
Deep Spatio-Temporal Graph Network with Self-Optimization for Air Quality Prediction

 , , ,
, , ,
Abstract
:1. Introduction
- (1)
- BGraphSAGE for the spatial dimension: A GNN model (GraphSAGE) is used to extract the spatial features, and the Bayesian method is used to optimize the model’s hyperparameters. The model can extract hidden spatial information while eliminating the unstable performance of the model caused by the experience-based selection of hyperparameters.
- (2)
- BGraphGRU for the temporal dimension: Graph convolution is used to replace the linear operation of the GRU with the Bayesian hyperparameter optimization method so that the network can extract the temporal dependency with suitable hyperparameters.
- (3)
- BGGRU with the combined model: This consists of a spatial dimension (BGraphSAGE) module and temporal dimension (BGraphGRU) module, which can thoroughly learn the data from the time and space dimensions so as to effectively improve the prediction accuracy and generalization performance of the prediction model.
2. Related Work
2.1. The Traditional PM2.5 Prediction Method
2.2. PM2.5 Prediction Method Based on Deep Learning
2.3. PM2.5 Prediction Method Based on Graph Neural Network
3. Methods
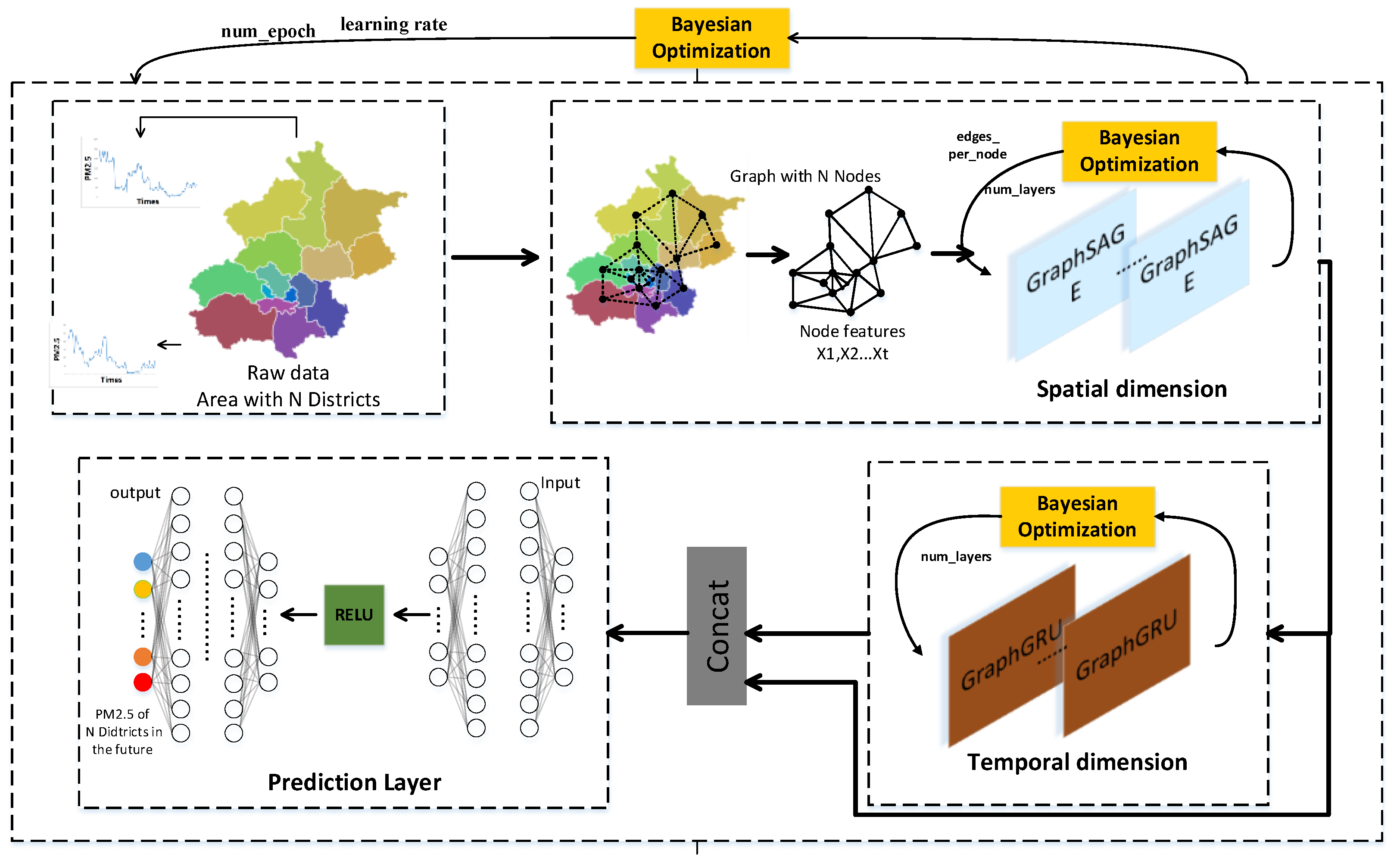
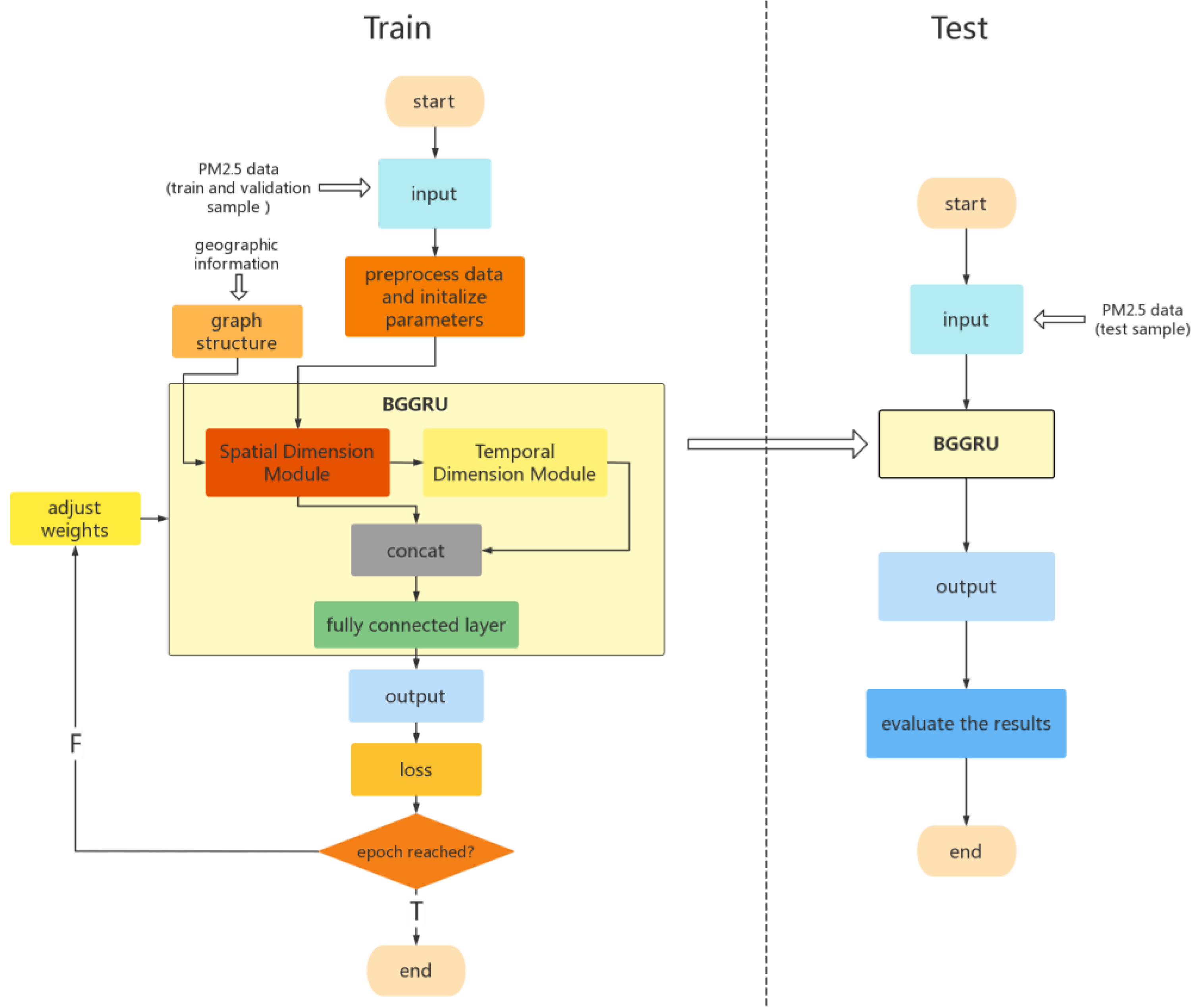
3.1. Overall Structure of BGGRU
3.1.1. Spatial Dimension Module of BGGRU (BGraphSAGE)
3.1.2. Temporal Dimension Module of BGGRU (BGraphGRU)
3.2. Bayesian Hyperparameter Optimization
