
An Improved Deep Reinforcement Learning Method for Dispatch Optimization Strategy of Modern Power Systems


Abstract
:1. Introduction
2. Wind-Storage Cooperative Model and D3QN
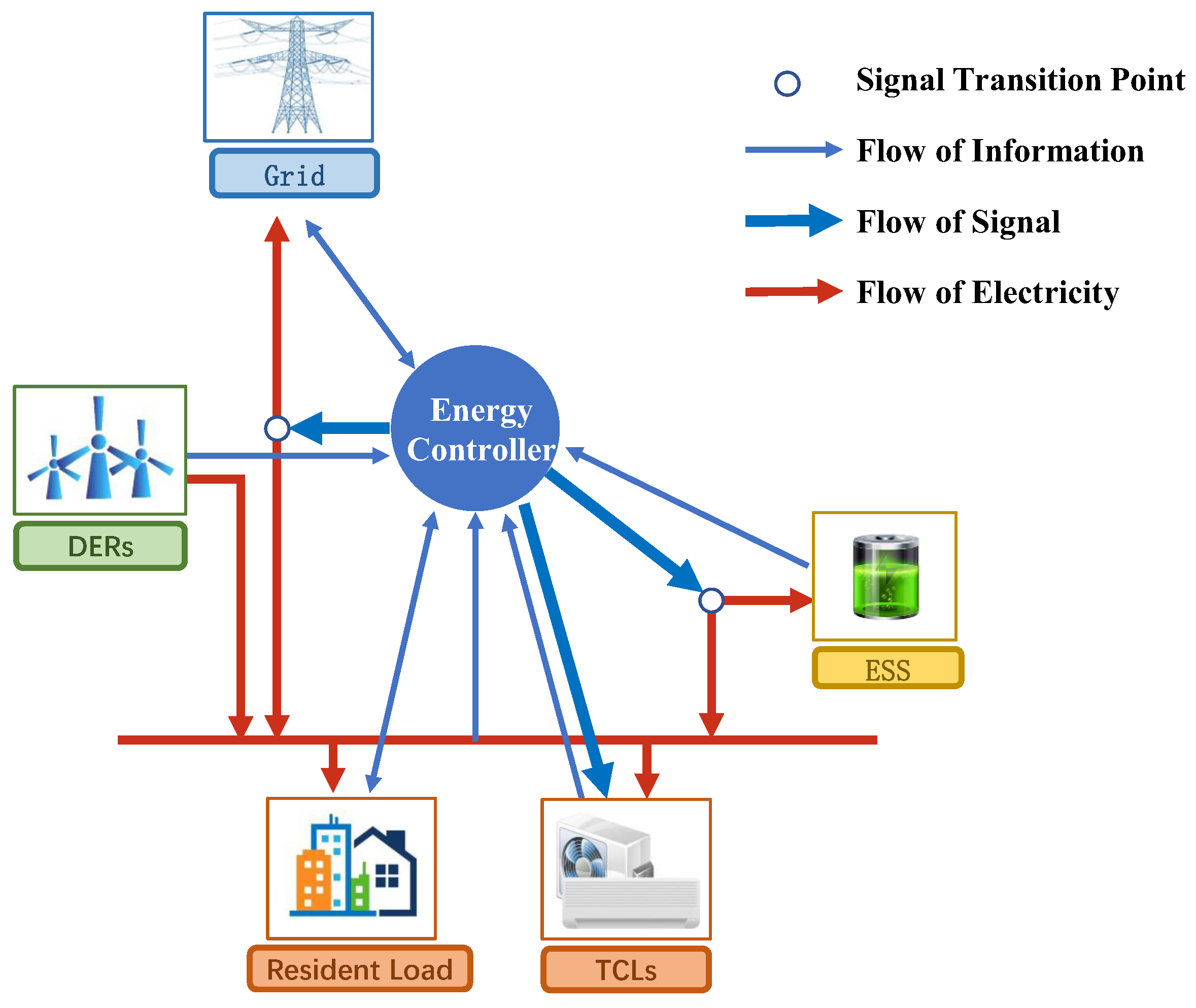
2.1. Wind-Storage Cooperative Decision-Making Model
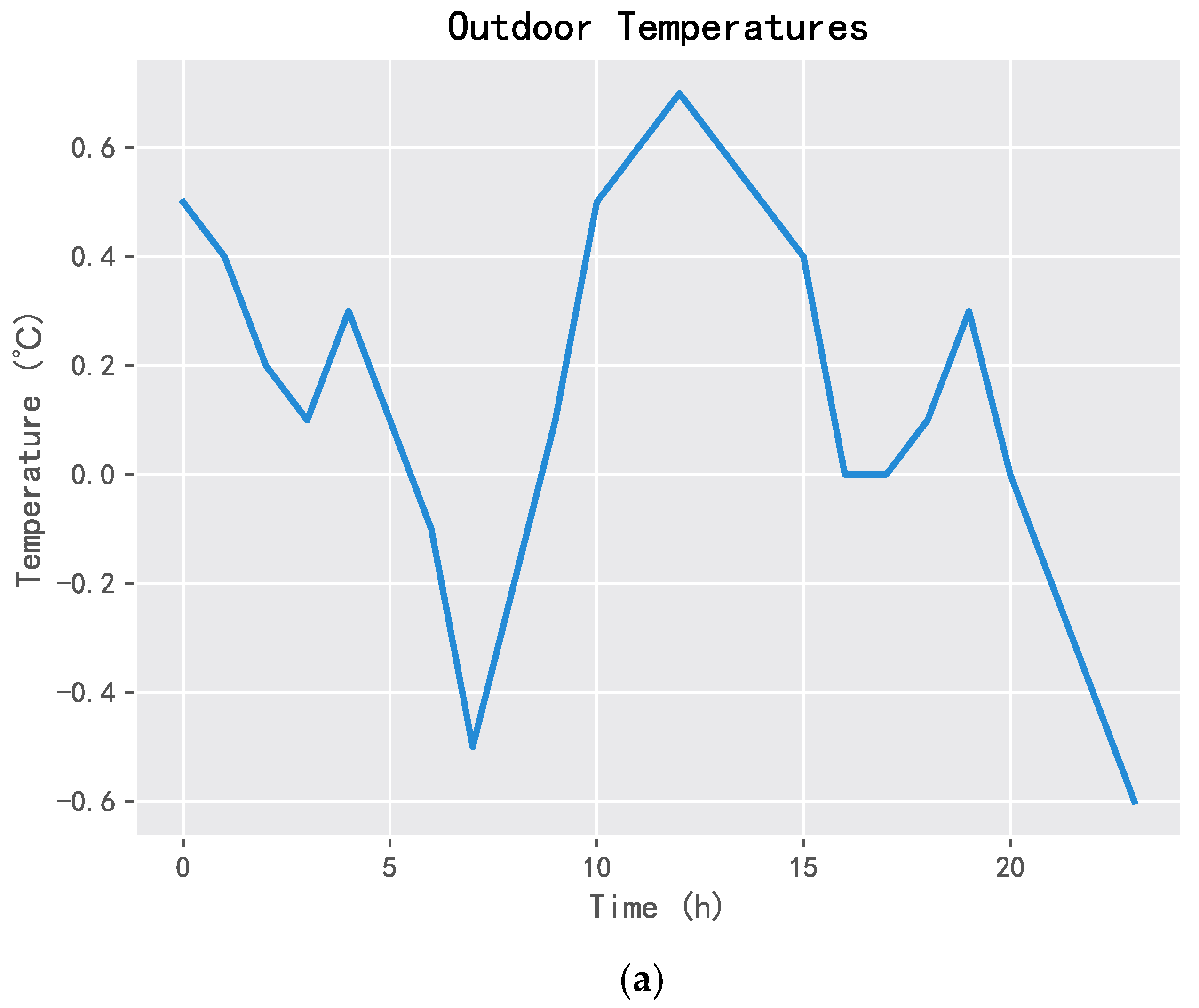
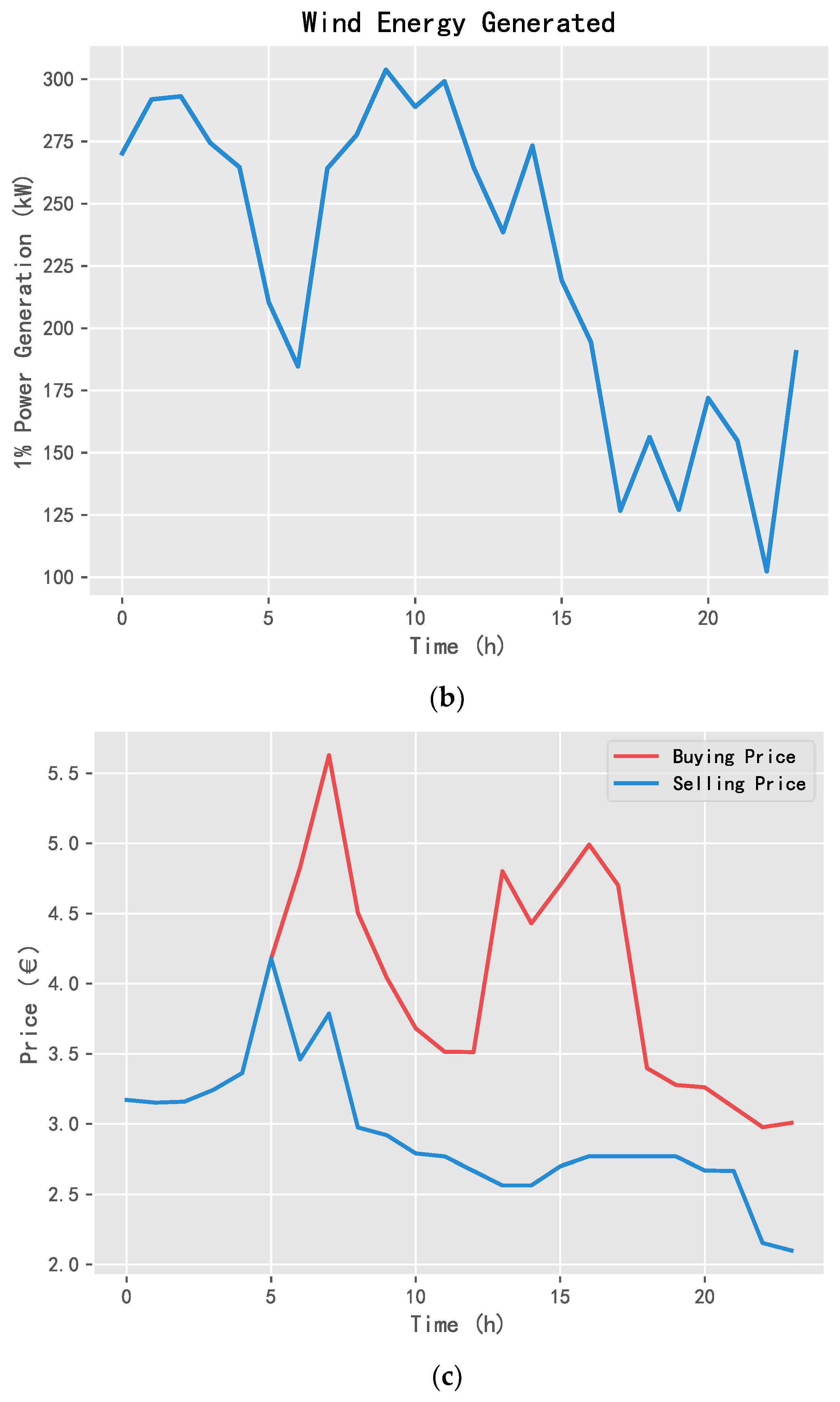
2.1.1. External Power Grid
2.1.2. Distributed Energy Module
2.1.3. Energy Storage System Module
2.1.4. Thermostatically Controllable Load
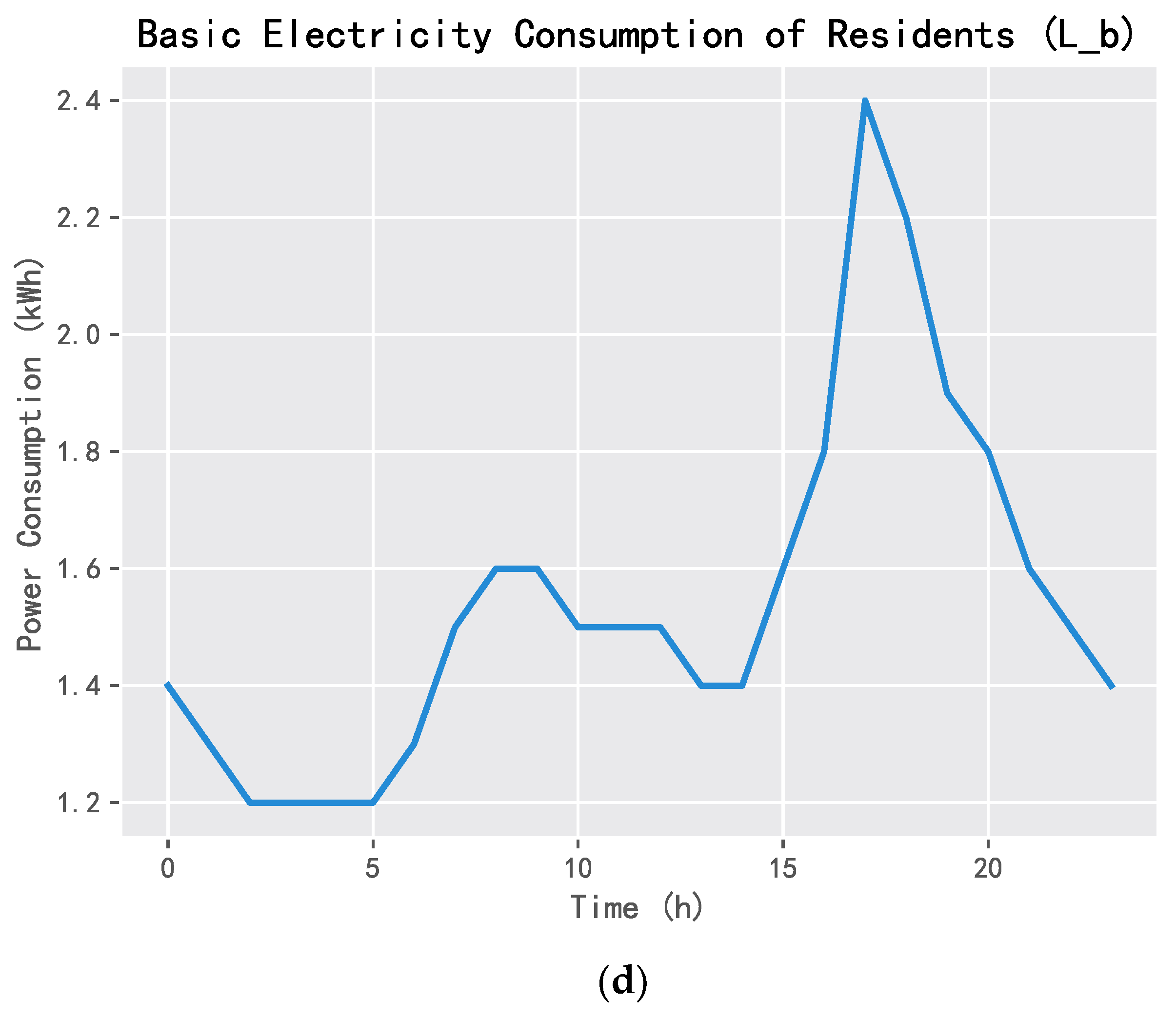
2.1.5. Resident Price Response Load
2.1.6. Energy Controller
- (1)
- TCL direct control
- (2)
- Price level control
- (3)
- Energy deficiency action
- (4)
- Energy excess action
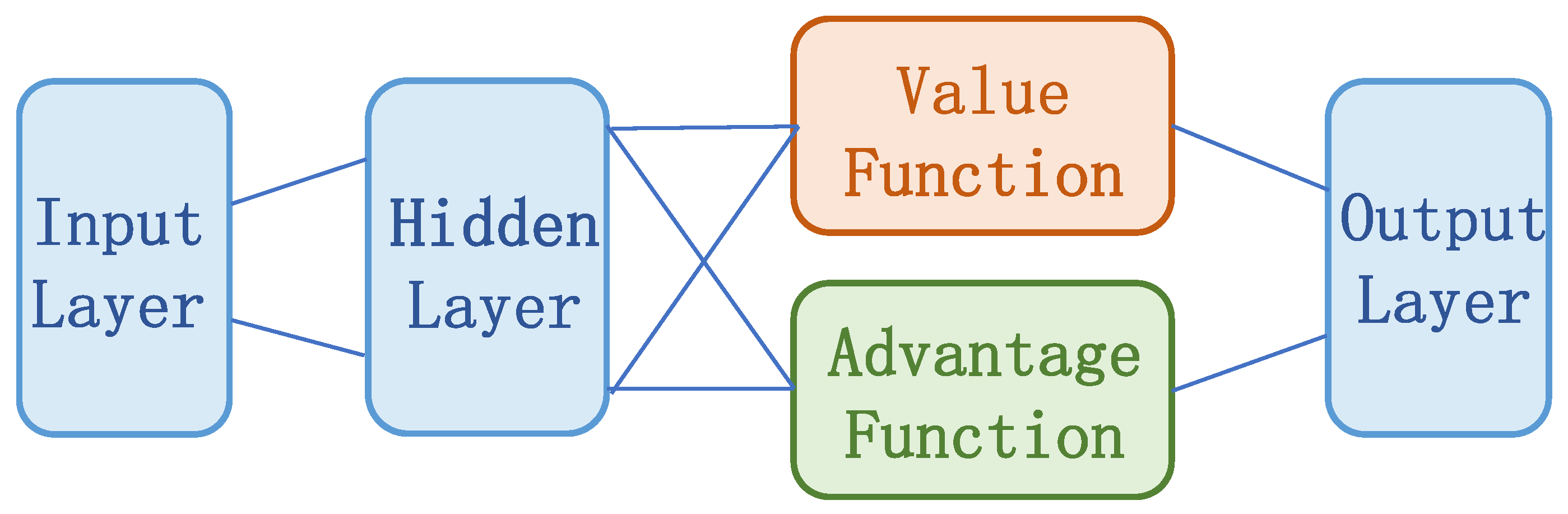
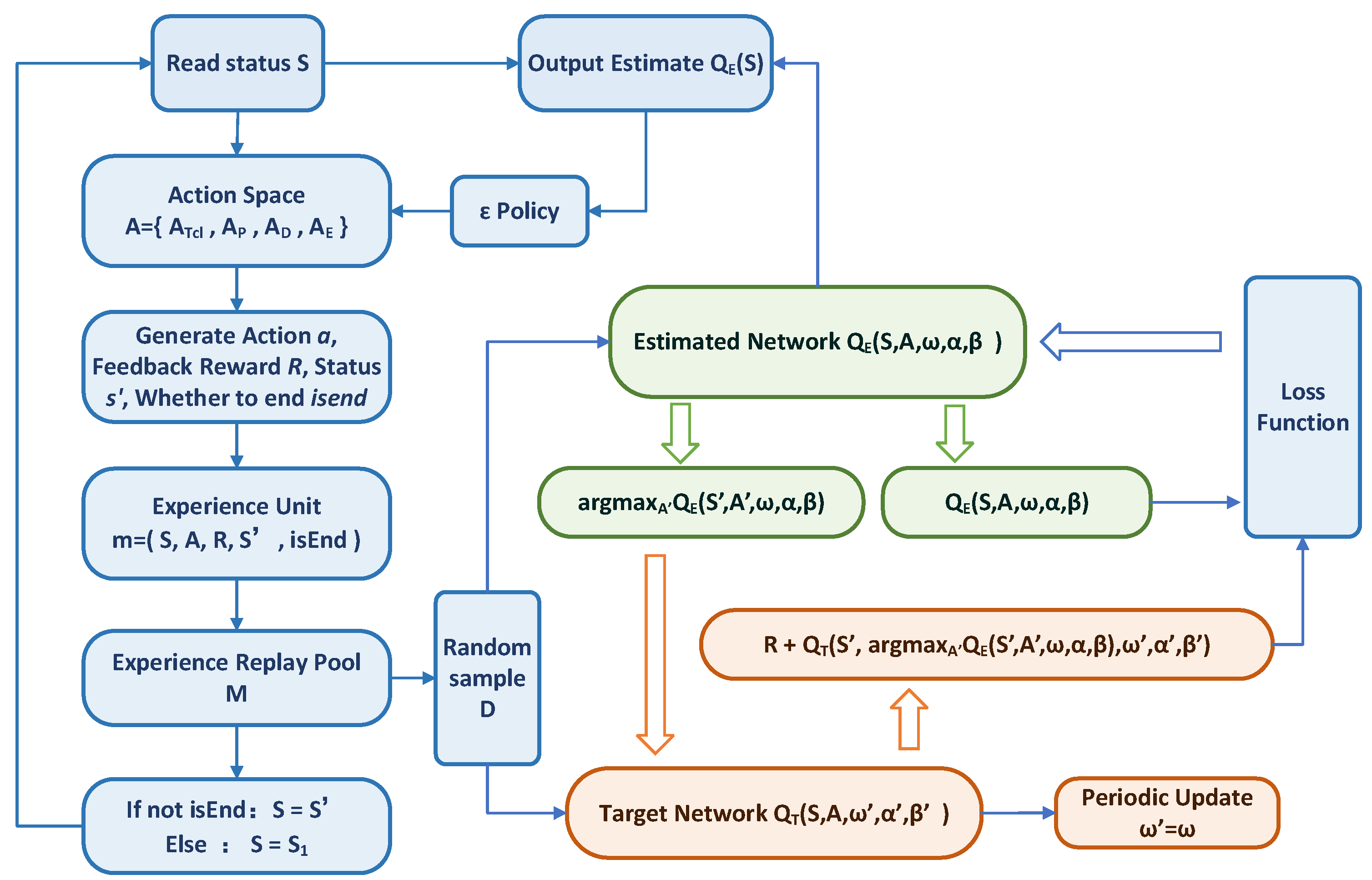
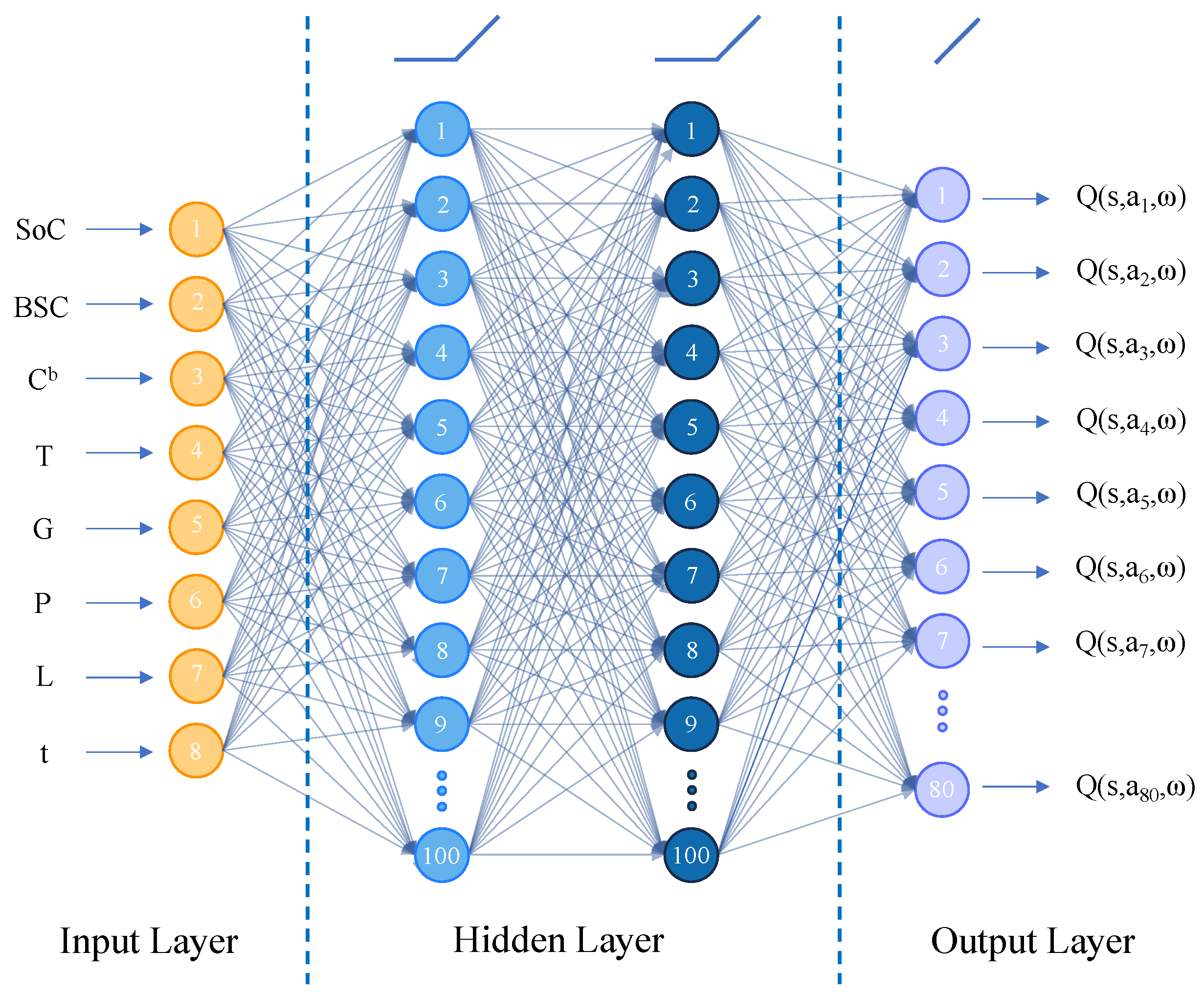
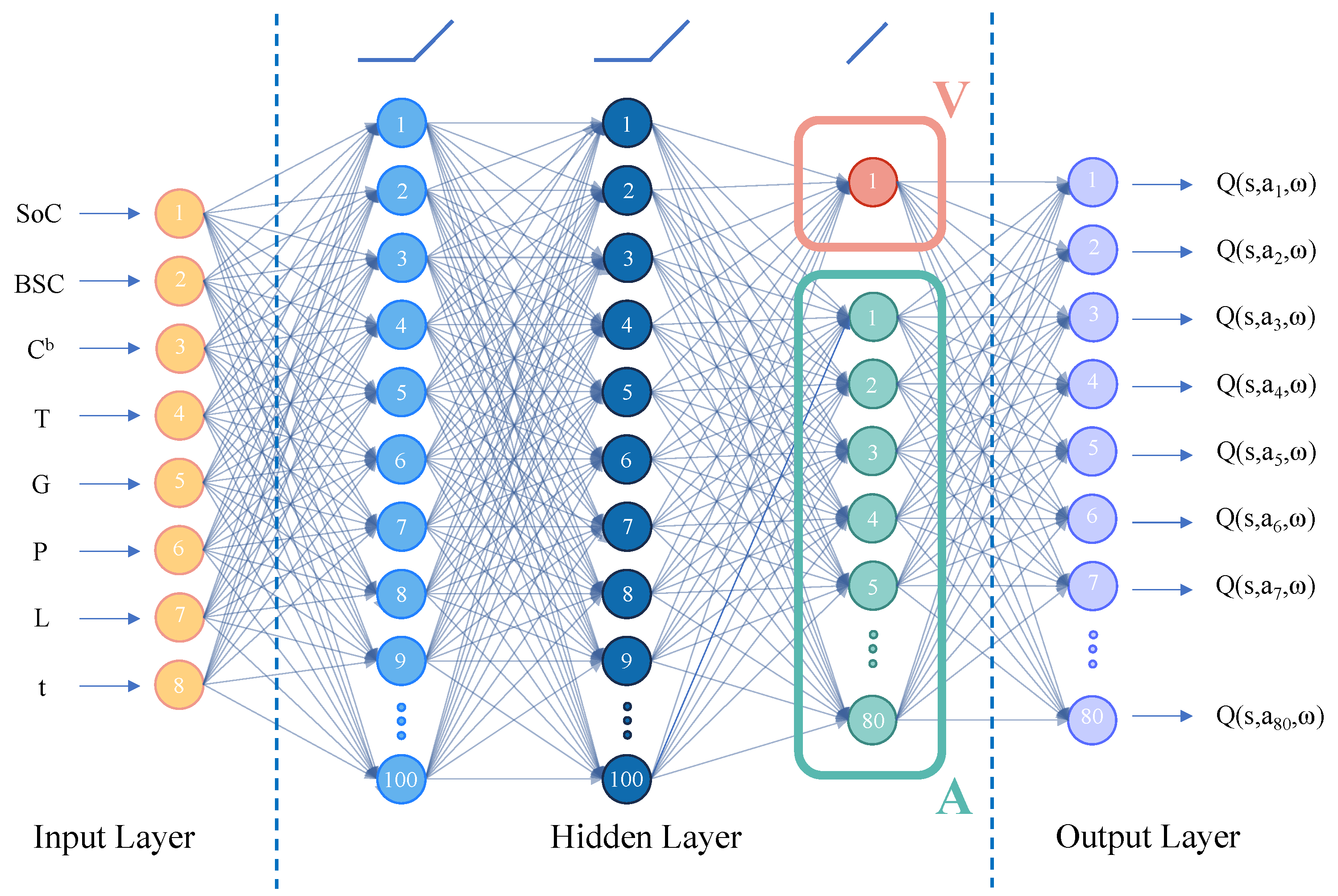
2.2. D3QN
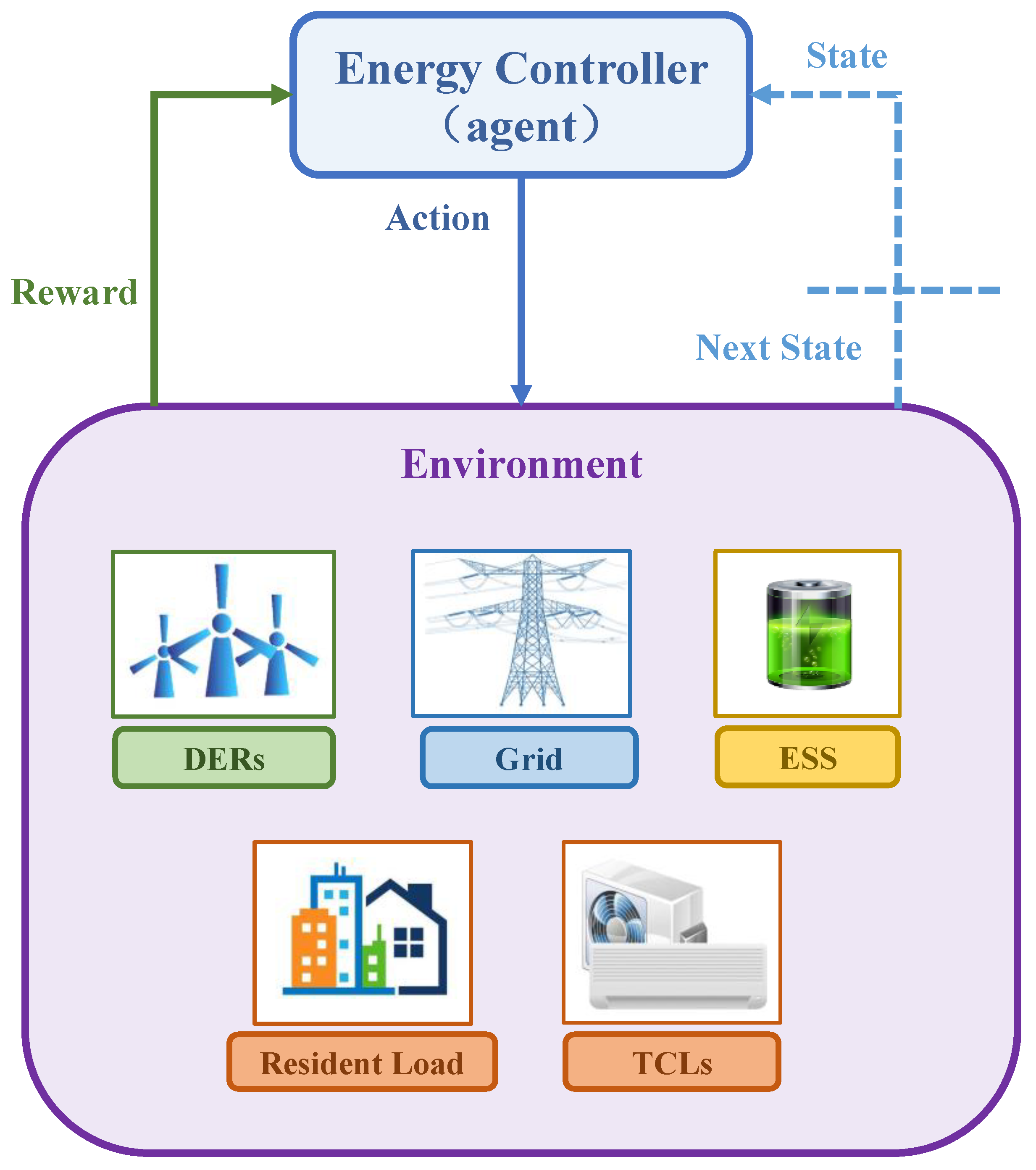
3. Wind-Storage Cooperative Decision-Making Based on D3QN
3.1. State Space
3.2. Action Space
3.3. Reward Function and Penalty Function
4. Implementation Details
5. Algorithm Evaluation
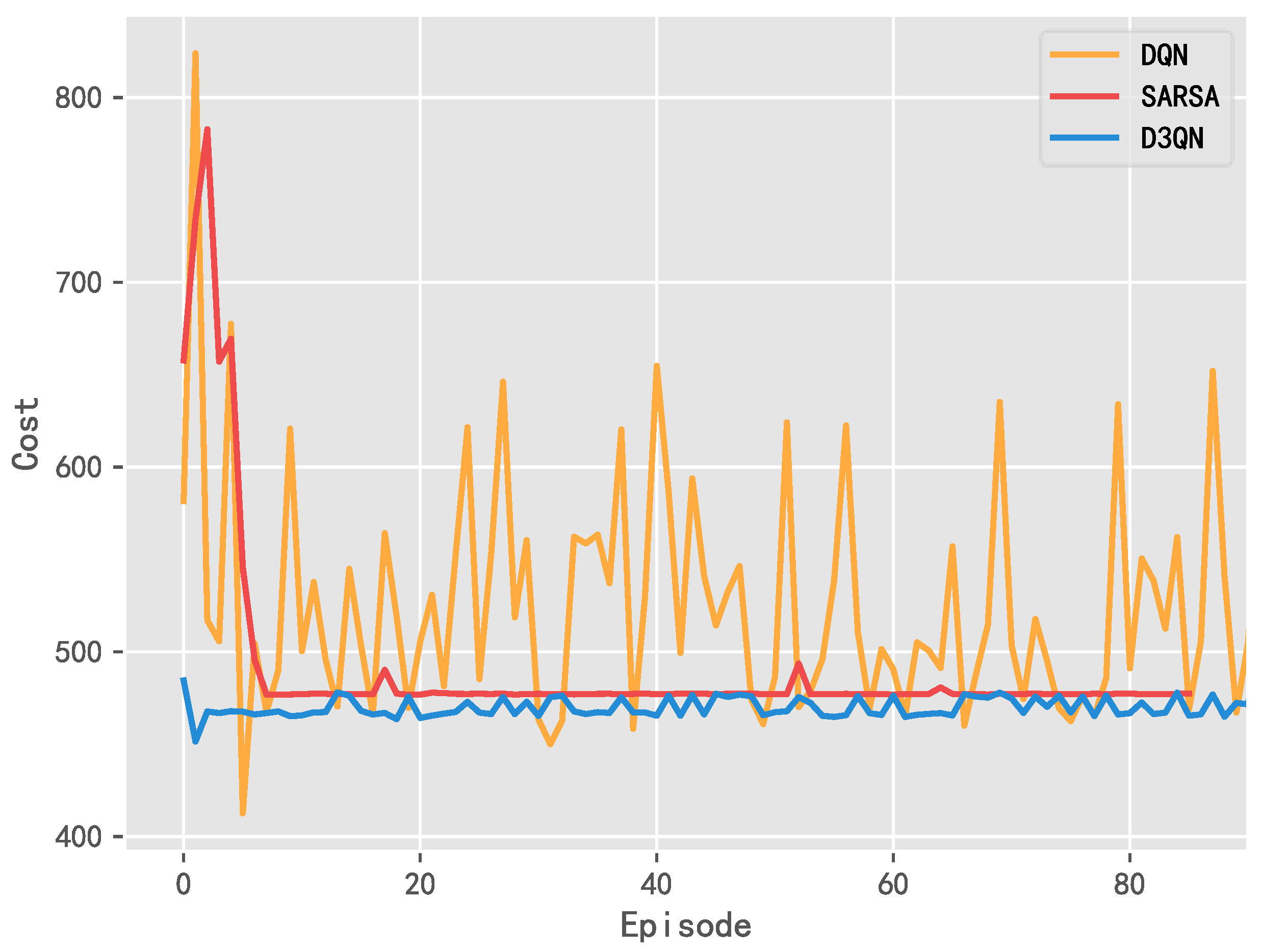
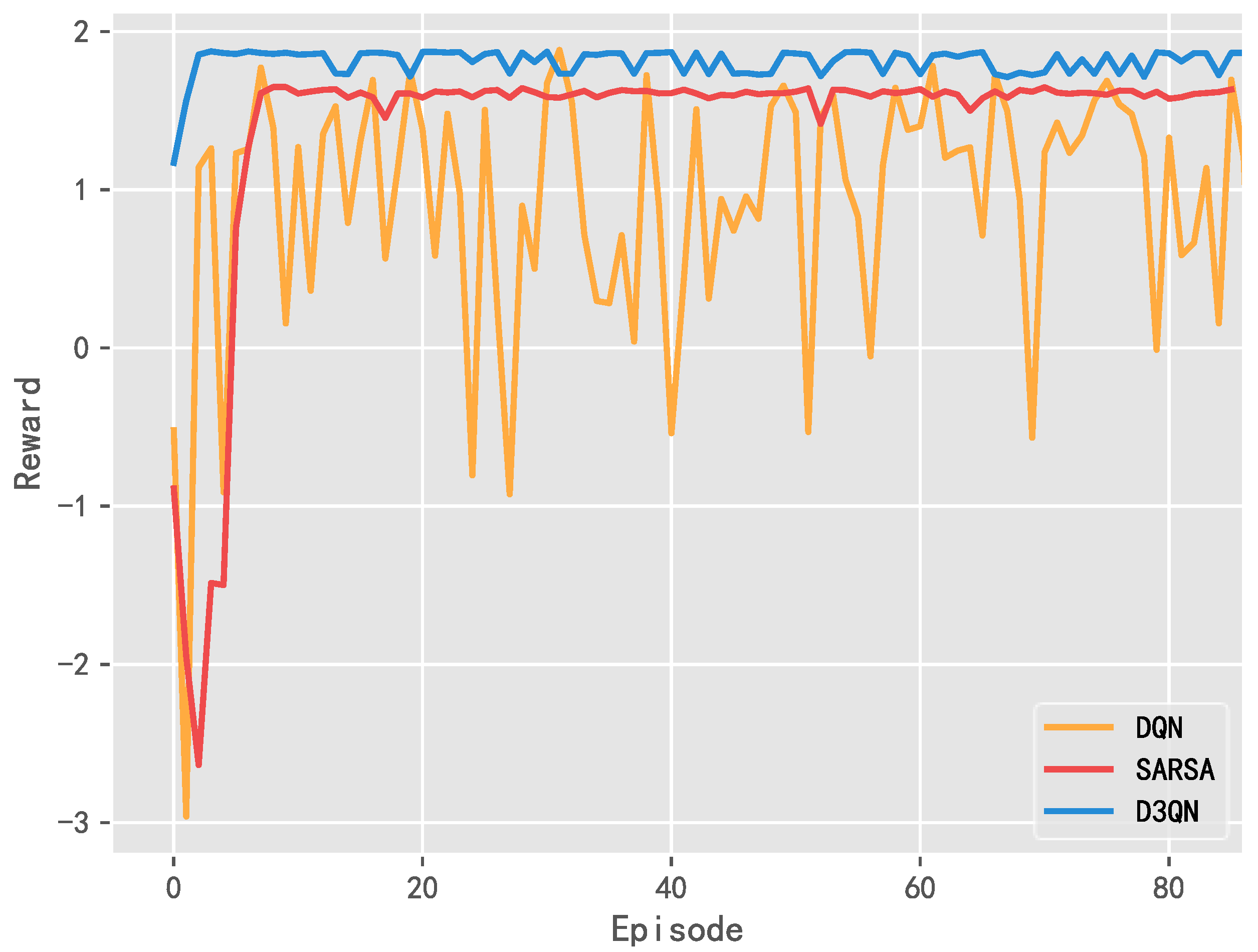
5.1. Comparisons of Training Results
5.1.1. Penalty Value Curve
5.1.2. Reward Value Curve
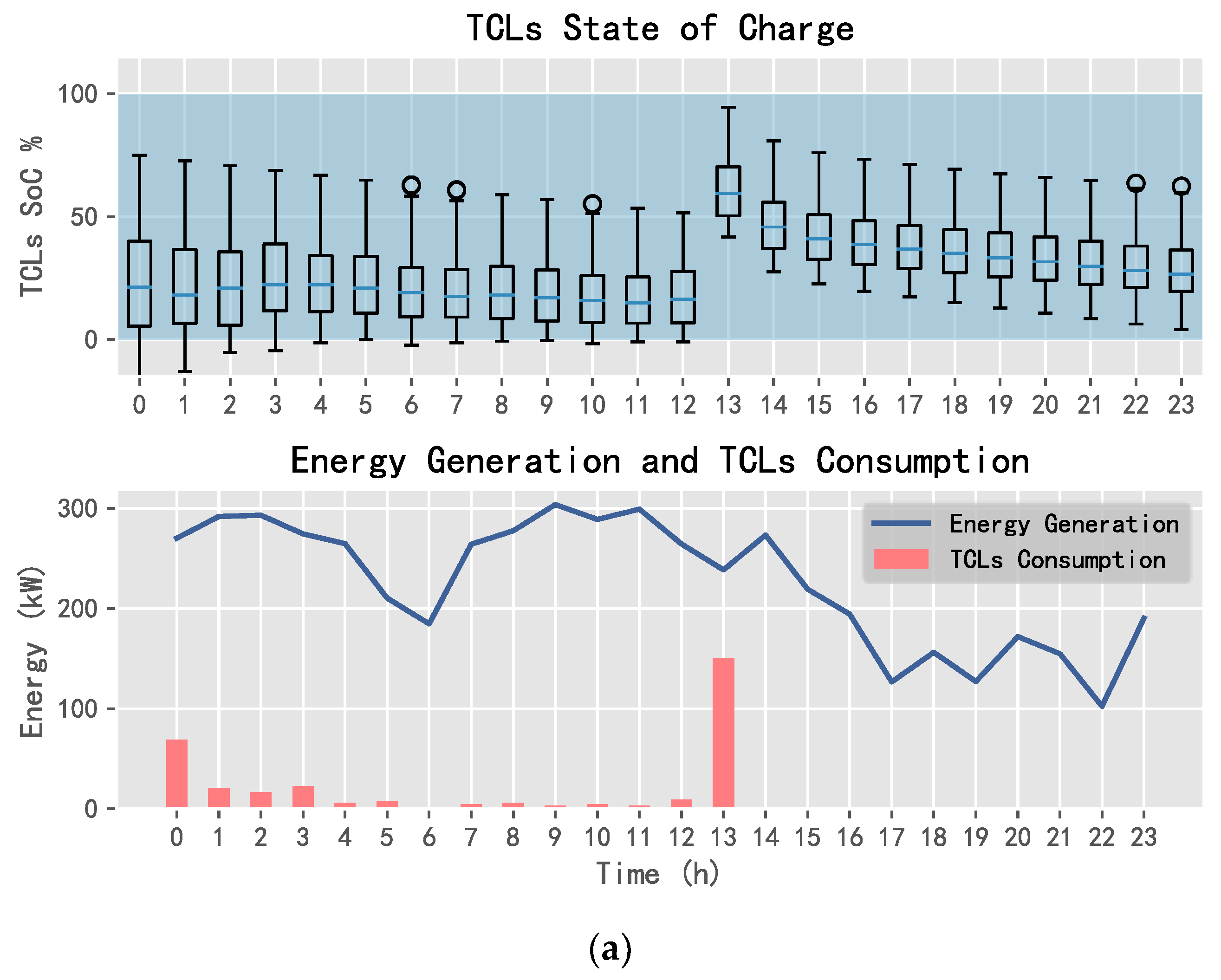
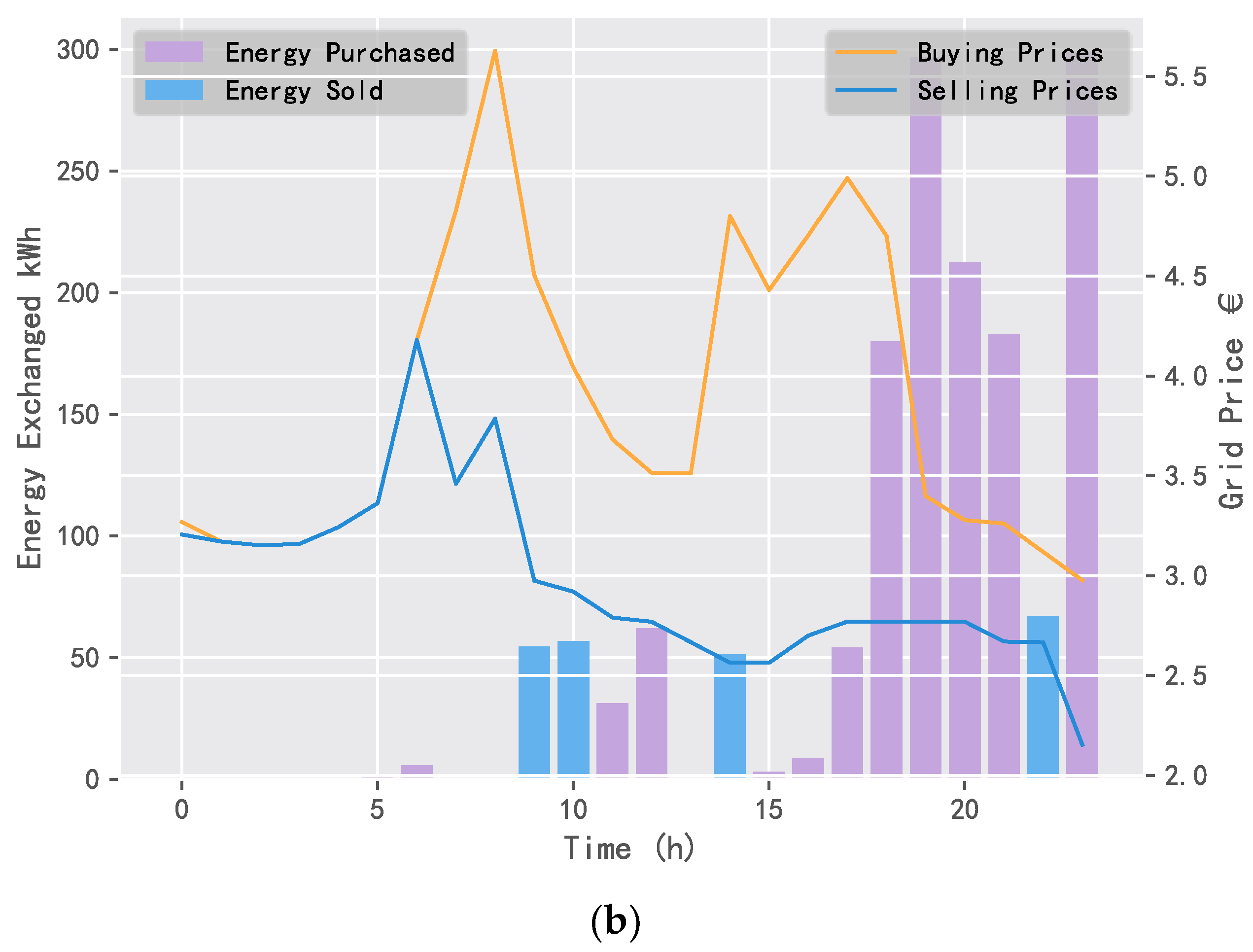
