
Multi-Receptive Field Soft Attention Part Learning for Vehicle Re-Identification

Abstract
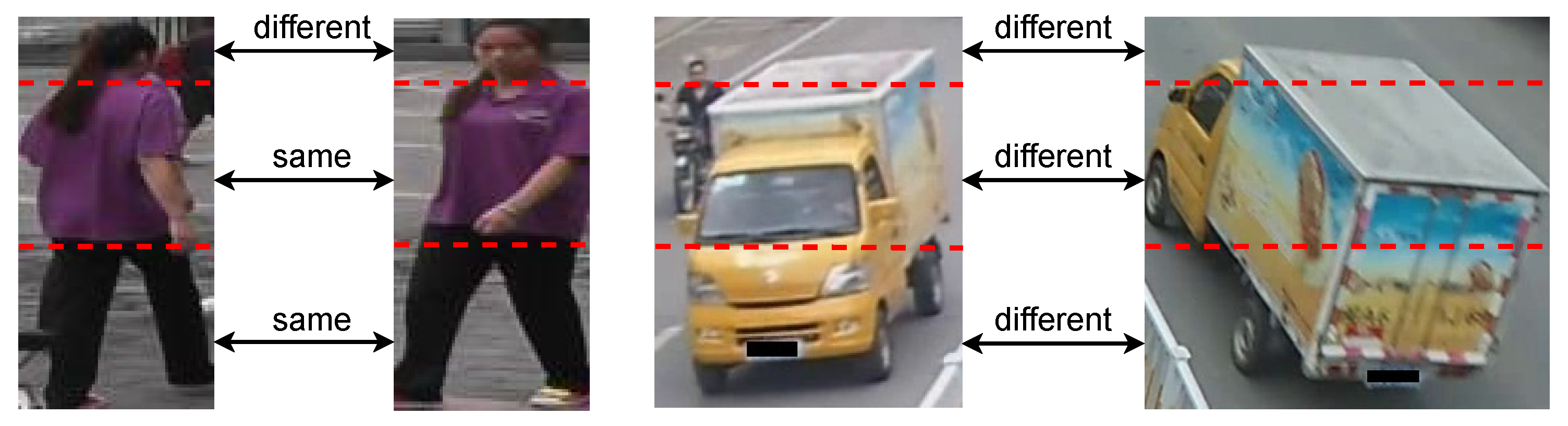
:1. Introduction
- (1)
- We propose a multi-receptive soft attention part learning (MRF-SAPL) model for vehicle Re-ID that does not require rigid space partitioning or additional labeling and can flexibly discover enough part-level features with multiple semantic levels;
- (2)
- To align the vehicle part features from different images, we exploit soft attention to adaptively divide the space of the feature map to obtain the locations of parts with internal semantic continuity;
- (3)
- Extensive experimental results show that a higher performance can be obtained compared to that of other state-of-the-art methods on two large datasets, where a new loss function, ORP, is proposed to force each local branch of MRF-SAPL to semantically learn complementary part-level features.
2. Related Work
2.1. Local-Based Re-ID
2.2. Multiscale Features
3. Method
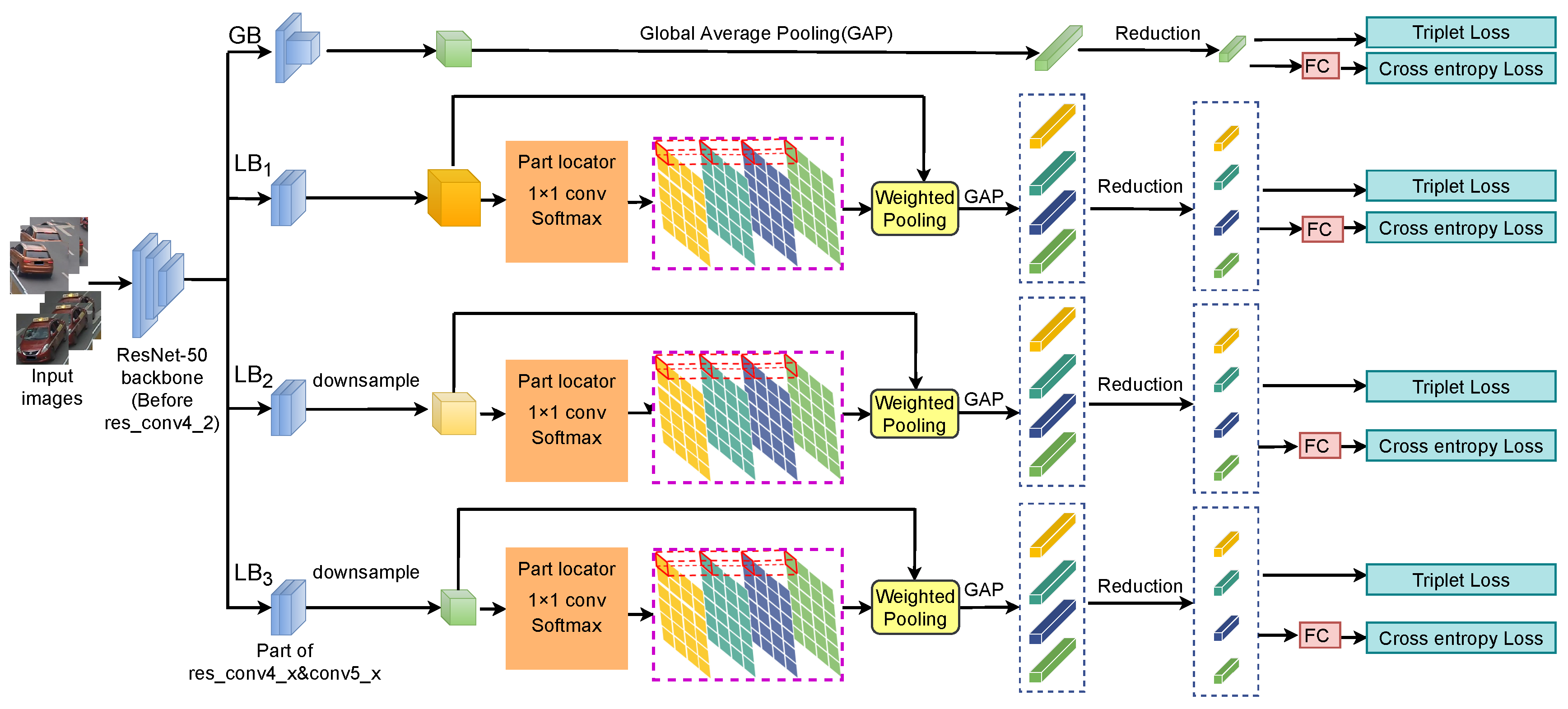
3.1. Network Structure
3.2. Soft Attention Part Learning Module
3.3. Multi-Receptive-Field Granularity
3.4. Multitask Training
4. Experiments
4.1. Datasets and Evaluation Metric
4.2. Implementation Details
4.3. Comparison with State-of-the-Art Methods
4.4. Ablation Study
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Conflicts of Interest
References
- Shen, Y.; Xiao, T.; Li, H.; Yi, S.; Wang, X. Learning deep neural networks for vehicle re-id with visual-spatio-temporal path proposals. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 1918–1927. [Google Scholar]
- Liu, X.; Liu, W.; Mei, T.; Ma, H. PROVID: Progressive and multimodal vehicle reidentification for large-scale urban surveillance. IEEE Trans. Multimed. 2018, 20, 645–658. [Google Scholar] [CrossRef]
- Zheng, A.; Lin, X.; Li, C.; He, R.; Tang, J. Attributes guided feature learning for vehicle re-identification. arXiv 2019, arXiv:1905.08997. [Google Scholar]
- He, L.; Sun, Z.; Zhu, Y.; Wang, Y. Recognizing partial biometric patterns. arXiv 2018, arXiv:1810.07399. [Google Scholar]
- Sun, Y.; Zheng, L.; Yang, Y.; Tian, Q.; Wang, S. Beyond part models: Person retrieval with refined part pooling (and a strong convolutional baseline). In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 480–496. [Google Scholar]
- Fan, X.; Luo, H.; Zhang, X.; He, L.; Zhang, C.; Jiang, W. Scpnet: Spatial-channel parallelism network for joint holistic and partial person re-identification. In Proceedings of the Asian Conference on Computer Vision, Daejeon, Republic of Korea, 5–9 November 2018; Springer: Berlin/Heidelberg, Germany, 2018; pp. 19–34. [Google Scholar]
- He, L.; Liang, J.; Li, H.; Sun, Z. Deep spatial feature reconstruction for partial person re-identification: Alignment-free approach. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7073–7082. [Google Scholar]
