex (representing international trade in different commodities among countries [30]), which showed that, despite the fact that each layer of the multiplex is separately well described by a maximum entropy model with given node degrees [31,32,33], the observed trade overlap across different commodity-specific layers is significantly different from the overlap predicted by a null model with independent layers [28]. This result is not unexpected, since one can imagine that the trade of a certain product between two countries may increase/decrease the possibility of the trade of a different product between the same two countries. Other examples of networks displaying a significant overlap are airport networks, on-line social games, collaboration networks, and citation networks [34,35,36].
An important conclusion that has been reached after comparing real-world multiplexes against null models with independent layers is that a significant part of the observed overlap in many real networks could actually be spuriously created by the correlations among node degrees across different layers, even if the latter are conditionally independent of each other, instead of resulting from genuine inter-layer dependencies [28,29]. Indeed, if node degrees are correlated among layers, then there will be an increased probability of a link between two nodes being present in multiple layers, while the probability of a link occurring in one layer will not necessarily influence the presence of a link occurring in another layer. The measured overlap of the network therefore consists of a part resulting from ‘spurious’ coupling between the layers and of a part resulting from genuine coupling between the layers. This spurious coupling increases as the density and/or heterogeneity of the degrees of the network increases. Real-world networks are often dense and have strongly heterogeneous degrees; therefore, the assessment of inter-layer coupling in these real-world networks will be severely affected.
The focus of this paper is the introduction of interdependencies between the layers of a multilayer network in the ERGM through the explicit inclusion of the overlap as an extra constraint. This inclusion of the overlap in the ERGM will aid us in understanding which (higher-order) properties of the network structure may be (highly) dependent on the overlap. Additionally, it will help us distinguish between the overlap in the network due to the correlation of single-node properties across layers and the overlap due to a genuine coupling between the layers. Finally, it will allow us to generate null models with the desired amount of spurious overlap and genuine overlap. It turns out that this problem is mathematically identical to solving the Ising model on a complete graph (which is also known as the mean-field Curie–Weiss model) and leads to a phase transition between a ‘multiplexed’ (magnetized) and a ‘non-multiplexed’ (non-magnetized) phase. However, the problem is more general because the locality of the constraints on the degrees of nodes will imply different parameter values, and hence different properties for the phase transitions relative to different pairs of nodes. For instance, it will, in general, not be possible to enforce a ‘zero-field’ spontaneous symmetry breaking condition for all pairs of nodes simultaneously. Therefore, for a given specification of the constraints, different pairs of nodes may realize different symmetry-broken values of their contribution to the overall inter-layer overlap. Crucially, this property arises only from the simultaneous presence of the two constraints (on the global overlap and on the heterogeneous local degrees), and would not be realized in the absence of one of them.
The rest of the paper is organized as follows: In Section 2, we mathematically define quantities and models that are relevant to this paper. This includes the derivation of a benchmark model, where the layers of the multiplex network are independent. In Section 3, we introduce, and solve analytically, our new model, where the layers of the multiplex are interdependent due to the inclusion of the overlap. Section 4 contains a discussion regarding the possible local phase transitions of the model. In Section 5, we explore our model by using various numerical methods. In Section 6, we briefly analyze the World Trade Multiplex, and show that the empirical overlap in this real-world network is not merely the result of the heterogeneity of the network, but requires a nonzero coupling between the layers in its modeling. Finally, we provide some concluding remarks in Section 7, and some technical details in Appendix A and Appendix B.
2. Background Theory
This section contains some background notions, definitions, and models.
2.1. Single-Layer Network Definitions
We will limit our discussion to the case of binary and undirected networks. A binary undirected network can be defined as a graph that is an ordered pair , where is a set of N vertices or nodes, and E is a set of unordered pairs of different vertices called edges or links. Note that the definition of E depends on the relevant class of relations between the constituents of the system. The vertex will be referred to simply as i throughout the rest of the paper. If , the vertices i and j are said to be connected, and may be referred to as neighbors of each other. The number of links L of the graph is given by the cardinality of E: .
- Matrix Representation
A graph G is represented by its adjacency matrix . This is an matrix where
We define E as containing pairs of distinct vertices, which means that a vertex cannot have a connection to itself (self-loop). It is then natural to define the diagonal elements as . Since we limit our discussion to undirected graphs, the adjacency matrix is always symmetric, , and it therefore contains independent elements that fully specify the matrix and ultimately the graph.
- Degrees and Degree Distribution
One of the main topics in the analysis of complex networks is the identification of the different roles that nodes play [37]. For instance, there are a variety of measures that characterize the structural importance of a node in a network. The degree of the graph G is defined as the number of connections node i has to other nodes in the network.
The list of degrees is called the degree sequence of the graph G. The degree distribution is defined as the fraction of nodes in the network with degree k. Real-world networks systematically show a degree distribution with heavy tails, where the degrees vary over a broad range, often spanning several orders of magnitude [38,39]. The majority of the vertices of these real-world networks have a small number of links to other vertices, while a few vertices have a relatively high number of links to other vertices, which are also referred to as ‘hubs’. An example is the World Wide Web, where some pages are incredibly popular and are pointed to by thousands of other pages, while generally, most pages are almost unknown. The heavy tails of real-world degree distributions can often be, but not necessarily, approximated by power laws of the form . In any case, vertices with a degree much larger than the average degree occur with a non-negligible probability. This is a signature of a high level of statistical heterogeneity in real-world networks. Encoding this heterogeneity will be a crucial ingredient of our models.
2.2. Multiplex Network Definitions
A binary undirected multiplex network can be defined in terms of the previously defined single-layer networks. A multiplex network is a set of M undirected binary graphs that share the same set of N nodes. In the context of multilayer networks, is called a layer of , and will be referred to simply as throughout the rest of the paper. Note that a multiplex network is a type of multilayer network that does not allow inter-layer connections between two layers and where .
- Matrix Representation
The layer and its intra-layer links can then be represented by the adjacency matrix . This is an matrix where
- Multilinks in Multiplex Networks
In order to capture the information regarding the presence of the links between the pair of nodes in any of the M layers, we define the object
which is also known as the multilink of . Additionally, we define the set as the set that contains all the possible configurations of .
- Multidegrees
The multidegree of a node of a multiplex network is the object
where
is the degree of the node i in the layer [9,40]. From the vector definition of the multidegree, one can obtain a scalar quantity defined as the layer-averaged degree:
which is the degree of node i averaged over all the M layers. Note that, in each layer , the total layer-specific degree of all nodes equals twice the number of links in that layer, which we denote as :
Summing the above relationship for the M layers, we get
where denotes the total number of links over the entire multiplex:
- Overlap
There are many properties that encode the interdependence between the layers of a multilayer network, but we will limit our discussion to one such property: the overlap. The overlap between two layers and of the multiplex is defined as the number of links that appear in both layers and [34,41]:
where, throughout the paper, using and , we denote a double sum and a double product for all possible (unrepeated) pairs of values of the two indices, a and b (with ), respectively. The global overlap is defined as the sum of for all pairs of layers:
As the names of these properties suggest, they are a measure of how overlapping the layers of the multiplex network are.
2.3. Exponential Random Graph Models for Multiplexes
ERGMs are ensemble models, which means that they are defined as probability distributions over many possible (multiplex) networks. Given the observed (or desired) value for K graph properties defined on each possible multiplex (where represents a particular, e.g., real-world, multiplex of interest), an ERGM generates a probability distribution over multiplex networks that maximizes the entropy, under the constraint that the expected value of equals , for all . This method provides us with a general framework for modeling maximally random (maximum entropy) multiplex networks, to be used as null models that can be compared against the empirical multiplex to detect higher-order patterns that are irreducible to the K enforced constraints. Maximizing the entropy subject to a set of constraints is also widely used in problems with incomplete information [42,43].
Let be the set of (binary undirected) multiplex networks consisting of N vertices and M layers (note that this set includes single-layer networks for ), let be a multiplex network in that set, and let be the sought-for probability of within the ensemble. We want to be such that the expectation value of each graph observable (in the chosen set of K observables) is equal to the corresponding observed or desired value . This type of probability distribution is also referred to as a canonical ensemble. The ideal probability distribution is the one that maximizes the Gibbs–Shannon entropy
under the normalization condition
and the other K constraints
where
The maximization of the entropy is achieved by introducing a global Lagrange multiplier for the normalization condition and a specific multiplier for each constraint , . This leads to the parametric solution
where is the graph Hamiltonian
and is the partition function determined by the normalization condition
The parametric form of , if inserted back into Equation (13), leads to the explicit expression for the entropy:
2.4. Maximum Likelihood Parameter Estimation
Equations (17)–(19) fully define the ERGM, apart from the specification of the parameters . In principle, by treating these Lagrange multipliers as free parameters, one can study the effects that the specification of certain graph observables has on other aspects of network structure [27,44,45,46,47]. This approach, however, does not allow one to consider ERGMs as null models of a particular real network [17,19]. In the latter case, maximum likelihood parameter estimation leads to the unique (given the choice of constraints) ERGM representing a null model for a particular real (multiplex) network , and hence, enforcing Equation (15) exactly, as we briefly recall below. This null model can then be used to detect statistically significant deviations of empirical structural properties of from the ensemble.
Equation (22) means that the stationary points of are precisely those that satisfy the constraints (15), i.e.,
where indicates that the ensemble average is evaluated at the values . Equation (23) indicates that is concave, since the matrix with entries has the form of a negative covariance matrix, and must therefore be non-positive definite [48]. The solutions of the coupled equations in Equation (15) can therefore be found by maximizing the log-likelihood . If is negative definite, which will be true if the functions are linearly independent [48] (i.e., the chosen constraints are non-redundant), then there will be, at most, one solution, and it will be the unique maximum of . Maximizing a concave function is generally easier than solving the system of coupled nonlinear equations in Equation (24). Once the solution is found, it can be used to generate a null model of . Moreover, inserting the value back into Equation (21) and using Equation (20), we obtain the important relation
i.e., the maximized log-likelihood equals minus the entropy for the particular value , which in turn represents the ‘entropy of the data’ given the chosen constraints. This result allows one to easily calculate the entropy of the data automatically as part of the likelihood maximization procedure, rather than as a much more complicated formal sum of all configurations, as in the general definition (13).
2.5. Benchmark: Independent Layers Model
As anticipated in the Introduction, our goal is that of considering how the empirical overlap between links in different layers of a multiplex is jointly determined by both a ‘genuine’ coupling between the M layers and a ‘spurious’ correlation resulting from the heterogeneous (and correlated across layers) degrees of the N nodes. As a null benchmark before inserting both components in an ERGM of a multiplex, we first consider only the layer-averaged degrees of all vertices as constraints, as defined in Equation (7). We can therefore create a null model of a real multiplex using the ERGM in combination with the maximum likelihood method. This model will be referred to as the Average Configuration Model (ACM), and will allow us to study the sole effects of correlated heterogeneous degrees on the inter-layer overlap. The Hamiltonian of this model, denoted as , since it represents a benchmark for a more complicated model to be defined later, is
where we have reparametrized by exposing M for convenience. The partition function is
The probability distribution over the ensemble is then given by
from which we see that pairs of nodes and pairs of layers are all independent of each other, each entry being an independent Bernoulli random variable with success probability and expected value given by
Clearly, is the probability that a link occurs between node i and j in layer , which turns out to be independent of given our choice of the layer-averaged (not layer-specific) degree as a constraint.
The log-likelihood of the multiplex is
where . The parameter value maximizing the log-likelihood must satisfy
or equivalently,
The above results show that, as expected from the general result reported in Equation (24), according to the maximum likelihood principle, the empirical layer-averaged degree of the real multiplex is equal to the ensemble average :
The probability distribution can then be written as a product of the layers:
where is the probability distribution over a single layer, i.e.,
This means that each layer can be generated by using the link probability that is equal throughout the layers. This is again a consequence of exclusively constraining properties defined as the overall averages of the layers. This null model can be used as a benchmark to determine the expected value of the inter-layer overlap defined in Equation (12), which is due solely to the correlation between the degree of the same node i across the M layers, and not to any genuine inter-layer dependency. This expected value is
where we have used the independence between layers . Deliberately, we have chosen the layer-averaged degree as the only constraint so that the expected degree of a node is the same across all layers, thereby creating a strong correlation between degrees in different layers, while keeping the layers themselves independent. Using Equations (25) and (30), we can calculate the entropy of the data, given the model, as
which only requires the knowledge of and of the layer-averaged degrees , .
3. The Overlapping Average Configuration Model
Having illustrated all the ingredients that are necessary to define and model basic properties of multiplex networks within a maximum entropy framework, in this section, we introduce a model of multiplex networks with genuinely interdependent layers. To this end, we incorporate the overlap as an extra constraint in the ERGM, and study the model in combination with the maximum likelihood method. This model is a generalization of the previous ACM benchmark, and will therefore be referred to as the Overlapping Average Configuration Model (OACM), as it includes not only the intra-layer degrees, but also the inter-layer coupling, as building blocks.
