1. Introduction
Hand pose estimation is one of the most important topics in natural human–computer interaction. Moreover, it has become a key technology in human–computer interaction (HCI), virtual reality (VR), sign language recognition, medical treatments, and interactive entertainment [
1,
2,
3,
4,
5,
6], which can help humans to communicate with machines in a more natural way. However, due to the complex articulation and high flexibility of hand fingers, hand pose estimation remains challenging [
7]. To address these difficulties, it is important to adopt multi-view images of the hand [
8,
9]. Unfortunately, a multi-view acquisition system requires expensive hardware and strict environmental configurations. In recent years, alternative schemas with RGB-D images with depth information have been proposed for hand pose estimation due to the popularity of low-cost depth sensors [
10,
11,
12]. However, this method has limited scenarios and is easily affected by the surrounding environment, so it cannot be widely used. Compared with the data format above, RGB images can be readily available via low-cost optical sensors, such as webcams and smartphones, which makes hand pose estimation based on RGB images widely popular.
Even for 3D hand pose estimation directly from RGB images [
13,
14,
15,
16,
17,
18], most proposed methods still need to estimate 2D hand poses first, and then upgrade the estimated 2D poses to 3D [
15,
16,
17]. With regard to 2D hand images, it is crucial to locate the occluded joints that are pervasive in various hand poses. To tackle this challenge, the methods are mainly divided into two categories: one is to mine the hand image features and locate the keypoints by learning the keypoint information hidden in the hand features, and the other is to mine the geometric relationship between the keypoints of the hand and locate the keypoints by learning the physical constraint relationship between them. YG Wang et al. [
7] constructed a cascade network, including mask prediction and attitude estimation, to provide some soft constraints to hand-feature learning. S Kyeongeun et al. [
19] proposed a new implicit semantic data augmentation method that can generate additional training samples in the feature space and improve the performance of hand pose estimation. TH Pen et al. [
20] proposed an optimized convolutional pose machine (OCPM) for accurately estimating hand poses. OCPM uses the CBAM attention module and information processing module to extract hand features more effectively, leading to higher performance. Moreover, YG Wang et al. [
21] iteratively used the interested region of the hand as feedback information to strengthen hand feature representation by an encoder–decoder framework. DY Kong et al. [
22] proposed an adaptive graph model network (AGMN) that combines deep learning with a graph model to better learn the geometric relationship between hand closing points, thus improving the accuracy of hand pose estimation. Additionally, YF Chen et al. [
23] proposed a new nonparametric structure regularization machine (NSRM) for hand attitude estimation. NSRM learns the representation of hand composition and structure to regularize the confidence graph of keypoints in a nonparametric way, effectively strengthening the structural consistency of the predicted hand posture. Although the overall hand constraint is enhanced by extracted feature methods, such as mask, attitude, and ROI, the occluded keypoints are in need of information on the adjacent keypoints on the inside of the hand to assist the characterization. the graph model and structural constraint methods are usually carried out after feature representation, but the feature learning of occluded joints has not been effectively guided, and there is still room for improvement in its effectiveness.
When examining variable keypoints, traditional feature learning networks work well for clear visible keypoints. For obscure ones, additional perceptual fields can capture the features, and for invisible points, more contextual information is necessary. Therefore, we propose a novel repeated cross-scale fusion network to learn semantic-induced features in hand images. Our network is divided into two parts: GlobalNet and RegionalNet. In GlobalNet, four different scales of features are generated through ResNet50, providing rich neighborhood information among keypoints. Then, we merge the deep semantic features with the shallow features, one by one, to roughly locate the keypoints of the hand. In RegionalNet, GlobalNet generates four features of different scales in parallel. These features undergo multiple cross-scale convolutional fusions, allowing the deep features to continuously exchange information with the shallow features, allowing the network to learn rich deep semantic and contextual information, which is beneficial for locating occlusion keypoints.
We show the efficiency of our proposed method on two public datasets: STB [
24] and RHD [
15]. Our approach significantly outperforms the current state-of-the-art algorithms on both datasets. Qualitative results show that our method can locate hand keypoints more efficiently when self-occlusion is present.