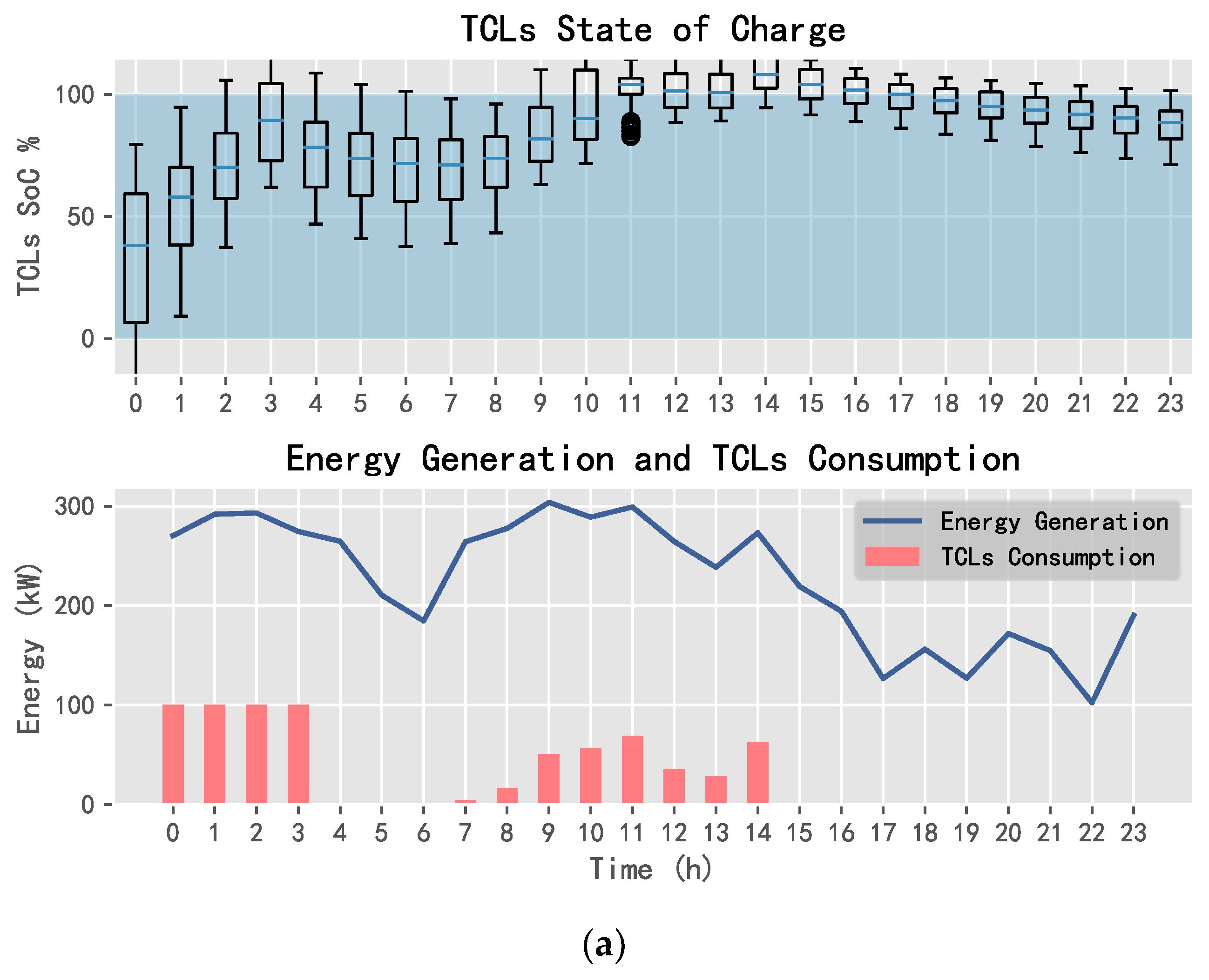
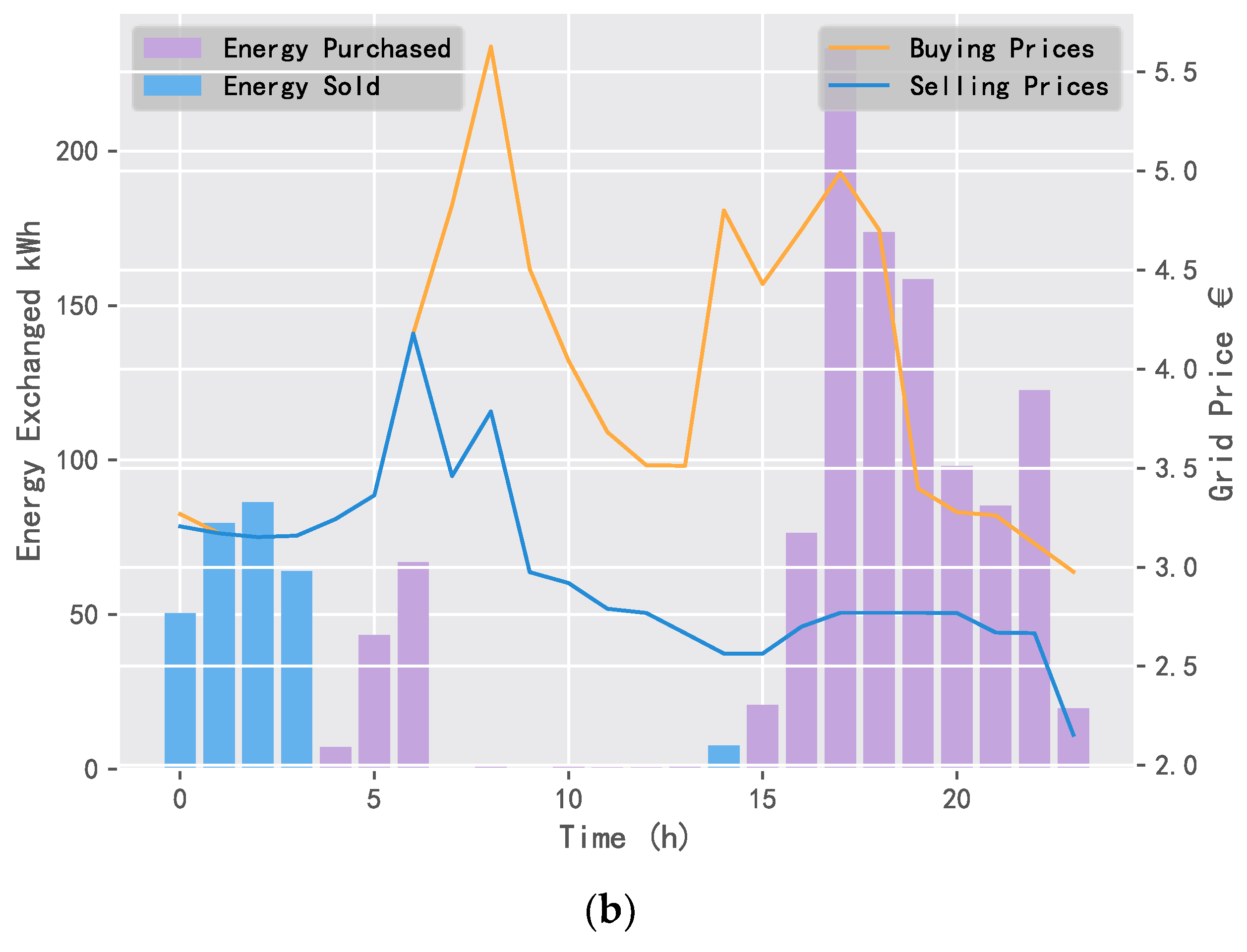
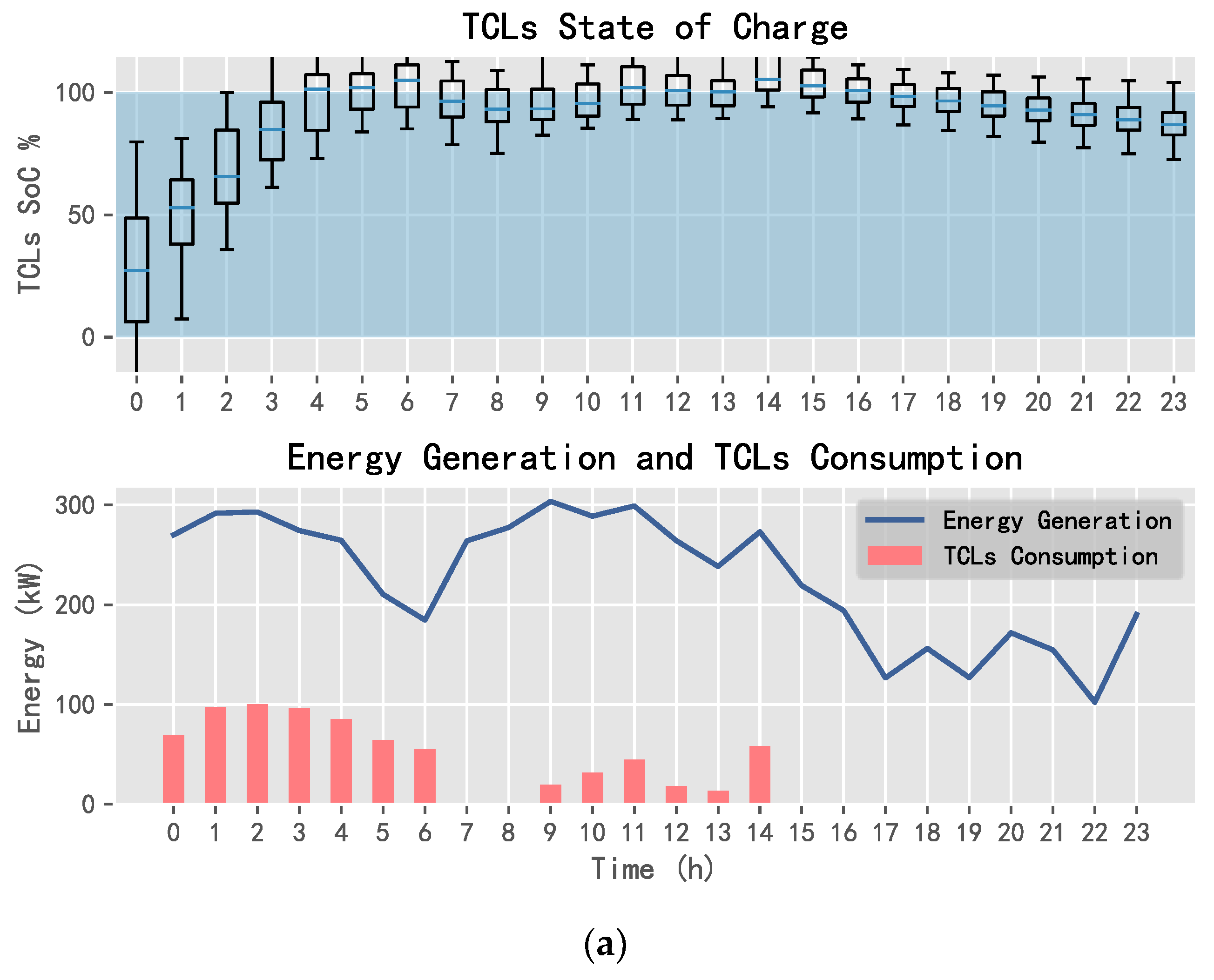
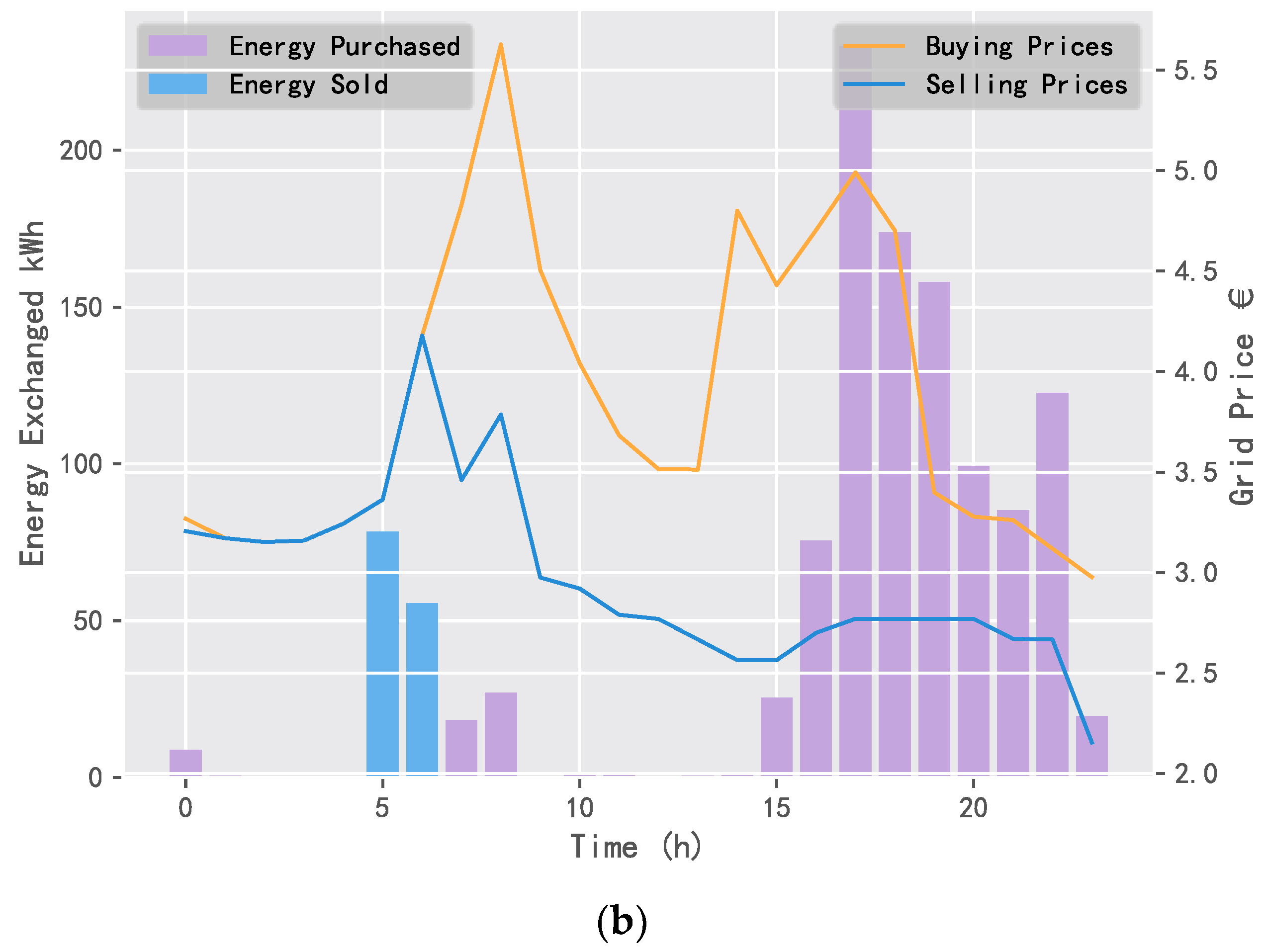
5.2. Comparison of Application Results
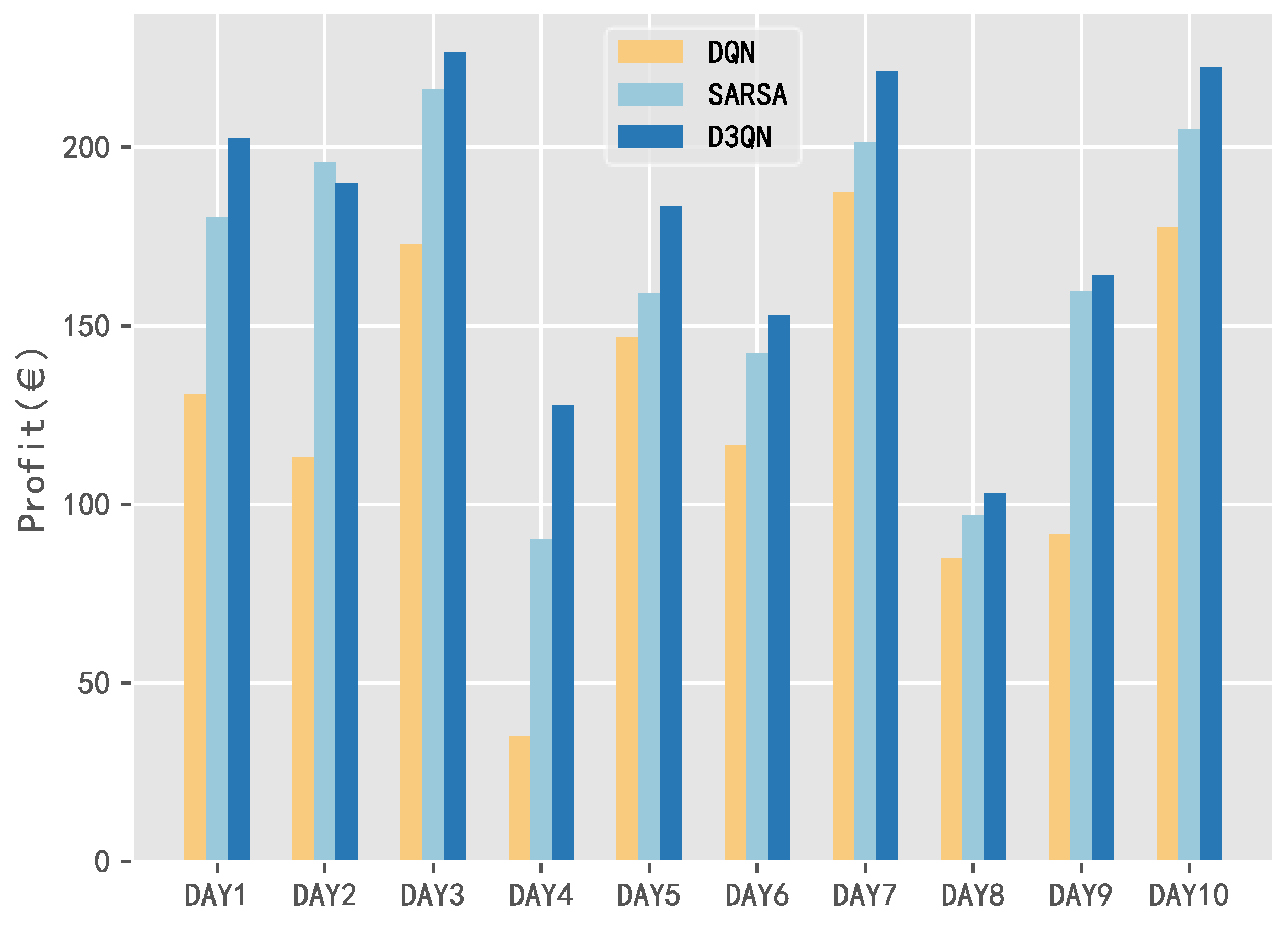
5.2.1. 10 Day Revenue Comparison
5.2.2. Daily Electricity Trading Comparison
5.2.3. Computational Efficiency Comparison
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Conflicts of Interest
References
- Li, J.; Zhao, H. Multi-Objective Optimization and Performance Assessments of an Integrated Energy System Based on Fuel, Wind 541 and Solar Energies. Entropy 2021, 23, 431. [Google Scholar] [CrossRef] [PubMed]
- Bin, L.; Shahzad, M.; Javed, H.; Muqeet, H.A.; Akhter, M.N.; Liaqat, R.; Hussain, M.M. Scheduling and Sizing of Campus Microgrid Considering Demand Response and Economic Analysis. Sensors 2022, 22, 6150. [Google Scholar] [CrossRef]
- Chu, Y.; Fu, S.; Hou, S.; Fei, J. Intelligent Terminal Sliding Mode Control of Active Power Filters by Self-evolving Emotional Neural Network. IEEE Trans. Ind. Inform. 2022. [Google Scholar] [CrossRef]
- Almughram, O.; Ben Slama, S.; Zafar, B. Model for Managing the Integration of a Vehicle-to-Home Unit into an Intelligent Home Energy Management System. Sensors 2022, 22, 8142. [Google Scholar] [CrossRef]