3.1. Constructing the Hamiltonian
We want to define a model of a multiplex with M layers, N vertices, and given expected layer-averaged degrees (as defined in Equation (7)) and global inter-layer overlap (as defined in Equation (12)). The Hamiltonian of our ERGM is, in this case,
where are the Lagrange multipliers coupled to the constraints. We have defined the Lagrange multiplier for the overlap as for later convenience. Clearly, where is the benchmark Hamiltonian of the ACM without overlap defined in Equation (26). Using the multilink defined in Equation (4) and defining
the Hamiltonian in Equation (38), this can be written as a sum of the pairs of vertices:
where
will be referred to as the pair Hamiltonian. As we shall see in a moment, the pair Hamiltonian can be mapped exactly to a mean-field Ising model coupling the M layers homogeneously. To arrive at this mapping, we transform the Boolean variables to new ‘spin’ variables , as follows:
From now on, we assume that M is large (multiplex with several layers) and expand expressions accordingly. By defining
as the multilink for the node pair in terms of the variables, we see that Equation (42) can be used to transform Equation (41) into
If we define
then the pair Hamiltonian finally reduces to
From the above expression, we see that, for every specific pair of nodes , the variables can be thought of as Ising spins residing in the M nodes of a fully connected graph, where every Ising spin interacts with every other spins and is coupled to a ‘field’ . In terms of the multiplex networks being modeled, this means that for every specific pair of nodes , the edges connecting i and j throughout the M layers are all coupled to a common ‘external’ field , and are also coupled to each other with a homogeneous interaction strength . A positive coupling favors more overlap (i.e., more alignment between links in different layers), while disfavors the overlap. The term is an inessential overall shift in energy independent of the spin configuration. This model is identical to the mean-field Ising or Curie–Weiss model. This exact mapping is what we use in Appendix in order to solve the model analytically, and in particular, to show the existence, for each pair of nodes, of a phase transition separating a ‘magnetized’ phase and a ‘non-magnetized’ phase, which here represent a ‘multiplexed’ phase (where links in different layers tend to ‘align’ to each other) and a ‘non-multiplexed’ phase, respectively.
The full Hamiltonian (40) is a summation of the Hamiltonians of non-interacting Ising systems, each for a distinct pairs of nodes. Note, however, that despite the independence of different pairs of nodes, the pair Hamiltonians share some parameters: J is common to all such Hamiltonians, and and (say) also share the parameter , because the latter appears in both and . This is the result of the original constraint on the degree of each node, which results in the same Lagrange multiplier appearing in all pair Hamiltonians involving the same node i. These common parameters imply that, even if all pairs of nodes are independent, the control parameters of all pair Hamiltonians cannot be chosen independently, resulting in a correlated phenomenology for the various pairs of nodes. In particular, as we shall see, each pair of nodes can undergo locally the typical phase transition of the mean-field Ising model, but the features of these pair-specific phase transitions are all nontrivially related to each other.
We also note, from Equations (44) and (47), that if (or equivalently, ), then the pair Hamiltonian (hence the graph probability) becomes invariant upon a global ‘spin flip’ ( ), which here corresponds to the replacement of each existing link with a missing link ( ) and, vice versa, of each missing link with an existing link ( ). This is due to the vanishing of the ‘external field’ that, when present, selects a preferred ‘spin direction’ (up versus down), which here means a preferred density (high versus low). We expect that with the parameter choice , the pair of nodes gains an expected density of links across the M layers, i.e., an expected number of links equal to , corresponding to half the maximum number of links for that node pair. Additionally, if J is smaller than the critical value, this expected number of links is also the typical value, and basically, the model is not fundamentally different from a model without constraints, where the intermediate density is produced as a result of a completely uniform probability distribution for the multilink. However, if J exceeds the critical value, the intermediate average density is no longer the typical one realized by individual graphs sampled from the model: rather, it is the ensemble average of two typical (high and low) values of the realized density, just like in the equivalent spin system, below the Curie temperature, and without an external field one would typically observe, with the same probability, overall positive and negative magnetization with a zero ensemble average. The numerical simulations access the typical realized values, while the equations still govern the expected value. This situation corresponds to a ‘symmetry-broken’ phase, where the typical realizations are less symmetric than the Hamiltonian that generates them. However, here, the heterogeneity of the degrees implies different values of the external field , which means that the zero-field spontaneous symmetry breaking condition cannot, in general, be realized for all pairs of nodes simultaneously, leading to a phenomenology governed by the interplay between the values of J and , and ultimately between the values of the inter-layer overlap and the node degrees.
3.2. Calculating the Partition Function
The partition function defined in (19) can be written as the product
where is the pair partition function, which is a sum of the set of all possible multilinks for :
The multiplex probability can be written in terms of the multilink probabilities :
where
The complete partition function and multiplex probability can therefore be obtained as products of pair-specific quantities, where each multilink can be regarded as a configuration of a Curie–Weiss system. To obtain an explicit expression for , we use a Hubbard–Stratonovich transformation and the Laplace theorem [49] in the limit . The details are provided in Appendix A and are a generalization of the approach used in [50]. The final result is
where is the solution to the equation
The solutions to the above equation will be discussed in the next section.
Now, given a particular real multiplex network , the log-likelihood, as defined, in general, in Equation (21), is
At a stationary point of , the derivatives of with respect to every Lagrange multiplier must equal zero. As we show in Appendix B, this leads to the maximum likelihood equations
where , being the solution to Equation (53) with replaced by , is implicitly related to the maximum likelihood parameters . Note that the quantities on the LHS of Equations (55) and (56) are precisely the quantities that we constrained from the start, namely, and , respectively. According to the maximum likelihood principle, these empirical quantities must equal their respective ensemble averages, and , which appear on the RHS. The quantity can therefore be considered as an average probability of a link occurring between the nodes i and j, which is equal throughout the M layers and is, therefore, a measure of the density of links in the multilink . This is similar to how we identified to be the connection probability in the ACM, which was based solely on the constraints . In support of this idea, we see that, in the case , the Lagrange multipliers reduce it to the value , such that
which is identical to the expression in Equation (29), providing the link probability obtained in Section 2.5 in the absence of the constraint for the overlap. The quantity can therefore possibly be interpreted as a mean-field quantity that globally incorporates the layer interdependence that was introduced through the overlap , but locally treats the layers as if they were independent. A characteristic of mean-field theories is that the effects of all elements of a system on a given element are approximated by a single, average effect.
Formally, we can calculate the entropy of the data, given the model, as the maximized likelihood using Equations (25) and (54):
which requires the knowledge of the parameters and (which are, however, defined only implicitly through ). Comparing the above expression with Equation (37), we see that , as expected, i.e., the model with has the same entropy as the equivalent ACM with no overlap, for the same value of . Similarly, for the maximized likelihood in the two models. In order to understand the relationship between the entropies of the two models when , let us first note that a positive (resp. negative) coupling strength means that the empirical overlap is larger (resp. smaller) than the expected overlap under the null model with , i.e.,
where we have used the notation in Equation (36). However, one should not naively conclude from the combination of Equations (58) and (59) that the entropy of the model with is larger than the entropy of the model with , because the two partition functions are different, and also because the two entropies are calculated for different Lagrange multipliers, i.e., when . In fact, we can actually show that the entropy of the model with is always smaller than the one for the model with . To see this, we introduce the relative entropy (or Kullback–Leibler divergence) between the two models, as follows:
where the last inequality is a well-known property of the relative entropy, and the equality is realized if, and only if, and are identical, which, in turn, requires , yielding and . For , we can write
where we have used the fact that has the same expectation value, equal to , under both and :
Now, applying the inequality in Equation (60) to Equation (62), we get
confirming that the entropy of the model with is always smaller than the one for the model with , consistent with the fact that the former is more constrained than the latter.
4. Local Phase Transitions in the Model
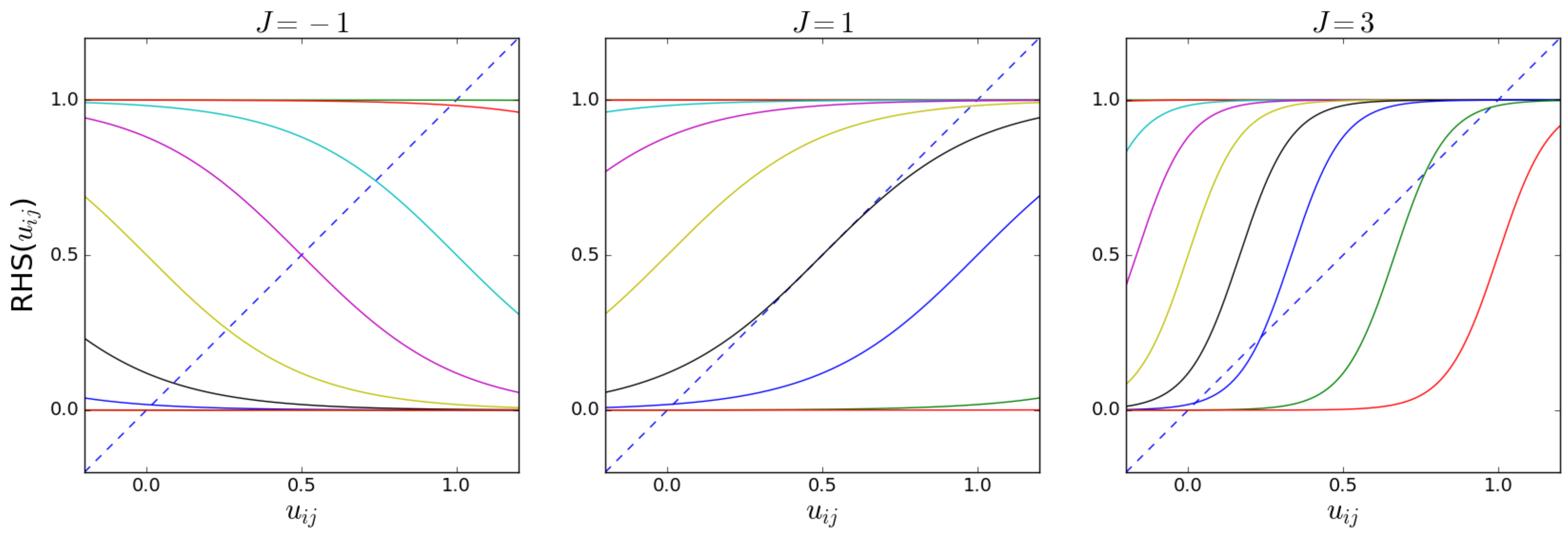
The number of solutions of Equation (53) depends on the values of the parameters and J. We illustrate this fact in Figure 1, where both the LHS and the RHS of Equation (53) are plotted as a function of for various values of and J. The appearance of multiple solutions signals the existence of phase transitions in the limit when the number M of layers diverges, which determine abrupt changes in the value of and, therefore, also in the properties of the multilink and the structure of the multiplex as a whole. The configurations for that are separated by a phase transition are the phases of the multilink. The point where multiple solutions appear or vanish is the bifurcation point.
Figure 1 shows that, at the interval , there can be either one, two, or three solutions, and that for or there is always one solution, namely, or , respectively. The number of solutions depends on whether the slope (derivative) of the RHS (which depends on the parameters) exceeds the slope of the LHS (which is always equal to 1) of Equation (53) at their intersection. From now on, we will consider only the case , which corresponds to a tendency to create an increased inter-layer overlap compared with the model with . The case corresponds to the opposite case where the overlap is suppressed, which we do not discuss here. New solutions appear or vanish at the point where Equation (53) is satisfied and the derivatives of the LHS and RHS of Equation (53) are equal:
Equation (64) cannot be satisfied if , since for , and, therefore, if , a phase transition is impossible, and there is a unique solution for . When , Equation (64) gives us two potential solution branches, , where we have used . Equation (53) can be written as using the identity . By then substituting into this expression for , we obtain the equations for the two curves in the plane that mark the points where additional solutions appear or vanish:
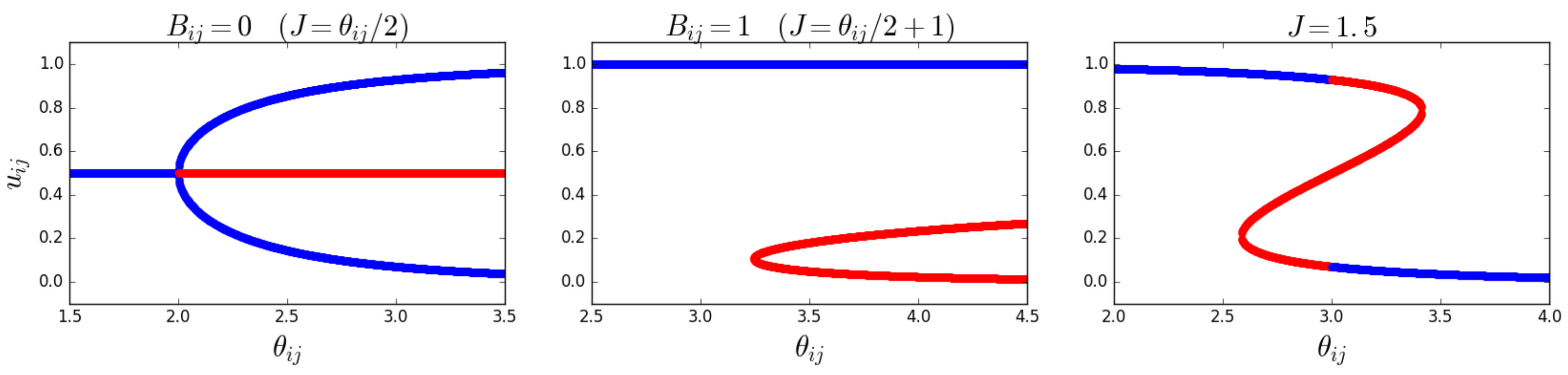
as shown in Figure 2. In the region between the two curves, there are three solutions to Equation (53). Note that the ‘zero-field’ condition is always in that region when . This means that the condition is sufficient to ensure that the system is in the magnetized (symmetry-broken) phase when in the absence of the external field. However, when , the condition is necessary but not sufficient. In particular, generally, it may happen that, for a given value of , different pairs of nodes will be in different (magnetized or non-magnetized) phases depending on the value of . This shows that the system can undergo a multitude of separate phase transitions if the parameters remain fixed and J is varied.