- Chen, H.; Lagadec, B.; Brémond, F. Partition and Reunion: A Two-Branch Neural Network for Vehicle Re-identification. In CVPR Workshops; IEEE: Piscataway, NJ, USA, 2019; pp. 184–192. [Google Scholar]
- Wang, Z.; Tang, L.; Liu, X.; Yao, Z.; Yi, S.; Shao, J.; Yan, J.; Wang, S.; Li, H.; Wang, X. Orientation invariant feature embedding and spatial temporal regularization for vehicle re-identification. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 379–387. [Google Scholar]
- Gao, S.; Wang, J.; Lu, H.; Liu, Z. Pose-guided visible part matching for occluded person reid. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 11744–11752. [Google Scholar]
- Zhou, Y.; Shao, L. Viewpoint-Aware Attentive Multi-View Inference for Vehicle Re-Identification. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6489–6498. [Google Scholar]
- Miao, J.; Wu, Y.; Liu, P.; Ding, Y.; Yang, Y. Pose-Guided Feature Alignment for Occluded Person Re-Identification. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 542–551. [Google Scholar]
- Liu, K.; Xu, Z.; Hou, Z.; Zhao, Z.; Su, F. Further Non-local and Channel Attention Networks for Vehicle Re-identification. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Seattle, WA, USA, 14–19 June 2020; pp. 2494–2500. [Google Scholar]
- Liao, S.; Hu, Y.; Zhu, X.; Li, S.Z. Person re-identification by local maximal occurrence representation and metric learning. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 2197–2206. [Google Scholar]
- Yang, Y.; Yang, J.; Yan, J.; Liao, S.; Yi, D.; Li, S.Z. Salient color names for person re-identification. In Proceedings of the Computer Vision—ECCV 2014: 13th European Conference, Zurich, Switzerland, 6–12 September 2014; Springer International Publishing: Berlin/Heidelberg, Germany, 2014; pp. 536–551. [Google Scholar]
- Liao, S.; Li, S.Z. Efficient psd constrained asymmetric metric learning for person re-identification. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 3685–3693. [Google Scholar]
- Khorramshahi, P.; Peri, N.; Chen, J.; Chellappa, R. The devil is in the details: Self-supervised attention for vehicle re-identification. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; pp. 369–386. [Google Scholar]
- Zheng, W.; Gong, S.; Xiang, T. Reidentification by relative distance comparison. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 35, 653–668. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kalayeh, M.M.; Basaran, E.; Gökmen, M.; Kamasak, M.E.; Shah, M. Human Semantic Parsing for Person Re-Identification. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 1062–1071. [Google Scholar]
- Li, W.; Zhu, X.; Gong, S. Harmonious attention network for person re-identification. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 2285–2294. [Google Scholar]