- Shi, J.; Lee, W.-J.; Liu, X. Generation Scheduling Optimization of Wind-Energy Storage System Based on Wind Power Output Fluctuation Features. IEEE Trans. Ind. Appl. 2018, 54, 10–17. [Google Scholar] [CrossRef]
- Sun, K.; Xiao, H.; Pan, J.; Liu, Y. VSC-HVDC Interties for Urban Power Grid Enhancement. IEEE Trans. Power Syst. 2021, 36, 4745–4753. [Google Scholar] [CrossRef]
- Kazda, J.; Cutululis, N.A. Model-Optimized Dispatch for Closed-Loop Power Control of Waked Wind Farms. IEEE Trans. Control Syst. Technol. 2020, 28, 2029–2036. [Google Scholar] [CrossRef]
- Zhang, Z.; Zhou, M.; Wu, Z.; Liu, S.; Guo, Z.; Li, G. A Frequency Security Constrained Scheduling Approach Considering Wind Farm Providing Frequency Support and Reserve. IEEE Trans. Sustain. Energy 2022, 13, 1086–1100. [Google Scholar] [CrossRef]
- Yin, X.; Zhao, X. Deep Neural Learning Based Distributed Predictive Control for Offshore Wind Farm Using High-Fidelity LES Data. IEEE Trans. Ind. Electron. 2021, 68, 3251–3261. [Google Scholar] [CrossRef]
- Zhang, K.; Geng, G.; Jiang, Q. Online Tracking of Reactive Power Reserve for Wind Farms. IEEE Trans. Sustain. Energy 2020, 11, 1100–1102. [Google Scholar] [CrossRef]
- Wei, X.; Xiang, Y.; Li, J.; Zhang, X. Self-Dispatch of Wind-Storage Integrated System: A Deep Reinforcement Learning Approach. IEEE Trans. Sustain. Energy 2022, 13, 1861–1864. [Google Scholar] [CrossRef]
