1. Introduction
In the medical field, it is necessary to judge the accuracy and the interchangeability of different diagnostics. Inter-rater agreement is widely used to quantify the closeness of ratings for subjects by two raters. The recommendation of an efficient and economical method should guarantee a high degree of agreement between its result and the gold-standard method. A simple example is that independent raters A and B assess each subject with binary outcomes (e.g.,
, and Yes/No). Let
be the numbers of independent subjects judged by two raters as
,
,
, and
, and
be the corresponding probabilities, respectively. Denote
. The data can be arranged into a
original table (
Table 1).
Researchers have developed several indices by which to measure the degree of agreement between raters on a nominal scale category, where the unordered categories are independent, mutually exclusive, and exhaustive. Denote
,
. We call
as the marginal probability. Cohen [
1] showed that the
test was indefensible because of the null hypothesis with independence, not agreement. Furthermore, he presented the kappa coefficient to compute the extent of agreement between raters. For the problem of nominal scale agreement between raters A and B in
Table 1, there are only two relevant quantities: the overall agreement probability
, and the chance–agreement probability
. Cohen’s kappa coefficient is defined by
where
,
. That is to say, the coefficient
is the proportion of agreement after the removal of chance agreement. Suppose that the distribution of proportions over the categories for the population is known and is taken to be equal for the judges. Thus, Scott [
2] proposed
coefficient
, where
is the percent agreement to be expected on the basis of chance, and
. Despite the wide range of applications, the limitations of these coefficients have two main aspects: (i) it highly depends on marginal probabilities [
3], and (ii) it is often affected by the composition of the population for subjects easy or difficult to agree upon [
4]. For example, Cicchetti and Feinstein [
3] illustrated one of the limitations by an example:
,
,
, and
. Through simple calculation,
,
. Thus, the estimator
. For Scott’s
coefficient, we have
because
. It is unreasonable that a high agreement has low
and
coefficients. To solve the problem, some alternative indices have been derived to measure the consistency, such as Holley and Guilford’s G index [
5], Aickin’s
agreement parameter [
6], Andr
s and Marzo’s delta measure [
7]. Gwet [
8] revealed the origin of these limitations and proposed the first-order agreement coefficient (AC
) as an alternative index. The definition of this coefficient is based on two premises: (a) chance agreement occurs when at least one rater rates an individual randomly, and (b) only an unknown portion of observed ratings is subjected to randomness. Define two events
Thus, the probability of agreement expected by chance can be defined by
Generally, a random rating may classify an individual into either category with the same probability of
. Since agreement may occur in either type, we have
. As for the probability of random rating
, a normalized measure of randomness (
) is used to approximate it as follows,
where
represents the probability that a random rater classifies a randomly chosen individual into the “+” category. That is to say,
can be quantified by
. Then, the AC
coefficient can be expressed as
where
denotes the agreement probability. In the above example,
and
. By the definition of AC
, we have
. Thus, the AC
coefficient is more consistent with the observed extent of agreement than Cohen’s
and Scott’s
coefficients. There have been quite a few pieces of literature about agreement coefficients [
9,
10,
11].
As with Scott’s
coefficient, Ohyama [
12] assumed that two raters have a common marginal probability, that is,
. Thus,
, and
Table 1 can be simplified as
Table 2. Define
for
. Suppose that the underlying probability of classifying a subject depends not on raters but subjects, which is
. We can obtain the overall agreement probability
based on the idea of Vanbelle and Albert [
13]. The agreement can occur in
and
, and the corresponding probabilities for
jth subject are
and
, respectively. Thus, the agreement probability of two raters for the
jth subject is
. We denote the mean of positive classification probability as
, and the corresponding variance as
, where
n is the size of the population. Then, the probabilities of
and
ratings over the population are
and
. Finally, the agreement probability over the population is
. The AC
coefficient (
) for a binary outcome judged by two raters is rewritten by
Up until now, the application [
14,
15] and the statistical inference [
12] of the AC
have been concentrated at the situation without stratification. However, the ignorance of confounding variables or covariates may lead to a biased conclusion. Researchers often stratify the data into multiple strata to control the influence of these factors. A stratified analysis is applied to evaluate the relationship between the nontreatment factors of a clinical trial (age, gender, or severity of disease, etc.) and agreement. A test of homogeneity is the first step of the stratified analysis. It is essential to analyze the factors that lead to heterogeneity when we reject the homogeneity hypothesis. Suppose
K levels of the subject covariates are introduced into
Table 2 for two raters with binary outcome, and the data can be arranged in a
table of observed cell counts. Generally speaking, a sample can be classified as a large or small sample by the sample size. Hannah et al. [
16] analyzed the data about the alcohol-drinking status of twins. A subject is categorised as nondrinker if he/she consumes less than 30 gm alcohol per week, and otherwise is a drinker. Thus, the binary outcome is the drinking status (drinker or nondrinker). A number of same-sex twins are stratified by zygosity, including monozygotic (MZ), and dizygotic (DZ). Nam [
17] used the kappa index to investigate the agreement of alcohol-drinking status between twins. The data structure of male twins is shown in
Table 3. The large-sample inference has been performed for the data type, including score, likelihood ratio, and Wald-type statistics [
18]. Honda and Ohyama [
19] proposed score and goodness-of-fit tests for the homogeneity test of stratified AC
. Unfortunately, both tests performed poorly due to the conservative or liberal type I error rates, especially for small sample sizes. Meanwhile, a high AC
may lead to conservative type I error rates for small and moderate sample sizes.
