

Quantile-Adaptive Sufficient Variable Screening by Controlling False Discovery

Abstract
:1. Introduction
2. Sufficient Screening Utility
2.1. A Quantile-Adaptive Correlation Test Statistic
- (I)
- (Quantile-Heterogeneity) the index set of sufficient active predictors satisfies that may be different for different ;
- (II)
- (Sparsity) the dimensionality for some constant , but , where is the cardinality of , and n is the sample size.
2.2. Asymptotic Properties of the Test Statistic
- (C1)
- There exists constants and , s.t. ;
- (C2)
- There exists , s.t. ;
- (C3)
- The grids number of response satisfies , where and .
3. False Discovery Control Model
3.1. Adaptive False Discovery Control Model
| Algorithm 1 QA-SVS-AFD algorithm. |
|
Input: Observation sample and the number of grids K Output: The screened sufficient variable set () Step 1 Calculate of Equation (5) for different ; Step 2 Compute by ; Step 3 Search for the screened sufficient active variable set in Equation (10). |
3.2. False Discovery Rate Control Model
| Algorithm 2 QA-SVS-FDR(K) algorithm. |
|
Input: Observation sample , the number of grids K, and the prespecified level Output: The screened sufficient variable sets () Step 1 Calculate of Equation (5) for different ; Step 2 Compute each of Equation (11) for by taking each value of ; Step 3 For given , search for the set in Equation (12); Step 4 Find and let ; Step 5 Separate the screened sufficient active set of Equation (11) by . |
| Algorithm 3 QA-SVS-FDR-S algorithm. |
| Input: Observation sample , the number of grids K, and the prespecified level Output: The screened sufficient variable sets Step 1 Calculate in Remark 5; Step 2 Compute each in Remark 5 for taking each value of ; Step 3 For given , separate for the set in Remark 5; Step 4 Find and let ; Step 5 Separate the screened sufficient active set in Remark 5 by . |
4. Simulation Studies
4.1. Performance of QA-SVS-A
4.2. Performance of QA-SVS-FD
- : the average number of screened variables;
- FDR: the average of empirical FDP;
- : the average of .
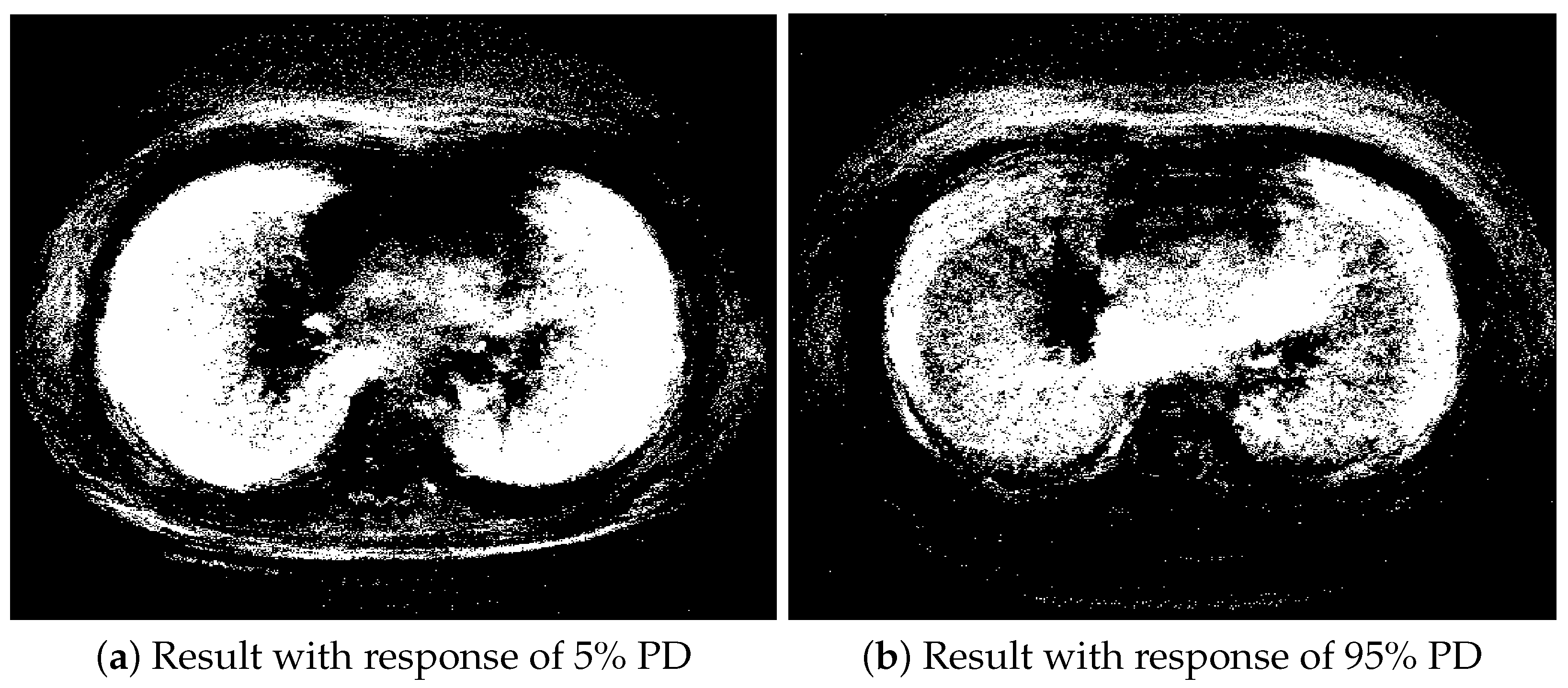
5. Real Dataset Research
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A. Main Proof
Appendix A.1. Proof of Remark 1
Appendix A.2. Proof of Lemma 1
Appendix A.3. Proof of Lemma 2
- For all , we obtain thatwhere is an odd power series that, for all sufficiently large N, is majorized by a power series with coefficients not depending on N, and is convergent in some discussions, and converges uniformly in n for sufficiently small values of v, where .