4. Experiment and Results
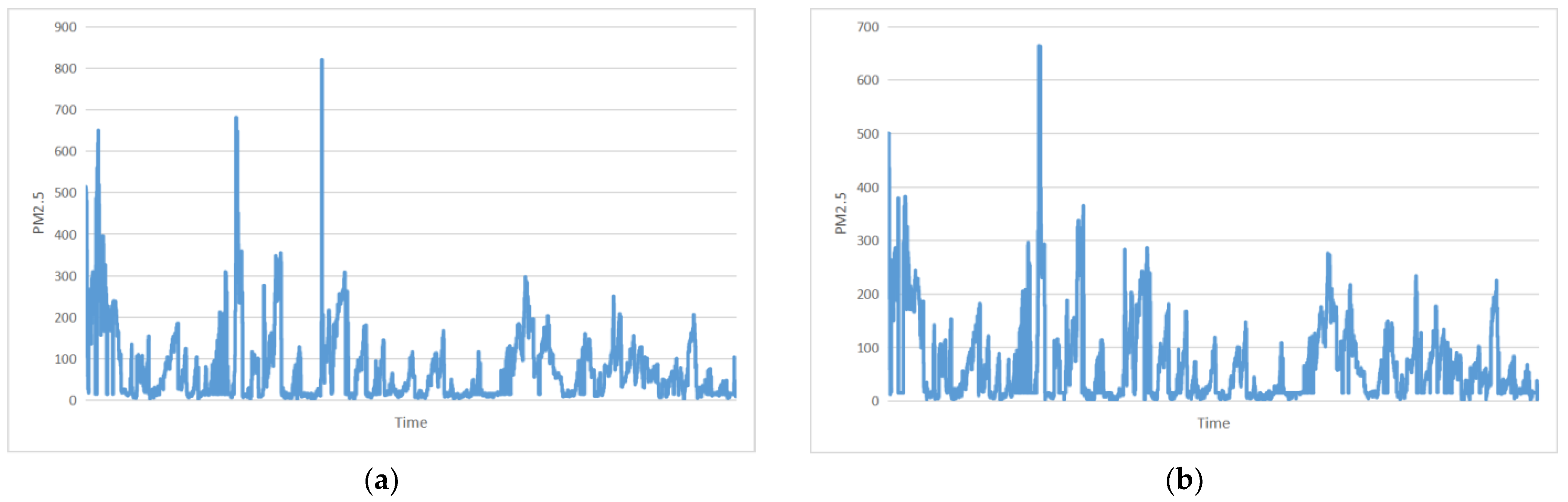
4.1. Dataset and Experimental Environment
4.2. Loss Function and Evaluation Index
4.3. Experimental Results
4.3.1. Bayesian Hyperparameter Optimization Results
4.3.2. Comparative Prediction Results
4.3.3. Ablation Study
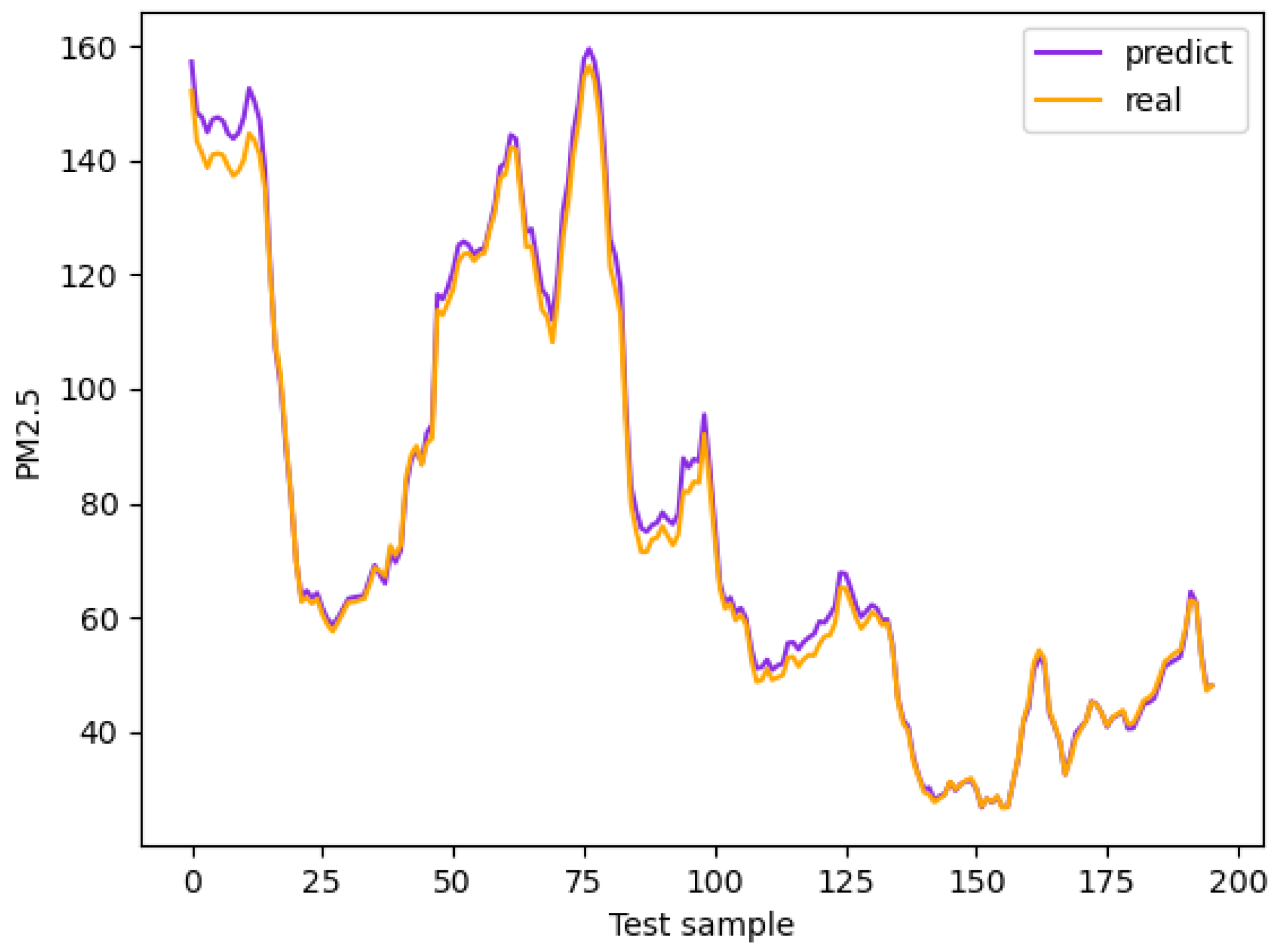
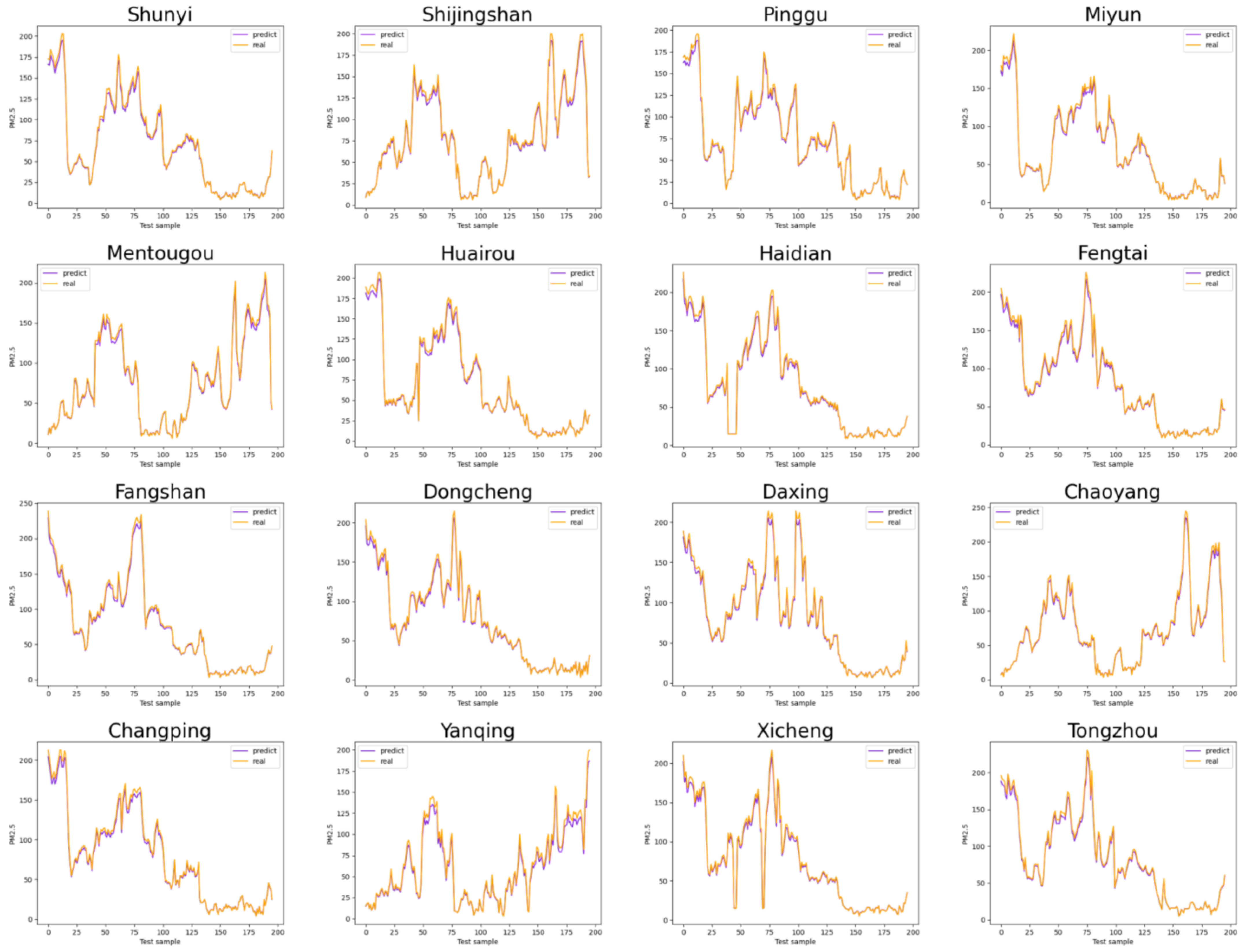
4.3.4. Display and Analysis
5. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Conflicts of Interest
References
- Tsai, F.; Smith, K.; Vichit, N. Indoor/outdoor PM10 and PM2.5 in Bangkok, Thailand. J. Expo. Sci. Environ. Epidemiol. 2000, 10, 15–26. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Gregory, R.; Adrian, S. Predicting air quality: Improvements through advanced methods to integrate models and measurements. J. Comput. Phys. 2007, 227, 3540–3571. [Google Scholar]
- Li, J.; Li, X.; Wang, K. Atmospheric PM2.5 concentration prediction based on time series and interactive multiple model approach. Adv. Meteorol. 2019, 2019, 1279565. [Google Scholar] [CrossRef] [Green Version]
- Guo, N.; Chen, W.; Wang, M. Appling an Improved Method Based on ARIMA Model to Predict the Short-Term Electricity Consumption Transmitted by the Internet of Things (IoT). Wirel. Commun. Mob. Comput. 2021, 2021, 6610273. [Google Scholar] [CrossRef]