In the magnetized phase, the phenomenon of symmetry breaking will occur: the typical realized values of the ‘magnetization’ will not coincide with the corresponding ensemble average. In the zero-field case (), the symmetry breaking is ‘spontaneous’, i.e., not induced by any field pointing in a preferred direction, while in the nonzero-field case, the symmetry is broken by the field itself. This well-known property of the Ising model has specific implications for our problem here. Indeed, while certain values of may solve the maximum likelihood Equations (55) and (56), the corresponding solutions to Equation (53) may not necessarily maximize the likelihood, and are therefore not ‘valid’ (or stable). Once the values and that solve the maximum likelihood equations are found, the graph probability corresponding to this set of values can be written as a function of the configuration of the graph (or the collection of configurations of the multilinks ), and one can check which typical configurations (those minimizing the Hamiltonian) arise. As Figure 1 suggests, in the regime where there are three solutions, , one value will be relatively high (which corresponds to a relatively high density of links in ), another value will be relatively low (which corresponds to a relatively low density of links in ), and the third value will be between the other two, corresponding to an intermediate density of links in . By inspecting the (pair) Hamiltonian in Equation (47) in terms of the variable, it becomes clear which of the three solutions are viable (stable). In the case where , or equivalently, when , the (pair) Hamiltonian is symmetric with respect to a change in sign, , which means that the high- and low-density solutions are equal. This is the symmetry-broken situation we have discussed in Section 3.1. In this case, the intermediate-density solution will result in a lower value for the Hamiltonian than the high- and low-density solutions. The viable (stable) solutions are therefore the high- and low-density ones. In the case where , it is clear that the high-density solution minimizes the Hamiltonian when and maximizes it when . The low-density solution minimizes the Hamiltonian when and maximizes it when . The intermediate solution will, however, never minimize the Hamiltonian when , and is therefore never viable (stable). From these considerations, it becomes clear that a phase transition, corresponding to a sudden change in , may only happen when we cross from a negative (positive) to a positive (negative) (when ). Figure 3 shows the symmetric stable solutions in the case where , with the bifurcation occurring at . In case of the positive field , it shows a single stable solution curve, which is the high-density solution (in the case where , this image would be flipped with respect to the axis). The right panel in Figure 3 shows that the value of the stable solution jumps when crosses from positive to negative, as expected.
Combining the above considerations for all multilinks simultaneously, and adding the other constraint on the layer-averaged degrees, the multiplex will undergo a sequence of phase transitions, determining a hierarchy of increasingly ordered (magnetized, or rather ‘multiplexed’ in this case) phases where, for an increasing number of pairs of nodes, the links in different layers will tend to ‘align’ to each other (for ). The separations between these phase transitions will depend on the values of the enforced layer-averaged degrees, which determine . The fully ordered phase, where all pairs of nodes are multiplexed, is the one where all the M layers of the multiplex are perfectly aligned, and are, therefore, basically an identical copy of each other. We might say that, in this case, the effective number of independent layers is , and the expected overlap is maximal and proportional to the expected number of links in the entire multiplex:
since for most pairs, i.e., , of layers. In the opposite extreme, we have a fully disordered phase where no pair of nodes is multiplexed (for instance, if ), so the effective number of independent layers is maximal (), and the expected overlap is basically of the order of that given by Equation (36) for the model with , i.e.,
since for most pairs of layers. The relationship between and will depend on the specific values of , so ultimately, on the enforced degree sequence. Between these two extremes, if the phases are well separated (which here means that the enforced degrees of different nodes have very different values), there will be intermediate regimes where and scale in a way that is between the two limiting scalings. All these general considerations will be confirmed in the next sections with numerical, analytical, and empirical analyses.
5. Numerical Analysis
Equations (53), (55), and (56) are the key equations of our OACM model. These equations are generally, however, very difficult to solve. Therefore, before creating a null model for a real-world network by solving the maximum likelihood equations to find the Lagrange multipliers, we shall first treat the Lagrange multipliers as free parameters in order to explore and analyze the properties of the model as a function of these parameters. This analysis shall be performed by utilizing the Metropolis–Hastings algorithm [51]. This algorithm can be used to sample the exponential probability distribution defined by the Hamiltonian of the model. By sampling the distribution, we numerically obtain various properties of the graph ensemble, which may then be compared to our analytical results in order to test the validity of the latter. Note that the sampling of the exponential distribution defined by a specific Hamiltonian may also be regarded as the simulation of a multiplex that corresponds to that Hamiltonian.
5.1. Exploring the Parameter Space
In order to explore the space of parameters, we are primarily interested in the difference between statistically homogeneous networks and statistically heterogeneous ones. To this end, we will explore the parameter space of the model by specifying a value for J and sampling certain transformed parameters from a distribution for each class, where . The quantity will be referred to as the ‘fitness’, or ‘hidden variable’, of node i. The broader the distribution of the fitness, the more heterogeneous the resulting network structure.
5.1.1. Homogeneous Fitness: Erdős–Rényi Graphs with Overlap
The simplest distribution from which we can sample is the delta distribution centered at x, such that and, therefore, , resulting in statistically homogeneous networks. With this choice of parameters, our model is an extension of the Erdős–Rényi model, which is a random graph model that can be derived within the ERGM by solely constraining the total number of links in the network, and where all links occur with the same probability. As we shall see, the extension derives from the fact that the extra constraint on the overlap can lead to a symmetry-breaking phase transition, although the broken symmetry might not manifest at first sight. Indeed, since the parameters are the same for all pairs of nodes, the condition for the existence of multiple solutions is also the same, and, therefore, there is a unique phase transition where, depending on the values of and J, pairs of nodes are either all ‘magnetized’ or all ‘non-magnetized’. Similarly, since here , the spontaneous symmetry-breaking condition discussed in Section 3.1 for the vanishing of the external field is the same for all pairs of nodes, and given by . In the symmetry-broken (magnetized) phase, for all pairs of nodes, the expected value of (or equivalently, of the ‘magnetization’ ) is the same, and is always between the two typical (high-density and low-density) realized values. However, since all pairs are independent, the actual realized values of are also independent across pairs, so on average, over the entire network, the magnetization will realize both the low-density and high-density values, with equal probability. In other words, different pairs of nodes are i.i.d. realizations of the same system. This is a peculiar situation where the realized values of L and O (which represent sums of all pairs of nodes) will still coincide with their expected values as if no symmetry breaking was present, even if different pairs of nodes actually realize different symmetry-broken values that are individually different from the expected value. The net result is an expected number of links ) equal to half the maximum one, or equivalently, an average zero magnetization in the associated spin system. Similar considerations apply to the case , with the difference that, in that case, the symmetry is not broken spontaneously, but by the direction of the external field (value of ), which implies that the two typical realized values of the magnetization for a given pair of nodes are no longer symmetric around the expected value. Still, both typical values will be realized, independently and with their probabilities, across the entire network, because different pairs of nodes are still independent. So, irrespective of the value of J and , we expect to observe realized values of L and O that correspond again to what one would observe without symmetry breaking, using the ensemble averages for each pair, irrespective of the phase of the system. All these considerations are confirmed below.
By looking at Equation (38), we can see that a uniform essentially means that instead of constraining the average layer degrees , we constrain the total number of links L in the multiplex network. In this case, the combined maximum entropy and maximum likelihood equations become
where is the solution to Equation (69). Note that we now have a single equation for u, confirming the existence of a single global phase transition across the multiplex network, rather than separate local phase transitions for every multilink . Additionally, we note that if can be considered as the density (and the link probability) of the network, then the value of is exactly the same as the value of the density p in the Erdős–Rényi model [14,27], which solely constrains the number of links in the network. The difference between our model and the Erdős–Rényi model is that our model contains the possibility of a phase transition. However, since the number of links also determines the overlap , the two quantities cannot be tuned independently of each other.
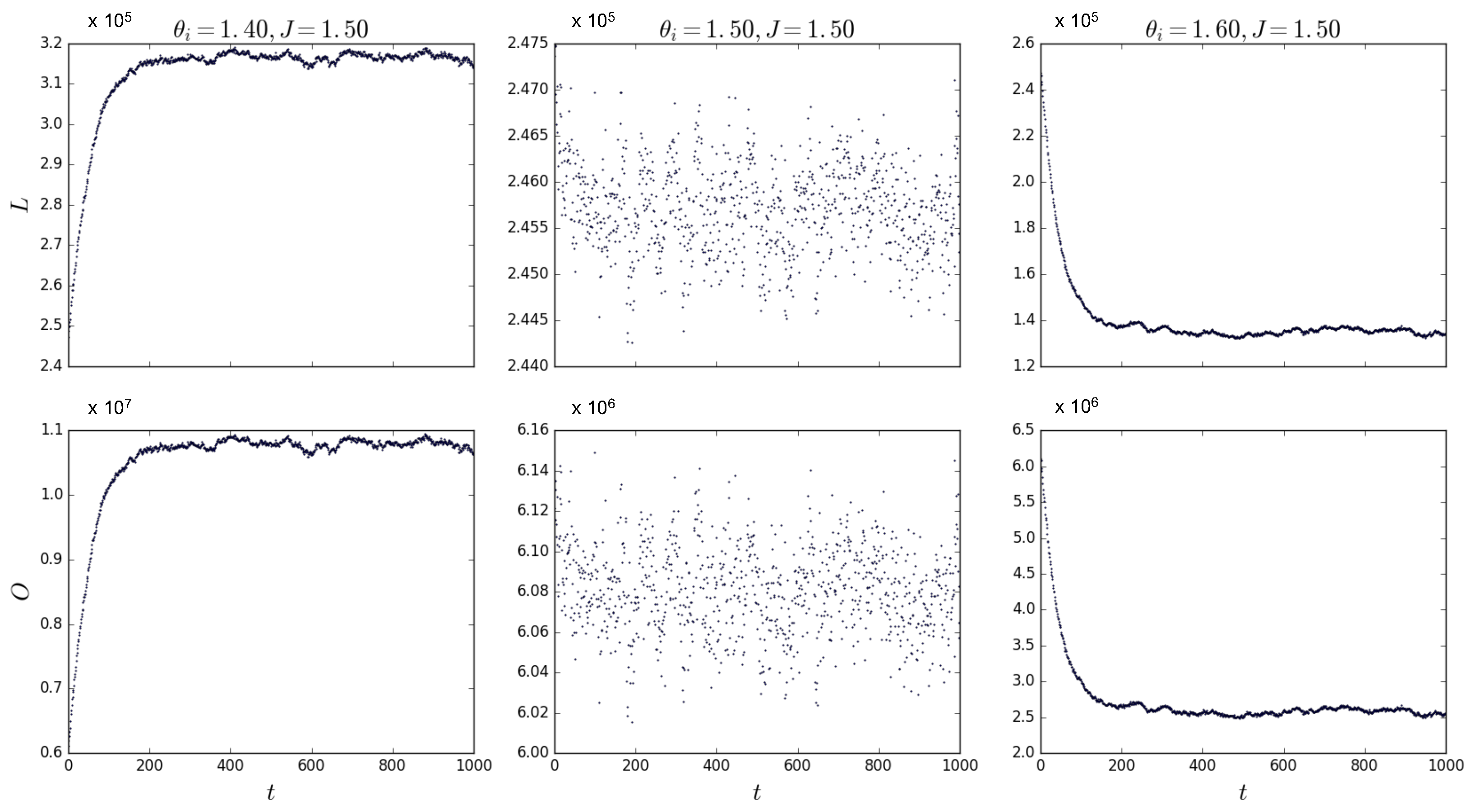
By using the Metropolis–Hastings algorithm, we have sampled our ERGM for multiplexes with layers and nodes for various values of and/or J. If we repeat the simulations for and , , and , the system must undergo a phase transition as per Figure 3. We expect an abrupt change in the value of , and according to Equations (70) and (71), we therefore expect an abrupt change in the equilibrium value of both L and O. Figure 4 shows simulations for confirming the transition from a relatively high to a low density as the value of the field changes sign. These simulations have been repeated for different combinations of values for J and around the point where B changes sign, confirming the results shown here. Note that the middle plot in Figure 4 shows that the algorithm converges to multiplexes with a density of , confirming that, when , L is approximately half of the total amount of possible links in the multiplex, as we expected above.