- Ding, T.; Zeng, Z.; Qu, M.; Catalão, J.P.S.; Shahidehpour, M. Two-Stage Chance-Constrained Stochastic Thermal Unit Commitment for Optimal Provision of Virtual Inertia in Wind-Storage Systems. IEEE Trans. Power Syst. 2021, 36, 3520–3530. [Google Scholar] [CrossRef]
- Zhang, Z.; Wang, D.; Gao, J. Learning Automata-Based Multiagent Reinforcement Learning for Optimization of Cooperative Tasks. IEEE Trans. Neural Netw. Learn. Syst. 2021, 32, 4639–4652. [Google Scholar] [CrossRef]
- Fei, H.; Zhang, Y.; Ren, Y.; Ji, D. Optimizing Attention for Sequence Modeling via Reinforcement Learning. IEEE Trans. Neural Netw. Learn. Syst. 2022, 33, 3612–3621. [Google Scholar] [CrossRef]
- Jia, Y.; Dong, Z.Y.; Sun, C.; Meng, K. Cooperation-Based Distributed Economic MPC for Economic Load Dispatch and Load Frequency Control of Interconnected Power Systems. IEEE Trans. Power Syst. 2019, 34, 3964–3966. [Google Scholar] [CrossRef]
- Shangguan, X.-C.; He, Y.; Zhang, C.K.; Jin, L.; Yao, W.; Jiang, L.; Wu, M. Control Performance Standards-Oriented Event-Triggered Load Frequency Control for Power Systems Under Limited Communication Bandwidth. IEEE Trans. Control Syst. Technol. 2022, 30, 860–868. [Google Scholar] [CrossRef]
- Chu, Y.; Hou, S.; Wang, C.; Fei, J. Recurrent-Neural-Network-Based Fractional Order Sliding Mode Control for Harmonic Suppression of Power Grid. IEEE Trans. Ind. Inform. 2023, 305. [Google Scholar] [CrossRef]
