
Towards Data-Driven Decision-Making in the Korean Film Industry: An XAI Model for Box Office Analysis Using Dimension Reduction, Clustering, and Classification


Abstract
:1. Introduction
- (1)
- We comprehensively understand the Korean film market using data collected from the Korean Film Council’s online integrated computer network. We offer a data visualization approach incorporating ML and data mining techniques to bridge the DDDM of Industry 4.0 and the film industry.
- (2)
- By considering various input variables representing movie characteristics, we identify the factors impacting a movie’s box office success in South Korea. Our proposed box office classification model is designed to assist film industry professionals in making data-driven decisions to increase the success of future films in the Korean market.
- (3)
- By reducing the feature dimension and applying data mining techniques, we effectively cluster movies and analyze box office trends for each cluster. Utilizing XAI, our model interprets the factors affecting the box office performance, providing valuable insights for decision-makers in the Korean entertainment industry to improve the box office success.
2. Related Studies
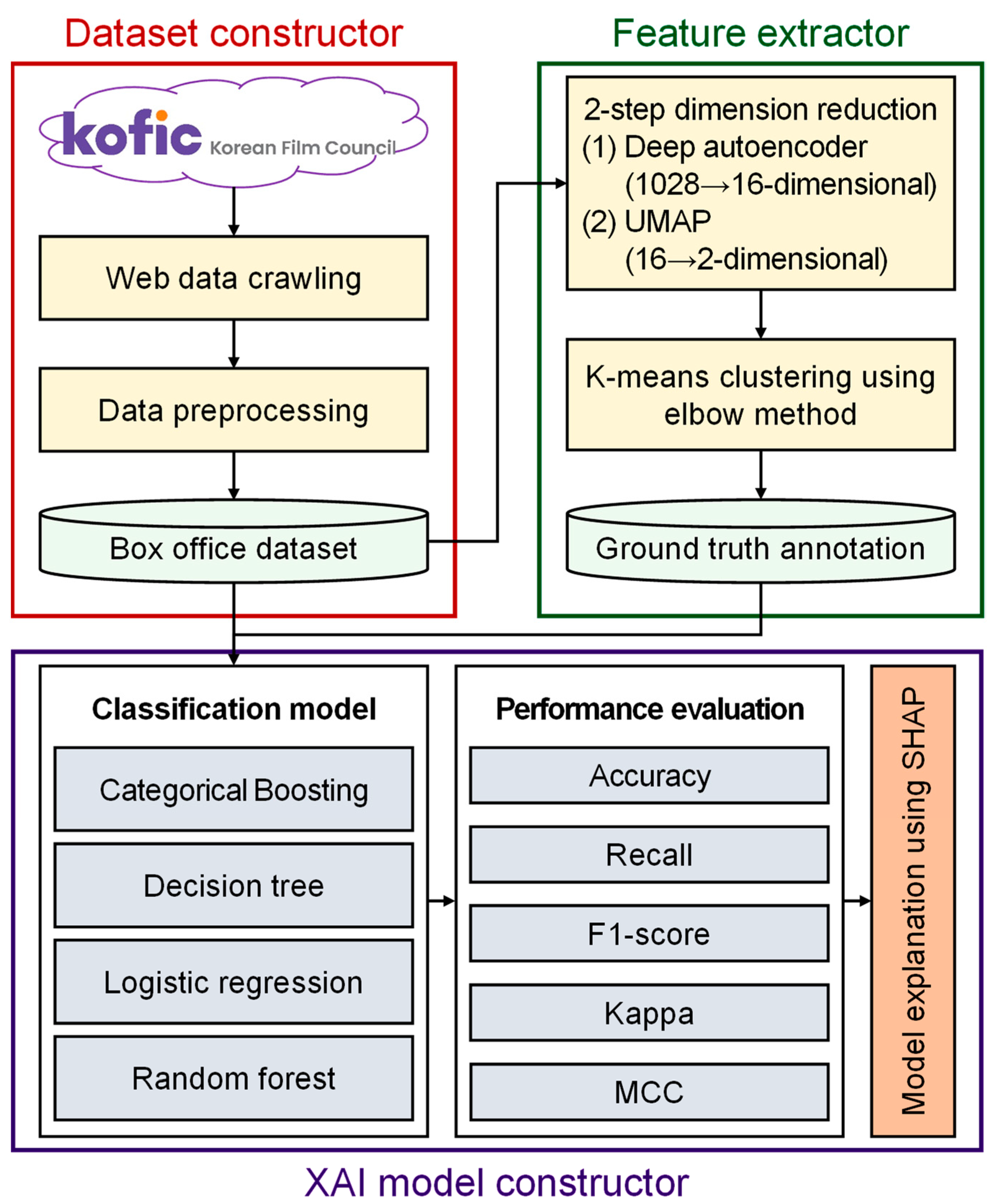
3. Materials and Methods
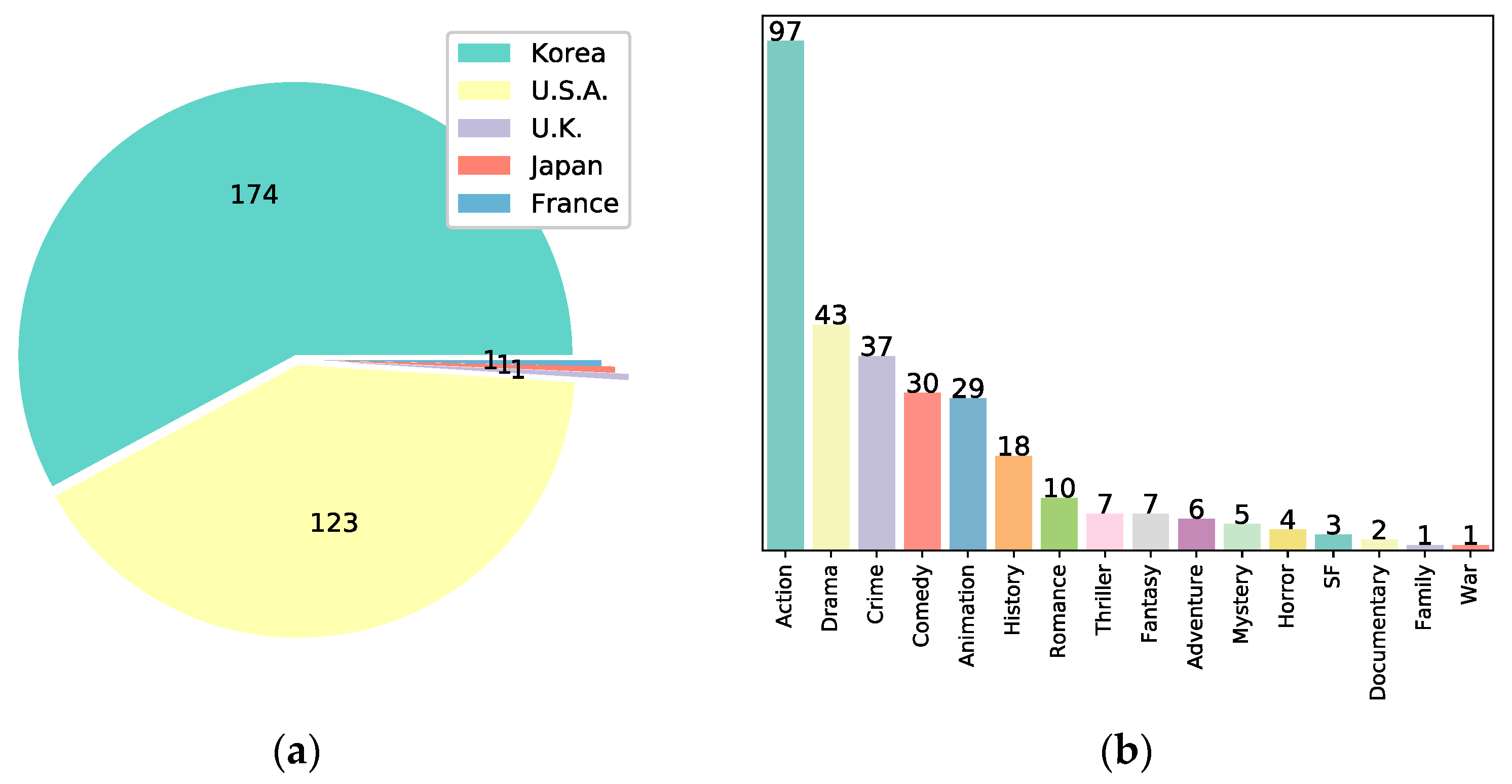
3.1. Data Collection and Preprocessing
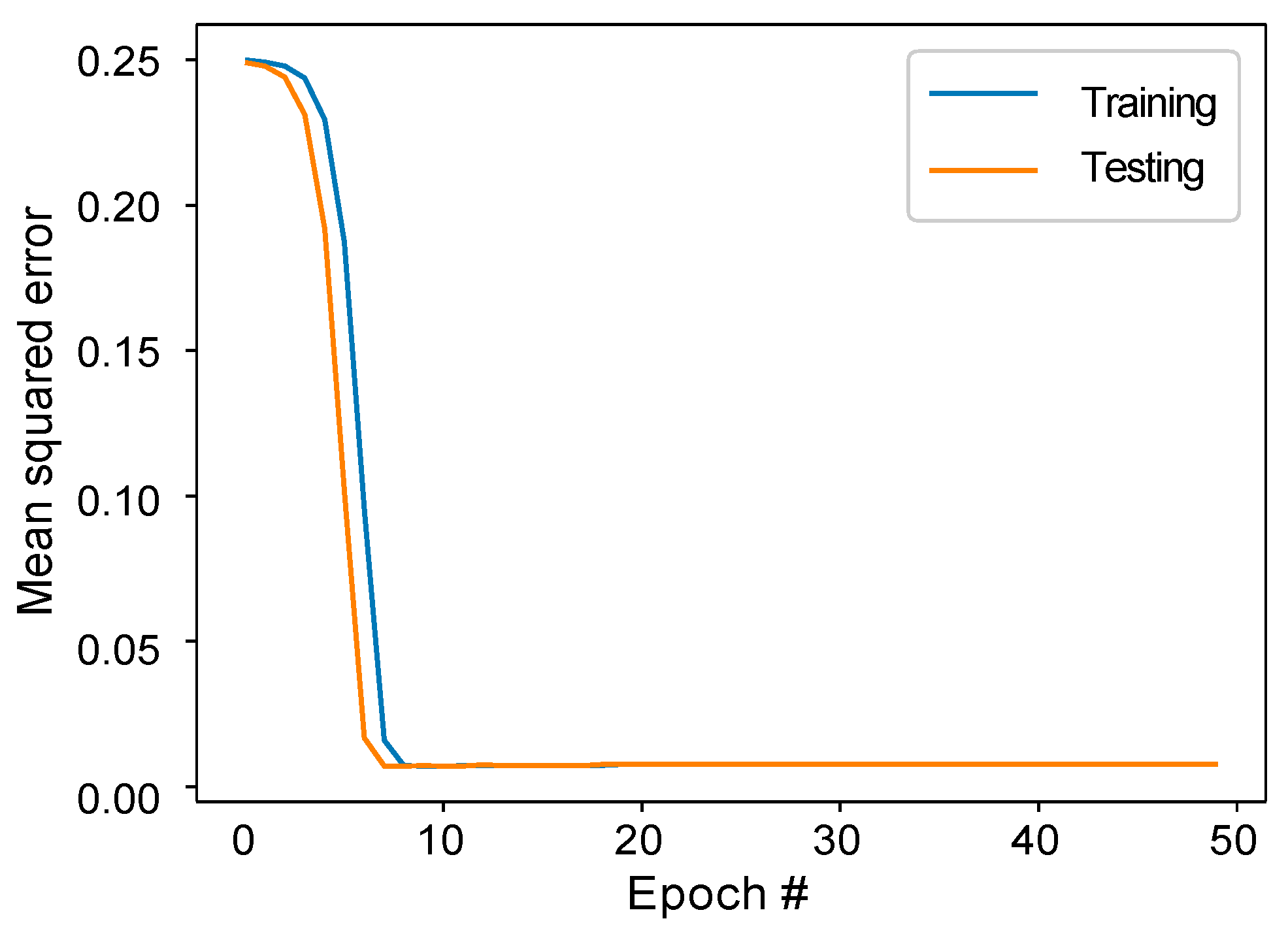
3.2. DRECE Model Construction
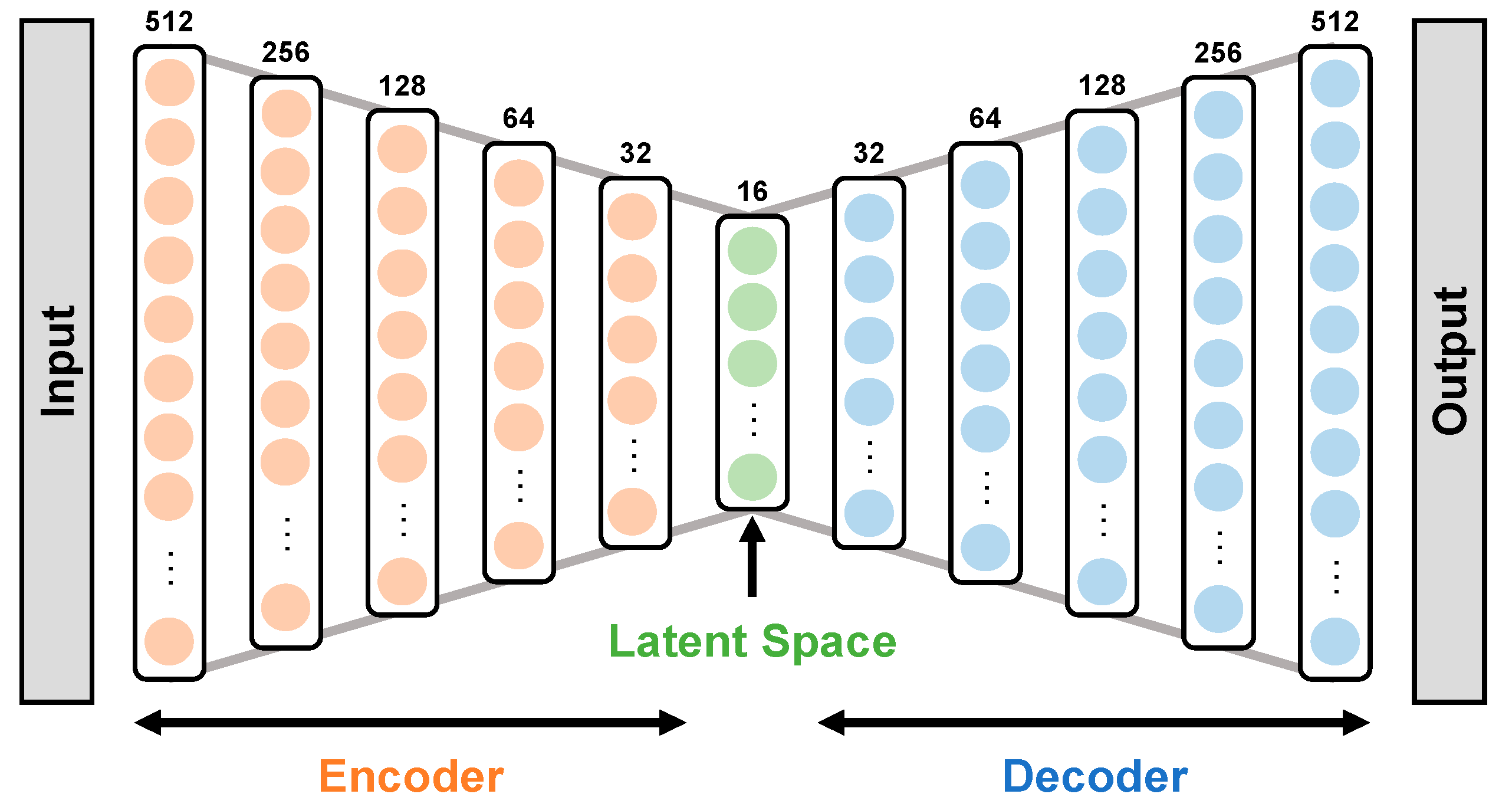
3.2.1. Dimension Reduction
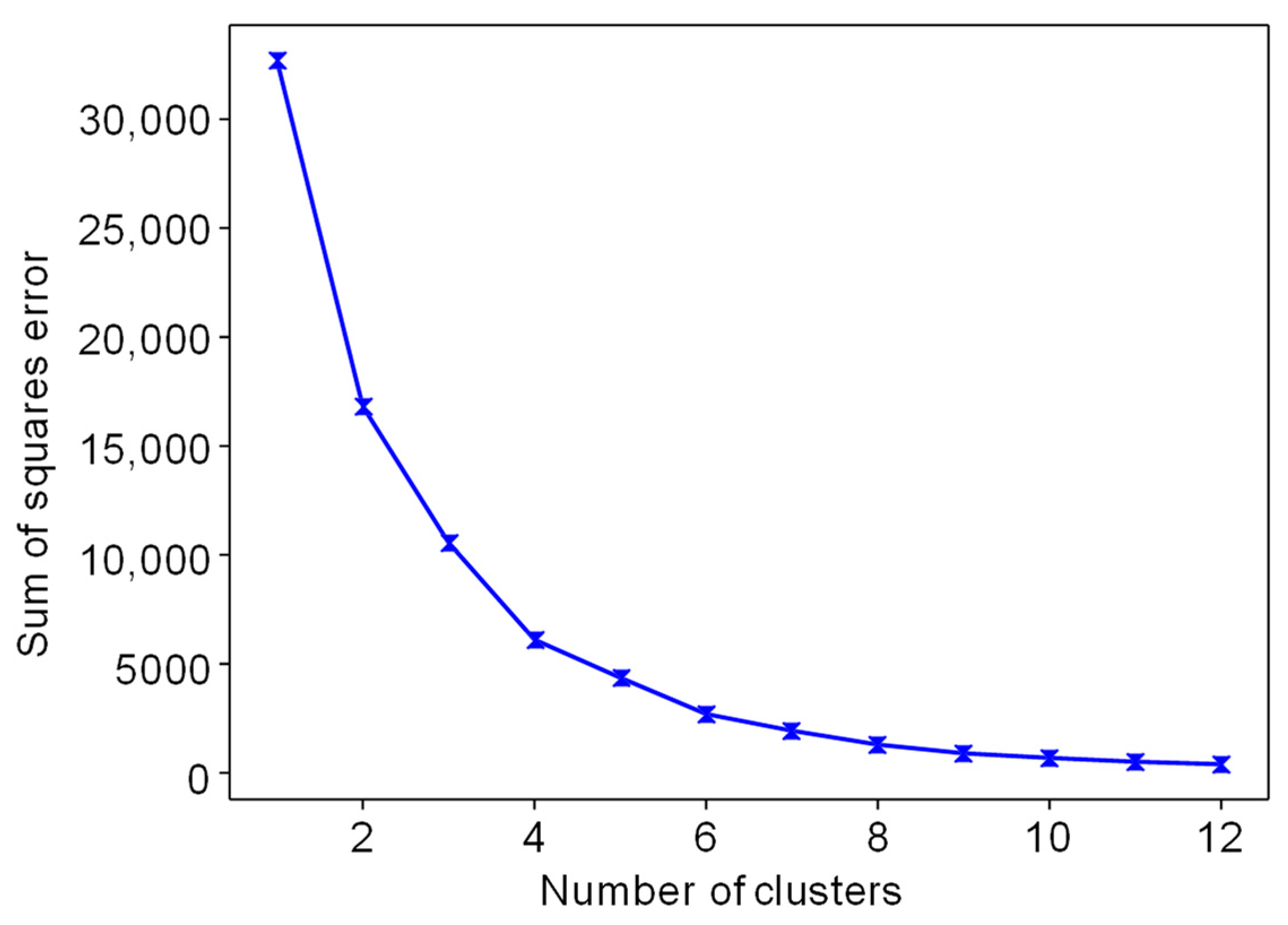
3.2.2. Clustering Analysis
3.2.3. Movie Classification
3.2.4. Model Interpretation
4. Experimental Results
4.1. Movie Data Compression and Clustering Analysis
4.2. Performance Comparison of Classification Models
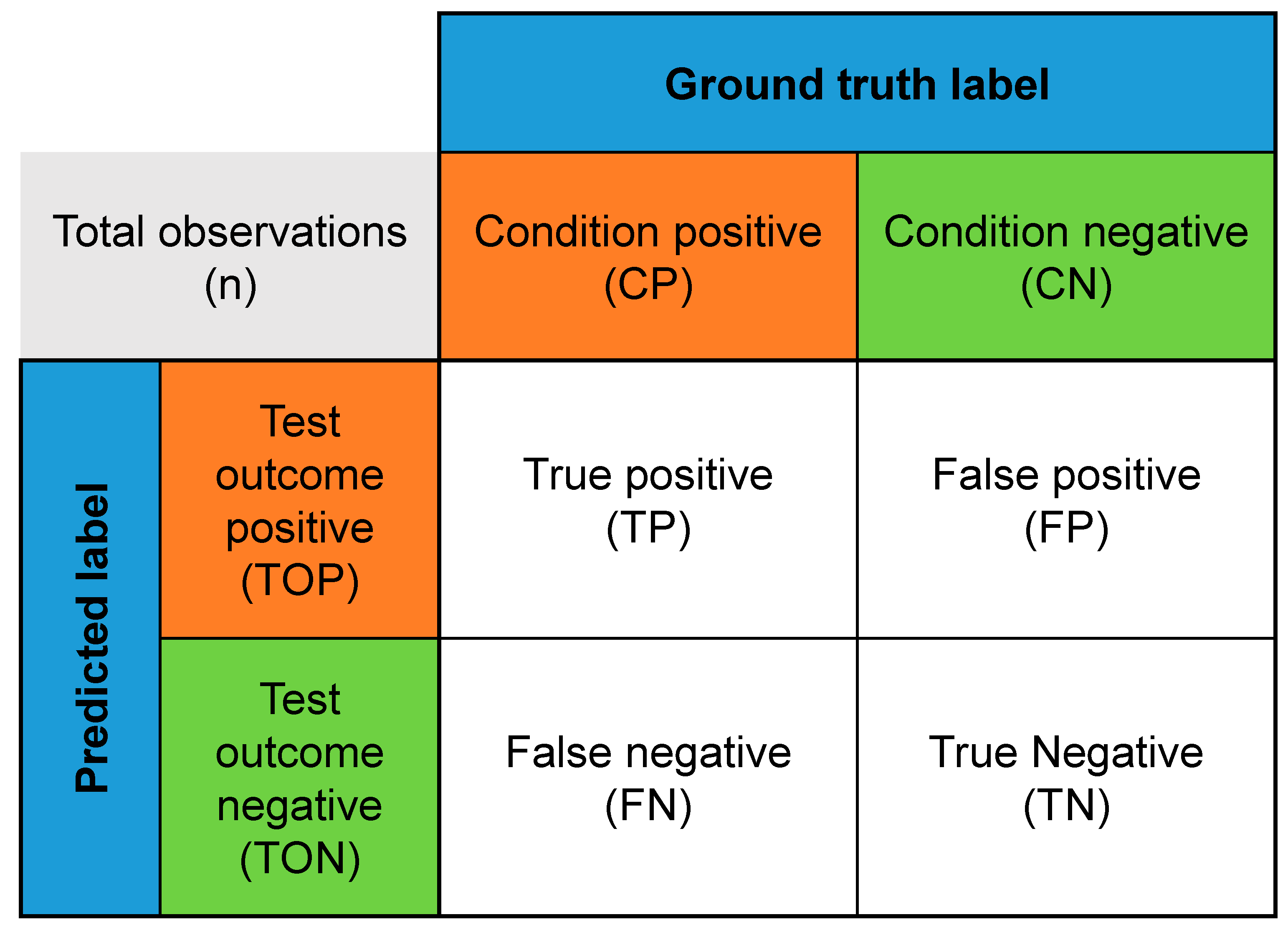
- True positives (TP): The number of correctly predicted instances as positive.
- False positives (FP): The number of instances predicted as positive but are negative.
- True negatives (TN): The number of correctly predicted instances as negative.
- False negatives (FN): The number of instances predicted as negative but are positive.
