
An Infusion Containers Detection Method Based on YOLOv4 with Enhanced Image Feature Fusion
Abstract
:1. Introduction
- (1)
- The neck part of YOLOv4 [6] is improved by using replacing the original modules with several more effective modules. We have improved SPP to CSP-SPP, which enhanced the feature extraction capability of the model. We have also added CA and ASFF to obtain more image information. These improvements validate the scalability of the YOLO architecture and also lay the foundation for further research.
- (2)
- The loss function of YOLOv4 is improved by replacing CIOU with EIOU in calculating the width-to-height ratio of the anchor box. This not only results in more stable and accurate prediction of boxes but also reduces the training time and calculation cost.
2. Related Work
3. The Methods of YOLOv4
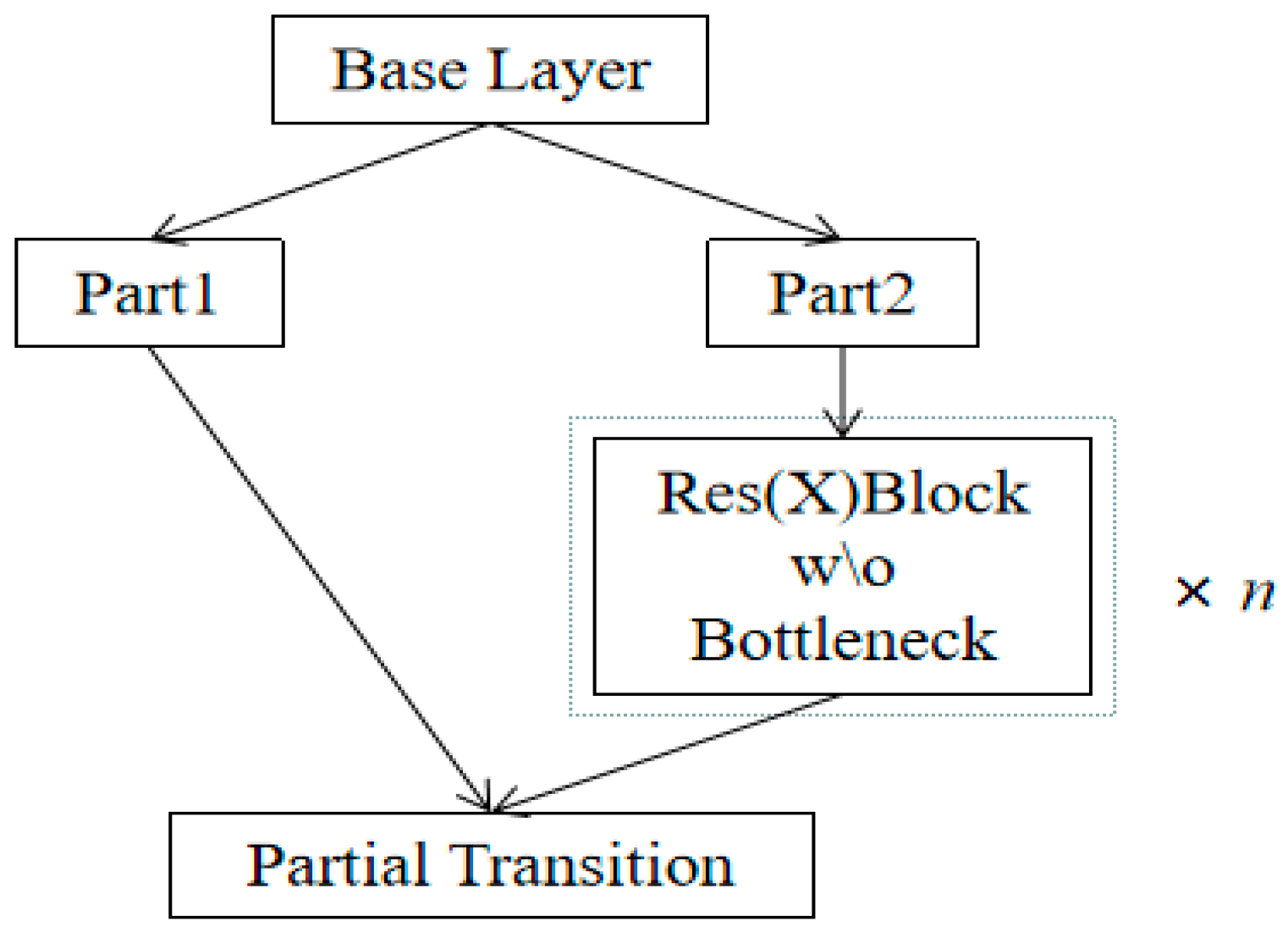
3.1. CSP Structure
3.2. YOLOv4
4. The Detail of NMYOLO
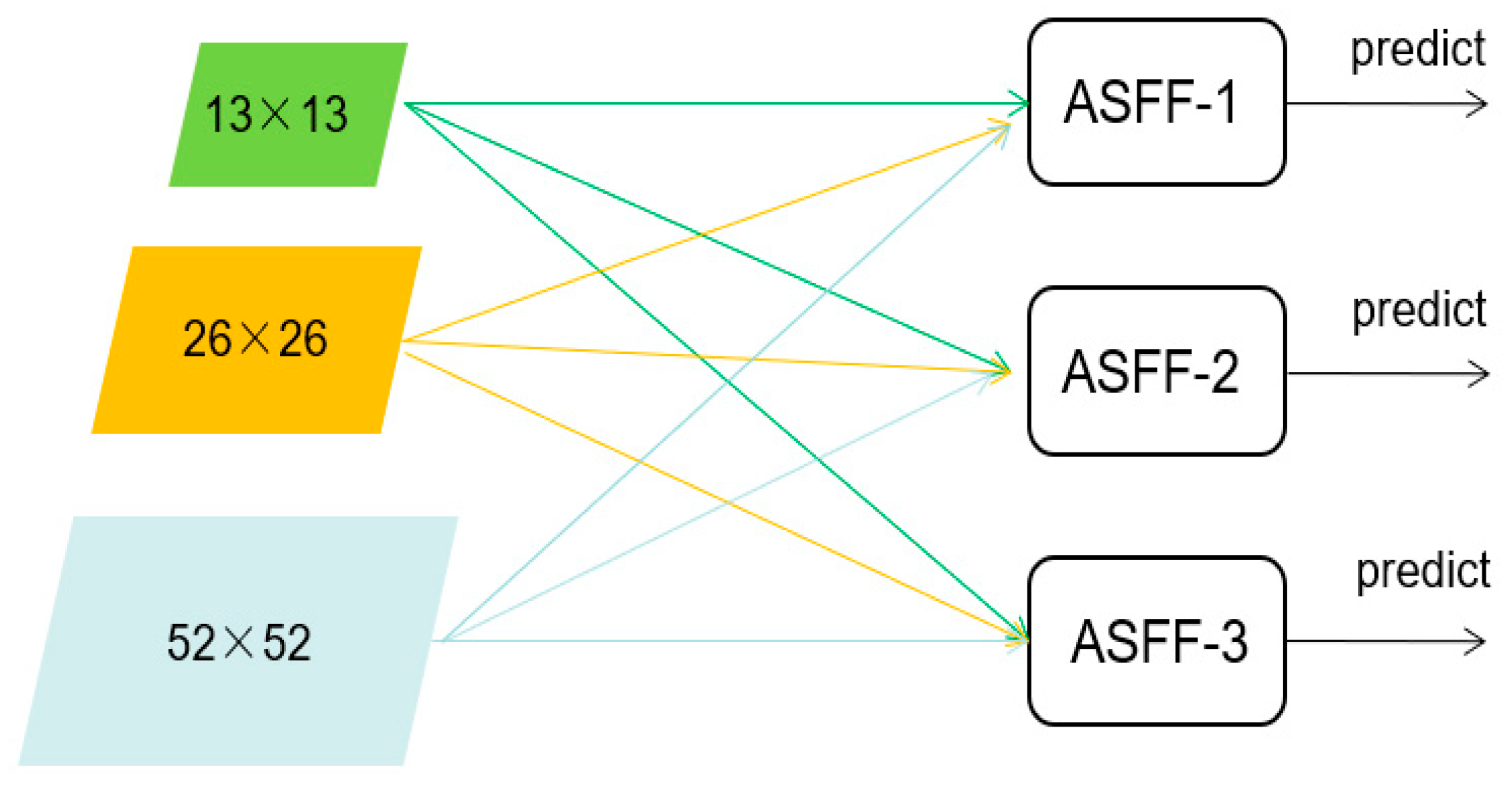
4.1. ASFF
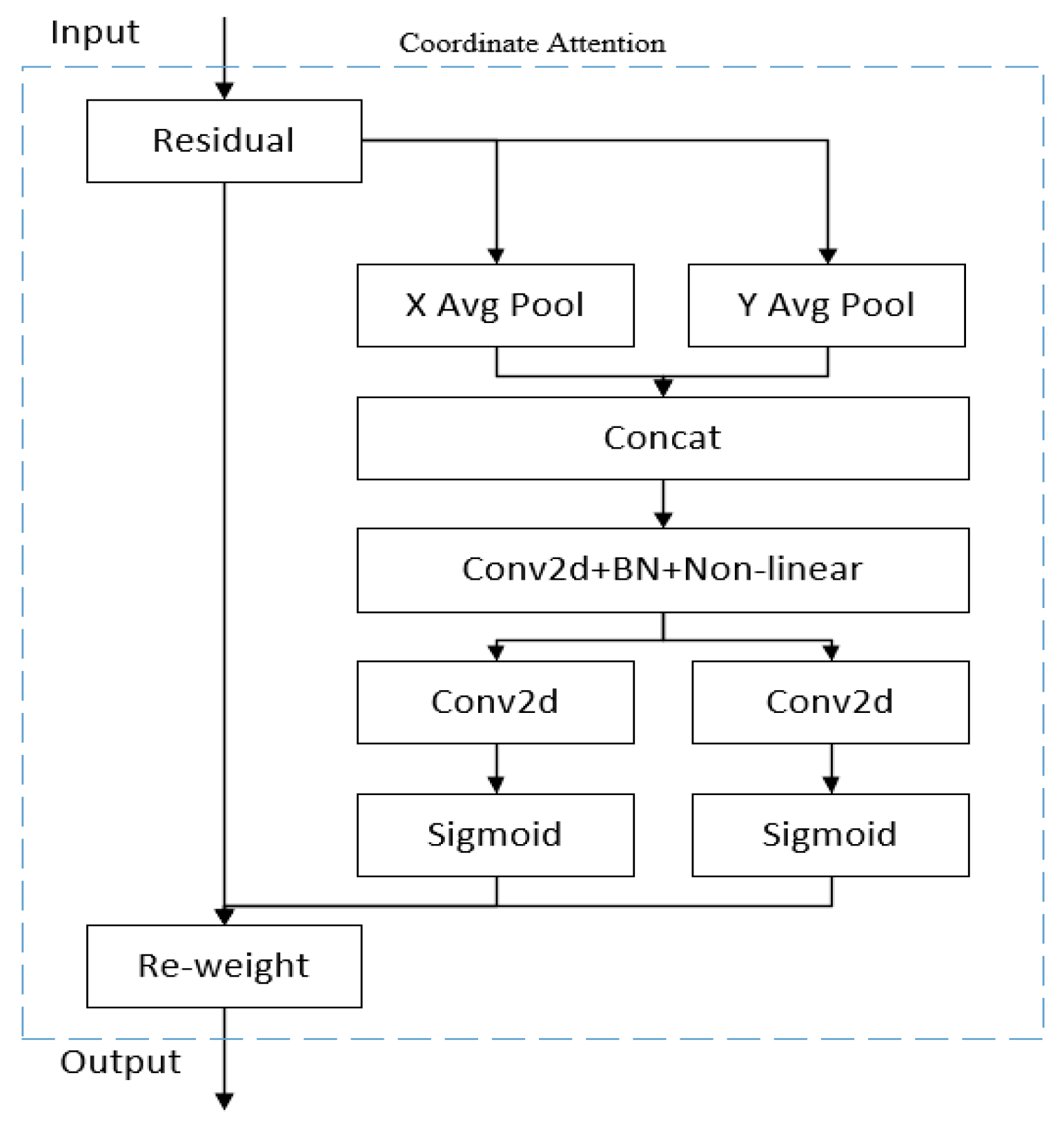