- Conde, R.A.; Colorado, D.; Hernández, S.L. Comparison of an artificial neural network and Gompertz model for predicting the dynamics of deaths from COVID-19 in México. Nonlinear Dyn. 2021, 104, 4655–4669. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Z.; Hong, W.C. Electric load forecasting by complete ensemble empirical mode decomposition adaptive noise and support vector regression with quantum-based dragonfly algorithm. Nonlinear Dyn. 2019, 98, 1107–1136. [Google Scholar] [CrossRef]
- Fang, Z.; Yang, H.; Li, C. Prediction of PM2.5 hourly concentrations in Beijing based on machine learning algorithm and ground-based LiDAR. Arch. Environ. Prot. 2021, 47, 98–107. [Google Scholar]
- Connor, J.T.; Martin, R.D.; Atlas, L.E. Recurrent neural networks and robust time series prediction. IEEE Trans. Neural Netw. 1994, 5, 240–254. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Pan, C.; Tan, J.; Feng, D. Prediction Intervals Estimation of Solar Generation Based on Gated Recurrent Unit and Kernel Density Estimation. Neurocomputing 2020, 453, 552–562. [Google Scholar] [CrossRef]
- Tian, Y.; Zhang, K.; Li, J. LSTM-based Traffic Flow Prediction with Missing Data. Neurocomputing 2018, 318, 297–305. [Google Scholar] [CrossRef]
- Shao, B.J.; Zico, K.; Vladlen, K. An Empirical Evaluation of Generic Convolutional and Recurrent Networks for Sequence Modeling. arXiv 2018, arXiv:1803.01271. [Google Scholar]
- Bruna, J.; Zaremba, W.; Szlam, A. Spectral network sand locally connected network son graphs. In Proceedings of the 2nd International Conferenceon Learning Representations, Banff, AB, Canada, 14–16 April 2014. [Google Scholar]