- Accuracy: Accuracy is a metric that measures the proportion of correctly classified instances by the classifier. It is calculated by dividing the number of correct classifications by the total number of instances in the data, as described in Equation (1). For example, if a classifier correctly classified 80 out of 100 movie instances, its accuracy would be 80%. However, in cases where the data are imbalanced, or false positive or negative results are costly, the accuracy may not be the best metric to use. For instance, if a classifier is designed to predict the box office hits, and it only correctly identifies 1 out of 10 movies as a hit, its accuracy would still be 10% even though it is not doing an excellent job of predicting the box office success.
- Recall: Recall, also known as the sensitivity or true positive rate, measures the proportion of box office hits correctly identified by the classifier in the dataset. It is calculated by dividing the number of box office hits correctly identified by the total number of hits in the dataset, as described in Equation (2). For example, if a classifier correctly identified 20 out of 25 box office hits, its recall would be 80%. The recall is an essential metric for evaluating the classifier’s ability to identify all box office hits, especially in cases where false negatives are costly. For instance, if a classifier is designed to predict which movies will be box office hits for a film production company, a high recall is crucial to ensure that all potentially successful movies are greenlit for production.
- F1-score: The F1-score is a metric that considers both the precision and recall, as described in Equation (3). It provides a balance between the precision and recall by considering metrics at the same time. The precision measures the ratio of the true positive box office hit predictions made by the classifier among all positive predictions. The recall measures the ratio of true positive box office hits among all actual positive box office hits in the data. The F1-score is the harmonic mean of the precision and recall and is calculated using a formula. An F1-score of 1 means perfect precision and recall, while 0 means the worst performance.