- Liu, X.; Zhao, H.; Tian, M.; Sheng, L.; Shao, J.; Yi, S.; Yan, J.; Wang, X. Hydraplus-net: Attentive deep features for pedestrian analysis. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 350–359. [Google Scholar]
- Sarfraz, M.S.; Schumann, A.; Eberle, A.; Stiefelhagen, R. A Pose-Sensitive Embedding for Person Re-Identification with Expanded Cross Neighborhood Re-Ranking. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 420–429. [Google Scholar]
- Xu, J.; Zhao, R.; Zhu, F.; Wang, H.; Ouyang, W. Attention-aware compositional network for person re-identification. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 2119–2128. [Google Scholar]
- Song, C.; Huang, Y.; Ouyang, W.; Wang, L. Mask-guided contrastive attention model for person re-identification. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 1179–1188. [Google Scholar]
- Wang, H.; Peng, J.; Jiang, G.; Xu, F.; Fu, X. Discriminative feature and dictionary learning with part-aware model for vehicle re-identification. Neurocomputing 2021, 438, 55–62. [Google Scholar] [CrossRef]
- Chen, T.; Liu, C.; Wu, C.; Chien, S. Orientation-aware vehicle re-identification with semantics-guided part attention network. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; pp. 330–346. [Google Scholar]
- Liu, J.; Ni, B.; Yan, Y.; Zhou, P.; Cheng, S.; Hu, J. Pose transferrable person re-identification. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4099–4108. [Google Scholar]
- He, B.; Li, J.; Zhao, Y.; Tian, Y. Part-Regularized Near-Duplicate Vehicle Re-Identification. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 3997–4005. [Google Scholar]
- Li, Y.; He, J.; Zhang, T.; Liu, X.; Zhang, Y.; Wu, F. Diverse Part Discovery: Occluded Person Re-Identification with Part-Aware Transformer. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 2898–2907. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1904–1916. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid Scene Parsing Network. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 6230–6239. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.E.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Tolstikhin, I.O.; Houlsby, N.; Kolesnikov, A.; Beyer, L.; Zhai, X.; Unterthiner, T.; Yung, J.; Steiner, A.; Keysers, D.; Uszkoreit, J.; et al. MLP-Mixer: An all-MLP Architecture for Vision. Adv. Neural Inf. Process. Syst. 2021, 34, 24261–24272. [Google Scholar]
- Li, Y.; Yao, T.; Pan, Y.; Mei, T. Contextual Transformer Networks for Visual Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 1489–1500. [Google Scholar] [CrossRef] [PubMed]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Wang, G.; Yuan, Y.; Chen, X.; Li, J.; Zhou, X. Learning Discriminative Features with Multiple Granularities for Person Re-Identification. In Proceedings of the 26th ACM international conference on Multimedia, Seoul, Republic of Korea, 22–26 October 2018; pp. 274–282. [Google Scholar]