In practice, we often encounter small sample cases of agreement data, for example, a clinical trial about coronavirus disease 2019 (COVID-19) [
20]. In this trial, the enzyme-linked immunosorbent assay (ELISA) and gold-standard methods are used to detect the novel coronavirus IgG and IgM antibodies, classifying each of them as either positive
or negative
. ELISA positive criterion is that the sample’s optical density (OD) value is greater than or equal to the critical value. The positive criterion of the gold-standard method is the appearance of two colored bands.
Table 4 lists the data stratified by the IgG and the IgM antibodies
, 17 patients in each group. Similar to
Table 3, “One” entry corresponds to the number of “
” and “
”.
Unfortunately, asymptotic test statistics do not apply to small data. Exact approaches are effective for small samples, such as Fisher’s exact test [
21,
22,
23], and its extensions [
24,
25,
26]. A conservative performance of Fisher’s exact method supported the appearance of other exact approaches. We note that there exist nuisance parameters in the model of AC
coefficient. Significant progress has been achieved in the elimination of nuisance parameters for decades [
27,
28,
29,
30,
31]. By fixing the marginal totals in the contingency table, Mehta [
27] extensively used the conditional test (referred to as the C approach) to analyze various classical categorical data. Liddell [
28] derived a test based on the exact distribution of the difference in sample proportions. As an alternative, Storer and Kim [
29] modified Liddell’s exact test, abbreviated as the E approach. Basu [
30] provided a new procedure by maximizing the tail probability over the whole range of parameters, called the M approach. The global maximum is a challenge when the parameter space is not finite. Lloyd [
31] pointed out the weakness of the M approach, and he suggested a so-called E+M approach by defining the tail area with the E approach and maximizing the tail probability over the parameter space. Generally, E, M, and E+M approaches are called unconditional tests. Tang et al. [
32] showed that the exact conditional approach was generally inferior to the exact unconditional approach for small samples. Shan and Wilding [
33] compared asymptotic and exact procedures for the kappa coefficient in a
table. However, little work has been carried out in extending the exact approaches to test the homogeneity of the AC
coefficients across several independent strata.
This paper aims to propose asymptotic and exact methods for the homogeneity test of stratified AC
. The novelty and contribution are shown by three main aspects as follows. (i) For large sample sizes, we propose two asymptotic statistics, including likelihood ratio and Wald-type tests, to extend the study of homogeneity test in Honda and Ohyama [
19] under large sample sizes. Our results show that the likelihood ratio test is more robust than other tests regarding type I error rates. The powers of these tests are close to each other. Thus, we recommend the likelihood ratio test for large samples’ homogeneity test of stratified AC
. (ii) Based on the asymptotic statistics, we derive three exact approaches (E, M, and E+M methods) to investigate the small sample cases (
). These exact methods can effectively improve the performance of the homogeneity test concerning type I error rates. Among these methods, the exact E approaches based on likelihood ratio and score tests are more robust in small samples. (iii) We investigate the strengths and weaknesses of asymptotic and exact methods through plentiful numerical analyses, respectively. Some beneficial conclusions are obtained from the analyses of actual examples. The rest of this paper is organized as follows. In
Section 2, we review the AC
coefficient in a stratified condition and establish a probability model. The maximum likelihood method and iterative algorithm are used to estimate the unknown parameters. We further review the score statistic and derive two asymptotic test statistics for large samples in
Section 3. Based on these statistics, several exact methods are used for small sample sizes in
Section 4. In
Section 5, we conduct numerical studies to investigate the performance of all the derived methods regarding type I error rates and powers. In
Section 6, we study the aforementioned real examples of large and small samples to illustrate these methods. Finally, a brief conclusion is given in
Section 7.
2. A Probability Model and Homogeneity Test
Following Ohyama [
12], we introduce
K covariates into
Table 2 and establish a probability model. Suppose that
N subjects are divided into
K independent strata. In the
kth (
) stratum, there are
, and
subjects in the three categories. Denote
as the total number of subjects in the
kth stratum.
Table 5 shows the data structure across the strata.
For the stratified analysis, we need to construct AC
for each stratum. Let
be an indicator of the
ith
rater’s judgement for the
jth
subject in the
kth
stratum. If there is a positive “
” classification, then
, and otherwise 0. Ohyama [
12] assumed that the underlying probability of classifying a subject does not depend on raters but on subjects; that is,
. The
N subjects are classified into
K strata based on covariates, and every stratum has different subjects. Thus, the data of every stratum is independent of each other. Denote
, and
. Then, AC
of the
kth stratum is
Suppose that
,
, and
are the corresponding probabilities in the
kth stratum, where
and
are the common positive classification probability and the AC
coefficient, respectively. As the AC
coefficient in the
kth stratum,
includes the information of
and
. It is obvious that there is no one-to-one correspondence between
and
. Denote
, and
,
,
. For the
kth stratum,
follows a trinomial distribution. Thus, the probability density of
is expressed as follows:
Through calculation, the probabilities
are obtained by
where
and
.