- Kappa: Cohen’s Kappa adjusts for chance agreement and evaluates the agreement between evaluators by considering both the observed agreement and the agreement expected by chance, as described in Equations (4) and (5). Kappa ranges from −1 to 1, with 1 indicating a complete agreement between the evaluators on the predicted box office hits and actual hits and a value less than 0 indicating an agreement worse than the chance. In other words, Kappa is a valuable metric for evaluating the performance of a classifier in cases where the data are imbalanced, and it considers both the observed agreement and disagreement in the predictions.
- MCC: Matthews correlation coefficient (MCC), as described in Equation (6), measures the quality of a binary classifier used to predict the box office types. It considers both the true and false positive and negative results. The MCC ranges from −1 to 1, with a value closer to 1 indicating a higher accuracy in the classifier’s predictions and closer to −1 indicating a lower accuracy. If a classifier’s predictions are random, its MCC value would be 0. The MCC is beneficial in cases where the dataset is uneven, as it considers both the accuracy and the ratios of true positive to false positive and true negative to false negative, making it a more reliable measure of performance in these cases.
- Inherent strengths of the RF model: As an ensemble model, RF builds multiple DTs and aggregates their predictions, reducing overfitting and improving generalization. Additionally, RF introduces randomness in the feature selection and bootstrapping samples, increasing the tree diversity and reducing the correlation between trees, resulting in a more robust and accurate model.
- Overfitting: The RF model may have to overfit the training data, resulting in perfect accuracy scores. Overfitting happens when the model learns the data’s noise rather than its patterns, leading to an exceptional performance on the training data but a poor performance on the new data. Evaluating the model on a separate validation or test set could be considered to check for overfitting.
- Entropy perspective: Entropy measures the impurity or randomness in the data. The RF’s trees use entropy to find the best-split points for each node. The perfect accuracy scores might result from the RF model’s ability to efficiently minimize the entropy at each split, producing highly accurate predictions.