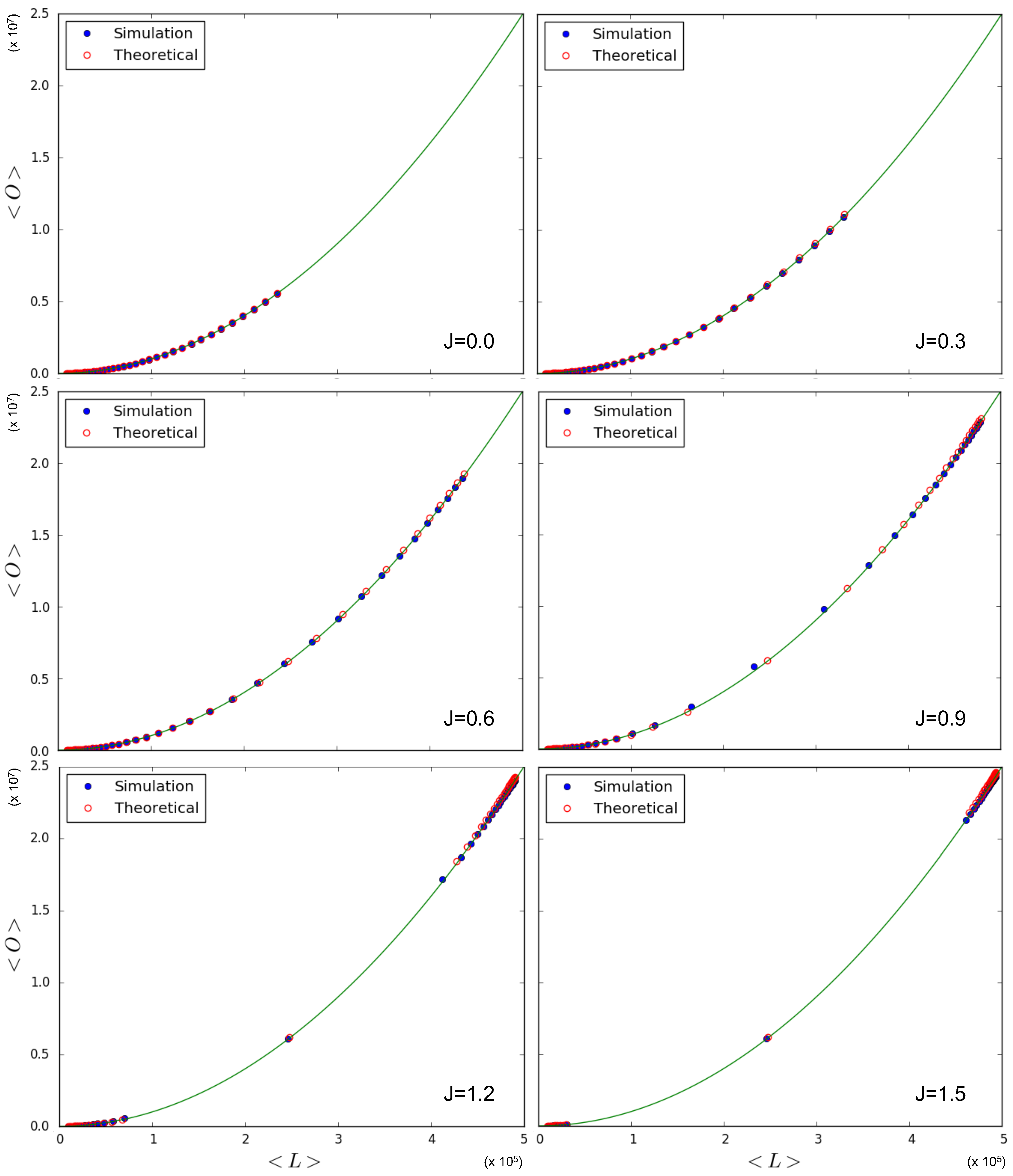
In Figure 5 we test the prediction, given by Equations (70) and (71), of the quadratic relationship . Note that this quadratic trend is predicted irrespective of the value of , and even coincides with what Equation (68) predicts in the case for a homogeneous multiplex with constant , as considered here. So, in this case, the expected relationship between and is not informative regarding the phase transition, although the specific values picked up by the system along the curve are. Indeed, we again simulate multiplexes with layers, nodes, and a variety of values for and J. Each simulation results in a value for and a value for , which we plot against each other. These points are then compared to the theoretical points predicted by Equations (69)–(71) for the chosen parameter values, and added to Figure 5. We see that the relationship between simulated quantities is in agreement with the one predicted by the model. As we had anticipated, this is the result of the fact that different pairs of nodes are i.i.d. realizations of the same system, so that the ensemble average is realized as a sample average of the pairs of nodes across the network, even if in the symmetry-broken phase, the ensemble average of is not representative of any of the values realized locally for individual pairs of nodes. Therefore, the only scaling we observe coincides with the one given in Equation (68) for the ‘non-magnetized’ regime in the case where is the same for all nodes. The only, although very important, signature of the phase transition we see in Figure 5 is the fact that, for and , both the simulated data and the corresponding theoretical predictions ‘drift away’ from the intermediate values of (which are still obtained for ) towards either low () or high () values of . This is because the realized multiplex networks are either low-density or high-density, which is an indication of a phase transition occurring when increasing the value of J, exactly as predicted by Figure 3.
We conclude our discussion of the homogeneous case by noting that, given an empirical multiplex of interest, the entropy of the data given, in general, by Equation (58) reduces, in this case, to
where we have used Equation (9) (denoting, via , the total number of links in the multiplex, which also equals the expected value ) and the fact that the pair partition function , given by Equation (52), has the same value for all the pairs of nodes. From Equation (72), we see that the entropy is determined, as expected, by both and . At the same time, we know that depends uniquely and quadratically on in this homogeneous model. The values achieved by the entropy are, therefore, bound by the relationship between and , which here is the same irrespective of the value of , including when . In any case, the entropy also depends on the specific values of , and Equation (63) guarantees that an upper bound for is given by the entropy of the ACM model with and (clearly, the homogeneity implies that for all in the ACM model as well).
5.1.2. Power-Law-Distributed Fitness: Scale-Free Networks with Overlap
We now move away from the homogeneous case and consider a situation where the fitness values are drawn from a heavy-tailed distribution, in particular, a power law. This choice will produce a high degree of heterogeneity. In the ACM (see Section 2.5), the expected degree distribution is determined by the Lagrange multipliers , or equivalently, the transformed hidden variables . If x is distributed according to a power law, the expected degree distribution shall be distributed according to a power law as well, with the modulo as an upper cut-off. Since our OACM is an extension of the ACM, we will still sample from a power law distribution for various values of , even though the expected degree distribution is not solely determined by the hidden variables , but depends on J as well. In any case, a higher level of heterogeneity in the hidden variables will lead to a higher level of heterogeneity in the degrees. Since the parameter space is rather large (-dimensional), we define
where z is a scaling factor. We sample only once from every chosen distribution. The value of is varied by varying the scaling factor z. The parameter space to be explored will then be , which is 2-dimensional. We deduce that
which shows that an increasing z leads to a decreasing . In the ACM, we have shown that the link probability is equal to , which means that larger values of lead to a larger expected degree, so that increasing all the fitness values will increase the density in the network. This qualitative relationship still holds with the addition of the constraint on the expected overlap (for fixed J).
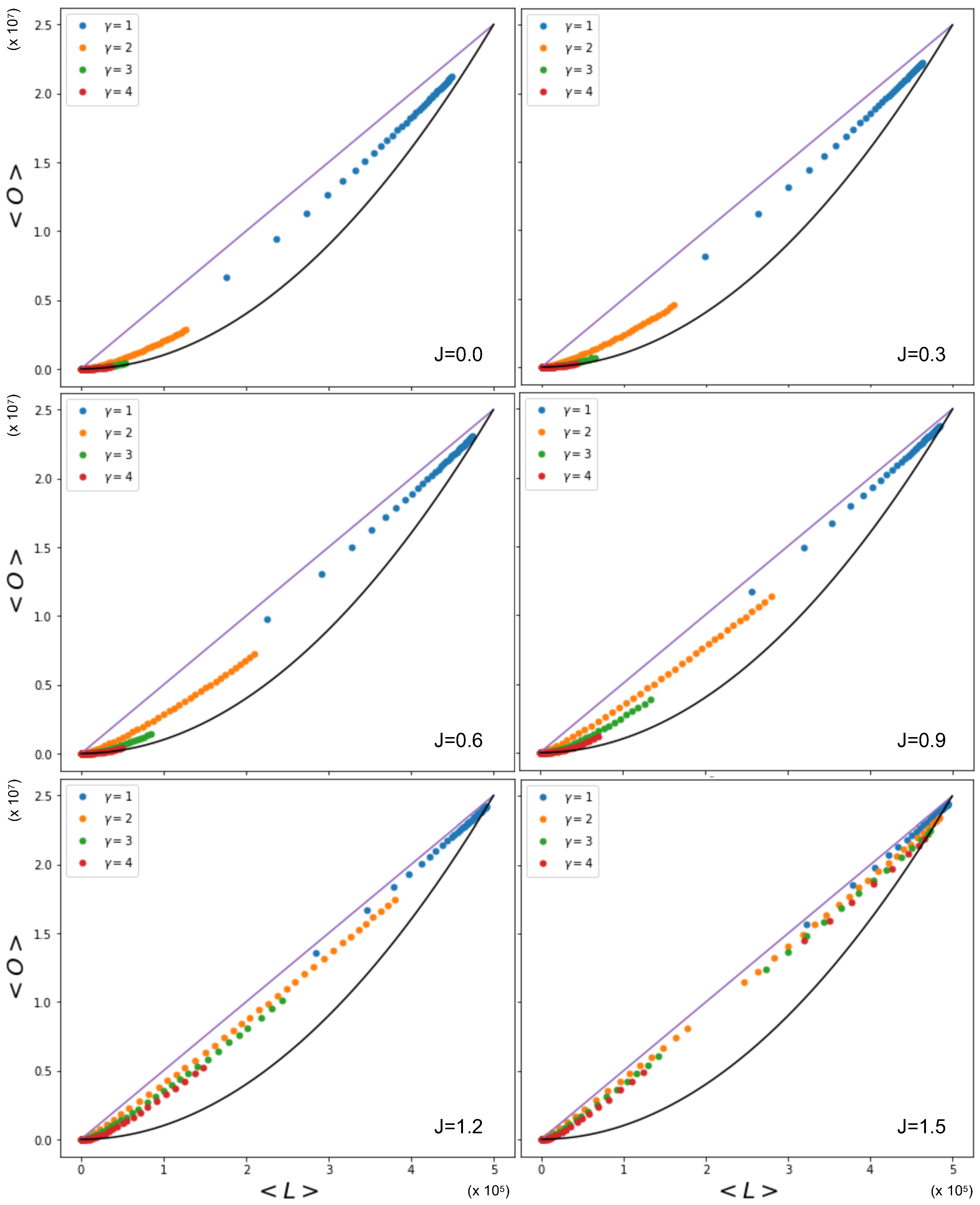
The complexity of Equations (53), (55), and (56) does not allow us to easily derive the expected relationship between the overlap and the number of links in the network, as was the case when was constant. It is, however, possible to visualize the relationship between the overlap and the number of links by using the Metropolis–Hastings algorithm. Figure 6 shows this relationship, where is sampled from power law distributions with various values of , alongside the expected quadratic term previously observed to occur for homogeneous values of the fitness (delta distribution). We see that the overlap for a given number of links is higher in the cases where x is drawn from a power law distribution than when x is drawn from a delta distribution, even though the coupling parameter J is kept constant. The cause of this difference lies in the level of heterogeneity of the fitness distribution: unlike the homogeneous case, now different pairs of nodes have very different values of , and, therefore, the condition for the vanishing of the ‘external field’ (spontaneous symmetry-breaking condition) cannot be realized simultaneously by all pairs. The figure also shows the effect of different exponents of the power law distributions of the fitness. A smaller value of leads to a higher overlap for a given number of links. By increasing the value of , the power law distribution becomes more sharply peaked, and will therefore lead to more homogeneous networks. Note, however, that increasing the value of the coupling parameter J itself also leads to an increase in the overlap for a given number of links for the same distribution.
Importantly, the phase transition now occurs for different pairs of nodes as J is varied. Some pairs of nodes will be in the non-magnetized phase, while others will be in the magnetized phase. The effective number of independent layers will, in general, depend on the choice of parameters. Among the magnetized pairs, the realized values of the overlap are no longer those corresponding to the ensemble average (as in the homogeneous case), but typically to the symmetry-broken solution with lower energy (hence dictated by the value of ), because no other pair of nodes will, in general, exist with the same parameters and such that the two symmetry-broken values are averaged by the resulting value of the realized overlap. In particular, while for all node pairs are in the non-magnetized phase, as J increases from 1 towards larger values, the pairs of nodes that first undergo the phase transition are the ones with values that fall between the limits set by Equations (65) and (66). As those equations and Figure 2 show, there are more and more combinations entering the magnetized phase as J increases. When J is sufficiently large, all pairs will be magnetized. Clearly, for any two pairs of nodes, and , that share the same node, i, the values of and will be correlated, as they share the same term . This means that the pairs of nodes entering the magnetized phase typically have nodes in common, even if it would be incorrect to say that individual nodes enter the magnetized phase ‘one by one’, while this is certainly correct for individual node pairs, if the sum is different across all of them.