- For all , we obtain that
- For all , we obtain that
- For all , we have
Appendix A.4. Proof of Corollary 1
Appendix A.5. Proof of Theorem 1
Appendix A.6. Proof of Theorem 2
Appendix A.7. Proof of Theorem 3
Appendix A.8. Proof of Corollary 2
Appendix A.9. Proof of Theorem 4
Appendix B

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | 5% | 25% | 50% | 75% | 95% | 5% | 25% | 50% | 75% | 95% |
|---|---|---|---|---|---|---|---|---|---|---|
| QA-SVS-A(4) | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 4.0 | 5.0 |
| QA-SVS-A(5) | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 4.0 | 4.0 | 5.0 |
| QA-SVS-A(6) | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 4.0 | 4.0 | 5.0 |
| QA-SVS-A(7) | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 4.0 | 5.0 |
| QA-SVS-A(8) | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 4.0 | 4.0 | 5.0 |
| QA-SVS-A(9) | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 4.0 | 4.0 | 5.0 |
| QA-SVS-A(10) | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 4.0 | 5.0 |
| QCS(4) | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.5 | 5.0 |
| QCS(5) | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 4.0 | 7.0 |
| QCS(6) | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 4.0 | 5.5 |
| QCS(7) | 3.0 | 3.0 | 3.0 | 3.0 | 3.5 | 3.0 | 3.0 | 3.0 | 4.0 | 11.5 |
| QCS(8) | 3.0 | 3.0 | 3.0 | 3.0 | 4.0 | 3.0 | 3.0 | 3.0 | 4.0 | 12.0 |
| QCS(9) | 3.0 | 3.0 | 3.0 | 3.0 | 4.5 | 3.0 | 3.0 | 3.0 | 4.0 | 7.5 |
| QCS(10) | 3.0 | 3.0 | 3.0 | 3.0 | 3.5 | 3.0 | 3.0 | 3.0 | 4.0 | 10.0 |
| SIS | 3.0 | 3.0 | 3.0 | 3.0 | 6.5 | 3.0 | 3.0 | 4.0 | 5.0 | 6.0 |
| DC-SIS | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 4.0 | 4.5 |
| QA-SIS(0.1) | 3.0 | 3.0 | 3.0 | 3.0 | 4.5 | 3.0 | 3.0 | 3.0 | 3.5 | 16.5 |
| QA-SIS(0.3) | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 4.0 |
| QA-SIS(0.5) | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 5.0 |
| QA-SIS(0.7) | 3.0 | 3.0 | 3.0 | 3.0 | 4.0 | 3.0 | 3.0 | 4.0 | 4.0 | 10.5 |
| QA-SIS(0.9) | 4.0 | 15.0 | 32.5 | 74.5 | 217.0 | 4.5 | 14.5 | 36.5 | 81.5 | 299.0 |
| QA-SVS-A(4) | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 4.0 | 5.0 |
| QA-SVS-A(5) | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 4.0 | 4.0 | 5.0 |
| QA-SVS-A(6) | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 4.0 | 4.0 | 6.0 |
| QA-SVS-A(7) | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 4.0 | 4.0 | 8.0 |
| QA-SVS-A(8) | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 4.0 | 6.0 |
| QA-SVS-A(9) | 3.0 | 3.0 | 3.0 | 3.0 | 3.5 | 3.0 | 3.0 | 3.0 | 4.0 | 7.0 |
| QA-SVS-A(10) | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 4.0 | 4.0 | 6.5 |
| QCS(4) | 3.0 | 3.0 | 3.0 | 3.0 | 4.0 | 3.0 | 3.0 | 3.0 | 4.0 | 6.0 |
| QCS(5) | 3.0 | 3.0 | 3.0 | 3.0 | 7.0 | 3.0 | 3.0 | 3.0 | 4.0 | 6.0 |
| QCS(6) | 3.0 | 3.0 | 3.0 | 3.0 | 5.0 | 3.0 | 3.0 | 3.0 | 4.0 | 54.0 |
| QCS(7) | 3.0 | 3.0 | 3.0 | 3.0 | 5.0 | 3.0 | 3.0 | 3.0 | 4.0 | 32.0 |
| QCS(8) | 3.0 | 3.0 | 3.0 | 3.0 | 8.0 | 3.0 | 3.0 | 3.0 | 4.0 | 60.5 |
| QCS(9) | 3.0 | 3.0 | 3.0 | 3.0 | 6.5 | 3.0 | 3.0 | 3.0 | 4.0 | 19.5 |
| QCS(10) | 3.0 | 3.0 | 3.0 | 3.0 | 7.5 | 3.0 | 3.0 | 4.0 | 6.0 | 92.0 |
| SIS | 3.0 | 3.0 | 3.0 | 3.0 | 18.5 | 3.0 | 3.0 | 4.0 | 5.0 | 11.5 |
| DC-SIS | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 4.0 | 5.0 |
| QA-SIS(0.1) | 3.0 | 3.0 | 3.0 | 3.0 | 31.0 | 3.0 | 3.0 | 3.0 | 4.0 | 28.0 |
| QA-SIS(0.3) | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 4.5 |
| QA-SIS(0.5) | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 4.0 | 7.5 |
| QA-SIS(0.7) | 3.0 | 3.0 | 3.0 | 4.0 | 18.5 | 3.0 | 3.0 | 3.0 | 7.0 | 27.5 |
| QA-SIS(0.9) | 16.0 | 58.5 | 130.5 | 323.5 | 1382.0 | 6.0 | 31.0 | 124.5 | 421.5 | 1844.0 |
| Method | 5% | 25% | 50% | 75% | 95% | 5% | 25% | 50% | 75% | 95% |
|---|---|---|---|---|---|---|---|---|---|---|
| QA-SVS-A(4) | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 |
| QA-SVS-A(5) | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 |
| QA-SVS-A(6) | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 |
| QA-SVS-A(7) | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 |
| QA-SVS-A(8) | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 |
| QA-SVS-A(9) | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 |
| QA-SVS-A(10) | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 |
| QCS(4) | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 4.0 |
| QCS(5) | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 7.0 |
| QCS(6) | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 5.0 |
| QCS(7) | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 5.0 |
| QCS(8) | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 8.0 |
| QCS(9) | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 6.5 |
| QCS(10) | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 7.5 |