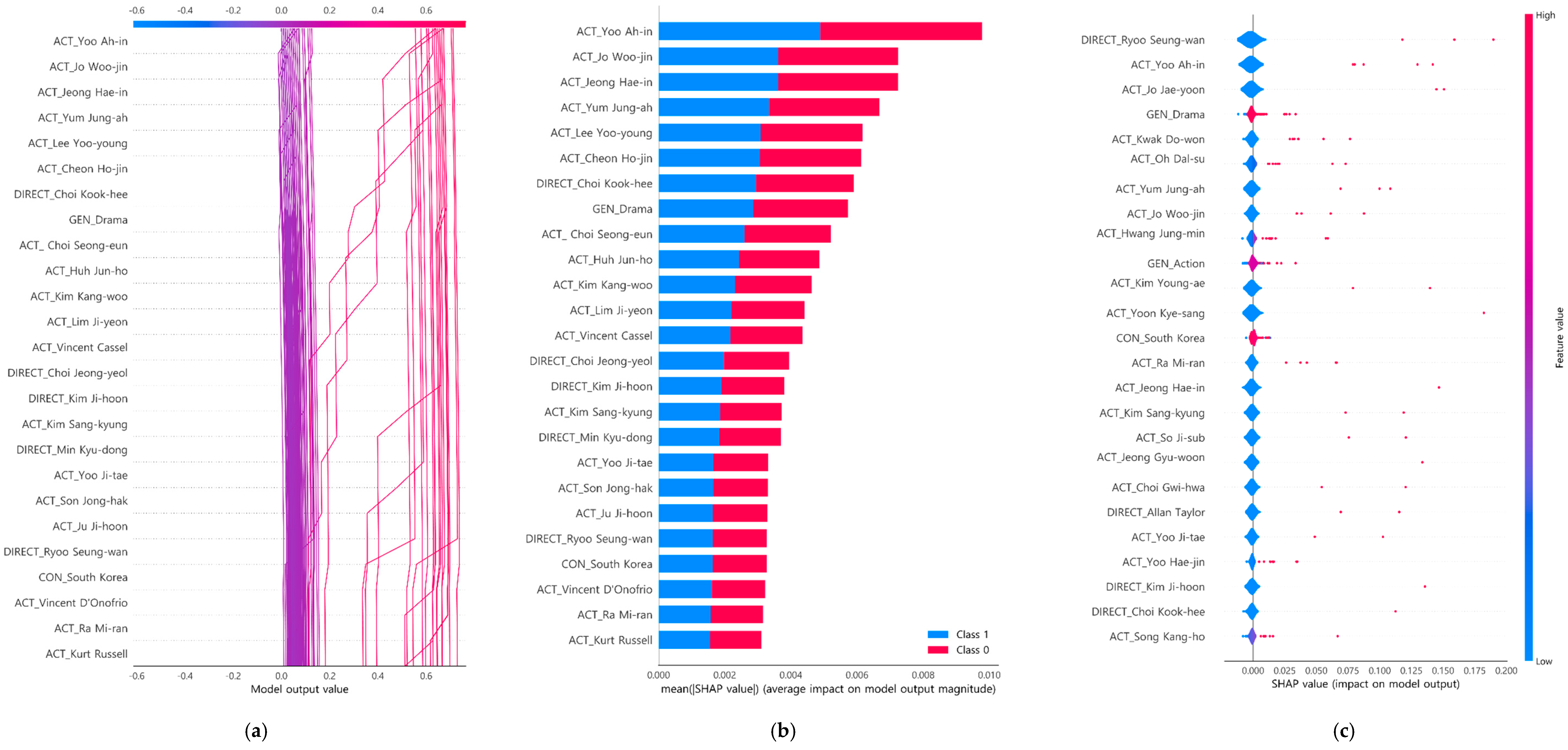
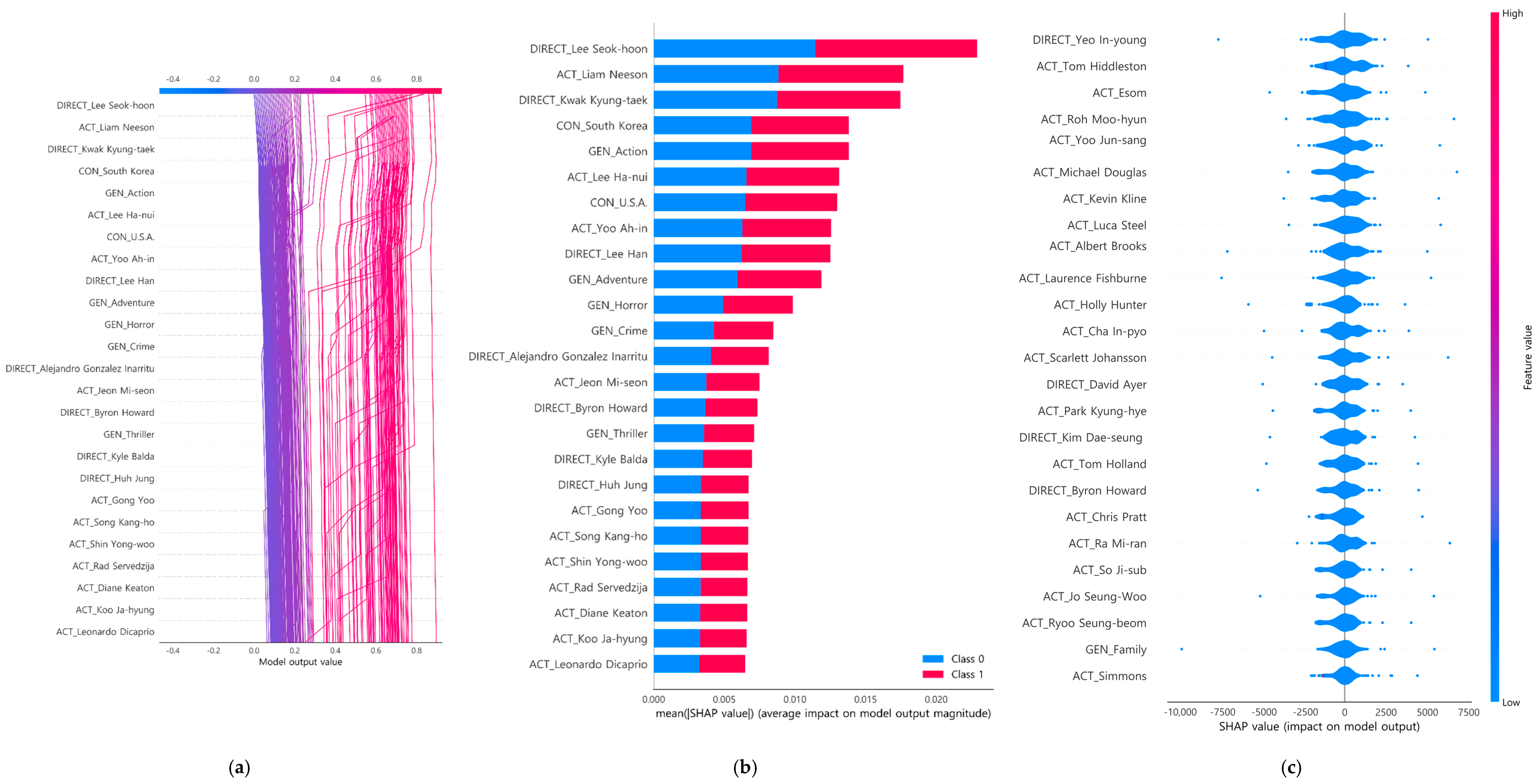
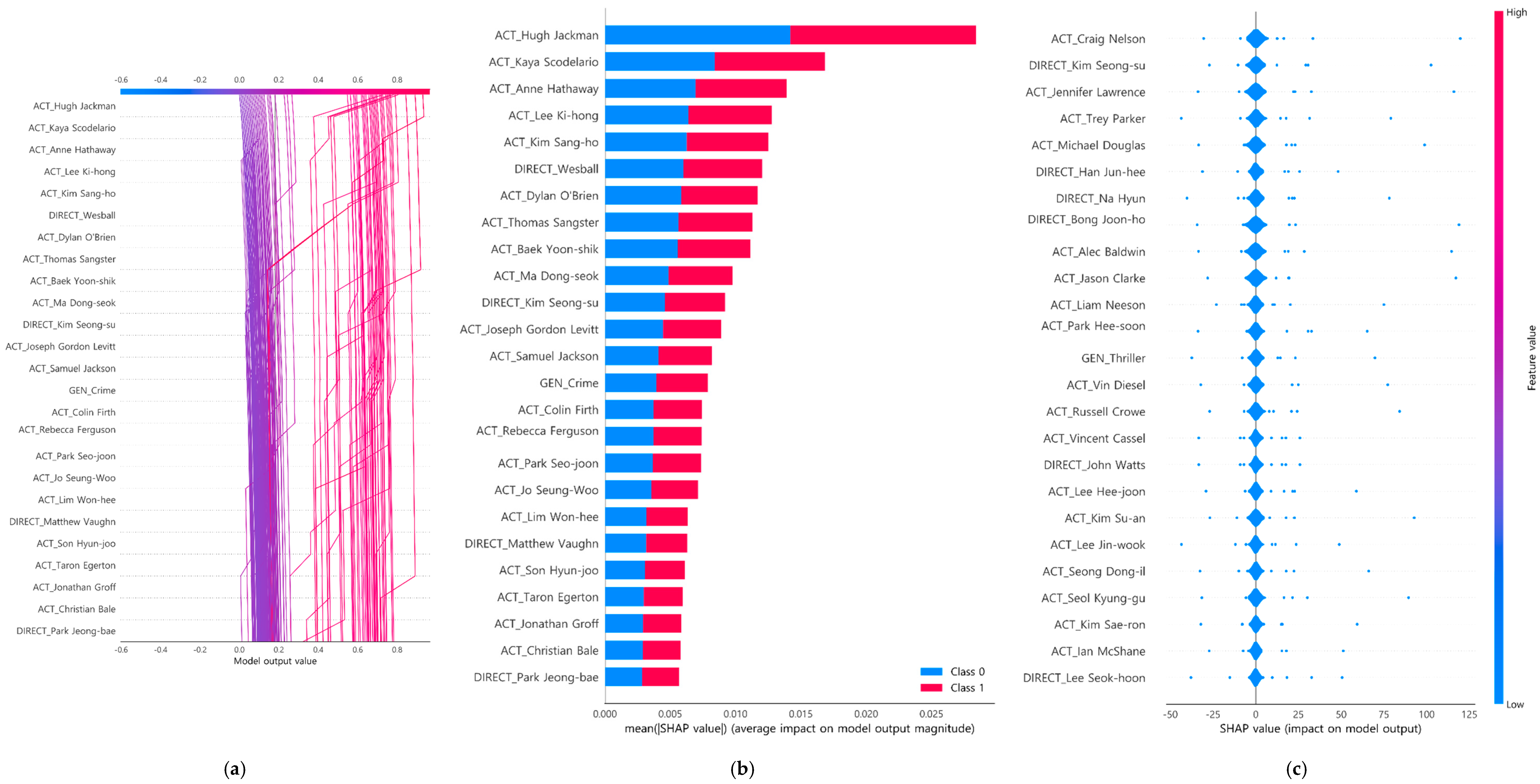
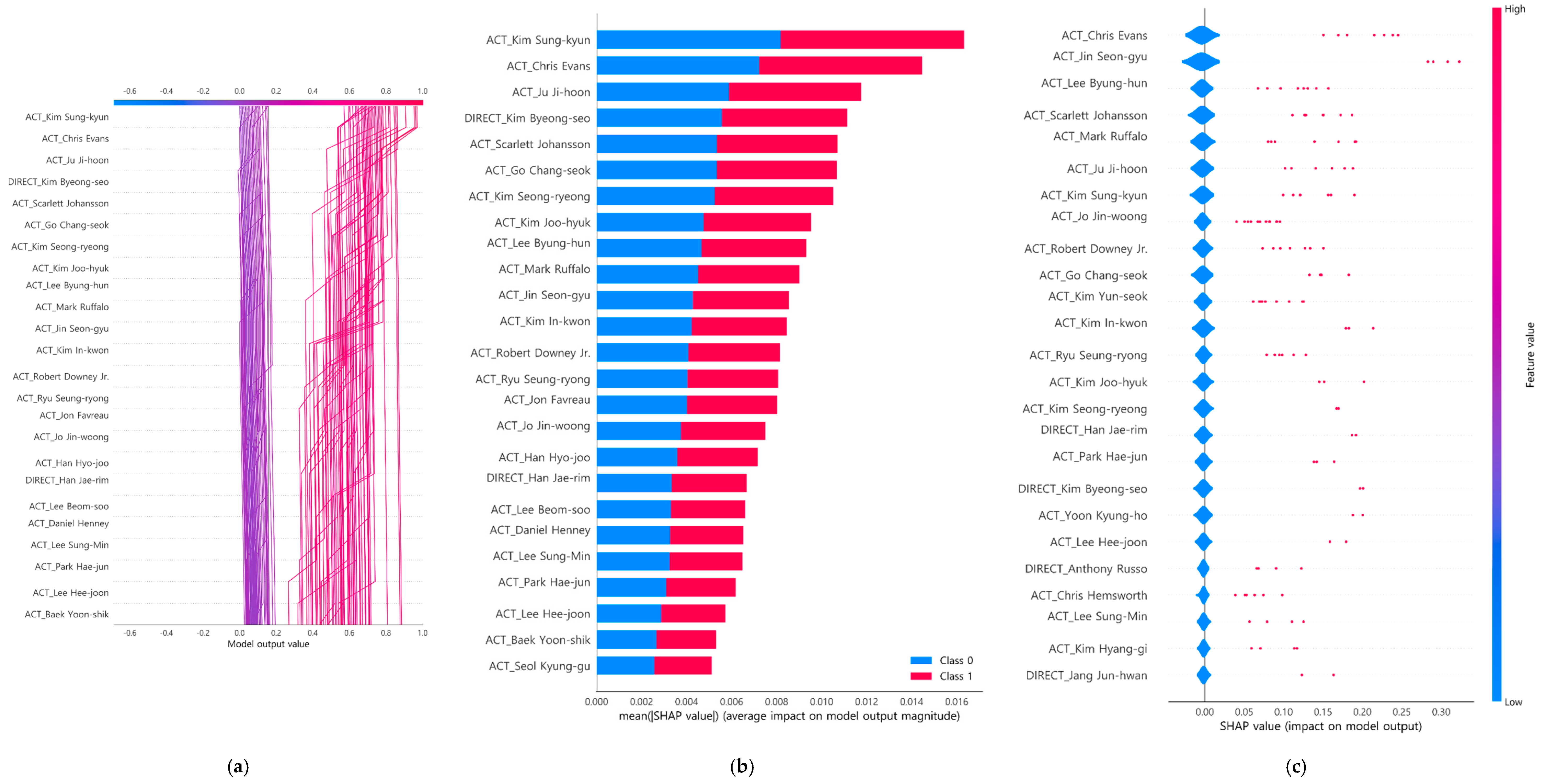
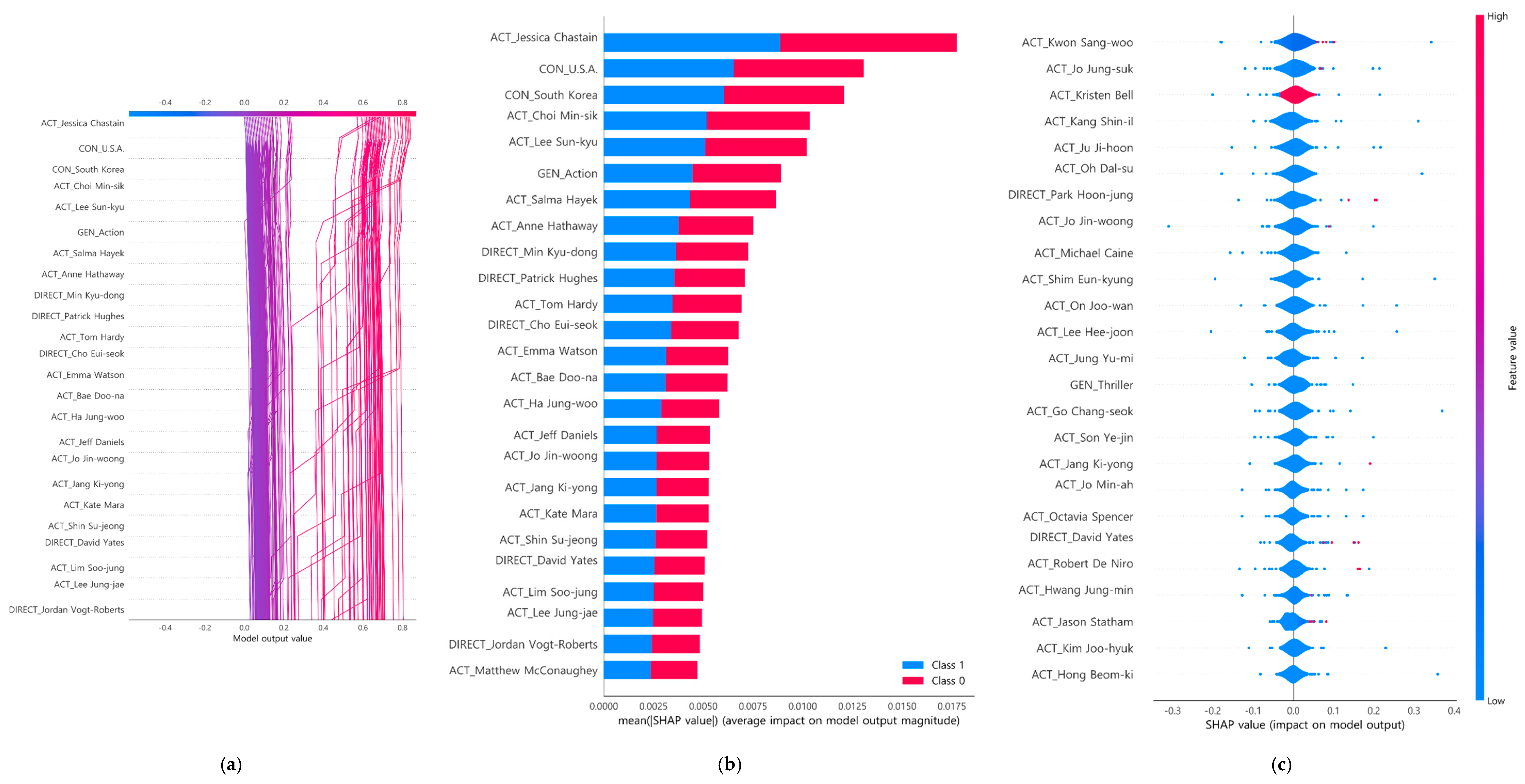
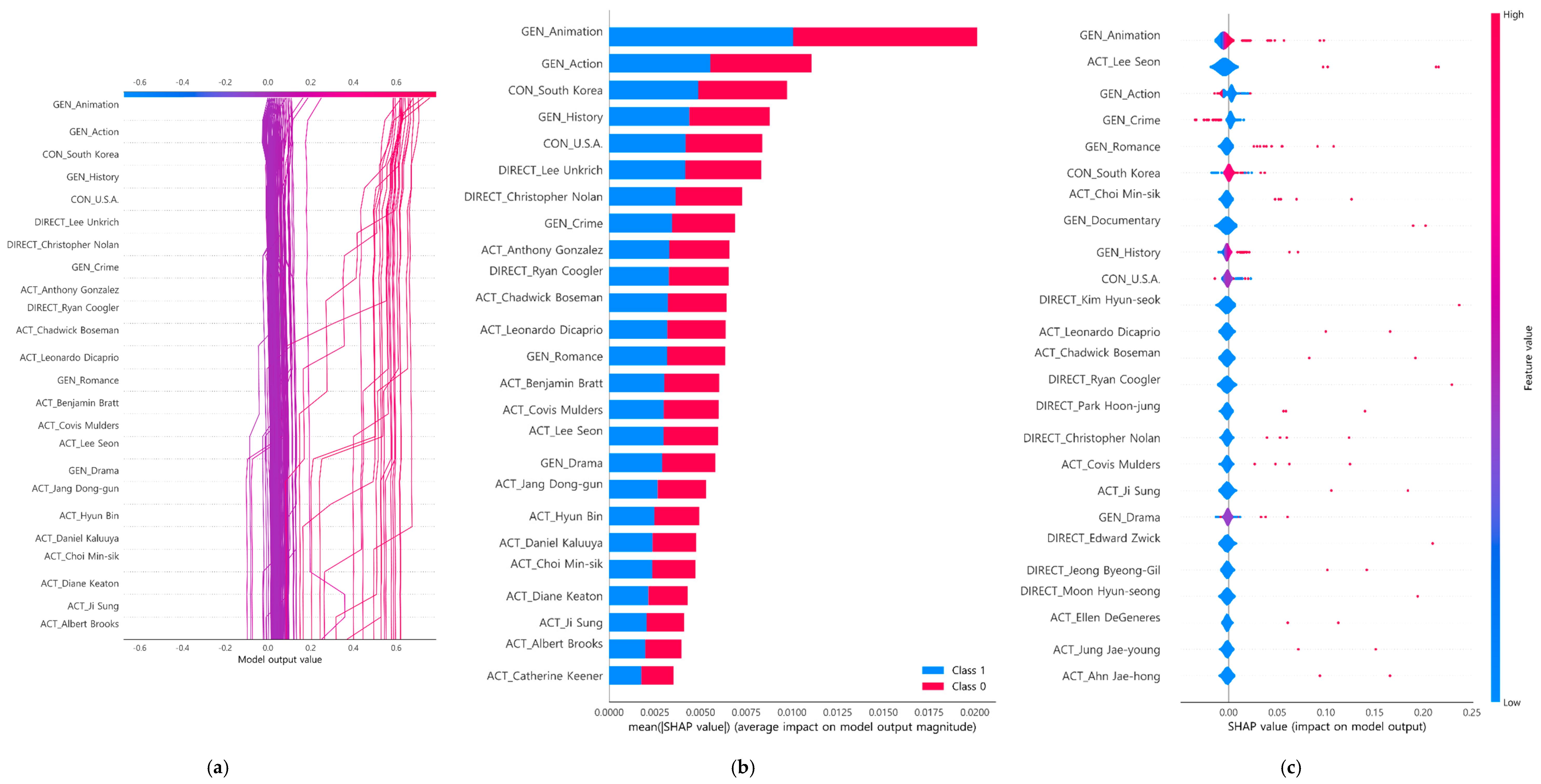
4.3. Interpretability of Box-Office-Type Classification Model
5. Discussion and Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A






References
- Gul, R.; Leong, K.; Mubashar, A.; Al-Faryan, M.A.S.; Sung, A. The Empirical Nexus between Data-Driven Decision-Making and Productivity: Evidence from Pakistan’s Banking Sector. Cogent Bus. Manag. 2023, 10, 2178290. [Google Scholar] [CrossRef]
- Jafari, M.; Ahmadi Safa, M. Data use in language schools: The case of EFL teachers’ data-driven decision making. J. Educ. Chang. 2022, 1–22. [Google Scholar] [CrossRef]
- Nouinou, H.; Asadollahi-Yazdi, E.; Baret, I.; Nguyen, N.Q.; Terzi, M.; Ouazene, Y.; Yalaoui, F.; Kelly, R. Decision-making in the context of Industry 4.0: Evidence from the textile and clothing industry. J. Clean. Prod. 2023, 391, 136184. [Google Scholar] [CrossRef]
- Maiti, M.; Vuković, D.; Mukherjee, A.; Paikarao, P.D.; Yadav, J.K. Advanced data integration in banking, financial, and insurance software in the age of COVID-19. Softw. Pract. Exp. 2022, 52, 887–903. [Google Scholar] [CrossRef]
- Yang, J.; Xiu, P.; Sun, L.; Ying, L.; Muthu, B. Social media data analytics for business decision making system to competitive analysis. Inf. Process. Manag. 2022, 59, 102751. [Google Scholar] [CrossRef]
- Chen, L.; Liu, H.; Zhou, Z.; Chen, M.; Chen, Y. IT-business alignment, big data analytics capability, and strategic decision-making: Moderating roles of event criticality and disruption of COVID-19. Decis. Support Syst. 2022, 161, 113745. [Google Scholar] [CrossRef]
- Zizic, M.C.; Mladineo, M.; Gjeldum, N.; Celent, L. From industry 4.0 towards industry 5.0: A review and analysis of paradigm shift for the people, organization and technology. Energies 2022, 15, 5221. [Google Scholar] [CrossRef]
- Kondapaka, P.; Khanra, S.; Malik, A.; Kagzi, M.; Hemachandran, K. Finding a fit between CXO’s experience and AI usage in CXO decision-making: Evidence from knowledge-intensive professional service firms. J. Serv. Theory Pract. 2023, 33, 280–308. [Google Scholar] [CrossRef]
- Maja, M.M.; Letaba, P. Towards a data-driven technology roadmap for the bank of the future: Exploring big data analytics to support technology roadmapping. Soc. Sci. Humanit. Open 2022, 6, 100270. [Google Scholar]
- Teng, Y.; Zhang, J.; Sun, T. Data-driven decision-making model based on artificial intelligence in higher education system of colleges and universities. Expert Syst. 2022, e12820. [Google Scholar] [CrossRef]
- Mollá, N.; Heavin, C.; Rabasa, A. Data-driven decision making: New opportunities for DSS in data stream contexts. J. Decis. Syst. 2022, 31, 255–269. [Google Scholar] [CrossRef]