- Veliovic, P.; CucurullG, C.A. Graph attention networks. In Proceedings of the 6th International Conference on Learning Representations, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Zhiwen, C.; Qiao, D.; Zhengrun, Z.; Bei, S.; Tao, P.; Chunhua, Y. Energy consumption prediction of cold source system based on GraphSAG. IFAC-Pap. OnLine 2021, 54, 37–42. [Google Scholar]
- Gori, M.; Monfardini, G.; Scarselli, F. A new model for learningin graph domains. In Proceedings of the International Joint Conference on Neural Networks, Montreal, QC, Canada, 31 July–4 August 2005; pp. 729–734. [Google Scholar]
- Snoek, J.; Larochelle, H.; Adams, R.P. Practical Bayesian optimization of machine learning algorithms. In Proceedings of the 25th International Conference on Neural Information Processing Systems, Lake Tahoe, NV, USA, 3–6 December 2012; pp. 2951–2959. [Google Scholar]
- Tong, L.; Alexis, K.H.; Lau, K.S. Time Series Forecasting of Air Quality Based on Regional Numerical Modeling in Hong Kong. J. Geophys. Res. Atmos. 2018, 123, 4175–4196. [Google Scholar]
- Zeng, Y.Y.; Daniel, A.J.; Xue, Q. Prediction of Potentially High PM2.5 Concentrations in Chengdu, China. Aerosol Air Qual. Res. 2020, 20, 956–965. [Google Scholar] [CrossRef] [Green Version]
- Shahriar, S.A.; Kayes, I.; Hasan, K. Potential of ARIMA-ANN, ARIMA-SVM, DT and CatBoost for atmospheric PM2.5 forecasting in Bangladesh. Atmosphere 2021, 12, 100. [Google Scholar] [CrossRef]