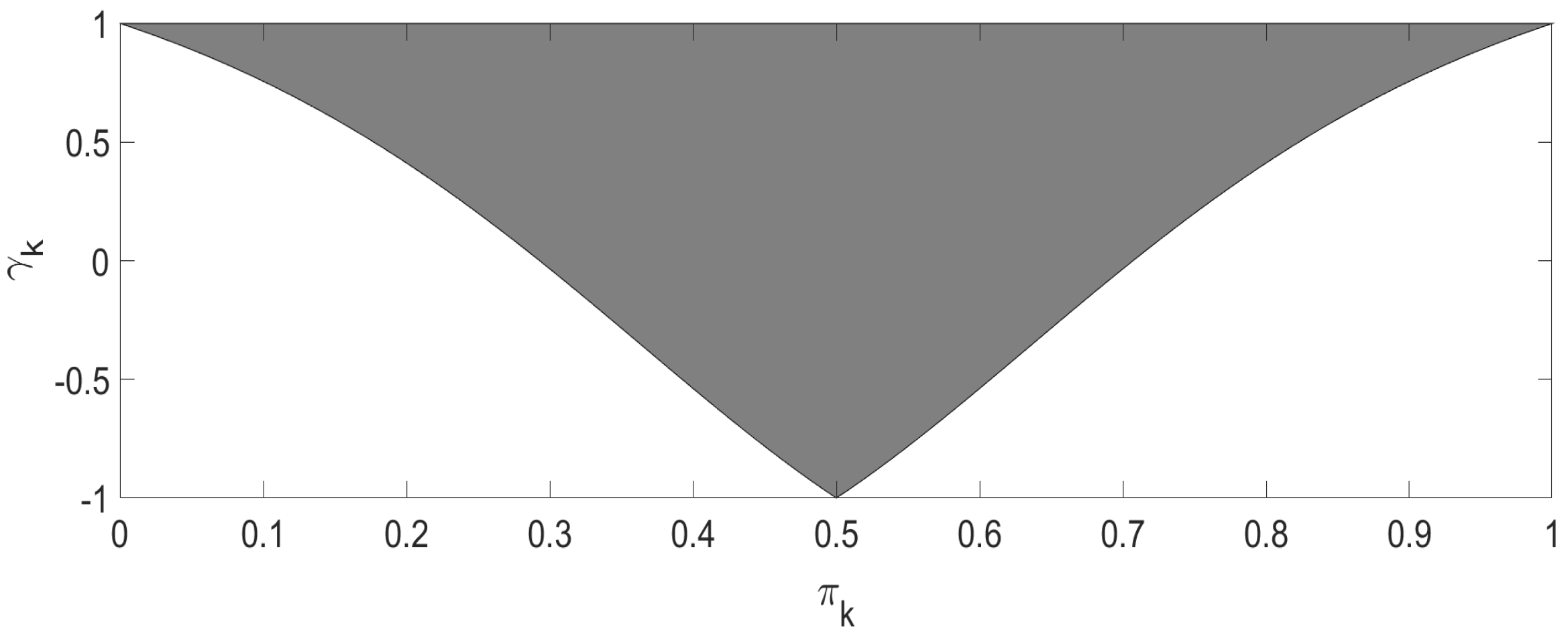
Figure 1 shows the admissible range of
, satisfying
Our work is interested in testing whether the AC
coefficients
are homogeneous among the
K independent strata, that is,
Denote
and
. First, we calculate the unknown parameters under the alternative hypothesis
. The corresponding log-likelihood function of the observed data
is
where
is a constant, and
is the log-likelihood function of the
kth stratum under
. Let
and
be the unconstrained maximum likelihood estimates (MLEs) of
and
under
. By solving the following equations,
we have
Next, we estimate the parameters
and
under the null hypothesis
. The log-likelihood function is rewritten by
where
is the log-likelihood function of the
kth stratum under
. Let
and
be the constrained MLEs of
and
under
. Similarly, we can differentiate
to
and
, and set them to zero as follows:
However, there are no closed-form solutions for the above equations. The Fisher scoring algorithm is used to obtain the constrained MLEs. Three steps describe the iteration process as follows.
- (i)
Given the initial values , and in the kth stratum.
- (ii)
The
-th approximates of
and
can be updated by
where
,
, and
is the
Fisher information matrix (
Appendix A.1).
- (iii)
Repeat the processes (i)–(ii) until the results converge.
4. Exact Methods
Researchers often use the p-value to summarise the evidence against a null hypothesis. Thus, the key to the exact method is the calculation of the exact p-value. We uniformly denote the aforementioned test statistics , and as . Instead of relying on the chi-square distribution, the exact test can use the true sampling distribution of and compute an exact p-value. The calculation process is as follows. First, we need to generate all possible tables. For a given observed data , the column margins are fixed. We enumerate all possible tables by varying the cell values. The detailed process is described as follows.
(i) Produce all possible values of each stratum, which is formed by all combinations such that , and is fixed. We take and as an example. There are six combinations in the kth stratum, including .
(ii) Enumerate all possible tables determined by the combination of all strata. For
and
, we can obtain 36 possible tables in
Table 6.
Note that each column corresponds to a categorical table with K strata.