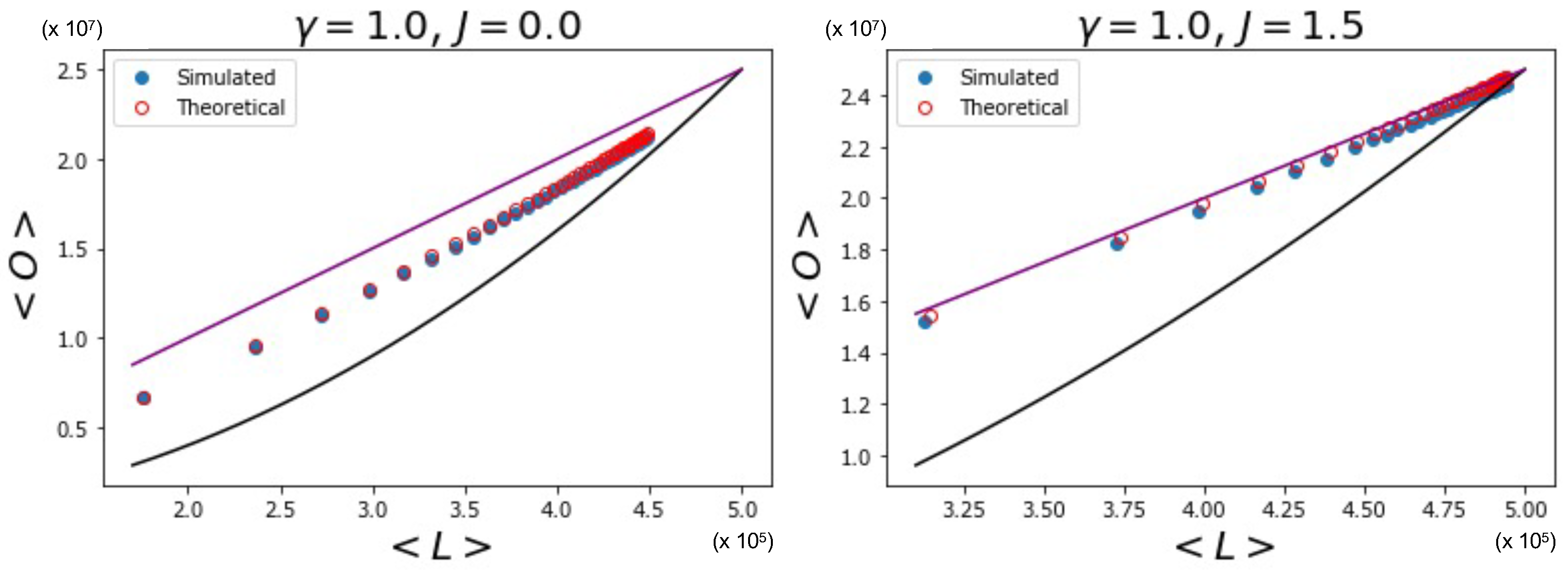
Figure 6 indeed shows the effect of the changing number of magnetized node pairs as J increases above 1. We note that, for larger and larger J, the relationship between and tends towards the ‘maximally multiplexed’ linear extreme (shown as a straight line) given in Equation (67). At the same time, we see that the ‘non-multiplexed’ case () described by Equation (68) now realizes values of the overlap that are very different from the quadratic trend achieved by the homogeneous model (also shown as a solid curve in Figure 6), which now turns out to represent a lower bound. We can ‘zoom in’ to better see this difference by looking at Figure 7, where, by using Equations (53), (55), and (56), we additionally calculate the theoretically predicted values of and and compare them to the simulation data, where is sampled from a power law distribution with (the results for are qualitatively similar and are therefore not shown here). The figure confirms a strong deviation from the curve for the homogeneous model, even when (signaling a much higher but spurious overlap, arising only from the rising correlation among node degrees across different layers), and a close agreement with the maximally overlapping value in Equation (67) already for (corresponding to a further increase in overlap, arising from an additional, genuine coupling between layers).
5.1.3. Log-Normally Distributed Fitness
The delta and power law distributions we have considered so far represent examples of completely homogeneous and extremely heterogeneous (especially for ) distributions, respectively. We now consider the log-normal distribution as a third example between these two extremes. This analysis will indeed lead to results that are in some sense intermediate between what we have observed so far, and useful for interpreting the real-world case that we will present later on. A log-normal distribution is the distribution of a random variable whose logarithm is normally distributed (i.e., if the random variable x is log-normally distributed, then follows a normal distribution). The probability density for a log-normal distribution is
where and correspond to the mean and the standard deviation of the normal distribution of . We will vary the value of by again introducing a scaling factor that can be changed such that and , where we sample once from the log-normal distribution for a variety of values for and .
The log-normal distribution allows us to inspect the transition in the relationship between the overlap and the number of links from the quadratic lower limit to the linear upper limit by varying the value of . Indeed, when , the normal distribution of is sharply peaked. By decreasing the value of towards 0, (and, therefore, as well) shall approach a delta distribution. This is the distribution that led us to the quadratic lower limit for the relationship between the overlap and the number of links in the network. Conversely, when , the log-normal distribution approaches a distribution with a power law tail with . This distribution led us to the linear upper limit between the overlap and the number of links in the network (when J was sufficiently large). By increasing the value of from 0 to a sufficiently large value (e.g., ), we can therefore increase the heterogeneity of the network from a completely homogeneous network achieving the quadratic lower limit to an extremely heterogeneous network close to the linear upper limit relationship in the simulation data.
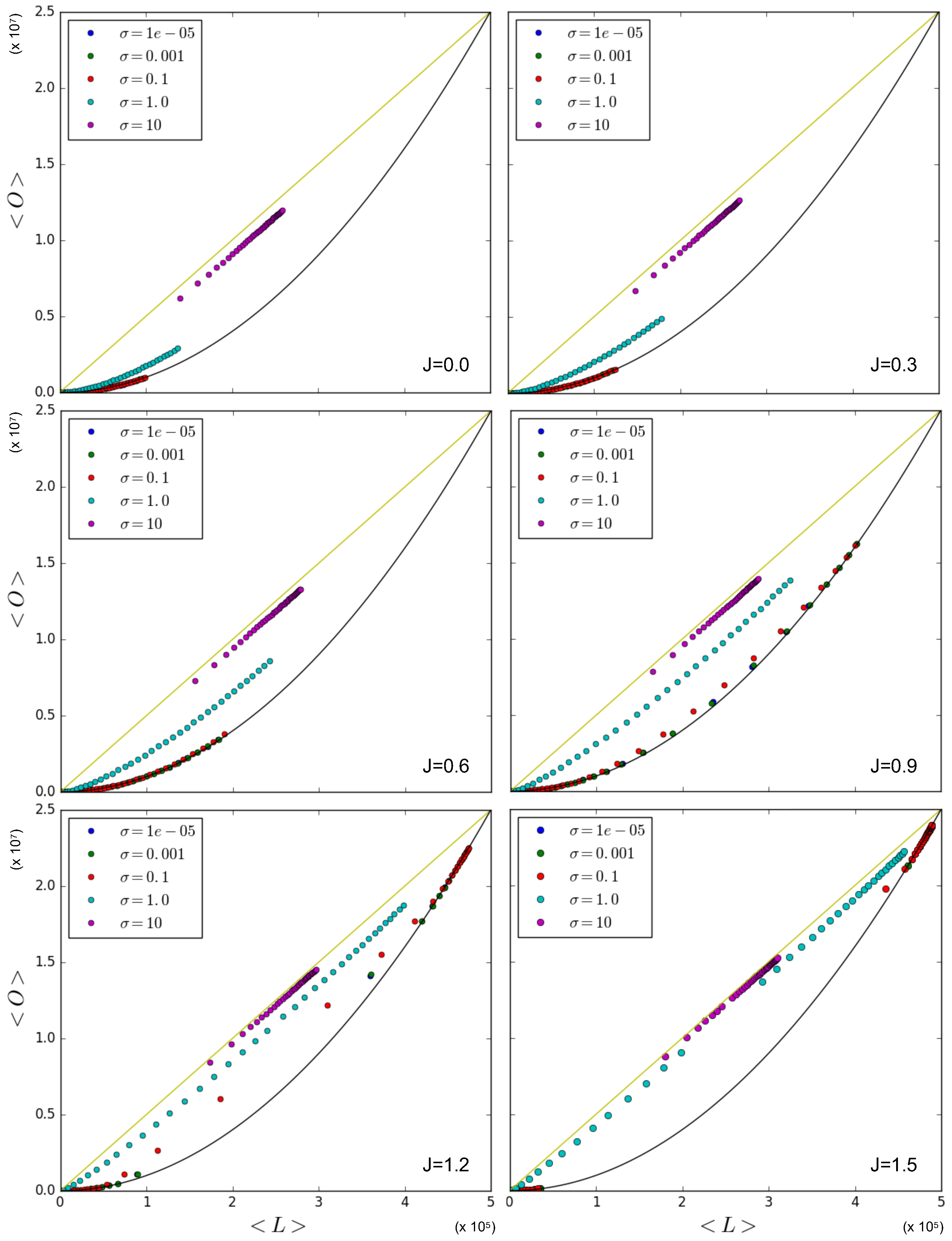
Figure 8 shows the relationship between the average overlap and the number of links in the network with simulation data that were obtained by using the Metropolis–Hastings algorithm for a variety of values for J and . Again, the linear upper limit is illustrated as a straight line and the quadratic lower limit as a solid curve. The figure confirms that in the case where , the data points that correspond to being sampled from a log-normal distribution with a relatively low value for are either on or close to the quadratic lower limit curve. On the other hand, the case where results in data points where the overlap in the network for a given number of links is almost maximal, and therefore approaches the linear upper limit. This first set of results confirms the strong role of node heterogeneity in determining increased correlations between the degrees of the same node across different layers, which, in turn, increase the inter-layer overlap even without any explicit coupling (), and hence, in a ‘spurious’ manner. On the other hand, when we increase the value of J, the data points corresponding to relatively low values of (e.g., and ) stay on or close to the quadratic lower limit, a finding similar to the results in Section 5.1.1, showing that the symmetry-broken values realized by different pairs of nodes, when averaged across the network, restore the ensemble average because the node pairs are all independent and (almost) identically distributed. Remarkably this means that, in a certain sense, node homogeneity ‘suppresses’ the effects of the true inter-layer coupling () on the realized overlap. For the intermediate value , the data are distributed close to the quadratic lower limit curve only for low values of J, while increasing the value of J leads to a more linear trend, eventually approaching the linear upper limit. In this case, the coupling is effective in producing a higher realized overlap. In the case where , the linear trend is instead achieved already for (although the points are aligned below it); hence, increasing the value of J barely influences the value of the overlap for a given number of links.
Therefore the effect of increasing J in networks with a moderate heterogeneity is a transition from multiplex configurations with densities of all levels towards multiplex configurations with either low or high density, which is a result of the phase transition. It also shows that a very high level of heterogeneity leads to an overlap in the network that is already close to maximal for a given number of links, irrespective of the phase transition and the value of J. However, in the case where we have an intermediate level of heterogeneity (), we observe that the effect of the coupling can be relatively strong, and we can therefore construct networks with a combination of the overlap and number of links falling between the extreme linear upper limit and the quadratic lower limit in a controlled, systematic manner. Note that Figure 8 also shows that, as J increases above 1, the (symmetry-broken) realized data start to ‘drift away’ from the intermediate densities, in a way similar to what we observed in Figure 5, but in a more pronounced manner. This is due to the fact that, as J increases, a larger number of multilinks shall be either in the low-density or high-density phase.
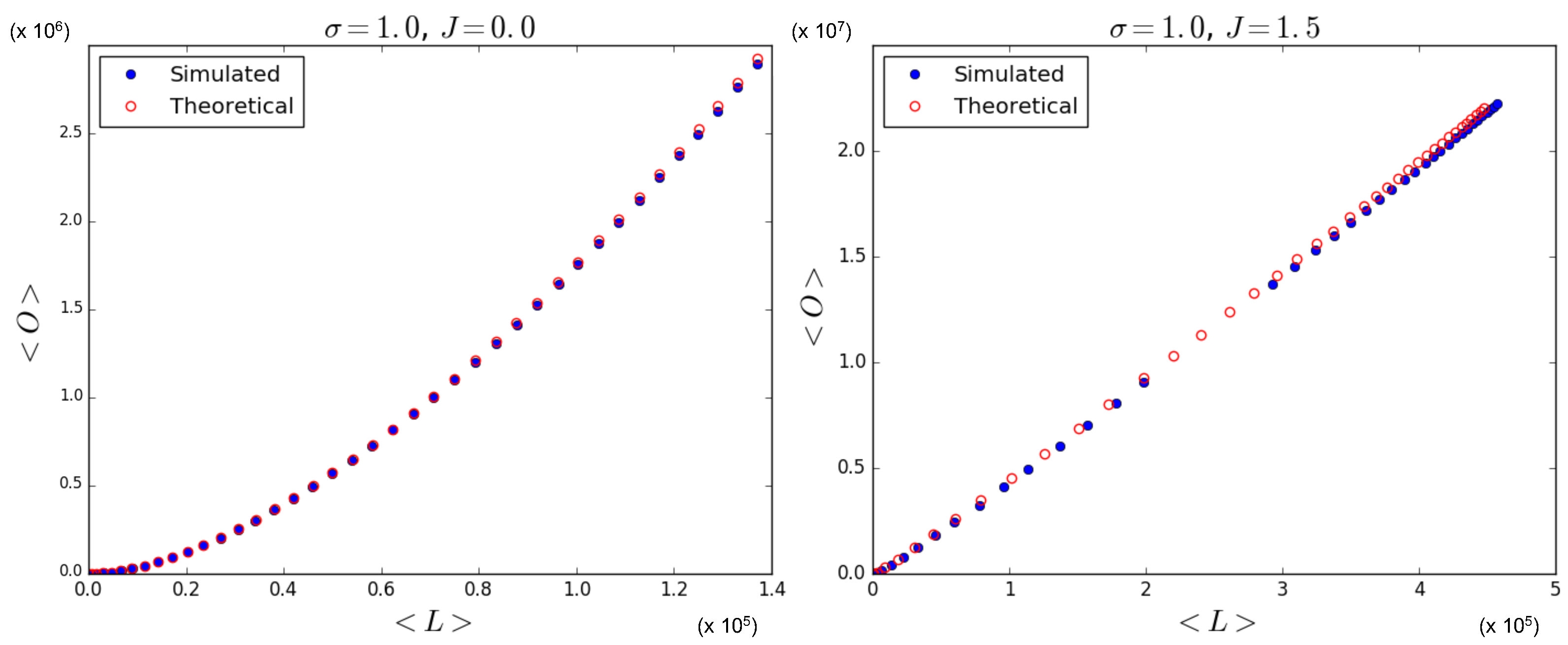
Again, in Figure 9 (which is the counterpart of Figure 7), we ‘zoom in’, and, using Equations (53), (55), and (56), we show the theoretically predicted values of and and compare them to the simulation data, where is sampled from a log-normal distribution with , for and . The results for are not shown here since relatively low and high values for lead to results similar to those we have shown in Section 5.1.1 and Section 5.1.2, respectively. Figure 9 confirms that the theoretical predictions are in good agreement with the simulation data, apart from the expected ‘drifting away’ of symmetry-broken values from the corresponding ensemble average.