The main contributions of this work are:
We propose a new and effective hand pose estimation network, which integrates the global feature pyramid network (GlobalNet) and then further refines the feature fusion network (RegionalNet). It can provide rich information through the relationship between features at different levels of abstraction.
We explore the impacts of various feature fusion methods that contribute to the localization of occlusion keypoints, and further demonstrate that the effective use of deep-level information is highly beneficial for the mining of occlusion keypoints.
Our model achieves high accuracy and can mine the keypoints of hand occlusion more effectively than other methods.
3. Method
Given a colored image of the hand , our task is to detect the hand pose by using the convolutional neural network (CNN). We express the 2D hand pose (Pk) as the position of the joint point in the image, i.e., (k is the number of labeled keypoints in the hand; here, we set ), where represents the 2D pixel coordinates of the k- keypoint in image .
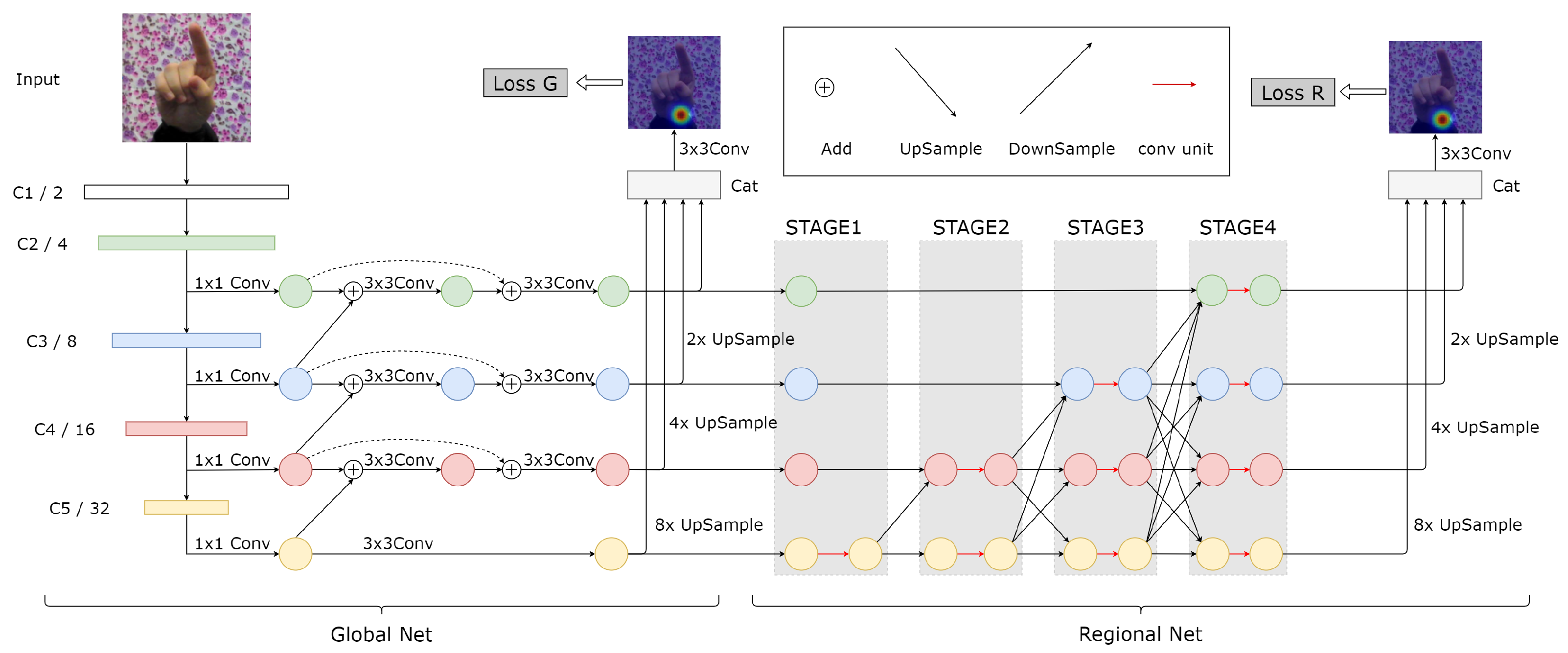
An overview of the proposed network structure, which includes two subnetworks, GlobalNet and RegionalNet, is illustrated in
Figure 1. The purpose of GlobalNet is to roughly locate the joint points and build the loss function in the first stage as intermediate supervision. The subsequent RegionalNet is responsible for predicting the joint points more precisely.