- Sadeghian, O.; Oshnoei, A.; Tarafdar-Hagh, M.; Kheradmandi, M. A Clustering-Based Approach for Wind Farm Placement in Radial Distribution Systems Considering Wake Effect and a Time-Acceleration Constraint. IEEE Syst. J. 2021, 15, 985–995. [Google Scholar] [CrossRef]
- Huang, S.; Li, P.; Yang, M.; Gao, Y.; Yun, J.; Zhang, C. A Control Strategy Based on Deep Reinforcement Learning Under the Combined Wind-Solar Storage System. IEEE Trans. Ind. Appl. 2021, 57, 6547–6558. [Google Scholar] [CrossRef]
- Liu, F.; Liu, Q.; Tao, Q.; Huang, Y.; Li, D.; Sidorov, D. Deep reinforcement learning based energy storage management strategy considering prediction intervals of wind power. Int. J. Electr. Power Energy Syst. 2023, 145, 108608. [Google Scholar] [CrossRef]
- Yang, J.J.; Yang, M.; Wang, M.X.; Du, P.J.; Yu, Y.X. A deep reinforcement learning method for managing wind farm uncertainties through energy storage system control and external reserve purchasing. Int. J. Electr. Power Energy Syst. 2020, 119, 105928. [Google Scholar] [CrossRef]
- Sang, J.; Sun, H.; Kou, L. Deep Reinforcement Learning Microgrid Optimization Strategy Considering Priority Flexible Demand Side. Sensors 2022, 22, 2256. [Google Scholar] [CrossRef] [PubMed]
- Sanaye, S.; Sarrafi, A. A novel energy management method based on Deep Q Network algorithm for low operating cost of an integrated hybrid system. Energy Rep. 2021, 7, 2647–2663. [Google Scholar] [CrossRef]