6. Analysis of the World Trade Multiplex
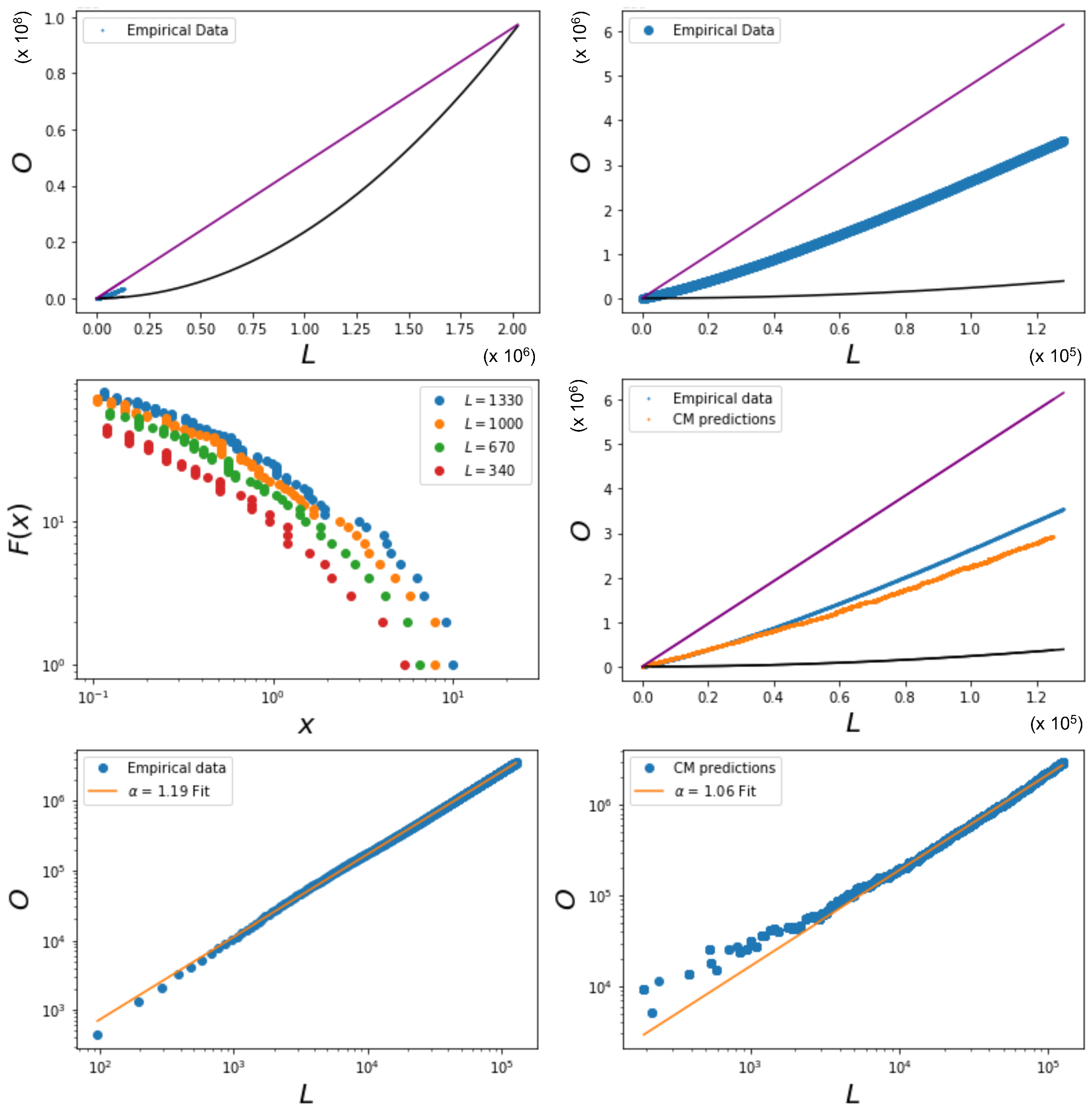
In this section, we finally consider an application of the model to a real-world economic network. Since our models lead to multiplex networks with independent pairs of nodes (i.e., independent multilinks) even when links are correlated across layers, it is important that the real-world network is consistent with this assumption. For instance, networks constructed from time series data [3,4,5] are not viable, because the known (and strong) correlations between the time series corresponding to different vertices generate dependencies between pairs of nodes (and higher-order patterns) through the triangular inequality [6,7]. For this reason, we select the World Trade Multiplex as an ideal case study for the present analysis, because each separate layer of that network has been successfully modeled in the past via maximum entropy models of networks with given degrees [31,32,33]. At the same time, it has been shown that certain structural properties of commodity-specific layers are very similar across the different layers of the multiplex [30], and that this similarity (in particular, the correlation among the degrees of the same node in different layers) generates a large spurious component of the inter-layer overlap [28,29], which is not necessarily due to a genuine coupling. In this sense, our analysis here will add a natural novel aspect to the modeling of the network, namely, the explicit comparison with a model with nontrivial coupling among layers, which has not been considered so far. We use the UN-COMTRADE dataset that represents the multiplex network of international trade (https://comtradeplus.un.org, accessed on 2 September 2019). The different layers of this multiplex network represent different commodities. The vertices in this network represent different countries, and a link exists between two countries in a given layer if there is trade between them in that commodity. The data include countries and commodities. Some examples of traded commodities are meat, fish, dairy products, coffee, and tobacco [30,33].
Using the international trade data, we wish to identify a possibly nontrivial overlap by creating plots similar to the ones depicted in Figure 6 and Figure 7 or Figure 8. We therefore repeatedly filter the network such that each layer has the same number of links (where ), and calculate the corresponding overlap O for the specified value of (note that this means that the total number of links in the entire multiplex is ). The criterion we follow is choosing the strongest (highest weight) links in every layer to obtain data with comparable degrees across layers, as in our models. Note that, by using this filtering method, the highest possible density we can achieve is limited by the density of the sparsest layer in the unfiltered network. The results are shown in Figure 10, which indicates that the overlap for a given number of links appears to be around halfway between the quadratic lower limit curve and the linear upper limit curve. This suggests that the degree of heterogeneity of the network is intermediate, similar to that realized by log-normally distributed fitness values, as in our example considered above.
As anticipated, we are currently unable to solve the maximum likelihood equations in order to obtain the joint values of all the Lagrange multipliers in the full OACM model with . However, after filtering the original empirical network such that every layer has links, we can use the values of the hidden variables for the null model corresponding to the absence of inter-layer coupling, i.e., to . As we have shown in Equations (57), this assumption reduces our model to the ACM discussed in Section 2.5. The maximum likelihood equations in this case are much easier to solve, and can be found using one of the numerical algorithms available at https://meh.imtlucca.it (accessed on 1 May 2023). This procedure is repeated for a range of values for . The cumulative distribution of the hidden variables are plotted in Figure 10 for various values of . The figure qualitatively shows that the shape of the cumulative distribution of x is fat-tailed and indeed similar to the one for a log-normal distribution. Moreover, it does not vary with , apart from an overall change of scale.
The null model with , when compared to the data for the same choice of , allows us to detect the presence of nontrivial coupling among the layers, when present. Indeed, from Figure 10, we see that the filtered networks have a relatively high overlap, the data points being distributed along a similar trend as the one corresponding to a nonzero J in our previous heterogeneous examples. By using the values of the hidden variables for the model with , we can calculate the corresponding expected number of links and the expected overlap under the null hypothesis of no coupling between the layers, but the same average degree sequence in the real network. The results are shown in Figure 10, alongside the curve corresponding to the empirical data. We see that the assumption leads to an insufficiently overlapping multiplex, demonstrating the necessity of a model that introduces dependencies between the layers of a network. The difference between the two curves can be quantified by fitting both to the curve
where A is a proportionality factor and is an exponent (not to be confused with the label of a layer of the multiplex). For the empirical data, we find a steeper increase characterized by an exponent , while for the predictions from the ACM, we find (see Figure 10). The difference between the two values implies that the difference between the realized and expected overlap increases as L increases, confirming that the observed overlap in the WTM is not only the spurious result of the correlated heterogeneity of the degrees of countries, but reflects genuine () inter-layer dependencies.
We conclude with a discussion about the entropy in the heterogeneous case, analogous to the one we made in Section 5.1.1 in the homogeneous case. Here we note that, given a multiplex of interest, the entropy of the data, given the OACM model, is the one given by Equation (58), which in the heterogeneous case cannot be, in general, reduced to a simpler formula. However, if we define the minimum and maximum values of the hidden variables as
respectively, we can bound the entropy as follows:
where we have defined
The bounds in Equation (78) are alternative to the general ones in Equation (63), and arguably more useful to characterize how the entropy is effectively constrained by, once again, the relationship between and . The latter, unlike the homogeneous case, is not necessarily quadratic, and can follow the diverse trends we have shown in Figure 6, Figure 8 and Figure 10. In particular, the power law relationship captured by Equation (76) for the empirical WTM provides a convenient way of bounding via Equations (78)–(80).
7. Conclusions
In this paper we have introduced a maximum entropy model, or ERGM, of multiplex networks with given degrees and inter-layer overlap. The model allowed us to separately control the effects of the correlations between node degrees across different layers (which lead to a spurious overlap) and that of a genuine inter-layer coupling. The nature of the enforced constraints is such that different pairs of nodes are statistically independent, even if the parameters governing them are correlated via those of the nodes they share.
For each pair of nodes, the model can be mapped exactly to a mean-field Ising model featuring a magnetization-like phase transition, which includes the possibility of (spontaneous) symmetry breaking. Given the difficulty of solving the maximum likelihood equations to obtain the values of the Lagrange multipliers corresponding to a particular real network, we first treated the Lagrange multipliers as free parameters in order to explore and analyze the properties of multiplex systems as a function of these parameters using numerical methods. Additionally, the numerical results were compared to our analytical results in order to test the validity of the latter. We have shown that the analytical equations are highly accurate. The combined result, at the level of the entire multiplex, of the properties of all node pairs is nontrivial and crucially depends on the values of the node-specific parameters, which ultimately depend on the enforced degrees.
In the fully homogeneous case, the phase transition occurs at the same critical point for all node pairs simultaneously, because the parameters are identical for all nodes. However, the independence of different node pairs implies that, even in the magnetized phase, the realized values of the inter-layer overlap and total number of links coincide with the ensemble average. This happens because different node pairs realize all the possible symmetry-broken values independently, so that an average of the realized values for a large number of independent node pairs asymptotically equals the ensemble average. The value of J has little effect on the relationship connecting the overlap to the number of links, which remains similar to what we observed for the case , showing that node homogeneity suppresses the effects of a genuine inter-layer coupling.
In the heterogeneous case, the phenomenology is very different since, despite the fact that node pairs are still independent, they are now governed by different parameters, and the ensemble average for a given pair can no longer be realized as an average of the realized values of pairs with the same parameters. This implies that the observed overlap and number of links will depend on the realized symmetry-broken values, whose typical value does not coincide in general with the ensemble average, and is determined by the node-specific parameters (hence, ultimately by the degrees). Moreover different pairs of nodes are, in general, found in different phases, so the multiplex displays, as a function of the parameters, a hierarchy of phase transitions. We have found that increasing the value of the coupling parameter J generally increases the (genuine) overlap for a given number of links, if there is enough node heterogeneity. However, we have also shown that increasing the heterogeneity of the network increases the (spurious) overlap for a given number of links as well. This is a consequence of the presence of large hubs that appear in a correlated manner across layers, due to the increased heterogeneity of the network. Additionally, every multilink that is connected to these hubs has a relatively low critical threshold for the coupling parameter J. Therefore, these multilinks have a higher probability to be in the high density phase, which leads to a higher overlap as well, which corresponds to increasing the amount of genuine correlation. In general, the overlap for a given number of links can be increased by increasing either the heterogeneity of the network or the value of the coupling parameter, with a subtle interplay between the two. In principle, this can be used in order to create multiplexes with a specific degree of overlap for a given of number of links, provided their combination is within the theoretical limits discussed in Section 5.