4.2. Coordinate Attention
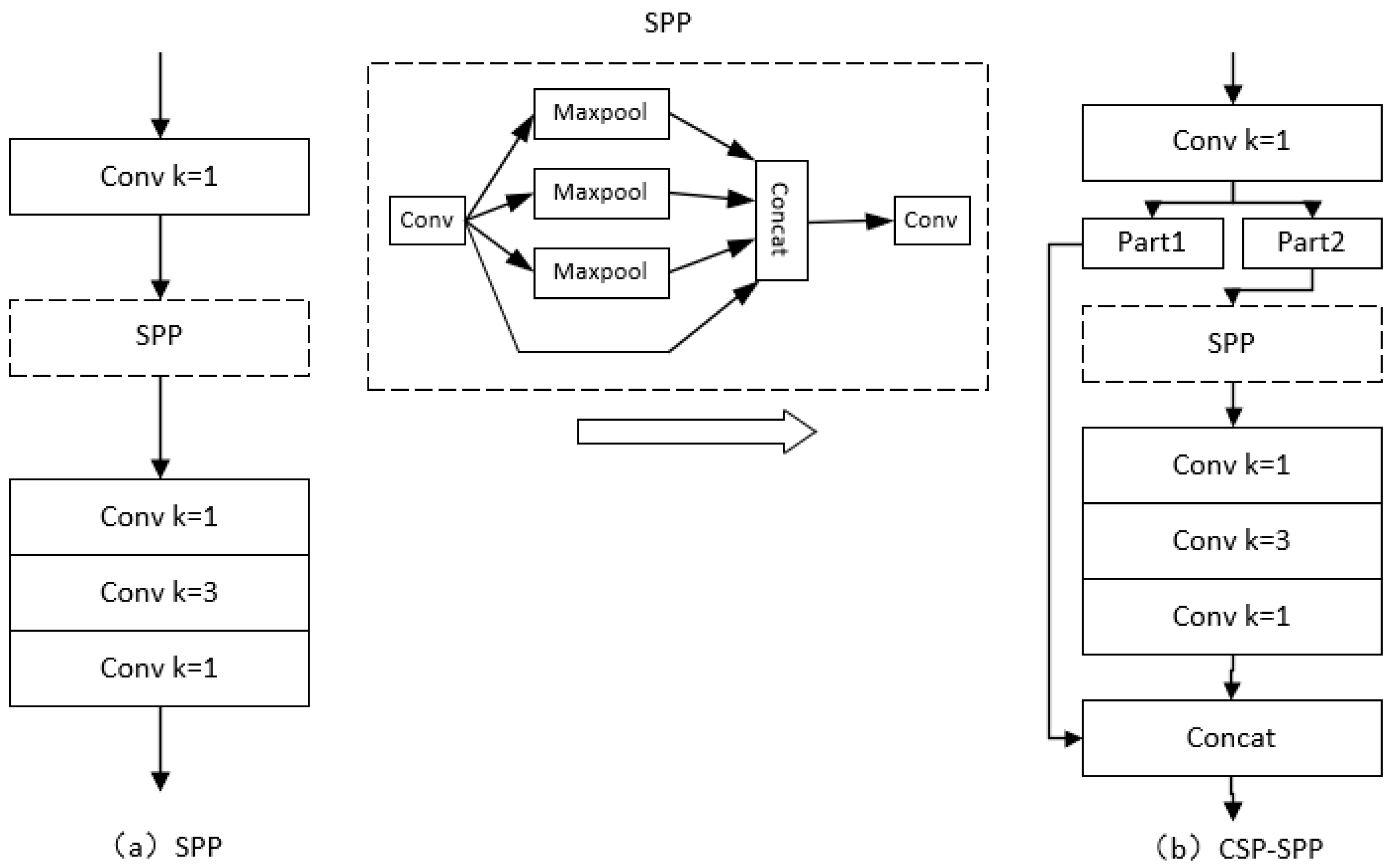
4.3. Improvements of SPP
4.4. The Structure of NMYOLO
4.5. Evaluation Metrics
5. Experiments and Results
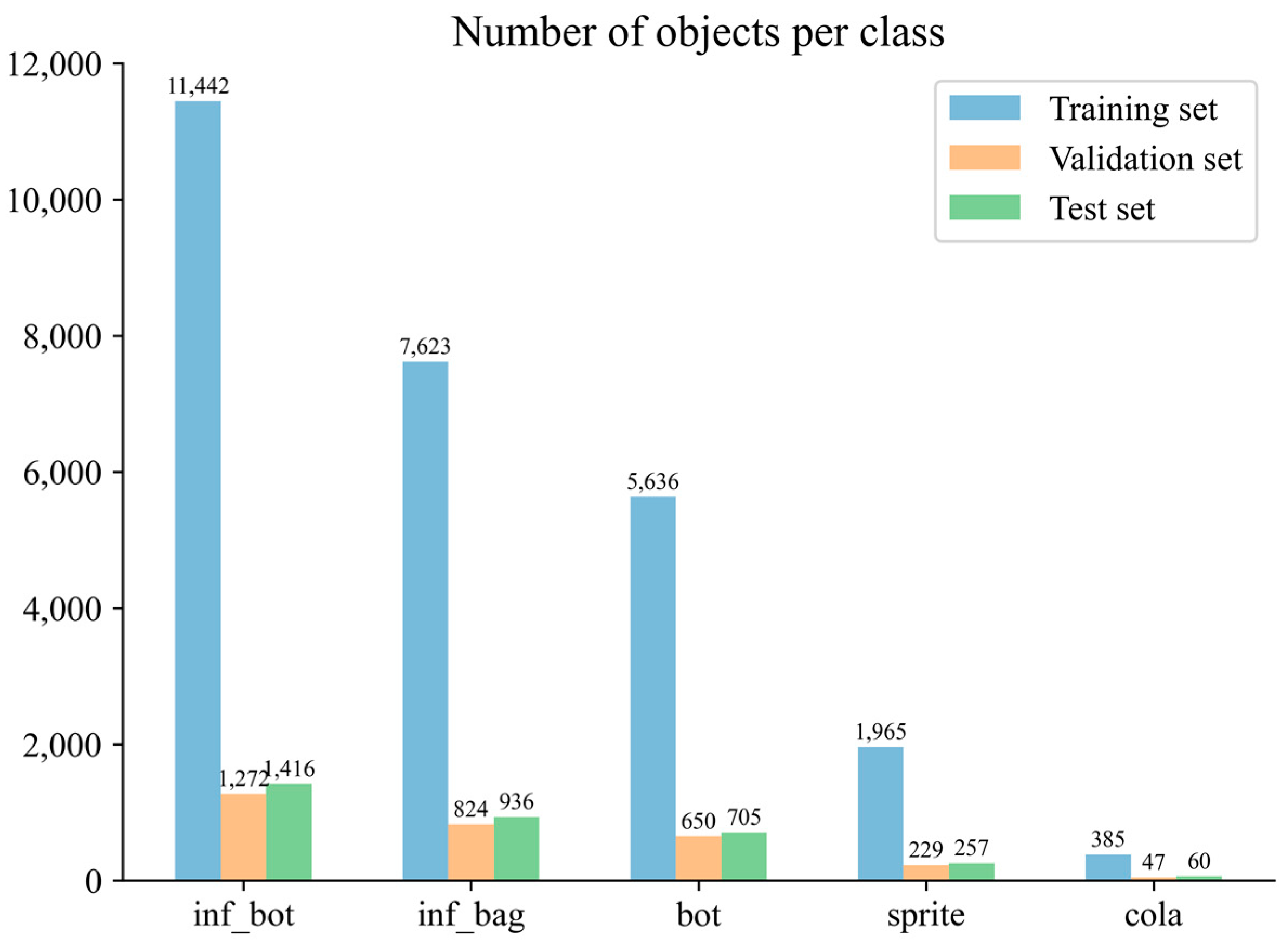
5.1. Dataset Preparation
5.2. Environment
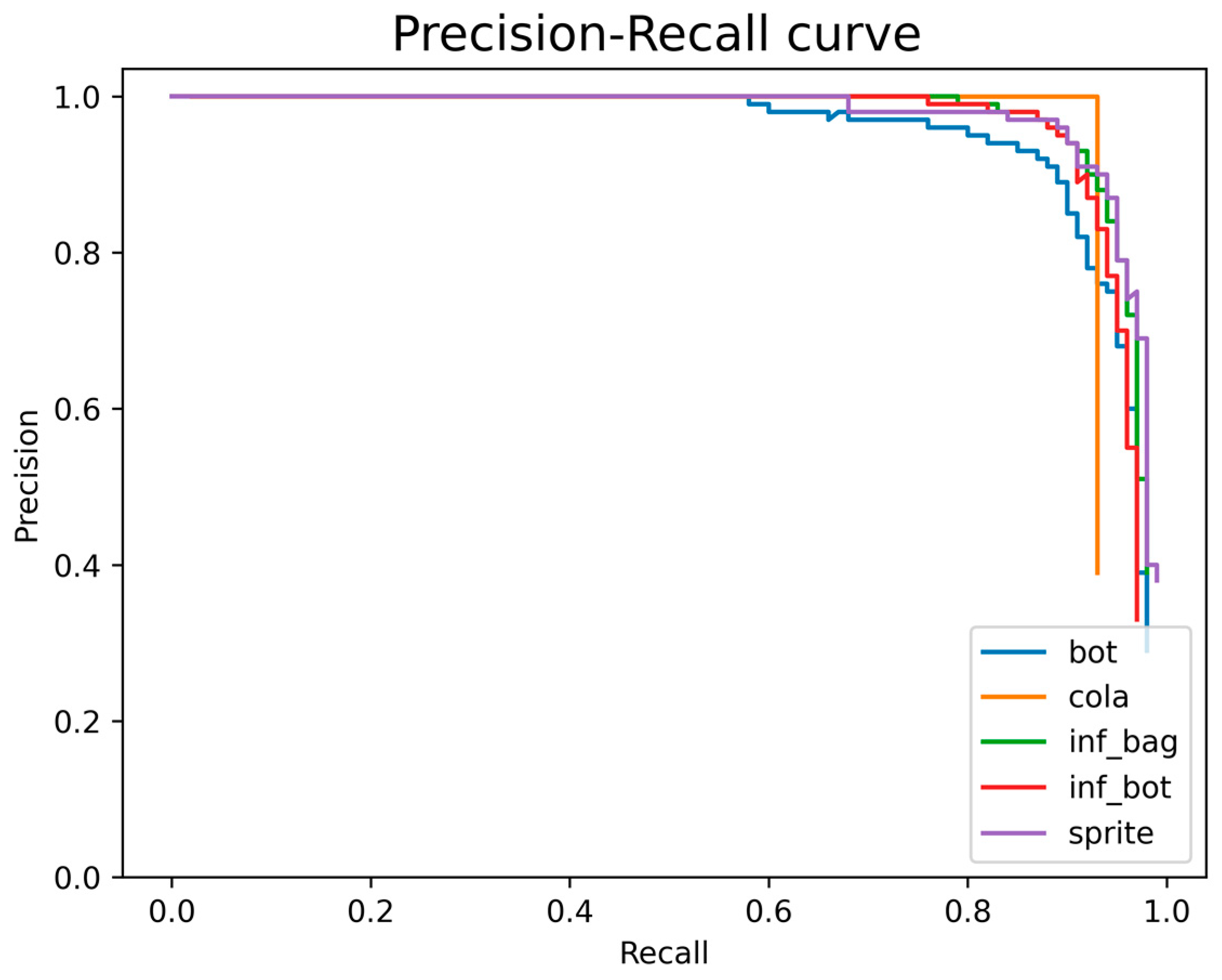
5.3. Results and Analysis
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| YOLO | You only look once |
| CSP | Cross stage partial |
| NMYOLO | Neck-modfied YOLO |
| SENet | Squeeze-and-excitation network |
| CBMA | Convolutional block attention module |
| SPP | Spatial pyramid pooling |
| ASFF | Adaptively spatial feature fusion |
| PANet | Path aggregation network |
| RCNN | Region-based convolutional neural network |
| SSD | Shot multi-box detector |
| CA | Coordinate attention |
| FPN | Feature pyramid networks |
| IOU | Intersection of union |
| EIOU | Efficient IOU |
| CIOU | Complete IOU |
| mAPx | mean average precision while confidence at 0.x |