3.1. GlobalNet
GlobalNet adopts a pyramid structure with four scale features, C2, C3, C4, and C5, from ResNet50. Shallow features, such as C2 and C3, have a higher spatial resolution but lower-level semantics, while deep features, such as C4 and C5, have the opposite characteristics. A jump connection is added to the FPN, as shown by the dashed line in
Figure 1, between the input and output nodes at the same scale to fuse more features without adding too much computational cost. The heatmaps output by GlobalNet are used to learn the approximate location of keypoints and serve as intermediate supervision. In CPN, the output of GlobalNet will perform upsampling and 3 × 3 convolution operations on four different scale features to generate four keypoint heatmaps. As far as we know, there is no significant difference between these four heatmaps. Therefore, we will upsample and merge the four scale features and then output one keypoint heatmap through 3 × 3 convolution operations, which will not only fulfill the intermediate supervision function of GlobalNet but also reduce the number of network parameters.
3.2. RegionalNet
After learning from GlobalNet, the network roughly located the keypoints. However, the prediction accuracy of the network did not achieve satisfactory results because the feature information learned by GlobalNet was minimal. Therefore, we attached a RegionalNet behind GlobalNet to obtain a more detailed prediction.
RegionalNet connects the four-scale features in parallel, as shown in
Figure 1. At the same time, the features from deep to shallow are gradually increased to form a new level. Therefore, the features of the parallel subnet at a certain level are composed of the features of the same scale from the previous level and other parallel features of different scales. The specific fusion mode is shown in
Figure 2. The four-way feature graphs in GlobalNet are added with the features of the corresponding scale at the beginning of each stage in RegionalNet. For features with the same resolution, the bottleneck blocks are stacked directly to maintain self-resolution. For the feature that needs to be increased in the resolution, an upsampling operation is used to add and fuse the feature with the corresponding resolution. For the feature that needs to reduce the resolution, we use 3 × 3 convolution and add/fuse with the corresponding resolution feature. Finally, the features of all scales are concatenated to compute the final heatmap prediction.
RegionalNet uses cross-scale convolutional fusion to fuse information of different scales. It is not a simple upsampling step that aggregates low-level and high-level information together. In this process, each level feature receives information repeatedly from other parallel features, allowing for the integration of rich spatial and semantic information. This greatly increases the ability to mine occluded keypoints.
3.3. Loss Functions
Estimated loss in GlobalNet. For GlobalNet, we apply L2 loss to 2D heatmaps of
k keypoints, and calculate the estimated loss of GlobalNet. The loss function
is defined as follows:
where
and
represent the estimated and ground truth heatmaps, respectively, for the
j-th keypoint in GlobalNet. The ground truth heatmaps for the
j-th keypoint are generated by applying a 2D Gaussian centered at its ground truth 2D keypoint location.
Estimated loss in RegionalNet. For RegionalNet, we use the method of online hard keypoint mining. We sort the loss values of 2D heatmaps of the
k keypoints and select only the top
m keypoints with larger losses for backward gradient propagation. The loss function is defined as follows:
where
and
represent the RegionalNet estimated and ground truth heatmaps of the
j-th keypoint, respectively.
m represents the number of selected heatmaps with the largest loss values (
).
Total Loss of Network. The total loss
of our entire network is defined as follows:
4. Experiments
In this section, several experiments are conducted to verify the performance of the proposed method; ablation experiments were carried out in STB [
24] and RHD [
15]. The experimental results show that our method can increase estimation precision compared with the state-of-the-art methods.