Through steps (i)–(ii), we can enumerate all possible tables for any observed data . Then we identify the tail area from this reference set. The tail area includes all the tables whose statistic values equal or exceed the statistics of the observed data . Finally, the exact p-value is calculated by summing the probabilities of all the tables in the tail area. The calculation of the exact p-value needs to eliminate the unknown parameters shown in the previous section. The following exact methods use different ways for the elimination of the unknown parameters.
4.1. E Approach
The E approach eliminates the unknown parameters by replacing them with the constrained MLEs. We first generate all possible tables. Define the tail area
based on the test statistic
. The exact
p-value of the observed data
is expressed by
where
and
are the constrained MLEs of
and
. Meanwhile, the probability of a table in the tail area is
, which is the likelihood function under the null hypothesis. For convenience,
, and
are collectively called the E approach.
4.2. M Approach
In Basu [
30], the size of a test is always understood as the maximum probability of the type I error rate. Thus, the elimination of the unknown parameters for the M approach is to find the values of parameters over the whole range of
and
, which can maximize the sum of probabilities of all the tables in the tail area. This maximum is the
p-value of the M approach. Denote
and
where
and
. Similar to the E approach, the tail area can be calculated by
. Under these conditions, the exact
p-value of the M approach can be defined as
where
is the likelihood function under
. M approaches based on the three statistics are denoted as
, and
.
4.3. E+M Approach
The E approach is not always effective because of unsatisfactory type I error rates. Lloyd [
31] used an additional maximization step to improve it, which is called the E+M approach. First, the
p-value of the E approach is used as a test statistic to define the tail area. Then, we maximize the sum of probabilities of all the tables in the tail area as the exact
p-value. Based on the above procedures, the tail area of the E+M approach is defined as
. The exact
p-value of the E+M approach is expressed as
where
is the same as the likelihood function in the M approach. The E+M approach includes
, and
.
7. Concluding Remarks
This article defines the stratified AC