Finally, by using a dataset that represents the empirical multiplex network of international trade in several commodity-specific layers, we have used the model to disentangle the spurious overlap arising from the documented strong correlation of node degrees across layers [28,29] from the genuine overlap arising from actual inter-layer coupling. We have found that the assumption that there is no coupling between the layers (), which reduces our model to the ACM, results in a multiplex with insufficient inter-layer overlap. This means that the empirical overlap is not merely the spurious result of the correlated heterogeneity of the network, but requires a true nonzero coupling between layers.
Our results demonstrate the subtleties of the interplay between node heterogeneity and inter-layer dependencies in multiplex networks, highlighting the need for null models that can control these factors separately. In this paper, we have introduced perhaps the simplest, although already very rich, model of this type. Our model can be seen as a minimal one, to be further generalized in the future.
Author Contributions
Conceptualization, D.G. and V.G.; methodology, D.G., V.G. and N.B.; software, N.B.; data curation, V.G. and N.B.; writing—original draft preparation, N.B.; writing—review and editing, V.G. and D.G.; visualization, N.B.; supervision, D.G.; project administration, V.G.; funding acquisition, D.G. All authors have read and agreed to the published version of the manuscript.
Funding
The APC was funded by Stichting Econophysics, Leiden, The Netherlands.
Data Availability Statement
For the empirical analysis of the World Trade Multiplex, the publicly available UN-COMTRADE dataset was analyzed in this study. The data are available at http://comtrade.un.org/ (accessed on 2 September 2019). The codes used for the numerical calculation of the parameters maximizing the likelihood are available at https://meh.imtlucca.it (accessed on 1 May 2023).
Acknowledgments
This work is supported by the European Union—Horizon 2020 Program under the scheme ‘INFRAIA-01-2018-2019—Integrating Activities for Advanced Communities’, Grant Agreement n.871042, ‘SoBigData++: European Integrated Infrastructure for Social Mining and Big Data Analytics’ (http://www.sobigdata.eu, accessed on 1 May 2023). This work is also supported by the European Union-NextGenerationEU-National Recovery and Resilience Plan (Piano Nazionale di Ripresa e Resilienza, PNRR), project ‘SoBigData.it-Strengthening the Italian RI for Social Mining and Big Data Analytics’-Grant IR0000013 (3264, 28/12/2021). We also acknowledge support from the project NetRes—‘Network analysis of economic and financial resilience’, Italian DM n. 289, 25-03-2021 (PRO3 Scuole), CUP D67G22000130001 (https://netres.imtlucca.it, accessed on 1 May 2023).
Conflicts of Interest
The authors declare no conflict of interest.
Appendix A. Hubbard–Stratonovich Transform
The pair Hamiltonian of our OACM in Equation (47) can be rewritten as
We want to obtain an expression for the pair partition function:
The argument of the exponent in the above expression can be linearized by using the Gaussian integral
In our case, by choosing the partition function factorizes with respect to the individual summations of :
Performing the change of variable we obtain
where
We are interested in the large M limit. To proceed in the calculation of , it is useful to define the quantity
which is the free energy per layer. By inserting the result (A5) into (A7), we obtain
In order to obtain a more explicit form of the function , we use the Laplace theorem [49]. Let and be continuous and positive functions within a range , then
For and , this results in
The derivative of with respect to is zero at its maximum:
The variable therefore obeys the equation
Note that this equation is identical to the one obtained for the magnetization in the Ising Model, and, depending on the values of J and , there are either one or three solutions that satisfy Equation (A12). The free energy can now be written as a function of J and :
We then finally arrive at the pair partition function
which, returning to the variables , coincides with Equation (52) in the main text, where is the solution to Equation (53).
Appendix B. Maximum Likelihood
To determine the parameters that maximize the log-likelihood of the OACM given in Equation (54), we first calculate the derivatives
We then set the derivatives with respect to to zero:
where we utilize the fact that and are symmetric with respect to the indices , i.e.,
Similarly, we set the derivative with respect to J to zero:
Taken together, the above calculations lead to the maximum likelihood Equations (55) and (56) in the main text.
References
- Krackhardt, D. Cognitive social structures. Soc. Netw. 1987, 9, 109–134. [Google Scholar] [CrossRef]
- Padgett, J.F.; Ansell, C.K. Robust Action and the Rise of the Medici, 1400–1434. Am. J. Sociol. 1993, 98, 1259–1319. [Google Scholar] [CrossRef]
- Bardoscia, M.; Barucca, P.; Battiston, S.; Caccioli, F.; Cimini, G.; Garlaschelli, D.; Saracco, F.; Squartini, T.; Caldarelli, G. The physics of financial networks. Nat. Rev. Phys. 2021, 3, 490–507. [Google Scholar] [CrossRef]
- Lacasa, L.; Luque, B.; Ballesteros, F.; Luque, J.; Nuno, J.C. From time series to complex networks: The visibility graph. Proc. Natl. Acad. Sci. USA 2008, 105, 4972–4975. [Google Scholar] [CrossRef] [PubMed]
- Tsiotas, D.; Magafas, L.; Argyrakis, P. An electrostatics method for converting a time-series into a weighted complex network. Sci. Rep. 2021, 11, 11785. [Google Scholar] [CrossRef]
- MacMahon, M.; Garlaschelli, D. Community Detection for Correlation Matrices. Phys. Rev. X 2015, 5, 021006. [Google Scholar] [CrossRef]
- Anagnostou, I.; Squartini, T.; Kandhai, D.; Garlaschelli, D. Uncovering the mesoscale structure of the credit default swap market to improve portfolio risk modelling. Quant. Financ. 2021, 21, 1501–1518. [Google Scholar] [CrossRef]
- De Domenico, M.; Solé-Ribalta, A.; Cozzo, E.; Kivelä, M.; Moreno, Y.; Porter, M.A.; Gómez, S.; Arenas, A. Mathematical formulation of multilayer networks. Phys. Rev. X 2013, 3, 041022. [Google Scholar] [CrossRef]
- Battiston, F.; Nicosia, V.; Latora, V. Structural measures for multiplex networks. Phys. Rev. E 2014, 89, 032804. [Google Scholar] [CrossRef]
- Kivelä, M.; Arenas, A.; Barthelemy, M.; Gleeson, J.P.; Moreno, Y.; Porter, M.A. Multilayer networks. J. Complex Netw. 2014, 2, 203–271. [Google Scholar] [CrossRef]
- Battiston, F.; Nicosia, V.; Latora, V. The new challenges of multiplex networks: Measures and models. Eur. Phys. J. Spec. Top. 2017, 226, 401–416. [Google Scholar] [CrossRef]
- Boccaletti, S.; Bianconi, G.; Criado, R.; Del Genio, C.I.; Gómez-Gardenes, J.; Romance, M.; Sendina-Nadal, I.; Wang, Z.; Zanin, M. The structure and dynamics of multilayer networks. Phys. Rep. 2014, 544, 1–122. [Google Scholar] [CrossRef] [PubMed]
- Verbrugge, L.M. Multiplexity in adult friendships. Soc. Forces 1979, 57, 1286–1309. [Google Scholar] [CrossRef]
- Erdos, P.; Rényi, A. On the evolution of random graphs. Publ. Math. Inst. Hung. Acad. Sci 1960, 5, 17–60. [Google Scholar]
- Albert, R.; Barabási, A.L. Statistical mechanics of complex networks. Rev. Mod. Phys. 2002, 74, 47. [Google Scholar] [CrossRef]
- Watts, D.J.; Strogatz, S.H. Collective dynamics of’small-world’networks. Nature 1998, 393, 440. [Google Scholar] [CrossRef]
- Squartini, T.; Garlaschelli, D. Analytical maximum-likelihood method to detect patterns in real networks. New J. Phys. 2011, 13, 083001. [Google Scholar] [CrossRef]
- Squartini, T.; Mastrandrea, R.; Garlaschelli, D. Unbiased sampling of network ensembles. New J. Phys. 2015, 17, 023052. [Google Scholar] [CrossRef]
- Squartini, T.; Garlaschelli, D. Maximum-Entropy Networks: Pattern Detection, Network Reconstruction and Graph Combinatorics; Springer: Berlin/Heidelberg, Germany, 2017. [Google Scholar]
- Cimini, G.; Squartini, T.; Saracco, F.; Garlaschelli, D.; Gabrielli, A.; Caldarelli, G. The statistical physics of real-world networks. Nat. Rev. Phys. 2019, 1, 58–71. [Google Scholar] [CrossRef]
- Holland, P.W.; Leinhardt, S. An exponential family of probability distributions for directed graphs. J. Am. Stat. Assoc. 1981, 76, 33–50. [Google Scholar] [CrossRef]
- Besag, J. Spatial interaction and the statistical analysis of lattice systems. J. R. Stat. Soc. Ser. B (Methodol.) 1974, 36, 192–236. [Google Scholar] [CrossRef]
- Frank, O.; Strauss, D. Markov graphs. J. Am. Stat. Assoc. 1986, 81, 832–842. [Google Scholar] [CrossRef]
- Contractor, N.S.; Wasserman, S.; Faust, K. Testing multitheoretical, multilevel hypotheses about organizational networks: An analytic framework and empirical example. Acad. Manag. Rev. 2006, 31, 681–703. [Google Scholar] [CrossRef]
- Wasserman, S.; Faust, K. Social Network Analysis: Methods and Applications; Cambridge University Press: Cambridge, UK, 1994; Voluem 8. [Google Scholar]
- Carrington, P.J.; Scott, J.; Wasserman, S. Models and Methods in Social Network Analysis; Cambridge University Press: Cambridge, UK, 2005; Volume 28. [Google Scholar]
- Park, J.; Newman, M.E. Statistical mechanics of networks. Phys. Rev. E 2004, 70, 066117. [Google Scholar] [CrossRef]
- Gemmetto, V.; Garlaschelli, D. Multiplexity versus correlation: The role of local constraints in real multiplexes. Sci. Rep. 2015, 5, 9120. [Google Scholar] [CrossRef]
- Gemmetto, V.; Squartini, T.; Picciolo, F.; Ruzzenenti, F.; Garlaschelli, D. Multiplexity and multireciprocity in directed multiplexes. Phys. Rev. E 2016, 94, 042316. [Google Scholar] [CrossRef]
- Barigozzi, M.; Fagiolo, G.; Garlaschelli, D. Multinetwork of international trade: A commodity-specific analysis. Phys. Rev. E 2010, 81, 046104. [Google Scholar] [CrossRef]
- Squartini, T.; Fagiolo, G.; Garlaschelli, D. Randomizing world trade. I. A binary network analysis. Phys. Rev. E 2011, 84, 046117. [Google Scholar] [CrossRef]
- Fagiolo, G.; Squartini, T.; Garlaschelli, D. Null models of economic networks: The case of the world trade web. J. Econ. Interact. Coord. 2013, 8, 75–107. [Google Scholar] [CrossRef]
- Mastrandrea, R.; Squartini, T.; Fagiolo, G.; Garlaschelli, D. Reconstructing the world trade multiplex: The role of intensive and extensive biases. Phys. Rev. E 2014, 90, 062804. [Google Scholar] [CrossRef]
- Szell, M.; Lambiotte, R.; Thurner, S. Multirelational organization of large-scale social networks in an online world. Proc. Natl. Acad. Sci. USA 2010, 107, 13636–13641. [Google Scholar] [CrossRef] [PubMed]
- Cardillo, A.; Gómez-Gardenes, J.; Zanin, M.; Romance, M.; Papo, D.; Del Pozo, F.; Boccaletti, S. Emergence of network features from multiplexity. Sci. Rep. 2013, 3, 1344. [Google Scholar] [CrossRef] [PubMed]
- Menichetti, G.; Remondini, D.; Panzarasa, P.; Mondragón, R.J.; Bianconi, G. Weighted multiplex networks. PLoS ONE 2014, 9, e97857. [Google Scholar] [CrossRef] [PubMed]
- Freeman, L.C. A set of measures of centrality based on betweenness. Sociometry 1977, 40, 35–41. [Google Scholar] [CrossRef]
- Clauset, A.; Shalizi, C.R.; Newman, M.E. Power-law distributions in empirical data. SIAM Rev. 2009, 51, 661–703. [Google Scholar] [CrossRef]
- Barabási, A.L.; Albert, R. Emergence of scaling in random networks. Science 1999, 286, 509–512. [Google Scholar] [CrossRef]
- Berlingerio, M.; Coscia, M.; Giannotti, F.; Monreale, A.; Pedreschi, D. Foundations of multidimensional network analysis. In Proceedings of the Advances in Social Networks Analysis and Mining (ASONAM), 2011 International Conference, Kaohsiung, Taiwan, 25–27 July 2011; pp. 485–489. [Google Scholar]
- Bianconi, G. Statistical mechanics of multiplex networks: Entropy and overlap. Phys. Rev. E 2013, 87, 062806. [Google Scholar] [CrossRef]
- Jaynes, E.T. Information theory and statistical mechanics. Phys. Rev. 1957, 106, 620. [Google Scholar] [CrossRef]
- Jaynes, E.T. On the rationale of maximum-entropy methods. Proc. IEEE 1982, 70, 939–952. [Google Scholar] [CrossRef]
- Garlaschelli, D.; Loffredo, M.I. Multispecies grand-canonical models for networks with reciprocity. Phys. Rev. E 2006, 73, 015101. [Google Scholar] [CrossRef]
- Newman, M.E.; Girvan, M. Finding and evaluating community structure in networks. Phys. Rev. E 2004, 69, 026113. [Google Scholar] [CrossRef] [PubMed]
- Anand, K.; Bianconi, G. Entropy measures for networks: Toward an information theory of complex topologies. Phys. Rev. E 2009, 80, 045102. [Google Scholar] [CrossRef] [PubMed]
- Garlaschelli, D.; Loffredo, M.I. Generalized bose-fermi statistics and structural correlations in weighted networks. Phys. Rev. Lett. 2009, 102, 038701. [Google Scholar] [CrossRef]
- Coolen, T.; Annibale, A.; Roberts, E. Generating Random Networks and Graphs; Oxford University Press: Oxford, UK, 2017. [Google Scholar]
- Pólya, G.; Szegő, G. Problems and Theorems in Analysis: Series, Integral Calculus, Theory of Functions; Aeppli, D., Translator; Springer: Berlin/Heidelberg, Germany, 1972. [Google Scholar]
- Park, J.; Newman, M.E. Solution of the two-star model of a network. Phys. Rev. E 2004, 70, 066146. [Google Scholar] [CrossRef]
- Hastings, W.K. Monte Carlo sampling methods using Markov chains and their applications. Biometrika 1970, 57, 97–109. [Google Scholar] [CrossRef]
Figure 1.