- Kalsoom, A.; Maqsood, M.; Yasmin, S.; Bukhari, M.; Shin, Z.; Rho, S. A computer-aided diagnostic system for liver tumor detection using modified U-Net architecture. J. Supercomput. 2022, 78, 9668–9690. [Google Scholar] [CrossRef]
- Jabeen, A.; Yasir, M.; Ansari, Y.; Yasmin, S.; Moon, J.; Rho, S. An Empirical Study of Macroeconomic Factors and Stock Returns in the Context of Economic Uncertainty News Sentiment Using Machine Learning. Complexity 2022, 2022, 4646733. [Google Scholar] [CrossRef]
- Maqsood, H.; Maqsood, M.; Yasmin, S.; Mehmood, I.; Moon, J.; Rho, S. Analyzing the stock exchange markets of EU nations: A case study of brexit social media sentiment. Systems 2022, 10, 24. [Google Scholar] [CrossRef]
- Li, X.; Ding, Y. Holistic governance for sustainable public services: Reshaping government–enterprise relationships in China’s digital government context. Int. J. Environ. Res. Public Health 2020, 17, 1778. [Google Scholar] [CrossRef] [Green Version]
- Yang, Z.; Liu, C.; Nie, R.; Zhang, W.; Zhang, L.; Zhang, Z.; Li, W.; Liu, G.; Dai, X.; Zhang, D. Research on Uncertainty of Landslide Susceptibility Prediction—Bibliometrics and Knowledge Graph Analysis. Remote Sens. 2022, 14, 3879. [Google Scholar] [CrossRef]
- Zhang, Y.; Yan, Q. Landslide susceptibility prediction based on high-trust non-landslide point selection. ISPRS Int. J. Geo-Inf. 2022, 11, 398. [Google Scholar] [CrossRef]
- Kim, H.; Kim, C.; Kim, H.; Cho, S.; Hwang, E. Panoptic blind image inpainting. ISA Trans. 2023, 132, 208–221. [Google Scholar] [CrossRef]
- Xie, Y.; Chen, Y.; Lian, Q.; Yin, H.; Peng, J.; Sheng, M.; Wang, Y. Enhancing real-time prediction of effluent water quality of wastewater treatment plant based on improved feedforward neural network coupled with optimization algorithm. Water 2022, 14, 1053. [Google Scholar] [CrossRef]
- Kogut, I.; Armbruster, F.; Polak, D.; Kaur, S.; Hussy, S.; Thiem, T.; Gerhardts, A.; Szwast, M. Antibacterial, Antifungal, and Antibiotic Adsorption Properties of Graphene-Modified Nonwoven Materials for Application in Wastewater Treatment Plants. Processes 2022, 10, 2051. [Google Scholar] [CrossRef]
- Ansari, Y.; Yasmin, S.; Naz, S.; Zaffar, H.; Ali, Z.; Moon, J.; Rho, S. A Deep Reinforcement Learning-Based Decision Support System for Automated Stock Market Trading. IEEE Access 2022, 10, 127469–127501. [Google Scholar] [CrossRef]
- Maqsood, M.; Yasmin, S.; Gillani, S.; Aadil, F.; Mehmood, I.; Rho, S.; Yeo, S.-S. An autonomous decision-making framework for gait recognition systems against adversarial attack using reinforcement learning. ISA Trans. 2022, 132, 80–93. [Google Scholar] [CrossRef] [PubMed]
- Moon, J.; Rho, S.; Baik, S.W. Toward explainable electrical load forecasting of buildings: A comparative study of tree-based ensemble methods with Shapley values. Sustain. Energy Technol. Assess. 2022, 54, 102888. [Google Scholar] [CrossRef]