- Caroline, M.; Alejandro, C.; Sergio, V. A support vector machine model to forecast ground-level PM2.5 in a highly populated city with a complex terrain. Air Quality. Atmos. Health 2021, 14, 399–409. [Google Scholar] [CrossRef]
- Rui, F.; Han, G.; Kun, L. Analysis and accurate prediction of ambient PM2.5 in China using Multi-layer Perceptron. Atmos. Environ. 2020, 232, 117534. [Google Scholar]
- Qin, D.; Yu, J.; Zou, G.D. A Novel Combined Prediction Scheme Based on CNN and LSTM for Urban PM2.5 Concentration. IEEE Access 2019, 7, 20050–20059. [Google Scholar] [CrossRef]
- Hamed, K.; Qi, L.; Chunlin, W. Evaluation of Different Machine Learning Approaches to Forecasting PM2.5 Mass Concentrations. Aerosol Air Qual. Res. 2019, 19, 1400–1410. [Google Scholar]
- Nagrecha, K. Sensor-Based Air Pollution Prediction Using Deep CNN-LSTM. In Proceedings of the 2020 International Conference on Computational Science and Computational Intelligence (CSCI), Las Vegas, NV, USA, 16–18 December 2020; pp. 694–696. [Google Scholar]
- Zhao, P.; Zettsu, K. MASTGN: Multi-Attention Spatio-Temporal Graph Networks for Air Pollution Prediction. In Proceedings of the 2020 IEEE International Conference on Big Data (Big Data), Atlanta, GA, USA, 10–13 December 2020; pp. 1442–1448. [Google Scholar]
- Wang, S.; Li, Y.; Zhang, J. PM2.5-GNN: A Domain Knowledge Enhanced Graph Neural Network for PM2.5 Forecasting. In Proceedings of the 28th International Conference on Advances in Geographic Information Systems, Seattle, WA, USA, 3–6 November 2020. [Google Scholar]