| SGD | Stochastic gradient descent |
| CNN | Convolutional neural networks |
References
- Cheng, M.M.; Hou, Q.B.; Zhang, S.H.; Rosin, P.L. Intelligent visual media processing: When graphics meets vision. J. Comput. Sci. Technol. 2017, 32, 110–121. [Google Scholar] [CrossRef]
- Hou, Q.; Zhou, D.; Feng, J. Coordinate attention for efficient mobile network design. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 13713–13722. [Google Scholar]
- Aloysius, N.; Geetha, M. A review on deep convolutional neural networks. In Proceedings of the International Conference on Communication and Signal Processing (ICCSP), Melmaruvathur, India, 6–8 April 2017; pp. 0588–0592. [Google Scholar]
- Liu, S.; Huang, D.; Wang, Y. Learning spatial fusion for single-shot object detection. arXiv 2019, arXiv:1911.09516. [Google Scholar]
- Zhang, Y.F.; Ren, W.; Zhang, Z.; Jia, Z.; Wang, L.; Tan, T. Focal and efficient IOU loss for accurate bounding box regression. Neurocomputing 2022, 506, 146–157. [Google Scholar] [CrossRef]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. Yolov4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Wu, X.; Sahoo, D.; Hoi, S.C. Recent advances in deep learning for object detection. Neurocomputing 2020, 396, 39–64. [Google Scholar] [CrossRef]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Boston, MA, USA, 7–12 June 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
- Khasawneh, N.; Fraiwan, M.; Fraiwan, L. Detection of K-complexes in EEG waveform images using faster R-CNN and deep transfer learning. BMC Med. Inform. Decis. Mak. 2022, 22, 297. [Google Scholar] [CrossRef] [PubMed]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Khasawneh, N.; Fraiwan, M.; Fraiwan, L. Detection of K-complexes in EEG signals using deep transfer learning and YOLOv3. Clust. Comput. 2022, 1–11. [Google Scholar] [CrossRef]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. Ssd: Single shot multibox detector. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; Springer: Cham, Switzerland; pp. 21–37. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30, 6000–6010. [Google Scholar]