- Nikolic, D.; Kostic-Stankovic, M.; Jeremic, V. Market Segmentation in the Film Industry Based on Genre Preference: The Case of Millennials. Eng. Econ. 2022, 33, 215–228. [Google Scholar] [CrossRef]
- Zhang, H.; Wu, Y. The Analysis and Implementation of Film Decision-Making Based on Python. Sci. Program. 2022, 2022, 4131316. [Google Scholar] [CrossRef]
- Gemignani, Z.; Gemignani, C.; Galentino, R.; Schuermann, P. Data Fluency: Empowering Your Organization with Effective Data Communication; John Wiley & Sons: Hoboken, NJ, USA, 2014. [Google Scholar]
- Loy, J. Project-Based Supply Chain Intelligence and Digital Fabrication for a Sustainable Film Industry. In Supply Chain Intelligence: Application and Optimization; Springer: Berlin/Heidelberg, Germany, 2020; pp. 37–59. [Google Scholar]
- Mbunge, E.; Fashoto, S.G.; Bimha, H. Prediction of box-office success: A review of trends and machine learning computational models. Int. J. Bus. Intell. Data Min. 2022, 20, 192–207. [Google Scholar] [CrossRef]
- Lipizzi, C.; Iandoli, L.; Marquez, J.E.R. Combining structure, content and meaning in online social networks: The analysis of public’s early reaction in social media to newly launched movies. Technol. Forecast. Soc. Chang. 2016, 109, 35–49. [Google Scholar] [CrossRef]
- Baek, H.; Oh, S.; Yang, H.-D.; Ahn, J. Electronic word-of-mouth, box office revenue and social media. Electron. Commer. Res. Appl. 2017, 22, 13–23. [Google Scholar] [CrossRef]
- Kim, D.; Kim, D.; Hwang, E.; Choi, H.-G. A user opinion and metadata mining scheme for predicting box office performance of movies in the social network environment. New Rev. Hypermedia Multimed. 2013, 19, 259–272. [Google Scholar] [CrossRef]
- Darban, Z.Z.; Valipour, M.H. GHRS: Graph-based hybrid recommendation system with application to movie recommendation. Expert Syst. Appl. 2022, 200, 116850. [Google Scholar] [CrossRef]
- Ding, C.; Cheng, H.K.; Duan, Y.; Jin, Y. The power of the “like” button: The impact of social media on box office. Decis. Support Syst. 2017, 94, 77–84. [Google Scholar] [CrossRef]
- Panaligan, R.; Chen, A. Quantifying Movie Magic with Google Search. Google Whitepaper—Industry Perspectives+ User Insights. 2013. Available online: https://docplayer.net/90506950-Quantifying-movie-magic-with-google-search.html (accessed on 31 January 2023).
- Mestyán, M.; Yasseri, T.; Kertész, J. Early prediction of movie box office success based on Wikipedia activity big data. PLoS ONE 2013, 8, e71226. [Google Scholar] [CrossRef] [PubMed]
- Chon, W. Beyond the International Film Festival: Contact Zones for the Agonistics and Solidarity. In Korean Film and Festivals; Routledge: London, UK, 2023; pp. 81–97. [Google Scholar]
- Parc, J. Evaluating the effects of protectionism on the film industry: A case study analysis of Korea. In Handbook of State Aid for Film: Finance, Industries and Regulation; Springer: Berlin/Heidelberg, Germany, 2018; pp. 349–366. [Google Scholar]