coefficients as the object of study and constructs the likelihood function of the observed data. The primary purpose is to derive various statistics for testing the homogeneity of stratified AC
in the case of two raters with a binary outcome. We constructed asymptotic and exact methods for large and small sample sizes. Two asymptotic test statistics and their explicit expressions are derived for large sample sizes, including the likelihood ratio statistic (
) and Wald-type statistic (
). Meanwhile, the score statistic (
) proposed by Honda and Ohyama [
19] is also reviewed. Asymptotic
p-values
under the statistics mentioned above are denoted as the A approach. Three exact methods (E, M, and E+M) are proposed based on
, and
for small sample sizes.
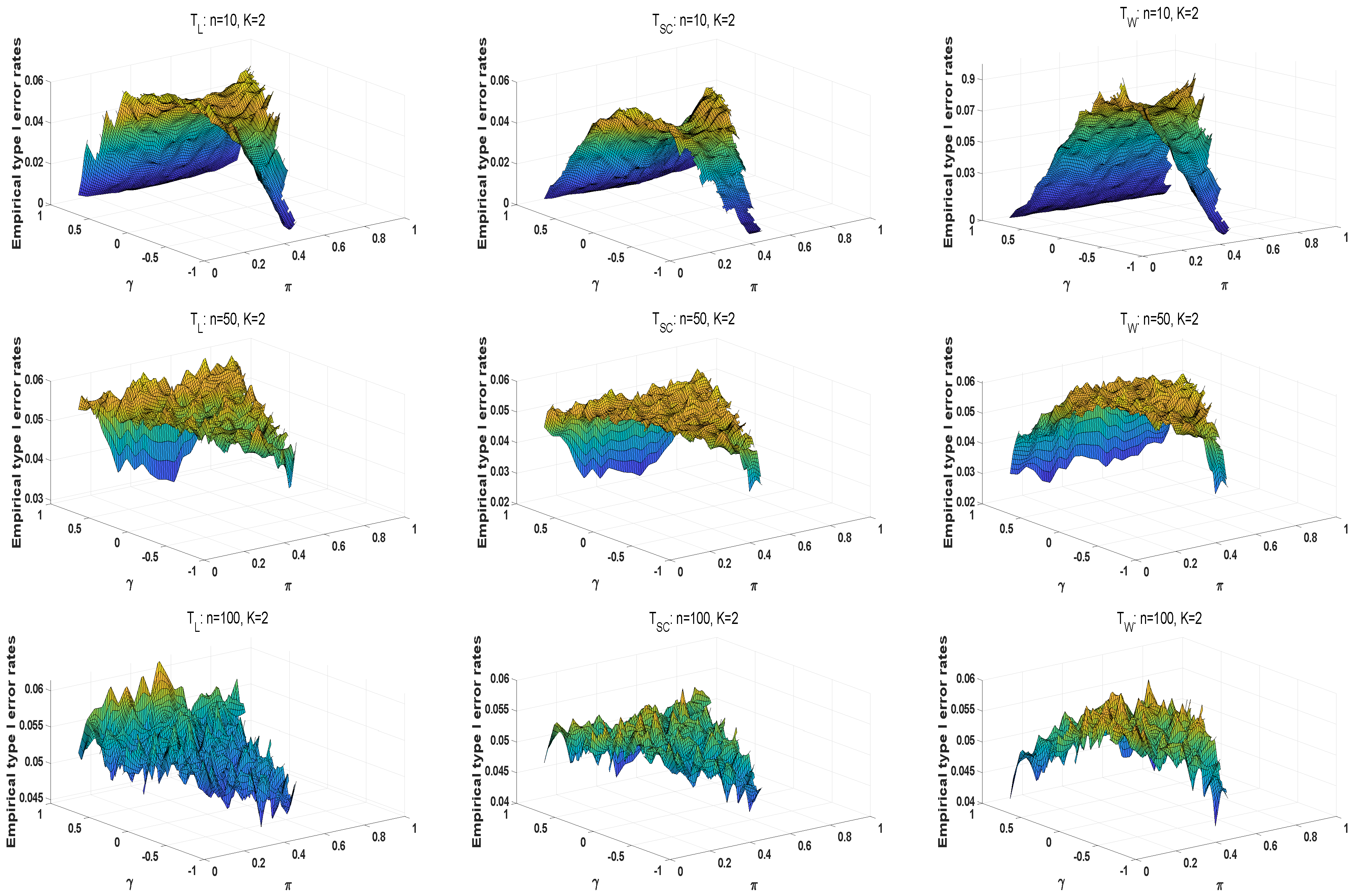
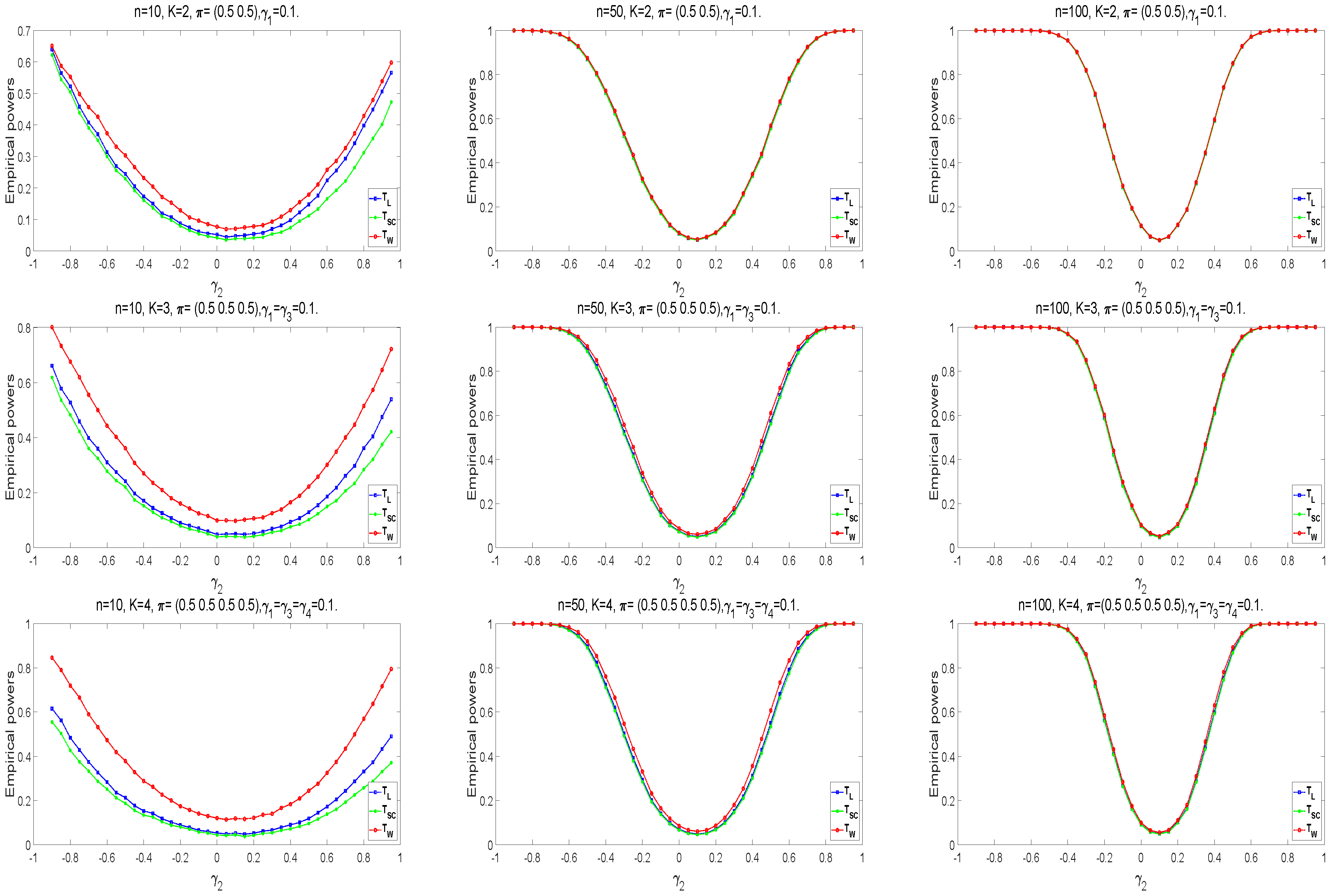
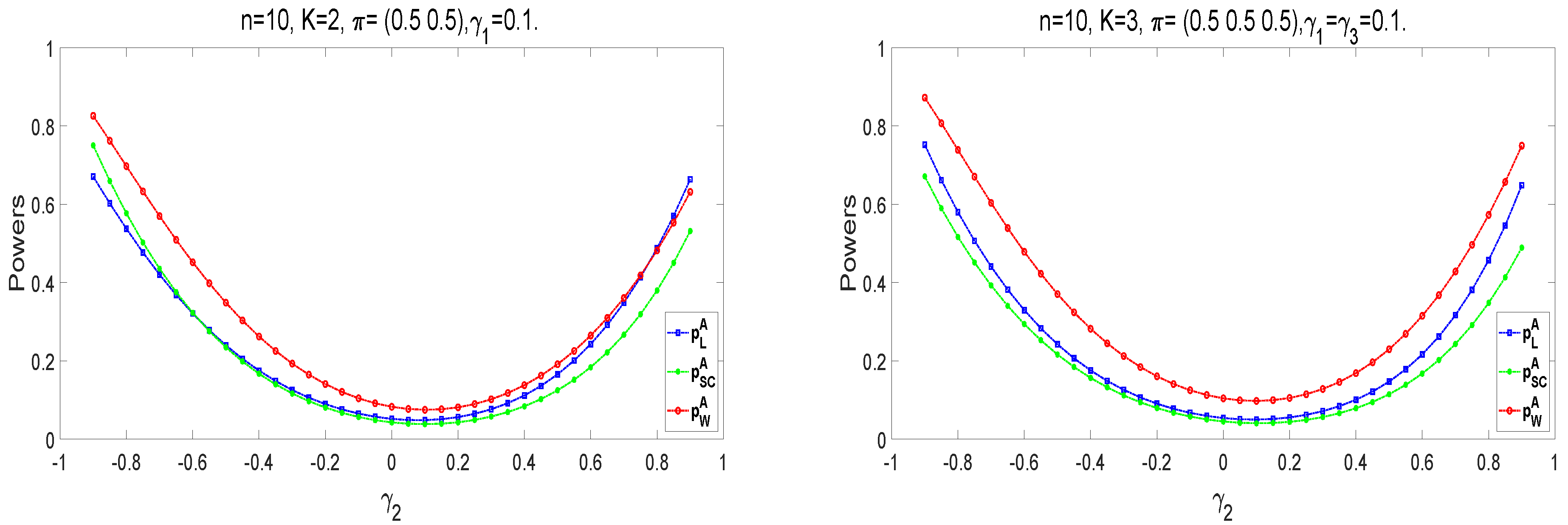
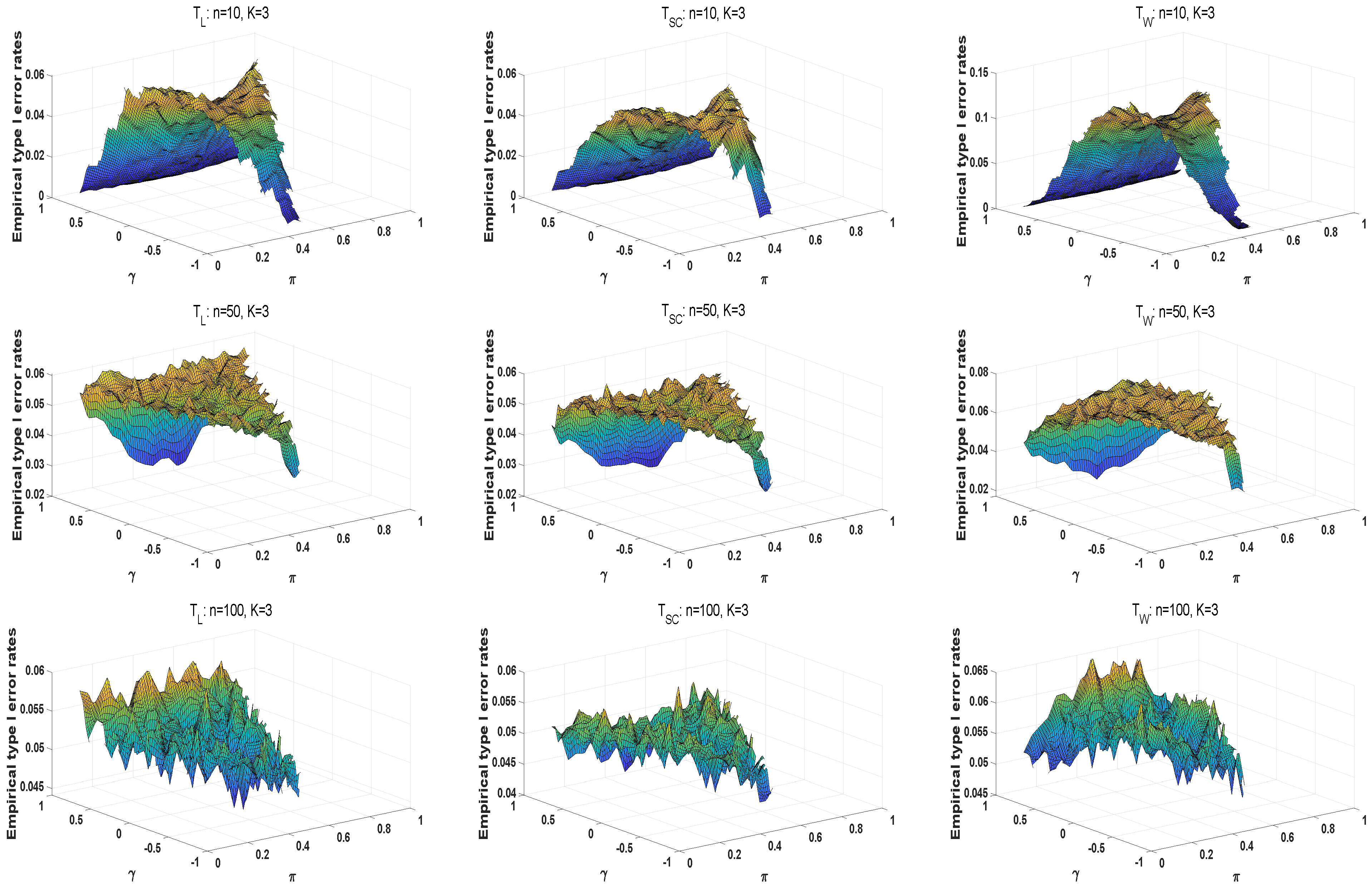
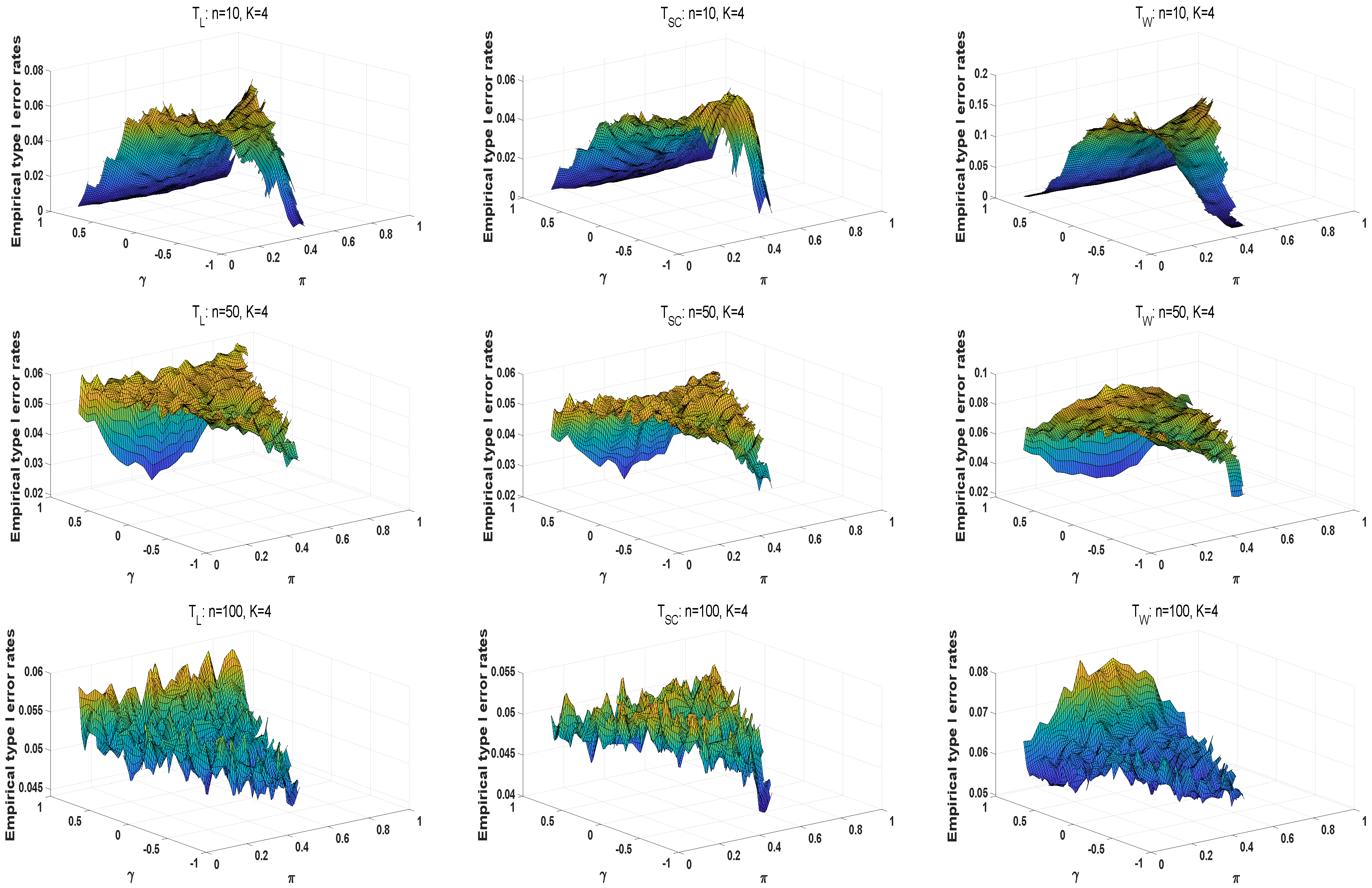
We conduct numerical studies to compare the performance of the above methods by type I error rates and powers. For large samples, the type I error rates of the likelihood ratio statistic are closer to the predetermined significance level of . The powers of statistics are better as the sample size increases. Overall, the likelihood ratio statistic is optimal among these three statistics in large sample sizes. However, asymptotic tests may generate unsatisfactory type I error rates at small sample scenarios and high . For small sample sizes in , and are liberal, and has the conservative type I error rates under different parameter settings. The type I error rates of the E approach are closer to the significance level of . The M and E+M approaches have conservative type I error rates. Moreover, and are more robust than . When , and is positive, the E approach has the robust type I error rates among three methods, in which and perform better. The type I error rates of the exact E method are closer to as the sample size increases. The E approach can improve the effectiveness of homogeneity tests at high . In the case of powers, the A approach has larger powers than these exact methods. Under the Wald-type statistic, each exact method has a higher power. Thus, the E approaches based on the likelihood ratio and score statistics have a robust performance for small sample sizes.