- Zhu, J.; Hu, W.; Xu, X.; Liu, H.; Pan, L.; Fan, H.; Zhang, Z.; Chen, Z. Optimal scheduling of a wind energy dominated distribution network via a deep reinforcement learning approach. Renew. Energy 2022, 201, 792–801. [Google Scholar] [CrossRef]
- Fingrid. Fingrid Open Datasets. 2019. Available online: https://data.fingrid.fi/open-data-forms/search/en/index.html (accessed on 12 December 2019).
- Barbour, E.; Parra, D.; Awwad, Z.; González, M.C. Community energy storage: A smart choice for the smart grid? Appl. Energy 2018, 212, 489–497. [Google Scholar] [CrossRef] [Green Version]
- Claessens, B.J.; Vrancx, P.; Ruelens, F. Convolutional neural networks for automatic state-time feature extraction in reinforcement learning applied to residential load control. IEEE Trans. Smart Grid 2018, 9, 3259–3269. [Google Scholar] [CrossRef] [Green Version]
- Nakabi, T.A.; Toivanen, P. Optimal price-based control of heterogeneous thermostatically controlled loads under uncertainty using LSTM networks and genetic algorithms. F1000Research 2019, 8, 1619. [Google Scholar] [CrossRef]
- Zhang, C.; Xu, Y.; Dong, Z.Y.; Wong, K.P. Robust coordination of distributed generation and price-based demand response in microgrids. IEEE Trans. Smart Grid 2018, 9, 4236–4247. [Google Scholar] [CrossRef]