- Lin, M.; Chen, Q.; Yan, S. Network In Network. arXiv 2014, arXiv:1312.4400. [Google Scholar]
- He, L.; Liu, W. Guided saliency feature learning for person re-identification in crowded scenes. In Computer Vision—ECCV 2020; Vedaldi, A., Bischof, H., Brox, T., Frahm, J.M., Eds.; Lecture Notes in Computer Science; Springer: Cham, Switzerland, 2020; pp. 357–373. [Google Scholar]
- He, L.; Wang, Y.; Liu, W.; Zhao, H.; Sun, Z.; Feng, J. Foreground-aware pyramid reconstruction for alignment-free occluded person re-identification. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 8450–8459. [Google Scholar]
- Chen, T.; Lee, M.; Liu, C.; Chien, S. Viewpoint-Aware Channel-Wise Attentive Network for Vehicle Re-Identification. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Seattle, WA, USA, 14–19 June 2020; pp. 2448–2455. [Google Scholar]
- Zhang, J.; Chen, J.; Cao, J.; Liu, R.; Bian, L.; Chen, S. Dual attention granularity network for vehicle re-identification. Neural Comput. Appl. 2022, 34, 2953–2964. [Google Scholar] [CrossRef]
- Liu, X.; Zhang, S.; Huang, Q.; Gao, W. RAM: A Region-Aware Deep Model for Vehicle Re-Identification. In Proceedings of the 2018 IEEE International Conference on Multimedia and Expo (ICME), San Diego, CA, USA, 23–27 July 2018; pp. 1–6. [Google Scholar]
- Lou, Y.; Bai, Y.; Liu, J.; Wang, S.; Duan, L. Embedding Adversarial Learning for Vehicle Re-Identification. IEEE Trans. Image Process. 2019, 28, 3794–3807. [Google Scholar] [CrossRef] [PubMed]
- Khorramshahi, P.; Kumar, A.; Peri, N.; Rambhatla, S.S.; Chen, J.; Chellappa, R. A Dual-Path Model with Adaptive Attention for Vehicle Re-Identification. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 6131–6140. [Google Scholar]
- Teng, S.; Zhang, S.; Huang, Q.; Sebe, N. Viewpoint and scale consistency reinforcement for UAV vehicle re-identification. Int. J. Comput. Vis. 2021, 129, 719–735. [Google Scholar] [CrossRef]
- Fu, X.; Peng, J.; Jiang, G.; Wang, H. Learning latent features with local channel drop network for vehicle re-identification. Eng. Appl. Artif. Intell. 2022, 107, 104540. [Google Scholar] [CrossRef]
- Chen, Y.; Ke, W.; Lin, H.; Lam, C.; Lv, K.; Sheng, H.; Xiong, Z. Local perspective based synthesis for vehicle re-identification: A transformation state adversarial method. J. Vis. Commun. Image Represent 2022, 83, 103432. [Google Scholar] [CrossRef]
- Liu, H.; Tian, Y.; Wang, Y.; Pang, L.; Huang, T. Deep relative distance learning: Tell the difference between similar vehicles. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 2167–2175. [Google Scholar]
- Li, K.; Ding, Z.; Li, K.; Zhang, Y.; Fu, Y. Vehicle and Person Re-Identification with Support Neighbor Loss. IEEE Trans. Neural Netw. Learn. Syst. 2022, 33, 826–838. [Google Scholar] [CrossRef] [PubMed]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | mAP | Top-1 | Top-5 |