The proposed methods can be used not only in medical research but also in biometrics and psychological measurements. Meanwhile, exact methods can be applied to other data types, such as binary outcomes on multiple raters. This work focuses on constructing parametric statistics through unconstrained and constrained MLEs. However, there are still many problems that need to be solved. For example, how to construct optimal tests? How to improve exact methods effectively for a larger K or sample size ? How to simplify the heavy computations caused by the consideration of all the tables? More studies should be conducted on these problems and be extended in the future.





{kind=link}
{kind=link}
{kind=link}
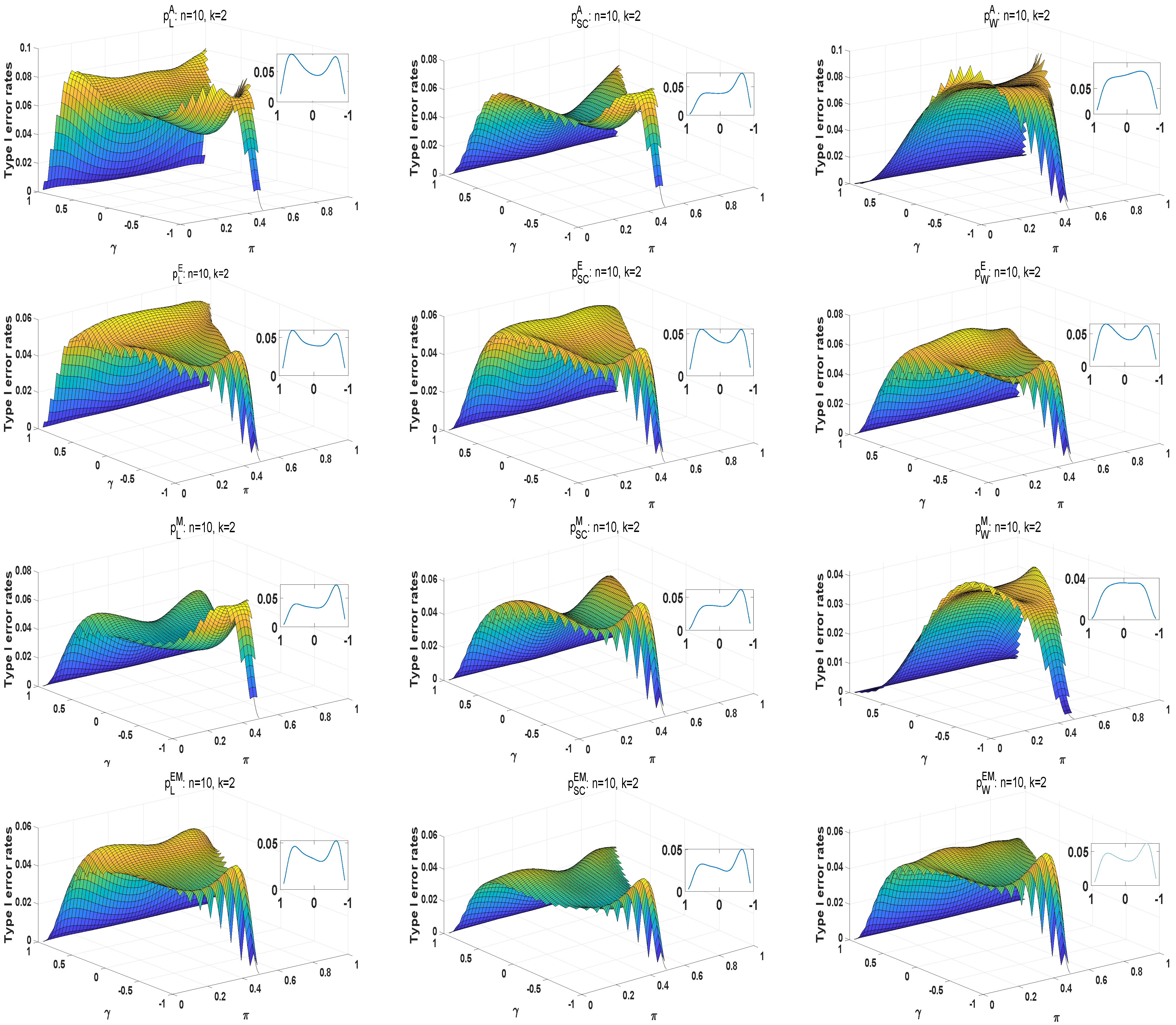{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}