- Linardatos, P.; Papastefanopoulos, V.; Kotsiantis, S. Explainable AI: A Review of Machine Learning Interpretability Methods. Entropy 2021, 23, 18. [Google Scholar] [CrossRef] [PubMed]
- Lee, J.; Jeong, J.; Jung, S.; Moon, J.; Rho, S. Verification of De-Identification Techniques for Personal Information Using Tree-Based Methods with Shapley Values. J. Pers. Med. 2022, 12, 190. [Google Scholar] [CrossRef] [PubMed]
- Leem, S.; Oh, J.; Moon, J. Towards an Effective Over-The-Top Platform Service: A Machine Learning Approach for Box Office Analysis. In Proceedings of the 2023 IEEE International Conference on Big Data and Smart Computing (BigComp), Jeju, Republic of Korea, 13–16 February 2023; pp. 413–416. [Google Scholar]
- Zhang, L.; Luo, J.; Yang, S. Forecasting box office revenue of movies with BP neural network. Expert Syst. Appl. 2009, 36, 6580–6587. [Google Scholar] [CrossRef]
- Kim, T.; Hong, J.; Kang, P. Box office forecasting using machine learning algorithms based on SNS data. Int. J. Forecast. 2015, 31, 364–390. [Google Scholar] [CrossRef]
- Hur, M.; Kang, P.; Cho, S. Box-office forecasting based on sentiments of movie reviews and independent subspace method. Inf. Sci. 2016, 372, 608–624. [Google Scholar] [CrossRef]
- Lee, S.; Bikash, K.; Choeh, J.Y. Comparing performance of ensemble methods in predicting movie box office revenue. Heliyon 2020, 6, e04260. [Google Scholar] [CrossRef]
- Lee, S.; Choeh, J.Y. Movie production efficiency moderating between online word-of-mouth and subsequent box office revenue. Sustainability 2020, 12, 6602. [Google Scholar] [CrossRef]
- Bogaert, M.; Ballings, M.; Van den Poel, D.; Oztekin, A. Box office sales and social media: A cross-platform comparison of predictive ability and mechanisms. Decis. Support Syst. 2021, 147, 113517. [Google Scholar] [CrossRef]
- Pan, C. Research on the Influencing Factors of Box Office: A Case Study of the Top 100 Films in the Chinese Box Office in 2019. In Proceedings of the 2021 5th Annual International Conference on Data Science and Business Analytics (ICDSBA), Changsha, China, 24-26 September 2021; pp. 189–195. [Google Scholar]
- Li, D.; Liu, Z.-P. Predicting Box-Office Markets with Machine Learning Methods. Entropy 2022, 24, 711. [Google Scholar] [CrossRef]
- Ni, Y.; Dong, F.; Zou, M.; Li, W. Movie Box Office Prediction Based on Multi-Model Ensembles. Information 2022, 13, 299. [Google Scholar] [CrossRef]
- Velingkar, G.; Varadarajan, R.; Lanka, S. Movie Box-Office Success Prediction Using Machine Learning. In Proceedings of the 2022 Second International Conference on Power, Control and Computing Technologies (ICPC2T), Raipur, India, 1–3 March 2022; pp. 1–6. [Google Scholar]
- VKOBIS. Available online: https://www.vkobis.or.kr/boxoffice/selectBoxofficeHistoryList.do (accessed on 25 February 2023).