4.1. Experimental Settings
Dataset and Evaluation Metrics. Our proposed method is a 2D hand pose estimation technique based on a single RGB image. Therefore, traditional hand pose datasets based on depth images, such as MSRA [
32] and NYU [
40], are not suitable for our approach. Therefore, we chose two open datasets, STB and RHD, both of which include RGB images of human hands and the position coordinates of 2D keypoints. Among them, RHD is a synthetic dataset, which consists of 39 different actions of 20 different hands, including 41,258 training samples and 2728 test samples, and the image pixels in the dataset are 320 × 320. We split RHD into 38,530 training images, 2728 validation samples, and 2728 test samples. The STB dataset is a real image dataset collected from different cameras; it contains 18,000 images and can be divided into 6 scenes. Each scene contains two RGB images and a depth image with the same action at different positions. The image pixels in the dataset are 640 × 480. We split STB into 12,000 training images, 3000 validation samples, and 3000 test samples. Following [
13], we transferred the root joint in STB from the palm to the wrist to make it consistent with RHD. In these two datasets, we mirrored the left hands to the right hands.
We used the probabilistic-predicted keypoint (PCK) [
9] to quantitatively compare the predicted results. PCK calculates the proportion of the normalized distance between the predicted keypoints and their corresponding ground truth that is less than the set threshold
. For the
k-
hand keypoint
, we used
to represent it, and approximate it to Formula (
4) on the verification dataset
.
where
represents the position of predicted keypoints,
represents the position of real keypoints. We used a normalized threshold
, ranging from 0 to 1, with respect to the size of the hand’s bounding box.
Implementation Details. Our model was implemented using PyTorch. Before the images were inserted into the model, all images were resized to 256 × 256, and a heatmap with a size of 64 × 64 was generated for each joint. The Adam optimizer was used for training, in which the batch training size was set to 32, and the initial learning rate was set to 5 × 10. In the 100th iteration, the learning rate was reduced to half of the original one, and the training stopped at the 150th iteration. Moreover, dropout and early stop strategies were used during the training process to avoid overfitting problems in the network. Our network parameters were randomly initialized, and no other external datasets were trained in advance. All our experiments were run on a desktop with NVIDIA 2080Ti GPU.
For a comprehensive assessment, we used CPN and HRNet as the baselines of our method. For CPN, we chose CPN50 and CPN101 structures. For HRNet, we tested the results of both HRNet-W32 and HRNet-W48 structures. In addition, we trained and tested CPN, HRNet, and our method under the same experimental settings, and all of the models were trained from scratch.
4.2. Ablation Experiment
The proposed subsection aims to validate the effectiveness of our network through various experiments. Unless specified otherwise, all experiments in this subsection are conducted on the STB and RHD datasets. The input size for all models is 256 × 256.