- Hz, A.; Feng, Z.; Zda, B. A theory-guided graph networks based PM2.5 forecasting method. Environ. Pollut. 2022, V293, 118569. [Google Scholar]
- Zhao, G.; He, H.; Huang, Y. Near-surface PM2.5 prediction combining the complex network characterization and graph convolution neural network. Neural Comput. Applic 2021, 33, 17081–17101. [Google Scholar] [CrossRef]
- Hamilton, W.L.; Ying, R.; Leskovec, J. Inductive Representation Learning on Large Graphs. arXiv 2017, arXiv:1706.02216. [Google Scholar]
- Jin, X.B.; Zheng, W.Z.; Kong, J.L. Deep-Learning Forecasting Method for Electric Power Load via Attention-Based Encoder-Decoder with Bayesian Optimization. Energies 2021, 14, 1596. [Google Scholar] [CrossRef]
- Chen, Y.; Kang, Y.; Chen, Y. Probabilistic forecasting with temporal convolutional neural network. Neurocomputing 2020, 399, 491–501. [Google Scholar] [CrossRef] [Green Version]
- Wang, K.; Qi, X.; Liu, H. Photovoltaic power forecasting based LSTM-Convolutional Network. Energy 2019, 189, 116225. [Google Scholar]
- Gilik, A.; Ogrenci, A.S.; Ozmen, A. Air quality prediction using CNN+LSTM-based hybrid deep learning architecture. Environ. Sci. Pollut. Res. 2022, 29, 11920–11938. [Google Scholar] [CrossRef]
- Wang, Y.; Liao, W.; Chang, Y. Gated Recurrent Unit Network-Based Short-Term Photovoltaic Forecasting. Energies 2018, 11, 2163. [Google Scholar] [CrossRef] [Green Version]