- Wang, X.; Girshick, R.; Gupta, A.; He, K. Non-local neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7794–7803. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Wang, C.Y.; Liao, H.Y.M.; Wu, Y.H.; Chen, P.Y.; Hsieh, J.W.; Yeh, I.H. CSPNet: A new backbone that can enhance learning capability of CNN. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Seattle, WA, USA, 13–19 June 2020; pp. 390–391. [Google Scholar]
- Xie, S.; Girshick, R.; Dollár, P.; Tu, Z.; He, K. Aggregated residual transformations for deep neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1492–1500. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial pyramid pooling in deep convolutional networks for visual recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1904–1916. [Google Scholar] [CrossRef] [PubMed]
- Liu, S.; Qi, L.; Qin, H.; Shi, J.; Jia, J. Path aggregation network for instance segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8759–8768. [Google Scholar]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Rivera-Castillo, J.; Flores-Fuentes, W.; Rivas-López, M.; Sergiyenko, O.; Gonzalez-Navarro, F.F.; Rodríguez-Quiñonez, J.C.; Básaca-Preciado, L.C. Experimental image and range scanner datasets fusion in SHM for displacement detection. Struct. Control Health Monit. 2017, 24, e1967. [Google Scholar] [CrossRef]
- Krishna, K.; Murty, M.N. Genetic K-means algorithm. IEEE Trans. Syst. Man Cybern. Part B (Cybern.) 1999, 29, 433–439. [Google Scholar] [CrossRef] [PubMed]
- Flores-Fuentes, W.; Alba-Corpus, I.Y.; Sergiyenko, O.; Rodríguez-Quiñonez, J.C. A structural health monitoring method pro posal based on optical scanning and computational models. Int. J. Distrib. Sens. Netw. 2022, 18, 15501329221112606. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Hyperparameters | Value |
|---|---|
| Optimizer | SGD |
| Learning rate | 0.02 |