Comparison with baselines. In
Table 1 and
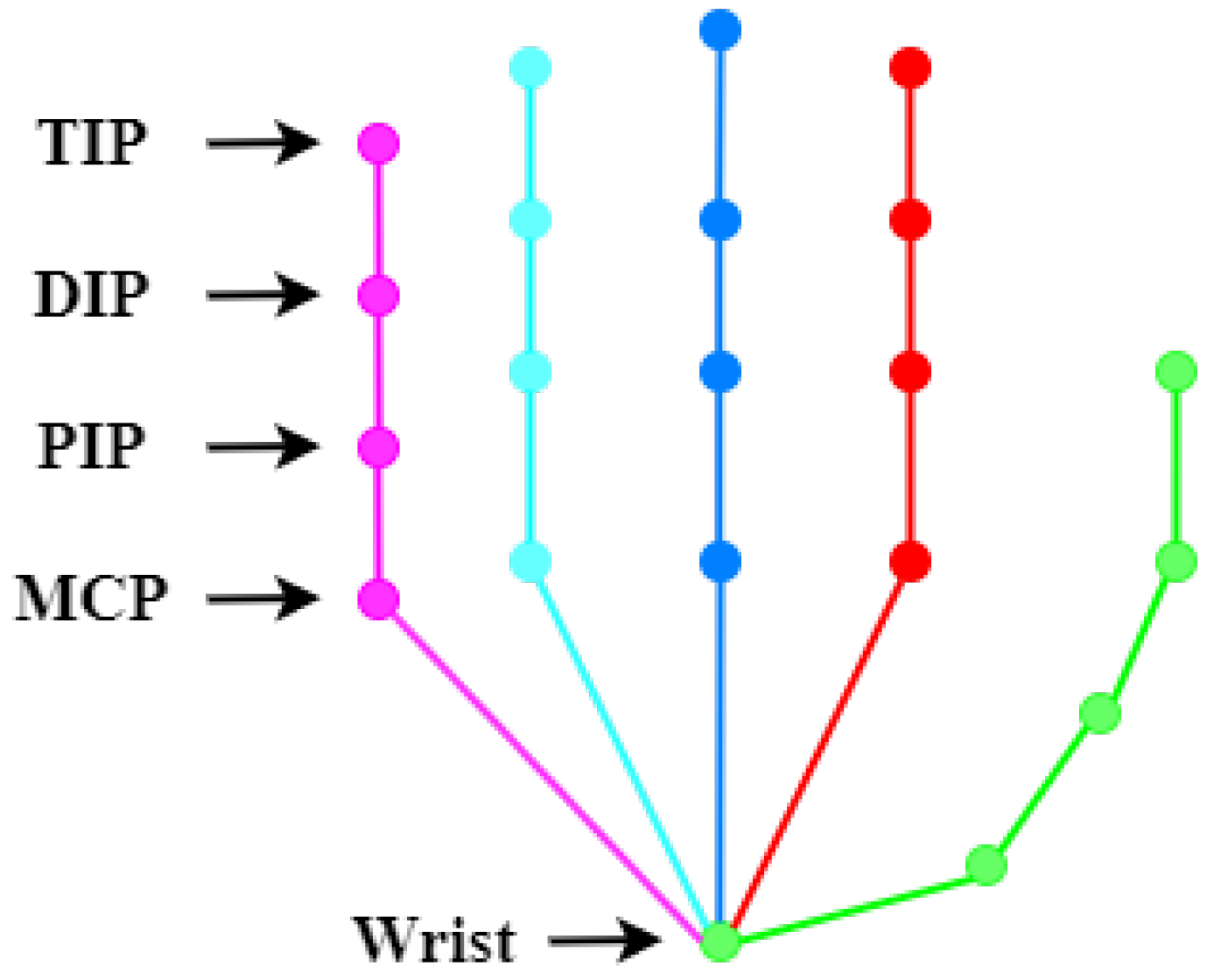
Table 2, we compare the performance of our method with two baseline methods, CPN and HRNet. In order to prove that our method can effectively solve the problem of identifying occluded keypoints, we list the recognition accuracy of the 21 keypoints in the tables. At the same time,
Figure 3 shows the corresponding schematic diagram of hand joint points.
As shown in
Table 1 for the STB dataset, the wrist and thumb locations have the lowest recognition accuracy compared to the other 19 joints in the 21 joints identified by the six methods. The reason may be that the wrist and thumb positions are similar to the nearby skin texture without more apparent details. In our method, GlobalNet can roughly identify the approximate location of each node, while the recognition accuracy of keypoints is greatly improved by adding RegionalNet to learn high-level semantic information. Compared with the baseline method, our method can achieve the best recognition of each keypoint. In addition, the accuracy of recognition is further improved by introducing the OHKM method.