- Saeed, A. Hybrid Bidirectional LSTM Model for Short-Term Wind Speed Interval Prediction. IEEE Access 2020, 8, 182283–182294. [Google Scholar] [CrossRef]
- Navares, R.; Aznarte, J.L. Predicting air quality with deep learning LSTM: Towards comprehensive models. Ecol. Inform. 2019, 55, 101019. [Google Scholar]
- Yu, S.; Wang, J.; Liu, J.S. Rapid Prediction of Respiratory Motion Based on Bidirectional Gated Recurrent Unit Network. IEEE Access 2020, 8, 49424–49435. [Google Scholar] [CrossRef]
- Li, J.W.; Zhu, H. A Practical Application for Text-Based Sentiment Analysis Based on Bayes-LSTM Model. J. Phys. Conf. Ser. 2020, 1631, 012035. [Google Scholar] [CrossRef]
- Jin, X.B.; Gong, W.T.; Kong, J.L. A Variational Bayesian Deep Network with Data Self-Screening Layer for Massive Time-Series Data Forecasting. Entropy 2022, 24, 335. [Google Scholar] [CrossRef] [PubMed]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Hyperparameter | Hyperparameter Set with Bayesian Optimization |
|---|---|
| num_layers of GraphSAGE | 4 |
| num_layers of GraphGRU | 1 |
| num_epoch | 11 |
| learning rate | 0.0327 |
| edges_per_node | 3 |
| Model | RMSE | MSE | MAE | R2 |
|---|---|---|---|---|
| TCN [31] | 26.91 | 724.33 | 21.65 | 0.4 |
| ConvLSTM [32] | 25.46 | 648.65 | 20.05 | 0.47 |
| CNN-LSTM [33] | 24.85 | 617.76 | 19.76 | 0.49 |
| GRU [34] | 15.93 | 253.85 | 11.49 | 0.86 |
| BiLSTM [35] | 15.78 | 248.88 | 11.93 | 0.87 |
| LSTM [36] | 15.27 | 233.35 | 10.66 | 0.87 |
| BiGRU [37] | 13.22 | 174.65 | 9.74 | 0.91 |