| Momentum | 0.937 |
| Input shape | 416 × 416 |
| Weight decay | 0.0005 |
| Training Epochs | 100 |
| Cos_lr | True |
| Mosaic | True |
| CA | ASFF | CSP-SPP | Loss | Precision | Recall | mAP50 | GFLOPs | FPS |
|---|---|---|---|---|---|---|---|---|
| ✗ | ✗ | ✗ | CIoU | 92.65 | 78.59 | 91.43 | 29.89 | 39.08 |
| ✓ | ✗ | ✗ | CIoU | 94.76 | 81.03 | 92.91 | 29.90 | 38.26 |
| ✓ | ✓ | ✗ | CIoU | 93.12 | 88.18 | 93.57 | 31.68 | 36.92 |
| ✓ | ✓ | ✓ | CIoU | 94.84 | 87.18 | 94.52 | 31.68 | 36.89 |
| ✓ | ✓ | ✓ | EIoU | 96.20 | 88.50 | 95.21 | 31.77 | 36.29 |
| Methods | Input size | Precision | Recall | mAP0.5:0.95 | mAP50 | mAP75 | FPS |
|---|---|---|---|---|---|---|---|
| SSD | 416 × 416 | 88.76 | 74.38 | 42.70 | 83.58 | 39.36 | / |
| YOLOv3 | 416 × 416 | 91.52 | 74.87 | 50.30 | 85.73 | 50.54 | 36.50 |
| YOLOv3-spp | 416 × 416 | / | / | 60.10 | 88.41 | 65.03 | 36.07 |
| YOLOv4 | 416 × 416 | 92.65 | 78.59 | 62.00 | 91.43 | 61.03 | 39.08 |
| YOLOv5m | 416 × 416 | 93.28 | 81.77 | 66.10 | 91.97 | 68.23 | 72.03 |