| SIS | 414.0 | 686.0 | 781.5 | 894.0 | 979.5 | 558.5 | 706.5 | 824.5 | 932.0 | 988.0 |
| DC-SIS | 441.5 | 619.0 | 742.5 | 840.0 | 962.0 | 341.5 | 601.0 | 747.5 | 895.0 | 971.0 |
| QA-SIS(0.1) | 135.5 | 223.0 | 321.5 | 428.5 | 626.5 | 82.5 | 134.5 | 201.5 | 303.0 | 543.0 |
| QA-SIS(0.3) | 14.0 | 28.0 | 49.5 | 93.5 | 237.5 | 10.0 | 24.5 | 65.0 | 116.0 | 593.5 |
| QA-SIS(0.5) | 8.0 | 20.0 | 32.0 | 54.5 | 162.5 | 3.0 | 5.0 | 6.0 | 8.0 | 15.0 |
| QA-SIS(0.7) | 37.5 | 73.0 | 146.5 | 223.0 | 394.5 | 9.0 | 15.5 | 20.0 | 32.5 | 56.5 |
| QA-SIS(0.9) | 152.5 | 291.0 | 418.0 | 562.0 | 816.0 | 60.5 | 145.0 | 215.5 | 307.5 | 548.5 |
| QA-SVS-A(4) | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 |
| QA-SVS-A(5) | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 |
| QA-SVS-A(6) | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 |
| QA-SVS-A(7) | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 |
| QA-SVS-A(8) | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 |
| QA-SVS-A(9) | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 |
| QA-SVS-A(10) | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 |
| QCS(4) | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 |
| QCS(5) | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 |
| QCS(6) | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 |
| QCS(7) | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 |
| QCS(8) | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 |
| QCS(9) | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 |
| QCS(10) | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 |
| SIS | 2126.0 | 3353.0 | 3956.5 | 4469.5 | 4874.5 | 3038.5 | 3633.5 | 4071.0 | 4528.5 | 4954.5 |
| DC-SIS | 1949.0 | 3324.0 | 4045.5 | 4387.5 | 4832.0 | 1485.5 | 3097.5 | 3959.0 | 4368.0 | 4702.0 |
| QA-SIS(0.1) | 507.5 | 1137.5 | 1470.0 | 1981.5 | 3183.0 | 433.0 | 747.5 | 1177.5 | 1573.5 | 2852.5 |
| QA-SIS(0.3) | 54.5 | 97.0 | 177.0 | 348.5 | 1122.5 | 39.0 | 126.0 | 288.0 | 595.5 | 2742.0 |
| QA-SIS(0.5) | 33.5 | 95.0 | 184.5 | 351.5 | 711.0 | 6.0 | 11.0 | 15.0 | 29.0 | 62.5 |
| QA-SIS(0.7) | 143.0 | 419.5 | 690.0 | 1263.5 | 2217.5 | 34.5 | 60.5 | 100.0 | 175.0 | 402.0 |
| QA-SIS(0.9) | 670.5 | 1140.0 | 1775.5 | 2586.5 | 3707.5 | 439.5 | 717.0 | 1022.0 | 1547.0 | 2662.5 |
| Method | 5% | 25% | 50% | 75% | 95% | 5% | 25% | 50% | 75% | 95% |
|---|---|---|---|---|---|---|---|---|---|---|
| QA-SVS-A(4) | 3.0 | 4.0 | 9.0 | 28.5 | 317.0 | 3.0 | 3.0 | 6.0 | 24.0 | 156.5 |
| QA-SVS-A(5) | 3.0 | 3.0 | 8.0 | 40.0 | 179.5 | 3.0 | 3.0 | 4.0 | 8.0 | 42.5 |
| QA-SVS-A(6) | 3.0 | 3.0 | 5.0 | 12.0 | 93.5 | 3.0 | 3.0 | 4.0 | 5.0 | 23.0 |
| QA-SVS-A(7) | 3.0 | 3.0 | 5.0 | 13.0 | 82.0 | 3.0 | 3.0 | 4.0 | 9.5 | 59.5 |
| QA-SVS-A(8) | 3.0 | 3.0 | 4.0 | 11.5 | 52.0 | 3.0 | 3.0 | 3.0 | 7.5 | 71.0 |
| QA-SVS-A(9) | 3.0 | 3.0 | 4.0 | 11.0 | 47.5 | 3.0 | 3.0 | 3.0 | 6.0 | 53.5 |
| QA-SVS-A(10) | 3.0 | 3.0 | 4.0 | 10.5 | 89.5 | 3.0 | 3.0 | 4.0 | 6.5 | 59.0 |
| QCS(4) | 3.0 | 3.0 | 4.0 | 10.0 | 46.0 | 3.0 | 3.0 | 3.0 | 6.0 | 60.5 |
| QCS(5) | 3.0 | 3.0 | 4.0 | 8.0 | 58.0 | 3.0 | 3.0 | 4.0 | 6.5 | 66.5 |
| QCS(6) | 3.0 | 3.0 | 4.0 | 11.0 | 251.0 | 3.0 | 3.0 | 3.0 | 6.0 | 44.0 |
| QCS(7) | 3.0 | 3.0 | 4.0 | 11.5 | 76.5 | 3.0 | 3.0 | 4.0 | 6.0 | 58.5 |
| QCS(8) | 3.0 | 3.0 | 6.0 | 17.5 | 118.0 | 3.0 | 3.0 | 4.0 | 9.5 | 76.5 |
| QCS(9) | 3.0 | 4.0 | 6.0 | 22.5 | 118.0 | 3.0 | 3.0 | 4.0 | 15.0 | 66.5 |
| QCS(10) | 3.0 | 4.0 | 7.0 | 20.0 | 156.5 | 3.0 | 3.0 | 5.0 | 9.5 | 72.5 |
| SIS | 260.0 | 559.0 | 802.5 | 922.5 | 981.5 | 227.5 | 574.5 | 769.5 | 907.0 | 988.0 |
| DC-SIS | 3.0 | 3.0 | 6.0 | 28.0 | 450.0 | 3.0 | 3.0 | 4.0 | 19.5 | 350.0 |
| QA-SIS(0.1) | 82.0 | 168.5 | 300.0 | 521.5 | 849.5 | 70.0 | 132.0 | 241.5 | 395.0 | 737.5 |
| QA-SIS(0.3) | 10.5 | 21.0 | 42.5 | 98.0 | 195.0 | 4.5 | 12.0 | 21.0 | 53.0 | 306.0 |
| QA-SIS(0.5) | 5.5 | 20.5 | 56.0 | 166.5 | 517.5 | 3.0 | 9.5 | 24.5 | 90.5 | 439.5 |
| QA-SIS(0.7) | 4.0 | 11.0 | 30.5 | 85.5 | 309.0 | 7.5 | 15.5 | 35.5 | 114.5 | 355.0 |
| QA-SIS(0.9) | 93.5 | 191.0 | 382.0 | 587.0 | 798.5 | 111.5 | 259.5 | 467.5 | 660.5 | 852.5 |
| QA-SVS-A(4) | 3.0 | 12.0 | 58.5.0 | 200.0 | 831.0 | 3.0 | 5.0 | 13.0 | 81.0 | 615.5 |
| QA-SVS-A(5) | 3.0 | 6.0 | 18.0 | 98.0 | 791.0 | 3.0 | 4.0 | 8.0 | 33.0 | 242.5 |
| QA-SVS-A(6) | 3.0 | 4.0 | 9.0 | 45.0 | 322.0 | 3.0 | 4.0 | 8.0 | 31.5 | 241.0 |
| QA-SVS-A(7) | 3.0 | 4.0 | 6.5 | 42.0 | 549.5 | 3.0 | 4.0 | 7.0 | 29.0 | 165.0 |
| QA-SVS-A(8) | 3.0 | 4.0 | 7.0 | 26.0 | 152.5 | 3.0 | 3.0 | 6.0 | 19.5 | 183.5 |
| QA-SVS-A(9) | 3.0 | 4.0 | 12.5 | 70.0 | 552.0 | 3.0 | 3.0 | 5.5 | 19.0 | 423.5 |
| QA-SVS-A(10) | 3.0 | 5.0 | 12.5 | 44.0 | 539.0 | 3.0 | 3.0 | 6.0 | 28.5 | 334.5 |
| QCS(4) | 3.0 | 3.0 | 6.0 | 14.5 | 166.0 | 3.0 | 3.0 | 4.0 | 14.5 | 163.5 |
| QCS(5) | 3.0 | 4.0 | 6.5 | 30.0 | 209.5 | 3.0 | 3.0 | 4.0 | 8.5 | 73.5 |
| QCS(6) | 3.0 | 4.0 | 9.5 | 40.0 | 594.5 | 3.0 | 3.0 | 5.0 | 17.0 | 160.5 |