- De Jonghe, C.; Hobbs, B.F.; Belmans, R. Value of price responsive load for wind integration in unit commitment. IEEE Trans. Power Syst. 2014, 29, 675–685. [Google Scholar] [CrossRef]
- Song, M.; Gao, C.; Shahidehpour, M.; Li, Z.; Yang, J.; Yan, H. Impact of Uncertain Parameters on TCL Power Capacity Calculation via HDMR for Generating Power Pulses. IEEE Trans. Smart Grid 2019, 10, 3112–3124. [Google Scholar] [CrossRef]
- Residential Electric Rates & Line Items. 2019. Available online: https://austinenergy.com/ae/residential/rates/residential-electric-rates-and-line-items (accessed on 16 December 2019).
- Littman, M.L. Markov decision processes. In International Encyclopedia of the Social & Behavioral Sciences; Elsevier: Amsterdam, The Netherlands, 2001; pp. 9240–9242. [Google Scholar]






















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Value |
|---|---|
| ESS | |
| 0.9 | |
| 0.9 | |
| 250 kW | |
| 250 kW | |
| 500 kWh | |
| DER | |
| 1% of the hourly wind power generation (kW) | |
| 32 €/MW | |
| Power grid | |
| Reduced electricity prices | |
| Increased electricity prices | |
| 9.7 €/MW | |
| 0.9 €/MW | |
| TCL | |
| 100 (Number of TCL) | |
| Outdoor temperature hourly | |
| 19 | |
| 35 | |
| Load | |
| 150 | |
| Basic load of residents | |
| Other parameters | |
| 24 | |
| {−2,−1,0,1,2} | |
| 1.5 | |
| 4 | |
| 5.48 €/kW | |