| YOLOv8m | 416 × 416 | 91.60 | 87.60 | 73.40 | 94.40 | / | 69.04 |
| YOLOX | 416 × 416 | 93.86 | 85.12 | 66.50 | 93.67 | 68.16 | 56.03 |
| YOLOv7 | 416 × 416 | 95.76 | 84.80 | 65.20 | 94.14 | 67.10 | 38.54 |
| NMYOLO | 416 × 416 | 96.20 | 88.50 | 66.80 | 95.21 | 67.90 | 36.29 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ju, L.; Zou, X.; Zhang, X.; Xiong, X.; Liu, X.; Zhou, L. An Infusion Containers Detection Method Based on YOLOv4 with Enhanced Image Feature Fusion. Entropy 2023, 25, 275. https://doi.org/10.3390/e25020275
Ju L, Zou X, Zhang X, Xiong X, Liu X, Zhou L. An Infusion Containers Detection Method Based on YOLOv4 with Enhanced Image Feature Fusion. Entropy. 2023; 25(2):275. https://doi.org/10.3390/e25020275
Chicago/Turabian StyleJu, Lei, Xueyu Zou, Xinjun Zhang, Xifa Xiong, Xuxun Liu, and Luoyu Zhou. 2023. "An Infusion Containers Detection Method Based on YOLOv4 with Enhanced Image Feature Fusion" Entropy 25, no. 2: 275. https://doi.org/10.3390/e25020275