| QCS(7) | 3.0 | 4.0 | 12.0 | 50.0 | 417.0 | 3.0 | 3.0 | 7.0 | 25.0 | 125.5 |
| QCS(8) | 3.0 | 5.0 | 20.0 | 64.5 | 619.0 | 3.0 | 3.0 | 7.0 | 25.0 | 94.0 |
| QCS(9) | 3.0 | 6.0 | 22.0 | 97.0 | 642.5 | 3.0 | 4.0 | 9.0 | 39.5 | 324.0 |
| QCS(10) | 3.0 | 6.0 | 21.5 | 163.0 | 1131.5 | 3.0 | 4.0 | 8.0 | 37.5 | 431.5 |
| SIS | 1341.0 | 3294.5 | 4114.0 | 4586.0 | 4968.0 | 1252.5 | 3027.5 | 3972.0 | 4524.0 | 4937.5 |
| DC-SIS | 3.0 | 5.0 | 12.0 | 110.0 | 1952.0 | 3.0 | 4.0 | 10.0 | 57.5 | 1297.5 |
| QA-SIS(0.1) | 423.0 | 1111.5 | 1827.0 | 3080.0 | 4736.5 | 350.0 | 709.5 | 1175.5 | 1655.0 | 3101.0 |
| QA-SIS(0.3) | 19.0 | 77.0 | 198.0 | 556.0 | 1755.5 | 14.0 | 45.5 | 128.0 | 402.0 | 1319.0 |
| QA-SIS(0.5) | 13.5 | 82.5 | 377.5 | 787.0 | 2140.0 | 4.0 | 32.0 | 177.5 | 469.5 | 2936.0 |
| QA-SIS(0.7) | 16.5 | 48.0 | 177.5 | 472.0 | 1475.0 | 22.5 | 96.5 | 336.0 | 777.5 | 2261.5 |
| QA-SIS(0.9) | 549.0 | 1025.5 | 1727.0 | 2413.0 | 3997.5 | 434.5 | 1132.5 | 2093.5 | 3309.0 | 4599.5 |
| Method | 5% | 25% | 50% | 75% | 95% | 5% | 25% | 50% | 75% | 95% |
|---|---|---|---|---|---|---|---|---|---|---|
| QA-SVS-A(4) | 3.0 | 11.0 | 41.5 | 211.0 | 717.0 | 3.0 | 3.0 | 3.0 | 4.0 | 5.0 |
| QA-SVS-A(5) | 3.0 | 4.5 | 26.5 | 126.5 | 380.5 | 3.0 | 3.0 | 3.0 | 3.0 | 4.0 |
| QA-SVS-A(6) | 3.0 | 3.0 | 13.0 | 69.5 | 319.0 | 3.0 | 3.0 | 3.0 | 3.0 | 4.0 |
| QA-SVS-A(7) | 3.0 | 3.0 | 6.0 | 18.0 | 309.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.5 |
| QA-SVS-A(8) | 3.0 | 3.0 | 6.0 | 16.5 | 107.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 |
| QA-SVS-A(9) | 3.0 | 3.0 | 4.5 | 10.0 | 94.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 |
| QA-SVS-A(10) | 3.0 | 3.0 | 4.0 | 13.0 | 112.5 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 |
| QCS(4) | 4.0 | 31.5 | 95.3 | 329.5 | 730.5 | 3.0 | 3.0 | 3.0 | 5.5 | 71.0 |
| QCS(5) | 8.0 | 39.0 | 148.5 | 437.0 | 742.0 | 3.0 | 3.0 | 3.0 | 4.0 | 10.5 |
| QCS(6) | 4.0 | 28.5 | 88.0 | 287.0 | 664.5 | 3.0 | 3.0 | 3.0 | 4.0 | 46.0 |
| QCS(7) | 3.5 | 22.5 | 95.5 | 256.0 | 563.5 | 3.0 | 3.0 | 3.0 | 3.0 | 6.0 |
| QCS(8) | 3.0 | 19.0 | 67.0 | 201.0 | 535.0 | 3.0 | 3.0 | 3.0 | 3.0 | 11.0 |
| QCS(9) | 3.0 | 8.0 | 50.0 | 165.5 | 494.5 | 3.0 | 3.0 | 3.0 | 3.0 | 11.0 |
| QCS(10) | 3.0 | 9.5 | 38.0 | 124.0 | 539.0 | 3.0 | 3.0 | 3.0 | 3.0 | 7.5 |
| SIS | 3.0 | 3.0 | 3.0 | 3.0 | 7.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 |
| DC-SIS | 3.0 | 3.0 | 3.0 | 3.0 | 4.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 |
| QA-SIS(0.1) | 4.0 | 7.5 | 14.5 | 28.0 | 152.0 | 3.0 | 4.0 | 5.0 | 7.5 | 15.0 |
| QA-SIS(0.3) | 4.0 | 35.0 | 110.0 | 247.0 | 840.5 | 3.0 | 3.0 | 3.0 | 5.0 | 17.0 |
| QA-SIS(0.5) | 27.5 | 141.0 | 262.0 | 516.5 | 880.5 | 3.0 | 4.0 | 7.0 | 35.5 | 258.0 |
| QA-SIS(0.7) | 49.5 | 185.0 | 425.0 | 736.5 | 929.0 | 8.5 | 32.0 | 160.5 | 385.5 | 865.0 |
| QA-SIS(0.9) | 241.5 | 456.5 | 648.5 | 878.0 | 985.0 | 67.0 | 275.0 | 541.5 | 754.5 | 972.0 |
| QA-SVS-A(4) | 6.0 | 52.0 | 347.0 | 1262.5 | 3451.5 | 3.0 | 3.0 | 3.0 | 3.0 | 5.5 |
| QA-SVS-A(5) | 3.0 | 17.5 | 149.0 | 472.0 | 2285.5 | 3.0 | 3.0 | 3.0 | 3.5 | 6.0 |
| QA-SVS-A(6) | 3.0 | 11.0 | 47.5 | 293.0 | 1288.0 | 3.0 | 3.0 | 3.0 | 3.0 | 4.0 |
| QA-SVS-A(7) | 3.0 | 5.0 | 19.5 | 89.5 | 1288.0 | 3.0 | 3.0 | 3.0 | 3.0 | 4.0 |
| QA-SVS-A(8) | 3.0 | 3.0 | 10.0 | 95.0 | 923.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 |
| QA-SVS-A(9) | 3.0 | 4.0 | 8.0 | 33.5 | 783.5 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 |
| QA-SVS-A(10) | 3.0 | 4.0 | 11.0 | 58.0 | 725.5 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 |
| QCS(4) | 40.5 | 329.0 | 853.5 | 1965.0 | 3801.0 | 3.0 | 3.0 | 4.0 | 32.0 | 277.0 |
| QCS(5) | 12.5 | 164.5 | 515.0 | 1677.5 | 3445.5 | 3.0 | 3.0 | 3.0 | 3.0 | 112.0 |
| QCS(6) | 6.5 | 62.5 | 262.0 | 917.0 | 2845.5 | 3.0 | 3.0 | 3.0 | 5.5 | 35.0 |
| QCS(7) | 18.5 | 105.0 | 404.5 | 937.0 | 2855.0 | 3.0 | 3.0 | 3.0 | 4.0 | 31.5 |
| QCS(8) | 5.5 | 84.0 | 333.0 | 788.5 | 3004.0 | 3.0 | 3.0 | 3.0 | 4.0 | 16.0 |
| QCS(9) | 3.0 | 46.0 | 173.5 | 596.5 | 1803.5 | 3.0 | 3.0 | 3.0 | 4.0 | 28.5 |
| QCS(10) | 6.5 | 40.5 | 213.5 | 939.0 | 2590.5 | 3.0 | 3.0 | 3.0 | 5.0 | 13.0 |
| SIS | 3.0 | 3.0 | 3.0 | 3.0 | 43.5 | 3.0 | 3.0 | 3.0 | 3.0 | 7.5 |
| DC-SIS | 3.0 | 3.0 | 3.0 | 3.0 | 4.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 |
| QA-SIS(0.1) | 8.0 | 23.0 | 52.5 | 149.0 | 919.0 | 5.0 | 11.0 | 17.5 | 27.0 | 55.5 |
| QA-SIS(0.3) | 3.0 | 117.5 | 562.0 | 1466.0 | 3196.5 | 3.0 | 3.0 | 4.0 | 6.5 | 109.0 |
| QA-SIS(0.5) | 69.5 | 611.5 | 1754.5 | 3333.5 | 4554.0 | 3.5 | 8.0 | 59.0 | 552.5 | 1786.5 |
| QA-SIS(0.7) | 184.5 | 1131.0 | 2307.0 | 3419.0 | 4573.0 | 17.0 | 287.5 | 886.5 | 1798.0 | 3692.5 |
| QA-SIS(0.9) | 867.0 | 1881.5 | 3007.0 | 3863.5 | 4763.5 | 841.5 | 1862.5 | 2873.0 | 3834.0 | 4603.0 |
| Method | QA-SVS-AFD(K) | QA-SVS-FDR(K) | QCS-FDR(K) | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| K | 2 | 3 | 4 | 5 | 6 | 2 | 3 | 4 | 5 | 6 | 2 | 3 | 4 | 5 | 6 |