| Parameters involved in the algorithm | |
| 80 | |
| {0,50,100,150} | |
| {−2,−1,0,1,2} | |
| {ESS,Grid} | |
| {ESS,Grid} | |
| 0.9 | |
| 1 h |
| Algorithm | Training Time (s) | Average Value of Final Reward | Performance Improvement Rate |
|---|---|---|---|
| DQN | 196.0111 | 1.2443 | - |
| SARSA | 415.5845 | 1.6239 | 30.5% |
| D3QN | 244.1469 | 1.7909 | 43.93% |
| Algorithm | Training Time (s) | Decision-Making Time (s) | The Number of Trainable Parameters | Performance Improvement Rate |
|---|---|---|---|---|
| DQN | 196.0111 | 0.347 | 8980 | - |
| SARSA | 415.5845 | 0.354 | 19,080 | 30.5% |
| D3QN | 244.1469 | 0.390 | 27,160 | 43.93% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhai, S.; Li, W.; Qiu, Z.; Zhang, X.; Hou, S. An Improved Deep Reinforcement Learning Method for Dispatch Optimization Strategy of Modern Power Systems. Entropy 2023, 25, 546. https://doi.org/10.3390/e25030546
Zhai S, Li W, Qiu Z, Zhang X, Hou S. An Improved Deep Reinforcement Learning Method for Dispatch Optimization Strategy of Modern Power Systems. Entropy. 2023; 25(3):546. https://doi.org/10.3390/e25030546
Chicago/Turabian StyleZhai, Suwei, Wenyun Li, Zhenyu Qiu, Xinyi Zhang, and Shixi Hou. 2023. "An Improved Deep Reinforcement Learning Method for Dispatch Optimization Strategy of Modern Power Systems" Entropy 25, no. 3: 546. https://doi.org/10.3390/e25030546