A graphical illustration of the solution(s) of Equation (53). The solid lines show the RHS of Equation (53) as a function of for the different parameters , while the dashed line shows the LHS, which equals itself. For a given parameter value, the solutions of Equation (53) are the intersection between the dashed and the corresponding solid line. Each panel corresponds to a different value of J (in the rest of the paper, we will consider only ).
Figure 1.
A graphical illustration of the solution(s) of Equation (53). The solid lines show the RHS of Equation (53) as a function of for the different parameters , while the dashed line shows the LHS, which equals itself. For a given parameter value, the solutions of Equation (53) are the intersection between the dashed and the corresponding solid line. Each panel corresponds to a different value of J (in the rest of the paper, we will consider only ).

Figure 2.
The upper (blue) and lower (red) curves correspond to Equations (65) and (66), respectively, which delimit the region of phase space (yellow area), for which Equation (53) has three solutions. Note that the ‘zero-field’ condition is always in the yellow area when , so the condition is sufficient to ensure that the system in zero field is in the magnetized (symmetry-broken) phase.
Figure 2.
The upper (blue) and lower (red) curves correspond to Equations (65) and (66), respectively, which delimit the region of phase space (yellow area), for which Equation (53) has three solutions. Note that the ‘zero-field’ condition is always in the yellow area when , so the condition is sufficient to ensure that the system in zero field is in the magnetized (symmetry-broken) phase.

Figure 3.
Solutions for as a function of for different parameter values. The blue and red segments of the curve(s) correspond to the stable and unstable solutions of Equation (53), respectively. Left panel: (with J varying accordingly). Middle panel: (with J varying accordingly). Right panel: constant value of , which translates to a non-constant .
Figure 3.
Solutions for as a function of for different parameter values. The blue and red segments of the curve(s) correspond to the stable and unstable solutions of Equation (53), respectively. Left panel: (with J varying accordingly). Middle panel: (with J varying accordingly). Right panel: constant value of , which translates to a non-constant .

Figure 4.
Total number of links L (top panels) and inter-layer overlap O (bottom panels) as a function of simulation time using the Metropolis–Hastings algorithm for , , . Left panels: . Middle panels: (symmetry-broken case). Right panels: . For fixed J, varying determines a phase transition from a high-density phase to a low-density phase.
Figure 4.
Total number of links L (top panels) and inter-layer overlap O (bottom panels) as a function of simulation time using the Metropolis–Hastings algorithm for , , . Left panels: . Middle panels: (symmetry-broken case). Right panels: . For fixed J, varying determines a phase transition from a high-density phase to a low-density phase.

Figure 5.
Relationship between the expected inter-layer overlap and the total number of links in homogeneous multiplexes with , , and for all . The blue points correspond to simulations obtained via the Metropolis–Hastings algorithm for and in steps of . The open red circles are the corresponding theoretically predicted points. The solid curve corresponds to the quadratic trend predicted for all . Multiple solutions for first appear when , but the system keeps following the quadratic trend, albeit drifting away from the central point obtained for the zero-field case (corresponding to a spontaneously broken symmetry).
Figure 5.
Relationship between the expected inter-layer overlap and the total number of links in homogeneous multiplexes with , , and for all . The blue points correspond to simulations obtained via the Metropolis–Hastings algorithm for and in steps of . The open red circles are the corresponding theoretically predicted points. The solid curve corresponds to the quadratic trend predicted for all . Multiple solutions for first appear when , but the system keeps following the quadratic trend, albeit drifting away from the central point obtained for the zero-field case (corresponding to a spontaneously broken symmetry).

Figure 6.
Relationship between the expected inter-layer overlap and the total number of links in heterogeneous multiplexes with , , and sampled from a power law distribution with different values for . The colored points correspond to simulations obtained via the Metropolis–Hastings algorithm for and in steps of . The straight line corresponds to the upper limit calculated in Equation (67). The solid curve corresponds to the quadratic trend (achieved by homogeneous multiplexes with constant ), which here turns out to mark a lower bound. For increasing values of J, and especially as , the system moves closer to the upper bound. For , we see that the points are concentrating towards high-density and low-density (symmetry-broken) regimes, drifting away from the intermediate values, like in the homogeneous case. However, this is now the combined result of the behavior of statistically different pairs of nodes, each having a different zero-field condition , so the spontaneous symmetry breaking cannot be realized for all node pairs simultaneously.
Figure 6.
Relationship between the expected inter-layer overlap and the total number of links in heterogeneous multiplexes with , , and sampled from a power law distribution with different values for . The colored points correspond to simulations obtained via the Metropolis–Hastings algorithm for and in steps of . The straight line corresponds to the upper limit calculated in Equation (67). The solid curve corresponds to the quadratic trend (achieved by homogeneous multiplexes with constant ), which here turns out to mark a lower bound. For increasing values of J, and especially as , the system moves closer to the upper bound. For , we see that the points are concentrating towards high-density and low-density (symmetry-broken) regimes, drifting away from the intermediate values, like in the homogeneous case. However, this is now the combined result of the behavior of statistically different pairs of nodes, each having a different zero-field condition , so the spontaneous symmetry breaking cannot be realized for all node pairs simultaneously.

Figure 7.
Relationship between the expected inter-layer overlap and the total number of links in heterogeneous multiplexes with , , and sampled from a power law distribution with . The blue points correspond to simulations obtained via the Metropolis–Hastings algorithm for in steps of with (left panel) and (right panel). The red open circles are the theoretically predicted values corresponding to the same parameters used in the simulations. The straight line corresponds to the upper limit calculated in Equation (67). The solid curve corresponds to the quadratic trend (achieved by homogeneous multiplexes with constant ), which here turns out to mark a lower bound. We see that, compared with the homogeneous lower bound, the heterogeneity of nodes increases the overlap dramatically, even in the absence of true coupling (). When coupling is present, the overlap is additionally increased and already approaches the upper bound for .
Figure 7.
Relationship between the expected inter-layer overlap and the total number of links in heterogeneous multiplexes with , , and sampled from a power law distribution with . The blue points correspond to simulations obtained via the Metropolis–Hastings algorithm for in steps of with (left panel) and (right panel). The red open circles are the theoretically predicted values corresponding to the same parameters used in the simulations. The straight line corresponds to the upper limit calculated in Equation (67). The solid curve corresponds to the quadratic trend (achieved by homogeneous multiplexes with constant ), which here turns out to mark a lower bound. We see that, compared with the homogeneous lower bound, the heterogeneity of nodes increases the overlap dramatically, even in the absence of true coupling (). When coupling is present, the overlap is additionally increased and already approaches the upper bound for .

Figure 8.
Relationship between the expected inter-layer overlap and the total number of links in heterogeneous multiplexes with , , and sampled from a log-normal distribution with different values for . The colored points correspond to simulations obtained via the Metropolis–Hastings algorithm for and in steps of . The straight line corresponds to the upper limit calculated in Equation (67). The solid curve corresponds to the quadratic trend (achieved by homogeneous multiplexes with constant ), which here marks a lower bound achieved when . For increasing values of J (genuine coupling) and (spurious coupling), the system moves closer to the upper bound. For , we see that, starting from the multiplexes with smaller values of , the points are concentrating towards high-density and low-density (symmetry-broken) regimes, drifting away from the intermediate values, like in the homogeneous and power law cases. To realize this separation for larger values of , a larger value of J is required.
Figure 8.
Relationship between the expected inter-layer overlap and the total number of links in heterogeneous multiplexes with , , and sampled from a log-normal distribution with different values for . The colored points correspond to simulations obtained via the Metropolis–Hastings algorithm for and in steps of . The straight line corresponds to the upper limit calculated in Equation (67). The solid curve corresponds to the quadratic trend (achieved by homogeneous multiplexes with constant ), which here marks a lower bound achieved when . For increasing values of J (genuine coupling) and (spurious coupling), the system moves closer to the upper bound. For , we see that, starting from the multiplexes with smaller values of , the points are concentrating towards high-density and low-density (symmetry-broken) regimes, drifting away from the intermediate values, like in the homogeneous and power law cases. To realize this separation for larger values of , a larger value of J is required.

Figure 9.
Relationship between the expected inter-layer overlap and the total number of links in heterogeneous multiplexes with , , and sampled from a log-normal distribution with . The blue points correspond to simulations obtained via the Metropolis–Hastings algorithm for in steps of with (left panel) and (right panel). The red open circles are the theoretically predicted values corresponding to the same parameters used in the simulations.
Figure 9.
Relationship between the expected inter-layer overlap and the total number of links in heterogeneous multiplexes with , , and sampled from a log-normal distribution with . The blue points correspond to simulations obtained via the Metropolis–Hastings algorithm for in steps of with (left panel) and (right panel). The red open circles are the theoretically predicted values corresponding to the same parameters used in the simulations.

Figure 10.
Comparison of the empirical World Trade Multiplex (WTM) with the zero-coupling () benchmark provided by the Average Configuration Model (ACM). The WTM consists of nodes, each representing a country, and layers, each representing a commodity group. The filtered data were obtained by retaining the same number of strongest links in each layer (hence links in the entire multiplex), and varying . Top left: relationship between the expected inter-layer overlap and the total number of links in the WTM (blue), compared with the upper limit calculated in Equation (67) (purple straight line) and the quadratic trend achieved by homogeneous multiplexes (black solid curve). Top right: zoomed-in version of the top left panel, showing that the empirical data follow an intermediate scaling between the two extremes. Center left: cumulative distributions reporting the number of nodes with hidden variable larger than x in the ACM, obtained for different values of (see legend). Center right: same as the top right panel with the addition of the relationship produced by the ACM benchmark, showing that the empirical WTM (blue) has a higher overlap than the corresponding null model having zero inter-layer coupling but the same degree heterogeneity (orange). Bottom left: log–log plot of the relationship between the overlap and the number of links in the empirical WTM, along with a power law fit of the form , where the fitted exponent is . Bottom right: log–log plot of the same relationship in the ACM benchmark with no coupling, along with a power law fit of the form , where the fitted exponent is .
Figure 10.
Comparison of the empirical World Trade Multiplex (WTM) with the zero-coupling () benchmark provided by the Average Configuration Model (ACM). The WTM consists of nodes, each representing a country, and layers, each representing a commodity group. The filtered data were obtained by retaining the same number of strongest links in each layer (hence links in the entire multiplex), and varying . Top left: relationship between the expected inter-layer overlap and the total number of links in the WTM (blue), compared with the upper limit calculated in Equation (67) (purple straight line) and the quadratic trend achieved by homogeneous multiplexes (black solid curve). Top right: zoomed-in version of the top left panel, showing that the empirical data follow an intermediate scaling between the two extremes. Center left: cumulative distributions reporting the number of nodes with hidden variable larger than x in the ACM, obtained for different values of (see legend). Center right: same as the top right panel with the addition of the relationship produced by the ACM benchmark, showing that the empirical WTM (blue) has a higher overlap than the corresponding null model having zero inter-layer coupling but the same degree heterogeneity (orange). Bottom left: log–log plot of the relationship between the overlap and the number of links in the empirical WTM, along with a power law fit of the form , where the fitted exponent is . Bottom right: log–log plot of the same relationship in the ACM benchmark with no coupling, along with a power law fit of the form , where the fitted exponent is .

Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Bayrakdar, N.; Gemmetto, V.; Garlaschelli, D. Local Phase Transitions in a Model of Multiplex Networks with Heterogeneous Degrees and Inter-Layer Coupling. Entropy 2023, 25, 828. https://doi.org/10.3390/e25050828
AMA Style
Bayrakdar N, Gemmetto V, Garlaschelli D. Local Phase Transitions in a Model of Multiplex Networks with Heterogeneous Degrees and Inter-Layer Coupling. Entropy. 2023; 25(5):828. https://doi.org/10.3390/e25050828
Chicago/Turabian StyleBayrakdar, Nedim, Valerio Gemmetto, and Diego Garlaschelli. 2023. "Local Phase Transitions in a Model of Multiplex Networks with Heterogeneous Degrees and Inter-Layer Coupling" Entropy 25, no. 5: 828. https://doi.org/10.3390/e25050828
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.