| Scenario 2.1 | |||||||||||||||
| 12.08 | 10.69 | 10.52 | 10.23 | 10.04 | 11.68 | 11.69 | 11.92 | 11.88 | 11.53 | 11.17 | 11.22 | 11.25 | 11.29 | 11.10 | |
| FDR | 0.16 | 0.06 | 0.05 | 0.02 | 0.00 | 0.14 | 0.14 | 0.16 | 0.15 | 0.13 | 0.10 | 0.10 | 0.10 | 0.11 | 0.09 |
| F-score | 0.91 | 0.97 | 0.98 | 0.99 | 1.00 | 0.92 | 0.92 | 0.91 | 0.92 | 0.93 | 0.95 | 0.94 | 0.94 | 0.94 | 0.95 |
| Scenario 2.2 | |||||||||||||||
| 50.33 | 48.23 | 45.02 | 38.21 | 27.37 | 52.35 | 51.98 | 52.22 | 52.19 | 52.05 | 50.22 | 50.67 | 49.77 | 49.41 | 48.43 | |
| FDR | 0.02 | 0.00 | 0.00 | 0.00 | 0.00 | 0.05 | 0.04 | 0.05 | 0.05 | 0.05 | 0.05 | 0.05 | 0.04 | 0.05 | 0.04 |
| F-score | 0.98 | 0.98 | 0.95 | 0.86 | 0.70 | 0.97 | 0.98 | 0.97 | 0.97 | 0.97 | 0.96 | 0.96 | 0.95 | 0.95 | 0.94 |
| Scenario 2.3 | |||||||||||||||
| 12.09 | 10.67 | 10.40 | 10.10 | 10.02 | 11.74 | 11.58 | 11.52 | 11.60 | 11.57 | 11.08 | 10.90 | 11.16 | 10.90 | 10.90 | |
| FDR | 0.17 | 0.06 | 0.04 | 0.01 | 0.00 | 0.14 | 0.13 | 0.13 | 0.13 | 0.13 | 0.09 | 0.08 | 0.10 | 0.08 | 0.08 |
| F-score | 0.91 | 0.97 | 0.98 | 1.00 | 1.00 | 0.92 | 0.93 | 0.93 | 0.93 | 0.93 | 0.95 | 0.96 | 0.95 | 0.96 | 0.96 |
| Scenario 2.4 | |||||||||||||||
| 50.05 | 45.91 | 39.33 | 25.62 | 15.27 | 52.23 | 51.96 | 51.91 | 52.07 | 51.56 | 49.53 | 48.03 | 47.22 | 44.47 | 43.53 | |
| FDR | 0.02 | 0.00 | 0.00 | 0.00 | 0.00 | 0.05 | 0.05 | 0.05 | 0.05 | 0.04 | 0.05 | 0.05 | 0.05 | 0.04 | 0.05 |
| F-score | 0.98 | 0.96 | 0.88 | 0.67 | 0.46 | 0.97 | 0.97 | 0.97 | 0.97 | 0.97 | 0.95 | 0.93 | 0.92 | 0.90 | 0.89 |
| 2 | 3 | 4 | 5 | 6 | 2 | 3 | 4 | 5 | 6 | 2 | 3 | 4 | 5 | 6 | |
| Scenario 2.5 | |||||||||||||||
| 10.89 | 9.88 | 9.30 | 7.95 | 5.90 | 10.47 | 10.43 | 10.54 | 10.47 | 10.40 | 10.00 | 10.09 | 9.88 | 9.62 | 9.48 | |
| FDR | 0.08 | 0.00 | 0.00 | 0.00 | 0.00 | 0.04 | 0.04 | 0.05 | 0.04 | 0.04 | 0.05 | 0.05 | 0.05 | 0.04 | 0.05 |
| F-score | 0.96 | 0.99 | 0.96 | 0.88 | 0.73 | 0.98 | 0.98 | 0.97 | 0.98 | 0.98 | 0.94 | 0.95 | 0.94 | 0.93 | 0.92 |
| Scenario 2.6 | |||||||||||||||
| 14.81 | 3.65 | 0.49 | 0.08 | 0.00 | 12.65 | 13.93 | 12.88 | 10.88 | 9.95 | 1.83 | 1.30 | 0.94 | 0.72 | 0.45 | |
| FDR | 0.05 | NaN | NaN | NaN | NaN | 0.04 | 0.04 | 0.05 | 0.04 | 0.04 | NaN | NaN | NaN | NaN | NaN |
| F-score | 0.43 | 0.13 | 0.02 | 0.00 | 0.00 | 0.38 | 0.41 | 0.38 | 0.33 | 0.31 | 0.06 | 0.05 | 0.03 | 0.02 | 0.02 |
| Scenario 2.7 | |||||||||||||||
| 10.92 | 10.02 | 9.99 | 9.99 | 9.90 | 10.39 | 10.51 | 10.46 | 10.52 | 10.60 | 10.66 | 10.72 | 10.63 | 10.53 | 10.50 | |
| FDR | 0.08 | 0.00 | 0.00 | 0.00 | 0.00 | 0.03 | 0.04 | 0.04 | 0.05 | 0.05 | 0.06 | 0.06 | 0.05 | 0.05 | 0.04 |
| F-score | 0.96 | 1.00 | 1.00 | 1.00 | 0.99 | 0.98 | 0.98 | 0.98 | 0.98 | 0.97 | 0.97 | 0.97 | 0.97 | 0.98 | 0.98 |
| Scenario 2.8 | |||||||||||||||
| 38.60 | 18.94 | 6.36 | 1.24 | 0.19 | 43.52 | 41.46 | 40.05 | 38.34 | 36.21 | 22.75 | 17.21 | 11.87 | 8.08 | 6.15 | |
| FDR | 0.02 | 0.00 | 0.00 | NaN | NaN | 0.05 | 0.04 | 0.05 | 0.05 | 0.04 | 0.04 | 0.05 | NaN | NaN | NaN |
| F-score | 0.85 | 0.55 | 0.22 | 0.05 | 0.01 | 0.89 | 0.86 | 0.84 | 0.83 | 0.80 | 0.59 | 0.48 | 0.35 | 0.26 | 0.20 |
Appendix C






References
- Fan, J.; Lv, J. Sure independence screening for ultrahigh dimensional feature space. J. R. Stat. Soc. Ser. B-Stat. Methodol. 2008, 70, 849–883. [Google Scholar]
- Liu, W.; Li, R. , P., Ed.; Springer: Cham, Switzerland, 2020; pp. 293–326.Screening. In Macroeconomic Forecasting in the Era of Big Data: Theory and Practice; Fuleky, P., Ed.; Springer: Cham, Switzerland, 2020; pp. 293–326. [Google Scholar]
- Fan, J.; Song, R. Sure Independence Screening in Generalized Linear Models with Np-Dimensionality. Ann. Stat. 2010, 38, 3567–3604. [Google Scholar] [CrossRef]
- Fan, J.; Feng, Y.; Song, R. Nonparametric Independence Screening in Sparse Ultra-High-Dimensional Additive Models. J. Am. Stat. Assoc. 2011, 106, 544–557. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Li, G.; Peng, H.; Zhang, J.; Zhu, L. Robust Rank Correlation Based Screening. Ann. Stat. 2012, 40, 1846–1877. [Google Scholar] [CrossRef] [Green Version]
- Chang, J.; Tang, C.Y.; Wu, Y. Marginal Empirical Likelihood In addition, Sure Independence Feature Screening. Ann. Stat. 2013, 41, 2123–2148. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zhu, L.P.; Li, L.; Li, R.; Zhu, L.X. Model-Free Feature Screening for Ultrahigh-Dimensional Data. J. Am. Stat. Assoc. 2011, 106, 1464–1475. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Li, R.; Zhong, W.; Zhu, L. Feature Screening via Distance Correlation Learning. J. Am. Stat. Assoc. 2012, 107, 1129–1139. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- He, X.; Wang, L.; Hong, H.G. Quantile-Adaptive Model-Free Variable Screening for High-Dimensional Heterogeneous Data. Ann. Stat. 2013, 41, 342–369. [Google Scholar] [CrossRef]