|---|---|---|---|
| Siames+Path [1] | 0.583 | 0.835 | 0.900 |
| VAMI [11] | 0.501 | 0.770 | 0.908 |
| RAM [42] | 0.615 | 0.886 | 0.940 |
| EALN [43] | 0.574 | 0.844 | 0.941 |
| AAVER [44] | 0.612 | 0.890 | 0.947 |
| PRN [28] | 0.743 | 0.943 | 0.989 |
| VCAM [40] | 0.686 | 0.944 | 0.969 |
| SPAN [26] | 0.689 | 0.940 | 0.976 |
| TCPM [25] | 0.746 | 0.940 | 0.971 |
| VSCR [45] | 0.755 | 0.941 | 0.979 |
| LCDNet+BRL [46] | 0.760 | 0.946 | 0.980 |
| Dual+SA [41] | 0.786 | 0.944 | 0.992 |
| MRF-SAPL (Ours) | 0.815 | 0.947 | 0.987 |
| Method | Small | Medium | Large | |||
|---|---|---|---|---|---|---|
| Top-1 | Top-5 | Top-1 | Top-5 | Top-1 | Top-5 | |
| DRDL [48] | 0.490 | 0.735 | 0.428 | 0.668 | 0.382 | 0.616 |
| OIFE [9] | - | - | - | - | 0.670 | 0.829 |
| VAMI [11] | 0.631 | 0.833 | 0.529 | 0.751 | 0.473 | 0.703 |
| RAM [42] | 0.752 | 0.915 | 0.723 | 0.870 | 0.677 | 0.845 |
| AAVER [44] | 0.747 | 0.938 | 0.686 | 0.900 | 0.635 | 0.856 |
| EALN [43] | 0.751 | 0.881 | 0.718 | 0.839 | 0.693 | 0.814 |
| PRN [28] | 0.784 | 0.923 | 0.750 | 0.883 | 0.742 | 0.864 |
| SAVER [17] | 0.799 | 0.952 | 0.776 | 0.911 | 0.753 | 0.883 |
| TCPM [25] | 0.820 | 0.964 | 0.788 | 0.943 | 0.746 | 0.907 |
| Dual+SA [41] | - | - | - | - | 0.738 | 0.835 |
| SN++ [49] | 0.767 | 0.870 | 0.748 | 0.842 | 0.739 | 0.836 |
| LRPT + TSAM + CP [47] | 0.779 | 0.935 | 0.779 | 0.907 | 0.745 | 0.865 |
| MRF-SAPL (Ours) | 0.843 | 0.977 | 0.796 | 0.941 | 0.763 | 0.916 |
| Method | mAP | Top-1 | Top-5 |
|---|---|---|---|
| Baseline | 0.726 | 0.918 | 0.973 |
| Baseline+ | 0.795 | 0.932 | 0.985 |
| Baseline+(W/O SAPL) | 0.784 | 0.928 | 0.980 |
| Baseline+ | 0.794 | 0.938 | 0.982 |
| Baseline+ | 0.773 | 0.924 | 0.983 |
| Baseline++ | 0.813 | 0.935 | 0.983 |
| Baseline++ | 0.805 | 0.935 | 0.982 |
| Baseline++ | 0.795 | 0.945 | 0.982 |
| ++ | 0.802 | 0.938 | 0.982 |
| Baseline+Single(++) | 0.771 | 0.923 | 0.979 |
| MRF-SAPL (Ours) | 0.815 | 0.947 | 0.987 |
| The Number of Parts | mAP | Top-1 | Top-5 |
|---|---|---|---|
| 2 | 0.801 | 0.944 | 0.985 |
| 3 | 0.807 | 0.939 | 0.984 |
| 4 | 0.815 | 0.947 | 0.987 |
| 5 | 0.802 | 0.938 | 0.982 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Pang, X.; Yin, Y.; Zheng, Y. Multi-Receptive Field Soft Attention Part Learning for Vehicle Re-Identification. Entropy 2023, 25, 594. https://doi.org/10.3390/e25040594
Pang X, Yin Y, Zheng Y. Multi-Receptive Field Soft Attention Part Learning for Vehicle Re-Identification. Entropy. 2023; 25(4):594. https://doi.org/10.3390/e25040594
Chicago/Turabian StylePang, Xiyu, Yilong Yin, and Yanli Zheng. 2023. "Multi-Receptive Field Soft Attention Part Learning for Vehicle Re-Identification" Entropy 25, no. 4: 594. https://doi.org/10.3390/e25040594