| bLSTM [38] | 7.02 | 49.28 | 5.15 | 0.97 |
| bGRU [39] | 6.71 | 45.09 | 5.07 | 0.97 |
| BGGRU (proposed) * | 2.66 | 7.11 | 1.99 | 0.99 |
| Model | RMSE | MSE | MAE | R2 |
|---|---|---|---|---|
| GGRU | 7.39 | 54.75 | 6.88 | 0.96 |
| BGGRU | 2.66 | 7.11 | 1.99 | 0.99 |
| Hyperparameter | Hyperparameter Set with Bayesian Optimization | Hyperparameter Set with Empirical Selection |
|---|---|---|
| num_layers of GraphSAGE | 4 | 3 |
| num_layers of GraphGRU | 1 | 3 |
| num_epoch | 11 | 10 |
| learning rate | 0.0327 | 0.05 |
| edges_per_node | 3 | 3 |
| Model | RMSE | MSE | MAE | R2 |
|---|---|---|---|---|
| GGRU | 3.37 | 11.35 | 2.78 | 0.99 |
| BGGRU | 2.66 | 7.11 | 1.99 | 0.99 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jin, X.-B.; Wang, Z.-Y.; Kong, J.-L.; Bai, Y.-T.; Su, T.-L.; Ma, H.-J.; Chakrabarti, P. Deep Spatio-Temporal Graph Network with Self-Optimization for Air Quality Prediction. Entropy 2023, 25, 247. https://doi.org/10.3390/e25020247
Jin X-B, Wang Z-Y, Kong J-L, Bai Y-T, Su T-L, Ma H-J, Chakrabarti P. Deep Spatio-Temporal Graph Network with Self-Optimization for Air Quality Prediction. Entropy. 2023; 25(2):247. https://doi.org/10.3390/e25020247
Chicago/Turabian StyleJin, Xue-Bo, Zhong-Yao Wang, Jian-Lei Kong, Yu-Ting Bai, Ting-Li Su, Hui-Jun Ma, and Prasun Chakrabarti. 2023. "Deep Spatio-Temporal Graph Network with Self-Optimization for Air Quality Prediction" Entropy 25, no. 2: 247. https://doi.org/10.3390/e25020247