- Lin, L.; Sun, J.; Zhu, L. Nonparametric feature screening. Comput. Stat. Data Anal. 2013, 67, 162–174. [Google Scholar] [CrossRef]
- Lu, J.; Lin, L. Model-free conditional screening via conditional distance correlation. Stat. Pap. 2020, 61, 225–244. [Google Scholar] [CrossRef]
- Mai, Q.; Zou, H. The Kolmogorov filter for variable screening in high-dimensional binary classification. BIOMETRIKA 2013, 100, 229–234. [Google Scholar] [CrossRef]
- Huang, D.; Li, R.; Wang, H. Feature Screening for Ultrahigh Dimensional Categorical Data with Applications. J. Bus. Econ. Stat. 2014, 32, 237–244. [Google Scholar] [CrossRef]
- Cui, H.; Li, R.; Zhong, W. Model-Free Feature Screening for Ultrahigh Dimenssional Discriminant Analysis. J. Am. Stat. Assoc. 2015, 110, 630–641. [Google Scholar] [CrossRef]
- Han, X. Nonparametric screening under conditional strictly convex loss for ultrahigh dimensional sparse data. Ann. Stat. 2019, 47, 1995–2022. [Google Scholar]
- Zhou, T.; Zhu, L.; Xu, C.; Li, R. Model-free forward screening via cumulative divergence. J. Am. Stat. Assoc. 2020, 115, 1393–1405. [Google Scholar] [CrossRef]
- Xie, J.; Lin, Y.; Yan, X.; Tang, N. Category-Adaptive Variable Screening for Ultra-High Dimensional Heterogeneous Categorical Data. J. Am. Stat. Assoc. 2020, 115, 747–760. [Google Scholar] [CrossRef]
- Hao, N.; Zhang, H.H. A note on high-dimensional linear regression with interactions. Am. Stat. 2017, 71, 291–297. [Google Scholar] [CrossRef] [Green Version]
- Tang, W.; Xie, J.; Lin, Y.; Tang, N. Quantile Correlation Based Variable Selection. J. Bus. Econ. Stat. 2021, 40, 1801–1903. [Google Scholar] [CrossRef]
- Liu, W.; Ke, Y.; Liu, J.; Li, R. Model-free feature screening and fdr control with knockoff features. J. Am. Stat. Assoc. 2022, 117, 428–443. [Google Scholar] [CrossRef]
- Guo, X.; Ren, H.; Zou, C.; Li, R. Threshold selection in feature screening for error rate control. J. Am. Stat. Assoc. 2022, 1–13. [Google Scholar] [CrossRef]
- Cook, R.D. Testing predictor contributions in sufficient dimension reduction. Ann. Stat. 2004, 32, 1062–1092. [Google Scholar] [CrossRef] [Green Version]
- Yin, X.; Hilafu, H. Sequential Sufficient Dimension Reduction for Large p, Small n Problems. J. R. Stat. Soc. Ser. B (Stat. Methodol.) 2015, 77, 879–892. [Google Scholar] [CrossRef]
- Yuan, Q.; Chen, X.; Ke, C.; Yin, X. Independence index sufficient variable screening for categorical responses. Comput. Stat. Data Anal. 2022, 174, 107530. [Google Scholar] [CrossRef]
- Hyndman, R.J.; Fan, Y. Sample Quantiles in Statistical Packages. Am. Stat. 1996, 50, 361–365. [Google Scholar]
- Mohamed, I.B.; Mirakhmedov, S.M. Approximation by Normal Distribution for A Sample Sum in Sampling Without Replacement from a Finite Population. Sankhya A 2016, 78, 188–220. [Google Scholar] [CrossRef] [Green Version]
- Benjamini, Y.; Hochberg, Y. Controlling The False Discovery Rate: A Practical and Powerful Approach to Multiple Testing. J. R. Stat. Soc. Ser. B (Methodol.) 1995, 57, 289–300. [Google Scholar] [CrossRef]
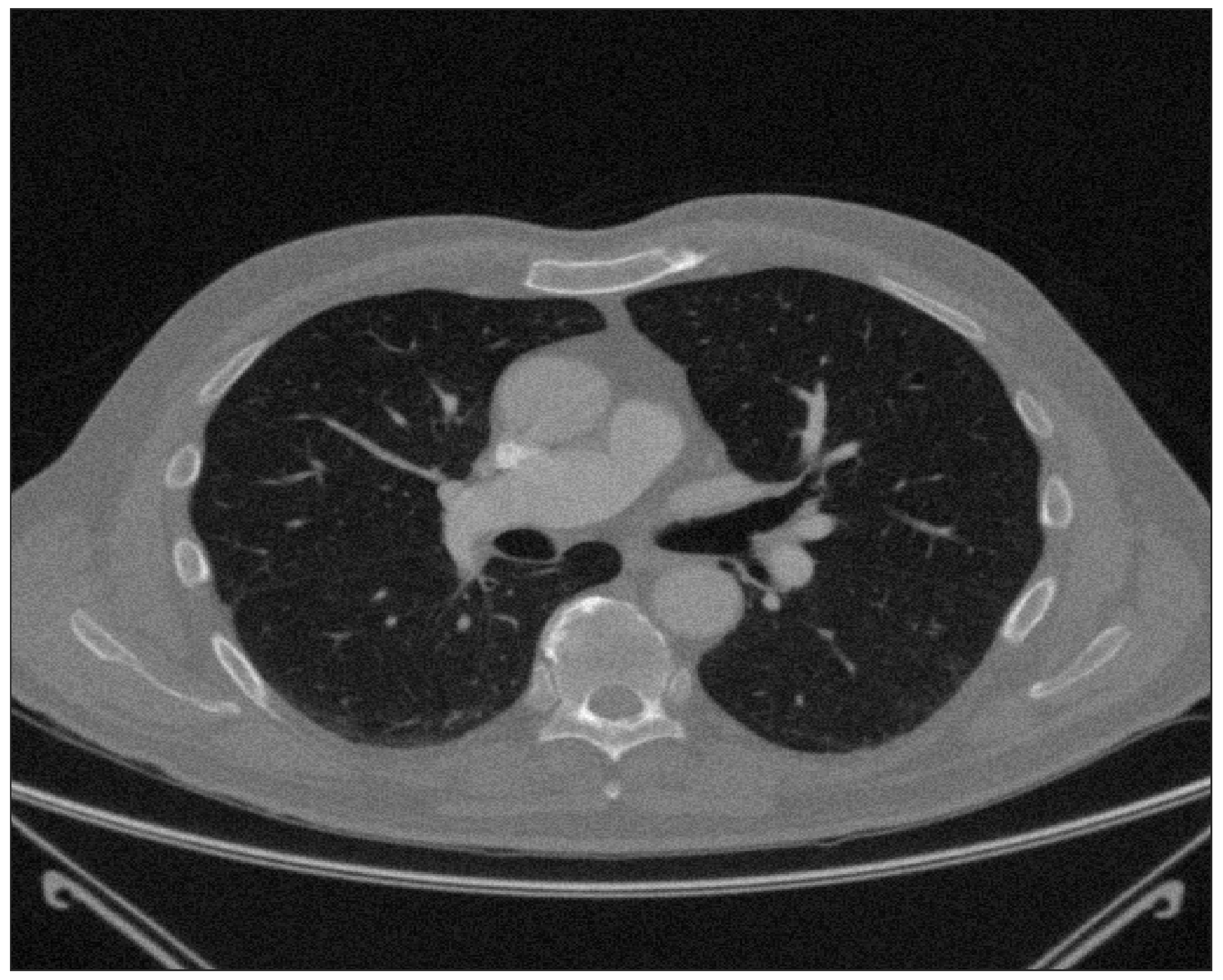
- Shalmon, T.; Salazar, P.; Horie, M.; Hanneman, K.; Pakkal, M.; Anwari, V.; Fratesi, J. Predefined and data driven CT densitometric features predict critical illness and hospital length of stay in COVID-19 patients. Sci. Rep. 2022, 12, 8143. [Google Scholar] [CrossRef]
| Method | 5% | 25% | 50% | 75% | 95% | 5% | 25% | 50% | 75% | 95% |
|---|---|---|---|---|---|---|---|---|---|---|
| QA-SVS-A(4) | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 4.0 |
| QA-SVS-A(5) | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 4.0 |
| QA-SVS-A(6) | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 4.0 |
| QA-SVS-A(7) | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 4.0 |
| QA-SVS-A(8) | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 4.0 |
| QA-SVS-A(9) | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 4.0 |
| QA-SVS-A(10) | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 |
| QCS(4) | 3.0 | 3.0 | 3.0 | 3.0 | 4.0 | 3.0 | 3.0 | 3.0 | 3.0 | 4.0 |
| QCS(5) | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 7.0 |
| QCS(6) | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 5.0 |
| QCS(7) | 3.0 | 3.0 | 3.0 | 3.0 | 4.0 | 3.0 | 3.0 | 3.0 | 3.0 | 5.0 |
| QCS(8) | 3.0 | 3.0 | 3.0 | 3.0 | 5.0 | 3.0 | 3.0 | 3.0 | 3.0 | 8.0 |
| QCS(9) | 3.0 | 3.0 | 3.0 | 3.0 | 10.5 | 3.0 | 3.0 | 3.0 | 3.0 | 6.5 |
| QCS(10) | 3.0 | 3.0 | 3.0 | 4.0 | 7.5 | 3.0 | 3.0 | 3.0 | 3.0 | 7.5 |
| SIS | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 4.0 |
| DC-SIS | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 4.0 |
| QA-SIS(0.1) | 3.0 | 3.0 | 5.0 | 10.0 | 60.0 | 3.0 | 3.0 | 3.0 | 5.0 | 23.0 |
| QA-SIS(0.3) | 3.0 | 3.0 | 3.0 | 3.0 | 4.0 | 3.0 | 3.0 | 3.0 | 3.0 | 4.5 |
| QA-SIS(0.5) | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 4.5 |