As RHD is a synthetic dataset, its appearance and posture distribution are different from those of real datasets. For example, the hand images in RHD do not have a knuckle pattern, and the difference between each joint is not obvious. Therefore, it is only possible to distinguish different joint points by simple features, such as the adjacent appearance of hands, which is why the accuracy of our GlobalNet test in
Table 2 is much higher. At the same time, CPN and HRNet achieve higher accuracy than our method, because CPN captures more deep semantic information through its RefineNet, and CPN101 can obtain more information due to its deeper layers compared to CPN50. However, our RegionalNet uses a multi-scale fusion method through repeated cross-line convolution. Each feature from deep to shallow continuously receives information from other parallel scales, allowing the network to learn richer semantic and spatial information of keypoints to improve the accuracy for occluded keypoints. Furthermore, the accuracy is further improved when OHKM is applied in RegionalNet.
The PCK performance of our proposed model on two standard datasets (STB and RHD) is presented in
Table 3. As observed, our model consistently outperforms the two baseline methods on both datasets. Moreover, we included some representative images to demonstrate the prediction results, as shown in
Figure 4 and
Figure 5. Our model can effectively detect occluded keypoints, such as the little finger part of the third row of images and the middle finger part of the sixth row of images. Our model performed significantly better than the baseline methods when tested on the RHD dataset.
As can be seen in
Figure 4 and
Figure 5, our model can recognize relatively complex hand poses, but there are still some instances of recognition errors in extreme cases, as shown in
Figure 5. Similar to the last picture in
Figure 6, the fingers in the photographed images are blurred due to the rapid movement of the hand. While our method may not accurately identify the keypoints of the middle finger, its performance is still better than the baseline method. Additionally, we found that when the fingers are close together, our method cannot accurately identify the keypoints of each finger, such as the little finger and the ring finger in the penultimate picture, but its performance is still better than that of the baselines.
Design Choices of RegionalNet. Here, we compare different design strategies of RegionalNet, as shown in
Table 4. The output of our pyramid based on GlobalNet is compared using the following implementations:
Prediction using only the heat map output from GlobalNet.
A structure similar to HRNet is connected behind GlobalNet, starting with a high-resolution sub-network as the first stage and gradually adding high-resolution to low-resolution sub-networks, one by one, to form more stages, connecting multi-resolution sub-networks in parallel.
In contrast to the structure in
, the low-resolution subnetwork is added to the high-resolution subnetwork, one by one, starting from the low-resolution subnetwork as the first stage, to form more stages, and connecting the multi-resolution subnetworks in parallel, as shown in
Figure 1.
Finally, a convolution layer is attached to generate the score maps for each keypoint.
We observed that both the models in and our method achieved better accuracy compared to keypoint prediction using GlobalNet only. Our method can be compared with , revealing that deep semantic information of the network is more beneficial for predicting hand keypoints compared to high-resolution information.
Online Hard Keypoint Mining. Here, we discuss the losses used in our network. In detail, the loss function of GlobalNet is the L2 loss of all labeled keypoints, while the second stage attempts to learn hard keypoints, i.e., we only penalize the loss of the first
m (
mm) keypoints in
k (the number of labeled keypoints in a hand, e.g., 21 in the STB dataset).
Table 5 shows the impact of
m. In the case of
, the performance of the second stage achieves the best results of the balanced training between hard and simple keypoints.
4.3. Comparison with the State-of-the-Art Methods
We compared our method with other state-of-the-art methods and reported the PCK test results with a threshold value of 0.02 in
Table 6. It can be observed that on the STB dataset, our method outperforms SRHandNet by 0.16 in terms of PCK, outperforms [
15] by 0.06, outperforms [
41] by 0.23, outperforms NSRM by 0.19, outperforms [
35] by 0.22, outperforms InterHand by 0.06, and outperforms [
30] by 0.09. The method also outperforms SRHandNet, [
41], NSRM and [
35] on the RHD dataset by 0.22.
In
Table 7, we present a comparison of the execution times, the number of model parameters, and the number of GFlops for all methods on a laptop configured with an NVIDIA 1650 GPU. The reported execution times are the forward inference times of the model without any acceleration. It is evident that our method can execute at 34.86 frames per second, indicating superior performance compared to the other methods. Although our method has a larger number of model parameters relative to the other methods, the GFlops of the network is not high, which further demonstrates the superiority of our proposed network.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}