- Abdullah, S.S.; Rostamzadeh, N.; Sedig, K.; Garg, A.X.; McArthur, E. Visual Analytics for Dimension Reduction and Cluster Analysis of High Dimensional Electronic Health Records. Informatics 2020, 7, 17. [Google Scholar] [CrossRef]
- Tang, Y.B.; Chen, D.; Li, X.L. Dimensionality reduction methods for brain imaging data analysis. ACM Comput. Surv. 2021, 54, 87. [Google Scholar] [CrossRef]
- González-Muñiz, A.; Díaz, I.; Cuadrado, A.A.; García-Pérez, D. Health indicator for machine condition monitoring built in the latent space of a deep autoencoder. Reliab. Eng. Syst. Saf. 2022, 224, 108482. [Google Scholar] [CrossRef]
- Kim, J.-Y.; Cho, S.-B. Explainable prediction of electric energy demand using a deep autoencoder with interpretable latent space. Expert Syst. Appl. 2021, 186, 115842. [Google Scholar] [CrossRef]
- An, J.; Ai, P.; Liu, C.; Xu, S.; Liu, D. Deep clustering bearing fault diagnosis method based on local manifold learning of an autoencoded embedding. IEEE Access 2021, 9, 30154–30168. [Google Scholar] [CrossRef]
- McInnes, L.; Healy, J.; Melville, J. UMAP: Uniform manifold approximation and projection for dimension reduction. arXiv 2018, arXiv:1802.03426 2018. [Google Scholar]
- Van der Maaten, L.; Hinton, G. Visualizing data using t-SNE. J. Mach. Learn. Res. 2008, 9, 2579–2605. [Google Scholar]
- Maćkiewicz, A.; Ratajczak, W. Principal components analysis (PCA). Comput. Geosci. 1993, 19, 303–342. [Google Scholar] [CrossRef]
- Hartigan, J.A.; Wong, M.A. Algorithm AS 136: A k-means clustering algorithm. J. R. Stat. Society. Ser. C Appl. Stat. 1979, 28, 100–108. [Google Scholar] [CrossRef]
- Bholowalia, P.; Kumar, A. EBK-means: A clustering technique based on elbow method and k-means in WSN. Int. J. Comput. Appl. 2014, 105, 17–24. [Google Scholar]
- Cerioli, A.; Farcomeni, A.; Riani, M. Wild adaptive trimming for robust estimation and cluster analysis. Scand. J. Stat. 2019, 46, 235–256. [Google Scholar] [CrossRef]
- García-Escudero, L.A.; Mayo-Iscar, A.; Morelli, G.; Riani, M. Advances in Robust Constrained Model Based Clustering. In Building Bridges between Soft and Statistical Methodologies for Data Science; Springer: Berlin/Heidelberg, Germany, 2022; pp. 166–173. [Google Scholar]
- Garcia-Escudero, L.A.; Mayo-Iscar, A.; Riani, M. Model-based clustering with determinant-and-shape constraint. Stat. Comput. 2020, 30, 1363–1380. [Google Scholar] [CrossRef]
- Torti, F.; Perrotta, D.; Riani, M.; Cerioli, A. Assessing trimming methodologies for clustering linear regression data. Adv. Data Anal. Classif. 2019, 13, 227–257. [Google Scholar] [CrossRef] [Green Version]
- Torti, F.; Riani, M.; Morelli, G. Semiautomatic robust regression clustering of international trade data. Stat. Methods Appl. 2021, 30, 863–894. [Google Scholar] [CrossRef]
- Kleinbaum, D.G.; Dietz, K.; Gail, M.; Klein, M.; Klein, M. Logistic Regression; Springer: Berlin/Heidelberg, Germany, 2002. [Google Scholar]
- Verwer, S.; Zhang, Y. Learning decision trees with flexible constraints and objectives using integer optimization. In Proceedings of the Integration of AI and OR Techniques in Constraint Programming: 14th International Conference, CPAIOR 2017, Padua, Italy, 5–8 June 2017; pp. 94–103. [Google Scholar]
- Liaw, A.; Wiener, M. Classification and regression by randomForest. R News 2002, 2, 18–22. [Google Scholar]
- Prokhorenkova, L.; Gusev, G.; Vorobev, A.; Dorogush, A.V.; Gulin, A. CatBoost: Unbiased boosting with categorical features. Adv. Neural Inf. Process. Syst. 2018, 31, 6639–6649. [Google Scholar]
- Le, T.-T.-H.; Kim, H.; Kang, H.; Kim, H. Classification and explanation for intrusion detection system based on ensemble trees and SHAP method. Sensors 2022, 22, 1154. [Google Scholar] [CrossRef]
- Kim, M.; Kim, D.; Jin, D.; Kim, G. Application of Explainable Artificial Intelligence (XAI) in Urban Growth Modeling: A Case Study of Seoul Metropolitan Area, Korea. Land 2023, 12, 420. [Google Scholar] [CrossRef]
- Gunning, D.; Stefik, M.; Choi, J.; Miller, T.; Stumpf, S.; Yang, G.-Z. XAI—Explainable artificial intelligence. Sci. Robot. 2019, 4, eaay7120. [Google Scholar] [CrossRef] [Green Version]
- grid_search—CatBoost. Available online: https://catboost.ai/en/docs/concepts/python-reference_catboost_grid_search (accessed on 25 February 2023).









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Author(s) | Year | AI Techniques | Input Variables (Features) | Output Variable |
|---|---|---|---|---|
| Zhang et al. [41] | 2008 | MLBP neural network | Cinema information, competition, content category, nation, propaganda, showing time, star value | Movie class or performance |
| Kim et al. [42] | 2014 | GPR, KNN, MLR, SVR | Number of SNS mentions, screening-related information, weekly trends | Box office earnings |
| Hur et al. [43] | 2016 | ANN, CART, ISM, SVR | Movie data, viewer sentiments from review text | Number of audiences |
| Lee et al. [44] | 2020 | Bagging, Boosting, DT, KNN, linear regression | Movie-related variables, number of eWOMs | Box office at weeks 1, 2, and 3 after release |
| Lee and Choeh [45] | 2020 | Bagging, DEA, DT, KNN, linear regression | Four eWOM (i.e., review depth, review rating, review volume, and the number of positive reviews) | Box office revenue |
| Bogaert et al. [46] | 2021 | Bagging, DT, GBM, KNN, linear regression, neural network, RF | Movie data (MOV), MGC, and UGC from both Facebook and Twitter | Movie sales data |
| Pan [47] | 2022 | ANOVA, regression analysis | Box office, film title, film theme, monthly film box office in 2019, the monthly number of film releases in 2019, number of potential audiences, place of origin, positive comment rate, schedule, score, WOM | Box office revenue |
| Li and Liu [48] | 2022 | ARIMA, DNN, linear regression, log-linear regression, ridge regression, RF, SVM | Historical (2002–2010) box office information | China GDP, China NMS, US GDP, US NMS |
| Ni et al. [49] | 2022 | Linear regression, stacking (CatBoost, GBM, LightGBM, RF, SVR, and XGBoost) | Baidu search index, China microdata, epidemic, movie attribute | Total box office performance |
| Velingkar et al. [50] | 2022 | CatBoost, LightGBM, ridge regression, RF, voting regression, XGBoost | Budget, cast, crew, genres, IMDb ID, IMDb rating, IMDb vote count, MPAA rating, original language, original title, overview, popularity rating, production companies, production countries, release date, revenue, runtime, spoken languages, star power, tagline, TMDb rating, TMDb vote count, title | Box office revenue |
| Ours | Unsupervised Learning: DAE, UMAP, K-means clustering; Supervised learning: logistic regression, DT, RF, CatBoost; XAI: SHAP | 16 genres, director’s name, leading actor’s name, production country | Cluster-specific box office success label | |
| No. | Name | Description | Data Type |
|---|---|---|---|
| 1 | Title | Movie title | Character |
| 2 | Country | Production country | Category |
| 3 | Genre | 16 genres | Category |
| 4 | Director | Director’s name | Character |
| 5 | Actor | Leading actor’s name | Character |
| Metric | Model | Cluster A | Cluster B | Cluster C | Cluster D | Cluster E | Cluster F |
|---|---|---|---|---|---|---|---|
| Accuracy | CatBoost | 0.94 | 0.76 | 0.83 | 0.88 | 0.83 | 0.94 |
| DT | 0.96 | 0.78 | 0.83 | 0.85 | 0.87 | 0.95 | |
| LR | 0.98 | 0.97 | 0.96 | 1.00 | 0.96 | 0.94 | |
| RF | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | |
| Recall | CatBoost | 0.10 | 0.06 | 0.19 | 0.46 | 0.04 | 0.14 |
| DT | 0.38 | 0.14 | 0.23 | 0.34 | 0.28 | 0.29 | |
| LR | 0.76 | 0.88 | 0.79 | 1.00 | 0.77 | 0.19 | |
| RF | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | |
| F1-score | CatBoost | 0.17 | 0.12 | 0.32 | 0.63 | 0.07 | 0.25 |
| DT | 0.55 | 0.25 | 0.36 | 0.50 | 0.43 | 0.44 | |
| LR | 0.86 | 0.94 | 0.88 | 1.00 | 0.87 | 0.32 | |
| RF | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | |
| Kappa | CatBoost | 0.16 | 0.09 | 0.28 | 0.57 | 0.06 | 0.24 |
| DT | 0.53 | 0.20 | 0.30 | 0.44 | 0.38 | 0.43 | |
| LR | 0.86 | 0.92 | 0.86 | 1.00 | 0.85 | 0.30 | |
| RF | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | |
| MCC | CatBoost | 0.30 | 0.22 | 0.40 | 0.63 | 0.18 | 0.37 |
| DT | 0.60 | 0.33 | 0.39 | 0.52 | 0.47 | 0.52 | |
| LR | 0.87 | 0.92 | 0.87 | 1.00 | 0.86 | 0.42 | |
| RF | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Leem, S.; Oh, J.; So, D.; Moon, J. Towards Data-Driven Decision-Making in the Korean Film Industry: An XAI Model for Box Office Analysis Using Dimension Reduction, Clustering, and Classification. Entropy 2023, 25, 571. https://doi.org/10.3390/e25040571
Leem S, Oh J, So D, Moon J. Towards Data-Driven Decision-Making in the Korean Film Industry: An XAI Model for Box Office Analysis Using Dimension Reduction, Clustering, and Classification. Entropy. 2023; 25(4):571. https://doi.org/10.3390/e25040571
Chicago/Turabian StyleLeem, Subeen, Jisong Oh, Dayeong So, and Jihoon Moon. 2023. "Towards Data-Driven Decision-Making in the Korean Film Industry: An XAI Model for Box Office Analysis Using Dimension Reduction, Clustering, and Classification" Entropy 25, no. 4: 571. https://doi.org/10.3390/e25040571