| QA-SIS(0.7) | 3.0 | 3.0 | 3.0 | 3.0 | 4.0 | 3.0 | 3.0 | 3.0 | 3.0 | 5.0 |
| QA-SIS(0.9) | 3.0 | 3.0 | 4.0 | 12.0 | 56.0 | 3.0 | 3.0 | 3.0 | 7.5 | 38.5 |
| QA-SVS-A(4) | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.5 |
| QA-SVS-A(5) | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 4.0 |
| QA-SVS-A(6) | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 4.0 |
| QA-SVS-A(7) | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 4.0 |
| QA-SVS-A(8) | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 4.0 |
| QA-SVS-A(9) | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 4.0 |
| QA-SVS-A(10) | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 |
| QCS(4) | 3.0 | 3.0 | 3.0 | 3.0 | 5.0 | 3.0 | 3.0 | 3.0 | 3.0 | 7.0 |
| QCS(5) | 3.0 | 3.0 | 3.0 | 3.0 | 6.0 | 3.0 | 3.0 | 3.0 | 3.0 | 5.0 |
| QCS(6) | 3.0 | 3.0 | 3.0 | 3.0 | 5.0 | 3.0 | 3.0 | 3.0 | 3.0 | 8.5 |
| QCS(7) | 3.0 | 3.0 | 3.0 | 3.0 | 10.0 | 3.0 | 3.0 | 3.0 | 3.0 | 14.5 |
| QCS(8) | 3.0 | 3.0 | 3.0 | 3.0 | 30.0 | 3.0 | 3.0 | 3.0 | 3.0 | 24.0 |
| QCS(9) | 3.0 | 3.0 | 3.0 | 4.0 | 28.5 | 3.0 | 3.0 | 3.0 | 4.0 | 46.5 |
| QCS(10) | 3.0 | 3.0 | 3.0 | 5.0 | 36.5 | 3.0 | 3.0 | 3.0 | 5.5 | 71.5 |
| SIS | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 4.0 |
| DC-SIS | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 4.0 |
| QA-SIS(0.1) | 3.0 | 4.0 | 11.5 | 56.5 | 241.0 | 3.0 | 3.0 | 5.0 | 18.0 | 254.0 |
| QA-SIS(0.3) | 3.0 | 3.0 | 3.0 | 3.0 | 8.5 | 3.0 | 3.0 | 3.0 | 4.0 | 6.5 |
| QA-SIS(0.5) | 3.0 | 3.0 | 3.0 | 3.0 | 4.0 | 3.0 | 3.0 | 3.0 | 3.0 | 4.5 |
| QA-SIS(0.7) | 3.0 | 3.0 | 3.0 | 3.0 | 14.0 | 3.0 | 3.0 | 3.0 | 3.0 | 9.0 |
| QA-SIS(0.9) | 3.0 | 4.0 | 13.0 | 55.0 | 160.0 | 3.0 | 3.0 | 6.0 | 14.0 | 222.5 |
| Method | 5% | 25% | 50% | 75% | 95% | 5% | 25% | 50% | 75% | 95% |
|---|---|---|---|---|---|---|---|---|---|---|
| QA-SVS-A(4) | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 4.0 |
| QA-SVS-A(5) | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 4.0 |
| QA-SVS-A(6) | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 4.0 |
| QA-SVS-A(7) | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 4.0 |
| QA-SVS-A(8) | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 4.0 |
| QA-SVS-A(9) | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 4.0 |
| QA-SVS-A(10) | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 |
| QCS(4) | 3.0 | 3.0 | 3.0 | 3.0 | 11.0 | 3.0 | 3.0 | 3.0 | 3.0 | 4.0 |
| QCS(5) | 3.0 | 3.0 | 3.0 | 3.0 | 17.0 | 3.0 | 3.0 | 3.0 | 3.0 | 7.0 |
| QCS(6) | 3.0 | 3.0 | 3.0 | 4.0 | 12.5 | 3.0 | 3.0 | 3.0 | 3.0 | 5.0 |
| QCS(7) | 3.0 | 3.0 | 3.0 | 4.0 | 15.5 | 3.0 | 3.0 | 3.0 | 3.0 | 5.0 |
| QCS(8) | 3.0 | 3.0 | 3.0 | 5.0 | 35.0 | 3.0 | 3.0 | 3.0 | 3.0 | 8.0 |
| QCS(9) | 3.0 | 3.0 | 3.0 | 9.0 | 127.0 | 3.0 | 3.0 | 3.0 | 3.0 | 6.5 |
| QCS(10) | 3.0 | 3.0 | 3.0 | 6.0 | 32.5 | 3.0 | 3.0 | 3.0 | 3.0 | 7.5 |
| SIS | 287.0 | 486.5 | 697.5 | 870.0 | 986.5 | 127.5 | 330.5 | 573.5 | 824.0 | 971.0 |
| DC-SIS | 3.0 | 3.0 | 3.0 | 3.0 | 260.0 | 3.0 | 3.0 | 3.0 | 3.0 | 17.0 |
| QA-SIS(0.1) | 176.5 | 262.0 | 394.5 | 576.5 | 814.5 | 61.5 | 147.5 | 257.0 | 394.0 | 630.5 |
| QA-SIS(0.3) | 3.0 | 3.0 | 4.0 | 6.0 | 21.5 | 3.0 | 3.0 | 3.0 | 3.0 | 4.0 |
| QA-SIS(0.5) | 3.0 | 3.0 | 3.0 | 3.0 | 6.5 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 |
| QA-SIS(0.7) | 3.0 | 5.0 | 8.5 | 23.5 | 67.0 | 3.0 | 3.0 | 3.0 | 4.0 | 5.5 |
| QA-SIS(0.9) | 100.5 | 238.0 | 368.0 | 517.5 | 866.5 | 35.5 | 85.5 | 143.5 | 301.0 | 601.0 |
| QA-SVS-A(4) | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 |
| QA-SVS-A(5) | 3.0 | 3.0 | 3.0 | 3.0 | 5.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 |
| QA-SVS-A(6) | 3.0 | 3.0 | 3.0 | 3.0 | 4.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 |
| QA-SVS-A(7) | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 |
| QA-SVS-A(8) | 3.0 | 3.0 | 3.0 | 3.0 | 4.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 |
| QA-SVS-A(9) | 3.0 | 3.0 | 3.0 | 3.0 | 4.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 |
| QA-SVS-A(10) | 3.0 | 3.0 | 3.0 | 3.0 | 4.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 |
| QCS(4) | 3.0 | 3.0 | 3.0 | 3.5 | 46.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 |
| QCS(5) | 3.0 | 3.0 | 3.0 | 8.0 | 72.5 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 |
| QCS(6) | 3.0 | 3.0 | 3.0 | 6.5 | 38.5 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 |
| QCS(7) | 3.0 | 3.0 | 3.0 | 10.5 | 171.5 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 |
| QCS(8) | 3.0 | 3.0 | 4.0 | 12.0 | 124.5 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 |
| QCS(9) | 3.0 | 3.0 | 4.0 | 15.5 | 353.5 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 |
| QCS(10) | 3.0 | 3.0 | 4.0 | 20.0 | 221.5 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 |
| SIS | 1391.0 | 2628.5 | 3487.0 | 4254.5 | 4810.5 | 1165.5 | 2144.0 | 3288.5 | 4218.5 | 4937.5 |
| DC-SIS | 3.0 | 3.0 | 3.0 | 4.0 | 1197.5 | 3.0 | 3.0 | 3.0 | 3.0 | 57.5 |
| QA-SIS(0.1) | 439.0 | 1062.5 | 1653.5 | 2543.5 | 3717.0 | 260.5 | 629.0 | 1142.0 | 1813.5 | 3317.0 |
| QA-SIS(0.3) | 4.0 | 6.0 | 9.5 | 20.5 | 110.5 | 3.0 | 3.0 | 4.0 | 5.0 | 9.5 |
| QA-SIS(0.5) | 3.0 | 3.0 | 3.0 | 5.0 | 13.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 |
| QA-SIS(0.7) | 5.0 | 11.0 | 25.0 | 61.0 | 377.0 | 3.0 | 3.0 | 4.0 | 5.0 | 9.5 |
| QA-SIS(0.9) | 625.0 | 1510.5 | 2279.0 | 3218.0 | 4569.0 | 175.0 | 500.0 | 868.0 | 1592.5 | 2403.0 |
| Method | QA-SVS-AFD(K) | QA-SVS-FDR(K) | QCS-FDR(K) | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 2 | 3 | 4 | 5 | 6 | 2 | 3 | 4 | 5 | 6 | 2 | 3 | 4 | 5 | 6 | |
| Scenario 2.1 | |||||||||||||||
| 12.17 | 10.81 | 10.57 | 10.23 | 10.05 | 11.70 | 11.74 | 11.76 | 11.75 | 11.52 | 11.33 | 11.24 | 11.29 | 11.09 | 11.10 | |
| FDR | 0.17 | 0.07 | 0.05 | 0.02 | 0.00 | 0.14 | 0.14 | 0.14 | 0.14 | 0.13 | 0.11 | 0.10 | 0.11 | 0.09 | 0.09 |
| F-score | 0.90 | 0.96 | 0.97 | 0.99 | 1.00 | 0.92 | 0.92 | 0.92 | 0.92 | 0.93 | 0.94 | 0.94 | 0.94 | 0.95 | 0.95 |
| Scenario 2.2 | |||||||||||||||
| 50.40 | 48.14 | 44.87 | 37.95 | 26.82 | 52.16 | 52.29 | 52.28 | 52.21 | 52.35 | 50.53 | 50.52 | 50.16 | 49.59 | 48.59 | |
| FDR | 0.02 | 0.00 | 0.00 | 0.00 | 0.00 | 0.05 | 0.05 | 0.05 | 0.05 | 0.05 | 0.05 | 0.05 | 0.05 | 0.05 | 0.05 |
| F-score | 0.98 | 0.98 | 0.95 | 0.86 | 0.69 | 0.97 | 0.97 | 0.97 | 0.97 | 0.97 | 0.96 | 0.95 | 0.95 | 0.94 | 0.94 |
| Scenario 2.3 | |||||||||||||||
| 11.98 | 10.66 | 10.38 | 10.13 | 10.02 | 11.48 | 11.51 | 11.70 | 11.40 | 11.59 | 11.11 | 11.02 | 11.22 | 10.96 | 11.00 | |
| FDR | 0.16 | 0.06 | 0.03 | 0.01 | 0.00 | 0.12 | 0.12 | 0.14 | 0.12 | 0.13 | 0.09 | 0.09 | 0.10 | 0.08 | 0.08 |
| F-score | 0.91 | 0.97 | 0.98 | 0.99 | 1.00 | 0.93 | 0.93 | 0.92 | 0.94 | 0.93 | 0.95 | 0.95 | 0.94 | 0.96 | 0.95 |
| Scenario 2.4 | |||||||||||||||
| 50.31 | 46.07 | 39.30 | 26.54 | 14.55 | 52.22 | 52.26 | 51.75 | 51.88 | 51.77 | 49.77 | 47.84 | 46.93 | 44.97 | 43.69 | |
| FDR | 0.02 | 0.00 | 0.00 | 0.00 | 0.00 | 0.05 | 0.05 | 0.05 | 0.05 | 0.05 | 0.05 | 0.04 | 0.05 | 0.05 | 0.05 |
| F-score | 0.98 | 0.96 | 0.88 | 0.69 | 0.45 | 0.97 | 0.97 | 0.97 | 0.97 | 0.97 | 0.95 | 0.93 | 0.92 | 0.90 | 0.89 |
| Scenario 2.5 | |||||||||||||||
| 10.82 | 9.93 | 9.16 | 7.84 | 5.71 | 10.36 | 10.73 | 10.50 | 10.44 | 10.55 | 9.93 | 9.99 | 9.76 | 9.57 | 9.09 | |
| FDR | 0.08 | 0.00 | 0.00 | 0.00 | 0.00 | 0.04 | 0.06 | 0.05 | 0.04 | 0.05 | 0.05 | 0.05 | 0.04 | 0.05 | 0.05 |
| F-score | 0.96 | 0.99 | 0.95 | 0.87 | 0.72 | 0.98 | 0.97 | 0.97 | 0.98 | 0.97 | 0.94 | 0.95 | 0.94 | 0.93 | 0.90 |
| Scenario 2.6 | |||||||||||||||
| 14.87 | 3.63 | 0.53 | 0.07 | 0.01 | 12.86 | 15.04 | 12.49 | 10.79 | 9.23 | 1.54 | 1.35 | 1.07 | 0.61 | 0.48 | |
| FDR | 0.06 | NaN | NaN | NaN | NaN | 0.05 | 0.05 | 0.03 | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| F-score | 0.43 | 0.13 | 0.02 | 0.00 | 0.00 | 0.38 | 0.43 | 0.38 | 0.33 | 0.29 | 0.05 | 0.04 | 0.03 | 0.02 | 0.02 |
| Scenario 2.7 | |||||||||||||||
| 11.11 | 10.00 | 10.00 | 9.99 | 9.93 | 10.66 | 10.44 | 10.65 | 10.45 | 10.54 | 10.62 | 10.60 | 10.64 | 10.45 | 10.61 | |
| FDR | 0.09 | 0.00 | 0.00 | 0.00 | 0.00 | 0.06 | 0.04 | 0.06 | 0.04 | 0.05 | 0.05 | 0.05 | 0.05 | 0.04 | 0.05 |
| F-score | 0.95 | 1.00 | 1.00 | 1.00 | 1.00 | 0.97 | 0.98 | 0.97 | 0.98 | 0.98 | 0.97 | 0.97 | 0.97 | 0.98 | 0.97 |
| Scenario 2.8 | |||||||||||||||
| 38.86 | 19.20 | 5.93 | 1.26 | 0.29 | 43.22 | 42.34 | 40.35 | 37.54 | 36.33 | 23.00 | 16.93 | 11.91 | 8.62 | 6.20 | |
| FDR | 0.03 | 0.00 | 0.00 | NaN | NaN | 0.05 | 0.05 | 0.05 | 0.04 | 0.05 | 0.05 | 0.04 | 0.04 | 0.05 | NaN |
| F-score | 0.85 | 0.55 | 0.21 | 0.05 | 0.01 | 0.88 | 0.87 | 0.85 | 0.82 | 0.80 | 0.59 | 0.48 | 0.36 | 0.27 | 0.20 |
| K | 2 | 3 | 4 | 5 | 6 |
|---|---|---|---|---|---|
| 5% PD | |||||
| QA-SVS-AFD(K) | 20,152 | 2435 | 28 | 0 | 0 |
| QA-SVS-FDR(K) | 89,353 | 85,426 | 83,991 | 76,492 | 74,106 |
| QCS-FDR(K) | 262,144 | 262,144 | 262,144 | 262,144 | 262,144 |
| 95% PD | |||||
| QA-SVS-AFD(K) | 5151 | 502 | 15 | 0 | 0 |
| QA-SVS-FDR(K) | 76,800 | 76,442 | 75,863 | 78,157 | 66,473 |
| QCS-FDR(K) | 262,144 | 262,144 | 262,144 | 262,144 | 262,144 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yuan, Z.; Chen, J.; Qiu, H.; Huang, Y. Quantile-Adaptive Sufficient Variable Screening by Controlling False Discovery. Entropy 2023, 25, 524. https://doi.org/10.3390/e25030524
Yuan Z, Chen J, Qiu H, Huang Y. Quantile-Adaptive Sufficient Variable Screening by Controlling False Discovery. Entropy. 2023; 25(3):524. https://doi.org/10.3390/e25030524
Chicago/Turabian StyleYuan, Zihao, Jiaqing Chen, Han Qiu, and Yangxin Huang. 2023. "Quantile-Adaptive Sufficient Variable Screening by Controlling False Discovery" Entropy 25, no. 3: 524. https://doi.org/10.3390/e25030524